
神文解析:AVX 是怎么让你的CPU频率更慢的?
- 文章翻译
- 2025-11-06
- 824 Views
- 0 Comments
- 11556 Words
GB!
本文依旧是超神作者 Travis Downs https://x.com/trav_downs 的技术博客解读。文章链接 Gathering Intel on Intel AVX-512 Transitions https://travisdowns.github.io/blog/2020/01/17/avxfreq1.html 本文是在其基础上的分析与解读,若内容涉及侵权,请与我联系,我将立即进行修正或删除。
AVX/AVX-512 指令虽然能极大提升向量运算吞吐量,但它们功耗高、发热大,常常会触发 CPU 的动态电压与频率调整(DVFS)机制,使得 CPU 降频运行。
作者提到,虽然已有不少资料谈论过“AVX 会让性能反而下降”的问题,但这些多是宏观经验总结,比如:
- “使用 AVX-512 可能导致频率下降”
- “不同代 CPU 的降频阈值不同”
作者希望更进一步,研究频率转变的具体时序行为——也就是从“发出 AVX 指令”到“CPU 真正降频”、“频率恢复”等阶段的微观细节......
背景学习:使用AVX指令会降低你的 CPU 频率
作者列出了一篇文章(以下链接)作为引子,其发现在使用OpenSSL时,由于使用AVX指令而降频,进而使得总体性能下降。
https://blog.cloudflare.com/on-the-dangers-of-intels-frequency-scaling/
在我撰写那篇比较高通新服务器芯片 Centriq 与我们现有 基于 Intel Skylake 架构的 Xeon 处理器 的文章时,我注意到一个令人不安的现象。
在对 OpenSSL 1.1.1dev 进行基准测试时,我发现 ChaCha20-Poly1305 这种加密算法的性能扩展性并不好。单线程性能大约是 2.89 GB/s,而在 24 个核心 48 个线程下,性能只有 35 GB/s 左右。这个数值虽然很高,但我本希望能接近 69 GB/s。35 GB/s 意味着每核 1.46 GB/s,只有单核性能的 50% 左右。相比之下,AES-GCM 的扩展性好得多,能保持 80% 的单核性能。这可以理解,因为 CPU 在单核负载时能保持更高的 Turbo 频率,但多核运行时无法如此。
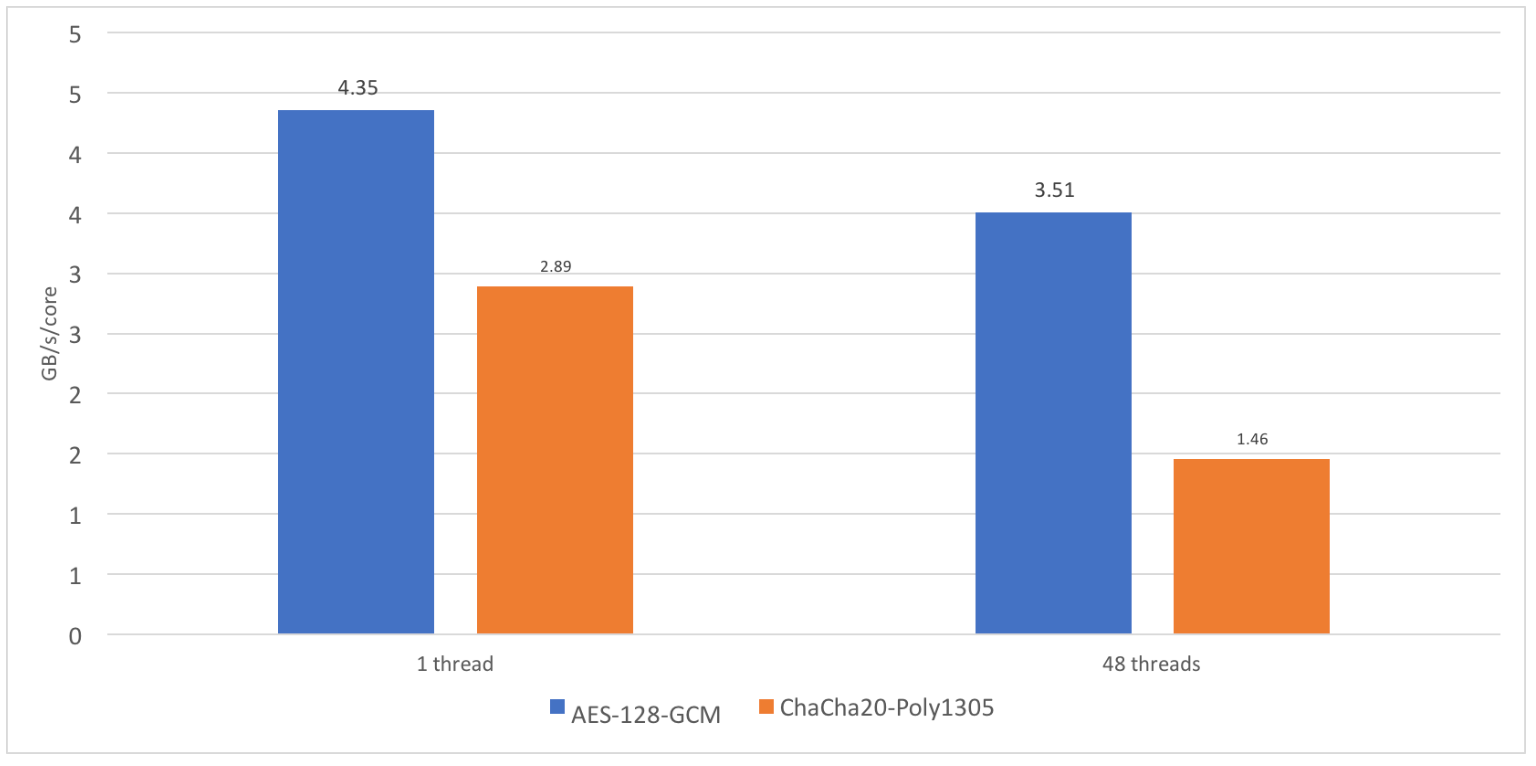
那么,为什么 ChaCha20-Poly1305 的扩展性如此糟糕?答案是——AVX-512。
AVX-512 是 Intel 引入的一套新的 512 位宽 SIMD 指令集,它在原有指令基础上扩展为 512 位,并增加了许多新指令。这类宽指令的问题在于——它们耗电量非常大。想象一下,一条指令完成了 64 条普通字节指令,或 8 条完整 64 位指令的工作量。
为了控制功耗,Intel 引入了一种机制叫 动态频率调节(Dynamic Frequency Scaling)。当处理器运行 AVX2 或 AVX-512 指令时,会自动降低基准频率。这并不是新鲜事,自 Haswell 引入 AVX2 以来,这种机制已经存在了三年。
当更多核心同时执行 AVX-512 代码,尤其涉及乘法运算时,降频情况会更严重。如果程序完全使用 AVX-512 指令,那么一切都没问题——虽然频率下降,但每条指令完成的工作更多,总体吞吐仍然更高。
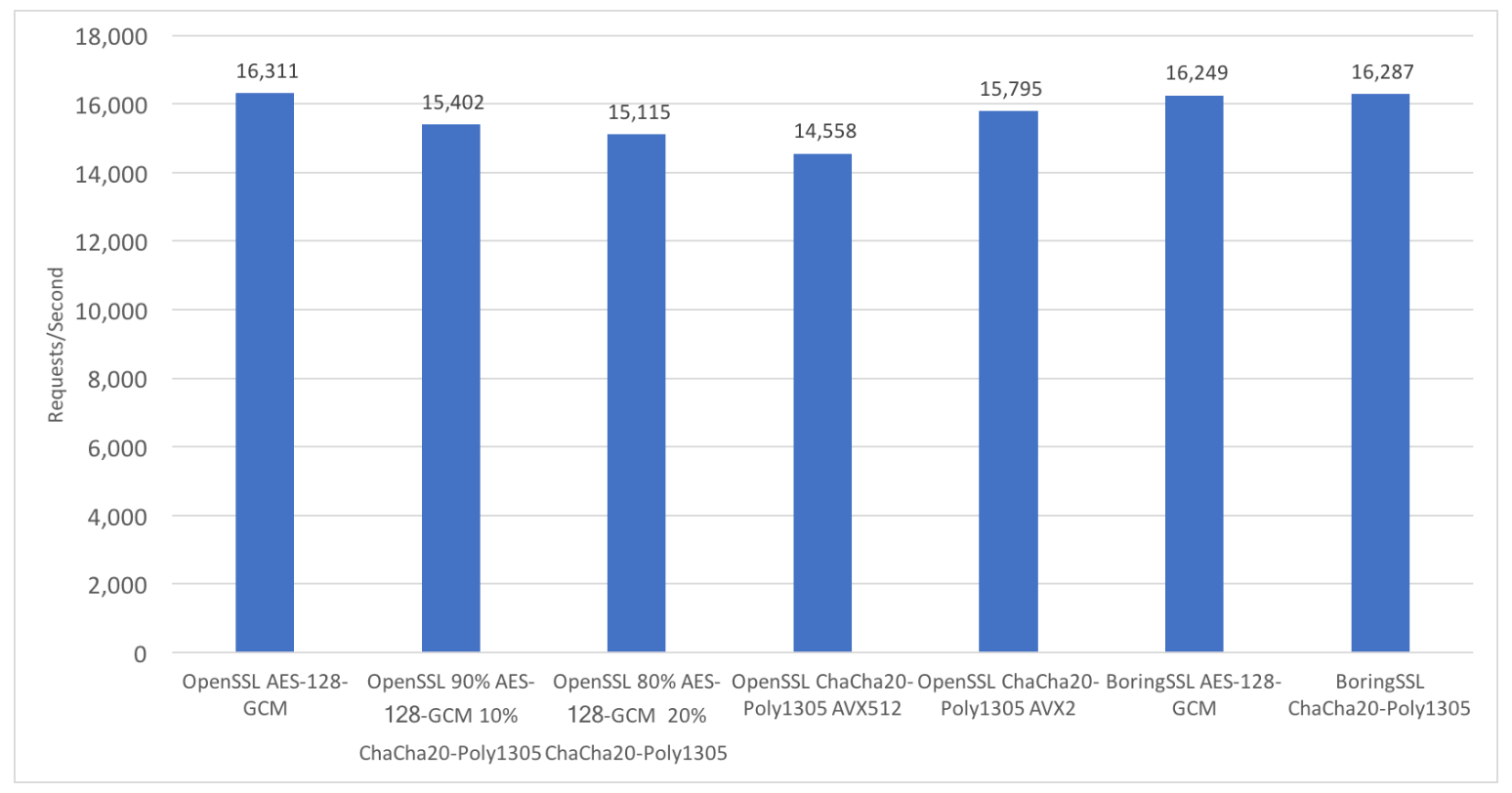
OpenSSL 1.1.1dev 中实现了多个 ChaCha20-Poly1305 的变体,包括 AVX2 和 AVX-512 版本。而 BoringSSL 则实现了另一种不同的 AVX2 版本。由此可见,BoringSSL 在单核上仅 1.6 GB/s 的性能,也就不难理解了——相比 OpenSSL 的 2.89 GB/s。
那么,如果在你的真实工作负载中混入少量 AVX-512 指令,会发生什么? 我们使用的是 Xeon Silver 4116 CPU,基准频率 2.1 GHz,双插槽配置(共 24 核心)。根据 wikichip 的资料,即使仅在一个核心上运行 AVX-512 ,也会将基准频率降到 1.8 GHz;如果所有核心都运行 AVX-512 ,则会降至 1.4 GHz。
正文
文章结构

文章的背景与动机
这是关于 AVX 和 AVX-512 相关频率缩放 的一篇文章。
目前,关于这个主题已经有不少内容被写过,包括一些关于性能损失的警示故事以及一些广泛的指导原则——所以,我们真的还需要再添一笔吗?
