ParslFest 25 会议记录
- Conference
- 2025-08-29
- 804 Views
- 0 Comments
- 1866 Words

ParslFest
会议的目标是找到新的idea和设计,以及展示一些用户案例。
Parsl: Parallel Scripting in Python
Join our dedicated #parslfest2025 channel on Slackto connect with fellow attendees, ask questions, etc.
- Not on Parsl Slack yet? Join our space for free.
Below is a high-level overview of the ParslFest program. All talks will be presented over Zoom, recorded, edited, and uploaded to Parsl’s YouTube channel for later viewing.
Starts
Kyle给本次的会议做了开场
Codes, Collaboration, ideas for New Contribution on Parsl
WARTH: Workload Resilience Across Task Hierarchies in Task-based Parallel Programming Frameworks
来自Sicheng学姐在CCGRID25发表的工作
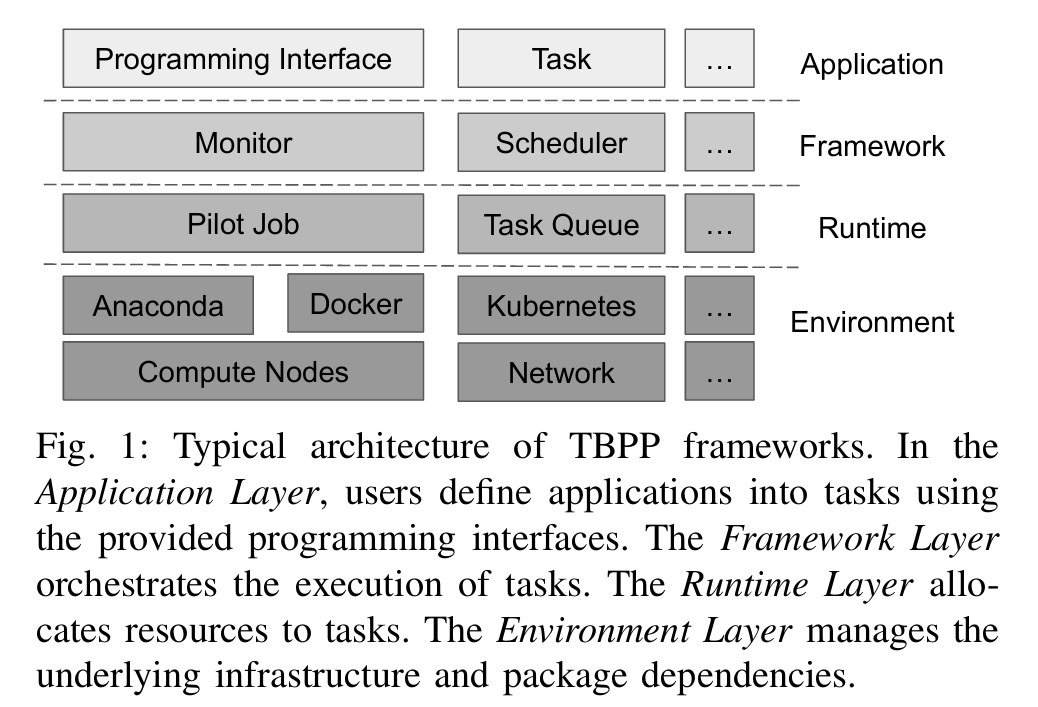
这份工作做的是TBPP的resilience框架。TBPP是将任务做成DAG执行流程图,随后在多节点上分布式启动。
TBPP以往的常见Resilience处理是Retry和checkpoint机制。这两个机制在DAG的异构执行图的情况下会出现这样的问题:节点间重启动/存储checkpoint时间/资源使用不均(有的节点可能存储100GB,重启动100次)
WARTH框架尝试将整个TBPP执行分解为多层结构的错误,并在对应层中存储logs和checkpoints去减少logs及错误。
处理事件失败的工作流程
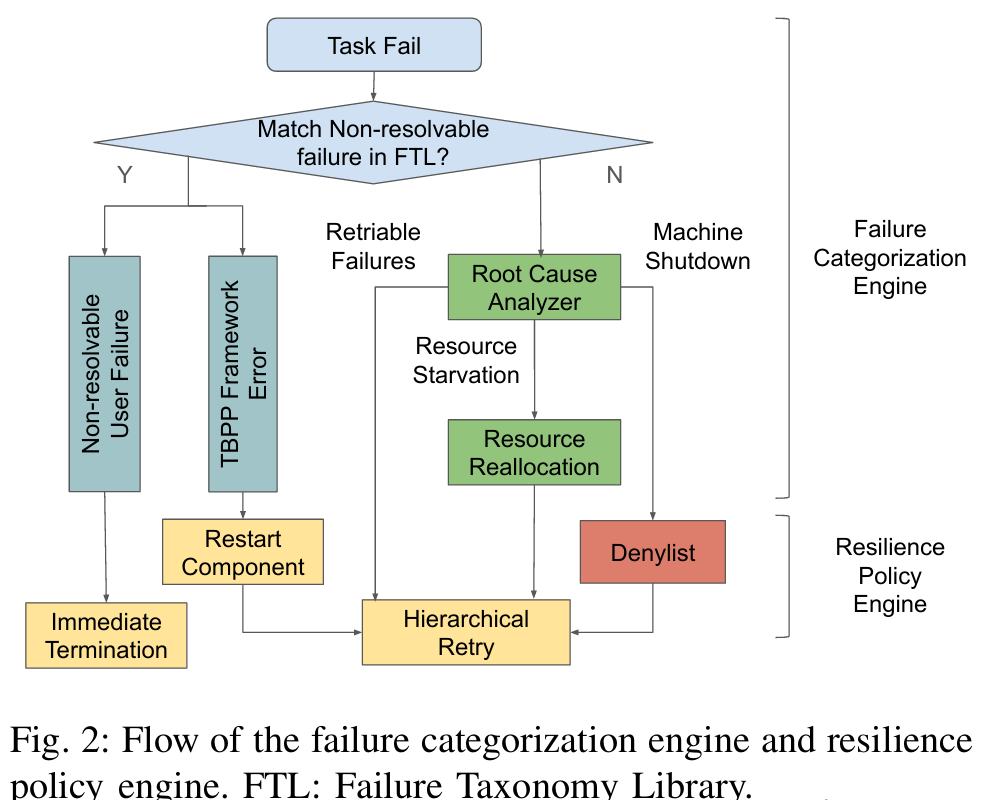

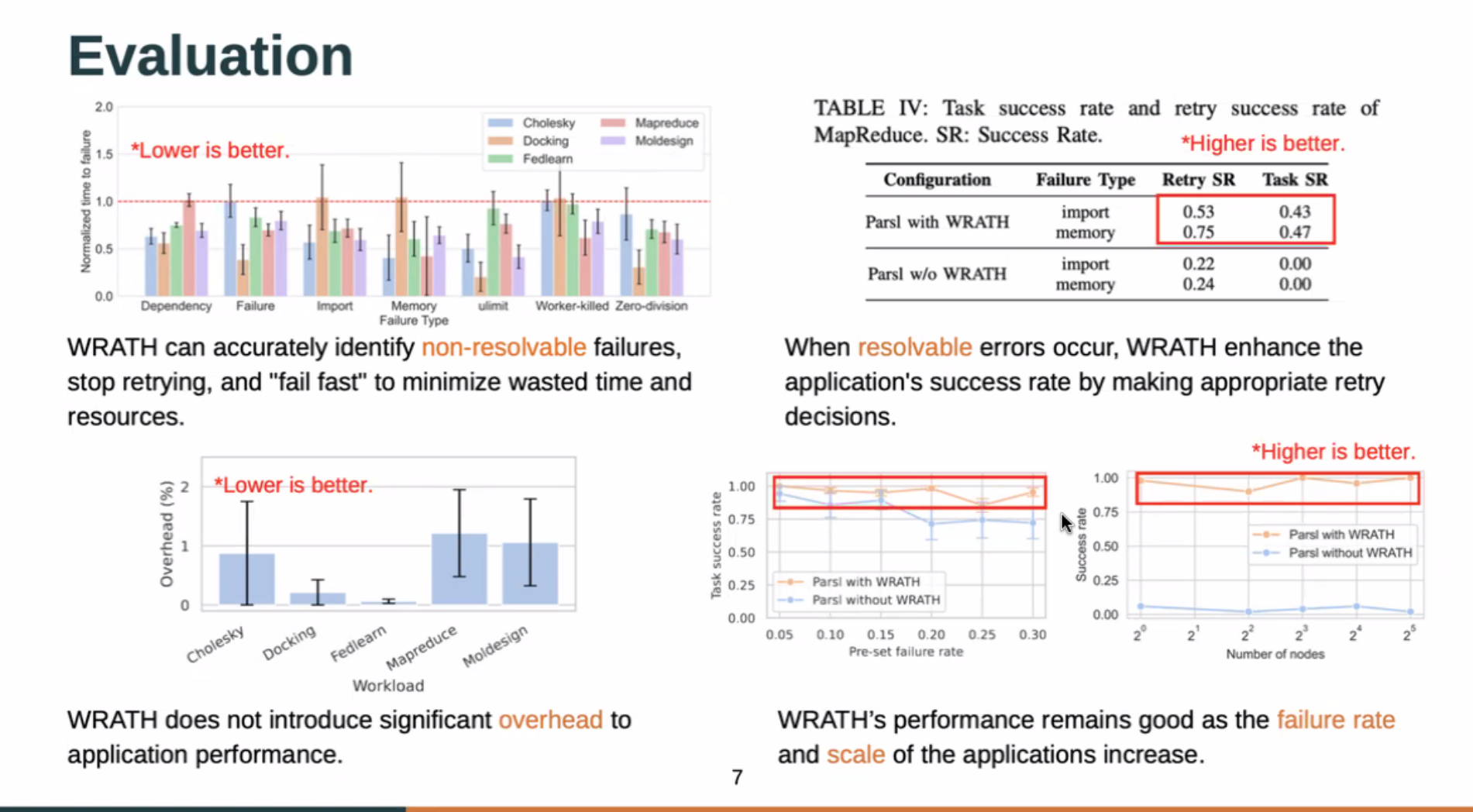

问题:
在globus compute里能否使用?毕竟这里边的jobs更多。
Scheduler
Implementing
João Gabriel Loureiro de Lima Lembo
冷启动时间优化 Techniques
这份工作研究的是分布式工作里的冷启动的时间优化。
在分布式系统冷启动时,我们的主要workload 是将我们的Jobs的data,codes发布到各个节点上,并完成基础的通信链接。

在尝试的很多优化中,新的数据分发算法得到的性能提升是最多的。
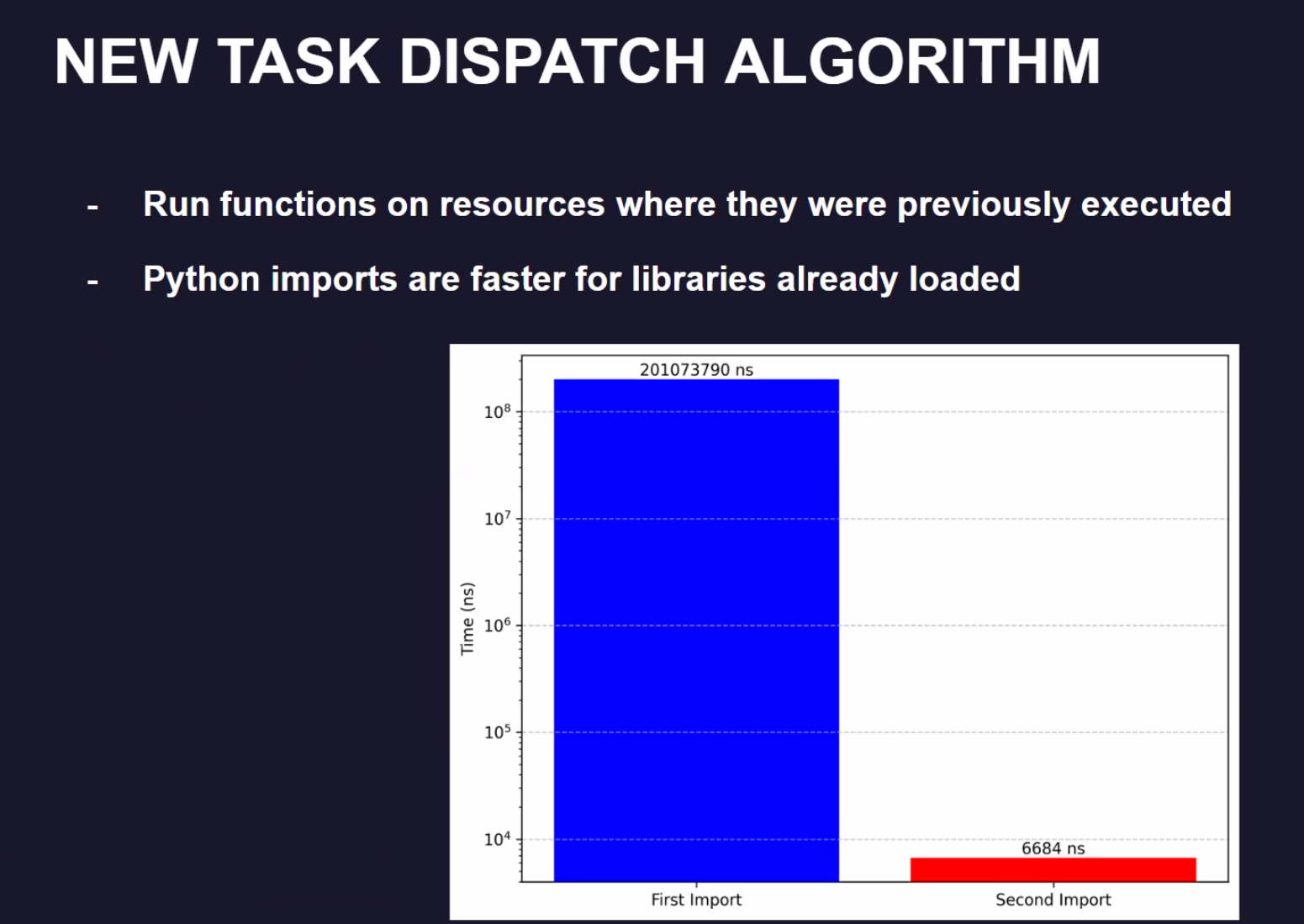

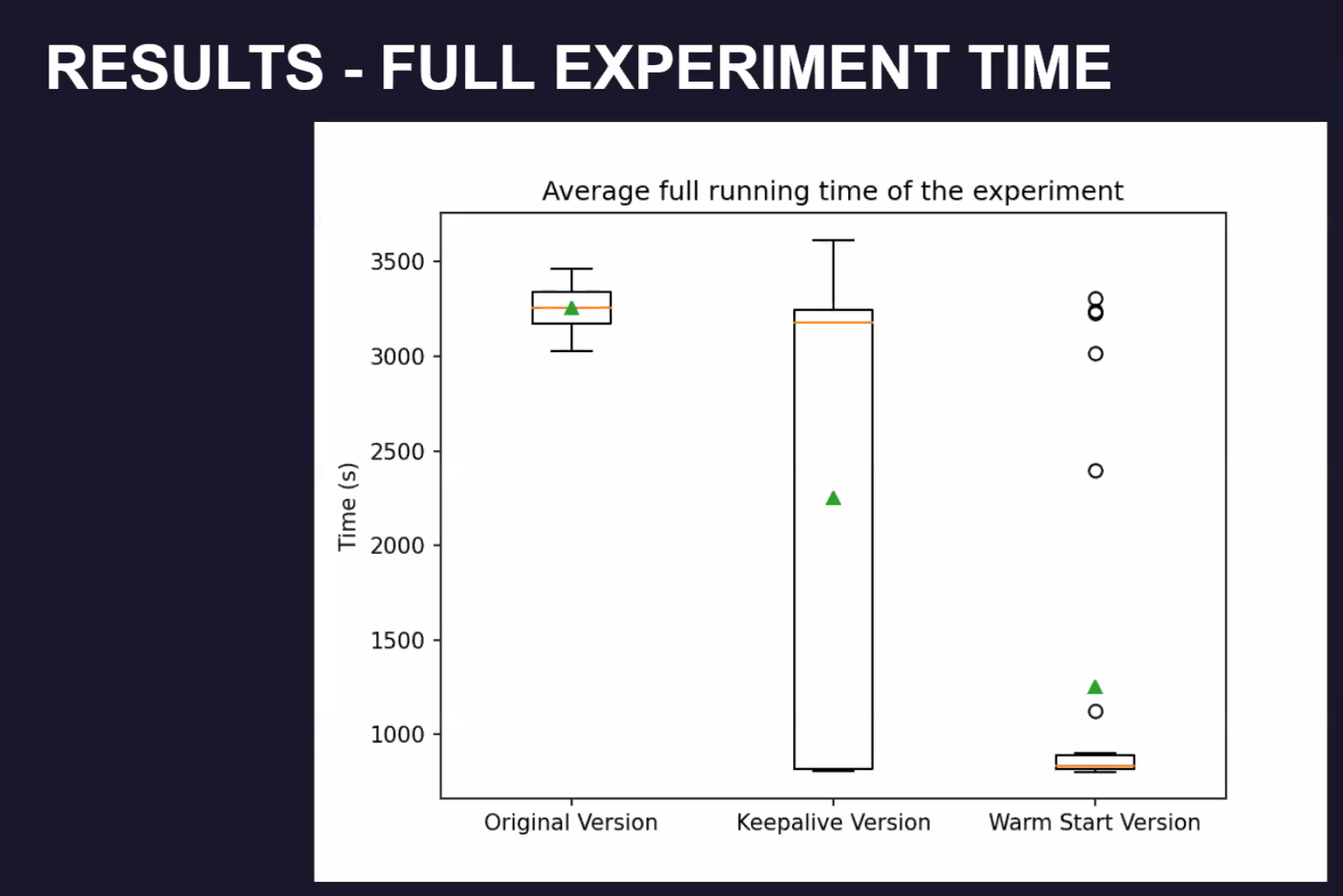
实验

Execution time
warm-start 实验情况

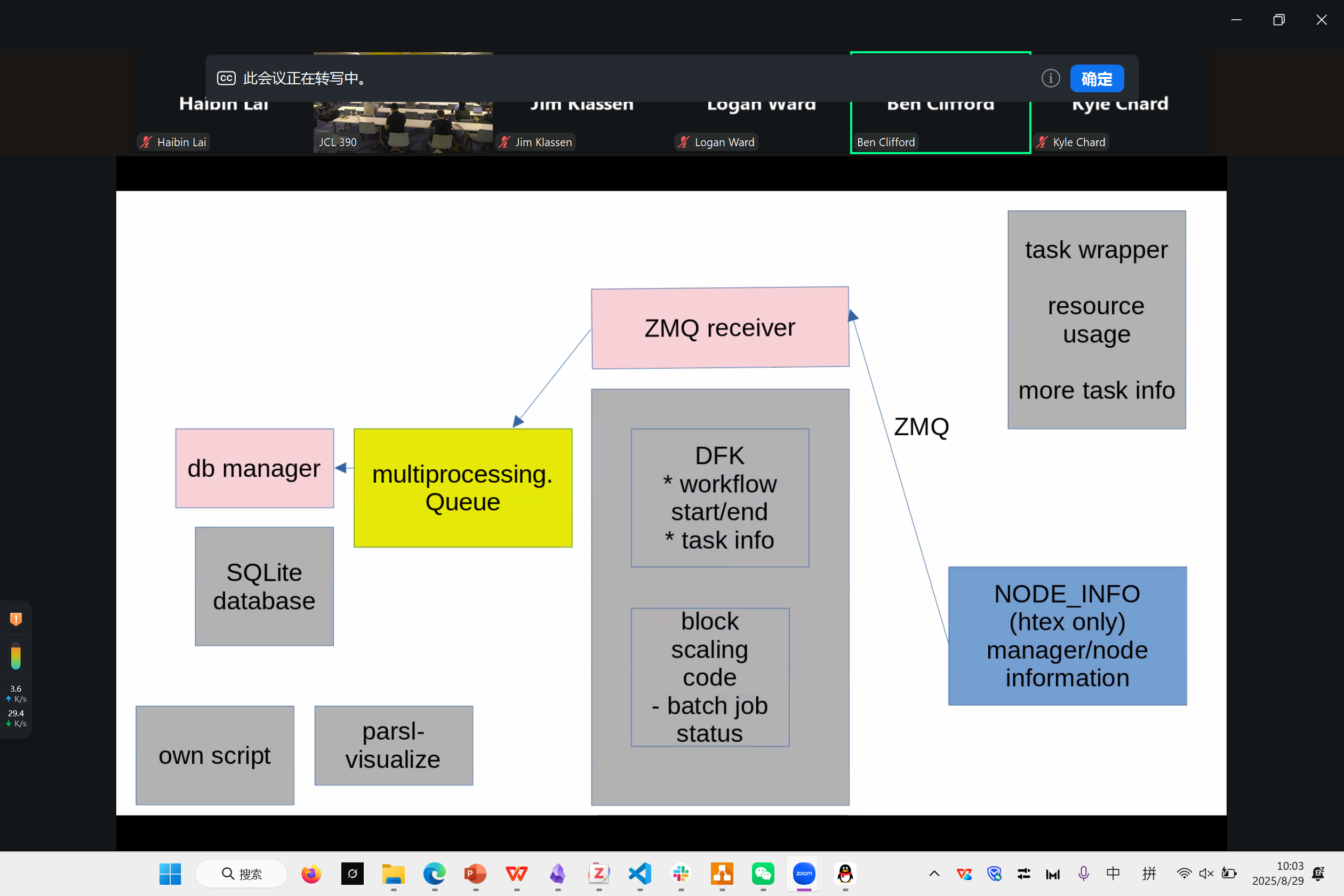
Parsl+Globus Compute Integration
来自科罗拉多大学的 Christopher Harrop
目标是将Parsl系统和Globus Compute系统执行的任务结合在一起,制作一些快速配置的脚本,并尝试进行一定的性能优化

为了尝试这个目标,在此之前我们需要配置好一个分布式config系统。现在我们只需要系统自动配置。
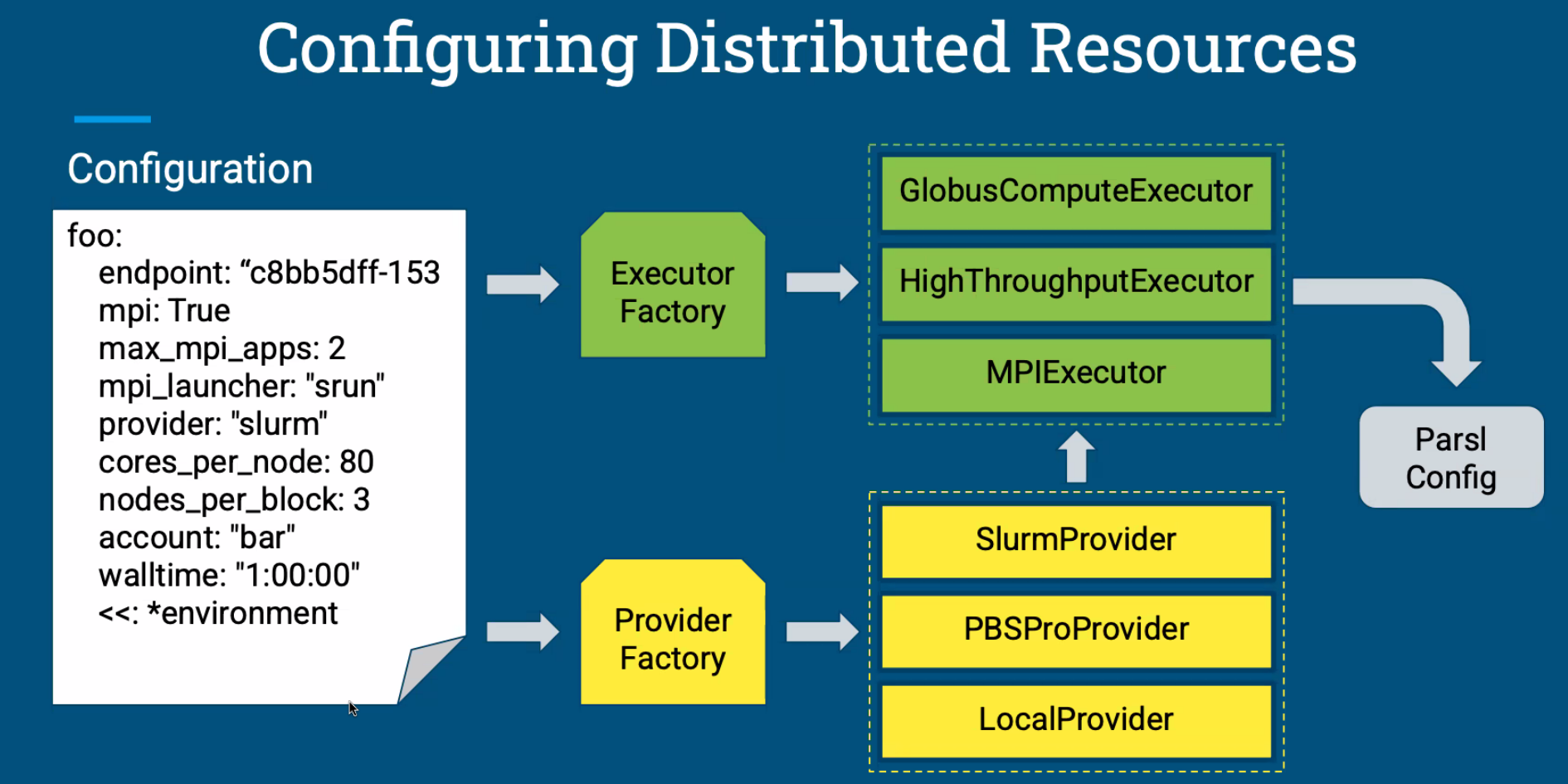
主要工作是完成了 启动脚本及机器管理 的系统。

