
1-bit量化
- Micro Topics
- 2025-05-22
- 1405 Views
- 0 Comments
- 2588 Words
用AI生成的。省着点看。
1-bit大模型指的是采用1-bit量化(即权重仅用+1或-1表示)的神经网络模型,具体在本文件中指的是BitNet,一种专为大规模语言模型设计的1-bit Transformer架构。以下是关于BitNet和1-bit大模型的关键点总结:
1. 什么是BitNet?
- BitNet 是一种1-bit Transformer架构,通过将模型权重量化为1-bit(二值化,+1或-1),并结合量化激活(如8-bit激活),显著降低内存占用和计算能耗,同时保持与全精度(FP16)Transformer模型相当的性能。
- 它通过替换传统Transformer中的线性层(nn.Linear)为BitLinear层来实现1-bit量化,训练时从头开始优化1-bit权重,而非依赖后训练量化(post-training quantization, PTQ)。
2. 1-bit量化的核心机制
-
权重二值化:使用符号函数(Sign function)将权重转换为+1或-1,并通过中心化和缩放因子(β)减少量化误差。
- 公式:
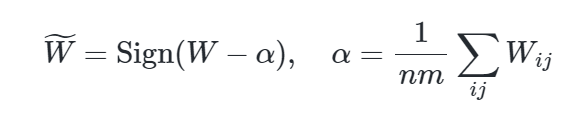
$$
\widetilde{W} = \operatorname{Sign}(W - \alpha), \quad \alpha = \frac{1}{nm} \sum{ij} W{ij}
$$
其中,(\alpha) 是权重的均值,(\beta) 用于调整量化后的权重以最小化误差。 - 公式:
- 激活量化:激活值通常量化为8-bit(W1A8配置),采用absmax量化方法,将激活值缩放到特定范围(如([-Q_b, Q_b]))。
- LayerNorm(SubLN):在激活量化前应用层归一化(LayerNorm),确保输出方差与全精度模型一致,提升训练稳定性。
- 矩阵乘法:使用1-bit权重和量化激活进行矩阵乘法,大幅降低计算复杂度(乘法操作被简化为加法为主)。
3. BitNet的特点
- 高效性:
- 内存占用低:1-bit权重显著减少模型存储需求。
- 能耗低:根据文档(如表1),BitNet在7nm和45nm工艺下的乘法(MUL)和加法(ADD)能耗远低于FP16或FP32 Transformer。例如,6.7B参数模型的BitNet在7nm工艺下,MUL能耗仅为0.02pJ,而FP32 Transformer为4.41pJ。
- 性能竞争力:
- 在语言建模任务中,BitNet的困惑度(perplexity)和下游任务(如Winogrande、Hellaswag等)的零样本(zero-shot)和少样本(few-shot)性能与FP16 Transformer接近。
- 表3和表4显示,BitNet在6.7B规模下,零样本平均准确率为52.3%,优于其他后训练量化方法(如Absmax、SmoothQuant)。
- 扩展性:
- BitNet遵循与全精度Transformer相似的缩放定律(scaling law),表明其可扩展到更大规模的模型,同时保持性能和效率优势(图3)。
- 提出推理优化缩放定律(Inference-Optimal Scaling Law),以推理能耗而非FLOPs衡量性能,显示BitNet在相同能耗下实现更低的损失。
4. 训练与优化
- 量化感知训练(QAT):BitNet采用量化感知训练,从头优化1-bit权重,优于后训练量化方法(PTQ),后者在低精度下性能损失较大。
- 直通估计器(STE):用于处理非可导函数(如Sign和Clip)的梯度近似,确保反向传播顺利进行。
- 混合精度训练:权重和激活低精度量化,但梯度和优化器状态保持高精度,以保证训练稳定性和准确性。
