
gcc是怎么实现OpenMP的?
- 高性能计算
- 2025-05-29
- 69热度
- 0评论
由于网上关于GNU openmp的解构比较少,今天我由于工作问题,我也来亲自解答:“为什么OpenMP不能完成 “小而多的并行任务” 的问题。(llvm的解构我之前在博客已经做过 llvm 如何实现OpenMP ,其实从结构来看,跟OpenMP的结构基本一致,都遵从OpenMP官方的fork-join 的idea,但是llvm的实现会比较复杂)
学习网页
我们所有的学习都可以从这里出发:
源码 doxygen文档:
Libgomp: Main Page
一位知乎大佬的源码解析
OpenMP task construct 实现原理以及源码分析 - 知乎
OpenMP For Construct dynamic 调度方式实现原理和源码分析 - 一无是处的研究僧 - 博客园
其他OpenMP的 usercase 学习案例网上比较多,大家搜索一下都能找到
一个简单的OpenMP的例子
在本节,我们将查看一个简单的OpenMP的例子,查看它的汇编及调用的函数,大概理解OpenMP编译后的情况。
这里大家也可以查看:
OpenMP Parallel Construct 实现原理与源码分析 - 知乎
我们先从一个最简单的OpenMP的例子开始:
#include <iostream>
#include <omp.h>
int main() {
#pragma omp parallel
{
int thread_id = omp_get_thread_num();
std::cout << "Hello from thread " << thread_id << std::endl;
}
return 0;
}
众所周知,它编译后将输出 N 个 "Hello from thread X",其中N是你的核数大小。
现在我们看看它的汇编结果:
g++ -S openmp_hello.cpp -fopenmp -o openmp_hello.S为了清晰的展示,在这里我略去了很多无关函数和调用。
编译后我们将得到两个重要的子函数:
- main
- main._omp_fn.0
main函数还会调用GOMP_parallel@PLT函数,这是OpenMP实现并行的关键函数,我们会在后面一并解析。main: 如何启动openmp并行域?
首先我们查看main 函数:
main:
.LFB1731:
pushq %rbp # 保存旧的栈帧指针(`%rbp`)到栈中。
movq %rsp, %rbp # 将当前栈指针赋值给帧指针,建立新的栈帧。
# 清空一些通用寄存器(为 `GOMP_parallel` 做准备)
movl $0, %ecx
movl $0, %edx
movl $0, %esi # %esi在 OpenMP 中通常作为 `data` 参数,代表共享数据指针。
# 把函数 `main._omp_fn.0` 的地址加载到 `%rax` 中;
leaq main._omp_fn.0(%rip), %rax
movq %rax, %rdi # 然后把这个函数地址传入 `%rdi`,作为第一个参数(x86_64 ABI 下第一个参数传入 `%rdi`)。
call GOMP_parallel@PLT # 调用 OpenMP 运行时的并行构造函数
movl $0, %eax # 设置返回值为 `0`,对应 `return 0;`。
popq %rbp # 恢复旧的栈帧指针(销毁当前栈帧)。
ret # `ret`:从 `main` 返回。代码中使用的寄存器及其作用如下表(基于 x86_64 System V ABI x86 psABIs / x86-64 psABI · GitLab)
| 寄存器 | 宽度 | ABI角色 | main中的作用 |
|---|---|---|---|
%rbp |
64位 | 栈帧基指针(base pointer) | 保存和恢复旧栈帧指针,构建新栈帧(函数入口和退出) |
%rsp |
64位 | 栈指针(stack pointer) | 指向当前栈顶,用于栈管理 |
%rax |
64位 | 函数返回值寄存器(返回值1) | 暂存 main._omp_fn.0 的地址;后用于 return 0 |
%rdi |
64位 | 第1个函数参数 | 保存 main._omp_fn.0 地址,作为 GOMP_parallel 的回调参数 |
%esi |
32位 | 第2个函数参数 | 设为 0,传给 GOMP_parallel 的 data 参数(共享上下文) |
%edx |
32位 | 第3个函数参数 | 设为 0,传给 GOMP_parallel 的 num_threads 参数(或动态) |
%ecx |
32位 | 第4个函数参数 | 设为 0,通常未使用 |
其中,movl 会同时清空64位数据(向低 32 位寄存器(如 %eax, %ecx, %edx, %esi)写入数据时,高 32 位会自动清零)
详细说明
完整行为:
- 准备调用openmp函数;
- 设置参数为
main._omp_fn.0(实际并行执行的函数),准备好openmp的调用; - 调用
GOMP_parallel启动 OpenMP 并行区域; - 设置返回值为 0, 恢复栈帧并返回。
我们可以看到,原始的 #pragma omp parallel 最终会被打包为 一个子函数main._omp_fn.0(%rip), %rax, 接着程序会调用 GOMP_parallel@PLT 启动子函数。
(@PLT 表示这个调用是通过 Procedure Linkage Table(过程链接表) 进行的,它会用PLT表做一次间接跳转,跳到libgomp.so库里的 GOMP_parallel 函数,在后续,你可以把它就当作是外部lib函数)
GOMP_parallel 函数可以在 gcc/libgomp/parallel.c at e2bf0b3910de7e65363435f0a7fa606e2448a677 · gcc-mirror/gcc 看到,我们稍后会深入解析它,但我们先看它的头:
void
GOMP_parallel (void (*fn) (void *), void *data, unsigned num_threads,
unsigned int flags)可以看到,我们的main函数将我们的main._omp_fn.0 函数传入给了这个GOMP_parallel函数。如果我们设置了data,num_threads,flags,这个函数也会接受。
子函数 main._omp_fn.0
我们来看看
main._omp_fn.0:
# 分配自己的函数栈空间
pushq %rbp
movq %rsp, %rbp
subq $32, %rsp
movq %rdi, -24(%rbp)
# 获取线程编号 并移到 -4(%rbp)
call omp_get_thread_num@PLT
movl %eax, -4(%rbp)
# 这段等价于 std::cout << "Hello from thread ";
leaq .LC0(%rip), %rax # LC0 是常量字符串 "Hello from thread "
movq %rax, %rsi
leaq _ZSt4cout(%rip), %rax # rax = std::cout 的地址
movq %rax, %rdi
call _ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@PLT
# 这段等价于 std::cout << thread_id;
movq %rax, %rdx
movl -4(%rbp), %eax
movl %eax, %esi
movq %rdx, %rdi
call _ZNSolsEi@PLT
# 打印 `std::endl` 并结束输出
movq _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_@GOTPCREL(%rip), %rdx
movq %rdx, %rsi
movq %rax, %rdi
call _ZNSolsEPFRSoS_E@PLT
# 清理栈帧,返回主线程
leave
ret子函数几乎没有动,就是parallel region 里的地方。
到这里我们基本上可以对OpenMP有概念了:主线程首先会准备好子函数的data,subfunction子函数,num_thread,并将他们传入 GOMP_parallel ,它将并行执行subFunction。
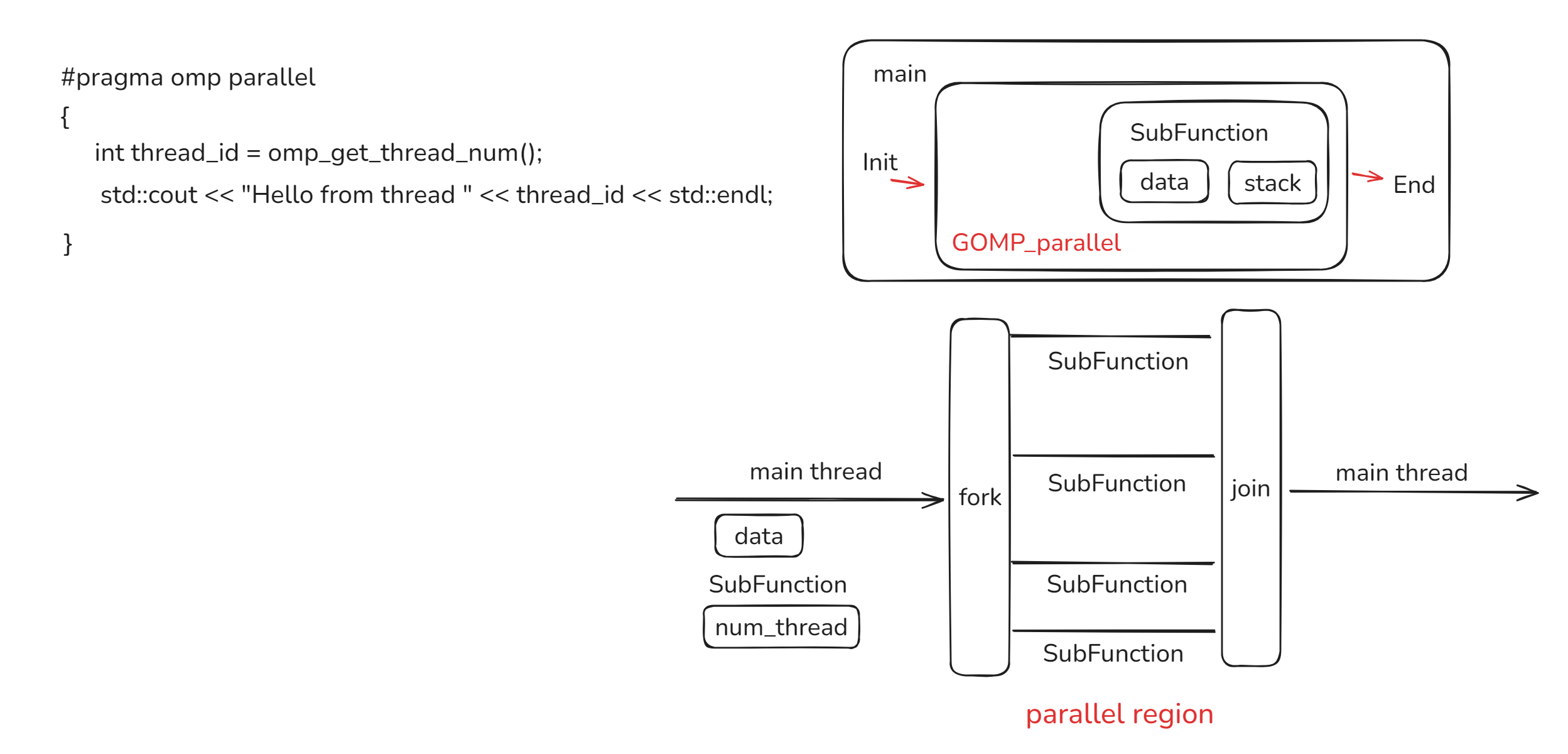
注:不同的openmp函数可能会调用不同的kernel,比如reduce 会调用 GOMP_parallel_reductions ,在用的时候要注意看看。
GNU gcc OpenMP底层机制
在本节,我们将通过 GOMP_parallel 了解GNU OpenMP 的底层实现。
gcc/libgomp/parallel.c at e2bf0b3910de7e65363435f0a7fa606e2448a677 · gcc-mirror/gcc
void
GOMP_parallel (void (*fn) (void *), void *data, unsigned num_threads,
unsigned int flags)
{
num_threads = gomp_resolve_num_threads (num_threads, 0);
gomp_team_start (fn, data, num_threads, flags, gomp_new_team (num_threads),
NULL);
fn (data);
ialias_call (GOMP_parallel_end) ();
}| 参数名 | 作用 |
|---|---|
fn |
每个线程执行的函数(刚刚我们看到的编译器生成的 .omp_fn.*) |
data |
传入 fn 的参数(由编译器生成) |
num_threads |
用户在 pragma 中设定的线程数 |
flags |
运行时行为控制位,比如是否绑定线程、是否有 if 子句等 |
我们可以看到OpenMP的大概结构:
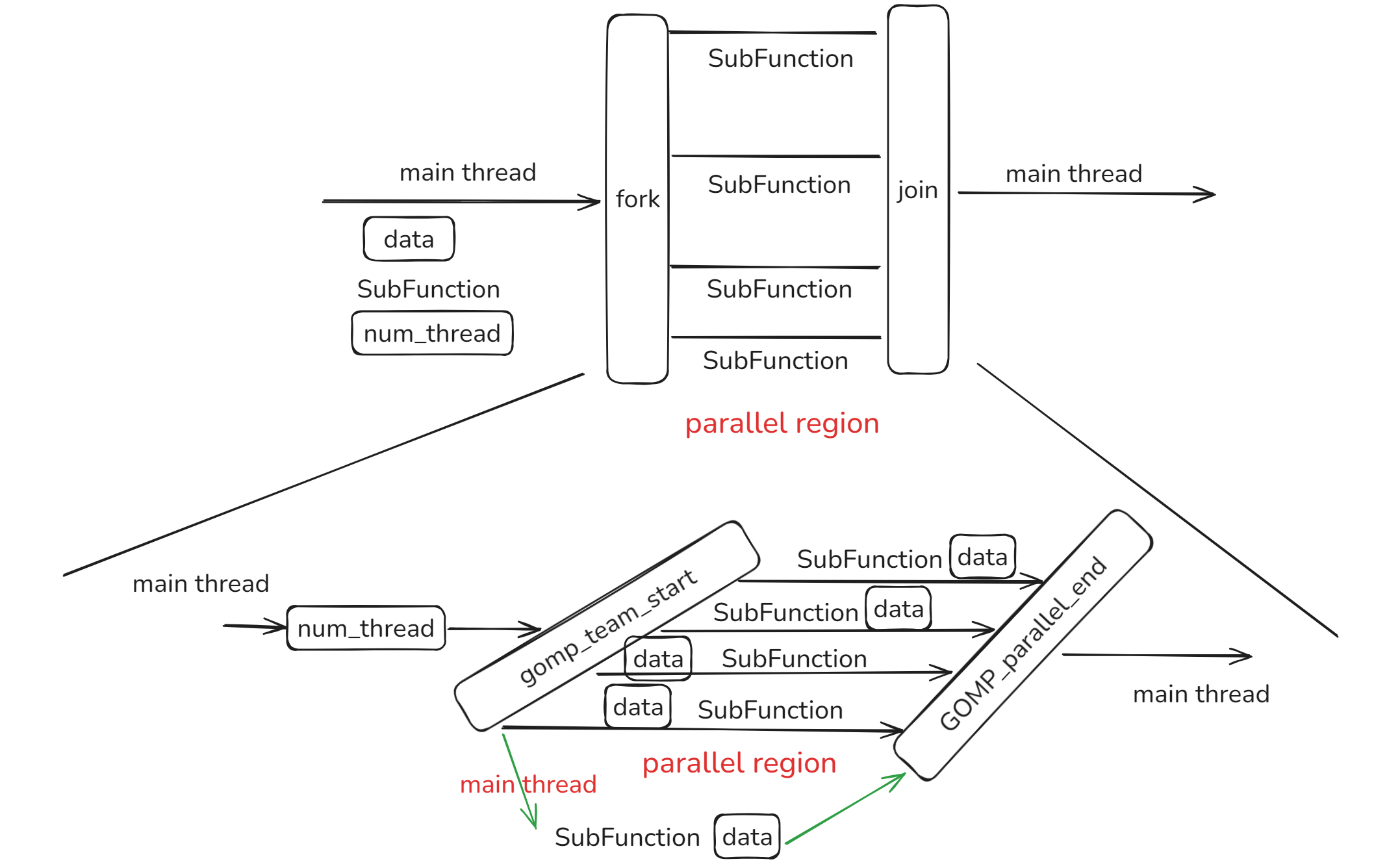
注意到主线程也会 fn(data),这是 OpenMP 的经典设计模式:主线程(即调用 GOMP_parallel 的线程)在创建工作线程后,不闲着,而是直接参与执行工作负载。
确定线程数量
num_threads = gomp_resolve_num_threads (num_threads, 0);根据当前上下文(比如 nested parallel region 或资源限制)动态决定实际使用的线程数。其函数注释如下:
Determine the number of threads to be launched for a PARALLEL construct.
