
MoE-Sys 文章记录
- High Performance Computing
- 2025-05-20
- 2975 Views
- 0 Comments
- 22191 Words
MoE Survey
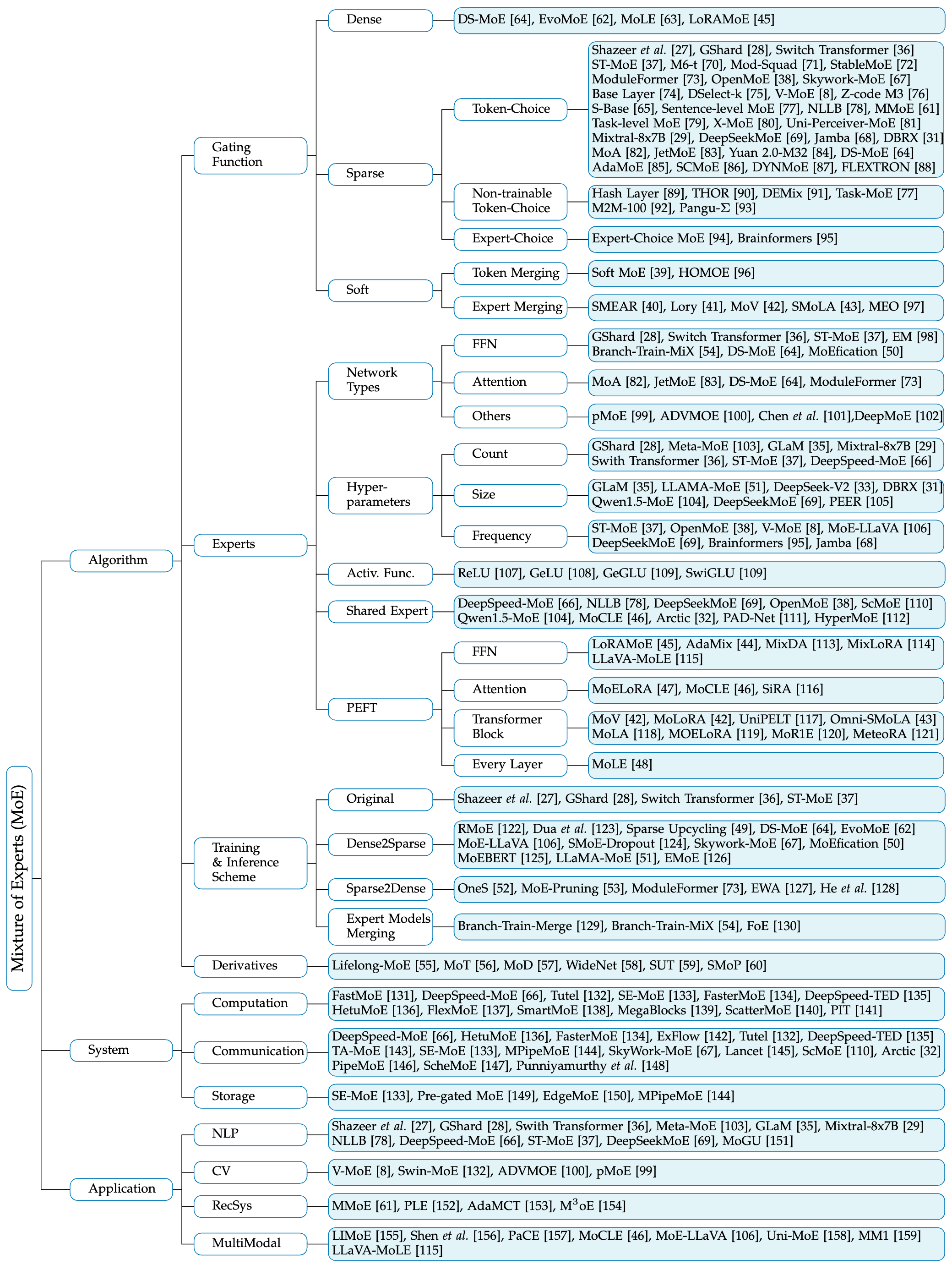
withinmiaov/A-Survey-on-Mixture-of-Experts-in-LLMs: The official GitHub page for the survey paper "A Survey on Mixture of Experts in Large Language Models".
一文弄懂Mixture of Experts (MoE)的前世今生 - 文章 - 开发者社区 - 火山引擎
Deepseek V3
DeepSeek原理介绍之——DeepSeek-V3 - 知乎
MoE Survey
专家混合模型(MOE)推理优化技术全景:从模型到硬件的深度解析 - 知乎
一文搞懂 蒸馏、量化、MoE 和 MHA !!_量化 蒸馏-CSDN博客
在这篇论文《A Survey on Mixture of Experts in Large Language Models》中,作者系统地梳理了不同MoE(Mixture of Experts)大语言模型的加速方式及其所面临的挑战,可总结如下:
🧠 不同类型的MoE加速方式
1. 稀疏MoE(Sparse MoE)
主流设计:仅激活Top-k个专家而非全部专家,以减少计算负载。
加速手段:
- Top-k路由(如Switch Transformer, Mixtral):仅选择概率最高的前k个专家,减少执行的FFN数量。
- 专家容量限制与溢出重定向(如GShard):控制每个专家处理的最大token数,溢出则随机分配次选专家。
- 批次优先路由(BPR):依据gating score优先安排token分配,减少早期token垄断资源的问题。
- 强化学习或平滑函数路由(如BASE, S-BASE, DSelect-k):利用最优传输或可微优化来实现token-expert映射。
- Adaptive gating(如DYNMoE, AdaMoE):为不同token自适应选择专家数量,减小资源浪费。
2. 密集MoE(Dense MoE)
主流设计:激活所有专家,将所有输出加权汇总。
适用场景:
- 高精度需求任务(如多任务学习、LoRA细调),如DS-MoE、MoLE。
- 在少专家模型或PEFT任务中可用低开销密集专家集合,提升性能。
3. 软MoE(Soft MoE)
主流设计:全部专家参与,但通过软分配减少不必要计算。
加速手段:
- Token Merging(如Soft MoE, HOMOE):将多个token聚合后统一分发专家。
- Expert Merging(如SMEAR, Lory, MoV):将多个专家参数按权重合并为一个“合成专家”,实现更少计算和更高稳定性。
- Segment Routing(如Lory):结合自回归结构的因果性,将专家合并于语义片段内。
4. 系统级优化
除了算法设计之外,论文强调系统优化是大规模MoE加速的关键:
-
计算并行优化(如DeepSpeed-MoE, Tutel, MegaBlocks):
- 异步推理、批次融合(batching fusion)
- 专家负载均衡(load balancing with aux loss)
-
通信优化(如PipeMoE, ExFlow, Skywork-MoE):
- 减少AllToAll通信开销(稀疏专家通信路径优化)
- 分层MoE结构
-
存储优化(如SE-MoE, Pre-gated MoE, EdgeMoE):
- 专家卸载(offloading experts)到主存或设备间切换
- 预路由(预选专家)以减少延迟
⚠️ 面临的主要挑战
-
专家负载不均(Load Imbalance)
- 部分专家频繁激活,部分闲置,导致利用率低。
- 解决方案:辅助损失(如Load balancing loss)、优化路由(如BASE、S-BASE)
-
路由不稳定(Routing Instability)
- 在训练初期或微调时,路由策略可能频繁震荡,影响学习。
- 解决方案:二阶段训练(如STABLEMoE)、门控参数蒸馏、soft routing等。
-
离散选择的可微性问题(Non-differentiability of Gating)
- 离散的专家选择难以进行有效的梯度传播。
- 解决方案:平滑门控策略(DSelect-k)、SMEAR(专家权重合并)
-
上下文独立专家选择(Context-Independent Specialization)
- 模型可能基于token ID等静态信息分配专家,缺乏语义适应性。
- 解决方案:重排序token输入、增加路由扰动、领域感知专家等。
-
训练开销与硬件负载大
- 尤其在多专家并行训练时,需要大带宽、高吞吐的通信与计算资源。
- 解决方案:稀疏激活、专家卸载系统、低精度计算。
| 类别 | 加速策略 | 代表模型/方法 | 核心思想 | 面临挑战 |
|---|---|---|---|---|
| 算法设计 | Sparse Gating(稀疏门控) | Switch Transformer, GShard, Mixtral | 激活Top-k专家,仅少量计算资源参与 | 负载不均、token拥堵、离散优化困难 |
| Token-Choice Gating | BASE, S-BASE, DSelect-k, AdaMoE | 通过优化或RL等方式选择专家 | 需辅助损失,受token顺序影响 | |
| Expert-Choice Gating | Expert-Choice MoE, Brainformer | 由专家选择token,减少辅助loss需求 | token覆盖率不足 | |
| Sentence/Task-level Routing | Sentence-level MoE, DEMix | 基于句子或任务选择专家 | 泛化性弱,需预定义标签/域 | |
| Dense Activation | DS-MoE, LoRAMoE, MoLE | 所有专家均激活,提升精度和多任务泛化 | 计算量大,仅适用于轻量/少专家模型 | |
| Soft MoE(可微门控) | SMEAR, Lory, MoV, Soft MoE | 合并专家或token,消除离散选择难题 | 复杂性高,推理吞吐下降 | |
| Expert Merging | SMEAR, MEO, Lory | 将多个专家参数融合为一个 | 精度损失、优化困难 |
| 类别 | 系统优化方向 | 代表系统/模型 | 技术要点 | 面临挑战 |
|---|---|---|---|---|
| 系统设计 | 计算优化 | FastMoE, DeepSpeed-MoE, MegaBlocks | Batch融合、专家并行、轻量执行路径 | GPU资源碎片化、动态分配开销 |
| 通信优化 | PipeMoE, ExFlow, Skywork-MoE | 减少AllToAll通信、专用拓扑设计 | 大规模通信开销,延迟瓶颈 | |
| 存储与卸载 | MoE-Infinity, SE-MoE, EdgeMoE | 专家缓存与动态卸载(GPU↔主存) | 参数传输延迟,缓存一致性管理 | |
| 专家部署策略 | DeepSeekMoE, Mixtral | 精细粒度专家切分,激活组合多样 | 调度复杂度高,专家碎片化 |
总结对比图:三种门控方式
| 方式 | 激活专家数 | 是否可微 | 优点 | 缺点 |
|---|---|---|---|---|
| Sparse Gating | Top-k(k≪N) | 部分可微(带辅助loss) | 高效稀疏,推理快 | 路由不稳定,需辅助loss |
| Dense Gating | 全部专家 | 可微 | 高精度,训练稳定 | 计算开销大 |
| Soft Gating / Merging | 所有专家参与合并 | 完全可微 | 优雅稳定,适合微调 | 推理慢,结构复杂 |
无法共用KV Cache
| 项目 | 原因 |
|---|---|
| 专家结构 | 每个 Expert 是独立的 FFN(或注意力)子网络,参数独立 |
| 上下文表示 | 输入相同的 token,在不同专家中激活的表示会完全不同 |
| 缓存语义不同 | 即使位置一样,KV 向量语义是绑定在对应专家参数上的 |
| 共享会引入错误语义信息 | 会污染注意力机制,影响模型输出准确性和稳定性 |
NEO
NEO: SAVING GPU MEMORY CRISIS WITH CPU OFFLOADING FOR ONLINE LLM INFERENCE
这篇论文题为 《NEO: Saving GPU Memory Crisis with CPU Offloading for Online LLM Inference》,主要研究如何缓解在线大语言模型(LLM)推理过程中 GPU显存不足 的问题,并提出了一个系统 NEO 来提升推理吞吐量。以下是论文的核心内容和贡献的中文概述:
🧩 背景问题:在线推理的 GPU 内存瓶颈
在线 LLM 推理(比如聊天机器人、智能助手)需要:
- 低延迟:用户交互式体验需要快速响应;
- 高吞吐量:为了高效利用昂贵的 GPU,系统往往通过 批处理(batching) 合并多个请求一起处理。
但批处理的大小受限于 GPU 显存:
- 模型本身已经占用大量内存(如 70B 模型可能占用数十 GB);
- 推理过程中还需要存储 KV Cache(注意力机制的中间状态),随着输入/输出 token 长度增长,KV Cache 线性增长。
结果:GPU计算资源没用完,但内存先满了,批处理做不大,吞吐量反而上不去。
🚀 核心解决方案:NEO 系统
NEO 的主要思路是:
将部分注意力计算(Attention)和对应的 KV Cache 从 GPU 卸载到本地 CPU 来节省 GPU 显存,从而提升吞吐量。
