
SC 24 Brief Summary 2
- Paper Reading
- 2024-12-07
- 2461 Views
- 0 Comments
- 19103 Words

总链接:
https://www.haibinlaiblog.top/index.php/sc-2024-passage/
ChatBLAS: The First AI-Generated and Portable BLAS Library
用GPT写的BLAS库
ChatBLAS: The First AI-Generated and Portable BLAS Library
We present ChatBLAS, the first AI-generated and portable Basic Linear Algebra Subprograms (BLAS) library on different CPU/GPU configurations. The purpose of this study is (i) to evaluate the capabilities of current large language models (LLMs) to generate a portable and HPC library for BLAS operations and (ii) to define the fundamental practices and criteria to interact with LLMs for HPC targets to elevate the trustworthiness and performance levels of the AI-generated HPCcodes. The generated C/C++ codes must be highly optimized using device-specific solutions to reach high levels of performance. Additionally, these codes are very algorithm-dependent, thereby adding an extra dimension of complexity to this study. We used OpenAI’s LLM ChatGPT and focused on vector-vector BLAS level-1 operations. ChatBLAS can generate functional and correct codes, achieving high-trustworthiness levels, and can compete or even provide better performance against vendor libraries.
Analysis of HPC Systems
Data Movement and Memory Performance Evaluation and/or Optimization ToolsResource ManagementState of the Practice
资源管理专题
Revisiting Computation for Research: Practices and Trends
在计算科学领域,要有效地支持研究人员,就必须深入了解他们是如何利用计算资源的。本研究以一项探索研究计算的实践与挑战的十年前调查为基础,旨在弥合计算资源提供者与依赖这些资源的研究人员之间的理解差距。本研究重新审视了关键调查问题,并从百余次访谈中收集了对开放式主题的反馈意见。对当前和过去结果的定量分析阐明了研究计算的现状定性分析,包括对大型语言模型的谨慎使用,以具体证据凸显了趋势和挑战。 考虑到计算科学的快速发展,本文提供了一个工具包,其中包含了简化未来研究的方法和见解,并确保了对该领域的持续审查。本研究及其发现和工具包可指导计算系统的改进,加深对用户需求的理解,并简化对计算前景的重新评估。
用调查来看看大家对HPC和计算的看法,也是有意思。
This section outlines themethodology employed in the designandexecutionof thesurvey.Thesurveymethodology involved a combination of open-ended andmultiple-choice questions, aiming to delve into researchers’ computational environments, theirprogrammingpreferences,andtheimpact of computational capabilities on their work. It details the structuredapproach taken toselect participants, categorizing themintotwodistinctgroups tocaptureabroadspectrumof computationalpractices.
那,我们来看看他们的结论吧:
研究对象:
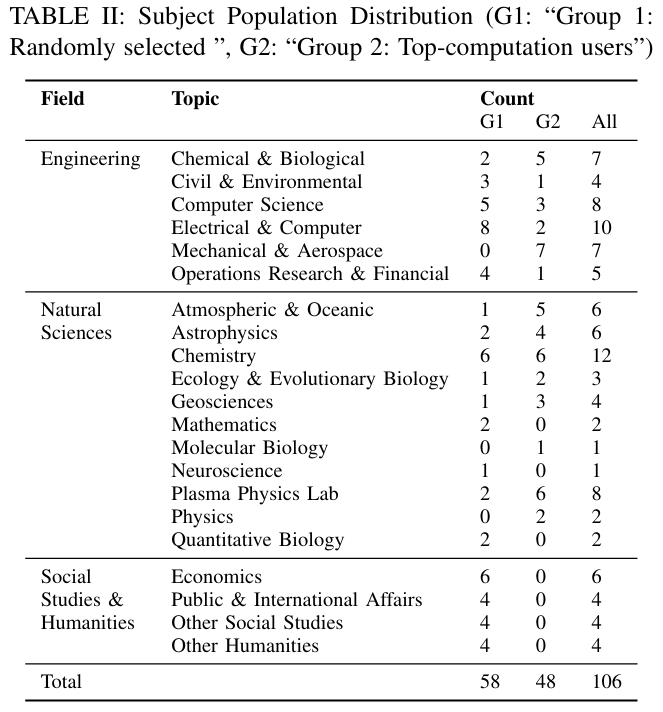
调查问卷结论:
计算在各学科中的使用率都很高。 总体而言,75% 的研究人员在研究中使用计算。在自然科学和工程学领域,几乎所有研究人员都使用计算方法(分别为 98% 和 96%)。在社会研究和人文科学领域,42% 的研究人员在研究中经常使用计算方法。
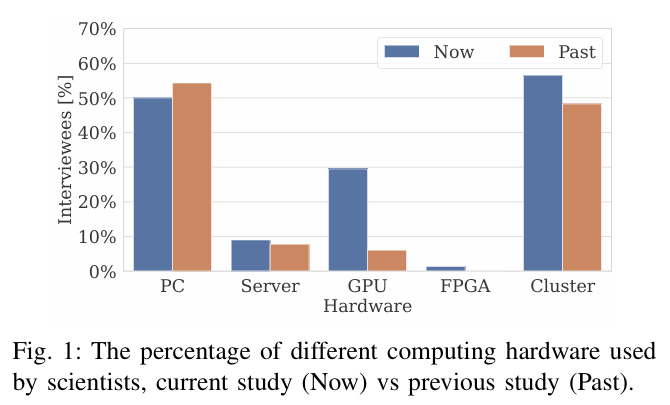
在台式机上运行代码的研究人员越来越少,而是转向在服务器或集群上运行代码。 GPU 正在成为一个新兴的计算平台。在我们采访的所有研究人员中,有三分之一正在使用 GPU 来加快计算速度。一些研究人员还将 FPGA 作为一种替代方法。
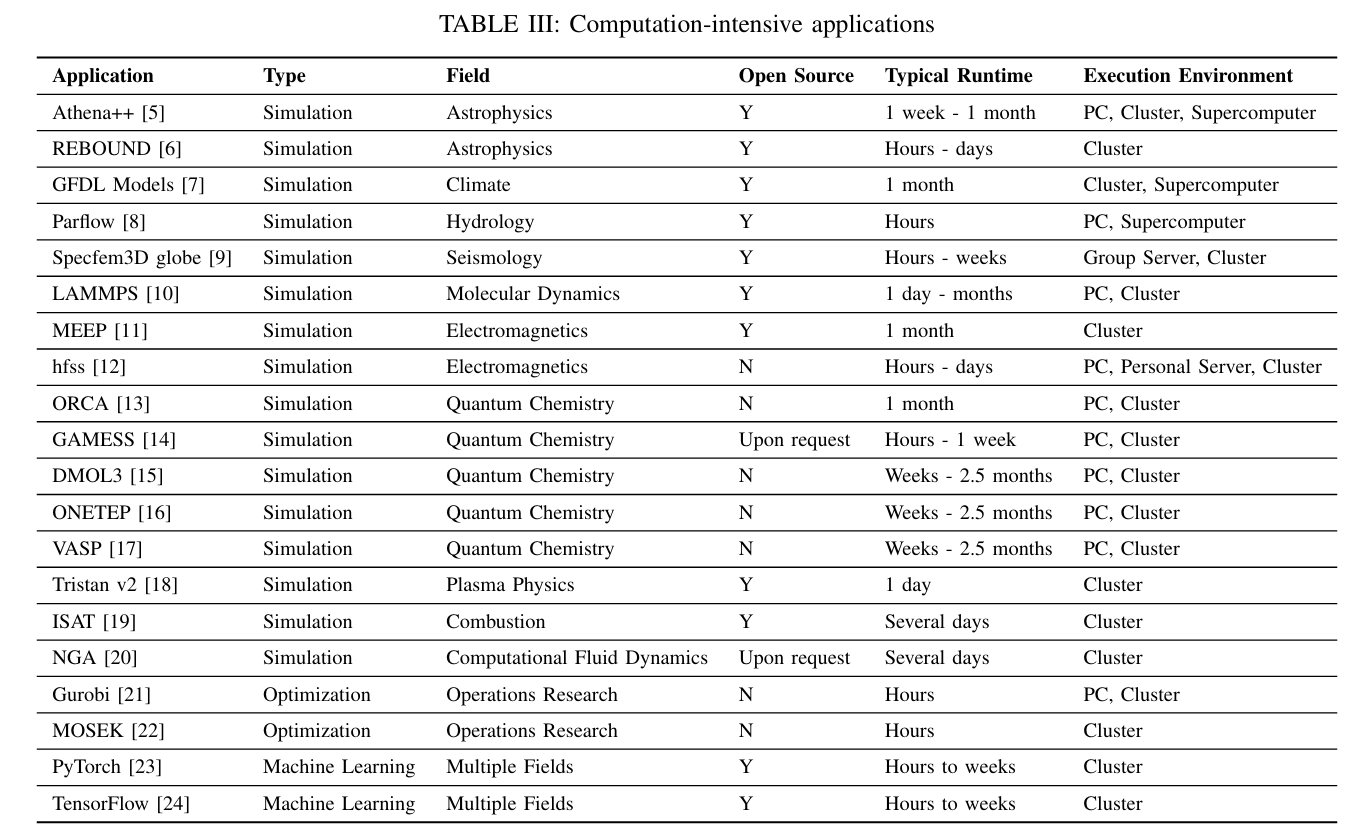
应用多元化 Researchers employ a diverse array of applications, soft ware, and libraries to support their work across various fields.
大家喜欢使用的计算密集型软件
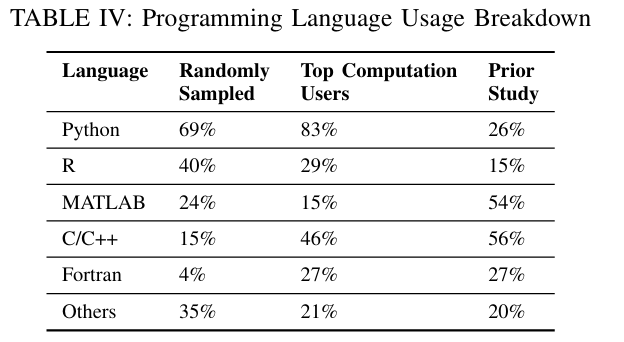
喜好Python,但是学的第一门是C++,很少人用Fortran
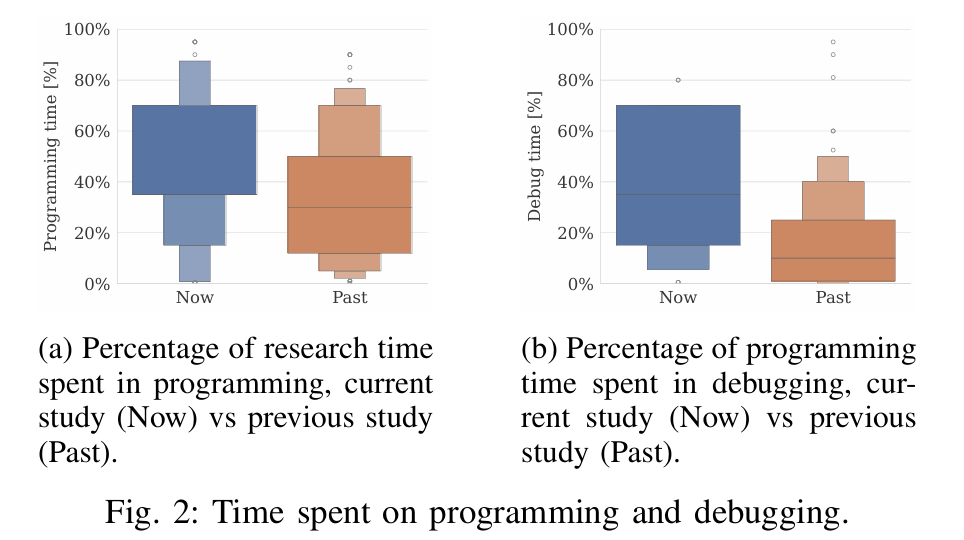
编程和测试的时间变多了。
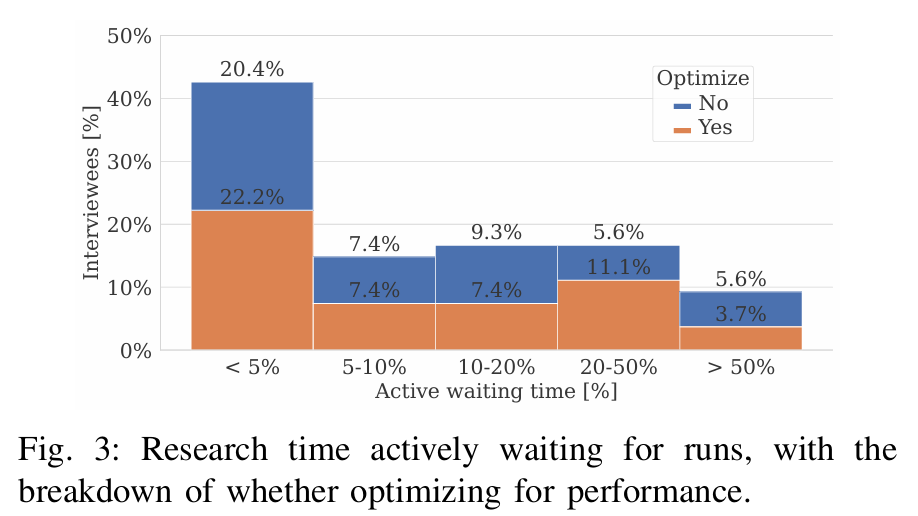
等待时间仍然是科学家面临的一个问题
虽然约 40% 的受访者表示他们的研究时间只有不到 5% 用于等待运行,但超过 25% 的科学家表示他们的研究时间有 20% 以上用于等待。 由于问题的表述方式不同,我们无法与之前的调查数据进行直接比较,但我们仍然可以得出结论,等待时间仍然是科学家面临的一个问题。
Debug方法主要是print()
调试是软件开发中的一个重要过程,包括识别和修复代码中的错误。在 46 位介绍调试方法的受访者中,最常用的技术是使用打印语句(50%),开发人员在此过程中显示变量值并跟踪程序状态。断点(35%)排在第二位,允许开发人员在特定点暂停代码执行以进行检查。代码检查(26%)是第三大最受欢迎的方法,它包括手动审查代码以找出错误。调试器工具(15%)排名第四,用于逐步检查代码、检查变量和监控执行。
最后,其他技术(11%)包括单元测试或向他人寻求帮助。与上次调查相比,调试器工具的使用明显减少,而打印和代码检查却大受欢迎。这种变化可能是由于 Python 这种动态类型语言的使用率高于其他静态编译的编程语言。
没想到大家的方法都好原始。能不能用gdb类似的好应用来帮助我们做这个事情?然后如果说,我们做一个AI集成的gdb来debug Python,是不是会很好?
