
回归决策树
- Machine Learning
- 2025-02-13
- 1424 Views
- 0 Comments
- 3659 Words
sci-kit learn 参考
https://scikit-learn.cn/1.6/modules/tree.html

决策树使用树(或者不雅观的说,使用几个嵌套if)来对数据进行分类。决策树的树种类不同,就造就了不同的模型,比如XGBoost,LightGBM。
在决策树算法中,分裂增益(Splitting Gain)通常指的是在选择分裂特征时,分裂某个特征对决策树模型性能的提升。这个提升通常是通过评估信息增益(Information Gain)或者基尼指数(Gini Index)的变化来衡量的。
1. 信息增益(Information Gain)
信息增益是决策树算法中最常用的分裂增益度量方式。它表示通过选择某个特征进行数据集分裂时,信息的不确定性(熵)减少的量。
-
熵(Entropy) 衡量了一个数据集的纯度或不确定性。熵值越高,表示数据集越不纯,分类越不确定。
熵的计算公式为:
H(D) = - \sum_{i=1}^{m} p_i \log_2 p_i其中,(p_i) 是数据集中类别 (i) 的概率。
-
信息增益(Information Gain) 是通过某个特征 (A) 分裂数据集 (D) 后,信息熵的减少量。其计算公式为:
\text{Information Gain}(D, A) = H(D) - \sum_{v \in A} \frac{|D_v|}{|D|} H(D_v)其中,(D_v) 是特征 (A) 取值为 (v) 时的数据子集,(|D_v|) 是子集的大小,(|D|) 是原始数据集的大小。
通过计算每个特征的信息增益,决策树算法会选择信息增益最大的特征进行分裂。这个过程有助于决策树逐步减少数据集的不确定性,从而提高分类准确度。
2. 基尼指数(Gini Index)
基尼指数是另一种用于衡量分裂增益的指标,通常用于CART(Classification and Regression Trees)算法中。基尼指数衡量的是一个数据集的不纯度,值越小表示纯度越高。
-
基尼指数的计算公式为:
Gini(D) = 1 - \sum_{i=1}^{m} p_i^2其中,(p_i) 是数据集中类别 (i) 的概率。
-
对于某个特征 (A) 分裂数据集 (D),计算新的基尼指数并与原始基尼指数进行比较,得到的增益为:
\text{Gini Gain}(D, A) = Gini(D) - \sum_{v \in A} \frac{|D_v|}{|D|} Gini(D_v)
3. 如何使用分裂增益选择特征?
在构建决策树时,算法会计算每个候选特征的分裂增益(通常是信息增益或基尼增益),然后选择分裂增益最大的特征作为当前节点的分裂特征。这个特征可以最大程度地减少数据集的混乱度(不确定性),从而更好地将数据分类。
在决策树中,分裂增益衡量了分裂特征对于决策树模型预测性能的提升。通常是通过信息增益或基尼增益来计算,分裂增益大的特征有助于构建一个更精确、更有效的决策树。
sci-kit learn中的分裂增益
在使用 from sklearn.tree import DecisionTreeRegressor 构建回归决策树时,其分裂增益方式 criterion 就有以下四个选择:
squared_error
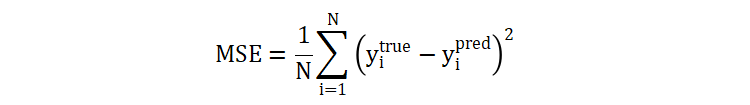
squared_error 是我们使用 scikit-learn 构建回归决策树时使用的默认分裂增益计算方法。当我们选择一个切分点时,会将树分为左右子树,我们使用 MSE 分别计算两个子树的 MSE,并加起来得到一个分裂后的误差,选择误差最小的切分点作为最终选择的切分点。
absolute_error
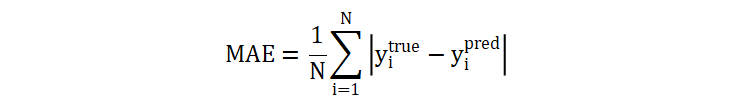
absolute_error 计算的是预测和真实之间的绝对误差,这种方式相对于 squared_error,对噪声相对不敏感。对噪声敏感意味着,数据集中的噪声数据带来的误差可能会影响到切分点的选择,进而影响到整个决策树的构建。由于 squared_error 通过平方会缩放误差,而 absolute_error 则计算真实误差,相对于前者相对更加不容易受到异常值的影响。
