Compiler: Intro
- Compilers
- 2025-09-17
- 455 Views
- 0 Comments
- 1401 Words
Operations on Languages
Languages: accountable for strings
Lexer
Lexical Analyzer(词法分析器,也叫 Scanner)在编译器中扮演着 前端第一步的角色。它的主要任务是把源代码(程序员写的字符序列)转化为 Token 序列,供后续的语法分析器(Parser)使用。下面我分点介绍它的作用:
1. 输入与输出
- 输入:源程序(字符流,如
if (x > 0) y = y + 1;) - 输出:Token 序列(如
IF, (, ID[x], >, NUM[0], ), ID[y], =, ID[y], +, NUM[1], ;)
2. 主要功能
- 扫描源程序
从左到右逐个读取字符,识别出有意义的词素(lexeme),如关键字if、标识符x、常数0。 - 生成 Token
每个词素会被归类为某种类型的 Token(如关键字、标识符、常数、运算符等),并可能带有属性值(如变量名、具体数值)。 - 删除无关内容
过滤掉 空格、换行、注释 等对语法分析无用的信息。 - 错误处理
如果遇到非法字符(如@出现在 C 代码中),会报错并尽量恢复继续扫描。
3. 在编译器中的作用
- 词法分析器相当于编译器的“分词器”,把原始的 字符流 转化成 结构化的 Token 流。
- 这样,后续的语法分析器就可以基于 Token 进行上下文无关文法(CFG)的语法解析,而不用处理复杂的字符细节。
例如:
源代码:
while (count < 10) count = count + 1;Lexical Analyzer 输出:
[WHILE], [(], [ID, "count"], [<], [NUM, 10], [)], [ID, "count"], [=], [ID, "count"], [+], [NUM, 1], [;]4. 工具与实现
在实践中,词法分析器常用 有限状态自动机(DFA) 来实现。
编译原理课里常见的工具有:
- Lex / Flex:自动生成词法分析器
- ANTLR:现代语言工具,支持词法和语法规则
✅ 一句话总结:Lexical Analyzer 的作用就是把源代码转化为 Token 流,充当编译器“读懂单词”的第一步。

Token Pattern Lexeme
编译原理老师经常会一起讲:Token、Pattern、Lexeme。我分开解释,并说明它们的联系。
1. Token(记号)
- 定义:Token 是词法分析器输出的“种类化单元”。
- 作用:相当于“词法类别”,表示源程序中一个最小的有意义单元。
-
例子:
if→ Token:IF(关键字)x→ Token:ID(标识符)123→ Token:NUM(数字常量)+→ Token:PLUS(运算符)
👉 可以把 Token 理解为“标签/类别”。
注意跟LLM token,是有区别的:
| 维度 | 编译器 Token | LLM Token |
|---|---|---|
| 来源 | 源代码字符流 | 自然语言文本 |
| 切分依据 | 严格定义的词法规则 | 数据驱动的分词算法(BPE、SentencePiece) |
| 语义性 | 对应语言文法中的基本语法单位(关键字、标识符等) | 只是统计学上的子词单元,语义不一定完整 |
| 用途 | 作为编译器语法分析的输入 | 作为神经网络的输入序列 |
| 粒度 | 比较大(关键字、变量、符号等) | 可能很小(一个字母/子词),也可能较大(整个单词) |
| 唯一性 | 每类 token 有唯一明确的 TokenType | 不同语料/模型的 token 化方式可能完全不同 |
2. Pattern(模式)
- 定义:Pattern 是描述某类 Token 的规则(通常用正则表达式)。
-
例子:
- 关键字
if→ Pattern 就是字符串"if" - 标识符
ID→ Pattern 可能是:letter (letter | digit)*(即以字母开头,后面跟若干字母或数字)
- 整数
NUM→ Pattern 可能是:digit+
(一个或多个数字)
- 关键字
👉 可以把 Pattern 理解为“描述 Token 的正则定义”。
3. Lexeme(词素)
- 定义:Lexeme 是实际出现在源程序中的具体字符序列,与某个 Token 相匹配。
- 例子:
- 在
if (x > 10)里: if是一个 Lexeme,对应 TokenIFx是一个 Lexeme,对应 TokenID10是一个 Lexeme,对应 TokenNUM
👉 可以把 Lexeme 理解为“程序中真正的单词实例”。
- 在
在编译原理里,Lexical Errors(词法错误) 指的是 词法分析阶段 发现的错误。它们通常出现在源程序的字符流里,不符合词法规则(Pattern) 的地方。
4. 三者关系总结
一句话总结三者关系:
-
Token = 类别(抽象类型)
-
Pattern = 描述这个类别的规则(正则/文法)
-
Lexeme = 源代码中出现的具体实例
-
Pattern(规则) → 定义一类 Token 的形式化描述(如
digit+) -
Token(类别) → 词法分析器输出的抽象类型(如
NUM) -
Lexeme(实例) → 程序中实际出现的字符串(如
123)
Pattern 定义 Token,Token 匹配 Lexeme。
例如:
| 源代码片段 | Lexeme | Token | Pattern |
|---|---|---|---|
if |
if |
IF |
关键字 "if" |
count |
count |
ID |
\letter (letter digit)\*\ |
123 |
123 |
NUM |
digit+ |
+ |
+ |
PLUS |
\+ |
✅ 一句话记忆法:
- Token:抽象种类
- Pattern:种类的规则
- Lexeme:程序里的具体单词
Lexical Example