优化:人们在优化的时间上花费更少了
我们的研究显示,37% 的受访者表示花费了大量时间来优化他们的计划,这一比例低于之前的研究(52%)。26 位受访者分享了他们用于优化程序的方法。在 26 位受访者中,有 4 人(15%)采用了算法变更,5 人(19%)采用了数据结构优化。 另有 4 位受访者(15%)喜欢使用专用库,而循环优化则有 7 位受访者(27%)。有 2 人(8%)使用了编译器标志。最后,有 7 人(27%)依靠配置运行来优化性能,例如在运行一个实验时使用的节点数量。这一分布情况与之前的研究类似。
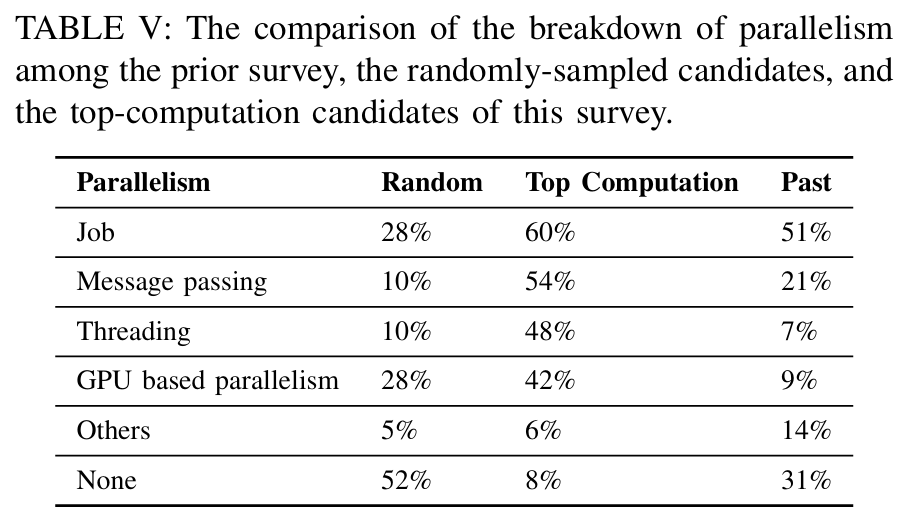
F. 并行性 被广泛使用
在我们的研究中,48% 的随机抽样受访者表示在研究中使用了某种形式的并行性,92% 的顶级计算受访者使用并行性。这两类受访者与以往访谈的详细对比见表 V。随机抽样受访者与顶级计算用户在并行化使用方面的鲜明对比,凸显了并行计算在处理计算密集型研究方面的重要性。 高端用户对并行技术的广泛应用凸显了并行技术在提高研究效率和应对复杂计算挑战方面的重要意义。
通过访谈,我们发现 73% 的研究人员对其项目的计算性能表示满意,与过去调查中 29% 的数字相比有了大幅提高。 对于计算性能总体满意度的上升,有很多可能的解释。这可能是由于研究人员现在可以使用性能显著提高的计算硬件和软件包,也可能是由于研究和工程人员帮助简化了编码和实验运行流程。此外,也可能是研究人员现在开始期待长时间运行的实验,并围绕这一点来计划他们的日程和研究,不过这可能并不适用于每一位研究人员,因为我们在图 3 中已经表明,对于许多研究人员来说,等待运行的时间仍然是不可忽略的。
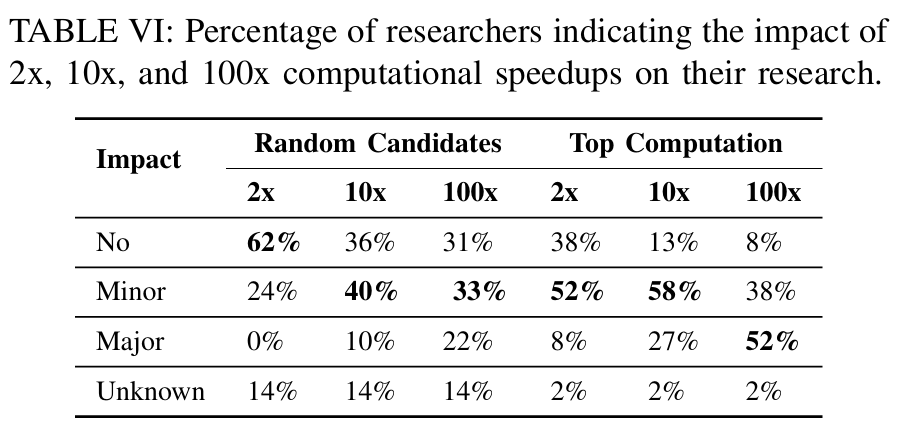
我们需要更多的计算速度、更多的内存!
53 interviewees discussed their understanding of why their computation is blocked. 36 interviewees (68%) attribute the cause to computation speed; 21 (40%) to memory, either memory IO or space; 3 (6%) to storage, either lack of storage space or IO; 4 (8%) to the lack of resources on the cluster; and 1 (2%) to other issues, in this case, lack of license.
但是,这个问题是不是跟科研人员的素质有关,他们如果发现不一定是IO呢?
我们很满意!
73% of researchers were satisfied with the computational performance of their projects, a great increase from the number of 29% in the past survey.
在面临计算挑战的研究人员中,39% 的研究人员采用了优化方法来适应计算限制,36% 的研究人员利用了资源扩充,22% 的研究人员寻求外部支持和合作资源,31% 的研究人员修改了研究范围或方法。
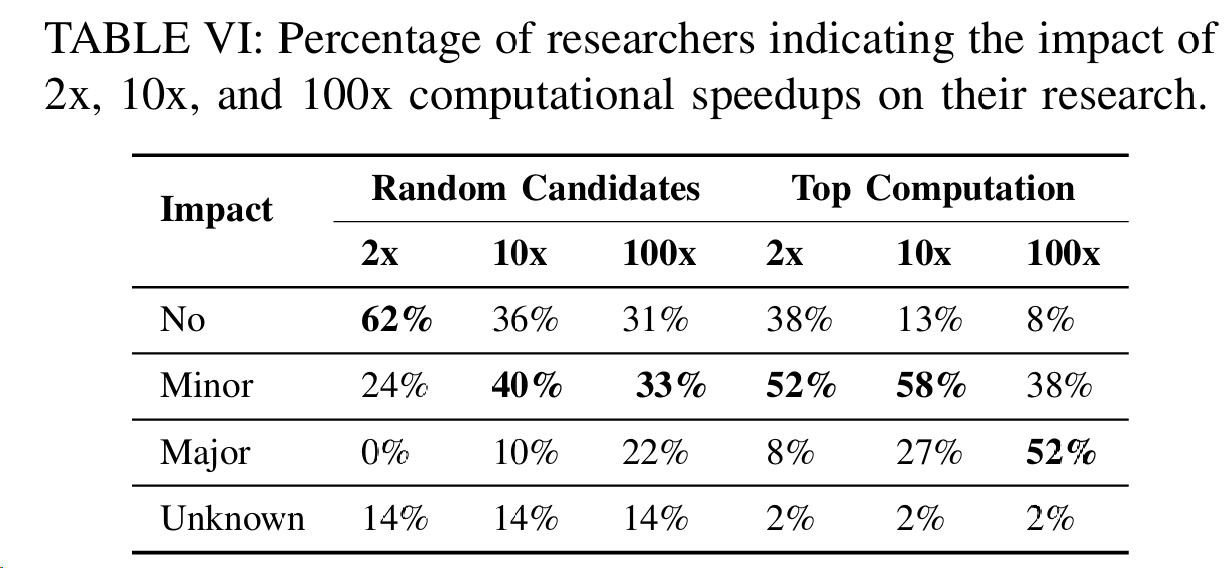
调查结果显示,现在有 26% 的研究人员认为,由于计算能力不足,他们无法实现更大的研究计划,而在过去的调查中,这一比例约为 70%。为了更深入地了解这一问题,我们追问了一个假设性问题--2 倍、10 倍或 100 倍的速度提升会如何改变他们的研究。表 VI 列出了四类回答的详细情况。
本研究的最终目标是了解计算社区应该开展哪些工作,以及如何更好地支持搜索者利用计算。建议的分析框架工作可以进行深入分析,确定重要趋势和挑战 与前几节介绍的侧重于对单个问题的回答的结果不同,这些分析跨越了多个问题,而且经常涉及重新查看记录誊本,以更深入地了解受访者。
建模过程:
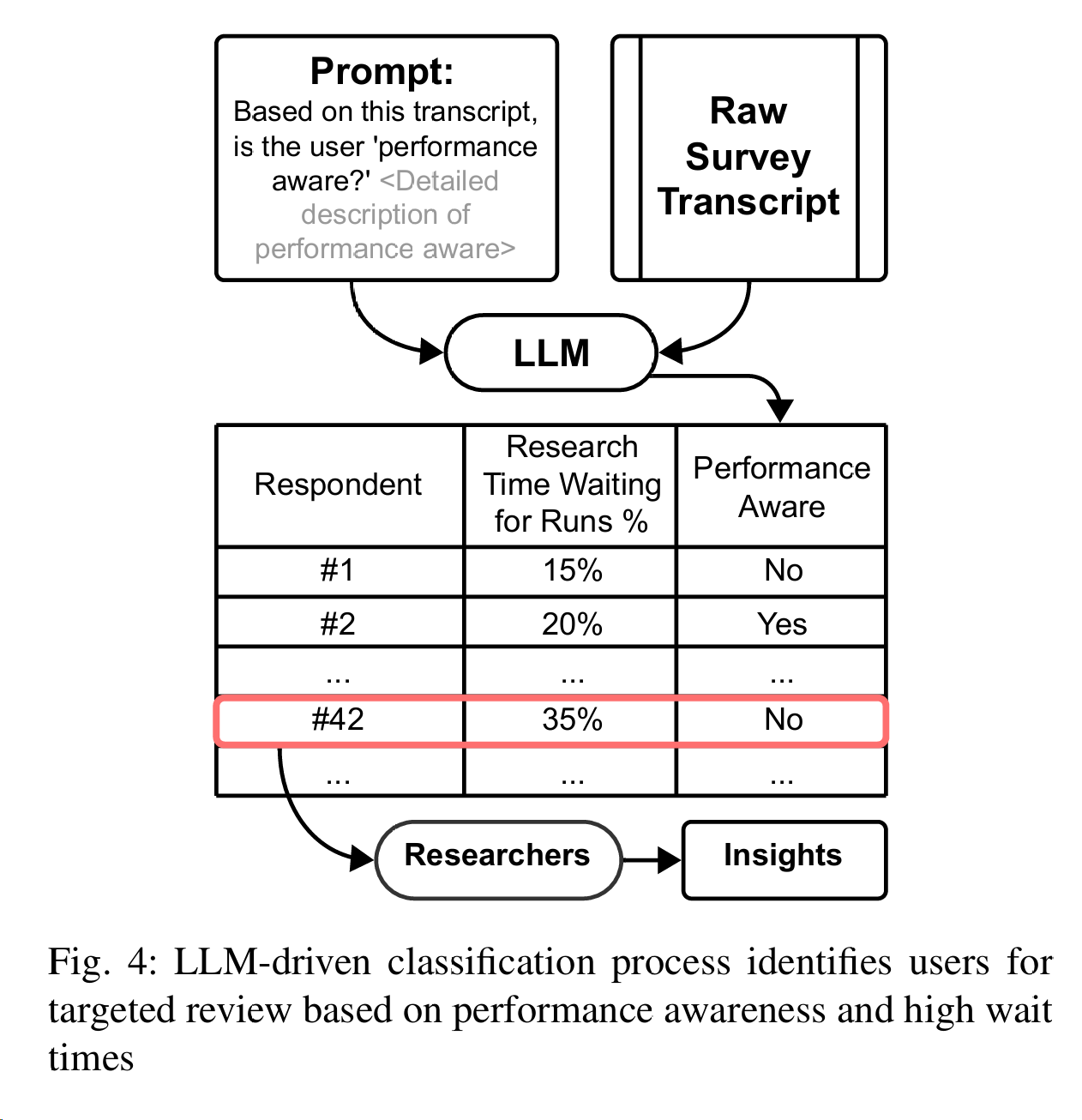
建模过程还是非常的神奇!第一次见到有人这样用LLM对研究做filter,和以往看到的人文的paper挺不一样的。Instead, we used LLMs to filter and highlight responses that required further investigation, effectively
streamlining the process of identifying critical feedback.
