
ICPP24 Grace Hopper GPU中的系统内存管理
- Paper Reading
- 2025-08-30
- 1182 Views
- 0 Comments
- 4719 Words
文章链接:Harnessing Integrated CPU-GPU System Memory for HPC: a first look into Grace Hopper
NVIDIA Grace Hopper 与 NVLink Fusion 架构对异构并行计算优化的影响 - William的文章 - 知乎
https://zhuanlan.zhihu.com/p/1911971133923754274
Grace Hopper Superchip 通过 NVLink Chip-to-Chip (C2C) 互连技术,将专为 AI 和 HPC 优化的 Grace CPU 与强大的 Hopper GPU 紧密集成,实现了高带宽、低延迟的缓存一致性内存共享。这种设计显著缓解了传统 PCIe 总线带来的数据传输限制,简化了编程模型,并提高了整体系统效率。凭借 NVLink-C2C 和一致性统一内存 ,传统意义上关于“CPU 数据”和“GPU 数据”的严格区分变得模糊。对于异构系统而言,“数据局部性”的含义也因此被重新定义。它不再仅仅关乎数据存储在哪块物理内存中,而更多地关乎数据在被任一处理器需要时是否能够被高效访问。高带宽使得 CPU 内存对于许多工作负载而言,成为了 GPU 内存的一个可行扩展。在这种架构中,CPU 与 GPU 共享一个统一的虚拟内存空间(即系统内存),而地址翻译由硬件加速完成,无需显式数据拷贝。

Harnessing Integrated CPU-GPU System Memory for HPC: a first look into Grace Hopper
这篇文章是对NVIDIA Grace Hopper Superchip(一个集成了ARM CPU和H100 GPU的系统)的首次深入研究,重点探讨其集成CPU-GPU系统内存管理在高性能计算(HPC)中的应用。该系统通过硬件加速的统一内存解决方案(如缓存一致的NVLink-C2C互连和共享系统页表)来解决传统CPU-GPU内存管理的局限性,例如显式数据拷贝、统一虚拟内存(UVM)的页故障开销和迁移瓶颈。
主要内容和方法
- 背景介绍:解释了Grace Hopper的内存子系统,包括两级内存架构(CPU的480GB LPDDR5X和GPU的96GB HBM3)、NVLink-C2C互连的缓存一致性和地址翻译服务(ATS)。比较了系统分配内存(使用malloc()等标准API,依赖单一系统页表)和CUDA managed内存(使用cudaMallocManaged(),依赖CPU和GPU的双页表)。