关键设计包括:
1. 不对称 GPU-CPU pipeline(Asymmetric Pipelining)
-
将一批请求划分为两部分:
- 一部分请求仍在 GPU 上运行(含 Prefill 和 Decode 阶段);
- 另一部分请求将 Decode Attention 阶段卸载到 CPU 执行。
-
两部分请求并发运行,使 GPU 和 CPU 都能被有效利用。
-
异于传统“对称划分”,NEO 根据负载动态决定分配,避免 CPU 变瓶颈。
2. 负载感知调度器(Load-aware Scheduling)
- 实时监控请求队列,根据输入输出长度动态选择哪些请求放到 GPU、哪些卸载到 CPU;
- 目标是最大化吞吐量、最小化资源空转,动态选择使用 NEO 的异构模式或回退为纯 GPU 模式。
⚙️ 实现细节
- 基于 SwiftLLM 实现;
- 使用 ISPC(Intel SPMD Program Compiler) 实现高效的 CPU Attention Kernel;
- 提供多 GPU 推理支持(支持模型分片、张量并行);
- 优化内核调用以减少 Python GIL 带来的性能损耗。
📈 实验结果
在不同模型(7B、8B、70B)、不同 GPU(T4、A10G、H100)下评估,使用真实数据集(Azure Coding trace、OpenAI Summary trace),结果显示:
-
吞吐量提升高达 7.5×(T4),A10G 提升 26%,H100 提升 14%;(仅少量GPU)
-
在相同延迟下(如 1–2 秒/token)依然保持吞吐优势;
-
比已有 CPU offloading 方案(如 FastDecode)更灵活、延迟更低;
-
CPU 越强,提升越明显(受 CPU 内存带宽影响最大);
-
在 CPU 资源充足、GPU 显存紧张场景下效果最优。
📌 总结与启示
NEO 提出了 更实用、延迟友好 的 CPU 卸载方案,充分利用本地 CPU 帮助缓解 GPU 显存瓶颈,不仅提升吞吐量,还能适应现实中动态变化的请求模式。它代表了 CPU-GPU 协同推理 的一个重要探索方向。
如果你对 MoE、推理系统架构或 CPU-GPU 协同执行感兴趣,这篇论文有很多启发。需要我再帮你提炼重点段落、画结构图、或者写一份讲解PPT的话,也可以继续告诉我。
GShard
这篇论文《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》提出了 GShard,一个用于大规模神经网络训练的模块,通过结合条件计算(Conditional Computation)和自动分片(Automatic Sharding)技术,解决了超大规模模型(如超过6000亿参数的MoE Transformer)在计算成本、编程复杂性和并行效率上的挑战。以下是对论文的核心内容、方法、贡献和意义的总结:
1. 背景与挑战
- 神经网络规模化的重要性:论文指出,增大神经网络规模(如更深的层或更宽的维度)在计算机视觉、自然语言处理(NLP)等领域显著提升模型质量。例如,Transformer模型的扩展在语言理解和多语言翻译任务中表现出色。
- 规模化面临的挑战:
- 计算成本:传统模型规模化(如增加层数或维度)导致计算成本呈线性甚至超线性增长,模型并行(如跨设备分割权重)引入通信开销和设备利用率低的问题。
- 编程复杂性:现有深度学习框架(如TensorFlow、PyTorch)对模型并行的支持不足,用户需手动优化并行策略或迁移到专用框架,工程负担重。
- 基础设施瓶颈:大规模模型的计算图表示随设备数增加呈 ( O(D) ) 或 ( O(D^2) ) 增长,导致编译时间不可接受。
- 分片策略实现难度:模型分片需协调跨设备通信,复杂的分片算法(如图分割或操作符并行)对开发者不友好,且模型架构变更可能引发通信策略重构。
2. GShard 的核心设计
GShard 是一个结合轻量级分片注解API和XLA编译器扩展的模块,通过以下设计克服上述挑战:
2.1 条件计算与稀疏MoE层
- 稀疏MoE Transformer:GShard 使用 Sparsely-Gated Mixture-of-Experts (MoE) 层替换Transformer中每隔一层的标准前馈层(Feed-Forward Layer),实现条件计算。
- MoE层包含 ( E ) 个前馈网络(专家),通过门控函数(GATE)为每个输入token选择最多两个专家,生成加权输出。
- 门控函数优化:
- 专家容量限制:设置每个专家处理token的上限(( O(N/E) )),避免热门专家过载。
- 本地组分派:将输入batch划分为 ( G ) 个组并行处理,确保负载均衡。
- 辅助损失:引入 ( \ell_{\text{aux}} ) 损失项,鼓励均匀分派token到所有专家。
- 随机路由:以概率分派次优专家,节省专家容量。
- 优势:MoE层的子网络规模与专家数量无关,计算成本随模型规模呈亚线性增长,显著降低训练开销。
2.2 自动分片与SPMD并行
- 分片注解API:
- 提供
replicate()和split()等API,允许用户为张量指定复制或分片策略。例如,注意力层按batch维度分片并复制权重,MoE层的专家则分片到多个设备。 - 通过分离模型描述与并行实现,开发者无需深入优化底层通信。
- 提供
- SPMD分片(Single Program Multiple Data):
- 传统MPMD(Multiple Program Multiple Data)为每个设备生成独立程序,编译时间随设备数 ( D ) 呈 ( O(D) ) 增长。
- SPMD生成单一程序,运行于所有设备,编译时间为 ( O(1) ),支持数千设备的高效扩展。
- SPMD支持任意张量维度的分片,灵活适应不同并行策略(如跨分区分派)。
- 通信优化:
- AllReduce:用于累积部分结果,执行时间与设备数无关(( O(1) ))。
- AllToAll:用于跨分区分派,成本为 ( O(\sqrt{D}) ),随设备数亚线性增长。
- CollectivePermute:用于一对一通信,成本为 ( O(1) ),适合halo交换。
2.3 编译器优化
- GShard扩展XLA编译器,通过SPMD分区转换生成高效并行程序。
- 支持复杂操作(如卷积的空间分片),通过halo交换和动态切片处理非均匀窗口配置,确保高效性。
- 编译器自动传播分片注解,减少手动优化的需求。
3. 实验与结果
- 模型与任务:
- 构建了一个 6000亿参数的多语言MoE Transformer,用于从100种语言翻译到英语。
- 使用2048个TPU v3核心训练4天,总成本为22 TPU v3核心年。
- 性能对比:
- 翻译质量:MoE Transformer在 (\triangle)BLEU上远超基线,6000亿参数模型的 (\triangle)BLEU为基线模型(2.3B参数,(\triangle)BLEU=6.1)的数倍。
- 训练效率:相比训练100个双语基线模型(29 TPU v3核心年),GShard的6000亿参数模型成本更低。
- 亚线性成本:模型规模从37.5B增至600B(16倍),计算成本仅从6增至22 TPU v3核心年(3.6倍)。
- 并行效率:
- 前馈层和投影操作利用TPU矩阵单元,达到>85%峰值FLOPS。
- 门控计算的Einsum操作成本为 ( O(1) ),通信成本(AllToAll)为 ( O(\sqrt{D}) ),支持高效扩展到2048个专家。
- 可扩展性:
- GShard支持多种操作(如卷积、Reduce)的亚线性扩展,适用于图像处理等场景。
- SPMD分片确保编译时间不随设备数增长。
4. 关键贡献
- 高效规模化:
- 通过稀疏MoE层实现亚线性计算成本,训练6000亿参数模型仅需4天,远低于传统方法的成本。
- 简易编程:
- 轻量级分片注解API分离模型开发与并行优化,降低开发复杂度。
- 编译器创新:
- SPMD分片和XLA扩展实现 ( O(1) ) 编译时间,支持数千设备的高效并行。
- 通用性:
- GShard支持多种模型架构(如Transformer、卷积)和并行策略,适用于NLP、图像处理等任务。
- 实证验证:
- 证明模型规模化未达质量瓶颈,条件计算在多任务(如多语言翻译)场景下兼顾质量与效率。
5. 与 MoEtion 的关联
- 共同点:
- 两者均针对大规模MoE模型的训练优化,解决计算效率和容错问题。
- 都利用MoE的稀疏激活特性,通过专家分片(GShard)或稀疏检查点(MoEtion)降低开销。
- 强调负载均衡(GShard的门控函数 vs. MoEtion的流行度调度)。
- 差异:
- 目标:GShard聚焦模型规模化和并行训练效率,MoEtion专注容错和检查点优化。
- 方法:GShard通过SPMD和分片API优化运行时计算,MoEtion通过稀疏检查点和局部恢复降低故障恢复成本。
- 场景:GShard适用于稳定的TPU集群训练,MoEtion针对高故障率环境(如云端集群)。
- 实现:GShard基于XLA和TensorFlow,MoEtion基于DeepSpeed,适用不同框架。
6. 意义与展望
- 意义:
- GShard为超大规模神经网络的训练提供了一个实用、高效的解决方案,推动了多语言翻译等复杂任务的性能突破。
- 通过条件计算和自动分片,GShard证明了规模化与训练效率可以兼得,降低了巨型模型的开发和部署门槛。
- SPMD分片和分片API的设计理念对现代分布式深度学习框架(如JAX、PyTorch)有深远影响。
- 未来方向:
- 优化门控函数的并行效率,减少AllToAll通信开销。
- 扩展GShard到更多任务(如多模态学习)或硬件平台。
- 结合MoEtion等容错机制,提升大规模训练在不稳定环境中的鲁棒性。
如果需要更深入的技术细节(如门控函数算法、SPMD分片的具体实现)或与MoEtion的进一步对比,请告诉我!
