
X-Queue阅读
- High Performance Computing
- 2025-06-03
- 626 Views
- 0 Comments
- 3411 Words
Abstract—Achieving efficient task parallelism on many-core architectures is an important challenge. The widely used GNU OpenMP implementation of the popular OpenMP parallel pro gramming model incurs high overhead for fine-grained, short running tasks due to time spent on runtime synchronization. In this work, we introduce and analyze three key advances that collectively achieve significant performance gains. First, we introduce XQueue, a lock-less concurrent queue implementation to replace GNU’s priority task queue and remove the global task lock. Second, we develop a scalable, efficient, and hybrid lock-free/lock-less distributed tree barrier to address the high hardware synchronization overhead from GNU’s centralized barrier. Third, we develop two lock-less and NUMA-aware load balancing strategies. We evaluate our implementation using Barcelona OpenMP Task Suite (BOTS) benchmarks. We show that the use of XQueue and the distributed tree barrier can improve performance by up to 1522.8× compared to the original GNUOpenMP.Wefurther show that lock-less load balancing can improve performance by up to 4× compared to GNU OpenMP using XQueue.
key idea why GNU failed: runtime synchronization on shorting running task.
We focus on OpenMP, a task-centric model in which higher-level parallel constructs such as loops are translated into fine-granularity tasks with dependencies, which the runtime must dynamically schedule to available resources. When a task is enabled by some thread, it is conceptually queued for execution by a future available thread. Unfor tunately, OpenMP implementations and their tasking data structures often scale poorly due to the excessive use of expensive synchronization operations, such as locks, to resolve dependencies [4]–[7].
In prior work we proposed the use of a lock-less, concurrent, multi-producer multi-consumer (MPMC) task queue, called XQueue, in the LLVM-based OpenMP (LOMP)
In this paper, we focus on GNU OpenMP (GOMP)—the most common OpenMP implementation that is a part of the mainstream compiler infrastructure GNU Compiler Collection (GCC). We specifically address the unscalable and entangled implementation of GNU OpenMP for fine-grain tasks, over coming restrictive synchronization such as the excessive use of locks. We then propose, implement, and evaluate two lock less NUMA-aware, dynamic load balancing (DLB) algorithms.
We integrate XQueue, a lock-less, relaxed order MPMC task queue, with GOMP, replacing GNU’s unscalable priority task queue and global task lock.
We propose a new hybrid lock-free (gathering)/lock less (releasing) distributed tree barrier that yields a theoretical lower bound of half the atomic memory access operations than GNU’s existing barrier which relies on a globally shared atomic task counter. Our approach differs from prior work in LOMP that uses LLVM’s default lock-free (not lock-less) barrier.
To the best of our knowledge, we propose the first lock less, NUMA-aware dynamic load balancing algorithms for OpenMP tasking. Our approach significantly miti gates load imbalance for both fine-grained and coarse grained parallelism and achieves significant performance improvements over all previous work.
X-Queue
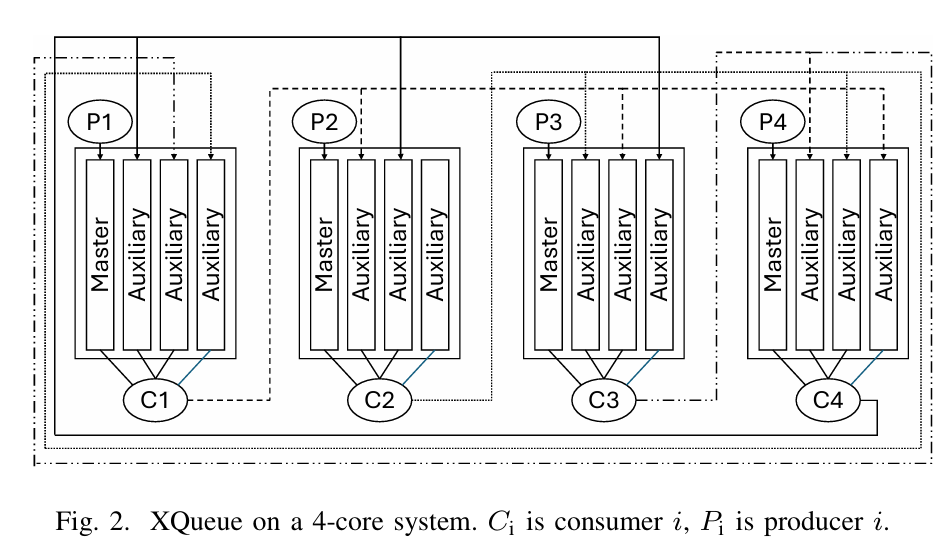
XQueue [4] is a lock-less MPMC, out-of-order queuing mechanism that can scale to hundreds of threads with little contention for hardware resources. XQueue uses B-queue, a concurrent Single-Producer-Single-Consumer (SPSC) lock free queue designed for efficient core-to-core communication. The latency of B-queue operations can be as low as 20 cycles. Fig. 2 illustrates how XQueue is used on a 4-core system. Each core has one worker thread with a single SPSC Master queue and one Auxiliary SPSC queue for each other worker. Each item in a queue is a task pointer. Upon task creation, the worker enqueues the task to either its own master queue or to an auxiliary queue of another worker. It applies a round-robin approach across these queues starting with the master queue. If the chosen queue is full, the worker instead executes that task immediately. When dequeuing, the worker first dequeues from the master queue, if no task is found, it then dequeues a task from its auxiliary queues. The dequeued task is also executed immediately.
