
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
- High Performance Computing
- 2025-06-16
- 557 Views
- 0 Comments
- 485 Words
模型并行性通常被视为一种将单个大型深度学习模型扩展到单个设备内存限制之外的方法。在本文中,我们证明了在为多个模型提供服务时,模型并行还可以用于多个设备的统计多路复用,即使单个模型可以适应单个设备。我们的工作揭示了模型并行性引入的开销与利用统计多路复用来减少突发工作负载下服务延迟的机会之间的基本权衡。我们探索了新的权衡空间,并提出了一种新的服务系统 AlpaServe,它确定了在分布式集群中放置和并行化大型深度学习模型集合的有效策略。对生产工作负载的评估结果表明,AlpaServe 可以以高达 10× 的速率或 6× 的突发性处理请求,同时超过 99% 的请求保持在延迟约束范围内。
OSDI23
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving | USENIX
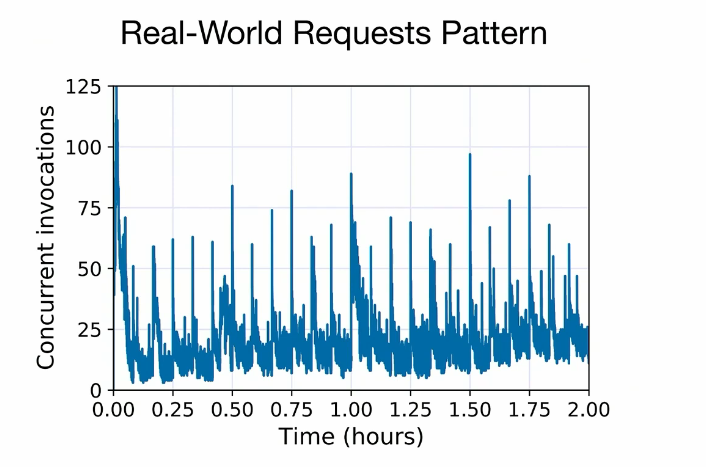
Serving 成本其实更高
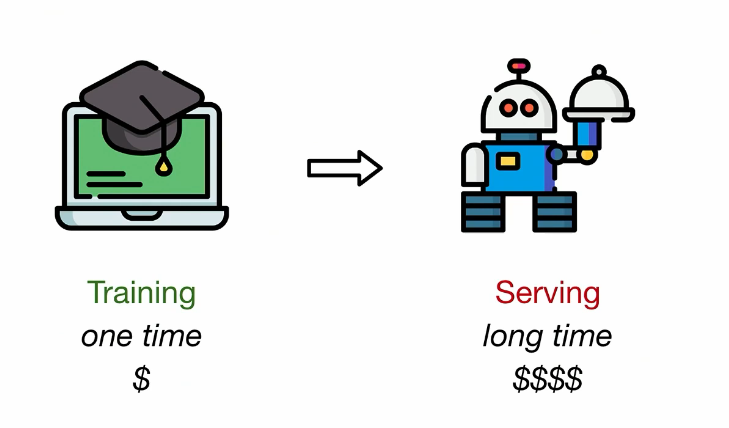
