
HGEMM
- High Performance Computing
- 2025-04-16
- 1033 Views
- 0 Comments
- 2764 Words
赖海斌
ROI on HGEMM
矩阵参数
不同size的标准矩阵: 32 256 2048 8192 16384 32768 ......
矩阵形式:
正常矩阵(256 X 256)
特殊形状矩阵(有边界条件) 257 2049 // ?
稀疏矩阵(不同处理方式)// ?
复杂矩阵(行列相差极大,如 M=2048, N=8, K=2048)
API
GEMM API
void hgemm(const float16_t* A, const float16_t* B, float* C,
int M, int N, int K, int lda, int ldb, int ldc)测试
正确性
假设检验
CPU
FCLC/avx512_fp16_examples: hosting simple examples of fp16 code
pytorch/aten/src/ATen/cpu/vec/vec256/vec256_16bit_float.h at main · pytorch/pytorch
希望大家能做的
BLAS API blasqr.pdf
OpenMP https://www.openmp.org/wp-content/uploads/OpenMP-4.5-1115-CPP-web.pdf
Loop Unroll and Jam
Matrix Tilling
SIMD
Compilers / Compile Config -O3
Profile your program perf, VTune, gprof
鼓励大家做的 (有学习价值、开源实现)
Good Optimization on FP16
Intel® AVX-512 - FP16 Instruction Set for Intel® Xeon® Processor-Based Products Technology Guide
任务切分,数据重排
Pytorch with your GEMM
高阶玩法 (可能闭源/未知)
good BLAS Kernel 去看看OpenBLAS的软件是怎么做的 代码 Openblas 源码架构 和 调用过程_openblas项目结构-CSDN博客
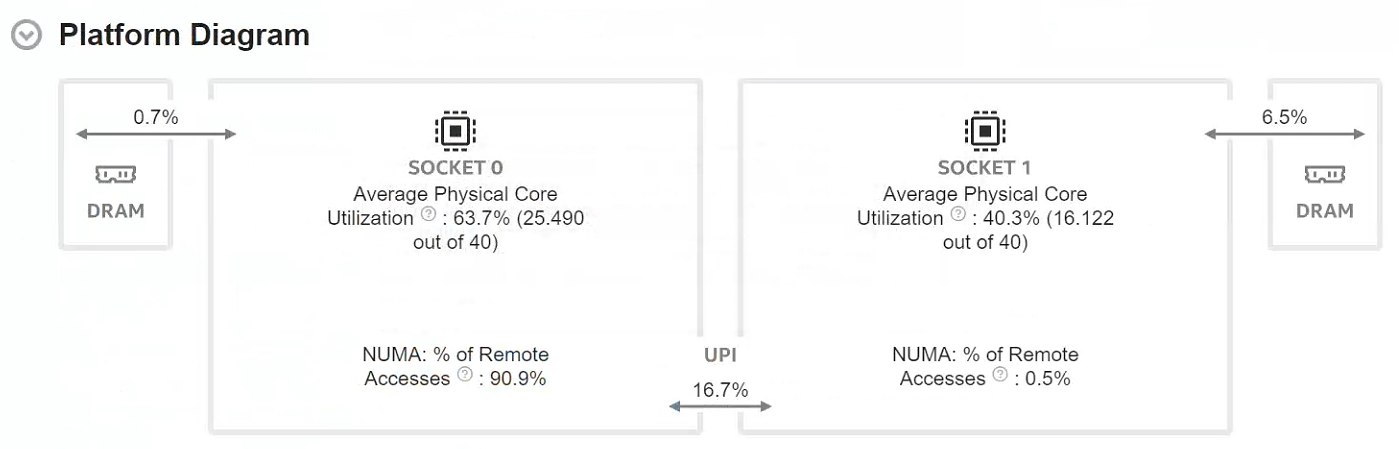
NUMA Aware Scheduling 如何更好的调配线程,更好的优化访存(来自VTune优化情况)
NUMA Aware Memory alloc (Jemalloc etc)
https://www.notion.so/Pytorch-OpenMP-1c25ab55420e80449eb4f7d4619fb85e?pvs=4#1c45ab55420e808db07ec882a485241a
https://pytorch.org/tutorials/intermediate/torchserve_with_ipex.html

首先,CPU上FP16计算非常少
似乎GNU也不支持FP16
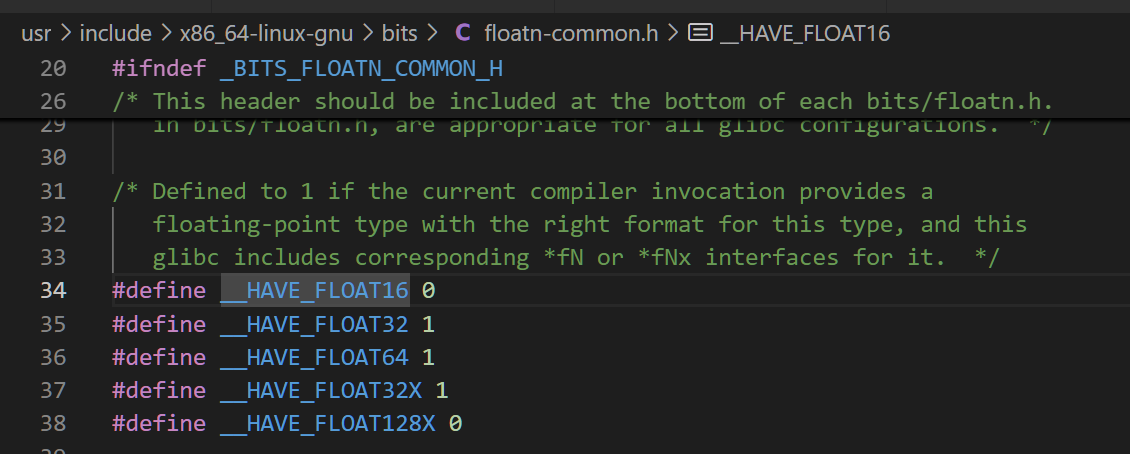
fp_avx2.cpp:5:19: error: ‘_Float16’ does not name a type; did you mean ‘_Float64’?
