
Where do interrupts happen? 中断触发点在OOO处理器中的分布——神文解析
- Architecture
- 2025-10-23
- 534 Views
- 0 Comments
- 11822 Words
神文解析:Where do interrupts happen?
原文:
https://travisdowns.github.io/blog/2019/08/20/interrupts.html
看完标题和第一句话,我就知道今晚这篇文章要让我睡不着了。看懂这篇文章需要一定的体系结构基础,对OoO,中断的机制比较了解。
在中文网站上我似乎没有看到类似的讨论。在考虑后,我决定将本文写为解析。我会将我的解析和信息汇总与原文翻译区分。本文的核心实验思路、基础代码与初始数据均源自 Travis Downs 的文章 《Where Do Interrupts Happen?》。原文链接:link。本文是在其基础上的分析与解读,若内容涉及侵权,请与我联系,我将立即进行修正或删除。
PS:这位作者在体系结构上经验相当丰富,在X上被 Jeff Dean 关注。我非常推荐大家回看原文。该作者的其他文章也真的是相当精彩!
原文翻译
On Twitter, Paul Khuong asks: Has anyone done a study on the distribution of interrupt points in OOO processors?
在 X 上,Paul Khuong提问:有人对乱序执行处理器里的中断点的分布进行过研究吗?
就个人而言,我尚未见过针对现代x86架构的相关研究,对此问题同样充满好奇。特别是当CPU接收到外部触发的中断信号(这里所说的"外部触发",基本上是指并非由当前逻辑核心上运行的代码直接引发的中断,比如int指令或某些故障/陷阱。它包括了定时器中断、跨CPU的处理器间中断等等。)时,究竟会中断指令流中的哪个执行节点?
对于简单的单发射顺序执行且无流水线的CPU而言,答案可能直截了当:中断要么发生在当前指令执行前,要么在执行后(这两种选择基本上对应着两种处理方式:要么让当前指令执行完毕,要么中止当前指令以响应中断)。但面对更复杂的架构,情况就变得棘手。现代乱序执行处理器可能同时维护着数百条飞行中的指令——部分等待执行,十余条正在执行,其余等待提交。在这纷繁的指令中,究竟哪条会被选为中断的牺牲品?
分析:这里作者在说什么?
我们在计算机组成原理课程上学习过中断和OoO的机制。但是大部分时候课本讲的是顺序执行处理器(即指令在CPU里的执行顺序完全跟在内存内记录的顺序完全一致)下的中断,在这种情况下中断点相对明确。在OoO(Out of Order 乱序执行)情况下,中断只能发生在固定的 architecturally consistent point(机器状态可恢复的位置,我们等会深度讨论)。那么在这种情况下,哪些point会被触发?这是本文想探讨的主题。
简单回顾:什么是中断
中断是一种改变处理器指令执行流程的机制,用于响应来自处理器内部或外部的异步事件。比如定时器中断(APIC Timer),Device中断(网络包到达、磁盘IO完成),性能采样中断(PMI,Performance Monitoring Interrupt,可能来自
perf或者vtune)
- 中断触发:硬件(如定时器、I/O设备)或软件(通过
INT指令)发出信号。- 现场保存:CPU自动将当前程序计数器(PC)和程序状态字(PSW)等关键上下文压入栈中
- 切换执行:CPU加载中断服务程序寄存器(ISR)的地址到PC,开始执行ISR。
- 现场恢复与返回:ISR执行完毕后,通过特定指令(如x86的
IRET)恢复之前保存的现场,继续执行原程序。中断的详细流程其实挺长的,具体流程可以看 intel 的手册(如http://www.infophysics.net/INTERRUPTS_CHAPTER_5.pdf )以及其他解析。
简单回顾:OoO
在现实世界的乱序 CPU 中,指令流不是严格顺序执行的,而是:
- 前端依次解码、分派;(源源不断的产生要执行的指令)
- 中端:寄存器重命名。(CPU有有限的架构寄存器(比如EAX, EBX),但程序中存在大量的假依赖(假依赖的指令只是重用寄存器,但是其实可以同时执行)。中端会尝试消除了假依赖,只保留真正的数据依赖)
