
SC 24 Brief Summary 4
- Paper Reading
- 2025-03-15
- 2109 Views
- 0 Comments
- 21703 Words

总链接:
https://www.haibinlaiblog.top/index.php/sc-2024-passage/
Parallel Program Analysis and Code Optimization
MCFuser: High-performance and Rapid-fusion of Memory-bound Compute-intensive Operators
Authors: Zheng Zhang, Donglin Yang, Xiaobo Zhou, Dazhao Cheng
摘要——算子融合是一项关键技术,用于提高数据局部性并减轻GPU内存带宽压力,但由于计算吞吐量的饱和,通常无法扩展到多个计算密集型操作符的融合。然而,张量维度大小的动态性可能导致这些操作符变成内存瓶颈,从而需要生成融合内核——这一任务受限于有限的融合策略搜索空间、冗余的内存访问以及长时间的调优过程,导致性能次优和低效的部署。
我们提出了MCFuser,这是一个开创性的框架,旨在通过为我们定义的内存瓶颈计算密集型(MBCI)操作符链生成高性能的融合内核,克服这些障碍。MCFuser利用高层次的平铺表达式来划定一个全面的搜索空间,并结合有向无环图(DAG)分析以消除冗余内存访问,从而简化了内核优化过程。通过实施裁剪搜索空间的指南,并结合带有启发式搜索的分析性能模型,MCFuser不仅显著加速了调优过程,还展示了优越的性能。在与像Ansor这样的领先编译器进行基准测试时,MCFuser在NVIDIA A100和RTX3080 GPU上实现了最多5.9倍的内核性能加速,并超越了其他基准,同时将调优时间缩短了70倍以上,展现了其灵活性。
关键词——算子融合、计算密集型、自动化探索、性能模型、GPU
memory-bound compute-intensive (MBCI) operator
Memory-bound compute-intensive (MBCI) operator 是一种在计算密集型的操作符中,受限于内存带宽或内存访问速度,而不是计算能力的性能瓶颈的情况。 MBCI操作符通常涉及大量的内存访问操作,例如读取和写入数据,但其计算过程可能相对较简单或不占用过多计算资源。这种操作符的性能主要受到内存访问延迟和带宽的限制,而不是处理器的计算能力。
计算密集性:操作符执行的计算量非常大,需要大量的计算资源。
内存瓶颈:尽管计算量大,但操作符的性能受到内存访问速度的限制。例如,频繁访问内存、读取数据或写入数据的过程会使得操作符的性能受到内存带宽和访问延迟的制约。
高内存访问需求:这些操作符需要大量的内存传输,可能导致内存访问成为性能瓶颈。
在现代计算中,尤其是涉及深度学习和大规模数据处理的任务中,很多操作符本身可能涉及复杂的计算(例如矩阵乘法、卷积等),但它们的性能往往受到内存访问速度的影响。如果内存访问不够高效,操作符的计算能力就无法充分发挥。因此,将内存访问优化与计算优化结合起来,可以有效提高系统的整体性能。
例子:
矩阵乘法:在深度学习中,矩阵乘法是一个典型的计算密集型操作。尽管计算量庞大,但如果矩阵存储在内存中并且内存带宽不够,内存访问可能成为限制性能的瓶颈。
卷积操作:在卷积神经网络中,卷积操作可能需要大量的内存读取和写入,尤其是当输入数据非常大时,内存带宽可能成为性能瓶颈。
MBCI的优化:
为了应对MBCI操作符带来的内存瓶颈,优化方法可能包括:
内存访问优化:减少内存访问次数,利用局部性原理(例如数据复用)来提高内存带宽利用率。
数据平铺(Tiling):将数据分块,使得每个计算块的数据尽可能留在高速缓存中,减少内存访问延迟。
操作符融合(Operator Fusion):将多个操作符合并成一个,以减少内存访问的次数和开销。
这些优化可以帮助减轻内存瓶颈,提高MBCI操作符的执行效率。

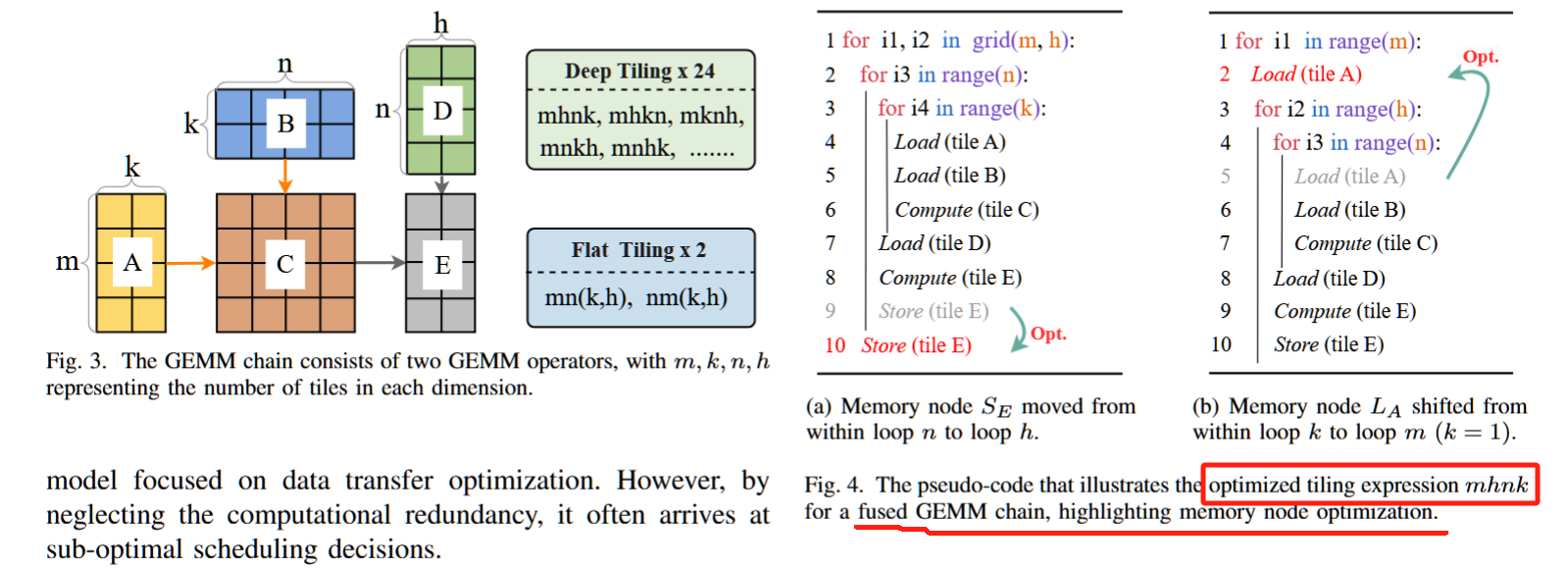
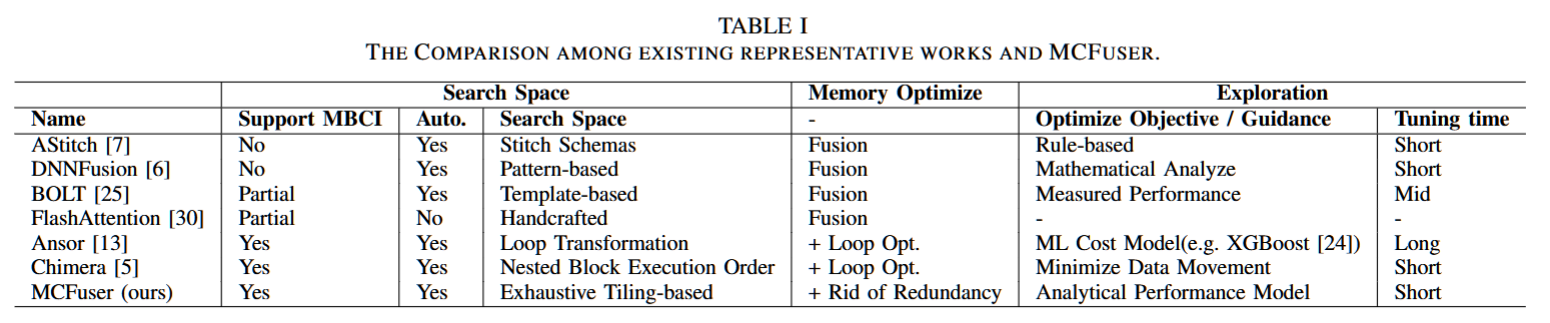
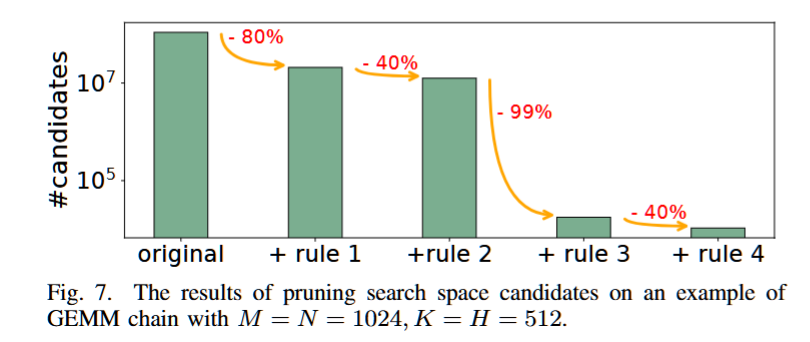
针对这些已识别的挑战,MCFuser 通过基于平铺表达式构建了一个全面的搜索空间。通过利用有向无环图(DAG)流分析,我们有效地最小化了冗余的内存访问,并筛选出了无效的搜索候选项,从而显著简化了探索过程,提高了效率。

规则 1,去重:我们优先将空间循环与 blockIdx 绑定,用于每个平铺表达式,并移除绑定到 blockIdx 的循环以推导子平铺表达式。因此,每个线程块共享相同子平铺表达式的候选项被视为等效。例如,mhnk 和 mnkh 都为每个线程块生成相同的子平铺表达式 nk。
规则 2,防止中间张量的共享内存过载:当缩减循环位于空间循环之外时,多个部分结果的平铺会被缓存到共享内存中(如图 6 所示),这可能导致共享内存过载。
规则 3,避免额外的填充:当平铺大小不能整除维度大小时,填充变得必要。为了避免过度填充,如果维度大小是 2 的幂,则丢弃需要填充的候选项。对于其他情况,填充比例保持在 0.05 以下。
规则 4,共享内存限制:平铺大小超过共享内存限制的候选项被认为是非法的。我们根据公式 (1) 估算占用的共享内存,其中 Shmmax 是每个特定硬件上每个块支持的最大共享内存。我们修剪满足 Shmestm > 1.2Shmmax 的候选项,其中 1.2 用于容纳估算误差。通过实验验证(第 VI-E1 节),我们的估算精度超过 90%,从而将候选项数量减少约 40%。

算子融合(Operator Fusion) 是一种优化技术,广泛应用于深度学习和高性能计算中,旨在减少计算图中的操作步骤,提升性能,特别是在计算和内存效率方面。算子融合的核心思想是将多个算子(操作符)合并为一个单一的操作,从而减少中间数据的传输和存储,减轻内存带宽瓶颈,提高计算效率。
算子融合的目标
- 减少内存访问:多个算子通常会产生中间结果,算子融合可以避免在不同的算子之间频繁的内存读写操作,从而减少内存带宽的压力。
- 减少计算冗余:一些操作可以在合并后进行优化,避免重复计算。
- 提高计算吞吐量:通过减少中间数据存储、数据传输和内存延迟,算子融合可以提高整体计算效率。
- 加速推理过程:特别是在推理阶段,算子融合能显著提升模型的执行速度。
算子融合通常由深度学习框架(如 TensorFlow、PyTorch、ONNX)或编译器(如TVM、XLA)自动进行,框架会根据计算图的结构和依赖关系来选择可以融合的算子。
假设我们有一个神经网络中的 卷积操作(Convolution)后接一个 批归一化操作(Batch Normalization)。传统的计算流程是:
- 卷积操作:对输入图像进行卷积计算,输出一个特征图。
- 批归一化操作:对卷积的输出进行批量归一化,标准化输出。
如果我们不进行算子融合,卷积操作的输出会存储到内存中,然后再读取用于批归一化计算。这会导致两次内存访问。
import numpy as np
# 简单的卷积操作
def convolution(input_data, kernel):
# 模拟卷积运算(这里只做简化,不是完全的卷积计算)
output = np.zeros((input_data.shape[0] - kernel.shape[0] + 1, input_data.shape[1] - kernel.shape[1] + 1))
for i in range(output.shape[0]):
for j in range(output.shape[1]):
output[i, j] = np.sum(input_data[i:i+kernel.shape[0], j:j+kernel.shape[1]] * kernel)
return output
# 简单的批归一化操作
def batch_normalization(input_data, epsilon=1e-5):
mean = np.mean(input_data)
variance = np.var(input_data)
normalized = (input_data - mean) / np.sqrt(variance + epsilon)
return normalized
# 进行卷积并立即进行批归一化(算子融合)
def conv_bn_fusion(input_data, kernel):
# 步骤 1: 卷积操作
conv_output = convolution(input_data, kernel)
# 步骤 2: 立即进行批归一化操作
fused_output = batch_normalization(conv_output)
return fused_output
# 创建一个简单的输入数据和卷积核
input_data = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]])
kernel = np.array([[1, 0],
[0, -1]])
# 执行算子融合
output = conv_bn_fusion(input_data, kernel)
print("Fused Output:")
print(output)
通过算子融合,我们可以将卷积和批归一化操作合并为一个单一的操作,在一个阶段内完成卷积计算并直接进行批归一化。这样做的好处是:
- 避免了中间结果的存储和内存访问。
- 在同一操作中进行卷积和归一化计算,减少了计算延迟和内存开销。
例如,在深度学习框架中,可能会将卷积和批归一化融合为一个 卷积加归一化(Conv + BN) 操作,直接得到最终的特征图,而不是先做卷积,再做归一化。
-
矩阵乘法与加法融合:
假设有一个操作序列,其中包括矩阵乘法和加法操作:A = B * C D = A + E如果不进行融合,首先会计算
B * C,然后将结果与E相加,产生一个中间结果A,再进行加法。这会涉及两次矩阵操作和多次内存访问。通过算子融合,可以将矩阵乘法和加法合并为一个操作:D = (B * C) + E,从而减少一次内存存取操作。 -
ReLU与卷积融合:
在一些神经网络层中,卷积操作后通常会跟随一个激活函数(如ReLU)。如果不融合,计算图将包含两次操作:首先进行卷积,然后进行 ReLU 操作。通过算子融合,卷积和 ReLU 可以同时进行,直接将负值置为零,减少计算和内存开销。
Static Generation of Efficient OpenMP Offload Data Mappings
Iowa State University
摘要——高性能计算(HPC)架构的异构性增加和编译器的进展,使得OpenMP在异构设备上的计算中得到了广泛应用。然而,在异构计算平台上高效的数据传输对于实现高利用率至关重要。程序员必须显式地在主机和连接的加速器设备之间映射数据,以实现高效的数据传输。确保数据传输高效需要程序员理清复杂的数据流动。 这是一个繁琐且容易出错的过程,因为程序员必须保持对多个数据环境中的数据有效性和生命周期的心理模型。我们提出了一种静态分析工具——OMPDart(OpenMP数据优化工具),用于OpenMP程序,能够建模主机和设备区域之间的数据依赖关系,并应用源代码转换来实现高效的数据传输。 在九个HPC基准测试中的评估表明,OMPDart能够生成有效的数据映射结构,显著减少主机和设备之间的数据传输。
关键词——高性能计算, 并行编程, 数据传输, 静态分析, GPU, 性能优化, 异构计算, OpenMP
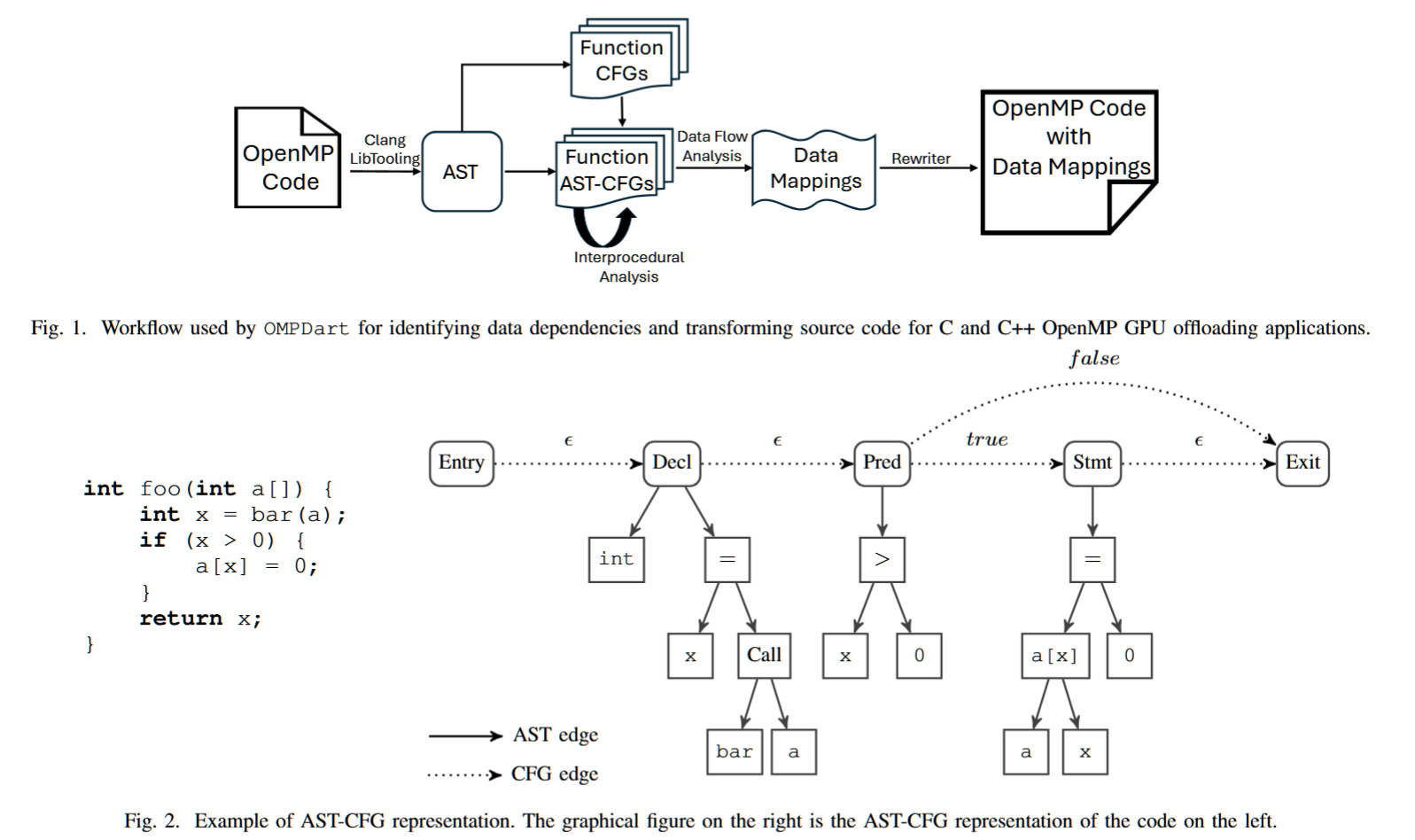