This algorithm is explicitly described in OpenMP 3.0 section 2.4.1.
SPECIFIED is a combination of the NUM_THREADS clause and the IF clause.
If the IF clause is false, SPECIFIED is forced to 1. When NUM_THREADS
is not present, SPECIFIED is 0.
unsigned gomp_resolve_num_threads (unsigned specified, unsigned count)线程数由 NUM_THREADS SPECIFIED 和系统条款 IF 共同确定。IF 条款的意义是控制并行区域是否实际以并行方式执行,IF 条款允许开发者根据运行时条件动态控制并行性,以避免在某些情况下(如数据规模小、开销高于并行收益)启用并行执行。
IF Clause |
NUM_THREADS Clause |
SPECIFIED Value |
Number of Threads Launched |
|---|---|---|---|
| Not present | Not present | 0 | Implementation-defined (e.g., OMP_NUM_THREADS or system default) |
| True | Not present | 0 | Implementation-defined (e.g., OMP_NUM_THREADS or system default) |
| False | Not present | 1 | 1 thread (sequential execution) |
| True | Present (value = N) | N | N threads (capped by implementation limits) |
| False | Present (value = N) | 1 | 1 thread (sequential execution) |
启动并行域 gomp_team_start
如果你用的是pthread,你的源码应该是在
gcc/libgomp/team.c at master · gcc-mirror/gcc
(否则你要去nvptx和gcn找找,nvptx应该是链接的GPU cuda库)
pthread实现这里源码有600行,其实大部分的代码都是主要是在设置线程亲和度,处理闲置线程等工作。但我们最重要的是启动线程。
OpenMP Parallel Construct 实现原理与源码分析 - 知乎 简单分析了OpenMP启动线程的操作,我们引用他的话:
"可以看到这是一个 for 循环并且启动 nthreads 个线程,
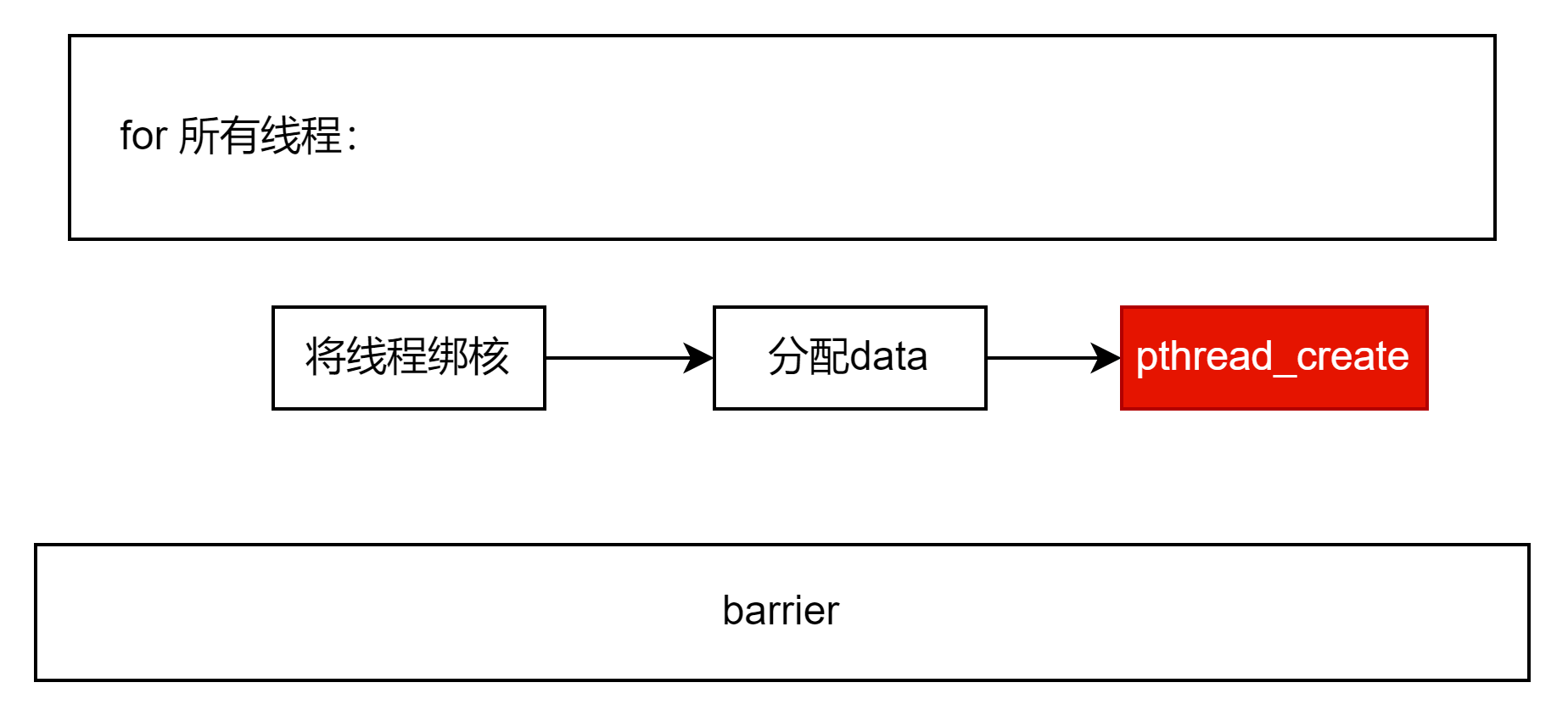
pthread_create是真正创建了线程的代码,并且让线程执行函数 gomp_thread_start 可以看到线程不是直接执行 subfunction 而是将这个函数指针保存到 start_data 当中,并且在函数 gomp_thread_start 真正去调用这个函数"gomp_thread_start 的函数体也相对比较长,在这里我们选中其中的比较重要的几行代码,其余的代码进行省略。对比上面线程启动的 pthread_create 语句我们可以知道,gomp_thread_start真正的调用了 subfunction,并且给这个函数传递了对应的参数。
我画了一个草图来演示这个函数的基础流程:
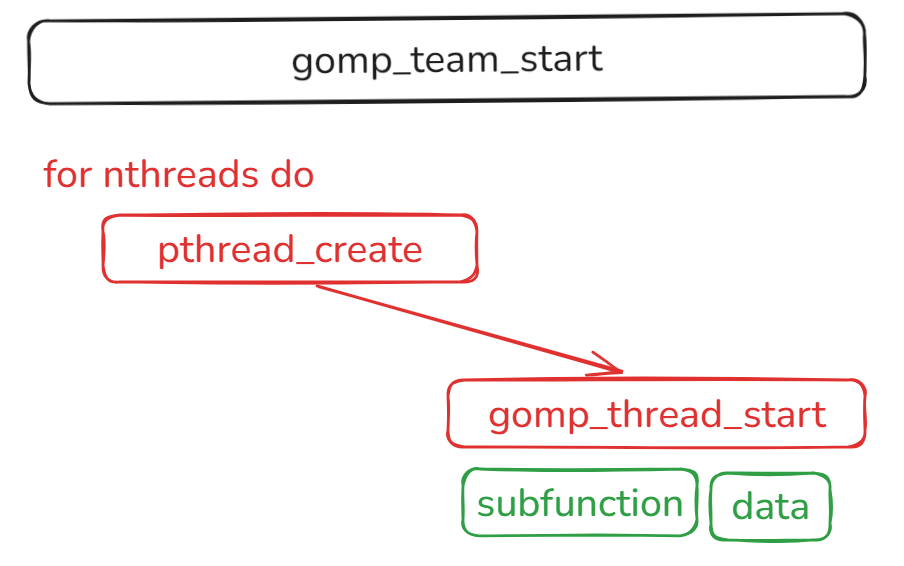
在看完600行代码后,我们可以总结gomp_team_start 的核心工程:
- 从线程池里拉出要跑的线程
- 判断当前team是否处于嵌套。
- 根据环境变量和参数计算线程数和绑定策略。
- 尝试复用空闲线程(线程池复用)。
