
NSDI23 Transparent GPU Sharing in Container Clouds for Deep Learning Workloads
- Paper Reading
- 2025-08-29
- 413 Views
- 0 Comments
- 1273 Words
这篇文章介绍了一种名为 TGS (Transparent GPU Sharing) 的系统,旨在在容器云环境中在OS层为深度学习(DL)训练工作负载提供透明的GPU共享,以提高GPU利用率并减少作业完成时间。
links:
https://www.usenix.org/conference/nsdi23/presentation/wu
1. 背景与动机
-
容器云与DL训练:容器(如Docker)在数据中心中广泛用于资源管理和部署,提供轻量级虚拟化和隔离。DL训练是数据中心的重要工作负载,通常使用GPU加速,但生产环境中GPU利用率低(例如,Microsoft报告的平均52%,Alibaba的中位数仅10%)。这是因为传统实践是将完整GPU静态绑定到容器,导致资源独占,即使GPU未充分利用,也会造成后续作业排队等待,延长作业完成时间(JCT)。

-
现有问题的分类:生产DL作业分为生产作业(需严格性能隔离)和机会作业(利用闲置资源)。现有解决方案包括:
- 应用层解决方案(如AntMan、Salus、PipeSwitch):通过修改DL框架(如TensorFlow、PyTorch)实现共享,提高利用率和隔离,但不透明,用户受限于特定框架版本。
- OS层解决方案(如NVIDIA MPS、MIG):在操作系统层共享GPU,但MPS需要应用知识设置资源限制、不支持内存超订阅且缺乏故障隔离;MIG依赖特定高端GPU硬件(如A100),分区固定且不支持动态调整或内存超订阅。

-
动机:需要一个透明的OS层解决方案,实现高GPU利用率、性能隔离和故障隔离,同时支持任意DL框架。

2. TGS 系统概述
-
架构:TGS位于容器和GPU之间的OS层轻量级间接层(indirection layer),拦截容器发出的系统调用和GPU内核,调节资源使用。系统对应用透明,用户可在容器中使用任何框架开发模型。
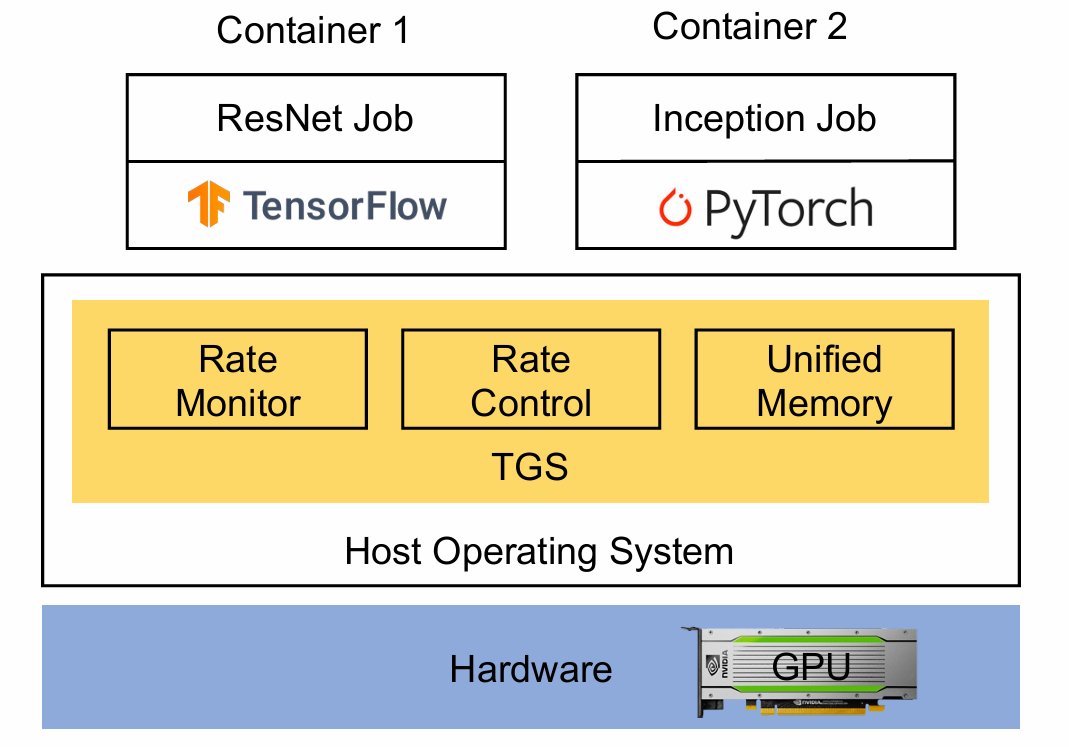
-
关键目标:
- 透明性:无需修改应用或框架。
- 高利用率:共享GPU计算和内存资源,提高整体利用率。
- 性能隔离:生产作业不受机会作业显著影响。
- 故障隔离:每个容器使用独立GPU上下文,避免一个容器故障影响他人(不像MPS的上下文合并)。
-
核心机制:结合自适应速率控制(分享计算资源)和透明统一内存(分享内存资源),允许生产和机会作业共享GPU,但优先保障生产作业性能。
3. 系统设计细节
-
分享GPU计算资源:
-
挑战:无应用知识下自适应共享,避免生产作业受干扰。简单优先级调度不可行,因为GPU内核执行时间长,队列空不代表GPU空闲。
-
自适应速率控制:监控生产作业的性能(如CUDA块数作为反馈信号),动态调整机会作业的GPU内核出队速率。控制循环自动收敛:机会作业使用剩余资源最大化利用率,同时保持生产作业吞吐量不降(<5%影响)。

-
优势:与GPU硬件解耦,通用性强;避免GPU利用率信号的模糊性(GPU有多种计算单元,如Tensor cores和CUDA cores)。

-
-
分享GPU内存资源:
- 挑战:支持内存超订阅(总需求超GPU容量),但需透明且优先生产作业。
- 透明统一内存:基于CUDA统一内存(unified memory)机制,拦截内存分配调用,重定向到统一地址空间(GPU+主机内存)。超订阅时,自动将机会作业数据逐出到主机内存,并更新虚拟地址映射。
- 放置偏好:优先为生产作业分配GPU内存,确保其性能;机会作业使用剩余或主机内存。
- 优势:无需应用层内存交换(如AntMan),透明且高效。

4. 实现与集成
- TGS已实现并集成到Docker和Kubernetes中,支持容器编排。
- 轻量级设计:低开销,符合容器原则。
5. 实验结果
-
在真实GPU集群上评估,使用生产DL工作负载(如ResNet、Inception模型)。

- 性能隔离:生产作业吞吐量影响最小(几乎无降)。
- 机会作业吞吐量:与应用层AntMan相似,高于OS层MPS达15倍。
- 整体利用率:显著提高GPU计算和内存利用率,减少排队时间。
- 比较:TGS在透明性、高利用率、隔离和故障隔离上优于现有方案(见表1)。
6. 主要贡献
- TGS系统:首个在OS层实现透明GPU共享的解决方案,适用于容器云DL训练。
- 机制创新:自适应速率控制和透明统一内存,同时实现高利用率和隔离。
- 实际影响:减少资源浪费,提高集群效率,适用于生产环境的多租户GPU集群。

文章强调TGS解决了生产GPU集群的低利用率问题,提供了一个通用、透明的共享框架。