我们要求 LLM 根据用户在记录誊本中提到的使用 GPU 等高性能硬件或进行性能优化的情况来判断用户是否具有 “性能意识”。 调查问卷中没有这样的直接问题,因此 LLM 搜索上下文提示的能力就显得尤为有用。然后,将 LLM 的分类与 “等待运行的研究时间百分比 ”进行比较,后者直接从现有的结构化调查回复中提取。人类研究人员将深入研究用户花费大量时间等待运行但却没有 “性能意识 ”的情况,并了解全部背景。
变化趋势
- More Time Spent In Programming
- More Diverse Needs for Computation
计算被广泛用于模拟、验证、机器学习任务和数据分析。 不同类型的应用表现出不同的性能模式,包括硬件要求和典型运行时间的差异(§IV-C)。从硬件方面来看,集群和服务器的使用越来越多,对 GPU 的依赖也显著增加(§IV-B)。此外,性能的提高对研究人员也有各种影响(§VI-B)。所有这些都意味着没有放之四海而皆准的解决方案。 - Programming Languages Shift: C++ Fortran -> R、Python
- Increased Machine Learning Usage:30%的人开始使用机器学习,并且是复杂机器学习(AlphaFold)
挑战
- 研究发现计算资源增长了,但是很多人是无法完全利用好的
“We don’t have a full understanding of the hard ware needed for parallelism. Providing tutorials and training on programming techniques for those unfamiliar with the hardware would be great“
只有不到三分之一的朋友会使用GPU - Making development tools more user-friendly
这些要求包括改进的自动完成功能、增强的连续集成和测试功能、从自然语言自动生成代码、包含实用示例的全面文档、类似于 Jupyter Notebook 的非 Python 语言的交互式开发环境、高级软件包管理和 API,以及对代码可移植性和兼容性的更多支持。
尽管编程环境和计算能力不断进步,调试任务仍然是研究工作中耗时且往往令人生畏的一个方面(§V-B)。 我们发现,与上次研究相比,调试器的使用率明显下降。这可能是因为 Python 的使用增加了。使用 Python 的开发人员可能会发现打印语句和代码检查技术更方便、更易用,从而导致它们在调试过程中越来越受欢迎。许多受访者提到,他们认为调试器笨重难用,而一些受访者直接表示需要更好的交互式调试工具,以减少调试代码所花费的时间,这表明需要更好的调试界面。值得注意的是,最近发布的大型语言模型和基于这些模型的工具已经部分满足了某些需求。这再次凸显了计算快速发展的本质,因此有必要经常重新审视这一领域。
-
Handling duplicated and legacy projects 整合相似的包
广泛的软件和软件包清单突出表明,有多种工具可用于类似的目的(§IV-C)。 例如,在机器学习方面,PyTorch 和 Tensorflow 等框架可用于类似任务。DMOL3[15]、Onetep[16]和 VASP[17]专注于量子化学和固体物理的类似任务。这些软件或库通常都有针对特定研究领域或使用不同方法的变体,有时差别非常细微。然而,这种重复会导致科学界的分裂,要求研究人员学习多种工具进行合作或领域转换。目前,人们正在努力创造抽象概念来统一不同的工具,例如用于磁约束热核聚变实验的 OMFIT [51]、用于凸优化问题的 CVXPY [52]、[53],以及用于机器学习的 Keras [54]。还有一些 Python/R 软件包用更高效的语言包装计算,如 Numba [55] 和 pyfftw [56],使研究人员更容易将这些工具集成到他们的工作流程中。将这些努力扩展到更多领域会有所帮助。 -
Supporting Machine Learning Application
“Something important would be a lecture series or educational program on the current workings of AI, particularly generative programming and ChatGPT, which are rapidly barreling into our field.” -
Providing adequate and diverse training
研究人员需要更多的机器学习课程
最后:
研究方法介绍。和我们在人文课学的方法差不多
本研究重新审视并扩展了之前的一项研究,探讨了普林斯顿大学的计算实践状况 。通过对一百多位研究人员的全面访谈以及与之前调查结果的比较,本研究捕捉到了计算实践的演变、新兴趋势以及需要进一步关注的领域。考虑到这一领域的快速发展,本研究还提供了一个工具包,用于今后重复开展此项研究,以简化从开展调查到数据分析的工作。这项研究的结果以及鼓励经常重新审视这一主题的工具包,为研究人员继续开发新技术和新系统,推动计算科学的发展奠定了坚实的基础。
Understanding Data Movement Patterns at HPC: A NERSC Case Study
劳伦斯国家实验室出品
在本文中,我们对来自 NERSC 的三年网络流量数据进行了广泛分析,并确定了关键数据移动趋势,同时发现了严重影响传输性能的瓶颈。我们的结果表明,数据移动模式在这三年中发生了变化,当前的基础设施无法充分处理相互竞争的传输,导致单个数据流的吞吐量下降高达 30%。此外,我们还为未来集成研究基础设施的数据移动管理提供了设计建议,旨在减少数据传输延迟,缩短取得科学成果的总体时间。
wow!很有趣的工作。我们主要观察,我们的数据都传去哪里了!并就此对我们的超算和网络进行优化。
科学实验正在产生前所未有的海量数据,并需要实时高性能计算(HPC)。在这些新兴的数据密集型工作负载中,了解并确保高效的数据移动对于成功执行工作流程至关重要。对端到端的需求,即跨设施整合计算、网络和存储资源,正在形成一种新的集成基础设施模式。
索引术语--数据移动、高性能计算、网络、性能、数据包丢失
对于这些工作流,科学时间(tscience)可抽象为三个主要特征:实际执行工作流的时间(称为 tcompute)、与特定工作流相关的作业开始在 HPC 资源上运行前所花费的时间(twait),以及将数据移动到可进行计算的位置(例如 HPC 数据中心的数据传输节点 DTN、实验设施边缘的中端计算等)所花费的时间(定义为 tmove)。因此,我们可以简化 tscience = tcompute +twait +tmove。
研究工作总结
高性能计算系统管理员和网络工程师可以利用我们的方法研究其系统中的数据传输性能,找出阻碍低延迟数据传输的瓶颈,最终改善实践状况。网络研究人员可以利用我们的分析和发现,对未来高性能计算网络的设计获得重要启示。我们将需要 a) 可编程网络,能够根据用户和数据传输的 QoS(延迟、吞吐量、时间等)要求管理数据流;b) 实时响应。 d) 基于智能监控和多模态数据关联(作业日志、主机日志、网络遥测日志)的跨 IRI 组件端到端协调环路;e) 分布式控制环路,用于实现跨 IRI 的协调和 QoS 执行。
超级计算机的应用 I/O、文件和 I/O 子系统一直是多项研究的重点[7] [8] [9] [10],而高性能计算数据中心的网络、用户行为趋势和数据移动却尚未得到研究。 如今,人们对高性能计算中心中务实的数据移动管理是否能满足当前和新兴工作流的净工作要求了解有限。在本文中,我们将研究数据移动模式,找出关键的性能瓶颈,并利用我们的研究结果为未来兼容 IRI 的网络架构设计提供参考。我们使用了从两个来源收集到的三年网络数据:美国国家能源研究科学计算中心(NERSC)的 DTN,以及使用能源科学网络 High-Touch 平台[11]的网络边界。NERSC 系统代表了当今的生产型 HPC 系统,必须满足从实时到数据密集型工作流等不同科学应用的数据移动和网络要求。我们的分析研究了标准的 HPC 网络实践(如使用科学 DMZ 模型 [12] 实现数据传输节点池)和当前的数据移动工具(如 Globus)能否保证低延迟数据。
我们的研究结果提供了对网络模式的以下重要见解。首先,从 2020 年到 2022 年,穿越 NERSC 边界的 DTN 流量百分比有所下降。我们认为,这一下降表明,需要始终保持弹性连接的工作流模式发生了显著变化,例如,交互式工作流、与托管在 NERSC 外部的数据库建立连接的跨设施工作流,以及将数据直接传输到登录节点以便资源直接访问的工作流。 其次,每个用户在每个会话中执行多次中等大小的传输。我们发现,用户使用 Globus 等自动化软件工具传输数据的比例逐年下降,这表明用户选择通过手动临时传输或其他工具来移动数据。此外,现有的数据移动管理解决方案也加剧了数据可用性的延迟。 我们的分析表明,在有多个并行竞争传输的繁忙流量窗口期间,DTN 被过度使用,导致重传比例激增,无论传输量大小,吞吐量都会下降 30%。 最后,NERSC 的流量监控策略限制了科学用户的可视性,并严重阻碍了对性能瓶颈的检测。
网络流检测器:Tstat
NERSC 利用通过 Tstat [26] 获得的终端主机测量数据来监控网络流性能。由于从网络设备收集高保真测量数据的成本非常高昂(度量数据的收集、传输和存储需要消耗不可忽略的资源),因此 NERSC 并不收集整个网络路径上的网络设备测量数据。Tstat 收集机制以日志格式组织数据,其中每一行对应一个不同的 5 元组流(源 IP、目的 IP、源端口、目的端口和协议),每一列与特定的测量值相关联。根据流量方向,获得的测量结果有两种不同的分组: 客户端到服务器(C2S)和服务器到客户端(S2C)。数据集每行包含 116 个测量值,其中包含所有已注册完成流量的完整信息集。
我们关于数据移动趋势分析的第一个轴心围绕以下问题展开:(1) 当今的高性能计算用户是否使用 Globus 等专用传输工具,遵循仪器-广域网-DTN-计算的事实数据移动范式? (2) 单个传输的数量概况如何?为了回答这个问题,我们从以下方面确定了高层次的流量趋势: (1) 随着时间的推移,指向 DTN 和来自 DTN 的流量,(2) 归因于 Globus 的流量,(3) Globus 和非 Globus(交互式)流量的大小分布,以及 (4) 每个用户会话的传输次数。
We use three years of network data collected from two sources: the National Energy Research Scientific Computing Center (NERSC) DTNs as well as its network border using Energy Science Network’s High-Touch platform
We have found that the percentage of data users transfer using automated software tools like Globus is reduced yearly, suggesting that users opt to move data through manual ad-hoc transfers or other tools.
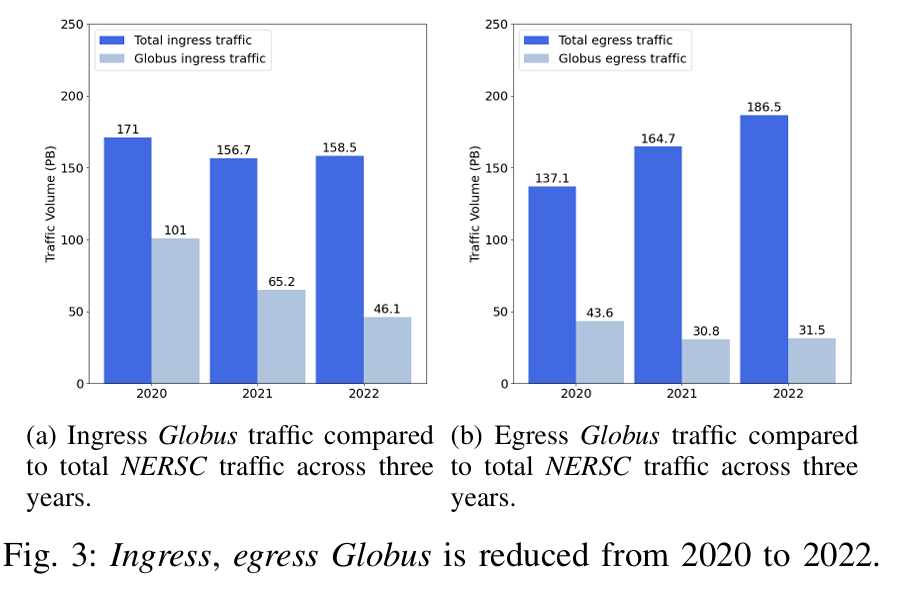
hey他们也用 Globus!虽然传输的数据在减少
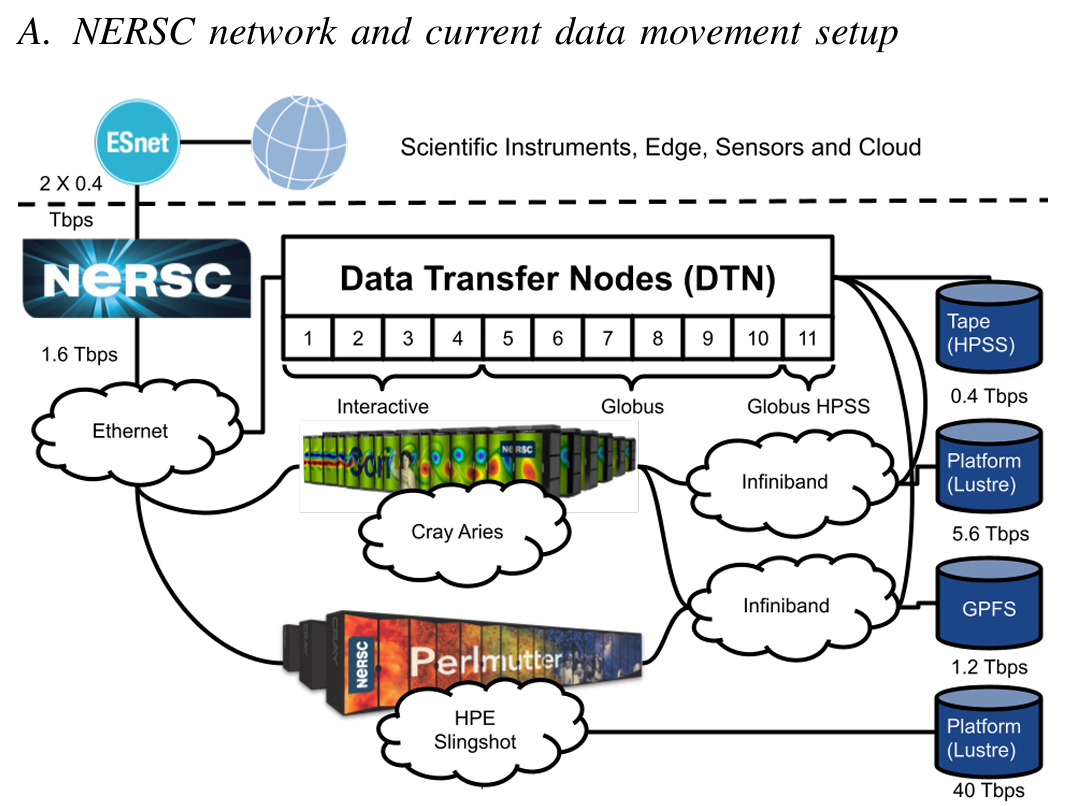
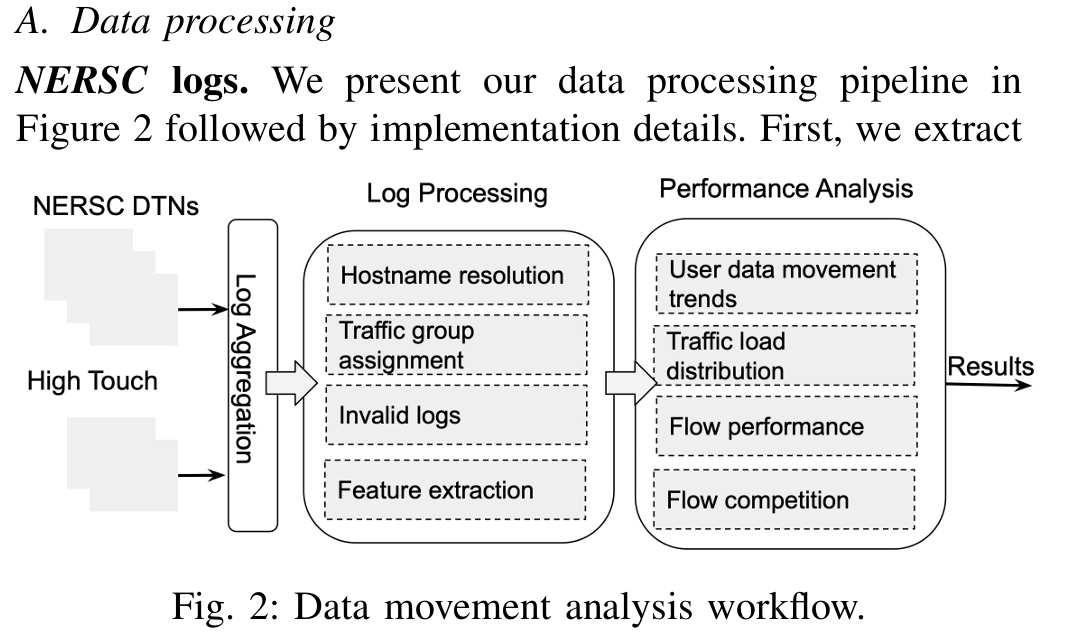
In this paper, we provide a detailed analysis of data movement trends and performance in HPC environments using traffic data collected at NERSC. Our findings indicate that users adopt dynamic movement patterns transferring data in small/medium chunks and shift from the traditional instrument-WAN-DTN-compute paradigm. Our results show that today’s data movement in HPC is not optimally designed for serving the new user patterns emerging from network requirements of science workflows with hard data availability temporal constraints. Our analysis demonstrates that the existing setup does not account for conditions where multiple competing transfers compete for resources, resulting up to 30% throughput degradation compared to non-competing circumstances.
Our recommendations include adopting intelligent traffic management that utilizes programmability and real-time event detection to reduce data transfer times for current and emerging science workflows.
学习:什么是DTN?
在高性能计算(HPC)数据中心的上下文中,数据传输节点(DTNs) 是用于在不同计算节点之间转移数据的关键设施。尤其是在像高性能计算中心这样的环境中,数据量通常非常庞大,而计算和存储资源分布广泛。因此,DTNs的作用是确保数据能够高效、可靠地在数据中心内部或外部进行传输,特别是在需要处理大量并行传输和延迟容忍的情况下。
在实验设施的边缘计算环境中,中型计算节点(mid-range compute) 可能位于离核心计算设施较远的地方,例如在实验现场或者其他边缘位置。此类计算节点通常需要将数据从实验设备传回主计算中心,或者从主数据存储系统获取数据。DTNs在这种环境中尤为重要,因为它们能够通过延迟容忍的方式处理边缘计算节点与主数据中心之间的数据传输问题,尤其是在网络不稳定或传输延迟较高的情况下。
总结来说,DTNs在HPC数据中心和实验设施边缘计算的作用是确保大规模数据传输的稳定性和高效性,即使在面临较大延迟或网络中断的情况下,依然能够保持数据的可靠传输。
CDF

我们对流量性能进行分析,以确定在过量使用期间的瓶颈和中断情况,在过量使用期间,传输会争夺有限的资源。我们的超额订购分析表明,流量竞争是 NERSC 一直存在的问题,这突出表明,无论 IRI 的科学模式如何,都亟需了解流量竞争对性能的影响,以确保科学应用中的数据可用性。 分析高流量窗口期间的吞吐量。我们首先分析了流量竞争的影响,即一个大流量(如第 II-B 节所述,在数据集成敏感性和长期活动工作流中很典型)与多个明显较小的流量(至少 100 数量级)(在时间敏感性工作流中很典型)竞争的情况。

Paper
Sparsity and Quantization in ML
Ramakrishnan Kannan B308
Algorithms Artificial Intelligence/Machine LearningHeterogeneous ComputingPerformance Optimization
MIXQ: Taming Dynamic Outliers in Mixed-Precision Quantization by Online Prediction
一键部署LLM混合精度推理,端到端吞吐比AWQ最大提升6倍!
清华大学计算机系PACMAN实验室发布开源混合精度推理系统——MixQ。
MixQ支持8比特和4比特混合精度推理,可实现近无损的量化部署并提升推理的吞吐。
动态离群值是高效混合精度量化的主要障碍
Dynamic outlier is the main obstacle to efficient mixed precision quantization. The sparsity and irregularity of outliers have introduced a large overhead in both detection and the process of outliers. MixQ tames the dynamic outliers by precisely predicting the outlier positions with a locality-based algorithm.