- 实验设置:在Grace Hopper平台上测试六个代表性HPC应用,包括Qiskit量子体积模拟器(处理30-34量子比特)、Rodinia基准套件的五个应用(needle、pathfinder、bfs、hotspot、srad)。这些应用覆盖规则、不规则和混合访问模式。作者开发了内存剖析工具,并使用NVIDIA工具(如Nsight Systems和Nsight Compute)监控内存利用、页故障和迁移。
- 关键分析:
- 集成页表的影响:研究第一触碰策略(first-touch policy)、页表条目初始化、系统页大小(4KB vs 64KB)和页迁移机制。
- 性能比较:在内存内和内存超订阅场景下,比较系统分配内存、CUDA managed内存与传统显式拷贝版本。系统分配内存在大多数情况下表现更好,尤其是CPU初始化数据的情景,因为它避免了昂贵的页故障处理,转而使用缓存线级远程访问。
- 页迁移评估:对比系统内存的自动访问计数器迁移(基于硬件计数器)和managed内存的按需迁移。针对迭代访问模式的应用(如SRAD),自动迁移可优化性能。
- 发现与优化:
- 系统分配内存适用于大多数用例,需要最小移植努力,但对GPU侧初始化敏感(页表初始化开销大)。
- 增加系统页大小(到64KB)可显著降低初始化和迁移开销,尤其在量子模拟中( speedup达4x)。
- 识别优化策略,如预填充页表(使用cudaHostRegister或人工循环)、调整迁移阈值和预取(cudaMemPrefetchAsync)。
- 结果显示,系统分配内存在避免读/写放大和简化内存管理方面优于managed内存,尤其在超订阅场景。
研究背景
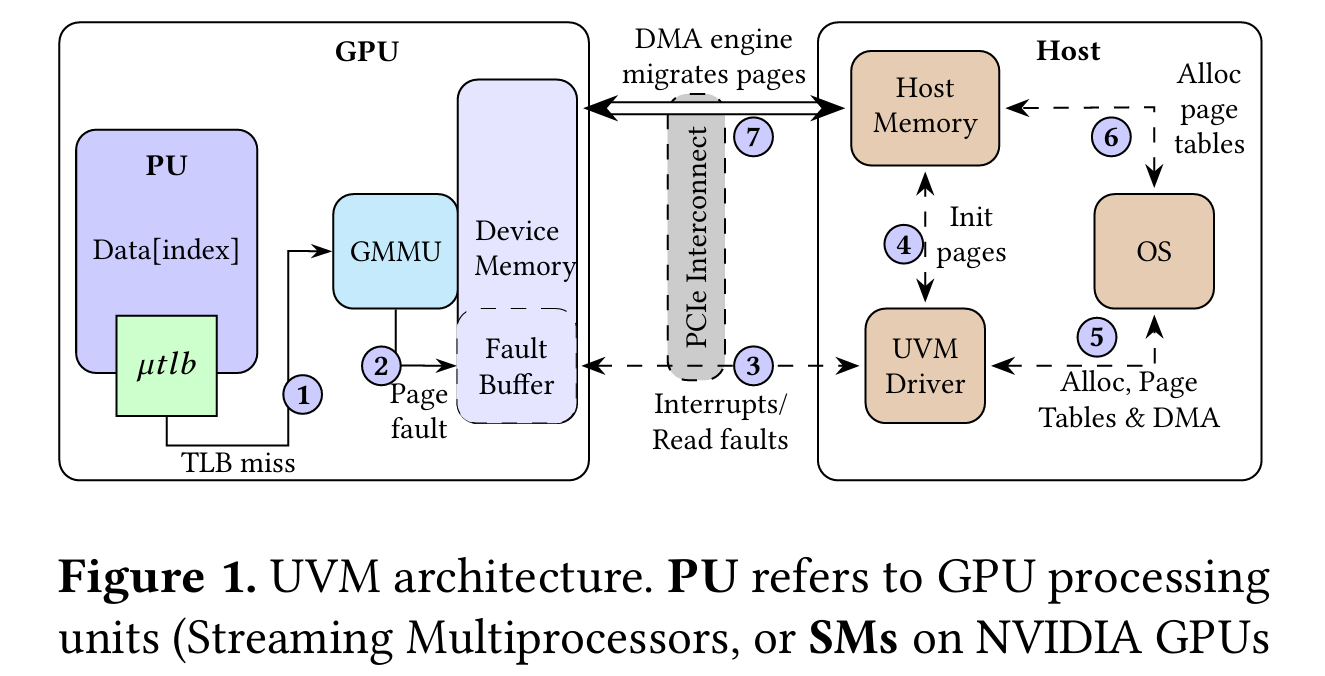
好的,我来给你简单介绍一下 统一虚拟内存(UVM) 和 数据对象卸载:
统一虚拟内存(UVM, Unified Virtual Memory)
https://arxiv.org/pdf/2411.05309v1
- 概念:由 NVIDIA 等提出的一种软硬件协同机制,把 CPU 内存和 GPU 内存抽象成一个统一的地址空间。
- 作用:应用程序可以像在单一内存里一样访问数据,而不需要显式调用
cudaMemcpy之类的拷贝接口。 - 优点:
- 编程模型简化,开发者不必手动管理 CPU-GPU 数据传输。
- 透明的内存迁移,程序访问时自动触发数据搬运。
- 缺点:
- 遇到 GPU 缺页时,页面迁移开销很大;
- 页粒度管理导致 读写放大;
- 数据频繁往返 CPU 与 GPU,会受限于 带宽与延迟瓶颈。
数据对象卸载(Data Object Offloading),来自 ZeRO-Offload
- 概念:通过分析应用,将部分大对象(如模型参数、稀疏矩阵、模拟数据块)放到 CPU 内存,只在需要时拷贝到 GPU。
简而言之,ZeRO‑Offload 将以下内容卸载至 CPU: - 梯度(Gradients)
- 优化器状态(Optimizer States)
