Hadoop:前世今生
- Big Data
- 2024-09-15
- 997 Views
- 0 Comments
- 3694 Words
Streaming system
A type of data processing engine that is designed with infinite datasets in mind.
Hadoop的起源:Nutch
Lucene 全文检索
1997年,Doug Cutting,后来hadoop的创始人之一,用Java写了Lucene并将其开源,目标是为各种应用软件加入全文检索功能。Lucene受到了大家的热烈追捧,大家知道的 ElasticSearch 和Solr,实际上他们的内核都是Lucene。
早期的时候,这个项目被发布在Doug Cutting的个人网站和SourceForge。后来,2001年底,Lucene成为Apache软件基金会jakarta项目的一个子项目。
但是此时Doug在想,自己的全文检索数据可以从哪里来?他想到了网页。
Nutch 网络爬虫框架
Doug尝试通过Lucene对网页进行索引,并且Mike Cafarella也加入进来,做了个新产品叫做Apache Nutch。在Lucene的基础上,他们添加了网络爬虫和一些网页相关的功能,
- Nutch 会解析抓取到的网页内容,提取网页的正文、标题、元数据等。
这些内容会被保存到本地存储中。
这样,很多人用了Nutch进行爬虫后,就可以将这些网页存储在本地,甚至提供给其他人使用。这样,Nutch被人们所利用的理由,很快从一个简单的站内检索,推广到全球网络的搜索上,就像Google一样。大批网站采用了Nutch平台,大大降低了技术门槛,使低成本的普通计算机取代高价的Web服务器成为可能。甚至有一段时间,在硅谷有了一股用Nutch低成本创业的潮流。
然而,随着时间的推移,从小型创业公司用的Nutch,乃至Google、Yahoo,都面临网页搜索对象“体积”不断增大的问题。1997年的谷歌,其所有的网页只需要一台PC即可存储,然而在2000年,网页上的数据已经来到世界上最强的超算都无法解决的量级。