CFG
Control Flow Graphs (CFGs) 是一种用于表示程序控制流的图形结构,广泛应用于程序分析和优化中。CFG 将程序中的各个基本块(基本块是没有跳转或分支的指令序列)视为节点,节点之间的边表示控制流的转移。
基本组成:
- 节点(Node):每个节点代表程序中的一个基本块。基本块是指一系列按顺序执行的指令,只有一个入口点和一个出口点,执行时没有跳转。
- 边(Edge):边表示从一个基本块到另一个基本块的控制流转移。比如,条件跳转语句(if-else、switch)会形成不同的控制流路径。
CFG 的作用:
- 程序分析:CFG 帮助分析程序的控制流结构,识别循环、条件分支等结构,有助于代码的理解与优化。
- 静态分析:通过静态分析 CFG,可以发现潜在的错误、性能瓶颈或死代码。
- 优化:编译器利用 CFG 进行代码优化,例如消除冗余的跳转或提高代码的局部性。
- 程序验证:CFG 还可以用于形式化验证程序的正确性,比如检查程序的终止性、可达性等。
假设一个简单的程序如下:
int example(int x) {
if (x > 0) {
return x;
} else {
return -x;
}
}这个程序的控制流图会有两个基本块:
- 第一个基本块包含判断
if (x > 0),并根据结果跳转到两个可能的分支。 - 第二个基本块包含
return x或return -x。
控制流图(CFG)的边将连接这些基本块,表示不同条件下的程序执行路径。
AST-CFG 是 Abstract Syntax Tree (AST) 和 Control Flow Graph (CFG) 的结合,通常在程序分析中被用于深入理解程序的结构和行为。它结合了抽象语法树(AST)和控制流图(CFG)的优点,能够从不同层次对程序进行分析。
-
抽象语法树(AST):
- 定义:AST 是程序的语法结构的树状表示,描述了程序的语法结构及其各个组件之间的关系。它将源代码中的语句、表达式、运算符等结构化为树节点。
- 功能:AST 关注的是程序的语法和语义层面,忽略了源代码的具体格式和语法细节,突出程序的逻辑结构。每个节点代表一个语言元素,如变量、常量、运算符等。
例如,考虑以下代码:
int x = a + b;该表达式在 AST 中可能表现为如下结构:
Assign ├── Variable(x) └── Add ├── Variable(a) └── Variable(b)-
控制流图(CFG):
- 定义:控制流图(CFG)表示程序执行时的控制流路径。每个节点表示一个基本块(没有跳转的指令序列),而每条边表示从一个基本块到另一个基本块的控制流转移。
- 功能:CFG 关注程序执行时的路径,特别是程序中分支、循环等控制结构,帮助分析程序执行的顺序和可达性。
-
AST-CFG(结合 AST 和 CFG):
AST-CFG 是将 AST 和 CFG 两种分析工具结合起来的结构,旨在综合表示程序的语法和控制流。具体来说,AST-CFG 在执行路径分析时考虑了程序的语法结构,并且通过控制流图的方式表示程序的执行顺序。
- AST-CFG 的目的:通过将 AST 和 CFG 结合,可以在对程序进行深度分析时,既能理解程序的结构(如表达式、语句的执行顺序),又能捕捉程序中复杂的控制流(如条件分支、循环等)。
- 应用场景:
- 程序优化:结合语法结构和控制流,编译器可以进行更高效的优化。
- 程序分析:有助于检测代码中的潜在错误、死代码、未处理的异常等问题。
- 漏洞检测:在安全分析中,AST-CFG 可以帮助发现潜在的安全漏洞(如控制流漏洞)。
假设你有如下的代码片段:
int foo(int x) {
if (x > 0) {
return x + 1;
} else {
return x - 1;
}
}在 AST 中,你会看到类似如下的结构:
Function(foo)
├── Parameter(x)
└── If
├── Condition(x > 0)
├── Then(Return(x + 1))
└── Else(Return(x - 1))而在 CFG 中,你会看到控制流的图示,表示 if 判断的两个分支(x > 0 和 else)以及相应的跳转关系。
在 AST-CFG 中,你会得到一种结构,既展示了程序的语法(如条件判断和返回值),又展示了程序的执行路径(例如从 if 分支到不同的返回语句)。
AST-CFG 是通过结合抽象语法树和控制流图,提供了一种综合性的分析工具。它既考虑程序的语法结构,又考虑程序执行的控制流路径,这使得它在程序优化、静态分析、漏洞检测等领域中具有重要的应用价值。
HiRace: Accurate and Fast Data-Race Checking for GPU Programs
Kahlert School of Computing
University of Utah
csl-iisc/iGUARD-SOSP21 at 934ae0030f625ecf2862290b4d7412b396f64673
摘要——数据竞争是严重的并发错误,尤其在以性能为导向的 GPU 代码中尤为棘手,因为大规模的线程数和多个共享内存区域往往会加剧此类问题。在本研究中,我们提出了一种新的动态数据竞争检测工具——HiRace,其关键创新在于设计了一种创新的状态机,旨在充分利用大规模同步的分层 GPU 编程模型。该状态机将任意长度的访问历史压缩为常数大小的状态。我们在一个大型、校准过的数据竞争基准测试套件上评估了 HiRace。在超过 3500 次研究的 580 个 CUDA 内核执行中,其中 346 个内核包含数据竞争,我们发现 HiRace 能够检测出其他工具未能发现的数据竞争,且不会引发虚假警报,并且在性能上平均比现有技术快 10 倍以上,同时内存开销只有其一半。
关键词——GPU 编程;并行性;调试;数据竞争检测
HiRace的设计基于对给定内存地址的访问模式的枚举。在细粒度的释放-获取线程通信的普遍情况下,这个空间是没有界限的,但我们观察到,在限制为大规模同步GPU编程模型时,它是有界的。通过选择一个层次感知的表示方法,机会性地将线程等同于最大的可能层次线程组,实际上相关的访问模式数量是非常小的。我们将所有这些访问模式表示为25个不同的状态,这涵盖了所有对单个内存位置的读、写和原子读-修改-写指令的交织情况,当这些线程同步仅通过范围限定的线程屏障(例如CUDA的syncthreads)时。
这个模型并没有改善当前通过释放-获取通信或基于锁的同步监控的现有技术。HiRace的方法回退到现有的同步追踪方法(例如,通过维护锁表来分析基于锁的程序)。实际上,这些传统的CPU并行编程模式在高性能GPU程序中并不常见,因为它们不是大规模同步编程模型的核心组件。GPU编程语言(如CUDA)没有提供显式的锁API,而是依赖于屏障,这也证明了这一点。
HiRace基于一个有限状态机(FSM),它编码了前面介绍的发生先后逻辑。尽管FSM是为当前的CUDA编程模型量身定制的,但它可以很容易地扩展到其他模型和更深的层次结构。HiRace的FSM有25个状态,并且在这些状态之间有1200个转换。它们足以描述所有对单个内存位置的原子和非原子读写操作,以及从warp作用域和block作用域屏障原语中获得的所有必要的同步历史。
为了避免详尽列出FSM的每个状态(其完整规格可以在 https://github.com/JohnJacobsonIII/HiRace-Artifact-SC24 找到),本节将逐步构建更简单的并发模型的类似状态机。为此,我们展示了两个场景,介绍了我们方法背后的关键思想:FSM如何执行原子更新,以及我们如何简洁地表达FSM的转换。
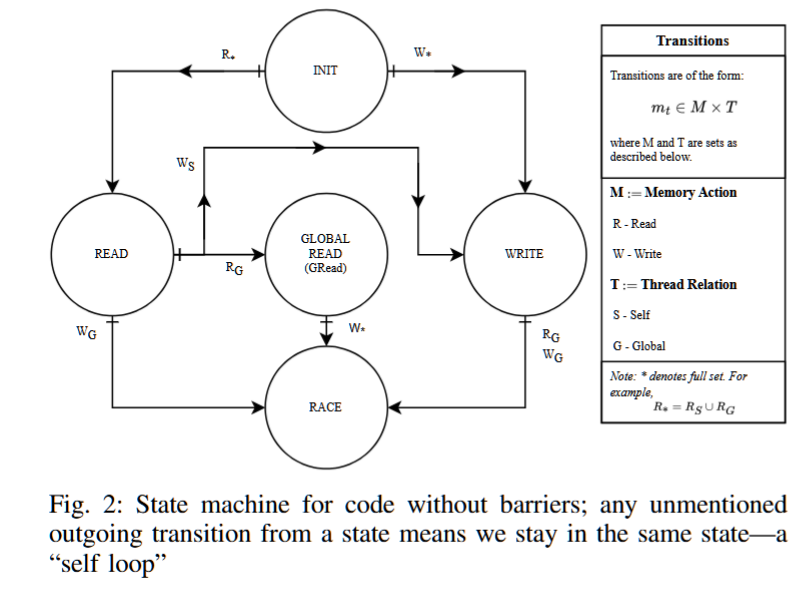
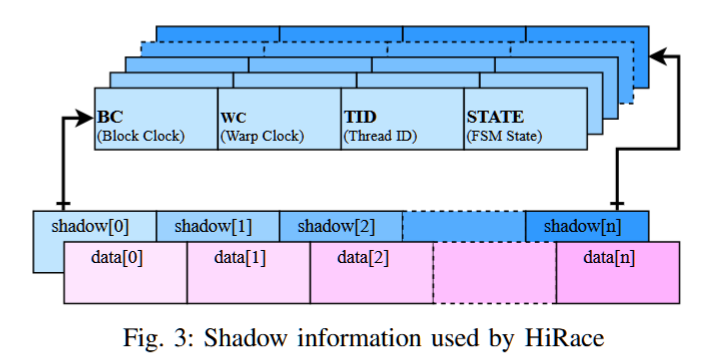
我们声称,图2中的有限状态机(FSM)以及一个先前的访问者ID,足以跟踪沿单个控制流路径可能发生的所有数据竞争。为了监控数据数组中的竞争,我们为每个数组元素data[k]创建一个shadow[k]条目,如图3所示。每个shadow[k]条目维护以下信息:块标量时钟(BC)、warp标量时钟(WC)、执行最近访问的线程ID(TID),以及图2中的FSM状态(State)。
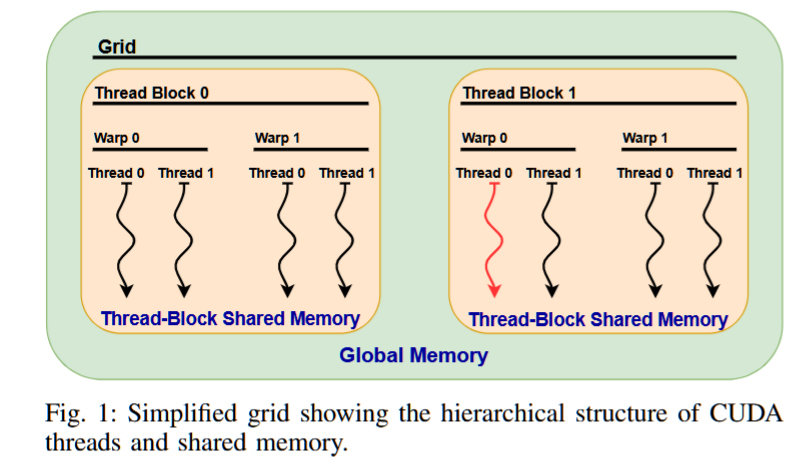
最初,所有的State值都设置为INIT,表示尚未发生任何内存访问。假设我们采用图1所示的线程组织。我们将八个线程标记为T000到T111,以指示它们的块、warp和TID。例如,“红色”线程是T100。

在我们描述的场景中,所有访问data[k]的CUDA线程都会通过我们的源代码插桩原子地复制shadow[k]到oShadow,其中oShadow是元组⟨oBC, oWC, oTID, oState⟩。然后,它们确定要写回到shadow[k]的新元组⟨nBC, nWC, nTID, nState⟩,并通过使用ATOMICCAS指令以无锁方式完成该操作。只有一个线程会成功;“失败者”会重新获取shadow[k]的副本并重试。为了说明这个过程,让我们通过几个具体的场景来演示。
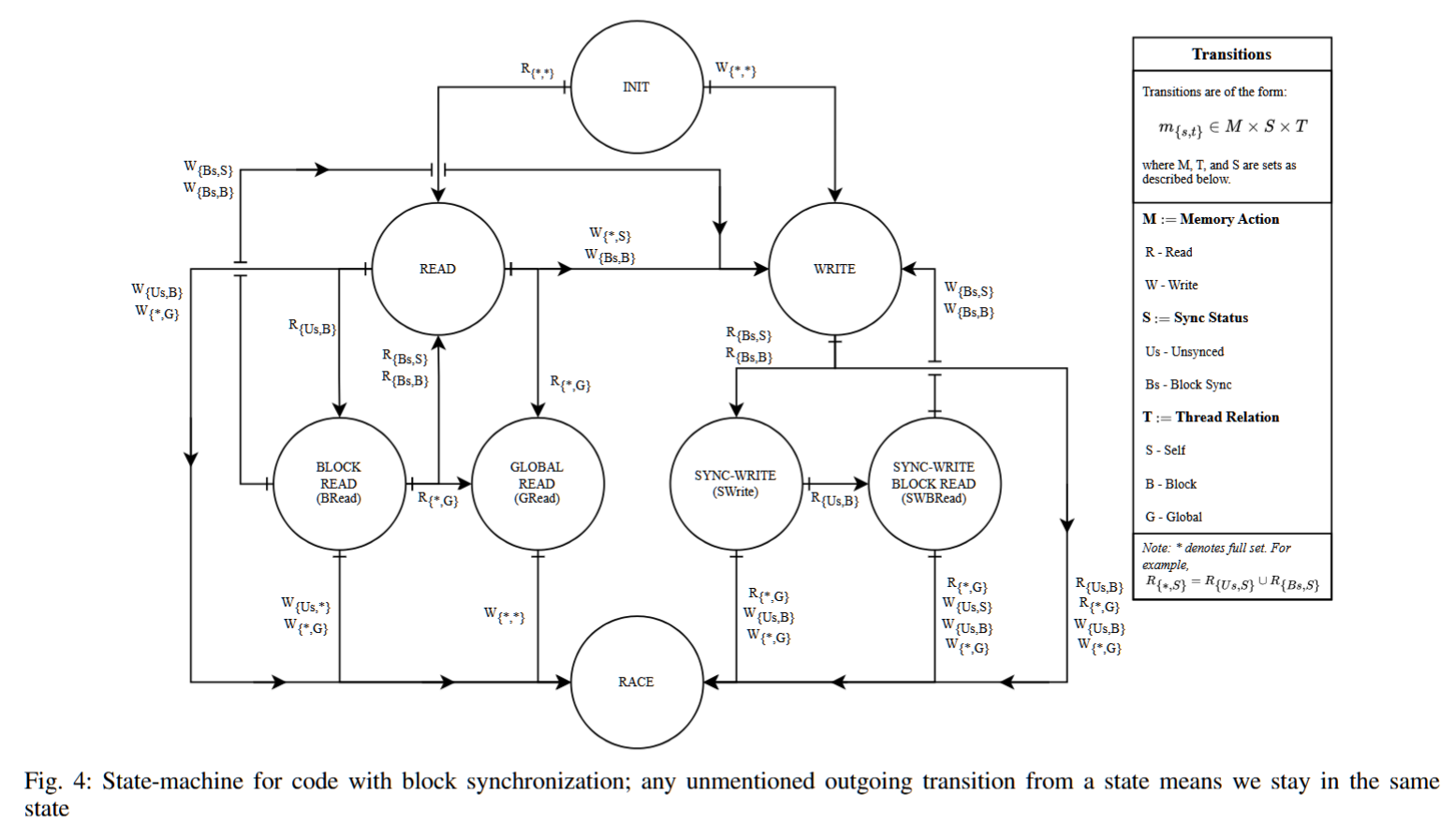
场景2:在这个场景中,我们考虑包含块作用域 syncthreads 屏障的程序,如列表3所示。为了说明在屏障存在时状态机的活动,我们扩展了读取和写入的下标表示法。下标的形式是{S, T},其中S是同步状态,可以是Us(“未同步”)或Bs(“块同步”),T是线程关系,现在除了原来的S(“自身”)和G(“全局”)外,还有B(“块”)选项。新的线程关系B表示一个屏障已“块同步”了访问(通过不同的块标量时钟BC值来指示)。通配符“∗”表示任何适用的字母。
考虑T011(图1中的“红色”线程)执行列表3中的第4行,其中它读取数据数组的位置0。此访问将shadow[0]的状态更新为READ,如图4中通配符下标的R{∗,∗}转换所示。假设T000,同一块中的另一个线程,现在执行第4行。此访问将shadow[0]更新为BREAD(块读取)——这是一个新状态——表示同一块范围内的两个线程已异步读取此位置,如标签R{Us,B}所示。只要同一块中的其他线程继续执行第4行,shadow[0]就会保持在BREAD状态。当来自不同块的线程,例如T110,执行第4行时,我们将shadow[0]提升为GREAD(全局读取),因为在“全局范围”内执行了读取操作(R{∗,G})。
一旦进入GREAD状态,任何线程的任何类型的写入(W{∗,∗})都会导致数据竞争,因为这个内存位置已经被至少两个块读取过。这个非常重要,因为syncthreads屏障不会同步跨块的线程,因此任何写入线程必须至少异步执行与之前的某个读取线程。
如果不是线程T110执行上述访问,而是让shadow[0]保持在BREAD状态,并让红色线程T011在第5行执行__syncthreads。由于屏障的语义,所有线程必须通过屏障后才能执行任何后续指令。因此,最终,所有该块中的线程的线程私有块标量时钟(BC)将更新为1。此时,块B0中的任何线程的写入将把状态转变为WRITE,如转换W{Bs,S}和W{Bs,B}所示。即便如此,T110最终执行了对该位置的读取操作,从而转到RACE状态。图4中FSM的其余转换也可以类似地进行探索。
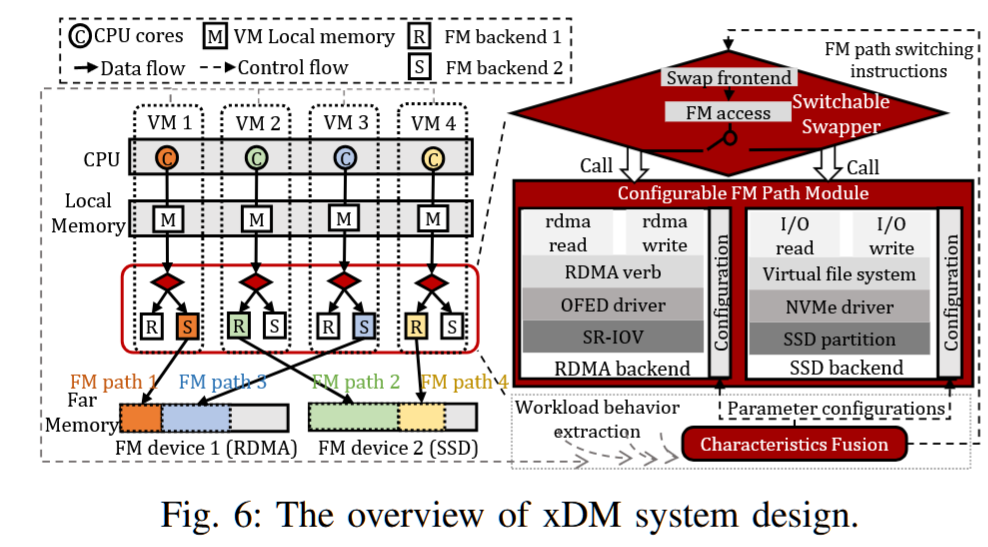
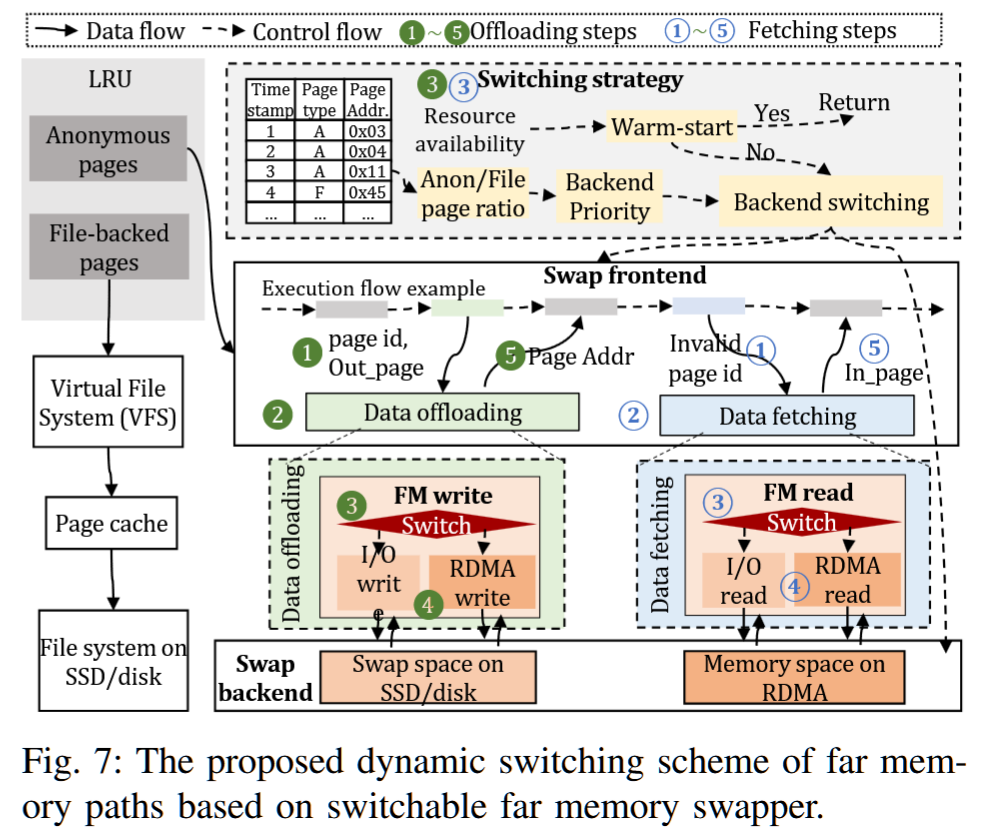
Serverless Computing and Disaggregated Memory
Boosting Data Center Performance via Intelligently Managed Multi-backend Disaggregated Memory
Shanghai Jiao Tong University
摘要——现有的分散内存(DM)系统面临远程内存带宽未充分利用的问题,这大大限制了在处理数据密集型应用时的数据吞吐量。具体而言,先前的研究主要针对单一基于PCIe的二级内存设备(即单后端远程内存)的运行时设计,该设备具有低数据带宽和高系统开销。
在这项工作中,我们迈出了实现精心设计的多后端DM系统的第一步,该系统具有可扩展的远程内存路径。我们提出了xDM,一种新的DM管理方案,可以动态构建并隐式选择适当的远程内存访问路径。作为xDM的一部分,我们设计了一种智能远程内存配置策略,能够通过根据应用程序页面数据的综合信息调整一系列关键参数,从而进一步优化带宽使用效果。我们的设计相较于现有最先进的工作,展示了最高3.9倍的数据交换性能加速、2.8倍的数据吞吐量提升和5.1倍的数据中心任务吞吐量改善。
关键词——多后端、远程内存、多路径、交换
https://zhuanlan.zhihu.com/p/541262524
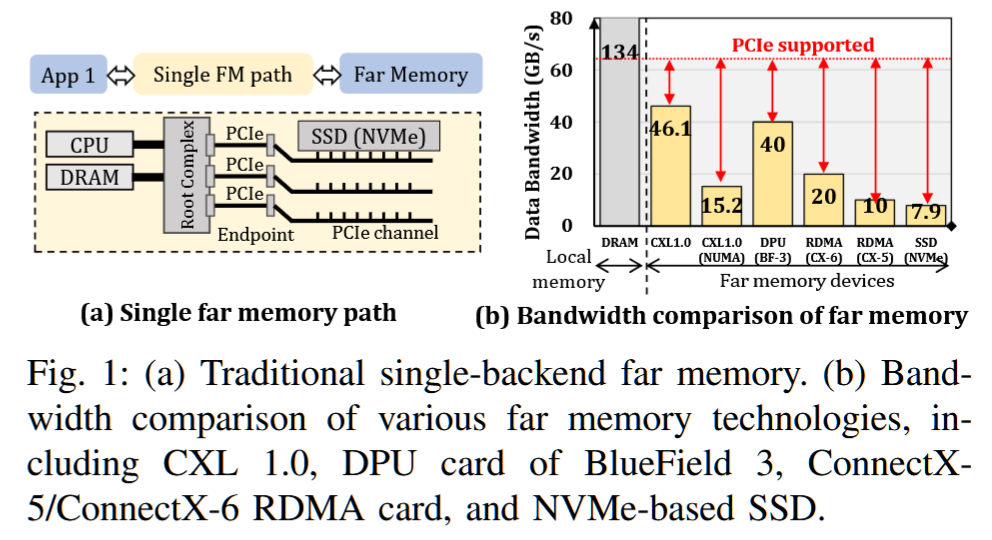
近年来,分散式内存(DM)架构脱颖而出,成为提升数据中心能力的一种方式,它通过提供高度灵活的内存扩展来实现这一目标[20]-[25]。在这种情况下,对内存需求极大的单体服务器能够以较低的数据访问延迟访问基于 PCI Express(PCIe)的二级内存设备(即远内存)。
集成多个FM设备并超配PCIe子系统,可以推动服务器数据吞吐量的极限,如图2-(a)所示。这种方法我们称之为多后端分散内存,但遗憾的是,仅基于当前的数据传输协议和设备驱动程序无法实现这一目标。主要原因在于,虚拟机(VM)仍然使用与主机操作系统(OS)相关的分层数据交换机制,这种机制不允许将页面交换到多个交换后端(每个后端关联着不同的后备存储)。
换句话说,现有的FM管理方案忽略了可能存在的多个物理FM通道:它们在逻辑上仅支持一个数据交换路径到FM设备。
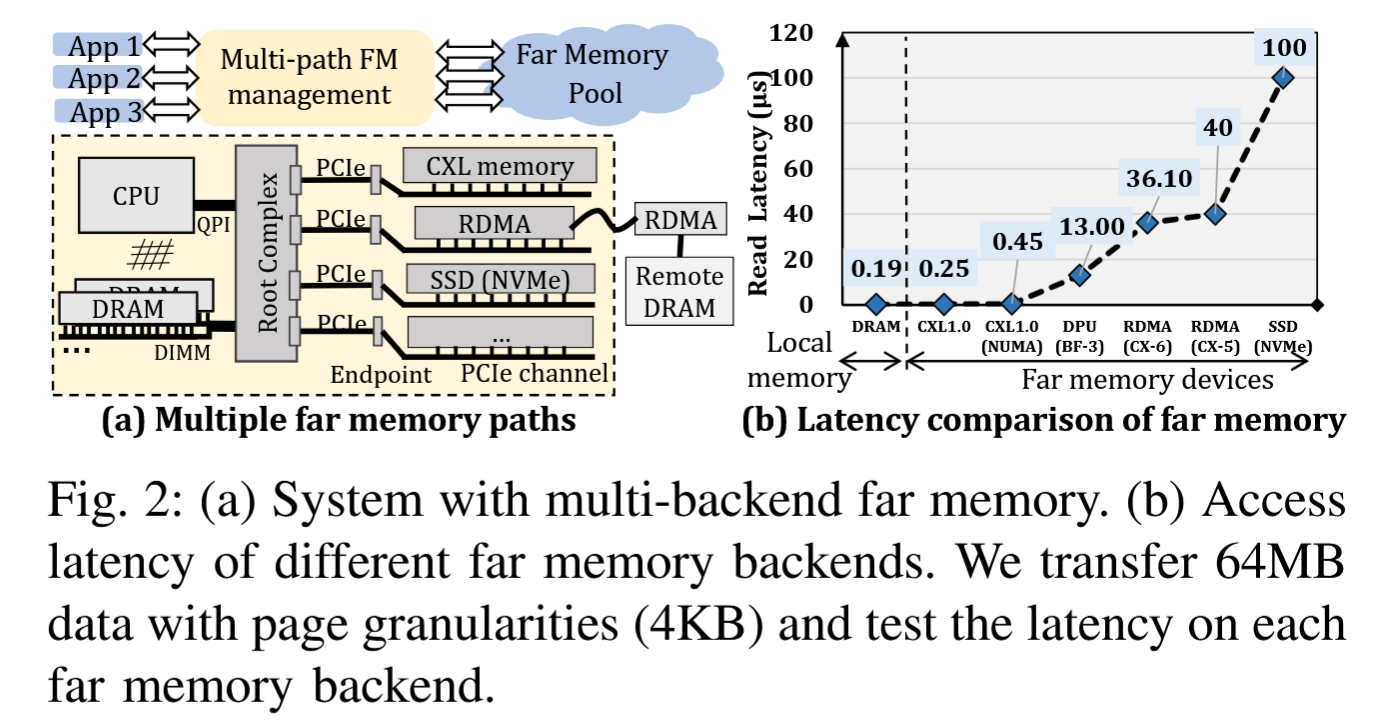
我们提出了xDM,一个新型的FM管理系统,旨在支持在新型多后端分散内存架构上运行的高性能数据分析工作负载。为了实现这一目标,需要从单路径到多路径内存管理进行非平凡的过渡。使用多个同时的FM访问路径使服务器能够并行访问FM设备,从而显著提高整体数据吞吐量。我们精心调整了VM操作系统,以支持多路径FM管理。xDM具有低开销的可切换数据交换模块,使得内存需求高的机器能够定制其FM访问路径。因此,不同的用户可以根据他们特定的工作负载特性和资源压力动态选择适当的FM后端,避免在等待机器带宽可用时阻塞任务。

