
TLB, ASID, TTBR And Context Switching
- OS
- 2024-11-27
- 1753 Views
- 0 Comments
- 6702 Words
本文是在实验课上看一些文章和GPT整理的,不完全
面试官:不同进程对应相同的虚拟地址,在 TLB 是如何区分的?-腾讯云开发者社区-腾讯云
Linux进程管理+内存管理:进程切换的TLB处理(ASID-address space ID、PCID-process context ID)_进程的asid-CSDN博客
TLB、PCID与ASID的故事_pcid机制-CSDN博客
1. ASID 的作用和 TLB 的工作原理
在 ARM 架构和大多数现代 CPU 中,TLB 的条目是按照 ASID 进行区分的。每个进程或线程都有一个唯一的 ASID,它用来标识该进程的虚拟地址空间。每个 TLB 条目不仅包含虚拟地址和物理地址的映射,还会附带一个 ASID,以标识该条目属于哪个地址空间。
- 每个进程/上下文的映射 都会有自己独立的 ASID。
- 当进程 A 和进程 B 切换时,操作系统会通过 按 ASID 无效化 来清除与当前进程不相关的 TLB 条目。
这种做法的目的是确保 TLB 中的条目不会在进程切换时出现混淆,不同进程的地址空间是 完全隔离 的。
2. 进程 A 和进程 B 的 TLB 条目隔离
当你提到“进程 A 的数据,刚好会放到 TLB 中 ASID 为 B 的位置”,实际上这是一种潜在的设计错误或是误解。因为按照 TLB 和 ASID 的设计,每个 ASID 对应的条目位置是独立的,不会相互覆盖。即使 TLB 是有限的,硬件和操作系统会通过有效的替换策略和无效化机制,避免进程 A 和进程 B 的映射冲突。
3. 如何避免进程 A 和进程 B 的映射冲突?
在实际的 TLB 操作中,硬件和操作系统确保不同 ASID 的条目不会混淆:
-
进程切换时的 TLB 清空:当进程切换时,操作系统通常会通过
TLBI ASID指令来清除不属于当前进程的 TLB 条目。这样,即使进程 A 和进程 B 使用相同的 TLB 存储空间,硬件会确保它们的地址映射是独立的,不会互相覆盖。 -
TLB 的替换机制:当进程 A 和进程 B 使用 TLB 时,如果它们有相同的虚拟地址映射,硬件会根据 ASID 和虚拟地址的组合来进行 匹配,以确保它们的映射不会冲突。换句话说,即使 TLB 空间有限,硬件会使用 虚拟地址 + ASID 作为唯一的键来区分不同进程的映射。只要 ASID 不相同,即使虚拟地址相同,也不会冲突。
-
TLB 行为:假设 TLB 中有一个条目,在存储映射时,硬件会检查 ASID,确认该条目是否属于当前进程。如果是另一个进程的 ASID,硬件会忽略该条目,或者在替换时根据替换策略将其清除。