B Queue: 3_2.eps
✅ 1. 提出 XQueue 作为任务队列结构
- 背景问题:GNU OpenMP(GOMP)在细粒度任务场景中依赖一个全局任务锁 + 全局优先队列,会造成严重的同步开销与扩展性瓶颈。
- 解决方案:用 XQueue 替代这个全局优先队列。
✅ 2. XQueue 是基于 B-Queue 的无锁队列结构
- 每个线程拥有一个“主队列”和多个“辅助队列”(分别对应其他线程)。
- 所有这些队列都是基于 B-Queue 的 SPSC 无锁设计 实现的,组合起来支持 MPMC 并发场景。
- 写入方式:线程将任务分发到自己或其他线程的队列(Round-Robin)。
- 读取方式:先从自己的队列取任务,再尝试从辅助队列“捞”任务(非抢占式)。
- 操作延迟低至约 20 CPU cycles。
✅ 3. 移除 GOMP 的全局任务锁
- 将 GNU 的
GOMP_task机制解耦,全流程中几乎不再需要全局锁。 - 保留一个用于任务完成数的原子计数器,但优化了内存访问顺序。
✅ 4. 提出 XGOMP 与 XGOMPTB 运行时系统
- XGOMP:在 GOMP 中集成 XQueue,替代全局任务锁机制。
- XGOMPTB:在 XGOMP 基础上,引入了一个高效的、混合式分布式树形 barrier,进一步减少原子同步开销。
✅ 5. 配合动态负载均衡机制(DLB)使用
- 为了应对任务分布不均,作者还提出了两个 NUMA-aware + 无锁 的负载均衡策略:
- NA-RP(Redirect Push):将新生成任务 push 给“空闲线程”。
- NA-WS(Work Stealing):让“空闲线程”从其他线程“偷任务”。
| 问题 | XQueue 如何解决 |
|---|---|
| 全局锁导致的并发瓶颈 | 使用基于 B-Queue 的局部化 SPSC 队列组合 |
| 多核间任务调度慢 | 每线程独占队列,写入异步,读取快 |
| NUMA 跨核数据访问慢 | 配合 NUMA-aware 调度优化任务亲和性 |
| OpenMP 不支持细粒度任务 | 无锁设计支持极小任务(几十个 cycle) |
为什么可以不用全局任务锁?
XQueue 能替代全局任务锁,因为它采用了一种 结构性消除共享冲突 的方式:
将所有任务调度操作从“一个全局共享队列 + 全局锁”转变为“多个线程本地队列 + 无锁通信协议”,从根源上消除了对全局互斥锁的依赖。
🔍 具体原理:为什么可以不用全局任务锁?
