
Understanding the Bias-Variance Tradeoff 解读
- Machine Learning
- 2024-10-09
- 1014 Views
- 0 Comments
- 1934 Words
Webpage: Understanding the Bias-Variance Tradeoff (fortmann-roe.com)
Introduction
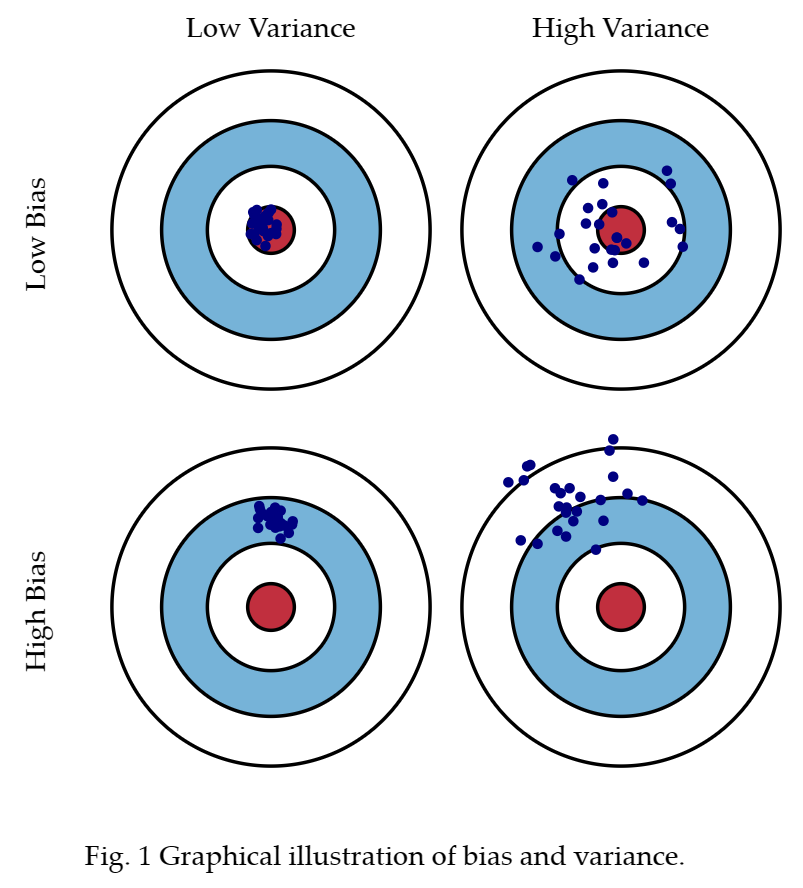
When we discuss prediction models, prediction errors can be decomposed into two main subcomponents we care about: error due to "bias" and error due to "variance". There is a tradeoff between a model's ability to minimize bias and variance. Understanding these two types of error can help us diagnose model results and avoid the mistake of over- or under-fitting.
在模型拟合中,会出现error,而error的主要原因主要是这两个:
- bias
- variance
对这两个的理解才能明白over/under fitting
bias:太偏了(偏移值)
The error due to bias is taken as the difference between the expected (or average) prediction of our model and the correct value which we are trying to predict.
variance:太散了(方差)
The error due to variance is taken as the variability of a model prediction for a given data point.
Mathematical Definition
假设需要预测的随机变量 Y 和 协变量 X 满足如下关系:
Y = f(X) + \epsilon
其中,\epsilon 满足正态分布N(0,\sigma_E)
我们在评估中使用以下函数作为损失函数:
Err(x) = E[(Y-\hat f(x))^2]
This error may then be decomposed into bias and variance components:
Err(x) = (E[\hat f(x)]-f(x))^2 + E[(\hat f(x) - E[\hat f(x)])^2] + \epsilon_e ^ 2
which is:
Bias^2+Variance+Irreducible Error
That third term, irreducible error, is the noise term in the true relationship that cannot fundamentally be reduced by any model. Given the true model and infinite data to calibrate it, we should be able to reduce both the bias and variance terms to 0. However, in a world with imperfect models and finite data, there is a tradeoff between minimizing the bias and minimizing the variance.