尽管增加远程内存(FM)可以缓解服务器的内存压力,但遗憾的是,它无法满足当今数据中心中对高数据/任务吞吐量的需求。如图1-(a)所示,先前的工作大多将设计限制在单一的FM设备上,该设备通常插入服务器的PCIe附加卡(AIC)接口,作为一个快速的后备存储[26]–[31]。图1-(b)比较了多种商业FM技术。单一FM设备所能支持的数据传输带宽(从7.9 GB/s到46 GB/s)[25],[32]–[35]与现代PCIe协议所能提供的最大可用带宽(PCIe 4.0×16提供64 GB/s)[36]之间存在很大的差距。这意味着,单一的远程内存设备可能成为扩展应用程序的关键瓶颈。
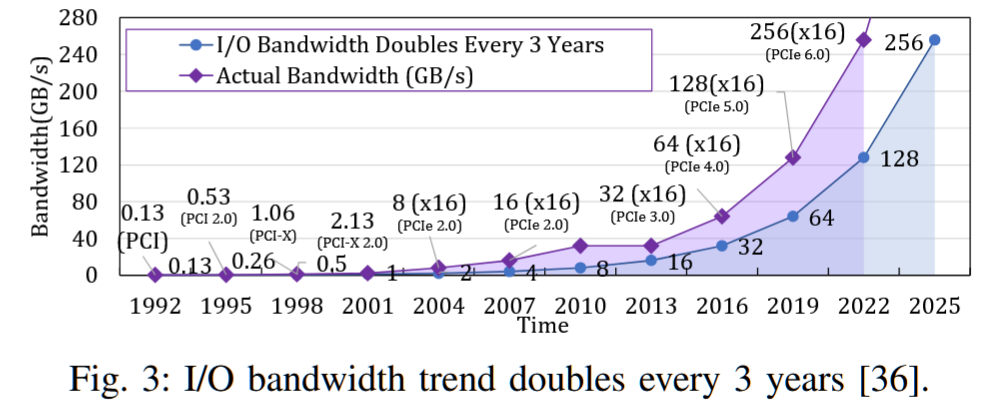
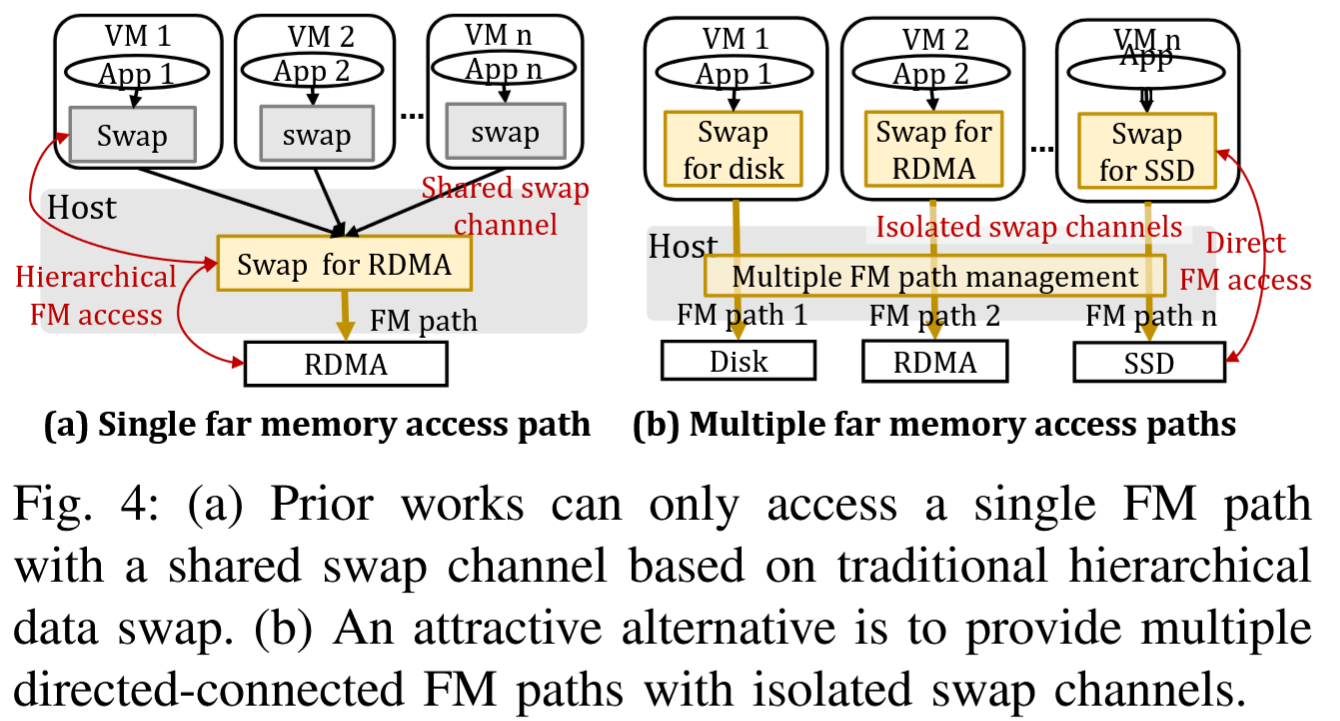
• 动态性和隐式性。一种可能的解决方案是使系统静态且隐式。这意味着用户在 FM 启用的机器上启动计算实例时必须指定一种类型。实际上,这将实例绑定到特定的物理 FM 通道(例如,RDMA 或 SSD)。将不同用户的实例共置允许服务器节点同时访问不同的 FM 后端,从而提高带宽利用率。由于工作负载行为在运行时经常发生变化,这种设计只能产生次优性能。
在本工作中,我们的目标是使系统具有动态性:每个实例都能在运行时评估任务偏好,并隐式选择最优的远内存路径,而无需用户干预。据我们所知,以往的工作从未实现过静态的多路径远内存系统,更不用说动态的了。我们的工作与相关研究之间的差异如表 I 所示。
• 使其通用且智能。xDM 不仅仅是简单地在本地 DRAM 和远内存设备之间分配数据,而是旨在成为一个真正通用的系统。为了提高远内存带宽使用效率并提升数据中心性能,需要考虑更多的可配置参数。重要的是要利用丰富的应用程序页面数据,并根据包括数据分布、数据粒度以及 I/O 特性在内的多维系统信息来调整系统设置。这使我们能够做出明智的决策,并使 xDM 能够智能地配置每条远内存路径。据我们所知,以往的工作都采用了简单直接的数据管理策略。我们的工作与相关研究之间的差异总结在表 II 中。
不是很理解,就用了Deepseek翻译一下:
💭
用户提到,xDM的基本思想是将远内存后端的管理与传统交换机制解耦,以实现高带宽的数据交换。传统基于层次结构的内存访问模式在深层内存层次结构中效率低下,主要是因为单一的数据交换路径。因此,他们提出了一种扁平化的数据管理方法,允许应用程序直接、快速选择合适的远内存路径。
接下来,系统设计了两个主要模块:可切换的FM交换模块和多个FM路径配置模块。FM交换模块负责选择适当的路径并分配远内存空间,而配置模块则调整路径的可调参数,以降低开销。此外,xDM从三个维度提取工作负载行为,结合系统信息智能切换和配置访问路径,从而优化性能,减少数据获取开销。
在可扩展性和可移植性方面,xDM的系统级页面分析对应用透明,能够轻松迁移到其他远内存环境和实际应用。FM交换模块支持新设备的无缝扩展,路径配置模块可纳入更多系统属性以适应新场景。
现在需要将这些要点组织成连贯的中文摘要,确保技术术语准确,逻辑清晰。需要注意避免直接翻译,而是用更自然的中文表达。同时,要突出xDM的创新点,如解耦管理、扁平化数据管理、智能路径选择与配置,以及系统的扩展性和适用性。
最后检查是否有遗漏的关键点,比如三个维度的行为分析、绕过某些数据获取开销的优势,以及实际应用中的迁移便捷性。确保摘要涵盖所有重要内容,结构合理,语言流畅。
这段文字描述了一种名为xDM的新型远内存管理系统,其核心创新点及技术要点如下:
核心思想
通过解耦远内存后端管理与传统的交换机制,打破传统内存层次结构的单一路径限制,构建扁平化数据管理体系,使应用程序能够直接选择最优远内存路径,实现高带宽数据交换。
关键技术模块
- 可切换FM交换模块
- 动态选择适合的远内存路径(FM Path)
- 智能分配远内存空间资源
- 多路径配置模块
- 支持低开销调整路径参数(如带宽配额、缓存策略)
- 可扩展集成新系统属性以适应不同场景
智能决策机制
- 从工作负载特征、硬件状态、路径性能三个维度提取关键指标
- 结合系统级信息(如页面访问模式、设备延迟)动态配置路径
- 通过绕过非必要的数据获取步骤(如冗余元数据传输)降低开销
系统优势
- 性能优化:利用定制化路径选择充分发挥硬件设计优化(如RDMA、NVM)
- 扩展性:支持新设备即插即用,模块化设计便于迁移到其他远内存架构
- 透明性:系统级页面数据分析对应用程序完全无感知
- 场景适应:通过参数配置快速适配云计算、边缘计算等不同应用场景
该设计解决了传统分层内存架构在超深层次下的效率瓶颈,为分布式内存系统提供了高灵活性的资源管理方案。
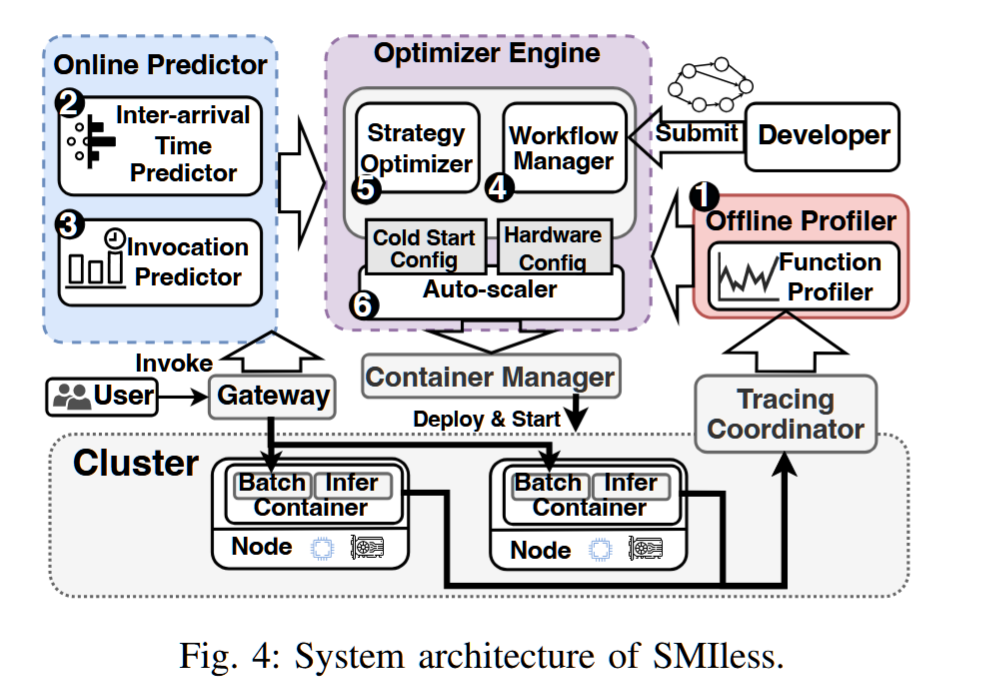
SMIless: Serving DAG-based Inference with Dynamic Invocations under Serverless Computing
Shenzhen Institute of Advanced Technology, CAS
State Key Lab of Internet of Things for Smart City, University of Macau
叶可江,博士,研究员,博士生导师,中国科学院深圳先进技术研究院云计算研究中心主任。
摘要——基于无服务器平台部署机器学习(ML)服务应用程序,具有多个推理功能,已获得显著的普及,导致了许多新系统的发展。然而,这些系统通常将资源配置优化和冷启动管理分开处理,最终导致更高的金钱成本。
本文介绍了SMIless,一个为异构环境中的基于DAG的ML推理服务量身定制的高效无服务器系统。SMIless在动态调用的背景下,能够有效地共同优化资源配置和冷启动管理。这是通过无缝集成自适应预热窗口来实现的,从而在性能和成本之间达到有效的平衡。我们在OpenFaaS上实现了SMIless,并使用真实世界的ML服务应用程序进行了广泛评估。实验结果表明,SMIless能够在满足所有用户请求的服务水平协议(SLA)要求的同时,将总体成本减少最多5.73倍,超越了现有最先进解决方案的性能。
关键词——无服务器、基于DAG的推理、动态调用
什么是 Serverless computing ?
https://zhuanlan.zhihu.com/p/50694361
最近,serverless一词在越来越多的对话中出现。让我们先弄明白这个概念以及与之相关的一些东西,例如无服务器计算和无服务器平台。
Serverless 经常被当做FAAS(函数既服务)。serverless不是说没有服务器。事实上,服务器有很多,甚至性能还很强劲,这是为公共云提供商提供了部署、运行和管理应用程序的服务器。
Serverless平台提供api,允许用户运行代码函数(也称为操作)并返回每个函数的结果。无服务器平台还提供HTTPS终端,允许开发人员检索函数结果。这些终端可以用作其他函数的输入,从而提供相关函数的触发事件(或链接)。
在大多数serverless平台上,用户在执行函数之前部署(或创建)函数。serverless平台拥有所有必要的代码,以便在需要的时候执行这些函数。serverless函数的执行可以由用户通过命令手动调用,也可以由事件源触发,该事件源配置为在响应cron作业告警、文件上传或其他事件时激活函数
Serverless是云计算的进一步延伸,所以,它继承了云计算的最大特点——按需弹性伸缩、按需付费。
https://cloud.tencent.com/developer/article/2203381
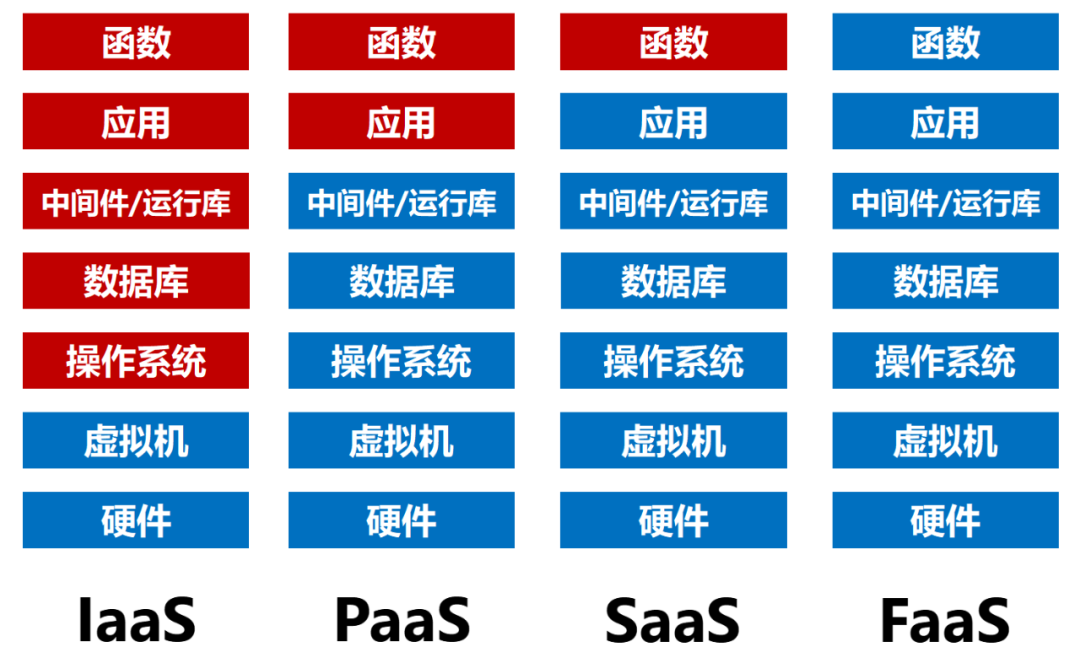
现在的互联网服务,基本上都是采用微服务架构。也就是把一整套服务,拆分为多个细分服务,由不同的服务器完成运算。
Serverless的特点是,这个服务足够“细小”,变成了“函数级”的颗粒度。
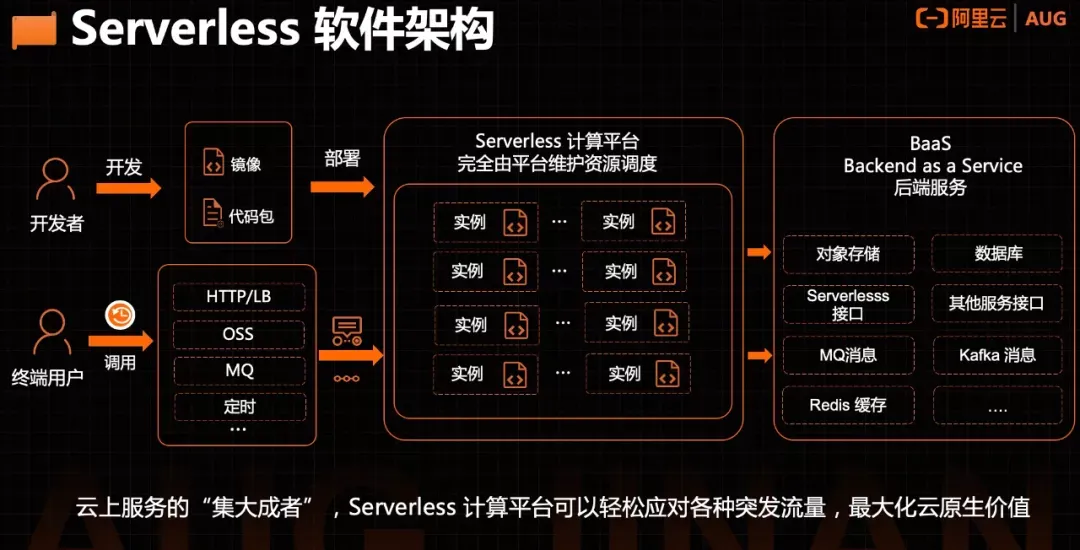
Serverless的背后,依然是虚拟机和容器。只不过,服务器部署、runtime安装、编译等工作,都由Serverless计算平台负责完成了。对开发人员来说,只需要维护源代码和Serverless执行环境的相关配置即可。这就叫“无服务器计算”。
Serverless架构的最大优势,显然就是帮助用户彻底摆脱了基础设施管理这样的“杂事”,更加专注于业务开发,从而提升了效率,降低了开发和运营成本。
根据业界的统计,在商业和企业数据中心里的典型服务器,日常仅仅只提供了5%~15%的平均最大处理能力的输出。这是一种算力资源的巨大浪费。
Serverless的出现,可以让用户按照实际算力使用量进行付费,属于真正的“精确计费”。
换言之,用户的每一分钱,都花在了刀刃上。
https://developer.aliyun.com/article/857454



