
ICML25 Rocket KV – KV Cache Compression
- Paper Reading
- 2025-09-16
- 1546 Views
- 0 Comments
- 1468 Words
kaixin li
github repo:
NVlabs/RocketKV: [ICML 2025] RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
To learn LLM KV Cache Compression
October2001/Awesome-KV-Cache-Compression: 📰 Must-read papers on KV Cache Compression (constantly updating 🤗).
LLM Decode bottleneck:
Attention with KV Cache
only a small subset of tokens is crucial at each decode step
-
Permanent KV token eviction
-
Dynamic KV token selection
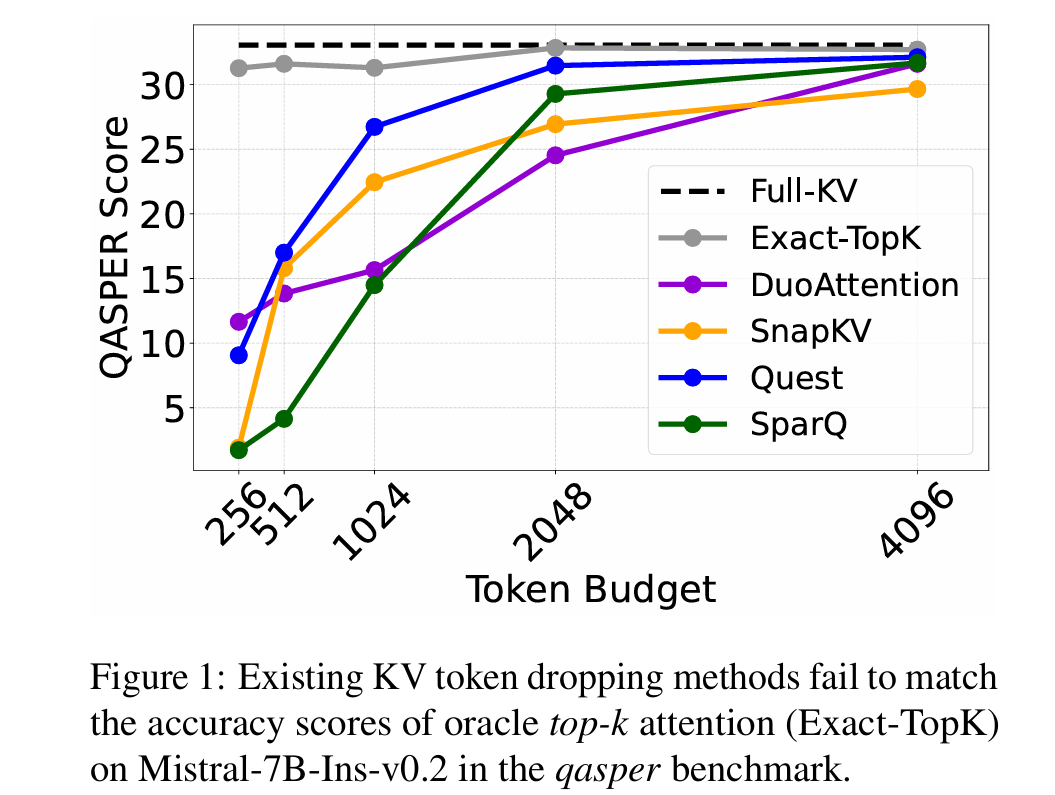
existing kv cache compression methods fail to match exact top-k attention
This document is a research paper titled "RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression," presented at the 42nd International Conference on Machine Learning (ICML) in 2025. The authors, affiliated with NVIDIA and Georgia Institute of Technology, address the challenges of efficiently handling the Key-Value (KV) cache in Transformer-based Large Language Models (LLMs) during long-context inference, particularly in the decode phase.
Main Content Summary:
-
Abstract and Introduction:
- The KV cache, critical for efficient decoding in LLMs, grows linearly with input length, straining memory bandwidth and capacity (e.g., 320GB for Llama3.1-70B with 32K context).
- Existing methods like permanent KV token eviction or dynamic selection fail to maintain accuracy under low token budgets compared to an ideal "oracle top-k" approach.
- RocketKV introduces a training-free, two-stage compression strategy to optimize memory usage and speed.
-
Proposed Method: RocketKV:
-
Two-Stage Approach:
- First Stage: Coarse-grain permanent KV cache eviction using SnapKV to remove low-importance tokens, reducing storage and bandwidth.