MixQ同时量化权重和激活,使用低精度张量核心(INT8/INT4 Tensor Core)实现推理加速;同时,MixQ提取激活中少量的离群值,使用高精度张量核心(FP16 Tensor Core)保持推理准确性,通过系统优化掩盖高精度访存开销。

Mixed-precision quantization has shown to be a promising method for enhancing the efficiency of LLMs. This technique boosts computational efficiency by processing most values with low-precision, high-throughput compute units and maintains accuracy by processing outliers in high-precision. However, due to the dynamic, irregular, and sparse nature of outliers, this approach is far from using hardware efficiently. In this work, we propose MixQ, an efficient mixed-precision quantization system. Through our in-depth analysis of outlier distribution, we introduce a locality-based outlier prediction algorithm that can predict all outliers of 95.8% of tokens. Based on this accurate prediction, we propose a quantization ahead of detection (QAD) technique that can verify the correctness of prediction. A new data structure is proposed for efficient outlier processing. Evaluation shows that MixQ achieves 1.52× and 1.78× speedup over FP16 and Bitsandbytes on 8-bit quantization; plus 1.48×, 1.93× and 6× speedup over QUIK, FP16, and AWQ on 4-bit quantization.
Index Terms—Mixed-Precision, Dynamic Outlier, Enhancing Throughput
AuthorsYidong ChenChen ZhangRongchao DongHaoyuan ZhangYonghua Zhang Zhonghua Lu Jidong Zhai
AlgorithmsArtificial Intelligence/Machine LearningHeterogeneous ComputingPerformance Optimization
9:30am - 10am EST
Long Exposure: Accelerating Parameter-Efficient Fine-Tuning for LLMs under Shadowy Sparsity
Authors:Tuowei Wang Kun Li Zixu Hao Donglin BaiJu Ren Yaoxue Zhang Ting Cao Mao Yang
LoRA学习参考:LORA详解(史上最全)_lora模型-CSDN博客
【HPHEX组会[SC'24] Long Exposure:当PEFT中大部分参数都被冻结,大模型的微调是否可以重新理解为是一种特殊的推理】 https://www.bilibili.com/video/BV1yCqLYJEh9/?share_source=copy_web&vd_source=72eac555730ba7e7a64f9fa1d7f2b2d4
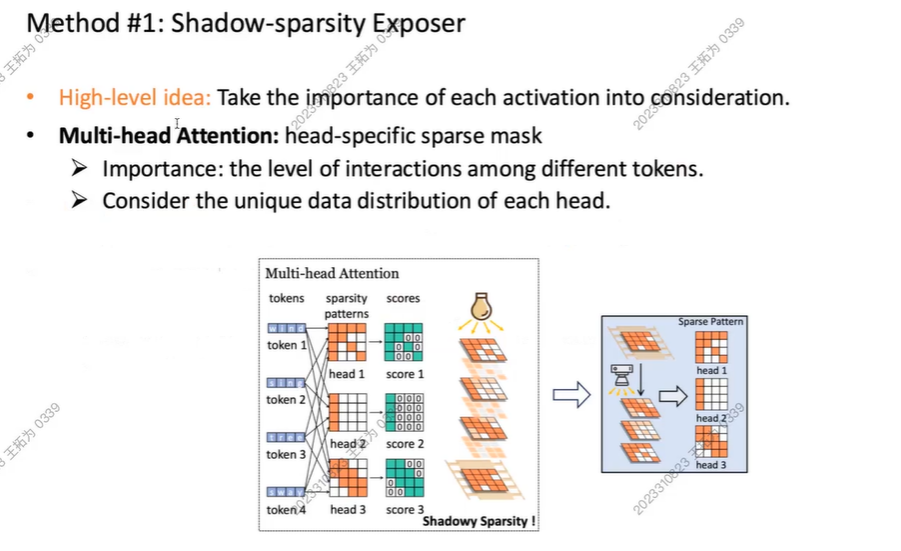
我们关注到模型训练中特殊的稀疏性
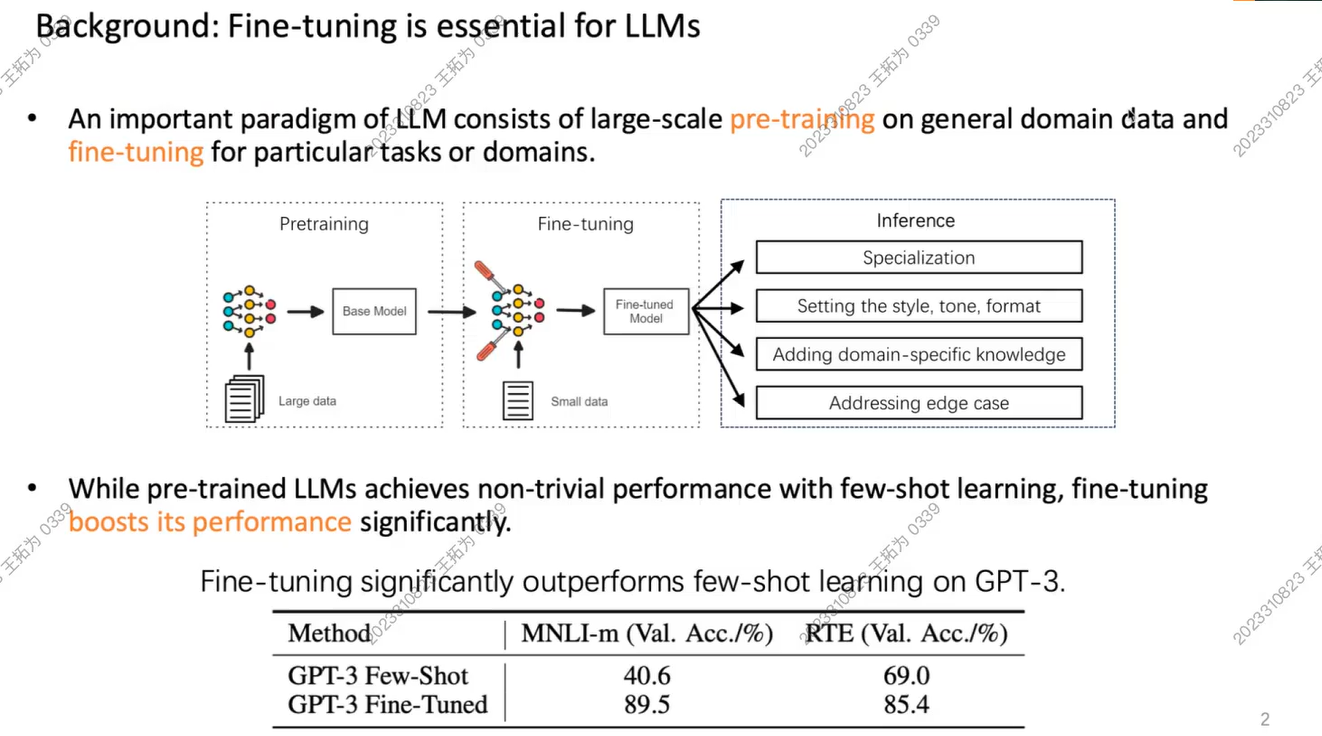
没有经过微调,模型在特定任务上Acc较低,微调后准确率才提升
背景2:目前的模型size不断提升,而微调

Fine Tuning 可以看做这样的修改:
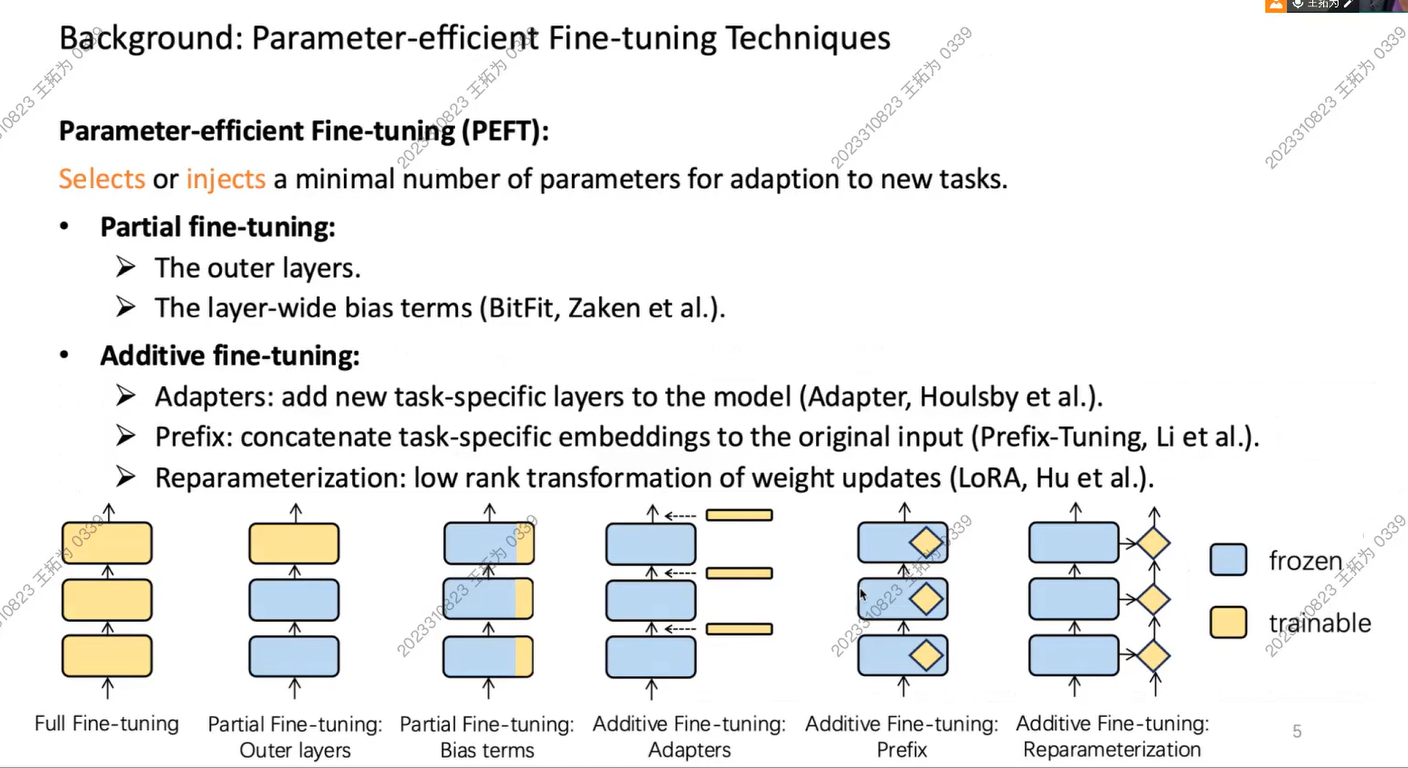
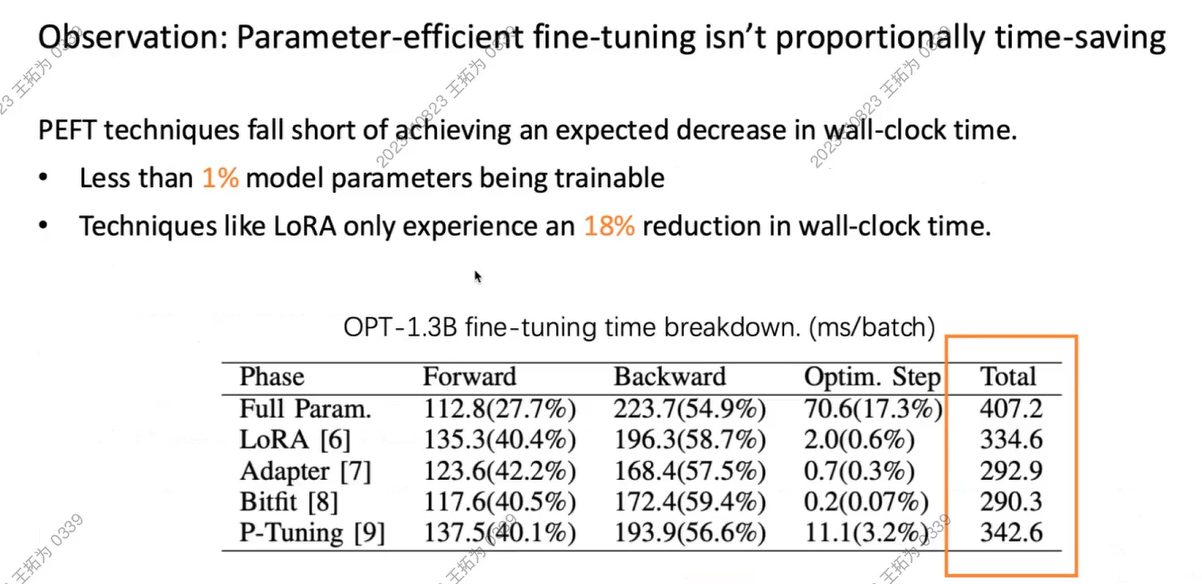
但是,他们并没有带来时间节省
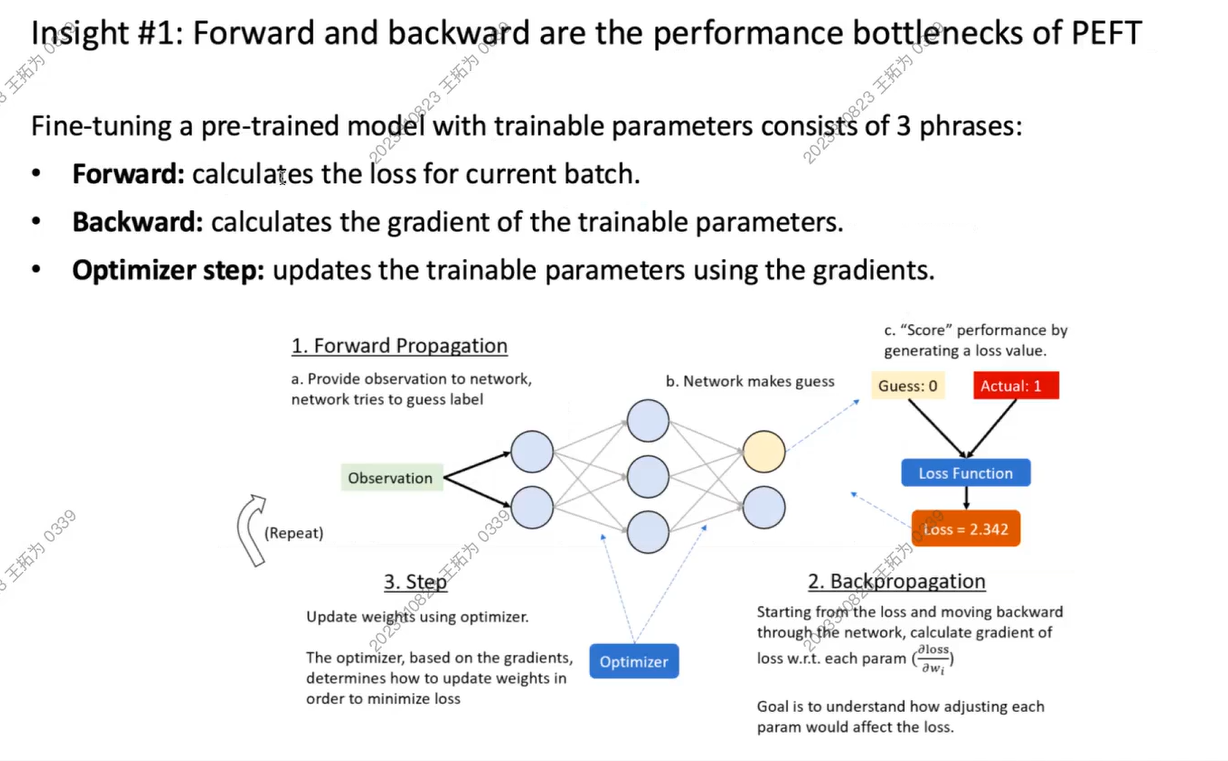
我们将整个训练任务分成3个阶段
PEFT后,在反向传播阶段,我们需要多计算一次偏导,这样的计算使得Backward的计算量反而会多了!