本文:
在机器学习服务中,通过在一个应用中整合多个机器学习推理模型来提供全面服务至关重要[8]。例如,一个对话式人工智能流水线由三个模块构成:自动语音识别模块将输入的音频波形转换为文本,大语言模型(LLM)模块理解输入并生成相关回应,以及负责将大语言模型输出转化为语音的文本转语音模块[9]。这些模型通常以并行、串行或混合方式组织,并可通过有向无环图(DAG)进行表示
传统文献中关于在异构环境中为基于DAG的应用分配资源的研究忽视了冷启动问题,导致资源浪费,并未能满足端到端(E2E)延迟的服务水平协议(SLA)要求。在使用无服务器计算进行ML服务应用的研究中,主要强调了孤立的优化,或者完全忽视了DAG结构。
现有的研究倾向于将冷启动和资源配置视为独立的问题,未能有效管理动态调用到达,导致显著提高了金钱成本。此外,完全忽视DAG结构的方法可能会导致整体资源利用率的大幅下降。
本文介绍了SMIless,一个用于通过无服务器计算在异构资源上为基于DAG的ML推理应用提供服务的新系统。SMIless的独特之处在于其自适应预热窗口的设计,该窗口根据函数在DAG拓扑中的位置以及调用模式动态更新。此外,SMIless通过重新定义可管理的路径搜索问题来解决级联效应。在多路径树中的路径搜索过程中,每个经过的节点代表了一个关键决策,涉及异构资源配置和所有函数的冷启动缓解策略。为了加速搜索符合最低成本并最终满足SLA要求的路径,SMIless利用高效的排序机制来最小化搜索开销。为了解决广泛搜索空间带来的困难,SMIless采用了分解方法,将复杂的DAG分成多个简单路径,并对每个路径进行并行优化。此外,SMIless还实现了动态批处理和有效扩展,以处理因多个调用在短时间内到达而产生的突发工作负载。
我们使用流行的框架OpenFaaS实现了SMIless[28]。SMIless系统包括一个分析器,有效地衡量各个函数的推理和初始化时间。此外,SMIless还结合了新的在线预测器,能够准确预测请求到达模式。该实现还支持GPU复用,使得一个函数实例可以仅使用可用GPU的一部分。我们使用真实世界的ML应用程序[5]以及类似于Azure Functions[29]的工作负载对SMIless进行了评估。实验结果证明,与现有解决方案相比,SMIless能够实现最多5.73倍的总体成本降低,同时不违反端到端延迟的SLA要求。
级联效应
A cascading effect refers to an unforeseen chain of events that occurs when a negative impact on one system leads to negative impacts on other related systems.
https://snap-stanford.github.io/cs224w-notes/network-methods/network-effects-and-cascading-behavior
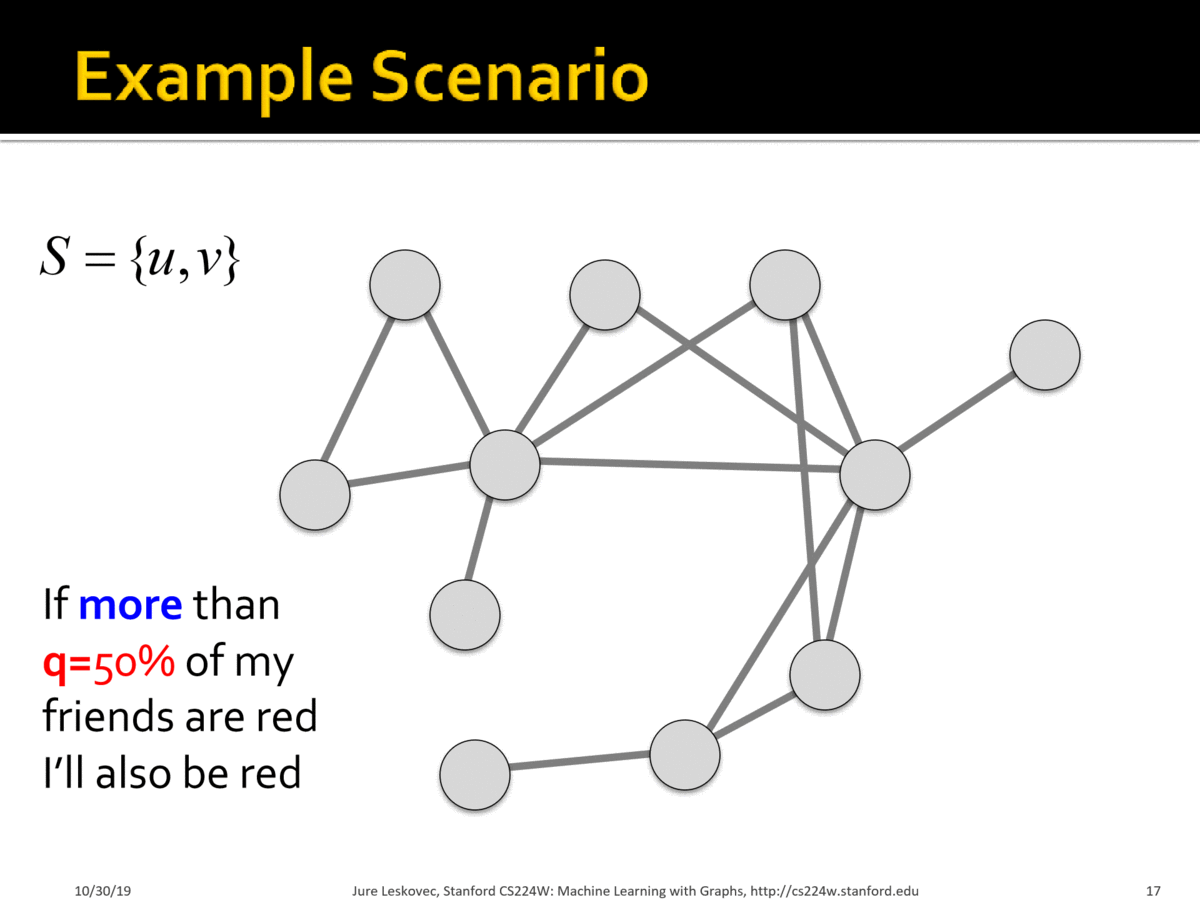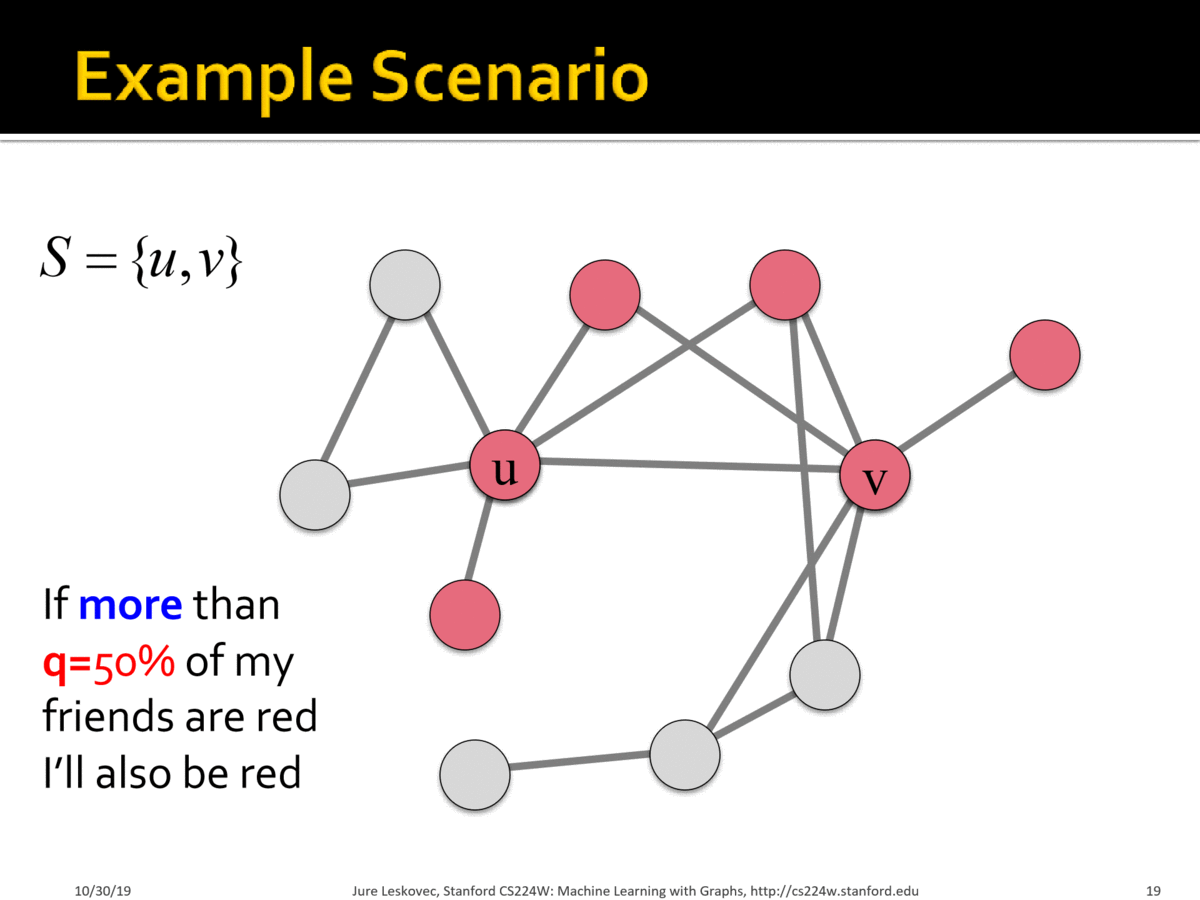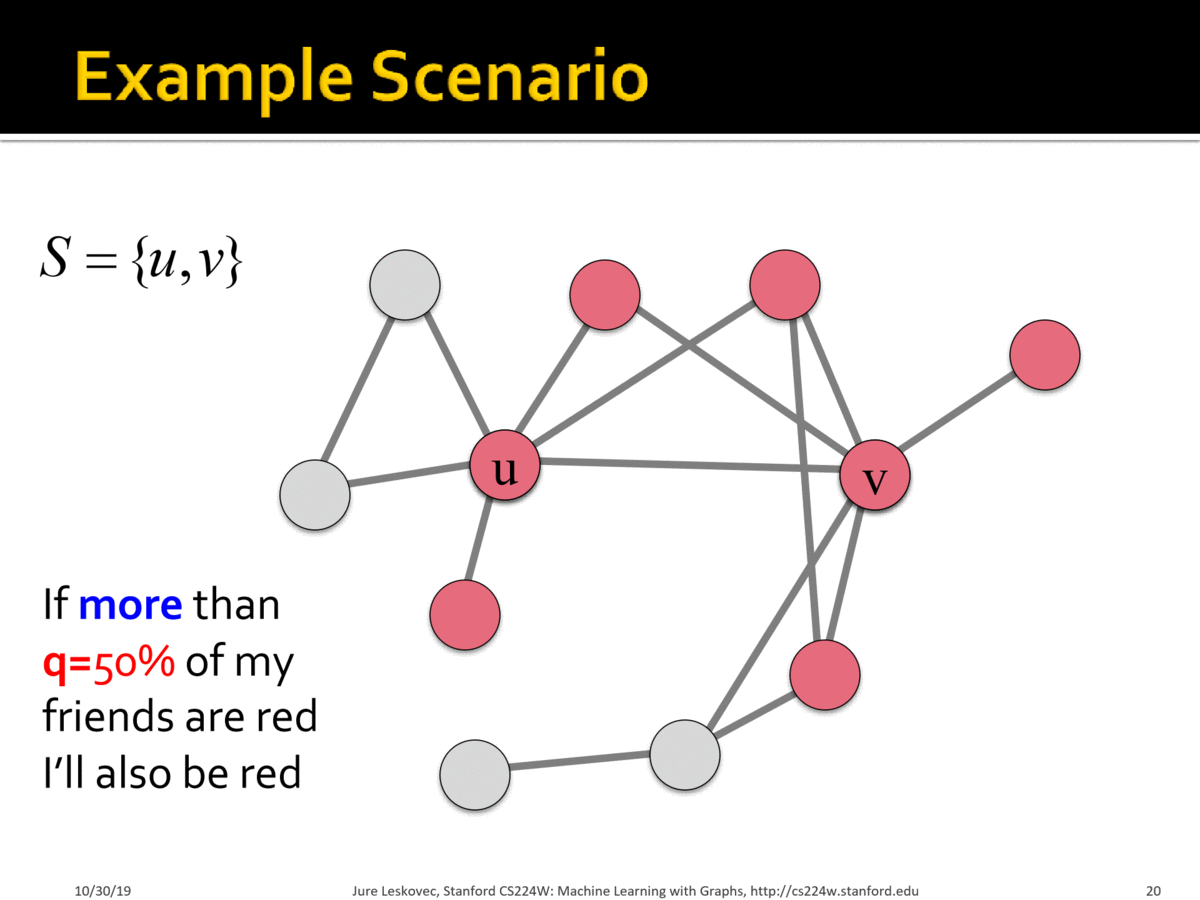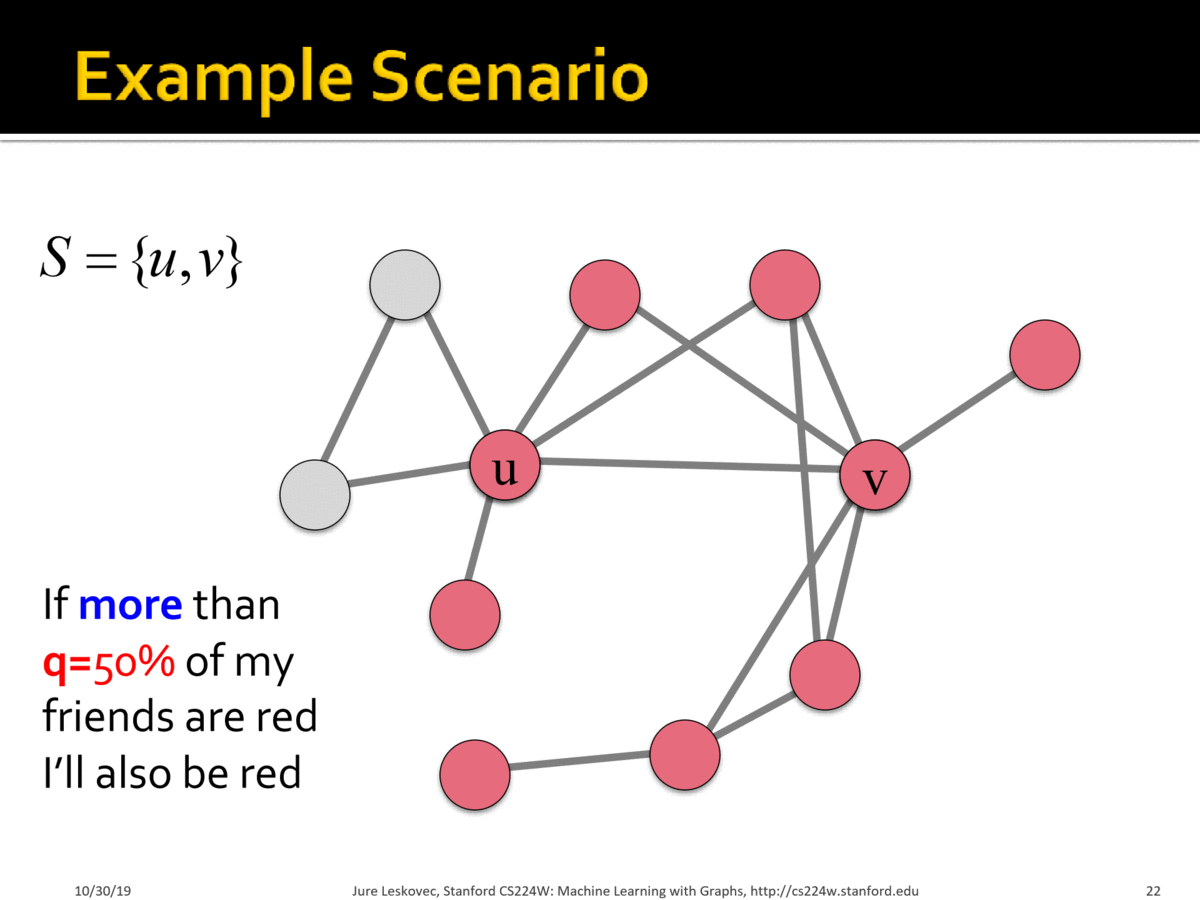
SLA(服务等级协议)
学习链接:
https://blog.csdn.net/Listron/article/details/117653075
https://www.jianshu.com/p/25855d0775ed
SLA(Service-Level Agreement),也就是服务等级协议,指的是系统服务提供者(Provider)对客户(Customer)的一个服务承诺。这是衡量一个大型分布式系统是否“健康”的常见方法。
在开发设计系统服务的时候,无论面对的客户是公司外部的个人、商业用户,还是公司内的不同业务部门,我们都应该对自己所设计的系统服务有一个定义好的SLA。
因为SLA是一种服务承诺,所以指标可以多种多样。根据我的实践经验,给你介绍最常见的四个SLA指标,可用性、准确性、系统容量和延迟。
- 可用性(Availabilty)
可用性指的是系统服务能正常运行所占的时间百分比。
如果我们搭建了一个拥有“100%可用性”的系统服务,那就意味着这个系统在任何时候都能正常运行。是不是很完美?但真要实现这样的目标其实非常困难,并且成本也会很高。
我们知道,即便是大名鼎鼎的亚马逊AWS云计算服务这样大型的、对用户来说极为关键的系统,也不能承诺100%的可用性,它的系统服务从推出到现在,也有过服务中断(Service Outage)的时候。
对于许多系统而言,四个9的可用性(99.99% Availability,或每年约50分钟的系统中断时间)即可以被认为是高可用性(High availability)。
说到这里,我来为你揭开一开始所提到的“99.9% Availability”的真实含义。
“99.9% Availability”指的是一天当中系统服务将会有大约86秒的服务间断期。服务间断也许是因为系统维护,也有可能是因为系统在更新升级系统服务。
86秒这个数字是怎么算出来的呢?
99.9%意味着有0.1%的可能性系统服务会被中断,而一天中有24小时 × 60分钟 × 60秒,也就是有(24 × 60 × 60 × 0.001) = 86.4秒的可能系统服务被中断了。而上面所说的四个9的高可用性服务就是承诺可以将一天当中的服务中断时间缩短到只有(24 × 60 × 60 × 0.0001) = 8.64秒。
- 准确性(Accuracy)
准确性指的是我们所设计的系统服务中,是否允许某些数据是不准确的或者是丢失了的。如果允许这样的情况发生,用户可以接受的概率(百分比)是多少?
这该怎么衡量呢?不同的系统平台可能会用不同的指标去定义准确性。很多时候,系统架构会以错误率(Error Rate)来定义这一项SLA。
怎么计算错误率呢?可以用导致系统产生内部错误(Internal Error)的有效请求数,除以这期间的有效请求总数。
例如,我们在一分钟内发送100个有效请求到系统中,其中有5个请求导致系统返回内部错误,那我们可以说这一分钟系统的错误率是 5 / 100 = 5%。
下面,我想带你看看硅谷一线公司所搭建的架构平台的准确性SLA。
Google Cloud Platform的SLA中,有着这样的准确性定义:每个月系统的错误率超过5%的时间要少于0.1%,以每分钟为单位来计算。
而亚马逊AWS云计算平台有着稍微不一样的准确性定义:以每5分钟为单位,错误率不会超过0.1%。
你看,我们可以用错误率来定义准确性,但具体该如何评估系统的准确性呢?一般来说,我们可以采用性能测试(Performance Test)或者是查看系统日志(Log)两种方法来评估。
具体的做法我会在后面展开讲解,今天你先理解这项指标就可以了。
- 系统容量(Capacity)
在数据处理中,系统容量通常指的是系统能够支持的预期负载量是多少,一般会以每秒的请求数为单位来表示。
我们常常可以看见,某个系统的架构可以处理的QPS (Queries Per Second)是多少又或者RPS(Requests Per Second)是多少。这里的QPS或者是RPS就是指系统每秒可以响应多少请求数。
我们来看看之前Twitter发布的一项数据,Twitter系统可以响应30万的QPS来读取Twitter Timelines。这里Twitter系统给出的就是他们对于系统容量(Capacity)的SLA。
你可能会问,我要怎么给自己设计的系统架构定义出准确的QPS呢?以我的经验看,可以有下面这几种方式。
第一种,是使用限流(Throttling)的方式。
如果你是使用Java语言进行编程的,就可以使用Google Guava库中的RateLimiter类来定义每秒最多发送多少请求到后台处理。
假设我们在每台服务器都定义了一个每秒最多处理1000个请求的RateLimiter,而我们有N台服务器,*在最理想的情况下,我们的QPS可以达到1000 N**。
这里要注意的雷区是,这个请求数并不是设置得越多越好。因为每台服务器的内存有限,过多的请求堆积在服务器中有可能会导致内存溢出(Out-Of-Memory)的异常发生,也就是所有请求所需要占用的内存超过了服务器能提供的内存,从而让整个服务器崩溃。
第二种,是在系统交付前进行性能测试(Performance Test)。
我们可以使用像Apache JMeter又或是LoadRunner这类型的工具对系统进行性能测试。这类工具可以测试出系统在峰值状态下可以应对的QPS是多少。
当然了,这里也是有雷区的。
有的开发者可能使用同一类型的请求参数,导致后台服务器在多数情况下命中缓存(Cache Hit)。这个时候得到的QPS可能并不是真实的QPS。
打个比方,服务器处理请求的正常流程需要查询后台数据库,得到数据库结果后再返回给用户,这个过程平均需要1秒。在第一次拿到数据库结果后,这个数据就会被保存在缓存中,而如果后续的请求都使用同一类型的参数,导致结果不需要从数据库得到,而是直接从缓存中得到,这个过程我们假设只需要0.1秒。那这样,我们所计算出来的QPS就会比正常的高出10倍。所以在生成请求的时候,要格外注意这一点。
第三种,是分析系统在实际使用时产生的日志(Log)。
系统上线使用后,我们可以得到日志文件。一般的日志文件会记录每个时刻产生的请求。我们可以通过系统每天在最繁忙时刻所接收到的请求数,来计算出系统可以承载的QPS。
不过,这种方法不一定可以得到系统可以承载的最大QPS。
在这里打个比喻,一家可以容纳上百桌客人的餐馆刚开业,因为客流量还比较小,在每天最繁忙的时候只接待了10桌客人。那我们可以说这家餐馆最多只能接待10桌客人吗?不可以。