- 后端将指令乱序执行(只要依赖满足);
- 组件:保留站
- 过程:
3.1 从重命名阶段来的微操作进入保留站等待。
3.2 每个微操作都监视着操作数是否就绪。
3.3 一旦某个微操作的–所有操作数都就绪(即它所依赖的前面指令已经产生结果),并且它需要的执行单元空闲,那么无论它在原始程序中的顺序如何,它都可以立即被发射到执行单元执行。
3.4 执行单元(如ALU、加载/存储单元等)并行工作。- 执行完后进入 Reorder Buffer (ROB) 等待(指令在后端执行完毕后,结果并不会立即写回到架构寄存器,而是先写回ROB中对应的条目,并标记为“已完成”。所有被分派的指令都会在ROB中占一个位置,形成一个按程序顺序排列的队列。)
- 只有当ROB头部的指令是“已完成”状态时,退休单元才会将它的结果最终提交到架构寄存器或内存。然后这条指令被移出ROB,下一条指令成为新的头部最后由退休(retirement/commit)单元按顺序提交结果到寄存器文件或内存。(这个“顺序退休”是关键,它确保了程序的最终结果与按顺序执行一模一样,从而维护了程序的正确性。)
关于中端如何重命名解构假依赖的,可以了解Tomasulo算法。
借用“乱序执行Out-of-Order Execution - Wil的文章 - 知乎” 的图:
https://zhuanlan.zhihu.com/p/26184755002
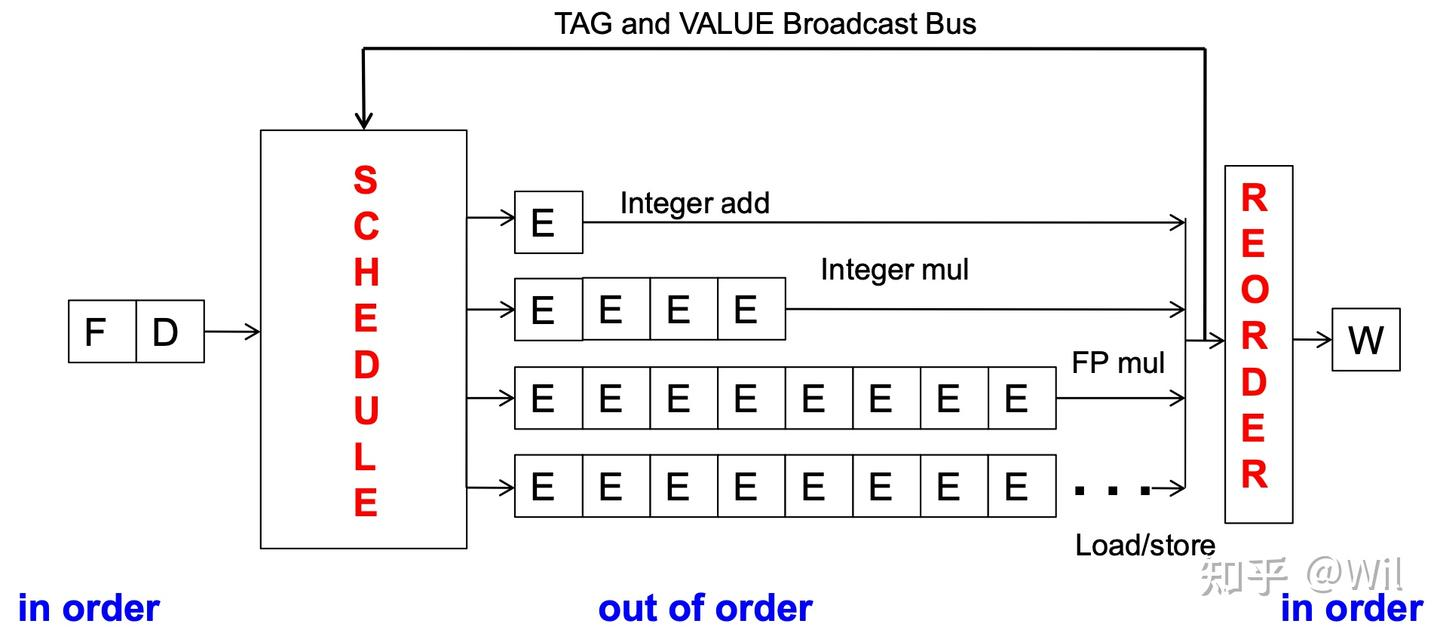
体系结构状态
在 x86 架构中,当我们谈到“architectural state(体系结构状态)”时,指的是在架构层面对软件可见、受体系结构规范约束的所有状态信息。也就是说,这是 CPU 在某一时刻对外“承诺”的机器状态,它定义了“机器此刻长什么样”,而不是微架构层面的暂存值、乱序执行状态、寄存器重命名表、ROB(Reorder Buffer)等内部实现细节。
当中断发生时,CPU 会确保乱序执行的所有中间状态都被整理到一个一致的 architectural state,再切换到中断服务程序执行。
OOO Execution 下的中断
所以当一个外部中断信号到来时,一般的CPU 并不会立即中断某个“正在执行的”指令(因为同时在执行的指令有几十甚至上百条)。 (当然不同的CPU架构对中断处理不同,所以也不一定。有的CPU处理中断的模式是马上处理,此时其会抹去全部正在运行的指令并直接运行中断流程,我们在这里就讨论延迟处理中断的架构,对于详细信息,可以看推荐阅读环节的《超标量处理器设计》)
在延迟处理中断的CPU中,其必须选择一个 architecturally consistent point,即一个已经完成、并且可以保证机器状态可恢复的位置 —— 通常是 最近退休(retired)的指令之后。(也可以叫 处理器状态 Architectural state)
在这种架构下中断不会发生在乱序窗口内某条“尚未退休”的指令上。
否则处理器状态(寄存器、标志位等)不可恢复。中断点一般在某个已退休指令之后:
CPU 收到中断信号 → 标记 pending → 等到当前指令退休后 → 执行中断入口。在 Intel 的文档中,外部中断被定义为 “precise interrupts”:
状态总是对应于中断指令“刚执行完”的那一刻,所有先前指令都提交,后面的都未提交。在Intel等架构中,这类中断被称为 精确中断:中断点的架构状态是明确的,所有之前的指令都已提交,所有之后的指令都如同未执行。
所以,作者想研究什么?
当用
perf record这类工具采样时,性能监控单元 (PMU) 会在计数溢出时触发 Performance Monitoring Interrupt (PMI)。 但由于中断只能在退休点精确触发,样本的 EIP/IP 实际上反映的是“最近退休的一条指令”,而不一定是“真正导致事件的那条指令”。这也正如开始上文说说,作者和 Paul Khuong 想探究的:
“既然中断只能在退休点发生,那么在乱序流水线中,哪些指令更容易成为‘中断命中点’?分布如何?这种分布会影响采样精度吗?”
这个问题的研究价值在于,它能帮助我们理解通过中断进行性能分析时,精确中断定位的有效性:我们能否从指令位置提取有价值信息?抑或只应相信更宏观层面的数据(比如以数百条指令为单位的区间)?
