
LLM Parameter Estimation
- High Performance Computing
- 2025-05-12
- 535 Views
- 0 Comments
- 518 Words
大模型参数量估计推导
1. 为什么需要估计参数量?
大模型(如 BERT、GPT、LLaMA)参数量通常亿级甚至万亿级,估计参数量有助于:
- 硬件需求评估:参数量影响内存和计算资源需求。
- 模型规模比较:参数量反映复杂度和潜在能力。
- 优化设计:在资源有限时,调整结构以平衡性能和效率。
参数量由模型的各个组成部分(层、权重矩阵、偏置等)决定,以下以 Transformer 架构为例推导。
2. Transformer 架构核心组件
Transformer 模型由多个堆叠的 Encoder 和 Decoder 组成(以 GPT 为例,通常只有 Decoder)。一个 Transformer 层包含:
- 多头自注意力(Multi-Head Self-Attention, MHSA):计算查询(Query)、键(Key)、值(Value)矩阵。
- 前馈神经网络(Feed-Forward Network, FFN):逐位置的 MLP。
- 归一化层(Layer Normalization):标准化输入。
- 残差连接:不引入额外参数。
此外,模型还包括:
- 嵌入层(Embedding Layer):将 token 映射到高维向量。
- 输出层:将隐藏状态映射到词汇表(常共享嵌入层权重)。
我们将逐一计算每个部分的 参数量。
3. 参数量推导

注意:部分模型(如 RoPE)不引入可学习的位置编码参数。
3.2 单层 Transformer 参数量
一个 Transformer 层包含以下部分:



3.3 所有 Transformer 层参数量

4. 简化公式(近似估计)

5. 示例:BERT-base 参数量估计

5.1 嵌入层

5.2 单层 Transformer

5.3 所有层

5.4 输出层
BERT 共享嵌入层和输出层权重,仅偏置:
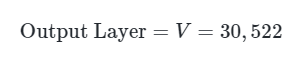5.5 总参数量
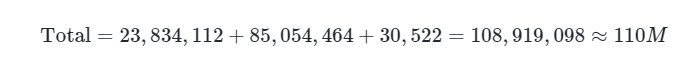
结果:BERT-base 参数量约为 1.1 亿,与官方一致。
6. 扩展:其他模型估计

7. 注意事项
- 权重共享:嵌入层和输出层共享时,需调整计算。
- 优化技术:如 LoRA、量化影响存储需求,但不改变原始参数量。
- 变体架构:如 Linformer、Performer 可能减少参数。
- 偏置和 LayerNorm:大模型中占比小,小模型中不可忽略。
8. 总结
