
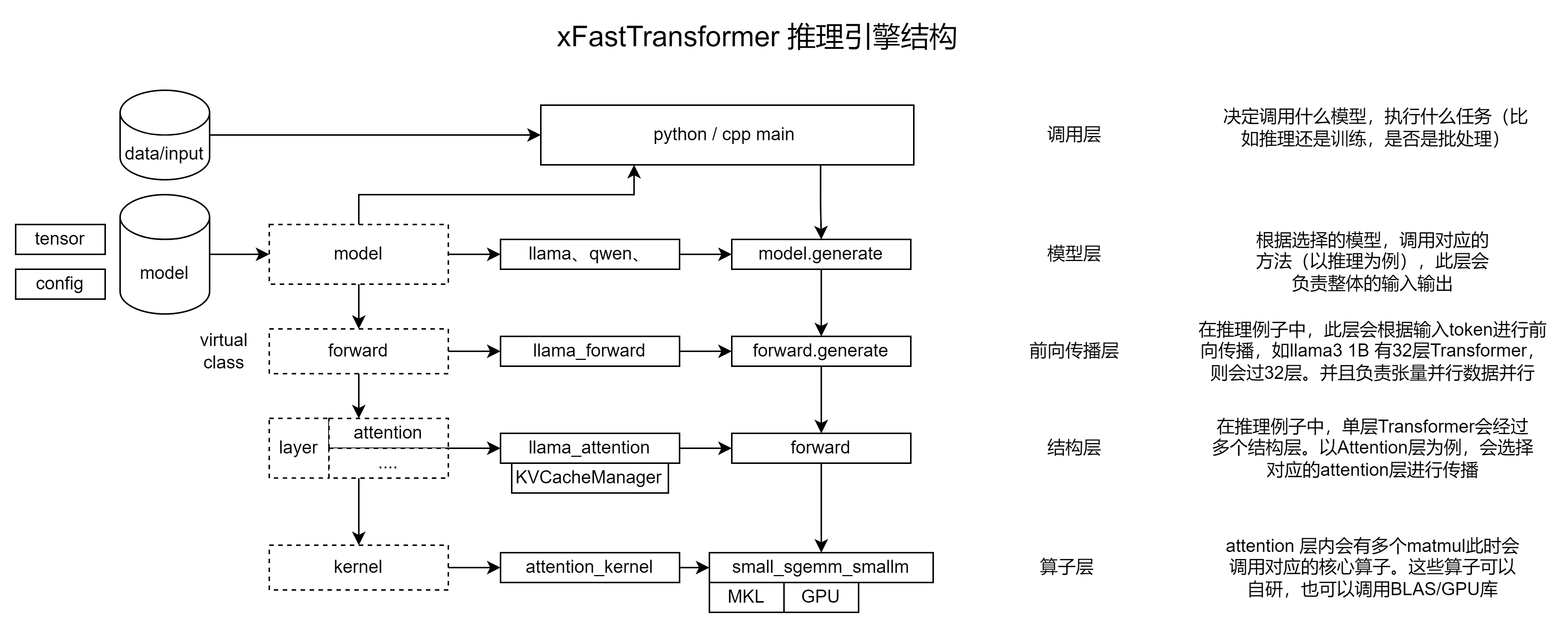
xFastTransformer 架构解读
- Frameworks
- 2025-06-13
- 815 Views
- 0 Comments
- 5435 Words
省流:这东西2年前做的,最麻烦的是文档很少,基本都要从零开始研究代码,考虑时间成本我没有花很多精力。
如果大家想在单机上用CPU推理,也可以试试intel pytorch extension或者llama.cpp。(不过xFt相比他们俩的好处是,它的代码结构也相对比较简单易懂,大家都可以自由选择)
但是目前这个东西没有用计算图优化,它每次计算都要重开openmp并行域,感觉这会出点问题。
Examples — Intel® Extension for Transformers 0.1.dev1+g087056c documentation
Intel® Extension for Transformers: Accelerating Transformer-based Models on Intel Platforms — Intel® Extension for Transformers 0.1.dev1+g087056c documentation
介绍文章
CPU也能玩转LLM:如何使用xFasterTransformer加速百亿级参数大模型_AI&大模型_黄文欢_InfoQ精选文章
全球领先的 LLM CPU 解决方案 xFasterTransformer - 知乎
github
intel/xFasterTransformer
官方文档和微信群
Home · intel/xFasterTransformer Wiki
与Pytorch对比是真的狗,因为Pytorch本身就很烂
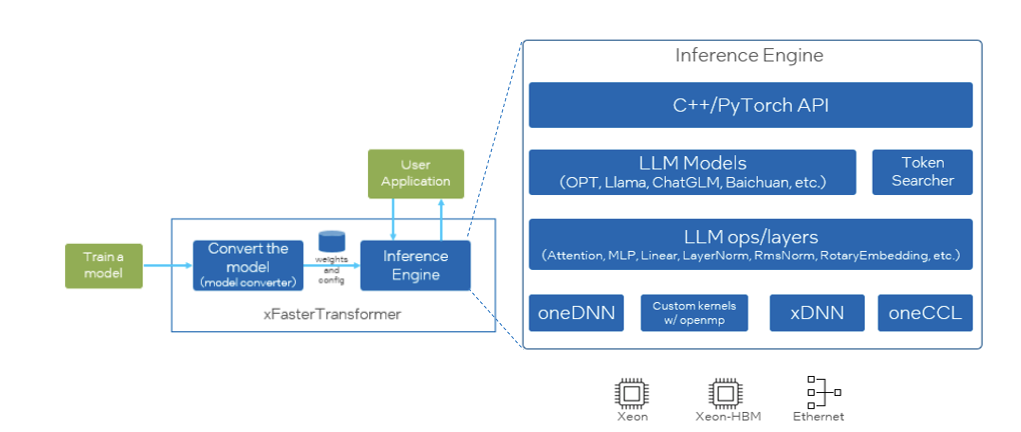
xFasterTransformer 是英特尔开源的推理框架,其遵循 Apache2.0 许可,为 LLM 在 CPU 平台上的推理加速提供了一种深度优化的解决方案。xFasterTransformer 支持分布式推理,支持单机跨 socket 的分布式部署,也支持多机跨节点的分布式部署。并提供了 C++和 Python 两种 API 接口,涵盖了从上层到底层的接口调用,易于用户使用并将其集成到自有业务框架中。xFasterTransformer 支持 BF16,FP16,INT8,INT4 等多种数据类型及多种 LLM 主流模型,比如 ChatGLM,ChatGLM2/3, Llama/Llama2,Baichuan,QWEN,OPT 以及 SecLLM(YaRN-Llama)等。其框架设计如图 1 所示。
优化策略
根据论文,有这么几个优化
- 分布式推理通信优化,减少通信次数
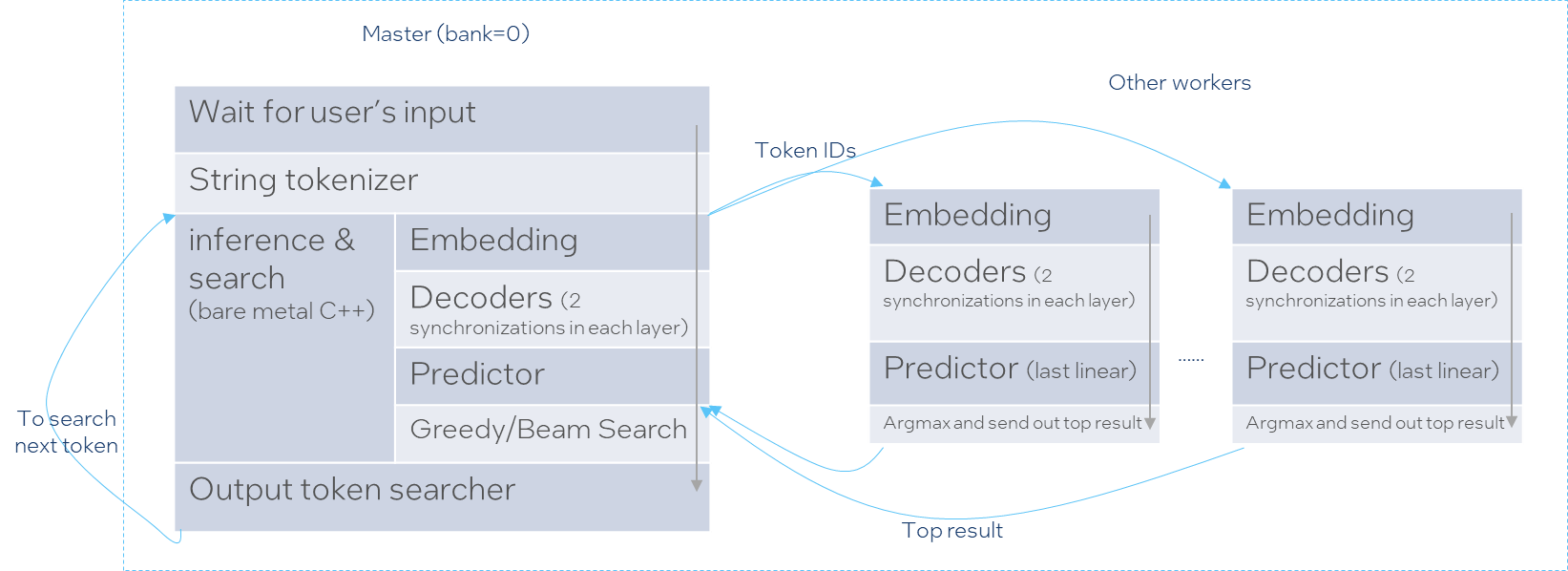
- 使用MKL/oneDNN加速库
- 算子融合,针对不同长度的序列采用不同的kernel,保证访存效率最高,采取不同的优化算法来进行优化
- -低精度量化和稀疏化
整体架构
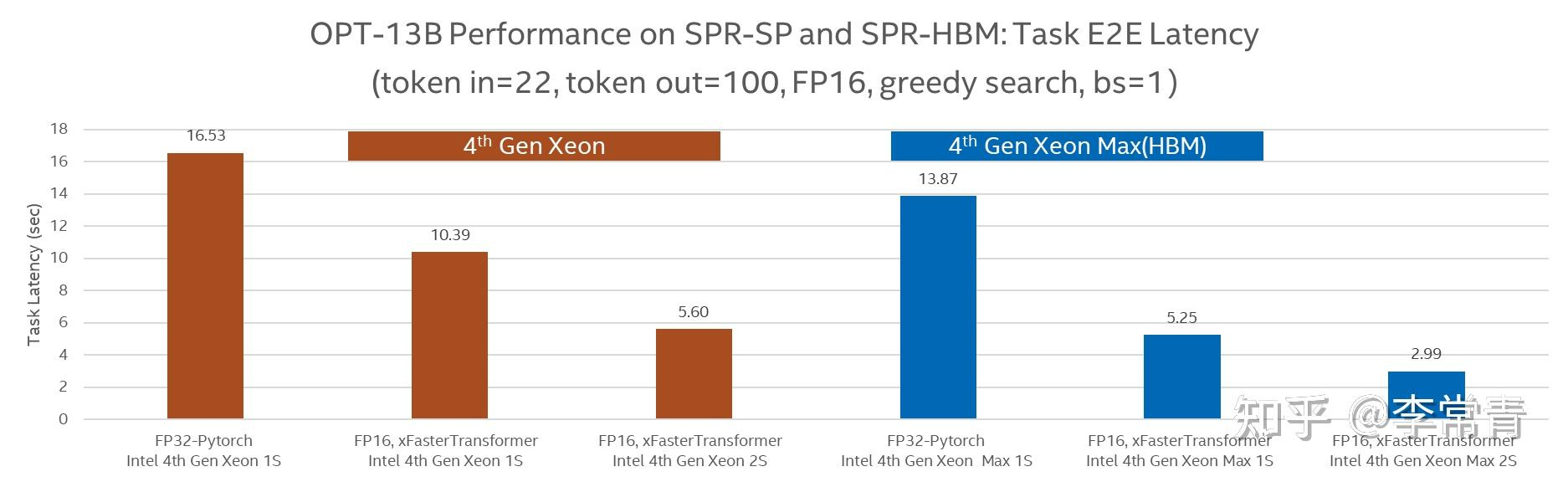
对比LLM推理的走过的整个结构 (Qwen2.5-32B)

大语言模型所有算子逻辑 - 骑虎南下的文章 - 知乎
https://zhuanlan.zhihu.com/p/1909996866432668841
xFt example解读
我们可以从这个例子开始研究
xFasterTransformer/examples/cpp/README.md at main · intel/xFasterTransformer
我们可以从它给的example开始研究
xFasterTransformer/examples/cpp/example.cpp at main · intel/xFasterTransformer
在导入模型后,这里我们就开始生成token了:
for (int i = 0; i < loop; ++i) {
secondIdCount = 0;
// New path
model.set_input(inputs, /*maxLen*/ maxLen, /*numBeams*/ numBeams, /*numBeamHypsToKeep*/ 1,
/*lenPenalty*/ 1.0,