FlexInfer
这篇论文介绍了 FlexInfer,一个针对大语言模型(LLMs)推理的系统,专注于在内存受限的GPU环境下结合CPU计算,实现低延迟、高效率的模型推理。以下是论文的核心内容总结:
🎯 背景与问题
现代大语言模型(如 GPT、LLaMA)模型庞大,单靠 GPU 内存难以容纳:
- 模型参数和 KV 缓存(Key-Value Cache)体积巨大。
- 用于解决的主流方案是“CPU 内存 offloading”,但会因 PCIe 传输瓶颈导致推理性能严重下降。
举例:OPT-66B 仅 KV 缓存就可能占用 288GB 内存。
💡 论文贡献
作者提出了 FlexInfer,一个动态选择推理执行策略的系统,以优化 GPU + CPU 混合系统中的延迟表现。
📌 FlexInfer 的关键特点:
-
动态执行策略选择:
-
针对 LLM 推理中的两个阶段:
- Prefill(初始化阶段):处理整个输入序列,计算量大。
- Decode(逐token生成阶段):每次只生成一个 token,内存绑定明显。
-
针对不同阶段、硬件配置、batch size 等运行时参数,选择最优策略:
- CPU-only
- GPU with Offloading(FlexGen 风格)
- CPU-GPU 分层执行(SplitGen)
-
-
延迟预测器(Estimator):
- 使用 analytical model 估计 TTFT(Time To First Token)与 TPOT(Time Per Output Token)。
- 综合考虑 CPU/GPU 吞吐、内存带宽、PCIe 带宽等硬件特性。
-
混合执行器(Inference Executor):
- 执行由 planner 决定的策略组合,处理数据加载、同步和执行。
🔬 评估结果
FlexInfer 在两种硬件平台(分别为 Xeon+NVIDIA A100 和 Xeon AMX+H100)上进行了测试,结果如下:
-
相比 FlexGen:
- 端到端推理延迟降低 75%\~76%
- Prefill 阶段:GPU + offload 通常更快(高吞吐)
- Decode 阶段:CPU 反而更快(无需 PCIe 传输)
此外,FlexInfer 在:
- 批大小(1\~32)、
- 输入长度(128\~1024)、
- 输出长度(128\~1024)、
- 模型类型(OPT-66B、LLaMA2-70B、LLaMA3-70B)
中都显示出显著优势。
📊 相较其他系统的对比
| 系统 | 支持 CPU | 动态策略 | 优化解耦阶段 |
|---|---|---|---|
| FlexGen | 部分 | 否 | 否 |
| HeteGen | 是 | 否 | 否 |
| FlexInfer | ✅ | ✅ | ✅ |
📘 结论
FlexInfer 提出一种灵活、动态的执行策略选择机制,在 GPU 内存不足或 PCIe 成为瓶颈的场景下,充分利用 CPU 的内存与计算资源,大幅度降低了 LLM 推理的延迟。
这篇论文 《FlexInfer: Flexible LLM Inference with CPU Computations》 的核心工作是:
🧩 问题背景
当前大语言模型(LLM)推理主要依赖 GPU,但由于模型参数和 KV Cache(注意力缓存)占用大量内存,即使使用高端 GPU(如 A100、H100)也容易发生显存瓶颈。为此,很多系统(如 FlexGen)采用 CPU offloading:把模型权重和缓存放在 CPU 内存里,推理时通过 PCIe 从 CPU 把数据传到 GPU。
问题是: PCIe 的带宽有限,这种方式虽然节省了 GPU 显存,但极大地拖慢了推理速度 ,传输时间占到总耗时的 90%以上。
🚀 本文提出的系统:FlexInfer
为了解决这个问题,本文提出了 FlexInfer —— 一个能够灵活选择推理阶段执行策略的系统,核心思想是:
根据不同的推理阶段(prefill / decode)、运行时配置(序列长度、batch size)以及硬件资源(CPU/GPU性能、PCIe带宽),动态选择最佳的执行策略(在 CPU、GPU 之间调度计算任务)。
🔑 三种执行策略
FlexInfer 在推理中可以选择以下三种策略:
- **CPU-only:** 完全使用 CPU 推理,适用于长输出、KV cache 很大的场景;
- **GPU + CPU offloading(FlexGen):** 数据存储在 CPU,计算在 GPU,适用于计算密集但 GPU 显存不足的场景;
- **SplitGen(CPU-GPU 静态划分):** 模型前半在 CPU 执行、后半在 GPU 执行,适用于部分层可以长驻 GPU、减少 PCIe 传输的情况;
FlexInfer 的创新点在于:
- 分别为 prefill 阶段(生成第一个 token)和 decode 阶段(生成后续 token)选择策略;
- 使用一个估算器,根据模型、输入长度、batch size、系统配置,预测各策略的延迟,选最优方案。
⚙️ 实现与支持
- 修改 HuggingFace 和 Intel Extension for PyTorch 实现策略切换;
- 支持模型包括:OPT-30B/66B、LLaMA2-70B、LLaMA3-70B;
- 使用 Intel AMX 加速 CPU 上的 GEMM 操作;
- 使用 CUDA Stream 实现异步 CPU-GPU 数据传输。
📊 实验结果(重点)
在两个平台上评估:
- Server 1:A100 + Ice Lake(无 AMX)
- Server 2:H100 + Sapphire Rapids(有 AMX)
结果显示:
| 对比方案 | 相对 FlexGen 的 E2E 延迟改善 |
|---|---|
| FlexInfer | 降低 75%(Server 1)/ 76%(Server 2) |
| SplitGen | 降低 37% / 61.7% |
| FlexGen_Opt | 降低 23% / 50% |
此外,FlexInfer:
- 在 prefill 阶段利用 GPU 提高吞吐;
- 在 decode 阶段利用 CPU 缓解 PCIe 压力;
- 能根据输入长度、输出长度、batch size 灵活切换策略;
- 在 decode 每 token 的延迟(TPOT)上降低了近 80%;
✅ 总结:这篇论文做了什么?
提出 FlexInfer 系统,在预填充(prefill)和生成(decode)阶段动态选择 CPU、GPU 或混合执行策略,以在 GPU 显存受限时最大化 LLM 推理性能。相较现有方案,平均减少约 75% 的推理延迟,特别适合低内存、高通量的部署环境。
dLoRA
dLoRA: Dynamically Orchestrating Requests and Adapters for LoRA LLM Serving
它发表在 OSDI 2024 上,由北京大学和上海AI实验室的研究者联合完成。以下是这篇论文的核心贡献总结:
🎯 核心目标
这篇文章针对“LoRA微调模型的推理部署问题”提出了一种新的系统——dLoRA,以提升 多LoRA模型共享同一基础模型时的推理效率。
🧠 关键背景
- LoRA(Low-Rank Adaptation) 是一种参数高效微调(PEFT)方法,在保持基础模型不变的前提下,仅训练少量可学习的低秩矩阵(adapter)。
-
在部署多个 LoRA 模型时,传统方案如 vLLM 和 HuggingFace PEFT:
- 无法共享基础模型的计算资源,导致显存浪费;
- 无法有效合并不同 LoRA 请求的推理,造成低 GPU 利用率;
- 难以在多 worker 之间实现高效负载均衡。
🛠 dLoRA 的两个核心机制
1. 动态批处理与合并策略(Dynamic Cross-Adapter Batching)
- 动态决定是合并 LoRA adapter 到 base 模型(merged),还是在请求中单独加 adapter(unmerged)。
- 提出一种 credit-based batching 机制,根据请求分布自适应切换合并策略。
- 避免 GPU 空闲、请求饥饿、排队延迟等问题。
2. 请求-Adapter 协同迁移(Request-Adapter Co-Migration)
- 针对跨 worker 的负载不均问题,引入 proactive + reactive 迁移机制。
- 使用整数线性规划(ILP)建模请求和 LoRA adapter 的联合迁移,解决显存占用不均、负载倾斜的问题。
- 提出近似迁移算法,提升 ILP 的可扩展性,支持大规模集群。
⚙️ 系统实现与优化点
-
基于 vLLM 实现,支持:
- LoRA adapter 异步加载与预取;
- PyTorch einsum 实现 unmerged 推理并行计算;
- 对 Llama-2 等多种模型支持,包括 70B 分布式推理。
- 使用 Ray、FastAPI、Pulp(ILP solver)进行组件调度、API调用和优化计算。
📊 性能成果
在实际部署与仿真测试中,dLoRA 展示出显著优势:
- 比 vLLM 提高 最高 57.9× 吞吐量;
- 比 HuggingFace PEFT 提高 最高 26.0× 吞吐量;
- 相比 S-LoRA 平均 降低 1.8× 延迟;
- 即使在高并发、长上下文、adapter 数量多的情景下也保持良好扩展性。
📌 你可以从本文站上的点:
-
内存与计算解耦:
- 设计更加系统化的 adapter 缓存与调度策略(例如:冷 adapter 存 CPU、热 adapter 存 GPU)。
- 融合 KV cache 与 adapter 迁移的层次调度模型。
-
稀疏性利用:
- 结合上下文稀疏性(如只有部分 adapter 激活)与 fine-grained GPU offloading。
- 在 unmerged 模式下更智能地裁剪 adapter 的执行。
-
异构系统支持:
- 扩展 dLoRA 在 CPU-GPU 混合系统中的迁移策略:如部分 adapter 在 CPU 推理、GPU 上只处理重要计算。
-
推理与系统联合优化:
- 在 LoRA 推理过程中加入 token-level 或 layer-level 微调结构变化,以支持更细粒度的动态负载迁移。
如果你对 CPU-GPU 资源协同、adapter 缓存设计、或者动态资源调度有兴趣,这篇文章是一个极好的跳板。你想要我基于这篇文章,帮你草拟一个更进一步的系统研究方向吗?
fMoE
fMoE: Fine-Grained Expert Offloading for Large Mixture-of-Experts Serving
这篇文章提出了一种名为 fMoE 的细粒度专家卸载系统,用于优化基于混合专家(Mixture-of-Experts, MoE)的大型语言模型(LLM)的服务效率。以下是文章的核心内容和贡献的总结:
主要工作
-
问题背景:
- MoE架构是现代大型语言模型的常用设计,通过稀疏激活专家(experts)降低训练成本。然而,在推理阶段,MoE模型因需要将所有专家参数加载到GPU内存中,导致内存效率低下。
- 现有专家卸载方案在延迟与内存占用之间难以取得平衡,要么推理延迟高,要么内存占用大,主要因为它们采用粗粒度的专家选择模式,难以准确预测和保留必要的专家。
-
fMoE 系统设计:
- 专家图(Expert Map):提出了一种新的数据结构,用于记录MoE模型在每次推理迭代中基于门控网络的专家选择概率分布,提供细粒度的专家激活模式。
- 语义与轨迹搜索:利用输入提示的语义嵌入和历史专家选择轨迹,结合语义相似性和轨迹相似性进行专家图匹配,指导专家的预取、缓存和卸载决策。
- 异步架构:采用发布-订阅模式,将专家图匹配和预取与推理过程解耦,降低系统开销。
- 专家缓存管理:基于最少使用频率(LFU)算法和专家概率分布,动态管理GPU内存中的专家缓存,优化预取和驱逐优先级。
-
实现与实验:
- 在HuggingFace Transformers框架上基于MoE-Infinity代码库原型化了fMoE,并在配备6个NVIDIA GeForce RTX 3090 GPU的测试平台上进行部署。
- 使用三个开源MoE模型(Mixtral-8×7B、Qwen1.5-MoE、Phi-3.5-MoE)和真实世界数据集(LMSYS-Chat-1M、ShareGPT)进行广泛实验。
- 结果表明,fMoE相比最先进的基线方法(MoE-Infinity、ProMoE、Mixtral-Offloading、DeepSpeed-Inference):
- 平均推理延迟降低了47%;
- 专家命中率提高了36%;
- 在内存受限场景下(如6GB缓存)仍保持优异性能,显著优化了延迟-内存权衡。
-
关键贡献:
- 设计了fMoE系统,通过细粒度专家卸载实现低延迟和高内存效率的MoE服务。
- 提出了专家图数据结构,结合语义和轨迹信息优化专家预取和卸载。
- 验证了fMoE在多种MoE模型和真实工作负载下的优越性能,特别是在在线服务场景中。
意义
fMoE通过细粒度的专家管理策略,解决了MoE模型服务中内存效率低和推理延迟高的核心问题,为高效服务大型MoE模型提供了实用解决方案。其异步设计和对模型及提示异构性的适应性使其在实际部署中具有广泛适用性。