事实证明这非常有价值。我们之前在用
perf或者vtune测量高性能程序性能时,经常发现在程序线程的细节运行上,他们测量的结果往往是不准的。其中断位置的问题有可能是其中一个原因。尤其是在面对大量单一的循环结构时,可能会有很多指令没有被 Profiler 采集到。
现在让我们通过编译若干小型纯汇编程序并实际运行,来探究中断的工作机制(至少在我的 Skylake i7-6700HQ 处理器上)。所有测试源码均已开源至相关git代码库,方便读者复现实验或编写新测试。选择汇编语言是因为我们需要精确控制每条指令,且测试程序均短小精悍。无论如何,当讨论"哪些指令会被中断"时,我们终究绕不开汇编层面的分析。
首先,我们来看一段没有任何特殊指令的汇编代码,它只是一系列常规指令mov(这里我使用mov指令是为了避免产生任何依赖链。与大多数既读取又写入第一个操作数的x86整数指令不同,mov指令的目标操作数是只写的)。其核心部分的源码如下:
.loop:
%rep 10
mov eax, 1
mov ebx, 2
mov edi, 3
mov edx, 4
mov r8d, 5
mov r9d, 6
mov r10d, 7
mov r11d, 8
%endrep
dec rcx
jne .loop这里展示了完整循环结构,其中%rep 10指令会将包含的代码块按指定次数展开重复。但后续内容中,我可能只展示内部核心代码块,请理解这些代码块都通过%rep进行了若干次展开(以降低循环开销的影响),并封装在约100万次的循环中,从而获得足够数量的采样点。如需查看精确代码,请随时参考代码仓库 https://github.com/travisdowns/interrupt-test/blob/master/indep-mov.asm 。
这段代码就是循环执行8个常数赋值到寄存器的操作,每次循环重复10次。实测该代码的IPC(每周期指令数)达到预期值4 (通常我会直接说明"这段代码如此执行"或"瓶颈在于此",而不作进一步解释,因为这些示例通常简单明了,瓶颈显而易见。尽管不会每次都提及,但我已通过性能分析工具(通常是perf stat)验证过这些示例的表现符合预期,比如确认了IPC或每次迭代的周期数等指标)。
中断测试
接下来进入研究的关键部分。我们使用perf record -e task-clock ./indep-mov 命令运行该二进制文件,该命令会定期中断进程并记录指令指针(IP)。随后通过perf report分析被中断的位置(我使用的完整命令类似于perf annotate -Mintel --stdio --no-source --stdio-color --show-nr-samples。若要进行交互式分析,只需去掉--stdio参数即可启用文本用户界面),输出结果如下(以下将省略头部信息,仅展示采样点):
Samples | Source code & Disassembly of indep-mov for task-clock (1769 samples, percent: local period)
-----------------------------------------------------------------------------------------------------------
:
: Disassembly of section .text:
:
: 00000000004000ae <_start.loop>:
: _start.loop():
: indep-mov.asm:15
16 : 4000ae: mov eax,0x1
15 : 4000b3: mov ebx,0x2
22 : 4000b8: mov edi,0x3
25 : 4000bd: mov edx,0x4
14 : 4000c2: mov r8d,0x5
19 : 4000c8: mov r9d,0x6
25 : 4000ce: mov r10d,0x7
18 : 4000d4: mov r11d,0x8
22 : 4000da: mov eax,0x1
24 : 4000df: mov ebx,0x2
20 : 4000e4: mov edi,0x3
29 : 4000e9: mov edx,0x4
28 : 4000ee: mov r8d,0x5
18 : 4000f4: mov r9d,0x6
21 : 4000fa: mov r10d,0x7
19 : 400100: mov r11d,0x8
26 : 400106: mov eax,0x1
18 : 40010b: mov ebx,0x2
29 : 400110: mov edi,0x3
19 : 400115: mov edx,0x4第一列显示的是每条指令所接收到的中断次数。具体来说,这个数字反映了该指令在中断发生后被记录为"即将执行的下一条指令"的次数。
无需进行深入的统计分析,我们在这里并未观察到明显的规律性模式。 所有指令都获得了被中断采样的机会。虽然某些列的数值相对较高,但若重复进行测量,这些高数值列的出现位置并不具有必然的重复性。
我们可以尝试采用完全相同的测试方法,但这次使用如下所示的加法指令add:
源码:
https://github.com/travisdowns/interrupt-test/blob/master/indep-add.asm
add eax, 1
add ebx, 2
add edi, 3
add edx, 4
add r8d, 5
add r9d, 6
add r10d, 7
add r11d, 8我们预期其执行行为会与mov指令的情况相似:虽然这里确实存在依赖链,但由于我们为每个目标寄存器设置了8条独立的依赖链,且每条链仅包含单周期指令,因此实际影响应该微乎其微。事实上,实验结果与上一个测试基本一致,这里就不再重复展示(您可以通过indep-add测试自行验证)。
分析:到这里我们发现,在仅有没有依赖链或者单条依赖链的指令情况下,我们的中断处理似乎都是均匀地分布在每条指令上。
现在让我们继续探索更有趣的情况。这次我们仍然全部使用add指令,但其中两条指令将相互依赖,而另外两条保持独立。 这样一来,这两条相互依赖的指令所形成的依赖链长度(2个周期)将是其他独立指令依赖链(各1个周期)的两倍。具体代码如下:
源码:
https://github.com/travisdowns/interrupt-test/blob/master/add-2-1-1.asm
add rax, 1 ; 2-cycle chain
add rax, 2 ; 2-cycle chain
add rsi, 3
add rdi, 4此处的rax依赖链将限制上述重复代码块的吞吐量为每2周期完成1次迭代——实际测量的IPC值确实为2(4条指令 ÷ 2周期 = 2 IPC)。
中断分布情况如下所示:
0 : 4000ae: add rax,0x1
82 : 4000b2: add rax,0x2
112 : 4000b6: add rsi,0x3
0 : 4000ba: add rdi,0x4
0 : 4000be: add rax,0x1
45 : 4000c2: add rax,0x2
144 : 4000c6: add rsi,0x3
0 : 4000ca: add rdi,0x4
0 : 4000ce: add rax,0x1
44 : 4000d2: add rax,0x2
107 : 4000d6: add rsi,0x3
(pattern repeats...)为了防止你忘记:第一列显示的是每条指令所接收到的中断次数
这确实是个新发现。我们看到所有中断都集中在中间两条指令上,其中一条属于加法依赖链,另一条则不是。而后一条指令的中断次数约是前一条的2到3倍。
