
SC 24 brief Summary 1
- Paper Reading
- 2024-11-18
- 2647 Views
- 1 Comments
- 5807 Words
SC 24 Passage
My summary and understanding of the papers presented at the SC24 conference.

总链接:
https://www.haibinlaiblog.top/index.php/sc-2024-passage/
Jensen Huang NVIDIA speech
主题:NVIDIA GPU的历史、目前进展与突破,在CFD、蛋白质等科学计算、LLM AI训练中的应用

发布:
CuPyNumeric GPU版本的Numpy
Blackwell与下一代NVIDIA GPU
SpectrumX 以太网系统: 通信,在X最新超算Colossus中部署
NIM微服务;DiffDoc 2.0 预测药物与靶蛋白相互作用
Quantum Computing 量子计算模拟
关键词:
AI、Scaling Law、GPU
Video Link:
[(12) NVIDIA SC24 Special Address - YouTube](https://www.youtube.com/watch?v=eKzNKxWUeCE
中文字幕
【科技前沿】11月19日,黄仁勋英伟达(NVIDIA)SC24特别讲话_哔哩哔哩_bilibili
Test of time award
SC04
GPU Cluster for High Performance Computing
Zhe Fan, Feng Qiu, Arie Kaufman, Suzanne Yoakum-Stover
we propose to use a cluster of GPUs for high perfor mance scientific computing. As an example application, we have developed a parallel flow simulation using the lattice Boltzmann model (LBM) on a GPU cluster and have sim ulated the dispersion of airborne contaminants in the Times Square area of New York City. Using 30 GPU nodes, our simulation can compute a 480x400x80 LBM in 0.31 sec ond/step, a speed which is 4.6 times faster than that of our CPUcluster implementation.
IEEE Xplore Full-Text PDF:
英伟达评价:开启了HPC+GPU for Science
戈登贝尔奖 Gordon Bell Prize
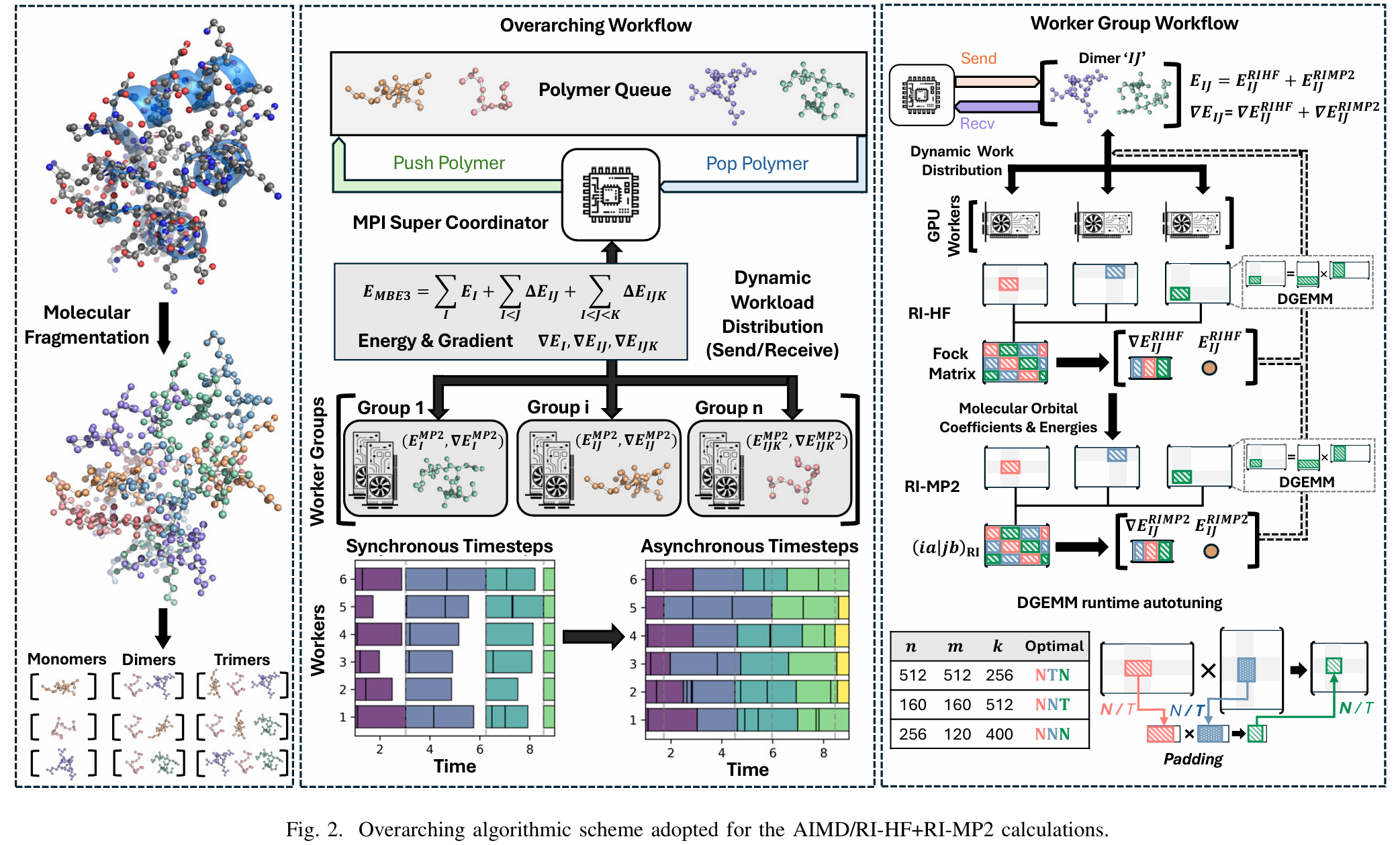
2024 ACM Gordon Bell Prize Awarded to International Team for Record-Breaking Algorithm to Advance Understanding of Chemistry and Biology
“戈登·贝尔奖”是国际高性能计算应用领域最高奖,设立于1987年,由美国计算机协会颁发,被誉为“超级计算应用领域的诺贝尔奖”。 每年颁发一次,奖金1万美元,由戈登·贝尔提供。
paper: SC41406.2024.00015
Breaking the Million-Electron and 1 EFLOP/s Barriers: Biomolecular-Scale Ab Initio Molecular Dynamics Using MP2 Potentials
相关采访
yt采访(Cerebras Company) https://www.youtube.com/watch?v=1-hXBSfxXVE
Energy and Carbon-Efficient Architectures
Energy and Carbon-Efficient Architectures
M3XU
M3XU: Achieving High-Precision and Complex Matrix Multiplication with Low-Precision MXUs
利用低精度 MXU 实现高精度复杂矩阵乘法
2024SC-M3XU.pdf
This paper presents M3XU, multi-mode matrix processing units that support IEEE 754 single-precision and complex 32 bit floating-point numbers. M3XU does not rely on more precise but costly multipliers. Instead, M3XU proposes a multi-step approach that extends existing MXUs for AI/ML workloads. The resulting M3XU can seamlessly upgrade existing systems without programmers’ efforts and maintain the bandwidth demand of existing memory subsystems. This paper evaluates M3XU with full-system emulation and hardware synthesis. M3XU can achieve a 3.64× speedup for 32-bit matrix multiplications and 3.51× speedup for complex number operations on average compared with conventional vector processing units.