- 优化器计算(Optimizer Computation)
而保留在 GPU 上的是:
- 模型参数
- 前向和反向传播计算
这样的划分基于最优策略,能够在最大限度节省 GPU 内存的同时,控制 CPU 计算与通信开销,使整体训练效率不下降。
两种方法总结
| 特性 | 【自动挡】OpenVM(UVM) | 【手动挡】数据对象卸载(ZeRO-Offload) |
|---|---|---|
| 卸载对象 | 基于页级别的 CPU–GPU 统一虚拟内存 | 梯度、优化器状态与计算,从 GPU 卸载至 CPU |
| 编程难度 | 自动,不需改代码 | 仅需修改 DeepSpeed 配置,模型无需重构 |
| 性能方式 | 页迁移与交换,存在开销与读写放大问题 | 优化通信和计算,尽量减少 CPU–GPU 数据移动 |
| 内存提升能力 | 有限 | 单 GPU 支持训练模型规模提升约 10 倍,支持数十亿参数 |
| 可扩展性 | 一般有限 | 支持线性扩展至多 GPU,多 GPU 联合训练规模提升明显 |
尽管这些方案各有优点,但也存在一些会影响性能和易用性的局限性。
例如,UVM 在 GPU 中处理缺页时会产生较大的开销,并且由于基于页的交换机制,还会导致读写放大问题。
数据对象卸载则需要离线分析和应用重构,从而限制了方案的通用性。
此外,这两种方案的性能都受到 CPU 与 GPU 之间数据传输瓶颈的制约,因为通信延迟和带宽限制会阻碍整体执行速度。
本文贡献
英伟达 Grace Hopper Superchip 的推出为解决现有方案的局限性带来了新的机遇。
该系统通过 缓存一致性互联(NVLink-C2C, chip-to-chip) 将一颗 ARM CPU 与一颗 Nvidia H100 GPU 连接在一起。在这种架构中,CPU 与 GPU 共享一个统一的虚拟内存空间(即系统内存),而地址翻译由硬件加速完成,无需显式数据拷贝。
这种设计使应用开发者能够在 透明的统一内存模型 下管理 CPU 与 GPU 内存,而数据传输则由硬件负责,分为两个层次:
- 缓存行粒度的直接远程访问;
- 启发式驱动的页迁移。
通过引入 缓存行级别访问 和 地址转换服务(ATS)(允许对 CPU 和 GPU 所有内存分配进行完全访问),系统内存消除了传统 UVM 中的缺页处理开销,并显著减少了内存迁移的需求。与 UVM 将虚拟内存空间拆分为系统页表与 GPU 页表不同,系统内存采用 单一的系统级页表,由 CPU 与 GPU 共享。
目前对 Grace Hopper 上这种 CPU–GPU 一致性系统内存 的研究仍然有限,尤其在 内存分配策略、内存管理机制以及页迁移开销 等方面的理解不足。而这些因素对开发者和研究人员来说至关重要,因为它们决定了如何充分利用这一首个 硬件加速的统一内存系统。