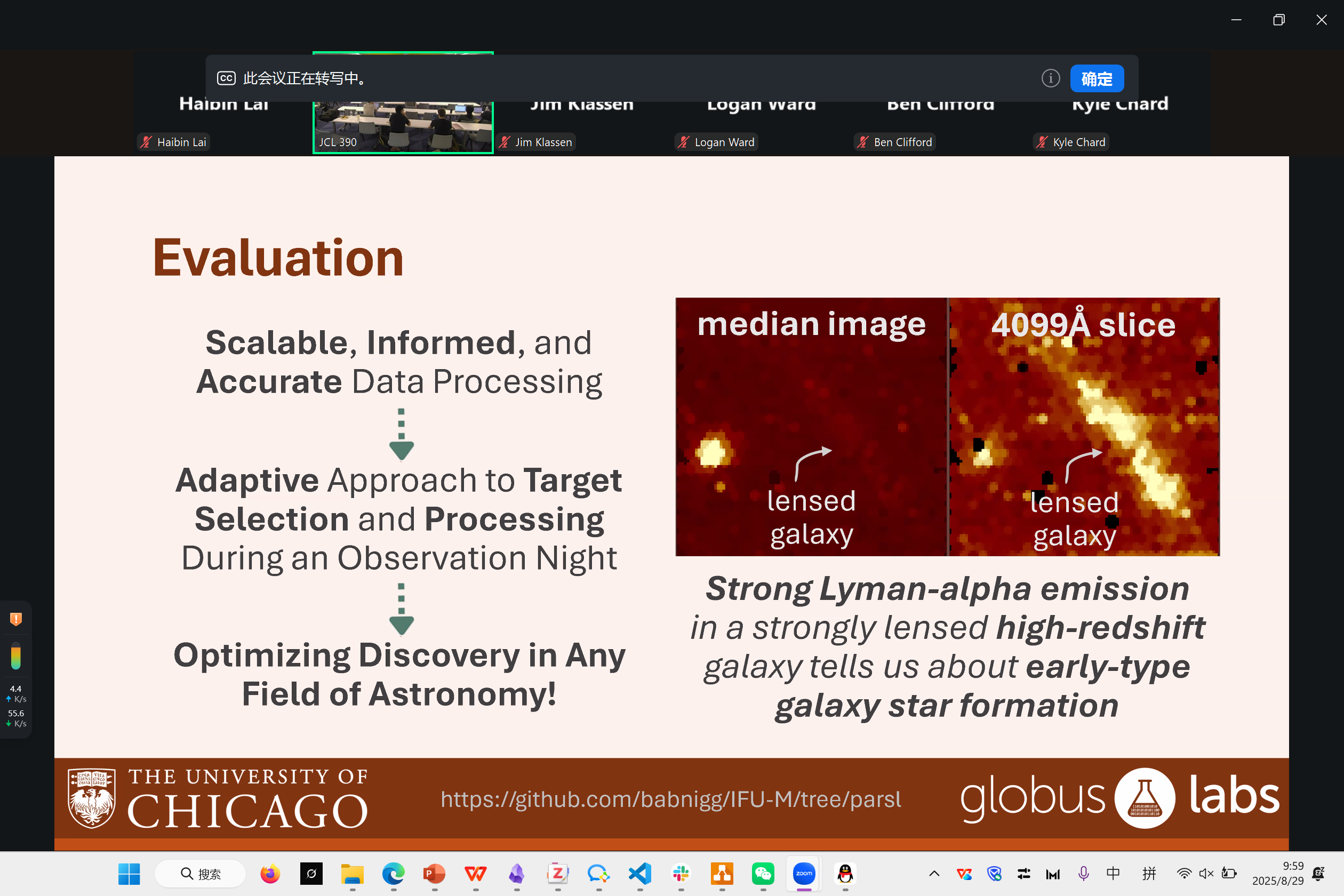
Resilient Solutions for Tomographic Reconstruction
来自好哥们Hai
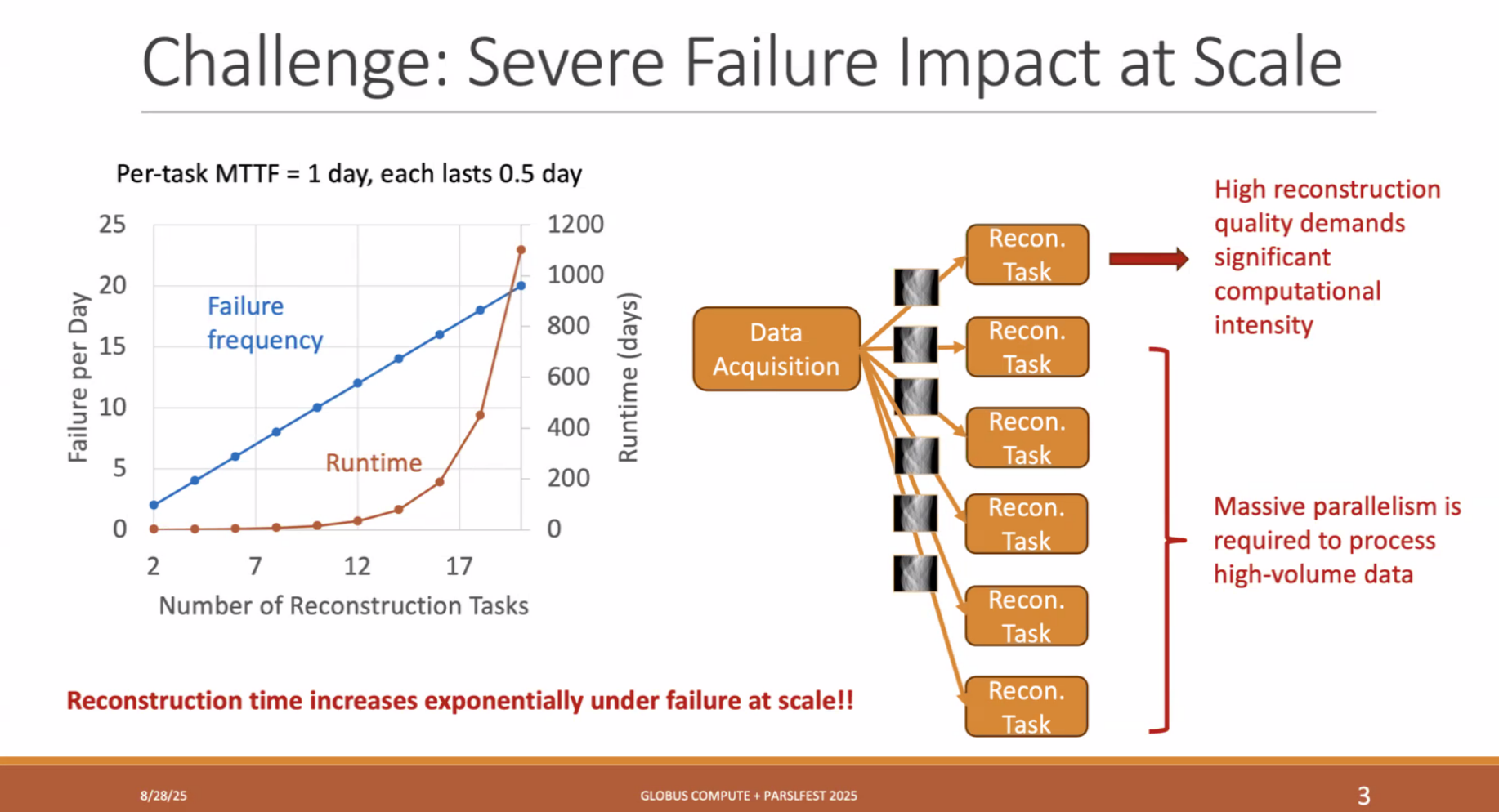
这份工作尝试在三维重建这一个workflow里构建一个可靠的分布式系统
Frontiers | Resilient execution of distributed X-ray image analysis workflows

Tomographic 多维层析成像
层析成像又称断层扫描、层析术,是使用任何类型的穿透波,对物体以分段(sections)或切片(sectioning)形式成像的方法或技术。层析成像所呈现的图像称为层析成像图(tomogram)或断层扫描图。
整个workflow如下图

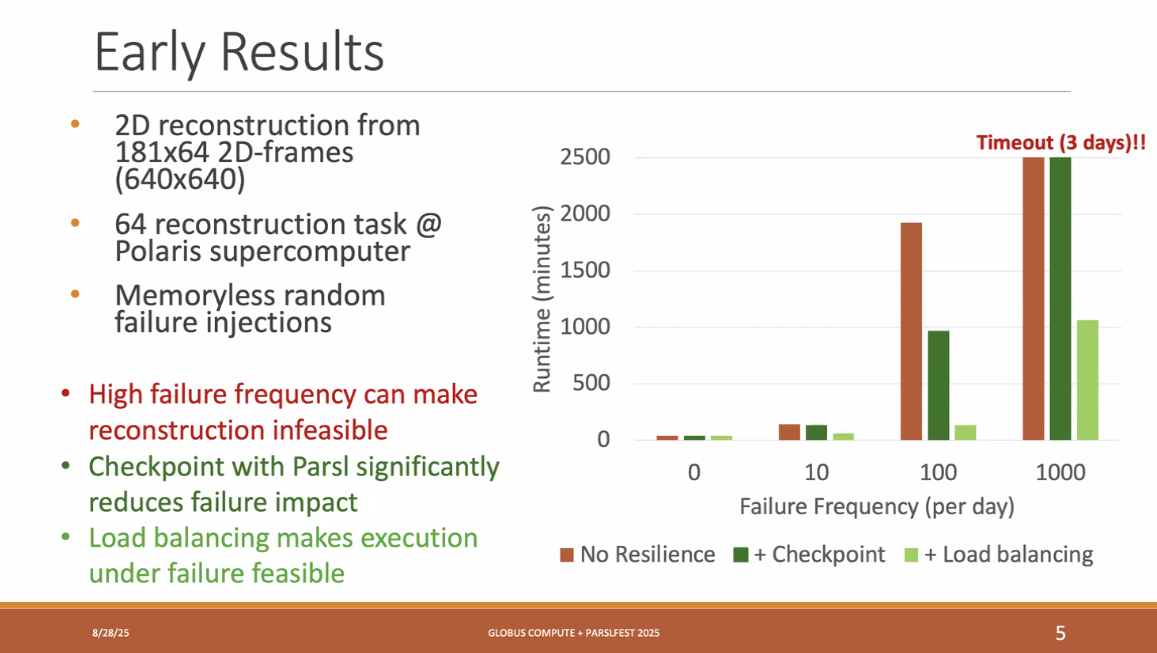
随着我们的workload数量增加,我们的Failure Frequency变得更高了
主要设计是 加入checkpoint机制+节点迁移load balancing。
Making DAG-Based Automation Accessible on Android & Low-Power Device
这份工作尝试在 Android 等低功耗系统上运行DAG执行
2024 Aug -> 2025 Aug
从 Parsl 魔改的prototype

主要关注的点:
Offline 优先,尽可能不要发到更多节点上
能耗
Termux ready。这是一个安卓模拟器,可以模拟手机
Plugin:可扩展性

主要workflow:parslet启动->发布到各个节点->记录和汇总logs ->收集结果


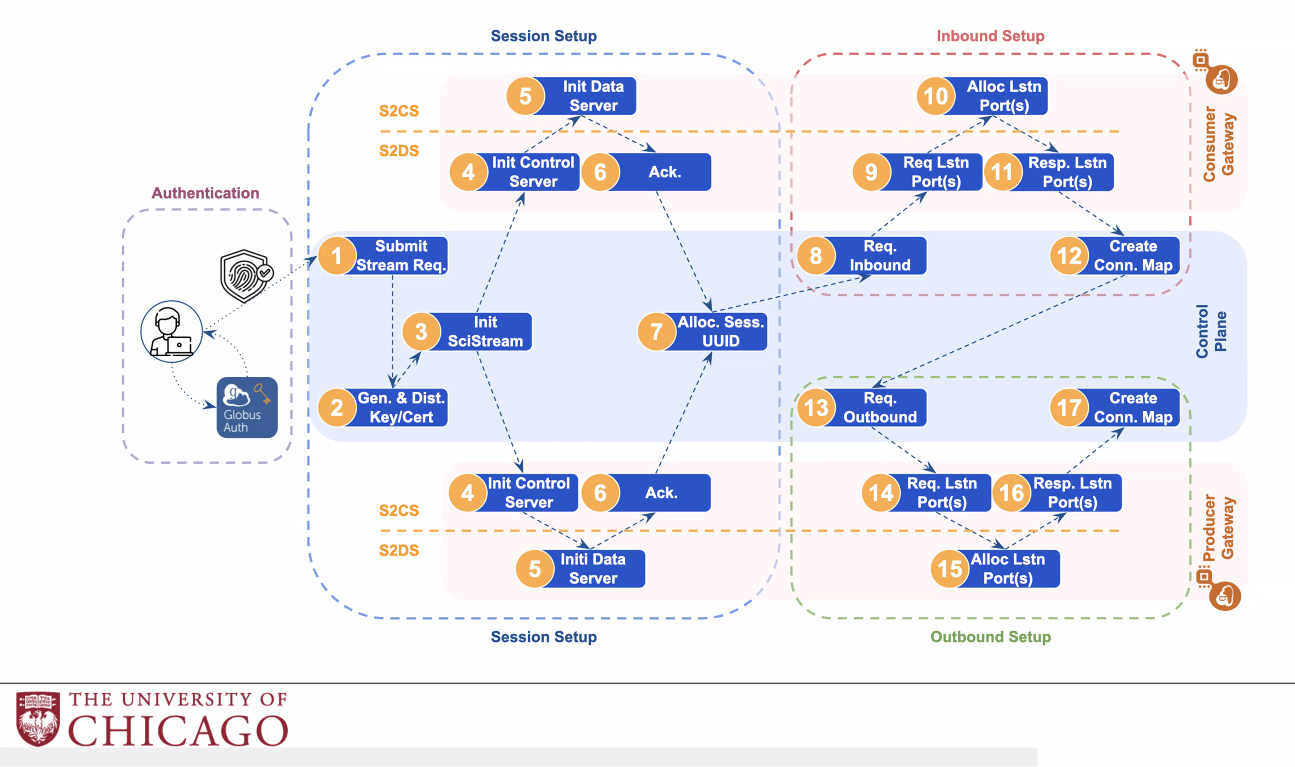
Scientific Data Streaming
这篇工作是在globus compute上做一个面向科学工作流的高性能流式系统

目前的科学工作流的数据情况:
- 数据密集:来自天文望远镜等数据数据收集器的数据量是相当大的
- 高成本:大量的科学计算数据处理需要大量CPU进行支撑,造成成本高
- HPC Infra成本:配置环境很累

SciStream 便是
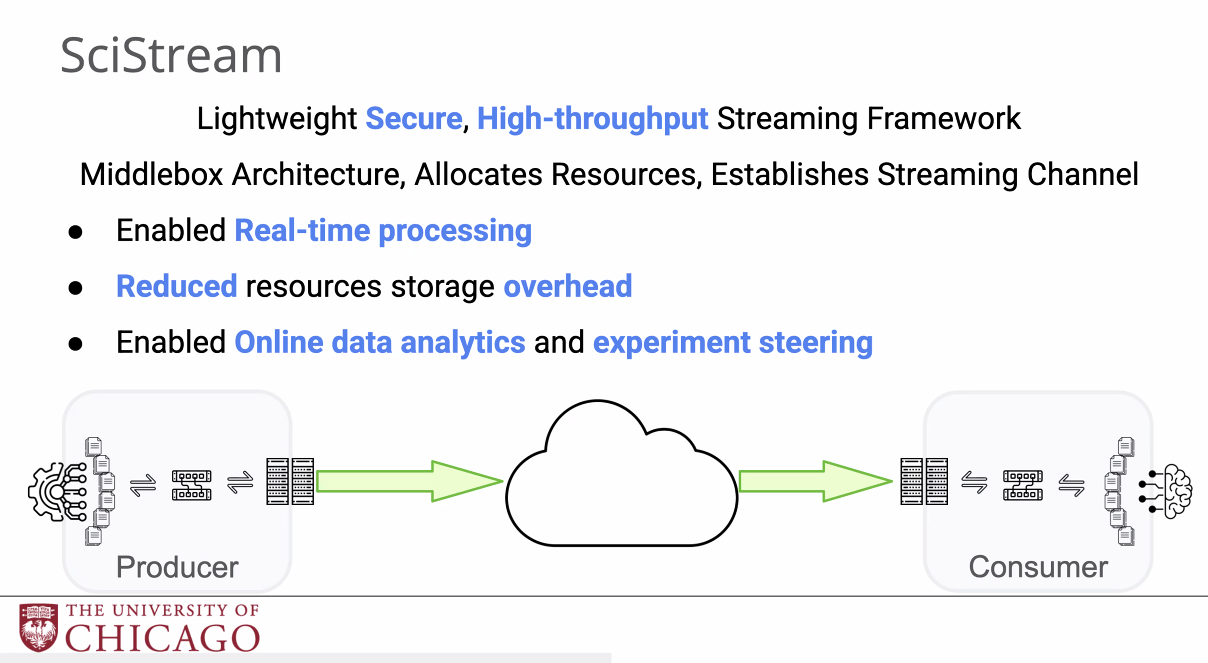
目前工作流的缺陷

工作流演示
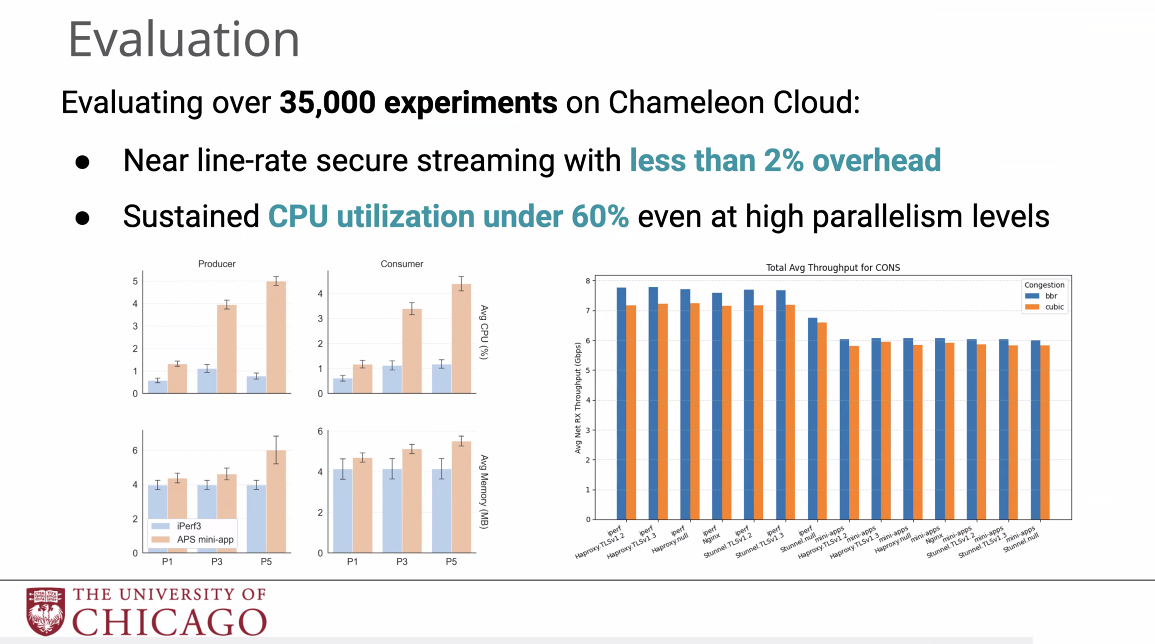
Extensive 实验
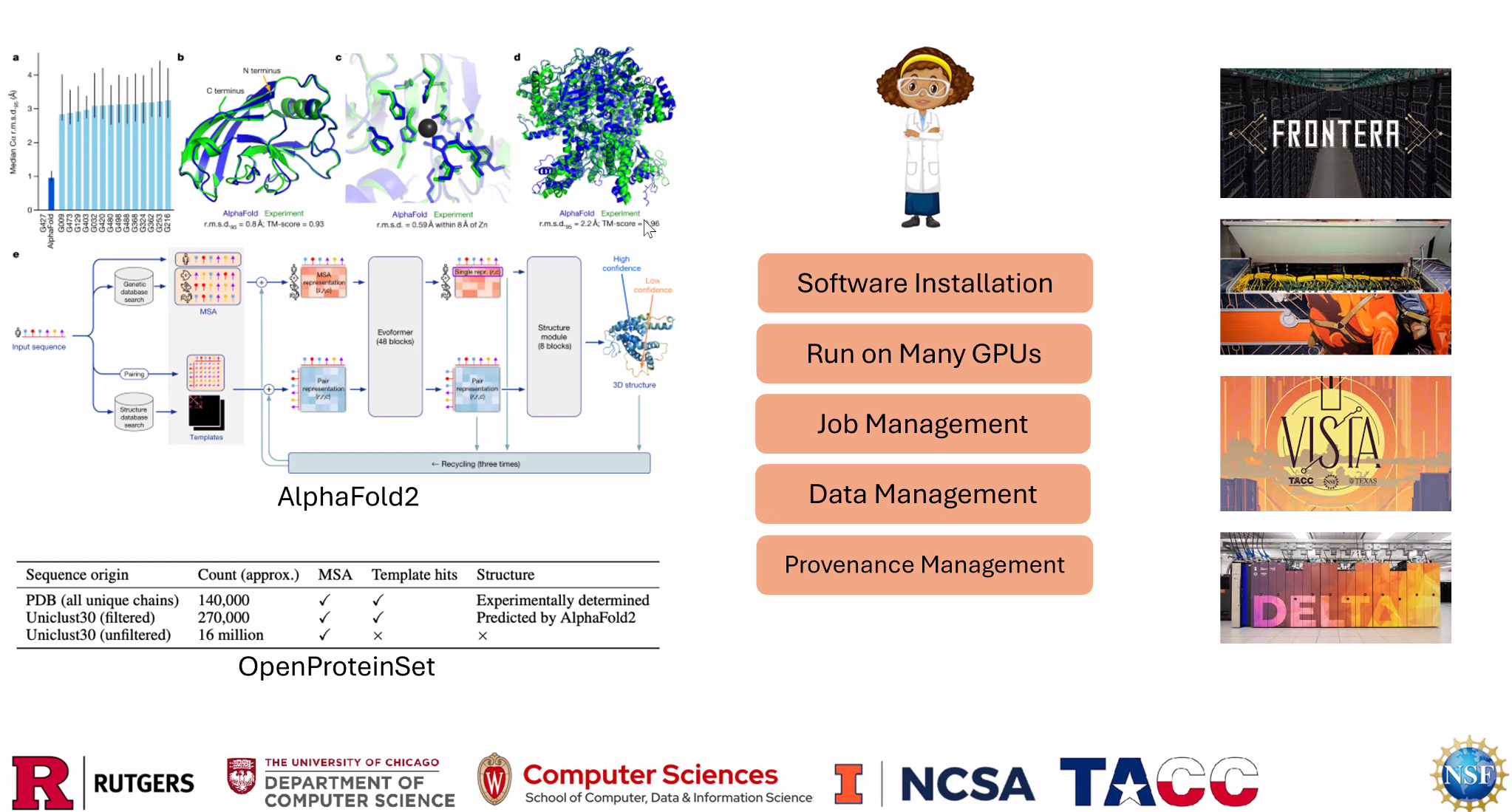
Training Neural Networks with Diamond
Haotian Xie / Zhao Zhang: Training Neural Networks with Diamond
Diamond是一个用于加速AI工作流的HPC系统,Diamond提供了一个UI,你可以轻松的用它将AI工作交到Globus Compute系统中。
Introduction – Nextra

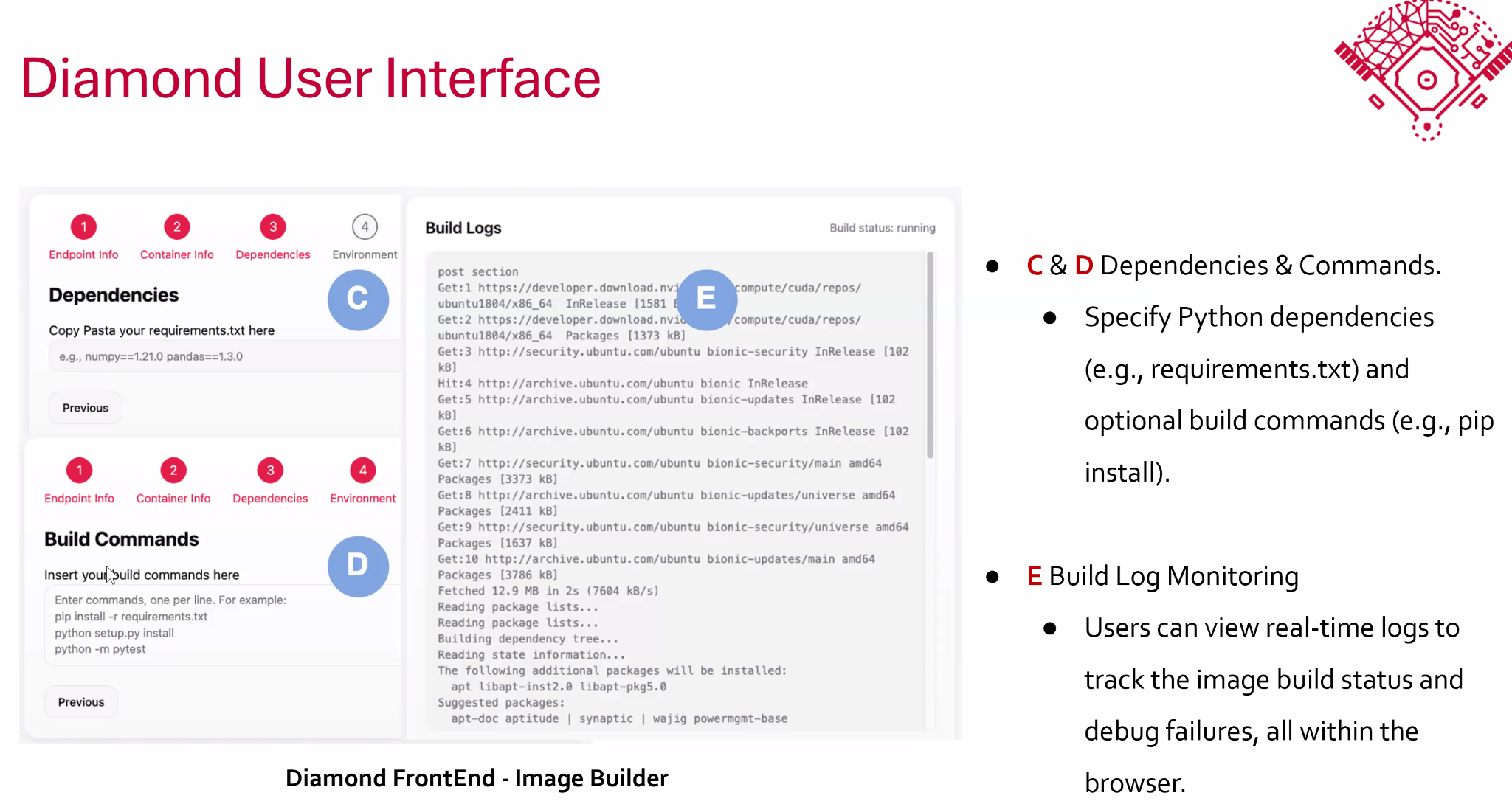
体验前端

A Multifidelity, Multiobjective Optimization Workflow With Parsl
Laura Walizer: A Multifidelity, Multiobjective Optimization Workflow With Parsl
基于Parsl的多目标优化进化算法