本文介绍了 M3XU,一种支持 IEEE 754 单精度和复数 32 位浮点数的多模式矩阵处理单元。 M3XU 不依赖于更精确但成本更高的乘法器。相反,M3XU 提出了一种多步骤方法,可扩展现有 MXU 的 AI/ML 工作负载。由此产生的 M3XU 可以无缝升级现有系统,无需程序员的努力,并维持现有内存子系统的带宽需求。本文通过全系统仿真和硬件综合来评估 M3XU。与传统矢量处理单元相比,M3XU 的 32 位矩阵乘法平均可实现 3.64 倍加速,复数运算平均可实现 3.51 倍加速。
Matrix multiplication units(MXU)是专门设计来加速矩阵乘法计算的硬件模块,出现在TPU、TensorCore中。
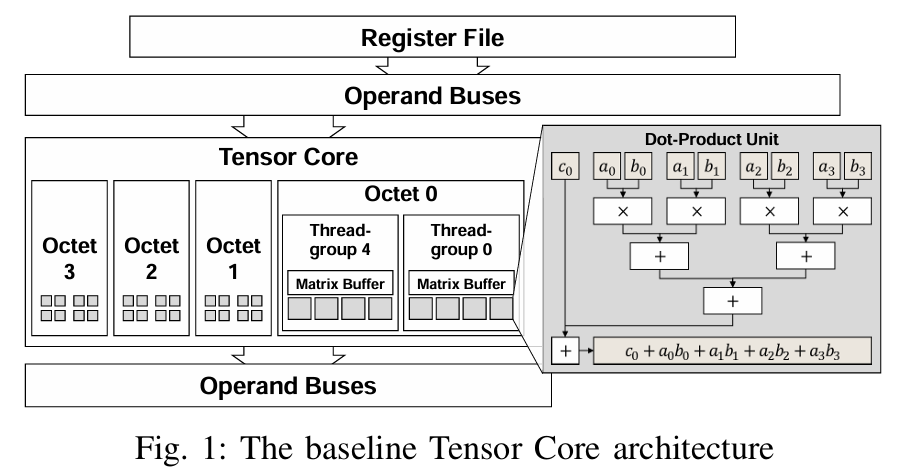
图:Tensor Core 架构
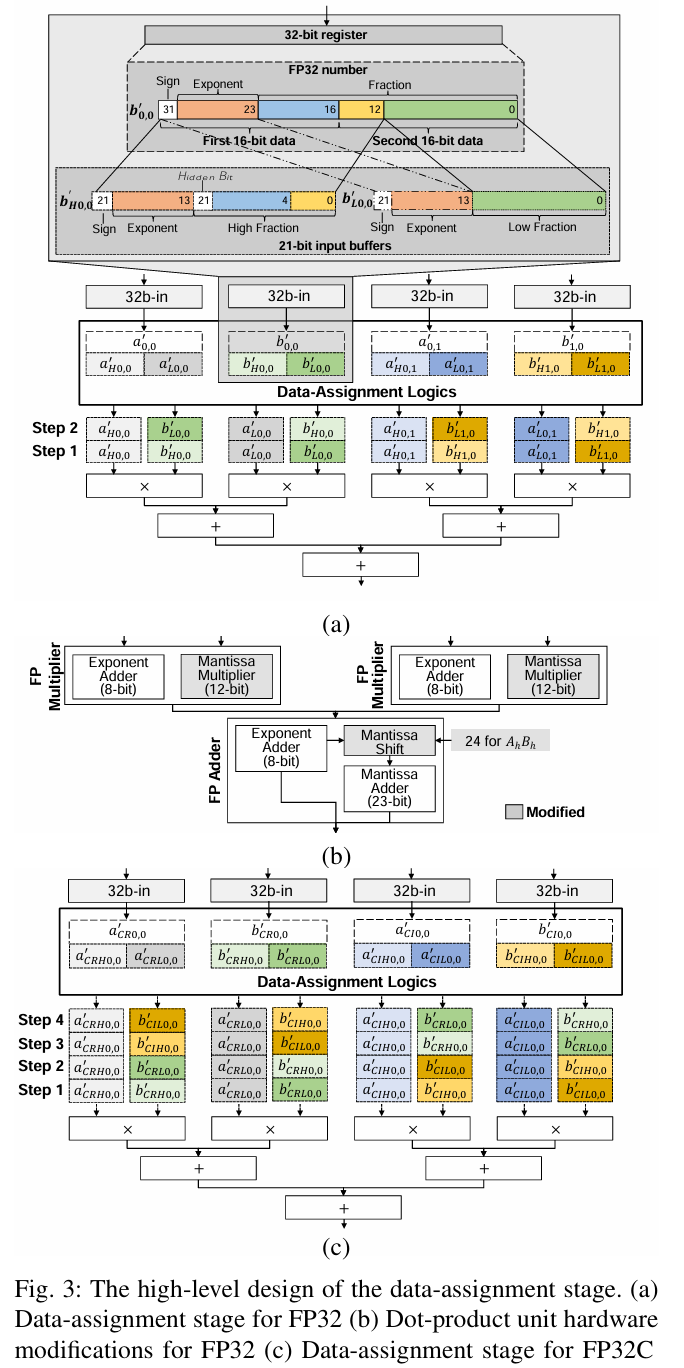
扩展 MXU 以支持更高精度的浮点或复数的成本很高。 FMA 逻辑的成本大致是输入位宽的二次方。例如,从 16 位浮点输入变为 32 位浮点输入并保持每个周期的操作数量大约使硬件面积增加四倍。此外,即使我们愿意支付 MXU 的二次方硬件成本,加倍的数据宽度也需要加倍内存子系统带宽才能匹配消耗率
受数学观察的启发,本文提出了 M3XU,这是一种多模式 MXU,它扩展了半精度 MXU,除了以低硬件成本支持低精度浮点数之外,还支持使用 FP32 和 FP32C 输入的矩阵运算。

图 2 比较了 FP16 MXU 和 FP32 MXU 上现有的基于软件的 FP32 GEMM 解决方案。同样的原理也适用于基于软件的 FP32C 实现。 如果没有硬件支持,软件解决方案需要额外的指令来计算、移位和分割指数、尾数部分,并在将数据输入 MXU 之前翻转符号位。相反,适当的硬件支持可以隐式处理位分配、移位和分割,而不会产生指令。
通过重新审视具有更高精度和复数的矩阵乘法的数学运算,我们可以将每个计算步骤分解为输入矩阵的不同分量之间的一系列低精度矩阵乘法。此外,考虑到从内存向 MXU 提供数据的限制,如果我们使用多个低精度步骤来执行高精度和复杂的矩阵乘法,我们可以达到现有内存层次结构的极限。换句话说,如果我们在 MXU 上的不同矩阵组件上启用操作,矩阵硬件就可以重用现有组件,以合理的性能执行更广泛和/或复杂的乘法。
Hydrogen
Hydrogen: Contention-Aware Hybrid Memory for Heterogeneous CPU-GPU Architectures
Hydrogen: Contention-Aware Hybrid Memory for Heterogeneous CPU-GPU Architectures
将混合存储器与异构处理器集成在一起,可以利用计算域和存储器域的异构性提高系统效率。为了确保性能隔离,我们引入了 Hydrogen,这是一种新型硬件架构,用于优化 CPU-GPU 异构系统的混合内存资源分配。Hydrogen 支持在 CPU 和 GPU 两个内存层之间进行高效的容量和带宽分配。由于 CPU 和 GPU 对内存容量和带宽表现出不同的偏好,因此 Hydrogen 可以在 CPU 和 GPU 之间以灵活的分配比例实现容量和带宽的解耦分配。它还通过一种基于令牌的机制来控制 GPU 过多的数据迁移。为了有效探索庞大的多维设计空间并支持动态变化的应用行为,Hydrogen 采用了基于纪元的在线搜索优化配置,并结合了减少数据移动的轻量级重新配置。
For instance, HBM can deliver the necessary bandwidth for GPU operations, while conventional DDR4 DRAM can provide ample capacity for all processing cores.
ECOLIFE
ECOLIFE: Carbon-Aware Serverless Function Scheduling for Sustainable Computing
[2409.02085v1] EcoLife: Carbon-Aware Serverless Function Scheduling for Sustainable Computing
这项工作介绍了 ECOLIFE,它是首个碳感知无服务器功能调度器,可共同优化碳足迹和性能。ECOLIFE 基于智能利用多代硬件实现高性能和低碳足迹的关键见解。在无服务器执行环境下,ECOLIFE 对粒子群优化(PSO)进行了多种新颖的扩展设计,以在实现高性能的同时有效减少碳足迹。

有趣的碳排放公式
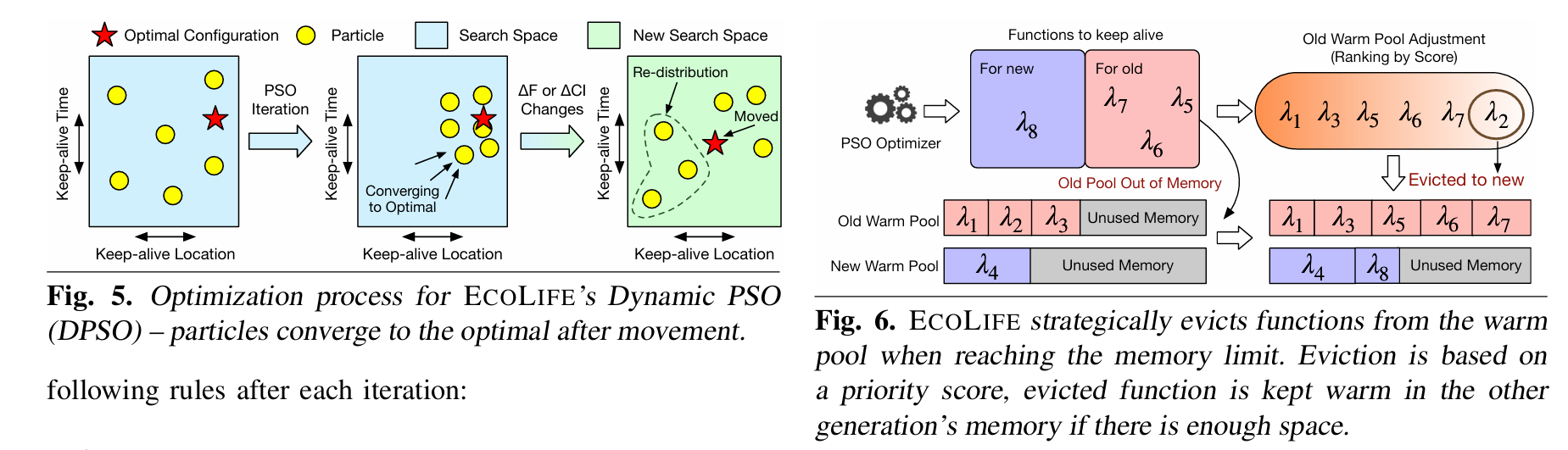
使用PSO对High Performance 和 Carbon footprint 进行优化
Compression and I/O
High-Performance Compression and I/O Management
Background:
Cache Bypassing
A Survey of Cache Bypassing Techniques
Improving Cache Management Policies Using Dynamic Reuse Distances
PKU: untitled
Compression on GPUs
High-ratio Scientific Lossy Compression on GPUs with Optimized Multi-level Interpolation
我们推出了一种名为 CUSZ-i 的新型基于 GPU 的有误差科学有损压缩器,其贡献如下:(1)一种基于 GPU 优化的插值预测方法显著提高了压缩率和解压缩数据的质量。(2)优化了 CUSZ-i 中的哈夫曼编码模块,以提高效率。(3) CUSZ-i 首次集成了 NVIDIA Bitcomp 无损压缩作为额外的压缩比增强模块。 评估结果表明,在相同误差范围(即所需质量)下,CUSZ-i 的压缩率明显优于其他最新的基于 GPU 的有损压缩器,与第二名相比,CUSZ-i 的压缩率提高了 476%。
Tango:HPC科学工作流存储系统
Tango: A Cross-layer Approach to Managing I/O Interference over Local Ephemeral Storage
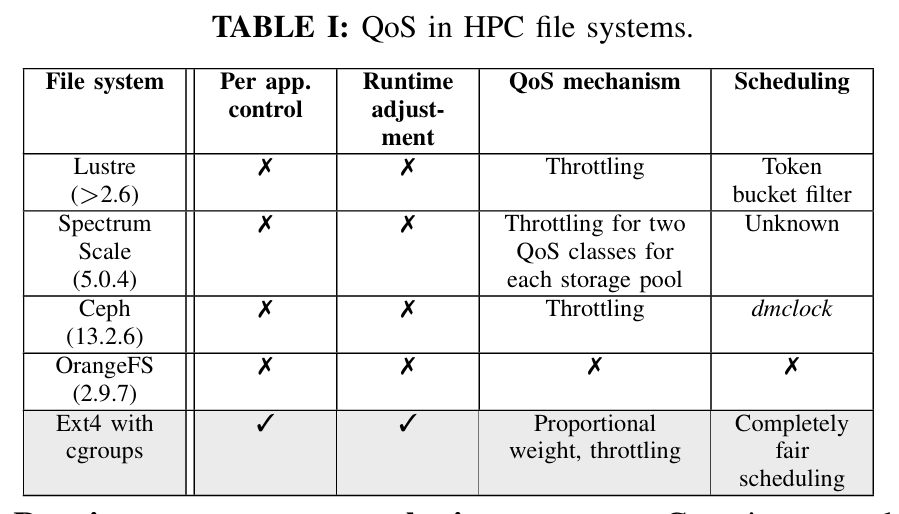
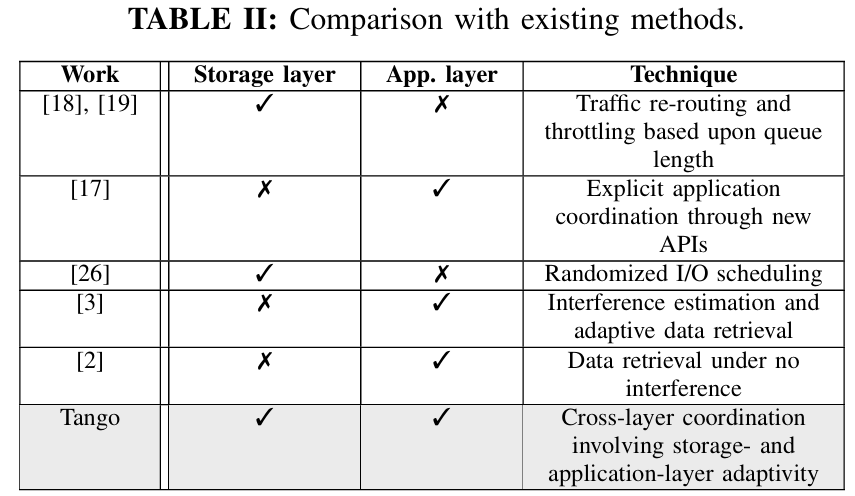
As HPC storage systems have become deeper and more complex with the recent addition of NVMe, die-stacked memory, and burst buffer, it requires fundamentally rethinking new paradigms and methods for data storage and analysis. This paper aims to address the issue of I/O interference for data analytics over local ephemeral storage, which is shared by multiple applications in a non-exclusive node usage scenario often configured for small- to medium-sized clusters.