在 ARM 架构中,ASID(Address Space Identifier) 是一种用于区分不同地址空间的标识符,尤其在 虚拟内存管理中,主要用来区分不同进程的虚拟地址空间。TLB(Translation Lookaside Buffer)是硬件缓存,用于加速虚拟地址到物理地址的转换。
进程切换时 TLB 的处理
在 ARM 架构中,当进程切换时,通常会面临两个主要问题:
- 虚拟地址空间的切换:每个进程有独立的虚拟地址空间。
- TLB 缓存的内容:由于 TLB 缓存了虚拟地址到物理地址的映射,进程切换时,如果不清除 TLB,可能会导致进程 A 使用进程 B 的地址映射,从而导致错误的地址翻译。
为了应对这个问题,ARM 使用 ASID 来为每个进程的虚拟地址空间标记一个唯一标识符,从而可以通过 ASID 来区分不同进程的 TLB 缓存条目。
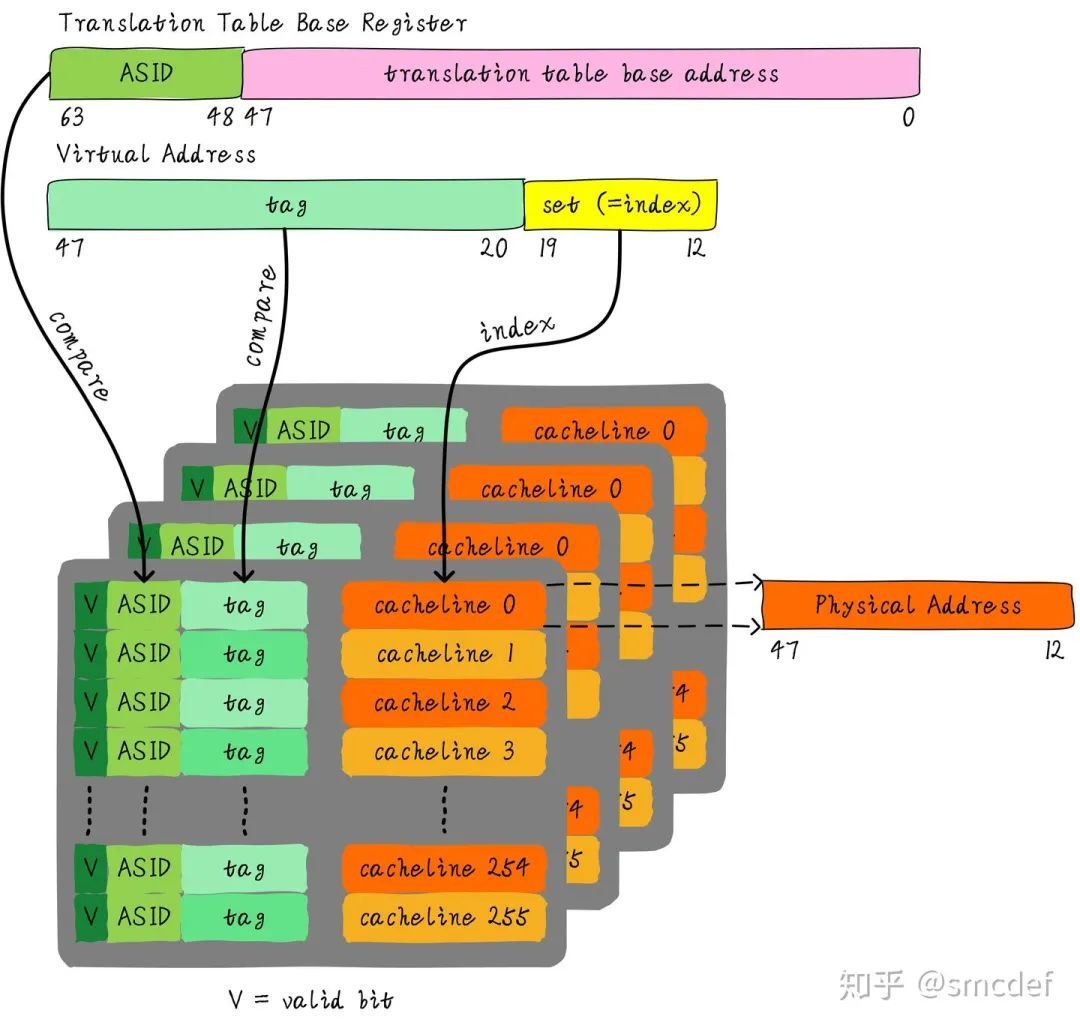
1. ASID 和 TLB
- 每个进程在 ARM 系统中都有一个唯一的 ASID,该 ASID 被加到每个虚拟地址的地址转换过程中。
- TLB 的每个条目都保存了与虚拟地址和物理地址映射相关的信息,并且通常会携带一个与当前地址空间相关的 ASID。当进程 A 和进程 B 切换时,即使它们的虚拟地址空间的映射不同,只要它们的 ASID 不同,它们的 TLB 缓存也能正确区分各自的映射。
2. 进程切换时的 TLB 管理策略
当进程切换时,ARM 处理 TLB 的方式通常有几种:
-
使用 ASID 区分 TLB 条目:
ARM 系统在虚拟地址到物理地址的转换过程中,会考虑到 ASID。每个 TLB 条目会携带一个 ASID,只有当访问的虚拟地址与当前进程的 ASID 匹配时,TLB 才会提供有效的地址映射。因此,不同进程的 TLB 条目会携带不同的 ASID。 -
TLB 无效化(TLB Invalidation):
在进程切换时,为了确保进程 A 和进程 B 之间的地址空间隔离,通常会使用 TLB 无效化机制。具体来说,操作系统会在进程切换时通过写控制寄存器的方式使当前 TLB 中与当前进程无关的条目失效。这样做有以下两种方式:- 全局 TLB 无效化:清除所有的 TLB 条目,不论 ASID 是什么。
- 按 ASID 无效化:通过 TLB 无效化操作,清除所有不属于当前进程(即不匹配当前 ASID)的条目。
3. 具体的 TLB 无效化操作
-
ARMv7及更早版本:在 ARMv7 之前的版本(例如 ARMv6),进程切换时往往需要清除所有的 TLB 条目。这是因为早期的 ARM 架构并没有像 ARMv7 及更高版本那样,提供针对 ASID 的精细控制。
-
ARMv7及以后版本:在 ARMv7 及更高版本的架构中,系统支持 TLB 按 ASID 无效化,这意味着系统可以仅清除与当前 ASID 不匹配的条目,而不是清除所有条目。ARMv7 引入了新的指令,例如