- 大学习率:BitNet通过大学习率加速收敛(图5),比FP16 Transformer更稳定,尤其在训练初期。
5. 与后训练量化的对比
- BitNet(W1A8)与后训练量化方法(如Absmax、SmoothQuant、GPTQ、QuIP)相比,在低比特场景下性能更优。例如:
- 4-bit模型中,BitNet优于权重量化+激活量化的方法(如W4A4),甚至优于仅权重量化的方法(如W4A16)。
- 图6表明,BitNet在不同模型规模(1.3B到6.7B)的零样本和少样本任务中一致优于基线。
6. 应用与未来
- 应用场景:BitNet适用于对内存和能耗敏感的场景,如边缘设备部署或大规模分布式推理。
- 未来工作:
- 扩展BitNet到更大模型规模和更多训练步数。
- 探索BitNet在其他架构(如RetNet)中的应用。
- 研究更低精度的激活量化(如低于8-bit)。
7. 总结
1-bit大模型(如BitNet)通过极端的权重二值化(1-bit)和量化感知训练,实现高效、低能耗的大规模语言模型,同时保持与全精度模型相当的性能。其创新点在于BitLinear层、SubLN、组量化和大学习率优化策略,使其在内存、能耗和性能之间取得平衡,适合未来超大规模模型的开发与部署。
简介:什么是 DeepLearning 量化
量化(Quantization)是深度学习中一种优化技术,通过将神经网络中的高精度数值(通常是浮点数,如FP32或FP16)转换为低精度表示(如8-bit整数、4-bit整数或1-bit二值),以减少模型的内存占用、计算复杂度和能耗,同时尽量保持模型的性能。以下是对量化的详细解释,结合文档《BitNet: Scaling 1-bit Transformers for Large Language Models》中提到的内容:
1. 量化的定义
量化是将神经网络的参数(如权重)和激活值从高精度浮点数映射到低精度离散值的过程。目的是在不显著牺牲模型精度的情况下,降低存储需求和计算成本。量化可以分为:
- 权重量化:仅对模型权重进行低精度表示。
- 激活量化:对网络中间层的激活值(输入/输出)进行量化。
- 全量化:同时对权重和激活进行量化。
在BitNet中,权重被量化为1-bit(+1或-1),激活通常量化为8-bit,形成W1A8(1-bit权重,8-bit激活)的配置。
2. 量化的类型
根据量化的时机和方法,量化主要分为以下两类:
- 后训练量化(Post-Training Quantization, PTQ):
- 在模型训练完成后,对预训练的全精度模型(如FP16或FP32)进行量化。
- 优点:简单,无需重新训练。
- 缺点:低精度(如4-bit或1-bit)下可能导致较大的性能损失,因为模型未针对量化优化。
- 文档中提到的PTQ方法包括Absmax、SmoothQuant、GPTQ和QuIP,BitNet通过实验证明其性能优于这些方法(表3)。
- 量化感知训练(Quantization-Aware Training, QAT):
- 在训练过程中引入量化操作,使模型从头优化低精度表示。
- 优点:性能更优,因为模型适应了量化的数值表示。
- 缺点:训练复杂性增加,需处理非可导函数(如符号函数)的梯度问题。
- BitNet采用QAT,通过直通估计器(STE)解决非可导函数的梯度传播问题,并在训练中优化1-bit权重。
3. BitNet中的量化机制
BitNet是1-bit量化的典型案例,具体实现包括:
- 权重量化(1-bit):
- 使用符号函数(Sign function)将权重二值化为+1或-1。
- 公式:
$$
\widetilde{W} = \operatorname{Sign}(W - \alpha), \quad \alpha = \frac{1}{nm} \sum{ij} W{ij}
$$