Doug的团队将Apache Nutch项目部署在一台机器上,每秒能够索引100个页面。由于是单机部署,很快他们的系统就遇到了瓶颈,索引页面的数量的极限是1亿个。
而对于Google来说,当时的情况更加严重。无论是存储,还是计算上,都面临很大的挑战。在存储上,作为互联网搜索引擎,需要存储大量的网页,且还要不断优化自己的搜索算法,提升搜索效率。在计算上,Google 的基础算法PageRank 来自于它的两位创始人,Larry Page 和 Sergey Brin,其在用户给定搜索查询的时候返回最相关搜索结果的算法。这一算法对计算量的需求很大,需要更强的分布式计算才能解决。
多机存储?
Doug的团队开始尝试解决Nutch拓展到集群的问题。
(能不能写一个分布式的项目?)(多机多卡)
于是他们开始通过部署更多的机器(构建集群)来对系统进行扩展,让其能够索引更多的网页。可想而知,随之而来的是大量的运维问题,Doug和Mike只期望把精力放在Nutch应用的开发和调优上,而不是浪费在大量的运维工作上。他们基于自己的痛苦经历,提出了他们理想中的分布式系统应该具备的特性:
- 容错性:这个系统应该能够独立完成系统宕机的自动恢复,也就是说有机器挂掉不会影响上层应用;
- 负载均衡:如果一台机器宕机了,那么这个系统应该可以自动将工作负载平均的分派到其他活跃的机器上。
- 数据防丢失:这个系统应该能够保证数据一单写入磁盘,那么即使有机器坏掉,数据也不会丢失。
GFS、NDFS 分布式文件系统
Sanjay Ghemawat
此时GFS出现:
GFS
启发了Doug和Mike,于是他们决定参照这篇论文进行实现,并且与2004年完成,命名为NDFS(Nutch Distributed File System),也HDFS的前身,一个分布式的文件系统,这样的系统解决了我们前面提到的这些问题(容错、负载均衡、防丢失)。
**软件系统可以抽象为存储能力和计算能力的合计:
存储能力解决数据的持久化,
计算能力解决业务过程的有序执行。
