
Linux如何把运行程序从一个CPU核切换到另一个核
- OS
- 2025-05-12
- 920 Views
- 0 Comments
- 6365 Words
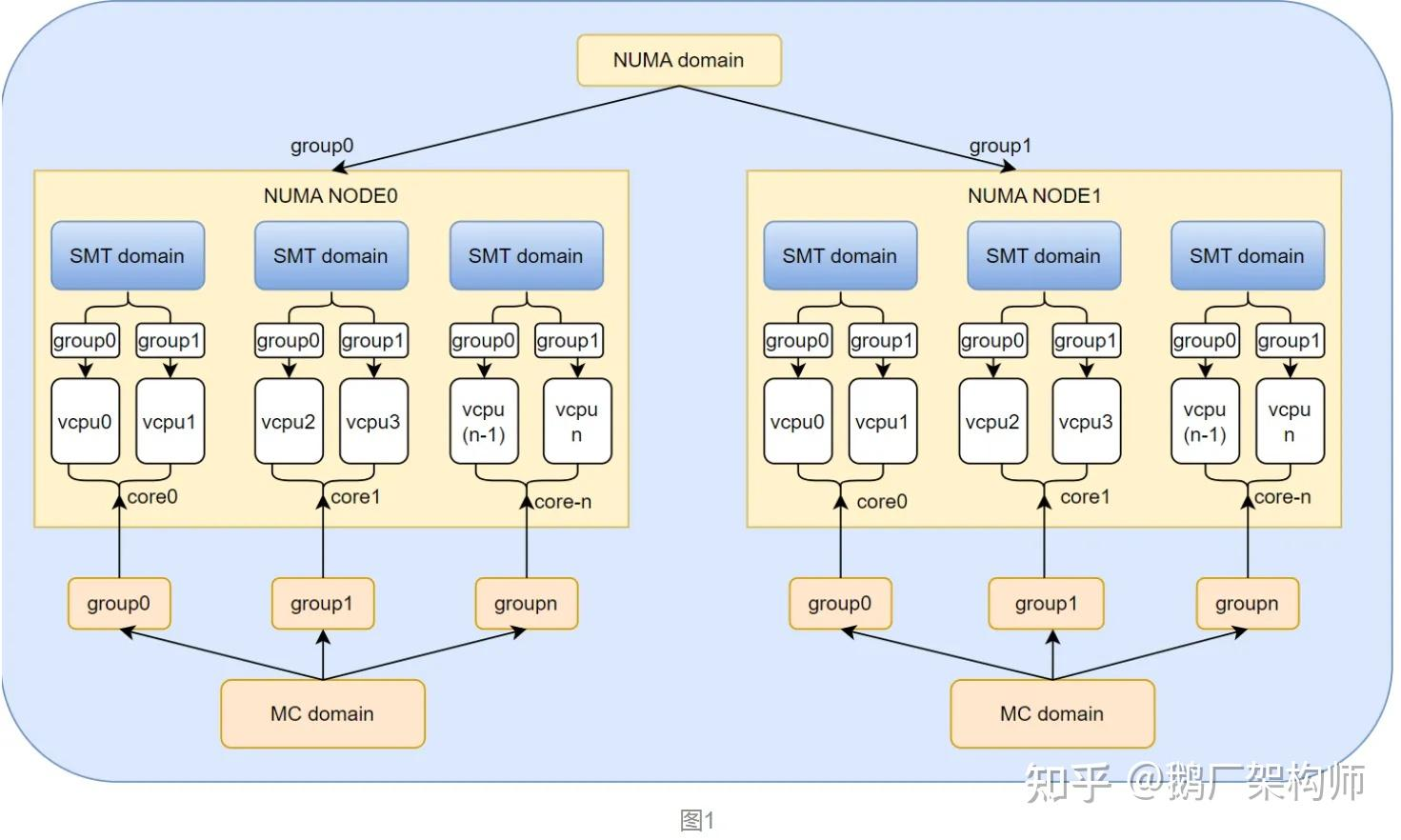
Linux 通过以下机制实现多核识别和任务并行分配:
-
识别多核硬件:
- Linux 内核在启动时通过 CPU 拓扑信息(从硬件和固件获取)来检测系统中可用的 CPU 核心数量和特性。这些信息通常由 ACPI(高级配置与电源接口) 或 Device Tree 提供。
- 内核通过读取 /proc/cpuinfo 或 sysfs(如
/sys/devices/system/cpu/)中的信息,了解每个核心的 ID、频率、缓存等细节。 - 内核模块(如
sched)会初始化对多核的支持,确保系统知道有多少逻辑处理器(包括物理核心和超线程)。
-
任务调度与并行计算:
- Linux 使用 CFS(完全公平调度器,Completely Fair Scheduler) 作为默认的任务调度器,负责将进程或线程分配到不同的 CPU 核心。
- 任务分配:CFS 维护每个核心的运行队列(runqueue),根据任务优先级、负载均衡和核心的空闲状态,将任务动态分配到合适的核上。
- 负载均衡:调度器会定期检查各核心的负载情况,如果某个核心过载而其他核心空闲,任务会通过 迁移(migration) 被重新分配,以充分利用所有核心。
- NUMA 优化:在多核系统中,Linux 还会考虑 NUMA(非均匀内存访问) 架构,尽量将任务分配到靠近其内存的核上,减少跨节点访问的延迟。
-
并行计算支持:
- 多线程与多进程:应用程序通过 POSIX 线程(pthreads)或 fork 创建的多线程/多进程会被内核识别为独立的可调度任务,调度器会自动将这些任务分配到不同核心。
- 亲和性(CPU Affinity):用户或程序可以通过
taskset或sched_setaffinity指定任务绑定到特定核心,优化性能。 - 并行框架:像 OpenMP 或 MPI 这样的并行计算框架会与内核协作,生成多个线程或进程,Linux 调度器负责将它们分配到多核上。
-
内核参数与优化:
- 内核参数(如
sched_smt、isolcpus)允许用户调整多核调度策略。例如,可以隔离某些核心以运行特定任务。 - 内核还支持 中断亲和性,将硬件中断分配到特定核心,减少任务中断的开销。
- 内核参数(如
当你在 Linux 上启动一个任务(进程或线程),Linux 内核通过以下步骤完成“将任务放到 CPU 1 上”的操作(假设调度器决定将任务分配到 CPU 1):
-
任务创建:
- 当你启动一个程序(如通过
fork()创建进程或pthread_create()创建线程),内核会为该任务分配一个 任务结构体(task_struct),记录任务的状态、优先级、堆栈等信息。 - 新任务被添加到调度器的 运行队列(runqueue),等待分配到某个 CPU 核心。
- 当你启动一个程序(如通过
-
调度器决策:
- Linux 的 CFS(完全公平调度器) 或其他调度器会根据任务的优先级、当前负载、CPU 亲和性(affinity)等因素,决定将任务分配到哪个 CPU 核心(这里假设是 CPU 1)。
- 调度器会检查 CPU 1 的运行队列状态,确保它适合接受新任务。如果 CPU 1 负载过高,调度器可能选择其他核心(除非任务明确绑定到 CPU 1,例如通过
sched_setaffinity)。