/*doEarlyStopping*/ false, /*eosTokenId*/ -1, /*padTokenId*/ -1,
/*doSample*/ doSample, /*temperature*/ temperature,
/*topK*/ topK, /*topP*/ topP, /*repetitionPenalty*/ repetitionPenalty);
std::vector<int> firstIds;
std::vector<int> secondIds;
if (!model.isDone()) {
Timer t(isMaster, "[INFO] First token");
firstIds = model.generate();
}
Timer timerSecond;
if (!model.isDone()) {
secondIds = model.generate();
secondIdCount++;
}
if (isMaster && streamingOutput) {
if (!firstIds.empty()) {
tokenizer->printResult(firstIds, batchSize, numBeams);
if (!secondIds.empty()) { tokenizer->printResult(secondIds, batchSize, numBeams); }
}
}
while (!model.isDone()) {
auto nextIds = model.generate();
secondIdCount++;
if (isMaster && streamingOutput) { tokenizer->printResult(nextIds, batchSize, numBeams); }
}
if (isMaster && secondIdCount > 0) {
auto avgDuration = timerSecond.getTime() / float(secondIdCount);
std::cout << std::endl << "[INFO] Second token time: " << avgDuration << " ms" << std::endl;
}
auto result = model.finalize();
if (isMaster) {
std::cout << "\n[INFO] Final output is: " << std::endl;
std::vector<std::string> sent = tokenizer->batchDecode(result, batchSize);
for (auto str : sent) {
std::cout << "==============================================" << std::endl;
std::cout << str << std::endl;
}
}
}可以看到,在第一第二个id出来后,模型将不停的调用model.generate()方法生成新的id
总体结构可以用下面这段概括:
auto nextIds = model.generate();
secondIdCount++;
if (isMaster && streamingOutput) { tokenizer->printResult(nextIds, batchSize, numBeams); }model.generate
这段代码在xFasterTransformer/src/models/models.cpp at main · intel/xFasterTransformer
Model::generate 函数的目的是根据输入的 token(inputIds)或当前状态,从语言模型中生成下一个 token 或一系列 token。也就是自回归生成(autoregressive generation),即模型逐步生成输出序列。
// We assume all gen kwargs in the batch are the same
// and all sequences are all prompts(step==0) or all decodes(step>0)
std::vector<int32_t> Model::generate() {
// 这段代码处理了一个特殊情况,即模型没有用自己generate的方法,而是使用了外部的 searcher 对象来生成 token。