- 启动新线程,设置线程亲和和任务状态。
- 等待线程全部启动完成后释放。
我们换一个方向,从结构的角度进行解读。
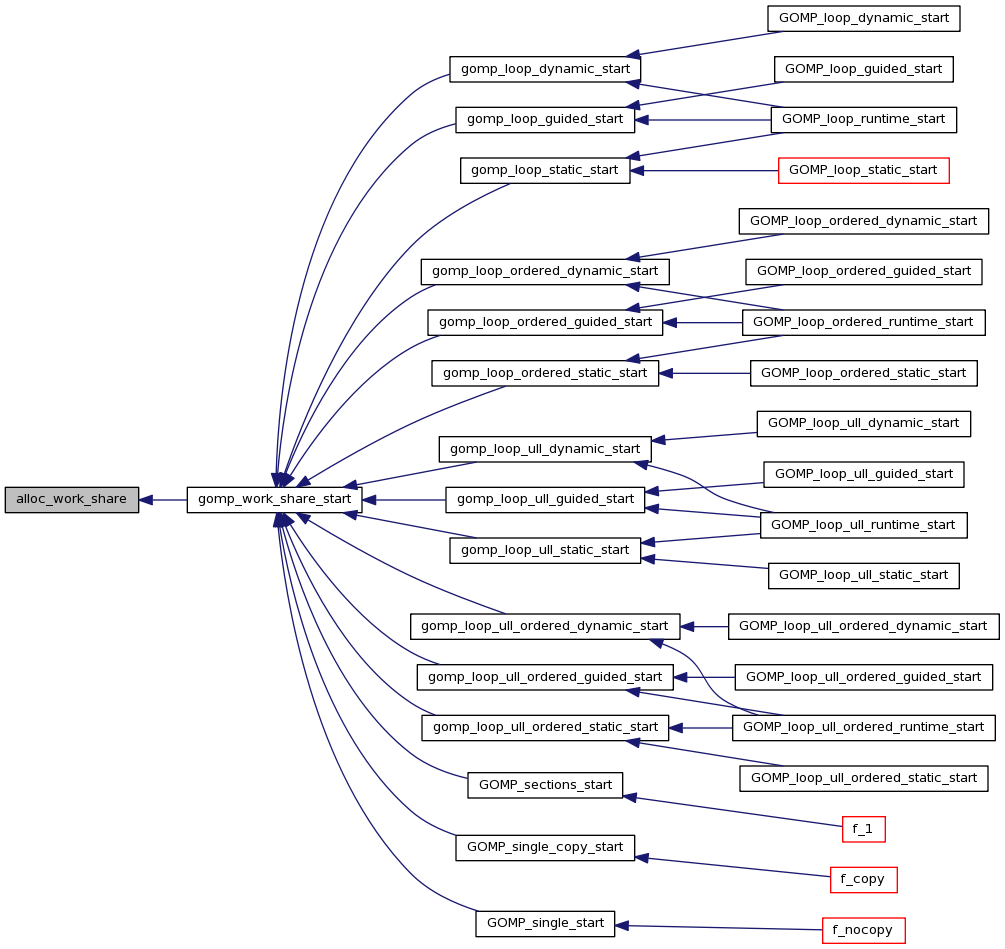
首先我们看看整个OpenMP工程结构(整理自 Libgomp: work.c File Reference)
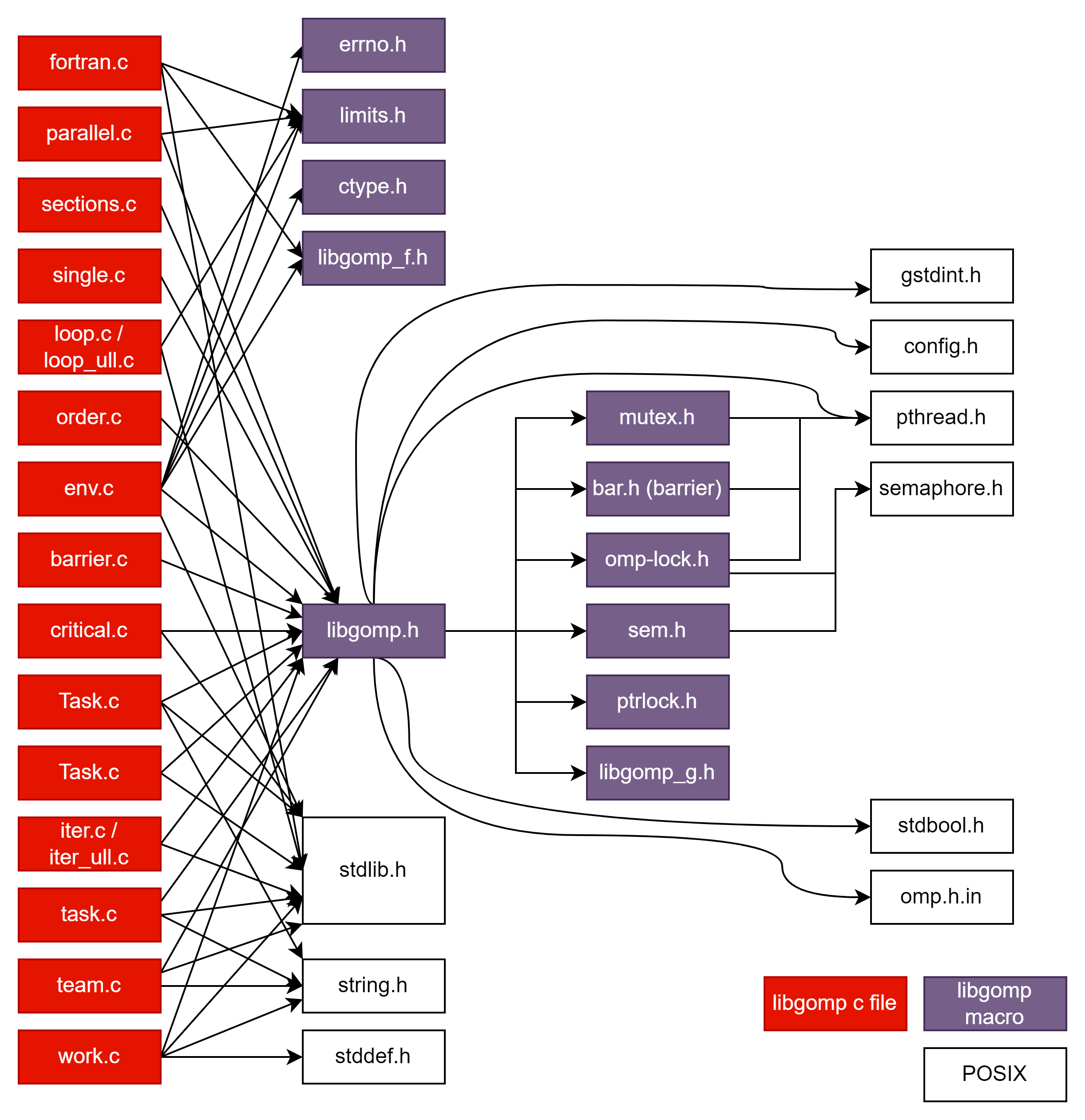
可以看到,我们在写入各种openmp的函数后( #pragma omp parallel XXX)他们会被call到不同的具体的实现,如task,team。
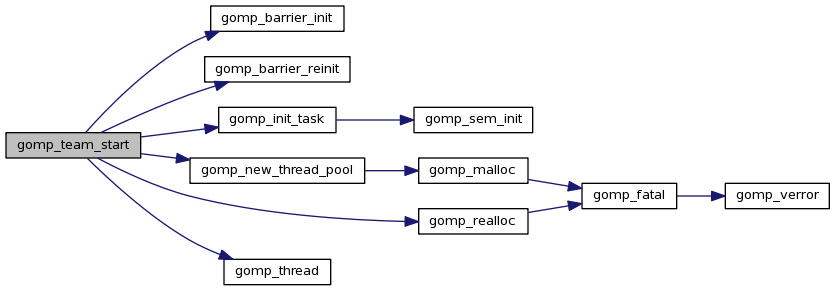
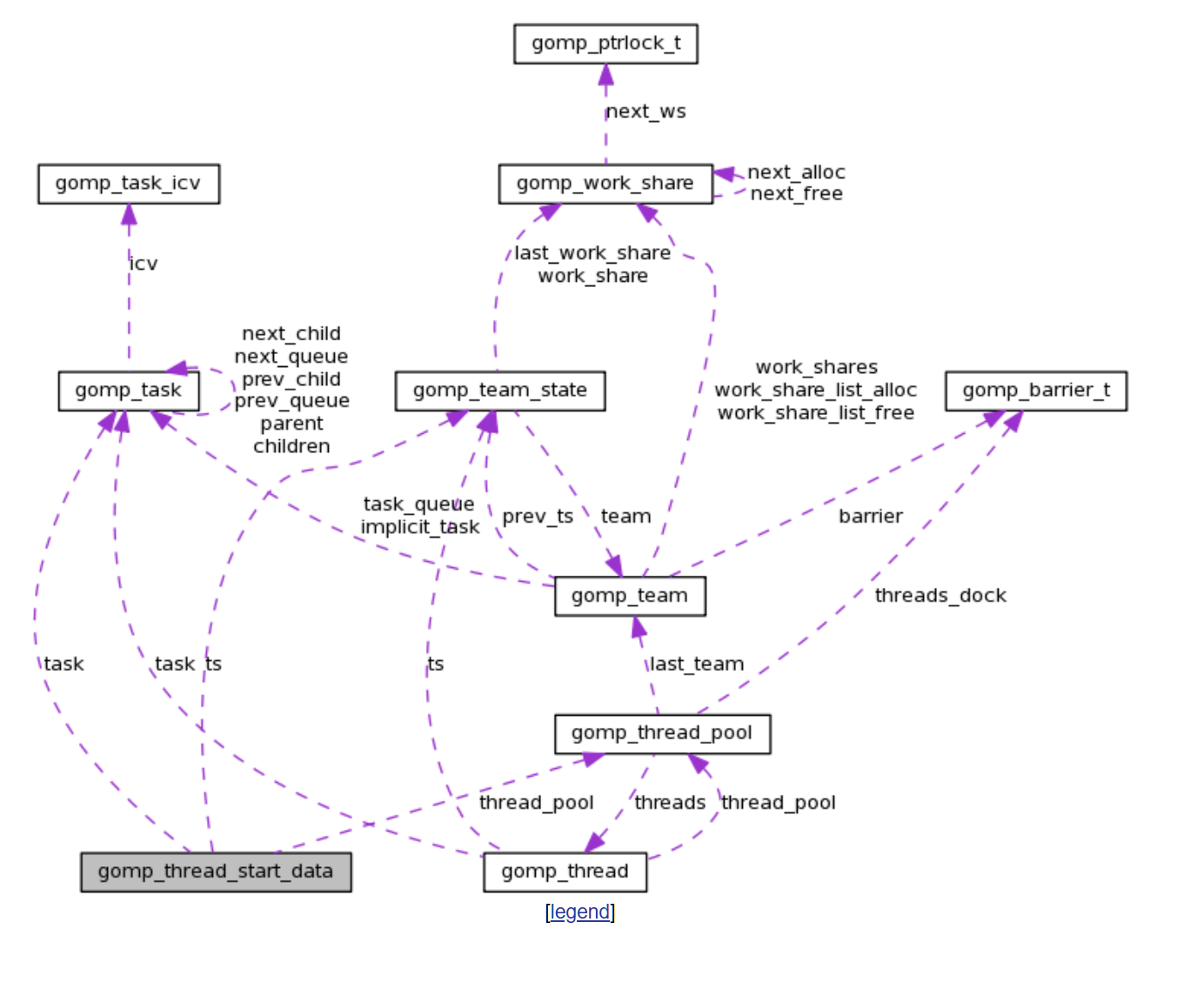
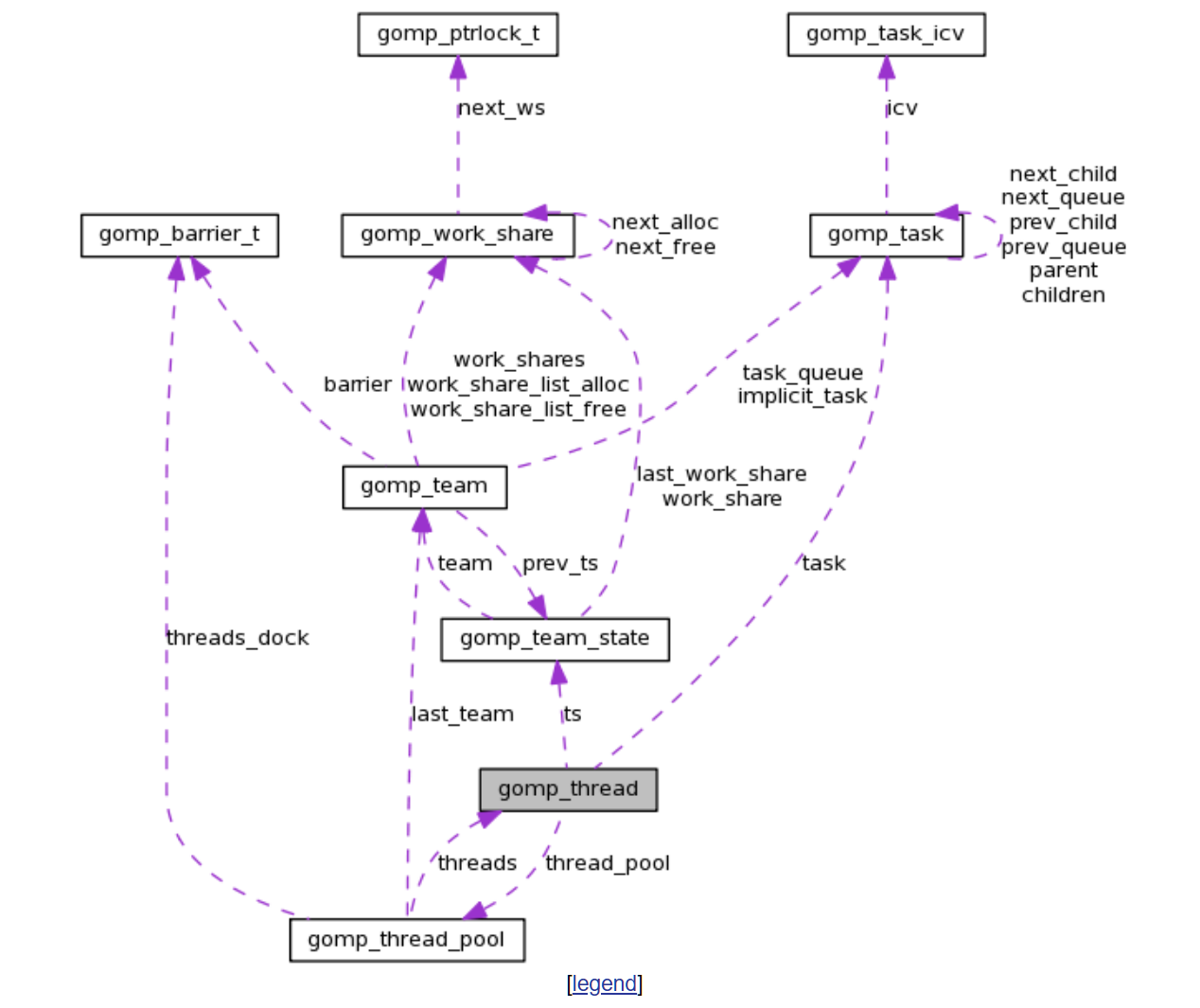
从Libgomp: gomp_team Struct Reference 我们可以看看team的结构:
gomp_team
gomp_team 是 libgomp 中定义的一个 C 结构体,用于表示一个 OpenMP 并行区域的线程团队。
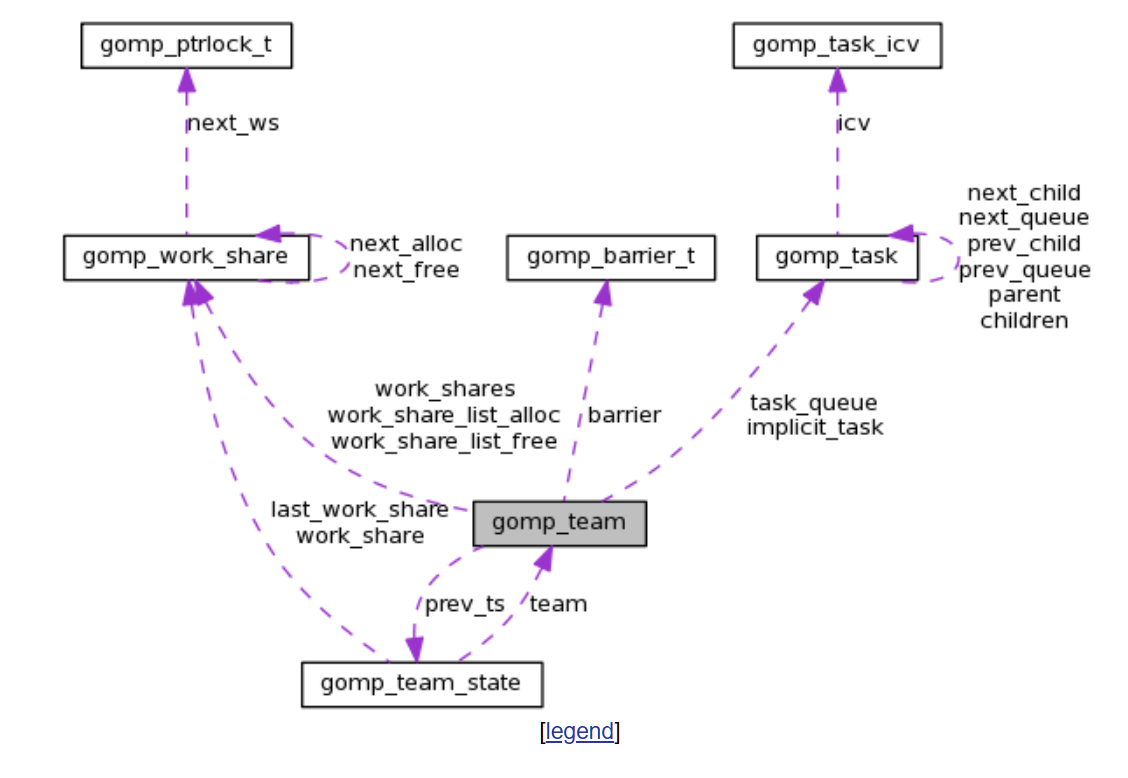
team的结构可以在 libgomp.h 找到 Libgomp: libgomp.h Source File
| 字段名 | 类型 | 说明 |
|---|---|---|
nthreads |
unsigned |
当前 team 中的线程数量。 |
work_share_chunk |
unsigned |
上次批量分配的 gomp_work_share 数量。 |
prev_ts |
struct gomp_team_state |
保存 master 线程在进入该 team 前的 team 状态。用于恢复。 |
master_release |
gomp_sem_t |
master 线程专用信号量。用于嵌套并行时避免信号量冲突。 |
ordered_release |
gomp_sem_t ** |
指向所有线程有序释放用的信号量数组(用于 ordered 子句)。 |
work_share_list_alloc |
struct gomp_work_share * |
可用的 gomp_work_share 链表,用于新的 worksharing 构造。仅首线程分配。 |
work_share_list_free |
struct gomp_work_share * |
已释放的 gomp_work_share 链表。并发安全追加。 |
MARKDOWN_HASH87314a1443a69743d1247abae5c6f785MARKDOWNHASH (或)_ work_share_list_free_lock |
unsigned long 或 gomp_mutex_t |
若支持原子指令,则为 simple single 区域计数器;否则用 mutex 保护 free 列表。 |
barrier |
gomp_barrier_t |
用于 team 间同步的 barrier。大多数同步操作使用它。 |
work_shares[8] |
struct gomp_work_share[8] |
初始 work share 缓存,常见场景避免动态分配。 |
task_lock |
gomp_mutex_t |
用于串行化 task 队列的锁。 |
task_queue |
struct gomp_task * |
当前的任务队列头。 |
task_count |
int |
当前队列中任务总数。 |
task_running_count |
int |
正在执行的任务数。 |
implicit_task[] |
struct gomp_task[] |
各线程的隐式 task(比如 parallel region 中默认的 task)。这是个灵活数组成员。 |
wowowow,这里有好多好多结构,怎么分析?