TLBI(TLB Invalidate)指令,用来进行更加精细的 TLB 无效化操作。例如:TLBI ASID:用于无效化与指定 ASID 不匹配的 TLB 条目。TLBI ALL:清空所有 TLB 条目。
-
使用
ACTLR控制 TLB 行为:在 ARM 中,ACTLR(Auxiliary Control Register)可以用于配置一些关于 TLB 的行为,操作系统可以通过这些寄存器来调整 TLB 的管理方式。
总结
在 ARM 架构中,ASID 是用于区分不同进程地址空间的标识符。当进程切换时,ARM 会通过以下方式来管理 TLB:
- 通过为每个进程分配不同的 ASID,保证每个进程的 TLB 条目可以被正确区分。
- 在进程切换时,通过 TLB 无效化操作,确保进程 A 和进程 B 的虚拟地址空间不会混淆,避免旧进程的映射影响新进程。
随着 ARM 架构的发展,ARMv7 及以后版本支持更加精细的 TLB 无效化操作(如按 ASID 无效化),从而使得 TLB 管理更加高效,不需要完全清空 TLB,减少了性能开销。
TLB 无效化(TLB Invalidation)并不是一条一条逐个执行的,而是通过特定的硬件指令来批量清除不再需要的 TLB 条目。虽然在某些情况下,操作系统可能需要精细控制 TLB 中的条目,但是现代 ARM 架构允许批量、按组、甚至按特定条件清除 TLB 条目,这比逐个条目清除更加高效。
TLB 无效化的方式
在 ARM 架构中,TLB 无效化的方式有很多种,通常都能够在硬件级别进行一次性批量操作。这里有几种常见的 TLB 无效化方式:
1. 全局 TLB 无效化
在进程切换时,操作系统可能会选择无效化所有的 TLB 条目。这种操作可以通过单条指令来完成,不需要逐个清除 TLB 条目。
-
ARMv7 及以上版本:在 ARMv7 及更新的架构中,
TLBI(Translation Lookaside Buffer Invalidate)指令用于无效化 TLB 条目。常见的指令有:TLBI ALL: 这条指令会使所有 TLB 条目失效,也就是说,无论 TLB 条目对应的 ASID 或虚拟地址如何,它们都会被清除。这是一个全局性的无效化操作,通常用于进程切换时。
执行这条指令后,所有 TLB 条目都会被标记为无效,不再存储有效的地址映射。
2. 按 ASID 无效化
ARM 架构支持按 ASID(Address Space Identifier)来无效化特定进程的 TLB 条目。这样,只有与当前进程地址空间无关的条目会被清除,而其他进程的 TLB 条目不会受到影响。这种方式比全局无效化更高效,因为它避免了对整个 TLB 的清除。
-
ARMv7 及以上版本:使用