提出假设
现在让我们建立一个假设,以便设计更多测试。
我们推测,中断会选择最年长的未退休指令作为选中指令,并允许该指令执行完毕,因此采样点会落在其后的指令上(我们称这条后续指令为被采样指令)。我刻意区分"选中指令"和"被采样指令",而非简单表述为"中断采样最年长未退休指令的后继指令",是因为我们的模型将完全围绕选中指令构建,故需为其命名。而被采样指令的特征(除其位于选中指令之后这一属性外)几乎无关紧要(当然我们会发现,在某些可中断指令的情况下,被选中采样的指令实际上可能相同。)。
在缺乏更详细的指令退休模型的情况下,我们尚无法完全解释观察到的所有现象——但基本思路是:执行时间更长的指令更可能成为最年长的未退休指令,从而成为被选中的对象。 特别地,如果存在关键依赖链,该链上的指令很可能(关于为什么是很可能而非必然:最初我以为关键路径上的指令必然符合采样条件,但事实并非如此:后续我们将构建一个关键指令始终不会被选中的示例)会在某个时刻被采样。
(请注意,我特意没有说只有关键链上的指令才会被选中。正如即将看到的,由于提交带宽的限制,除非关键链指令分布足够密集(即至少每4条指令中出现1条),否则其他指令也可能出现在采样结果中。)
让我们继续研究更多案例。接下来我将改用mov rax, [rax]作为长延迟指令(4周期延迟),并用nop作为不参与任何依赖链的填充指令。不必担心,nop和其他指令一样需要分配与退休资源:它只是跳过了执行阶段。您完全可以用实际指令(如add)构建这些示例,其表现规律将保持一致。
(我选用nop指令是因为它既无输入也无输出,这样我就不必担心会意外创建依赖链(例如需要确保每个add指令使用不同的寄存器),而且它不占用任何执行单元,因此不会从关键路径上的依赖链中抢占执行资源)
现在我们来观察一条加载指令后跟10条nop的情况:
源码
https://github.com/travisdowns/interrupt-test/blob/master/load-nop10.asm
.loop:
%rep 10
mov rax, [rax]
times 10 nop
%endrep
dec rcx
jne .loop结果:
0 : 4000ba: mov rax,QWORD PTR [rax]
33 : 4000bd: nop
0 : 4000be: nop
0 : 4000bf: nop
0 : 4000c0: nop
11 : 4000c1: nop
0 : 4000c2: nop
0 : 4000c3: nop
0 : 4000c4: nop
22 : 4000c5: nop
0 : 4000c6: nop
0 : 4000c7: mov rax,QWORD PTR [rax]
15 : 4000ca: nop
0 : 4000cb: nop
0 : 4000cc: nop
0 : 4000cd: nop
13 : 4000ce: nop
1 : 4000cf: nop
0 : 4000d0: nop
0 : 4000d1: nop
35 : 4000d2: nop
0 : 4000d3: nop
0 : 4000d4: mov rax,QWORD PTR [rax]
16 : 4000d7: nop
0 : 4000d8: nop
0 : 4000d9: nop
0 : 4000da: nop
14 : 4000db: nop
0 : 4000dc: nop
0 : 4000dd: nop
0 : 4000de: nop
31 : 4000df: nop
0 : 4000e0: nop
0 : 4000e1: mov rax,QWORD PTR [rax]
22 : 4000e4: nop
0 : 4000e5: nop
0 : 4000e6: nop
0 : 4000e7: nop
16 : 4000e8: nop
0 : 4000e9: nop
0 : 4000ea: nop
0 : 4000eb: nop
24 : 4000ec: nop
0 : 4000ed: nop为了防止你忘记:第一列显示的是每条指令所接收到的中断次数
观察:采样点(左侧数字大于0的行)清晰地集中在三个特定位置,形成了一个固定的模式:
- 紧跟长延迟
mov指令之后的那条nop- 在
mov指令后的第 5 条nop(即地址间隔中的第 2 个有数字的nop)- 在
mov指令后的第 9 条nop(即地址间隔中的第 3 个有数字的nop)
这个模式在每个mov ... nop x 10的代码块中稳定重复。
被选中的指令不仅包括长延迟的mov依赖链指令,还涵盖了其后10条nop中的两条特定指令:分别位于mov指令后第4和第8条的位置。这里我们可以观察到提交吞吐量的影响:虽然mov链是唯一影响执行延迟的因素,但这款Skylake CPU每个周期(每线程)最多只能提交4条指令。因此当mov指令最终提交时,需要经过两个周期(每次提交4条指令)才能处理到下一个mov nop mov mov mov nop mov指令。
; retire cycle
mov rax,QWORD PTR [rax] ; 0 (execution limited)
nop ; 0
nop ; 0
nop ; 0
nop ; 1 <-- selected nop
nop ; 1
nop ; 1
nop ; 1
nop ; 2 <-- selected nop
nop ; 2
nop ; 2
mov rax,QWORD PTR [rax] ; 4 (execution limited)
nop ; 4
nop ; 4在此例中,mov指令的退休属于"执行受限"(execution limited)——即其退休周期完全取决于执行完成时间,与退休引擎本身的处理细节无关。相反,其他nop指令的退休则受退休机制行为(retirement behavior)支配:它们早已"准备就绪",却因按序退休指针被尚未执行完毕的mov指令阻塞而无法退休。
Execution limited
mov指令之所以不能退休,是因为它自身的执行阶段还没完成(它在慢悠悠地等内存数据)。它的退休时间完全由它自己的执行速度决定。Retirement limited
nop指令早就执行完毕了,状态是“准备就绪”。但它们还是不能退休,原因是 CPU 必须按顺序退休指令。
因此,这些被选中的nop指令本身并无特殊之处:它们的执行速度并不比其他指令慢,也未造成任何瓶颈。其所以被选中,纯粹是因为在mov指令之后形成的退休模式具有可预测性。特别要注意的是,被选中的正是原本会以4条为一批退休的nop组中排在首位的指令。
(我们在之前的所有示例中都已观察到这种效应:这正是为什么长延迟的add指令会被选中,即便在它退休的那个周期内,后续三条指令也会同时退休。这种行为非常理想,因为它能确保通常是较长延迟的指令被选中,而非某些无关指令(也就是说,常见的指令滑移是+1,而非+4))
这些被选中的
nop(第1、5、9条)本身并不特殊,它们和其他nop一样快。它们之所以“幸运”地被采样到,纯粹是因为它们恰好处在退休流水线的关键节拍点上(即每个退休批次的第一条指令),在这个时间窗口内,它们扮演了“最老未退休指令”的角色。关于最多只能提交4条指令,作者列出了下面的链接,他应该是从此找到的。
https://www.realworldtech.com/forum/?threadid=161978&curpostid=162222分析:
A. 场景回顾:
关键指令:一条长延迟的mov rax, [rax]指令(需要4个周期才能得到结果)。
后续指令:10条nop指令(无延迟,可快速执行完毕)。
CPU能力:Skylake CPU每个周期最多可以提交 4 条指令。B. 发生了什么?