-
上下文切换(Context Switch):
- 内核通过 上下文切换 将任务“放到” CPU 1 上。具体步骤如下:
- 保存当前状态:如果 CPU 1 正在运行另一个任务,内核会保存该任务的寄存器状态(如程序计数器、栈指针等)到其
task_struct中。 - 加载新任务状态:内核加载新任务的上下文,包括其寄存器值、内存映射(页表)和程序计数器等。这些信息存储在任务的
task_struct中。 - 更新 CR3 寄存器(如果需要):内核可能更新 CPU 的页表基址寄存器(CR3),以切换到新任务的内存空间。
- 保存当前状态:如果 CPU 1 正在运行另一个任务,内核会保存该任务的寄存器状态(如程序计数器、栈指针等)到其
- 内核通过 上下文切换 将任务“放到” CPU 1 上。具体步骤如下:
-
分配到 CPU 1:
- 内核通过 调度器 调用硬件级指令(如
switch_to),将任务的执行上下文加载到 CPU 1 的寄存器中。 - 内核确保 CPU 1 的 运行队列 中包含该任务,并通过硬件的中断机制(例如定时器中断)触发 CPU 1 执行新任务。
- 如果任务有 CPU 亲和性设置(例如通过
taskset绑定到 CPU 1),内核会严格遵守此设置,只将任务分配到 CPU 1。
- 内核通过 调度器 调用硬件级指令(如
-
硬件执行:
- 一旦上下文切换完成,CPU 1 的程序计数器(PC)指向新任务的代码入口,CPU 1 开始执行该任务的指令。
- 内核可能通过 SMP(对称多处理) 机制与 CPU 1 通信,确保任务正确运行在指定核心上。
-
中断与重新调度:
- 在任务运行期间,定时器中断或其他事件可能触发调度器重新评估 CPU 1 的运行队列。如果任务的时间片用尽或有更高优先级的任务,内核会再次进行上下文切换,将 CPU 1 分配给其他任务。
关键点
- 运行队列:每个 CPU 核心有自己的运行队列,调度器通过管理这些队列实现任务分配。
- 硬件支持:内核依赖 CPU 的中断机制和寄存器操作来完成上下文切换和任务执行。
- 亲和性控制:如果任务未绑定到特定 CPU,调度器可能动态迁移任务到其他核心以实现负载均衡。
- 低层次操作:内核通过汇编指令(如
iret或sysret)与 CPU 硬件交互,确保任务在正确核心上运行。
举例
假设你运行 taskset -c 1 ./my_program,内核会:
- 创建
my_program的任务结构体。 - 检查 CPU 1 的运行队列,确保任务被分配到 CPU 1(因为
taskset设置了亲和性)。 - 在 CPU 1 上执行上下文切换,将
my_program的代码和数据加载到 CPU 1 的寄存器和缓存中。 - CPU 1 开始执行
my_program的指令。
总结来说,Linux 内核通过调度器管理运行队列,结合上下文切换和硬件指令,将任务精准分配到指定核心(如 CPU 1),确保高效执行。
1. taskset 的底层原理
taskset 是一个用户态工具,它通过调用 Linux 内核提供的系统调用来设置或查询进程/线程的 CPU 亲和性(CPU affinity),从而控制任务在哪些 CPU 核心上运行。底层依赖以下机制:
-
系统调用:
taskset主要使用sched_setaffinity系统调用(或sched_getaffinity查询亲和性)。- 系统调用原型:
int sched_setaffinity(pid_t pid, size_t cpusetsize, const cpu_set_t *mask); pid:目标进程或线程的 ID(0 表示调用者自身)。cpusetsize:CPU 掩码的大小。mask:一个位图,表示允许任务运行的 CPU 核心(例如,mask的第 1 位为 1 表示允许运行在 CPU 1 上)。
-
工作流程:
- 当你运行
taskset -c 1 ./my_program,taskset会:- 解析命令行参数,生成一个 CPU 掩码(例如,只允许 CPU 1)。
- 调用
sched_setaffinity系统调用,将掩码传递给内核。 - 内核更新目标任务的
task_struct中的cpus_allowed字段,限制任务只能运行在指定的 CPU 核心(这里是 CPU 1)。 - 如果任务当前运行在不允许的 CPU 上(例如 CPU 0),内核会触发任务迁移(migration)到允许的 CPU(CPU 1)。
- 当你运行
-
用户态到内核态:
taskset本身是用户态程序,依赖 glibc 或其他库提供的sched_setaffinity函数封装。最终通过系统调用陷入内核,内核完成实际的亲和性设置和任务调度。
2. 内核如何知道 CPU 核心并切换任务到另一个核心(如 CPU 1)
Linux 内核通过以下步骤实现任务从一个核心(例如 CPU 0)切换到另一个核心(例如 CPU 1):
(1) 内核初始化时的 CPU 拓扑信息
- 在系统启动时,内核通过 ACPI 或 Device Tree 从硬件获取 CPU 拓扑信息,包括:
- 物理 CPU 数量、每个 CPU 的核心数、超线程(SMT)信息。
- 每个核心的 ID(例如 CPU 0, CPU 1, ...)。
- 这些信息存储在内核的数据结构中(如
cpu_possible_mask和cpu_online_mask),供调度器使用。 - 内核的 SMP(对称多处理) 子系统初始化每个 CPU 核心的运行队列(runqueue),并为每个核心分配一个唯一的标识符。
(2) 任务的 CPU 亲和性设置
- 当
sched_setaffinity被调用,内核会:- 检查传入的 CPU 掩码(
cpu_set_t),验证指定的 CPU 是否有效(例如,CPU 1 是否在线)。 - 更新目标任务的
task_struct中的cpus_allowed字段,记录允许运行的 CPU 核心。 - 如果任务当前运行的 CPU(例如 CPU 0)不在
cpus_allowed中,内核会标记该任务需要迁移。
- 检查传入的 CPU 掩码(
(3) 任务迁移到另一个核心(CPU 1)
任务迁移是内核将任务从一个 CPU 核心的运行队列移动到另一个 CPU 核心的过程。以下是详细步骤:
-
触发迁移:
- 迁移可能由以下事件触发:
sched_setaffinity更改了任务的cpus_allowed,导致当前 CPU 不再合法。- 调度器的负载均衡检测到某个 CPU 过载,需要将任务迁移到空闲 CPU(如 CPU 1)。
- 用户通过
taskset或其他工具手动绑定任务到特定 CPU。
- 内核的 调度器(如 CFS)会检查任务的
cpus_allowed和当前运行的 CPU 是否匹配。
- 迁移可能由以下事件触发:
-
选择目标 CPU(CPU 1):
- 调度器根据任务的
cpus_allowed掩码选择目标 CPU。如果taskset设置了只允许 CPU 1,调度器会选择 CPU 1。 - 如果有多个允许的 CPU,调度器会考虑负载、缓存亲和性(cache affinity)和 NUMA 拓扑,选择最优的核心。