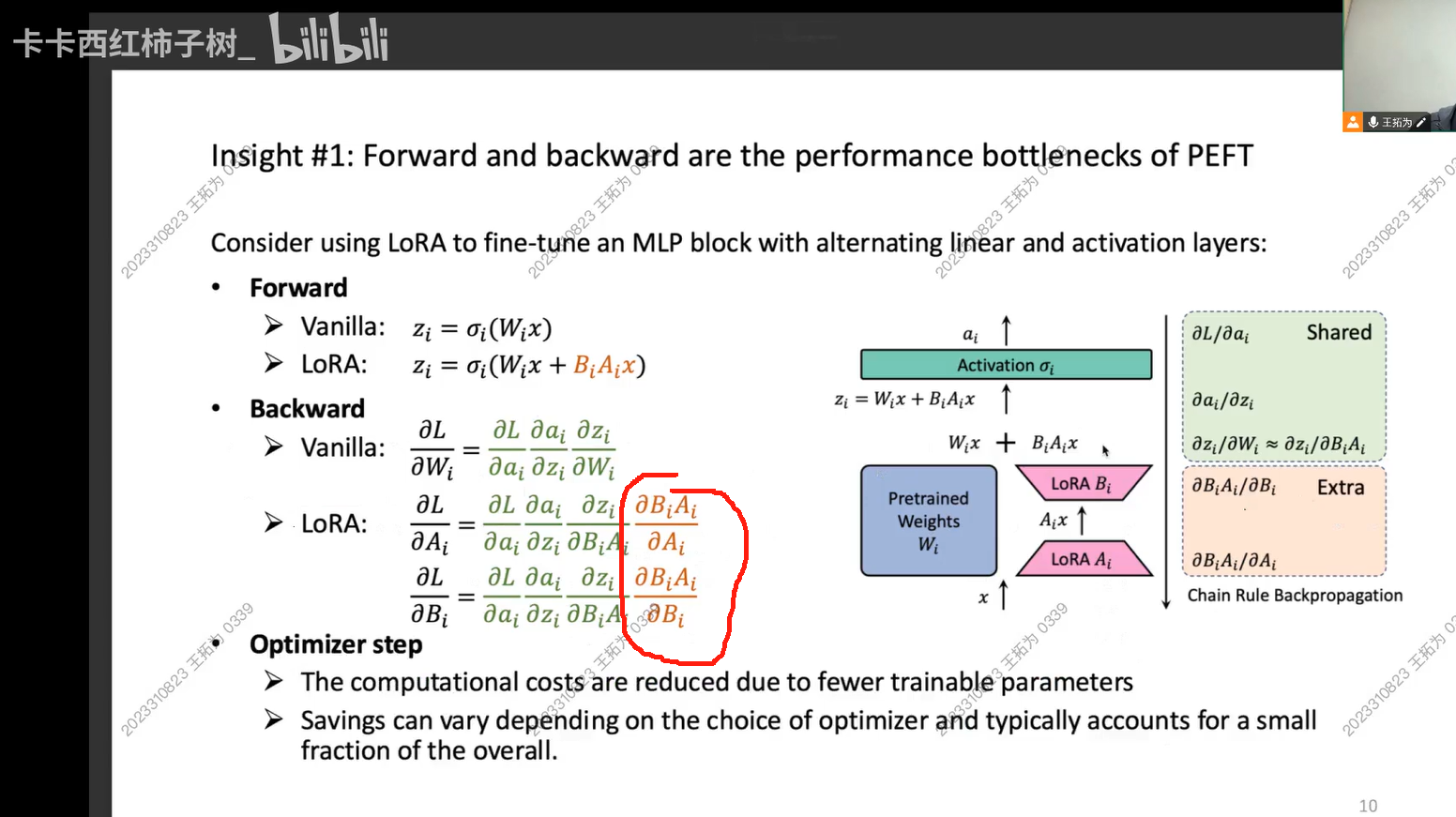
所以我们发现,PEFT的优化虽然确实让Optim 过程变快了,但是它让Forward和Backward变慢了。

确定优化核心问题:我们想优化PEFT的前向和反向过程。这时我们发现,模型的PEFT和推理呈现高相似度,此时模型的全部参数基本保持不变。

而此时,我们知道“稀疏”是个很好的概念,比如在稀疏矩阵内我们可以忽略0。比如我们的Multi-head attention, MLP里的ReLU,会使得我们的矩阵里有很多0.
LLM可以进行剪枝从LLM A变成B,减少参数。但是会:
- 剪枝需要重训练,会加重负担
- 损失泛化能力
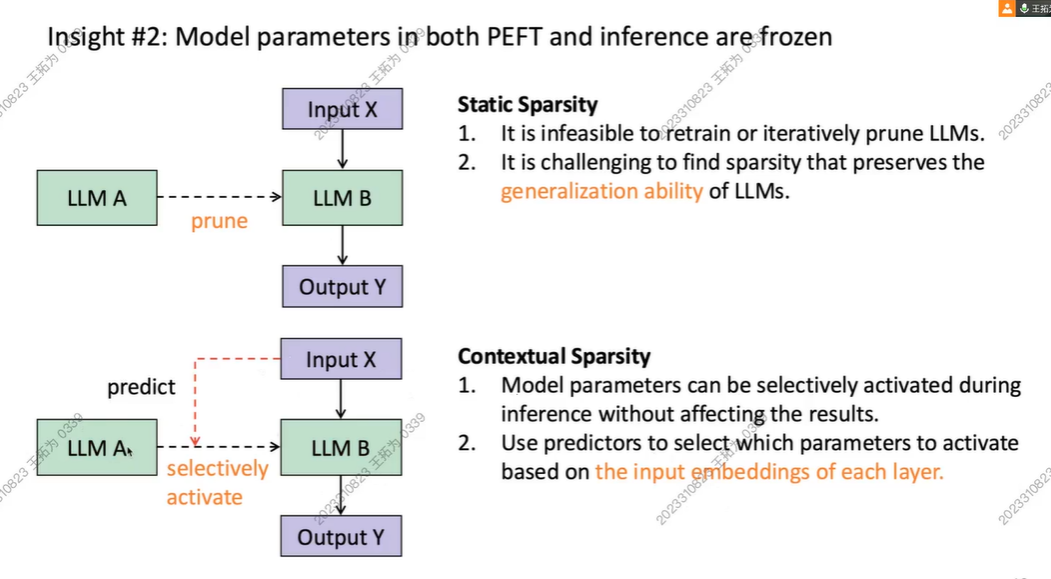
之前的方法:deja vu
我们不剪参数,在推理时动态激活参数,这样我们不会剪参数,但是能加速。
此时他们的稀疏性可以到85%,并且可以被预测出来
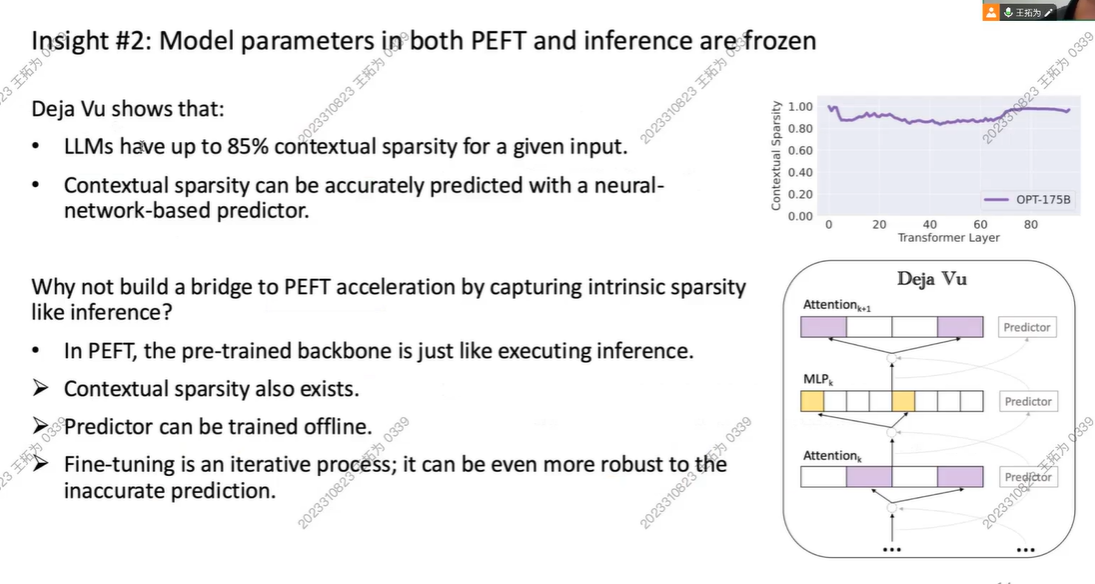
所以:idea:既然我们可以用稀疏性来加速大模型推理,而PEFT优化跟大模型inference很像,我们为什么不能用稀疏性来加速!!
前向计算时为0,反向计算仍为0,那就可以剪枝减少计算
挑战1:
inference 和 Fine tune 的模型输入的尺寸不同
infer: token
fine tune: a sequence of tokens
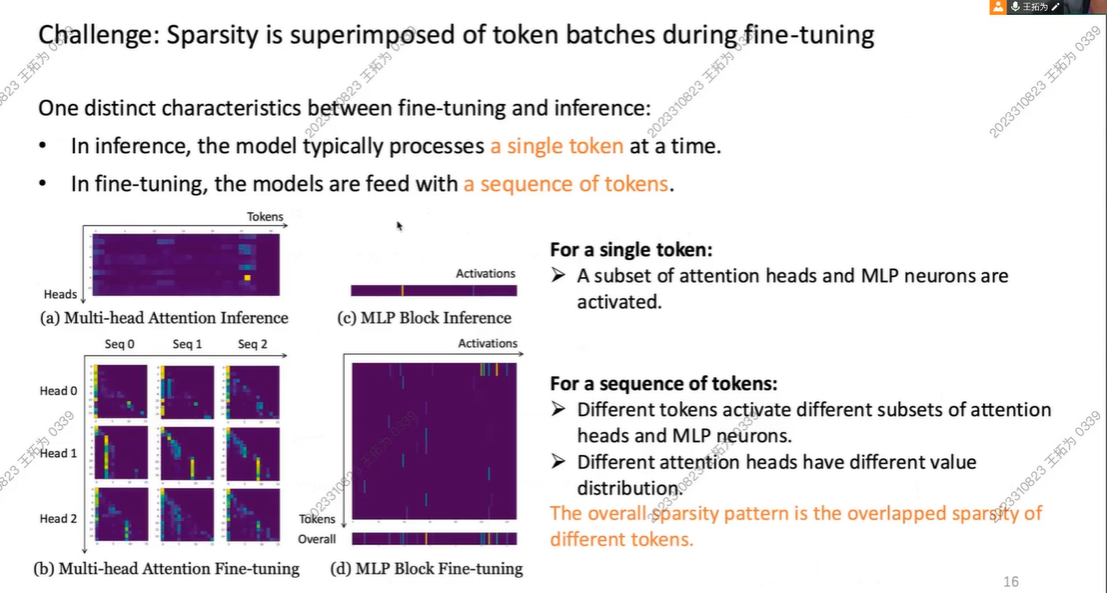
此时,当我们用 a sequnence of tokens 时,我们发现,此时 我们的矩阵不再稀疏!
我们称之为:Shadowy Sparsity!
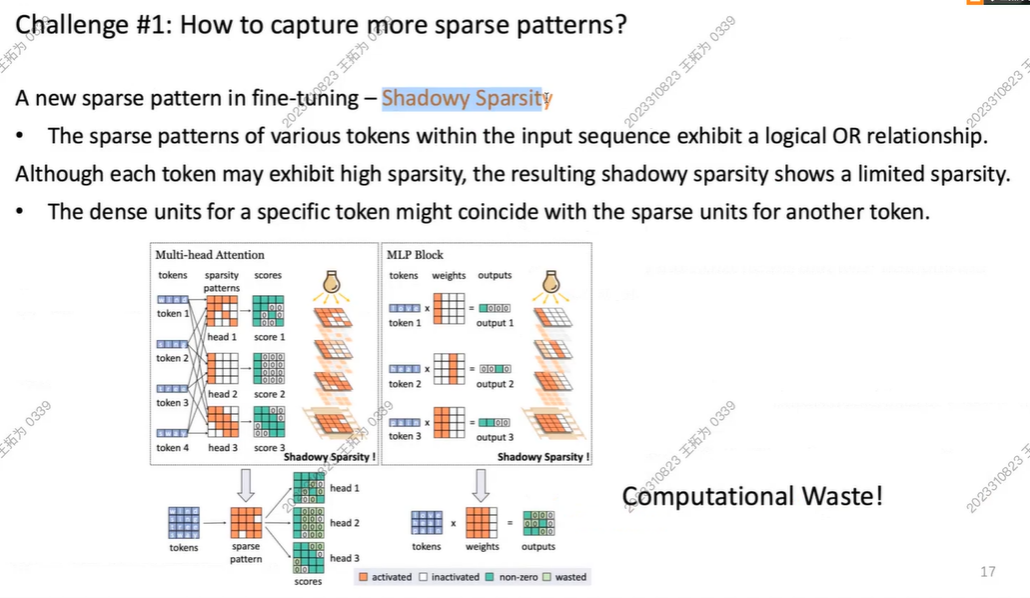
挑战2:如何实时预测稀疏Pattern?
以往方法:神经网络base方法
但是我们在Fine tune中,用不了
- 以前人是针对 一个token
- 在Fine tune中,参数会少量更新
问题3:就算我们预测了稀疏,我们怎么加速?
