
Distributed System 1: RPC
- Distributed Systems
- 2025-09-17
- 312 Views
- 0 Comments
- 608 Words
This is a course taught in SUSTech 2025 Fall by Prof. Zhuozhao Li.
RPC
为什么要有RPC
因为我们不想socket编程
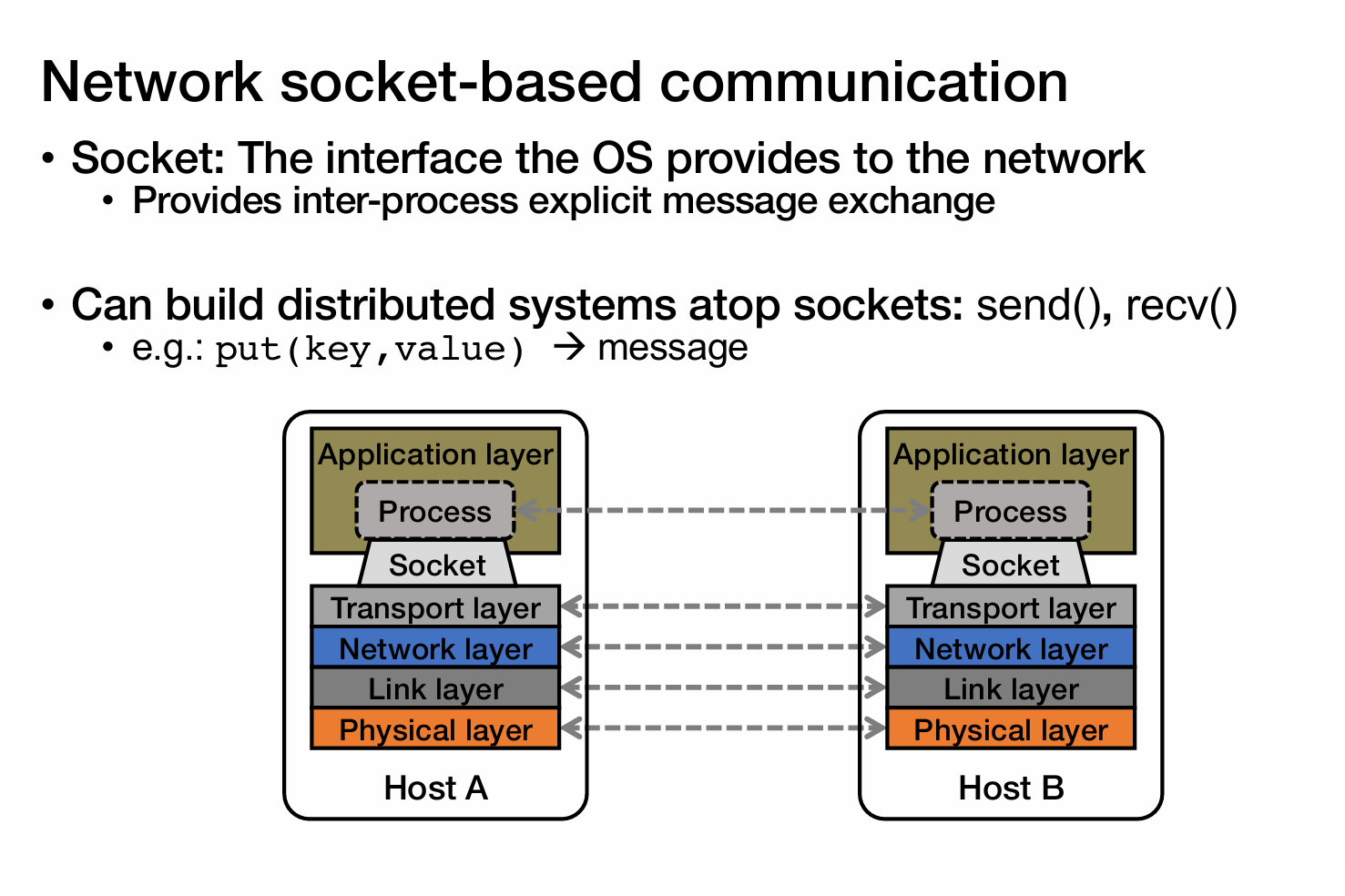


Goal: Easy-to-program network communication that makes
client-server communication transparent