这篇论文的摘要讨论了如何在超大规模计算(exascale)下优化数据存储和复杂物理分析的联合设计,特别是减少后处理的时间。这项工作面临的一个主要挑战是如何处理在后处理过程中才显现出来的数据分析需求,而现有的方法(如在现场处理)往往无法有效支持这些分析需求。随着高性能计算(HPC)存储系统变得更深层次和复杂,特别是最近加入了NVMe、堆叠内存和突发缓冲区,必须重新思考数据存储和分析的新范式和方法。
该论文的主要目标是解决在本地临时存储上的I/O干扰问题,这种存储在多应用共享、非独占节点使用的场景下常见,通常配置用于小型到中型集群。文章提出了一种协调的跨层次方法,这种方法能够响应来自存储层和应用层的存储干扰。通过将分析数据分解并分布到存储层次结构中,数据分析可以适应干扰——在干扰很高时减少或完全避免访问低层次存储,同时维持预定的误差范围,以避免信息丢失。此外,存储层还采取适当的措施,确保为获取增强数据分配足够的带宽,增强数据的获取根据增强数据的基数和准确性,以及应用程序的性质来决定。
论文通过在Chameleon上评估三个实际的数据分析案例——XGC、GenASiS和CFD——并通过量化评估证明,使用该方法后,I/O性能有了显著提升。例如,相较于不采用适应性的方法,性能提高了52%,相比于单层适应性方法则提高了36%,同时确保了数据分析结果的可接受性。
关键点:
- 挑战: 如何处理在后处理过程中才显现的数据分析需求,这些需求无法通过现有的方法(如在现场处理)来有效支持。
- 目标: 提供一种解决方案,通过协调的跨层次方法处理存储干扰,提高数据分析的I/O性能。
- 方法: 数据分析通过将分析数据分配到不同存储层次,并根据干扰情况调整存储访问,确保在高干扰时减少低层存储的访问,并控制误差。
- 评估: 通过对实际数据分析的评估,证明该方法能显著提高I/O性能,同时保持数据分析结果的有效性。
CUSZP2
CUSZP2: A GPU Lossy Compressor with Extreme Throughput and Optimized Compression Ratio
This work proposes CUSZP2, a generic single-kernel error-bounded lossy compressor purely on GPUs designed for applications that require high speed, such as large-scale GPU sim ulation and large language model training. In particular, CUSZP2 proposes a novel lossless encoding method, optimizes memory access patterns, and hides synchronization latency, achieving extreme end-to-end throughput and optimized compression ratio.
CUSZP2 exhibits 332.42 and 513.04 GB/s end-to-end through put on NVIDIA A100 GPU for compression and decompres sion, respectively.
依然是使用GPU压缩,看起来评测标准是吞吐量,或者说,压缩的速度,我会以为是压缩的大小。
Workflow Characterization and Optimization
LLM Pilot
LLM-Pilot: Characterize and Optimize Performance of your LLM Inference Services
IBM Research, ETH Zurich
LLM Pilot performs benchmarking of LLM inference services, under a realistic workload, across a variety of GPUs, and optimizes the service configuration for each considered GPU to maximize performance.
In addition, LLM Pilot can recommend which GPU will meet performance requirements in the most cost-effective way for a previously unseen LLM, achieving on average 33% higher success rate and 60% lower cost compared to state-of-the-art methods.
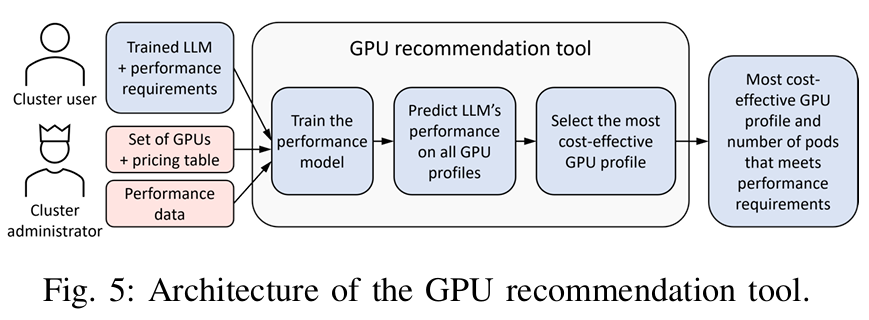
IBM:LLM推理服务性能评估工具_llm-pilot: characterize and optimize performance o-CSDN博客
利用收集的历史性能数据,构建性能预测模型,用于预测未见过的LLM在不同GPU配置下的nTTFT和ITL。 基于性能预测模型,推荐最成本有效的GPU配置和所需pod数量,以满足LLM服务的性能要求。
IBM有趣的工作,通过估算AI工作量来分配机器和workflow
DFTracer
DFTracer: An Analysis-Friendly Data Flow Tracer for AI-Driven Workflows
Lawrence Livermore National Laboratory 2Argonne National Laboratory 3Illinois Institute of Technology 4Florida State University
DFTracer: An Analysis-Friendly Data Flow Tracer for AI-Driven Workflows | Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis
current tools are not designed to work with an AI-based I/O software stack that requires tracing at multiple levels of the application. To this end, we developed a data flow tracer called DFTracer to capture data-centric events from workflows and the I/O stack to build a detailed understanding of the data exchange within AI-driven workflows
DFTracer has the following three novel features, including a unified interface to capture trace data from different layers in the software stack, a trace format that is analysis-friendly and optimized to support efficiently loading multi-million events in a few seconds, and the capability to tag events with workflow-specific context to perform domain-centric data flow analysis for workflows.