Serving DL models
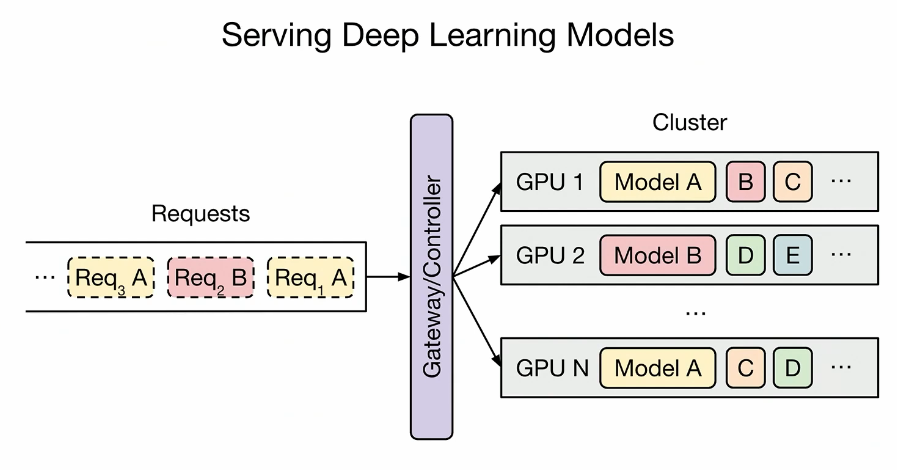
Real world request pattern
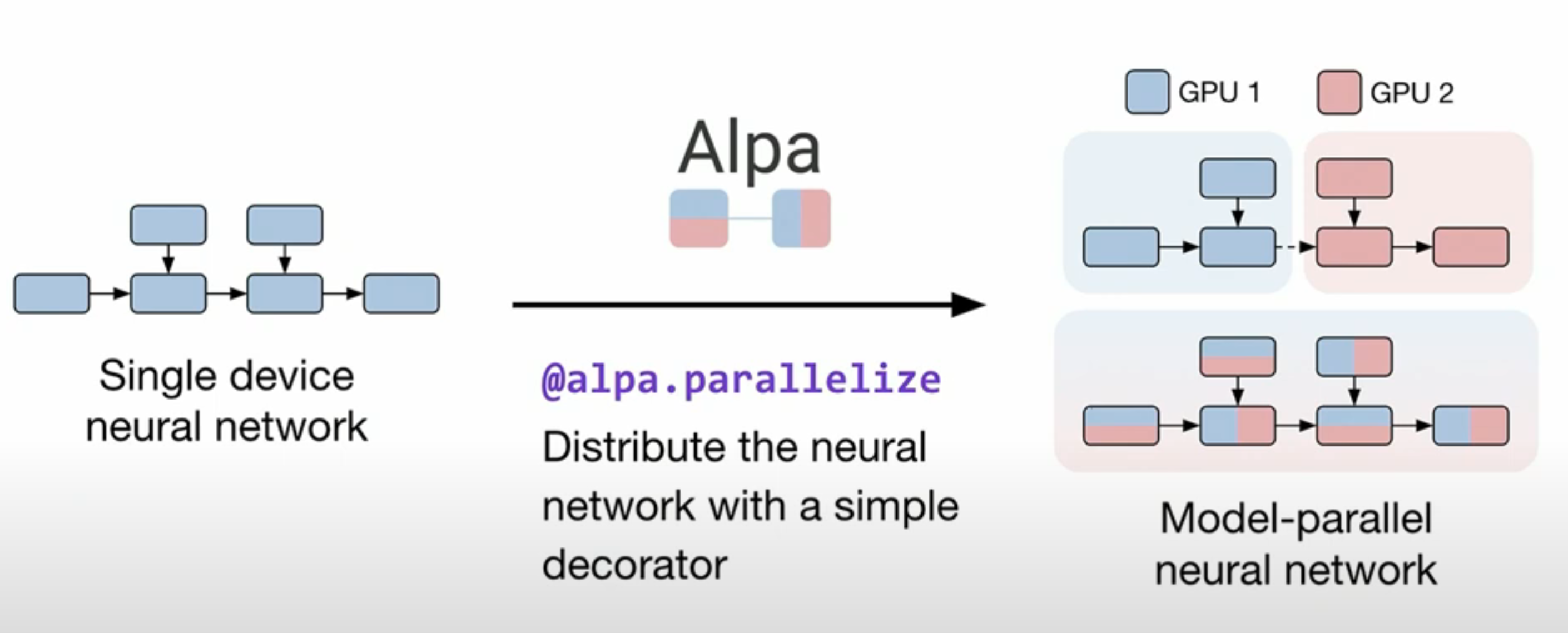
So, model parallelism
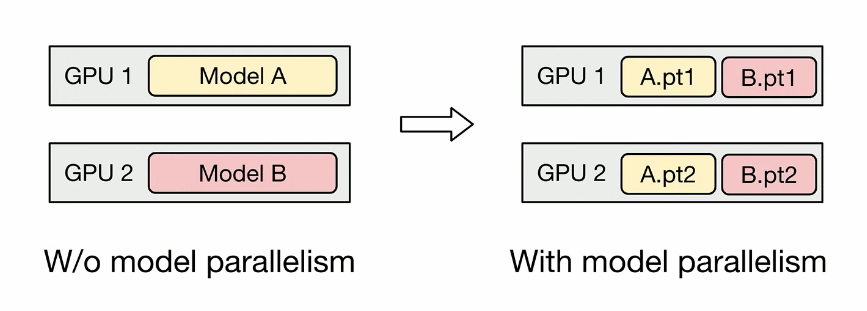
拼好G的好处:
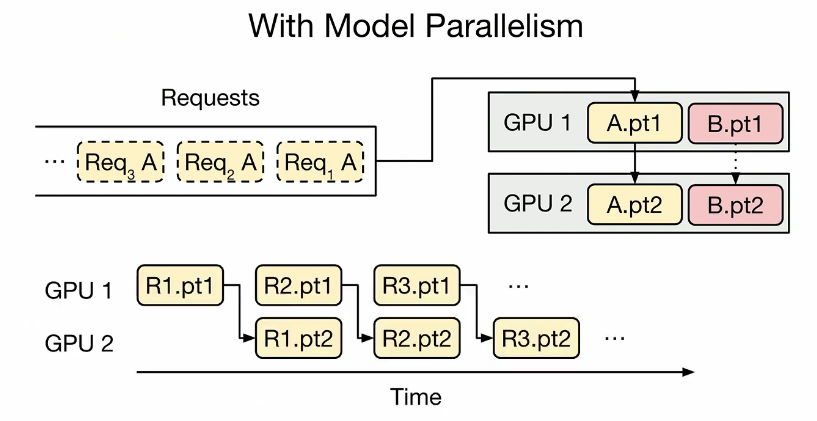
100% utilization of GPU

Model parallelism gains benefits:
Example Cluster Utilization:
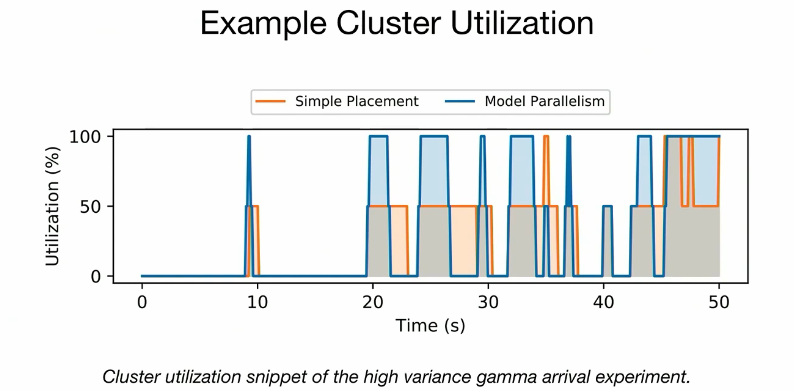
So you can see that utilization comes up!
But, we need 100GPU except from 2 GPU
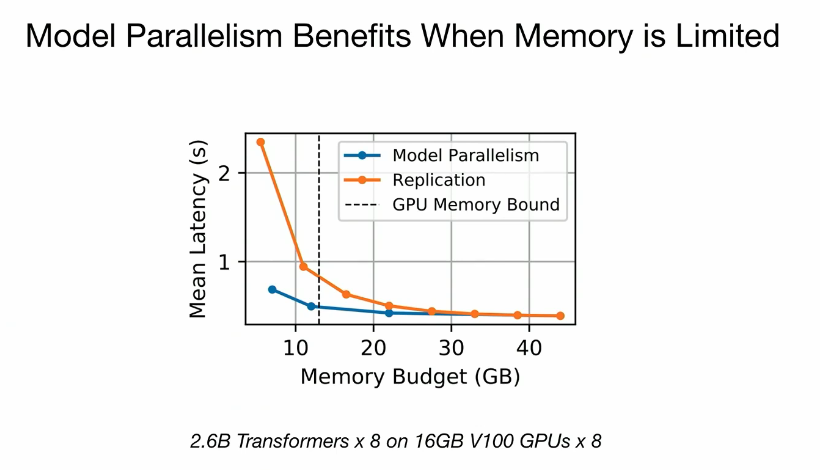
拼好GPU的好处

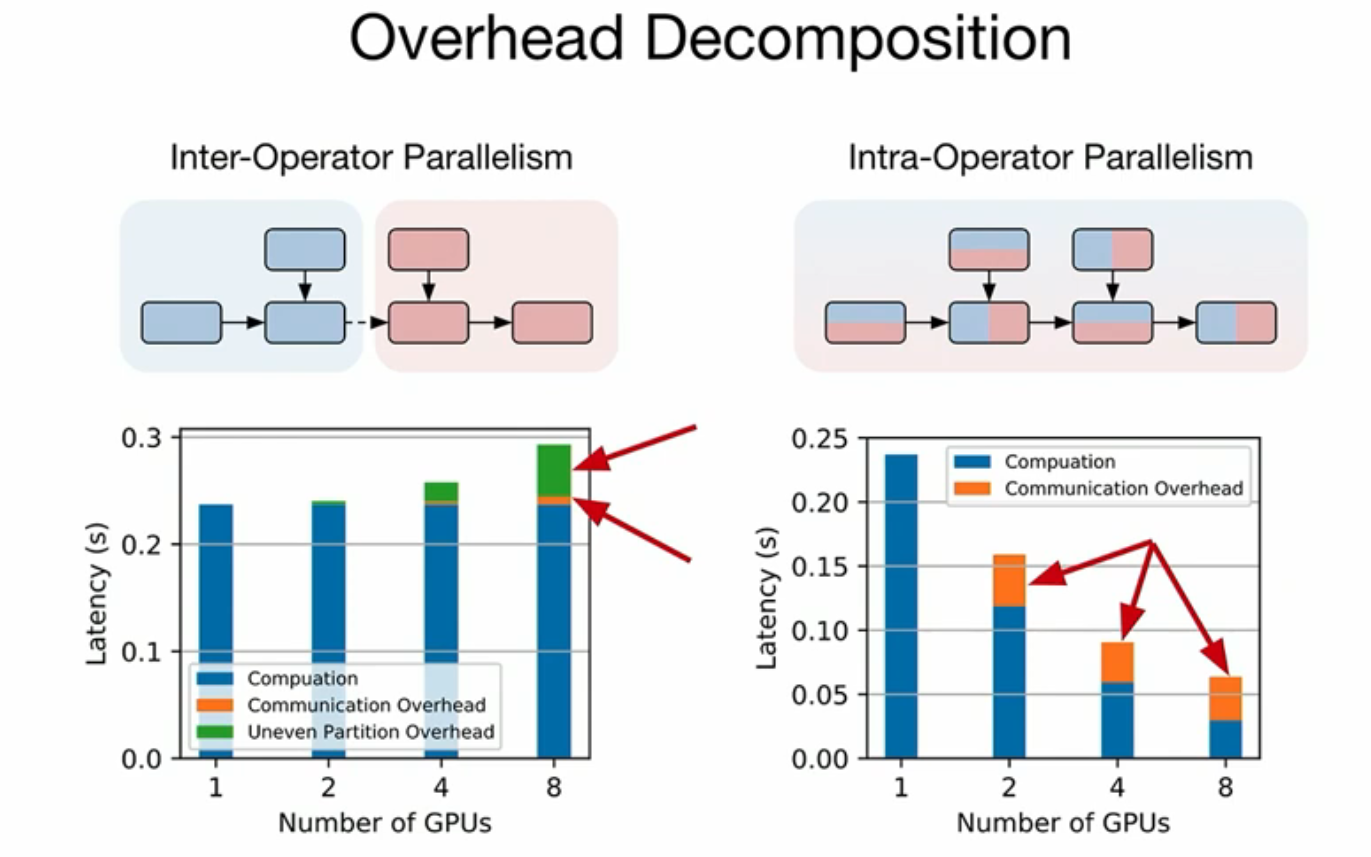
Decomposition


3D