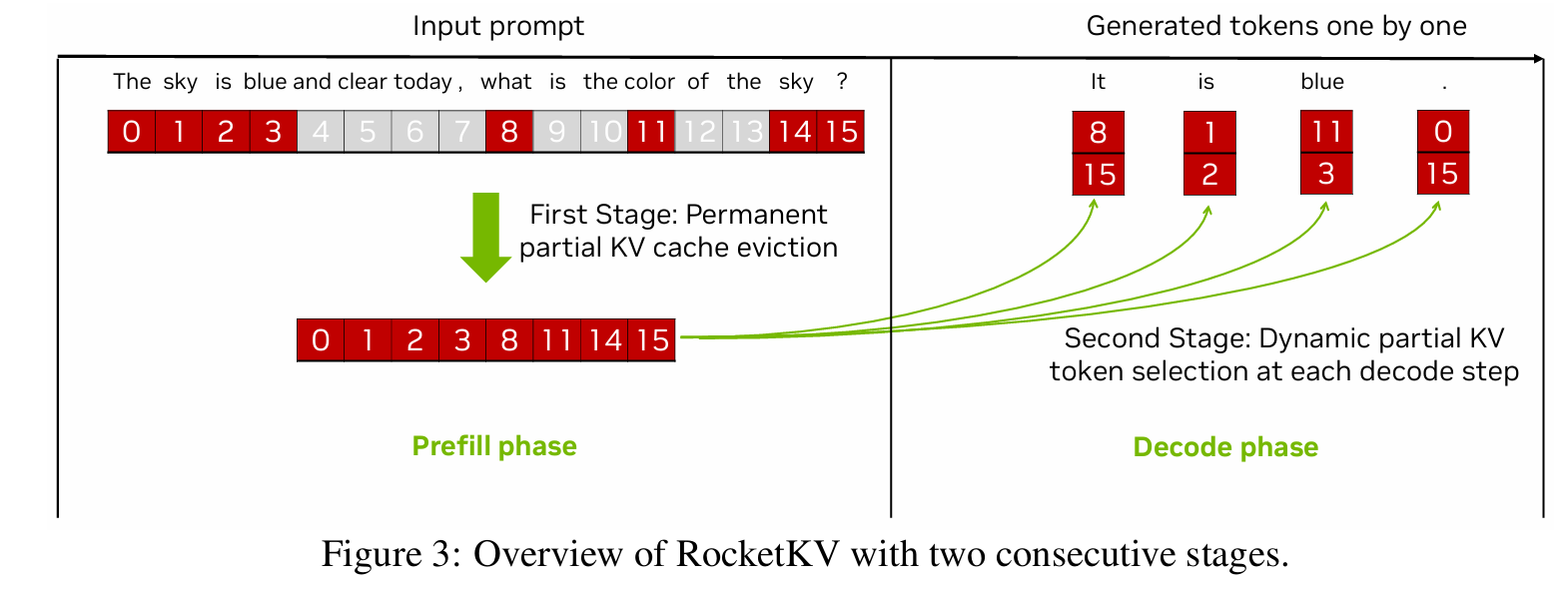
- Second Stage: Fine-grain dynamic KV token selection with Hybrid Sparse Attention (HSA), approximating top-k attention scores via two-dimensional (head and sequence) reductions.

- First Stage: Coarse-grain permanent KV cache eviction using SnapKV to remove low-importance tokens, reducing storage and bandwidth.
-
Adaptive Compression: Balances compression across stages to achieve up to 400× compression, 3.7× speedup, and 32.6% peak memory reduction on an NVIDIA A100 GPU.
-
RocketKV-MT Variant: For multi-turn scenarios, retains all KV tokens (no permanent eviction) but filters dynamically per turn, avoiding accuracy loss while maintaining speed. (在第一次使用时保存全部的kv cache,后面压缩)
-
-
Technical Details:
- SnapKV in First Stage: Uses an observation window and pooling (kernel size 63) to select critical KV token clusters, optimized for Grouped-Query Attention (GQA).
- HSA in Second Stage: Combines sequence paging (max/min values) and head dimension sparsity to predict top-k indices, enhancing accuracy over one-dimensional methods.
- Evaluation: Tested on models like Mistral-7B and Llama3.1-8B across LongBench, RULER, SCBench, and Needle-in-a-Haystack tasks, showing negligible accuracy loss.

-
Results and Contributions:
- Achieves high compression with minimal accuracy drop, outperforming methods like Quest and SparQ.
- Open-source code is available on GitHub, making it accessible for practical deployment.