或许不需要,但我还是要写。我的角度是一个更低层次的观察,几乎可以说是显微镜式的,去研究具体的频率转换行为。人们希望这能带来一些具体的、定量化的建议,比如在什么情况下各种类型的指令会真正值得使用,但(剧透)我在这篇文章里还没走到那一步。
其实我原本并没有打算现在就写这篇文章,但我在一个(嵌套的)跑题过程中被带到了这里。既然如此,我们就来用一些目标性测试(target tests)看看 AVX-512 的降频行为。至少这对下一篇文章来说是必要的背景知识,但我也希望它本身就足够有趣。
注释:如果你想要最简短的版本,可以直接跳到总结部分,不过那你今天剩下的时间要干嘛呢?
源代码
本文中所有的代码都可以在 freq-bench https://github.com/travisdowns/freq-bench/tree/post1 的 post1 分支中找到,因此你可以在家跟着操作,检查我的工作,并在自己的硬件上查看行为表现。它需要 Linux 操作系统,README 文件中提供了基本的入门提示。
源代码中包括了数据生成脚本【scripts】以及用于生成图表的脚本 【plots】。由于我并不擅长 Shell 脚本和 Python,所以请轻点手。
测试结构 (Test Structure)
我们想要研究的是:当程序的指令流在不同类型的指令之间切换时,CPU 的性能状态会发生怎样的变化。
最典型的例子,就是当你在很长一段时间没有执行 AVX-512 指令后,突然再次执行一条 AVX-512 指令时,CPU 会如何响应。不过,接下来我们会看到,这种“状态切换”并不只在这种场景下发生。
整个测试的核心思路是这样的:
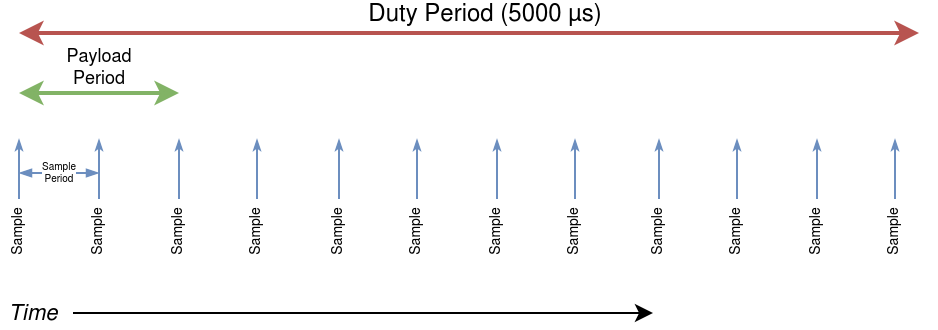
我们把运行过程划分成一个个工作周期(duty period)。在每个周期的开始,我们会执行一段特定负载(payload)——这段负载的持续时间称为负载周期(payload period),里面包含一组“有趣的”指令,比如 AVX、AVX-512 或普通标量指令,具体取决于测试类型。
在测试运行的全过程中,我们会以固定频率不断采样各种性能指标,比如功耗、时钟频率或温度变化。这种采样是“尽最大努力”实现的固定间隔采样。
整个测试会重复这样的周期,直到到达预定的测试时间。通常,采样的时间间隔会远小于工作周期。
在本文的实验中,我们大多数情况下使用的是 5000 微秒的工作周期 和 1 微秒的采样周期。
如果用图来表示,大致可以想象成这样:
每个测试由多个连续的工作周期组成,而上图展示的只是其中的一个周期。每个周期中,CPU 会经历“执行负载—采样—等待下一个周期”的完整过程。
负载时长的说明
上图中,我们把负载周期(payload period)画成了一个占据一定时间的阶段,看起来好像那段计算持续了挺久。 但在最初的几组实验中,情况其实并不是这样。
在这些早期测试里,负载阶段几乎可以忽略不计——负载函数只执行了一次,而且里面只有几条指令。 换句话说,它并不是一个真正的“负载周期”,而更像是一个瞬时的负载事件(payload moment)。
这个测试框架本质上模拟了一种周期性工作负载调度,非常类似于调度算法中的“占空比(duty cycle)”概念。每个周期中 CPU 会经历“执行 AVX 负载 → 暂停(或执行轻量指令)→ 再次执行负载”的循环过程。
硬件 (Hardware)
具体的配置可以看看原文
We are running these tests on a SKX architecture W-series CPU: a W-21046 with the following license-based frequencies7:
| Name | License | Frequency |
|---|---|---|
| Non-AVX Turbo | L0 | 3.2 GHz |
| AVX Turbo | L1 | 2.8 GHz |
| AVX-512 Turbo | L2 | 2.4 GHz |
For one (voltage) test I also use my Skylake (mobile) i7-6700HQ, running at either it’s nominal frequency of 2.6 GHz, or the turbo frequency of 3.5 GHz.
测试 (Test)
本篇文章的基本思路,是利用前面提到的测试框架来观察 CPU 的行为,主要通过改变负载内容(payload) 以及观测的性能指标(metrics) 来进行分析。 那我们就从 256 位指令(256-bit instructions) 开始吧。Let’s get the ball rolling!
256 位整数 SIMD(AVX)
在第一个测试中,我们使用如下函数作为 负载(payload)。它只包含一条 256 位指令,后面接一条 vzeroupper 指令:
vporymm_vz:
vpor ymm0,ymm0,ymm0
vzeroupper
ret在每个 工作周期(duty period) 的开始,我们只调用一次这个负载函数。
测试参数设置如下:
- 工作周期:5000 微秒
- 采样周期:1 微秒
- 总测试时长:31,000 微秒
因此,负载函数会执行大约 7 次。
补充说明:这里的
vpor ymm0, ymm0, ymm0是一条典型的 256 位 AVX 位逻辑“或”指令,用于对寄存器自身进行逻辑操作,几乎没有计算负载,但仍然触发 CPU 的 AVX 频率域(AVX frequency domain),从而引发频率降档行为。
vzeroupper则是清空上半部分 YMM 寄存器,以避免在返回到标量或 SSE 代码时出现性能惩罚(transition penalty)。