TLBI指令时,可以通过指定 ASID 来进行按需的无效化。例如:TLBI ASID:无效化所有与指定 ASID 不匹配的 TLB 条目。TLBI VA:无效化与指定虚拟地址相关的 TLB 条目。
这些操作可以按批次进行,避免了逐条逐条清除 TLB 条目的低效。
3. 按虚拟地址无效化
有时操作系统可能只想无效化某个特定虚拟地址的映射。这种方式通常用于针对某些特定的内存区域进行操作,如在内存映射修改后。
- ARMv7 及以上版本:使用
TLBI指令时,操作系统可以指定一个虚拟地址,来无效化与该地址相关的 TLB 条目。例如:TLBI VA:这条指令会根据指定的虚拟地址无效化对应的 TLB 条目,而不影响其他虚拟地址的映射。
是否逐条执行?
现代的 ARM 架构通过这些指令来批量无效化 TLB 条目,而不需要逐个条目进行处理。对于 ARMv7 及以上版本,它们通常采用硬件加速来一次性无效化多个条目,而不是逐条清除。这样可以显著提高 TLB 无效化的效率,避免逐条执行带来的性能开销。
具体来说:
- 全局无效化(如
TLBI ALL)会一次性清除所有 TLB 条目。 - 按 ASID 无效化(如
TLBI ASID)会清除与特定 ASID 不匹配的所有条目。 - 按虚拟地址无效化(如
TLBI VA)会针对某个特定虚拟地址清除映射。
在硬件层面,这些操作是通过控制寄存器、TLB 标签以及硬件逻辑一次性批量执行的,因此不会是逐条逐条地清除,而是按批次进行高效的无效化。
总结
TLB 无效化并不是一条一条执行的。在现代 ARM 架构中,硬件通常通过 批量 或 按条件 的方式来进行 TLB 无效化操作,而不需要逐个条目清除。这使得 TLB 无效化操作在进程切换或内存管理过程中能够更高效地执行,避免了逐条操作带来的性能开销。
2. 按 ASID 无效化的操作
ARM 支持按 ASID 无效化 TLB 条目。按 ASID 无效化的操作可以通过以下指令完成:
TLBI ASID 指令
ARM 提供了 TLBI(Translation Lookaside Buffer Invalidate)指令来执行 TLB 无效化操作。在 ARMv7 及以上版本中,TLBI 指令可以指定 ASID,从而无效化与该 ASID 不匹配的所有 TLB 条目。
具体来说,按 ASID 无效化的过程如下:
- 操作系统首先决定要切换到哪个进程。
- 在切换进程之前,操作系统会根据当前进程的 ASID,通过
TLBI ASID指令将与当前进程 ASID 不匹配的所有 TLB 条目清除掉。 - 然后,操作系统将新的 ASID(新进程的 ASID)加载到控制寄存器中,确保新的地址空间能够正确访问。
- 如果新进程的虚拟地址与当前 TLB 中的条目匹配,TLB 将会继续提供有效的地址映射。
TLBI 指令格式
根据 ARM 架构版本,TLBI 指令有不同的具体格式:
- ARMv7 和 ARMv8 的