B.1mov指令执行中:当mov rax, [rax]还在执行(计算内存地址、等待数据从缓存载入)的4个周期里,它后面的10条nop指令早已执行完毕。但它们不能“毕业”,必须排在mov指令后面,在重排序缓冲区 里排队等待按顺序提交。
B.2mov指令终于完成:在第4个周期结束时,mov指令的所有工作都做完了,它终于可以“退休”了。
B.3 退休流水线开始工作:此时,CPU的退休单元开始按顺序批量处理积压的指令:
第1个周期:退休单元提交完mov指令,并且还能在同一周期内继续提交紧随其后的3条nop指令(因为退休带宽是4条/周期)。这样,排在队列最前面的4条指令(1条mov+ 3条nop)就全部退休了。
第2个周期:退休单元继续提交接下来的4条nop指令。
第3个周期:退休单元提交最后剩下的3条nop指令。C. 中断采样
根据之前的假设,中断会选择“最年长的未退休指令”作为选中指令。
C.1 在mov指令漫长的执行过程中,它始终是队列里最“老”的指令。因此,如果中断在此期间到来,它极有可能被选中,导致采样点落在它后面的第一条nop上。
C.2 但是,在mov指令退休后的那两个退休周期里,情况发生了变化:
C.3 在第1个退休周期,当退休单元正在处理那4条指令时,队列中新的“最老”指令变成了第5条nop指令(即第1组4条指令之后的那一条)。如果中断在这个时间点到来,选中指令就是这条第5条nop,采样点则会落在第6条nop上。
C.4 在第2个退休周期,同理,新的“最老”指令变成了第9条nop,如果中断在此刻到来,采样点就会落在第10条nop上。因此,我们分析看到为什么
mov和nop有这样的出现频率?
即使关键路径上只有一条慢指令,但由于CPU的退休单元像一条宽度固定的传送带(每周期4条),慢指令后面堆积的快速指令必须分批退休。这种分批退休的节奏,就创造了多个不同的时间窗口。在每个窗口期内,都有一条不同的指令会成为“最老的未退休指令”,从而成为中断捕获的目标。我与GPT的共同分析:让我们就考虑第一行,如下
0 : 4000ba: mov rax,QWORD PTR [rax] ; 【长延迟指令】
33 : 4000bd: nop ; 【位置 A】采样点 1
0 : 4000be: nop
0 : 4000bf: nop
0 : 4000c0: nop
11 : 4000c1: nop ; 【位置 B】采样点 2
0 : 4000c2: nop
0 : 4000c3: nop
0 : 4000c4: nop
22 : 4000c5: nop ; 【位置 C】采样点 3
0 : 4000c6: nop
0 : 4000c7: mov rax,QWORD PTR [rax] ; 下一个代码块开始这个分布是如何形成的?
- 【位置 A】的 33 次采样:
- 当长延迟
mov指令正在执行时,它是 最老的未退休指令。- 在此期间到来的中断都会选中它,采样点则记录在它正后方的
nop(4000bd) 上。- 因为
mov指令占了4个周期,所以这个时间窗口很长,捕获到的中断数量最多。- 【位置 B】的 11 次采样:
- 当
mov指令终于完成并进入退休阶段时,CPU开始以每周期4条指令的速率退休积压的nop。- 在第一个退休周期,CPU会退休
mov及其后面的3条nop(4000bd, 4000be, 4000bf, 4000c0)。- 此时,队列中新的最老指令变成了第5条
nop(4000c1)。- 如果中断在这个退休周期内到来,它就会选中 4000c1 这条
nop,采样点则落在它后面的指令上(但下一条指令还是nop,且由于nop执行快,采样几乎立即发生,所以记录点就是 4000c1 自己)。- 这个时间窗口只有一个周期,比
mov执行的4个周期短,所以采样数量较少。- 【位置 C】的 22 次采样:
- 在第二个退休周期,CPU退休了接下来的4条
nop(4000c1, 4000c2, 4000c3, 4000c4)。- 此时,队列中新的最老指令变成了第9条
nop(4000c5)。- 如果中断在这个退休周期内到来,它就会选中 4000c5,采样点记录在 4000c5。
- 这个时间窗口也只有一个周期,但采样数比位置B多,可能与中断到达的时间统计分布有关。
验证猜想
由刚刚到理论,我们由此可以构建一个示例,其中处于关键路径上的指令永远不会被选中:
%rep 10
mov rax, [rax]
nop
nop
nop
nop
nop
add rax, 0
%endrep结果:
0 : 4000ba: mov rax,QWORD PTR [rax]
94 : 4000bd: nop
0 : 4000be: nop
0 : 4000bf: nop
0 : 4000c0: nop
17 : 4000c1: nop
0 : 4000c2: add rax,0x0
0 : 4000c6: mov rax,QWORD PTR [rax]
78 : 4000c9: nop
0 : 4000ca: nop
0 : 4000cb: nop
0 : 4000cc: nop
18 : 4000cd: nop
0 : 4000ce: add rax,0x0这条add指令位于关键路径上:它将代码块的执行时间从4个周期延长到了6个周期,然而它却从未被选中。其退休模式呈现如下规律:
; /- scheduled
; | /- ready
; | | /- complete
; | | | /- retired
mov rax, [rax] ; 0 0 5 5 <-- selected
nop ; 0 0 0 5 <-- sample
nop ; 0 0 0 5
nop ; 0 0 0 5
nop ; 1 1 1 6 <-- selected
nop ; 1 1 1 6 <-- sampled
add rax, 0 ; 1 5 6 6
mov rax, [rax] ; 1 6 11 11 <-- selected
nop ; 2 2 2 11 <-- sampled
nop ; 2 2 2 11
nop ; 2 2 2 11
nop ; 2 2 2 12 <-- selected
nop ; 3 3 3 12 <-- sampled
add rax, 0 ; 3 11 12 12
mov rax, [rax] ; 3 12 17 17 <-- selected
nop ; 3 3 3 17 <-- sampled在右侧,我为每条指令标注了几个关键的周期数值,具体说明如下:
调度列(scheduled column)表示指令进入调度器的周期,此时若所有依赖项均已满足即可执行。该列非常简单:我们假设不存在前端瓶颈,因此每个周期按程序顺序调度(即"分配 allocate")4条指令。
就绪列(ready column)表示已调度指令的所有依赖项均执行完毕、可立即执行的周期。在此简化模型中,指令一旦就绪便立即开始执行。更复杂的模型还需考虑执行端口的争用情况,但本例中不存在此类争用。指令就绪时间呈乱序特征:可见许多较晚的指令反而比较早的指令(如mov/add)更早就绪。该列数值取以下两者的最大值:当前指令的调度周期,以及所有前驱指令输出作为当前指令输入时的完成周期。
完成列(complete column)显示指令执行结束的周期。在此模型中,该值直接取自就绪周期加上指令延迟——nop指令延迟为0(它们不执行,有效延迟为0),add指令延迟为1,mov指令延迟为5。与就绪列类似,指令完成时间也是乱序的。
最终我们关注的退休列(retired column),则显示了指令退休的周期。规则很简单:指令必须执行完成后才能退休,且前一条指令必须已完成退休或在本周期内同步退休。每个周期最多只能退休4条指令。由于"前序指令必须完成退休"这一约束,退休周期是严格递增的,因此与第一列相同,退休过程始终保持顺序性。
当我们完成退休周期的填充后,就能识别出 <-- 被选中(selected)的指令 :它们正是退休周期发生跃增处的指令。在此案例中,被选中的指令始终只有两种:要么是因长延迟而阻塞退休流程的mov指令,要么是mov指令后的第四条nop指令(受"每周期仅退休4条"规则限制,该nop正好是mov退休后下一批退休指令组的首条)。最终,实际出现在中断报告中的被采样指令,其实就是每条被选中指令的紧随其后那条。
(当然,这并不意味着这些指令就一定会被选中——我们在上百万次中断中仅采集到几千个样本,因此大多数情况下中断到来时并不会触发采样。这些位置仅仅代表了当中断确实需要被处理时,最有可能被选中的指令地址)
为什么这里
add指令不会被选中?