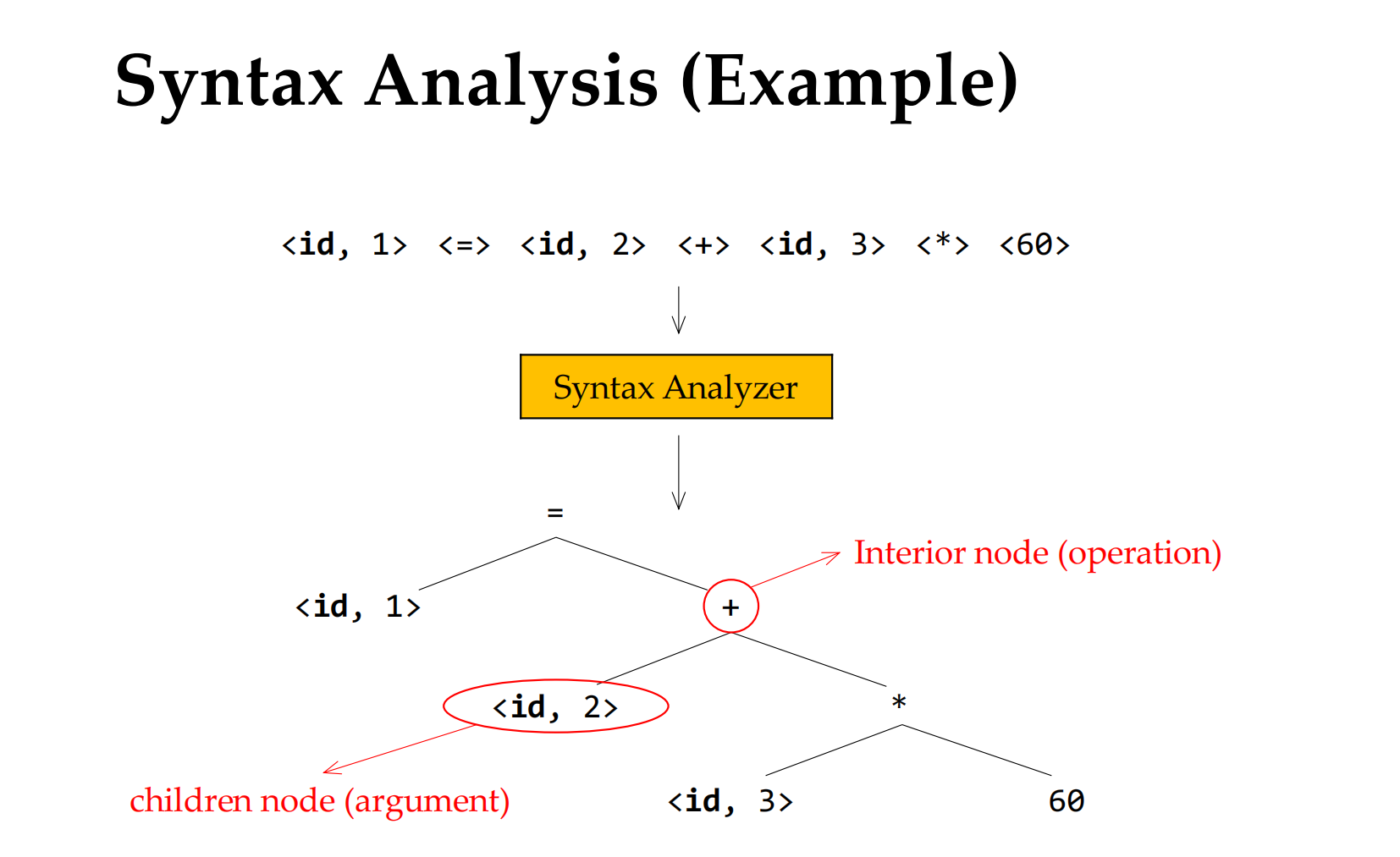
Syntax Analysis 语法分析,建立分析树
build a syntax tree
语义分析



