
ICPP25 Conference story: Day 2
- Academic
- 2025-09-16
- 500 Views
- 0 Comments
- 1081 Words

Anne Elster, "Parallel Computing and Geophysical Forecasting"
Professor Anne C. Elster Norwegian Univ. of Science and Technology Center for Geophysical Forecasting University of Texas at Austin
Geophysical forecasting offers the opportunity to leverage some of the cutting-edge technologies from the oil and gas sector to improve, for instance, geohazard monitoring and forecasting sudden events along roads and railways. This also includes the use of new methods for monitoring and mapping life and geophysical events at sea and near the seabed. Modern seismic sensors and DAS (Distributed Acoustic Sensing) systems also generate vast datasets we will need both AI and parallel computing techniques to fully make use of. These tasks thus offer many interesting research challenges related to parallel and distributed computing over the next several years.
This talk will highlight some of the ongoing work my group and colleagues are involved in at The Center for Geophysical Forecasting at NTNU. This includes discussing some of our work related to utilizing AI and HPC techniques such as autotuning and combining real experimentation with modeling and vice versa, and how these can impact applications.
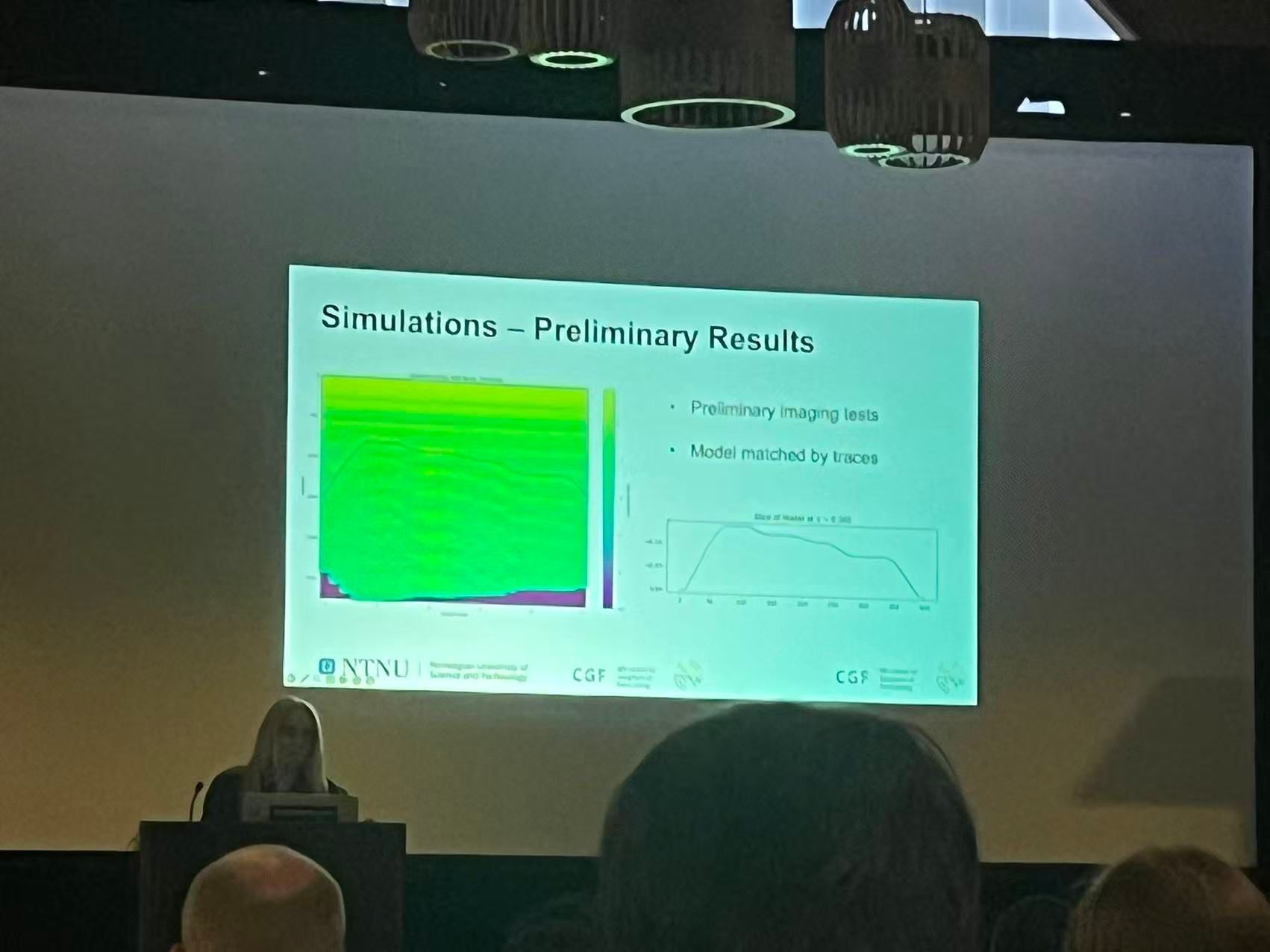
They are developing a good Geophysical Forecasting software using OpenMP and CUDA. And they accerlate the running time from 4 hour to 6 seconds (?)
Their software running result:

Smoothed Particle Hydrodynamics
Some of the main computational methods they used is SPH:
SPH simulation -> Smoothed Particle Hydrodynamics(光滑粒子流体动力学方法 in Chinese)
How it works
- Imagine each particle has a “smoothing kernel” (like a soft sphere around it).
- Physical quantities (like density or pressure) at any point are computed by taking a weighted average of nearby particles inside this kernel.
- The fluid equations (mass, momentum, energy conservation) are rewritten in terms of particle interactions.
So the particles move according to physics, and together they behave like a continuous fluid.

Full Waveform Inversion

Full Waveform Inversion (FWI) is a computational method in geophysics used to create very detailed images of the Earth’s subsurface.
- Input: Seismic data (waves recorded after they travel through the Earth).
- Output: A high-resolution model of underground properties (like velocity, density, etc.).
It’s widely used in oil & gas exploration, earthquake studies, and geothermal energy research.
How it works
- Start with a guess: Assume an initial Earth model (e.g., velocity distribution).
- Simulate waves: Use numerical methods (like finite differences) to compute how seismic waves would travel through this model.
- Compare with real data: Compare the simulated seismic waveforms with the actual recorded seismic signals.
- Update the model: Adjust the Earth model to reduce the difference (the misfit).
- Iterate: Repeat the process until simulated and real data match closely.
AI+HPC
That's a little close to Lucas' jobs!