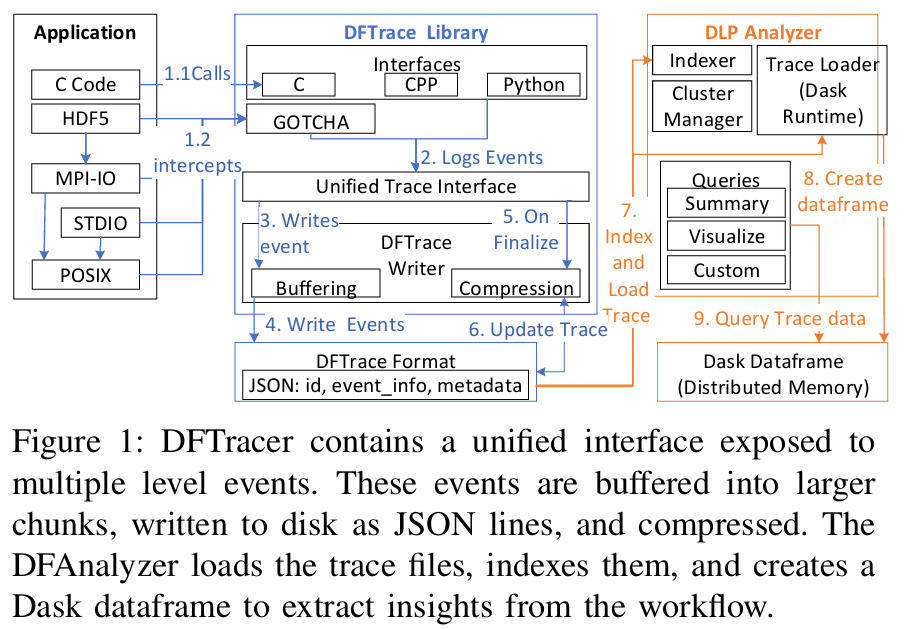
分布式的任务tracer,有趣。
Weighted Graph Matching
Efficient Weighted Graph Matching on GPUs
在静态图上找Weighted matching(加权匹配)。加权匹配是指在一个图中找出一个最大的边子集,使这些边之间没有任何共同的顶点
难点:
- irregular memory access patterns and load imbalances.
- memory
方法:
we present efficient approximation algorithms for locally dominant matching, and we demon strate scalability via batching and distributing graph data across multiple NVIDIA A100/V100 GPUs of NVIDIA DGX dense GPU platforms. Our locally dominant (pointer-based) matching method exhibits 2-45× performance improvements
https://www.cs.rpi.edu/~slotag/pub/Matching-SC24.pdf
Compiler Analysis and Code Generation
Background: 模版计算 Stencil computation
模板计算(01)模板计算简介 - 知乎
“所谓模板计算,就是整体的计算问题可以划分为局部模板的计算。相比通用矩阵乘法,模板计算拥有更一般的形式,适用于更多的场合,同时它的优化也很重要。最常见的微分方程的数值解法,就可以转换为模板计算问题。”
实验二:模板计算 - 高性能计算导论实验文档
MIT lab3.pdf
This access pattern of points needed to calculate a value at the next time step is commonly referred to as a stencil:

value at a point (m,ℓ) in space at time step n requires only “local” values, that is, values from neighboring points of (m,ℓ) from a few previous time steps.
Code Gen for Stencils
Automated Code Generation of High-Order Stencils for a Dataflow Architecture
TotalEnergies EP Research & Technology US, LLC., Houston, TX, USA
SC41406.2024.00025
Implementations of stencil computations for dataflow architectures must address unique challenges, such as managing the routing of data communications and accom modating a significantly constrained memory footprint. These make hand-crafting code for a dataflow architecture difficult and time-consuming.
This paper describes a framework for developing portable, high-performance implementations of stencil computations for modern node architectures. The paper focuses on code generation strategies for the Cerebras wafer-scale engine, including code generation of router configurations and sequenc ing of communication for high-order stencils.