- 调度器根据任务的
-
迁移任务:
- 内核通过以下步骤将任务从当前 CPU(例如 CPU 0)迁移到 CPU 1:
- 从源 CPU 运行队列移除:
- 内核将任务从 CPU 0 的运行队列中移除。
- 如果任务正在 CPU 0 上运行,内核会触发上下文切换,暂停任务并保存其状态(寄存器、堆栈等)到
task_struct。
- 添加到目标 CPU 运行队列:
- 内核将任务插入 CPU 1 的运行队列(通常是一个红黑树或优先级队列,具体取决于调度器实现)。
- 任务的
task_struct中的cpu字段更新为 CPU 1。
- 通知目标 CPU:
- 内核通过 IPI(处理器间中断,Inter-Processor Interrupt) 通知 CPU 1,告知其运行队列有新任务需要调度。
- IPI 是一个硬件机制,允许一个 CPU(例如运行内核代码的 CPU)向另一个 CPU(如 CPU 1)发送中断信号。
- 上下文切换到新任务:
- 当 CPU 1 响应 IPI 或下一次调度点(如定时器中断),调度器会从 CPU 1 的运行队列中选择新任务。
- 内核加载任务的上下文(寄存器、页表等)到 CPU 1 的硬件寄存器,更新 CR3(页表基址寄存器)以切换内存空间。
- CPU 1 的程序计数器(PC)指向任务的代码入口,任务开始在 CPU 1 上执行。
- 从源 CPU 运行队列移除:
- 内核通过以下步骤将任务从当前 CPU(例如 CPU 0)迁移到 CPU 1:
-
硬件级操作:
- 上下文切换涉及底层汇编指令,例如:
- 保存和恢复寄存器状态(
push/pop或mov指令)。 - 更新 CR3 寄存器(通过
mov指令)。 - 返回用户态(通过
iret或sysret指令)。
- 保存和恢复寄存器状态(
- IPI 由内核通过写入 APIC(高级可编程中断控制器) 寄存器触发,通知 CPU 1 执行调度。
- 上下文切换涉及底层汇编指令,例如:
(4) 确保任务在 CPU 1 上运行
- 一旦任务被迁移到 CPU 1 的运行队列,且
cpus_allowed限制其只能运行在 CPU 1,调度器会确保后续调度只在 CPU 1 上进行。 - 如果任务尝试迁移到其他 CPU(例如由于负载均衡),内核会检查
cpus_allowed并阻止非法的迁移。
3. 具体到 taskset -c 1 的例子
假设你运行 taskset -c 1 ./my_program,底层流程如下:
-
用户态:
taskset解析-c 1,生成一个 CPU 掩码(仅 CPU 1 的位为 1)。- 调用
sched_setaffinity(0, sizeof(cpu_set_t), &mask),将掩码传递给内核。
-
内核态:
- 内核更新
my_program的task_struct->cpus_allowed,限制其只能运行在 CPU 1。 - 如果
my_program当前在 CPU 0 上运行,内核触发迁移:- 从 CPU 0 的运行队列移除任务。
- 将任务插入 CPU 1 的运行队列。
- 通过 IPI 通知 CPU 1,触发调度。
- CPU 1 执行上下文切换,加载
my_program的上下文并开始运行。
- 内核更新
-
硬件态:
- CPU 1 的寄存器加载
my_program的状态,CR3 指向其页表,程序计数器指向代码入口。 - CPU 1 执行
my_program的指令。
- CPU 1 的寄存器加载
4. 为什么能精准切换到 CPU 1?