Industry Session: Max Chung, Supermicro

Max introduce what supermicro are selling

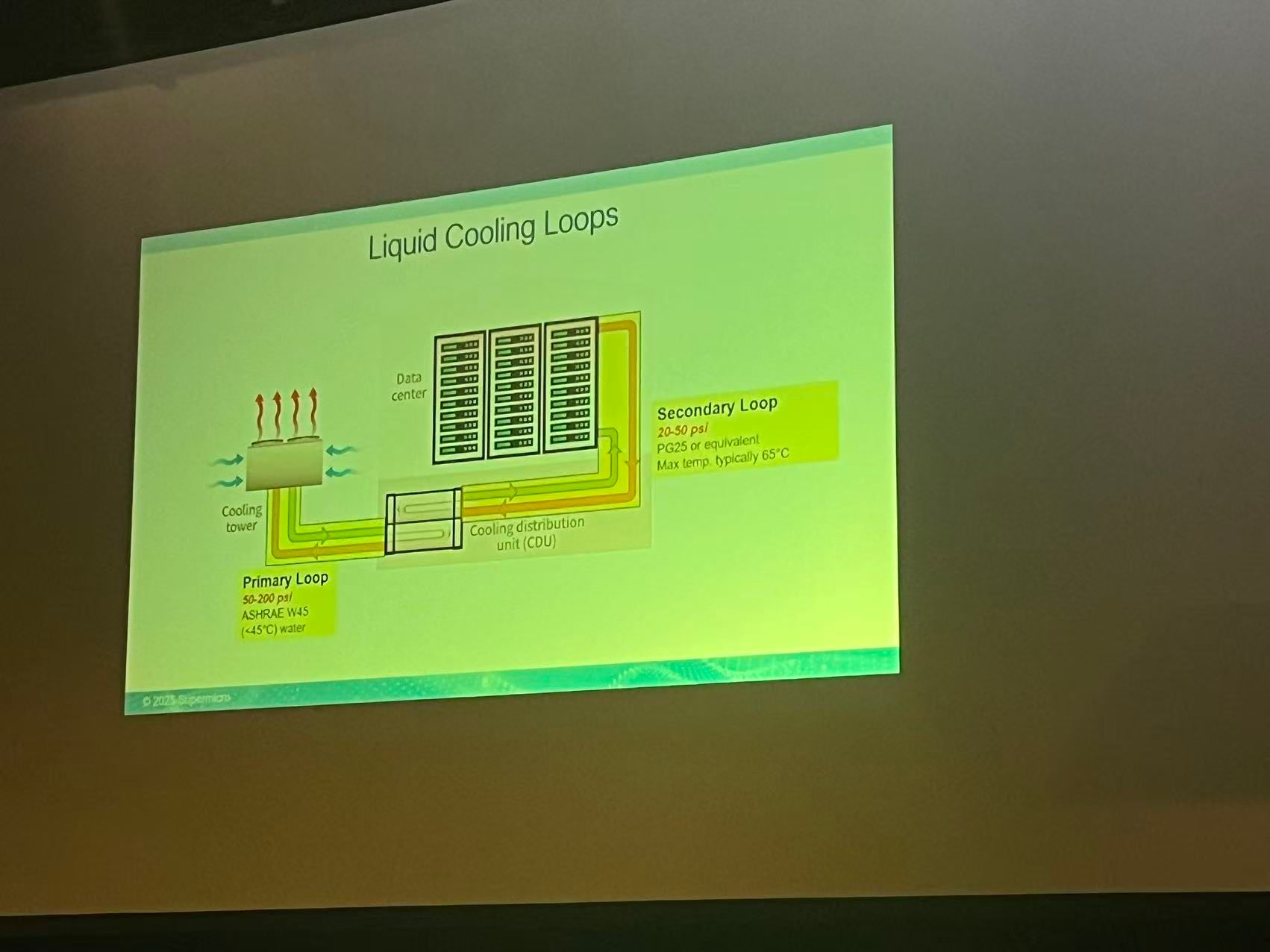

How much is their NVLink speed:
200GB/s for RDMA

CXL still lack of scenario

How do you know that how many power do you want?
Run HPL to measure the full power
How to control power on each node?
On board Hardware:
BMC
PDU: power distribution unit
break

Paper Session 7: Architecture
Toucan
Chairman: Taisuke Boku
LLaMCAT: Optimizing Large Language Model Inference with Cache Arbitration and Throttling

We introduce LLaMCAT, a novel approach to optimize the LLC for LLM inference. LLaMCAT combines Miss Status Holding Register (MSHR)- and load balance-aware cache arbitration with thread throttling to address stringent bandwidth demands and minimize cache stalls in KV Cache access. We also propose a hybrid simulation framework integrating analytical models with cycle-level simulators via memory traces, balancing architecture detail and efficiency.
Problem
LLM decoding is memory bound.
We found that decoding here they only utilize LLC well, but for the first level Cache, that's not very good

Key Pain
Miss Handling Arch contention stalls even hit traffic
LLC is shared among CPU cores / GPU cores.
GQA reduces but not eliminates memory-boundedness

Cache has 2 bandwidth

upstream bandwidth (SRAM bandwidth)
downstream bandwidth (more related to the miss handling throughput)