Cache
MoE infinity
这篇文章提出了 MOE-INFINITY,一个专为个人机器(配备有限 GPU 内存)设计的高效 MoE(混合专家模型)推理系统,通过 稀疏感知专家缓存(Sparsity-Aware Expert Cache) 优化了 MoE 模型在单用户环境下的推理性能。以下是文章的主要工作和贡献总结:
主要工作
-
研究背景:
- MoE 模型通过路由器动态选择少量专家处理输入标记,显著降低计算和内存带宽需求,适合大型语言模型(LLMs)推理。
- 个人机器通常配备单一消费级 GPU(内存 24-48GB),无法完全加载大型 MoE 模型(参数量可超 100GB,如 DeepSeek-MoE 236B)。因此,推理依赖 卸载(offloading),即将模型参数存储在主机内存,动态加载激活的专家到 GPU。
- 现有推理系统(如 DeepSpeed、vLLM、Ollama、BrainStorm)在卸载场景下性能较差,主要因缓存设计未考虑 MoE 的稀疏激活特性,导致 PCIe 总线 I/O 瓶颈和高 GPU 空闲时间。
-
核心问题与观察:
- 在个人机器上,MoE 推理通常以 批量大小为 1 运行(单用户环境),专家激活高度稀疏,仅少量专家在解码阶段被频繁重用。
- 现有系统(如 DeepSpeed、Mixtral-Offloading)基于预测的缓存方法假设所有专家需加载,忽略稀疏性,导致低缓存命中率和高延迟。
- 专家重用模式在单请求(prompt)内呈 偏斜分布(某些专家频繁激活),但跨多请求后趋于均匀,传统缓存策略(如 LRU、统计计数)无法有效利用这一模式。
-
MOE-INFINITY 系统设计:
- 稀疏感知专家缓存:核心创新,通过追踪专家的稀疏激活模式,优化缓存替换和预取,显著降低 每输出标记时间(TPOT)。
- 关键组件:
- 专家激活矩阵(EAM):
- 定义为 ( L \times E ) 矩阵(( L ) 为 MoE 层数,( E ) 为每层专家数),记录每层专家处理标记的数量。
- 分为 迭代级 EAM(iEAM)(每推理迭代更新)和 请求级 EAM(rEAM)(累积整个请求的激活频率)。
- 专家激活矩阵集合(EAMC):
- 存储历史 rEAM,容量有限(数百至数千),通过余弦距离匹配当前 iEAM 与历史 rEAM,预测未来专家激活概率。
- 替换策略:移除与新 EAM 最相似的旧 EAM,保持多样性和适应工作负载变化。
- 激活预测(PredictEAM):
- 基于当前 iEAM 和 EAMC,计算预测 EAM(pEAM),为每专家生成激活概率。
- 考虑层接近性(layer proximity),优先缓存靠近当前层的专家,公式为 ( (1 - (i - l) / L) ),其中 ( l ) 为当前层,( i ) 为未来层。
- 缓存优化:
- 预取:根据 pEAM 预测下一层可能激活的专家,提前加载到 GPU,减少 GPU 停顿。
- 专家位置信息:优先缓存初始层的专家,因其预测置信度较低,缓解预取失败。
- 缓存替换:基于 pEAM 选择重用概率最低的专家移除,结合层衰减(layer decay)优化优先级。
-
算法实现:
- 算法 1(专家缓存检索):
- 若专家在缓存中,直接返回。
- 若缓存未满,执行按需加载(FetchOnDemand)。
- 若缓存满,基于 PredictEAM 计算 pEAM,移除重用概率最低的专家,加载新专家。
- 预取机制集成在 FetchOnDemand 中,优化数据传输。
- 运行时优化:
- EAMC 容量有限(3% 请求数即可捕获激活模式),匹配成本低(1K EAMs 21μs,10K EAMs 226μs,占推理延迟 <1%)。
- 支持多 GPU,通过哈希函数分配专家,优化 NUMA 节点数据传输。
- 使用固定内存管理,密集参数和 KV 缓存常驻 GPU,专家参数卸载到主机内存。
- 算法 1(专家缓存检索):
-
实验评估:
- 模型:测试了 DeepSeek-V2-Lite (31GB)、Mixtral-8x7B (120GB)、NLLB-MoE (220GB)、Switch Transformers (30-100GB)、Snowflake-Arctic (900GB)。
- 数据集:BIGBench(166 任务)、FLAN(66 任务)、MMLU(58 任务),共 290 个 LLM 任务。
- 硬件:单 NVIDIA RTX A5000 GPU(PCIe 4.0,32GB/s),主机内存 32GB-1TB。
- 基线:DeepSpeed-Inference、Llama.cpp (Ollama)、Mixtral-Offloading、BrainStorm、vLLM。
- 结果:
- 端到端性能(提示长度 512,解码长度 32):
- Mixtral(最差场景,高激活率):MOE-INFINITY 延迟 836ms,较基线提升 1.4x。
- DeepSeek、Switch、NLLB:延迟 155-531ms,接近全 GPU 运行性能,较基线提升 3.1-16.7x。
- Arctic(900GB):MOE-INFINITY 是唯一能在单 GPU 上提供竞争性能的系统。
- 长上下文性能(解码长度 4K-128K):
- MOE-INFINITY 在长上下文下延迟增加较少(50ms 至 160ms),因 KV 缓存常驻 GPU。
- vLLM 因 KV 缓存卸载导致延迟显著增加,DeepSpeed 因预取阻塞表现稳定但较差。
- EAMC 容量:容量 120 时达最低延迟,3% 请求数即可捕获激活模式,跨模型通用。
- 工作负载变化:
- 同数据集任务切换:平均 50 请求恢复低延迟(最差 5% 请求)。
- 跨数据集切换(如 MMLU 到 BIGBench):平均 30 请求恢复(<0.1% 请求),因任务间激活模式重用。
- 缓存命中率:MOE-INFINITY 通过 rEAM 匹配和预取,显著提高命中率,减少 PCIe 流量。
-
与现有工作的对比:
- 传统卸载系统(FlexGen、DeepPlan、SwapAdvisor):不支持 MoE,视 MoE 层为密集层,效率低。
- 通用卸载系统(DeepSpeed-Inference、HuggingFace-Accelerate):未优化稀疏激活,缓存命中率低。
- MoE 推理系统:
- vLLM:按需加载减少 I/O 竞争,但缓存利用率低(485ms TPOT)。
- Llama.cpp:在 CPU 计算专家参数,性能较差。
- Mixtral-Offloading:优化 MoE 卸载,但预测不考虑稀疏性。
- BrainStorm:针对动态神经网络,未能处理 MoE 路由器动态性(934ms TPOT)。
- InfiniGen、TensorRT-LLM:为多 GPU 云服务器设计,不适配个人机器。
- 后验预测器局限:
- 依赖性预测(DeepSpeed):忽略稀疏性和分组激活。
- 计数预测(BrainStorm):忽略请求级稀疏性,跨请求均匀分布。
- 局部性预测(LRU/LFU):未跨迭代应用重用预测。
主要贡献
- 稀疏性分析:
- 证明单用户环境下(批量大小 1),MoE 模型专家激活高度稀疏(<5% 专家频繁激活,Mixtral 25%),GPU 内存足以缓存常用专家。
- 发现专家重用在单请求内偏斜,跨请求均匀,需请求级追踪。
- 在线预测问题形式化:
- 定义 EAM(专家激活矩阵)及预测问题,通过 iEAM 和 rEAM 建模激活和重用概率。
- 提出 EAMC 数据结构,基于余弦距离匹配历史 rEAM,预测未来激活。
- 稀疏感知专家缓存:
- 结合预取、层接近性和专家位置信息,优化缓存命中率和 PCIe 带宽利用。
- 算法实现高效替换和预取,显著降低 TPOT(3.1-16.7x 提升)。
- 开源与实际影响:
- MOE-INFINITY 开源于 GitHub,支持 PyTorch 和 HuggingFace 格式,集成 FlashAttention 等优化。
- 使个人机器高效运行大型 MoE 模型(如 DeepSeek、Arctic),降低部署门槛,获行业和学术关注。
结论
MOE-INFINITY 通过稀疏感知专家缓存,针对个人机器的单用户环境(批量大小 1)优化 MoE 推理,显著降低延迟(3.1-16.7x 提升),支持超大模型(如 900GB Arctic)在单 GPU 上运行。其创新点包括请求级稀疏激活追踪、EAMC 设计和高效缓存算法,克服了传统系统在稀疏性利用和 I/O 瓶颈上的局限。更多细节见原文 arXiv:2401.14361v3 或代码仓库 GitHub。
Fault Tolerance
Gemini
这篇文章提出了 GEMINI,一个分布式训练系统,旨在通过在主机 CPU 内存中存储检查点(checkpoints),实现大型深度学习模型训练中的快速故障恢复。以下是文章的核心内容和贡献的总结:
主要工作
-
问题背景:
- 大型模型训练(如语言模型 PaLM、OPT-175B)因涉及大规模计算资源(如数千 GPU)和长时间训练(数月),故障频繁。例如,OPT 模型训练每天平均发生两次故障,导致大量计算资源浪费(高达 178,000 GPU 小时)。
- 现有检查点方案依赖远程持久存储(如云存储),受限于低带宽(通常 20Gbps),检查点频率低(例如每三小时一次),故障恢复时间长(高达数十分钟),平均浪费时间(包括丢失的训练进度和检查点检索时间)严重影响训练效率。
-
GEMINI 系统设计:
- CPU 内存检查点:GEMINI 利用主机 CPU 内存的高带宽(相比远程存储)存储检查点,支持高频率检查点(理想情况下每迭代一次),显著降低故障恢复时间(从分钟级降至秒级)。
- 分层存储:采用本地 CPU 内存、远程 CPU 内存和远程持久存储的分层设计。故障恢复优先从本地 CPU 内存获取检查点,其次从远程 CPU 内存,最后才从远程持久存储获取。
- 检查点放置策略(Checkpoint Placement Strategy):
- 提出混合放置策略(Mixed Placement Strategy),通过分组和环形放置优化检查点副本分布,最大化从 CPU 内存恢复故障的概率。
- 当机器数 ( N ) 可被副本数 ( m ) 整除时,策略为最优;否则,接近最优,性能差距有界(由定理 1 和推论 1 证明)。
- 流量调度算法(Traffic Scheduling Algorithm):
- 通过检查点分区(Checkpoint Partitioning)和流水线传输(Pipelining),将检查点流量插入训练过程中的网络空闲时间段,最大程度减少检查点流量对训练流量的干扰。
- 在线分析(Online Profiling)前几轮迭代的网络空闲时间,确保检查点流量调度精准。
- 故障恢复模块:
- 区分软件故障(无需替换硬件,直接从本地 CPU 内存恢复)和硬件故障(需替换机器,从其他机器的 CPU 内存或远程存储恢复)。
- 使用分布式键值存储(etcd)和根代理(Root Agent)协调故障检测和机器替换,配合云运营商(如 AWS Auto Scaling Group)实现快速机器替换。
-
实现与实验:
- 在 DeepSpeed 框架上实现 GEMINI,使用 ZeRO-3 设置,部署在 AWS EC2 的 p4d.24xlarge(NVIDIA A100 GPU)和 p3dn.24xlarge(NVIDIA V100 GPU)实例上。
- 测试模型包括 GPT-2(10B-100B)、BERT 和 RoBERTa,数据集为 Wikipedia-en 语料库。
- 与基线方法(Strawman 和 HighFreq)相比:
- 检查点检索时间减少高达 250×;
- 检查点频率提高高达 8×,实现每迭代一次检查点;
- 平均故障恢复时间(浪费时间)减少超过 13×;
- 对训练吞吐量无显著影响(得益于流量交织算法)。
- 可扩展性测试表明,即使在高故障率(每天 8 次故障)或大规模集群(1000 个实例)场景下,GEMINI 仍保持高效,训练有效时间比例高达 91%。
-
关键贡献:
- 首次提出利用 CPU 内存检查点实现大型模型训练的高效故障恢复,解决远程存储带宽瓶颈问题。
- 设计了近似最优的检查点放置策略,最大化 CPU 内存恢复概率(例如,16 个实例、2 个副本时,恢复概率达 93.3%)。
- 提出流量交织算法,通过分区和流水线传输消除检查点流量对训练的干扰。
- 提供了透明的故障恢复机制,支持软件和硬件故障,适应工业级同步训练需求。
意义
GEMINI 通过利用 CPU 内存的高带宽和优化检查点管理,显著降低了大型模型训练的故障恢复开销,同时保持训练吞吐量。其设计对多种并行策略(如数据并行、流水线并行)具有普适性,为高效训练超大规模模型提供了重要解决方案。未来工作包括扩展到其他加速器(如 AWS Trainium)和并行策略。
MoC System
pytorch/torchft: PyTorch per step fault tolerance (actively under development)
