
Scalability! But at what COST 文章介绍
- Paper Reading
- 2025-05-12
- 509 Views
- 0 Comments
- 1589 Words
Scalability! But at what COST 文章介绍
这篇文章讲了一个很重要的问题:在图计算这一领域中,我们要去思考,Scalable是否真的带来Effective?
即使算法的逻辑(如PageRank的迭代公式)看起来相同,分布式系统的实现方式(通信、同步、数据分区、语言开销)引入了大量额外工作,导致性能低于单线程。
多线程或分布式系统的性能不如单线程,可以用一个类比来理解:
- 假设你要计算100个人的工资。单线程就像一个人用计算器快速算完,数据都在一张纸上,计算直接且高效。
- 多线程(或分布式系统)就像把任务分给100个人,每人算一部分,但:
- 你需要把数据分成100份,分发给每个人(数据分区)。
- 每个人算完后需要把结果传给其他人(通信)。
- 所有人都要等到最后一个人算完才能开始下一轮(同步)。
- 如果用的是慢速计算器(集群硬件)或需要额外记录数据(序列化),效率会进一步降低。
- 如果任务本身不复杂(像PageRank或连通分量),这些额外步骤(分区、通信、同步)的开销可能比计算本身还大,导致总时间比单线程长。
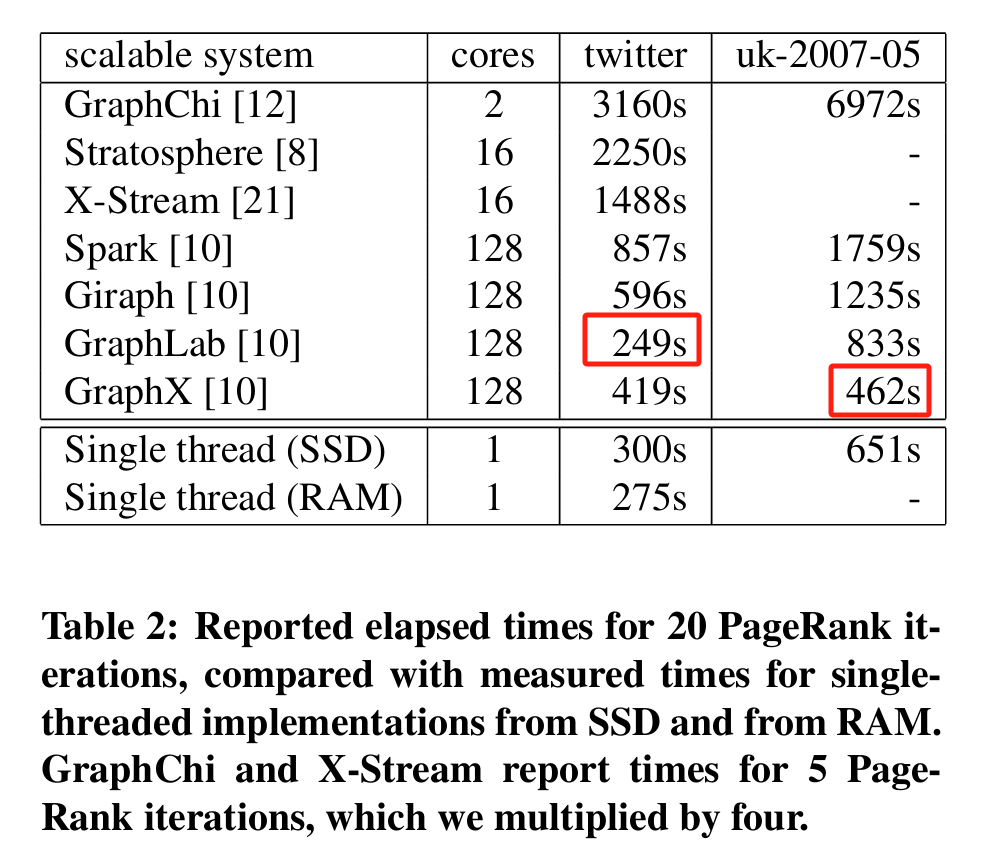
这篇论文中提到的多线程或分布式系统在某些情况下无法超越单线程实现的原因,主要可以归结为以下几个方面,这些原因在论文中被详细分析并与实际测量结果相关联:
-
分布式系统的额外开销(Overheads)
分布式系统为了实现可扩展性,通常引入了额外的开销,这些开销在单线程实现中不存在或较少。例如:- 通信开销:分布式系统中,节点之间需要频繁通信以交换数据(如PageRank中的边数据或标签传播中的标签)。论文提到,GraphLab和GraphX通过更复杂的边分区方案减少通信,但仍无法完全消除这一开销(见Table 2和Section 3.1)。
- 同步开销:分布式系统通常采用类似Pregel的“think like a vertex”模型或Map-Reduce模型,需要同步多个节点的计算步骤。这种同步增加了延迟,而单线程实现无需此类同步。
- 系统实现开销:分布式系统可能使用高级语言或未优化的原型实现,导致额外的性能损失,如垃圾回收、内存拷贝或序列化开销(Section 5)。论文指出,许多系统在研究阶段未对这些部分进行充分优化。
-
计算模型的限制
分布式系统为了确保可扩展性,通常限制了计算模型,导致算法效率不高。例如:- Pregel模型:Pregel要求图计算以“每个顶点基于邻居状态的迭代局部计算”方式表达,这限制了算法的选择。论文指出,标签传播(Label Propagation)算法因其易于并行化而常用于分布式系统,但其计算效率远低于更优的算法(如Union-Find,Section 3.2)。