- SMP 架构:Linux 的 SMP 子系统为每个 CPU 核心分配了唯一的 ID(通过硬件提供),并维护独立的运行队列。内核通过这些 ID 精确控制任务分配。
- IPI 机制:内核使用 IPI 直接与目标 CPU 通信,确保任务被调度到正确的核心。
- 运行队列隔离:每个 CPU 的运行队列独立,任务一旦被放入 CPU 1 的队列,只有 CPU 1 会调度它。
- 硬件寄存器:上下文切换直接操作 CPU 1 的寄存器,确保任务在 CPU 1 上运行。
5. 可能的复杂情况
- 负载均衡干扰:如果没有
taskset限制,调度器可能将任务迁移到其他 CPU 以平衡负载。通过taskset -c 1,cpus_allowed强制任务留在 CPU 1,绕过负载均衡。 - NUMA 影响:在 NUMA 系统中,内核可能优化内存访问,但
taskset的亲和性设置优先级高于 NUMA 优化。 - 中断延迟:IPI 或调度可能因系统负载而稍有延迟,但内核保证任务最终运行在指定核心。
总结
taskset通过sched_setaffinity系统调用设置任务的 CPU 亲和性,底层更新task_struct->cpus_allowed。- 内核通过运行队列管理、IPI 通知和上下文切换,将任务从一个核心(例如 CPU 0)迁移到另一个核心(例如 CPU 1)。
- 迁移涉及从源 CPU 移除任务、插入目标 CPU 队列、通知目标 CPU 并执行上下文切换,依赖 SMP 和硬件中断机制。
- 硬件级操作(如寄存器更新和 IPI)确保任务精准运行在 CPU 1 上。
希望这次解释清楚了!如果还有疑问,请告诉我,我可以进一步细化或举例说明。
感谢你的提问!你想深入了解 Linux 内核如何将任务从一个核心(例如 CPU 0)迁移到另一个核心(例如 CPU 1),特别是“如何把代码搬移到另一个核心”的具体过程。我会聚焦于任务迁移的底层机制,解释清楚代码和数据的搬移过程,以及内核和硬件如何协作完成这一操作。
澄清“代码搬移”的概念
在 Linux 中,“把代码搬移到另一个核心”并不是真的将程序的代码(指令)或数据从一个 CPU 核心的物理内存复制到另一个核心的内存。相反,任务迁移是指:
- 将任务的 执行上下文(包括寄存器状态、程序计数器、栈指针等)从一个 CPU 核心的运行队列转移到另一个 CPU 核心的运行队列。
- 让目标 CPU 核心(例如 CPU 1)开始执行任务的代码,代码和数据本身仍然存储在主内存(RAM)中,CPU 核心通过共享的内存总线访问它们。
下面我将详细解释 Linux 内核如何实现任务从 CPU 0 迁移到 CPU 1 的过程,涵盖调度器、运行队列、上下文切换和硬件操作。
任务迁移的整体流程
任务迁移是 Linux 内核调度器将一个任务(进程或线程)从一个 CPU 核心(源 CPU,例如 CPU 0)的运行队列移动到另一个 CPU 核心(目标 CPU,例如 CPU 1)的运行队列,并让目标 CPU 开始执行该任务的过程。以下是详细步骤:
1. 触发迁移
任务迁移可能由以下原因触发:
- 用户指令:例如,通过
taskset -c 1或sched_setaffinity系统调用,设置任务的 CPU 亲和性,限制任务只能运行在 CPU 1 上。 - 调度器负载均衡:调度器检测到 CPU 0 负载过高,而 CPU 1 较空闲,决定迁移任务以平衡负载。
- 其他事件:如 CPU 热插拔、电源管理或调度策略变化。
当迁移触发时,内核的调度器(通常是 CFS,Completely Fair Scheduler)会标记任务需要从 CPU 0 迁移到 CPU 1。
2. 选择目标 CPU(CPU 1)
- 调度器检查任务的
task_struct中的cpus_allowed字段(一个位图,表示任务允许运行的 CPU 核心)。 - 如果
cpus_allowed只允许 CPU 1(例如通过taskset -c 1设置),调度器直接选择 CPU 1 作为目标。 - 如果允许多个 CPU,调度器会根据以下因素选择目标 CPU:
- CPU 1 的运行队列负载(避免过载)。
- 缓存亲和性(cache affinity):尽量选择与任务最近使用的 CPU 共享缓存的核心。