使用 torchrun 进行容错分布式训练 — PyTorch 教程 2.7.0+cu126 文档 - PyTorch 深度学习库
这篇文章提出了 MoC-System,一个针对 稀疏混合专家(MoE)模型训练的高效 容错系统,通过优化检查点(checkpoint)机制解决大规模分布式训练中 MoE 模型因参数量激增导致的存储和效率挑战。以下是文章的主要工作和贡献总结:
主要工作
-
研究背景:
- MoE 模型通过稀疏激活的专家(FFN)网络显著增加参数量(可达千亿级),但计算需求与密集模型相当,适合大规模语言模型(LLMs)训练。
- 分布式训练系统扩展至超 10k 节点,故障频发,检查点是主要容错策略,但 MoE 模型的检查点体积巨大(因专家参数占比高,如 GPT-350M-16E 模型中专家参数占 86%),对分布式文件系统造成存储和传输瓶颈。
- 现有容错系统(如 Megatron-DeepSpeed)未针对 MoE 的稀疏性优化,导致检查点开销高($O_{\text{save}}$)、训练迭代延迟大。
-
核心问题与观察:
- MoE 模型检查点大小随专家数量线性增长,远超密集模型,传统方法直接保存所有参数效率低下。
- 微调实验表明,更新非专家参数即可保持模型精度,而专家参数对少量更新的敏感度较低,提示可通过部分专家检查点(Partial Experts Checkpointing, PEC)减少存储需求。
- 现有系统(如 DeepSpeed)在专家并行(EP)场景下缺乏高效的分布式分片策略,检查点负载集中在少数 rank(如 EP-Group-0),导致瓶颈。
-
MoC-System 设计:
- 部分专家检查点(PEC):
- 创新的算法-系统协同设计,仅保存每 MoE 层 $K_{\text{pec}}$ 个专家(而非全部 $N$ 个),非专家参数全部保存。
- 检查点大小从 $C{\text{full}} = (P{\text{ne}} + P{\text{e}}) \cdot (B{\text{w}} + B{\text{o}})$ 减至 $C{\text{pec}} \approx (P{\text{ne}} + \frac{K{\text{pec}}}{N} P{\text{e}}) \cdot (B{\text{w}} + B{\text{o}})$,当 $K{\text{pec}}=1$ 时接近密集模型大小。
- 提出 失.token比例(PLT) 指标,量化 PEC 导致的更新丢失对精度的影响,公式为:
$$
\text{PLT} = \frac{1}{N{\text{moe}}} \sum{l=1}^{N{\text{moe}}} \frac{\sum{j=1}^{N{\text{fault}}} L{i,j}(I{\text{ckpt}}, K{\text{pec}}, F)}{T_i \cdot \text{TopK}_i}
$$ - 实验表明,PLT 低于 3.75% 时,模型精度与无故障情况相当(验证损失波动在 4.8808-4.8856 vs. 4.8851)。
- 专家选择策略:
- 顺序选择:按序轮换保存专家,跨 MoE 层和 EP rank 交错调度,确保负载均衡,降低 PLT。
- 负载感知选择:优先保存未保存更新最多的专家,精度相当但控制成本高,顺序选择更实用。
- 完全分片检查点:
- 针对专家部分:以专家为最小单位,跨多 EP 组均分(如图 7),解决 Megatron-DeepSpeed 仅用 EP-Group-0 保存的问题。
- 针对非专家部分:以层为单位粗粒度分片,提出均等分片和自适应分片(基于 PEC 选择模式动态分配),降低瓶颈 rank 负载(12%-29% 减少)。
- 两级检查点管理:
- 分为 内存快照(snapshot) 和 存储持久化(persist),利用 GPU-to-CPU 高带宽和分布式存储可靠性。
- 引入 $K{\text{snapshot}}$ 和 $K{\text{persist}}$ 区分快照和持久化保存的专家数(如 $K{\text{snapshot}}=4, K{\text{persist}}=1$),减少 PLT。
- 异步检查点与三缓冲机制:快照与前向/反向传播(F\&B)重叠,持久化独立运行,三缓冲(快照、持久化、恢复)确保数据完整性和一致性(图 9)。
- 自适应配置:动态调整 $K{\text{snapshot}}, K{\text{persist}}, I{\text{ckpt}}$,优化快照重叠,降低 $O{\text{save}}$ 和 $I_{\text{ckpt}}$。
- 动态 K 策略:根据故障累积调整 $K_{\text{pec}}$,保持 PLT 低于 3.75%(图 15b)。
- 实现:
- 基于 Megatron-DeepSpeed,支持 ZeRO-2 数据并行(DP)与专家并行(EP),兼容其他并行策略(如 TP、PP)。
- 使用键值对管理检查点模块,支持高效检索。
- 部分专家检查点(PEC):
-
实验评估:
- 模型:GPT-125M-8E、GPT-350M-16E(语言模型,基于 GPT-3),SwinV2-MoE(视觉模型)。
- 数据集:Wikitext-2(预训练 GPT-125M),SlimPajama-627B(预训练 GPT-350M),ImageNet-1K(SwinV2-MoE),Alpaca(微调 OLMoE)。
- 硬件:60 节点集群,每节点 8×A800 SXM4-80GB GPU,模拟 A800/H100 GPU 扩展实验。
- 配置:三种 GPT-350M-16E 训练配置(表 2),DP=8-16,EP=8-16。
- 基线:Megatron-DeepSpeed 默认检查点方法。
- 结果:
- 检查点大小:PEC 使 GPT-350M-16E 检查点大小降至 42.3%($K_{\text{pec}}=1$),总大小减小 57.7%(图 10a)。
- 瓶颈 rank 负载:完全分片策略降低 12%-29%,自适应分片额外减少 3.7%-6.1%(图 10b-d)。
- 检查点时间:优化后检查点时间减少约 50%,快照可完全被 F\&B 覆盖(图 11)。
- 异步检查点:MoC-Async 降低 $O{\text{save}}$ 98.2%-98.9%,训练迭代加速 3.25-5.12×(图 12),$I{\text{ckpt}}$ 减半(如 Case 2 从 2.3 降至 1.2)。
- 扩展性:模拟 128-2048 GPU,MoC-Async 在 DP+EP 和 DP+EP+TP 下保持高效,F\&B/Snapshot 重叠随 GPU 数增加而提升(图 13)。
- 精度:
- 预训练:GPT-350M-16E 验证损失与无故障相当,SwinV2-MoE 测试精度方差 <0.0012%(图 14b)。
- 下游任务:平均精度提升 0.62%-1.08%,BoolQ 任务提升 2.75%-6.97%(表 3),可能因 PEC 类似 dropout 防止过拟合。
- 微调:OLMoE 在 Alpaca 数据集上,FT-PEC 精度(64.06%)接近 FT-Full(64.09%),冻结专家仍提升 2.16%(表 4)。
- 两级 PEC:$K{\text{snapshot}}=4, K{\text{persist}}=1$ 降低 PLT,精度最高(图 15a)。
- 动态 K:有效控制 PLT <3.75%(图 15b)。
-
与现有工作的对比:
- 传统检查点(TRANSOM, CheckMate):针对密集模型,未优化 MoE 的稀疏性和专家分布。
- 数据并行分片(ZeRO-1/2/3, FSDP):未针对 EP 优化,Megatron-DeepSpeed 仅用部分 rank 保存专家。
- 异步检查点(DeepSpeed, CheckFreq):MoE 检查点体积大导致快照无法完全重叠,$I_{\text{ckpt}}$ 较大。
- 部分检查点(DLRM, PS):未探索 MoE 的稀疏性,MoC-System 首次将部分检查点与 MoE 结合。
- MoC-System 通过 PEC、完全分片和两级管理,显著优于基线,适应大规模 MoE 训练。
主要贡献
- MoC-System 设计:
- 提出综合容错系统,整合 PEC、完全分片和两级检查点管理,优化 MoE 模型训练的容错效率。
- PEC 机制:
- 创新算法-系统协同设计,显著减小检查点大小(57.7%),通过顺序选择和 PLT 指标保持精度。
- 完全分片策略:
- 针对专家和非专家部分提出均等和自适应分片,均衡负载,降低瓶颈 rank 开销。
- 两级检查点管理:
- 异步快照与持久化、三缓冲机制、动态 K 策略,降低 $O_{\text{save}}$ 和 PLT,支持高效恢复。
- 广泛实验验证:
- 在语言(GPT)和视觉(SwinV2-MoE)模型上验证效率(98.9% 减小 $O_{\text{save}}$,5.12× 加速)和精度(提升 1.08%),支持预训练和微调,扩展至 2048 GPU。
结论
MoC-System 通过 PEC、完全分片和两级检查点管理,针对 MoE 模型的稀疏性和分布式训练特点,显著降低检查点开销(98.9% 减少,5.12× 加速),保持甚至提升模型精度(1.08% 平均提升)。其创新在于首次将部分检查点与 MoE 稀疏性结合,提出 PLT 指标量化精度影响,并通过自适应策略适应大规模场景。未来工作将进一步探索 LLM 稀疏性,优化训练和容错的协同设计。更多细节见原文 ACM DOI: 10.1145/3676641.3716006。
MoEtion
这篇文章提出了 MoEtion,一个专为大规模 Mixture-of-Experts (MoE) 模型设计的分布式、内存检查点系统,旨在解决传统检查点方法在 MoE 模型训练中的效率和可靠性问题。以下是文章的核心工作和贡献的总结:
主要工作
-
问题背景:
- MoE 模型通过稀疏激活专家(experts),显著增加参数规模(如 DeepSeekV3 的 671B 参数),但计算成本较低。然而,其大规模训练状态(参数和优化器状态)导致传统检查点方法(如 CheckFreq、Gemini)面临三大挑战:
- 运行时-恢复权衡:频繁检查点导致高运行时开销(如 CheckFreq 每迭代检查点慢 27.4×),而延长间隔增加恢复时的重计算成本,降低有效训练时间比率(ETTR)。
- 正确性与效率矛盾:部分专家检查点方法(如 MoC-System)通过轮询检查点减少开销,但恢复时未检查点的专家状态过时,导致令牌丢失和同步训练语义破坏。
- 全局回滚开销:传统方法在故障时要求所有 GPU 回滚到全局检查点,造成大量不必要重计算,尤其在 MoE 模型的大规模集群中。
- MoE 模型通过稀疏激活专家(experts),显著增加参数规模(如 DeepSeekV3 的 671B 参数),但计算成本较低。然而,其大规模训练状态(参数和优化器状态)导致传统检查点方法(如 CheckFreq、Gemini)面临三大挑战:
-
MoEtion 系统设计:
- 稀疏检查点(Sparse Checkpointing):
- 利用专家激活频率的偏差(部分专家更“热门”),在多个迭代(稀疏检查点窗口 ( W_{\text {sparse }} ))内增量检查点模块子集,优先检查点不常激活的专家,减少运行时开销。
- 每个迭代仅检查点部分模块的 FP32 状态(参数和优化器状态),其余模块保存轻量 FP16 参数,完全重叠检查点操作与训练计算,避免训练停顿。
- 稀疏到稠密检查点转换(Sparse-to-Dense Checkpoint Conversion):
- 解决稀疏检查点的时间不一致问题(模块在不同迭代检查点)。恢复时,MoEtion 通过重放微批次(microbatches),从 FP16 参数和 FP32 状态增量重建逻辑一致的稠密检查点。
- 未检查点的模块保持“冻结”状态(仅执行前向传播和输入梯度计算,跳过权重梯度更新),确保同步训练语义和模型准确性。
- 轻量上游激活与梯度日志(Upstream Activation and Gradient Logging):
- 在流水线阶段边界记录前向激活和反向梯度(在上游阶段记录,确保下游故障不影响日志可用性)。
- 故障恢复时,仅受影响的数据并行组回滚到最近稀疏检查点,使用日志局部重放计算,限制重计算范围,避免全局回滚。
- 基于流行度的检查点调度(Popularity-Based Scheduling):
- 动态跟踪专家激活频率,优先检查点不常激活的专家,推迟热门专家检查点以减少恢复时计算开销(冻结状态计算成本约低 33%)。
- 算法 1 计算最小 ( W_{\text {sparse }} ),确保检查点开销适应 GPU 空闲时间,保持无停顿检查点。
- 稀疏检查点(Sparse Checkpointing):
-
实现与实验:
- 在 DeepSpeed 框架上实现 MoEtion,测试模型包括 MoE-LLaVa(2.9B/4E)、QWen(14.3B/64E)、DeepSeek(16.4B/64E)等,使用 NVIDIA A100 GPU 集群。
- 与基线方法(CheckFreq、Gemini、MoC-System)比较:
- 检查点开销降低高达 4×(相较 MoC-System),实现每迭代检查点无停顿。
- 恢复时间减少高达 31×(相较 CheckFreq)和 17×(相较 Gemini),在 MTBF 低至 20 分钟时恢复时间仅 74-267 秒。
- ETTR 保持在 0.956-0.981,即使在高故障率(MTBF=19 分钟)下,优于 CheckFreq(0.765)、Gemini(0.807)、MoC-System(0.168)。
- 在 Google Cloud Platform 6 小时故障轨迹测试中,MoEtion 吞吐量(goodput)比 CheckFreq、Gemini、MoC-System 高 1.25×、1.15×、1.98×。
- 模型准确性测试表明,MoEtion 与无故障基线一致,MoC-System 因令牌丢失导致显著准确性下降(例如 TriviaQA 得分从 54.8 降至 37.5)。
- 内存开销低,平均仅占检查点大小的 17%(FP16 快照 15%,日志 2%)。
-
关键贡献:
- 稀疏检查点:通过增量检查点和流行度调度,消除运行时停顿,支持高频检查点,解决运行时-恢复权衡。
- 稀疏到稠密转换:确保恢复正确性,维持同步训练语义,解决正确性-效率矛盾。
- 局部恢复:通过上游日志限制重计算范围,显著降低恢复延迟,解决全局回滚问题。
- 提供通用性强的解决方案,适应多种 MoE 模型和并行策略(如数据并行、流水线并行、专家并行),无需依赖训练冗余。
意义
MoEtion 针对 MoE 模型的稀疏激活特性,创新性地解决了传统检查点方法在大规模训练中的瓶颈。其高效的检查点和快速的局部恢复机制显著提高了训练效率(高 ETTR),同时保持模型准确性和同步语义。MoEtion 为下一代稀疏激活模型(如大规模 MoE 模型)提供了一个健壮、可扩展的容错解决方案。未来工作包括优化日志内存使用和扩展到其他稀疏模型架构。
APTMoE
APTMoE: Affinity-aware Pipeline Tuning for MoE Models on Bandwidth-constrained GPU Nodes
AuthorsYuanxin WeiJiangsu DuJiazhi JiangXiao ShiXianwei ZhangDan HuangNong XiaoYutong Lu
Artificial Intelligence/Machine Learning
Distributed Computing Heterogeneous Computing Performance Optimization
摘要——近年来,sparsely-gated 混合专家(MoE)架构引起了广泛关注。为了让更多人受益,将 MoE 模型在更具成本效益的集群上进行微调,通常这些集群由有限数量的带宽受限的 GPU 节点组成,这一方法具有较大潜力。然而,由于数据与计算之间的比例增大,将现有的成本效益微调方法应用于 MoE 模型并非易事。本文提出了一种名为 APTMoE 的方法,它采用了感知亲和性的流水线并行技术,在带宽受限的 GPU 节点上微调 MoE 模型。我们提出了一种感知亲和性的卸载技术,通过增强流水线并行性来提高计算效率和模型大小,并且从分层加载策略和需求优先调度策略中受益。为了提高计算效率并减少数据移动量,分层加载策略设计了三个加载阶段,并在这些阶段中高效地将计算分配到 GPU 和 CPU,利用不同级别的专家流行度和计算亲和性。为了缓解三个加载阶段之间的相互干扰并最大化带宽利用率,需求优先调度策略主动并动态地协调加载执行顺序。实验表明,APTMoE 在大多数情况下优于现有方法。特别地,APTMoE 成功地在 4 台 Nvidia A800 GPU(40GB)上微调了一个 61.2B 的 MoE 模型,相较于现有最先进方法(SOTA)提高了最多 33%的吞吐量。
关键词——大规模语言模型,硬件加速,高性能计算
MoELoRA
这篇文章提出了一种名为 MoELoRA 的新型参数高效微调(PEFT)方法,用于优化大型语言模型(LLMs)。MoELoRA 将低秩适应(LoRA)与专家混合(MoE)框架结合,通过对比学习解决 MoE 中的随机路由问题。与传统 PEFT 方法(如 LoRA)相比,MoELoRA 在参数量相同的情况下性能更优,在数学推理任务中平均比 LoRA 高 4.2%,在常识推理任务中也展现出竞争力,与 1750 亿参数的 GPT-3.5 相比表现接近。研究在 11 个数据集上进行了实验,并通过消融实验验证了对比学习的有效性。
引言
本节介绍了大型语言模型微调因参数量巨大而面临的高计算成本问题,概述了 PEFT 方法(如 LoRA)的发展,并提出 MoELoRA,通过结合 LoRA 和 MoE,并利用对比学习提升专家模块在下游任务中的专精能力。
相关工作
回顾了 PEFT 方法(如 LoRA、AdaLoRA、QLoRA)、MoE 架构(如稀疏门控 MoE、Switch-Transformer)以及对比学习在计算机视觉和自然语言处理中的应用。MoELoRA 被定位为将 MoE 融入 PEFT 的创新方法,弥补现有方法的不足。
提出的方法
MoELoRA 框架
MoELoRA 将多个 LoRA 模块视为 MoE 中的专家,通过门控网络动态选择和组合 LoRA 输出以适应特定任务,通过稀疏激活保持计算效率。
MoELoRA 的挑战
主要挑战包括负载不平衡(令牌分配不均)和随机路由(专家缺乏专精),这些问题影响模型性能。
辅助损失
为解决上述问题,MoELoRA 引入了:
- 负载平衡损失:促进令牌在专家间的均匀分配。
- 专家对比损失:通过将同一专家的输出视为正样本、不同专家的输出视为负样本,鼓励专家学习不同特征。
实验
实验设置
实验基于 LLaMA-7B 模型,在 6 个数学推理数据集(例如 AddSub、AQuA、gsm8k)和 5 个常识推理数据集(例如 ARC-C、BoolQ)上进行。MoELoRA 和 LoRA 配置为相同可训练参数量(1890 万)。
主要结果
MoELoRA 在数学推理任务中平均比 LoRA 高 4.2%,在常识推理任务中高 1.0%,与 GPT-3.5(1750 亿参数)相比具有竞争力,尽管参数量远少。
消融实验
消融实验表明,专家对比损失使数学推理任务性能提升 3.0%,常识推理任务提升 0.9%。选择每个令牌的 top-2 专家相较于 top-1 或 top-4 效果最佳。
分析
为何常识任务的改进不明显?
常识任务高度依赖预训练知识,微调效果受限于模型的知识储备,MoELoRA 的改进因此较小。
令牌路由追踪
分析显示,特定专家擅长处理数值令牌,但在较深层由于注意力机制影响,路由趋于均匀。数据集令牌频率差异使负载平衡具有挑战性。
结论与未来工作
MoELoRA 在数学推理任务中显著优于 LoRA,在常识推理任务中也具竞争力。未来可探索将常识任务重构为知识编辑任务,或冻结不同任务的 LoRA 模块,仅训练门控网络。
参考文献
列举了支持 MoELoRA 方法的大型语言模型、PEFT、MoE 和对比学习相关研究。
常识任务案例研究
通过案例分析 ARC、BoolQ 等基准测试,说明常识任务对预训练知识的依赖导致微调改进有限。
负载均衡策略
从 GShard 到 DeepSeek-V3,我们不难发现负载均衡已经成为 MoE 模型能否取得成功的关键因素之一。GShard 提出了 top-2 gating 和容量限制的雏形;Switch 用 top-1 gating 证明了简单路由也能支撑大规模;GLaM 强调能效;DeepSpeed-MoE 则兼顾了训练和推理;ST-MoE 用 z-loss 解决稳定性;Mixtral 强调路由的时间局部性;OpenMoE 暴露了末端 token 掉队等问题;JetMoE 尝试 dropless;DeepSeekMoE 做了细粒度拆分和共享专家;最后,DeepSeek-V3 又带来了更“轻量级”的偏置调节策略。
主要启示:负载均衡永远在动态平衡——过度干预会损害模型本身的学习目标,完全无视则会出现专家闲置或拥堵。往后我们大概率会看到更多 HPC 技巧与更灵活的 gating 机制,以及更多针对推理部署的优化。MoE 研究还在不断前进,我对未来的发展方向也非常期待。
关于 MoE 大模型负载均衡策略演进的回顾:坑点与经验教训 - 知乎
PEFT
PEFT的主要方法包括Prefix Tuning(在模型输入层添加可训练的前缀嵌入),LoRA(通过低秩矩阵近似模型参数更新),以及Adapter Tuning(在模型层间插入小型神经网络adapters)。
-
Prefix Tuning
Prefix Tuning通过在模型输入层之前添加可训练的前缀嵌入(prefix embeddings)来影响模型的输出。这些前缀嵌入与原始输入拼接后一起输入到模型中,而模型的其他部分保持不变。 -
LoRA(Low-Rank Adaptation)
LoRA通过在原始模型权重矩阵附近添加一个低秩矩阵来近似模型参数的更新。这种方法通过优化这个低秩矩阵来实现微调,而不需要修改原始模型参数。 -
Adapter Tuning
Adapter Tuning通过在模型的每个层之间插入小型神经网络(称为adapters)来实现微调。这些adapters包含可训练的权重,而模型的原始参数保持不变。
Parameter-Efficient Fine-Tuning:PEFT技术综述:算法的进展与挑战
Parameter-Efficient Fine-Tuning:PEFT技术综述:算法的进展与挑战 - 知乎
一文彻底搞懂大模型参数高效微调(PEFT)-CSDN博客
LoRA MoE
由于大模型全量微调时的显存占用过大,LoRA、Adapter、IA 这些参数高效微调(Parameter-Efficient Tuning,简称 PEFT)方法便成为了资源有限的机构和研究者微调大模型的标配。PEFT 方法的总体思路是冻结住大模型的主干参数,引入一小部分可训练的参数作为适配模块进行训练,以节省模型微调时的显存和参数存储开销。
传统上,LoRA 这类适配模块的参数和主干参数一样是稠密的,每个样本上的推理过程都需要用到所有的参数。近来,大模型研究者们为了克服稠密模型的参数效率瓶颈,开始关注以 Mistral、DeepSeek MoE 为代表的混合专家(Mixure of Experts,简称 MoE)模型框架。
在该框架下,模型的某个模块(如 Transformer 的某个 FFN 层)会存在多组形状相同的权重(称为专家),另外有一个路由模块(Router) 接受原始输入、输出各专家的激活权重,最终的输出为:
如果是软路由(soft routing),输出各专家输出的加权求和;
如果是离散路由(discrete routing),即 Mistral、DeepDeek MoE 采用的稀疏混合专家(Sparse MoE)架构,则将 Top-K(K 为固定的 超参数,即每次激活的专家个数,如 1 或 2)之外的权重置零,再加权求和。
在 MoE 架构中,每个专家参数的激活程度取决于数据决定的路由权重,使得各专家的参数能各自关注其所擅长的数据类型。在离散路由的情况下,路由权重在 TopK 之外的专家甚至不用计算,在保证总参数容量的前提下极大降低了推理的计算代价。
那么,对于已经发布的稠密大模型的 PEFT 训练,是否可以应用 MoE 的思路呢?近来,笔者关注到研究社区开始将以 LoRA 为代表的 PEFT 方法和 MoE 框架进行结合,提出了 MoV、MoLORA、LoRAMOE 和 MOLA 等新的 PEFT 方法,相比原始版本的 LORA 进一步提升了大模型微调的效率。
本文将解读其中三篇具有代表作的工作,以下是太长不看版:
MoV 和 MoLORA 1:提出于 2023 年 9 月,首个结合 PEFT 和 MoE 的工作,MoV 和 MoLORA 分别是 IA 和 LORA 的 MOE 版本,采用 token 级别的软路由(加权合并所有专家的输出)。作者发现,对 3B 和 11B 的 T5 大模型的 SFT,MoV 仅使用不到 1% 的可训练参数量就可以达到和全量微调相当的效果,显著优于同等可训练参数量设定下的 LoRA。
LoRAMOE 2:提出于 2023 年 12 月,在 MoLORA 1 的基础上,为解决微调大模型时的灾难遗忘问题,将同一位置的 LoRA 专家分为两组,分别负责保存预训练权重中的世界知识和微调时学习的新任务,并为此目标设计了新的负载均衡 loss。
MOLA 3:提出于 2024 年 2 月,使用离散路由(每次只激活路由权重 top-2 的专家),并发现在每一层设置同样的专家个数不是最优的,增加高层专家数目、降低底层专家数目,能在可训练参数量不变的前提下,明显提升 LLaMa-2 微调的效果。
【2025】LoRA + MoE,大模型微调新范式,从零基础到精通,精通收藏这篇就够了!_moe lora-CSDN博客
原文链接:https://blog.csdn.net/leah126/article/details/145872040
MoE Lora Boost
LoRA遇上MoE,大模型再也不会健忘了 - 知乎
liuqidong07/MOELoRA-peft: [SIGIR'24] The official implementation code of MOELoRA.