- 计算问题:分布式系统通过增加计算节点来解决计算瓶颈,从而提升处理效率。
- 存储问题:分布式文件系统通过分布式存储、数据副本和负载均衡等机制,解决传统集中式存储中的单点问题。这使得存储和数据管理变得更加可靠和高效。
那么分布式软件系统核心所要解决的核心问题就是单点计算问题,通过增加计算节点数(CPU数)以提升整体的处理效率。但是在解决了单点计算问题的同时也带来了一个附加问题就是存储单点问题,计算问题可以通过增加机器来解决,存储单点问题则没有那么简单,也就是会面临上面提到的三个问题。借助分布式文件系统,则可以将存储单点问题从应用系统层面剥离出来,使其专心解决计算问题即可。
不知道是谁说的“当你解决了一个问题之后,就会引入一个新的问题”,也就是当我们通过分布式文件系统解决了存储单点问题之后,引入的一个新问题:
如何能够高效的利用分布式文件存储系统中存储的数据?
原因很简单,对比过去的单点存储,所有数据都在一块磁盘上;但是分布式文件系统数据是分散在多块磁盘上,如果要计算就会涉及到多个磁盘上的数据的传输和同步,从而造成大量的网络开销。
针对这个问题,Map Reduce框架应运而生.
Map Reduce
传奇程序员 Jeff Dean, Sanjay Ghemawat
Jeff Dean的传奇人生:超级工程师们拯救谷歌_文化 & 方法_James Somers_InfoQ精选文章
MapReduce计算模型的核心是通过并行、容错处理以及本地化访问的特性。本地化访问的意思是,与我们传统的思考数据找计算不同(在从程序中从远程存储介质中读取数据进行处理),MapReduce计算模型采用的是计算找数据的模式,也就是MapReduce这个框架会自动的进行计算任务的调度和分配,确保每个原子的计算任务都在数据所在节点上执行,从而减少了不必要的网络开销,提升了整体的处理性能。
-
Map阶段:将输入的数据分割成独立的块,并将这些数据块并行处理,得到中间结果。
-
Reduce阶段:对Map阶段的结果进行聚合,得出最终结果。MapReduce实现了可扩展的并行计算模型,适用于大数据处理。