例子:分析 type

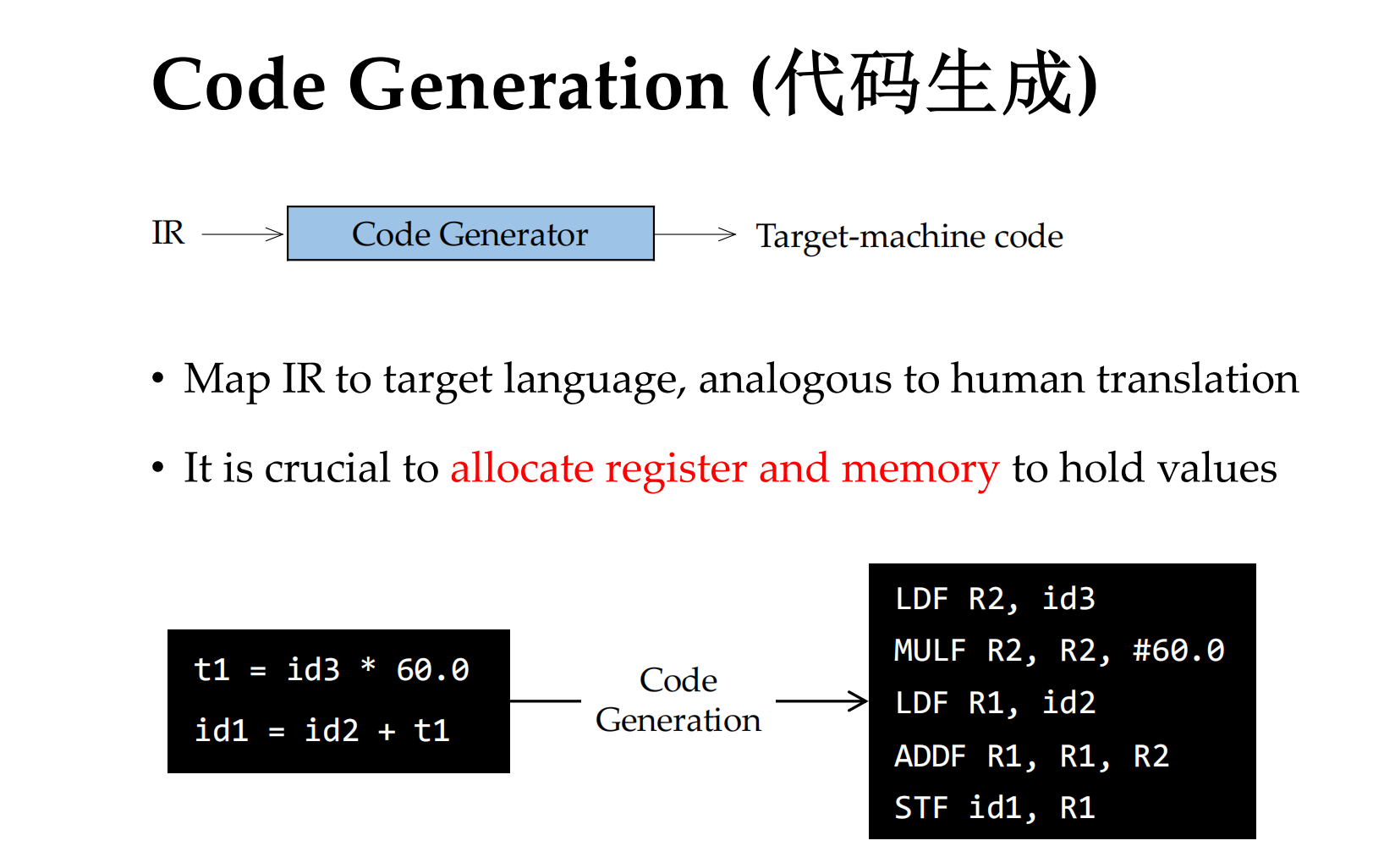
三地址码是编译器常见的一种 中间表示 (IR, Intermediate Representation)。
它把源程序翻译成一种 类似汇编语言的伪代码,每条语句最多包含 三个地址/操作数:
- 一个 结果地址
- 两个 源操作数
形式大致是:
x = y op z
其中 x、y、z 可以是变量名、临时变量或常量;op 是运算符(+、-、*、/ 等)。
- 为什么用三地址码
- 易于优化:比源代码简洁,保留了程序结构信息,方便编译器做常量折叠、公共子表达式消除等优化。
- 独立于机器:不依赖具体 CPU 指令集,可以在生成目标代码前做多层优化。
- 便于映射到汇编:三地址码的形式和汇编指令很接近(load、store、add 等)。

机器无关的优化

最终机器 代码生成