poisson
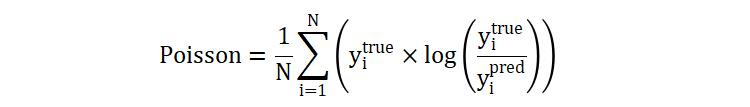
泊松偏差的原本的计算公式如下:
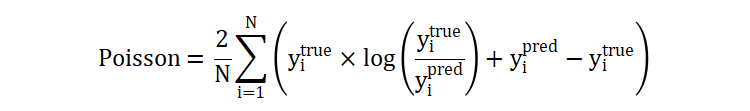
针对决策树场景,有:
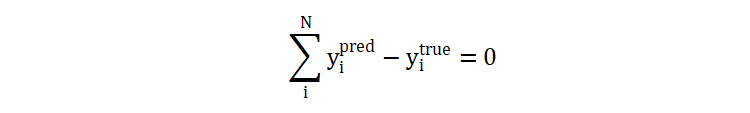
原公式中的 2 舍弃,就得到现在的计算公式。公式中,最终的部分是对数计算部分,这部分的值是可正可负:
- 当预测值小于真实值时,得到的 Poisson 偏差就大于 0,表示模型给出的预测值偏小;
- 当预测值大于真实值时,得到的 Poisson 偏差就小于 0,表示模型给出的预测值偏大;
- 当预测值等于真实值时,表示预测的结果精确,没有偏差。
所以,从这个过程来看,poisson 更加倾向于选择偏差较小的切分点。
friedman_mse

mean_left表示左子树样本平均值mean_right表示右子树样本平均值diff表示左右子树输出差值n_left表示分裂之后,左子树样本数量n_right表示分裂之后,右子树样本数量
- 如果 n_left×n_right 较大,说明分裂之后左右子树样本数量较为均衡,反之,则说明左右子树样本数量不平衡;
- 如果 diff2 较大,说明左右子树的输出差异较大,有助于区分不同的数据点。反之,则说明两个子树输出的差异较小。
在决策树回归(Decision Tree Regression)中,决策树被用来预测连续的数值输出,而不是离散的类别标签。这种方法基于将数据集逐步划分成多个子集,并在每个子集上做出一个预测。决策树回归的核心思想和分类问题类似,但它的目标是预测数值,而不是类别。
1. 决策树回归的构建过程
与分类任务中选择最佳分裂特征来分类不同,回归树的目标是通过选择最佳的特征来最小化子集的预测误差,通常使用均方误差(Mean Squared Error, MSE)来衡量误差。
1.1 分裂标准
在回归任务中,决策树的分裂标准通常是通过减少均方误差(MSE)来选择特征。每次分裂都会选择能将数据集分裂成尽可能小的误差(即每个子集的均方误差最小)的特征。
- 均方误差(MSE) 是用来衡量回归模型预测误差的常用指标。对于一个数据集 (D),MSE的计算公式为:
[
MSE(D) = \frac{1}{|D|} \sum_{i=1}^{|D|} (y_i - \hat{y})^2
]
其中,(y_i) 是数据集中实际的输出值,(\hat{y}) 是预测值,(|D|) 是数据集的大小。
在回归树中,每次选择一个特征进行分裂时,算法会计算分裂后每个子集的均方误差(MSE),并选择能最大程度降低总体MSE的特征进行分裂。
1.2 递归分裂
- 选择特征:选择一个特征,使得分裂后数据集的均方误差最小化。
- 继续分裂:在每个子集上继续进行分裂,直到满足某些停止条件(如树的最大深度、叶节点的最小样本数或最小均方误差阈值)。
- 生成树:通过递归的方式生成决策树,每个叶节点代表一个预测值。
2. 回归树的预测过程
当决策树建立完成后,预测时的过程如下:
- 对于每一个新的输入样本,决策树会从根节点开始,根据该样本的特征值逐步向下遍历树。
- 每次分裂都会根据样本的特征选择合适的分支。最终,样本会到达一个叶节点。
- 该叶节点的输出值就是模型的预测值。
对于回归树中的叶节点,预测值通常是叶节点中的所有样本的平均值。
3. 回归树的特性
- 灵活性:决策树回归可以处理线性和非线性的数据,因此在很多复杂的回归问题中表现良好。
- 过拟合:如果决策树的深度设置得太深,它可能会过度拟合训练数据,捕捉到数据中的噪声。因此,需要使用剪枝(pruning)技术来防止过拟合。
- 易于理解和解释:决策树回归可以通过树状结构直观地展示如何进行预测,非常容易理解。
4. 常用的决策树回归算法
- CART(Classification and Regression Trees):CART 是一种常见的决策树算法,可以同时处理分类和回归任务。在回归任务中,CART使用均方误差(MSE)作为分裂标准,最终预测每个叶节点的平均值。
5. 回归树的优缺点
优点:
- 简单易理解:决策树回归模型通过树结构进行预测,非常直观,易于解释。
- 无需特征预处理:不像线性回归那样需要对特征进行标准化,决策树回归可以直接使用原始数据。