- NUMA 拓扑:选择与任务内存更接近的 CPU(在 NUMA 系统中)。
3. 从源 CPU(CPU 0)移除任务
-
任务的元数据存储在内核的
task_struct结构体中,包括程序计数器、寄存器状态、内存映射等。 -
如果任务正在 CPU 0 上运行,内核会:
- 暂停任务:通过上下文切换保存任务的当前状态。
- 保存 CPU 0 的寄存器(通用寄存器、程序计数器、栈指针等)到
task_struct。 - 保存浮点寄存器(如果任务使用了 FPU)。
- 保存 CPU 0 的寄存器(通用寄存器、程序计数器、栈指针等)到
- 从运行队列移除:
- 每个 CPU 核心有一个独立的 运行队列(runqueue),存储待执行任务的列表(通常用红黑树或优先级队列实现)。
- 内核将任务从 CPU 0 的运行队列中移除(更新队列指针,移除任务的
task_struct引用)。
- 暂停任务:通过上下文切换保存任务的当前状态。
-
如果任务未在 CPU 0 上运行(例如处于等待或休眠状态),只需直接从 CPU 0 的运行队列中移除。
4. 将任务添加到目标 CPU(CPU 1)的运行队列
- 内核将任务的
task_struct插入 CPU 1 的运行队列:- 更新任务的
task_struct->cpu字段,标记其当前绑定到 CPU 1。 - 将任务加入 CPU 1 的运行队列(根据优先级插入红黑树或其他数据结构)。
- 更新任务的
- 任务的代码和数据不需要物理搬移,因为:
- 代码和数据存储在主内存(RAM)中,所有 CPU 核心通过内存总线共享访问。
- 任务的内存映射(页表)存储在
task_struct->mm中,指向相同的物理内存地址。
5. 通知目标 CPU(CPU 1)
- 内核通过 IPI(处理器间中断,Inter-Processor Interrupt) 通知 CPU 1,其运行队列有新任务需要调度。
- IPI 的具体过程:
- 运行迁移代码的 CPU(可能是 CPU 0 或其他核心)向 CPU 1 的 APIC(高级可编程中断控制器) 写入中断请求。
- CPU 1 接收到 IPI 后,暂停当前执行(可能是空闲状态或其他任务),跳转到内核的中断处理程序。
- 中断处理程序调用调度器,检查 CPU 1 的运行队列,发现新任务。
6. 上下文切换到新任务(在 CPU 1 上)
-
CPU 1 的调度器从运行队列中选择新任务(假设是刚迁移的任务),并执行上下文切换:
- 保存当前任务状态(如果 CPU 1 正在运行其他任务):
- 保存 CPU 1 当前任务的寄存器状态到其
task_struct。
- 保存 CPU 1 当前任务的寄存器状态到其
- 加载新任务状态:
- 从新任务的
task_struct中恢复寄存器状态(程序计数器、栈指针、通用寄存器等)。 - 更新 CR3 寄存器(页表基址寄存器),指向新任务的内存页表,确保 CPU 1 访问正确的虚拟内存空间。
- 如果任务使用了浮点运算,恢复 FPU 状态。
- 从新任务的
- 跳转到任务代码:
- 程序计数器(PC)被设置为
task_struct中保存的代码入口地址。 - CPU 1 通过
iret(中断返回)或sysret指令从内核态返回用户态,开始执行任务的代码。
- 程序计数器(PC)被设置为
- 保存当前任务状态(如果 CPU 1 正在运行其他任务):
-
此时,任务正式在 CPU 1 上运行。代码和数据仍然在主内存中,CPU 1 通过内存总线和缓存访问它们。
7. 缓存与内存访问优化
- 缓存一致性:
- 现代多核 CPU 使用 缓存一致性协议(如 MESI),确保 CPU 0 和 CPU 1 访问的内存数据是一致的。
- 如果任务的数据在 CPU 0 的缓存中,CPU 1 可能通过缓存一致性协议从 CPU 0 的缓存获取数据,或直接从主内存加载。
- 缓存预热:
- 迁移可能导致“冷缓存”(cache miss),因为 CPU 1 的缓存没有任务的数据。
- 调度器会尽量减少跨核心迁移(保持缓存亲和性),但
taskset的强制亲和性可能导致性能开销。
为什么代码和数据不需要物理搬移?