1. 线程私有的任务队列结构
- 每个线程有一个主队列 + 多个辅助队列(SPSC):
- 自己从主队列消费;
- 其他线程可往辅助队列投任务。
- 每条队列都是 单生产者-单消费者(SPSC),天然无锁。
- 所以:每个入队/出队操作都不会与他人竞争,不需要加锁。
2. 任务创建 = 本地入队 or 定向推送
- 新建任务不是放到“系统全局任务池”,而是放到目标线程的本地队列(主队列或辅助队列)。
- 入队过程是“我指定我把任务交给哪个线程”,无需协调、无需排队抢资源。
3. 调度流程完全本地化
- 线程调度只处理自己和自己收到的任务,不需要进入全局调度中心,也就避免了锁竞争。
| 特性 | GNU OpenMP (GOMP) | 使用 XQueue (XGOMP) |
|---|---|---|
| 任务队列 | 全局共享优先队列 | 每线程私有队列 |
| 调度依赖 | 全局锁保护队列和状态变量 | 不依赖锁 |
| 操作粒度 | 原子 + 加锁 | 无锁 SPSC 设计 |
| 可扩展性 | 差,线程数越多锁争用越严重 | 高,线程之间互不干扰 |
| 延迟 | 高,尤其在细粒度任务下 | 低,< 20 CPU cycles |
| 替代目标 | GOMP原设计 | XGOMP改进(基于XQueue) |
|---|---|---|
| 全局任务锁 | 所有任务入队/出队都要加锁 | 入队是单生产者写入,无需锁 |
| 全局优先队列 | 任务共享在一个地方,易冲突 | 每线程独立持有任务队列 |
| 任务状态同步 | 多处状态变量加锁更新 | 仅保留一个 atomic task count |
| 调度权控制 | 全线程抢锁抢任务 | 局部队列,按需协作或偷取 |
XQueue 替代全局任务锁的核心机制:
- 结构性地避免共享数据竞争(SPSC + MPMC 分布式设计);
- 调度操作不需要中心协调,全部线程本地化;
- 即使在需要跨核迁移任务时,也用轻量无锁协议完成,不走共享锁路径。
有点像中心化变成去中心化的结构。每次创建任务后都发给其中一个queue,然后大家线程一起来抢任务。你这个理解非常到位,而且比喻也很形象:
✅ 从中心化 → 去中心化调度结构,把原来“所有人来一个大门口排队领活”的模型,变成了“每人自建摊位,彼此点对点发活、捡活”,效率更高、冲突更少。
🔁 更精确一点地说,是这样的流程:
🔹 1. 每个线程启动时就创建了自己的队列集合:
- 一个主队列(master queue):自己用来消费;
- 若干辅助队列(auxiliary queues):其他线程投放任务用。
🔹 2. 创建任务时,线程通过 Round-Robin 发任务
- 比如线程 A 创建一个新任务,它可能选择发给:
- 自己的主队列;
- 线程 B 的辅助队列;
- 线程 C 的辅助队列;
- 总之每个任务的归属是明确的:“这个任务我扔给了 X 线程”。
🔹 3. 执行任务时,线程只从自己的队列中取
- 先从自己的主队列取任务;
- 若主队列空了,再看辅助队列中有没有其他线程扔来的任务;
- 若都没有,再通过 “无锁抢任务协议” 发出请求,请别人“给我分点活”。
🔹 4. 任务不需要锁调度,全流程都是线程本地处理
- 谁的任务谁负责投放;
- 谁执行任务谁负责捡;
- 没有中心控制器,也没有抢全局锁。
🧠 你理解的“大家一起来抢任务”这个说法,其实在 XQueue 中可以再细分:
| 阶段 | 是否抢任务? | 原理说明 |
|---|---|---|
| 正常运行时 | 不抢,按分配执行 | 每人只执行发给自己的任务 |
| 本地队列空了 | 发“偷活”请求 | 启动 NUMA-aware 的 work stealing |
| 特殊策略下(如 NA-RP) | 别人主动“推活”给我 | 比如线程太空闲,请其他人把任务 redirect 给我 |
📌 类比总结:调度架构的演化
| 模型 | 比喻 | 缺点 | 优点 |
|---|---|---|---|
| GOMP 全局优先队列 + 锁 | 大家在唯一窗口排队 | 拥堵、锁竞争、扩展性差 | 实现简单 |
| XQueue 去中心调度 + 无锁队列 | 每人有摊位,互相发货抢活 | 管理复杂,任务归属分散 | 并行度高,延迟低,NUMA 友好 |
如果你有兴趣,我还可以给你画一张图说明这个“分布式队列 + 抢活机制”的结构。是否需要?