因此,本文旨在填补这一空白,通过对比 系统内存 与现有 托管内存(managed memory, UVM) 的表现,评估其在六个代表性 HPC 应用中的性能影响。这些应用包括前沿的 Qiskit 量子计算机模拟器、图计算应用和科学计算应用,从而为未来 CPU-GPU 平台上的统一内存优化提供参考。
Grace Hopper Superchip 的内存子系统
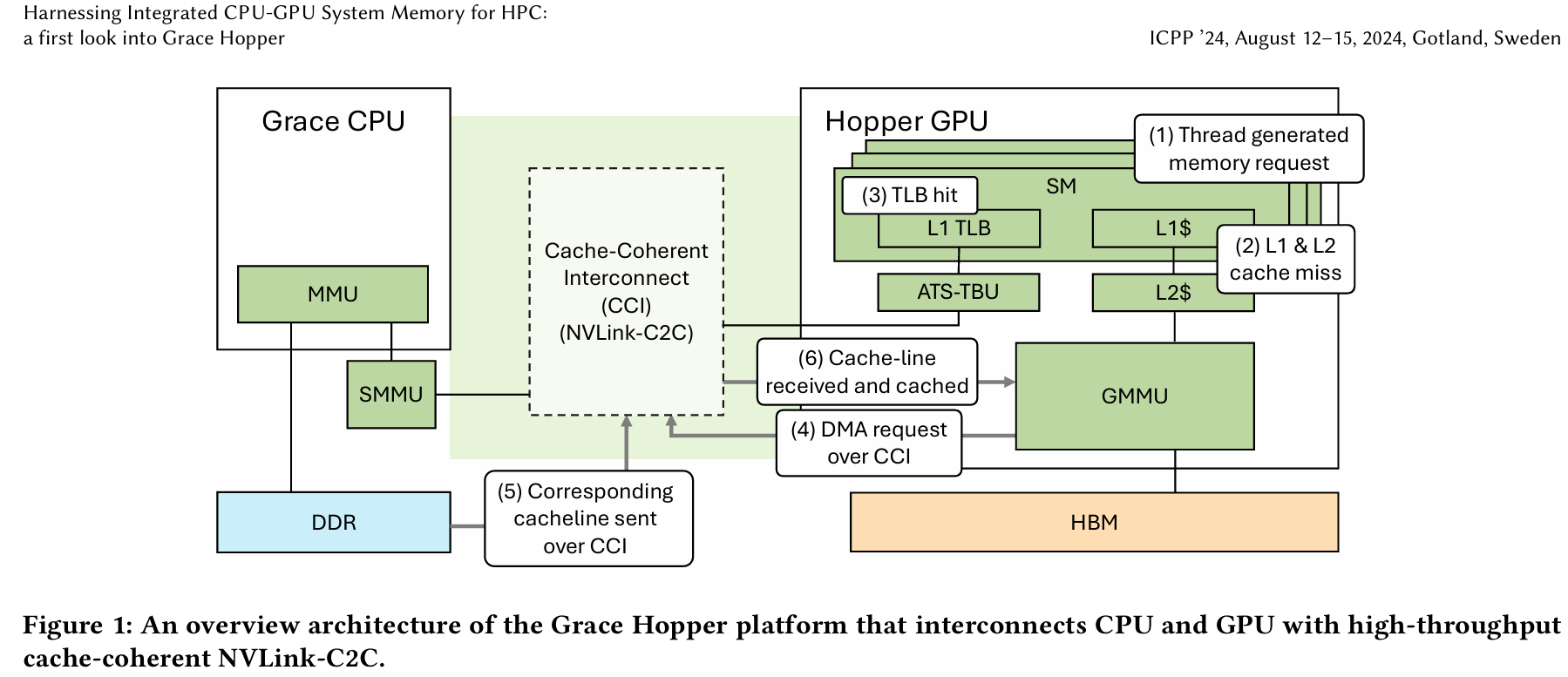
我们介绍 Grace Hopper Superchip 的内存子系统,重点关注在单一共享 CPU–GPU 内存域内的硬件与操作系统(OS)层面的内存管理。我们进一步讨论该内存系统如何通过两种统一内存管理方案暴露给程序员:系统分配内存(system-allocated memory) 和 CUDA 托管内存(CUDA managed memory)。
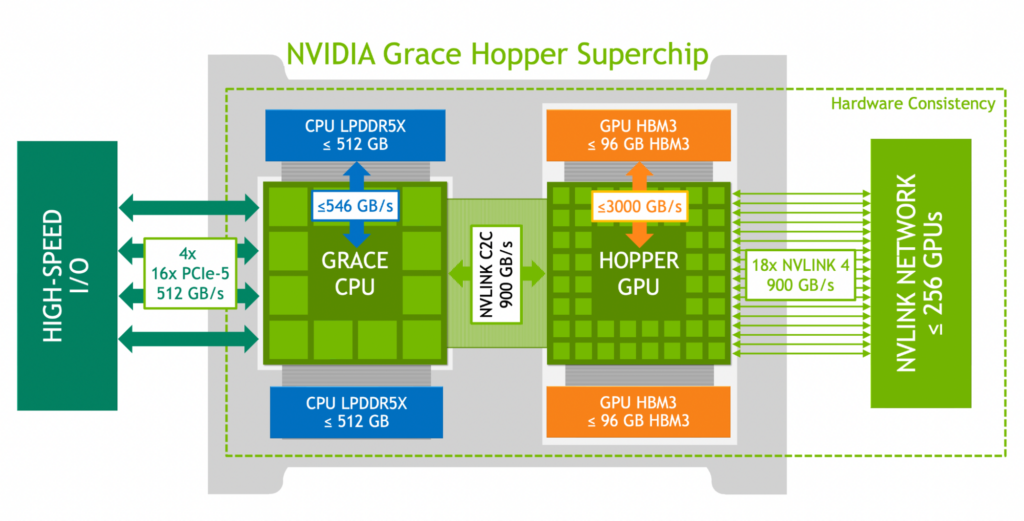
Grace Hopper 系统采用 两层内存架构,CPU 与 GPU 各自配备独立的物理内存:
- Grace CPU:连接 480 GB LPDDR5X 内存;
- Hopper GPU:配备 96 GB HBM3 内存;
二者通过 Nvidia NVLink-C2C 互联相连。CPU到GPU的连接带宽由传统PCIE GEN5 128GB/s带宽升级为C2C link带来的900GB/s,提升7倍。
该双层内存系统以 两个非一致内存访问(NUMA)节点 的形式对外呈现,使 CPU 与 GPU 可以无缝访问彼此的内存。
2.1.2 系统级地址转换
在 Grace Hopper 内存系统中,Grace CPU 包含一个特殊的硬件单元 —— 系统内存管理单元(SMMU) [21],其定义来源于 Arm 的 SMMUv3 规范。SMMU 负责通过执行页表遍历,将虚拟地址转换为物理地址。与传统 MMU 相比,SMMU 额外支持来自 GPU 的虚拟到物理地址转换请求。
图 1 展示了 Grace Hopper 系统中一次虚拟地址访问的工作流程(假设该虚拟–物理映射已缓存于 GPU TLB 中,且数据驻留于 CPU 内存):
- GPU 线程访问某个虚拟地址;
- 该数据未命中 GPU 的缓存层级,产生一次缓存未命中;
- GPU TLB 中查找虚拟–物理地址映射,由于已缓存,直接命中;
- GMMU 通过 NVLink-C2C 互联发起 DMA(直接内存访问),以缓存行粒度进行传输;
- 数据从 CPU 内存中读取并返回 GPU;
- 访问完成,数据被缓存到 GPU 的常规缓存层级中。
与 Grace Hopper 之前的系统(依赖 GPU 缺页处理来访问 CPU 内存)相比,这种新方法有两个主要改进:
- 第一,GPU 访问 CPU 内存时不再总是触发 GPU 缺页;
- 第二,缺页由 SMMU 生成,并可直接由操作系统的缺页处理机制处理,从而简化了整体流程。
| 特性 | 传统 UVM | Grace Hopper 系统分配内存 | Grace Hopper CUDA 管理内存 |