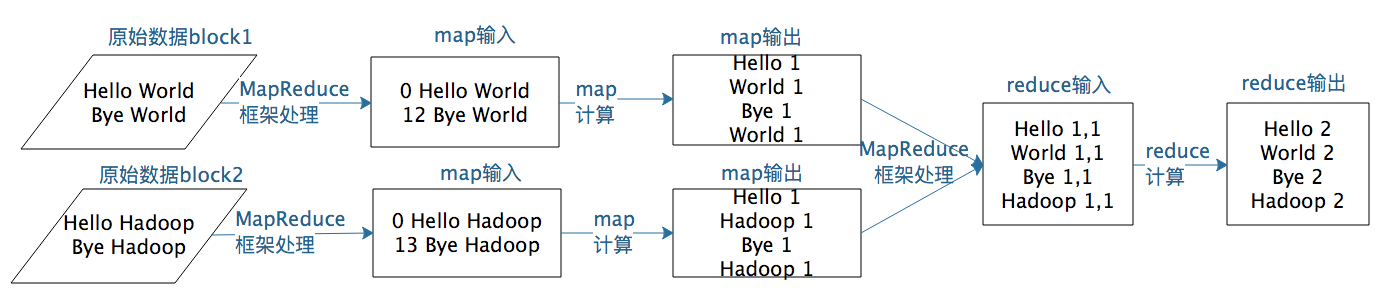
当然可以!下面是一个简单的 MapReduce 例子:单词计数(Word Count)。
Case Study
任务描述
计算一组文档中每个单词的出现次数。
MapReduce 过程
-
Map阶段
MapRead: 从输入文件中读取数据。
Map: 对每一行文本进行处理,将其拆分成单词,并为每个单词生成键/值对,键是单词,值是1。例如,对于文本“hello world hello”产生的输出是:
("hello", 1) ("world", 1) ("hello", 1)MapWrite: 将这些键/值对按键分组并写入临时存储。例如:
("hello", [1, 1]) ("world", [1]) -
Reduce阶段
ReduceRead: 从临时存储中读取键/值对列表。
Reduce: 对每个键及其对应的值列表进行归约操作,计算单词的总出现次数。例如,对于 ("hello", [1, 1]),计算结果是:
("hello", 2)ReduceWrite: 将最终的单词计数结果写入输出存储。例如:
("hello", 2) ("world", 1)
总结
- Map:处理输入数据,将其转化为中间键/值对。
- Shuffle:对中间数据进行分组和排序。
- Reduce:对分组后的数据进行汇总,产生最终结果。
Hadoop
在2005年,Doug将MapReduce加入到了Nutch项目。次年也就是2006年,Doug创建了一个新项目包含HDFS(把Nutch的N改为Hadoop的H)、MapReduce和Hadoop Common,也就是后来的Apache Hadoop项目。
hadoop这个名字是Doug的黄色小象玩具的名字。
以Hadoop 1为例,MapReduce运行过程涉及三类关键进程。
- 大数据应用进程。这类进程是启动MapReduce程序的主入口,主要是指定Map和Reduce类、输入输出文件路径等,并提交作业给Hadoop集群,也就是下面提到的JobTracker进程。这是由用户启动的MapReduce程序进程,比如WordCount程序。
