
Google File System
- Big Data
- 2024-09-18
- 960 Views
- 0 Comments
- 3020 Words
Google File System (GFS) 是 Google 为满足大规模数据存储和处理需求而设计的分布式文件系统。GFS 的设计目标是处理大量数据并提供高吞吐量的数据访问,这对于 Google 这样的公司在运行其搜索引擎和其他大规模应用时至关重要。
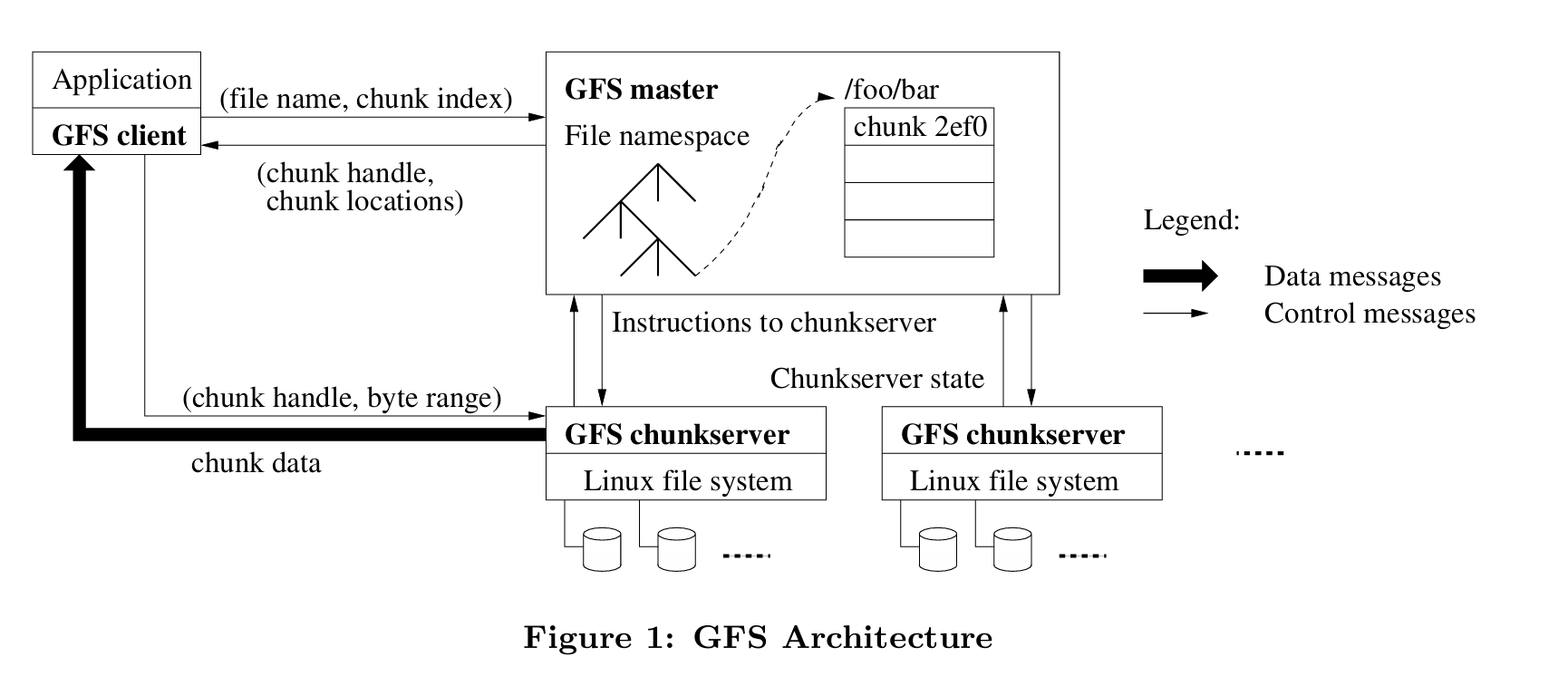
设立一个master可以极大的简化系统的设计,可以很方便地进行全局信息的管理。然而单一的master很容易成为系统的瓶颈,所以只能让其尽可能少的参与读写。客户端从来不从master中读写文件数据,而是向master询问它需要的文件在哪,然后访问这些chunkserver去进行文件交互。
GFS 的主要特点和设计原则
- 分布式架构:
GFS 将文件数据分布在多台机器上,这样可以在多个服务器上并行处理数据,提升性能和扩展性。系统的主要组件包括 NameNode(主服务器)和 ChunkServer(存储服务器)。 - 数据块和副本:(数据防丢失)
文件在 GFS 中被划分为固定大小的数据块(通常为 64 MB)。每个数据块在系统中有多个副本(通常是三份),这些副本分布在不同的 ChunkServer 上。这样做的目的是提高数据的可靠性和系统的容错能力。
更大的chunk size的优势在于:
负责查询的server压力比较小
- 减少客户端请求的chunk数量,减少客户端与master的交互需求。
- 大的chunk可以让客户端执行很多操作,通过较长时间与chunkserver的持续的tcp连接来减少网络开销
- 减少了chunk的个数,从而减少了存储在master的元数据的大小
当然,大的chunk size也有缺点:
chunk server(提供文件的机器压力会比较大)
-
可能会出现更多客户端访问一个chunk从而导致这个chunk成为hot spots。一般来说还好,不过如果某个可执行文件被写入了某个chunk,然后在数百台机器上同时启动,那个chunkserver就很容易超载。一个解决方法是将可执行文件复制更多份,并使批队列系统错开启动时间。还有一个解决方法是允许客户机从其他客户机读取数据。
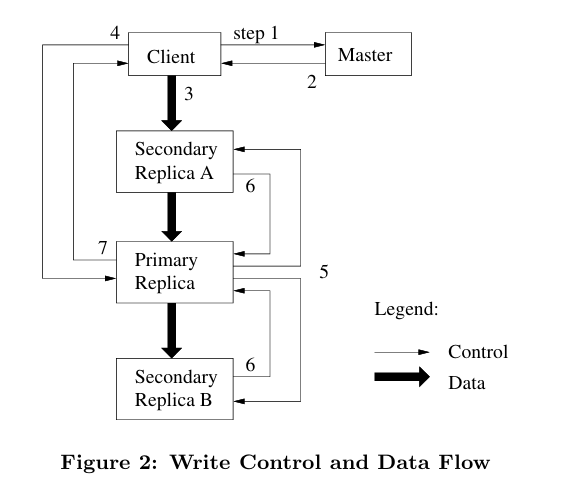
-
客户端询问master哪个chunkserver持有当前chunk的租约,以及其他副本的位置。如果没有服务器有租约,master就选择一个副本服务器分给它租约
-
服务器返回primary和副本chunkserver的位置,客户端把它们存在缓存中,如果未来短期内再次访问就不需要请求master。除非primary不可达或者primary告知客户端它没有租约了。
-
客户端知道副本位置后,将数据push进所有的副本中,可以按照任何顺序。每个chunkserver将数据存储在一个内部的LRU缓存中
-
一旦所有的副本都确认接受到了数据,客户端就向primary发送写请求,标识了之前push的数据,primary会分配序列号给这些mutations,提供必要的序列化
-
primary将写请求转发给各个备用副本,每个备份副本按照序列号执行更改