同样的,以分析系统日志的方法计算出来的QPS并不一定是服务器能够承载的最大QPS。想要得到系统能承受的最大QPS,更多的是性能测试和日志分析相结合的手段。
- 延迟(Latency)
延迟指的是系统在收到用户的请求到响应这个请求之间的时间间隔。
在定义延迟的SLA时,我们常常看到系统的SLA会有p95或者是p99这样的延迟声明。这里的p指的是percentile,也就是百分位的意思。如果说一个系统的p95 延迟是1秒的话,那就表示在100个请求里面有95个请求的响应时间会少于1秒,而剩下的5个请求响应时间会大于1秒。
下面我们用一个具体的例子来说明延迟这项指标在SLA中的重要性。
假设,我们已经设计好了一个社交软件的系统架构。这个社交软件在接收到用户的请求之后,需要读取数据库中的内容返回给用户。
为了降低系统的延迟,我们会将数据库中内容放进缓存(Cache)中,以此来减少数据库的读取时间。在系统运行了一段时间后,我们得到了一些缓存命中率(Cache Hit Ratio)的信息。有90%的请求命中了缓存,而剩下的10%的请求则需要重新从数据库中读取内容。
这时服务器所给我们的p95或者p99延迟恰恰就衡量了系统的最长时间,也就是从数据库中读取内容的时间。作为一个优秀架构师,你可以通过改进缓存策略从而提高缓存命中率,也可以通过优化数据库的Schema或者索引(Index)来降低p95或p99 延迟。
总而言之,当p95或者p99过高时,总会有5%或者1%的用户抱怨产品的用户体验太差,这都是我们要通过优化系统来避免的。
异构无服务器计算
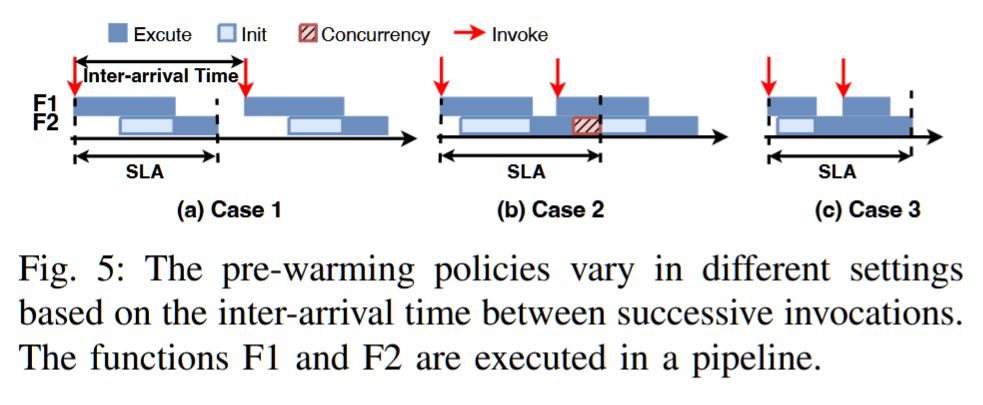
在生产环境中,使用高端和低端硬件资源来执行无服务器函数涉及到显著的设计权衡,这些权衡必须仔细考虑。在16核CPU与V100 GPU上执行三种常用的机器学习模型——人体活动姿态(HAP)、文本生成(TG)和翻译(TRS)时,其推理延迟存在显著差异。同时,这两种硬件选项之间的价格差异也很大。特别地,TRS模型在GPU上执行时,热启动的推理延迟大约降低了10倍,而GPU的单价仅比CPU高8倍。因此,在GPU上执行TRS模型更具成本效益。然而,在服务的初始阶段,当函数初始化以处理第一个请求时,也就是所谓的冷启动阶段,由于高初始化开销,TRS模型在V100 GPU上的推理延迟超过了CPU,从而使GPU失去了优势。
A. 关键设计思想
I1:利用自适应预热管理动态调用。SMIless引入了一种创新的自适应冷启动策略,用于DAG应用程序中的函数。该策略基于给定的资源配置和调用到达率,计算所有无服务器函数的预热大小。这一能力使得SMIless能够有效地制定复杂DAG应用程序的端到端延迟和整体成本。
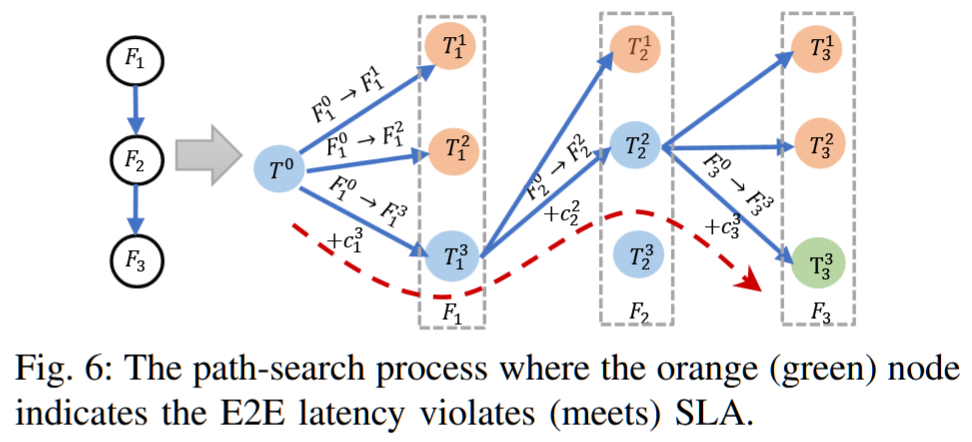
I2:通过路径搜索公式解决级联效应。SMIless通过将问题重新定义为多路径树中的路径搜索,启动其优化方法。DAG中所有函数的自适应冷启动策略和资源分配策略的每一种不同组合都被视为一个独特的节点,这些组合的变化则表示为边。SMIless系统地导航这个树,优先选择那些能够最小化成本的组合。这种战略性探索使得SMIless能够有效地解决级联效应,接近最优解,而无需进行穷举式的探索。
Stellaris: Staleness-aware Distributed Reinforcement Learning with Serverless Computing
SC 2024 (Best Student Paper Finalist)
https://github.com/IntelliSys-Lab/Stellaris-SC24
不是,这哥们念了两个PhD??
https://hanfeiyu.github.io/publications/
摘要——深度强化学习(DRL)在多个领域取得了显著成功,包括游戏AI、科学仿真和大规模(HPC)系统调度。DRL训练涉及试错过程,需求大量的时间和计算资源。为了克服这一挑战,已经开发了分布式DRL算法和框架,通过利用大规模资源加速训练。然而,现有的分布式DRL解决方案依赖于服务器式基础设施的同步学习,导致训练效率低下和训练成本过高。
本文提出了Stellaris,这是首个引入无服务器计算的分布式DRL训练的通用异步学习范式。我们设计了一种重要性抽样截断技术来稳定DRL训练,并开发了一种基于陈旧感知的梯度聚合方法,专门针对异步无服务器DRL训练中的动态陈旧性。通过在AWS EC2常规测试平台和HPC集群上的实验,结果表明,Stellaris在训练质量(奖励)上比现有的最先进DRL基准高出2.2倍,并且将训练成本降低了41%。
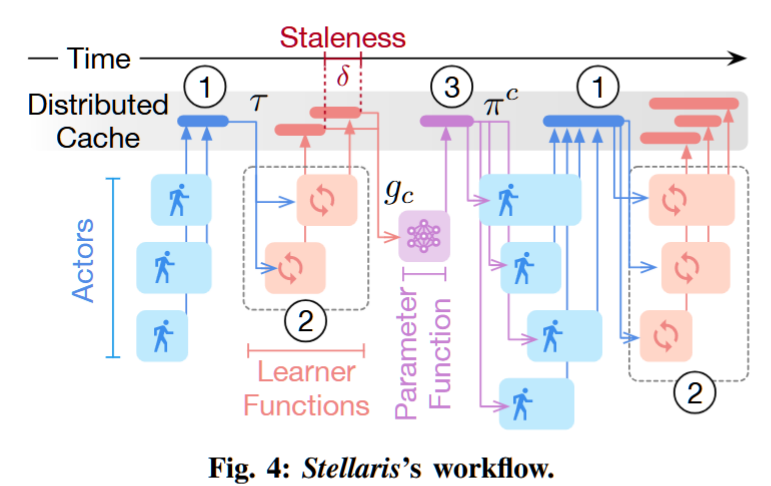
Fig. 5(a) shows an example of cross-learner policy drift. When Learner 2 computes its local importance sampling ratio π2 π1 , it ignores the other learner (Learner 2) that also contributes to the policy update. As a result, π3 π1 may still explode and hinder the training if no cross-learner truncation is applied.
GPU Optimizations for ML
PipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation
Branden Butler, 1Sixing Yu, 2Arya Mazaheri, 1Ali Jannesari
https://swapp.cs.iastate.edu/people/ali-jannesari
Iowa State University
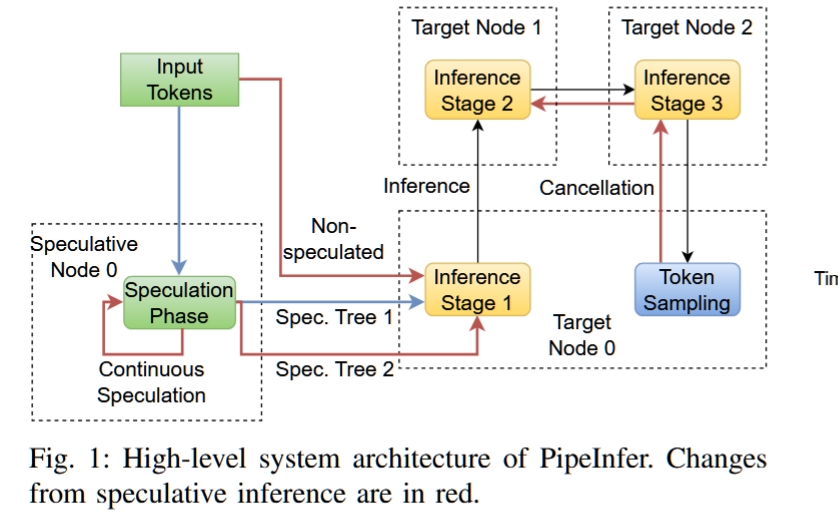
摘要—在计算机集群上推断大型语言模型(LLMs)已成为近期研究的重点,许多加速技术从CPU的猜测执行中获得灵感。这些技术减少了与内存带宽相关的瓶颈,但也增加了每次推断运行的端到端延迟,需要较高的猜测接受率来提高性能。结合任务间接受率的变化,猜测推断技术可能导致性能下降。此外,管道并行设计需要大量用户请求才能保持最大利用率。为此,我们提出了PipeInfer,一种流水线式猜测加速技术,用于减少令牌间的延迟,并提高单请求场景下的系统利用率,同时改善对低猜测接受率和低带宽互连的容忍度。与标准猜测推断相比,PipeInfer在生成速度上提高了最多2.15倍。PipeInfer通过持续异步猜测和早期推断取消实现了性能提升,前者通过与多个猜测运行同时进行单令牌推断来改善延迟和生成速度,后者通过跳过无效运行的计算,即使在推断中途,也能提高速度和延迟。
关键词—大型语言模型,推断,猜测,加速,分布式, 并行
没理解,需要深究.
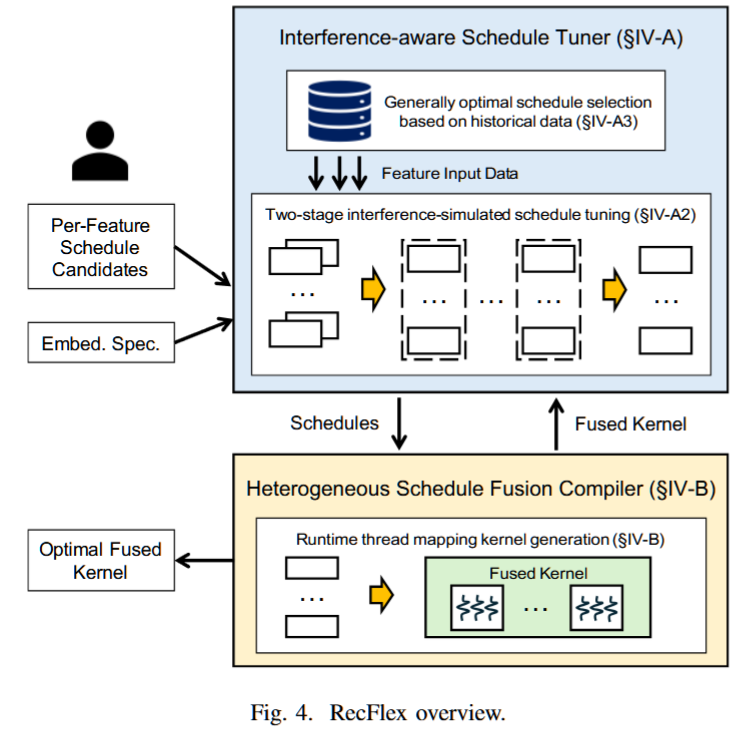
RecFlex: Enabling Feature Heterogeneity-Aware Optimization for Deep Recommendation Models with Flexible Schedules
摘要—工业推荐模型通常涉及多个特征字段。这些字段的嵌入计算工作负载是异构的,因此需要不同的最优代码调度。尽管现有的解决方案对嵌入操作应用了基本的融合优化,但它们低效地对所有特征字段采用相同的调度,导致性能次优。
本文介绍了RecFlex,它为不同特征字段生成具有不同调度的融合内核。RecFlex采用干扰感知调度调优器来调优调度,并通过异构调度融合编译器生成融合内核,从而解决了两个主要挑战。为了确定融合内核中不同特征字段的最优调度,RecFlex提出了一种两阶段的干扰仿真调优策略。为了应对挑战调优和融合的动态工作负载,RecFlex结合了编译时调度调优和运行时内核线程映射。RecFlex超越了最先进的库和编译器,分别在TorchRec、HugeCTR和RECom上实现了2.64倍、20.77倍和11.31倍的平均加速。RecFlex已公开发布,地址为https://github.com/PanZaifeng/RecFlex 。
关键词—推荐系统,机器学习编译器
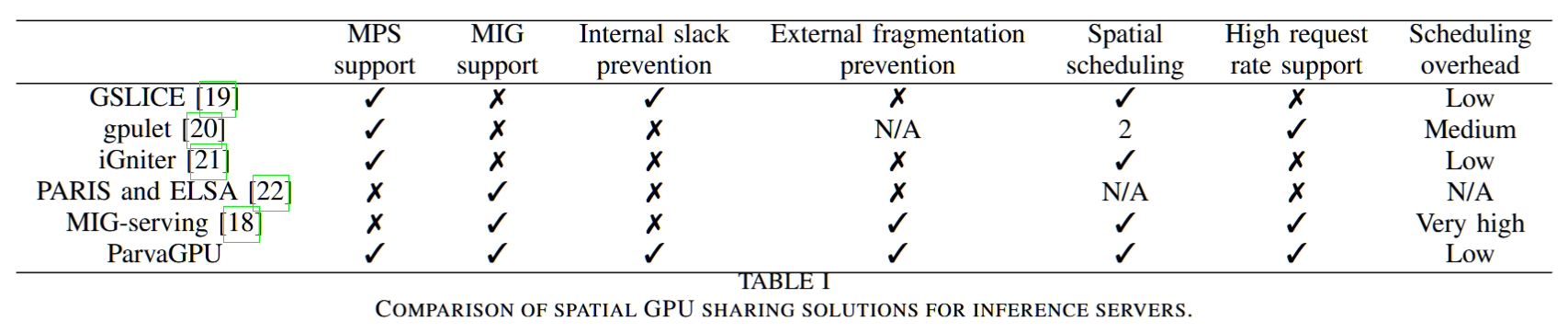
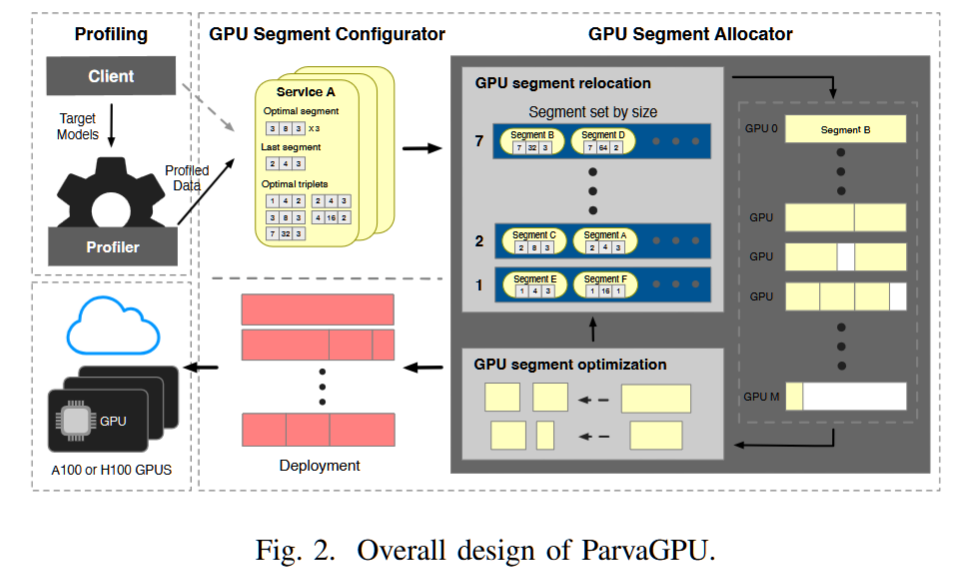
ParvaGPU: Efficient Spatial GPU Sharing for Large-Scale DNN Inference in Cloud Environments
Chung-Ang University, Seou
https://github.com/MunQ-Lee/ParvaGPU_SC24
摘要—在云环境中,基于GPU的深度神经网络(DNN)推断服务器需要在指定的请求率下满足每个工作负载的服务水平目标(SLO)延迟,同时最小化GPU资源消耗。然而,先前的研究未能完全实现这一目标。本文提出了ParvaGPU,一种促进大规模DNN推断在云计算中进行空间GPU共享的技术。ParvaGPU结合了NVIDIA的多实例GPU(MIG)和多进程服务(MPS)技术,以提高GPU利用率,旨在满足每个工作负载的不同SLO,并减少总体GPU使用。具体而言,ParvaGPU解决了在分配的GPU空间分区内最小化利用率不足和在结合MIG和MPS环境中外部碎片化的问题。我们在多台A100 GPU上进行了评估,评估了11种具有不同SLO的DNN工作负载。我们的评估结果显示,与最先进的框架相比,ParvaGPU没有违反任何SLO,并显著减少了GPU的使用。
关键词—空间GPU共享,DNN推断,云计算