- JobTracker进程。这类进程根据要处理的输入数据量,命令下面提到的TaskTracker进程启动相应数量的Map和Reduce进程任务,并管理整个作业生命周期的任务调度和监控。这是Hadoop集群的常驻进程,需要注意的是,JobTracker进程在整个Hadoop集群全局唯一。
- TaskTracker进程。这个进程负责启动和管理Map进程以及Reduce进程。因为需要每个数据块都有对应的map函数,TaskTracker进程通常和HDFS的DataNode进程启动在同一个服务器。也就是说,Hadoop集群中绝大多数服务器同时运行DataNode进程和TaskTacker进程。
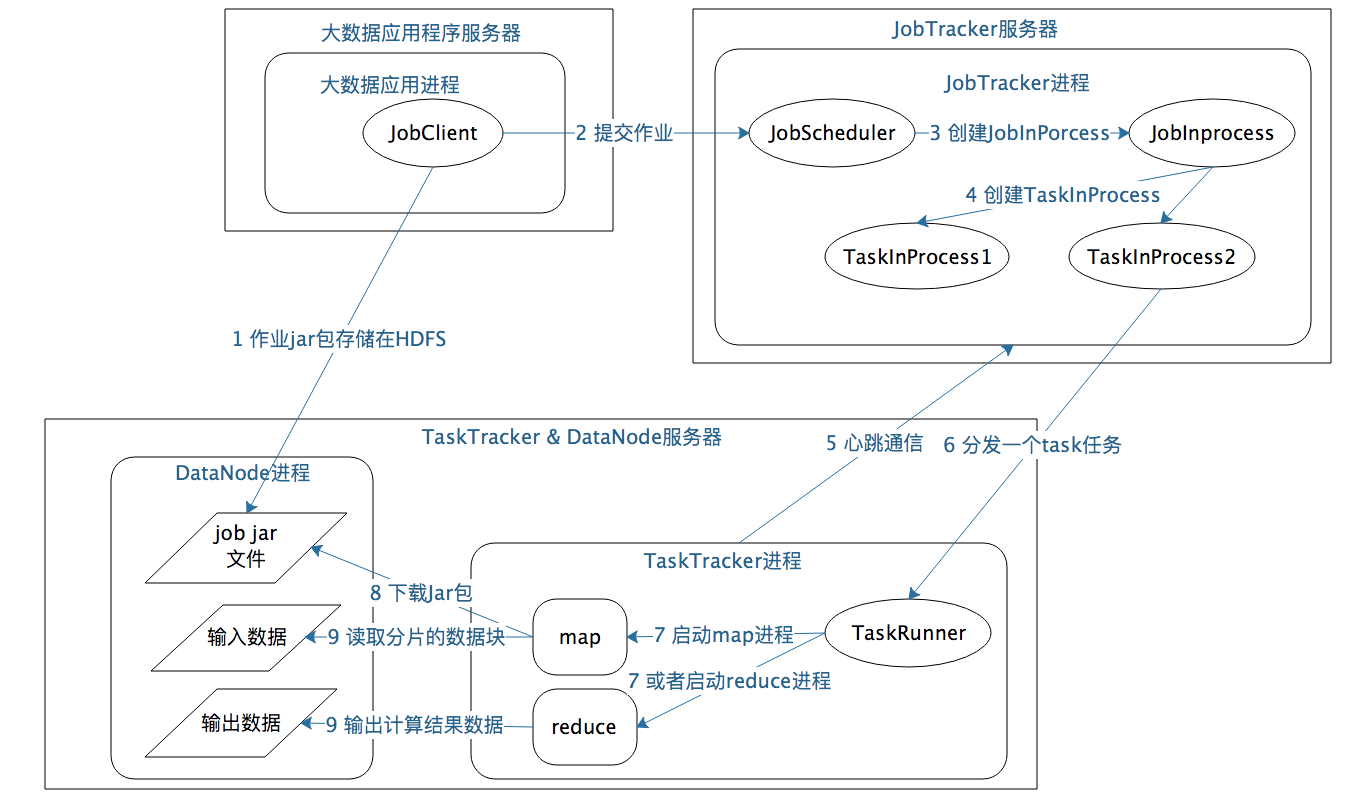
看到没有,是不是很像 GFS+MapReduce?
MapReduce计算真正产生奇迹的地方是数据的合并与连接。
还是回到WordCount例子中,我们想要统计相同单词在所有输入数据中出现的次数,而一个Map只能处理一部分数据,一个热门单词几乎会出现在所有的Map中,这意味着同一个单词必须要合并到一起进行统计才能得到正确的结果。
在map输出与reduce输入之间,MapReduce计算框架处理数据合并与连接操作,这个操作有个专门的词汇叫 shuffle。那到底什么是shuffle?shuffle的具体过程又是怎样的呢?请看下图。
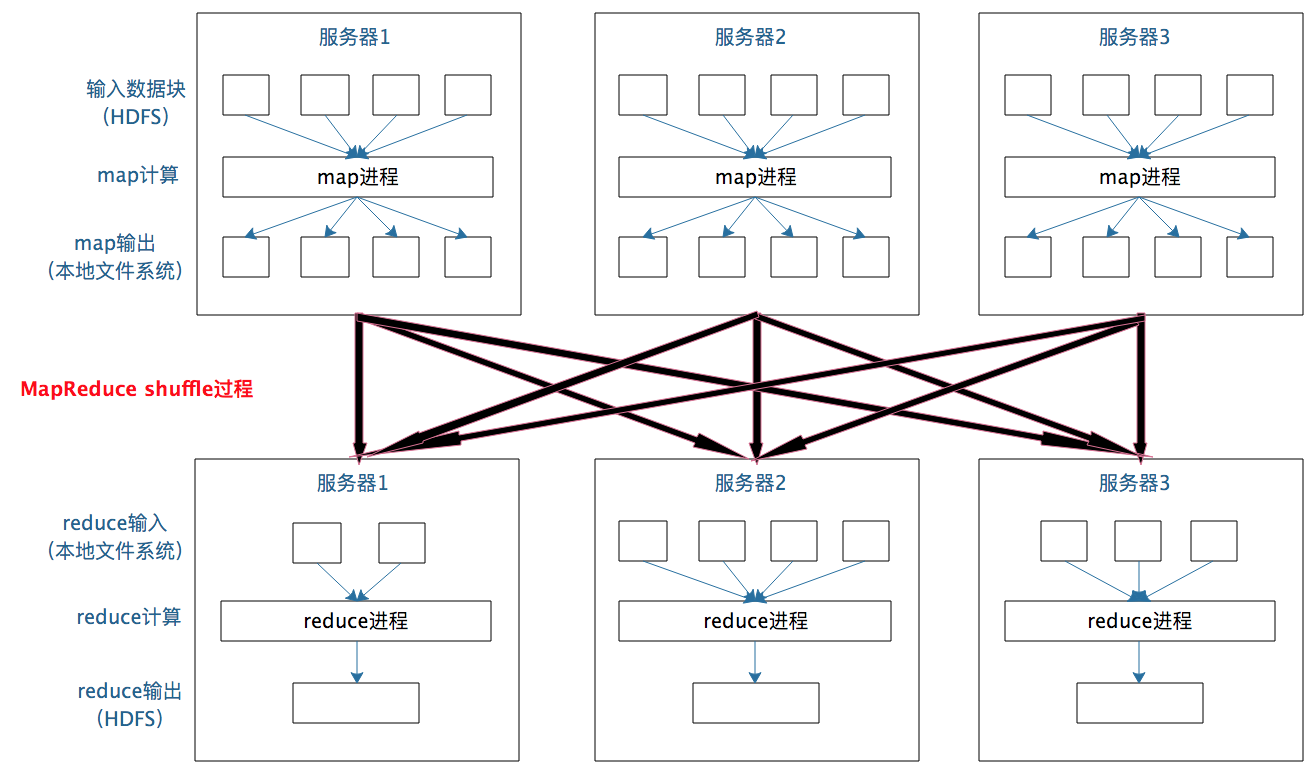
每个Map任务的计算结果都会写入到本地文件系统,等Map任务快要计算完成的时候,MapReduce计算框架会启动shuffle过程,在Map任务进程调用一个Partitioner接口,对Map产生的每个<Key, Value>进行Reduce分区选择,然后通过HTTP通信发送给对应的Reduce进程。这样不管Map位于哪个服务器节点,相同的Key一定会被发送给相同的Reduce进程。Reduce任务进程对收到的<Key, Value>进行排序和合并,相同的Key放在一起,组成一个<Key, Value集合>传递给Reduce执行。