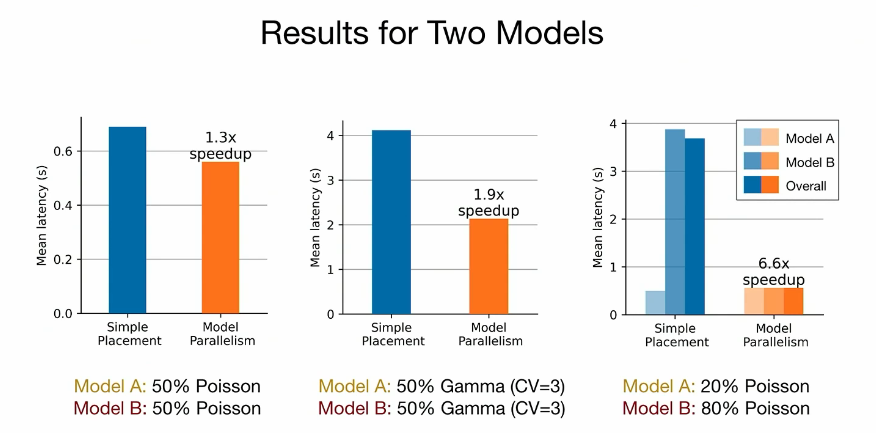
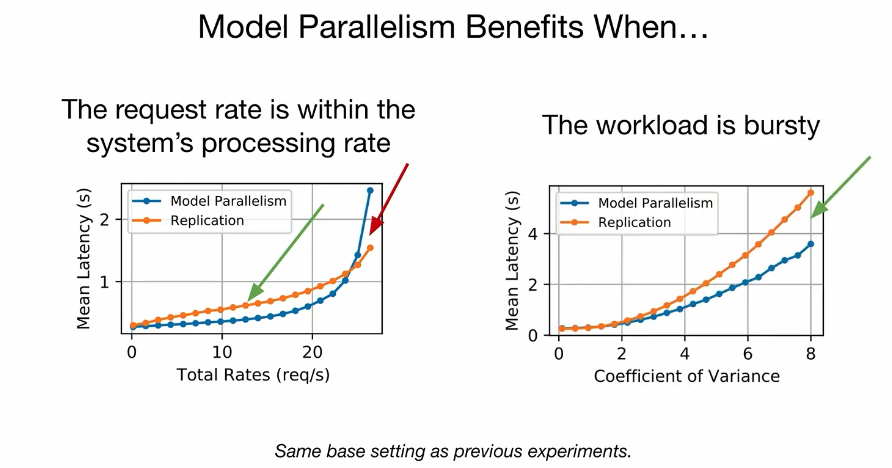
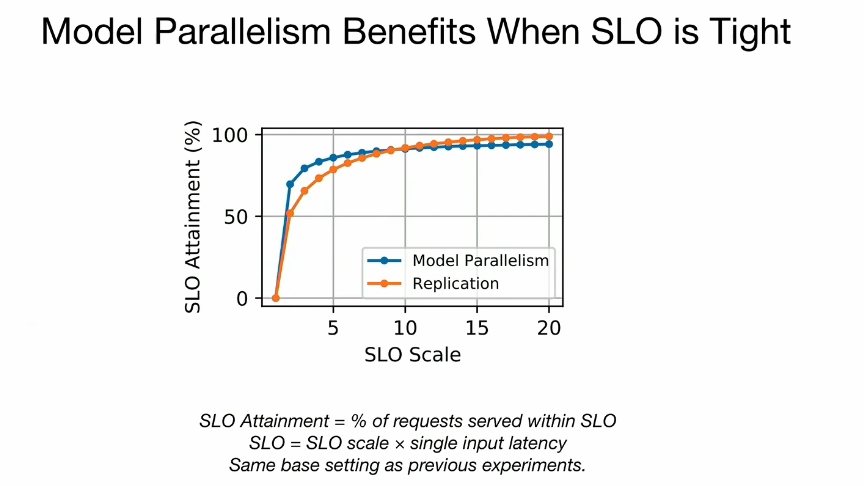
how to navigate this 3D? 当设备内存有限、请求率低、请求CV高或SLO要求严格时,模型并行通过统计复用可以提高模型服务的性能。(OSDI 2023论文评述 Day3 - 知乎)

alpha serve
AlpaServe,利用一个Controller将请求分派到不同的组中。
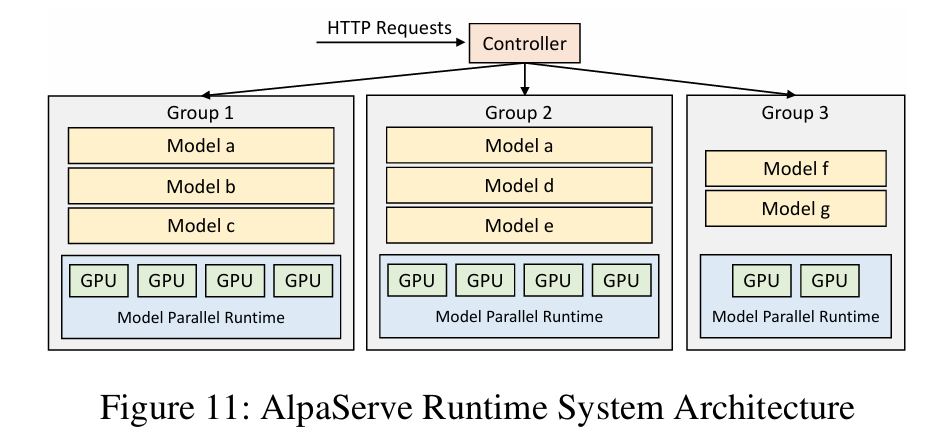