多目标优化算法框架
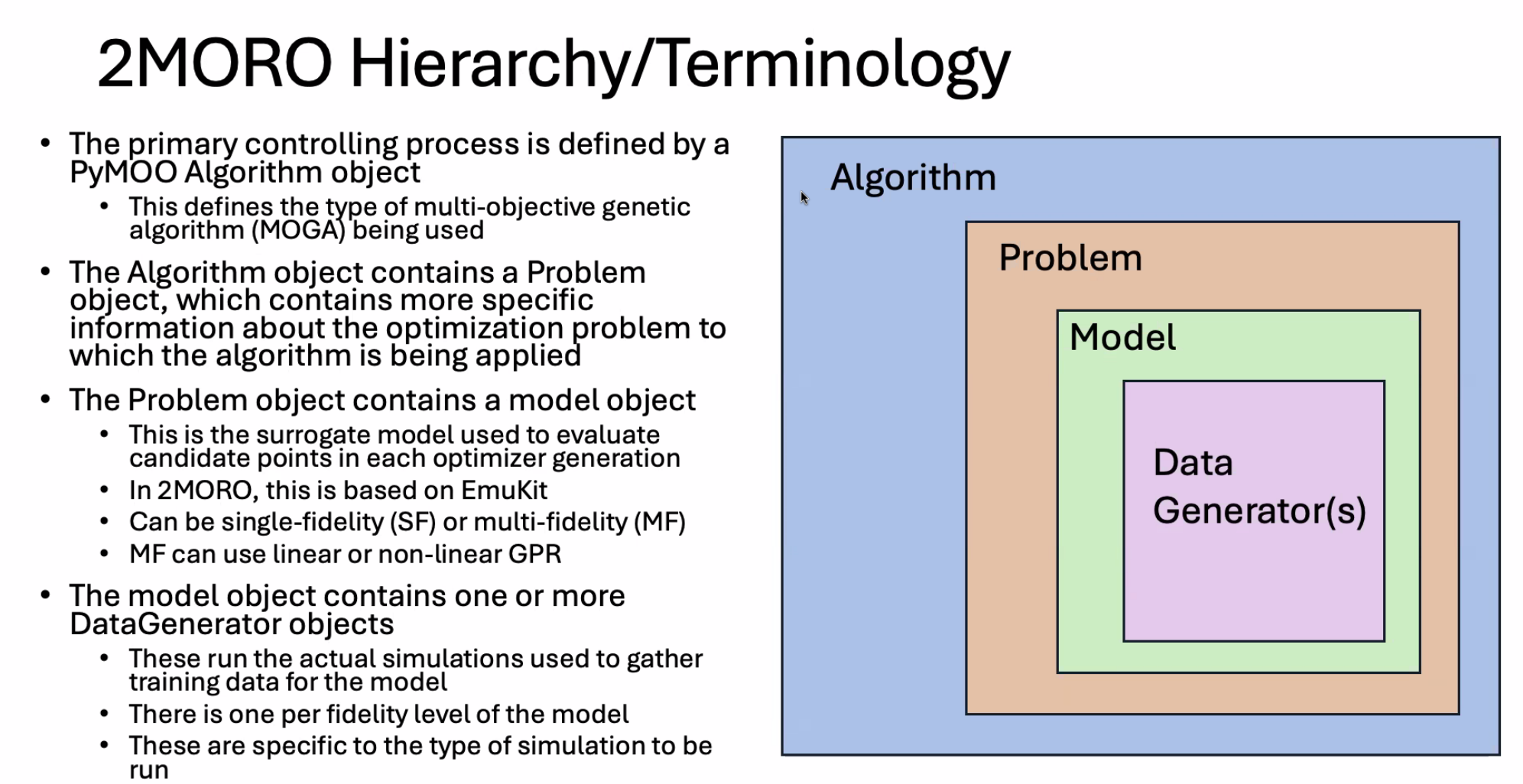
Pasl config 配置
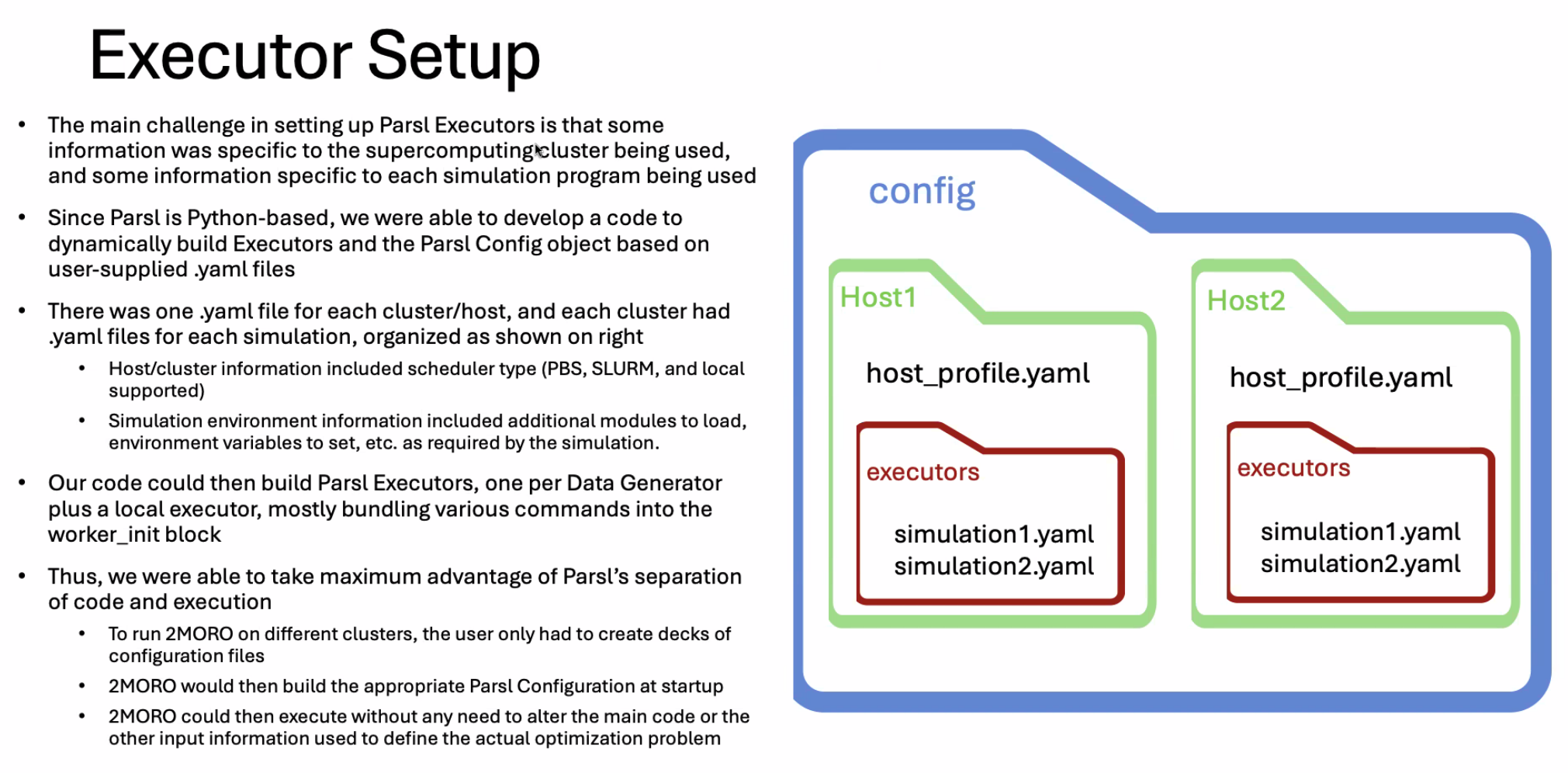
实验
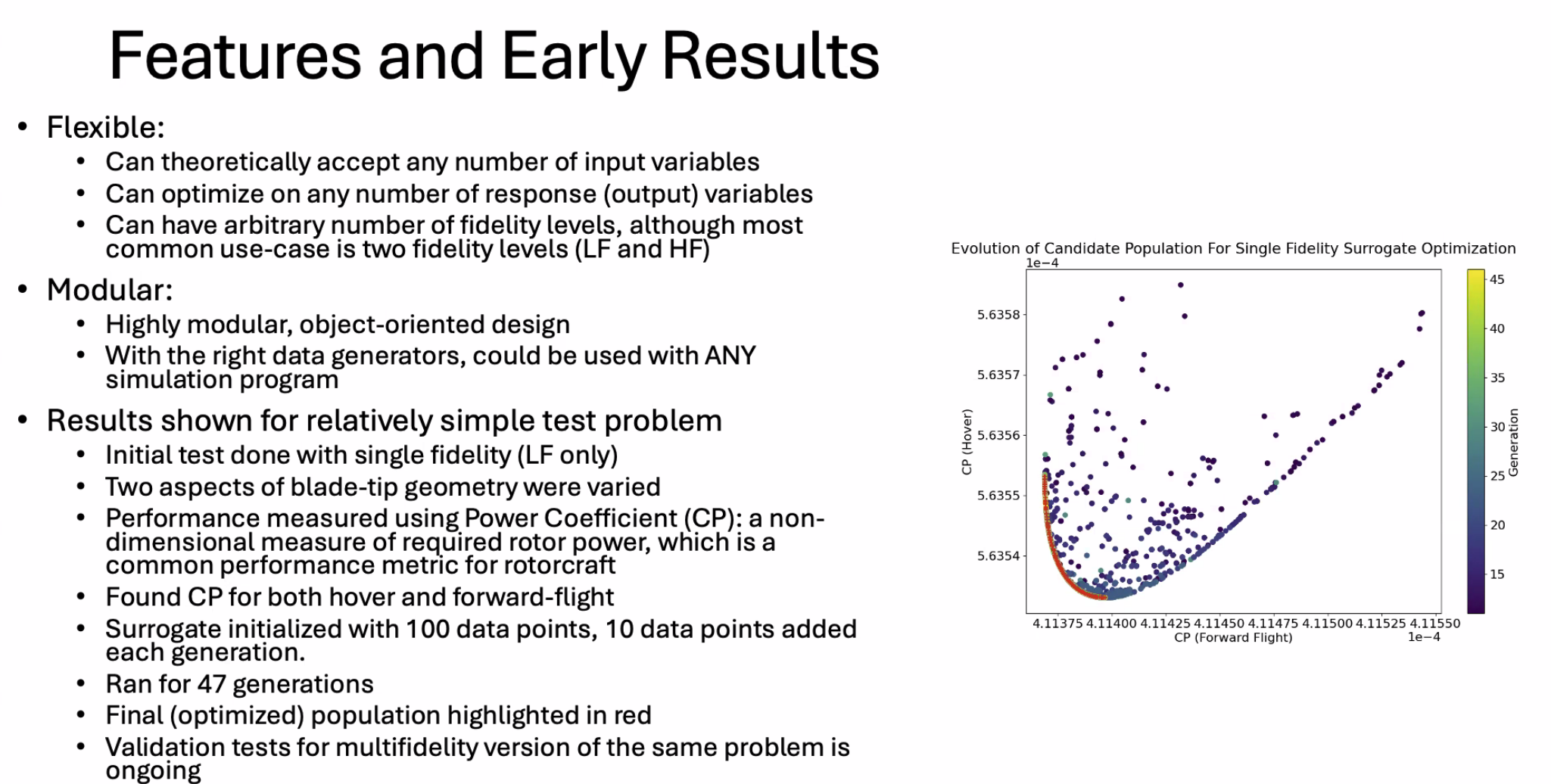
问题:
- 你感觉Parsl用的怎么样?
回答 - 有点tricky,然后感觉要看一些stack去查bug,有的时候像要搞python practice
Garden: Lessons Learned from Serving AI for Science Models with Globus Compute
来自好哥们 Will Engler
我们在搭建AI4Sci工程平台时遇到的困难

Graden是一个提供Model服务的系统,类似于集成huggingface+部署的AI部署系统,同时其支持很多的科学工作流AI model。

Some of my best friends are LLMs.
What does it means for "sharing a model":
Open weights and metadata
Code for practical inference
Inference code running remotely
我们的回答:a model "ready to run"


非LLM的AI模型仍然没有那么好的支持,科学工作流AI会很好的支持这方面的工作

Distributed on-the-fly Training of Neural Network Potentials with Parsl and Colmena
Michael Tynes, Logan Ward
Mike的笑话每次都让我笑死了
AI-HPC的工作是用AI尝试加速传统的科学数值模拟
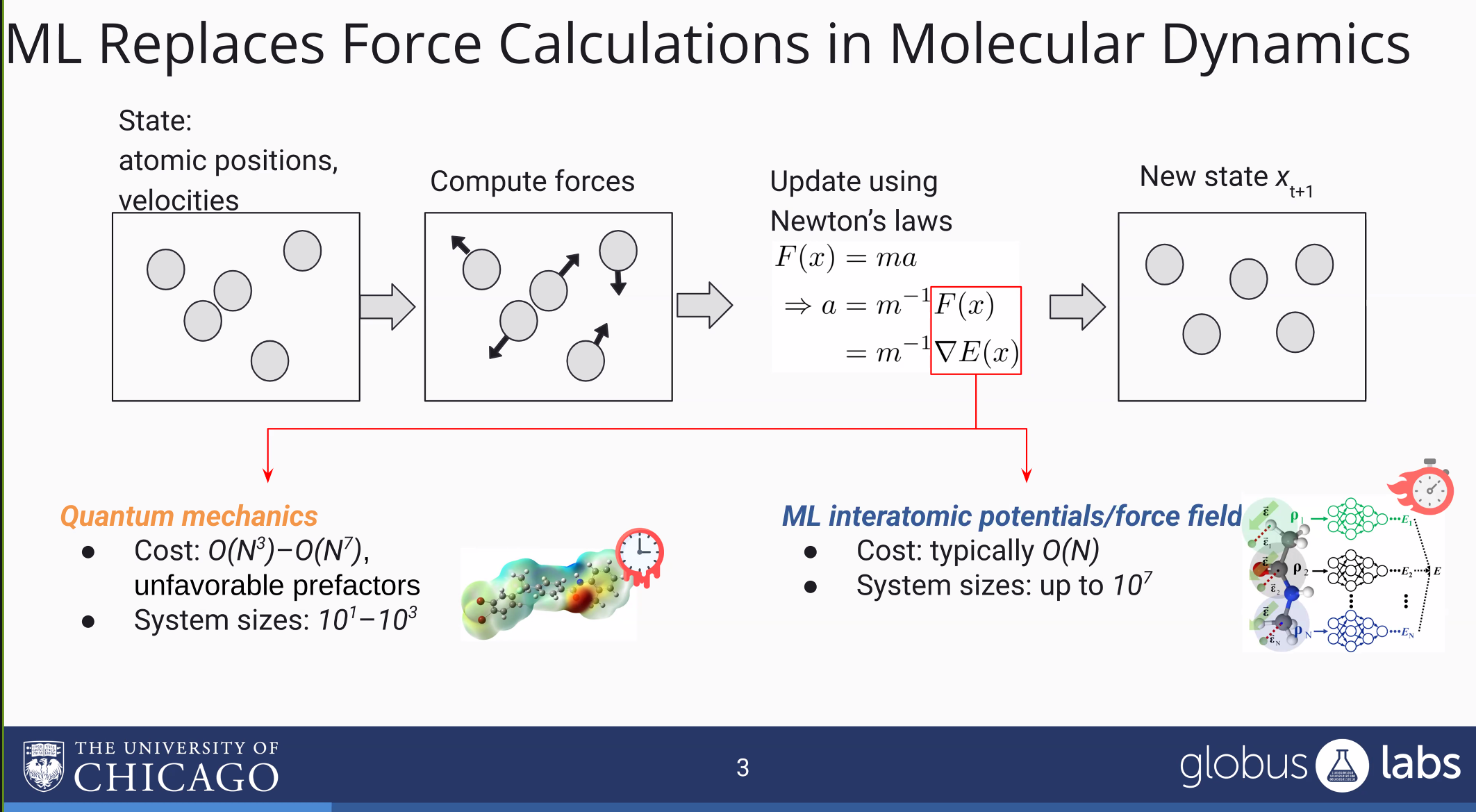
但是很明显的,这种AI很可能是会有acc低的问题,
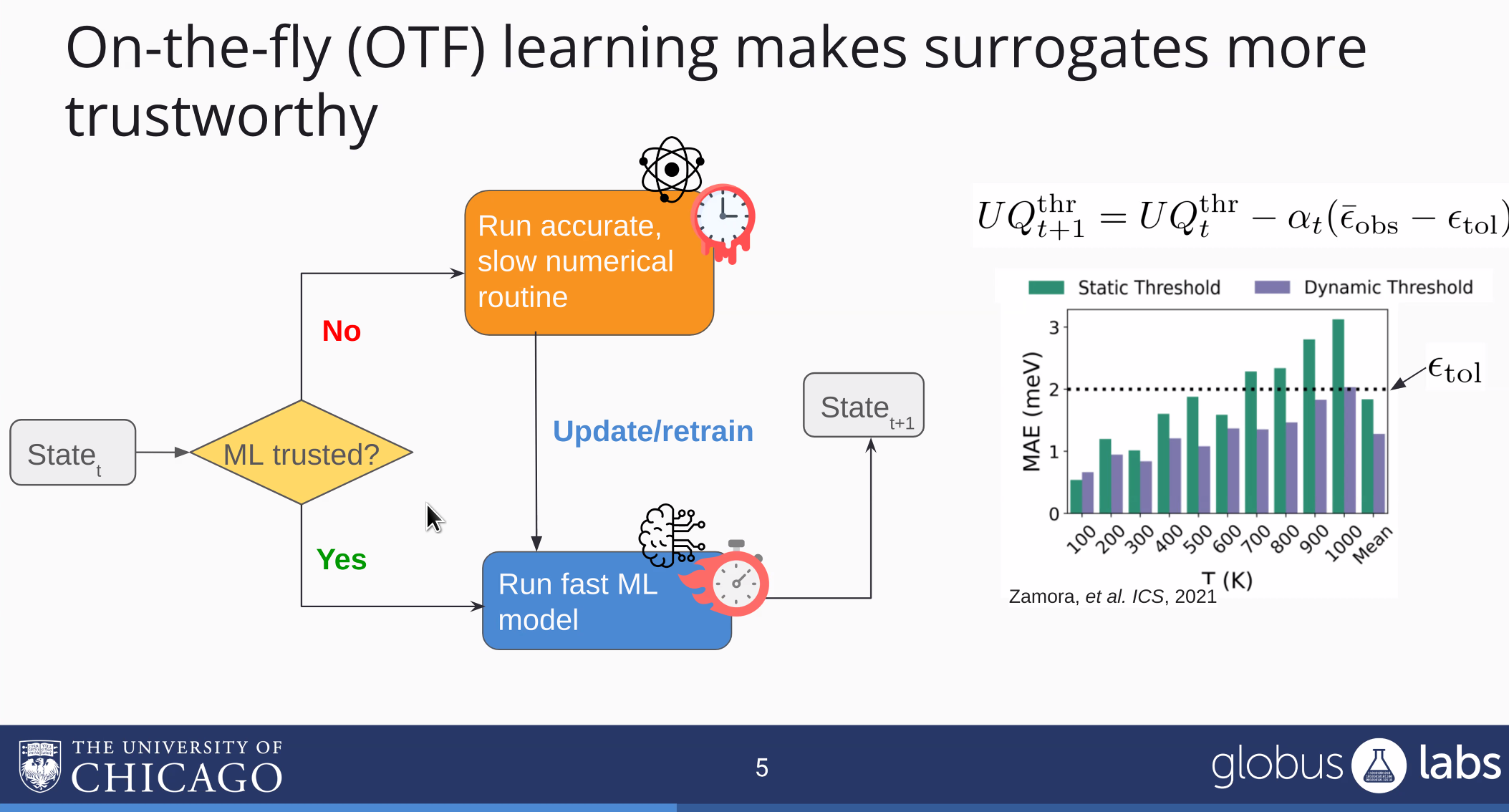
听起来不错,让我们把OTF搬入分布式系统,就变成了:
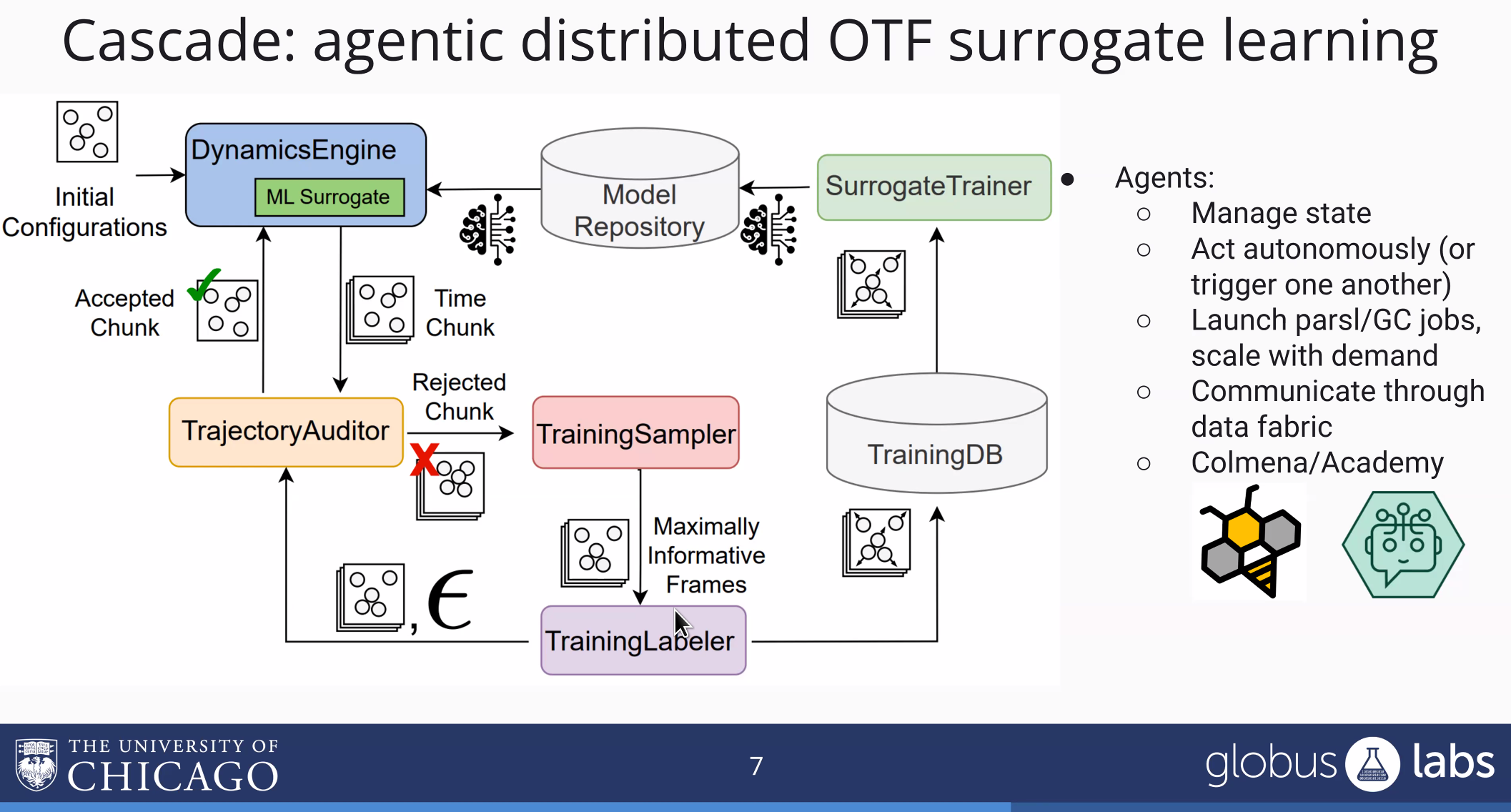
Deploying AI+Simulation Workflows for MOF Design (with Parsl)
Logan
Logan在Globus待了8年,目前去了Nvidia AI4Sci 部门。
Logan曾经做过自己8年经验分享的组会,
commit on daytime
long career
在Parsl上部署AI模拟的科学工作流
Logan 原本
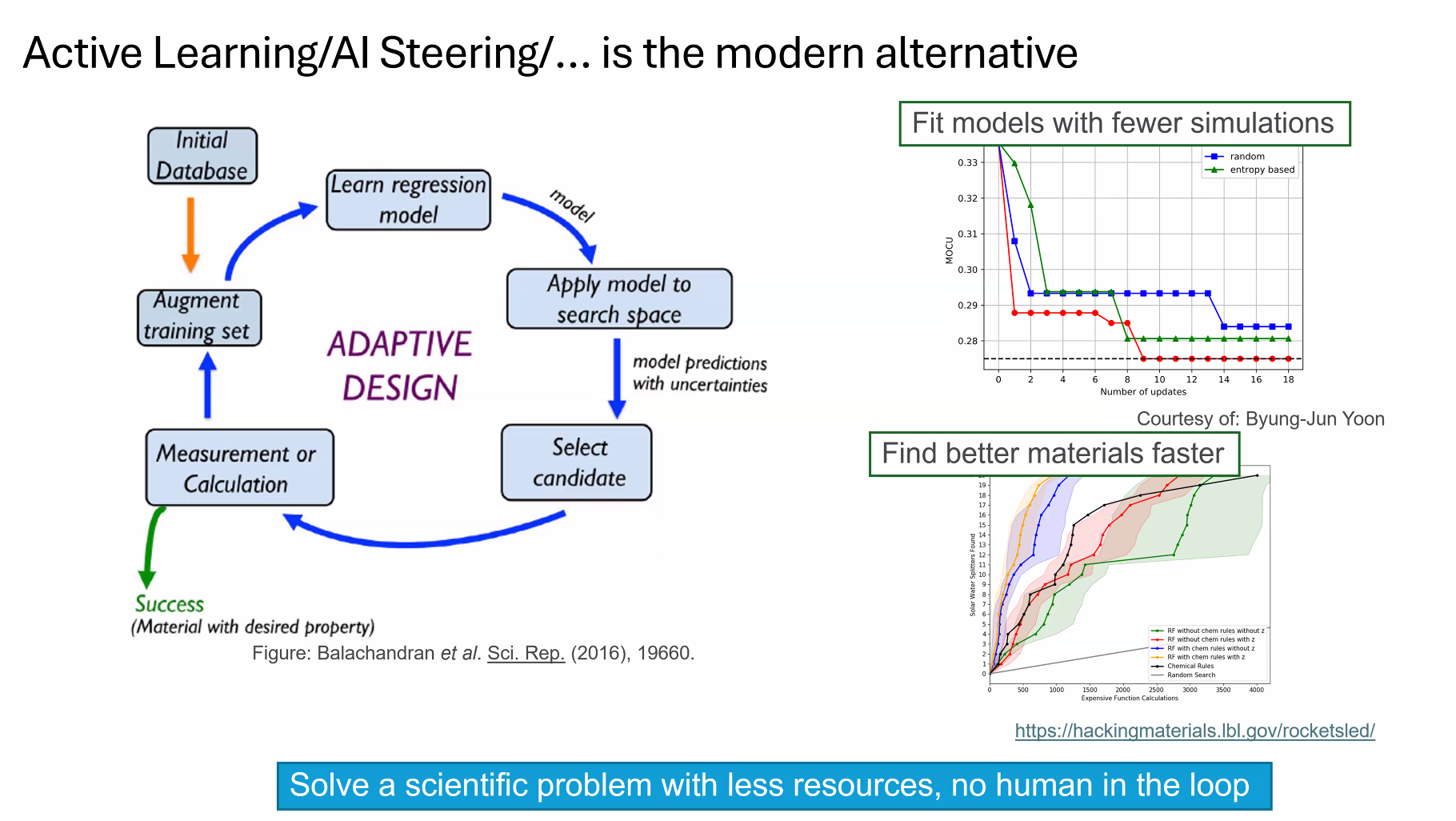
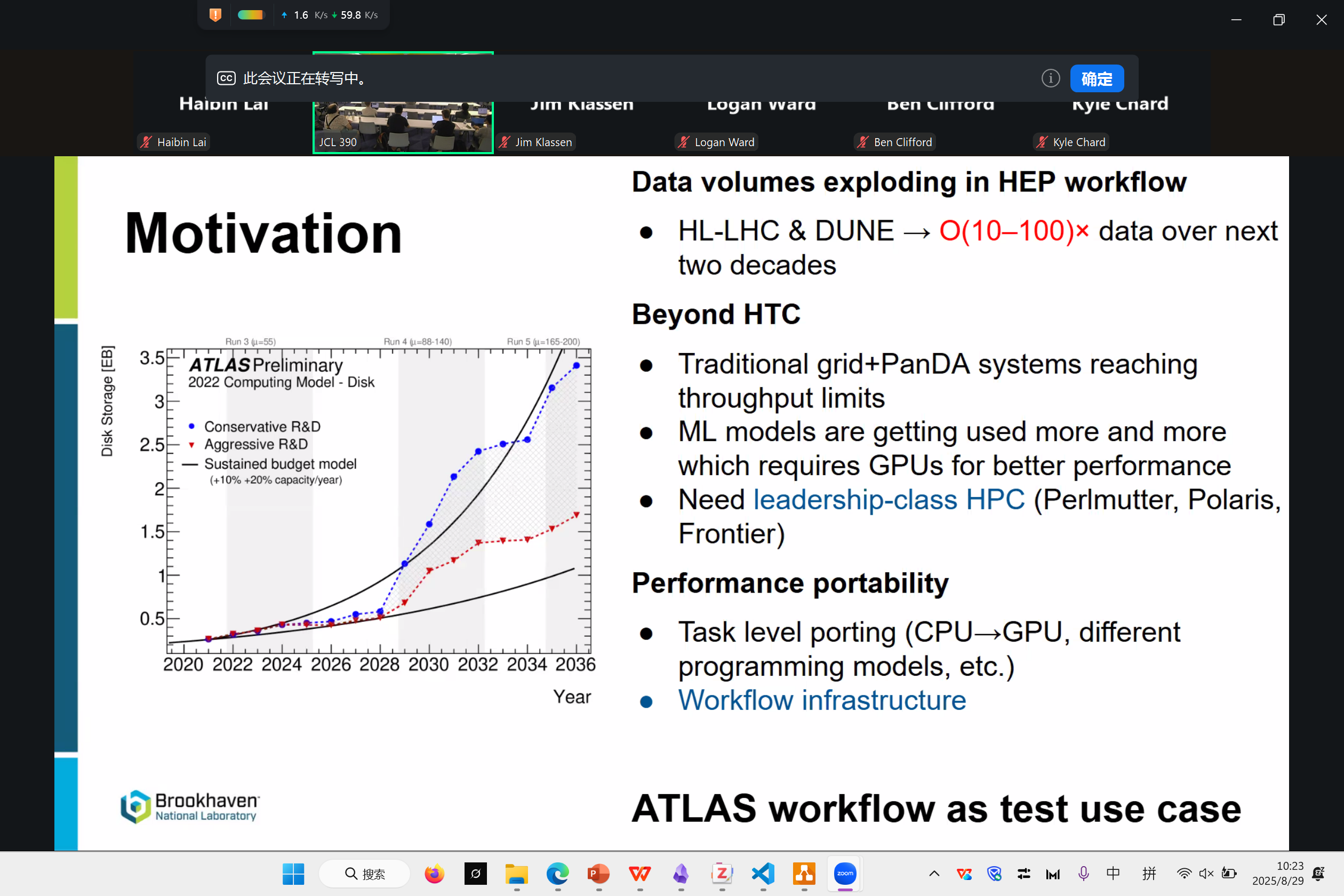
目前我们用 Parsl+MOF(AI)+LAMMPS(HPC) 来尝试科学工作流
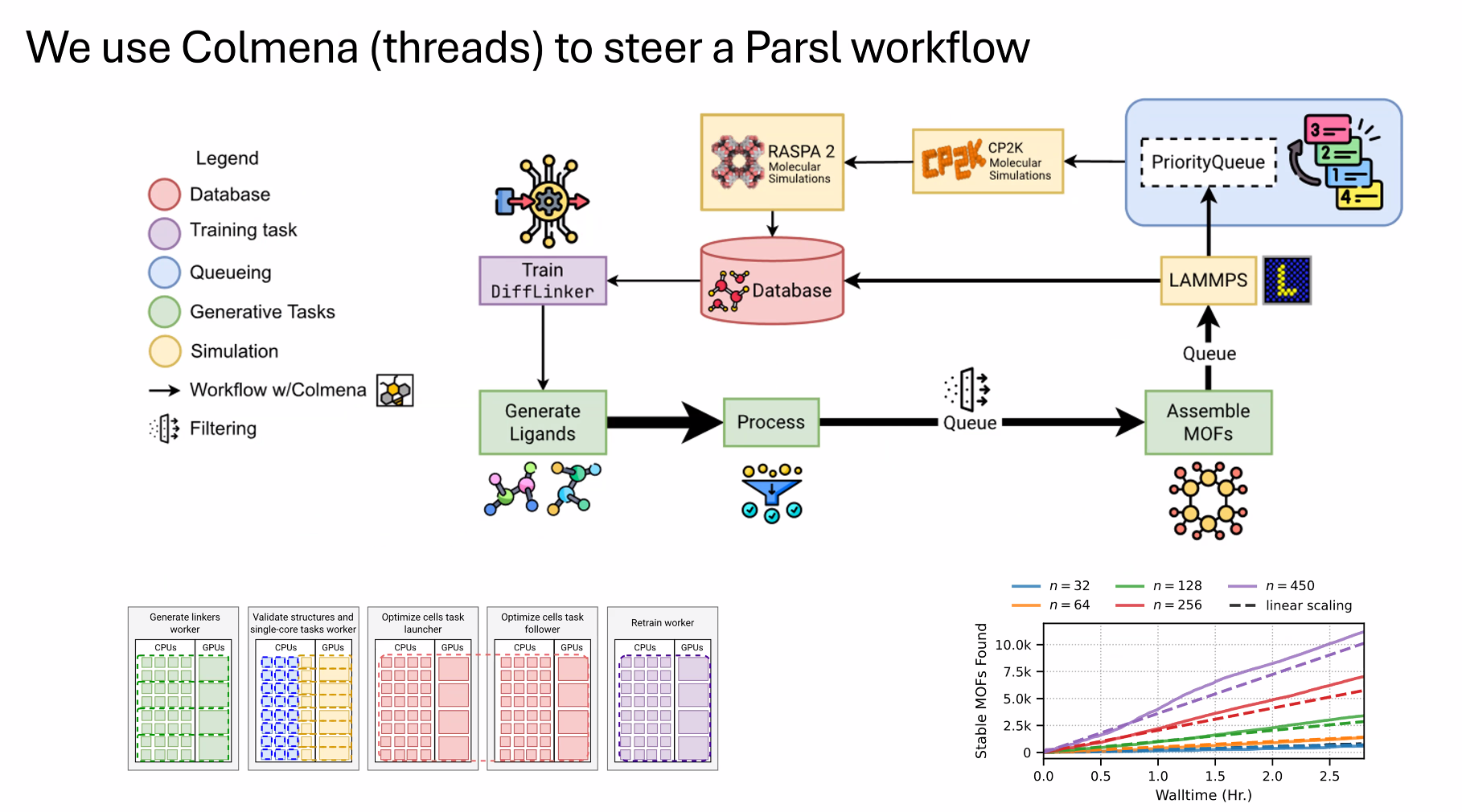
最大的问题是节点的配置与数据分发。任何事情发到2000节点的超算上,都会行成大问题。
目前两个解决方案是 Proxy Store / 打成CUDA container
Leveraging Parsl for Scalable Data Parsing for AuroraGPT
Robert Underwood: Leveraging Parsl for Scalable Data Parsing for AuroraGPT