也就是说,这个测试专门用来观察:CPU 在周期性执行极少量 AVX 指令时,是否会触发 AVX 降频机制,以及频率恢复的时间特征。
┌──────────────────────────────────────────────────────────────┐
│ 一个工作周期(5000 μs) │
│ ┌────────────┐ ┌───────────────────────────┐ │
│ │ 负载执行 │ → │ 空闲 阶段 │ → 循环下一周期 │
│ │ (payload) │ │ (collect frequency/power) │ │
│ └────────────┘ └───────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
采样(每1us一次),持续31000us下图展示了测试结果(见注释 10),横轴为时间(x 轴),纵轴为每次采样测得的 CPU 频率(共展示了三次独立的测试运行结果)。
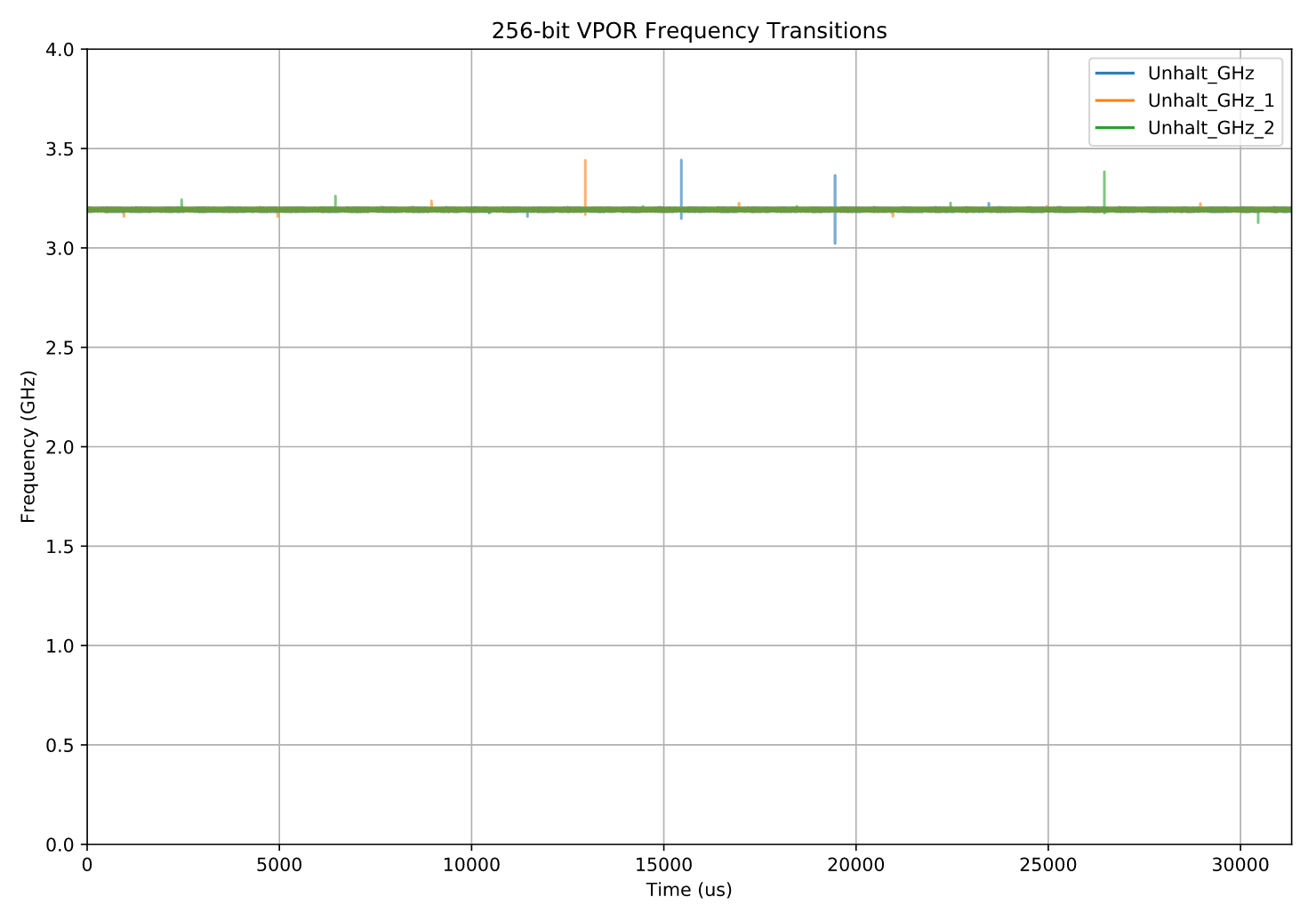
老实说,这一部分有点无聊。整个测试过程中,CPU 一直稳定运行在 3.2 GHz —— 也就是它的标称频率(L0 license 频率)。
如果忽略几个无关紧要的采样异常点,那整个曲线几乎是一条平直的线,没有任何有趣的变化。
512 位整数 SIMD(AVX-512)
在大家开始失望之前,我们马上进入下一个测试。
这个测试和前一个几乎完全一样,唯一的区别是:这次使用的是 512 位的寄存器(zmm),也就是说,负载部分换成了 AVX-512 整数向量指令 zmm。
vporzmm_vz:
vpor zmm0,zmm0,zmm0
vzeroupper
retHere is the result:
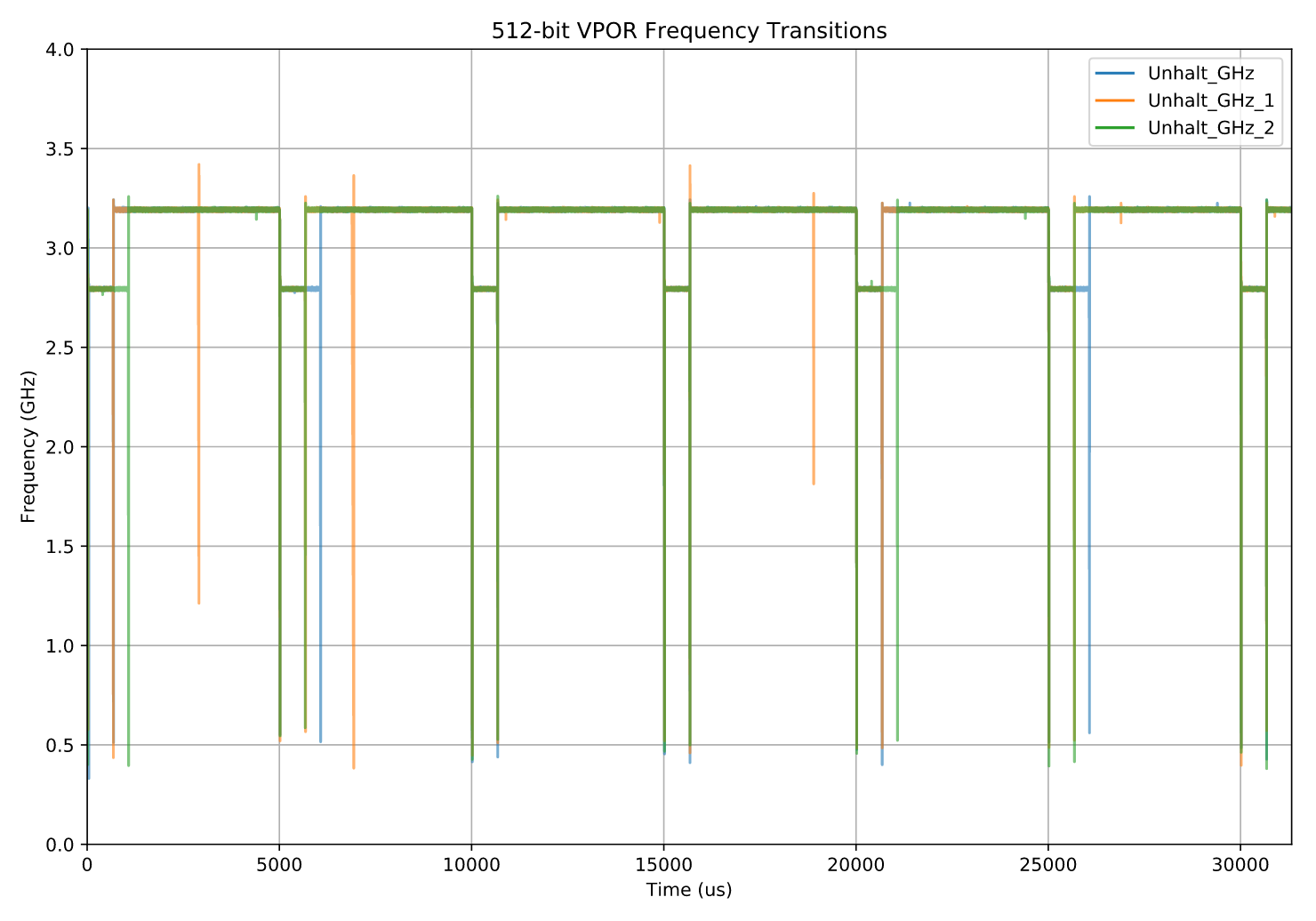
图:AVX512情况下的CPU频率
终于出现点有意思的东西了!
(原文是 “We’ve got something to sink our teeth into!”)
要记得,我们的工作周期(duty cycle)是 5000 微秒。
也就是说,每当时间轴走到一个新的 5000 μs 位置时,我们就会执行一次负载指令。
现在行为变得非常清晰了:
每当那条负载指令被执行时(即每隔 5000 μs),CPU 的频率就会从最初的 3.2 GHz(L0 许可频率) 降到 2.8 GHz(L1 许可频率) (见Hardware测试表格)。
到目前为止,这一切都完全符合预期。
接下来,我们把镜头拉近,看一看 15 000 μs 处 的其中一个频率转换点,看看降频的瞬态细节。
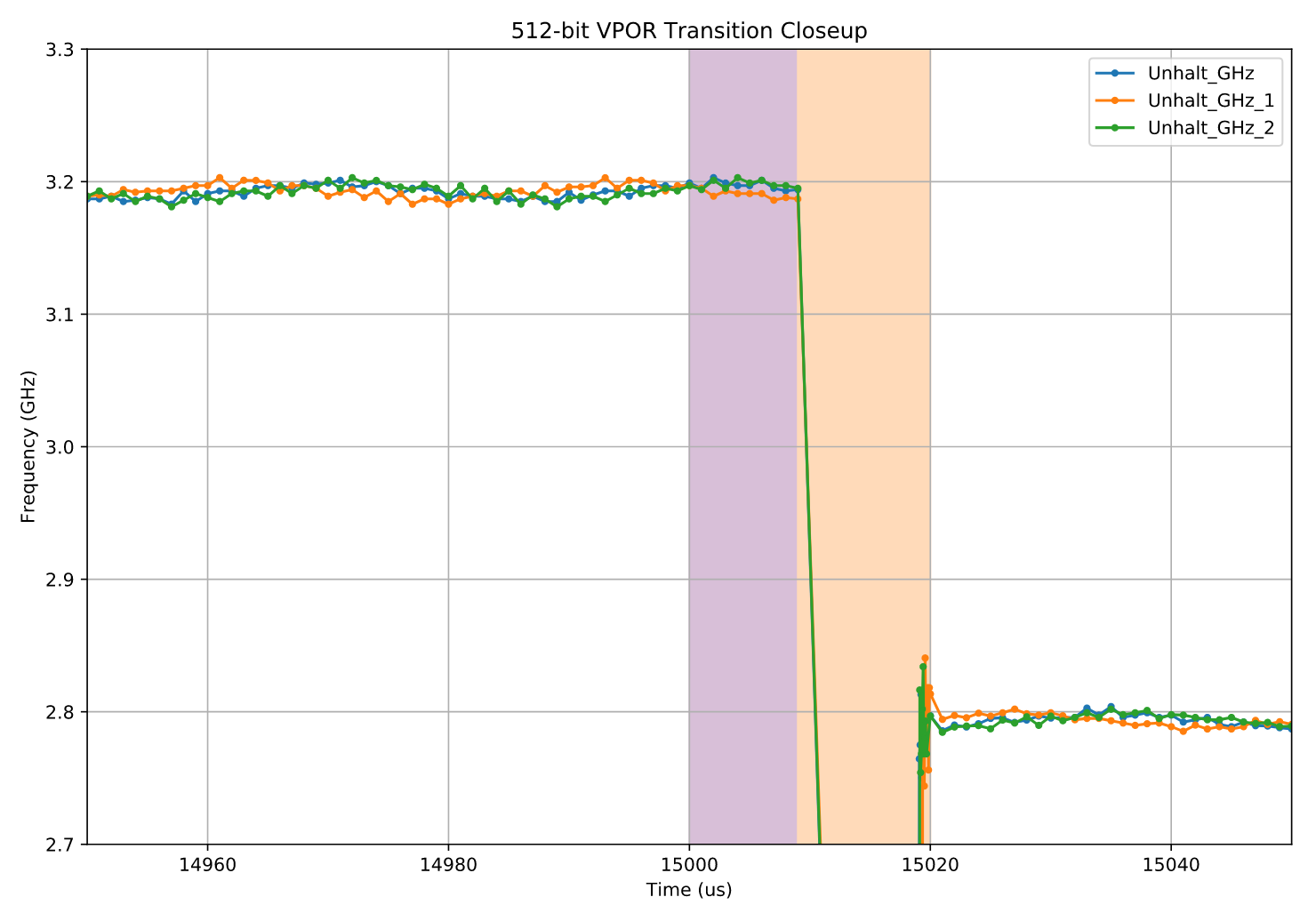
将AVX512情况下的CPU频率变化图进行局部放大
频率转换的细节观察
我们可以从图中看到以下几个现象:
-
频率转换期(橙色阴影区域)
在右边的橙色阴影部分,可以看到大约 11 微秒 的过渡阶段。
在这段时间内,CPU 处于完全停顿(halted) 状态——采样记录也完全中断。
出于趣味,我们称这段时间为一次“ 频率转换(frequency transition) ”。 -
电压转换期(紫色阴影区域)
左边的紫色阴影区域紧挨着负载执行点(15,000 μs 处),位于停顿期之前,持续大约 9 微秒。
在这段时间里,频率保持不变。
这并不是测量误差或测试瑕疵——这段时间的存在是可重复的。
虽然看起来这 9 微秒似乎“什么也没发生”,但实际上它非常特殊。
稍后我们会看到,这段时期对应的是一次仅电压变化的阶段(voltage-only transition)。 -
低频运行期
在放大的图中虽然没有完全展示,但我们可以确定:
CPU 在较低的 2.8 GHz 频率下运行大约 650 微秒。
作者在这里说的是低频运行和低频回高频区(下图的3和4)
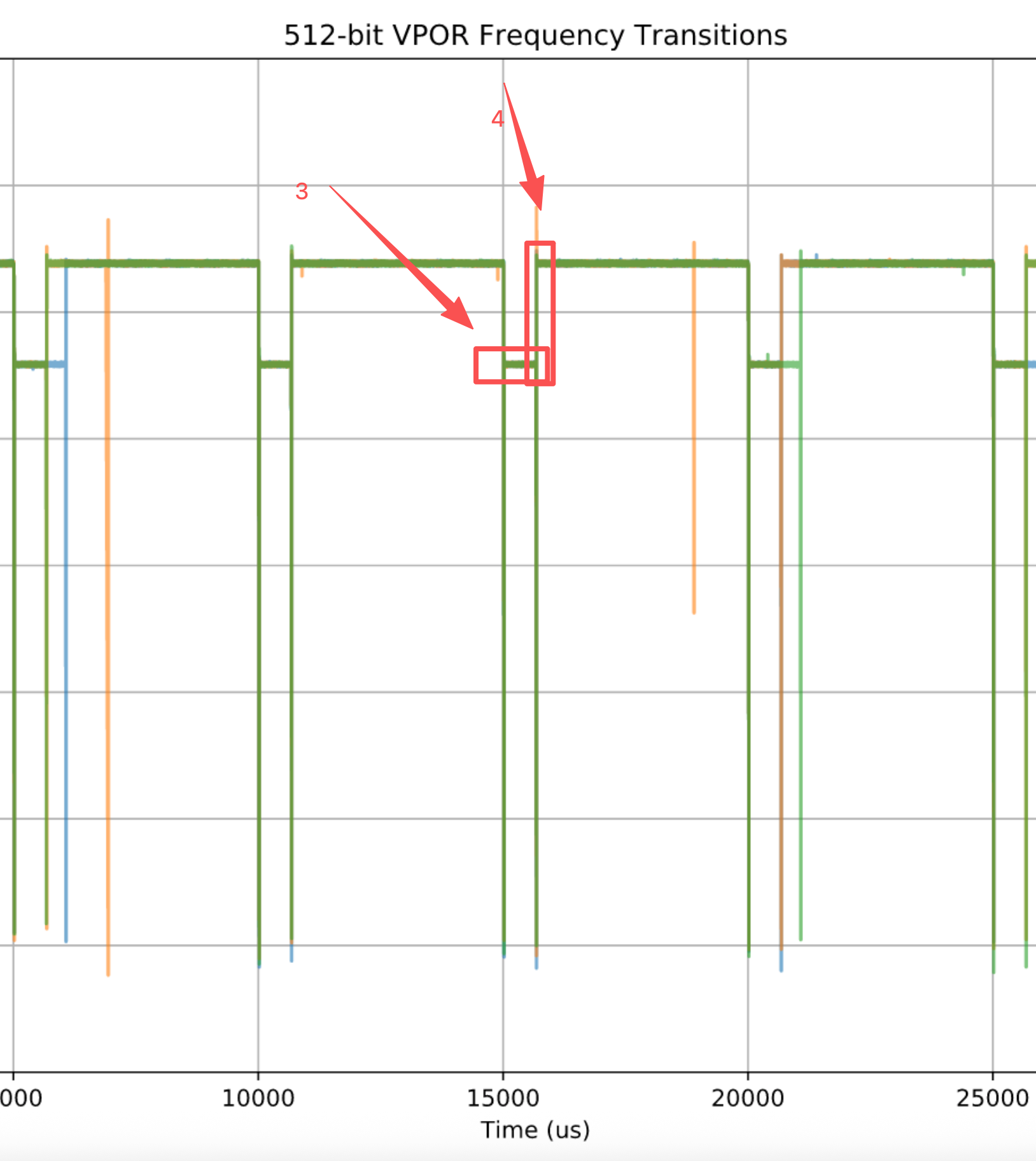
- 恢复阶段的再次停顿
在完整图中还能看到第二个向下的频率尖峰:
在经历约 650 微秒的低频运行后,CPU 再次经历一次大约 11 微秒 的完全停顿,
随后才恢复到最高的 3.2 GHz(L0 license)。
这些特征在三次运行中基本一致(以至于绿色的曲线几乎重叠并遮住了其他曲线)——
但也存在一些异常点,即返回 3.2 GHz 的时间略长。
这种现象在多次运行中都是一致的:恢复时间从未比约 650 微秒更短,但有时会更长。
我认为这发生在 L1 区间期间有中断发生,从而“重置了计时器”。
指令吞吐量(IPC)观察
虽然在这张图中看不到,但 512 位指令在第一个阴影区域(紫色区域)中的行为很特别——
也就是在负载指令执行之后、随后的停顿期之前的 9 微秒 内:
它们的执行速度比平时慢得多。
这点最容易看出来的方法是延长负载周期:
不再是每 5000 微秒只执行一次负载函数、然后等待下一次采样, 而是在新的工作周期开始后,连续执行 100 微秒的负载函数(即将负载周期设为 100 微秒)。 在这段时间里,我们仍然保持每 1 微秒采样一次—— 但在两次采样之间,CPU 正在执行负载指令。
因此,一个完整的工作周期现在变为:100 微秒的负载 + 4850 微秒的无负载高频空转(hot spinning)。我们延长负载周期是为了检查负载指令的性能。 有几个指标可以观察,但最简单的是看每周期指令数(IPC)。 只要确保绝大部分执行的指令都是负载指令,IPC 基本就能反映负载的执行情况。
在这里,我选择了负载是一个非常简单的函数,作为负载,我们使用一个只包含 1000 条相互依赖的 512 位 vpord 指令 的函数:
vpord zmm0, zmm0, zmm0
vpord zmm0, zmm0, zmm0
; ... 共 1000 条类似指令
vpord zmm0, zmm0, zmm0
vzeroupper
ret我们已知 vpord 指令的延迟是 1 个周期(cycle)。
由于这些指令是串行依赖的,因此理论上整个函数大约需要 1000 个周期,
换算下来,IPC ≈ 1.0。
下图展示了相同过渡点(15,000 μs 附近)的放大视图, 这次除了频率外,还在副坐标轴上绘制了 IPC 曲线。
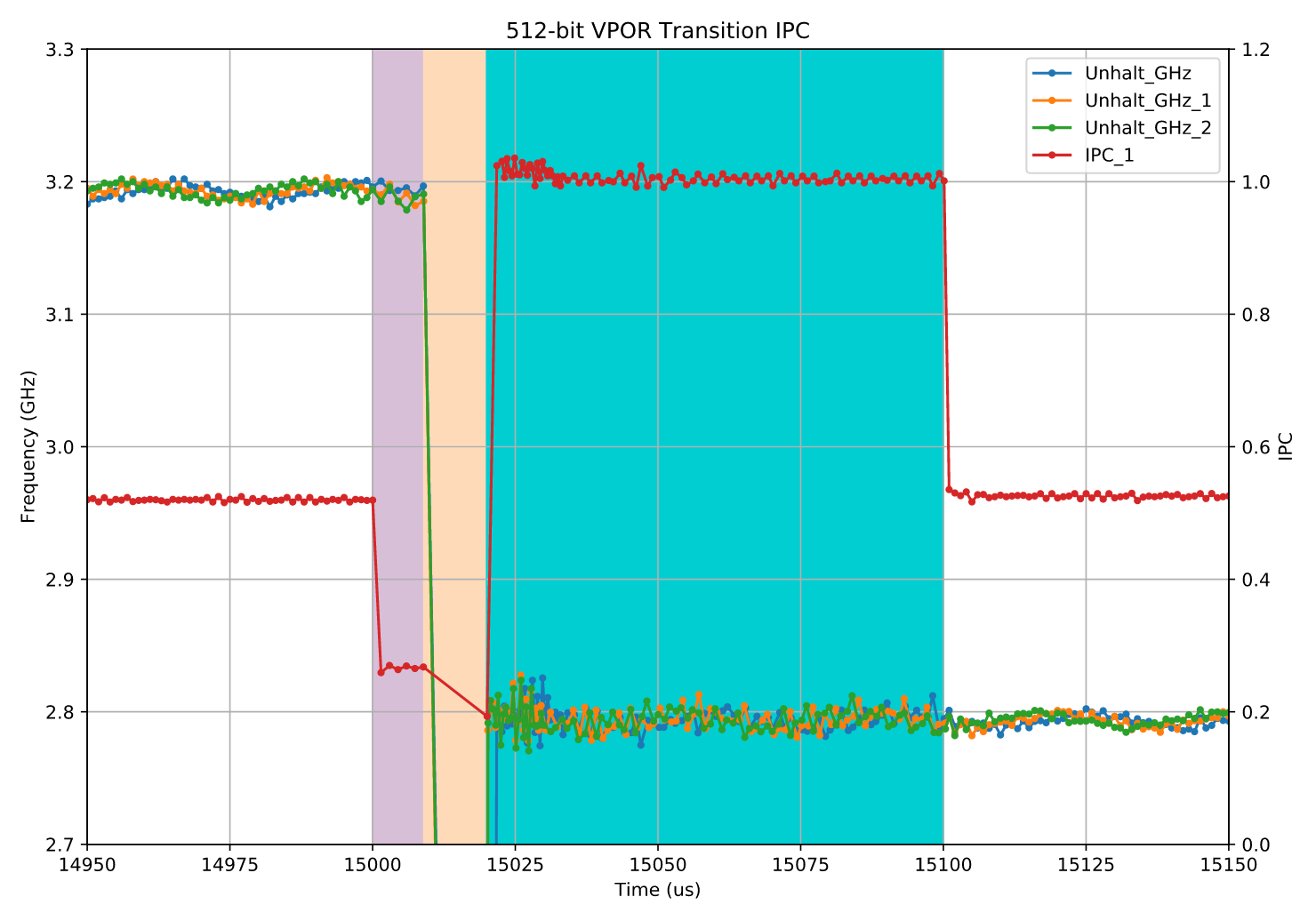
首先请注意,在左侧(15,000 微秒之前)和右侧(15,100 微秒之后)的未着色区域中,IPC 基本上没有意义:没有执行任何负载指令,因此这些位置的 IPC 只是测量代码本身的结果。我们只关心那些有着色的区域,也就是负载正在执行的部分。
让我们从右往左分析这些区域,这样的顺序恰好对应从显而易见到较不明显的部分。
我们有蓝色区域,从大约 15020 微秒延伸到 15100 微秒(也就是额外负载阶段结束的地方)。在这里,IPC 正好是每周期 1 条指令。因此,负载正以预期速率执行,也就是全速运行。细心的人可能会注意到,在蓝色区域的起始处,IPC(以及测得的频率)略显噪声,并且略高于 1。这不是 CPU 的效应,而是测量问题:在这个阶段,基准测试正在补上前一个停顿阶段遗漏的采样,这改变了负载与开销的比例,从而使 IPC 略有上升(详见注释 22)。
注释22
本测试中的采样方式可以描述为一种 “锁定间隔且不跳过(locked interval without skipping)” 的策略。 其中,“锁定间隔”指的是:我们基于 上一个目标采样时间(target sample time) 来计算下一个目标采样时间,而不是基于实际采样发生的时间。换句话说,下一个采样时间等于上一个目标时间加上采样周期。例如,当我们以 10 微秒为采样间隔时,目标采样时间始终是 10 μs、20 μs、30 μs 等。 特别地,这一系列目标采样时间与测试过程中发生的实际情况无关——它并不依赖实际采样时间。即使我们实际上在 12 μs 而不是 10 μs 处进行了采样,下一次目标采样仍然是 20 μs,而不是 12 + 10 = 22 μs。
这引出了一个问题:当某些延迟(例如中断或频率转换)导致我们错过了一个甚至多个完整采样周期时,会发生什么?例如,在 10 μs 分辨率下,我们刚刚在 90 μs 处采样,因此下一次目标采样时间是 100 μs,但由于某种延迟,下一次实际采样发生在 125 μs。此时我们“落后”了! 按照原计划,下一次采样应该在 110 μs,但那已经是过去的时间了。 当前测试的设计会尽快补上所有遗漏的采样(但在额外负载阶段至少执行一次负载函数)——这就是所谓的“不跳过(no skipping)”。 在上述例子中,意味着我们会连续快速地执行多次采样以追赶进度,例如在 125 μs(目标 110 μs)、126 μs(目标 120 μs)、130 μs(目标 130 μs)处各采样一次,最后一次采样与目标时间对齐。
这些补采样的速度很快:在正常情况下,每次采样耗时不到 0.2 μs;而在额外负载阶段,由于执行了一次负载调用,耗时会增加到大约 0.5 μs。 这正是绿色区域中发生的事情:我们刚经历了约 10 μs 的频率转换停顿,因此“落后”了约 10 个采样,于是接下来的采样会更加密集(你可以看到数据点的间距更近),每次只包含一次负载调用(而平时通常有 2 到 3 次)。 这改变了负载指令与开销指令的比例,从而使 IPC 略有上升(同样的原因也导致补偿完成后的蓝色区域中 IPC 接近甚至略高于 1)。 通过增加采样周期,可以减弱或消除这种效应,因为这会减少需要补采样的次数。
顺带一提,这也解释了蓝色区域中出现的振荡模式: 为了达到 1 μs 的采样率,理想的负载调用次数大约是 2.5 次,因此采样策略会在两次和三次调用之间交替。 调用次数更多时,IPC 趋近于 1;因此振荡曲线的“峰值”对应两次调用,而“谷值”对应三次调用。
中间的橙色区域展示了我们已经看到的情况:CPU 处于停顿状态,因此没有采样发生。IPC 在这里并不能提供太多信息。
电压转换阶段(Voltage Only Transitions)
最有趣的部分是第一个着色区域(紫色区域):在负载开始运行之后、但在停顿(halt)发生之前。我称这一段为“仅电压转换(voltage only transition)”,原因很快就会显而易见。
在这一阶段,我们可以看到负载的执行速度明显变慢,IPC 约为 0.25。 也就是说,在这一时期,指令的执行延迟似乎是平常的 4 倍。 我还通过另一种相同的测试 https://github.com/travisdowns/freq-bench/blob/434c7cf5db73e2d48061e78525c7bbf7eb7757a3/basic-impls.cpp#L64 (唯一不同的是指令之间相互独立)观察到了相同的 4 倍减速现象。
或许令人意外的是,这种减速现象同样出现在 256 位指令 上。
这与传统认知相矛盾——过去的经验认为,在支持 AVX-512 的处理器上,执行较轻量的 256 位指令(YMM 寄存器) 并不会带来额外的性能惩罚。
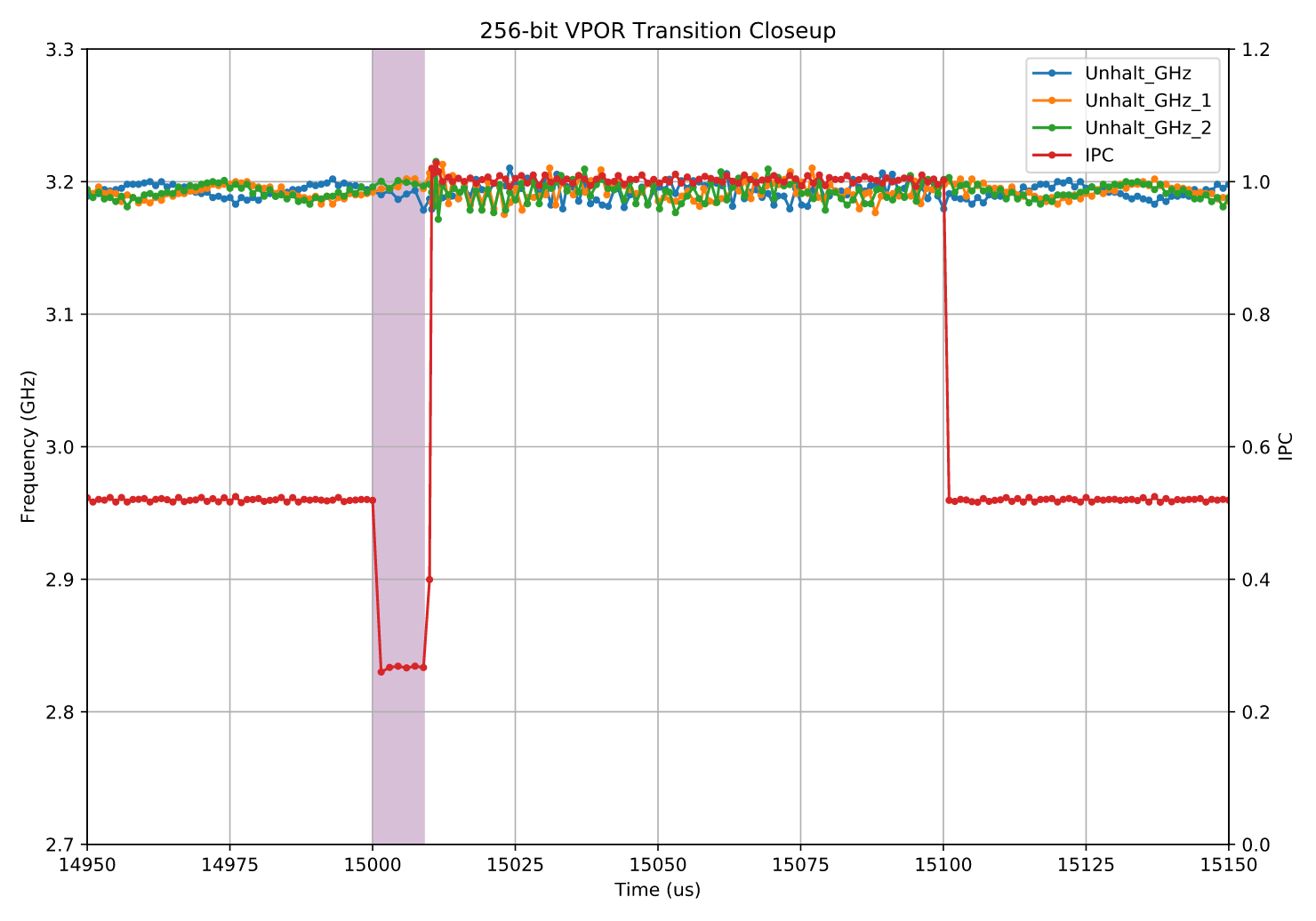
上面的结果来自一个与 512 位版本完全相同的测试,只是负载部分改为使用 256 位指令。
结果显示,在负载开始执行后的大约 9 微秒 内,同样出现了性能下降,但没有随后出现的停顿或频率转换。