Example: Voting Intentions
我们在电话抽取了人来进行美国大选预测
这里边bias 和 variance都有,其实不一定是我们样本量太小的原因,我们的调查方法也有问题
你为什么只用电话抽?没有电话的选民投给谁? variance
选民们后面真的这么投了吗? bias
An Applied Example: Voter Party Registration
选民的投票、财富、地区的分布图
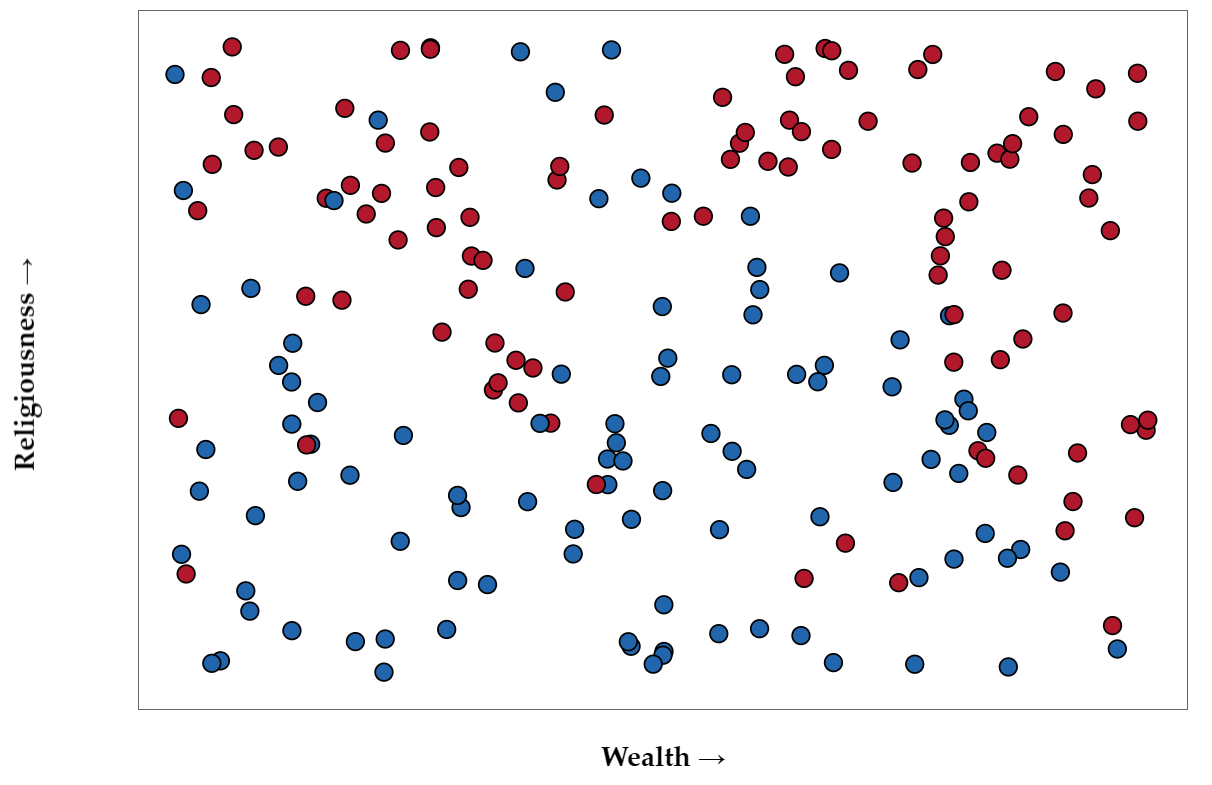
Hypothetical party registration. Plotted on religiousness (y-axis) versus wealth (x-axis).
我们使用KNN算法来确定新的选民的选票:
k 越大,每次预测的平均投票人数就越多。这使得预测曲线更加平滑。当 k 值为 1 时,民主党和共和党之间的分界非常模糊。此外,在通常情况下,共和党人的领地中会出现民主党人的 “孤岛”,反之亦然。当 k 值增加到 20 时,过渡变得更加平滑,“孤岛 ”消失,民主党和共和党之间的分界也能很好地遵循边界线。随着 k 值的增大,比如 80,两个类别之间的区别变得更加模糊,边界预测线也完全不匹配。
在 k 值较小的情况下,锯齿状和孤岛是差异的表现。随着新数据的收集,岛屿的位置和边界的确切曲线会发生很大变化。另一方面,当 k 值较大时,过渡非常平滑,因此差异不大,但边界线不匹配则是偏差较大的表现。
我们在这里观察到的是,k 越大,方差越小,偏差越大。而减少 k 则会增加方差,减少偏差。 看看不同数据集在低 k 时的预测结果有多大差异。但是,如果我们将 k 增加太多,那么我们就不再遵循真正的边界线,我们就会观察到高偏差。这就是偏差-方差权衡的本质。
Loss Estimation
方差项是不可还原误差和 k 的函数,随着 k 的增加,方差误差稳步下降。偏差项是模型空间粗糙程度的函数。空间越粗糙,偏差项增加的速度就越快,因为更远的邻居会被纳入估计值。
Err(x) = (f(x) - \frac{1}{k}\sum_{i=1}^k{f\left( x_i \right)})^2 + \frac{\sigma_{\epsilon}^2}{k} +\sigma_{\epsilon}^2
Managing Bias and Variance
How do we do?