-
备份副本回复primary表示已经完成了操作
-
primary响应客户端,任何遇到的错误也会报告
-
高容错性:(容错)
GFS 的副本机制确保即使部分 ChunkServer 发生故障,系统仍然能够继续工作。GFS 监控各个 ChunkServer 的状态,并在发现副本丢失或损坏时自动恢复数据。 -
一致性和原子性:
GFS 通过日志和检查点机制来保持文件系统的一致性。每个数据块的操作是原子的,即要么完全成功,要么完全失败。系统使用主服务器(NameNode)来管理文件的元数据(如文件名、数据块位置等),而实际的数据存储在 ChunkServer 上。 -
优化大文件和高吞吐量:
GFS 设计时考虑了大文件的存储和处理需求,优化了大文件的顺序读取和写入操作。对于大量小文件,GFS 的效率可能较低,因此更适合处理大文件或大量大文件的场景。 -
简单的数据模型:
GFS 的数据模型较为简单,文件被视为由一系列数据块构成的线性序列。文件系统对数据块进行管理,不需要像传统文件系统那样处理复杂的文件夹结构和文件属性。
关键组件
NameNode(主服务器):
- 负责管理文件的元数据,如文件名到数据块的映射、文件和目录的层次结构等。
- 处理客户端的元数据请求,并与 ChunkServer 协作处理数据存储和访问。
ChunkServer(存储服务器):
- 负责存储实际的数据块。
- 处理数据的读写请求,并与 NameNode 协作进行数据块的复制和恢复。
Client:
- 客户端通过 NameNode 获取文件的元数据,然后直接与 ChunkServer 进行数据的读写操作。
- 客户端可以读取文件的特定数据块,也可以在写入时选择合适的 ChunkServer 进行操作。
应用和影响
GFS 的设计和实现对后来的分布式文件系统有着深远的影响,特别是在大规模数据处理和存储领域。GFS 的思想和技术被广泛应用于分布式计算和存储系统中,例如 Apache Hadoop 的 Hadoop Distributed File System (HDFS) 就是受到 GFS 的启发而设计的。
GFS 不仅是 Google 内部数据处理的基础,也为其他技术提供了重要的参考框架,使得大规模数据存储和处理变得更加高效和可靠。
RPC
是的,Google File System (GFS) 使用 RPC(远程过程调用)机制来更新数据。具体来说,GFS 的主服务器(master server)通过 RPC 与块服务器(chunkservers)进行通信。主服务器负责管理文件系统的元数据和操作请求,而块服务器负责实际的数据存储和读取操作。
工作流程简述:
1.主服务器更新
当客户端需要更新文件或执行其他操作时,它会向主服务器发起 RPC 请求。主服务器处理这些请求并更新其元数据。
2.数据写入
对于数据写入操作,主服务器会通过 RPC 命令通知相关的块服务器(chunkservers)执行写操作。这些块服务器接收到更新请求后,会将数据写入其本地存储中,并在完成后确认写入成功。
3.副本管理
主服务器也会通过 RPC 机制管理副本的创建和修复。如果某个块的副本需要恢复,主服务器会通过 RPC 指示其他块服务器执行复制操作。
通过 RPC 机制,GFS 能够实现高效的分布式数据管理和操作,确保数据的正确性和一致性。
RPC优点
-