TLBI指令:TLBI<operation>: 指定无效化的方式,比如无效化所有条目、按 ASID 无效化、按虚拟地址无效化等。<target>: 指定目标,如ASID或ALL等。
对于 按 ASID 无效化,我们通常会看到类似的指令:
TLBI ASID, <ASID_value>这条指令将会使所有 TLB 条目中 ASID 不匹配 的条目失效。即,当前进程的 TLB 条目会被保留,而其他进程的 TLB 条目将被清除。
在 ARM 架构中,新的进程不能直接访问 TLB 中属于其他 ASID 的数据,这是因为 TLB 中的条目是按照 ASID(Address Space Identifier) 来隔离的。每个进程都有自己的 ASID,用来标识其独立的虚拟地址空间。当进程切换时,操作系统会确保 TLB 中的条目仅包含当前进程的虚拟地址到物理地址的映射,而其他进程的 TLB 条目会被标记为无效,以避免地址空间之间的混淆。
-
ASID 和 TLB 条目的关联
- 每个 TLB 条目包含了虚拟地址到物理地址的映射信息,但不仅仅是虚拟地址和物理地址,ASID 也会被记录在 TLB 中。
- 这意味着 TLB 中的每个条目都与某个特定的 ASID 关联,表示这个映射属于某个特定的进程或线程的虚拟地址空间。
-
新的进程访问 TLB 数据的限制
- 当新的进程开始执行时,只有 当前进程的 ASID 对应的 TLB 条目是有效的。换句话说,新的进程无法直接访问 TLB 中属于其他进程或线程的映射数据。
- 如果新的进程的虚拟地址和 TLB 中的条目不匹配,或者没有有效的映射,处理器会触发一个 缺页异常(page fault),然后操作系统会加载适当的地址映射。
-
硬件支持的地址空间隔离
- ARM 处理器在硬件层面通过 ASID 实现了强隔离。这种隔离确保了一个进程的地址空间不会与其他进程的地址空间发生冲突,即使它们共享同一块物理内存。
- 通过这种机制,当进程切换时,硬件确保 只访问当前进程的虚拟地址空间,并且不会允许跨进程的地址访问。
-
TLB 条目的替换与共享
- 在一些特殊情况下(比如多核系统或虚拟化环境中),不同的核心可能会共享同一组 TLB。在这种情况下,虽然不同核心的 TLB 可能会访问到相同的物理内存,但由于每个核心会根据自己的 ASID 进行映射,每个核心只会访问与它当前 ASID 相关的条目。
- 此外,在虚拟化环境中,虚拟化管理程序(hypervisor)可能会做更多的管理,确保不同虚拟机的 TLB 条目不会互相干扰。
TLB 颠簸效应
对于A和B进程,它们各种有自己的独立的用户地址空间,也就是说,同样的一个虚拟地址X,在A的地址空间中可以被翻译成Pa,而在B地址空间中会被翻译成Pb,如果在地址翻译过程中,TLB中同时存在A和B进程的数据,那么旧的A地址空间的缓存项会影响B进程地址空间的翻译
因此,在进程切换的时候,需要有tlb的操作,以便清除旧进程的影响,具体怎样做呢?