我把我们主要要分析的结构分成了3类:
config类:
nthreads- team status:
prev_ts
work sharing 类: work_shares[8]work_share_list_alloc等等
task 类:task_lock、task_queue等等
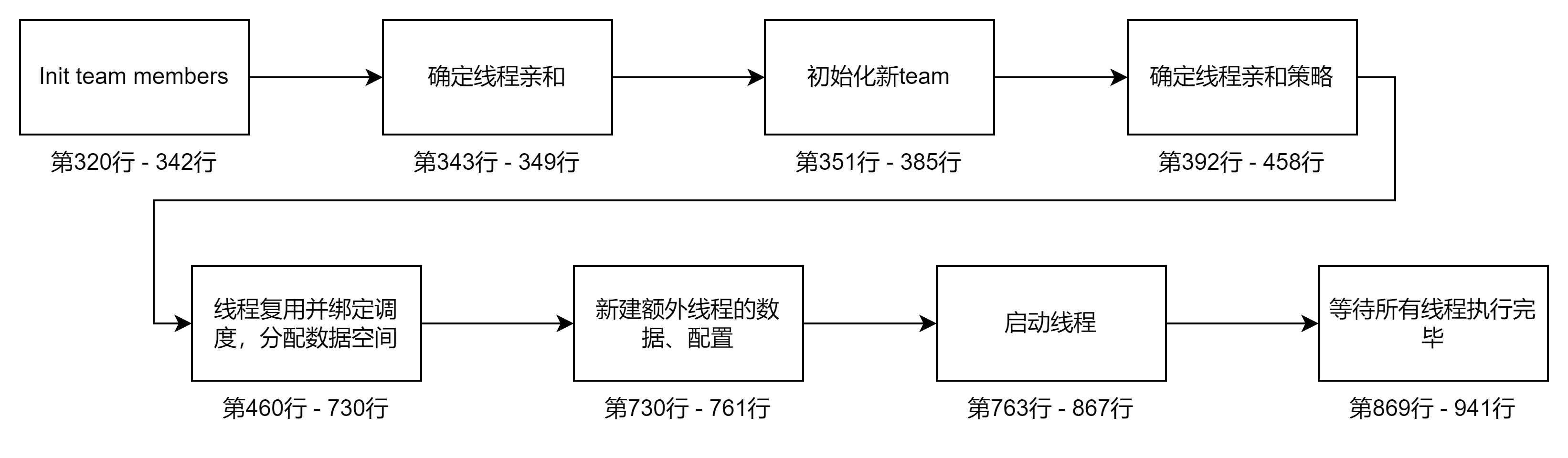
初始化team data
提前分配好本函数要用的各种数据结构。
初始化线程亲和配置
从343行开始
gcc/libgomp/team.c at master · gcc-mirror/gcc
这是它的大致流程:
| 步骤 | 操作 | 目的 |
|---|---|---|
检查并初始化 gomp_places_list |
设置可用 CPU 核的 place 列表 | 为亲和性策略准备 place 列表 |
pthread_setaffinity_np |
绑定主线程到第一个 place | 限制线程运行在哪些核上,提高 cache locality |
设置 thr->ts.* 字段 |
初始化线程的 place 分区信息 | 为 team 中其他线程的亲和性分配做准备 |
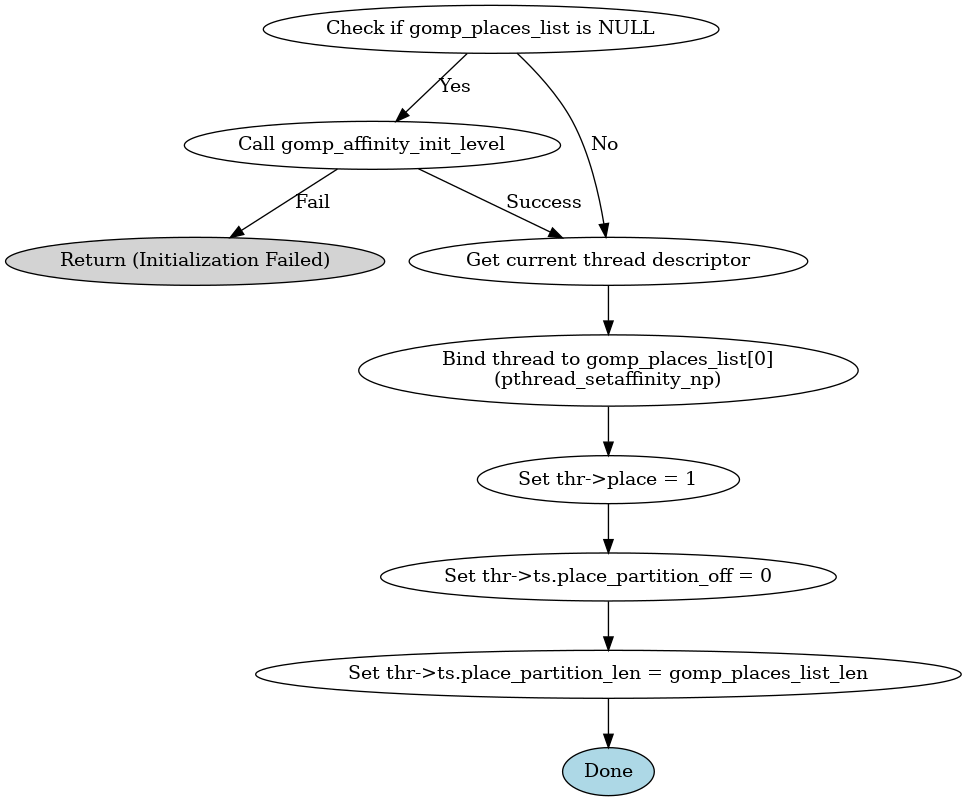
初始化team
这部分将保存 team之前的状态,然后负责主线程(master thread)在创建或加入一个新 team(线程团队)时初始化其线程状态 (thread_state)、任务 (task)、调度器信息以及线程控制变量 (ICV) 的继承与设置。
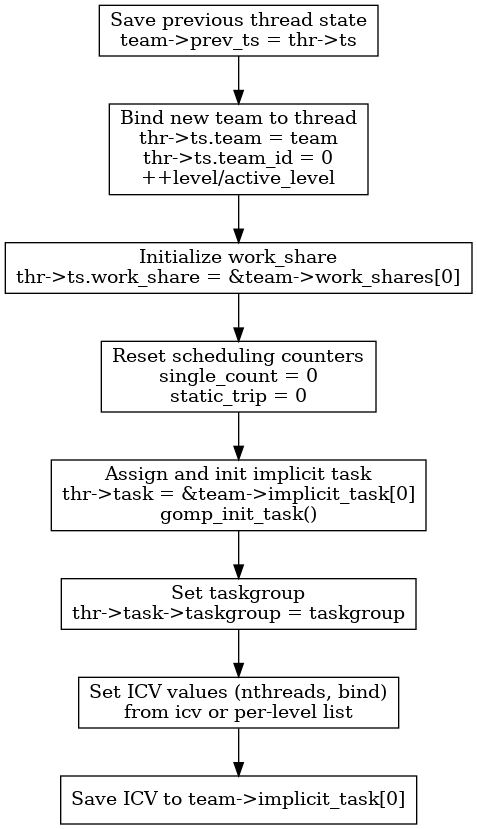
为什么会有prev_ts: 之前的team state
在 OpenMP 的实现中,prev_ts(即 prev_ts: previous team state)是一个非常关键的数据结构,主要用于支持嵌套并行(nested parallelism) 和线程状态回溯。我们来深入解释这个设计的动机和作用。
场景:嵌套 #pragma omp parallel
#pragma omp parallel num_threads(2)
{
// Outer team: T0, T1
#pragma omp parallel num_threads(4)
{
// Each outer thread creates its own inner team
}
}
在这个例子中:
- 外层并行区域创建了 2 个线程(一个“团队”),我们称它为 Outer Team。
- 每个线程又创建了一个新的
#pragma omp parallel区域,也就是说每个线程又生成了一个 Inner Team。 - 此时同一个线程(例如主线程)可能属于两个 team:当前 team(Inner),和之前的 team(Outer)。
struct gomp_team_state
{
/* 线程当前所属的团队 */
struct gomp_team *team;
/* 线程当前正在处理的work share构造(比如并行for循环等) */
struct gomp_work_share *work_share;
/* 上一个work share构造,当前构造执行完后,可以释放上一个 */
struct gomp_work_share *last_work_share;
/* 线程在线程团队中的编号,0 到 N-1 */
unsigned team_id;
/* 嵌套层级,用于支持嵌套的parallel区域 */
unsigned level;
/* 活跃的嵌套层级,只计数活跃的parallel区域 */
unsigned active_level;
#ifdef HAVE_SYNC_BUILTINS
/* 计数single语句执行的次数 */
unsigned long single_count;
#endif
/* 对于某些静态调度的循环,记录这是第几次进入该循环 */
unsigned long static_trip;
};
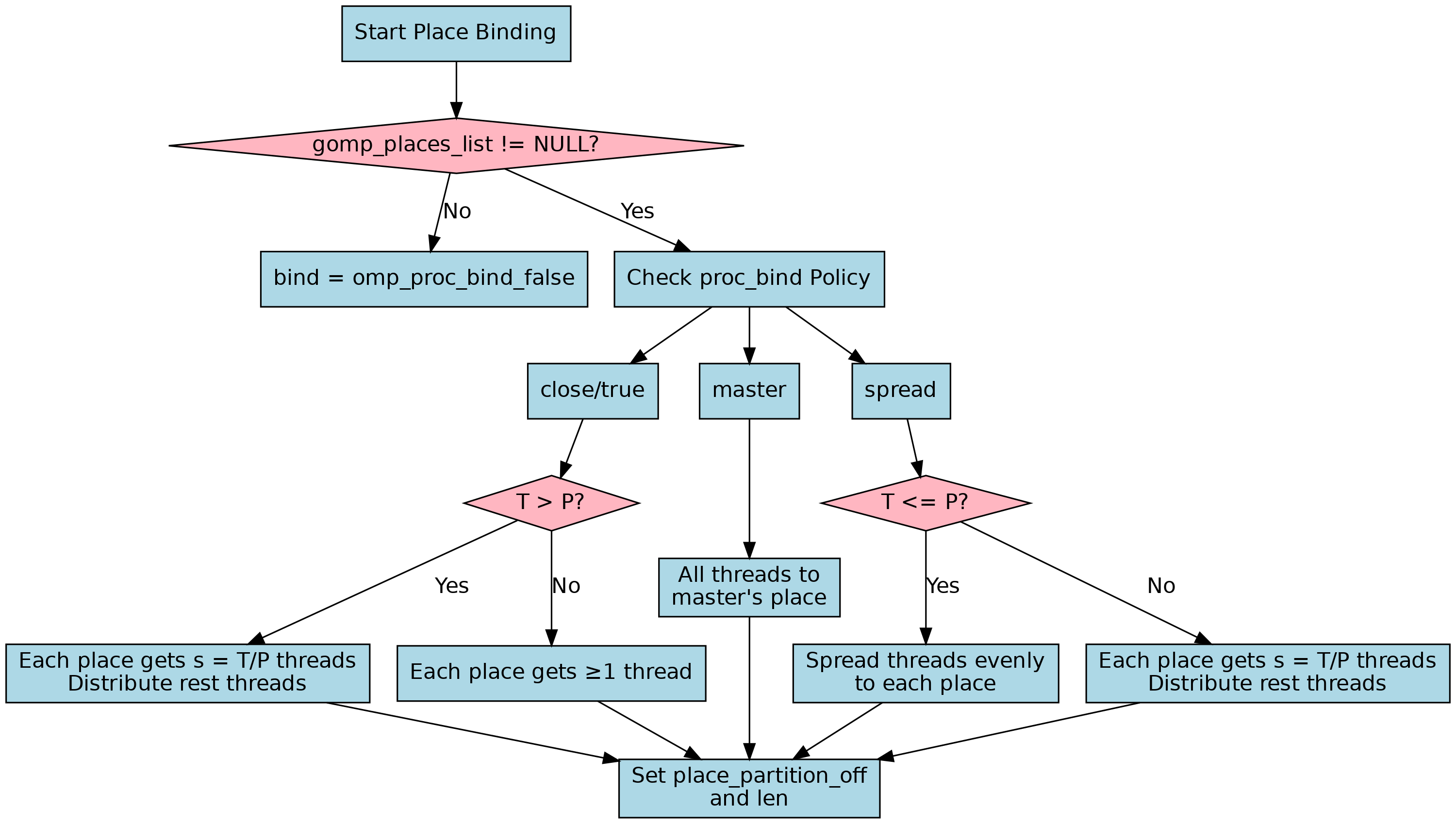
确定线程亲和策略
绑核代码从 392行开始
gcc/libgomp/team.c at master · gcc-mirror/gcc
根据线程数量 nthreads 和 place 列表 gomp_places_list,绑核为每个线程计算它将绑定到哪个“place”(逻辑 CPU 核心集合)。
if ( (gomp_places_list != NULL, 0))
{
/* Depending on chosen proc_bind model, set subpartition
for the master thread and initialize helper variables
P and optionally S, K and/or REST used by later place
computation for each additional thread. */
p = thr->place - 1;
switch (bind)
{
case omp_proc_bind_true:
case omp_proc_bind_close:
if (nthreads > thr->ts.place_partition_len)
{
/* T > P. S threads will be placed in each place,
and the final REM threads placed one by one
into the already occupied places. */
.........