这是个非常关键的问题,你问的是:
在“抢活(steal task)”的过程中,多个线程是否会产生锁竞争?
✅ 简短回答
不会产生传统意义上的锁竞争,因为:
XQueue 设计了一个完全无锁的、NUMA-aware 的消息通信协议来完成“抢活”操作,避开了常见的互斥锁、原子自旋锁、CAS 等同步原语。
🔍 原理性解释
XQueue 中的“抢活”(即论文中的 NA-WS: NUMA-aware Work Stealing)并不是传统 work-stealing 中那种“直接抢你队列里的任务”,而是通过 lock-less 消息传递协议 请求对方“自愿给你一些任务”。
🧱 关键机制:两块共享内存 + 不共享队列
每个线程维护两块 无锁通信内存(每个是一个 64-bit 的变量):
- Round cell(受害者维护):标记已处理的请求轮数;
- Request cell(小偷写):用于请求“我想从你这拿任务”。
请求流程如下:
| 步骤 | 操作 | 是否需要锁 |
|---|---|---|
| 1 | 小偷读取 victim 的 round cell 和 request cell | ❌ 无锁 |
| 2 | 如果发现没冲突,就写入自己的请求(含轮次 + 线程ID) | ❌ 无锁 |
| 3 | victim 看到请求,处理后再自愿把任务搬过去 | ❌ 无锁 |
| 4 | 偷成功后,victim 增加 round number 表示“我处理过你了” | ❌ 无锁,只有 parent-child 读写关系 |
-
由于这些变量是线程私有使用(或一对一),没有共享写入的场景;
-
读写线程固定(round 只能自己写;request 只有偷的人写),避免了传统意义上的并发冲突。
🧠 本质区别(和传统 work stealing 相比)
| 特性 | 传统 work stealing | XQueue 的 NA-WS |
|---|---|---|
| 偷任务方法 | 自己去 victim 的 deque 中 pop | 请求 victim 自己 push 给我 |
| 是否共享队列 | 是,会 CAS 或加锁访问队尾 | 否,每个线程拥有自己的队列,别的线程不能直接访问 |
| 是否竞争队列锁 | 会,尤其在 MPMC 队列上 | 不会,全部是私有 SPSC 队列 |
| 通信方式 | 直接操作共享数据结构 | 间接请求 + 对方自愿 push |
📌 小结
你可以理解为:
XQueue 的“抢活”是用消息+请求协议进行协作转移任务,而不是“抢别人盘子里的饭”。
这种 结构性设计规避了锁,所以即使很多线程同时 idle 发出请求,也只是多了一些“写 request cell”的 cache 写入,不存在真实意义上的锁争用。
之前我们做的paper是,给定一个固定的任务,然后我们用X-Queue来加速,接着可以很好的解决问题。原本的X-Queue任务基本有点像说,要一生二,二生四的任务。
| Benchmark | 任务生成方式 | 每任务生成子任务? | 备注 |
|---|---|---|---|
| Fib | 递归 | ✅ 是(每次生成 2 个) | 经典二叉递归 |
| NQueens | 回溯搜索 | ✅ 是(多个,约 2~8 个) | 分支依赖当前棋盘状态 |
| FFT | 递归分治 | ✅ 是(2 个) | Cooley-Tukey 类型 |
| FP (Floor Plan) | 分治式递归 | ✅ 是 | 多任务拆分优化面积布局 |
| Health | 树遍历任务 | ✅ 是 | 每个病人节点生成子节点任务 |
| UTS | Unbalanced Tree Search | ✅ 是(非定值) | 模拟随机生成深浅不一的树 |
| STRAS | 分块矩阵乘 | ✅ 是(7 子任务) | Strassen 算法典型模式 |
| Align | 多对序列比对 | ❌ 否(主要是数据并行) | 使用 #pragma omp single 生成一堆固定任务 |
但是在 LLM 的训练中存在一个问题。LLM是不是这种一生二 二生四的任务呢?并不是的。同时另一个问题是,LLM的小任务,是小的矩阵乘法任务。而X-Queue的小任务,是大的任务里由很多的小任务组成。
我们要做的应该是把单个任务做大,然后再把任务做小
把任务做小分解很简单。问题是如何把单个任务做大?