- 不连续访问
- dynamic, varified
以前的工作都有一定问题(PPT内)

我们的解决方案:
融合:finetune parameter + Computation efficient
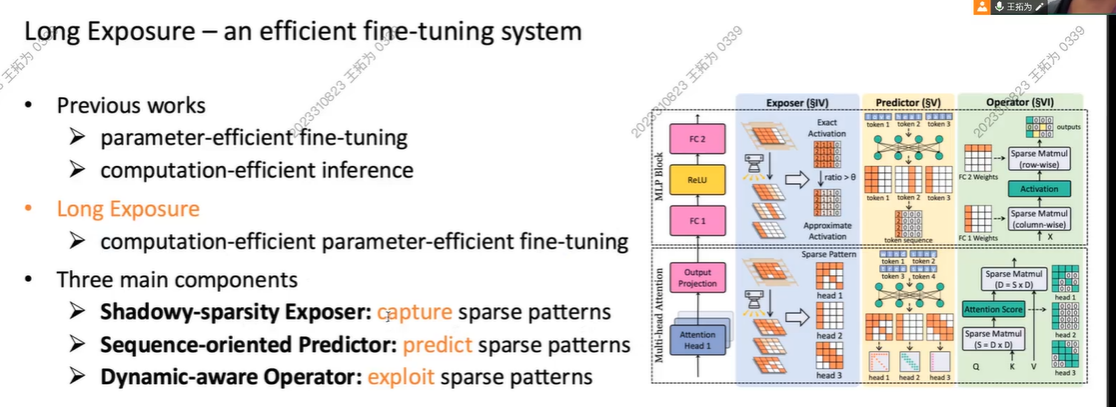
Exposer
- 细粒度,使用header
- MLP:考虑到每一个token激活,threshold base
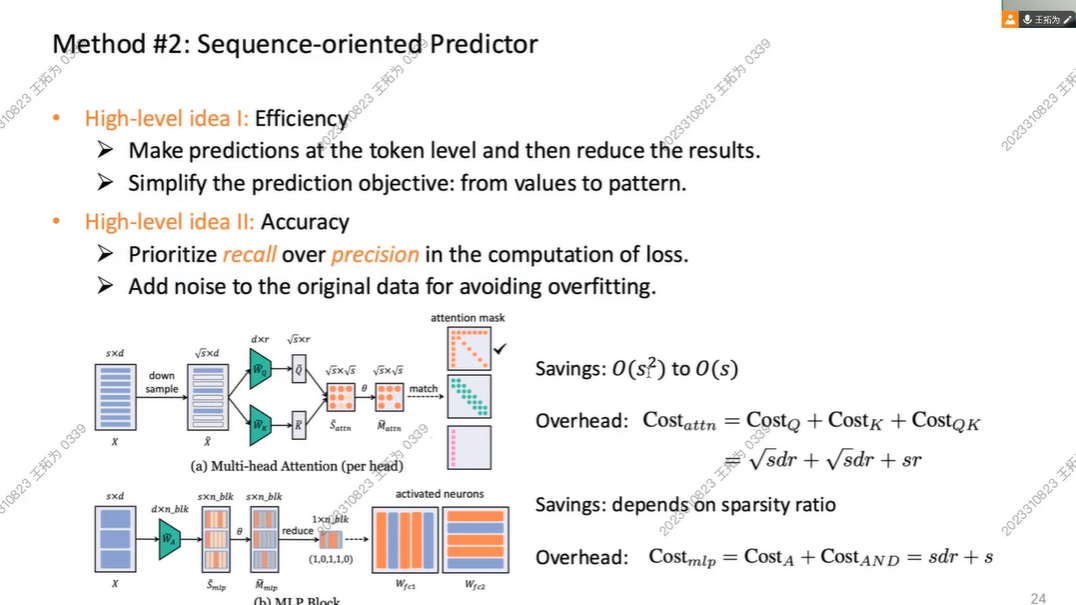
Predictor
- token based prediction with simplication on pattern
- recall,允许预测器多预测一些神经元,不想影响准确率
- 针对过拟合对数据进行
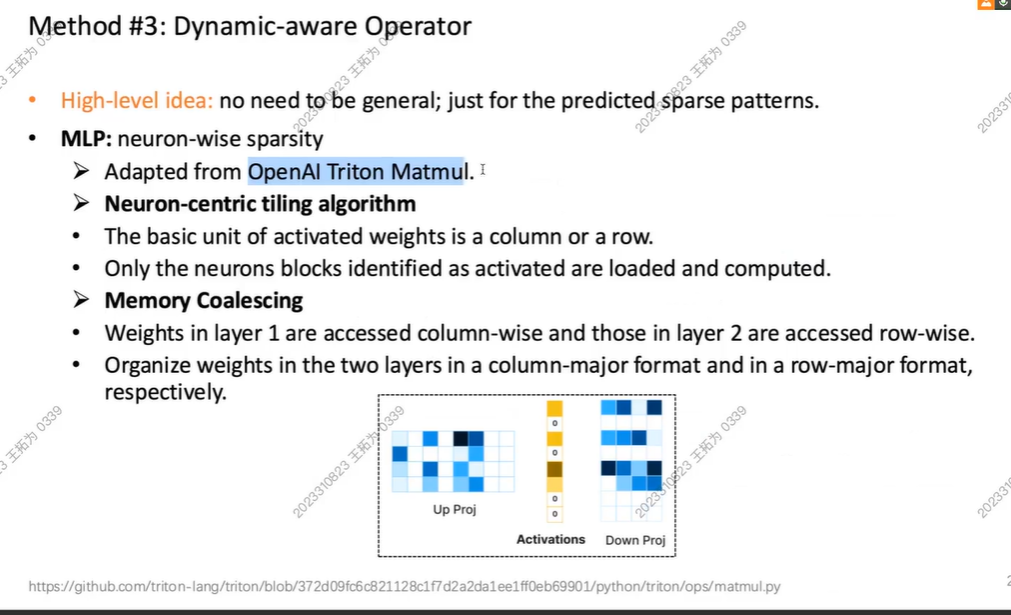
Operator
我们不需要太general,能预测稀疏pattern即可
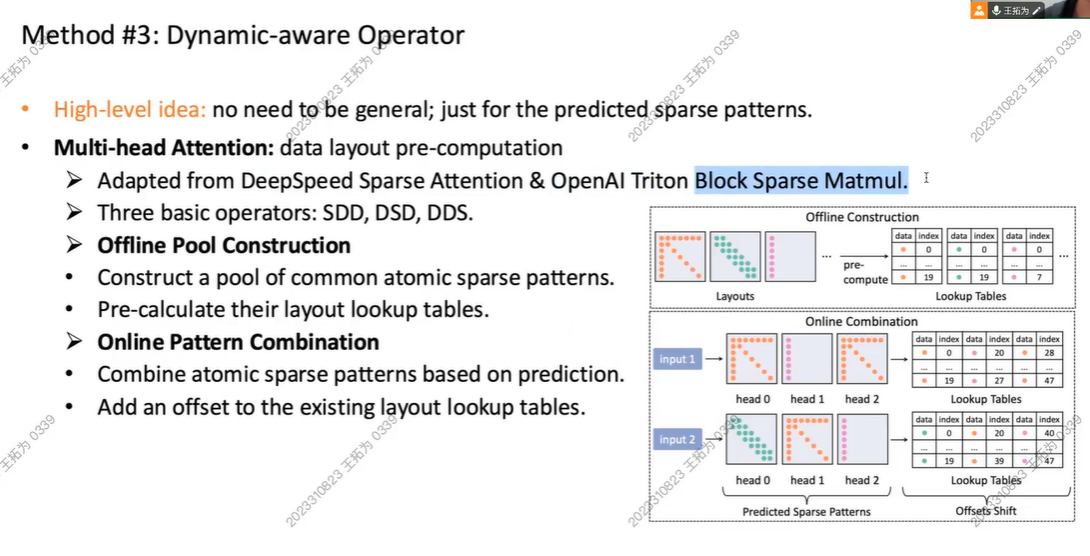
引入稀疏性,其中一个块为0,那一行一列的都是稀疏的(0)
我们会把内存连在一起,访问速度++
实验
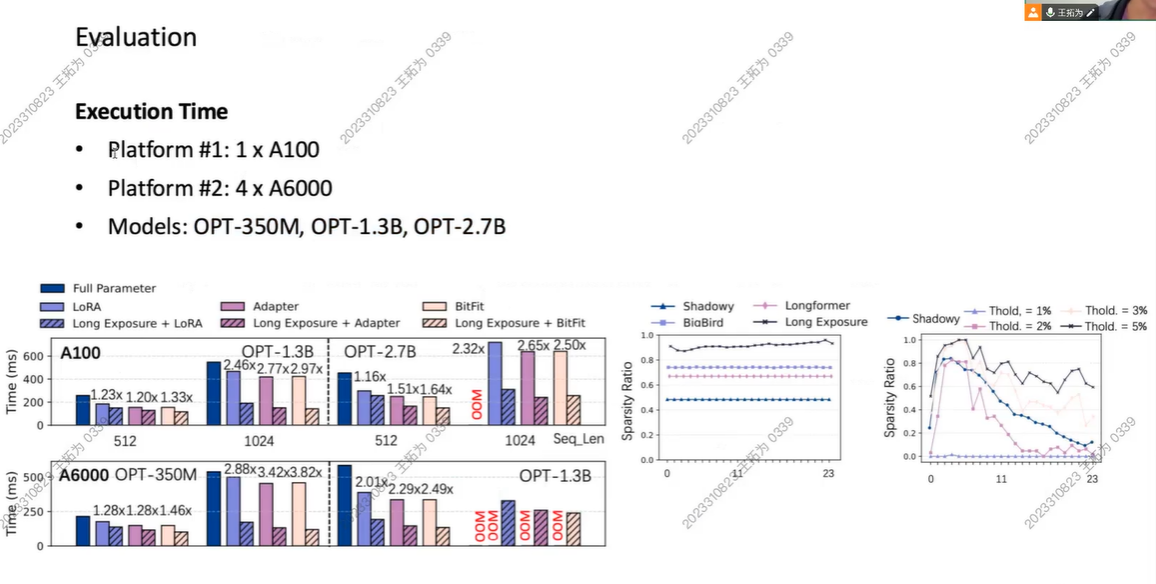
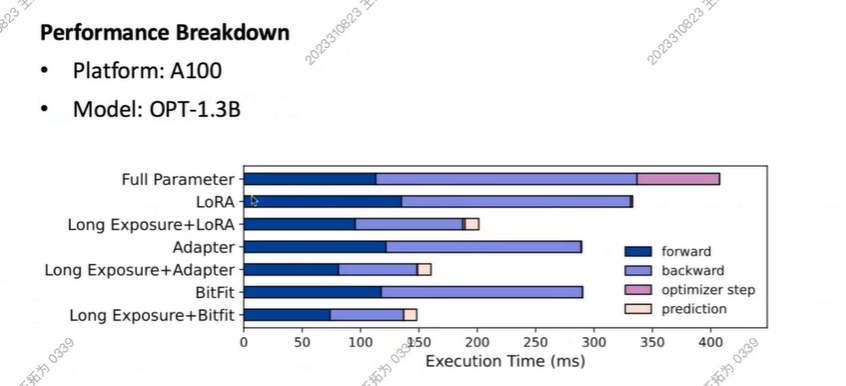
Forward和Backward都加快
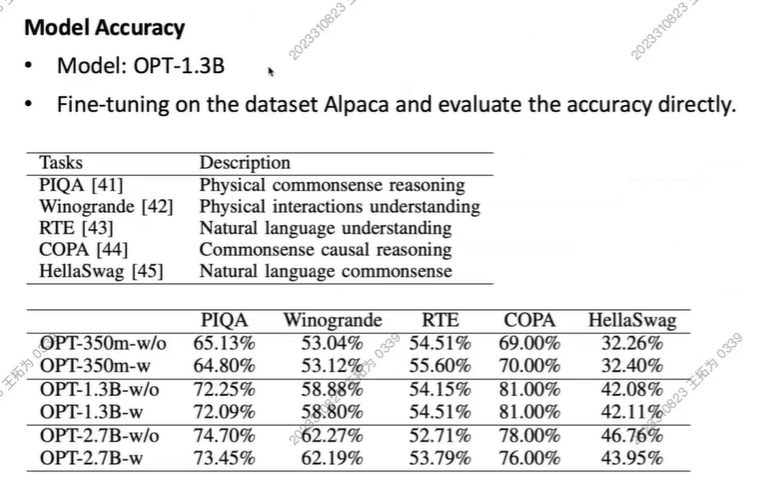
Acc损耗不大
稀疏:mem使用减少
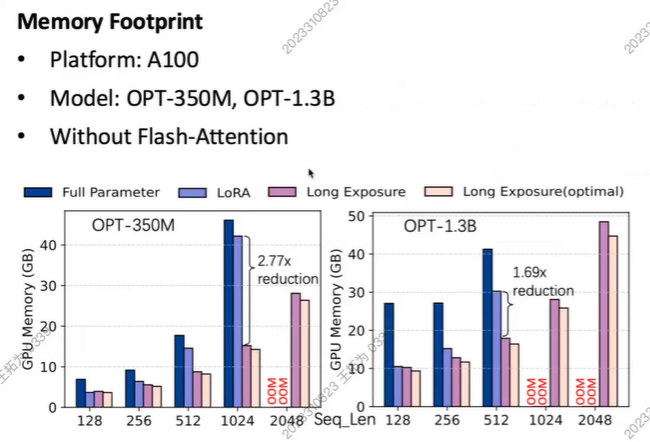
Sensitivity and Scalability
Summary

Author:
https://pairshoe.github.io
Very Nice!!!
Paper
Efficient Transformers
Brian C. Van Essen B308
AcceleratorsAlgorithmsArtificial Intelligence/Machine LearningGraph AlgorithmsPerformance Optimization
TP
Session ChairBrian C. Van Essen
Presentations
10:30am - 11am EST
Adaptive Patching for High-resolution Image Segmentation with Transformers
patching
patching(图像分块) 指的是将一张图像划分为多个较小的、通常是不重叠的区域(或称为“块”)。这些图像块被视为单独的单元(或令牌),然后输入到模型中进行处理,特别是像Transformer这样的模型,它们是通过处理令牌序列来进行工作的。
这种方法的核心思想是减少输入数据的维度,从而让模型能够更高效地处理高分辨率的图像。例如,在处理如显微病理图像等高分辨率图像时,整个图像的处理可能会消耗过多的计算和内存资源。通过将图像切分为小块,模型可以逐个处理这些小块,而不是直接处理整个大图,从而避免了资源瓶颈。
作者提到使用自适应图像分块作为一种方法,根据图像的细节信息动态选择哪些区域需要被划分为图像块。这样可以显著减少传递给模型的图像块数量,从而在不丢失重要信息的情况下提高计算效率。通过这种方式,图像处理变得更加高效,同时提高了模型的性能(比如图像分割质量),并减少了计算开销。
We demonstrate superior segmentation quality over SoTA segmentation models for real world pathology datasets while gaining a geomean speedup of 6.9× for resolutions up to 64K2, on up to 2,048 GPUs.
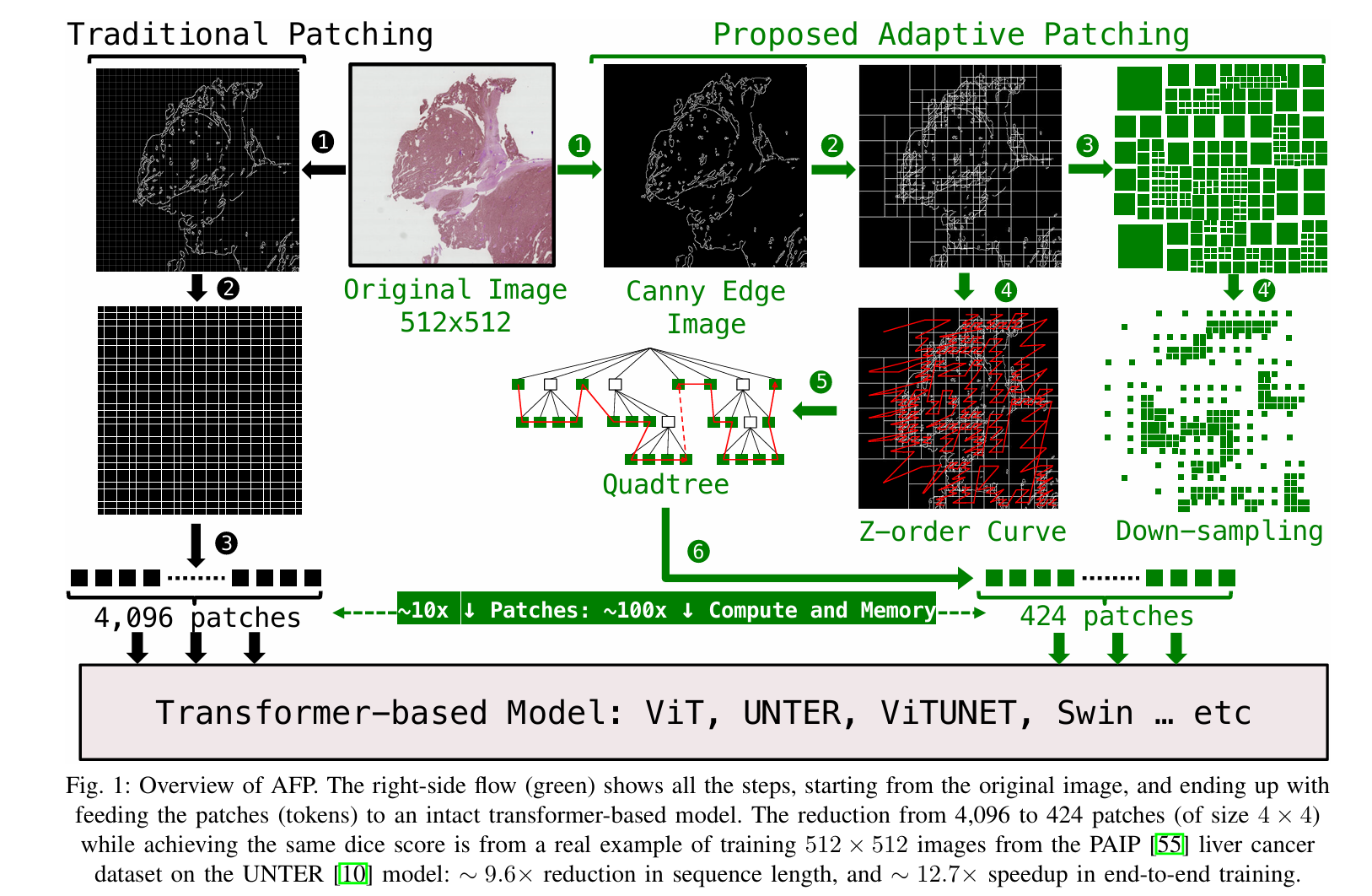
Vision Transformers
Vision Transformers (ViTs) 是一种将Transformer模型应用于计算机视觉任务(如图像分类、目标检测、图像分割等)的模型架构。与传统的卷积神经网络(CNN)不同,ViTs使用自注意力机制(self-attention)来处理图像数据,而不是通过卷积层来提取特征。以下是ViTs的工作原理和关键特点:
1. 图像分块(Patching)
ViT的第一步是将输入的图像划分为多个小块(patches)。例如,对于一张32x32的图像,ViT会将其划分成多个16x16的小块。每个小块会被展平成一维向量,作为模型的输入令牌(token)。这些令牌与自然语言处理中的单词向量类似,经过模型的处理后会得到图像的高层特征表示。
2. 线性嵌入
每个图像块(patch)在输入Transformer之前,会通过一个线性层将其嵌入到一个固定的维度空间(通常是较高维度的向量)。这种嵌入过程类似于将自然语言中的词语转化为词向量。
3. 位置编码(Positional Encoding)
因为Transformer模型本身是顺序无关的(即它不考虑输入数据的空间位置),ViT使用位置编码来提供图像块在图像中的位置信息。这样模型才能理解图像的空间结构。每个图像块的嵌入向量会与相应的位置信息进行加和,形成最终的输入表示。
4. Transformer编码器
经过预处理的图像块(包括嵌入向量和位置编码)会输入到Transformer编码器中。Transformer由多层自注意力机制和前馈神经网络组成。在自注意力机制中,模型能够根据不同图像块之间的相关性动态地调整每个块的权重,从而捕捉图像中不同区域的上下文信息。通过多层自注意力和前馈网络的交替操作,ViT能够逐渐提取出图像的高级特征。
5. 分类头(Classification Head)
在ViT的最后,通常会有一个分类头(classification head)来进行具体的视觉任务。比如,对于图像分类任务,ViT会在Transformer编码器的输出中提取出一个“[CLS]”标记(类似于BERT模型中的[CLS]标记),并通过一个全连接层输出最终的分类结果。
挑战/本文想关注的问题:
The challenge of handling long sequences in ViTs arises from the quadratic computational complexity associated with self-attention mechanism, leading to significant computational demands [14]. Consequently, traditional ViTs encounter limi tations when applied to high-resolution images, where detailed information spans extensive spatial contexts.