当系统发生进程切换,从进程A切换到进程B,从而导致地址空间也从A切换到B,这时候,我们可以认为在A进程执行过程中,所有TLB和Cache的数据都是for A进程的,一旦切换到B,整个地址空间都不一样了,因此需要全部flush掉
这种方案当然没有问题,当进程B被切入执行的时候,其面对的CPU是一个干干净净,从头开始的硬件环境,TLB和Cache中不会有任何的残留的A进程的数据来影响当前B进程的执行。
当然,稍微有一点遗憾的就是在B进程开始执行的时候,TLB和Cache都是冰冷的(空空如也),因此,B进程刚开始执行的时候,TLB miss和Cache miss都非常严重,从而导致了性能的下降。
我们管这种空TLB叫做cold TLB,它需要随着进程的运行warm up起来才能慢慢发挥起来效果,而在这个时候有可能又会有新的进程被调度了,而造成TLB的颠簸效应。
我们采用进程地址空间这样的术语,其实它可以被进一步细分为内核地址空间和用户地址空间。
对于所有的进程(包括内核线程),内核地址空间是一样的,因此对于这部分地址翻译,无论进程如何切换,内核地址空间转换到物理地址的关系是永远不变的,其实在进程A切换到B的时候,不需要flush掉,因为B进程也可以继续使用这部分的TLB内容(上图中,橘色的block)。
对于用户地址空间,各个进程都有自己独立的地址空间,在进程A切换到B的时候,TLB中的和A进程相关的entry(上图中,青色的block)对于B是完全没有任何意义的,需要flush掉。
在这样的思路指导下,我们其实需要区分global和local(其实就是process-specific的意思)这两种类型的地址翻译,因此,在页表描述符中往往有一个bit来标识该地址翻译是global还是local的,同样的,
在TLB中,这个标识global还是local的flag也会被缓存起来。有了这样的设计之后,我们可以根据不同的场景而flush all或者只是flush local tlb entry。
TTBR寄存器的位置
在 ARM 架构中,TTBR 寄存器通常存在于 CPU 的控制寄存器组中。具体位置和数量取决于 ARM 的版本和模式(如 ARMv7、ARMv8 等)。TTBR 寄存器是 处理器级寄存器,它们与 CPU 的工作模式(如 EL0、EL1、EL2、EL3)以及地址空间相关。
ARMv8 及更高版本的 TTBR
在 ARMv8 及更高版本的架构中,TTBR 寄存器被分为 TTBR0 和 TTBR1。这两个寄存器分别对应 一级页表(L1)和 二级页表(L2),用于管理不同的地址空间(如用户空间、内核空间)。
- TTBR0:指向 第一级页表(一级映射),通常用于用户态地址空间或当前进程的地址空间。
- TTBR1:指向 第二级页表(二级映射),用于内核空间或系统级地址空间。
存储在何处?
TTBR 寄存器本质上是存在于 处理器的寄存器文件中。它们是 处理器内部的硬件寄存器,位于 CPU 的寄存器组中。具体的寄存器位置和访问方式依赖于 ARM 处理器的实现和所使用的操作模式(例如,EL0,EL1,EL2,EL3 等)。