- Map-Reduce模型:Map-Reduce禁止内存驻留状态,导致需要反复从磁盘读取数据,增加了I/O开销(Section 5)。相比之下,单线程实现可以充分利用内存和缓存。
-
算法选择的不优
分布式系统常选择易于并行化的算法,但这些算法本身可能不是最高效的。论文以连通分量任务为例:- 分布式系统通常使用标签传播算法(Figure 3),因为其更新操作是可交换和可结合的,易于并行化。但该算法需要多次迭代,计算量较大。
- 单线程实现则可以使用Union-Find算法(Figure 4),只需扫描一次边,复杂度为O(m log n),显著减少了计算量。Table 5显示,Union-Find在单线程上的运行时间(15秒和30秒)远低于分布式系统的标签传播(242秒至800秒)。
-
硬件环境的差异
分布式系统通常运行在集群上,而单线程实现运行在高性能笔记本电脑上。论文指出(Section 5):- 集群硬件(如较慢的核心、存储和内存)更注重容量和吞吐量,而笔记本电脑的核心更快,延迟更低,适合单线程计算。
- 单线程实现利用了现代硬件的高速SSD和内存大页面(2MB),优化了缓存行为(如Hilbert曲线边排序,Section 3.1),进一步提升了性能。
-
边布局和缓存效率
分布式系统通过边分区减少通信,但单线程实现可以通过优化边顺序(如Hilbert曲线排序)显著提高缓存命中率(Section 3.1)。Table 4显示,单线程PageRank在Hilbert顺序下运行时间从300秒降至110秒(twitter_rv数据集),超越了所有分布式系统。这种优化对单线程实现尤其有效,因为它避免了分布式系统的通信成本。 -
分布式系统的COST过高
论文引入的COST指标(Configuration that Outperforms a Single Thread)显示,许多分布式系统需要数百个核心才能超越单线程实现。例如,Spark和Giraph在128核心上的PageRank性能(857秒和596秒)仍不如单线程的300秒(Table 2)。这表明,分布式系统的可扩展性往往掩盖了其低效的绝对性能。
总结
多线程或分布式系统在论文中的表现不如单线程,主要因为它们引入了通信、同步和实现上的开销,采用了次优的计算模型和算法,且未能充分利用现代硬件的缓存和低延迟特性。 单线程实现通过更高效的算法(如Union-Find)、优化的边布局(如Hilbert顺序)和直接的内存访问,显著减少了计算和I/O开销。论文强调,分布式系统的可扩展性并不等同于高效,研究应更关注如何降低COST并选择更优的算法和实现方式。