|---|---|---|---|
| MMU 数量 | 两个(CPU MMU 和 GPU GMMU) | 主要依赖 SMMU,GMMU 辅助(仅处理 TLB) | 两个(SMMU 和 GMMU),但 SMMU 更主导 |
| 页表 | 双页表(CPU 系统页表 + GPU 专属页表,2MB) | 单一系统页表(4KB 或 64KB) | 双页表(系统页表 + GPU 专属页表,2MB) |
| 页故障处理 | GPU 页故障由 CUDA 驱动和 OS 协作处理,软件开销高 | SMMU 和 OS 直接处理,GPU 无传统页故障 | GPU 页故障仍由 CUDA 驱动处理,但 ATS 优化翻译 |
| 数据访问 | 通过 PCIe 传输,需页面迁移,带宽低(~32GB/s) | NVLink-C2C 直接访问(缓存线粒度,~375GB/s),无需强制迁移 | NVLink-C2C 支持直接访问,页面迁移仍需 CUDA 驱动 |
| 页面迁移 | 按需迁移(on-demand),依赖 CUDA 驱动,软件干预多 | 自动访问计数器迁移,硬件驱动,透明高效 | 按需迁移 + 预取(显式/隐式),部分依赖 CUDA 驱动 |
| 缓存一致性 | 无硬件级缓存一致性,依赖软件同步 | NVLink-C2C 提供硬件级缓存一致性 | NVLink-C2C 提供缓存一致性,减少同步开销 |
因此GH200这里省去了OS层的开销,并对内存拷贝、一致性进行了优化。
2.1.3 Grace Hopper 的内存管理
Grace Hopper 系统使用 两张不同的页表:
-
系统级页表(System-wide Page Table)
- 位于 CPU 内存,由操作系统直接管理;
- OS 创建并维护页表项(PTE);
- SMMU 使用该页表,为 CPU(当用户应用需要时)和 GPU(通过 NVLink-C2C 请求时)提供虚拟–物理地址转换;
- 页框可物理驻留在 CPU 或 GPU 内存中;
- 页大小由操作系统层定义,并受 CPU 架构限制(Grace CPU 下为 4 KB 或 64 KB)。
-
GPU 独占页表(GPU-exclusive Page Table)
- 从前代 GPU 沿用,位于 GPU 内存,仅 GPU 可访问;
- 存储
cudaMalloc分配的内存,以及当物理数据驻留在 GPU 内存时的cudaMallocManaged分配; - 页大小为 2 MB。
因此,CPU MMU是主管,GPU MMU只管GPU,然后GPU MMU干不了时,就叫CPU MMU来干。
在本文中,我们重点研究那些数据既可以驻留在 CPU 也可以驻留在 GPU 内存中的分配方式,即 系统分配内存(system-allocated memory) 和 CUDA 托管内存(CUDA managed memory)。
性能评估