-
EL0:用户模式下,访问 TTBR0(对于用户空间的页表基地址)。
-
EL1:内核模式下,访问 TTBR1(对于内核空间的页表基地址)。
-
TTBR0 管理 用户空间,通常指向 L1 页表,但可能会根据需要指向 L2 页表,具体取决于虚拟地址空间的大小和系统设计。
-
TTBR1 管理 内核空间,通常指向 L1 页表,并且可能会指向多级页表以支持更大的地址范围。
3.2 提高性能和缓存效率
-
L1 TLB:由于它的访问速度更快,通常用于缓存用户空间的映射(即 TTBR0 指向的页表)。用户态的地址空间通常较小,并且切换频繁,因此 L1 TLB 作为一个较小且快速的缓存,能够显著提高性能。
-
L2 TLB:L2 TLB 通常更大,存储更多的映射条目。因为内核空间的映射比较大且较为稳定,所以使用 L2 TLB 存储内核空间的映射(即 TTBR1 指向的页表)是一个合理的选择。L2 TLB 能够缓存更多的条目,提高系统的整体性能,特别是在内核代码和操作系统服务执行期间。
寄存器的访问
在 ARMv8 中,TTBR 寄存器通常与 MMU(内存管理单元) 配合使用,负责虚拟地址到物理地址的映射。操作系统和虚拟化管理程序(hypervisor)会管理这些寄存器,以确保虚拟地址空间的正确映射。
- 访问 TTBR0 或 TTBR1 需要特权权限(如 EL1 或 EL2)。
- 一般的用户程序不能直接访问 TTBR 寄存器,操作系统会在适当的时机为不同的进程设置和切换 TTBR。
ARMv7及更早版本的 TTBR
在 ARMv7 等较早版本中,TTBR 的功能与 ARMv8 类似,但其实现有所不同:
- ARMv7 支持的 TTBR0 用于用户模式的地址空间映射。
- ARMv7 采用的通常是 L1 页表,支持较简单的虚拟内存机制。
总结
TTBR 寄存器是 内存管理单元(MMU) 的一部分,它们存储在 处理器的内部寄存器文件中。TTBR0 和 TTBR1 分别用于存储不同地址空间的页表基地址,具体使用哪一个取决于当前 CPU 的特权级别和运行模式(如用户模式、内核模式)。因此,TTBR 寄存器在 ARM 体系结构中是内存管理的重要组成部分,负责支持虚拟地址到物理地址的转换。
更上一层楼
我们知道内核空间和用户空间是分开的,并且内核空间是所有进程共享。
既然内核空间是共享的,进程A切换进程B的时候,如果进程B访问的地址位于内核空间,完全可以使用进程A缓存的TLB。但是现在由于ASID不一样,导致TLB miss。
我们针对内核空间这种全局共享的映射关系称之为global映射。针对每个进程的映射称之为non-global映射。所以,我们在最后一级页表中引入一个bit(non-global (nG) bit)代表是不是global映射。
当虚拟地址映射物理地址关系缓存到TLB时,将nG bit也存储下来。当判断是否命中TLB时,当比较tag相等时,再判断是不是global映射,如果是的话,直接判断TLB hit,无需比较ASID。当不是global映射时,最后比较ASID判断是否TLB hit。