map输出的<Key, Value>shuffle到哪个Reduce进程是这里的关键,它是由Partitioner来实现,MapReduce框架默认的Partitioner用Key的哈希值对Reduce任务数量取模,相同的Key一定会落在相同的Reduce任务ID上。
讲了这么多,对shuffle的理解,你只需要记住这一点:分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是shuffle。
所以:
- Map 本地
- Shuffle HTTP
- Reduce 本地
全面了解大数据“三驾马车”的开源实现 - 知乎 (zhihu.com)
李智慧,同程艺龙交通首席架构师、Apache Spark源代码贡献者,长期从事大数据、大型网站架构的研发工作,曾担任阿里巴巴技术专家、Intel亚太研发中心架构师、宅米和WiFi万能钥匙CTO,有超过6年的线下咨询、培训经验,著有畅销书《大型网站技术架构:核心原理与案例分析》。
Hadoop 三驾马车
【征服大象】1. hadoop的前世今生 - 知乎 (zhihu.com)
《Mastring Hadoop3》
一、HDFS(Hadoop 分布式文件系统)
HDFS的设计基于Google的GFS,它采用了类似的架构,将数据分布在一个或多个服务器节点上。核心设计理念是将大文件切分成多个块,并将每个块存储在不同的服务器节点上,来提高数据的可靠性和可用性。
一般采用了主从结构,包含一个NameNode和多个DataNode,NameNode负责管理文件系统的命名空间和客户端访问权限,DataNode负责实际存储数据块。
二、MR(MapReduce编程模型)
MapReduce 是一种分布式计算模型,它将大规模的数据集分成若干个小的子集,然后将这些子集分配到不同的节点上并行处理,最后将处理结果合并起来得到最终结果。分为Map阶段和Reduce阶段,MapReduce的运行过程可以分为两个主要阶段:Map阶段和Reduce阶段。