RPC 要解决的问题
- 异构
- Failure
- 性能

For a remote procedure call, a remote machine may:
• Run process written in a different language
• Represent data types using different sizes
• Use a different byte ordering (endianness)
• Represent floating point numbers differently
• Have different data alignment requirements
• e.g., 4-byte type begins only on 4-byte memory boundary
RPC的example
注意,RPC的底层不一定是一定要tcp,udp也可以
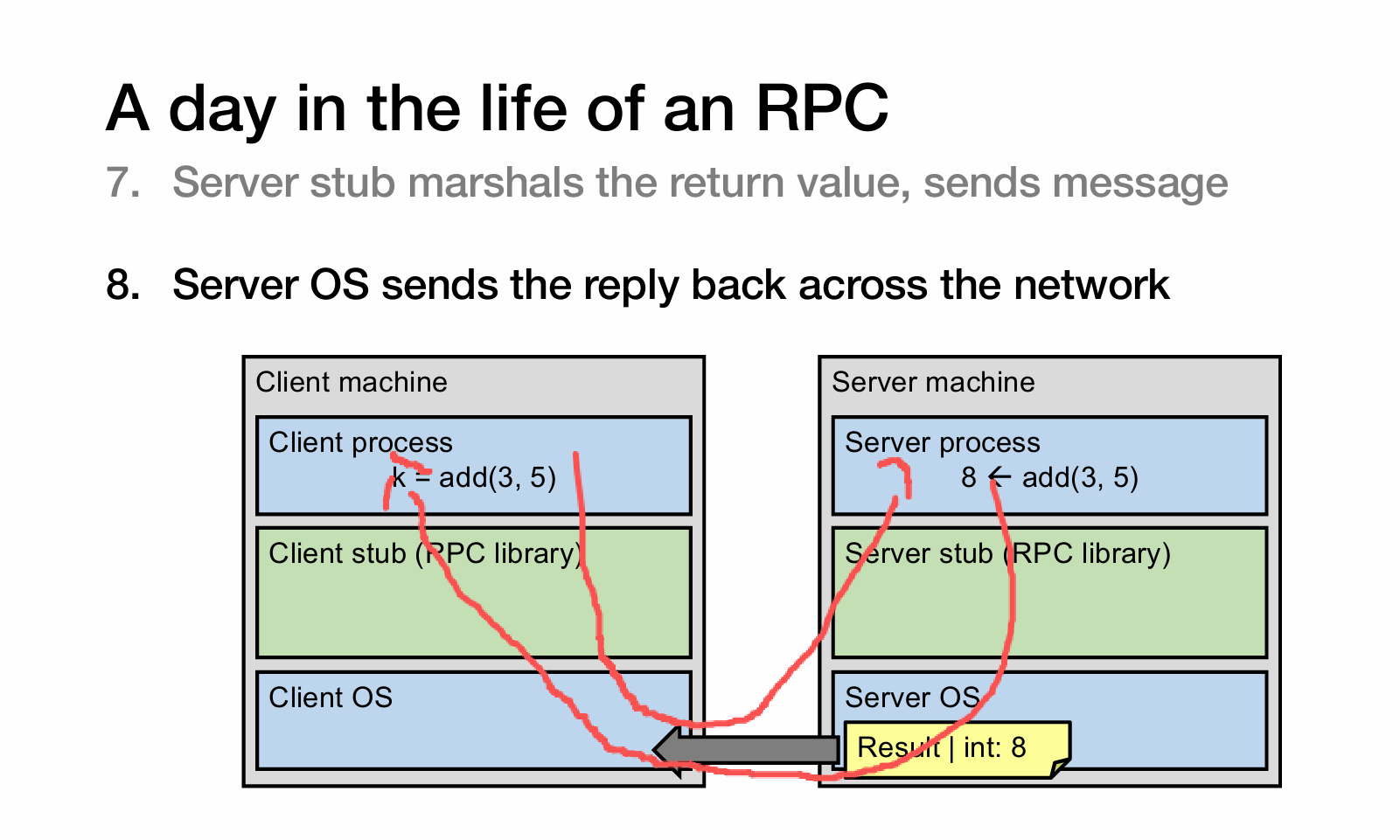
RPC 是一种远程调用的协议

Fault Tolerance
为什么会 错误?
- Client may crash and reboot
- Packets may be dropped
• Some individual packet loss in the Internet
• Broken routing results in many lost packets - Server may crash and reboot
- Network or server might just be very slow
- Packets may be dropped
gRPC: 用Http实现的RPC,是一种计算范式
至少一次机制
在分布式系统里,“至少一次 (at-least-once)” 是一种消息投递或任务执行的交付语义 (delivery semantics)。它主要用于描述在消息队列、事件流系统、RPC 调用、或者分布式作业调度中,系统如何保证一条消息最终被处理。