提高性能:由于主系统不需要等待备份系统的写入完成,可以更快地响应客户端请求,从而提高整体系统的性能和吞吐量。
-
减少延迟:异步复制可以减少写操作的延迟,因为主系统可以在写操作完成后立即返回成功,而不必等待所有副本的写入。
-
系统弹性:适用于需要高写入性能和对实时性要求较低的应用场景。例如,日志记录、数据仓库等。
RPC缺点
-
数据一致性:异步复制可能导致数据在主系统和备份系统之间存在一定的延迟。在这种情况下,如果主系统发生故障,可能会导致备份系统上的数据与主系统上的数据不完全一致。
-
恢复复杂性:在主系统故障的情况下,恢复操作可能更加复杂,因为需要确保备份系统上的数据与主系统的数据一致性。
-
潜在的数据丢失:由于复制是异步的,如果主系统在数据完全复制到备份系统之前发生故障,可能会导致数据丢失。
适用场景
-
日志存储:对于日志系统或事务系统,异步复制可以有效地处理大量数据写入请求,同时保证较高的系统性能。
-
数据备份:在需要定期备份数据的场景中,异步复制可以用于将数据备份到远程存储系统,降低备份对主系统的影响。
-
分布式数据库:在分布式数据库系统中,异步复制可以用来将数据分发到不同的数据节点,从而提高系统的可扩展性和性能。
示例
-
Google File System (GFS):在GFS中,异步复制用于将数据块的副本异步地写入多个块服务器,以提高系统的写入性能和可靠性。
-
数据库系统:许多分布式数据库(如Cassandra、MongoDB等)使用异步复制来同步主数据库和从数据库,以提高写入速度和系统的扩展性。
总的来说,异步复制机制通过分离数据写入和数据复制的操作,能够有效提高系统的性能和响应速度,但也带来一定的风险和挑战,尤其是在数据一致性和恢复方面。
负载均衡
Google File System (GFS) 实现负载均衡的方式包括以下几个关键机制:
1. 块分配和副本管理
-
块分配:主服务器(master server)在将新的文件块写入系统时,会根据当前块服务器的负载和存储容量,将块分配到负载较轻的块服务器上。这种策略有助于避免单个块服务器过载,并保持整个系统的平衡。
-
副本管理:每个数据块在系统中有多个副本(通常是3个),这些副本被分布到不同的块服务器上。主服务器会根据块服务器的负载和可用空间来选择副本的存储位置,从而实现负载均衡。
2. 块服务器健康检查
-
健康监测:主服务器定期检查块服务器的健康状态。如果发现某个块服务器负载过高或发生故障,主服务器会重新调整块的分配或创建新的副本来维护系统的负载均衡。
-
副本修复:当某个块服务器的负载变得过高或出现故障时,主服务器会通过 RPC 命令将数据块的副本移动到负载较轻的服务器上,这样可以缓解负载并保持系统的稳定性。
3. 动态调整
-
负载均衡策略:GFS 在运行时会动态调整数据块的位置和副本。主服务器会根据实时负载情况和存储利用率,自动进行调整,确保数据和请求在各个块服务器之间均匀分布。
-
请求重定向:客户端的读取和写入请求可以被主服务器重定向到负载较轻的块服务器上,以优化性能和减少延迟。
4. 数据访问优化
- 局部性优化:为了减少网络传输负担和提高性能,GFS 会根据数据访问模式优化块的存储位置。例如,将频繁访问的数据块存储在靠近相关客户端的块服务器上。
通过这些机制,GFS 能够有效地平衡负载,提高系统的性能和可靠性。