// TODO: Deprecate the following Path
if (searcher != nullptr) {
if (inputIds.empty()) {
printf("Please set input tokens by model.input().\n");
exit(-1);
}
if (isNewInput) {
isNewInput = false;
return searcher->getNextToken(inputIds.data(), batchSize, inputIds.size() / batchSize);
} else {
return searcher->getNextToken();
}
} else // 模型使用自己的方法生成token
{
// TODO
// Assume that all sequences in the group are all prompts or all decodes.
// Prepare input data for the decoder.
std::vector<SequenceMeta *> workingSeqs;
for (auto x : workingGroup) {
workingSeqs.push_back(x->get(0));
if (x->getGroupSize() > 1 && x->getStep() > 1) {
for (int32_t i = 1; i < x->getGroupSize(); i++) {
workingSeqs.push_back(x->get(i));
}
}
}
std::tuple<float *, int, int> result = decoder->forward(workingSeqs, false);
float *outBuf = std::get<0>(result);
int sampleOffset = std::get<1>(result);
int sampleSize = std::get<2>(result);
// Assume all gen kwargs in the batch are the same
auto &config = workingGroup[0]->getSamplingMeta()->config;
if (config.numBeams != 1) {
// TODO: BeamSearch
throw std::logic_error("Beam Search Method not implemented");
} else {
// Logits processor
// Repetition penalty
if (config.repetitionPenalty != 1.0) {
repetitionPenaltyLogitsProcess(outBuf, sampleOffset, sampleSize, workingGroup);
}
std::vector<int> result;
if (config.doSample) {
//TODO: samling
throw std::logic_error("Sampling Method not implemented");
} else {
// Greedy search
result = greedySearch(outBuf, sampleOffset, sampleSize, batchSize);
}
// Check stop status
stopCheck(result, workingGroup);
// Step forward on all seqs
for (int i = 0; i < workingGroup.size(); i++) {
workingGroup[i]->get(0)->stepForward(result[i]);
}
return result;
}
throw std::logic_error("Method not implemented");
return {};
}
}准备token
// TODO
// Assume that all sequences in the group are all prompts or all decodes.
// Prepare input data for the decoder.