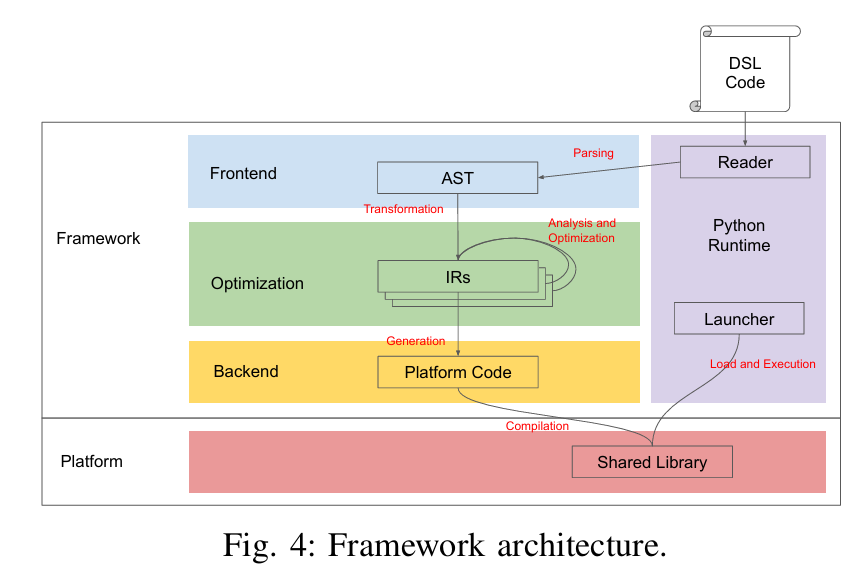
一个有限元/模版计算的代码框架生成器
Generating Stencil with Global Optimizations
Moirae: Generating High-Performance Composite Stencil Programs with Global Optimizations
Moirae: Generating High-Performance Composite Stencil Programs with Global Optimizations | Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis
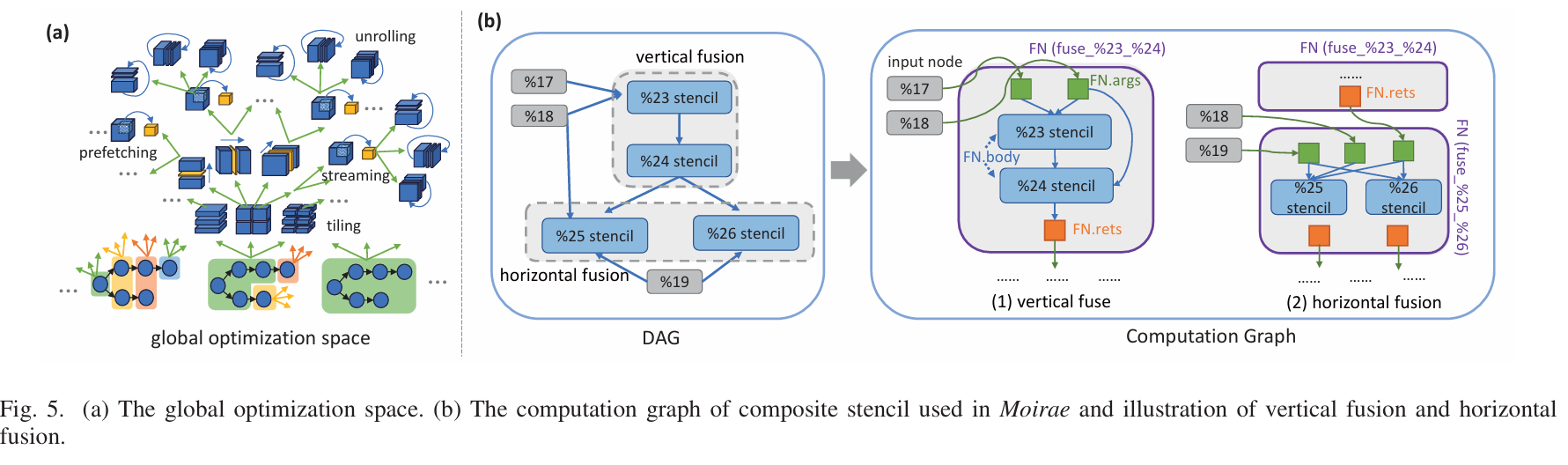
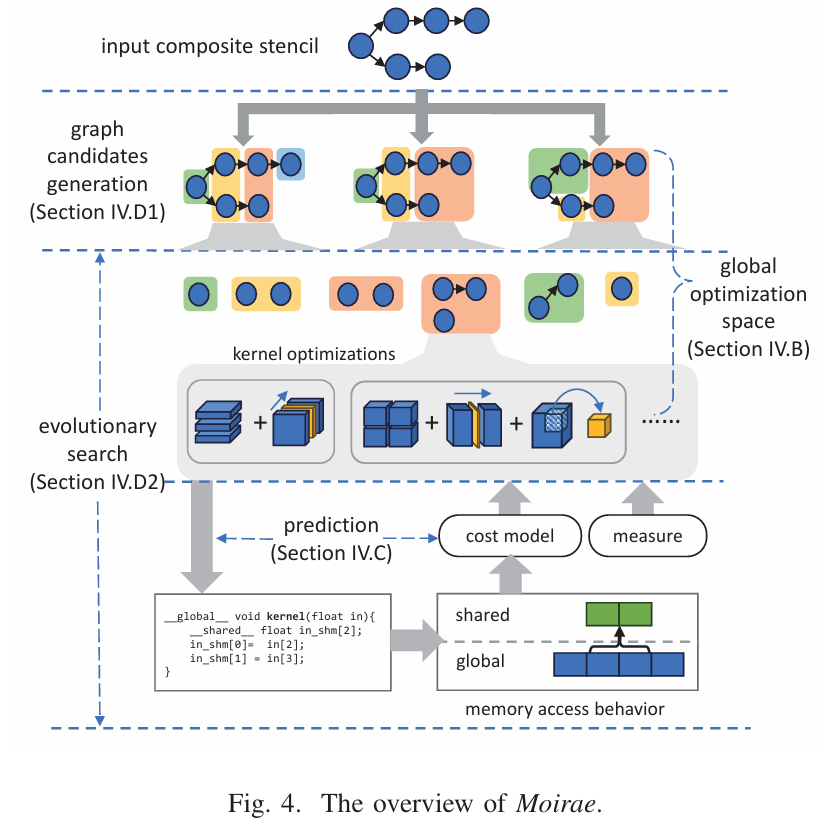
我第一次知道模版计算这个概念,所以这里也很不了解。跟上一个文章的具体区别,也不清楚。
AutoGEMM
link: TVM_GEMM_SC2024.pdf
autoGEMM: Pushing the Limits of Irregular Matrix Multiplication on Arm Architectures
autoGEMM 通过自动组合自动生成的微内核的片段,为各种硬件配置生成优化的内核,这些微内核采用手写优化来最大限度地提高计算效率
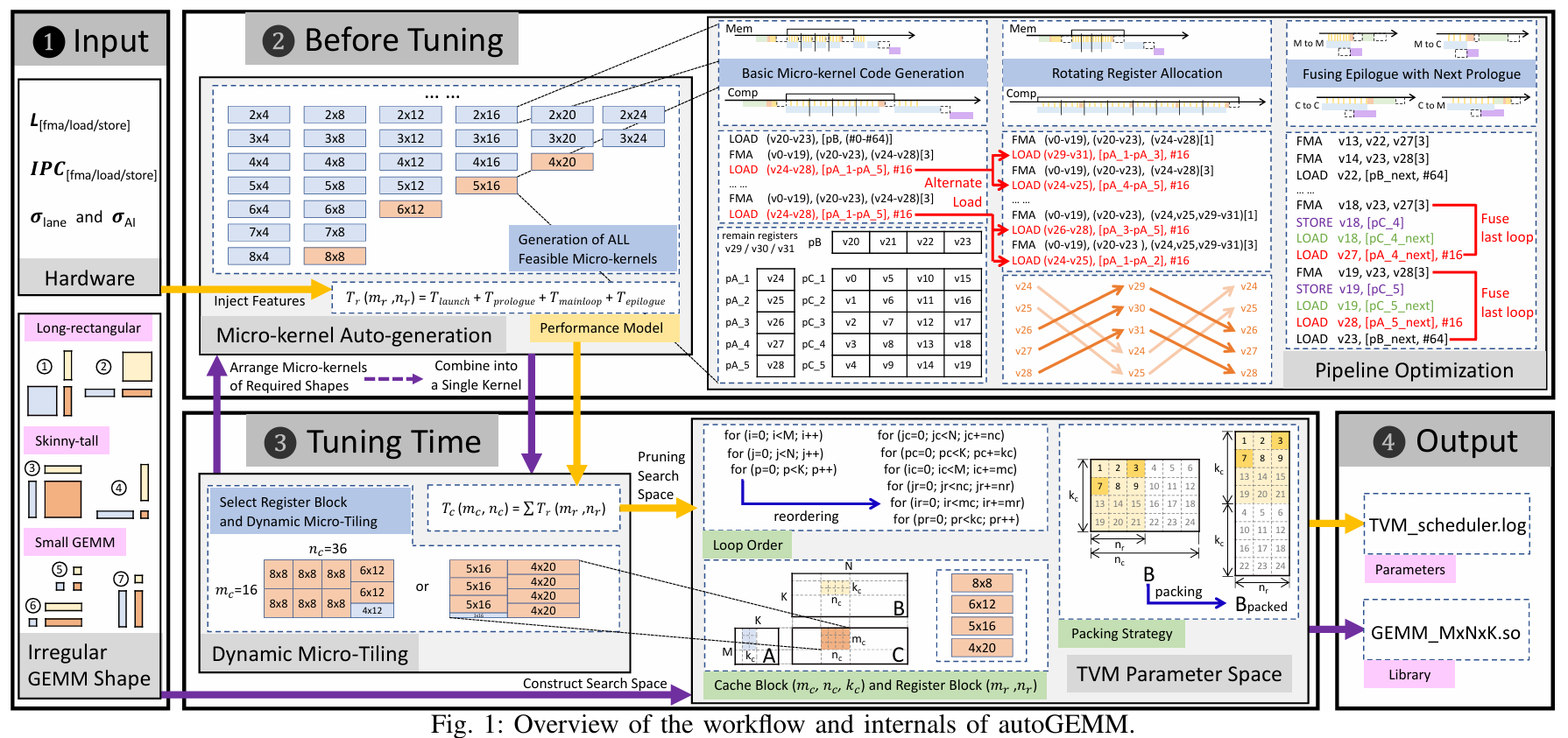
评价:非常有意思的 Scheduling 和 Generation 的工作。
Power Management and Cooling
A better nvidia-smi
Accurate and Convenient Energy Measurements for GPUs: A Detailed Study of NVIDIA GPU's Built-in Power Sensor
link: Accurate and Convenient Energy Measurements for GPUs: A Detailed Study of NVIDIA GPU’s Built-In Power Sensor
我们评估了12个架构代际中的70多款不同GPU,并发现了一些意想不到的问题,这些问题可能导致能源消耗的严重低估或高估。例如,在A100和H100 GPU上,仅有25%的运行时间被采样。我们提出了几种缓解措施,能够在我们展示的测试用例中将能源测量误差平均减少35%。
评价:有趣的工作,更好地测量GPU的功耗。
Our study seeks to elucidate the internal mechanisms of the power readings provided by nvidia-smi and assess the accuracy of the measurements. We evaluated over 70 different GPUs across 12 architectural generations, and identified several unforeseen problems that can lead to drastic under/overestimation of energy consumed, for example on the A100 and H100 GPUs only 25% of the runtime is sampled.
We proposed several mitigations that could reduce the energy measurement error by an average of 35% in the test cases we present.

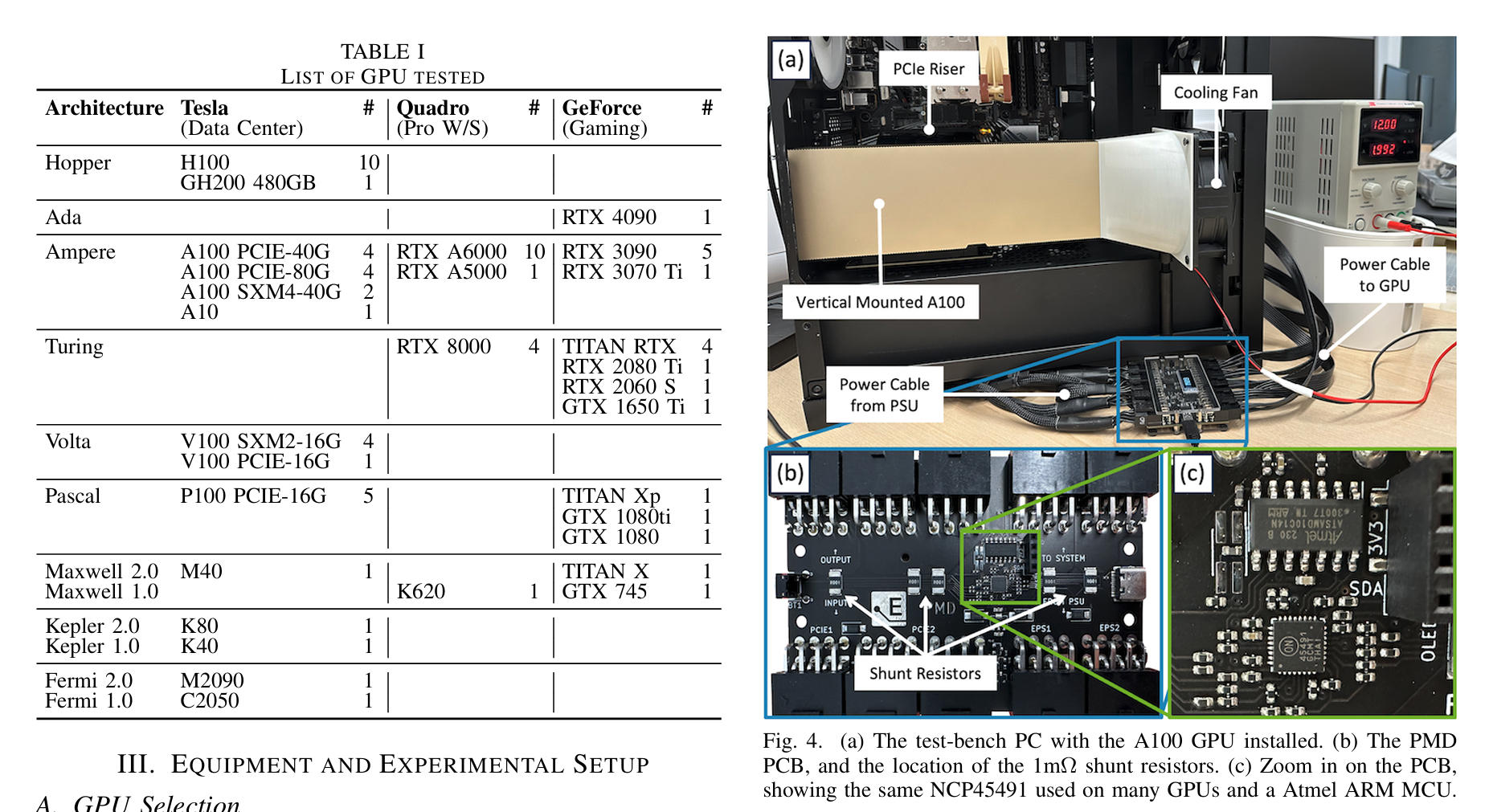
搁这做物理实验呢?