我们通过基准测试评估该内存架构的性能:
- 使用 STREAM benchmark 测得内存带宽:
- GPU HBM3 内存:3.4 TB/s(理论峰值 4 TB/s);
- CPU LPDDR5X 内存:486 GB/s(理论峰值 500 GB/s)[20]。
- 使用 Comm|Scope benchmark [23] 测得 NVLink-C2C 互联性能:
- 主机到设备(H2D):375 GB/s;
- 设备到主机(D2H):297 GB/s;
- 理论带宽:450 GB/s。
2.1.1 NVLink-C2C 互联
在 Grace Hopper 系统中,CPU 或 GPU 可以通过 NVLink-C2C 直接访问对方的物理内存:
- 缓存行粒度传输:CPU 端最小 64B,GPU 端最小 128B;
- 透明缓存:访问的数据会被透明地缓存到两处理器的缓存层级中(如图 1 所示);
- 缓存一致性:CPU 与 GPU 的缓存保持完全一致;
- 支持原子操作:允许跨处理器原子读写与修改物理内存位置;
- 协议:基于 Arm 的 AMBA CHI 协议实现,硬件级支持,用户无需干预。
✅ 总结:
Grace Hopper 内存系统通过 NVLink-C2C 互联、SMMU 支持的系统级页表 以及 硬件加速的虚拟–物理地址转换,实现了统一的 CPU–GPU 内存域。相比传统的托管内存(UVM),该方案减少了 GPU page fault 处理开销,并支持缓存行粒度的透明远程访问,大幅优化了 CPU–GPU 协同内存管理的效率。
System-Allocated Memory
-
系统分配内存的基本概念
使用标准malloc()分配内存,依赖系统页表;延迟物理内存映射,支持超订阅;采用第一触碰策略,首次访问触发页故障并映射物理页。-
GPU访问流程
GPU首次访问触发TLB未命中,ATS-TBU发送翻译请求至SMMU;SMMU处理页表遍历和故障,更新页表指向GPU内存;后续通过NVLink-C2C直接DMA访问。 -
自动访问计数器迁移
硬件计数器跟踪GPU访问次数;超过阈值(默认256)触发中断;驱动程序决定迁移页面至GPU内存,优化高频访问性能,透明执行。
-
2.3 CUDA Managed Memory
-
基本概念
通过cudaMallocManaged()分配内存,提供 CPU-GPU 共享虚拟地址空间,依赖 CUDA 运行时和双页表(CPU 系统页表和 GPU 2MB 页表),首次访问触发物理内存映射。 -
按需页面迁移
GPU 访问未驻留页面触发页故障,页面从 CPU 迁移到 GPU(或反向),ATS 提供硬件级地址翻译,降低开销。 -
推测性预取
通过显式(cudaMemPrefetchAsync)或隐式(GPU 预取器)方式预迁移页面,减少页故障开销,尽管 Grace Hopper 的直接访问能力可能降低其必要性。
两种分配方式总结