5 | using float16_t = _Float16;
| ^~~~~~~~
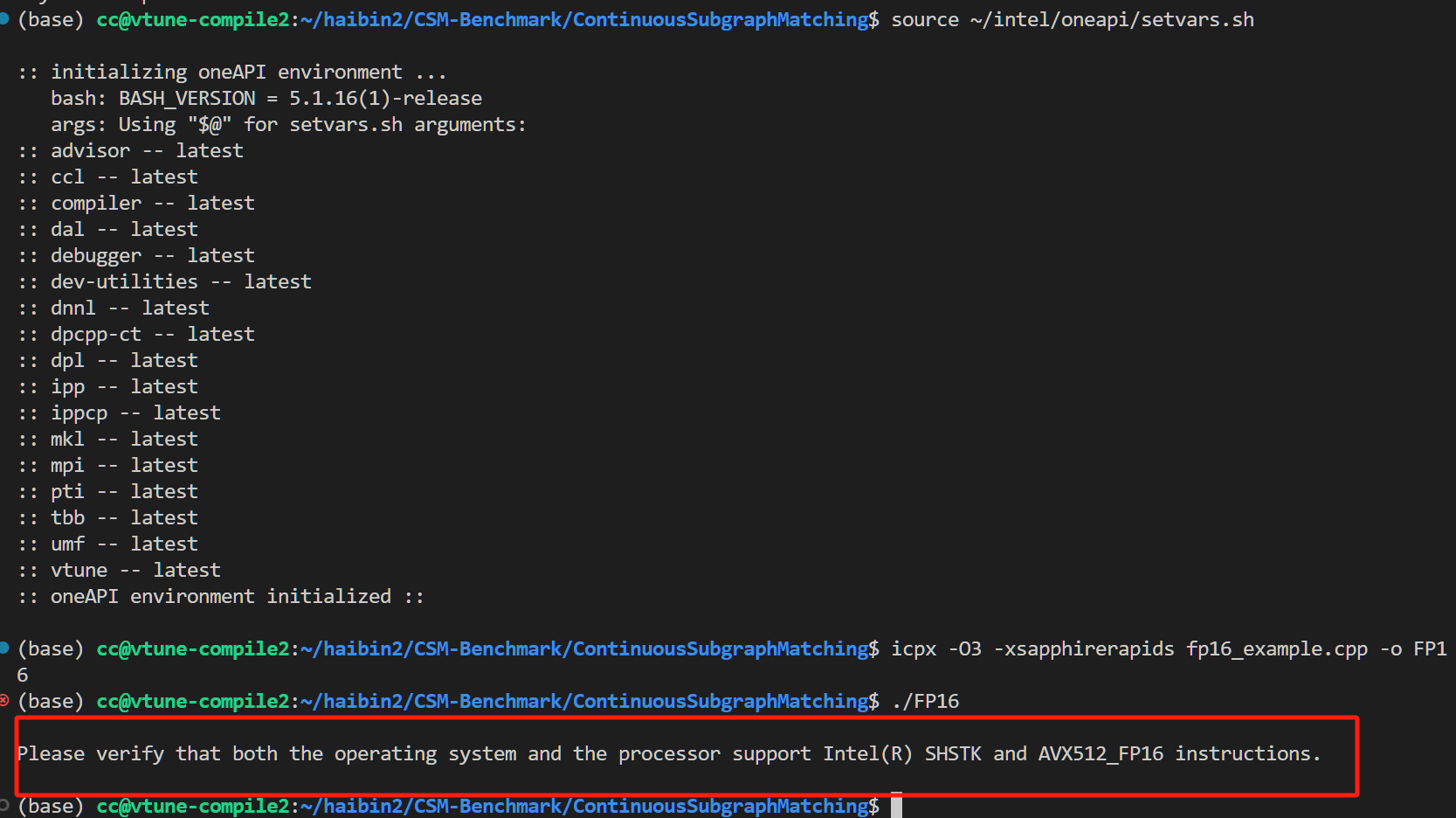
| _Float64思路:看看 Intel icx 编译器支不支持 / AVX指令集支不支持
发现好像这方面的支持都是在AVX指令集里。
查AVX FP16, 找到这么个指令手册
Intel® AVX-512 - FP16 Instruction Set for Intel® Xeon® Processor-Based Products Technology Guide
按照手册进行编程,发现:
但,好像很多机器不能用AVX512
思路:从Pytorch 下手
import torch
from transformers import pipeline
import time
torch.set_num_threads(20) # 设置为 20 个线程
# 设置随机种子以确保结果可重复
torch.manual_seed(123)
# 模型 ID
model_id = "meta-llama/Llama-3.2-1B"
# 创建文本生成 pipeline
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.half, # 使用 float16
device_map="auto", # 自动选择设备(CPU 或 GPU)
max_new_tokens=256, # 生成的最大 token 数
)
# 运行模型生成文本
prompt = "The key to life is"
res = pipe(prompt)
# 输出结果和耗时
print("Generated text:", res[0]["generated_text"])
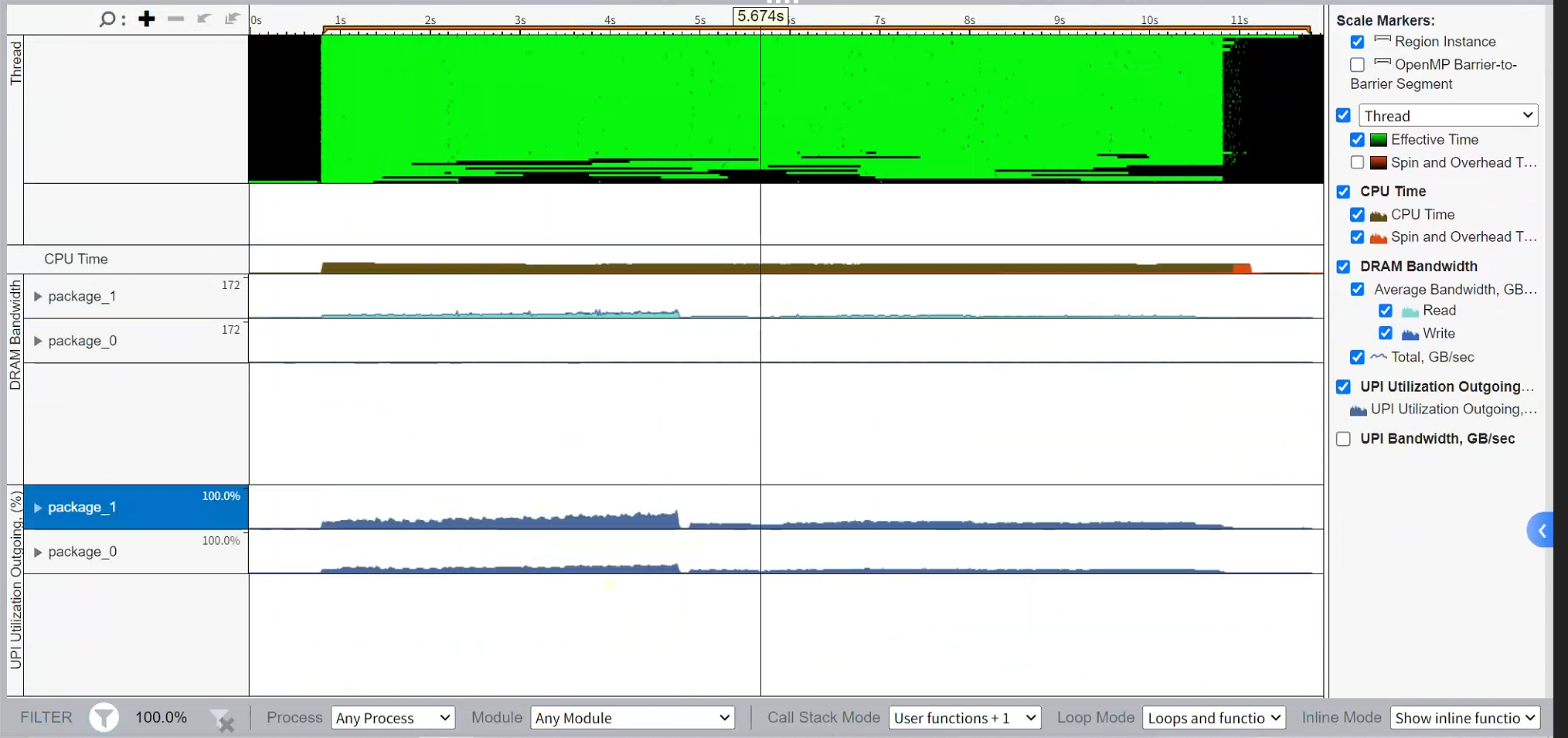
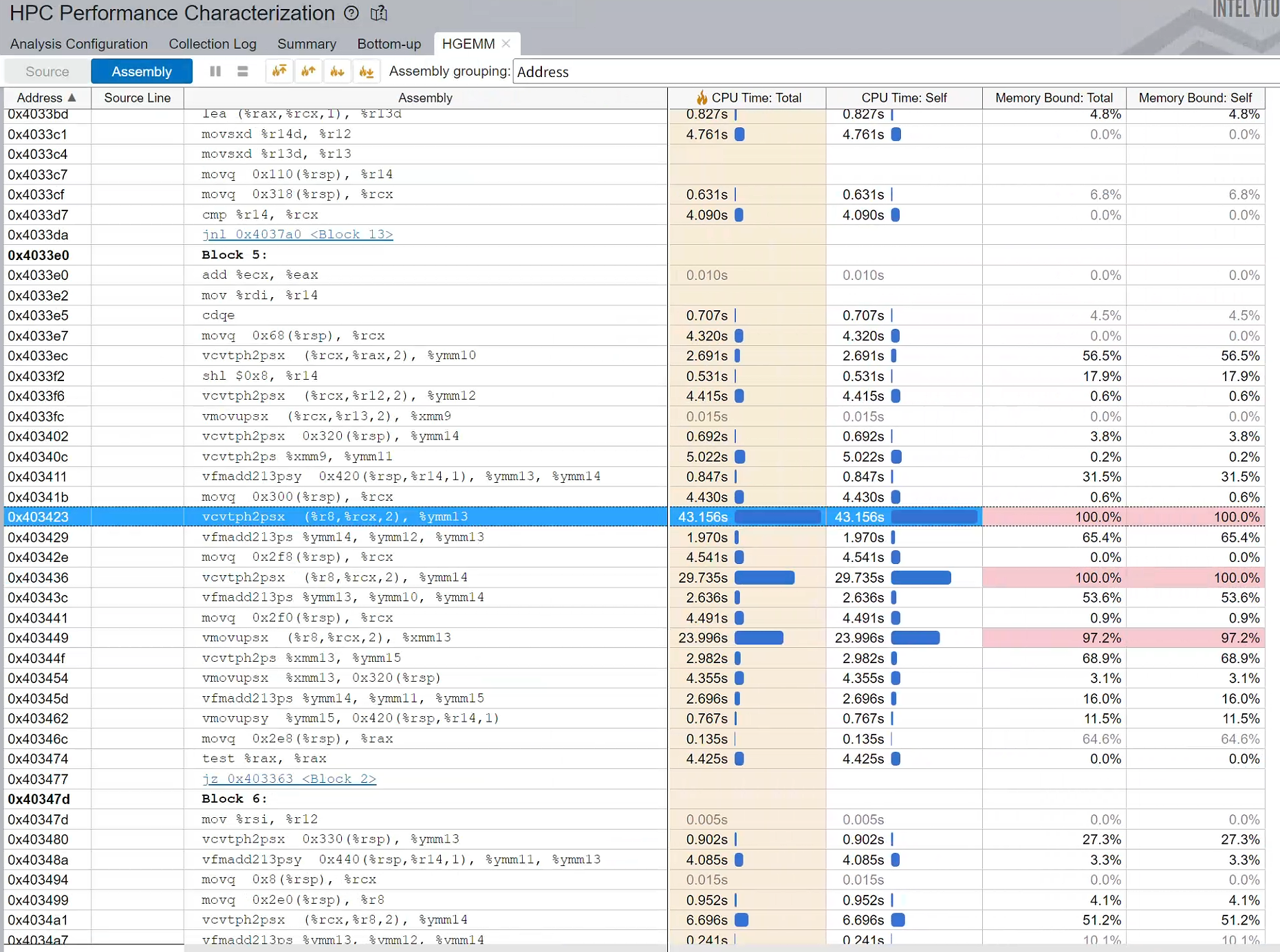
使用VTune观察使用了哪个函数:
CPU Time: 435.732s
Effective Time: 435.708s
Spin Time: 0.024s
Overhead Time: 0s
Total Thread Count: 486
Paused Time: 0s
Top Hotspots
Function Module CPU Time % of CPU Time(%)
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- -------------------------------- -------- ----------------
at::native::AVX2::fp16_dot_with_fp32_arith libtorch_cpu.so 152.235s 34.9%
func@0x18ad0 libgomp-a34b3233.so.1 123.269s 28.3%
func@0x18c30 libgomp-a34b3233.so.1 122.646s 28.1%
blas_thread_server libscipy_openblas64_-99b71e71.so 7.560s 1.7%
c10::function_ref<void (char**, long const*, long, long)>::callback_fn<at::TensorIteratorBase::loop_2d_from_1d<at::native::AVX2::copy_kernel(at::TensorIterator&, bool)::{lambda()#1}::operator()(void) const::{lambda()#2}::operator()(void) const::{lambda()#1}::operator()(void) const::{lambda()#4}::operator()(void) const::{lambda(char**long const*, long)#1}>(, signed char, at::native::AVX2::copy_kernel(at::TensorIterator&, bool)::{lambda()#1}::operator()(void) const::{lambda()#2}::operator()(void) const::{lambda()#1}::operator()(void) const::{lambda()#4}::operator()(void) const::{lambda(char**long const*, long)#1} const&)::{lambda(char**long const*, long, long)#1}> libtorch_cpu.so 4.353s 1.0%
[Others] N/A 25.668s 5.9%
Effective Physical Core Utilization: 6.5% (12.508 out of 192)
| The metric value is low, which may signal a poor physical CPU cores
| utilization caused by:
| - load imbalance
| - threading runtime overhead
| - contended synchronization
| - thread/process underutilization
| - incorrect affinity that utilizes logical cores instead of physical
| cores
| Explore sub-metrics to estimate the efficiency of MPI and OpenMP parallelism
| or run the Locks and Waits analysis to identify parallel bottlenecks for
| other parallel runtimes.