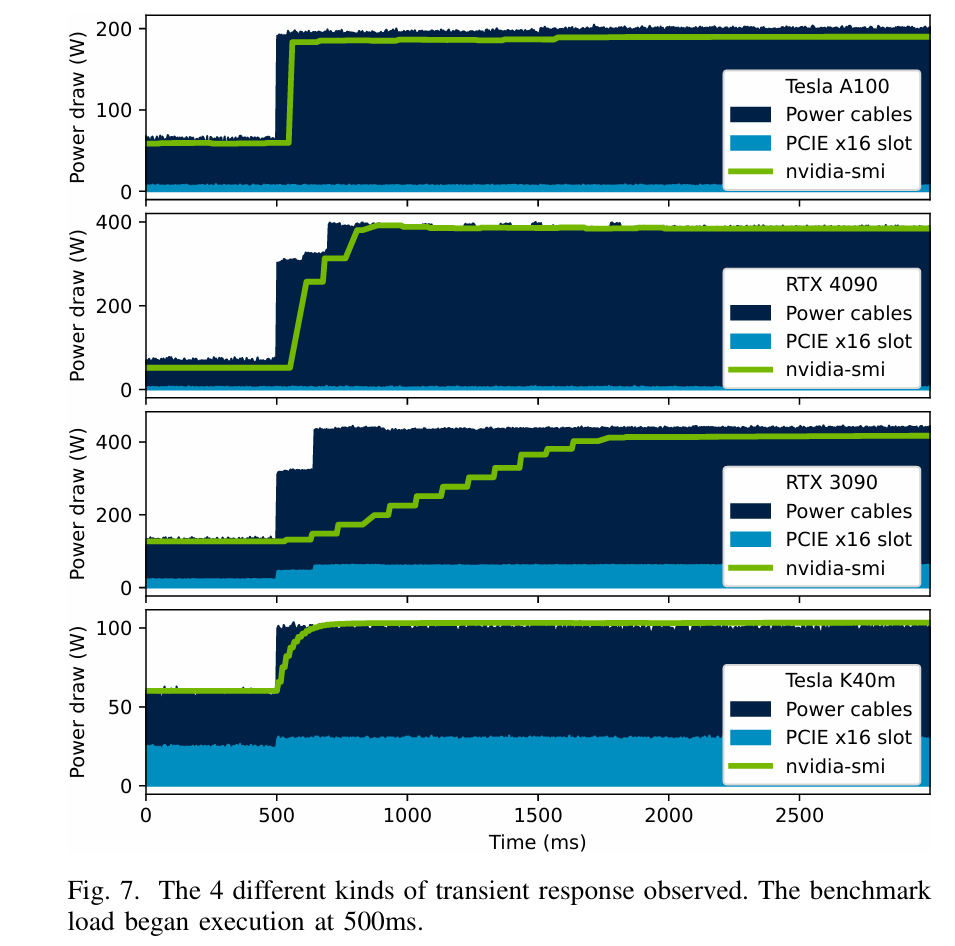
没想到平常经常用的nvidia-smi也是不完美的,如果这份工作做的好,在压功耗上就更强了。
Digital Twin for Super Computer
A Digital Twin Framework for Liquid-cooled Supercomputers as Demonstrated at Exascale
Oak Ridge National Laboratory
Paper tables with annotated results for A Digital Twin Framework for Liquid-cooled Supercomputers as Demonstrated at Exascale | Papers With Code
We present ExaDigiT, an open-source framework for developing comprehensive digital twins of liquid-cooled su percomputers. It integrates three main modules: (1) a resource allocator and power simulator, (2) a transient thermo-fluidic cooling model, and (3) an augmented reality model of the supercomputer and central energy plant.
水冷超算的数字孪生!这听起来很有趣。
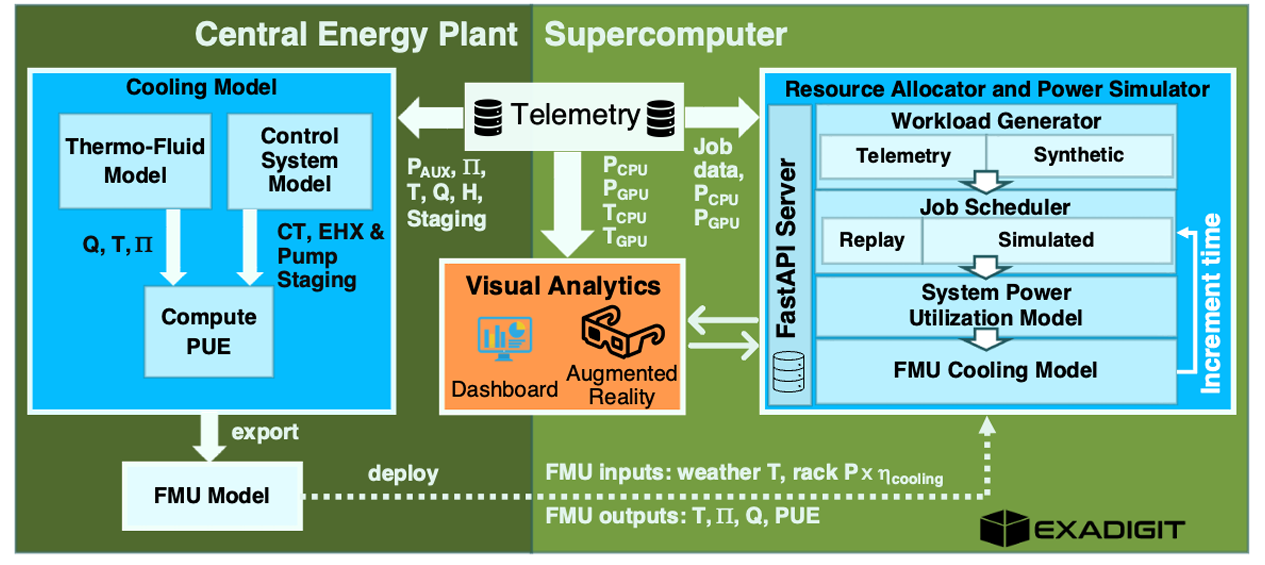
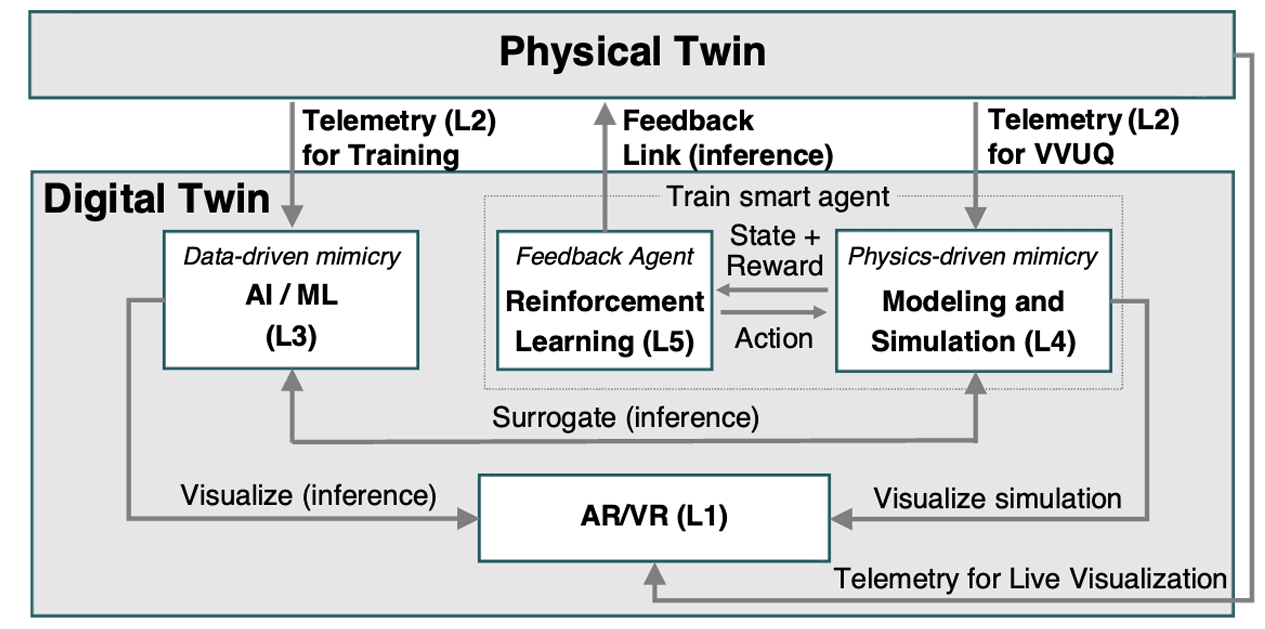

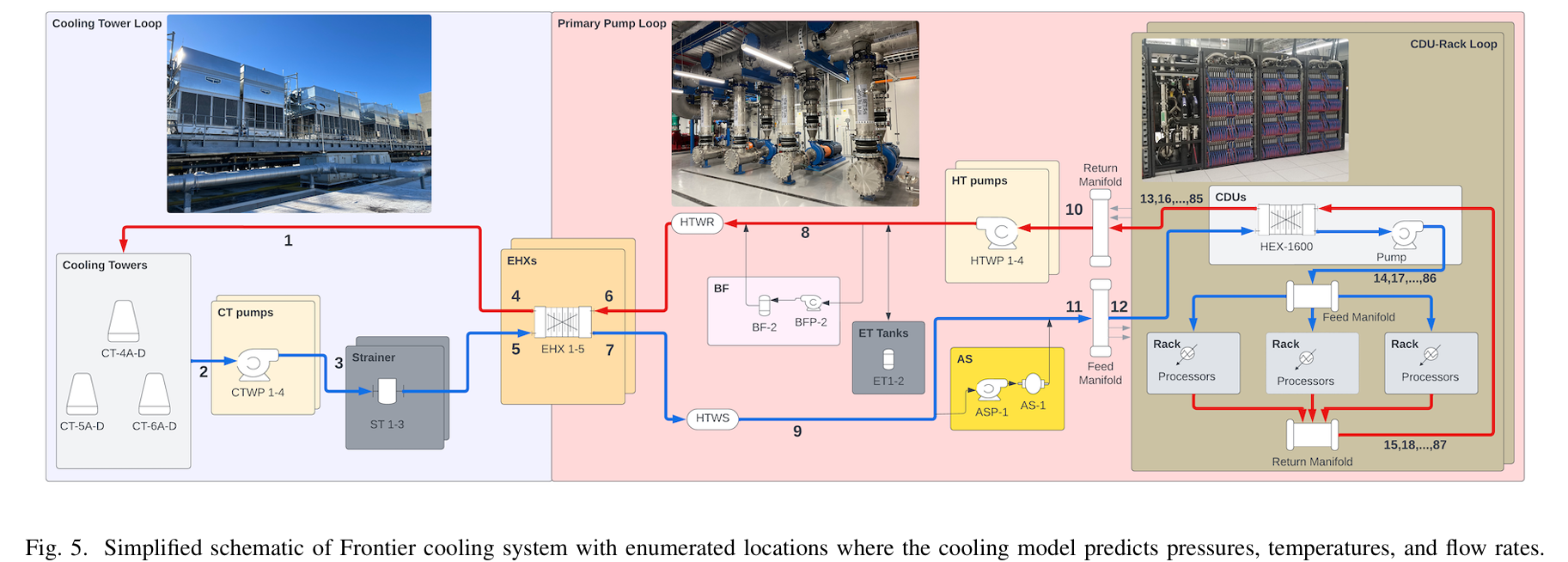
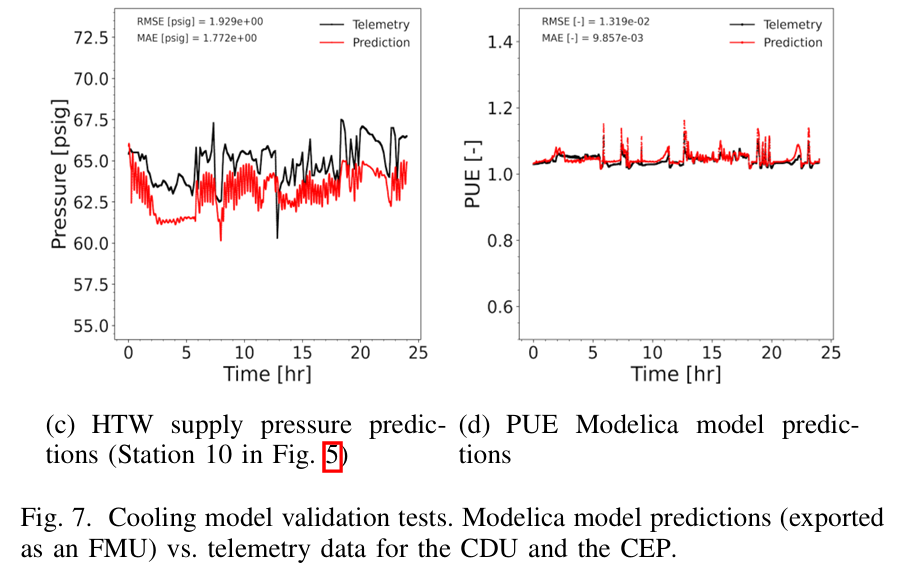
While we initially developed ExaDigiT to model Frontier, we later worked on generalizing the framework to be able to support development of a variety of architectures. To this end, we determined to use a number of JSON files for input specification, to minimize the level of code changes that must be made to model a particular system.
ACKNOWLEDGMENTS
Finally, ChatGPT was utilized for converting Python code into pseudocode in Algorithm 1, grammar enhancements, and assisting with table formatting.
感谢GPT,我们成功交稿了(
How did we build Fugaku Supercomputer?
Toward Sustainable HPC: In-Production Deployment of Incentive-Based Power Efficiency Mechanism on the Fugaku Supercomputer
Fugaku是之前TOP500超算的第二,看来是她的运维团队(R-CCS)来分享经验了
RIKEN Center for Computational Science RIKEN Website | RIKEN R-CCS
今年的HPCG和Graph500都是他们第一