Main Design

Contribution

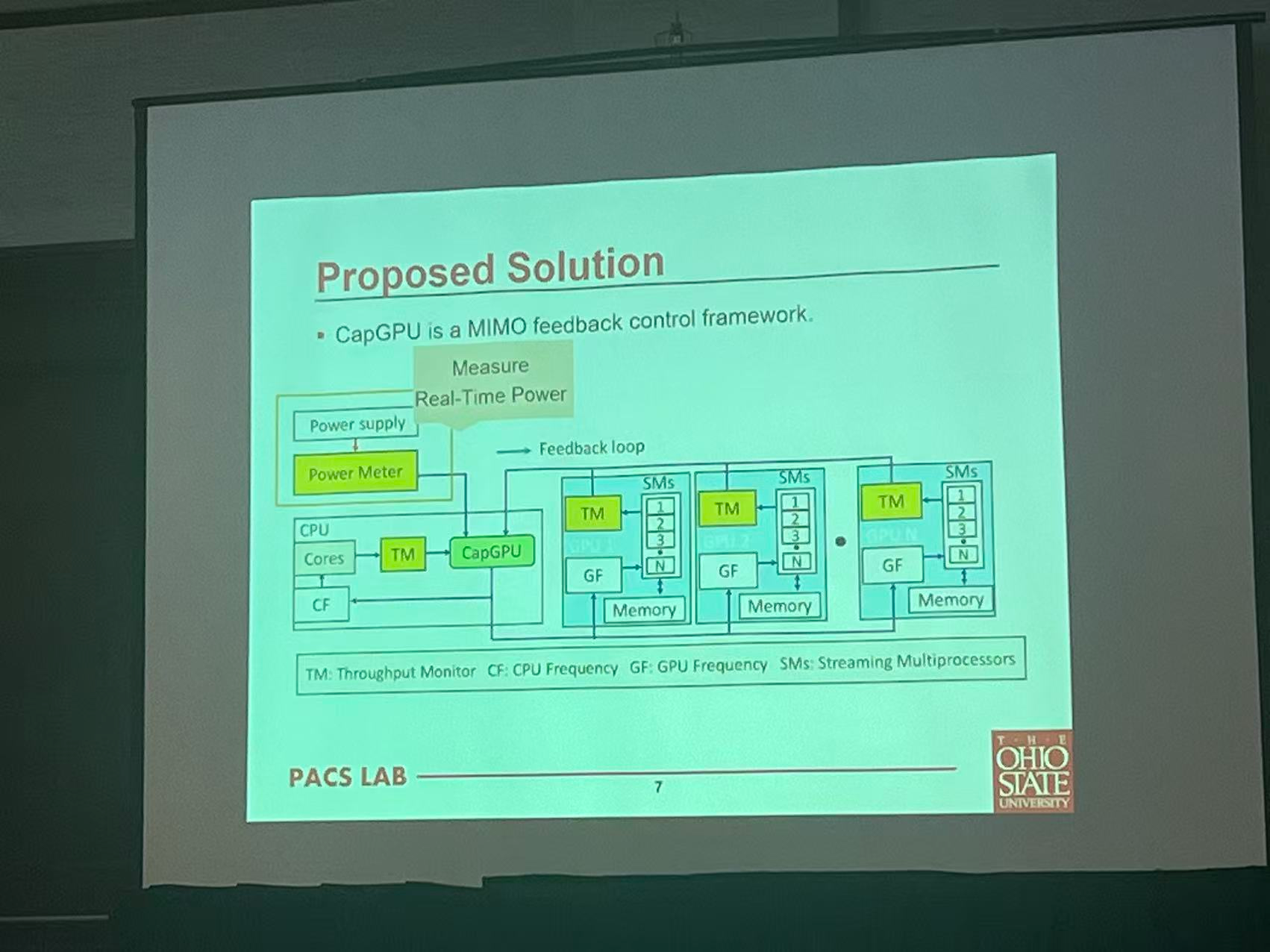
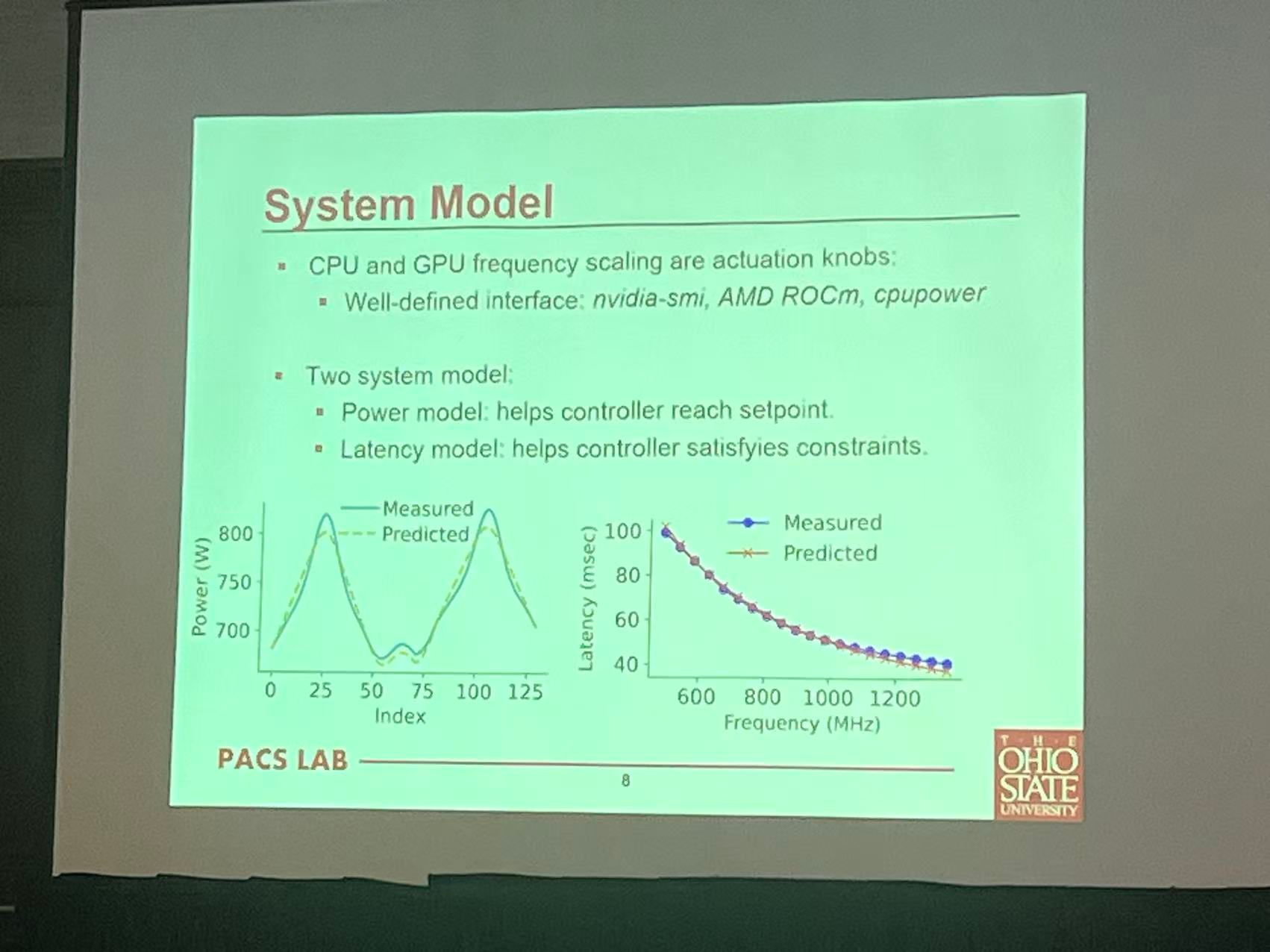
Power Capping of GPU Servers for Machine Learning Inference Optimization
OSU Mayuan