std::vector<SequenceMeta *> workingSeqs;
for (auto x : workingGroup) {
workingSeqs.push_back(x->get(0));
if (x->getGroupSize() > 1 && x->getStep() > 1) {
for (int32_t i = 1; i < x->getGroupSize(); i++) {
workingSeqs.push_back(x->get(i));
}
}
}- 功能:为解码器准备输入数据(workingSeqs),从 workingGroup 中提取序列元数据(SequenceMeta)。
- 逻辑:
- workingGroup 是一个包含多个序列组的容器,每个组可能包含多个序列(可能是为了支持束搜索或多序列生成)。
- 默认情况下,每个组的第一个序列(x->get(0))被添加到 workingSeqs。
- 如果某个组有多个序列(getGroupSize() > 1)且生成步骤大于 1(getStep() > 1),则将该组中的其他序列也添加到 workingSeqs。
- 假设:代码假设所有序列要么全都是提示(prompt,初始输入),要么全都是解码(decode,已生成部分序列)。
Forward
std::tuple<float *, int, int> result = decoder->forward(workingSeqs, false);
float *outBuf = std::get<0>(result);
int sampleOffset = std::get<1>(result);
int sampleSize = std::get<2>(result);- 功能:调用解码器(decoder->forward)进行前向传播,生成 logits。
- 输入:
- workingSeqs:待处理的序列元数据。
- false:可能是控制某些行为的标志(例如是否缓存中间状态)。
- 输出:
- outBuf:包含 logits 的数组,表示模型对下一个 token 的概率分布。
- sampleOffset 和 sampleSize:用于指定 logits 的有效范围(可能是为了处理批处理或序列长度不一致)。
采样+后处理
auto &config = workingGroup[0]->getSamplingMeta()->config;
if (config.repetitionPenalty != 1.0) {
repetitionPenaltyLogitsProcess(outBuf, sampleOffset, sampleSize, workingGroup);
}
std::vector<int> result;
if (config.doSample) {
throw std::logic_error("Sampling Method not implemented");
} else {
result = greedySearch(outBuf, sampleOffset, sampleSize, batchSize);
}根据配置选择生成下一个 token 的方法。
logits 是模型在预测下一个单词(或 token)时,给出的“原始分数”。这些分数还没有被转换成概率,所以可以看作是模型对每个可能结果的“偏好”或“信心”。
**- 在 Model::generate 代码中,decoder->forward 生成了 logits(outBuf),这些 logits 就是模型对每个可能 token 的原始分数。
- 然后,代码通过 greedySearch(贪婪搜索)直接选分数最高的 token,或者在未来可能通过采样(doSample)根据概率随机选一个。
greedy Search
贪婪搜索是一种简单的策略:在每个生成步骤中,选择概率最高的下一个词(或 token)。在代码中,输入的 logits 是模型对每个可能 token 的“分数”,贪婪搜索的任务是找到每个序列中分数最高的 token ID。
其实它的本质是:多线程找一个数组内的最大值
例如:
- 输入 logits:
[2.5, 1.3, 4.7, 0.8](对应 token ID 0, 1, 2, 3) -
贪婪搜索会选择 4.7 对应的 token ID 2,因为它分数最高。
贪婪搜索的具体流程
- 输入 logits:
- logits 是一个大数组,包含 batchSize 个序列的 logits,每个序列有 sampleSize 个分数。
- 例如,若 batchSize=2, sampleSize=4,logits 可能是:
[2.5, 1.3, 4.7, 0.8, // 序列 1
1.1, 3.2, 0.9, 2.8] // 序列 2- 并行处理:
- 如果线程数多,每个序列的 logits 分给多个线程,每线程找局部最大值,然后归约。
- 如果线程数少,每个序列由一个线程处理,直接找最大值。
- 分布式归约:
- 如果有多个节点(msgerSize > 1),各节点计算的局部最大值通过 allgatherv 收集,找到全局最大值。
- 输出:
- 返回 maxIds,例如 [2, 1](序列 1 选 token ID 2,序列 2 选 token ID 1)。
namespace xft {
// Assume all samples have the same sampling params.
std::vector<int> greedySearch(float *logits, int sampleOffset, int sampleSize, int batchSize) {
TimeLine t("GreedySearch");
Messenger &messenger = Messenger::getInstance();
int numThreads = 0;
#pragma omp parallel
{
int tid = omp_get_thread_num();
if (tid == 0) { numThreads = omp_get_num_threads(); }
}
auto msgerSize = messenger.getSize();
// Max ID and value for each sample
std::vector<int> maxIds(batchSize);
float maxVals[batchSize];
// Small batch size (each sample can have at least 2 threads)
if (numThreads / batchSize >= 2) {
int thrPerSample = numThreads / batchSize;
int sizePerThr = (sampleSize + thrPerSample - 1) / thrPerSample;
int maxIndices[batchSize * thrPerSample];
float maxValues[batchSize * thrPerSample];
// TODO: if size is small, possible to cause out of boundary
#pragma omp parallel for collapse(2)
for (int b = 0; b < batchSize; ++b) {
for (int t = 0; t < thrPerSample; ++t) { // thread index inside the sample
int start = t * sizePerThr;
int end = (start + sizePerThr) > sampleSize ? sampleSize : (start + sizePerThr);
float *p = logits + b * sampleSize;
int maxIdx = start;
float maxVal = p[start];
for (int off = start + 1; off < end; ++off) {
if (p[off] > maxVal) {
maxVal = p[off];
maxIdx = off;
}
}
// False sharing happens, but since only one time, not avoided
maxIndices[b * thrPerSample + t] = maxIdx;
maxValues[b * thrPerSample + t] = maxVal;
}
}
// Local reduction
for (int i = 0; i < batchSize; ++i) {
int *pIndices = maxIndices + i * thrPerSample;
float *pValues = maxValues + i * thrPerSample;
int maxIdx = pIndices[0];
float maxVal = pValues[0];
for (int j = 1; j < thrPerSample; ++j) {
if (pValues[j] > maxVal) {
maxVal = pValues[j];
maxIdx = pIndices[j];
}
}
maxIds[i] = maxIdx;
maxVals[i] = maxVal;
}
}
// Each thread handle one sample (one row)
else {
#pragma omp parallel for
for (int i = 0; i < batchSize; ++i) {
int maxId = 0;
float *p = logits + i * sampleSize;
float maxVal = p[0];
for (int j = 1; j < sampleSize; ++j) {
if (p[j] > maxVal) {
maxVal = p[j];
maxId = j;
}
}
maxIds[i] = maxId;
maxVals[i] = maxVal;
}
}
// Reduce to get the max index (any better method??)
if (msgerSize > 1) {
float sendBuf[2 * batchSize];
float recvBuf[2 * batchSize * msgerSize];
for (int i = 0; i < batchSize; ++i) {
sendBuf[2 * i] = (float)(maxIds[i] + sampleOffset);
sendBuf[2 * i + 1] = maxVals[i];
}
std::vector<long unsigned int> recvCount(msgerSize, static_cast<long unsigned int>(2 * batchSize));
messenger.allgatherv(sendBuf, 2 * batchSize, recvBuf, recvCount);
for (int i = 0; i < batchSize; ++i) {
int maxId = (int)(recvBuf[2 * i] + 0.5f);
float maxVal = recvBuf[2 * i + 1];
for (int j = 1; j < msgerSize; ++j) {
if (recvBuf[2 * j * batchSize + 2 * i + 1] > maxVal) {
maxVal = recvBuf[2 * j * batchSize + 2 * i + 1];
maxId = (int)(recvBuf[2 * j * batchSize + 2 * i] + 0.5f);
}
}
maxIds[i] = maxId;
}
}
return maxIds;
}
前向传播
在刚刚的学习中,我们看到有这段话:
result = decoder->forward(workingSeqs, false);
它才是整个架构的精髓。
xFasterTransformer/src/models/models.cpp at main · intel/xFasterTransformer
这段 Model::forward 函数是语言模型(LLM)推理过程中的一个关键部分,负责执行模型的前向传播,生成 logits(模型对每个可能 token 的原始分数)。它支持单机和分布式环境,并处理批次中的序列(prompt 或 decode)。
std::tuple<float *, int, int> Model::forward(bool logitsAll) {
// This forward will sync and gather all logits.