This paper describes the deployment and operational experience of a novel incentive-based power-control strategy on the Fugaku supercomputer. Our incentive-based program, termed Fugaku Points, provides knobs to users to apply power control functions to improve the overall power efficiency of the supercomputer toward achieving HPC sustainability in terms of its environmental implications. We also discuss new operational opportunities, challenges, and future directions.
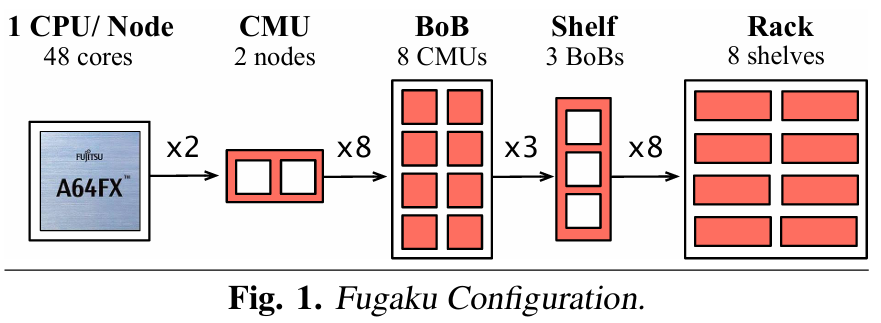
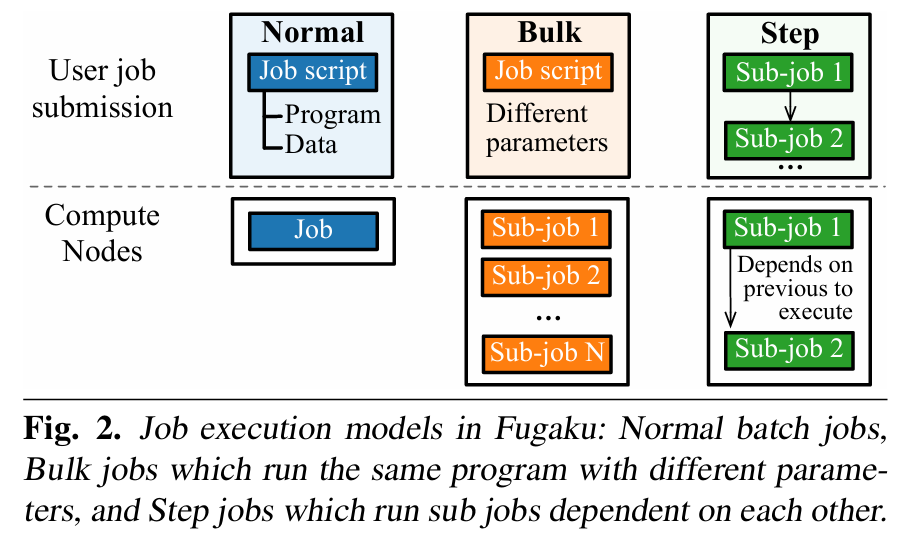
Scheduling
IO-aware Workflow Scheduling
Towards Highly Compatible IO-aware Workflow Scheduling on HPC Systems
现有的解决方案往往无法实现计算和I/O资源的协同调度,并且缺乏与HPC系统软件的兼容性。在本文中,我们介绍了一种在 HPC 系统上调度工作流的性能模型,以增强对工作流调度的理解并促进调度算法的测试。
—Scientific workflows on High-Performance Comput ing (HPC) consist of multiple data processing and computing tasks with dependencies. Efficiently scheduling computing re sources and multi-tier storage across workflow tasks is crucial for optimizing performance. Existing solutions often fall short in achieving the co-scheduling of computing and I/O resources and lack compatibility with HPC system software. In this paper, we introduce a performance model for scheduling workflows on HPC systems to enhance the understanding of workflow scheduling and facilitate the testing of the scheduling algo rithm. Additionally, we propose THman, an open-source scientific workflow scheduler featuring our heuristic scheduling algorithm, Highest Contribution First (HCF). THman achieves online co scheduling of computing and I/O resources for workflows and is designed to work with traditional HPC batch schedulers for high compatibility. We evaluate THman using simulated workloads and real-world workflow applications. Experimental results show that THman reduces workflow makespan by up to 30.9% compared to alternative methods.