| 特性 | cudaMalloc | malloc |
|---|---|---|
| 分配位置 | GPU 物理内存(HBM3,96GB) | CPU(LPDDR5X,480GB)或 GPU 物理内存,取决于首次触碰 |
| 页表 | GPU 专属页表(2MB 页面) | 系统级页表(4KB 或 64KB 页面,由 OS 定义) |
| 管理方式 | CUDA 运行时和 GPU 驱动管理 | 操作系统管理,依赖 SMMU 进行地址翻译 |
| 数据访问 | 仅 GPU 直接访问,CPU 需显式 cudaMemcpy |
CPU 和 GPU 共享虚拟地址,GPU 可通过 NVLink-C2C 直接访问 CPU 内存 |
| 页故障 | 无页故障,内存直接分配在 GPU | 首次触碰触发页故障,由 OS 和 SMMU 处理,映射至 CPU 或 GPU 内存 |
| NVLink-C2C 交互 | 用于显式数据传输(H2D 375GB/s,D2H 297GB/s),不利用缓存一致性 | 利用缓存一致性,GPU 以缓存线粒度(CPU 64B,GPU 128B)直接访问 CPU 内存 |
| 页面迁移 | 无自动迁移,需显式管理数据移动 | 自动访问计数器迁移(默认阈值 256 次),高频页面从 CPU 迁移至 GPU |
| 性能特点 | GPU 内存访问高效(HBM3 带宽 3.4TB/s),但数据拷贝增加开销 | 适合超订阅场景,减少页故障和拷贝开销,初始化敏感(GPU 侧较慢) |
| 适用场景 | GPU 密集型、小数据集、传统 CUDA 应用 | HPC 应用、大数据集、需最小移植努力的 CPU-GPU 协同任务 |
| 局限性 | 内存容量受限(96GB),显式管理复杂 | GPU 侧初始化可能因页表更新导致延迟,需优化(如预填充页表) |
总结
这篇文章的核心内容是对 NVIDIA Grace Hopper Superchip 的 CPU-GPU 集成内存管理机制的首次深入研究,重点探讨其统一内存系统在高性能计算(HPC)中的表现。文章详细分析了两种内存管理方式:系统分配内存(System-Allocated Memory,基于 malloc() 和单一系统页表)和 CUDA 管理内存(CUDA Managed Memory,基于 cudaMallocManaged() 和双页表)。通过六个代表性 HPC 应用(包括 Qiskit 量子模拟器和 Rodinia 基准套件),作者研究了内存分配、页面迁移、首次触碰策略和页面大小对性能的影响,揭示了 Grace Hopper 的硬件特性(如 NVLink-C2C 缓存一致互连和 SMMU 地址翻译)如何减少页故障开销、优化数据访问。实验表明,系统分配内存在大多数场景下性能优于管理内存,尤其是 CPU 初始化场景,且需最少代码修改,同时提出优化策略如调整页面大小和预取机制以进一步提升性能。
文章剩下部分为详细实验,测量这些优化对性能的影响。