- 能够处理非线性关系:决策树回归不需要事先假设数据的线性关系,能够很好地处理非线性数据。
缺点:
- 过拟合:如果树过深,容易在训练数据上过拟合,导致模型泛化能力差。
- 不稳定性:小的训练数据变化可能导致决策树结构发生很大变化。
- 难以捕捉平滑的趋势:决策树回归适合捕捉数据中的局部模式,对于数据中的平滑趋势(如线性关系)捕捉较差。
如果你的数据在实数轴上,决策树回归依然能够用来进行预测。在这种情况下,数据的特征值是连续的,决策树会根据这些连续的特征值进行分裂,并通过分裂后叶节点的平均值来做出预测。
1. 实数轴数据的回归过程
假设你有一个一维特征数据集,其中每个数据点是一个实数值(例如,房屋的面积、温度等)。决策树回归会在该实数轴上进行分裂,每次选择一个特征值作为分裂点,将数据划分成两个子集,然后在每个子集上继续分裂,直到满足停止条件。
步骤如下:
-
选择分裂点:假设你的数据特征(例如房屋面积)是一个实数值。在每个节点,决策树会考虑每一个可能的分裂点,这些分裂点是数据中的实际数值。通过计算每个可能的分裂点(例如,某个面积值)可以最小化均方误差(MSE),选择最优的分裂点。
例如,假设数据集中的一个特征是房屋的面积,决策树会考虑不同的面积值作为分裂点,比如:10平米、20平米、30平米等,并计算在每个分裂点下的均方误差,选择使得误差最小的分裂点。
-
递归分裂:选择最佳的分裂点后,数据集被分成两个子集。然后,决策树会对每个子集递归进行相同的操作,直到满足停止条件(如树的深度达到限制,或子集的均方误差小于某个阈值)。
-
叶节点的预测值:在每个叶节点,决策树会输出该子集的平均值作为预测结果。这个平均值就是该叶节点的预测值,代表了在该区域内的输出趋势。
2. 预测过程
当训练完成后,预测过程与其他回归任务相似。对于一个新的输入样本,决策树会根据该样本的特征值(在实数轴上的值)沿着树向下遍历,直到到达一个叶节点。在这个叶节点,输出的预测值是该叶节点数据的均值。
3. 举个例子
假设你有如下数据集(房屋面积 vs. 房屋价格):
| 房屋面积(平方米) | 房屋价格(万元) |
|---|---|
| 40 | 100 |
| 60 | 150 |
| 80 | 200 |
| 100 | 250 |
| 120 | 300 |
- 决策树会尝试在房屋面积的不同数值(例如,40、60、80、100等)上进行分裂,以最小化均方误差。
- 假设决策树选择的分裂点为“60平方米”,它会把数据分为两部分:面积 ≤ 60 和 面积 > 60。
- 对于面积 ≤ 60 的子集,预测值是这些房屋价格的平均值(100 + 150)/ 2 = 125万元。
- 对于面积 > 60 的子集,预测值是这些房屋价格的平均值(200 + 250 + 300)/ 3 = 250万元。
最终,给定一个新的房屋面积(例如,70平方米),决策树会根据该面积的数值沿树结构向下遍历,最终预测该房屋价格为250万元(因为70平方米大于60平方米,落在面积 > 60的子集中)。
4. 如何选择分裂点
对于实数轴上的数据,选择分裂点时有以下几种常见方法:
-
选择每两个相邻数据点之间的中值作为潜在的分裂点:例如,在上面的数据集中,可能的分裂点是(40,60)、(60,80)、(80,100)等相邻数据点的中值。这是因为,对于连续数据,分裂点通常是在数据的相邻位置之间。
-
寻找最小均方误差(MSE):每次尝试不同的分裂点,计算分裂后子集的MSE,并选择能最小化MSE的分裂点。
5. 回归树的优势和局限性
-
优势:
- 适应连续数据:决策树回归可以很自然地处理连续的实数数据。
- 无需特征缩放:决策树不需要像线性回归那样对数据进行标准化或归一化。
- 处理非线性关系:决策树能够捕捉到数据中的非线性关系,这是传统线性回归方法难以做到的。
-
局限性:
- 过拟合问题:如果树的深度过大,决策树可能会过拟合训练数据,导致模型泛化能力差。
- 对噪声敏感:决策树对数据中的噪声较为敏感,可能导致不必要的复杂分裂。
对于实数轴上的数据,决策树回归会通过递归地选择最佳的分裂点来构建树,每个叶节点的预测值是该节点内数据点的平均值。在预测时,根据新样本的特征值,决策树会沿树结构向下遍历,并给出叶节点的平均值作为预测结果。这种方法能够处理连续的数据,并能够捕捉数据中的非线性关系。