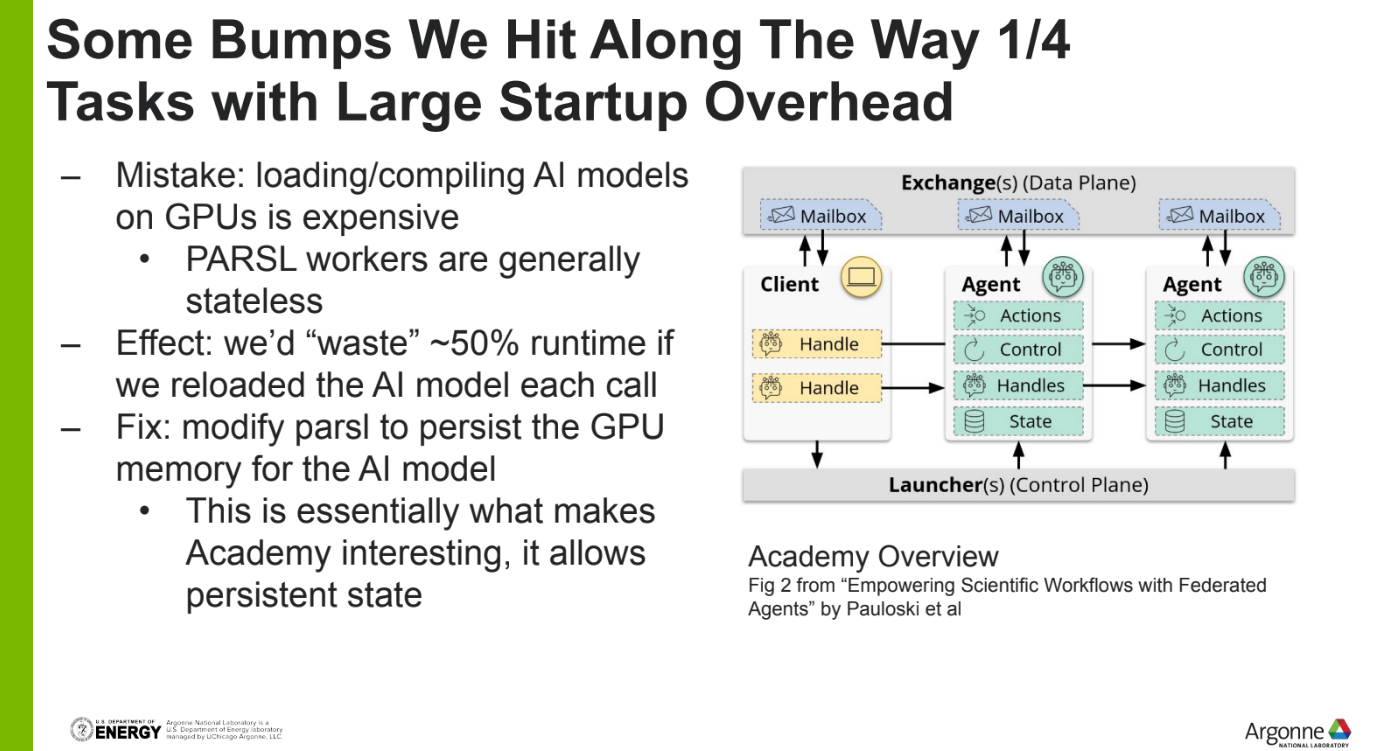
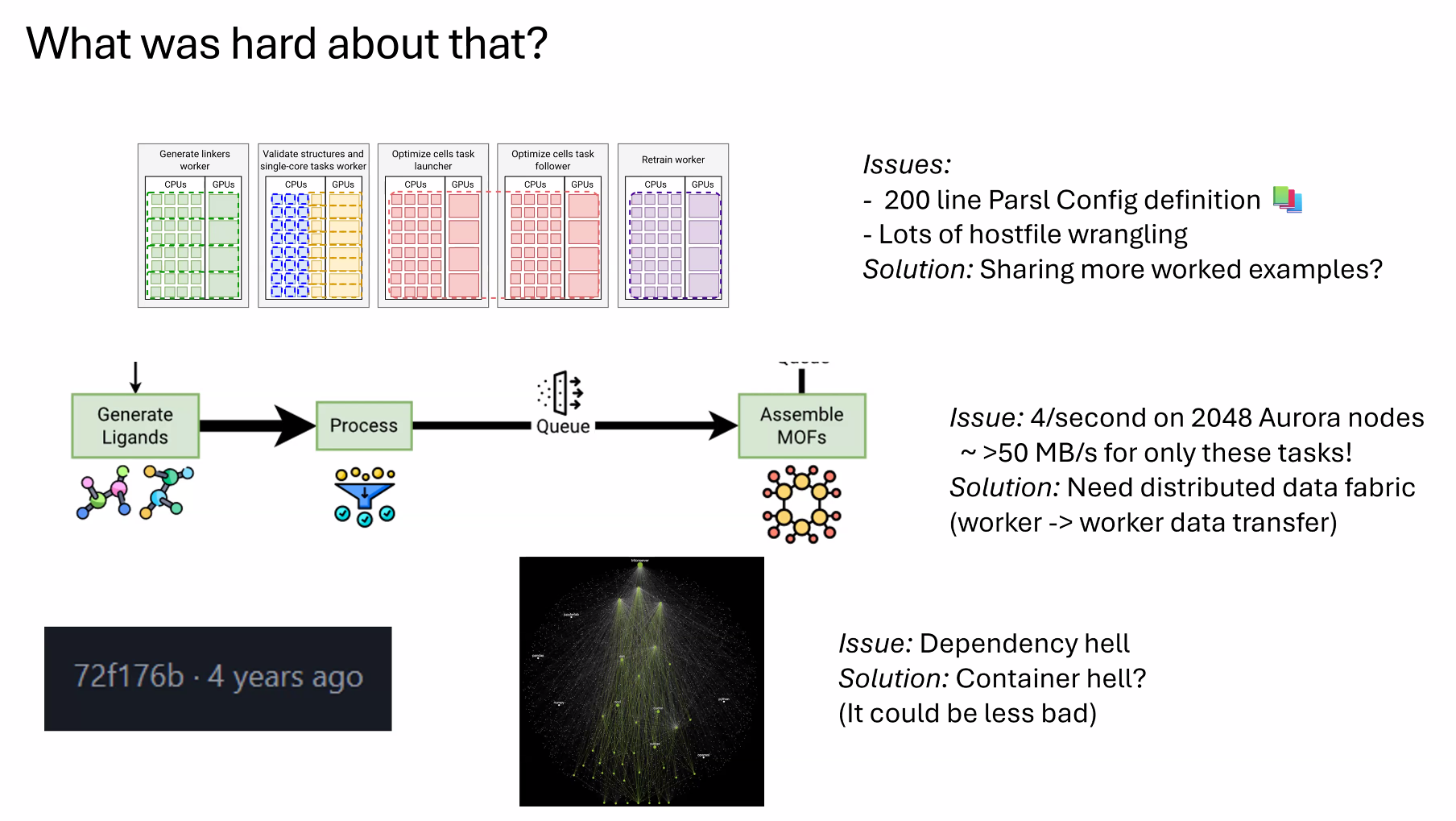
在debugging上,我们用了一些多节点的debug和profile工具
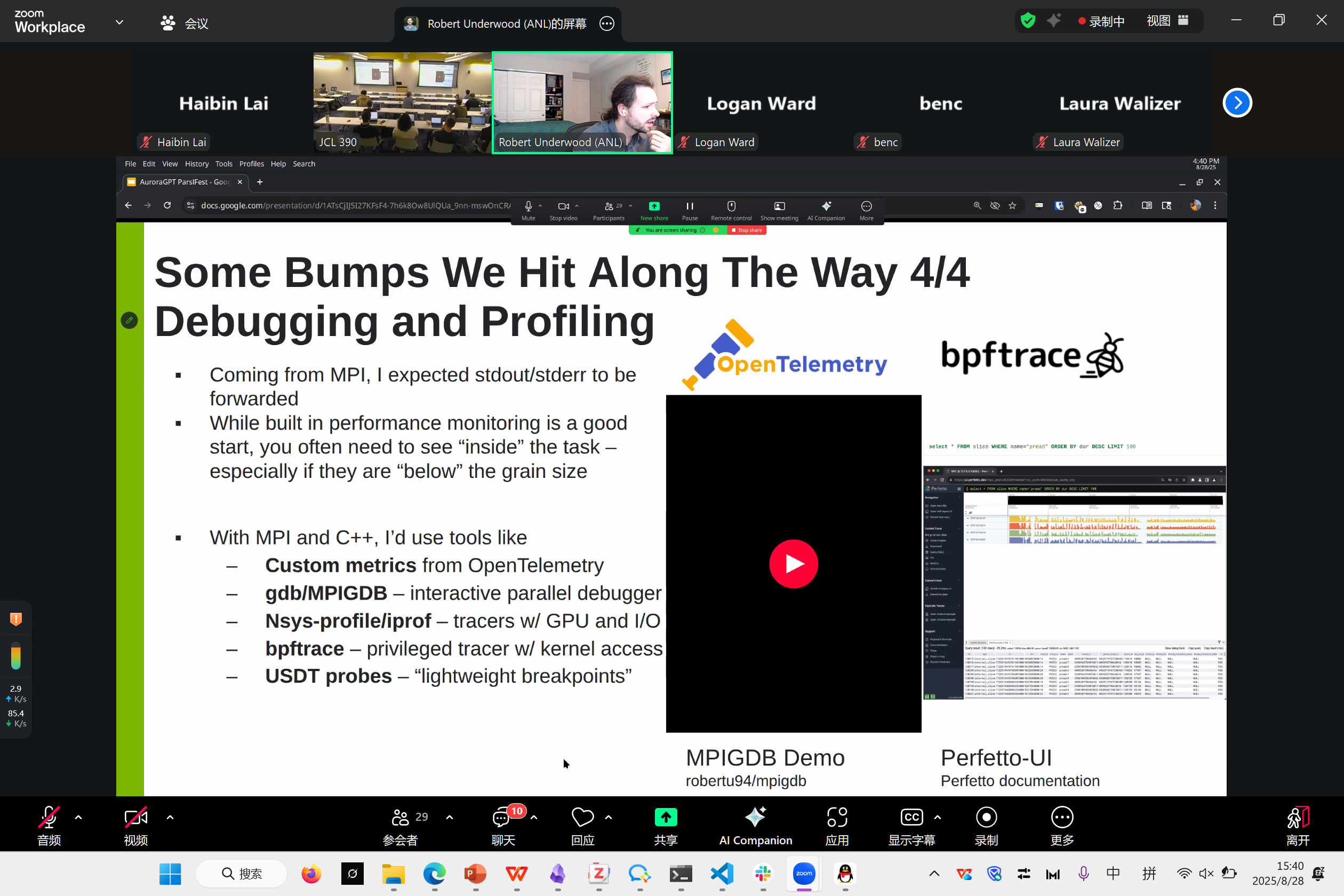
Lesson learned
fuse task+jobs to reduce scheduling time
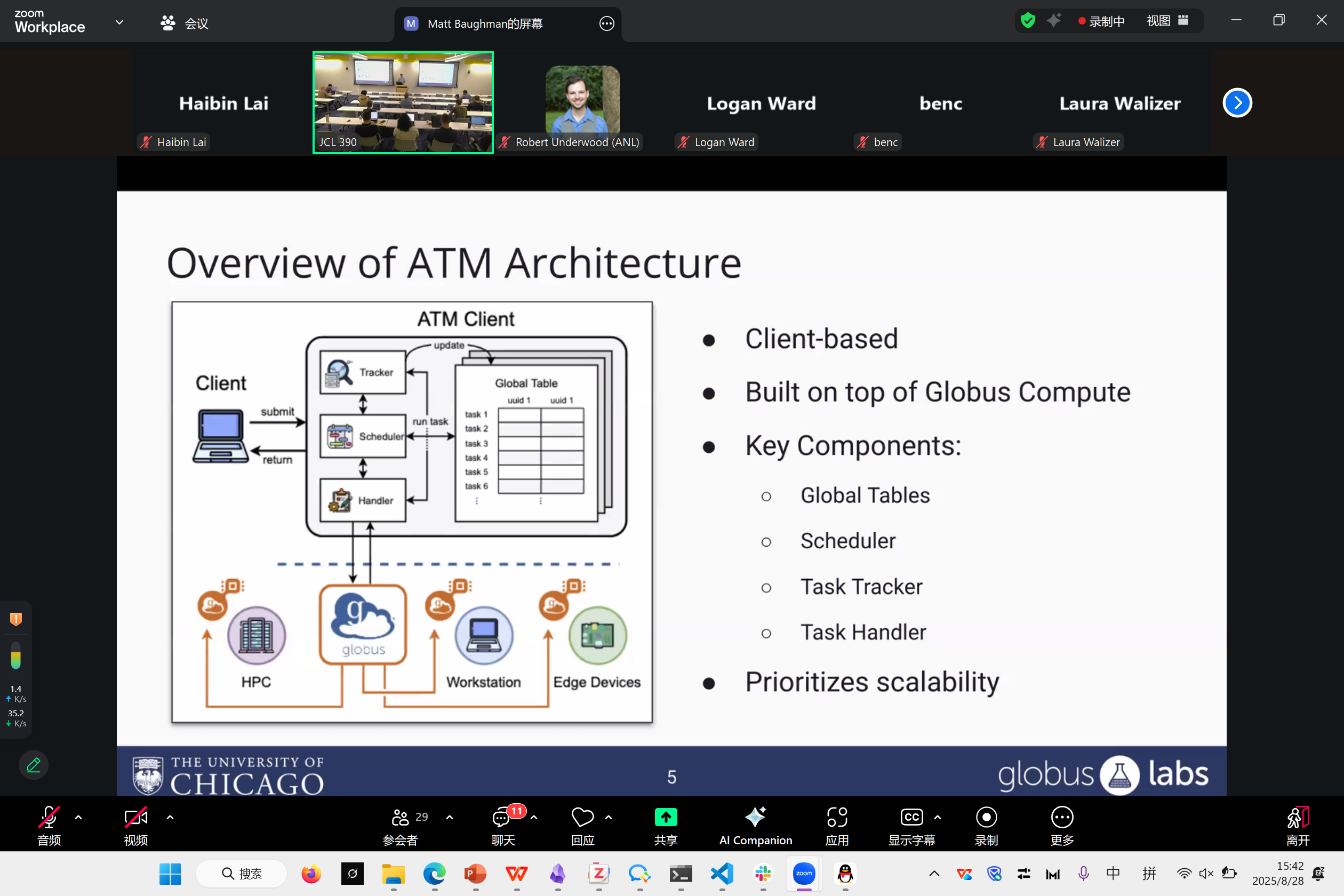
Adaptive Task Management: Enabling Multi-Site Workflows with Globus Compute
Matt Baughman
来自好哥们Matt!
尝试将多地的工作连接在一起的一个大型分布式框架
ATM是一个分布式框架,主要由Checker, Scheduler, Handler组成
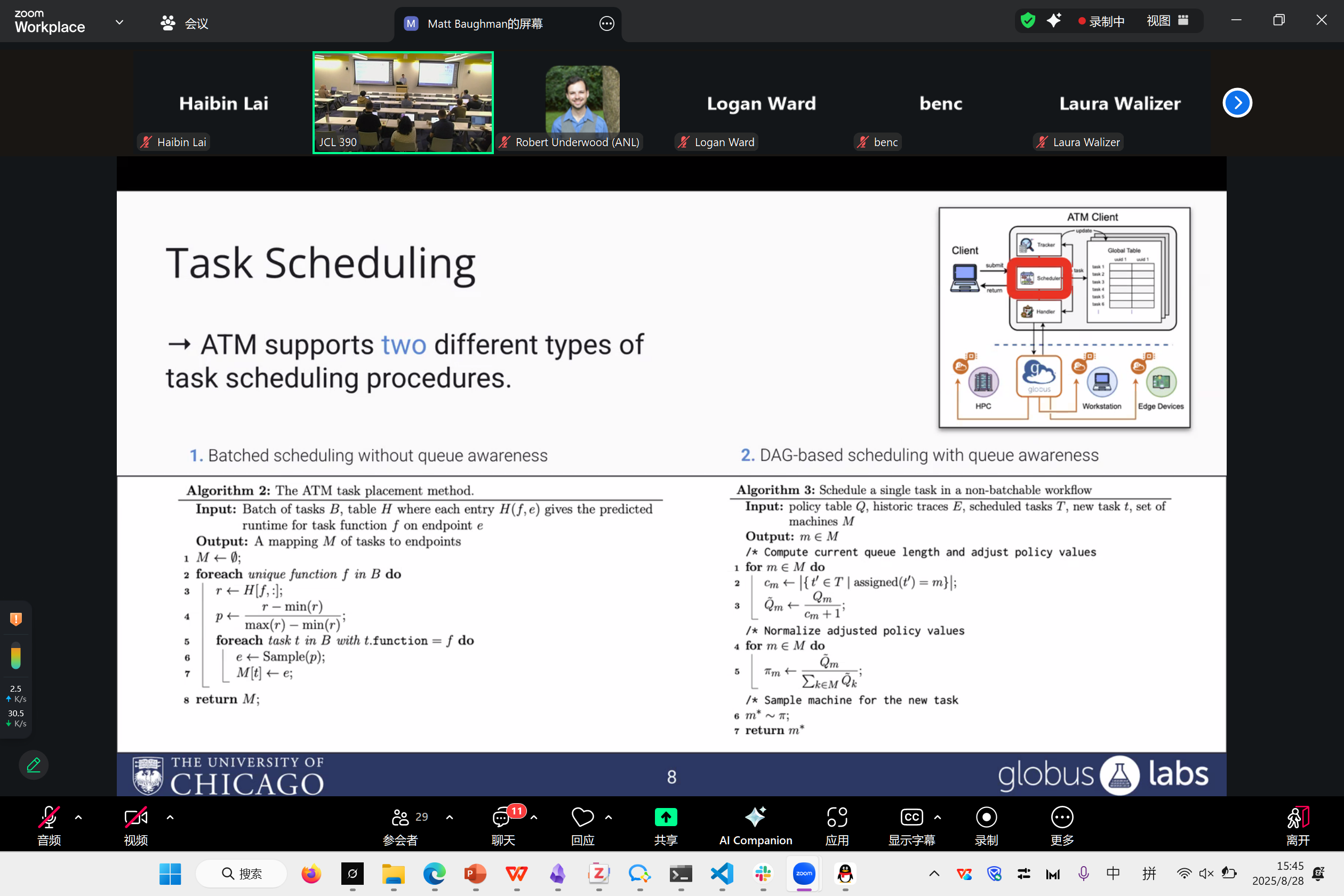
Scheduling的组件如图。其他的工作都比较类似了
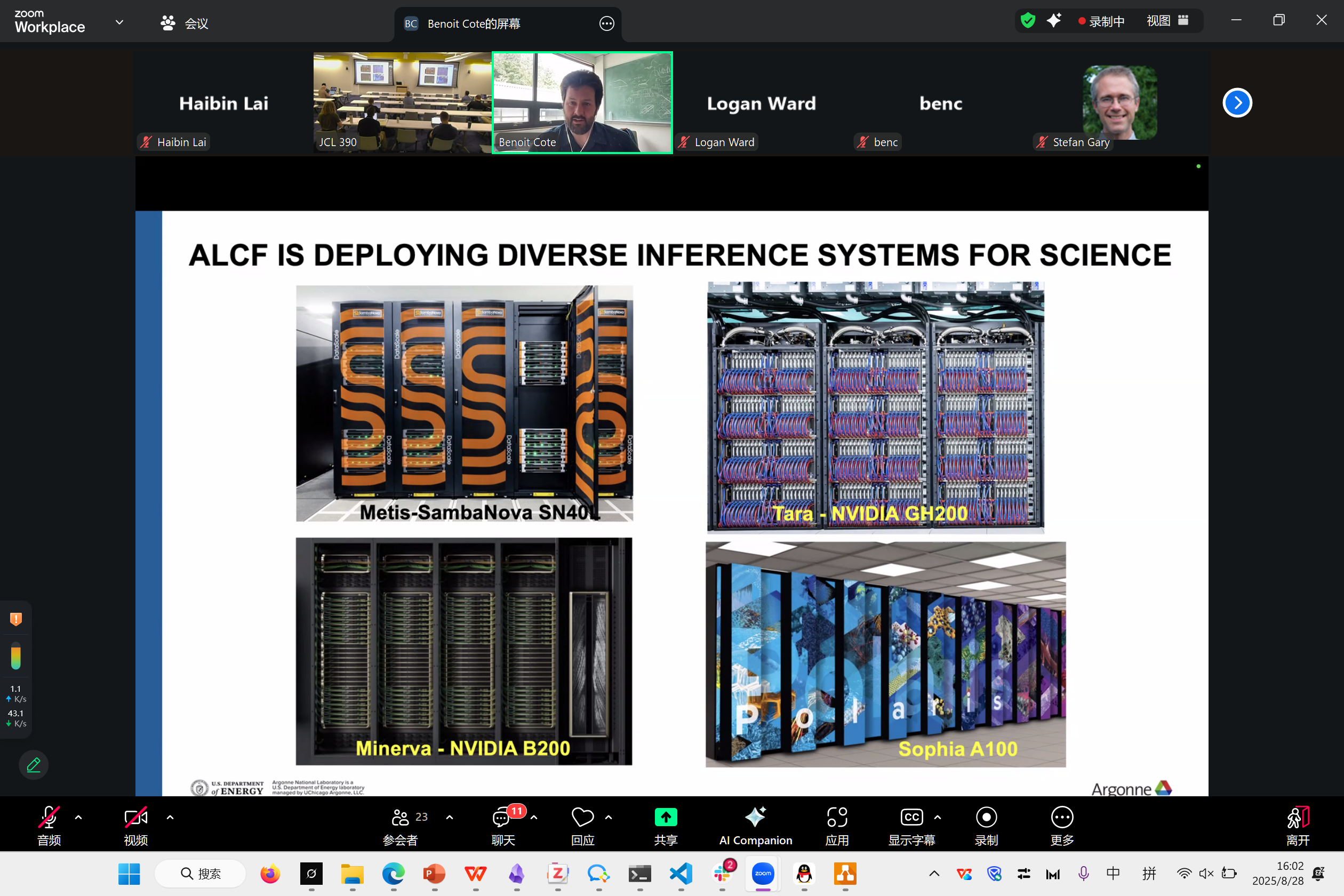
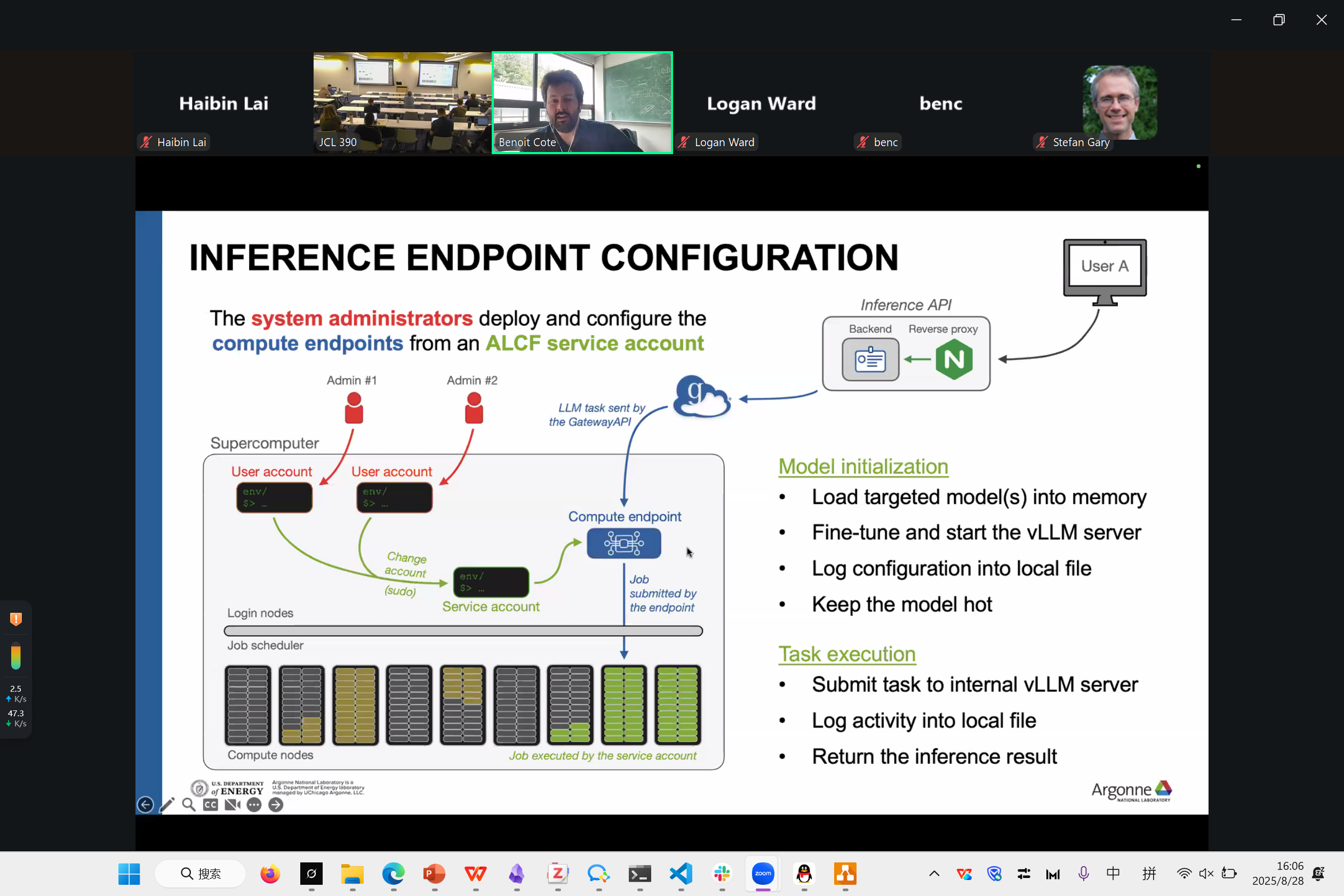
Deploying Inference Services at ALCF
Benoit Cote
这是在他们超算内部部署AI推理系统的工程工作
Argonne硬件。真有钱啊
推理service例子
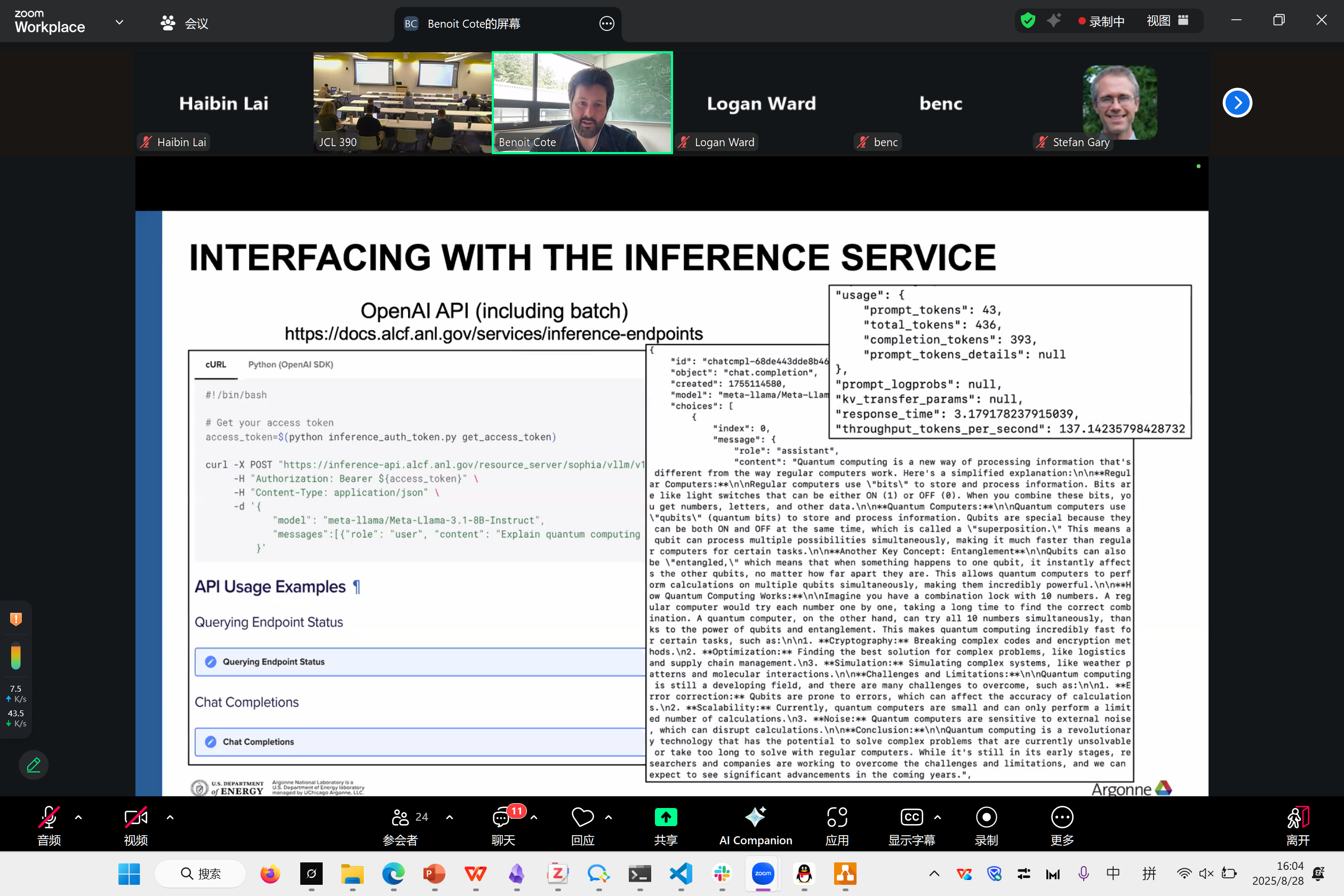
inference推理
https://blog-1327458544.cos.ap-guangzhou.myqcloud.com/N2025/20250828160613143.png
{kind=link}
目前的模型情况
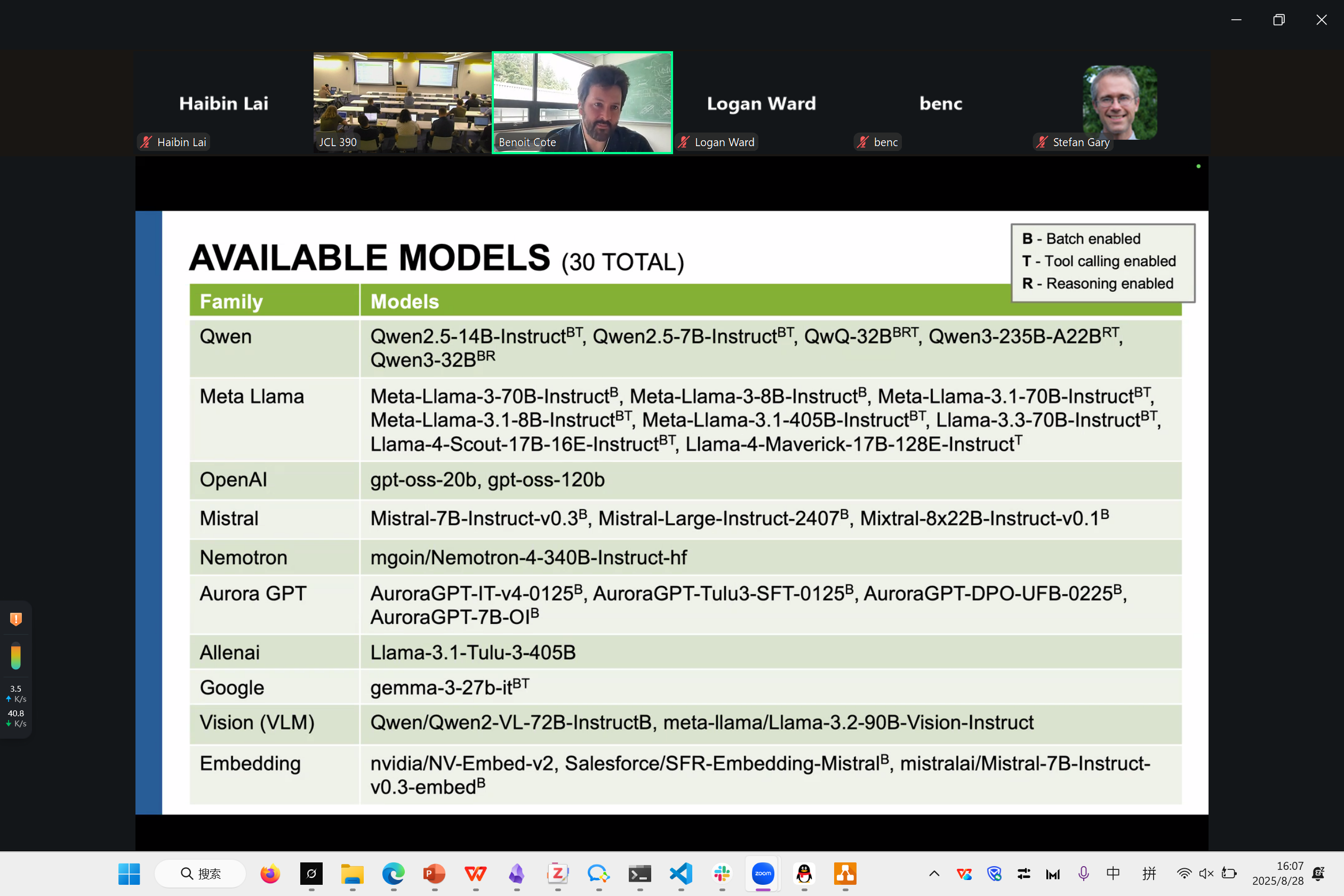
70users, 10 billion tokens generated. 目前 3500token/s
Globus Compute Past and Future
Josh Bryan
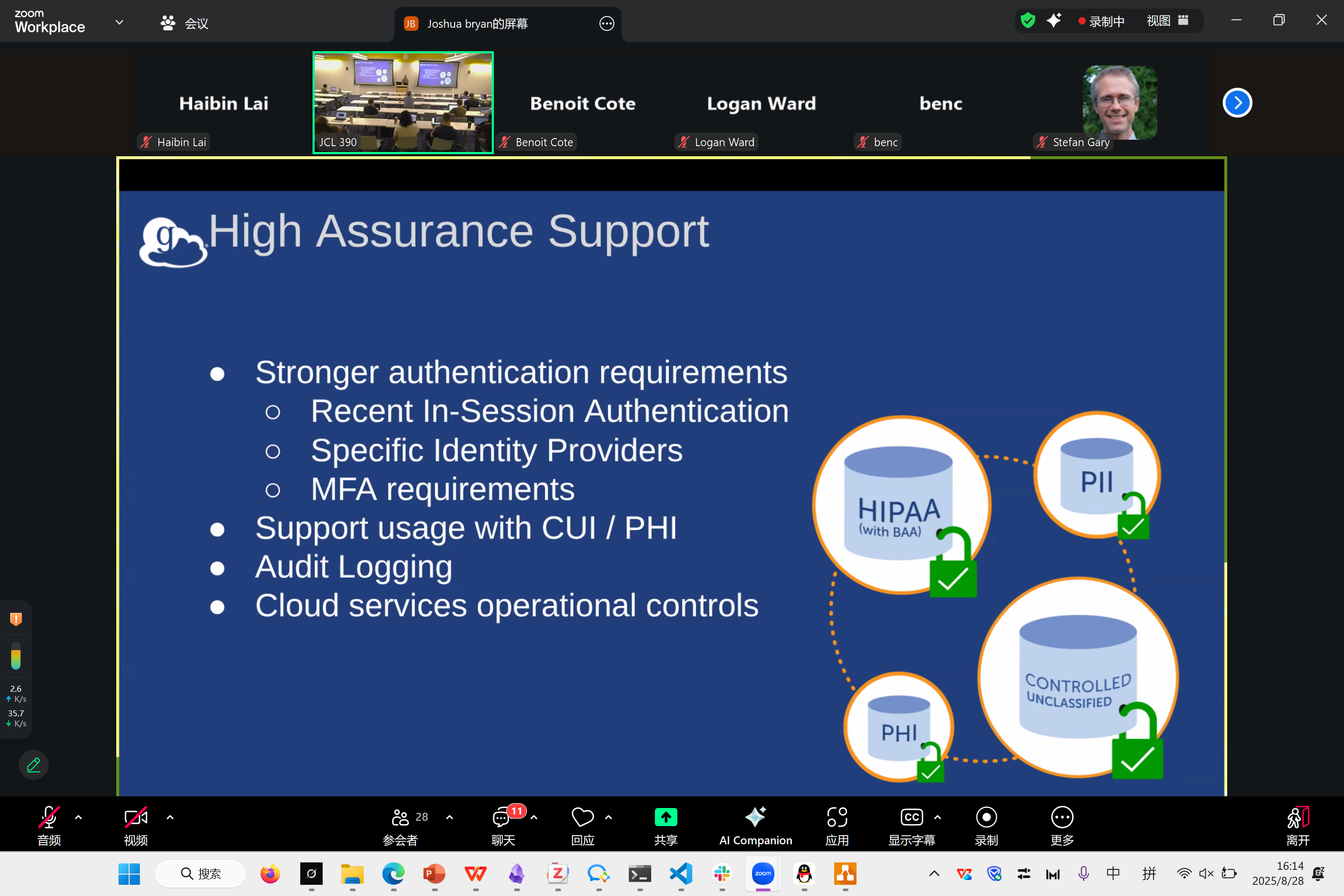
Globus 做了这么几年,基本上做了好多在分布式系统配置及计算上的工作