也就是说,它只表现出一次仅电压转换(voltage-only transition)。 (缺少频率转换是预期中的,因为对于较轻的 256 位指令,我们并不期望出现“睿频许可等级(turbo license)”的变化。)
使用的负载指令为:
vpor ymm0, ymm0, ymm0此时你可能会好奇:那 128 位寄存器 呢? 好消息是,它们完全没有受到任何影响:
xmm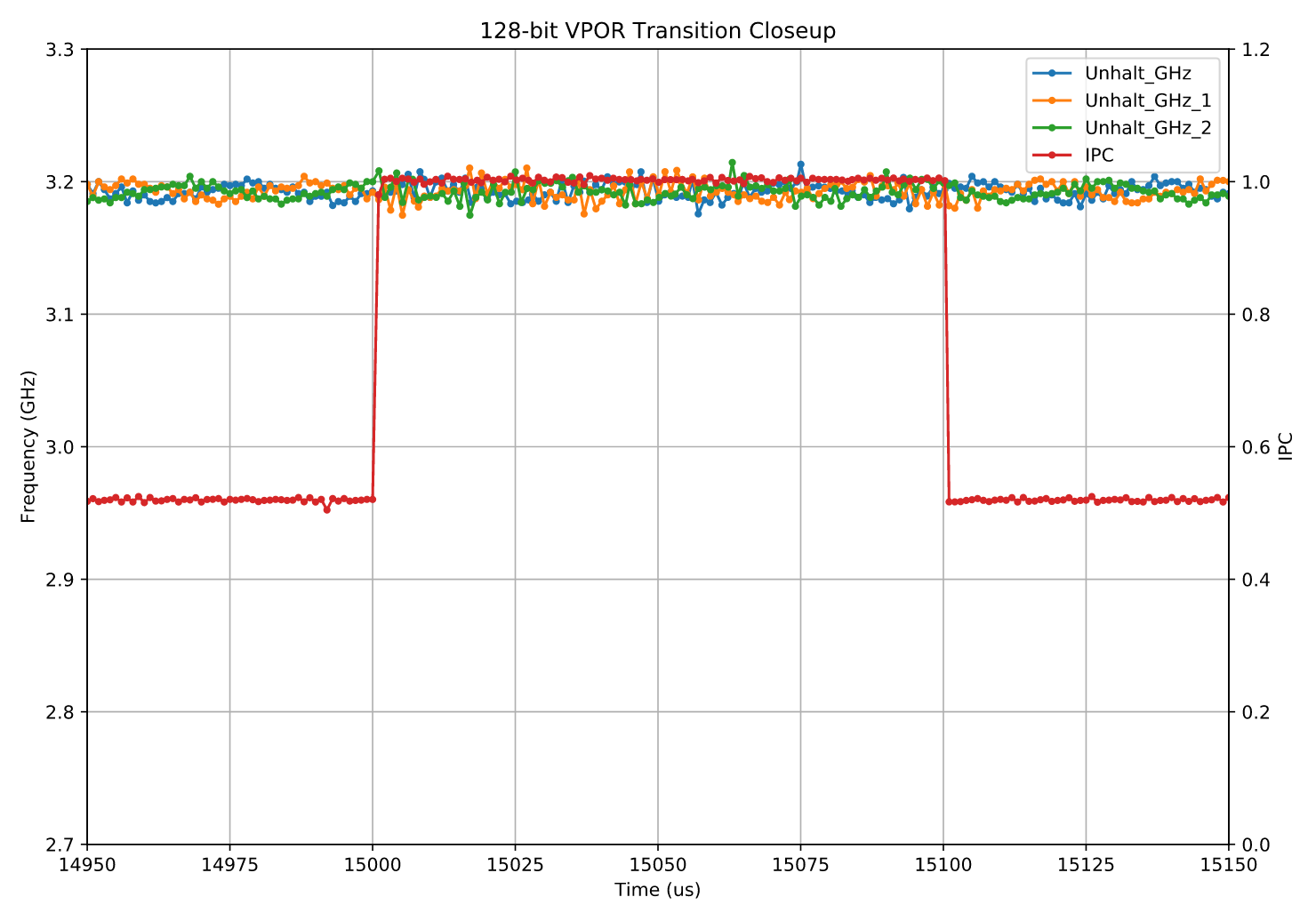
在这里,IPC 立即跳到了预期值。这表明 CPU 始终运行在一种状态下,在该状态下 128 位计算单元(lanes)始终处于就绪状态。
关于这种“预热(warmup)”阶段的传统解释是:当不使用时,向量单元的上半部分会被关闭,并且在重新启用时需要一定时间来上电。在此上电阶段,CPU 无需完全停顿,但会以降低的吞吐量执行 SIMD 指令——即将输入拆分为多个 128 位块,并将数据在已激活的 128 位单元中重复处理两次或更多次。
然而,有一些现象似乎与这种假设相矛盾(从说服力较弱到较强依次列出):
作者认为传统推测 / 最初的解释:“CPU 可能关闭了部分向量单元(上半部分),当再次使用时需要时间上电。” 可能是错误的,主要矛盾如下。
- 对延迟与吞吐量的观测影响约为 4 倍,但对于像
vpor这样简单的指令,我预期只会出现 2 倍减速。 - 这种现象在 256 位和 512 位指令 中的持续时间完全相同,尽管 512 位指令的工作量至少是 2 倍——也就是说,它们至少需要通过 128 位单元四次。
- 某些指令用这种“分割执行”方式很难实现,例如那些高、低输出部分都依赖所有输入通道的指令(如
vpermd,可参考其在 Zen 架构下的低速表现)。我原本预期这些指令在分割模式下会更慢,但测试结果显示其性能为 4L4T,而正常情况下是 3L1T。
因此(包括 512 位版本在内),vpermd并没有比vpor更慢,甚至在相对意义上减速更小(例如延迟仅从 3 增加到 4)。
延迟与吞吐量对这条指令的反应方式不同,这看起来很奇怪;而且它现在与vpor拥有完全相同的 4L4T 时序,也显得是一个奇特的巧合。 - 奇怪的是,当我尝试更精确地测量减速比例时,结果始终是 约 4.2 倍而不是 4.0 倍,这似乎与“仅仅是工作模式不同”这一解释相矛盾——因为不同模式的延迟理应是整数倍。
- 事实证明,所有 ALU 指令 在这种模式下都会变慢,而不仅仅是宽 SIMD 指令。
无论是 256 位还是 512 位指令,减速时间都一样;所有 ALU 指令(不仅仅是 SIMD)都会受影响;延迟与吞吐量都降低 4 倍,而不是 2 倍。
第五点基本可以确认,这种减速并不是由于分割执行造成的。我认为,真正发生的情况是:
当较宽的指令在核心中执行时,CPU 会进行极细粒度的限速(throttling)。也就是说,宽向量单元的上层确实在被使用(要么根本未被关闭,要么开启时间极短,不足 1 微秒),但 CPU 会将执行频率暂时降低 4 倍,因为此时供电系统尚未准备好支撑全速执行。
在 CPU 等待(例如等待电压上升、扩大安全裕度)以允许更高功耗执行的这段时间内,就会发生这种精细的限速。
作者推测的机制:当 CPU 刚开始执行宽向量指令时,功耗瞬间上升,而此时电源电压还没完全准备好支持满速运行。 为了避免超出功耗/热设计范围,CPU 会临时把内部执行频率降低 4 倍,等待电压上升、供电稳定。 这段短暂的“限速”过程,就是所谓的 voltage-only transition。
这种限速同样影响非 SIMD 指令,使它们的执行延迟和吞吐量也同时变为原来的 4 倍。
我们可以通过下面的测试来说明这一点:该测试将一条 vpor ymm0, ymm0, ymm0 指令与若干串联的 add eax, 0 指令组合在一起,这里以 N = 3 为例:
vpor ymm0, ymm0, ymm0
add eax, 0x0
add eax, 0x0
add eax, 0x0
; 重复 9 次如果只有 vpor 被减速,那么每 4 条指令(1 条 vpor + 3 条 add)应该花费 4 个周期,受限于 add 链的长度(3 个周期)。
然而,我实际测得约 12 个周期,这表明真正的瓶颈在于这条 add 链——每条 add 现在需要 4 个周期,总共 12 个周期。
结果发现不仅 SIMD 慢了,连 add 也同样慢 4 倍。 这验证了减速并非来自“指令拆分执行”,而是整个核心都在低速运行。因此,在执行宽 AVX/AVX-512 指令的前几微秒内,CPU 会为了让电压上升而主动“踩刹车”,所有指令都暂时变慢 4 倍。 等电压稳定后,CPU 再进入正常频率,开始高速运行。这解释了为什么频率尚未下降时,性能却已经变慢——那其实是 CPU 在“等电压”。
我们可以更改不同数量的 add 指令(更改N)来看看这种效应会持续多久。下面这张表格是基于此给出的:
| ADD instructions (N) | Cycles/ADD | Delta Cycles (slow) | Delta Cycles (fast) |
|---|---|---|---|
| 2 | 4.1 | 2.3 | -0.2 |
| 3 | 4.1 | 4.0 | 0.8 |
| 4 | 4.1 | 4.1 | 1.1 |
| 5 | 4.0 | 3.9 | 1.1 |
| 6 | 4.1 | 4.3 | 0.7 |
| 7 | 4.0 | 3.4 | 1.1 |
| 8 | 4.0 | 4.2 | 0.9 |
| 9 | 4.1 | 3.9 | 0.8 |
| 10 | 4.1 | 4.3 | 1.1 |
| 20 | 4.0 | 4.0 | 1.0 |
| 30 | 4.0 | 4.0 | 1.0 |
| 40 | 4.1 | 4.3 | 1.0 |