|
Effective Logical Core Utilization: 3.3% (12.808 out of 384)
| The metric value is low, which may signal a poor logical CPU cores
| utilization. Consider improving physical core utilization as the first
| step and then look at opportunities to utilize logical cores, which in
| some cases can improve processor throughput and overall performance of
| multi-threaded applications.
|
Collection and Platform Info
Application Command Line: python3 "hello_LLM.py"
Operating System: 5.15.0-134-generic DISTRIB_ID=Ubuntu DISTRIB_RELEASE=22.04 DISTRIB_CODENAME=jammy DISTRIB_DESCRIPTION="Ubuntu 22.04.4 LTS"
Computer Name: eightsocket
Result Size: 40.9 MB
Collection start time: 18:28:29 12/04/2025 UTC
Collection stop time: 18:29:03 12/04/2025 UTC
Collector Type: Driverless Perf per-process counting,User-mode sampling and tracing
CPU
Name: Intel(R) Xeon(R) Processor code named Skylake
Frequency: 2.100 GHz
Logical CPU Count: 384
LLC size: 34.6 MB
Cache Allocation Technology
Level 2 capability: not detected
Level 3 capability: availablex86 - Half-precision floating-point arithmetic on Intel chips - Stack Overflow
AVX2 using intel icx:
#include <immintrin.h> // AVX2 and F16C
#include <iostream>
// 定义FP16类型
using float16_t = _Float16;
int main() {
// 定义两个FP16数字
float16_t a = 1.5f; // FP16: 1.5
float16_t b = 2.5f; // FP16: 2.5
// 转换为FP32并加载到AVX2向量
__m128i a_ph = _mm_set1_epi16(*reinterpret_cast<uint16_t*>(&a)); // FP16 as 16-bit int
__m128i b_ph = _mm_set1_epi16(*reinterpret_cast<uint16_t*>(&b));
__m256 a_ps = _mm256_cvtph_ps(a_ph); // F16C: FP16 -> FP32
__m256 b_ps = _mm256_cvtph_ps(b_ph);
// 使用AVX2进行FP32加法
__m256 result_ps = _mm256_add_ps(a_ps, b_ps);
// 转换回FP16
__m128i result_ph = _mm256_cvtps_ph(result_ps, _MM_FROUND_TO_NEAREST_INT | _MM_FROUND_NO_EXC);
float16_t result;
*reinterpret_cast<uint16_t*>(&result) = _mm_extract_epi16(result_ph, 0);
// 输出结果(转换为float以便打印)
std::cout << "FP16: " << float(a) << " + " << float(b) << " = " << float(result) << std::endl;
return 0;
}icpx -O3 -mavx2 -mf16c fp16_add_avx2.cpp -o fp16_add_avx2
./FP_AVX
FP16: 1.5 + 2.5 = 4Example from grok3
#include <immintrin.h> // AVX2 and F16C
#include <omp.h>
#include <vector>
#include <iostream>
#include <random>
#include <cmath>
#include <chrono>
// 定义FP16类型
using float16_t = _Float16;
// AVX2内核:计算C[m:m+8, n:n+8] += A[m:m+8, k:k+K] × B[k:k+K, n:n+8]
void hgemm_kernel_avx2(const float16_t* A, const float16_t* B, float* C,
int M, int N, int K, int lda, int ldb, int ldc,
int m_start, int m_end, int n_start, int n_end) {
for (int m = m_start; m < m_end; m += 8) { // 每次处理8行
for (int n = n_start; n < n_end; n += 8) { // 每次处理8列
// 累加器:FP32,8x8子块
__m256 acc[8][8];
for (int i = 0; i < 8; ++i)
for (int j = 0; j < 8; ++j)
acc[i][j] = _mm256_setzero_ps();
// 沿K维度计算
for (int k = 0; k < K; ++k) {
// 加载A的8个FP16值(一行)
__m128i a_ph[8];
for (int i = 0; i < 8 && m + i < M; ++i) {
a_ph[i] = _mm_loadu_si128(
reinterpret_cast<const __m128i*>(&A[(m + i) * lda + k]));
}
// 加载B的8个FP16值(一列)
__m128i b_ph[8];
for (int j = 0; j < 8 && n + j < N; ++j) {
b_ph[j] = _mm_loadu_si128(
reinterpret_cast<const __m128i*>(&B[k * ldb + n + j]));
}
// 转换为FP32并计算
for (int i = 0; i < 8 && m + i < M; ++i) {
__m256 a_ps = _mm256_cvtph_ps(a_ph[i]); // FP16 -> FP32
for (int j = 0; j < 8 && n + j < N; ++j) {
__m256 b_ps = _mm256_cvtph_ps(b_ph[j]);
acc[i][j] = _mm256_fmadd_ps(a_ps, b_ps, acc[i][j]);
}
} // ?