- 长延迟指令:
mov rax, [rax]需要4个周期完成(从它被调度的周期算起)。对应completed 跟retried 列标记为 5- 依赖链:
add rax, 0x0依赖于mov的结果,因此它必须等mov执行完毕才能开始自己的执行。- 退休带宽:CPU每周期最多退休4条指令。
add指令之所以“隐身”,是因为一个不幸的退休对齐:- 在它终于能够执行之前,前面已经堆积了多条早已完成的nop。
CPU的4指令/周期的退休带宽,恰好使得add总是被包含在一个退休批次的末尾,而不是开头。
只有处在退休批次开头的指令,才有机会在某个时间窗口内成为“最老未退休指令”,从而被中断选中。引用GPT的话:"这个例子完美地证明了,一条指令是否出现在性能分析的采样结果中,不仅取决于它是否在关键路径上(它确实是!),还取决于它在退休流水线中的相对位置这个看似偶然的因素。 这解释了为什么性能剖析工具的数据需要审慎解读。"
此处的add指令之所以从未被选中,是因为它在mov指令执行完毕后的下一个周期才执行。这意味着它可以在紧随其后的周期内进入退休状态,因此并不会拖慢退休流程——从退休机制的角度看,其行为模式与nop指令并无二致。
我们可以稍微调整add指令的位置,使其与mov指令落入同一个4指令退休窗口,如下所示:
源码:
https://github.com/travisdowns/interrupt-test/blob/master/load-add3.asm
%rep 10
mov rax, [rax]
nop
nop
add rax, 0
nop
nop
nop
%endrep我们只是将add指令的位置略微上移了几行。指令总数保持不变,该代码块的执行周期仍为6个周期,与上个示例完全相同。然而现在add指令却总是被选中:
21 : 4000ba: mov rax,QWORD PTR [rax]
54 : 4000bd: nop
0 : 4000be: nop
0 : 4000bf: add rax,0x0
15 : 4000c3: nop
0 : 4000c4: nop
0 : 4000c5: nop
0 : 4000c6: mov rax,QWORD PTR [rax]
88 : 4000c9: nop
0 : 4000ca: nop
0 : 4000cb: add rax,0x0
14 : 4000cf: nop
0 : 4000d0: nop
0 : 4000d1: nop
0 : 4000d2: mov rax,QWORD PTR [rax]
91 : 4000d5: nop
0 : 4000d6: nop
0 : 4000d7: add rax,0x0
13 : 4000db: nop这是该版本的周期分析与退休模式示意图:
; /- scheduled
; | /- ready
; | | /- complete
; | | | /- retired
mov rax, [rax] ; 0 0 5 5 <-- selected
nop ; 0 0 0 5 <-- sample
nop ; 0 0 0 5
add rax, 0 ; 0 5 6 6 <-- selected
nop ; 1 1 1 6 <-- sampled
nop ; 1 1 1 6
nop ; 1 1 1 6
mov rax, [rax] ; 1 6 11 11 <-- selected
nop ; 2 2 2 11 <-- sampled
nop ; 2 2 2 11
add rax, 0 ; 2 11 12 12 <-- selected
nop ; 2 2 2 12 <-- sampled
nop ; 3 3 3 12
nop ; 3 3 3 12
mov rax, [rax] ; 3 12 17 17 <-- selected
nop ; 3 3 3 17 <-- sampled现在或许是个合适的时机指出,我们不仅关注采样点是否出现,更在意其实际采样频次。在此例中,与mov指令相关的采样数量远高于add指令。实际上,mov与add的采样比例约为4.9:1(基于完整结果计算)。这个数值几乎完全对应了mov指令5周期延迟与add指令1周期延迟的比例——这意味着mov指令担任最老未退休指令的时长是add指令的5倍。由此可见,在此类场景下采样计数具有重要参考价值。
回到周期示意图,我们知道被选中的指令对应着退休周期发生跃增的位置。在此基础上还需认识到:跃增的幅度决定了它们的被选权重。以mov指令为例,其权重为5(比如退休周期从6跃增至11,意味着它持续担任最老未退休指令长达5个周期),而nop指令的权重则为1。
这种方法使得我们能够实地测量各种指令的延迟周期,只要准确掌握了退休机制的行为特征。例如,通过测量以下代码块(运行时rdx值为零)即可实现:
mov rax, [rax]
mov rax, [rax + rdx]实验结果显示,第一行与第二行指令的采样数量呈现出4:5的比例分布:这准确反映了第二条加载指令因复杂地址计算需要5周期延迟,而第一条加载指令仅需4个时钟周期的事实。
Branch 分支指令测试
那么分支指令的情况如何呢?我发现分支指令并无特殊之处:无论分支是否被采纳,它们似乎都能正常完成退休流程,并符合上文所述的模式。在此我不再展示具体实验结果,但您若有兴趣可以自行运行分支测试进行验证。
源码:
https://github.com/travisdowns/interrupt-test/blob/master/branches.asm
原子操作 指令
那么原子操作的情况如何?这里的情况就变得有趣了。
我将默认使用 lock add QWORD [rbx], 1 作为原子指令代表,不过其他原子指令的表现也大致类似。单独来看,这条指令的"延迟"(注意)为18个周期。现在我们将它与几条总延迟为20周期的SIMD指令并行执行。
(此处的“延迟”之所以加上引号,是因为原子操作的表面延迟特性与其他大多数指令截然不同:如果你测量连续原子操作的吞吐量,会发现当这些指令形成依赖链时,性能反而比不存在依赖链时更高!原子操作的延迟无法简单套用输入到输出的传统模型,因为它们在退休时执行的特质会引发其他瓶颈。)
vpmulld xmm0, xmm0, xmm0 # SIMD指令,延迟约为20周期
vpmulld xmm0, xmm0, xmm0
lock add QWORD [rbx], 1 # 原子指令,延迟大约为18周期这个循环仍然需要20个周期来执行。也就是说,原子操作在运行时几乎没有产生额外开销:即使将其注释掉,性能表现也完全一致。vpmulld依赖链的长度足以掩盖原子操作的成本。现在让我们观察一下这段代码的中断分布情况:
0 : 4000c8: vpmulld xmm0,xmm0,xmm0
12 : 4000cd: vpmulld xmm0,xmm0,xmm0
10 : 4000d2: lock add QWORD PTR [rbx],0x1
244 : 4000d7: vpmulld xmm0,xmm0,xmm0
0 : 4000dc: vpmulld xmm0,xmm0,xmm0
26 : 4000e1: lock add QWORD PTR [rbx],0x1
299 : 4000e6: vpmulld xmm0,xmm0,xmm0
0 : 4000eb: vpmulld xmm0,xmm0,xmm0
35 : 4000f0: lock add QWORD PTR [rbx],0x1
277 : 4000f5: vpmulld xmm0,xmm0,xmm0
0 : 4000fa: vpmulld xmm0,xmm0,xmm0
33 : 4000ff: lock add QWORD PTR [rbx],0x1
302 : 400104: vpmulld xmm0,xmm0,xmm0
0 : 400109: vpmulld xmm0,xmm0,xmm0
33 : 40010e: lock add QWORD PTR [rbx],0x1
272 : 400113: vpmulld xmm0,xmm0,xmm0
0 : 400118: vpmulld xmm0,xmm0,xmm0
31 : 40011d: lock add QWORD PTR [rbx],0x1
280 : 400122: vpmulld xmm0,xmm0,xmm0
0 : 400127: vpmulld xmm0,xmm0,xmm0
40 : 40012c: lock add QWORD PTR [rbx],0x1
277 : 400131: vpmulld xmm0,xmm0,xmm0
0 : 400136: vpmulld xmm0,xmm0,xmm0
21 : 40013b: lock add QWORD PTR [rbx],0x1
282 : 400140: vpmulld xmm0,xmm0,xmm0
0 : 400145: vpmulld xmm0,xmm0,xmm0
35 : 40014a: lock add QWORD PTR [rbx],0x1
291 : 40014f: vpmulld xmm0,xmm0,xmm0
0 : 400154: vpmulld xmm0,xmm0,xmm0
35 : 400159: lock add QWORD PTR [rbx],0x1
270 : 40015e: dec rcx
0 : 400161: jne 4000c8 <_start.loop>为了方便查看,我截取了原图,它对高频的指令涂了红色:

尽管lock add指令对总执行时间没有影响,但它们被中断选中的概率却接近90%。 根据我们的模型,这些指令本应能在vpmulld循环之前提前执行,从而在成为ROB头部时立即退休。我们观察到的这种现象源于带lock前缀的指令采用退休时执行机制——这是一种特殊类型的指令,它会一直等待直到自己成为ROB头部才开始执行。
因此这类指令作为最老未退休指令时,总会占据固定的最小时长:无论周围指令如何,它都永远不会立即退休。在本案例中,这意味着退休阶段大部分时间在等待加锁指令,而执行阶段大部分时间在等待vpmulld指令。值得注意的是,加锁指令带来的退休时间延迟并未与vpmulld的延迟简单叠加:其在退休阶段的等待时间,恰好抵消了原本需要等待乘法指令退休的时间。这就导致了采样比例呈现非对称分布,而非均等的50/50分割。
lock add指令必然会阻塞退休流水线一段时间
- 普通指令:在乱序执行核心中,只要操作数就绪就可以被执行,执行完毕后进入ROB等待退休。
lock指令(如lock add):它会被解码并放入ROB,但不会被发送到执行单元。它会一直等在ROB中,直到它成为ROB的头部(即最老的未退休指令)时,才会被“唤醒”并执行。
若将乘法指令数量增至4条,这一现象将更为清晰:
vpmulld xmm0, xmm0, xmm0
vpmulld xmm0, xmm0, xmm0
vpmulld xmm0, xmm0, xmm0
vpmulld xmm0, xmm0, xmm0
lock add QWORD [rbx], 1这需要40 周期来执行,而其中断的pattern如下:
0 : 4000c8: vpmulld xmm0,xmm0,xmm0
18 : 4000cd: vpmulld xmm0,xmm0,xmm0
49 : 4000d2: vpmulld xmm0,xmm0,xmm0
133 : 4000d7: vpmulld xmm0,xmm0,xmm0
152 : 4000dc: lock add QWORD PTR [rbx],0x1
263 : 4000e1: vpmulld xmm0,xmm0,xmm0
0 : 4000e6: vpmulld xmm0,xmm0,xmm0
61 : 4000eb: vpmulld xmm0,xmm0,xmm0
160 : 4000f0: vpmulld xmm0,xmm0,xmm0
168 : 4000f5: lock add QWORD PTR [rbx],0x1
251 : 4000fa: vpmulld xmm0,xmm0,xmm0
0 : 4000ff: vpmulld xmm0,xmm0,xmm0
59 : 400104: vpmulld xmm0,xmm0,xmm0
166 : 400109: vpmulld xmm0,xmm0,xmm0
162 : 40010e: lock add QWORD PTR [rbx],0x1
267 : 400113: vpmulld xmm0,xmm0,xmm0
0 : 400118: vpmulld xmm0,xmm0,xmm0
60 : 40011d: vpmulld xmm0,xmm0,xmm0
160 : 400122: vpmulld xmm0,xmm0,xmm0
155 : 400127: lock add QWORD PTR [rbx],0x1
218 : 40012c: vpmulld xmm0,xmm0,xmm0
0 : 400131: vpmulld xmm0,xmm0,xmm0
58 : 400136: vpmulld xmm0,xmm0,xmm0
144 : 40013b: vpmulld xmm0,xmm0,xmm0
154 : 400140: lock add QWORD PTR [rbx],0x1
pattern continues...