// Return is a tuple of (logits, totalSeqSize, VocabSize)
// TODO: Deprecate the following Path
// Old path reture is (logits, offset, size)
if (searcher != nullptr) {
int64_t dims[3] = {batchSize, 1, seqLen};
return decoder->forward(inputIds.data(), dims, 0, logitsAll);
}
// TODO: checking waiting queue
if (workingGroup.empty()) {
printf("Please input prompt first.\n");
exit(-1);
}
// Assume that all sequences in the group are all prompts or all decodes.
// Prepare input data for the decoder.
std::vector<SequenceMeta *> workingSeqs;
for (auto x : workingGroup) {
workingSeqs.push_back(x->get(0));
if (x->getGroupSize() > 1 && x->getStep() > 1) {
for (int32_t i = 1; i < x->getGroupSize(); i++) {
workingSeqs.push_back(x->get(i));
}
}
}
std::tuple<float *, int, int> result = decoder->forward(workingSeqs, logitsAll);
int totalSeqSize = workingSeqs.size();
if (logitsAll && workingSeqs[0]->getStep() == 0) {
totalSeqSize = 0;
for (auto x : workingSeqs) {
totalSeqSize += x->getInputSeqLen();
}
}
Messenger &messenger = decoder->getMessenger();
if (messenger.getSize() > 1) {
// Sync and gather all logits
float *outBuf = std::get<0>(result);
int workers = messenger.getSize();
int splitSize = vocabSize / workers;
std::vector<long unsigned int> recvCount(workers);
std::vector<long unsigned int> splitSizes(workers);
for (int i = 0; i < workers; i++) {
splitSizes[i] = splitSize;
if (i < vocabSize % workers) { splitSizes[i]++; }
recvCount[i] = splitSizes[i] * totalSeqSize;
}
// warning: vocabSize * totalSeqSize may exceed the range of int when seq and batch size is large.
logits.resize(vocabSize * totalSeqSize);
logitsRecvBuf.resize(vocabSize * totalSeqSize);
messenger.allgatherv(outBuf, recvCount[messenger.getRank()], logitsRecvBuf.data(), recvCount);
// Reorder
int offset = 0;
for (int i = 0; i < workers; ++i) {
for (int j = 0; j < totalSeqSize; ++j) {
memcpy(logits.data() + (offset + j * vocabSize),
logitsRecvBuf.data() + offset * totalSeqSize + j * splitSizes[i],
splitSizes[i] * sizeof(float));
}
offset += splitSizes[i];
}
return std::tuple<float *, int, int>(logits.data(), totalSeqSize, vocabSize);
} else {
return std::tuple<float *, int, int>(std::get<0>(result), totalSeqSize, vocabSize);
}
}推理过程图
/*
Pipeline parallel and tensor parallel introduction:
1) MPI_Instances = 16,XFT_PIPELINE_STAGE = 4 => ctx->ppSize = 4, ctx->tpSize = 4
2) TP sync by oneCCL(row_comm) or shared_memory
3) PP sync by MPI MPI_COMM_WORLD
World Rank: => Row Rank: => Rank: tp0 tp1 tp2 tp3
[ 0, 1, 2, 3, [ 0, 1, 2, 3]; pp0 [ 0, 1, 2, 3];
4, 5, 6, 7, [ 0, 1, 2, 3]; pp1 [ 0, 1, 2, 3];
8, 9, 10, 11, [ 0, 1, 2, 3]; pp2 [ 0, 1, 2, 3];
12, 13, 14, 15]; [ 0, 1, 2, 3]; pp3 [ 0, 1, 2, 3];
Prompts
│
┌──────────────────┬─────────┴────────┬──────────────────┐
│ │ │ │
▼ ▼ ▼ ▼
Embedding(PP0) Embedding(PP0) Embedding(PP0) Embedding(PP0)
│ │ │ │
PP0 │ │ │ │
┌─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┐
│ TP0 │ TP1 │ TP2 │ TP3 │ layer0-7 │
│ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ │
│ │ OMP │ │ OMP │ │ OMP │ │ OMP │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │
│ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ │
│ ┌───────┼──────────────────┼─────AllReduce────┼──────────────────┼────────┐ │
│ └───────┼──────────────────┼──────────────────┼──────────────────┼────────┘ │
└─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┘
PP1 │ MPI Send/Recv │ │ │
┌─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┐
│ TP0 │ TP1 │ TP2 │ TP3 │ layer8-15 │
│ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ │
│ │ OMP │ │ OMP │ │ OMP │ │ OMP │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │
│ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ │
│ ┌───────┼──────────────────┼─────AllReduce────┼──────────────────┼────────┐ │
│ └───────┼──────────────────┼──────────────────┼──────────────────┼────────┘ │
└─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┘
PP2 │ MPI Send/Recv │ │ │
┌─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┐
│ TP0 │ TP1 │ TP2 │ TP3 │ layer16-23 │
│ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ │
│ │ OMP │ │ OMP │ │ OMP │ │ OMP │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │
│ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ │
│ ┌───────┼──────────────────┼─────AllReduce────┼──────────────────┼────────┐ │
│ └───────┼──────────────────┼──────────────────┼──────────────────┼────────┘ │
└─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┘
PP3 │ MPI Send/Recv │ │ │
┌─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┐
│ TP0 │ TP1 │ TP2 │ TP3 │ layer24-31 │
│ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ ┌───────▼────────┐ │
│ │ OMP │ │ OMP │ │ OMP │ │ OMP │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │ ▼ ▼ ▼ ▼ ▼ ▼ ...│ │
│ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ └───────┬────────┘ │
│ ┌───────┼──────────────────┼─────AllReduce────┼──────────────────┼────────┐ │
│ └───────┼──────────────────┼──────────────────┼──────────────────┼────────┘ │
└─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────┘
│ │ │ │
▼ ▼ ▼ ▼
Predictor(PP3) Predictor(PP3) Predictor(PP3) Predictor(PP3)
│ MPI Send/Recv │ │ │
▼ ▼ ▼ ▼