-
Related Work and Observations:
- Reviews prior techniques (e.g., StreamingLLM, H2O) and highlights their limitations, motivating RocketKV’s hybrid approach.
- Analyzes attention head data (e.g., Figure 2) to show that unique top-k indices (1200) are far fewer than maximum sequence length (25K), justifying the two-stage design.
In summary, the paper presents RocketKV as an innovative solution to accelerate long-context LLM inference by efficiently compressing the KV cache, with practical implications for memory-constrained environments.
这篇文章发表于 ICML 25 ,标题为《RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression》(RocketKV:通过两阶段 KV 缓存压缩加速长上下文 LLM 推理)。作者来自 NVIDIA 和佐治亚理工学院,主要讨论 Transformer-based 大型语言模型(LLM)在处理长上下文时面临的 KV 缓存(Key-Value Cache)瓶颈问题,并提出一种无需训练的优化策略。
主要内容概述:
-
问题背景(引言与观察):
- LLM 在解码阶段依赖 KV 缓存来存储过去的注意力键值对,以避免重复计算。但 KV 缓存的大小随输入序列长度线性增长,导致内存带宽和容量负担加重。例如,Llama3.1-70B 模型在批大小 32、上下文 32K 时需要 320GB 存储。
- 现有方法(如永久 KV 令牌驱逐或动态选择)在低令牌预算下准确率下降明显,无法匹配理想的“oracle top-k”注意力方案。
- 作者观察到:解码过程中只需少量独特 KV 令牌(例如在 qasper 基准中,最大序列长 25K,但独特 top-k 索引仅 1200),因此提出两阶段压缩:先粗粒度永久驱逐,再细粒度动态选择。
-
相关工作:
- 回顾了注意力机制优化方法,包括架构修改(如 MQA、GQA)、训练无关技术(如 StreamingLLM、DuoAttention)、预填充阶段加速(如 MInference)和解码阶段优化(如 H2O、SnapKV、Quest、SparQ)。
- 强调现有方法单一维度稀疏化(如序列或头维度)的局限性,RocketKV 结合两类方法优势。
-
提出方法:RocketKV:
- 框架概述:两阶段压缩,仅针对解码阶段加速。第一阶段:对输入序列进行粗粒度永久 KV 缓存驱逐(减少存储和带宽)。第二阶段:在剩余 KV 上进行细粒度动态 top-k 选择,使用混合稀疏注意力(HSA)近似注意力分数。
- 第一阶段:SnapKV:采用改进的 SnapKV,根据观察窗口的聚合注意力分数选择关键 KV 簇。针对 GQA 模型,按组选择以减少冗余。使用较大池化内核(63)以保留信息完整性。
- 第二阶段:混合稀疏注意力(HSA):结合序列和头维度减维。步骤包括:分页存储 KV 的元素级 max/min 值;为每个查询 q 沿头维度选 top-k1 大值索引,计算近似分数;选 top-k2 序列索引进行稀疏注意力。兼容 GQA。
- 多轮变体:RocketKV-MT:不永久驱逐 KV,而是保留全部用于后续轮次,但每轮解码仅在过滤子集上动态选择。牺牲存储节省,但避免多轮准确率损失。
- 自适应压缩分解:智能分配目标压缩比到两阶段,基于序列长度 S 和目标令牌预算 t,确保内存流量最小化。
-
实验与结果:
- 设置:在 Llama3.1-8B-Instruct、Mistral-7B-Instruct-v0.2、LongChat-7B-v1.5 等模型上测试。基准包括 LongBench(单/多 QA、摘要等)、RULER(合成检索任务)、SCBench(多轮对话)、Needle-in-a-Haystack(NIAH,针在大海中检索)。
- 准确率结果:RocketKV 在压缩比高达 400× 时,准确率接近全 KV 缓存和 oracle top-k(例如在 LongBench 上,256 令牌预算下仅降 1.1%)。RocketKV-MT 在多轮场景中优于其他方法。
- 效率结果:在 NVIDIA A100 GPU 上,端到端解码加速高达 3.7×,峰值内存节省 32.6%。在 H100 上,加速 2.3×。内存流量和存储显著减少。
- 消融研究:验证 HSA 优于 Quest/SparQ,自适应分解优于静态分配。
-
结论:
- RocketKV 解决了长上下文 LLM 推理的内存瓶颈,提供高压缩比下的高效解决方案。开源代码在 GitHub 上可用,适用于各种模型和任务。