其中,(\alpha) 是权重均值,用于中心化权重,减少量化误差。 - 引入缩放因子(\beta = \frac{1}{nm}|W|_1),以最小化二值化权重与原始权重之间的L2误差。
- 激活量化(8-bit):
- 使用absmax量化,将激活值缩放到([-Q_b, Q_b])((Q_b = 2^{b-1}),如8-bit时(Q_b = 128))。
- 公式:
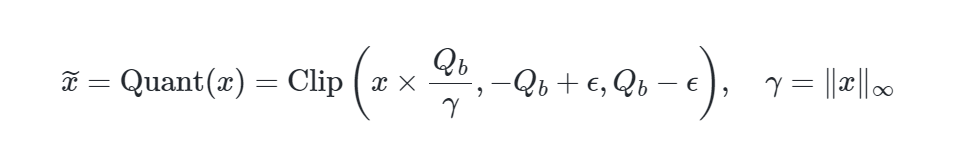
$$
\widetilde{x} = \operatorname{Quant}(x) = \operatorname{Clip}\left(x \times \frac{Q_b}{\gamma}, -Q_b + \epsilon, Qb - \epsilon\right), \quad \gamma = |x|{\infty}
$$
其中,\(\gamma\) 是输入矩阵的最大绝对值,\(\epsilon\) 防止溢出。- 对于非线性函数前的激活(如ReLU),通过减去最小值(\eta = \min{ij} x{ij}),将值缩放到([0, Q_b])。
- 层归一化(SubLN):
- 在激活量化前应用层归一化(LayerNorm),确保量化后输出的方差与全精度模型一致,提升训练稳定性。
-
公式:
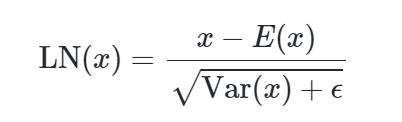
$$
\operatorname{LN}(x) = \frac{x - E(x)}{\sqrt{\operatorname{Var}(x) + \epsilon}}
$$- 组量化(Group Quantization):
- 为支持模型并行,将权重和激活分成多个组,独立计算量化参数(如(\alpha, \beta, \gamma, \eta)),避免跨设备通信开销,提升并行效率。
4. 量化的优势
- 降低内存占用:1-bit权重仅需1位存储,相比FP32(32位)或FP16(16位),内存需求大幅减少。例如,6.7B参数的BitNet模型权重存储仅需约0.84GB(6.7B位 ≈ 0.84GB),而FP16需要约13.4GB。
- 减少能耗:低精度计算(特别是1-bit)将矩阵乘法简化为加法为主,显著降低能耗。文档表1显示,BitNet在7nm工艺下,6.7B模型的乘法能耗仅为0.02pJ,远低于FP16的1.14pJ。
- 加速推理:低精度运算减少计算复杂度,适合边缘设备或高吞吐量场景。
- 环境友好:降低能耗有助于减少大型语言模型的碳足迹。
5. 量化的挑战
- 精度损失:低精度量化可能导致模型性能下降,尤其在PTQ中。BitNet通过QAT和SubLN等技术缓解这一问题。
- 训练稳定性:低精度模型优化更困难,BitNet通过大学习率和STE解决收敛问题(图5)。
- 非可导性:量化函数(如Sign)不可导,需使用STE近似梯度。
- 硬件支持:1-bit运算需专用硬件支持,否则效率可能受限。
6. BitNet中的量化效果
- 性能:BitNet在语言建模(困惑度)和下游任务(如Winogrande、Hellaswag)的零样本和少样本性能上,与FP16 Transformer接近,优于PTQ方法(表3、表4)。
- 效率:通过1-bit权重和8-bit激活,BitNet显著降低内存和能耗,同时遵循全精度模型的缩放定律(图3)。
- 稳定性:BitNet在高学习率下更稳定,收敛速度更快(图5)。
7. 总结
量化是一种将神经网络参数和激活从高精度转换为低精度的技术,以优化存储、计算和能耗。BitNet通过1-bit权重量化和8-bit激活量化,结合QAT、STE、SubLN和组量化等技术,实现高效且性能接近全精度的1-bit大模型。这种极端量化(1-bit)是量化的极限形式,为大规模语言模型的低成本部署和环境友好型计算提供了新路径。