lock add 指令的采样数量保持相似,但 vmulld 指令的总采样数现已增长到与之相当的水平。实际上,我们可以利用 lock add 被选中的比率与已知的代码块吞吐量(40周期)来计算出该指令的退休耗时。通过几次运行,我测得约38%-40%的选中率,对应15-16周期的退休时间,仅略低于该指令在连续执行时的延迟周期。
(作者注:vpmulld指令之间出现的不均匀分布模式,如有的是59次,有的是166次,有的是267次,是由于lock add指令吞噬了其后首批vpmulld指令的退休周期(这些指令因早已执行完毕而能够快速退休),因此只有排列在更后位置的vpmulld指令才能获得完整的退休时隙分配。)
作者意识到,这种“偏差”并非随机,其比例精确地反映了不同指令在退休流水线中占据“最老未退休指令”状态的相对时长。
我们能否利用这些信息做些研究?
一个可行的思路是,这种方法能让我们精确描绘指令的退休时序。例如,我们可以设置一条待测指令,并搭配一条已知延迟的并行指令链。通过观察中断选中的是待测指令还是已知延迟链的末端,就能判断哪个具有更长的退休延迟;通过调整已知延迟链的长度,就能精确测定待测指令的退休时长。
类似于一场 “延迟退休赛跑”:
- 选手A:待测指令(如
lock add,store等)。- 选手B:一个已知延迟的、并行的依赖链(如一长串
vpmulld)。
在同一个循环体中,两位“选手”同时开始(从退休顺序上看)。谁的退休延迟更长,谁就更有可能在更多的时间里担任“最老未退休指令”,从而在中断采样中被更多地捕获。- 通过调整“选手B”(已知延迟链)的长度,观察采样比例的拐点。当采样比例从偏向A变为偏向B时,就意味着B的延迟刚刚超过了A,从而可以精确界定A的退休延迟。
当然,这听起来比传统的延迟测量方法(使用长串连续指令)更为复杂,但其优势在于能够在不构建长依赖链的情况下进行原位测量,尤其适用于那些难以形成明显依赖链的指令(例如没有输出的存储指令或跨域指令)。
这里作者想指出这种测量方法的优势:有的指令的执行时间可能只在那个特定的指令上下文,或者很难用传统的输入输出模型来测量该指令的周期(比如我们看到这里的
lock add指令,它的退休时间并没有一个固定的周期时长,想获取它实际每次的运行时间,就可以用我们这里的这个方法)。此时我们使用该方法,能够在更“自然”的环境中进行测量。
待探究事项
- 从退休窗口模式的角度解释实验结果中的变量(非自同步)现象(作者可能在实验中观察到了一些不稳定、无法简单重复的现象,当然这里具体是什么,我也不知道了)
- 验证可中断指令(interruptible instructions)的特性
- 测试内存屏障指令(如
mfence指令)及其相关指令 - 探究原子指令(atomic instructions)对执行单元的影响(例如阻塞加载端口)
评论
欢迎任何形式的反馈。我目前尚未搭建评论系统,因此照例将讨论交由这个HackerNews主题帖进行。
致谢与署名
感谢HN用户rrss指正我周期图表中的错误。
感谢Alex Dowad指出文本中的笔误。
英特尔8259芯片图片由维基百科用户German在CC BY-SA 3.0协议下授权使用。
个人总结
这篇文章了却了我多年的心结:我的 vtune 到底为什么测不准?!终于在看完这些机制后,我认为是可以定下这个结论了。在进行高性能的CPU程序分析时,面对一些微小的指令部分,我们是不能过于相信程序测试工具的,可能还是要用最简单的时间指令来计时与profile。同时,通过这篇文章,我们对体系结构里的中断与OOO有了更深刻的理解。
最后,作者在体系结构上经验丰富,我非常推荐大家回看原文,该作者的其他文章也真的是相当精彩!
推荐阅读
Interrupt
《Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3》
Intel® Manual Chapter 7 | Intel手册第七章中文翻译:中断和异常处理
https://sov710.github.io/columns/intel-manual-translate/07-interrupt-and-exception-handling.html#_7-3-1-%E5%A4%96%E9%83%A8%E4%B8%AD%E6%96%AD
从电路底层来了解CPU中断机制 - 翛翾的文章 - 知乎
https://zhuanlan.zhihu.com/p/611038805
OOO
乱序执行Out-of-Order Execution - Wil的文章 - 知乎
https://zhuanlan.zhihu.com/p/26184755002
玄铁C910微架构学习(17)——退休单元 - Taurus的文章 - 知乎
https://zhuanlan.zhihu.com/p/608282924
《超标量处理器设计》学习笔记(10) - 退休 - yang97e1696的文章 - 知乎
https://zhuanlan.zhihu.com/p/713879982
乱序执行Out-of-Order Execution - Wil的文章 - 知乎
https://zhuanlan.zhihu.com/p/26184755002
Others
In x86 Intel VT-X non-root mode, can an interrupt be delivered at every instruction boundary?
https://stackoverflow.com/questions/54821523/in-x86-intel-vt-x-non-root-mode-can-an-interrupt-be-delivered-at-every-instruct?utm_source=chatgpt.com
Arch State
https://www.sciencedirect.com/topics/computer-science/architectural-state