}
// 存储结果到C
for (int i = 0; i < 8 && m + i < M; ++i) {
for (int j = 0; j < 8 && n + j < N; ++j) {
float* acc_ptr = reinterpret_cast<float*>(&acc[i][j]);
for (int l = 0; l < 8; ++l) {
C[(m + i) * ldc + (n + j)] += acc_ptr[l];
}
}
}
}
}
}
// 并行HGEMM
void hgemm_parallel(const float16_t* A, const float16_t* B, float* C,
int M, int N, int K, int lda, int ldb, int ldc) {
const int BLOCK_SIZE = 128; // 缓存友好的分块大小
#pragma omp parallel for collapse(2) num_threads(8)
for (int m = 0; m < M; m += BLOCK_SIZE) {
for (int n = 0; n < N; n += BLOCK_SIZE) {
int m_end = std::min(m + BLOCK_SIZE, M);
int n_end = std::min(n + BLOCK_SIZE, N);
hgemm_kernel_avx2(A, B, C, M, N, K, lda, ldb, ldc,
m, m_end, n, n_end);
}
}
}
// 测试代码
int main() {
int M = 2560, N = 2560, K = 2560;
std::vector<float16_t> A(M * K), B(K * N);
std::vector<float> C(M * N, 0.0f);
// 初始化矩阵(随机值)
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<float> dis(0.0f, 1.0f);
for (auto& x : A) x = dis(gen);
for (auto& x : B) x = dis(gen);
// 运行HGEMM
auto start = std::chrono::high_resolution_clock::now();
hgemm_parallel(A.data(), B.data(), C.data(), M, N, K, K, N, N);
auto end = std::chrono::high_resolution_clock::now();
// 计算时间和TFLOPS
double duration = std::chrono::duration<double, std::milli>(end - start).count();
double flops = 2.0 * M * N * K;
double gflops = (flops / (duration / 1000.0)) / 1e9;
std::cout << "HGEMM Time: " << duration << " ms, "
<< "gFLOPS: " << gflops << std::endl;
// 验证结果(简单求和检查)
float sum = 0.0f;
for (float x : C) sum += x;
std::cout << "Result sum: " << sum << std::endl;
return 0;
}icpx -O3 -mavx2 -mf16c -qopenmp -mfma fp_GEMM.cpp -o HGEMM
./HGEMM
HGEMM Time: 2170.78 ms, gFLOPS: 15.4573
Result sum: 3.35483e+10Benchmark:
用pytorch的ATen API(可能调用的是OneDNN的API,要去看他们怎么做的)
去做矩阵乘法的baseline
要做的工作
- 写一个自己的高效的kernel
- 给一个simple example和计时,和高效的输出
- 给一个介绍博客+视频
- 给一个优化方向的博客
- 给一个调优VTune的介绍文档+如何在Pytorch里跑起来的文档

CPP Project2 Matrix Multiplication-CPP-Haibin's blog
GPU
xlite-dev/CUDA-Learn-Notes: 📚Modern CUDA Learn Notes: 200+ Tensor/CUDA Cores Kernels🎉, HGEMM, FA2 via MMA and CuTe, 98~100% TFLOPS of cuBLAS/FA2.