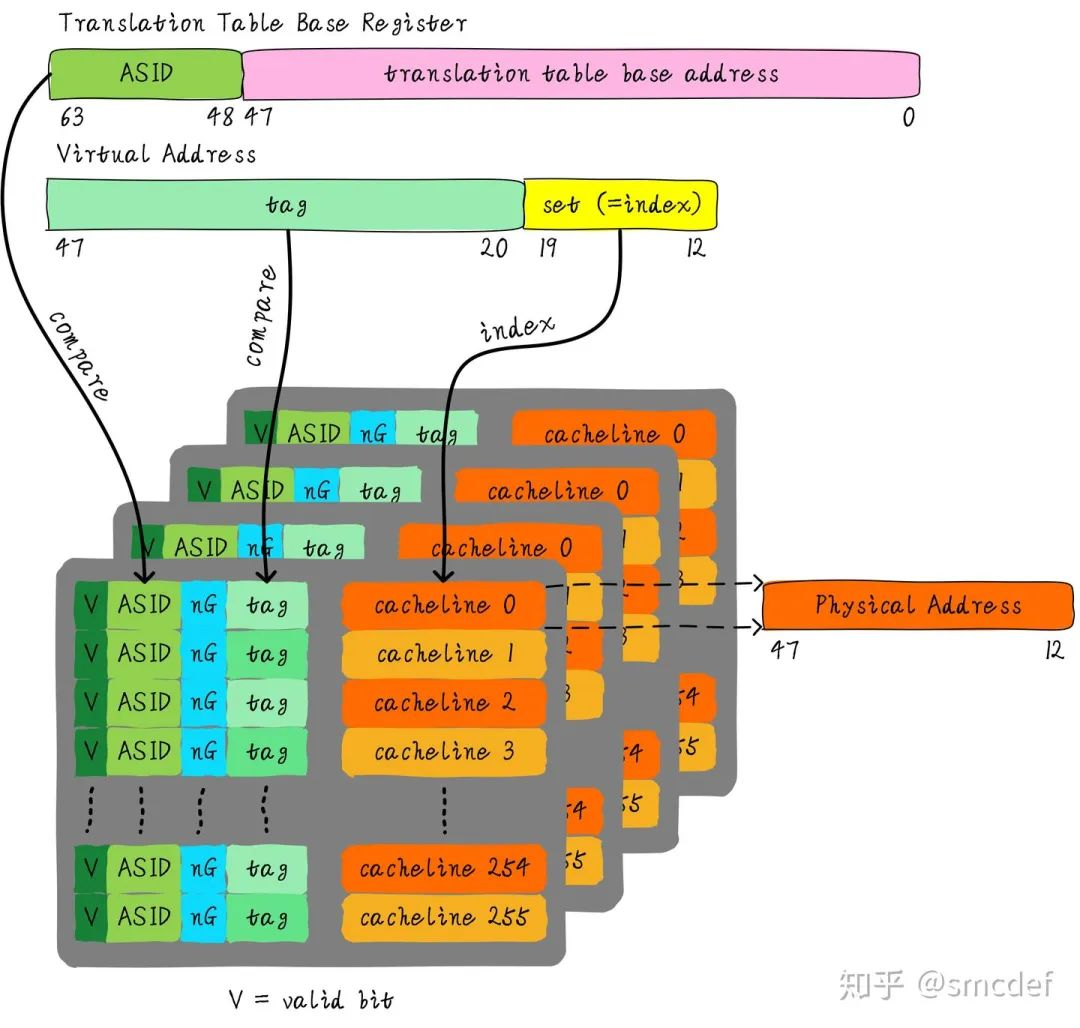
在 ARM 架构中,nG 是页表条目中的一个标志位(bit),表示 "Non-Global"。它用于控制一个页表条目是否指向“全局”(Global)地址,具体地,nG 位在页表项中的作用是决定该映射是否对所有的处理器(在多核系统中)共享。
这东西的存储:页表和 TLB 都会存储 nG 位,但它们的作用是有所区分的:页表中主要用于描述映射的全局性,而 TLB 中则用于管理缓存的一致性和共享
1. nG 标志位的作用
-
nG = 0: 表示该条目是 Global 地址映射,即该映射对所有 CPU 核心可见和共享。换句话说,所有处理器核心在访问该虚拟地址时都将看到相同的物理内存映射。这通常用于内核空间或其他需要全局访问的内存区域(如 I/O 映射等)。
-
nG = 1: 表示该条目是 Non-Global 地址映射。即该映射只对当前的 CPU 核心有效,对其他核心不可见。这通常用于用户空间的内存映射或者私有数据,确保不同处理器核心之间的内存隔离。
2. nG 位的设定
nG 位是由操作系统或内核在创建或修改页表时设定的。页表的内容是由操作系统通过其内存管理单元(MMU)设置的,操作系统通过相应的系统调用或内核代码来配置页表项。
具体来说,操作系统会在以下几种情况下设置 nG 位:
-
在内核启动时:操作系统的内核负责设置初始的页表,可能会将一些页表条目标记为
nG = 0,以确保内核空间在多个核心之间共享。 -
在用户空间和内核空间之间切换时:操作系统会设置用户空间的内存为
nG = 1,确保用户空间的地址不会被其他 CPU 核心访问。内核空间的映射可能会设置为nG = 0,以保证不同 CPU 核心之间的共享和同步。 -
当涉及多核处理时:在多核系统中,操作系统需要合理配置
nG标志,以确保内核数据结构在多个核心之间共享而用户数据则保持隔离。
3. nG 和缓存一致性
nG 位也与缓存一致性相关,尤其是在多核处理器中,控制缓存一致性和内存访问的行为。通过将 nG 设置为 1,可以保证某些数据在一个核心中是私有的,不会被其他核心缓存或访问,这有助于防止缓存污染和缓存一致性问题。
4. 实际例子
假设操作系统在内核启动时将页表中的内核地址空间条目标记为 nG = 0,这意味着这些内存区域可以被多个 CPU 核心访问和修改。而对于用户空间,操作系统可能将页表条目标记为 nG = 1,以确保用户程序只能在本地 CPU 上访问和修改这些内存,避免不同核心之间的干扰。
5. 总结
nG 位的设置由操作系统或内核在配置页表时决定。它的主要目的是控制一个地址映射是否对多个 CPU 核心可见,通常由内核在设置内核空间和用户空间时进行配置。nG 位的设定影响到内存的共享、缓存一致性及多核处理器中的数据访问方式。
lazy tlb
Linux进程管理+内存管理:进程切换的TLB处理(ASID-address space ID、PCID-process context ID)_进程的asid-CSDN博客