}
}
else
bind = omp_proc_bind_false;这里的T, P 分别指的是:
T:团队中线程的数量(nthreads),即 ThreadsP:place partition 中的 slot 数量(place_partition_len),即 Places
我把执行的逻辑画在了下边:
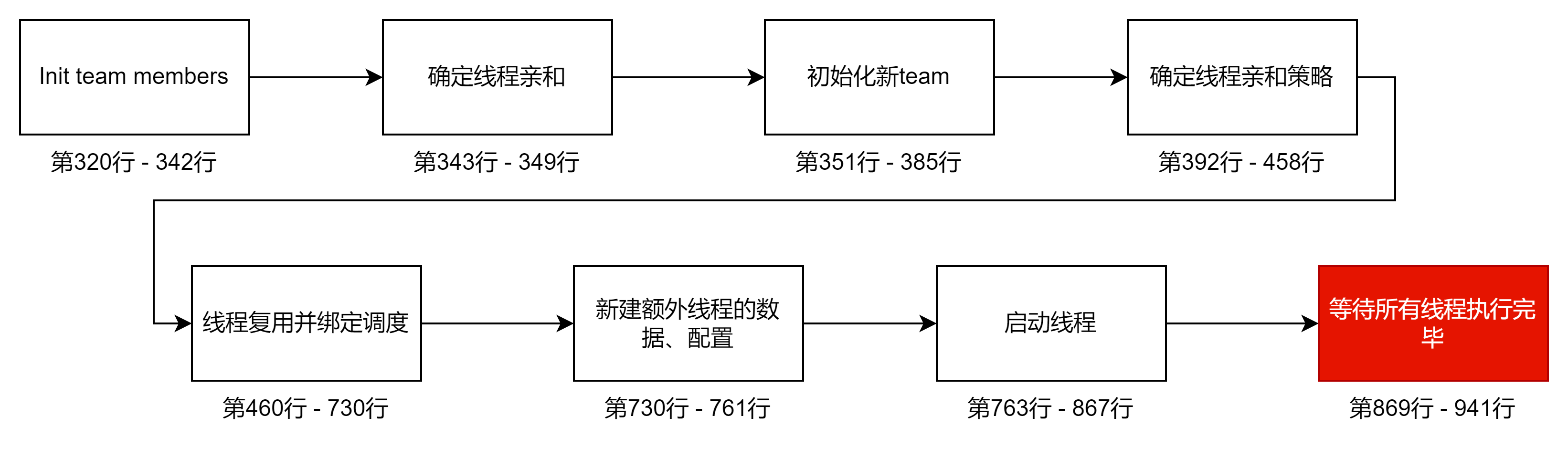
线程复用并绑定调度
第460行 - 730行
openmp在这里会用上我们的线程池 pool 里的空闲线程,并尝试将其重新绑核到cpu cores上。
线程复用/创建时绑定 place,按策略分配
| 步骤 | 功能 |
|---|---|
| 1️⃣ | 如果是非嵌套 parallel,尝试从线程池复用已有线程 |
| 2️⃣ | 根据 proc_bind 策略分配线程到合适的 CPU 绑定(place) |
| 3️⃣ | 如果绑定不符合要求,则替换线程或重新分配 |
| 4️⃣ | 设置线程的执行上下文,如 team、task、level 等 |
| 5️⃣ | 若 affinity 失败则 fallback 重试 |
| 6️⃣ | 初始化 barrier,同步所有即将被释放/复用的线程 |
后面的详细逻辑我用GPT生成了,大家可以按照自己的需要看看:
https://www.haibinlaiblog.top/index.php/proc_bind-%e5%90%84%e7%ad%96%e7%95%a5%e7%9a%84-place-%e8%ae%a1%e7%ae%97%e9%80%bb%e8%be%91%e3%80%81affinity_thr-%e7%9a%84%e5%86%85%e5%ad%98%e7%ae%a1%e7%90%86%ef%bc%8cgomp_simple_barrier_reinit/
其有3个核心逻辑:
| 关键机制 | 核心作用 | 实现重点 |
|---|---|---|
proc_bind 策略 |
控制线程分布在 CPU 上的拓扑 | 按策略计算每线程绑定的 place |
affinity_thr |
临时结构,复用线程时按核域分类 | 栈/堆分配,使用后可释放 |
gomp_simple_barrier_reinit |
线程同步起点屏障 | 轻量级 barrier,等待所有线程 ready 后统一起跑 |
这里可以看到有一个重点,gomp需要创建完全部的线程才能启动。并且,我们的每一个线程都要初始化自己的堆栈。如果openmp被频繁调用,这是一个非常耗时的点。
另外,还会给线程预留数据空间:
if (team->prev_ts.place_partition_len > 64)
affinity_thr
= gomp_malloc (team->prev_ts.place_partition_len
* sizeof (struct gomp_thread *));
else
affinity_thr
= gomp_alloca (team->prev_ts.place_partition_len
* sizeof (struct gomp_thread *));
memset (affinity_thr, '\0',
team->prev_ts.place_partition_len
* sizeof (struct gomp_thread *));
for (j = i; j < old_threads_used; j++)
{
if (pool->threads[j]->place
> team->prev_ts.place_partition_off
&& (pool->threads[j]->place
<= (team->prev_ts.place_partition_off
+ team->prev_ts.place_partition_len)))
{
l = pool->threads[j]->place - 1
- team->prev_ts.place_partition_off;
pool->threads[j]->data = affinity_thr[l];
affinity_thr[l] = pool->threads[j];
}新建额外线程的数据、配置
在730行后有大概30行
这段代码处于 gomp_team_start() 的 线程创建阶段,紧接在线程池复用逻辑之后,它的核心任务是:
✳️ 根据当前需要的线程数(nthreads + affinity_count)与线程池中已有的线程数(old_threads_used)之差,决定是否需要新建线程,并执行相应的创建前初始化。
| 步骤 | 内容 | 目的 |
|---|---|---|
| 1️⃣ | 判断是否需要新建线程 | 避免不必要的线程创建,节省资源 |
| 2️⃣ | 更新 gomp_managed_threads |
准确统计当前系统中管理的线程数 |
| 3️⃣ | 初始化线程属性 pthread_attr |
设置栈大小或为 affinity 做准备 |
| 4️⃣ | 分配线程启动参数数组 | 为新建线程准备启动时的上下文数据 |
初始化要传入的数据的大小
start_data = gomp_alloca (sizeof (struct gomp_thread_start_data)
* (nthreads - i));alloca源码:gcc/libgomp/libgomp.h at 0629924777ea20d56d9ea40c3915eb0327a22ac7 · gcc-mirror/gcc
/* Avoid conflicting prototypes of alloca() in system headers by using
GCC's builtin alloca(). */
#define gomp_alloca(x) __builtin_alloca(x)最后:创建实际运行的线程并启动
从730行开始,到最后的函数结束,函数将创建实际运行的线程,他们将调用subfunction
OpenMP Parallel Construct 实现原理与源码分析 - 知乎
进行了叙述
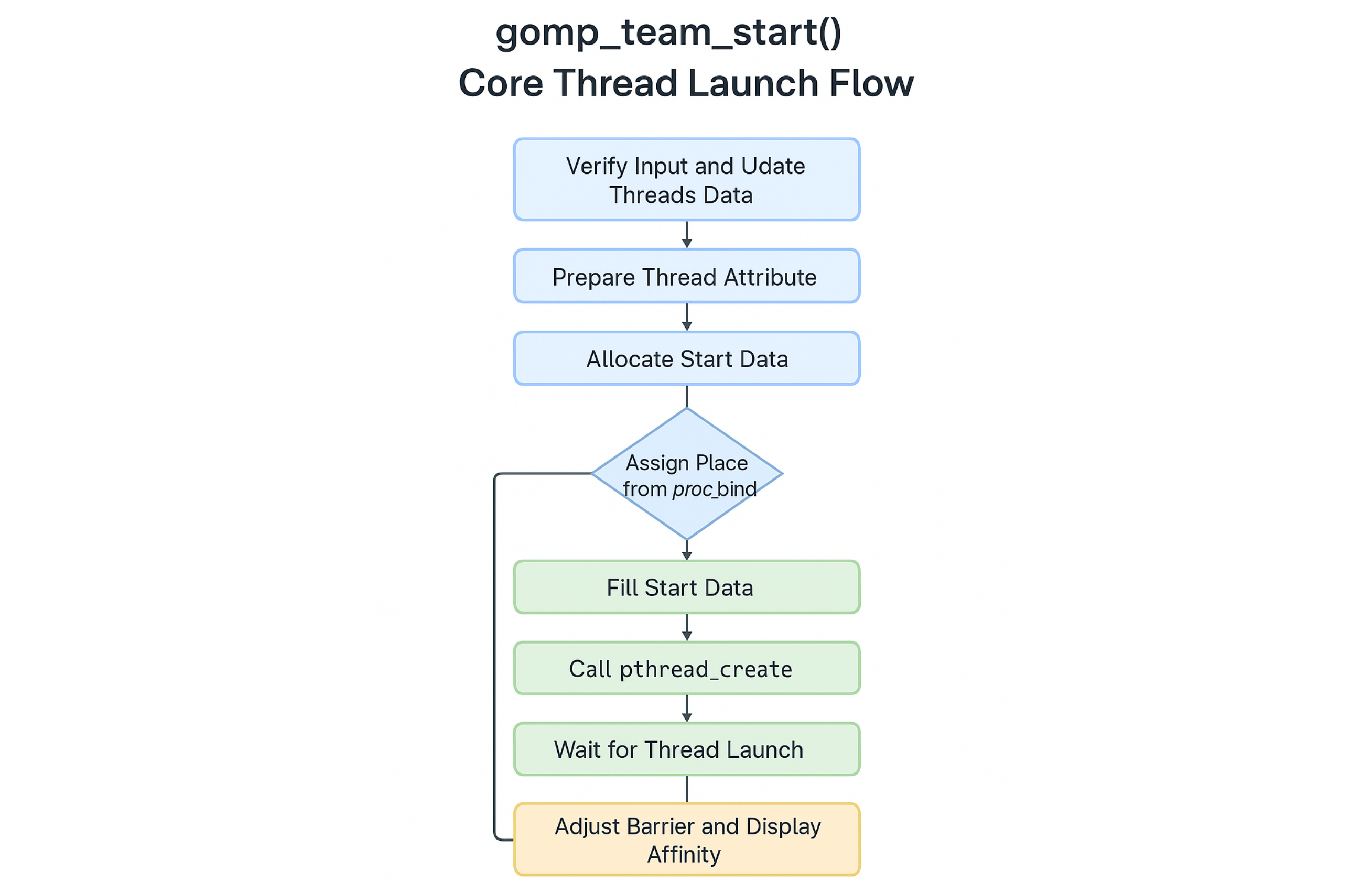
| 模块 | 作用 |
|---|---|
proc_bind 策略 |
控制线程如何与 place 绑定 |
gomp_init_thread_affinity |
设置线程 CPU 亲和性 |
start_data |
启动线程时的配置项和 thread-local storage 信息 |
pthread_create |
实际创建 POSIX 线程 |
gomp_simple_barrier_reinit |
动态调整线程启动后的 barrier 等待阈值 |
affinity_thr |
用于临时绑定多个 affinity 信息的缓存,可被释放 |
线程亲和
for (; i < nthreads; ++i)
{
int err;
start_data->ts.place_partition_off = thr->ts.place_partition_off;
start_data->ts.place_partition_len = thr->ts.place_partition_len;
start_data->place = 0;
if ( (gomp_places_list != NULL, 0))
{
switch (bind)
{
case omp_proc_bind_true:
case omp_proc_bind_close:
if (k == s)
{
++p;
if (p == (team->prev_ts.place_partition_off
+ team->prev_ts.place_partition_len))