三种常见交付语义
- 至多一次 (at-most-once)
- 消息最多被处理一次,可能丢失,但不会重复。
- 优点:延迟低,性能好。
- 缺点:可能丢数据。
- 至少一次 (at-least-once)
- 消息保证最终会被处理,但可能被处理多次(即重复)。
- 典型实现:失败重试机制。如果处理失败或超时,消息会被重新投递,直到确认成功。
- 缺点:需要应用层自己处理幂等性 (idempotence),否则会出现重复处理的问题。
- 解决方案是用一个独立id
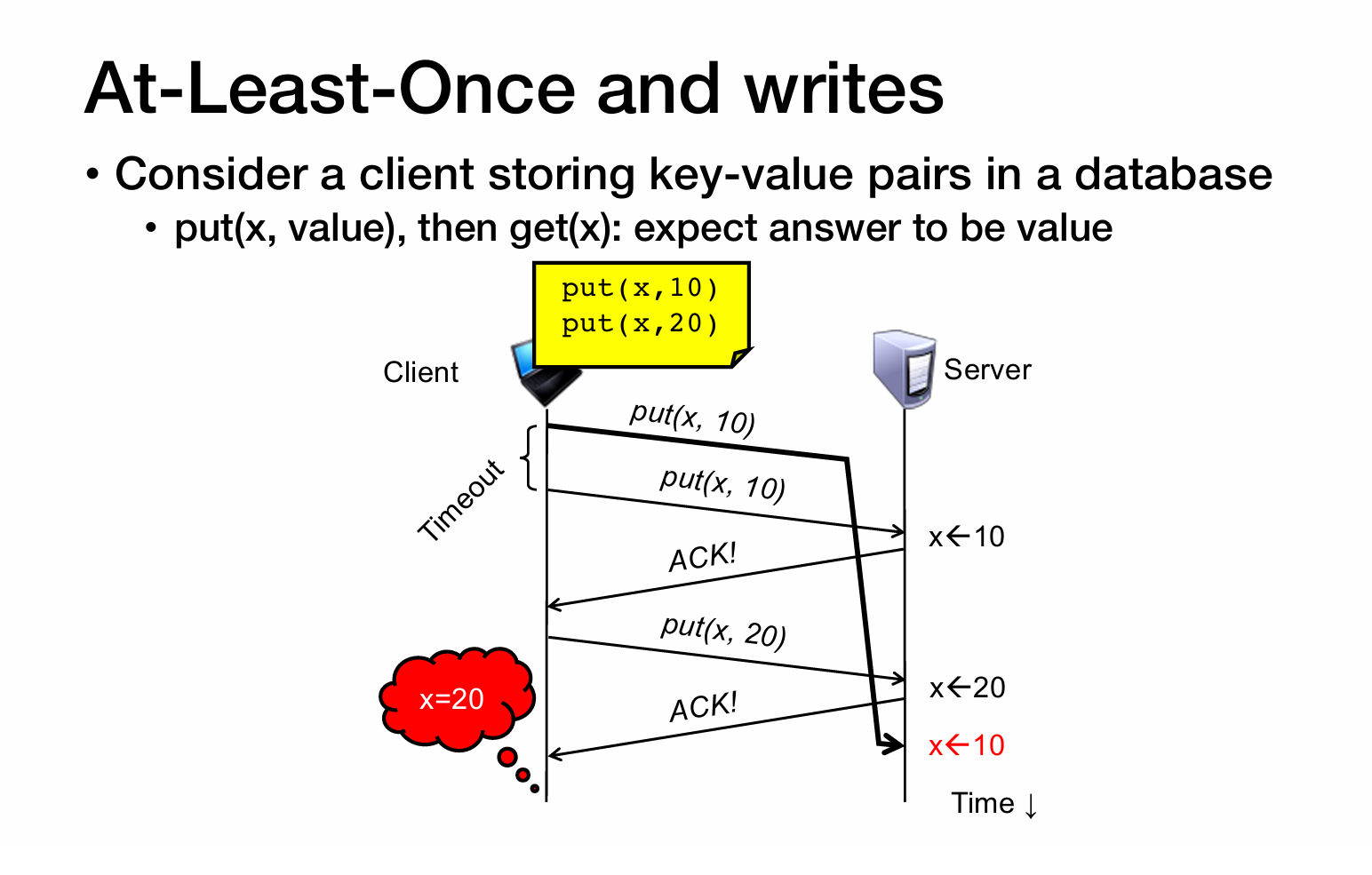


这里有可能id数量会太大,一种解决方案是discarding server state

- 恰好一次 (exactly-once)
- 消息保证不丢失且只处理一次。
- 实现复杂,常需要事务、日志或两阶段提交,性能开销较大。


举个例子
- Kafka 默认提供 at-least-once 语义。消费者如果处理失败或崩溃,broker 会再次投递消息 → 消息一定能被处理,但可能被消费多次。
- 分布式 RPC 重试:如果客户端调用服务超时,可能会重试 → 服务端其实已经执行过一次,重试时就会再次执行 → 至少一次。
At least once 至少读一次
这个场景面对的是读取数据的情况
Summary