Searchers(PP0) Searchers(PP0) Searchers(PP0) Searchers(PP0)
│
▼
Output
*/flash attention
xFasterTransformer/src/layers/attention.h at main · intel/xFasterTransformer

template <typename KVCacheT>
void flashAttention(DecoderContext *ctx, xft::Matrix<ImT> &query, xft::Matrix<ImT> &key, xft::Matrix<ImT> &value,
xft::Matrix<ImT> &result, KVCacheTensor<KVCacheT> &presentKey, KVCacheTensor<KVCacheT> &presentValue,
const float *attnMask, int pastSeqLen) {
using AttnT = typename AttnTypeSelector<ImT>::type;
// How many heads this task should do
int batchSize = ctx->batchSize;
int respQHeads = this->endQHead - this->startQHead;
int respKVHeads = this->endKVHead - this->startKVHead;
int headSize = ctx->attHeadSize;
int qCols = respQHeads * headSize;
int kvCols = respKVHeads * headSize;
int qkvCols = qCols + kvCols * 2;
float scale = ctx->attFactor;
const int groupNum = ctx->attHeadNum / ctx->kvHeadNum;
int totalTokenSize = 0;
int inputSeqLens[batchSize], pastSeqLens[batchSize];
for (int i = 0; i < batchSize; ++i) {
inputSeqLens[i] = ctx->inputSeqLen;
pastSeqLens[i] = pastSeqLen;
totalTokenSize += inputSeqLens[i];
}
// TODO: kv dtype conversion for prefixSharing
AttnT *k, *v;
int kvStride;
// convert to AttnT forcely for accelerating purpose
if constexpr (!std::is_same_v<AttnT, ImT>) {
kvStride = kvCols * 2;
AttnT *kvBuf = (AttnT *)SimpleMemPool::instance().getBuffer(
"flashKVBuf", totalTokenSize * kvStride * sizeof(AttnT));
#pragma omp parallel for collapse(2)
for (uint64_t seq = 0; seq < totalTokenSize; ++seq)
for (uint64_t i = 0; i < kvCols * 2; i += headSize) {
const ImT *srcPtr = key.Data() + seq * qkvCols + i;
AttnT *dstPtr = kvBuf + seq * kvStride + i;
if constexpr (std::is_same_v<AttnT, bfloat16_t> && std::is_same_v<ImT, float>) {
bfloat16_t::cvt_float_to_bfloat16(srcPtr, dstPtr, headSize);
} else if constexpr (std::is_same_v<AttnT, float16_t> && std::is_same_v<ImT, float>) {
float16_t::cvt_float_to_float16(srcPtr, dstPtr, headSize);
} else if constexpr (std::is_same_v<AttnT, float> && std::is_same_v<ImT, bfloat16_t>) {
bfloat16_t::cvt_bfloat16_to_float(srcPtr, dstPtr, headSize);
} else if constexpr (std::is_same_v<AttnT, float> && std::is_same_v<ImT, float16_t>) {
float16_t::cvt_float16_to_float(srcPtr, dstPtr, headSize);
} else {
printf("Not supported Type in Flash Attention yet\n");
exit(-1);
}
}
k = kvBuf;
v = kvBuf + kvCols;
} else {
kvStride = qkvCols;
k = key.Data();
v = value.Data();
}
// [batch, src, head, headsize]
xft::selfScaledDpAttention<ImT, AttnT>(result.Data(), query.Data(), k, v, respQHeads, respKVHeads, headSize,
result.Stride(), query.Stride(), kvStride, batchSize, inputSeqLens, pastSeqLens, true, alibiSlopes,
attnMask, scale, ctx->numThreads,
[&](int qHeadIdx) { return (this->startQHead + qHeadIdx) / groupNum - this->startKVHead; });
// copy current key/values to cache
copyKVCache(ctx, key, value, presentKey, presentValue, pastSeqLen);
}- 功能:调用 selfScaledDpAttention 执行 Flash Attention 计算。
- 关键参数:
- query.Data(), k, v:输入 Query、Key、Value 数据。
- respQHeads, respKVHeads, headSize:查询头、键/值头数量和头大小。
- batchSize, inputSeqLens, pastSeqLens:批次和序列长度信息。
- attnMask, scale:注意力掩码和缩放因子。
- ctx->numThreads:并行线程数。
- GQA 映射函数:
(int qHeadIdx) { return (this->startQHead + qHeadIdx) / groupNum - this->startKVHead; }- 决定每个查询头(
qHeadIdx)对应的键/值头索引。 groupNum(attHeadNum/kvHeadNum)实现 GQA 的分组逻辑,例如 8 个查询头分成 2 组,每组 4 个头共享 1 个键/值头。
- 决定每个查询头(
- 作用:计算注意力输出,存入 result,支持 GQA 的共享键/值机制。
缩放点积
selfScaledDpAttention 实现了缩放点积注意力,结合 Flash Attention 和 GQA 的优化,具体功能:
- 计算注意力:根据输入的 Query(query)、Key(key)、Value(value),生成注意力输出,存入 output。
- 支持 GQA:通过 qHeadNum、kvHeadNum 和 headMap 实现查询头分组,减少内存和计算量。
- 分块计算:将序列分成小块(srcBlk 和 tgtBlk),减少内存占用。
- 因果掩码:支持因果注意力(causal),防止模型看到未来的 token(用于解码)。
- 并行优化:使用 OpenMP 多线程和内存池(SimpleMemPool)加速计算。
// scaled dot-product attention: bmm1 + softmax + bmm2
// query key value are all in [*, seqLen, headnum, headsize] order
template <typename T, typename AttnT>
void selfScaledDpAttention(T *output, const T *query, const AttnT *key, const AttnT *value, int qHeadNum, int kvHeadNum,
int headSize, int oStride, int qStride, int kvStride, int batchSize, const int *inputSeqLens,
const int *pastSeqLens, bool causal, const float *alibiSlopes, const float *attnMask, const float scale,
int threadNum, std::function<int(int)> headMap = nullptr) {
// output = softmax(query * trans(key)) * value
// causal = True: llama-family, chatglm2; extra alibiSlopes for baichuan
// causal = False: just chatglm (prefixLLM, 0:startid) need attnMask for now
// get the max seqLen
int maxSrcLen = 0, maxTgtLen = 0;
for (int i = 0; i < batchSize; ++i) {
maxSrcLen = std::max(maxSrcLen, inputSeqLens[i]);
maxTgtLen = std::max(maxTgtLen, inputSeqLens[i] + pastSeqLens[i]);
}
// compute the seqStartLoc
int seqStartLoc[batchSize + 1];
seqStartLoc[0] = 0;
for (int i = 0; i < batchSize; ++i) {
seqStartLoc[i + 1] = seqStartLoc[i] + inputSeqLens[i];
}
// closest value of power of 2
int minBlk = (int)std::pow(2, int(std::log2((maxSrcLen + 1) / 2)));
// Split sequence to make sure a moderate sync frequency and the intermediate
// result [srcSeq * tgtSeq] in cache. The current block size is derived from practical experience.