在Map阶段,输入数据被分割为多个数据块,每个数据块都被分配到不同的计算机节点上进行处理。在每个节点上,都会运行一个Map函数,它会对每个数据块进行处理,生成一系列的键值对。这些键值对会被传输到Reduce阶段。
在Reduce阶段,Map阶段产生的键值对将根据其键进行分组。每个组的数据都将传输到不同的计算机节点上进行处理。在每个节点上,都会运行一个Reduce函数,它将根据键值对进行聚合,并生成一个最终的输出结果。
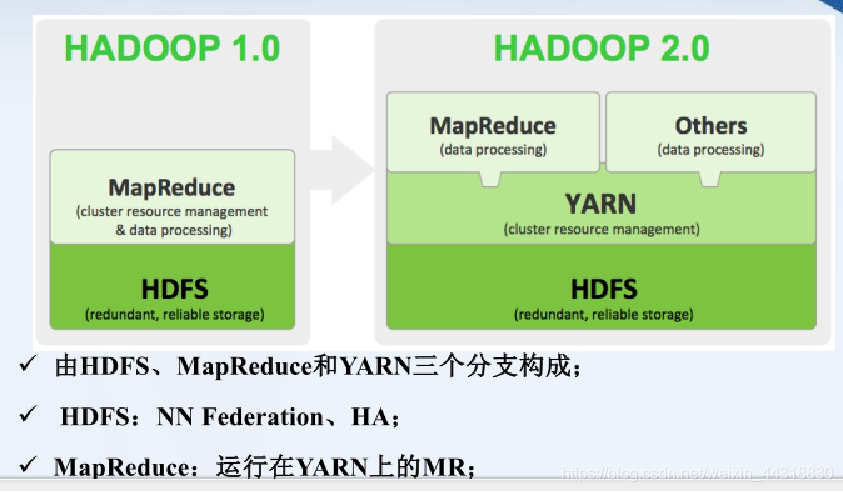
三、Yarn(分布式资源管理器)
Yarn是Hadoop2.0版本后用于管理Hadoop集群中的计算资源。它的主要作用是为各个应用程序分配资源,确保每个应用程序都能够获取到它所需的资源。YARN采用了一个分层的体系结构,由ResourceManager(RM)和NodeManager(NM)两个组件构成。
ResourceManager(RM):RM是整个集群中的资源管理器,它负责为集群中的所有应用程序分配资源。当一个应用程序向RM请求资源时,RM将为该应用程序分配容器,容器是一个虚拟的计算单元,可以包含多个处理器和内存等资源。
NodeManager(NM):NM是每个节点上的资源管理器,它负责监控该节点上的资源使用情况,并向RM报告该节点上的资源可用情况。当RM向NM分配容器时,NM将负责启动和停止该容器中的应用程序,并监控该容器中的资源使用情况。
作者:王天宇
链接:https://www.zhihu.com/question/591086579/answer/2953945503
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
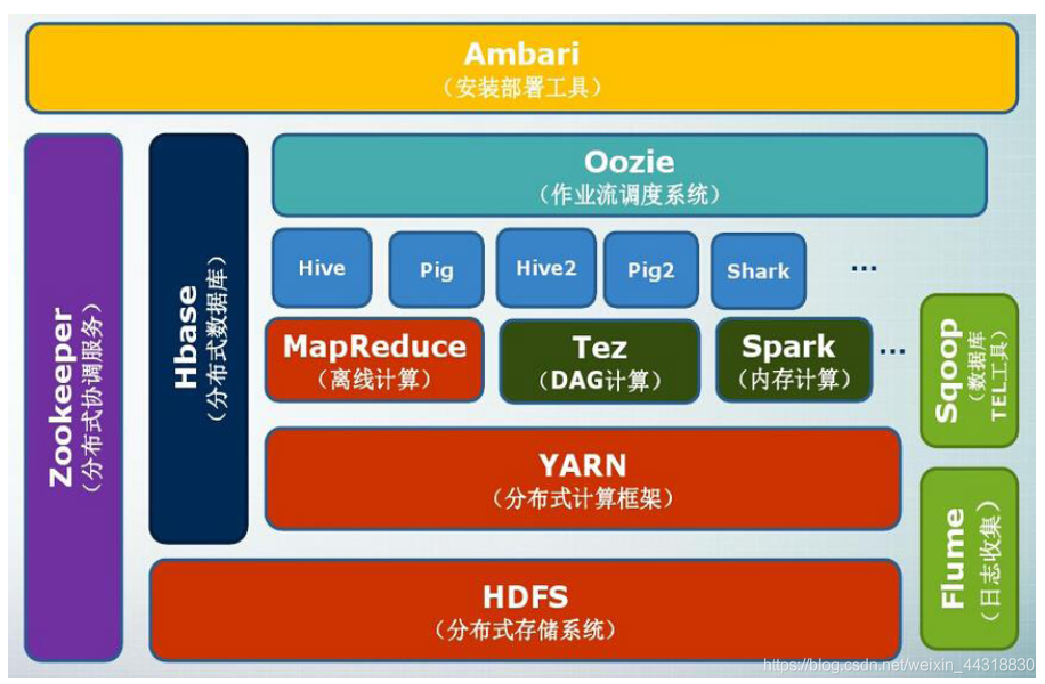
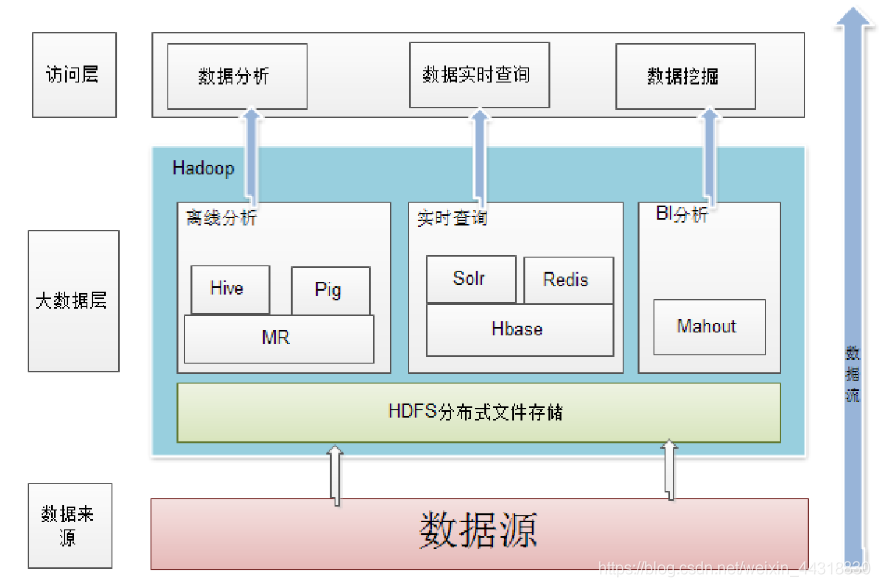
Hadoop今天的架构/生态