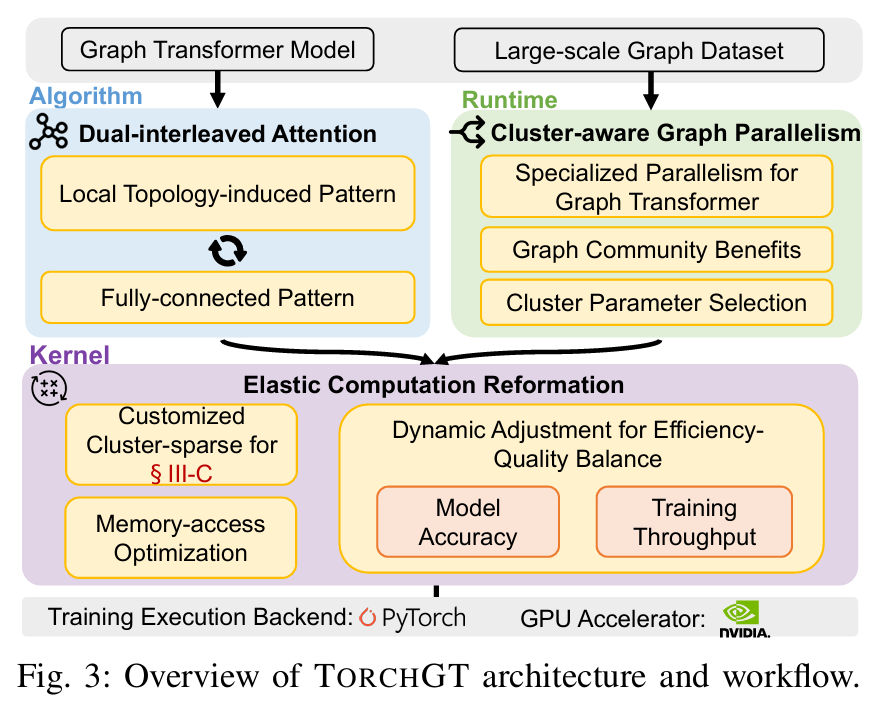
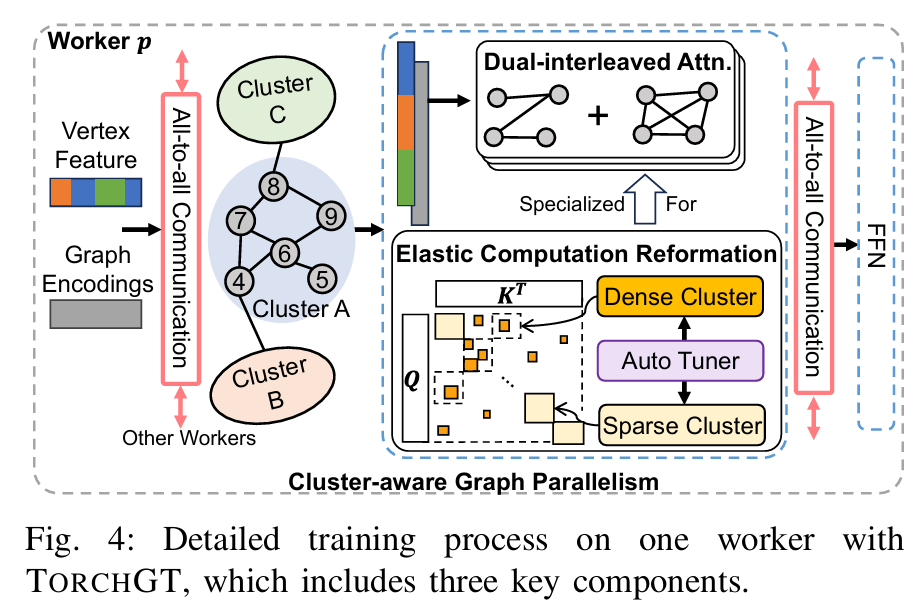
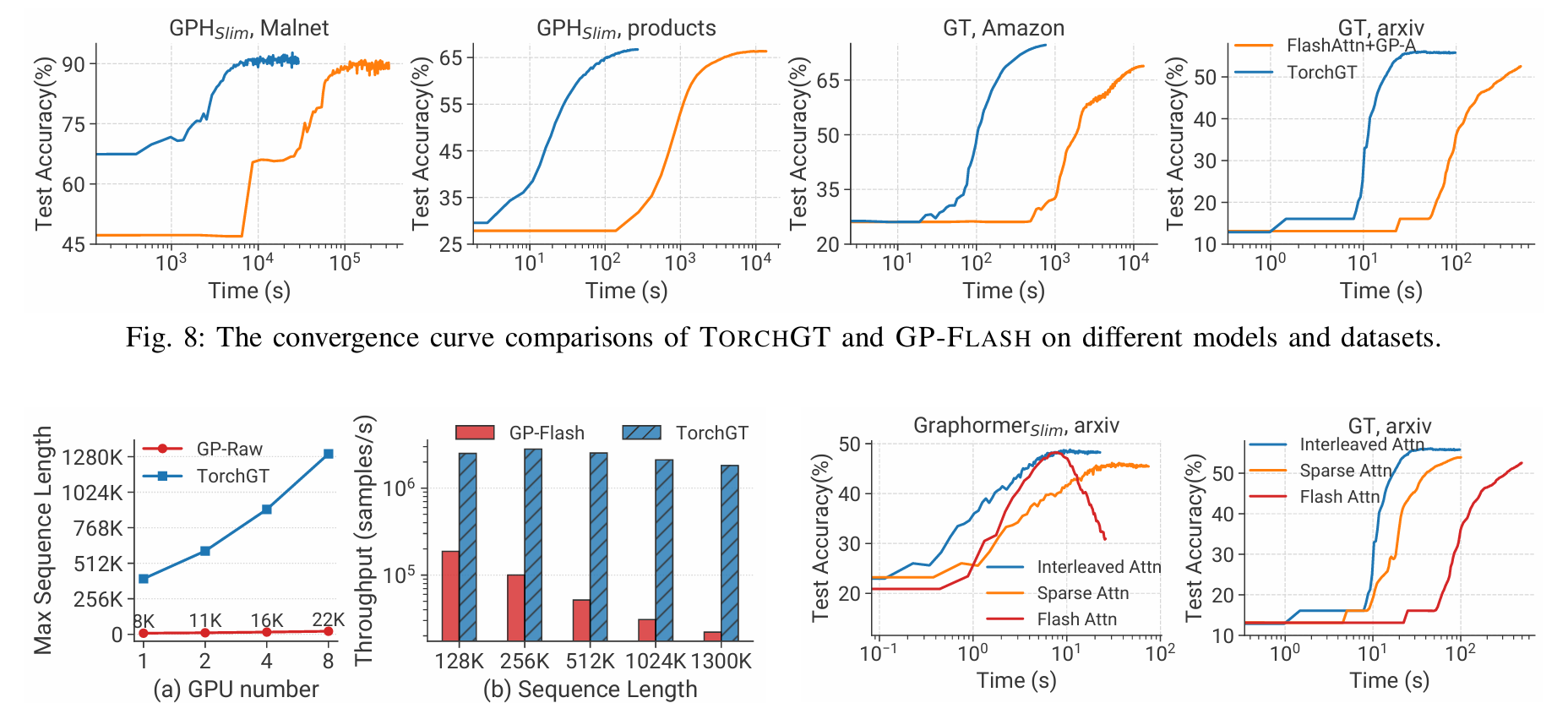
TorchGT: A Holistic System for Large-scale Graph Transformer Training
摘要: Graph Transformer 是一种新的架构,超越了图神经网络在图学习中的表现。虽然出现了令人振奋的算法进展,但它们在实际应用中仍然受到限制,特别是在涉及数百万节点的真实世界图中。我们观察到现有的图转换器在大规模图上失败主要是由于计算量大、可扩展性有限和模型质量较差。受到这些观察的启发,我们提出了 TorchGT,这是第一个高效、可扩展且准确的图转换器训练系统。TorchGT 在不同层面上优化训练。在算法层面上,通过利用图的稀疏性,TorchGT 引入了一种双交错注意力机制,这种机制既高效又能保持准确性。在运行时层面上,TorchGT 通过一种通信轻量级的集群感知图并行性,实现跨工作节点的训练扩展。在内核层面上,一种弹性计算重构进一步优化计算,通过动态方式减少内存访问延迟。大量实验证明,TorchGT 可以将训练提升高达 62.7 倍,并支持长达 1M 的图序列长度。
论文链接: https://arxiv.org/abs/2407.14106
https://blog.csdn.net/wjjc1017/article/details/140620956
Graph Transformer
Graph Transformer 是一种将 Transformer 模型应用于图结构数据的架构,旨在解决传统图神经网络(GNN)在建模图结构时的一些限制。与传统的图神经网络通过节点和边的局部信息传递进行学习不同,Graph Transformer 将 Transformer 的自注意力机制引入图数据的处理,通过全局信息的建模来提高图数据学习的效果。
1. 基本概念
图数据是一种非欧几里得结构,不同于图像或文本等顺序数据,它由节点(vertices)和边(edges)构成。每个节点和边都可能具有不同的属性或特征。在图上进行学习的任务(如节点分类、图分类、链接预测等)要求模型能够有效地处理这些复杂的关系。
传统的图神经网络(GNN)通过消息传递机制(message passing)将节点的信息传递给其邻居,逐渐更新节点的表示。然而,GNN通常关注的是局部邻域的特征,对于图的全局信息捕捉不足。Graph Transformer通过引入Transformer的自注意力机制,能够更好地捕捉图结构中的长距离依赖关系和全局信息。
2. Graph Transformer的工作原理
-
节点嵌入(Node Embedding):图中每个节点都会通过一个嵌入层转换为一个固定维度的向量,类似于ViT中图像块的处理。每个节点的特征向量将作为Transformer模型的输入。
-
位置编码(Positional Encoding):与ViT在图像中使用位置编码类似,Graph Transformer需要考虑节点在图中的位置。为了让模型理解节点在图中的结构关系,可以加入位置编码来提供空间信息。
-
自注意力机制(Self-Attention):Graph Transformer利用Transformer的自注意力机制,计算每个节点与其他节点的相关性,从而捕捉图中长距离的依赖关系。在计算注意力权重时,节点之间的关系可以基于它们的特征或图结构信息来进行建模。
-
图结构融合:不同于常规的Transformer应用,Graph Transformer需要将图的结构信息与节点特征一起输入模型。通常会使用图的邻接矩阵或者图卷积方法来融合结构信息,以增强模型对图结构的理解。
-
全局信息建模:通过多层的自注意力机制,Graph Transformer能够在全图范围内传播信息,进而捕捉到节点之间的全局依赖关系和长距离的交互信息。
应用场景
-
图分类:例如分子结构的分类,社交网络分析等。
-
节点分类:例如社交网络中用户分类,知识图谱中的实体分类等。
-
链接预测:在图中预测节点之间可能存在的边,如社交网络中的好友推荐,或学术网络中的引用预测等。
-
图生成:例如图生成模型可以应用于分子结构的生成、网络的设计等。
本文提出了一种名为TORCHGT的高效、可扩展且精确的图Transformer训练系统,主要针对大规模图(如包含数百万节点的真实世界图)中现有方法面临的计算量大、扩展性差和模
型质量不高的问题。通过在算法层面引入双交错注意力机制,在运行时层面采用通信轻量级的集群感知图并行策略,并在内核层面优化内存访问延迟,TORCHGT显著提升了训练效
率和扩展能力。实验表明,该系统将训练速度提高了62.7倍,并支持处理长度达1百万节点的图序列。
Exploring Efficient Partial Differential Equation Solution using Speed Galerkin Transformer
这篇论文讨论的是Fourier神经算子(FNO)在偏微分方程求解问题中的应用,特别是针对达西流方程的解决方案。
FNO已经被证明是一种通用且有效的深度学习框架,在PDE求解方面表现出了令人瞩目的准确性。
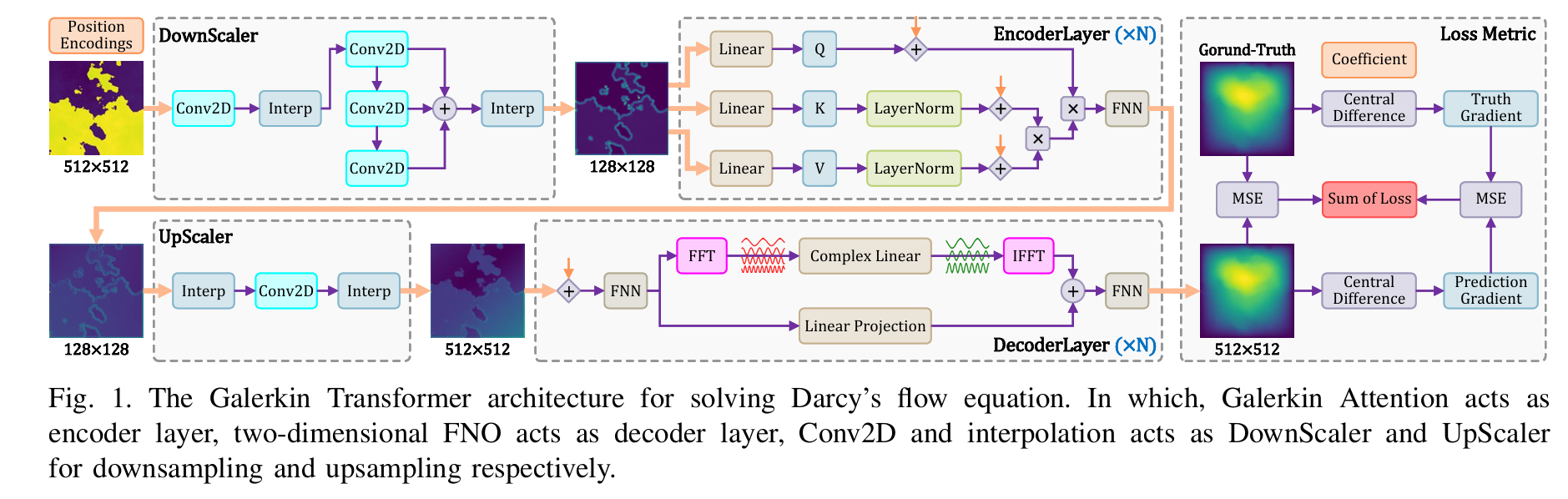
然而,作者指出,现有的基于FNO的模型中存在一些关键组件无法充分发挥硬件潜力的问题,这使得它们难以在高分辨率和需要实时处理的场景下应用。为了克服这些限制,本文