p = team->prev_ts.place_partition_off;
k = 1;
if (i == nthreads - rest)
s = 1;
}
else
++k;
break;
case omp_proc_bind_master:
break;
case omp_proc_bind_spread:
if (k == 0)
{
/* T <= P. */
if (p < rest)
p += s + 1;
else
p += s;
if (p == (team->prev_ts.place_partition_off
+ team->prev_ts.place_partition_len))
p = team->prev_ts.place_partition_off;
start_data->ts.place_partition_off = p;
if (p < rest)
start_data->ts.place_partition_len = s + 1;
else
start_data->ts.place_partition_len = s;
}
else
{
/* T > P. */
if (k == s)
{
++p;
if (p == (team->prev_ts.place_partition_off
+ team->prev_ts.place_partition_len))
p = team->prev_ts.place_partition_off;
k = 1;
if (i == nthreads - rest)
s = 1;
}
else
++k;
start_data->ts.place_partition_off = p;
start_data->ts.place_partition_len = 1;
}
break;
}
start_data->place = p + 1;
if (affinity_thr != NULL && pool->threads[i] != NULL)
continue;
gomp_init_thread_affinity (attr, p);
}这段代码是 gomp_team_start() 中为新线程进行 place 绑定(affinity placement) 的关键部分。它的核心作用是:根据 OpenMP 的 proc_bind 策略,为每个新线程分配合适的 CPU 运行位置(place),并初始化线程亲和性(thread affinity)。
兼容 affinity_count 情况(CPU 绑定时预分配用的占位)。
为后续 pthread_create 分配启动数据结构数组。
分配data
start_data->fn = fn;
start_data->fn_data = data;
start_data->ts.team = team;
start_data->ts.work_share = &team->work_shares[0];
start_data->ts.last_work_share = NULL;
start_data->ts.team_id = i;
start_data->ts.level = team->prev_ts.level + 1;
start_data->ts.active_level = thr->ts.active_level;
start_data->ts.def_allocator = thr->ts.def_allocator;
#ifdef HAVE_SYNC_BUILTINS
start_data->ts.single_count = 0;
#endif
start_data->ts.static_trip = 0;
start_data->num_teams = thr->num_teams;
start_data->team_num = thr->team_num;
start_data->task = &team->implicit_task[i];
gomp_init_task (start_data->task, task, icv);
team->implicit_task[i].icv.nthreads_var = nthreads_var;
team->implicit_task[i].icv.bind_var = bind_var;
start_data->task->taskgroup = taskgroup;
start_data->thread_pool = pool;
start_data->nested = nested;核心调用逻辑
每个线程都会被创建
attr = gomp_adjust_thread_attr (attr, &thread_attr);
err = pthread_create (&start_data->handle, attr, gomp_thread_start,
start_data);
start_data++;
if (err != 0)
gomp_fatal ("Thread creation failed: %s", strerror (err));收尾同步所有的线程
详细分析:
https://www.haibinlaiblog.top/index.php/openmp%e7%9a%84barrier%e5%90%8c%e6%ad%a5/
下面是它的流程图
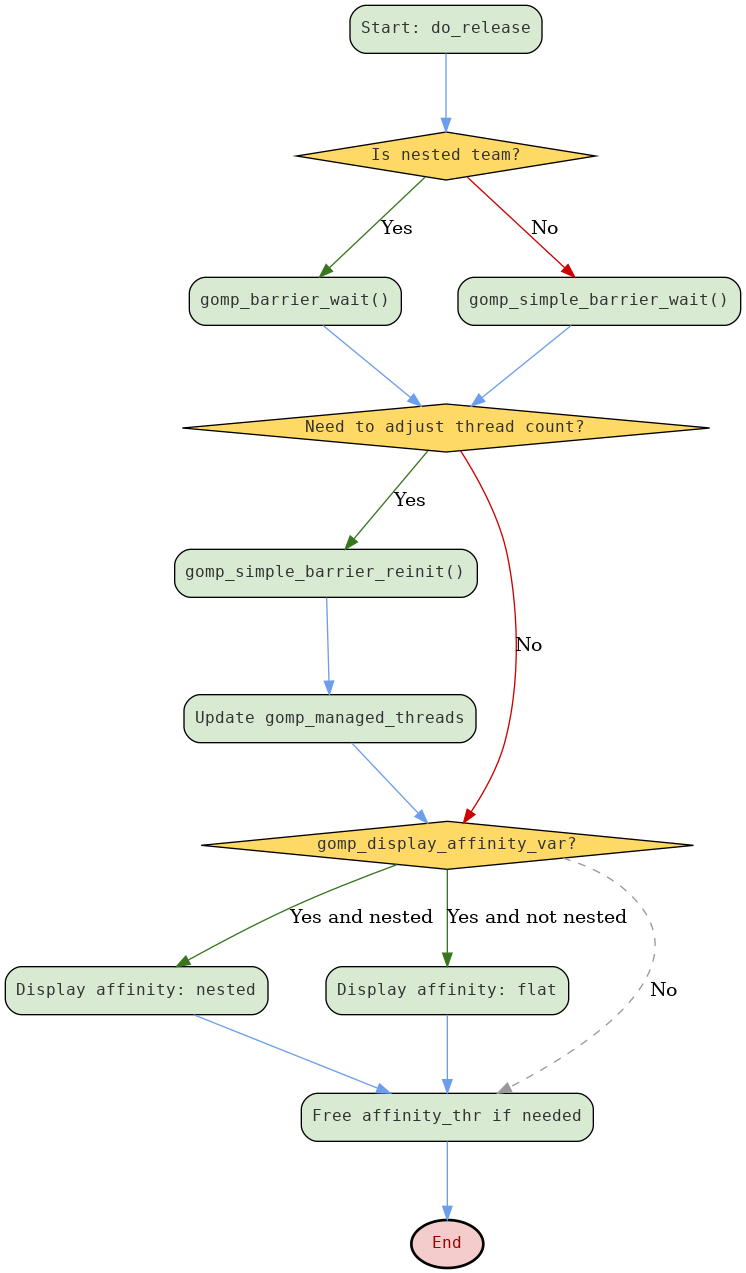
其中,gomp_display_affinity_var 是展示的变量,用来调试。最核心的代码还是barrier
这一部分的核心目的是主线程阻塞等待所有线程就绪、同步 barrier,然后根据需要动态调整线程和 barrier 状态,并完成资源清理与调试输出。
我们展示其中一段barrier是怎么完成wait的
void
gomp_barrier_wait_end (gomp_barrier_t *bar, gomp_barrier_state_t state)
{
if (__builtin_expect (state & BAR_WAS_LAST, 0))
{
/* Next time we'll be awaiting TOTAL threads again. */
bar->awaited = bar->total;
__atomic_store_n (&bar->generation, bar->generation + BAR_INCR,
MEMMODEL_RELEASE);
futex_wake ((int *) &bar->generation, INT_MAX);
}
else
{
do
do_wait ((int *) &bar->generation, state);
while (__atomic_load_n (&bar->generation, MEMMODEL_ACQUIRE) == state);
}
}
void
gomp_barrier_wait (gomp_barrier_t *bar)
{
gomp_barrier_wait_end (bar, gomp_barrier_wait_start (bar));
}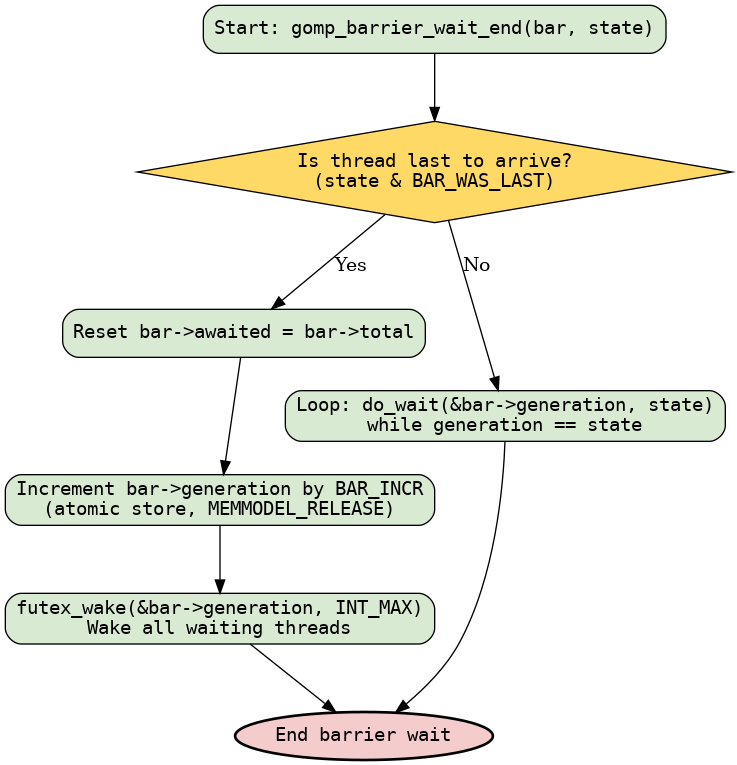
核心机制也是非常的简单:
- 每个线程调用
gomp_barrier_wait。 - 内部
gomp_barrier_wait_start会减计数,返回当前状态。 - 当最后一个线程到达时,更新
generation,将屏障标记为完成,并唤醒等待线程。 - 其他线程阻塞等待
generation发生变化。 - 这样实现线程同步,保证所有线程都到达屏障后才继续执行。
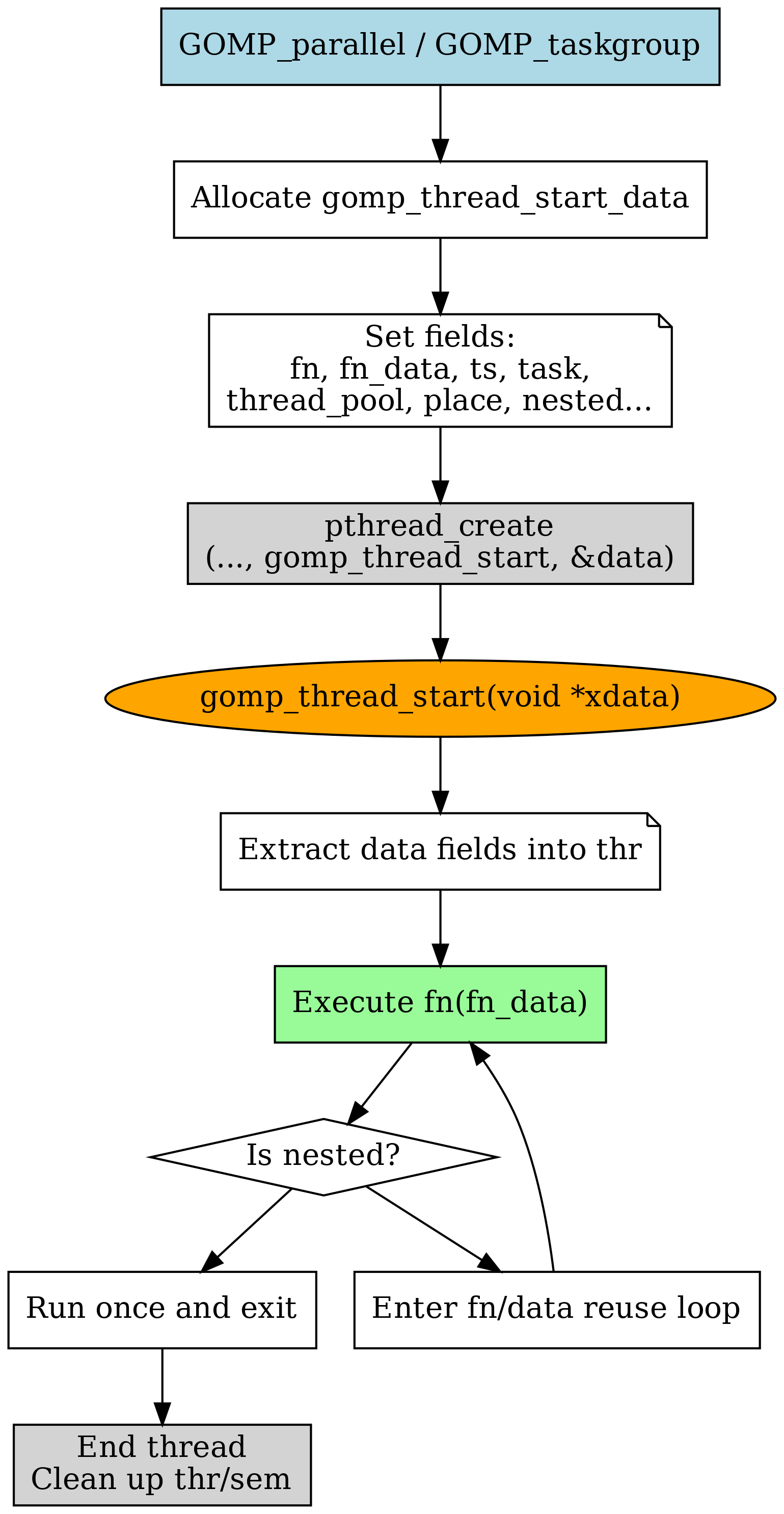
pthread_create发生了什么?