Ablustrund/LoRAMoE: LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment
THUDM/MoELoRA_Riemannian: Source code of paper: A Stronger Mixture of Low-Rank Experts for Fine-Tuning Foundation Models. (ICML 2025)
关键要点
- 研究表明,有使用 LoRA 微调 Mixture of Experts (MoE) 模型的工作。
- 证据显示,一些工作确实涉及加速或效率提升。
直接回答
概述
是的,有研究使用 LoRA(低秩适配)来微调 Mixture of Experts(专家混合,MoE)模型,并且其中一些研究还关注加速或效率的提升。这些工作旨在让大型语言模型在特定任务上表现更好,同时减少资源消耗。
LoRA 与 MoE 的结合
LoRA 是一种通过少量参数调整预训练模型的方法,特别适合适应新任务。MoE 则是一种架构,通过多个专家模型和门控机制选择适合的专家来处理输入。研究如 MixLoRA 和 MOLE 将 LoRA 集成到 MoE 中,例如在模型的 feed-forward 网络中插入 LoRA 专家,或将多个 LoRA 视为专家并通过门控函数组合。
加速与效率
一些研究明确提到加速和效率的改进。例如,MixLoRA 声称在训练和推理中减少了 40% 的 GPU 内存消耗和 30% 的令牌计算延迟。MOLE 强调以最小的计算开销保持灵活性,而 X-LoRA 通过冻结模型和适配器减少可训练参数,从而提高效率。
更多详情可参考相关论文和资源,例如 MixLoRA 论文 和 X-LoRA GitHub。
详细报告
引言
本文探讨了使用 LoRA(Low-Rank Adaptation,低秩适配)微调 Mixture of Experts (MoE,专家混合) 模型的研究工作,并分析其中是否涉及加速或效率提升的相关内容。LoRA 是一种高效的微调方法,特别适用于大型语言模型(LLMs),而 MoE 则通过多个专家模型和门控机制实现任务的分布式处理。结合这两者的研究近年来受到关注,尤其是在资源效率和性能优化方面。
LoRA 与 MoE 结合的研究概览
从近期研究来看,有多篇论文和项目明确探讨了 LoRA 与 MoE 的结合。以下是几个代表性工作:
-
MixLoRA:一项名为 "MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA-based Mixture of Experts" 的研究(arXiv:2404.15159)提出了一种资源高效的稀疏 MoE 模型。MixLoRA 在冻结的预训练密集模型的 feed-forward 网络块中插入多个基于 LoRA 的专家,并使用 top-k 路由器选择合适的专家。此外,它还通过独立的注意力层 LoRA 适配器来增强性能。实验结果显示,在多任务学习中,MixLoRA 比现有最先进的参数高效微调(PEFT)方法提高了约 9% 的准确率。
-
Mixture of LoRA Experts (MOLE):微软研究院的一项工作(Microsoft Research)提出了 MOLE 方法,将多个训练好的 LoRA 视为专家,并通过可学习的门控函数学习最佳组合权重,以适应特定领域目标。MOLE 强调在保持灵活性的同时实现计算开销最小化,特别适用于自然语言处理(NLP)和视觉与语言任务。
-
X-LoRA:一个名为 "X-LoRA: Mixture of LoRA Experts" 的项目(GitHub),其论文为 arXiv:2402.07148。X-LoRA 通过学习 LoRA 适配器的缩放值实现对 LoRA 专家的密集门控。所有 LoRA 适配器和基础模型都被冻结,这使得细调过程非常高效,因为可训练参数数量较少。项目强调了其在 HuggingFace Transformers 模型上的易用性和高效性。
-
Retrieval-Augmented Mixture of LoRA Experts (RAMLE):另一篇论文(AI Models FYI)提出 RAMLE,将检索增强的 LLM 与 MoE 架构结合,每个专家是一个 LoRA 模型。研究表明,RAMLE 在各种任务上优于对整个 LLM 进行微调,同时更高效,存储空间需求也更低。
-
社区讨论:在 Reddit 上有一个关于 Mixture of LoRA Experts 的讨论(Reddit),提出了一种想法:从 7B 或 13B 的预训练模型开始,通过添加多个小型 LoRA 模块作为专家来扩展模型容量,理论上可以在低计算成本下增加三倍的参数容量。
-
其他相关方法:Scale 的一篇博客(Scale Blog)讨论了使用 MoE 和 PEFT 的高效微调方法,如 MoLoRA 和 Mixture of Vectors (MoV),这些方法也涉及 LoRA 和 MoE 的结合,强调了在 LLaMA-2 模型上的应用。
加速与效率的分析
在这些工作中,许多研究都关注加速或效率的提升,以下是具体细节:
-
MixLoRA 的效率与加速:MixLoRA 特别提到其设计适合消费级 GPU(小于 24GB 内存),并在训练和推理中减少了 40% 的 GPU 内存消耗和 30% 的令牌计算延迟。这表明它在资源利用和计算速度上都有显著改进,特别适合资源受限的环境。
-
MOLE 的效率:MOLE 强调通过层次化控制和无限制的分支选择实现高效的 LoRA 组合,实验验证了其在 NLP 和视觉与语言任务中的计算开销最小化。虽然没有具体数字,但其设计目标是保持灵活性,同时减少计算成本。
-
X-LoRA 的效率:X-LoRA 通过冻结所有 LoRA 适配器和基础模型,显著降低了可训练参数数量,从而实现了高效的细调。项目描述中提到“高效细调:低可训练参数计数”,这表明其在资源效率上有优势。
-
RAMLE 的效率:RAMLE 声称比对整个 LLM 进行微调更高效,且存储空间需求更低,特别适合需要共享和上传的场景。这表明其在计算和存储效率上都有改进。
-
社区建议的效率:Reddit 上的讨论提出,通过将 LoRA 专家存储在快速 SSD 上并缓存常用专家,可以在生成推理中以低计算成本扩展模型容量,这是一种潜在的效率提升方式。
-
MoV 和 MoLoRA 的效率:Scale 的博客提到 MoV 和 MoLoRA 构建于类似的基础概念上,通过路由机制组合多个专家向量,强调了在微调过程中的效率,特别是对 LLaMA-2 模型的适应。
讨论与总结
综合来看,LoRA 与 MoE 的结合在近期研究中得到了广泛探索,特别是在多任务学习和资源效率方面。MixLoRA、MOLE 和 X-LoRA 代表了不同的实现方式,分别通过插入 LoRA 专家、组合 LoRA 权重和冻结模型来实现高效微调。加速和效率的提升是这些工作的共同关注点,特别是在 GPU 内存消耗、计算延迟和可训练参数数量方面。
以下表格总结了主要工作的关键特征:
| 工作名称 | LoRA 与 MoE 的结合方式 | 效率/加速的具体改进 |
|---|---|---|
| MixLoRA | 在 feed-forward 网络插入 LoRA 专家,使用 top-k 路由器 | 减少 40% GPU 内存消耗,30% 令牌计算延迟 |
| MOLE | 将 LoRA 视为专家,通过门控函数组合 | 保持灵活性,最小化计算开销(无具体数字) |
| X-LoRA | 学习 LoRA 适配器缩放值,密集门控 | 冻结模型,低可训练参数计数,提升细调效率 |
| RAMLE | 检索增强 LLM,与 LoRA 专家结合 | 比全模型微调更高效,存储空间需求低 |
| 社区讨论 (Reddit) | 添加小型 LoRA 模块作为专家,扩展容量 | 理论上低计算成本扩展三倍参数容量,存储在 SSD 上 |
| MoV/MoLoRA (Scale) | 通过路由机制组合专家向量 | 强调 LLaMA-2 模型的微调效率,无具体加速数据 |
这些研究为 LoRA 微调 MoE 模型提供了多种实现路径,并展示了在加速和效率方面的潜力,特别适合资源受限的场景或需要高性能的多任务应用。
关键引用
- MixLoRA Enhancing Large Language Models Fine-Tuning with LoRA-based Mixture of Experts
- Mixture of LoRA Experts Microsoft Research Publication
- X-LoRA Mixture of LoRA Experts GitHub Repository
- Retrieval-Augmented Mixture of LoRA Experts for Uploadable Machine Learning AI Research Paper
- Mixture of LoRA Experts Discussion on Reddit
- Efficient and Effective Fine-Tuning Using Mixture-of-Experts PEFT Scale Blog
- X-LoRA Mixture of LoRA Experts Research Paper
稀疏
是的,已有研究利用上下文稀疏性,将关键计算部分动态调度到 GPU,以提升推理效率。这种方法在系统层面上结合了模型结构优化和硬件资源管理,以下是两个代表性的工作:
1. DejaVu:基于上下文稀疏性的动态推理系统
核心思想:DejaVu 利用低成本算法,在推理过程中实时预测每层的上下文稀疏性,识别出对当前输入最关键的注意力头和前馈网络单元。随后,系统仅激活这些关键组件,并将其调度到 GPU 上执行,其余部分则保持非激活状态,从而减少不必要的计算。(arXiv)
系统实现:DejaVu 采用异步且硬件感知的实现方式,确保在不影响模型质量和上下文学习能力的前提下,加速大语言模型的推理过程。(X-MOL)
性能提升:在 OPT-175B 模型上,DejaVu 将推理延迟减少了两倍以上,相较于 FasterTransformer,实现了更高的加速比。
参考资料:
2. Dynamic-LLaVA:多模态大模型的动态稀疏化推理框架
核心思想:Dynamic-LLaVA 是首个同时对视觉和语言上下文进行稀疏化处理的多模态大模型推理加速框架。该框架在预填充和解码阶段,动态识别并保留对当前任务最重要的视觉和文本 token,将关键计算任务调度到 GPU 上执行,从而提高推理效率。(每时AI, 冷月清谈)
系统实现:Dynamic-LLaVA 引入图像预测器和输出预测器,分别用于判断视觉 token 和文本 token 的重要性。通过这种方式,系统能够在不同推理模式下(如有无 KV Cache)实现高效的稀疏化推理。(冷月清谈)
性能提升:在预填充阶段,计算开销减少约 75%;在无 KV Cache 的解码阶段,计算开销减少约 50%;在有 KV Cache 的解码阶段,GPU 显存占用减少约 50%。
参考资料:
🔧 系统层面的优化策略
基于上述研究,以下是一些系统层面的优化策略,您可以考虑在自己的研究中进一步探索:
-
动态专家调度:根据输入内容的复杂度,动态选择激活的专家模块,避免不必要的计算。
-
异构计算资源分配:将高频激活的模型组件部署在 GPU 上,低频组件部署在 CPU 上,充分利用异构计算资源。
-
稀疏化训练与微调:在训练和微调阶段,引入稀疏性约束,促进模型学习到更高效的表示。
如果您有兴趣进一步探讨这些方向,或需要关于特定系统优化策略的详细信息,欢迎继续交流!