此外,我们还提出了 THman,一个开源科学工作流程调度程序,采用我们的启发式调度算法“最高贡献优先”(HCF)。 THman实现了工作流计算和I/O资源的在线协同调度,旨在与传统HPC批量调度器配合使用,以实现高兼容性。我们使用模拟工作负载和真实工作流程应用程序来评估 THman。实验结果表明,与替代方法相比,THman 将工作流程完工时间缩短了 30.9%。

ML Scheduling
PAL: A Variability-Aware Policy for Scheduling ML Workloads in GPU Clusters
PAL: A Variability-Aware Policy for Scheduling ML Workloads in GPU Clusters | Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis
大规模计算系统越来越多地使用加速器(如GPU)来实现peta和exa级别的计算,以满足机器学习(ML)和科学计算应用的需求。鉴于ML的广泛和不断增长的使用,包括在一些科学应用中,为ML工作负载优化这些集群尤为重要。然而,最近的研究表明,这些集群中的加速器可能会遭受性能变化的影响,这种变化可能会导致资源未充分利用和负载不平衡。
在这项工作中,我们重点研究了如何使集群调度器(用于在许多并发的ML作业之间共享加速器丰富的集群)接受性能变化以减轻其影响。我们解决这一挑战的关键洞察是表征哪些应用程序更可能遭受性能变化,并在将作业放置在集群上时考虑这一点。我们设计了一种新颖的集群调度器PAL,它使用性能变化测量和应用程序特定的配置文件来提高作业性能和资源利用率。PAL还将性能变化与局部性平衡,以确保作业尽可能分布在尽可能少的节点上。
总的来说,PAL显著改善了GPU丰富的集群调度:跨越图像、语言和视觉模型等六个ML工作负载应用程序的跟踪,PAL将作业完成时间的几何平均值提高了42%,集群利用率提高了28%,并且makespan比现有最先进的调度器提高了47%。(PAL: A Variability-Aware Policy for Scheduling ML Workloads in GPU Clusters - 智源社区论文)

思考:目前的ML集群调度设计的如何?有没有对应的文献综述可以看?
High-Performance Blockchain System
Toward High-Performance Blockchain System by Blurring the Line between Ordering and Execution
通过模糊排序和执行之间的界限实现高性能区块链系统
Donghyeon Ryu (POSTECH System Software Lab)
Chanik Park (POSTECH System Software Lab)
高性能并行的区块链系统
最新区块链论文录用资讯CCF A—SC 2024_toward high-performance blockchain system by blurr-CSDN博客
在区块链技术中,DAG(有向无环图,Directed Acyclic Graph)共识是一种新型的共识机制,与传统的区块链结构(如比特币的链式结构)不同。DAG结构并不是通过线性链的方式记录交易,而是采用图形结构来实现去中心化的交易确认与数据存储。
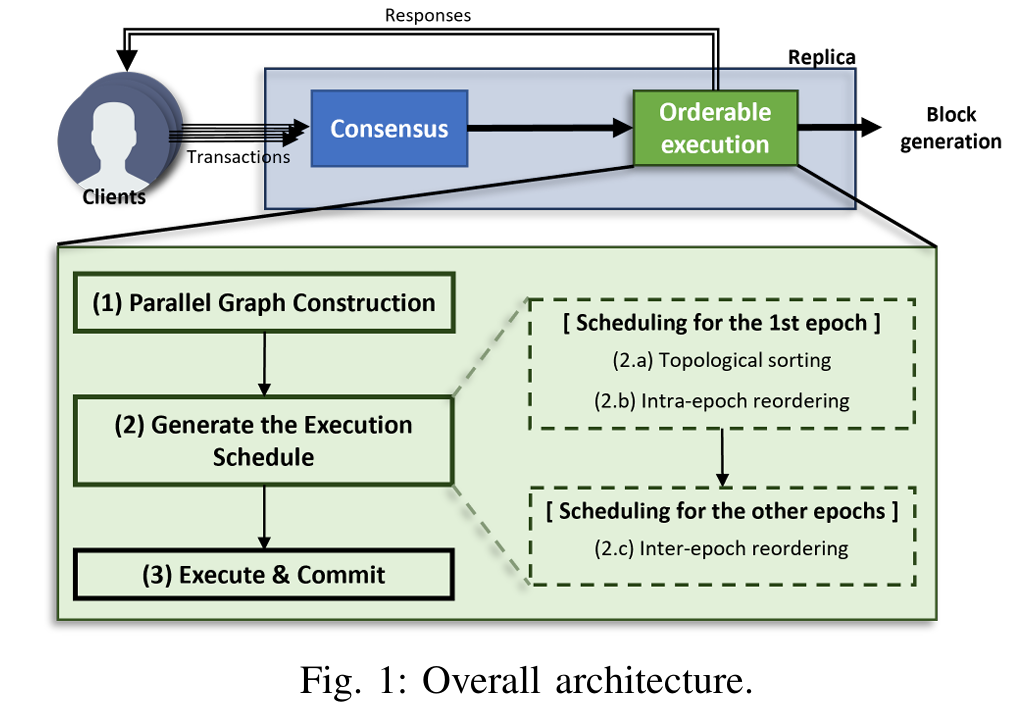
DAG共识机制的核心特点
-
无区块链结构:在DAG结构中,交易本身就是网络的基础,而不是传统的“区块”。每笔交易会指向一到多个先前的交易,从而形成图状结构。
-
并行处理:与传统的区块链不同,DAG并不要求每笔交易依赖前一笔交易的确认,多个交易可以并行进行,而不是依赖一个单一的区块链。这可以提高吞吐量,减轻网络负担。
-
去中心化:在DAG网络中,节点不需要像区块链那样通过矿工或验证者来达成一致,而是通过交易之间的相互引用来逐步建立共识。
Advanced Computational Methods and Architectures
All you don't need is Matrix
Matrix-Free Finite-Volume Kernels on a Dataflow Architecture
This work introduces a matrix-free algorithm to solve FV-based linear systems using a dataflow architecture to significantly minimize memory latency and bandwidth bottlenecks. Our implementation achieves two orders of magnitude speedup compared to a GPGPU-based reference implementation, and up to 1.2 PFlops on a single dataflow device.
What? Completely Don't understand. 
Pangenome Graph
Important
Rapid GPU-Based Pangenome Graph Layout
UTHSC, Technical University of Munich, Cornell University
一开始还在想为什么有医学院的人,一看摘要:
计算庞基因组学是一个新兴领域,它利用包含多个基因组的图结构研究遗传变异。可视化庞基因组图对于了解基因组多样性至关重要。然而,由于图布局过程的计算要求很高,处理大型图可能具有挑战性。
在这项工作中,我们对最先进的庞基因组图布局算法进行了全面的性能鉴定,发现了显著的数据级并行性,这使得 GPU 成为计算加速的一个有前途的选择。然而,不规则的数据访问和算法的内存绑定特性带来了重大障碍。为了克服这些挑战,我们开发了一种解决方案,实施了三项关键优化:缓存友好型数据布局、凝聚随机状态和翘曲合并。 此外,我们还提出了一种量化指标,用于可扩展地评估 pangenome 布局质量。
Scaling Molecular Dynamics with ab initio Accuracy to 149 Nanoseconds per Day
我们是怎么提升数值计算的速度的
招生方向:
高性能计算,智能科学计算(HPC+AI),AI for Science
Получить КОНСУЛЬТАЦИЮ и ПОДДЕРЖКУ профессиональных психологов. Онлайн чат с психологом без регистрации. Чат с психологом в телеге.
Консультация в кризисных состояниях.
Услуги психолога · — Консультация психолога.
Психологическая помощь онлайн.
Сколько встреч нужно?
Получить поддержку по широкому кругу вопросов.
Индивидуальное консультирование.