Parallel Programming Frameworks, Libraries and Runtimes
CUDASTF: Bridging the Gap Between CUDA and Task Parallelism
(Best Paper Finalist)
NVIDIA
摘要—将计算组织为具有数据驱动依赖关系的异步任务是一种简单高效的单GPU和多GPU程序模型。顺序任务流(STF)就是这样一种模型,它通过数据依赖关系推导任务图。我们提出了CUDASTF,这是一个实现STF的C++库,基于CUDA API,旨在促进可扩展和可组合算法的轻松创建。用户可以轻松选择使用CUDA图而不是流,这样可以提高小型内核的性能。结构化内核会自动在多个设备上分布,并且可以进行精细的亲和性控制。在实现方面,CUDASTF为异步并行库提供了一种基于事件的方法,具有很强的说服力。
我们在Cholesky分解上取得了比cuSolverMg库高达1.8倍的性能提升。在一个小型天气模拟任务上,我们展示了多GPU内核的接近最优可扩展性;此外,在单个GPU上,CUDA图提升了最多30%的性能。最后,我们成功实现了第一个在多个设备上执行的CKKS完全同态加密方案。

我们通过算法1中的简单示例讨论顺序任务流(STF)编程模型,该示例描述了三个变量上的一组四个操作,这些变量可以是向量、张量,甚至是加密的密文(见§VII-E)。无论底层数据表示如何,操作O2和O3都需要访问X,而X是操作O1的结果,操作O4则需要操作O2和O3的结果。因此,这样一系列操作可以仅根据数据访问来解释为图形,如图1中绿色节点所示。(附加的虚线节点说明了如何在配备加速器的机器上实例化这样的任务图需要各种附加的分配和传输操作。)这些操作由计算和数据的位置确定性地推断出来,因此理想情况下它们不应由程序员负责。生成的图形既不依赖于底层数据表示,也不依赖于异步操作的实际实现。
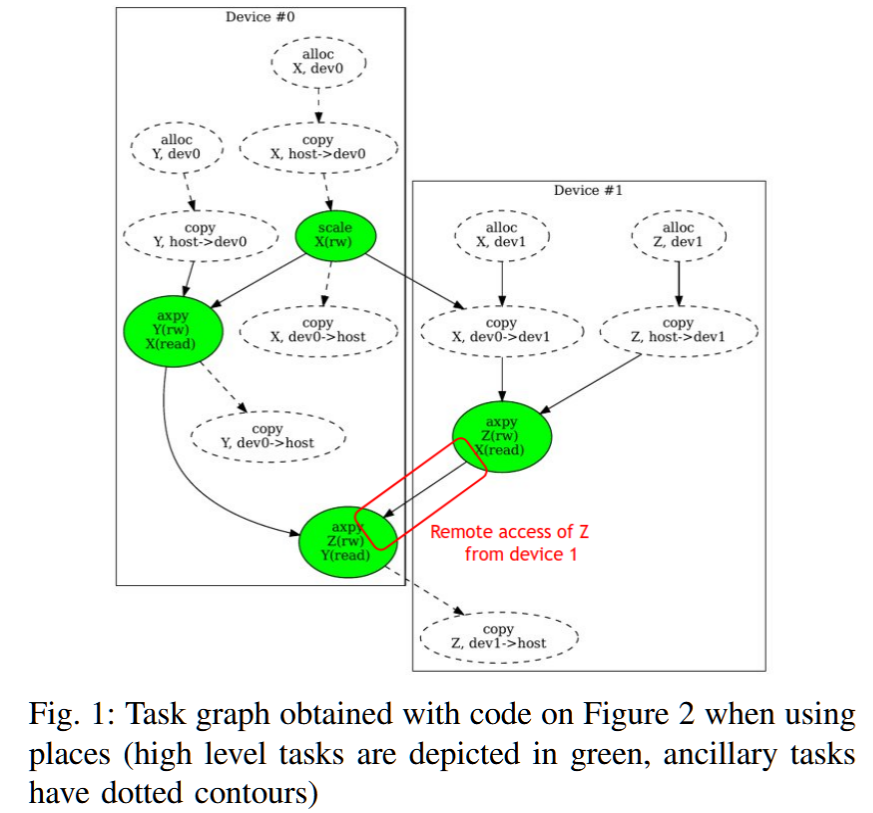
STF模型[1]将程序描述为一系列读写数据的操作,并将它们转化为相互依赖的任务图。这是一种数据流形式,它推断依赖关系,而不是像大多数数据流模型实现那样显式地指定依赖关系,从而简化了代码。
我们在CUDASTF中实现了这一模型,这是一个C++17库,旨在与CUDA环境[2](例如CUBLAS、CUB、Thrust)以及更大的并行计算生态系统(如OpenACC[3])进行互操作。一个重要的目标是促进现有代码的逐步迁移和增强。利用C++语言的建模能力,可以在不需要自定义语言或编译器扩展的情况下创建富有表现力和高效的抽象。

顺序任务流(STF)编程模型是一种旨在高效管理并行任务和数据流的框架。在CUDASTF编程模型中,任务操作的是逻辑数据(如变量或数组),并且自动推断任务之间的依赖关系。这些依赖关系决定了任务是可以并行执行,还是需要顺序执行,以最大限度地提高效率并确保正确的数据访问和计算。
主要概念:
-
数据访问注解:每个任务都通过注解标明它对数据的访问类型(只读、只写或读写)。这些注解有助于确定任务之间的依赖关系。
-
任务依赖关系:例如:
- 读后写:任务不能在所有修改该数据的前置任务完成之前读取数据。
- 写后读:修改数据的任务必须等到所有读取该数据的任务完成之后才能执行。
-
任务执行:
- 修改相同数据(写操作)的任务必须顺序执行,以避免冲突(串行化)。
- 仅进行数据读取(不修改数据)的任务可以并行执行,因为读取操作不会干扰其他读取操作。
-
有向无环图(DAG):任务及其依赖关系被表示为一个DAG。这个图结构帮助CUDASTF确定任务执行的顺序,从而确保数据流正确,并最大限度地提高并行性。
-
自动并行化:通过为数据访问提供注解,CUDASTF可以自动处理任务的并行化。程序员无需手动处理异步执行、数据传输或内存管理等问题,从而简化了并行程序的编写过程。
示例:
假设有任务T1、T2、T3和T4,它们操作的数据分别为X、Y和Z。每个任务的读写操作如下所示:
- T1 修改X。
- T2 读取X并修改Y。
- T3 读取X并修改Z。
- T4 读取Y和Z。
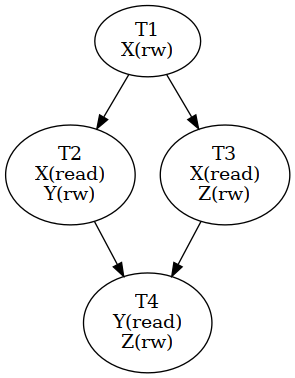
任务之间的依赖关系由它们访问的数据决定。例如,T2和T3都读取X,而X由T1修改,因此T2和T3必须等到T1完成后才能执行。T4依赖于T2和T3的完成,因为它读取Y和Z,而这些数据分别被T2和T3修改。
CUDASTF模型根据这些依赖关系生成执行计划,最大化并行性并确保数据流的正确性。
CUDASTF通过自动管理任务依赖和数据流动,简化了并行编程过程,使程序员可以专注于设计高效的任务驱动算法,而不必担心低层次的并行化和数据管理问题。
使用:
https://nvidia.github.io/cccl/cudax/stf.html#getting-started-with-cudastf
The code is organized into several steps, which will be described in more detail in the following sections:
-
include CUDASTF headers
-
declare a CUDASTF context
-
create logical data
-
submit and wait for the completion of pending work
#include <cuda/experimental/stf.cuh>
using namespace cuda::experimental::stf;
template <typename T>
__global__ void axpy(T a, slice<T> x, slice<T> y) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int nthreads = gridDim.x * blockDim.x;
for (int ind = tid; ind < x.size(); ind += nthreads) {
y(ind) += a * x(ind);
}
}
int main(int argc, char** argv) {
context ctx;
const size_t N = 16;
double X[N], Y[N];
for (size_t ind = 0; ind < N; ind++) {
X[ind] = sin((double)ind);
Y[ind] = col((double)ind);
}
auto lX = ctx.logical_data(X);
auto lY = ctx.logical_data(Y);
double alpha = 3.14;
/* Compute Y = Y + alpha X */
ctx.task(lX.read(), lY.rw())->*[&](cudaStream_t s, auto sX, auto sY) {
axpy<<<16, 128, 0, s>>>(alpha, sX, sY);
};
ctx.finalize();
}auto lX = ctx.logical_data(X);
auto lY = ctx.logical_data(Y);
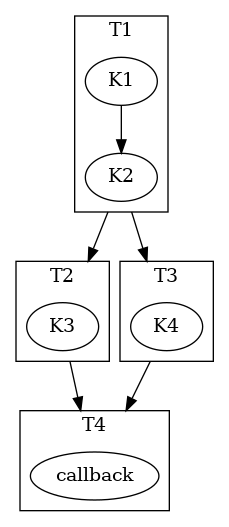
// Task 1
ctx.task(lX.read(), lY.read())->*[](cudaStream_t stream, auto sX, auto sY) {
K1<<<..., stream>>>(sX, sY);
K2<<<..., stream>>>(sX, sY);:
};
// Task 2
ctx.task(lX.rw())->*[](cudaStream_t stream, auto sX) {
K3<<<..., stream>>>(sX);
};
// Task 3
ctx.task(lY.rw())->*[](cudaStream_t stream, auto sY) {
K4<<<..., stream>>>(sY);
};
// Task 4
ctx.host_launch(lX.read(), lY.read())->*[](auto sX, auto sY) {
callback(sX, sY);
};
KaMPIng: Flexible and (Near) Zero-Overhead C++ Bindings for MPI
Karlsruhe Institute of Technology
摘要—消息传递接口(MPI)和C++构成了高性能计算的核心,但MPI仅提供C和Fortran绑定。虽然这提供了良好的语言互操作性,但像C++这样的高级编程语言使软件开发更快速且更少出错。
我们提出了新颖的C++语言绑定,涵盖了从低级MPI调用到便捷的STL风格绑定的所有抽象层次,在这些绑定中,大部分参数是通过从一小部分参数推断而来的,通过引入命名参数到C++中。这使得快速原型设计和精细调节运行时行为及内存管理成为可能。灵活的类型系统和额外的安全性保证有助于防止编程错误。
通过利用C++的模板元编程能力,该方法具有(几乎)零开销,因为只有在编译时生成需要的代码路径。
我们通过多个应用基准测试证明,我们的库是未来分布式标准库的坚实基础,这些基准测试涵盖了从教科书中的排序算法到系统发育干扰等多种应用。
关键词—消息传递,平行编程,软件库,分布式计算,C++
Contribute:
• A new approach to parameter handling, allowing for a flexible computation of default parameters and fine-grained control over memory management for highly engineered
distributed applications.
• Safety for non-blocking MPI communication calls by design.
• Reduction of verbosity and error-proneness of MPI code.
• (Near) zero overhead compared to using plain MPI.
• Compile-time error checking with human-readable error messages.
• Demonstration of real-world applicability using a large variety of application benchmarks.
• First steps towards integrated and extensible general algo-rithmic building blocks for distributed computing such asspecialized collectives for sparse and low-latency irregular personalized communication.