CUDA Ampere Tensor Core HGEMM 矩阵乘法优化笔记 —— Up To 131 TFLOPS! - 知乎
kernel 书写
FP16 计算
TensorCore计算
访存优化(reg, bank conflict, 异步拷贝, Cache Affinity )
SASS kernel optim
Nsight tuning
CUDA /
cuBLAS | NVIDIA Developer
NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines
aredden/torch-cublas-hgemm: PyTorch half precision gemm lib w/ fused optional bias + optional relu/gelu
CUTLASS库使用与优化指北(一) - 知乎
CUDA
TensorCore
TMA
TensorCore
bank conflict
ldgsts
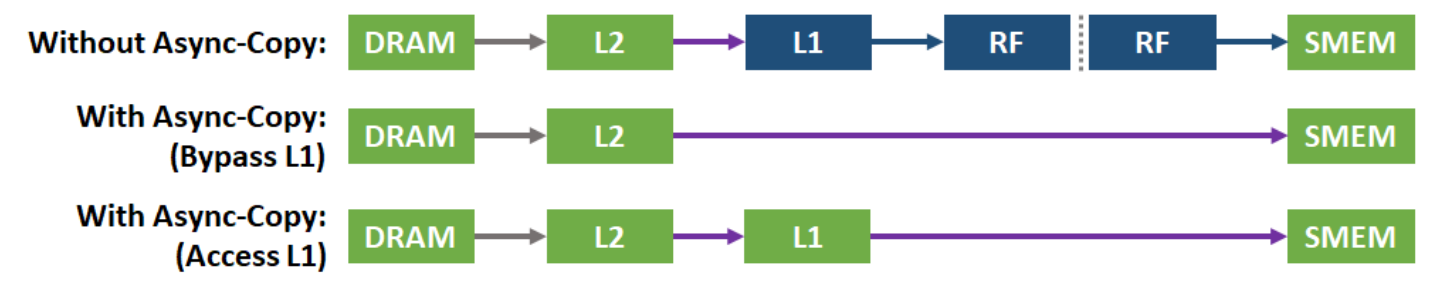
reg
prefetch
Nsight Compute
#include <cuda_fp16.h>
#include <mma.h>
#include <cuda.h>
#include <cuda_runtime.h>
#include <stdio.h>
using namespace nvcuda;
// 矩阵维度假设为16的倍数以匹配WMMA
#define MATRIX_M 256
#define MATRIX_N 256
#define MATRIX_K 256
// 检查CUDA错误
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error: %s (%s:%d)\n", \
cudaGetErrorString(err), __FILE__, __LINE__); \
exit(1); \
} \
} while(0)
// WMMA kernel
__global__ void wmma_gemm(half *A, half *B, float *C,
int M, int N, int K) {
// 声明WMMA fragments
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::col_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;
// 初始化累加器
wmma::fill_fragment(c_frag, 0.0f);
// 计算tile的位置
int warpM = (blockIdx.x * blockDim.x + threadIdx.x) / 32;
int warpN = (blockIdx.y * blockDim.y + threadIdx.y);
// 每个warp处理一个16x16的tile
for (int k = 0; k < K; k += 16) {
// 加载数据到fragments
wmma::load_matrix_sync(a_frag, A + warpM * 16 * K + k, K);
wmma::load_matrix_sync(b_frag, B + k * N + warpN * 16, N);
// 执行矩阵乘法
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
}
// 存储结果
wmma::store_matrix_sync(C + warpM * 16 * N + warpN * 16,
c_frag, N, wmma::mem_row_major);
}
// 初始化矩阵
void init_matrix(half *mat, int rows, int cols) {
for (int i = 0; i < rows * cols; i++) {
mat[i] = __float2half((float)rand() / RAND_MAX);
}
}
int main() {
half *h_A, *h_B;
float *h_C;
half *d_A, *d_B;
float *d_C;
// 分配主机内存
h_A = (half*)malloc(MATRIX_M * MATRIX_K * sizeof(half));
h_B = (half*)malloc(MATRIX_K * MATRIX_N * sizeof(half));
h_C = (float*)malloc(MATRIX_M * MATRIX_N * sizeof(float));
// 初始化矩阵
init_matrix(h_A, MATRIX_M, MATRIX_K);
init_matrix(h_B, MATRIX_K, MATRIX_N);
// 分配设备内存
CUDA_CHECK(cudaMalloc(&d_A, MATRIX_M * MATRIX_K * sizeof(half)));
CUDA_CHECK(cudaMalloc(&d_B, MATRIX_K * MATRIX_N * sizeof(half)));
CUDA_CHECK(cudaMalloc(&d_C, MATRIX_M * MATRIX_N * sizeof(float)));
// 复制数据到设备
CUDA_CHECK(cudaMemcpy(d_A, h_A, MATRIX_M * MATRIX_K * sizeof(half),
cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_B, h_B, MATRIX_K * MATRIX_N * sizeof(half),
cudaMemcpyHostToDevice));
// 设置grid和block维度
dim3 blockDim(128, 4);
dim3 gridDim((MATRIX_M + 15) / 16, (MATRIX_N + 15) / 16);
// 启动kernel
wmma_gemm<<<gridDim, blockDim>>>(d_A, d_B, d_C,
MATRIX_M, MATRIX_N, MATRIX_K);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaDeviceSynchronize());
// 复制结果回主机
CUDA_CHECK(cudaMemcpy(h_C, d_C, MATRIX_M * MATRIX_N * sizeof(float),
cudaMemcpyDeviceToHost));
// 释放内存
free(h_A); free(h_B); free(h_C);
CUDA_CHECK(cudaFree(d_A));
CUDA_CHECK(cudaFree(d_B));
CUDA_CHECK(cudaFree(d_C));
printf("HGEMM completed successfully!\n");
return 0;
}Trition
Group GEMM — Triton documentation
【Triton 教程】分组 GEMM - 智源社区