刚刚我们经过了下面图中的流程。但是,我们仍然不知道pthread_create创建了什么
attr = gomp_adjust_thread_attr (attr, &thread_attr);
err = pthread_create (&start_data->handle, attr, gomp_thread_start,
start_data);
start_data++;
if (err != 0)
gomp_fatal ("Thread creation failed: %s", strerror (err));这里pthread_create导入了一个 gomp_thread_start 函数。我们看看发生了什么:
gcc/libgomp/team.c at master · gcc-mirror/gcc
static void *gomp_thread_start (void *xdata)这里的xdata是 gomp_thread_start_data
gcc/libgomp/team.c at master · gcc-mirror/gcc
/* This structure is used to communicate across pthread_create. */
struct gomp_thread_start_data
{
void (*fn) (void *);
void *fn_data;
struct gomp_team_state ts;
struct gomp_task *task;
struct gomp_thread_pool *thread_pool;
unsigned int place;
unsigned int num_teams;
unsigned int team_num;
bool nested;
pthread_t handle;
};| 字段名 | 类型 | 作用 | 影响线程行为的部分 |
|---|---|---|---|
fn |
void (*)(void *) |
要在线程中执行的函数指针 | 核心行为函数,线程主循环或初始化函数 |
fn_data |
void * |
fn 函数的参数 |
控制 fn 执行上下文,如函数内部如何解析输入 |
ts |
struct gomp_team_state |
表示当前线程的 team 信息,如 team ID、大小等 | 控制线程在团队中的位置、barrier 的索引等 |
task |
struct gomp_task * |
当前线程绑定的任务对象(task) | 控制任务生命周期、task-finalization |
thread_pool |
struct gomp_thread_pool * |
线程所属的池 | 支持线程重用(非 nested),参与全局同步 |
place |
unsigned int |
NUMA/thread affinity placement 位置信息 | 控制线程在哪个 CPU 上运行(结合 proc_bind) |
num_teams |
unsigned int |
当前 parallel region 中的 team 总数 | 对于 teams 指令有用,决定并行分布策略 |
team_num |
unsigned int |
当前线程所属的 team 编号 | 多个 teams 中的标识,用于区分组 |
nested |
bool |
是否为嵌套 parallel region 启动的线程 | 控制线程是否执行完就退出,还是参与循环重用 |
handle |
pthread_t |
可选线程句柄,在某些平台用于 join 或取消 | 通常仅用于调试或手动管理线程 |
| 信息 | 来源字段 | 决定了线程... |
|---|---|---|
| 要做什么任务 | fn + fn_data |
执行哪个工作函数(比如 parallel region 函数) |
| 属于哪个 team | ts + team_num |
与哪些线程协作 |
| 属于哪个 pool | thread_pool |
是否可以被重用 |
| 退出还是循环执行 | nested |
生命周期策略 |
| 是否参与任务调度 | task |
是否绑定 OpenMP task |

static void *
gomp_thread_start (void *xdata)
{
struct gomp_thread_start_data *data = xdata;
struct gomp_thread *thr;
struct gomp_thread_pool *pool;
void (*local_fn) (void *);
void *local_data;
#if defined HAVE_TLS || defined USE_EMUTLS
thr = &gomp_tls_data;
#else
struct gomp_thread local_thr;
thr = &local_thr;
#endif
gomp_sem_init (&thr->release, 0);
/* Extract what we need from data. */
local_fn = data->fn;
local_data = data->fn_data;
thr->thread_pool = data->thread_pool;
thr->ts = data->ts;
thr->task = data->task;
thr->place = data->place;
thr->num_teams = data->num_teams;
thr->team_num = data->team_num;
#ifdef GOMP_NEEDS_THREAD_HANDLE
thr->handle = data->handle;
#endif
#if !(defined HAVE_TLS || defined USE_EMUTLS)
pthread_setspecific (gomp_tls_key, thr);
#endif
thr->ts.team->ordered_release[thr->ts.team_id] = &thr->release;
/* Make thread pool local. */
pool = thr->thread_pool;
if (data->nested)
{
struct gomp_team *team = thr->ts.team;
struct gomp_task *task = thr->task;
gomp_barrier_wait (&team->barrier);
local_fn (local_data);
gomp_team_barrier_wait_final (&team->barrier);
gomp_finish_task (task);
gomp_barrier_wait_last (&team->barrier);
}
else
{
pool->threads[thr->ts.team_id] = thr;
gomp_simple_barrier_wait (&pool->threads_dock);
do
{
struct gomp_team *team = thr->ts.team;
struct gomp_task *task = thr->task;
local_fn (local_data);
gomp_team_barrier_wait_final (&team->barrier);
gomp_finish_task (task);
gomp_simple_barrier_wait (&pool->threads_dock);
local_fn = thr->fn;
local_data = thr->data;
thr->fn = NULL;
}
while (local_fn);
}
gomp_sem_destroy (&thr->release);
pthread_detach (pthread_self ());
thr->thread_pool = NULL;
thr->task = NULL;
return NULL;
}
#endif- 线程私有数据初始化(TLS 或局部变量)
- 初始化信号量
release - 从
data中提取参数(函数指针、线程池、任务等) - 设置线程本地存储(pthread_setspecific,如果没TLS)
- 绑定线程信号量到团队
- 获取线程池指针
-
判断
data->nested:-
是嵌套线程:
gomp_barrier_wait等待团队barrier- 执行任务函数
gomp_team_barrier_wait_final等待团队结束barriergomp_finish_taskgomp_barrier_wait_last- 线程退出
-
不是嵌套线程:
- 将线程加入线程池数组
gomp_simple_barrier_wait等待所有线程准备- 循环执行:
- 执行任务函数
gomp_team_barrier_wait_finalgomp_finish_taskgomp_simple_barrier_wait- 更新任务函数指针
- 任务为空则退出循环
- 线程退出
-
- 清理信号量,线程detach,资源释放,线程结束
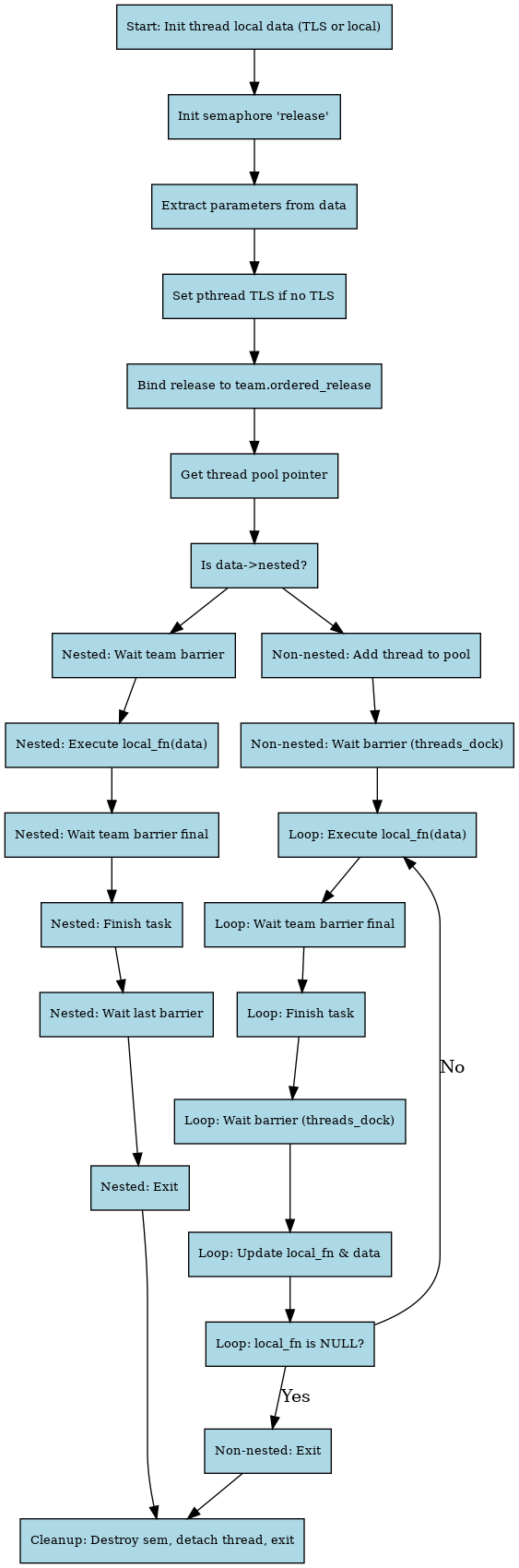
核心并行+执行函数区域:
if (data->nested)
{
struct gomp_team *team = thr->ts.team;
struct gomp_task *task = thr->task;
gomp_barrier_wait (&team->barrier);
local_fn (local_data);
gomp_team_barrier_wait_final (&team->barrier);
gomp_finish_task (task);
gomp_barrier_wait_last (&team->barrier);
}
else
{
pool->threads[thr->ts.team_id] = thr;
gomp_simple_barrier_wait (&pool->threads_dock);
do
{
struct gomp_team *team = thr->ts.team;
struct gomp_task *task = thr->task;
local_fn (local_data);
gomp_team_barrier_wait_final (&team->barrier);
gomp_finish_task (task);
gomp_simple_barrier_wait (&pool->threads_dock);
local_fn = thr->fn;
local_data = thr->data;
thr->fn = NULL;
}
while (local_fn);
}如果是嵌套并行区域(data->nested == true)
gomp_barrier_wait (&team->barrier);
local_fn (local_data);
gomp_team_barrier_wait_final (&team->barrier);
gomp_finish_task (task);
gomp_barrier_wait_last (&team->barrier);这段是标准的 Fork-Join 并行模式:
- 同步起点:等待所有线程都启动完成(
gomp_barrier_wait)。 - 执行并行区域:调用
local_fn(local_data)执行目标任务。 - 终点屏障:等待所有线程完成(
gomp_team_barrier_wait_final)。 - 结束任务:调用
gomp_finish_task(task)通知当前任务完成。 - 最后一次屏障:最后一个线程可能还要清理 barrier(
gomp_barrier_wait_last)。
如果是非嵌套(线程池中的 worker,data->nested == false)
pool->threads[thr->ts.team_id] = thr;
gomp_simple_barrier_wait (&pool->threads_dock);
do {
...
local_fn(local_data);
gomp_team_barrier_wait_final (&team->barrier);
gomp_finish_task (task);
gomp_simple_barrier_wait (&pool->threads_dock);
local_fn = thr->fn;
local_data = thr->data;
thr->fn = NULL;
} while (local_fn);
这段是一个 线程复用 loop,目的是线程池中的线程可以重复服务多个任务(节省创建销毁开销):
- 注册线程:把当前线程注册到线程池中对应的位置。
- 线程全部就绪:用
threads_dockbarrier 等待所有线程启动。 - 进入循环:
- 执行任务函数
local_fn(local_data)。 - 执行完等待 team barrier 完成。
- 通知任务完成。
- 再次等待
threads_dock,和主线程同步任务分发。 - 从
thr->fn,thr->data获取下一个任务。如果为 NULL,就退出。
- 执行任务函数
- 退出条件:直到
thr->fn == NULL,即主线程不再下发任务。
线程总结
- 所有线程执行同一个入口函数
fn,并共享同一个data参数指针。 - 线程的身份信息通过
gomp_thread()->ts.team_id区分。 - 线程根据自身id和线程数在入口函数内划分工作区间,从共享的
data结构中读取任务边界。 gomp_team_start()负责线程的创建、身份设置和传递入口函数及参数,但不具体划分工作细节,这由线程函数fn来完成。
总结:pthread+线程内的这部分函数
等等,那每个线程怎么知道自己要干什么工作?
这部分逻辑在哪儿?
-
这段“划分任务空间”不是在
gomp_team_start()里完成的。gomp_team_start()只负责线程启动、初始化和调用入口函数。 -
任务划分属于工作共享构造(work-sharing construct) 实现范畴,主要在 libgomp 的以下几个文件/函数中:
| 功能 | 相关源码文件/函数 |
|---|---|
| 并行循环任务划分(for循环调度) | libgomp/gomp_loop.c |
| 任务队列与任务调度 | libgomp/gomp_task.c |
| 线程和迭代区间调度器 | libgomp/gomp_work_share.c |
| 线程状态结构定义与操作 | libgomp/gomp_thread.c |
原来是我们之前的函数太简单,没有传入参数,因此编译器就没有这段的操作。
例子:任务调度
比如任务调度,他们的写法就不一样,同时运行的情况也完全不一样
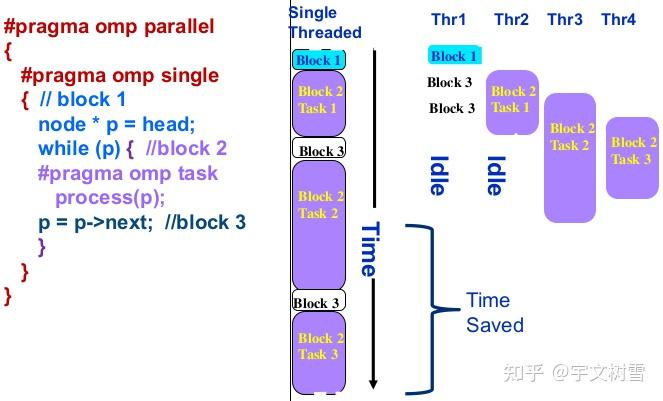
任务调度的源码可以从 OpenMP task construct 实现原理以及源码分析 - 知乎 看到
/* Called when encountering an explicit task directive. If IF_CLAUSE is
false, then we must not delay in executing the task. If UNTIED is true,
then the task may be executed by any member of the team. */
void
GOMP_task (void (*fn) (void *), void *data, void (*cpyfn) (void *, void *),
long arg_size, long arg_align, bool if_clause, unsigned flags)
{
struct gomp_thread *thr = gomp_thread ();
// team 是 OpenMP 一个线程组当中共享的数据
struct gomp_team *team = thr->ts.team;
#ifdef HAVE_BROKEN_POSIX_SEMAPHORES
/* If pthread_mutex_* is used for omp_*lock*, then each task must be
tied to one thread all the time. This means UNTIED tasks must be
tied and if CPYFN is non-NULL IF(0) must be forced, as CPYFN
might be running on different thread than FN. */
if (cpyfn)
if_clause = false;
if (flags & 1)
flags &= ~1;
#endif
// 这里表示如果是 if 子句的条件为真的时候或者是孤立任务(team == NULL )或者是最终任务的时候或者任务队列当中的任务已经很多的时候
// 提交的任务需要立即执行而不能够放入任务队列当中然后在 GOMP_parallel_end 函数当中进行任务的取出
// 再执行
if (!if_clause || team == NULL
|| (thr->task && thr->task->final_task)
|| team->task_count > 64 * team->nthreads)
{
struct gomp_task task;
gomp_init_task (&task, thr->task, gomp_icv (false));
task.kind = GOMP_TASK_IFFALSE;
task.final_task = (thr->task && thr->task->final_task) || (flags & 2);
if (thr->task)
task.in_tied_task = thr->task->in_tied_task;
thr->task = &task;
if (__builtin_expect (cpyfn != NULL, 0))
{
// 这里是进行数据的拷贝
char buf[arg_size + arg_align - 1];
char *arg = (char *) (((uintptr_t) buf + arg_align - 1)
& ~(uintptr_t) (arg_align - 1));
cpyfn (arg, data);
fn (arg);
}
else
// 如果不需要进行数据拷贝则直接执行这个函数
fn (data);
/* Access to "children" is normally done inside a task_lock
mutex region, but the only way this particular task.children
can be set is if this thread's task work function (fn)
creates children. So since the setter is *this* thread, we
need no barriers here when testing for non-NULL. We can have
task.children set by the current thread then changed by a
child thread, but seeing a stale non-NULL value is not a
problem. Once past the task_lock acquisition, this thread
will see the real value of task.children. */
if (task.children != NULL)
{
gomp_mutex_lock (&team->task_lock);
gomp_clear_parent (task.children);
gomp_mutex_unlock (&team->task_lock);
}
gomp_end_task ();
}
else
{
// 下面就是将任务先提交到任务队列当中然后再取出执行
struct gomp_task *task;
struct gomp_task *parent = thr->task;
char *arg;
bool do_wake;
task = gomp_malloc (sizeof (*task) + arg_size + arg_align - 1);
arg = (char *) (((uintptr_t) (task + 1) + arg_align - 1)
& ~(uintptr_t) (arg_align - 1));
gomp_init_task (task, parent, gomp_icv (false));
task->kind = GOMP_TASK_IFFALSE;
task->in_tied_task = parent->in_tied_task;
thr->task = task;
// 这里就是参数拷贝逻辑 如果存在拷贝函数就通过拷贝函数进行参数赋值 否则使用 memcpy 进行
// 参数的拷贝
if (cpyfn)
cpyfn (arg, data);
else
memcpy (arg, data, arg_size);
thr->task = parent;
task->kind = GOMP_TASK_WAITING;
task->fn = fn;
task->fn_data = arg;
task->in_tied_task = true;
task->final_task = (flags & 2) >> 1;
// 在这里获取全局队列锁 保证下面的代码在多线程条件下的线程安全
// 因为在下面的代码当中会对全局的队列进行修改操作 下面的操作就是队列的一些基本操作啦
gomp_mutex_lock (&team->task_lock);
if (parent->children)
{
task->next_child = parent->children;
task->prev_child = parent->children->prev_child;
task->next_child->prev_child = task;
task->prev_child->next_child = task;
}
else
{
task->next_child = task;
task->prev_child = task;
}
parent->children = task;
if (team->task_queue)
{
task->next_queue = team->task_queue;
task->prev_queue = team->task_queue->prev_queue;
task->next_queue->prev_queue = task;
task->prev_queue->next_queue = task;
}
else
{
task->next_queue = task;
task->prev_queue = task;
team->task_queue = task;
}
++team->task_count;
gomp_team_barrier_set_task_pending (&team->barrier);
do_wake = team->task_running_count + !parent->in_tied_task
< team->nthreads;
gomp_mutex_unlock (&team->task_lock);
if (do_wake)
gomp_team_barrier_wake (&team->barrier, 1);
}
}这就是这个机制的精髓:
-
当前线程跑完自己的任务代码后,该任务还有子任务,会接着去管理(或调度执行)这些子任务。
-
这样能保证任务间的依赖关系和执行顺序,避免任务丢失或死锁。
-
父任务和子任务之间用
children、next_child、prev_child形成循环链表结构维护层次关系。 -
当一个任务执行完后(
gomp_end_task()),如果它有子任务,当前线程会负责清理这些子任务(gomp_clear_parent())或者调度它们继续执行。
work_share
struct gomp_work_share 是 GNU OpenMP (libgomp) 中用于实现 工作共享(work-sharing)构造 的关键数据结构。它是 OpenMP 并行循环(如 for, sections, single )背后的运行时基础,负责协调多个线程对迭代任务的分配、同步与调度。
它的作用是:管理并协调线程之间对某个工作负载(work unit)的分配与同步。
work_share 其实是一种调度范式,对应的调度范式还有work-stealing(大家可以在taskflow,以及各种图算法里看到这样的结构,感兴趣的朋友可以看看一些理论paper - ARORA, N. S., BLUMOFE, R. D., AND PLAXTON, C. G. 1998.Thread scheduling for multiprogrammed multiprocessors. In Proceedings of the 10th Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA’98) (Puerto Vallarta, Mexico, June 28–July 2). ACM, New York, pp. 119–129.arora98thread.pdf 和一些文献6.2 工作窃取式调度 · golan基础 · 看云)

| 功能 | 对应字段 |
|---|---|
| 迭代调度策略 | sched, chunk_size, next, end, incr |
线程间同步 (ordered) |
ordered_team_ids, ordered_owner, ordered_cur |
| 互斥与状态维护 | lock, threads_completed |
支持单个 copyprivate 和 task reductions |
copyprivate, task_reductions |
| 动态结构链接 | next_alloc, next_free, next_ws |
1. 调度策略与循环参数
enum gomp_schedule_type sched:指定调度策略,如static、dynamic、guided等。对于sections构造,该值始终为DYNAMIC
gcc/libgomp/libgomp.h at master · gcc-mirror/gcc
/* This structure contains the data to control one work-sharing construct,
either a LOOP (FOR/DO) or a SECTIONS. */
enum gomp_schedule_type
{
GFS_RUNTIME,
GFS_STATIC,
GFS_DYNAMIC,
GFS_GUIDED,
GFS_AUTO,
GFS_MONOTONIC = 0x80000000U
};long chunk_size, end, incr:分别表示每个线程处理的迭代块大小、循环终止条件和步长。unsigned long long chunk_size_ull, end_ull, incr_ull:用于处理超大循环计数的无符号版本。long next/unsigned long long next_ull:记录下一个待分配的迭代起始值。
2. 有序区域(ordered)支持
unsigned *ordered_team_ids:循环队列,记录线程进入ordered区域的顺序。unsigned ordered_num_used:当前已注册进入ordered区域的线程数。unsigned ordered_owner:当前拥有ordered区域执行权的线程 ID。unsigned ordered_cur:当前允许进入ordered区域的线程在队列中的索引。
3. 同步与资源管理
gomp_mutex_t lock:互斥锁,保护共享数据的更新,确保线程安全。unsigned threads_completed:记录已完成工作共享构造的线程数。gomp_ptrlock_t next_ws/struct gomp_work_share *next_free:用于管理工作共享结构体的链表,支持资源的复用与释放。
4. single 与 copyprivate 支持
void *copyprivate:在single构造中,存储需要在多个线程之间共享的数据副本。
比如对应sched(dynamic), 就是在work_share这里实现的。具体的代码原理可以参照:
OpenMP For Construct dynamic 调度方式实现原理和源码分析 - 一无是处的研究僧 - 博客园
thread
struct gomp_thread
{
/* This is the function that the thread should run upon launch. */
void (*fn) (void *data);
void *data;
/* This is the current team state for this thread. The ts.team member
is NULL only if the thread is idle. */
struct gomp_team_state ts;
/* This is the task that the thread is currently executing. */
struct gomp_task *task;
/* This semaphore is used for ordered loops. */
gomp_sem_t release;
/* Place this thread is bound to plus one, or zero if not bound
to any place. */
unsigned int place;
/* User pthread thread pool */
struct gomp_thread_pool *thread_pool;
#ifdef LIBGOMP_USE_PTHREADS
/* omp_get_num_teams () - 1. */
unsigned int num_teams;
/* omp_get_team_num (). */
unsigned int team_num;
#endif
#if defined(LIBGOMP_USE_PTHREADS) \
&& (!defined(HAVE_TLS) \
|| !defined(__GLIBC__) \
|| !defined(USING_INITIAL_EXEC_TLS))
/* pthread_t of the thread containing this gomp_thread.