NetCL: A Unified Programming Framework for In-Network Computing
Vrije Universiteit Amsterdam
这篇文章介绍了一个名为 NetCL 的统一编程框架,旨在简化网络内计算(In-Network Computing, INC) 的开发过程。以下是对其工作的简单概述:
背景与动机
随着可编程数据平面(Programmable Data Plane, PDP)设备的兴起,例如支持 P4 语言的网络设备,网络内计算成为一种新兴范式,允许网络设备在数据传输过程中执行计算任务。然而,当前 PDP 编程主要依赖如 P4 这样的领域特定语言(DSL),这些语言专注于包处理,编程复杂且需要深厚的网络知识,导致 INC 的开发门槛较高,难以被广泛采用。
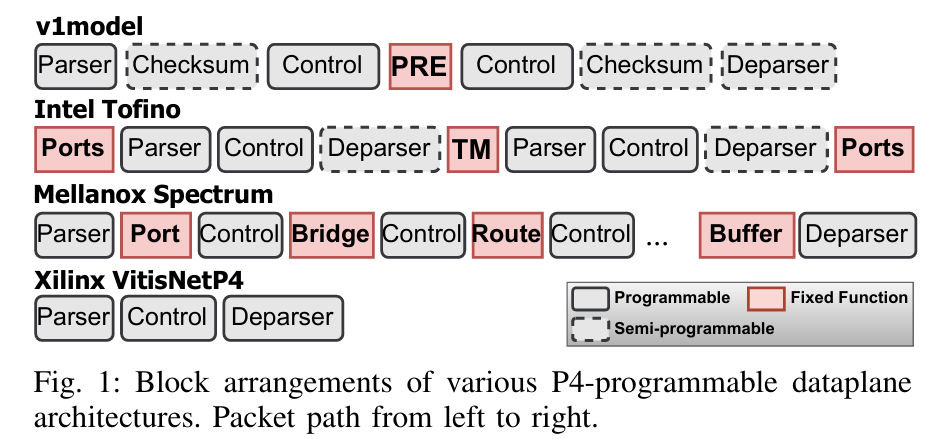
一文读懂P4可编程交换芯片-腾讯云开发者社区-腾讯云
NFV.p4替代甚至优化传统网元的实现,例如负载均衡,DDoS防火墙,云网关,流发生器,TAP分流器等;Cluster.p4通过可编程交换机加速特定的分布式集群,例如NetCache加速分布式键值对存储,NetChain加速分布式协调,SwitchML加速机器学习等;Fabric.p4则是通过CLOS结构组建的数据中心大交换机,目标是利用切片以及内网负载均衡实现云原生的Fabric集群;Telemetry.p4主要面向数据平面的在线诊断以及可视化需求,使得超高速的数据平面依旧可观可测。
NetCL 的核心贡献
为了解决这一问题,作者提出了 NetCL,其主要工作包括:
-
统一的编程接口:NetCL 基于 C/C++ 扩展,提供了一种计算导向的编程模型。开发者可以将 INC 任务表达为处理网络中流动消息的“内核函数”(kernel functions),无需直接处理低层次的网络细节。
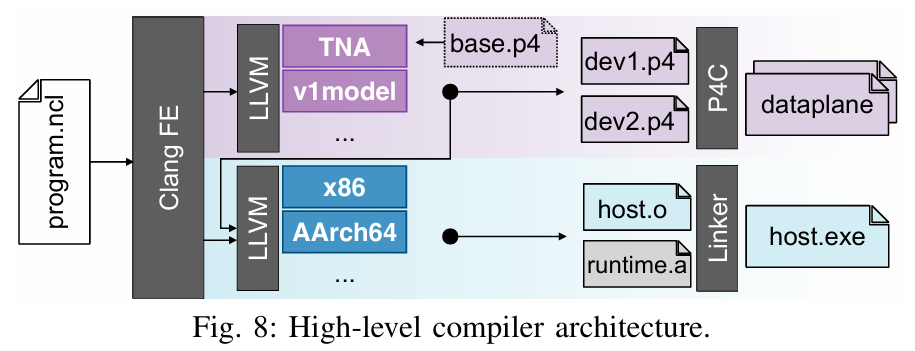
-
编译器与运行时支持:NetCL 包括一个编译器,将 C/C++ 编写的内核代码翻译成 P4 代码,同时提供轻量运行时,负责网络通信和设备管理的“管道工作”,屏蔽了底层复杂性。
-
目标与设计理念:NetCL 旨在让开发者像编程计算单元一样编写 INC 代码,同时保留对消息转发的基本控制,充分利用 PDP 的性能优势,并尽量保持目标无关性(target-independent)。
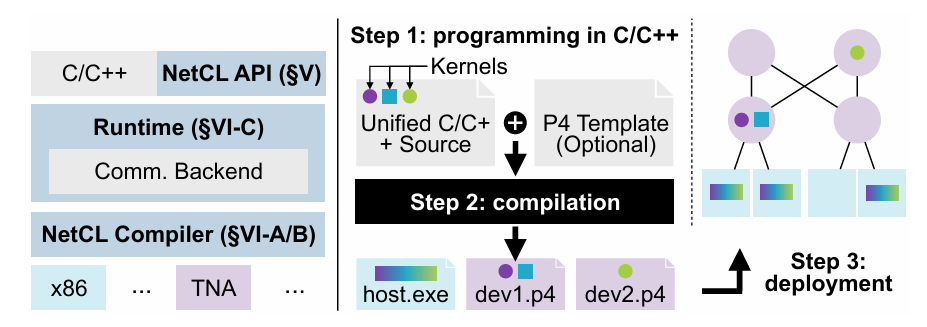
系统设计与功能
- 编程模型:通过简单的 API(如
send()和reflect()),开发者可以定义计算任务并控制消息流向。例如,一个网络缓存的实现只需几行代码即可完成。 - 工作流程:用户编写包含主机和设备代码的 C/C++ 程序,NetCL 编译器将其翻译为 P4 代码,最终由网络运营商部署到真实网络中。

- 执行模型:NetCL 支持“发送-计算”语义,计算任务由消息触发,可在多个设备上协同执行。
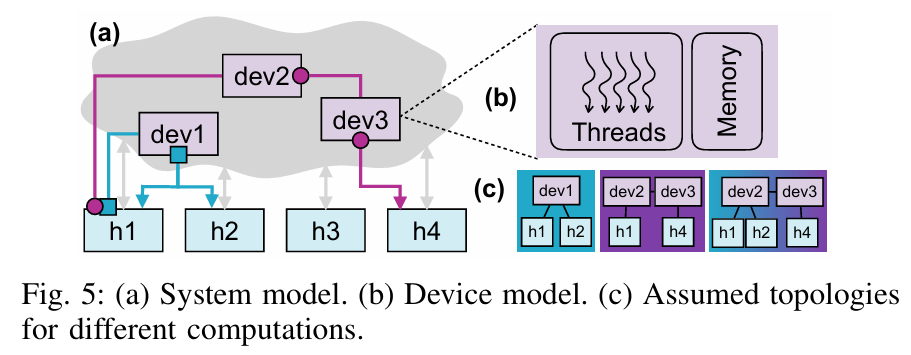
实现与评估
- 实现:NetCL 编译器基于 LLVM,支持 Intel Tofino 开关等硬件目标。运行时则处理通信和设备内存访问。
- 评估:作者在常见的 INC 应用(如缓存、聚合等)上测试了 NetCL,证明其相比手写 P4 代码大幅减少了代码量,同时生成的 P4 代码在资源占用和性能上与手写代码相当。

NetCL 的出现类似于 GPU 编程中的 CUDA,通过提供高级抽象降低了 INC 编程的复杂性,使其更易于被非网络专家使用,推动了 PDP 设备作为计算加速器的潜力。
总的来说,这篇文章提出了一种创新的编程框架,试图弥合分布式计算与网络编程之间的鸿沟,为网络内计算的普及和应用提供了重要支持。
Sparse Matrix Computations
Distributed-Memory Parallel Algorithms for Sparse Matrix and Sparse Tall-and-Skinny Matrix Multiplication
这篇文章介绍了一种针对稀疏矩阵与高瘦矩阵乘法(Tall-and-Skinny Sparse Matrix Multiplication, TS-SpGEMM) 的分布式内存并行算法。TS-SpGEMM 是一种特殊的稀疏矩阵乘法(SpGEMM)变体,其中一个矩阵是方阵($\mathbf{A} \in \mathbb{R}^{n \times n}$),另一个是高瘦矩阵($\mathbf{B} \in \mathbb{R}^{n \times d}$,且 $d \ll n$),在多源广度优先搜索(BFS)、图嵌入和代数多重网格求解器等应用中具有重要意义。
背景与动机
传统的分布式 SpGEMM 算法(如 Sparse SUMMA)在处理 TS-SpGEMM 时性能不佳,因为它们未针对高瘦矩阵的特性进行优化。作者提出了一种新的算法,通过定制的矩阵分区和稀疏性感知的瓦片(tiling)策略,提升性能并降低通信和内存开销。
核心贡献
-
算法设计:基于 Gustavson 算法,采用 1D 行分区,同时为方阵 $\mathbf{A}$ 额外维护一个列分区副本($\mathbf{A}^c$),结合瓦片计算减少内存需求。算法支持本地和远程计算模式,根据瓦片稀疏性动态选择以优化通信。
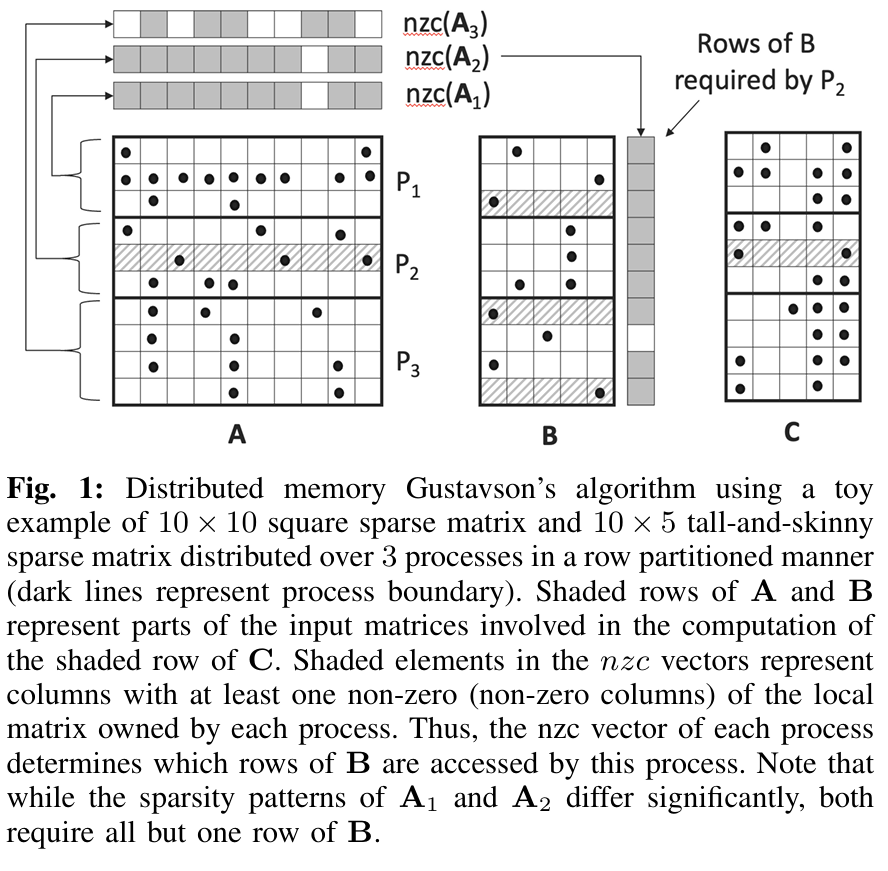
-
性能优化:通过瓦片分割和混合计算模式(本地+远程),平均比 2D 和 3D SUMMA 快 5 倍,且在 NERSC Perlmutter 超算上可扩展至 512 节点(65,536 核)。

-
应用实现:实现了多源 BFS 和稀疏图嵌入算法,展示了算法在实际场景中的高效性和可扩展性。

实现与评估
- 实现:算法使用 MPI+OpenMP 混合并行,在多种数据集上测试(如 SNAP 和 SuiteSparse)。
- 结果:TS-SpGEMM 在 $\mathbf{B}$ 稀疏度大于 50% 时优于稀疏矩阵-稠密矩阵乘法(SpMM),且在高瘦矩阵场景下显著优于 CombBLAS 和 PETSc 的现有实现。

意义与局限
该算法通过高效的瓦片和通信优化填补了 TS-SpGEMM 的研究空白,推动了其在图分析和科学计算中的应用。但其需要存储 $\mathbf{A}$ 的双份副本,增加了内存需求,且 1D 分区可能在某些规模-free 图上导致负载不均衡。
总的来说,这篇文章提出了一种创新的分布式算法,显著提升了 TS-SpGEMM 的性能,并在实际应用中展现了其潜力。代码已开源于 GitHub。
A Sparsity-aware Distributed-memory Algorithm for Sparse-sparse Matrix Multiplication
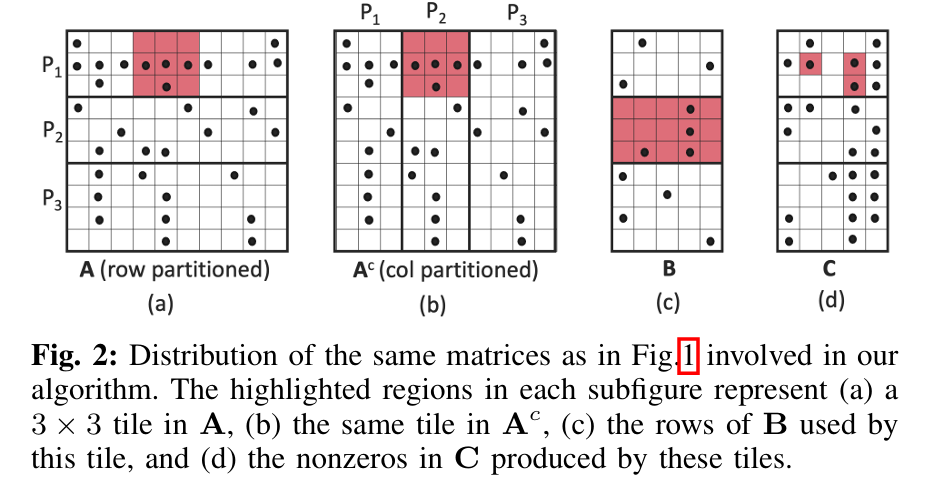
这篇文章提出了一种名为稀疏性感知的分布式内存一维SpGEMM算法(Sparsity-aware 1D SpGEMM),用于高效计算两个稀疏矩阵的乘法(Sparse-Sparse Matrix Multiplication, SpGEMM)。以下是对其工作的简要介绍:
背景与动机
SpGEMM 是一种在图算法、生物信息学、代数多重网格求解器等领域广泛使用的计算原语。传统的分布式内存 SpGEMM 算法多采用稀疏性无关(sparsity-oblivious)的二维(2D)和三维(3D)分区策略,这些方法通常需要随机置换以实现负载均衡,但可能增加通信开销。相比之下,稀疏性感知的一维(1D)算法通过只获取参与计算的非零元素,理论上可以减少通信量。然而,以往的 1D 实现因打包/解包子矩阵的开销或细粒度消息的增加而性能受限。

核心贡献
作者提出了一种新的分布式内存 1D SpGEMM 算法,主要特点包括:
-
稀疏性感知设计:利用输入矩阵的稀疏结构,避免不必要的非零元素传输,从而降低通信量。
-
MPI RDMA 优化:通过远程直接内存访问(RDMA)操作,减少了子矩阵打包/解包的开销。
-
块获取策略:将矩阵分块获取,限制 RDMA 消息数量,避免细粒度通信的性能瓶颈。
-
简单与高效:相比 2D 和 3D 算法,该方法概念上更简单,同时在多种配置和输入上性能优于 CombBLAS 中的现有实现。

实现与评估
- 实现:算法在 CombBLAS 库中实现,使用 MPI + OpenMP 编程模型,结合 ParMETIS 进行图分区优化,支持如矩阵平方、代数多重网格(AMG)中的限制算子计算和介数中心性(Betweenness Centrality)等应用。
- 评估:在 NERSC Perlmutter 超算系统上测试,结果显示该算法在强扩展性、对稀疏模式的利用以及特定数据集(如 hv15r、queen 等)上显著优于 2D 和 3D 算法。例如,在平方操作中比 2D/3D 算法快一个数量级,在介数中心性计算中可实现高达 3.5 倍的加速。
该算法通过保留矩阵的原始稀疏模式(或结合图分区)替代随机置换,结合 RDMA 和块获取策略,提供了一种高效、易集成的 SpGEMM 解决方案。它特别适用于具有特定稀疏结构的科学计算任务,并能与其他软件(如 PETSc、Trilinos)无缝衔接,为分布式稀疏矩阵乘法提供了一个高性能替代方案。
A Conflict-aware Divide-and-Conquer Algorithm for Symmetric Sparse Matrix-Vector Multiplication