22:46:42.052751 brk(0x55888cec9000) = 0x55888cec9000
22:46:42.054412 brk(0x55888ceea000) = 0x55888ceea000
22:46:42.055432 brk(0x55888cf0b000) = 0x55888cf0b000
22:46:42.055712 brk(0x55888cf2c000) = 0x55888cf2c000
22:46:42.055988 brk(0x55888cf4d000) = 0x55888cf4d000
22:46:42.056191 brk(0x55888cf6e000) = 0x55888cf6e000
22:46:42.056345 brk(0x55888cf90000) = 0x55888cf90000
22:46:42.058240 brk(0x55888cfb1000) = 0x55888cfb1000
22:46:42.059119 brk(0x55888cfd2000) = 0x55888cfd2000
22:46:42.060013 brk(0x55888cff3000) = 0x55888cff3000
22:46:42.060914 brk(0x55888d014000) = 0x55888d014000
22:46:42.061748 brk(0x55888d035000) = 0x55888d035000
22:46:42.062639 brk(0x55888d056000) = 0x55888d056000
22:46:42.063552 brk(0x55888d077000) = 0x55888d077000
22:46:42.064430 brk(0x55888d098000) = 0x55888d098000
22:46:42.065188 brk(0x55888d0bb000) = 0x55888d0bb000
22:46:42.070302 brk(0x55888d0dc000) = 0x55888d0dc000
22:46:42.071251 brk(0x55888d0fd000) = 0x55888d0fd000
22:46:42.072139 brk(0x55888d11e000) = 0x55888d11e000
22:46:42.072854 brk(0x55888d13f000) = 0x55888d13f000
22:46:42.073662 brk(0x55888d160000) = 0x55888d160000
22:46:42.074504 brk(0x55888d181000) = 0x55888d181000
22:46:42.075380 brk(0x55888d1a2000) = 0x55888d1a2000
22:46:42.076225 brk(0x55888d1c3000) = 0x55888d1c3000
22:46:42.077066 brk(0x55888d1e4000) = 0x55888d1e4000
22:46:42.077946 brk(0x55888d205000) = 0x55888d205000
22:46:42.078894 brk(0x55888d226000) = 0x55888d226000
22:46:42.080063 brk(0x55888d247000) = 0x55888d247000
22:46:42.081097 brk(0x55888d268000) = 0x55888d268000
22:46:42.082879 brk(0x55888d289000) = 0x55888d289000
22:46:42.083787 brk(0x55888d2aa000) = 0x55888d2aa000
22:46:42.084787 brk(0x55888d2cb000) = 0x55888d2cb000
22:46:42.085604 brk(0x55888d2ec000) = 0x55888d2ec000
22:46:42.086319 brk(0x55888d30d000) = 0x55888d30d000
22:46:42.087109 brk(0x55888d32f000) = 0x55888d32f000
22:46:42.087896 brk(0x55888d350000) = 0x55888d350000
22:46:42.088550 brk(0x55888d371000) = 0x55888d371000
22:46:42.089236 brk(0x55888d392000) = 0x55888d392000
22:46:42.089953 brk(0x55888d3b3000) = 0x55888d3b3000
22:46:42.090642 brk(0x55888d3d4000) = 0x55888d3d4000
22:46:42.091357 brk(0x55888d3f5000) = 0x55888d3f5000
22:46:42.092083 brk(0x55888d416000) = 0x55888d416000
22:46:42.092806 brk(0x55888d438000) = 0x55888d438000
22:46:42.093603 brk(0x55888d459000) = 0x55888d459000
22:46:42.094404 brk(0x55888d47a000) = 0x55888d47a000
22:46:42.095153 brk(0x55888d49b000) = 0x55888d49b000
22:46:42.095812 brk(0x55888d4bc000) = 0x55888d4bc000
22:46:42.096559 brk(0x55888d4dd000) = 0x55888d4dd000
22:46:42.097280 brk(0x55888d4fe000) = 0x55888d4fe000
22:46:42.098026 brk(0x55888d51f000) = 0x55888d51f000
22:46:42.098789 brk(0x55888d540000) = 0x55888d540000
22:46:42.099557 brk(0x55888d561000) = 0x55888d561000
22:46:42.100304 brk(0x55888d582000) = 0x55888d582000
22:46:42.101064 brk(0x55888d5a3000) = 0x55888d5a3000
22:46:42.101827 brk(0x55888d5c4000) = 0x55888d5c4000
22:46:42.102583 brk(0x55888d5e5000) = 0x55888d5e5000
22:46:42.103338 brk(0x55888d606000) = 0x55888d606000
22:46:42.104116 brk(0x55888d627000) = 0x55888d627000
22:46:42.104895 brk(0x55888d648000) = 0x55888d648000
22:46:42.105689 brk(0x55888d669000) = 0x55888d669000