On Linux when using initial-exec TLS,
(typeof (pthread_t)) gomp_thread () - pthread_self ()
is constant in all threads, so we can optimize and not
store it. */
#define GOMP_NEEDS_THREAD_HANDLE 1
pthread_t handle;
#endif
};Try it yourself
在这里我略去了很多的函数和调用(比如调试信息的局部函数标记LFBXXXX,DWARF 调试信息,防止栈帧攻击的CET指令,用于记录当前栈帧结构的 CFI 信息Call Frame Information),大家可以自行查看。
在自己比对的过程中,可以试图比对几个问题:
- 用-O2 编译出的结果跟 -O0编译出的结果有什么不同?
- 使用
#pragma omp parallel for reduction(+:sum)时,for语句和reduction语句是如何实现的?
小例子:
#include <iostream>
#include <vector>
#include <omp.h>
int main() {
const int size = 1000; std::vector<int> array(size); long sum = 0;
// 初始化数组
for (int i = 0; i < size; ++i) { array[i] = i + 1;}
// 使用 OpenMP 并行计算数组和
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < size; ++i) {
sum += array[i];
}
}objdump
你可以把程序编译成二进制,然后用objdump 查看它跳到哪了。(你看到的那些ZNS都是PLT跳到的地方)
g++ openmp_hello.cpp -fopenmp -o openmp_sum -O2
objdump -d openmp_sum | grep -A 5 "<GOMP_parallel@plt>" # 如果是sum 例子,调用可能会不一样
ldd openmp_sum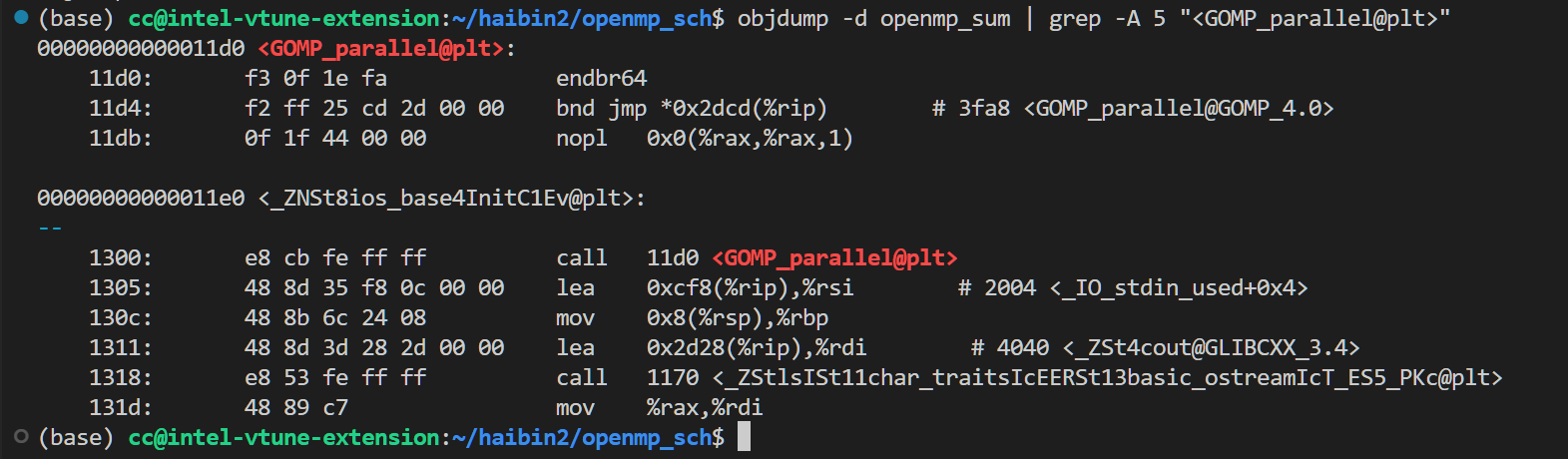
ICV是什么玩意???
在 OpenMP 中,ICV(Implementation-Defined Control Variables,内部控制变量)是一组由 OpenMP 运行时环境维护的变量,用于控制并行执行的行为。这些变量定义了 OpenMP 程序的运行时配置,例如线程数、调度策略等。gomp_icv 是 GNU OpenMP(GOMP,GCC 的 OpenMP 实现)中用于管理这些 ICV 的内部函数或结构。
说白了,就是你平常跑openmp的时候,export的那些东西。
下图是常见的OpenMP ICV 列表及解释
| ICV 名称 | 描述 | 默认值/典型行为 |
|---|---|---|
| nthreads-var | 指定并行区域的默认线程数。受 NUM_THREADS 条款或 OMP_NUM_THREADS 环境变量影响。 | 通常为系统核心数,或由 OMP_NUM_THREADS 设置。 |
| dyn-var | 控制是否启用动态线程调整(允许运行时调整线程数)。受 OMP_DYNAMIC 环境变量影响。 | 默认关闭(如 GCC 中通常为 false)。 |
| nest-var | 控制是否允许嵌套并行(并行区域内再创建并行区域)。受 OMP_NESTED 环境变量影响。 | 默认关闭(false),避免嵌套并行开销。 |
| run-sched-var | 定义 for 循环的调度策略(如 static、dynamic、guided)及块大小。受 OMP_SCHEDULE 环境变量影响。 | 通常为 static(均分)或实现定义。 |
| def-sched-var | 默认调度策略,当未指定调度类型时使用。 | 实现定义,通常为 static。 |
| bind-var | 控制线程绑定到处理器的方式(OpenMP 3.0 引入)。受 OMP_PROC_BIND 环境变量影响。 | 实现定义(如 false 或 spread)。 |
| stacksize-var | 设置每个线程的栈大小。受 OMP_STACKSIZE 环境变量影响。 | 实现定义,通常为几 MB。 |
| wait-policy-var | 控制线程等待行为(如主动旋转或休眠)。受 OMP_WAIT_POLICY 环境变量影响。 | 实现定义,通常为主动等待。 |
| max-active-levels-var | 限制嵌套并行层数。受 OMP_MAX_ACTIVE_LEVELS 环境变量影响。 | 默认 1(仅一级并行)。 |
| active-levels-var | 当前活跃的嵌套并行层数(运行时状态)。 | 动态维护,初始为 0。 |
| levels-var | 当前并行区域的嵌套深度(包括非活跃区域)。 | 动态维护,初始为 0。 |
以下是常见 OMP_* 环境变量和对应 ICV 的映射,帮你更清楚地看到它们的关系:
| 环境变量 | 对应的 ICV | 作用 |
|---|---|---|
| OMP_NUM_THREADS | nthreads-var | 设置默认线程数 |
| OMP_DYNAMIC | dyn-var | 是否允许动态调整线程数 |
| OMP_NESTED | nest-var | 是否启用嵌套并行 |
| OMP_SCHEDULE | run-sched-var | 设置循环调度策略(如 static、dynamic) |
| OMP_PROC_BIND | bind-var | 控制线程绑定到处理器的方式 |
| OMP_STACKSIZE | stacksize-var | 设置线程栈大小 |
| OMP_WAIT_POLICY | wait-policy-var | 控制线程等待行为(如主动/被动) |
| OMP_MAX_ACTIVE_LEVELS | max-active-levels-var | 限制嵌套并行层数 |
- ICV 是 OpenMP 的核心配置变量,控制线程数、调度、嵌套等行为。
- gomp_icv 是 GCC 的 OpenMP 运行时用来管理这些变量的机制。
- 每个 ICV 对应一个运行时特性,可通过指令、环境变量或 API 函数配置。
- 例如,nthreads-var 决定线程数,run-sched-var 控制循环调度,IF 条款(如前文讨论)与 nthreads-var 交互影响并行执行。
欢迎看看GNU的解释
Environment Variables (GNU libgomp)
如果你想详细的查表,它在这里:
Implementation-defined ICV Initialization (GNU libgomp)
什么是 __builtin_expect?
__builtin_expect 是 GCC(以及支持 GCC 扩展的编译器,如 Clang)提供的一个内置函数,用于向编译器提供分支预测的提示,优化条件分支的性能。OpenMP 运行时库(如 libgomp)的实现中,会用于优化线程管理或控制流逻辑。
源码分析入口
开始吧,噩梦!
gcc/libgomp/parallel.c at e2bf0b3910de7e65363435f0a7fa606e2448a677 · gcc-mirror/gcc
OpenMP的性能比较
这里我们使用 LAMMPS 这一经典的计算软件,来看看 OpenMP的线程数与 LAMMPS的性能表现:
LAMMPS Molecular Dynamics Simulator
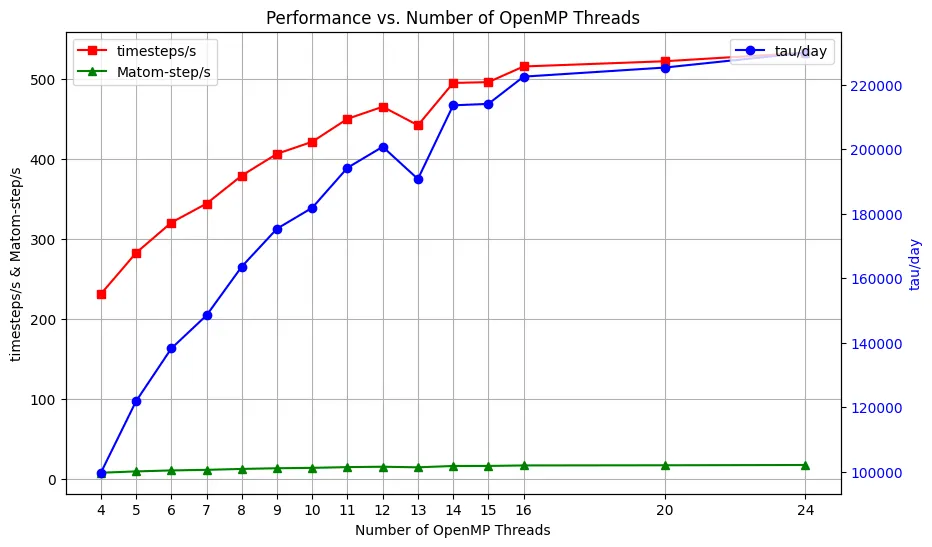
由于我们在一台2NUMA 24Core(没有超线程)的机器上运行,我们在这里能看到NUMA效应。
更多的并行加速分析,欢迎看阿姆达尔定律和logP定律的解析。
我把我的logP定律解析放在了这里:
https://www.haibinlaiblog.top/index.php/pram-bsp-logp-model/
欢迎做更多的实验!