- 共享内存架构:
- 在现代多核 CPU(如 x86、ARM)中,所有核心共享同一个主内存(RAM)。代码和数据存储在 RAM 中,通过内存总线和内存控制器访问。
- 每个 CPU 核心有自己的寄存器和缓存(L1/L2 缓存),但缓存只是数据的临时副本,最终数据源是主内存。
- 虚拟内存:
- 任务的代码和数据通过虚拟内存地址映射到物理内存。页表(存储在
task_struct->mm)定义了虚拟地址到物理地址的映射。 - 当任务迁移到 CPU 1,内核只需将页表加载到 CPU 1 的 CR3 寄存器,CPU 1 就能访问相同的代码和数据。
- 任务的代码和数据通过虚拟内存地址映射到物理内存。页表(存储在
- 任务上下文:
- “搬移”的本质是更新任务的执行上下文(寄存器和运行队列),而不是移动代码或数据的物理位置。
底层硬件操作的细节
任务迁移涉及以下硬件级操作:
- IPI 触发:
- 内核通过写入 Local APIC 的寄存器(例如
ICR,Interrupt Command Register)发送 IPI 到 CPU 1。 - CPU 1 响应中断,进入内核态,执行调度器代码。
- 内核通过写入 Local APIC 的寄存器(例如
- 上下文切换:
- 保存和恢复寄存器使用汇编指令(如
push/pop或mov)。 - 更新 CR3 寄存器:
mov %rax, %cr3(将新任务的页表基址加载到 CR3)。 - 返回用户态:
iret或sysret指令。
- 保存和恢复寄存器使用汇编指令(如
- 缓存访问:
- CPU 1 通过内存管理单元(MMU)将虚拟地址转换为物理地址,访问主内存或通过缓存一致性协议从 CPU 0 的缓存获取数据。
以 taskset -c 1 为例
假设任务 my_program 正在 CPU 0 上运行,你运行 taskset -c 1:
taskset调用sched_setaffinity,设置my_program的cpus_allowed只允许 CPU 1。- 内核检查
my_program当前在 CPU 0 上运行,但cpus_allowed要求 CPU 1,触发迁移。 - 内核暂停
my_program(保存寄存器到task_struct),从 CPU 0 的运行队列移除。 - 内核将
my_program插入 CPU 1 的运行队列,更新task_struct->cpu为 CPU 1。 - 内核通过 IPI 通知 CPU 1,CPU 1 响应后执行调度器。
- CPU 1 进行上下文切换,加载
my_program的寄存器状态和页表,跳转到其代码入口。 - CPU 1 开始执行
my_program,访问主内存中的代码和数据。
回答你的核心问题:Linux 如何“把代码搬移到另一个核心”?
- 代码不搬移:代码和数据始终在主内存中,迁移的是任务的 执行上下文(寄存器状态、运行队列归属)。
- 迁移的本质:
- 从 CPU 0 的运行队列移除任务,加入 CPU 1 的运行队列。
- 通过 IPI 通知 CPU 1,触发调度。
- 在 CPU 1 上加载任务的上下文(寄存器、页表),让 CPU 1 执行代码。
- 硬件支持:
- IPI 确保 CPU 1 被唤醒并调度新任务。
- 缓存一致性和共享内存架构保证 CPU 1 访问相同的代码和数据。
- 上下文切换通过寄存器操作和 CR3 更新实现无缝执行。
可能的性能开销
- 缓存失效:CPU 1 的缓存可能没有任务的数据,导致初始访问主内存的延迟。
- IPI 延迟:发送和处理 IPI 需要几十到几百个时钟周期。
- 上下文切换开销:保存和恢复寄存器、更新页表需要时间。
调度器尽量减少不必要的迁移(通过缓存亲和性),但 taskset 的强制亲和性会优先于优化。
总结
- Linux 通过调度器管理运行队列,将任务从 CPU 0 迁移到 CPU 1,具体是移除任务、插入新队列、通过 IPI 通知 CPU 1、执行上下文切换。
- 代码和数据不物理搬移,存储在共享主内存中,CPU 1 通过页表和内存总线访问。
- 底层依赖 IPI、寄存器操作、缓存一致性和上下文切换,确保任务无缝运行在 CPU 1 上。
如果你还有更具体的问题(例如想看某些内核代码片段或硬件指令细节),请告诉我,我可以进一步深入!