Globus Compute Serialization Overview
Chris Janidlo
Globus Compute 序列化的方法介绍
Compute Serialization - Lightning Talk - Google 幻灯片
PPT很详细,这里不介绍了
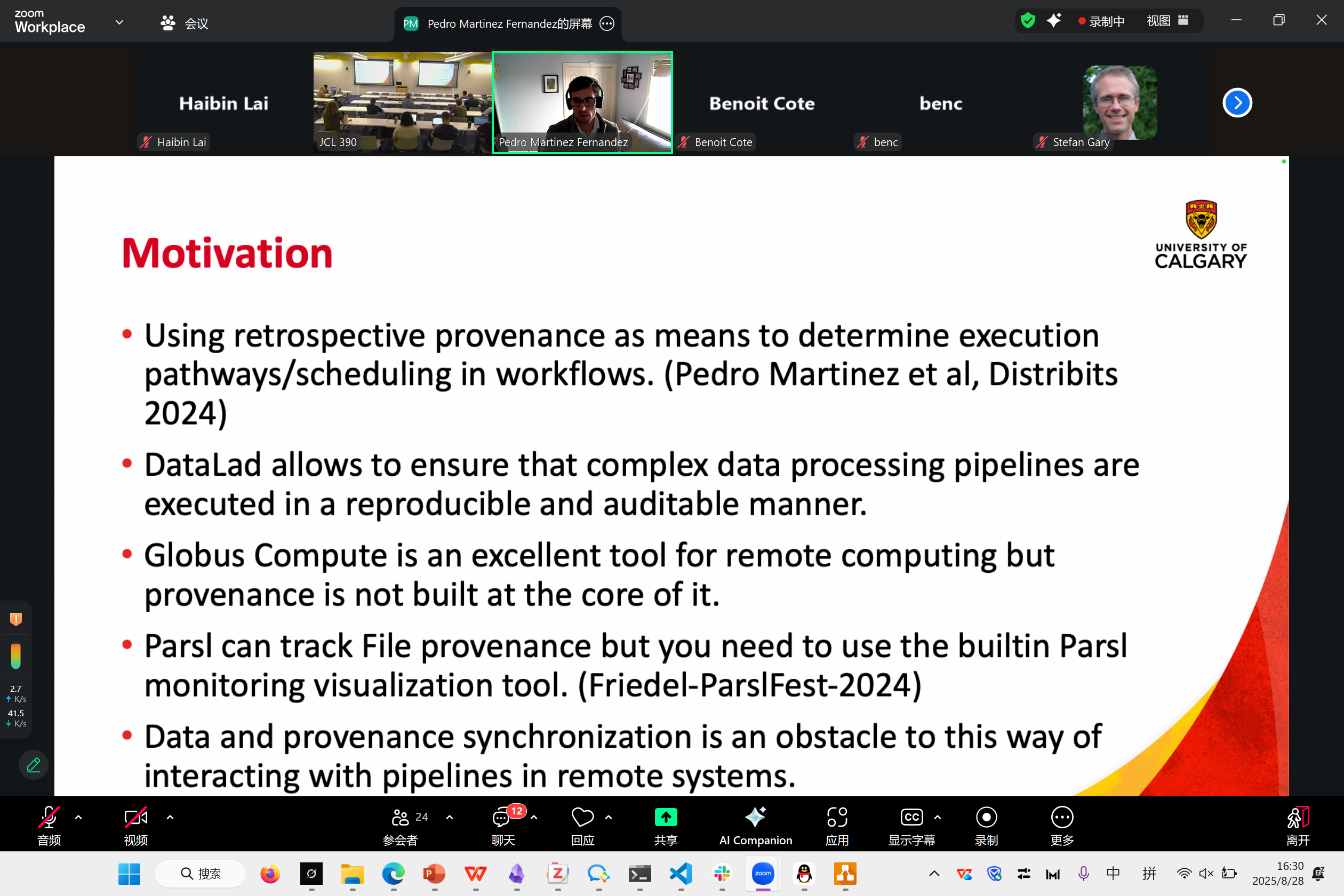
Globus Compute + DataLad: Provenance-Based Workflow Scheduling in Remote Infrastructure
Pedro Enrique Martinez Fernandez
主要是做在科学工作流的调度
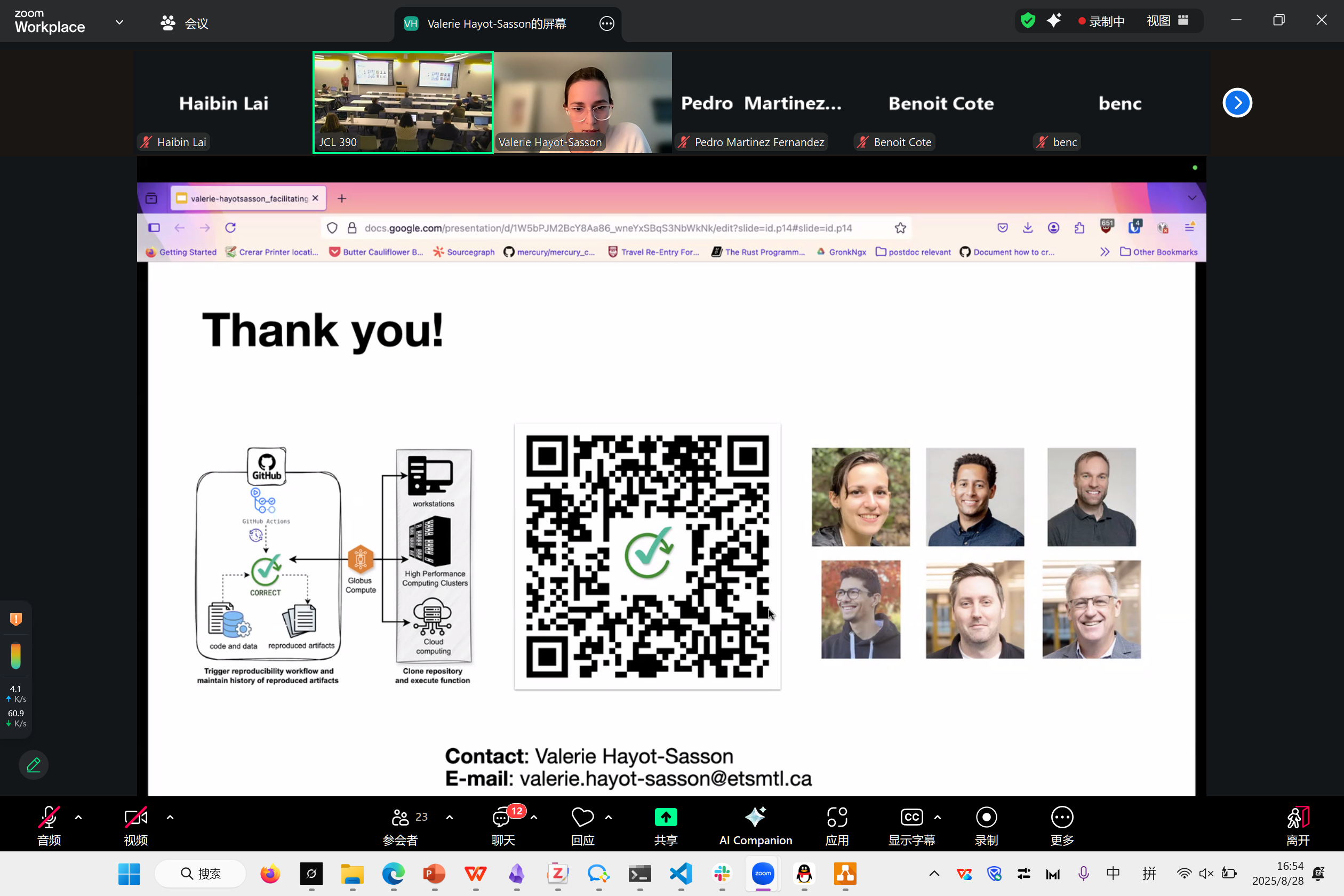
Facilitating Reproducibility Evaluations on HPC with Globus Compute and GitHub Actions
Valerie Hayot-Sasson
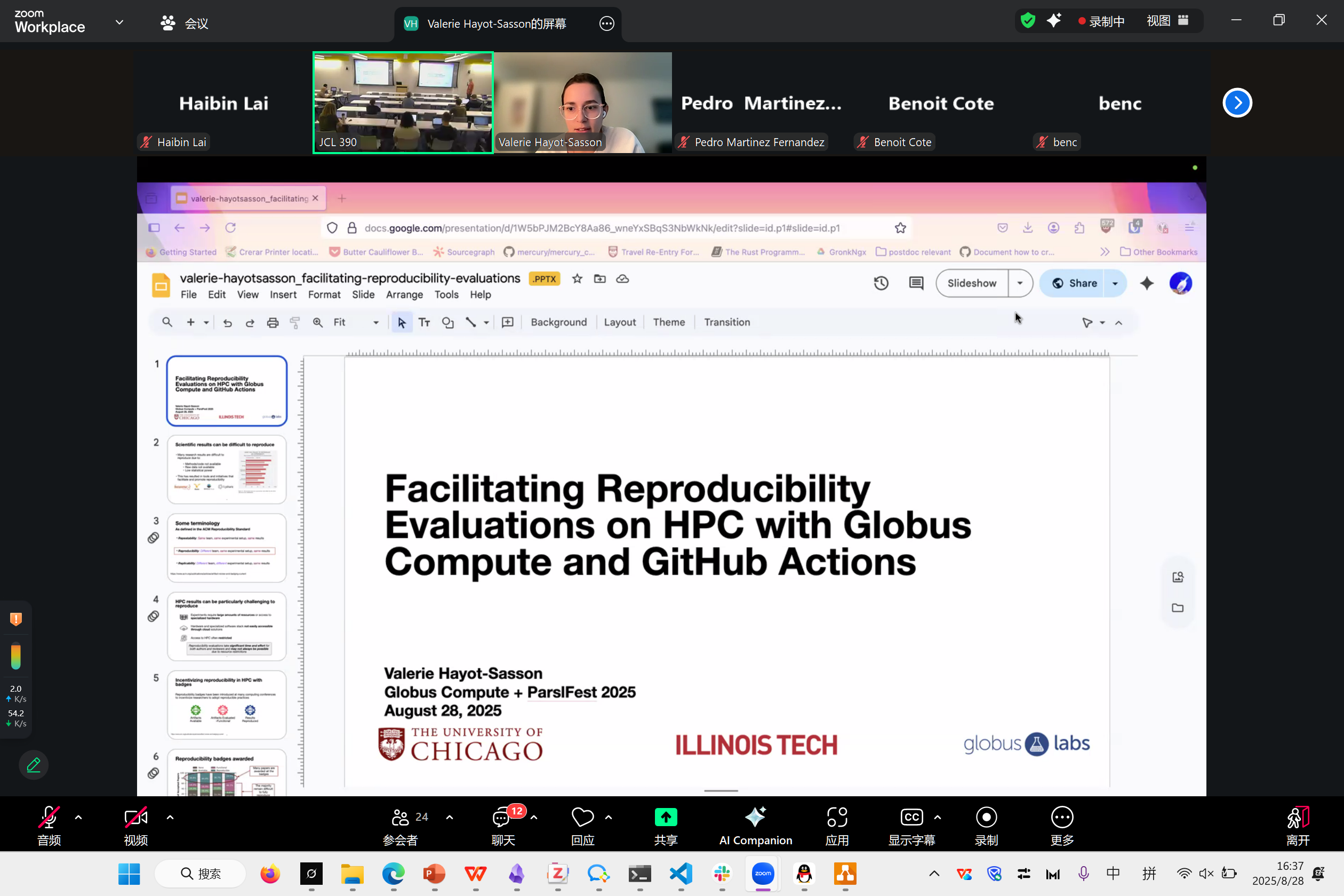
很多的科学计算难以复现,我们尝试去做一个自动化的框架,帮助你自动跑程序。