- Generate many strategies
- placement algo
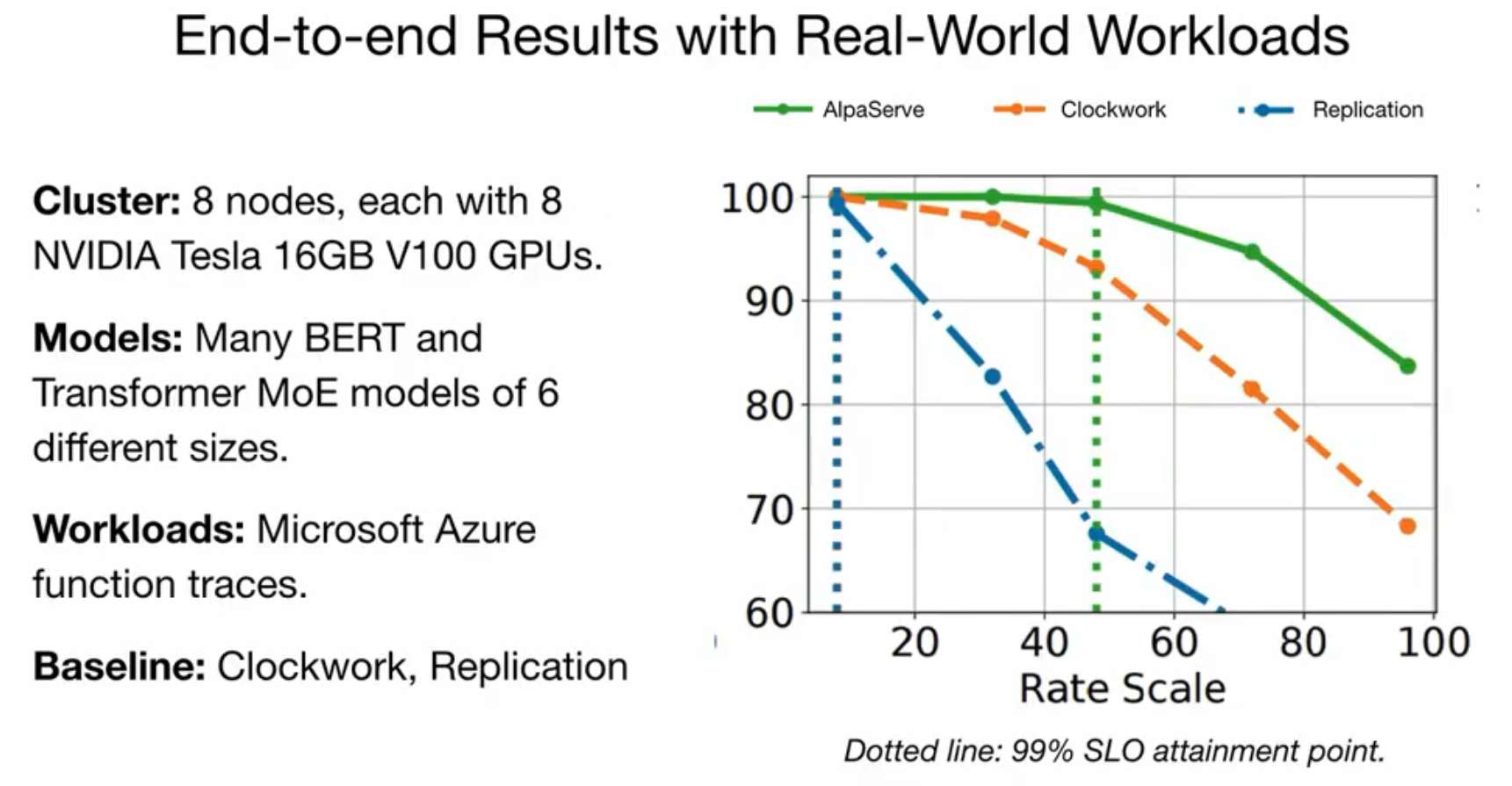
模拟器
这篇文章用一个真实系统+模拟器来做的实验。真实系统用于部署,然后看看用时。模拟器是用来看看调度策略和用时的,给你一个大概的估摸(也就是调度是可以数学建模出来的)
MIGER: Integrating Multi-Instance GPU and Multi-Process Service for Deep Learning Clusters 的实验也是由类似的组成部分,搭建了一个模拟器来查看效果