mLoRA
这篇文章介绍了一种名为 mLoRA 的系统,旨在高效地对多个 LoRA(低秩适配)适配器进行微调,特别是在多 GPU 和多机器环境下。以下是文章的主要贡献和内容总结:
主要工作
-
研究背景:
- 大型语言模型(LLMs)的微调成本高昂,传统全权重微调需要更新所有参数,计算和内存开销巨大。
- LoRA 是一种参数高效微调(PEFT)方法,通过冻结预训练模型权重,仅更新低秩矩阵(适配器权重),显著降低资源需求。
- 现有的模型并行方案(如张量并行和管道并行)在多 GPU 环境下训练多个 LoRA 适配器时,面临高通信开销和 GPU 利用率低的问题(如管道气泡)。
-
mLoRA 系统设计:
- 目标:提高多 LoRA 适配器并行微调的效率,降低训练延迟,提高吞吐量,并充分利用多 GPU 的计算和内存资源。
- 核心组件:
- LoRAPP(LoRA-aware Pipeline Parallelism):
- 提出了一种新的管道并行策略,利用 LoRA 适配器训练的独立性(无需同步梯度),消除管道气泡,实现“零气泡”状态。
- 通过在不同 LoRA 适配器之间交错执行前向和后向传播,最大化 GPU 利用率。
- 支持通信与计算重叠,隐藏 I/O 延迟,进一步提高效率。
- BatchLoRA 运算符:
- 将多个 LoRA 适配器的训练数据合并为一个大批量,执行一次矩阵乘法(而非逐个适配器计算),减少 GPU 内核启动开销。
- 通过计算图修剪优化后向传播,减少内存分配和复制开销,降低峰值内存使用量。
- 任务调度器:
- 采用优先级调度策略,满足用户优先级需求。
- 通过在线内存建模,动态估计任务内存需求,最大化并发任务数,同时避免内存溢出(OOM)错误。
-
关键技术创新:
- LoRAPP:通过利用 LoRA 适配器训练的独立性,消除传统管道并行(如 GPipe)中的气泡问题。相比 GPipe,LoRAPP 的气泡比例可降至零,当适配器数量大于等于 GPU 数量时,管道完全利用。
- BatchLoRA:通过批量处理多个 LoRA 适配器的数据,减少内核启动次数(从 ( k\alpha + k\beta ) 降至 ( \alpha + k\beta )),显著降低训练时间。
- 内存优化:共享预训练模型权重,节省 ((L-1)W\theta) 的内存(其中 (L) 为适配器数量,(W\theta) 为模型权重大小)。
- 通信优化:LoRAPP 的通信量为 (2(D-1)Bh)(其中 (D) 为 GPU 数量,(B) 为输入数据量,(h) 为隐藏层大小),低于张量并行(TP),并通过通信与计算重叠隐藏延迟。
-
实验评估:
- 实验设置:
- 使用 Llama-2-13B、Llama-2-7B 和 TinyLlama-1.1B 模型。
- 在单机多 GPU(4 或 8 个 NVIDIA RTX A6000,48GB)和多机多 GPU(8 个 NVIDIA RTX 3090,24GB,1Gbps 网络)环境下测试。
- 工作负载:使用 GSM8K 数据集,批大小 8,序列长度 512,LoRA 秩 16,10 个 epoch。
- 性能结果:
- 单 GPU 环境:BatchLoRA 减少高达 8% 的平均任务完成时间(1.1B 模型),因减少了内核启动开销。
- 多 GPU 环境:
- mLoRA 比 FSDP(Fully Sharded Data Parallelism)减少高达 45% 的微调时间(Llama-2-7B,fp32,4 个 A6000 GPU)。
- 支持同时微调两个 Llama-2-13B 模型(FSDP 因内存限制无法实现)。
- 在多机环境下,mLoRA 比 1F1B(一种管道并行策略)节省 30% 的平均任务完成时间。
- 吞吐量:
- 对于 1.1B 模型,mLoRA 吞吐量比 FSDP 高 75%,比 TP 高 86%。
- 对于 7B 模型,比 FSDP 高 35%,比 TP 高 58%。
- 对于 13B 模型,FSDP 因 OOM 失败,而 mLoRA 比 TP 高 46%。
- 可扩展性:mLoRA 的吞吐量随 GPU 数量(2 到 8)线性增加。
- 内存建模:内存估计模型的平均绝对百分比误差(MAPE)约为 0.25%,有效避免 OOM。
- 模型收敛:mLoRA 的损失曲线与 PEFT 相当,性能无损。
- 生产环境部署:在 AntGroup 生产环境中,mLoRA 减少了 30% 的超参数选择时间。
- 实验设置:
-
相关工作对比:
- 与其他 LoRA 微调方法:mLoRA 支持标准 LoRA 实现,并可扩展到其他 LoRA 变体(如 AdaLoRA、MixLoRA、MoeLoRA)。
- 与其他多任务系统:与 Punica 和 S-LoRA 不同,mLoRA 针对训练优化,而非仅推理,且解决了后向传播中的冗余运算问题。
- 与通用并行优化:相比 DeepSpeed-ZERO、FSDP(数据并行)和 GPipe、Megatron-LM(模型并行),mLoRA 通过 LoRAPP 消除管道气泡,降低通信量。
- 与 GPU 内核优化:相比 CUDA Graph 和深度学习编译器,mLoRA 通过 BatchLoRA 处理动态形状数据,减少内核启动开销。
-
结论:
- mLoRA 是一种高效的多 LoRA 适配器微调系统,通过 LoRAPP 和 BatchLoRA 显著提升训练效率和 GPU 利用率。
- 其创新点包括零气泡管道并行、批量运算减少内核启动开销、通信与计算重叠以及动态内存调度。
- mLoRA 在成本效益高的 GPU 上实现高效微调,使 LLMs 更易于访问,已在 AntGroup 生产环境中部署。
与 MoE 和加速的关系
- 与 MoE 的关系:
- 文章未直接提及 MoE(专家混合)架构,但提到 MixLoRA 和 MoeLoRA(参考文献 [47, 56])作为相关 LoRA 变体。MixLoRA 将 LoRA 适配器作为专家插入 feed-forward 网络,MoeLoRA 可能进一步结合 MoE 思想,但本文未深入探讨。
- mLoRA 的设计理念(如共享基模型、独立训练适配器)与 MoE 的专家并行处理有相似之处,但其核心是针对 LoRA 微调的并行优化,而非 MoE 架构的直接应用。
- 加速工作:
- mLoRA 明确聚焦于加速多 LoRA 适配器的微调:
- LoRAPP:通过消除管道气泡和重叠通信与计算,减少 30%-45% 的微调时间。
- BatchLoRA:通过批量处理减少内核启动开销,单 GPU 环境下减少高达 8% 的训练时间,多 GPU 环境下额外提升 10% 性能。
- 内存效率:共享基模型权重,节省 ((L-1)W_\theta) 内存,支持更大模型(如两个 Llama-2-13B)在有限 GPU 上微调。
- 通信优化:通信量低于 TP,且通过重叠隐藏延迟。
- 这些优化使 mLoRA 在单机和多机环境下均显著提升吞吐量和降低延迟,特别适合资源受限场景。
总结
mLoRA 是一个针对多 LoRA 适配器微调的高效系统,通过 LoRAPP 和 BatchLoRA 实现零气泡管道并行和内核启动优化,显著降低训练时间(最高 45%)和内存需求,同时保持模型性能。其虽未直接聚焦 MoE,但与 MixLoRA 和 MoeLoRA 的思想有一定关联,且在加速和效率提升方面表现突出。更多细节可参考原文 arXiv:2312.02515v2。
当然可以!以下是近年来在 Mixture of Experts (MoE) 微调方面的一些代表性工作,这些研究在参数高效性、专家路由机制、系统优化等方面取得了显著进展,为您在系统层面(如 CPU-GPU 协同加速)开展研究提供了坚实的基础。
🔬 代表性 MoE 微调研究工作
1. MoELoRA – 对比学习引导的专家分化
- 核心思想:将 LoRA 视为 MoE 架构中的专家,利用对比学习增强专家之间的差异性,减少随机路由带来的干扰。
- 实验结果:在数学推理任务中,MoELoRA 相较于传统 LoRA 提升了 4.2% 的性能,且在多个基准测试中表现接近 GPT-3.5。
- 论文链接: (arXiv)(arxiv.deeppaper.ai)
2. PT-MoE – 将 MoE 集成到 Prompt Tuning 中
- 方法概述:结合矩阵分解与 MoE 路由机制,提升 Prompt Tuning 的效率和性能。
- 性能提升:在问答和数学问题求解任务中,PT-MoE 分别比传统 Prompt Tuning 提高了 1.49 和 10.75 个百分点,同时参数数量减少了 25%。
- 论文链接: (arXiv)(arXiv)
3. S'MoRE – 结构化残差专家混合模型
- 创新点:引入层次化低秩分解的残差专家,通过图神经网络(GNN)建模专家之间的结构关系,提升模型的表达能力和灵活性。
- 论文链接: (arXiv)
4. PERFT – 参数高效的路由微调框架
- 框架特点:将参数高效微调(PEFT)模块直接集成到 MoE 架构中,提供灵活可扩展的微调策略。
- 实验验证:在 OLMoE-1B-7B 和 Mixtral-8×7B 等模型上,PERFT 展示了良好的适应性和可扩展性。
- 论文链接: (arXiv)(arXiv)
5. MiLoRA – 高效的低秩专家混合微调方法
🧠 研究启发与系统层面思考
上述工作主要聚焦于模型结构和微调策略的优化,在系统层面(如 CPU-GPU 协同加速)仍有广阔的研究空间。以下是一些可能的研究方向:
-
专家调度与缓存优化:设计高效的专家调度策略,将活跃专家加载到 GPU,冷专家保留在 CPU 端,利用统一的专家缓存调度策略(如 LRU、Greedy)优化内存使用。
-
异步训练与更新机制:探索异步训练策略,对不同专家采用异步更新或延迟更新,减少全量梯度同步的开销,提升训练吞吐量。
-
动态专家迁移机制:根据专家的活跃度,动态调整专家在 CPU 和 GPU 之间的分布,实现资源的最优配置。
-
系统级基准测试与仿真器开发:构建用于模拟 MoE 不同路由策略、批次大小、专家数量等对系统性能影响的基准测试系统,为系统设计提供可视化参考。
如果您有兴趣进一步探讨这些方向,或需要关于特定系统优化策略的详细信息,欢迎继续交流!
“上下文稀疏性”(Contextual Sparsity)是指在大语言模型(LLM)推理过程中,针对特定输入,模型的某些部分(如注意力头、前馈网络、激活单元等)并非全部参与计算,而是仅激活其中的一小部分。这种稀疏的激活模式可以在保持模型性能的同时,显著减少计算资源的消耗。(哔哩哔哩)
🔍 上下文稀疏性的核心概念
在传统的 LLM 推理中,模型的所有组件通常都会被激活,以处理输入序列。然而,研究发现,对于特定的输入内容,模型并不需要全部的计算资源即可生成高质量的输出。例如,在处理某些简单的句子时,模型可能只需激活部分注意力头和前馈网络单元。这种现象就是“上下文稀疏性”。
🧠 相关研究与应用
-
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
- 主要贡献:该研究提出了一种名为 DejaVu 的系统,能够在推理时动态预测每一层的稀疏性,并仅激活必要的模型组件,从而加速推理过程。
- 性能提升:在 OPT-175B 模型上,DejaVu 将推理延迟减少了两倍以上,相较于 Hugging Face 实现版本,提升达六倍。 (哔哩哔哩)
-
Dynamic-LLaVA: Efficient Multimodal Large Language Models via Dynamic Vision-language Context Sparsification
- 主要贡献:该研究提出了 Dynamic-LLaVA 框架,首次实现了同时对视觉和语言上下文的稀疏化处理,显著降低了多模态大模型的计算开销。
- 性能提升:在预填充阶段,计算开销减少约 75%;在无 KV Cache 的解码阶段,计算开销减少约 50%;在有 KV Cache 的解码阶段,GPU 显存占用减少约 50%。 (机器之心)
-
Sirius: Contextual Sparsity with Correction for Efficient LLMs
- 主要贡献:该研究提出了 Sirius 方法,通过上下文稀疏性校正,恢复稀疏模型在复杂推理任务中的性能,进一步提升了稀疏模型的实用性。 (CSDN 博客)
⚙️ 系统层面的优化策略
在系统设计中,利用上下文稀疏性可以实现以下优化:
-
动态专家调度:根据输入内容的复杂度,动态选择激活的专家模块,避免不必要的计算。
-
异构计算资源分配:将高频激活的模型组件部署在 GPU 上,低频组件部署在 CPU 上,充分利用异构计算资源。
-
稀疏化训练与微调:在训练和微调阶段,引入稀疏性约束,促进模型学习到更高效的表示。
如果您对上下文稀疏性在系统优化中的具体应用有更深入的兴趣,或者希望了解如何在实际项目中实现这些策略,欢迎继续交流!