这里边有几个问题
- data
- Codes
- HPC 环境
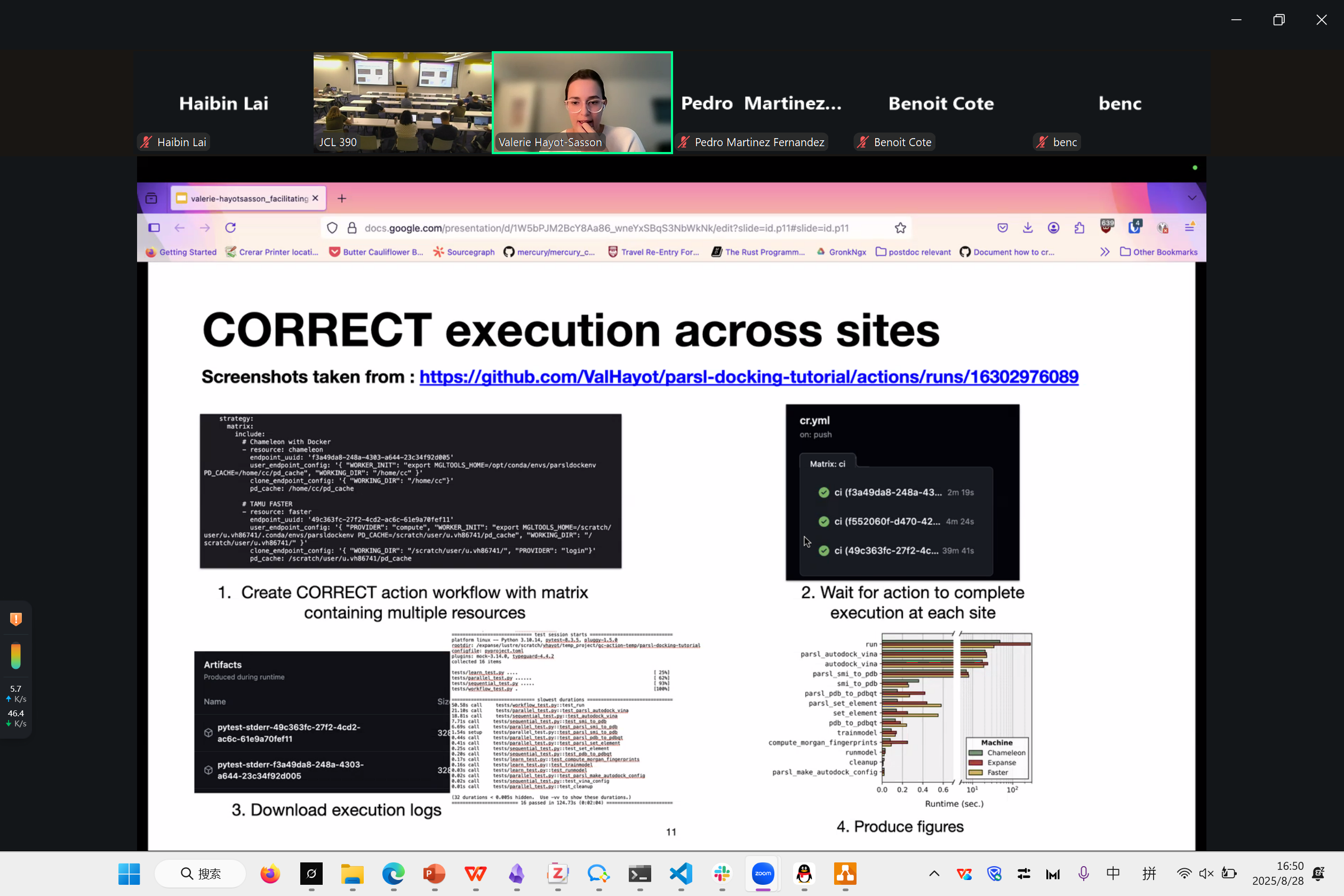
目前有各种 logging, data, commits
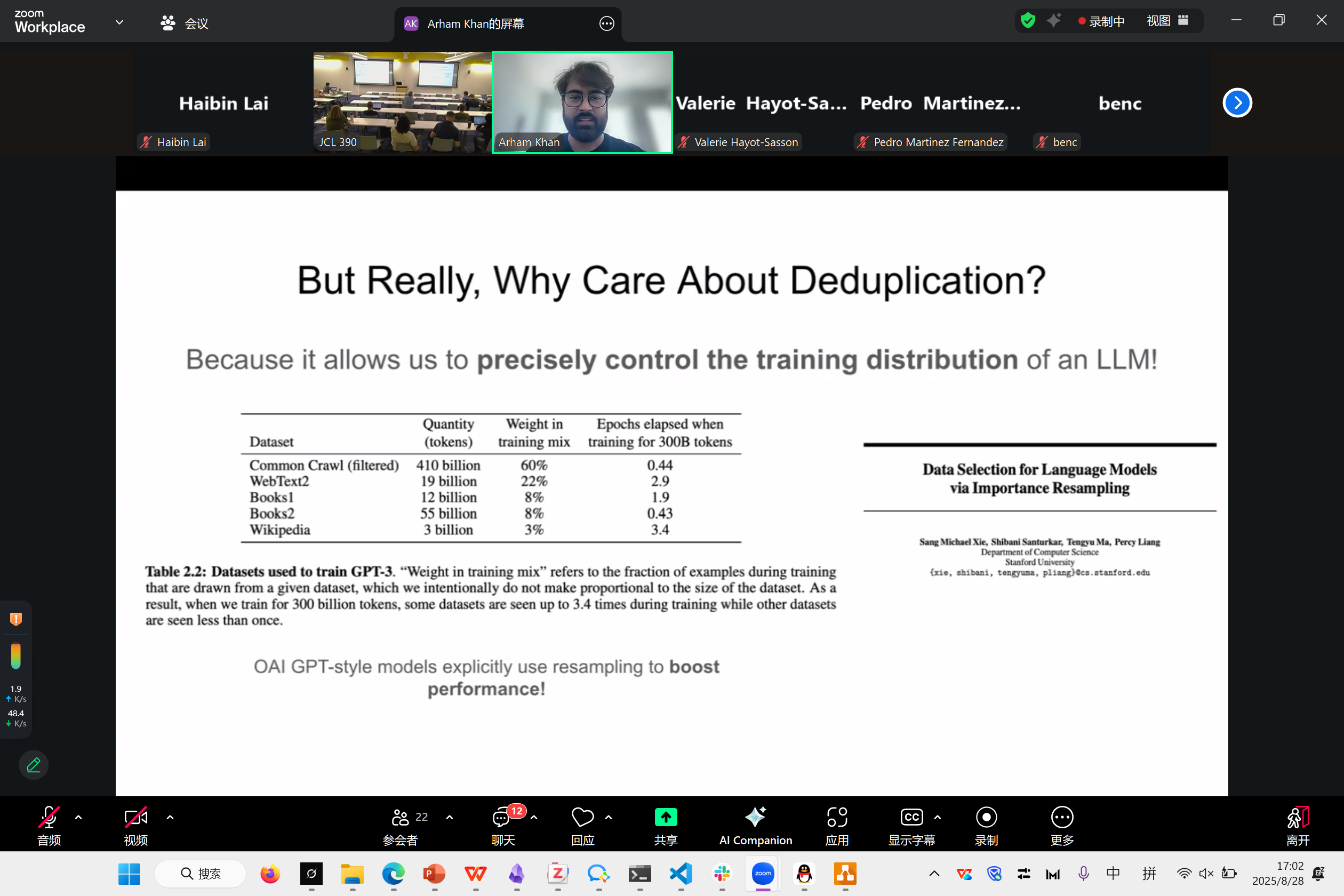
Deduplicating Billons of Documents for LLM Training
LSHBloom: Memory-efficient, Extreme-scale Document Deduplication
Arham
Accelerating QMCPy Notebook Tests with Parsl
Joshua Herman
这是一个Parsl在notebook的使用案例
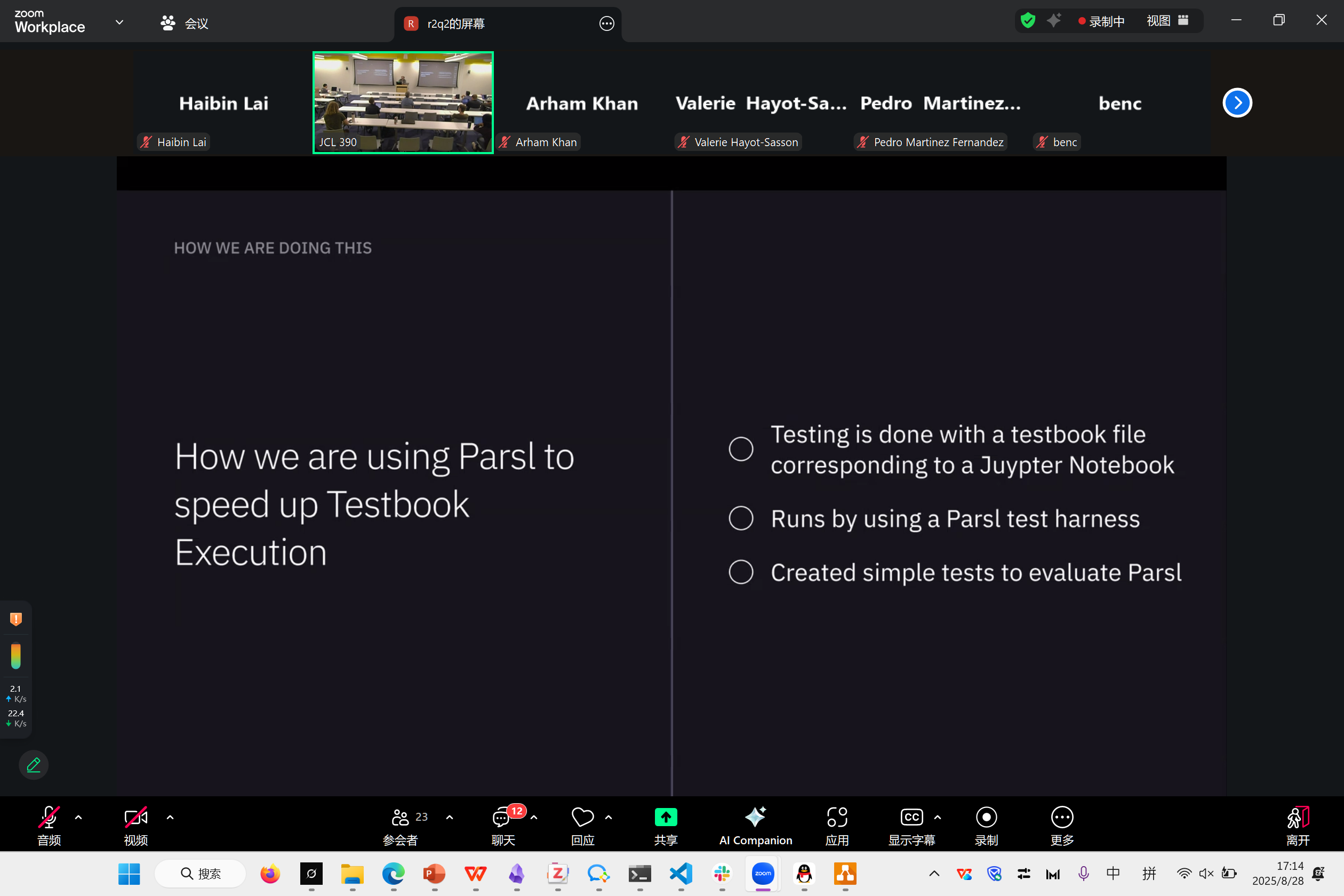
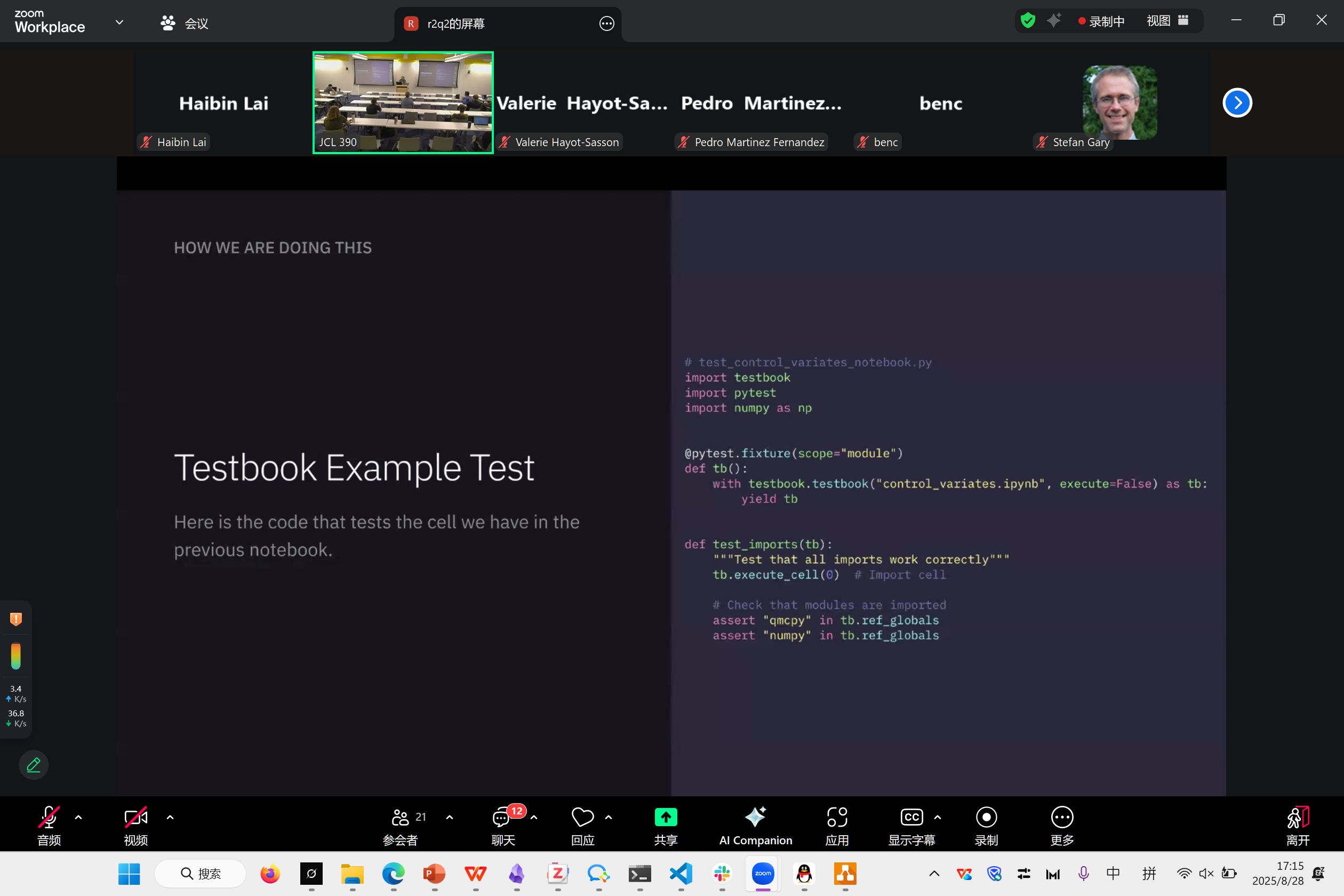
这哥们非常好玩,有很多有趣的经验和开发经历。