与本能作斗争
很多人都有一种直觉,那就是即使牺牲方差也要尽量减少偏差。他们认为,偏差的存在表明他们的模型和算法基本上出了问题。是的,他们承认,方差也是不好的,但方差大的模型至少在平均水平上可以预测得很好,至少它没有根本性的错误。
这是错误的逻辑。的确,高方差、低偏差的模型可以在某种长期平均意义上表现良好。然而,在实践中,建模者总是在处理数据集的单一实现。在这种情况下,长期平均值并不重要,重要的是模型在实际数据上的表现,在这种情况下,偏差和方差同样重要,不应该为了改善其中一个而过度牺牲另一个。
套袋和重采样
Bagging 和其他重采样技术可用于减少模型预测的方差。在布袋法(Bootstrap Aggregating)中,使用随机选择替换法创建原始数据集的无数个副本。然后使用每个衍生数据集构建一个新模型,并将这些模型汇集成一个集合。要进行预测,需要对集合中的所有模型进行轮询,并对其结果取平均值。
随机森林(Random Forests)是一种强大的建模算法,它很好地利用了袋集算法。随机森林的工作原理是根据对原始训练数据的不同重采样,训练出无数个决策树 。在随机森林中,完整模型的偏差等同于单棵决策树的偏差(决策树本身具有高方差)。通过创建许多这样的树,实际上就是一个 “森林”,然后对它们进行平均,最终模型的偏差就会比单棵树的偏差大大降低。在实践中,森林大小的唯一限制就是计算时间,因为可以训练无限多的决策树,而偏差不会不断增加,方差也会持续减少(即使是渐进减少)。
算法的渐近特性(大数据,更接近)
讨论预测算法的学术统计文章经常会提到渐进一致性和渐进效率的概念。实际上,这意味着当训练样本数量增长到无穷大时,模型的偏差会降至 0(渐进一致性),模型的方差也不会比其他可能使用的模型差(渐进效率)。
这两个特性都是我们希望模型算法具备的。然而,我们并不生活在一个样本量无限大的世界里,因此渐进特性通常没有什么实际用途。当你有一百万个数据点时,算法可能几乎没有偏差,但当你只有几百个数据点时,算法可能会有非常明显的偏差。更重要的是,一个渐进一致且高效的算法在小样本量数据集上的实际表现可能比一个既不渐进一致也不高效的算法更差。在处理真实数据时,最好抛开算法的理论属性,而关注其在特定情况下的实际准确性。
了解过度拟合和欠拟合
从根本上说,处理偏差和方差实际上就是处理过拟合和欠拟合。偏差的减少和方差的增加与模型的复杂性有关。随着模型中的参数越来越多,模型的复杂度就会上升,方差就会成为我们最关心的问题,而偏差则会稳步下降。例如,线性回归中加入的多项式项越多,模型的复杂度就越高。换句话说,偏差对模型复杂度的一阶导数为负4 ,而方差的斜率为正。
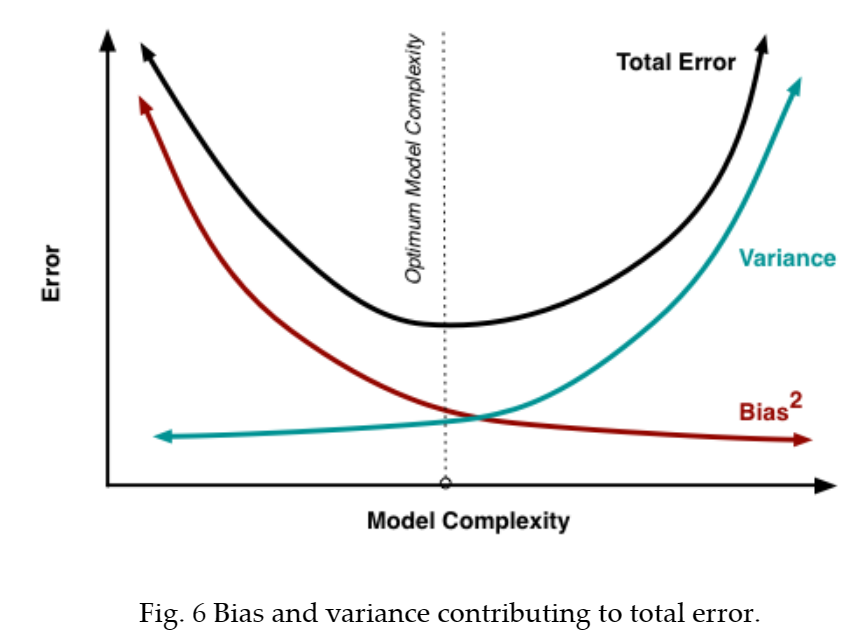
所以我们可以看出这么一个公式:
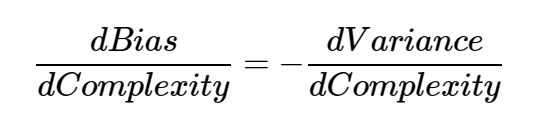
我们需要达到一个甜点 sweet spot, 达到两者的均衡