| 50 | 4.1 | 3.9 | 1.0 |
| 60 | 4.1 | 4.4 | 1.0 |
| 70 | 4.2 | 4.5 | 1.0 |
| 80 | 4.1 | 3.4 | 1.0 |
| 90 | 3.6 | -0.2 | 1.0 |
| 100 | 3.3 | 1.1 | 1.0 |
| 120 | 2.9 | 0.9 | 1.0 |
| 140 | 2.7 | 1.1 | 1.0 |
| 160 | 2.5 | 1.2 | 1.0 |
| 180 | 2.3 | 0.7 | 0.9 |
| 200 | 2.2 | 0.8 | 1.0 |
Cycles/ADD 一栏显示的是在整个慢速阶段(大约负载开始执行后前 8–10 微秒)中,每条 add 指令平均消耗的周期数。 Delta Cycles (slow) 一栏表示在慢速阶段中,相对于上一行,每增加 10 条指令所需的额外周期数。 例如,对于第 N = 30 行,它表示比第 N = 20 行多出的 10 条指令平均多花了多少个周期。 Delta Cycles (fast) 列的含义相同,只是对应于 CPU 恢复到全速运行后的采样(约在 10 微秒之后),该列显示了预期的每条新增 add 指令耗时 1.0 个周期。
从结果中我们可以清楚地看到,直到大约 70 条指令 为止,当它们与单条 vpor 指令交错执行时,所有指令都需要 4 个周期——也就是说,CPU 处于限速(throttled)状态。 在大约 80–90 条之间,发生了一次转换:新的指令开始只需 1 个周期,但整体上每条 add 的平均耗时仍接近 4 个周期。 这说明,当 add(或其他非宽 SIMD 指令)与最近的宽 SIMD 指令距离足够远时,它们就会恢复到全速执行。 因此,对更大 N 值的测量结果可以理解为一个混合过程: 前 70–80 条靠近 vpor 的指令以 1 条 / 4 周期的速度运行,而其余部分则以全速(1 条 / 1 周期)运行。
作者发现:在刚开始(N < 70)时,所有指令都需要 4 个周期,也就是说 CPU 还在“被压着跑”。当 N 逐渐增加(大概到 80~90 条
add之后),突然恢复成每条add只要 1 个周期,也就是CPU 从慢速恢复到了全速模式。而这说明:
只要普通指令离最近的宽 SIMD 指令(vpor)足够“远”,CPU 就不再认为系统处于高功耗状态,从而退出限速。换句话说,CPU 会检查自己当前的指令窗口(比如 Skylake 的 IDQ 大约 64 项,调度器约 97 项)中是否仍然有“宽指令”。如果有,就维持限速;如果没有,就恢复全速。
我们可以推断,CPU 的行为并不仅仅是降低频率或占空比执行(duty cycling)。 如果是那种机制,所有指令都会被按相同比例减速;
但实际情况更像是:指令延迟被扩展到下一个 4 的倍数,例如一条原本延迟为 3 个周期的 imul eax, eax, 0 指令,在限速状态下会被延长到 4 个周期。
因此,更可能的解释是限速发生在执行之前的某个管线阶段,比如指令发射(issue)或调度(dispatch)阶段。
当指令间距足够大时,系统恢复到高速模式,这种行为可能反映了某个硬件结构的大小限制,例如 IDQ(Skylake 架构中为 64 项) 或 调度器(据称为 97 项)。 核心可能会追踪这些结构中是否存在任何宽指令,如果有,就强制进入慢速模式。 当这些宽指令彼此靠得很近时,始终会至少有一条留在结构中,从而维持低速模式; 而当它们之间的间距足够大时,就会出现一些短暂的高速执行窗口。
作者推测出新的降频的机制:
这种限速并不是通过降低主频(DVFS)或周期占空比(duty cycling)实现的。 因为那样会让所有指令都按比例变慢。 而现在的现象是:延迟被“对齐”到了 4 的倍数。
举例来说:
imul eax, eax, 0这类本来延迟 3 个周期的指令,在限速模式下变成 4 个周期。 这说明限速机制可能发生在指令发射(issue)或调度(dispatch)阶段——也就是 CPU 暂时放慢了派发节奏,而不是改变时钟。因此:CPU 在执行宽 AVX/AVX-512 指令后,会临时放慢整个核心的发射速率(相当于 pipeline 降速),直到宽指令完全“退场”;
电压效应(Voltage Effects)
我们实际上可以验证这样一个理论:
这个转换过程是否与等待电源供给配置变化有关。
具体来说,我们可以通过读取 MSR_PERF_STATUS 寄存器的 第 47 到 32 位 来观察 CPU 内核电压。 Intel《软件开发手册》(Software Development Manual)第 4 卷中透露了一个“秘密”:
这些位(bits 47:32)实际上暴露了 CPU 核心电压的数值。
让我们像往常一样放大观察一个转换点。这次我们使用的是一个包含 1000 条相关依赖指令 的 256 位(ymm)负载。 这种 256 位负载的情况不会触发频率转换,而只会出现一种与重新执行 256 位指令相关的调度限速阶段(dispatch throttling period)——也就是在 CPU 很久没有执行 256 位指令之后再次执行时出现的现象。
我们在图中同时绘制了两条曲线: 一条表示执行一次负载迭代所需的时间, 另一条则表示测得的核心电压。 负载指令如下:
vpor ymm0, ymm0, ymm0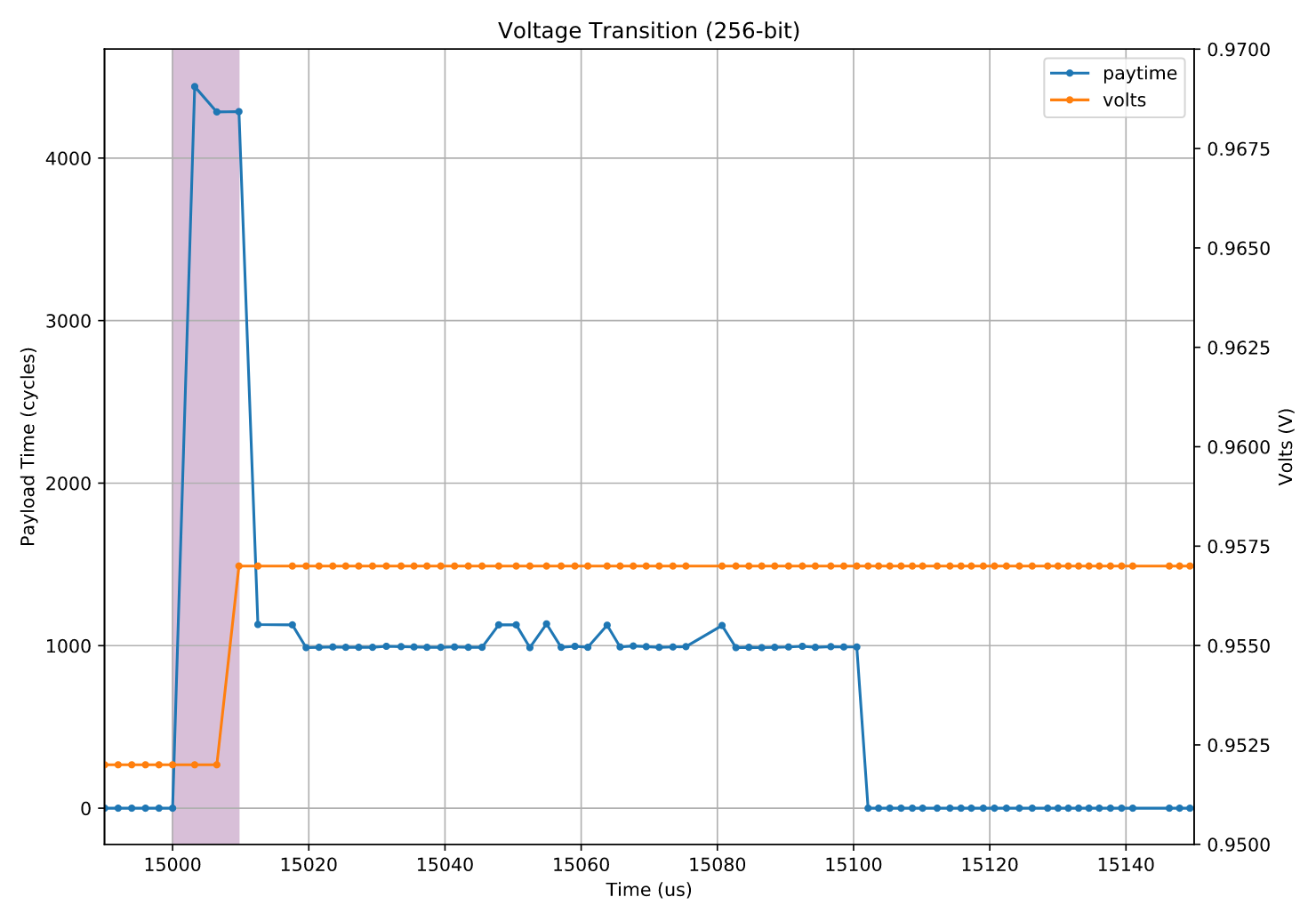
限速阶段(throttling period)的持续时间大约为 10 微秒,与以往一样。 从图中可以看出,在这一阶段中,负载执行一次迭代大约需要 4000 个周期,也就是典型的 4 倍限速现象。 在限速阶段内,CPU 的电压与转换前保持一致,约为 0.951 V。 当限速结束的那一刻,电压跃升至大约 0.957 V,即上升约 6 mV。