int srcBlk = std::min(256, minBlk);
int tgtBlk = std::min(512, maxTgtLen);
int groupNum = qHeadNum / kvHeadNum;
int numArr = 7;
int arrStride = (4 + tgtBlk + 2 * headSize) * srcBlk;
float *thrBuf
= (float *)SimpleMemPool::instance().getBuffer("threadBuffers", sizeof(float) * threadNum * arrStride);
float **thrPtrBuf
= (float **)SimpleMemPool::instance().getBuffer("threadPtrBuffers", sizeof(float *) * threadNum * numArr);
float **preSum = thrPtrBuf;
float **sum = thrPtrBuf + threadNum;
float **preMax = thrPtrBuf + threadNum * 2;
float **max = thrPtrBuf + threadNum * 3;
float **qkArr = thrPtrBuf + threadNum * 4;
float **expQkvArr = thrPtrBuf + threadNum * 5;
float **qArr = thrPtrBuf + threadNum * 6;
for (int i = 0; i < threadNum; ++i) {
preSum[i] = thrBuf + srcBlk * i;
sum[i] = thrBuf + srcBlk * threadNum + srcBlk * i;
preMax[i] = thrBuf + srcBlk * threadNum * 2 + srcBlk * i;
max[i] = thrBuf + srcBlk * threadNum * 3 + srcBlk * i;
qkArr[i] = thrBuf + srcBlk * threadNum * 4 + srcBlk * tgtBlk * i;
expQkvArr[i] = thrBuf + srcBlk * threadNum * (4 + tgtBlk) + srcBlk * headSize * i;
qArr[i] = thrBuf + srcBlk * threadNum * (4 + tgtBlk + headSize) + srcBlk * headSize * i;
}
#pragma omp parallel for collapse(3) schedule(dynamic)
for (uint64_t b = 0; b < batchSize; ++b) {
for (int h = 0; h < qHeadNum; ++h) {
for (int m = 0; m < maxSrcLen; m += srcBlk) {
int srcLen = inputSeqLens[b];
int tgtLen = inputSeqLens[b] + pastSeqLens[b];
if (m >= srcLen) { continue; }
int tid = omp_get_thread_num();
int qRealBlk = std::min(srcBlk, srcLen - m);
uint64_t srcOff = seqStartLoc[b] * qStride + h * headSize;
uint64_t outOff = seqStartLoc[b] * oStride + h * headSize;
const T *qbuf = query + srcOff + m * qStride;
AttnT *q = (AttnT *)qArr[tid];
T *out = output + outOff + m * oStride;
// reset out
for (int ii = 0; ii < qRealBlk; ++ii) {
#pragma omp simd
for (int jj = 0; jj < headSize; ++jj) {
out[ii * oStride + jj] = 0; // reset output
q[ii * headSize + jj] = (AttnT)(qbuf[ii * qStride + jj]); // reset output
}
}
// reset sum
#pragma omp simd
for (int ii = 0; ii < qRealBlk; ++ii) {
preSum[tid][ii] = 0;
sum[tid][ii] = 0;
preMax[tid][ii] = std::numeric_limits<float>::lowest();
max[tid][ii] = std::numeric_limits<float>::lowest();
}
int kvHeadIdx = (headMap == nullptr) ? h / groupNum : headMap(h);
uint64_t tgtOff = seqStartLoc[b] * kvStride + kvHeadIdx * headSize;
const AttnT *k = key + tgtOff;
const AttnT *v = value + tgtOff;
// split the target len dimension
for (int n = 0; n < tgtLen; n += tgtBlk) {
int kvRealBlk = std::min(tgtBlk, tgtLen - n);
// mask out. TODO: for prefixLLM
if (causal && m + qRealBlk - 1 < n) {
//printf("Skip bs %d head %d src %d tgt %d\n", b, h, m, n);
break;
}
const AttnT *kBlk = k + n * kvStride;
const AttnT *vBlk = v + n * kvStride; // 分块注意力计算 功能:将目标序列(Key/Value)分成块(tgtBlk),处理当前块(kBlk, vBlk)。
if (causal) { // 因果掩码:如果 causal=true(如 LLaMA 模型),跳过未来的 token(m + qRealBlk - 1 < n)。因果掩码是注意力机制中的一种规则,用来限制模型只能“看到”当前和之前的词,而不能看到未来的词。这在生成文本(像聊天机器人逐字生成回答)时非常重要,因为模型在生成某个词时,不应该“偷看”后面的词,否则就相当于作弊了。
// causal=True, build-in mask
float headSlope = alibiSlopes != nullptr ? alibiSlopes[h] : 0.0f;
DecoderUtil::incrementalTileAttentionCausal(q, kBlk, vBlk, headSlope, m, n, qRealBlk, headSize,
kvRealBlk, preSum[tid], sum[tid], preMax[tid], max[tid], scale, qkArr[tid],
expQkvArr[tid], out, headSize, kvStride, kvStride, oStride);
} else {
// causal=False, need mask matrix for now
const float *attnMsk = attnMask + seqStartLoc[b] * tgtLen + m * tgtLen + n;
DecoderUtil::incrementalTileAttention(q, kBlk, vBlk, attnMsk, qRealBlk, headSize, kvRealBlk,
tgtLen, preSum[tid], sum[tid], preMax[tid], max[tid], scale, qkArr[tid], expQkvArr[tid],
out, headSize, kvStride, kvStride, oStride);
}
}
}
}
}
return;
}Cross Attention Kernel
void crossAttention(bfloat16_t *output, bfloat16_t *query, bfloat16_t *key, bfloat16_t *value, int qHeadNum,
int kvHeadNum, int headSize, int qStride, int kvStride, int batchSize, int cacheBlkStride, int cacheBlkSize,
const int *contextSizes, const float scale, const float *alibiSlopes, const void *kcache, const void *vcache,
int *blockTables, int *blockNums, int *slots) {
int maxCtxSize = 0;