Data center analysis system
server lab
Scene: AI on datacenter
Power capping technique

Dynamic Voltage and Frequency Scaling
DVFS
Solution
Noon
A good part I didn't listen:
Efficient Cross-Datacenter Congestion Control with Fast Control Loops
Paper Session 10: Programming Environment
Design and Optimization of GPU-Aware MPI Allreduce Using Direct Sendrecv Communication
Optimizing NumPy with SVE Acceleration on ARM Architectures
pyGinkgo: A Sparse Linear Algebra Operator Framework for Python

afternoon 下午
Online Paper Session 8
Zoom online session
SmartBlock: Adaptive Block Floating Point Quantization for Efficient DNN Acceleration
Design of Interposer Interconnection Network Based on High-Radix Interposer Routers
Automated FPGA Accelerator Generation Framework for Transformers with Dataflow Optimization
Paper Session 8: Multidisciplinary
Now come to my part!
Performant Unified GPU Kernels for Portable Singular Value Computation Across Hardware and Precision
From MIT
They try to profile GPU kernel on computation for different GPU, on singular value
ParaCOSM: A Parallel Framework for Continuous Subgraph Matching

Full video:
【ICPP25 当高频交易遇上图计算】 https://www.bilibili.com/video/BV1njHhzbEAT/?share_source=copy_web&vd_source=72eac555730ba7e7a64f9fa1d7f2b2d4
Thievory: Graph Processing with Multi-GPU Memory Stealing
Paper Session 11: System Architecture and System Software
PTWalker: Cache-Efficient Random Walks via Alternating Dual-Subgraph Walker Updating
Accelerating an Electromagnetic Simulation via Memory-Constrained Task-Based Load Balancing
Leave No One Behind: Fair and Efficient Tiered Memory Management for Multi-Applications
Online Paper Session 9
Zoom online session
SINA: Accelerating Time Synchronization in Large-Scale Network Simulation Using In-Network Allreduce
Optimizing Direct Convolutions on High-Performance Multi-Core DSPs
SpeedSketch: An Ultra-Fast Sketch Generation and Delta Encoding Framework for Delta Compression
Online ICPP Paper session
Paper Session 9: AI in Computing & Performance
Toucan
Auto-Stencil: Performance-Driven Stencil Optimization with Hardware Feedback for LLMs
From Qinghua HPC-Science Team

Solving Extended Flexible Job Shop Scheduling Problems with Deep Reinforcement Learning
Architecture-Aware Models of AI Engines for High-Performance Matrix Matrix Multiplication
Onsite Paper
Paper Session 12: Algorithms & Performance
Macaw
Deadline-Aware Scheduling of Mixed-Criticality Tasks
Maxime focus on an AI4Sci Software: ALCF, to do scheduling works on different CPU nodes.

Now they are good for using DP linear scheduling, but on multiple CPU, it's NP hard.

So maxime use a greedy algorithm:

Fast Exact Diameter Computation of Sparse Graphs

Joint Prediction and Matching for Computing Resource Exchange Platforms
Wonderful Night






Just have a great day and a great conference!!