这组数据是在 2.6 GHz 下(即我的 i7-6700HQ 的标称非睿频频率)测得的。 当频率为 3.5 GHz 时,电压从 1.167 V 上升到 1.182 V, 因此无论是电压的绝对值还是电压变化幅度(约 15 mV)都更大, 这与基本原理一致:更高的频率需要更高的电压。
因此,其中一种理论是:
这种类型的转换代表着这样一个阶段—— CPU 已经请求提高供电电压(因为更宽的 256 位指令意味着更大的电流跃变,从而更严重的电压跌落风险), 而核心正在等待更高电压真正到位。 在等待过程中,CPU 启动了限速(throttling), 以减小最坏情况下的电压跌落。 如果不采取限速措施,就无法保证在一连串宽 SIMD 指令突发执行时,电压不会跌破该频率下安全运行所需的最低电压。
在这段workload里,CPU 在执行宽 SIMD 指令时,会暂时进入约 10 微秒的“限速”阶段。 这段时间里电压尚未升高,CPU 以 4 倍延迟运行,以等待更高电压到位。 等电压上升稳定后,CPU 恢复正常速度,从而避免突发功耗导致的电压跌落。
衰减(Attenuation)
这里作者的衰减指的是,当频率切换太频繁时,CPU 的电源管理系统会干脆保持在较低频率运行,以避免反复上下切换带来的性能损耗(因为每次转换都需要几微秒的停顿)。这类似于 CPU 在频繁切换活跃核心数量时的策略。为此,作者设计了一个实验:把工作周期(duty period)设为略长于 CPU 从低频恢复到高频所需的时间(760 μs),看看在这种情况下,CPU 是否仍然会触发频率转换,借此判断是否出现这种“转换衰减”效应。
我们可以检查是否存在任何类型的转换衰减(attenuation)。 这里的“衰减”指的是这样一种情况:
如果某个核心的频率转换发生得太频繁,电源管理算法可能会决定直接让核心保持在较低频率运行。 这样做在整体上可能获得更好的性能,因为频繁的上下转换会带来额外的停顿时间(halt period),抵消掉高频带来的收益。
这种现象实际上确实发生在活跃核心数量变化的情况下:
如果在短时间内多次发生核心数量转换(例如在 1 核涡轮频率与 2 核涡轮频率之间频繁切换),
CPU 就会选择直接以较低频率运行, 从而避免频繁切换时所需的停顿。
为了验证是否存在这种“衰减”,
我们设置了一个工作周期(duty period),略长于 CPU 从 2.8 GHz 恢复到 3.2 GHz 所需的观测恢复时间, 以观察此时是否仍然会发生频率转换。 下面展示的是一个 760 微秒 的工作周期,比该测试中观测到的恢复时间多约 10 微秒。
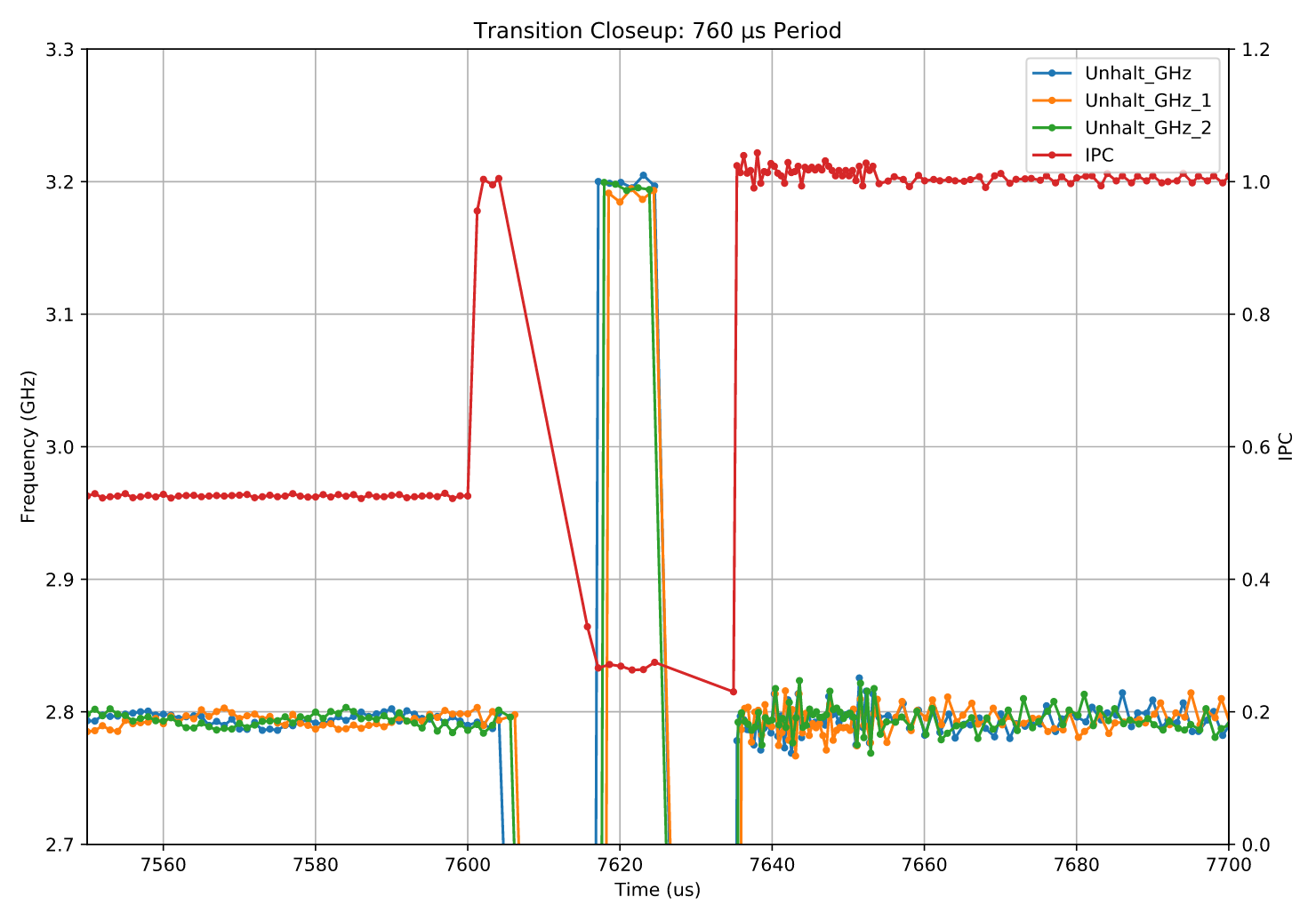
我这次不再为各个区域上色了,因为到现在为止,你们大概已经(过度?)熟悉它们了。
关键点如下:
- 负载在 7600 微秒 时开始执行,此时还没有发生向上的频率转换,我们仍在 2.8 GHz 下运行——因此一开始 IPC 很高,约为每周期 1 条指令。
- 尽管此时我们已经再次执行 512 位指令,但频率在几微秒后才上升。最可能的情况是:电源管理逻辑在更早的时候(大约在 7558 μs,也就是负载启动之前)就已经评估出需要进行一次升频转换,但正如我们之前看到的,响应通常会延迟 8 到 10 微秒,因此转换发生在负载开始执行之后。
- 当然,一旦频率转换发生,核心就不再处于适合全速宽 SIMD 执行的状态,因此 IPC 会下降到大约 0.25。
- 约 10 微秒后再次发生向低频的转换,然后才能恢复全速执行。
因此,可以看到并不存在衰减(attenuation),但实际上也不需要衰减:因为在最后一条宽指令和下一次升频之间有大约 650 微秒的冷却期(cooldown period),转换带来的停顿损耗非常有限。
这与“活跃核心数量”变化的情况不同,后者的转换频率由中断或线程调度驱动,CPU 无法控制。
在这里,我们构造的是最糟糕的情况——频率转换尽可能紧密地排列在一起——但整个 760 微秒周期中,两次转换总共只损失了约 20 微秒,影响不到 3%。 相比之下,长期保持在低频运行的代价要大得多:2.8 GHz 对比 3.2 GHz,相差 12.5%;如果降低频率对负载没有帮助(例如宽 SIMD 指令在总工作中只占极小比例),那反而会造成更大性能损失。
遗留的问题 (What Was Left Out)
还有许多我们没有讨论的内容。我们甚至尚未涉及以下几点:
- 检查在长时间未使用的情况下,xmm 寄存器(128 位) 是否也会触发“仅电压转换(voltage-only transition)”。 我们没有发现任何这样的效应,但也可以确定,在测量循环中出现了一些 128 位指令,这可能掩盖了这种现象。
- 检查由 256 位指令 引起的“仅电压转换”是否与 512 位指令 的相互独立。 也就是说,如果在一段时间没有执行任何宽指令后执行一条 256 位指令,会触发电压转换(上文已确认)。 那么,如果在放松期(relaxation period)尚未结束前,又执行了一条 512 位指令,是否会在频率转换前再经历一个新的限速阶段? 我认为答案是“会”,但我还没有验证。
- 任何关于“重型(heavy)” 256 位或 512 位指令的研究。 这些指令需要比轻量(light)指令更高一级(数字上)的许可级别(license),如果能了解这些指令下关键时间参数是否有所不同,将会非常有趣。
- 几乎没有研究这些时间(包括电压变化幅度)如何随频率变化。 例如,如果我们本身就在较低频率下运行,可能就不再需要频率转换,而“仅电压转换”的持续时间也可能会更短。
总结(Summary)
为了照顾那些直接跳到最后看,或者在中途已经神游的读者,这里总结一下主要发现:
- 当处理器大约 680 微秒 没有使用 AVX 的高位部分(255:128)或 AVX-512 的高位部分(511:256)后,再次使用这些位时,处理器会进入一种模式,在这种模式下至少需要一次电压转换(voltage transition),有时还需要频率转换(frequency transition)。
- 在电压转换期间,处理器仍会执行指令,但速度大大降低:指令发射速率仅为平时的 1/4。不过,这种限速是细粒度的(fine-grained)——只在宽指令正在执行(in flight)时才会发生。
- 电压转换会在电压上升到目标水平时结束;持续时间取决于转换幅度,但在我测试的硬件上通常为 8 到 20 微秒。
- 在某些情况下,还需要进行频率转换,例如因为相关指令需要更高的功率许可等级(power license)。 这类转换通常会先经历一个类似于电压转换的限速阶段,随后进入一个 8 到 10 微秒 的完全停顿阶段,以完成频率变化。
- 撰写本文的一个主要动机,是希望能提供一些具体且定性的指导,帮助开发者在了解这些行为的前提下编写尽可能高效的代码。 不过,这部分内容被推迟到第二篇文章中。
下面是GPT总结的:
- 宽 SIMD 指令(AVX、AVX-512)会触发电压和频率变化。
当 CPU 长时间未使用高位 SIMD 寄存器后,再次执行这些指令时,会先经历一次“电压转换”,有时还会进一步触发“频率转换”。 - 电压转换期间 CPU 不停,但速度变慢约 4 倍。
在等待电压升高的这段时间,所有指令(不仅是 SIMD)都以 1/4 的速率执行,这是一种细粒度限速机制。 - 频率转换需要完全停顿。
频率切换阶段 CPU 会暂停约 8–10 微秒;电压转换通常耗时 8–20 微秒。 - 恢复到正常状态需要约 680 微秒。
在此期间,CPU 会逐渐回到低功耗许可状态。
处于“电压转换阶段”时:
- CPU 频率还没真正降低,但为了避免电压骤降,CPU 会主动降低发射速率。 这种限速是 全局的(core-wide),并不是只针对 AVX 指令。因此,哪怕你此时执行的是普通标量指令(例如
add、imul),它们也会被拖慢,大约变成平时的 1/4 速度。
进入“频率转换阶段”后
- 在频率转换 Frequency transition 阶段,CPU 完全停顿 8–10 µs,等待频率切换完成;这段时间内 无论是什么指令,都不会执行。之后,整个核心以新的(更低的)频率恢复运行。所以在频率转换之后,所有指令(包括普通的)都在更低频率下执行。
这就是为什么在 AVX 密集代码和标量代码混用时,会出现“整段程序性能下降”的原因——因为 CPU 以“核心”为粒度执行电源管理,而不是针对单条指令。
我们还将关键的时间参数总结在下表中:
| 项目 | 时间 | 描述 | 备注 |
|---|---|---|---|
| 电压转换(Voltage Transition) | ~8–20 μs | 电压转换所需时间,取决于频率 | 38 |
| 频率转换(Frequency Transition) | ~10 μs | 频率转换中停顿阶段的持续时间 | 39 |
| 松弛期(Relaxation Period) | ~680 μs | 从最后一条高功率许可指令执行完毕到恢复为低功率许可所需时间 | 40 |
备注38: 我给出的 8 到 20 微秒 范围是基于我自己的测试结果;我测到的“仅电压转换(voltage-only transition)”最高频率为 3.5 GHz,对应的电压变化约 15 mV。 在更高频率或更高电压下,这个时间可能会更长。 此外,它也可能取决于硬件特性,例如系统中是否存在 FIVR(Fully Integrated Voltage Regulator,全集成电压调节器)。
备注39: 这种转换时间似乎是任何频率转换(无论升频还是降频、无论原因) 都需要的,包括本文未测试的情况: 例如,当最大睿频倍频因活跃核心数变化而调整时,或当理想频率因其他原因改变时,也需要类似的时间。
备注40: 同样的“松弛期(relaxation period)”似乎同时适用于本文讨论的两种转换类型(即电压转换与频率转换)。 每当执行了一条需要当前许可级别(license)的指令时,松弛计时器就会被重置。
在本例中,680 微秒的周期是从触发转换的那条指令(它也是唯一的负载指令)开始计时,直到 CPU 再次以高频率恢复执行为止。 这个周期包含一次调度限速阶段和两次频率转换,因此在整个 680 微秒中,约有 650 微秒 是以全速执行指令的。
致谢(Thanks)
感谢 Daniel Lemire,他提供了我用于测试的 AVX-512 系统的访问权限。
感谢 RWT 的 David Kanter,我们就现代芯片中的功率与电压管理进行了富有成果的讨论。
感谢 RWT 论坛成员 anon³、Ray、Etienne、Ricardo B、Foyle 和 Tim McCaffrey,
他们为本文提供了反馈,并帮助我理解了近代 Intel 芯片的电压调节(VR)架构。
感谢 Alexander Monakov、Kharzette 和 Justin Lebar 指出了文中的错别字。
感谢 Jeff Smith 向我讲解了扩频时钟(spread spectrum clocking)的相关知识。
讨论(Discuss)
本篇文章的讨论可见于 Hacker News、Twitter 和 lobste.rs。
也欢迎读者通过 电子邮件 或 GitHub issue 提出直接反馈。
如果你喜欢这篇文章,可以访问作者的主页,那里还有更多类似内容。 https://travisdowns.github.io/blog/2020/08/19/icl-avx512-freq.html