Day2
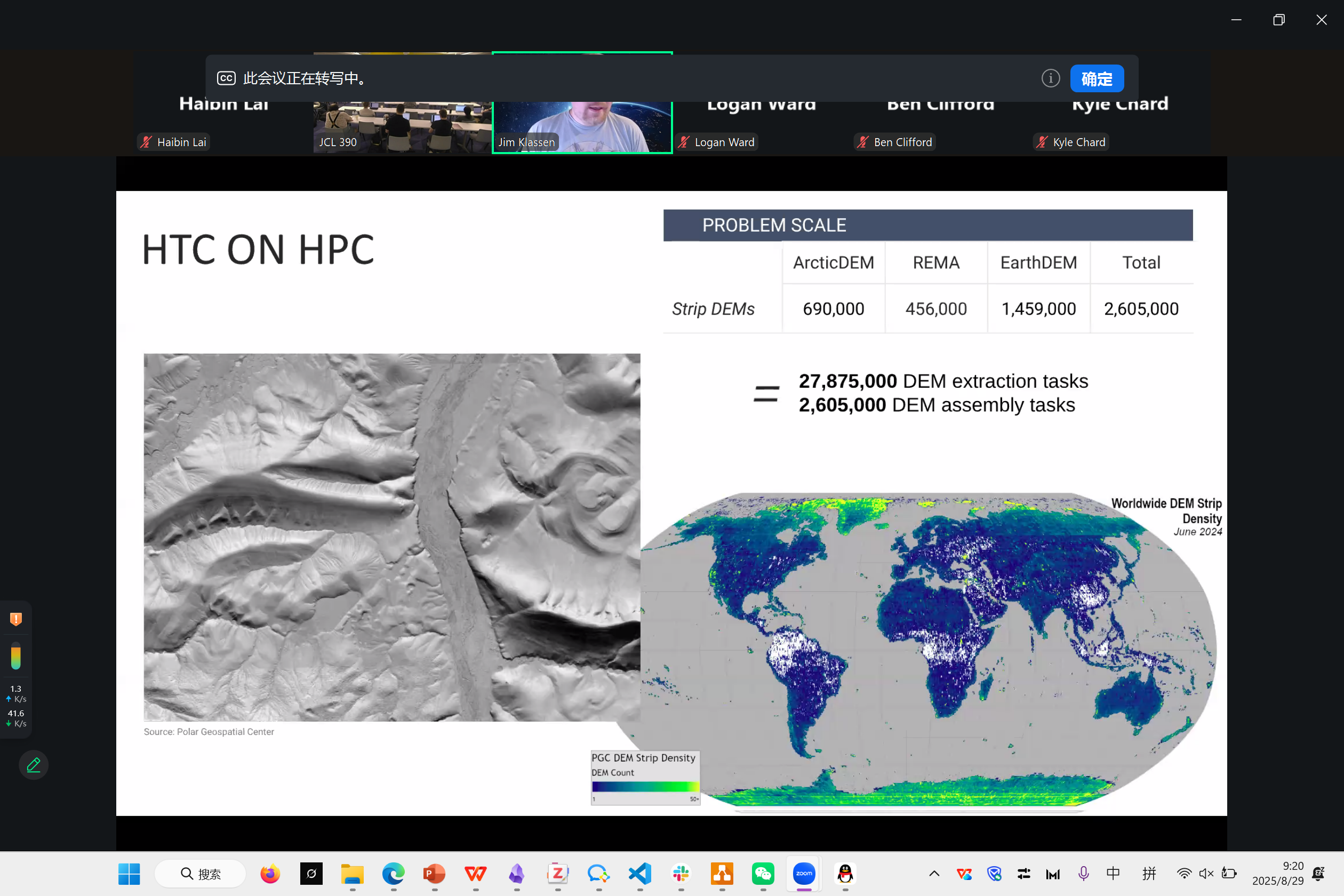
OpenCosmo
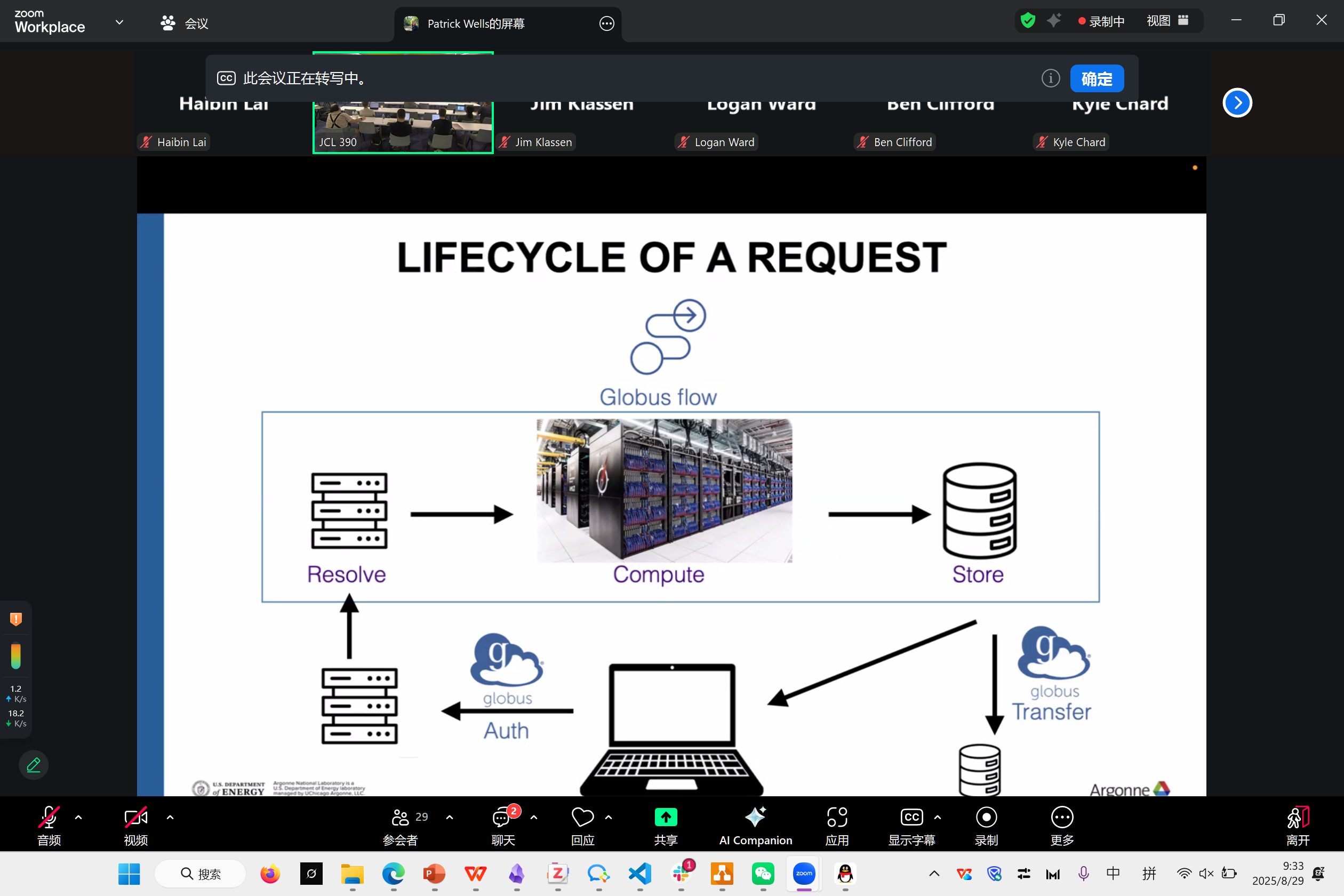
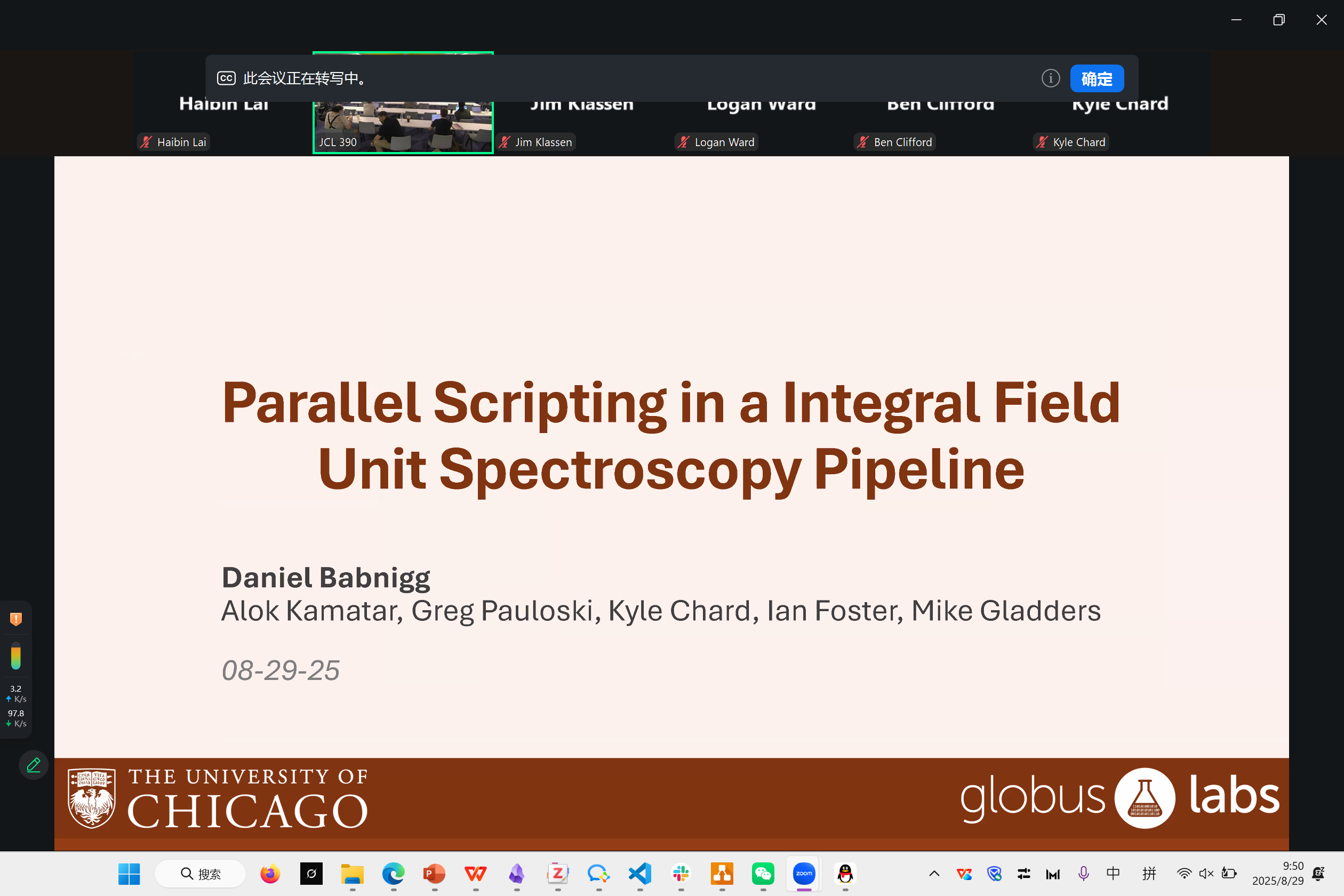
Spectroscopy Pipeline
Daniel
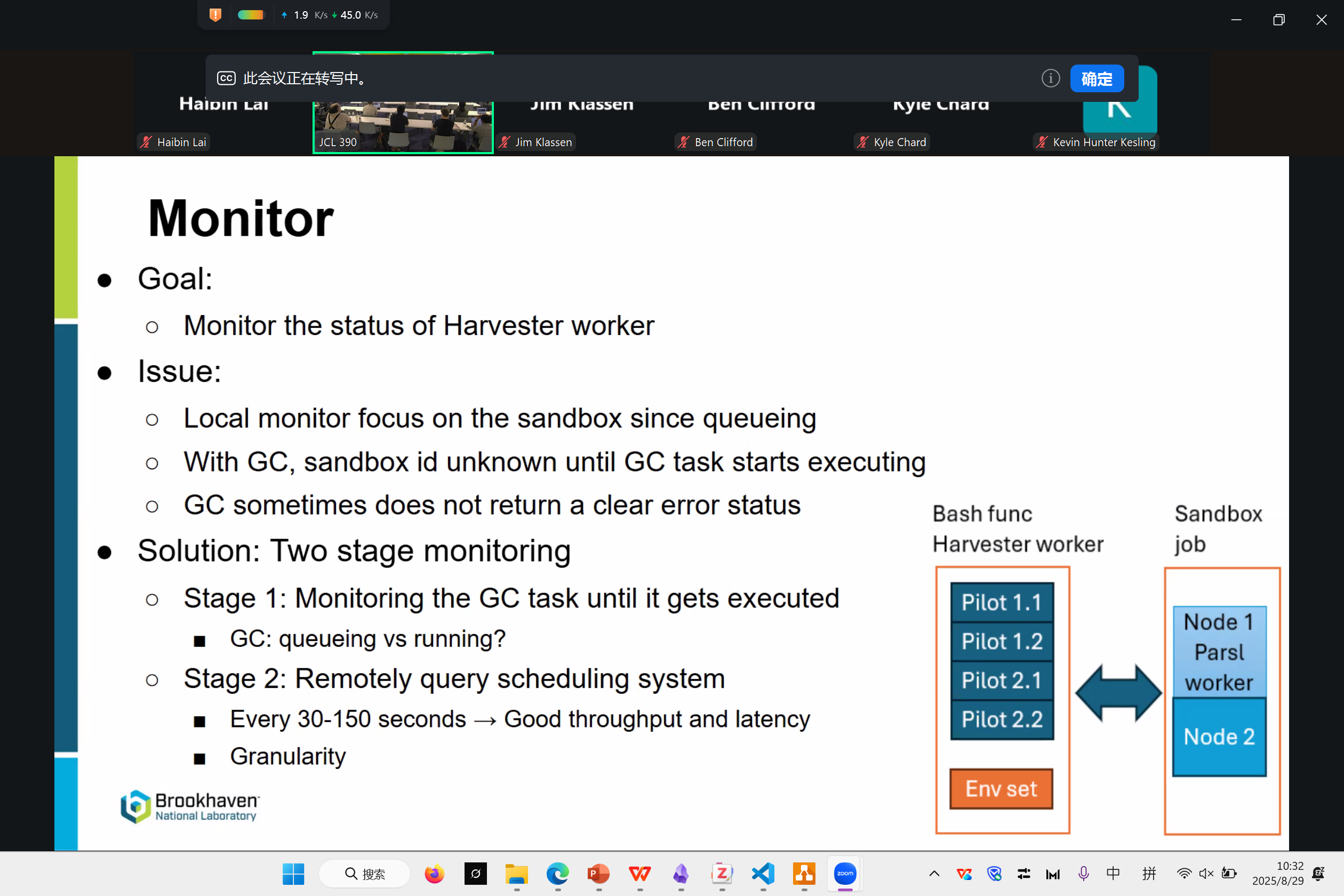
Model
Haochen
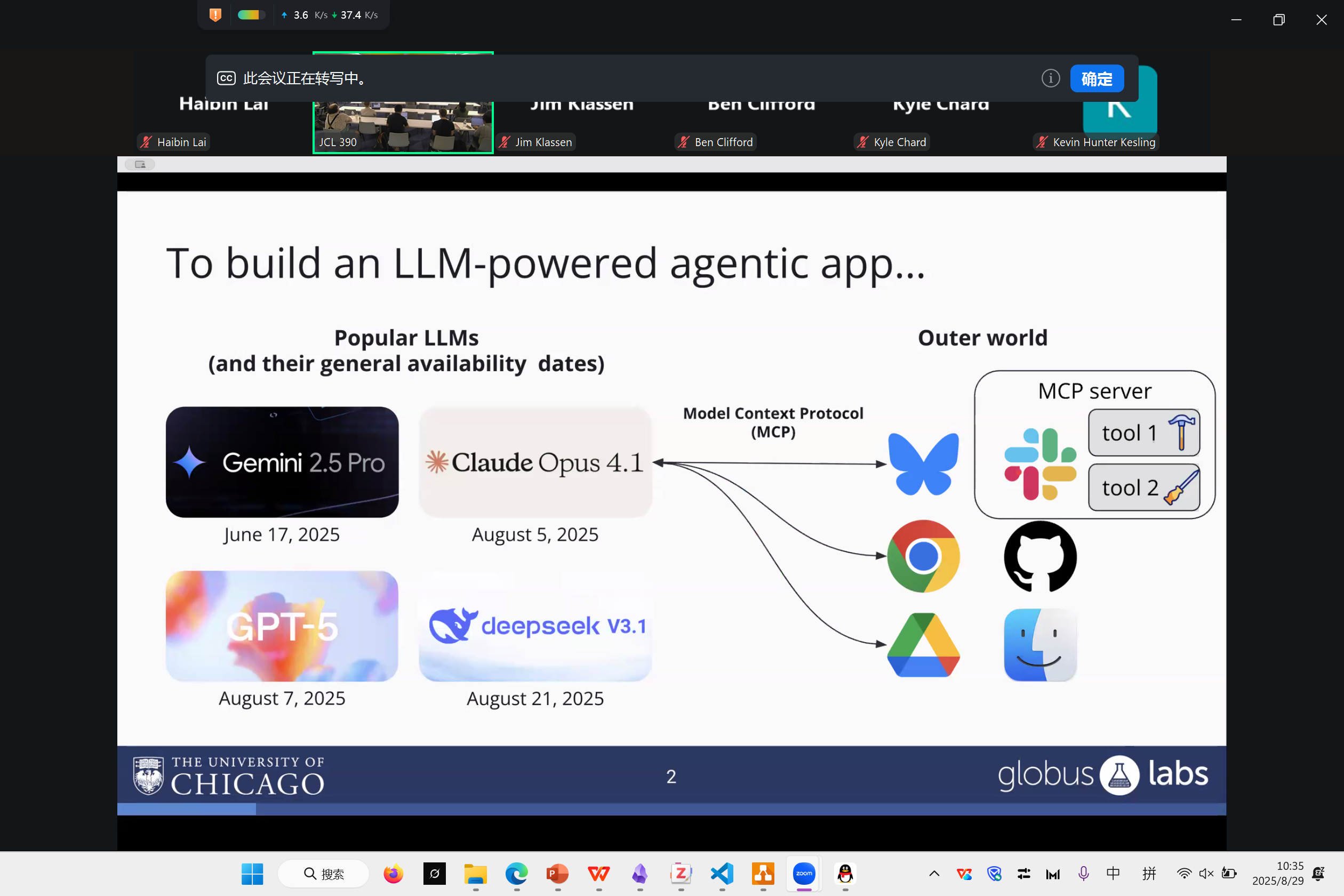
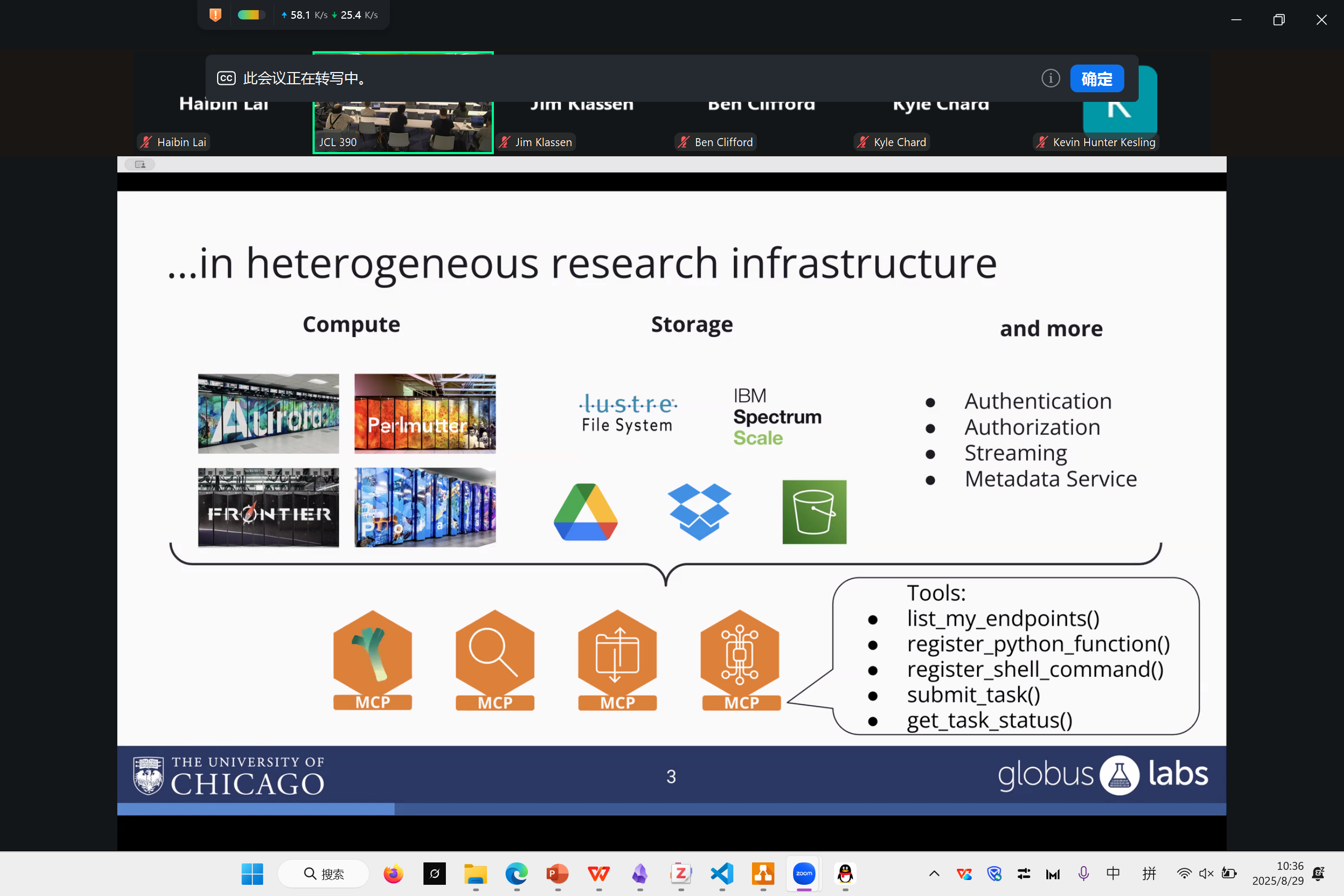
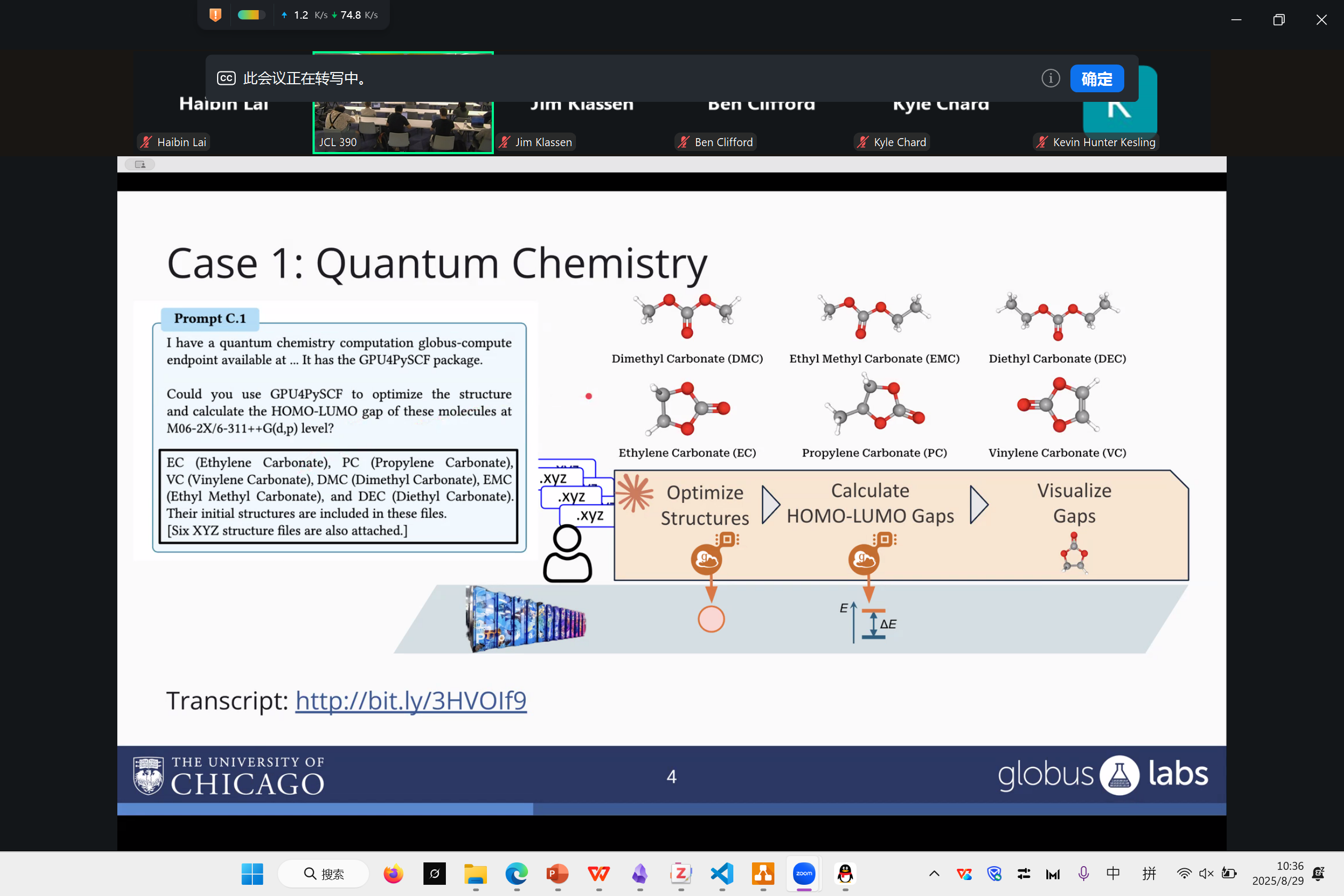
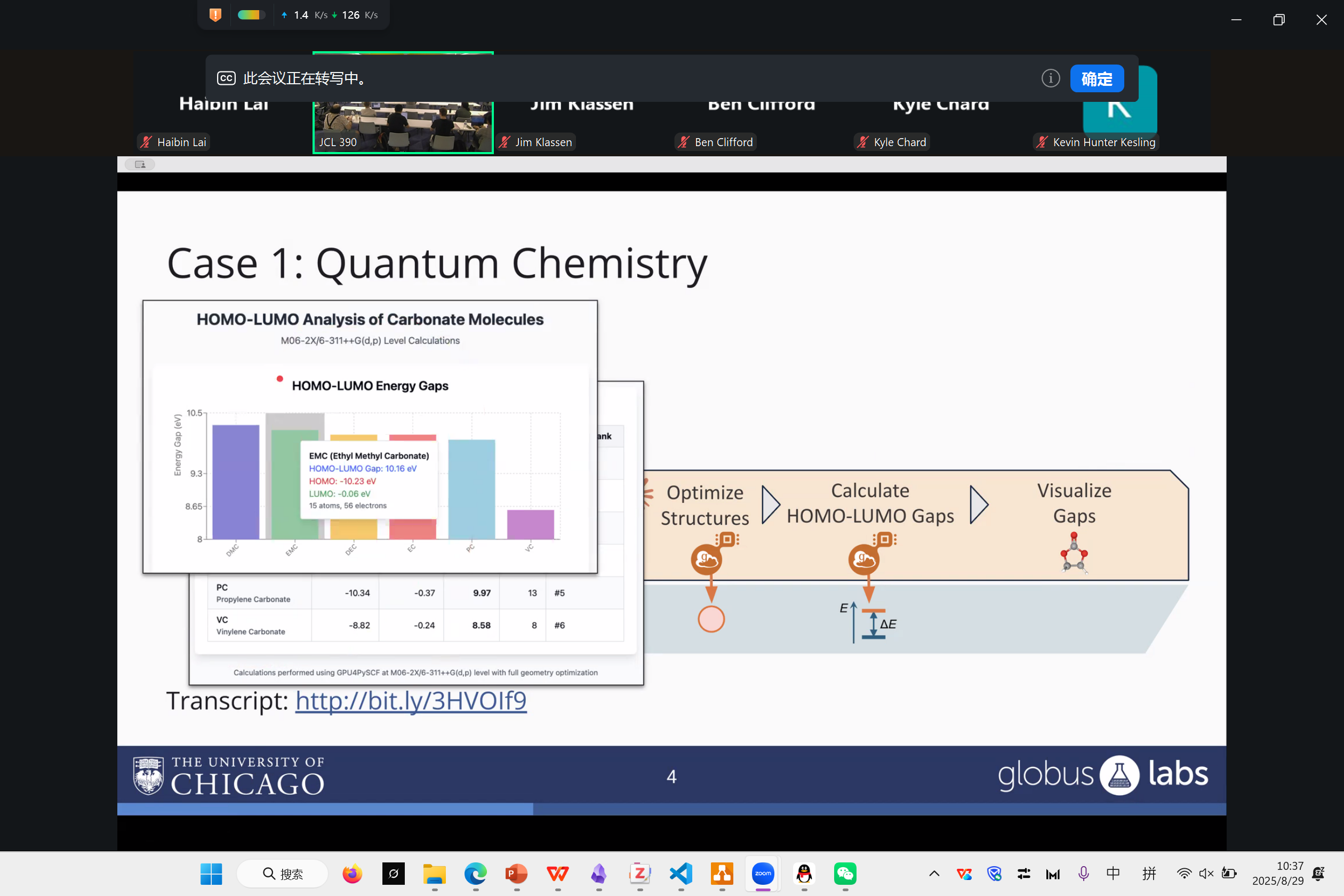
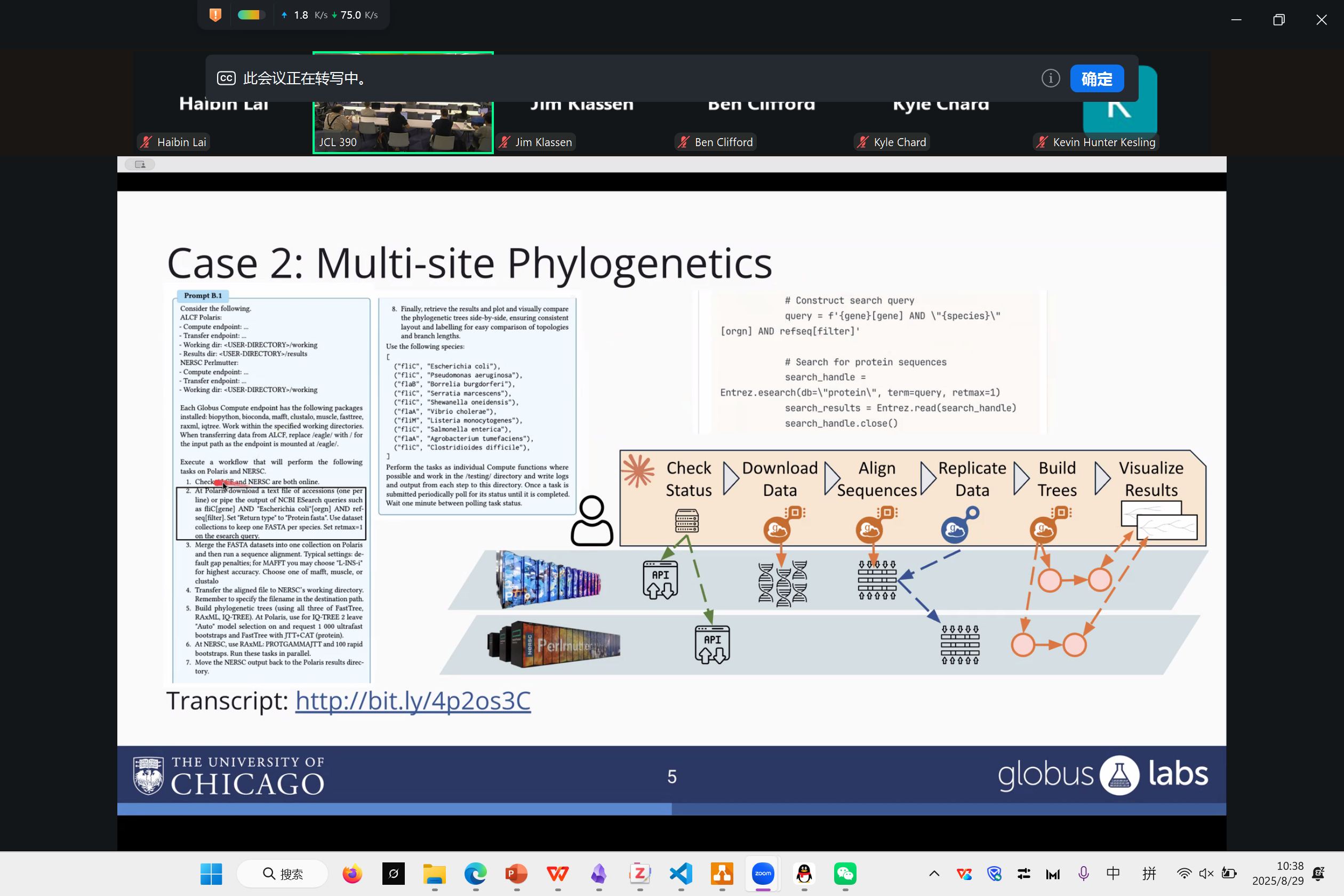