故事背景介绍及Motivation
对称稀疏矩阵-向量乘法(Symmetric Sparse Matrix-Vector Multiplication, SpMV)在科学计算和工程应用中的重要性。由于对称矩阵可以利用其对称性减少一半内存占用,这为加速内存受限的计算提供了机会。然而,在并行计算中,对称SpMV会因同时写入输出向量而产生数据冲突,现有方法(如基于约简或着色的方法)未能高效解决这一问题,特别是在高冲突矩阵上性能较差。这激发了作者开发一种新的共享内存方法,以提升对称SpMV的性能和可扩展性。
系统设计
作者提出了DCS-SpMV,一种基于分治(Divide-and-Conquer, DC)范式的算法。核心思想是通过特殊子图(分隔符)将矩阵分解为多个子图,避免竞争条件,并对子图重新排序以优化输入/输出向量的数据局部性。系统采用共享内存并行,通过在同一递归层并发执行子图上的对称SpMV来提高效率。此外,设计了一个冲突感知的混合DC方案,将矩阵分为低冲突和高冲突部分,分别用DCS-SpMV和传统SpMV处理,并引入机器学习模型预测最佳递归次数。
Challenge及方法
主要挑战在于如何高效处理对称SpMV中的数据冲突,尤其是在高冲突矩阵上传统方法性能下降的问题。作者通过分治策略将矩阵分解,利用分隔符避免竞争,同时优化数据局部性和负载均衡。对于高冲突矩阵,混合方法结合传统SpMV处理剩余部分,减少同步开销。机器学习模型则通过分析矩阵特征预测最佳递归深度,进一步提升适应性和性能。
实验
实验在28核Intel Xeon Gold 6258R(X86)和32核Kunpeng 920(ARMv8)处理器上进行,使用超过300个来自SuiteSparse矩阵集合的对称稀疏矩阵。作者将DCS-SpMV与Intel oneMKL库和最先进的着色方法(RACE)进行对比。结果显示,在X86上,DCS-SpMV比oneMKL的SpMV和对称SpMV平均加速2.33倍和1.26倍,比着色方法加速3.90倍;在ARM上最高加速达125.93倍。混合方法和机器学习模型进一步提升性能,预测准确率分别达91.6%和93.3%,验证了方法的有效性。未来计划探索其他存储格式及应用场景。
Machine Learning Applications
Accelerating Distributed DLRM Training with Optimized TT Decomposition and Micro-Batching
EcoRec 旨在加速分布式深度学习推荐模型(DLRM)的训练。DLRM在许多领域中至关重要,但其训练面临嵌入表高内存需求和分布式环境中通信开销大的挑战。传统的Tensor-Train(TT)分解方法虽然能压缩嵌入表,但引入了显著的计算负担,而现有分布式训练框架由于数据交换需求过高而效率不足。
EcoRec通过以下创新解决了这些问题:
- 优化的TT分解计算模式(C-M/M-C模式):通过消除TT操作中的冗余,显著减少计算时间。
- 排序索引的微批处理技术:在不增加额外计算成本的情况下降低内存需求。
- 表级流水线并行系统:结合特征重排序和斜坡特征计数策略,确保数据分布均衡并提升通信效率。
EcoRec基于PyTorch和CUDA开发,并在32个GPU集群上进行了评估。结果显示,相比现有最先进的EL-Rec系统,EcoRec实现了3.1倍的训练加速和38.5%的内存使用减少,展现了其在分布式DLRM训练中的优越性能和可扩展性。这项工作为大规模推荐系统的训练提供了高效的解决方案。
DLRM在推荐系统等多个领域中扮演着重要角色,但其训练过程面临两大难题:嵌入表的高内存需求以及分布式训练中巨大的通信开销。传统的Tensor-Train(TT)分解技术虽然能够有效压缩嵌入表以减少内存占用,却带来了显著的计算负担。此外,现有的分布式训练框架由于数据交换需求过高,难以满足高效训练的要求。
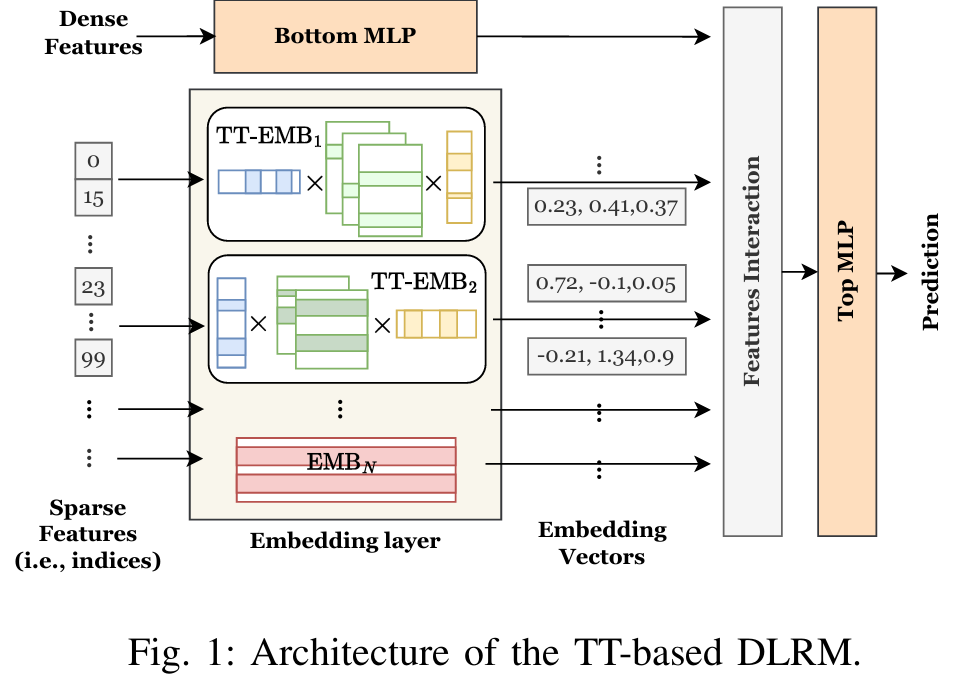
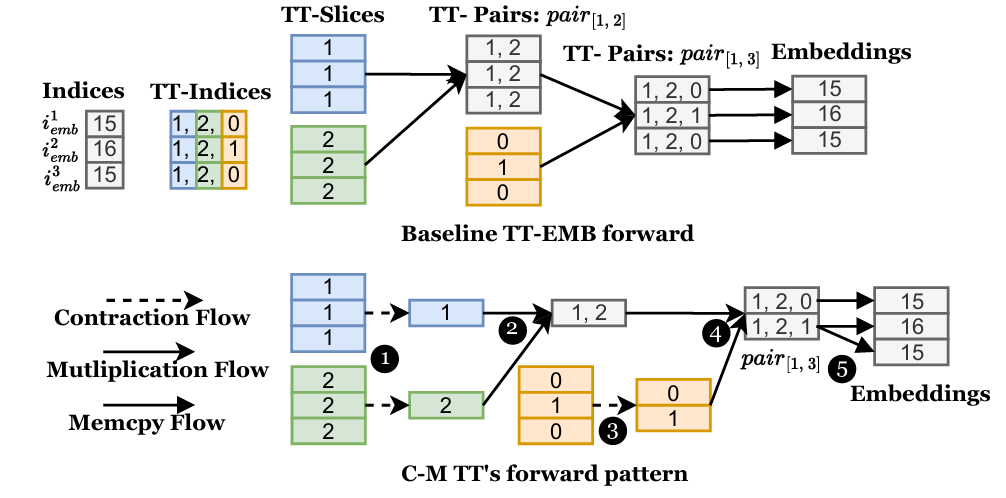
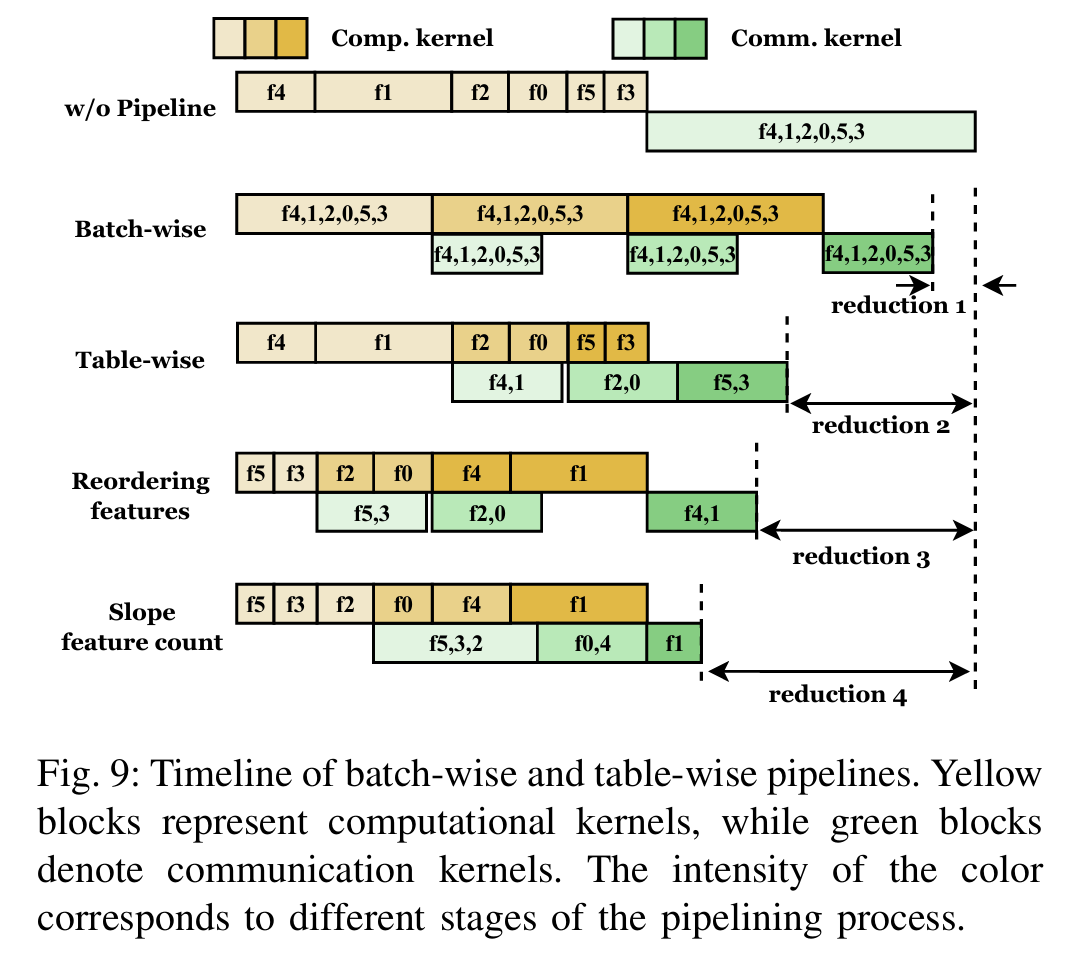
为了应对上述挑战,EcoRec引入了一系列创新技术。首先,它设计了一种优化的TT分解计算模式,称为C-M/M-C模式,通过消除TT操作中的冗余计算,大幅减少了计算时间。其次,EcoRec提出了排序索引的微批处理技术,这一方法在不增加额外计算成本的前提下有效降低了内存需求。最后,它开发了一种表级流水线并行系统,通过特征重排序和斜坡特征计数策略优化数据分布和通信效率,从而提升整体训练性能。
Scaling New Heights: Transformative Cross-GPU Sampling for Training Billion-Edge Graphs
这篇文章提出了 HyDRA,一个针对亿级边规模图的图神经网络(GNN)训练框架,旨在解决大规模图数据训练中的内存限制和数据传输瓶颈问题。以下是其工作的简要介绍:
背景与动机
GNN 在处理大规模图(如亿级边图)时,因内存需求和数据传输开销而面临挑战。传统方法要么受限于 CPU-GPU 数据传输瓶颈,要么在多 GPU 环境下因数据混洗和同步开销而效率低下。HyDRA 通过创新的多 GPU 采样和多节点特征检索技术,优化了基于采样的 GNN 训练。
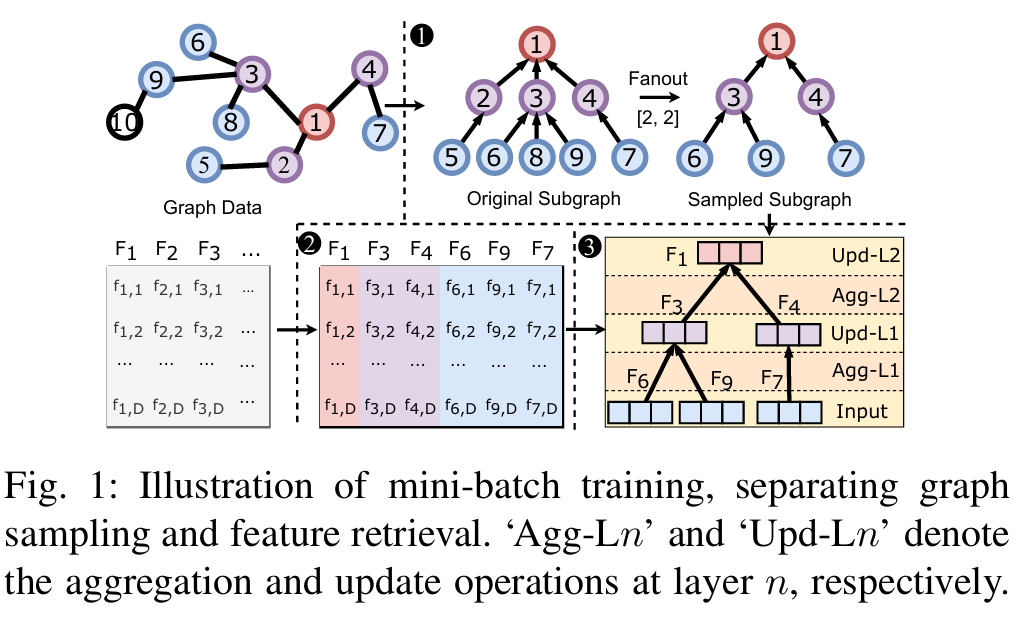
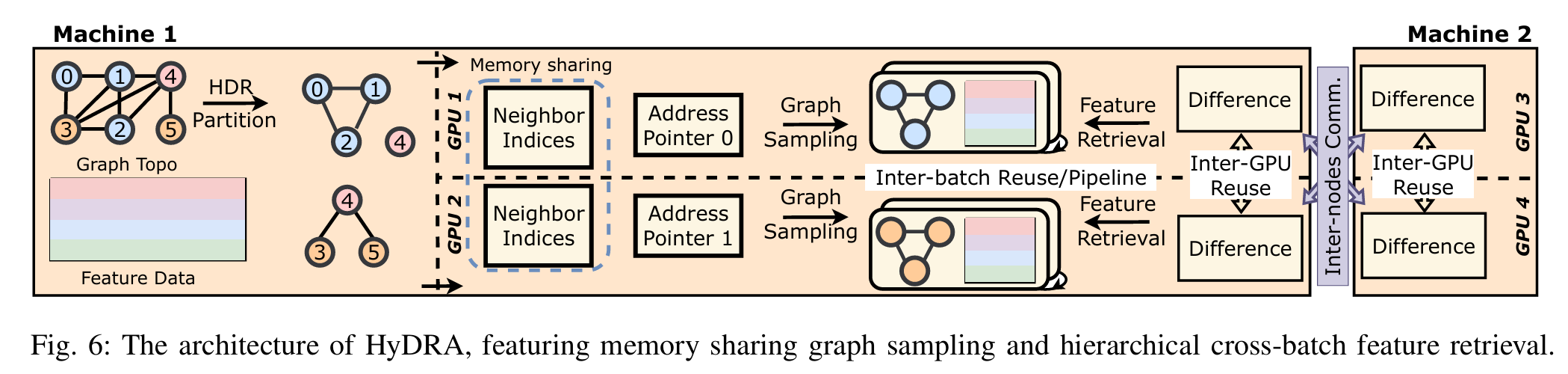
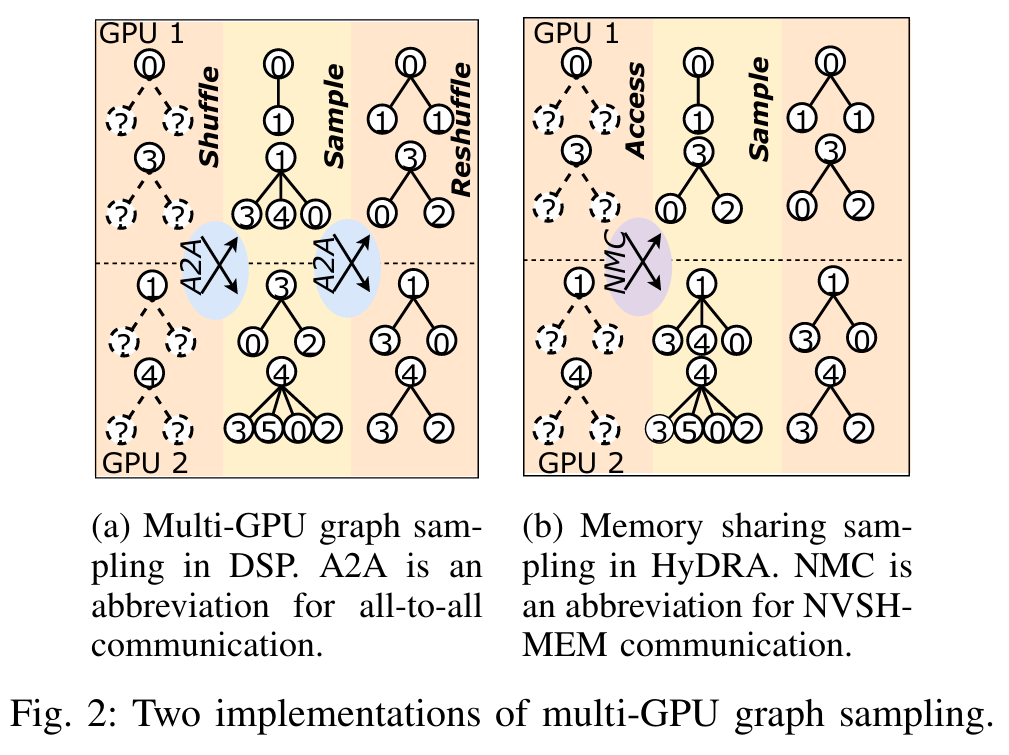
核心贡献
-
跨 GPU 采样优化:HyDRA 将采样和数据传输整合为单一内核操作,采用混合指针驱动的数据放置策略,提升邻居检索效率,并通过共享 GPU 内存消除数据混洗和同步开销。
-
高阶顶点复制策略:针对高阶顶点(度数大的顶点)导致的通信开销,HyDRA 复制这些顶点的邻居列表到每个 GPU 分区,将远程访问转为本地读取,大幅减少通信量。

- 动态跨批次数据编排:利用连续批次间的特征数据重叠,设计层次化的数据重用和流水线机制,减少冗余传输,提升多节点多 GPU 环境下的效率。
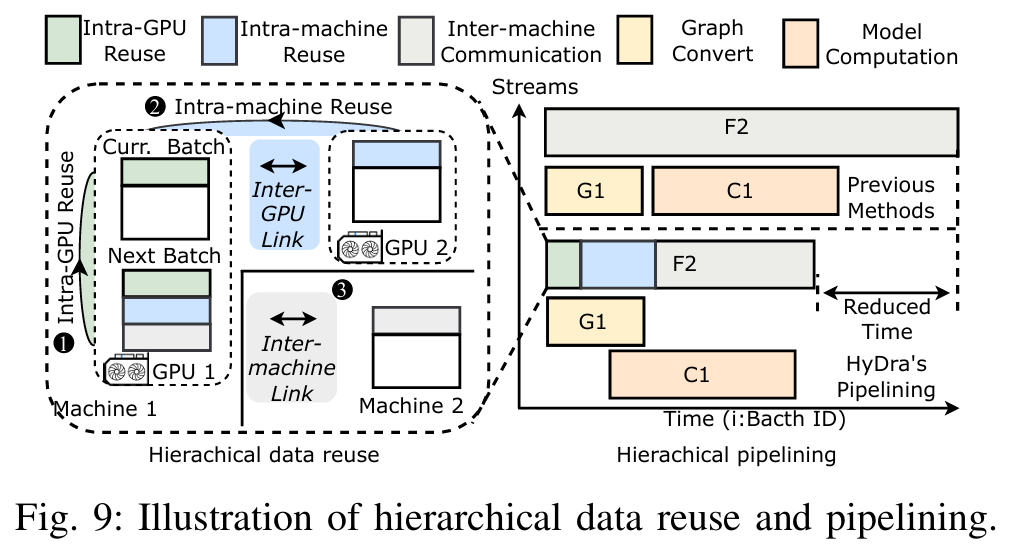
实现与评估
- 实现:基于 PyTorch 和 NVSHMEM 实现,支持多 GPU 和多节点环境。
- 评估:在配备 64 个 NVIDIA A100 GPU 的集群上测试,使用包括 Papers、MAG、Twitter 等亿级边数据集。结果显示,HyDRA 在采样效率上比 DGL-UVA 和 DSP 快 1.6x 至 18.9x,端到端训练加速达 1.4x 至 5.3x,在多节点设置中最高加速 42x,展现出优异的扩展性。
意义
HyDRA 通过内存共享、高阶顶点复制和动态数据重用,显著提升了大规模 GNN 训练的效率和可扩展性,适用于处理亿级边图的实际场景,为分布式 GNN 训练提供了高性能解决方案。
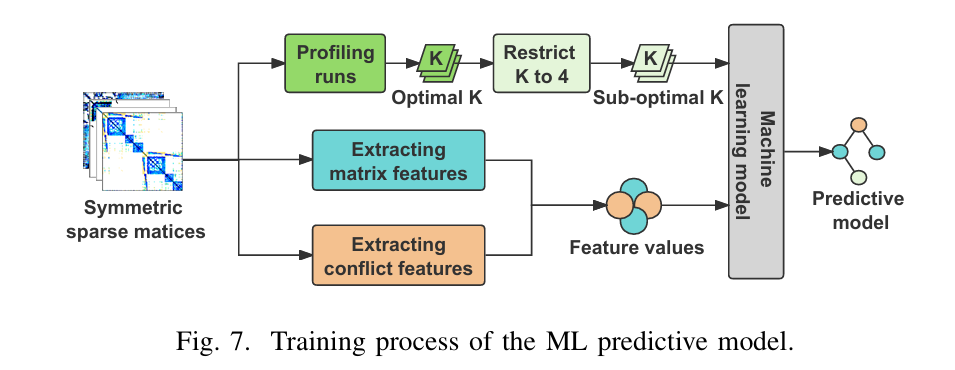
A Scalable Algorithm for Active Learning
主动学习(Active Learning),看这一篇就够了 - 知乎
监督学习问题中,存在标记成本较为昂贵且标记难以大量获取的问题。 针对一些特定任务,只有行业专家才能为样本做上准确标记。在此问题背景下,主动学习(Active Learning, AL)尝试通过选择性的标记较少数据而训练出表现较好的模型。
这篇文章提出了 Approx-FIRAL,一个针对多类分类任务的可扩展主动学习算法,改进了此前提出的 FIRAL 算法。以下是其工作的简要介绍:
背景与动机
FIRAL 是一种基于逻辑回归的确定性主动学习算法,具有较高的准确性和鲁棒性,并提供理论性能保证。然而,其存储复杂度为 (\mathcal{O}(c^2 d^2 + n c^2 d)) 和计算复杂度为 (\mathcal{O}(c^3 (n d^2 + b d^3 + b n)))(其中 (n) 是未标记点数,(d) 是特征维度,(c) 是类别数,(b) 是选择点数),使其在大规模数据集上难以扩展。Approx-FIRAL 通过近似方法和 GPU 并行实现解决了这些问题。
核心贡献
-
复杂度优化:通过引入块对角近似、随机化迹估计和快速矩阵-向量乘法,Approx-FIRAL 将存储需求降低至 (\mathcal{O}(n(d+c) + c d^2)),计算复杂度降至 (\mathcal{O}(b n c d^2)),显著提高了可扩展性。

-
高效 RELAX 步骤:使用预条件共轭梯度法(CG)和 Rademacher 随机向量加速梯度估计,优化了连续凸松弛问题的求解。
-
改进 ROUND 步骤:通过近似方法简化了点选择过程,减少了计算开销。
-
GPU 并行实现:设计了多 GPU 并行方案,支持强扩展和弱扩展,适用于大规模数据集。
实现与评估
- 实现:基于 Python 和 CuPy 开发,支持 NVIDIA GPU,具备与现有机器学习工作流的互操作性。
- 评估:在 MNIST、CIFAR-10、Caltech-101 和 ImageNet 等数据集上测试。结果显示,Approx-FIRAL 在保持与 Exact-FIRAL 相近准确性的同时,单 GPU 上对 ImageNet-50 提速约 29 倍,对 Caltech-101 提速约 177 倍。多 GPU 测试中,12 个 GPU 实现高达 11.4 倍的强扩展加速,弱扩展性能稳定。
意义
Approx-FIRAL 通过近似技术和并行优化,大幅提升了 FIRAL 的效率,使其适用于大规模多类分类任务,同时保持了样本选择的有效性。文章还指出了未来改进方向,如用稀疏迭代求解器替换直接求解器以进一步提升性能。
这期制作时还在工作,所以有很多仅走马观花。