int blkOffsets[batchSize]; // offset in blockTables
int curOff = 0;
// blocktables dim = 2
for (int i = 0; i < batchSize; ++i) {
if (contextSizes[i] > maxCtxSize) { maxCtxSize = contextSizes[i]; }
}
int max_block_num = (maxCtxSize + cacheBlkSize - 1) / cacheBlkSize;
for (int i = 0; i < batchSize; ++i) {
blkOffsets[i] = curOff;
curOff += max_block_num;
}
int thrScoreSize = (maxCtxSize + 15) / 16 * 16;
float *scores = (float *)SimpleMemPool::instance().getBuffer("qkscore", threadNum * thrScoreSize * sizeof(float));
#pragma omp parallel for collapse(2)
for (int b = 0; b < batchSize; ++b) {
for (int i = 0; i < qHeadNum; ++i) {
int *blkIndices = blockTables + blkOffsets[b];
// Copy one head of current key to cached keys
auto dst = (bfloat16_t *)kcache + slots[b] * kvHeadNum * headSize + i * headSize;
xft::copy(dst, key + i * headSize, headSize);
// Q * K
int m = 1;
int k = headSize;
int n = contextSizes[b] + 1;
int lda = qStride;
int ldb = kvHeadNum * headSize;
int ldc = n;
auto A = query + i * headSize;
auto baseB = (bfloat16_t *)kcache + i * headSize;
auto C = scores + omp_get_thread_num() * thrScoreSize;
small_sgemm_bf16bf16f32_b(true, m, n, k, (XDNN_BF16 *)A, lda, (XDNN_BF16 *)baseB, ldb, C, ldc, blkIndices,
cacheBlkStride, cacheBlkSize);
// Softmax(Q * K)
small_softmax_f32(C, scale, n);
// Copy current value to cached values
dst = (bfloat16_t *)vcache + slots[b] * kvHeadNum * headSize + i * headSize;
xft::copy(dst, value + i * headSize, headSize);
// Softmax * V
std::swap(k, n);
lda = ldc;
ldb = kvHeadNum * headSize;
ldc = qHeadNum * headSize;
baseB = (bfloat16_t *)vcache + i * headSize;
auto baseC = output + b * ldc + i * headSize;
small_sgemm_f32bf16bf16_b(false, m, n, k, C, lda, (XDNN_BF16 *)baseB, ldb, (XDNN_BF16 *)baseC, ldc,
blkIndices, cacheBlkStride, cacheBlkSize);
} // end for i
} // end for b
}
small_gemm_transb
这段代码是一个使用 AVX-512 指令集优化的小型矩阵乘法(GEMM,General Matrix Multiply)实现,专门处理矩阵 B B B 的转置形式(即 $C=A⋅BT C = A \cdot B^T C=A⋅BT$)。矩阵 A A A 是 $M×K M \times K M×K$,矩阵 B B B 是 $N×K N \times K N×K$(由于转置,存储为 K×N K \times N K×N),结果矩阵 C C C 是 M×N M \times N M×N。
template <typename TA, typename TB, int M, int N>
void small_gemm_transb(const TA *A, const TB *B, float *C, int K, int lda, int ldb, int ldc) {
// vc[0] vc[1] ... vc[N-1]
// vc[N] vc[N+1] ...
// ..
// vc[(M-1)*N] ...
__m512 vc[M * N];
int vecs = (K + 15) / 16; // vector size in AVX512 计算需要多少个 16 元素块:vecs=⌈K/16⌉ \text{vecs} = \lceil K / 16 \rceil vecs=⌈K/16⌉。
__mmask16 mask = (K % 16 == 0 ? 0xffff : (1 << (K % 16)) - 1); // mask for last vector 是一个 16 位掩码,用于控制最后一个向量的有效元素。
compile_time_for<M * N>::op([&vc](auto i) { vc[i] = _mm512_set1_ps(0); });
// The last vector is not included
for (int v = 0; v < vecs - 1; ++v) {
const TA *pA = A + v * 16;
const TB *pB = B + v * 16;
__m512 vb[N];
__m512 va;
compile_time_for<M * N>::op([&](auto i) {
constexpr int idx = i;
// Load from A when reach to first column in vc matrix
if constexpr (idx % N == 0) {
va = xft::load_avx512(pA);
pA += lda;
}
// Load from B when reach to first row in vc matrix
if constexpr (idx < N) {
vb[idx] = xft::load_avx512(pB);
pB += ldb;
}
constexpr int col = idx % N;
vc[idx] = _mm512_fmadd_ps(va, vb[col], vc[idx]);
});
}
// The last vector computing, together with data store
{
__m512 vb[N];
__m512 va;
const TA *pA = A + (vecs - 1) * 16;
const TB *pB = B + (vecs - 1) * 16;
float *pC = C;
compile_time_for<M * N>::op([&](auto i) {
constexpr int idx = i;
if constexpr (idx % N == 0) {
va = xft::load_avx512(mask, pA);
pA += lda;
}
if constexpr (idx < N) {
vb[idx] = xft::load_avx512(mask, pB);
pB += ldb;
}
constexpr int col = idx % N;
vc[idx] = _mm512_fmadd_ps(va, vb[col], vc[idx]); ///使用 FMA(Fused Multiply-Add)指令
pC[col] = _mm512_reduce_add_ps(vc[idx]);
// Reach to the row end
if constexpr (i % N == N - 1) { pC += ldc; }
});
}
}- 向量化:
- 使用 AVX-512 向量(512 位,16 个浮点数)加速计算。
- 将 K K K 维度分成多个 16 元素块,逐块处理。
- 最后一个块使用掩码处理不足 16 的元素。
- 优化:
- compile_time_for 展开循环,减少运行时开销。
- FMA 指令 (_mm512_fmadd_ps) 融合乘法和加法,提高性能。
- 转置 B B B 减少内存访问的非连续性。
- 内存布局:
- A A A、B B B、C C C 按行主序存储,步长分别为 lda、ldb、ldc。
- B B B 是转置形式,实际存储为 K×N K \times N K×N。
适用场景:适合小型矩阵(固定 M M M、N N N),模板参数允许编译时优化。