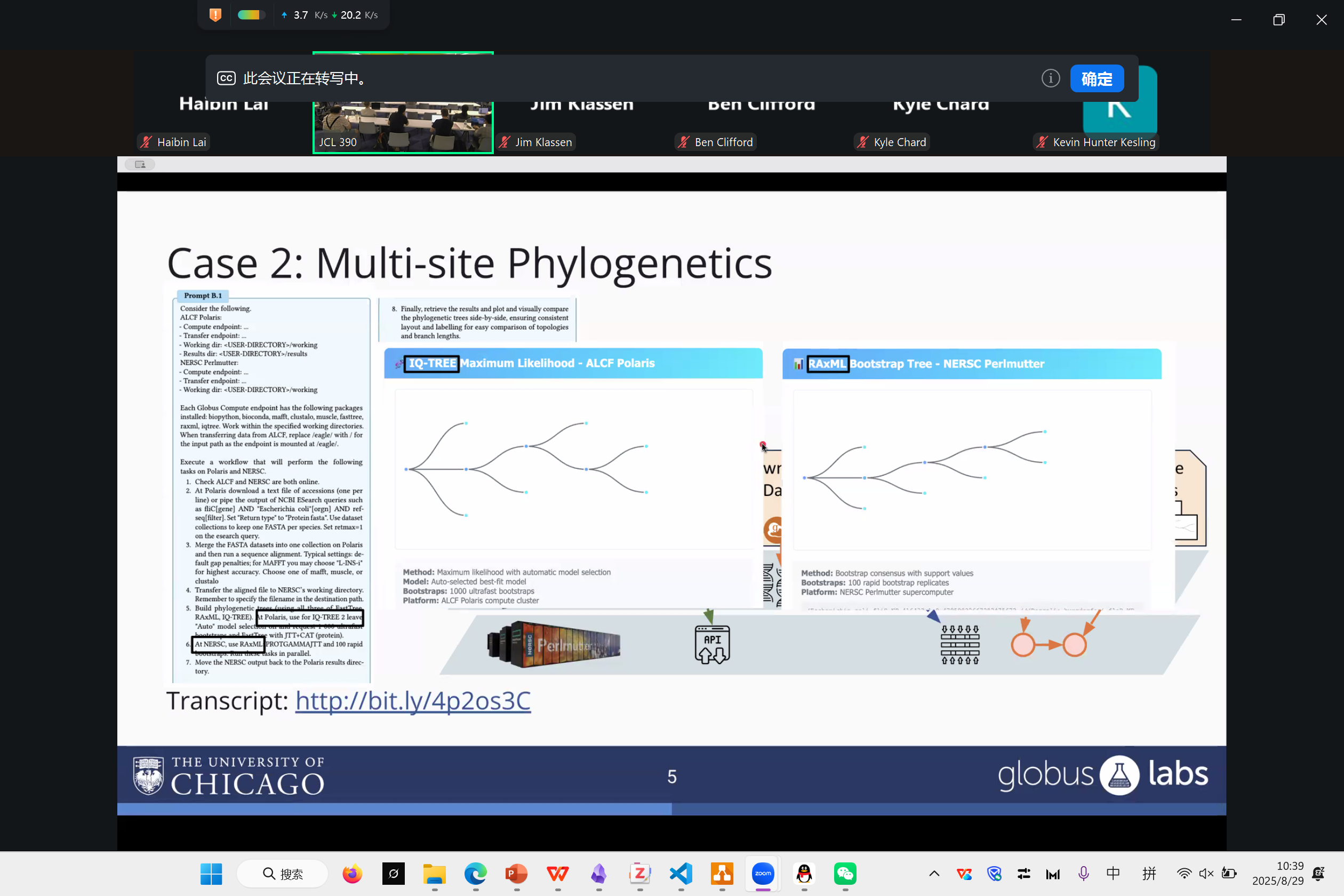
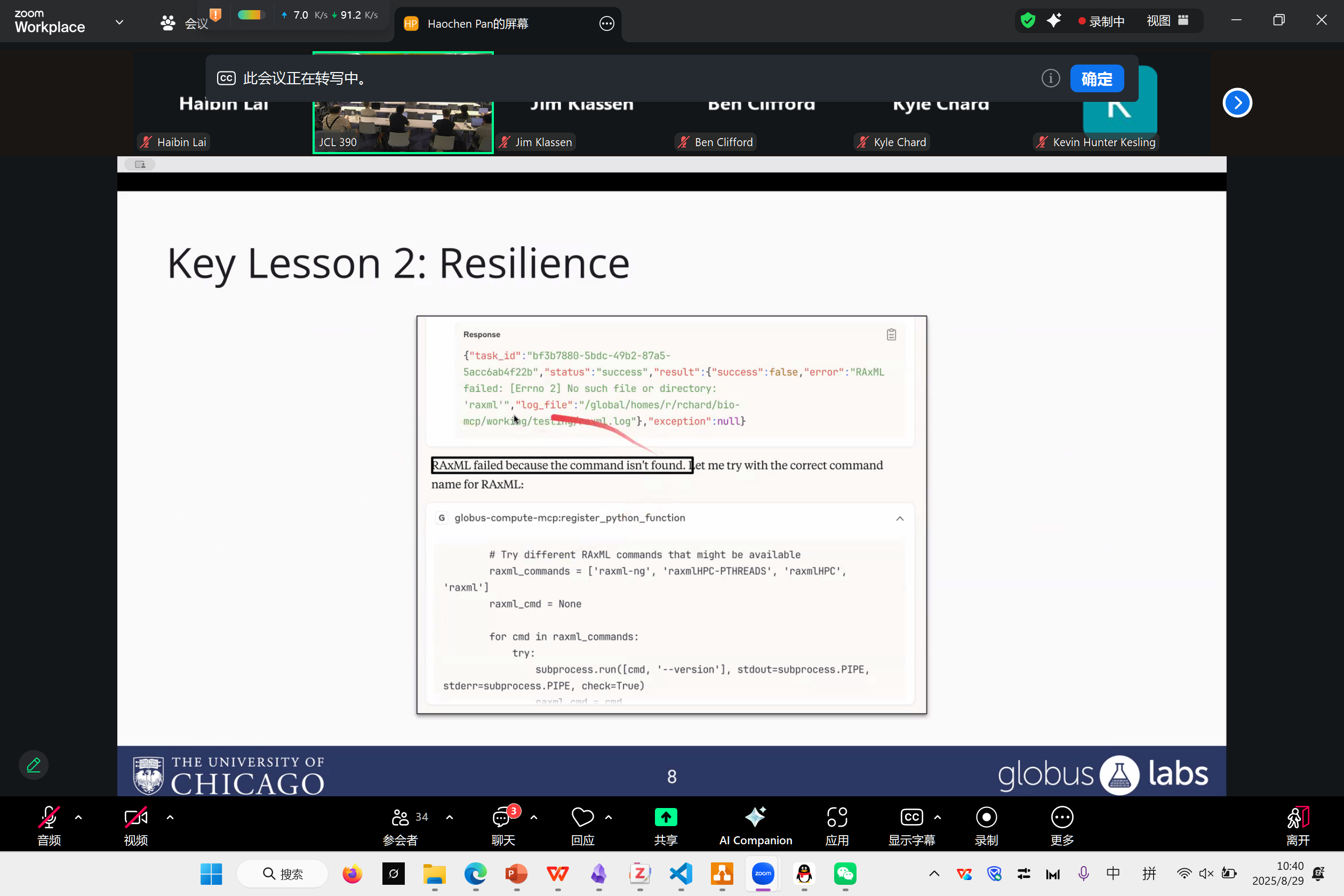
Nu Workflow
Agents
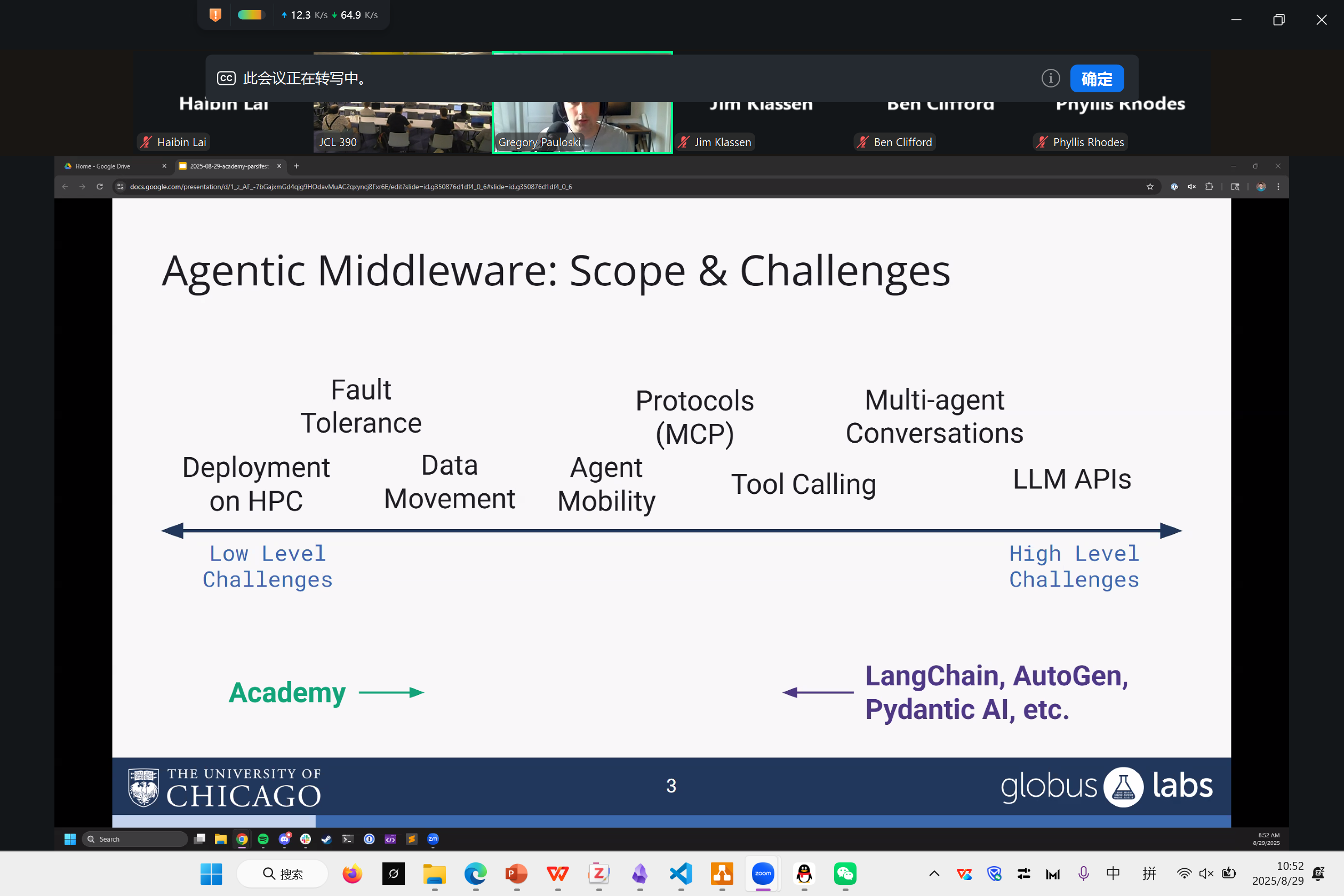
Greg
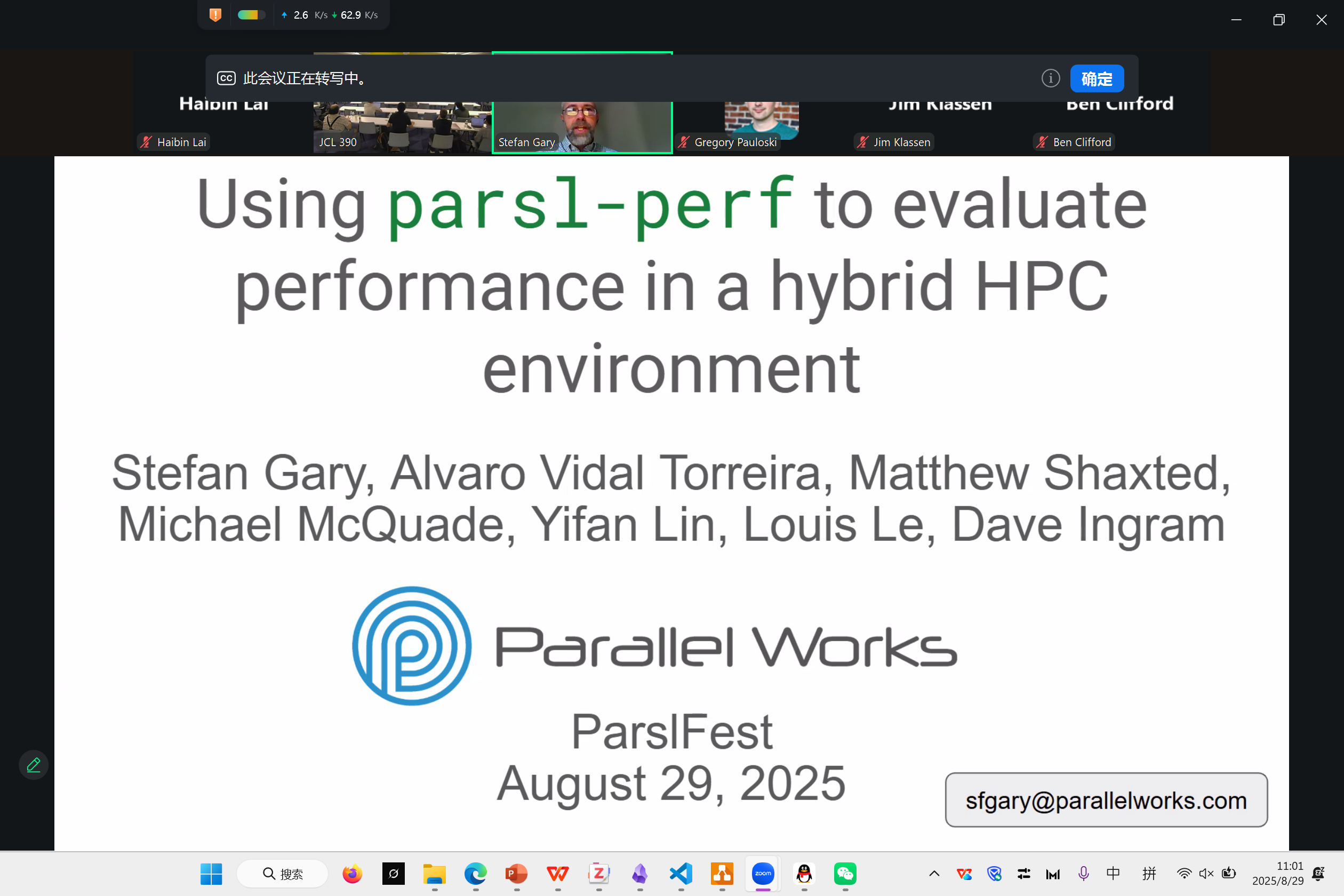
Parsl-Perf
fun proj
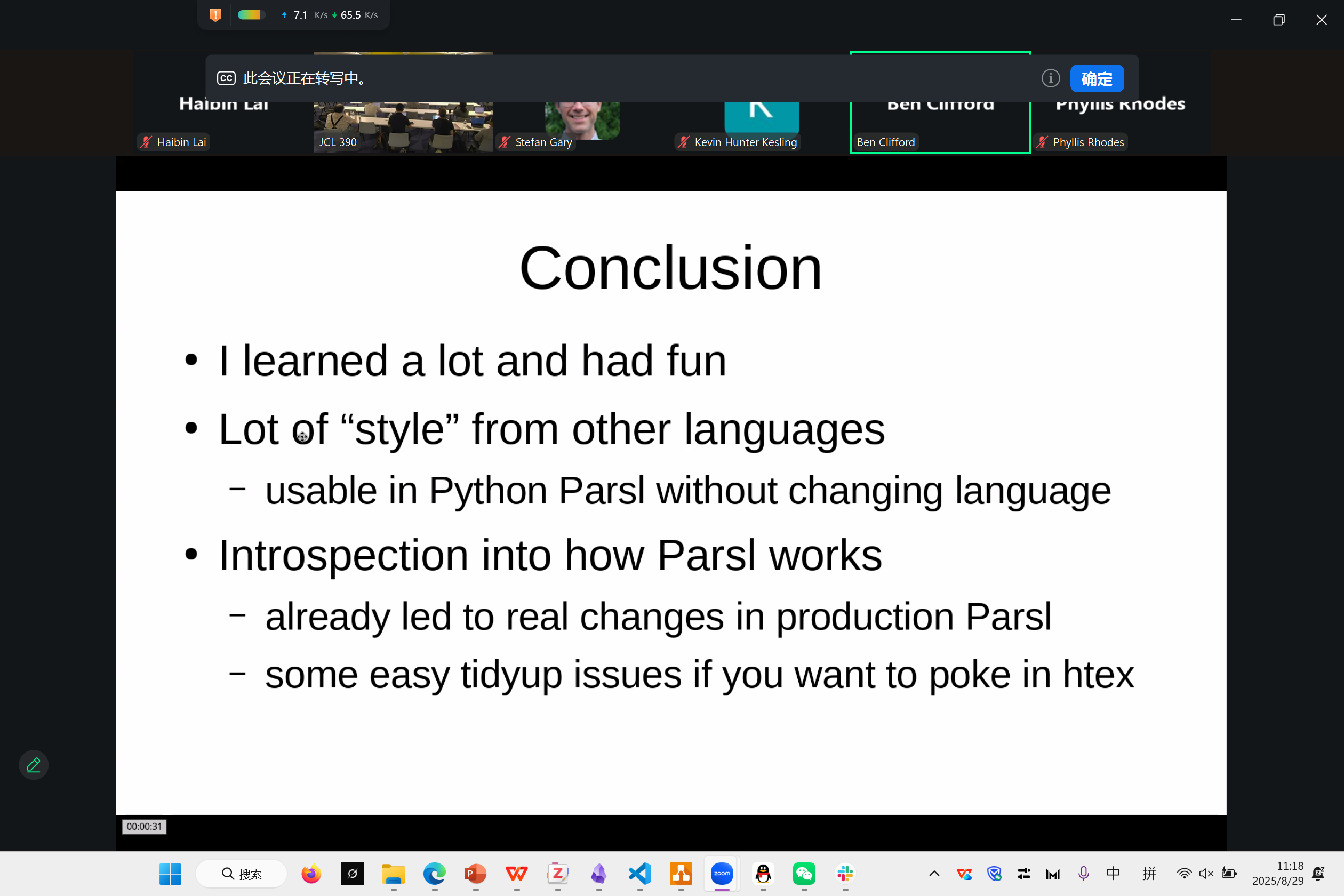
chmod 770 /stor/substor0/haibin
chmod 770 /stor/substor0/haibin
chmod 770 /stor/substor0/haibin
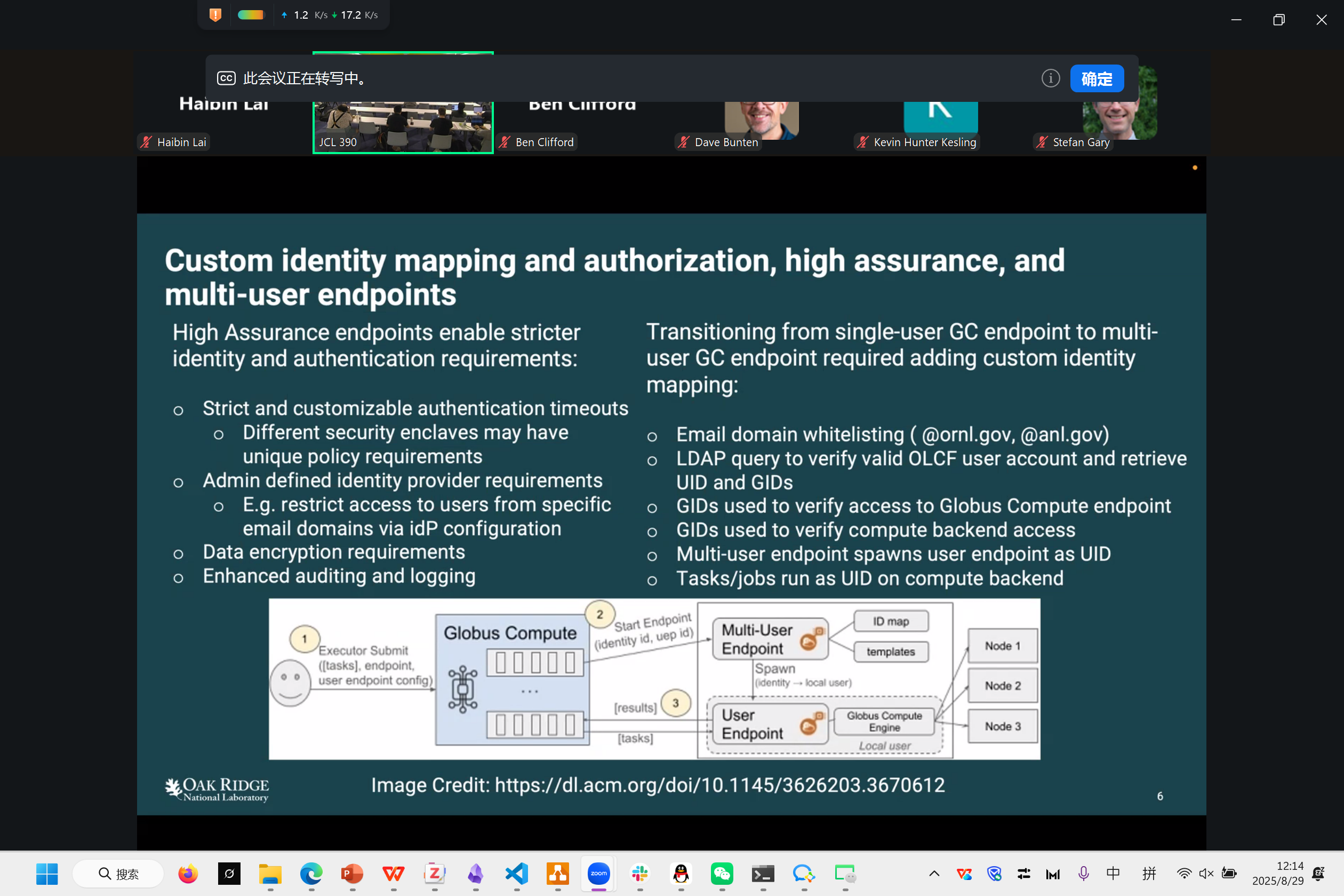
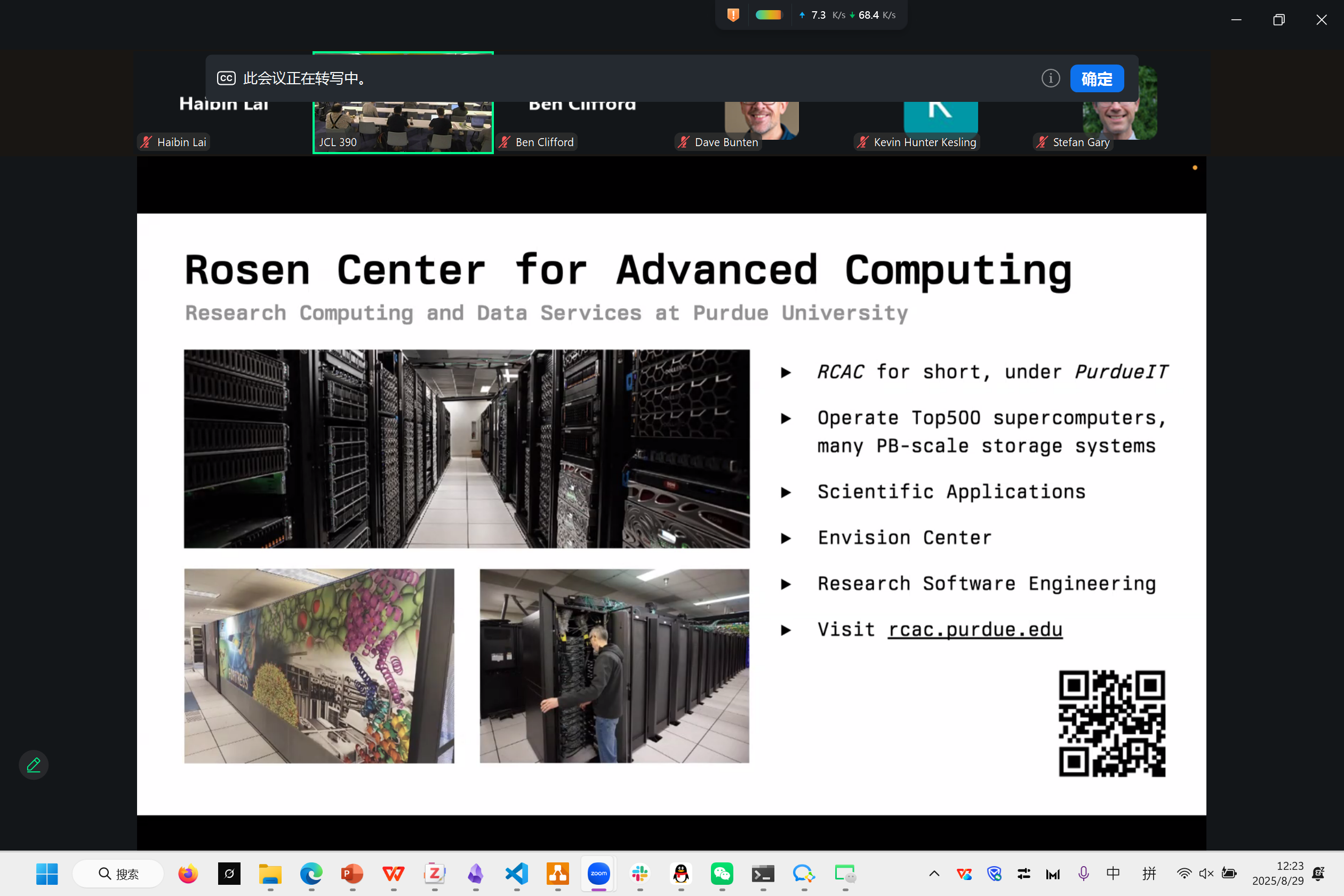
Yadu: Aurora + Parsl
10624 Nodes