提出了一种名为Speed Galerkin Transformer的高度优化模型,并详细介绍了一系列优化策略。
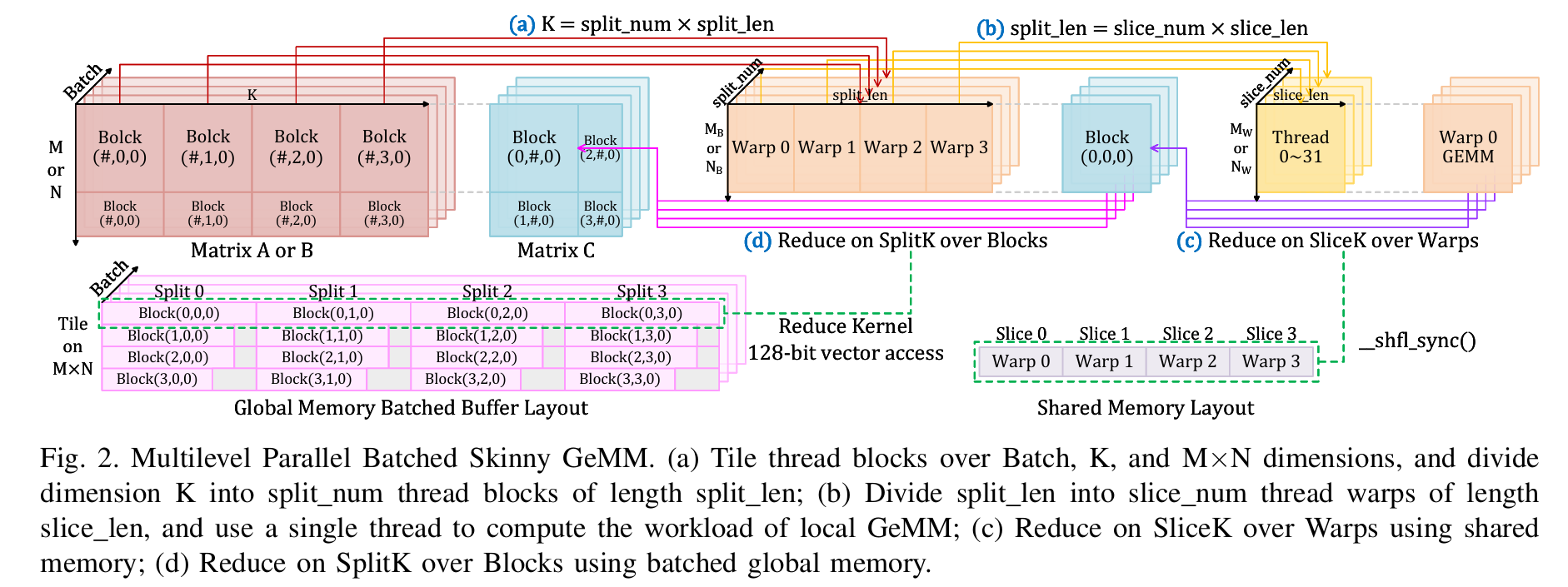
首先,文中提到了多级并行SliceK-SplitK-ReduceK策略用于批量瘦矩阵乘法(batched skinny matrix multiplication)。这听起来像是针对特定类型的矩阵运算进行优化,可
能涉及到将大规模的矩阵分解为更小的部分,并利用并行计算来加速这些操作。这种策略可能能够显著提高矩阵乘法的速度,尤其是在处理大量数据时。
其次,论文中提到对QKV矩阵和位置编码进行了内存布局优化。在Transformer模型中,Q、K、V(查询、键、值)矩阵的处理是核心部分之一,而合理安排这些矩阵在内存中的存
储方式可以减少访问延迟,提高计算效率。此外,结合多头层归一化融合也是一个关键点,可能通过将多个归一化操作合并来减少计算开销。
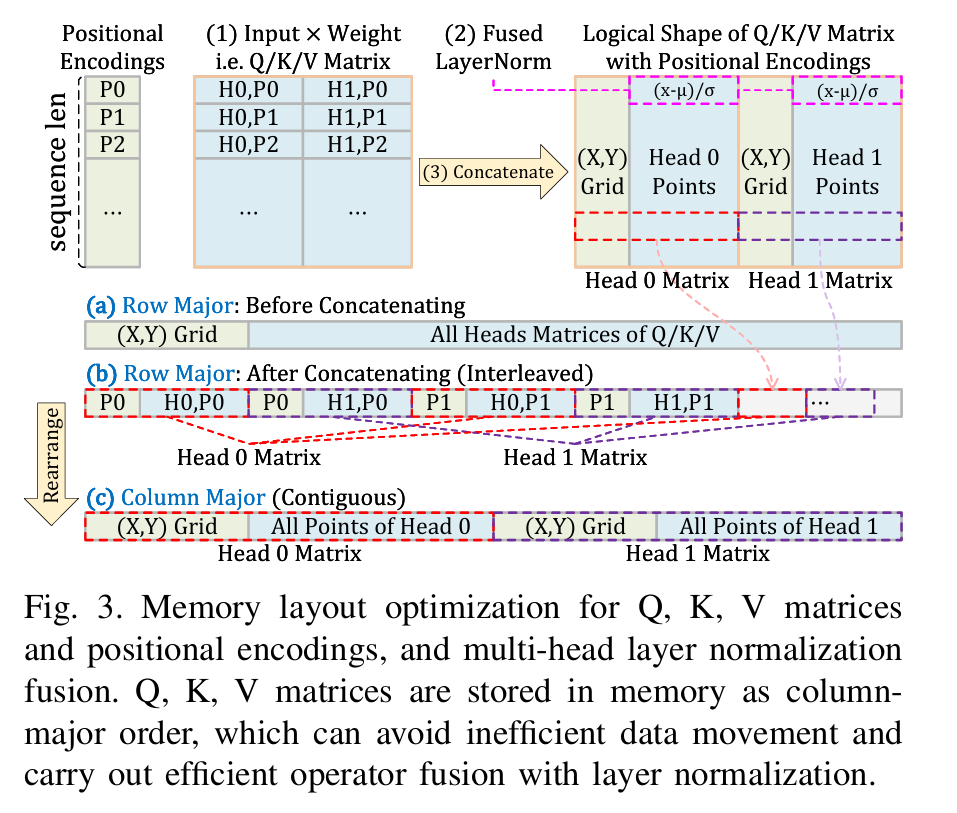
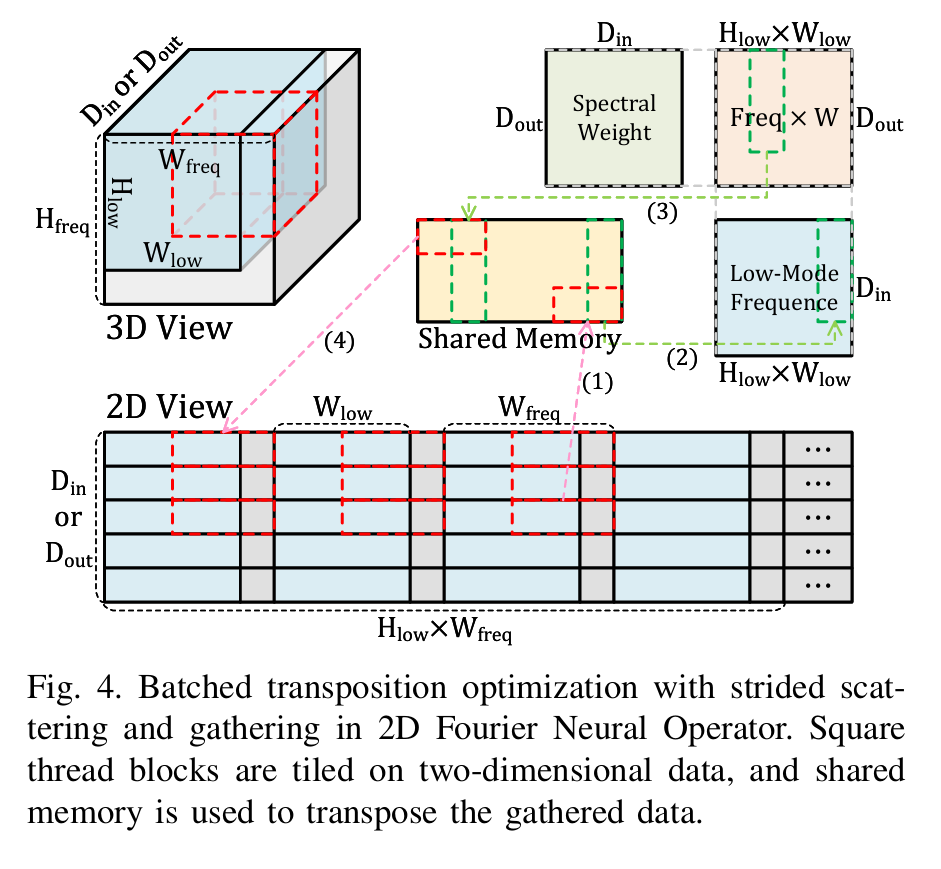
另外,文中还提到了二维FNO中的批量转置优化,特别是使用了带步进的散射和聚集(strided scattering and gathering)。这表明他们在处理矩阵的转置操作时采用了更高效
的方法,可能减少了数据移动的次数,从而提升了整体性能。
实验结果方面,这些策略在特定配置下分别实现了10.29倍、4.41倍和2.38倍的速度提升。这意味着每一项优化措施都对模型的整体性能有着显著的影响。当应用到512x512分辨率
的达西流方程求解时,Speed Galerkin Transformer模型实现了约1.72倍的速度提升,并在使用8块GPU的情况下达到了超过90%的并行效率。
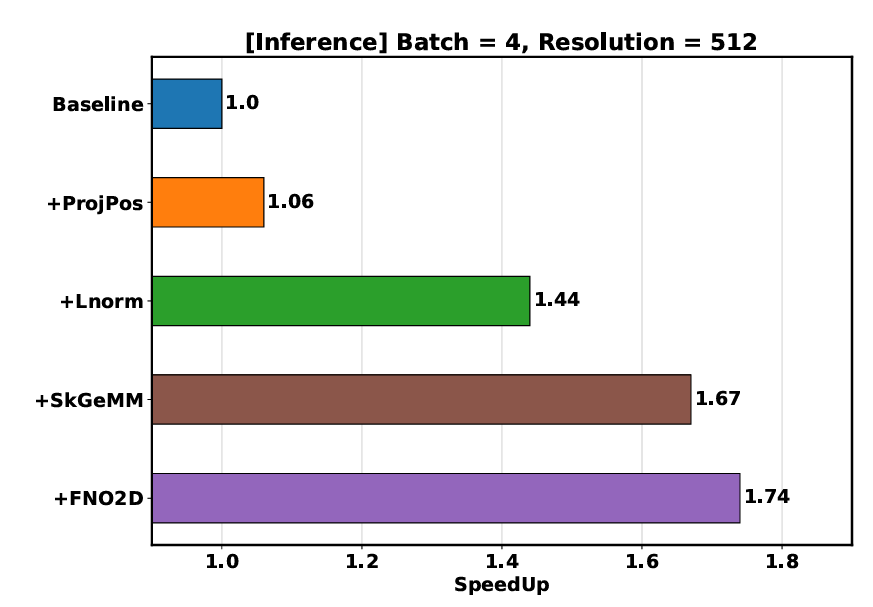
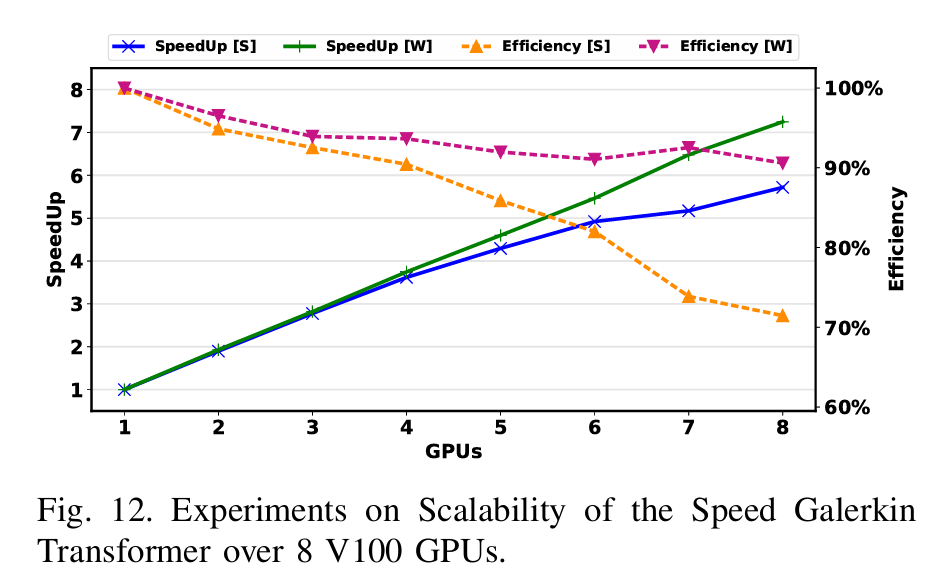
这些结果表明,作者提出的优化策略不仅显著提高了计算速度,还很好地利用了多GPU环境下的并行计算能力。这对于需要处理高分辨率和大规模数据的问题来说是非常重要的,尤其是在实时性和计算资源有限的场景中。
Quantum and Approximate Computing
并非物理专业,跳过这块。
Quantum and Approximate Computing I
-
LexiQL: Quantum Natural Language Processing on NISQ-era Machines
量子NLP
In this work, we present LEXIQL, a technique for the NLP task of text classification using quantum computing. We demonstrate the performance of LEXIQL on five datasets of varying difficulty and demonstrate the wide range of domain applicability for LEXIQL. We also demonstrate that LEXIQL can achieve high accuracy in noiseless simulation and can also effectively mitigate NISQ-era noise. LEXIQL is available as an open-source framework for quantum text classification at https://zenodo.org/records/10980744. -
Optimizing Quantum Fourier Transformation (QFT) Kernels for Modern NISQ and FT Architectures
-
On the Efficacy of Surface Codes in Compensating for Radiation Events in Superconducting Devices
Quantum and Approximate Computing II
-
HPAC-ML: A Programming Model for Embedding ML Surrogates in Scientific Applications
-
Parallax: A Compiler for Neutral Atom Quantum Computers under Hardware Constraints
Quantum and Approximate Computing III
-
Surpassing Sycamore: Achieving Energetic Superiority Through System-Level Circuit Simulation
-
Realizing Quantum Kernel Models at Scale with Matrix Product State Simulation
-
Atlas: Hierarchical Partitioning for Quantum Circuit Simulation on GPUs
用GPU做量子电路模拟,有趣。不知道Mindspore会不会跟上。
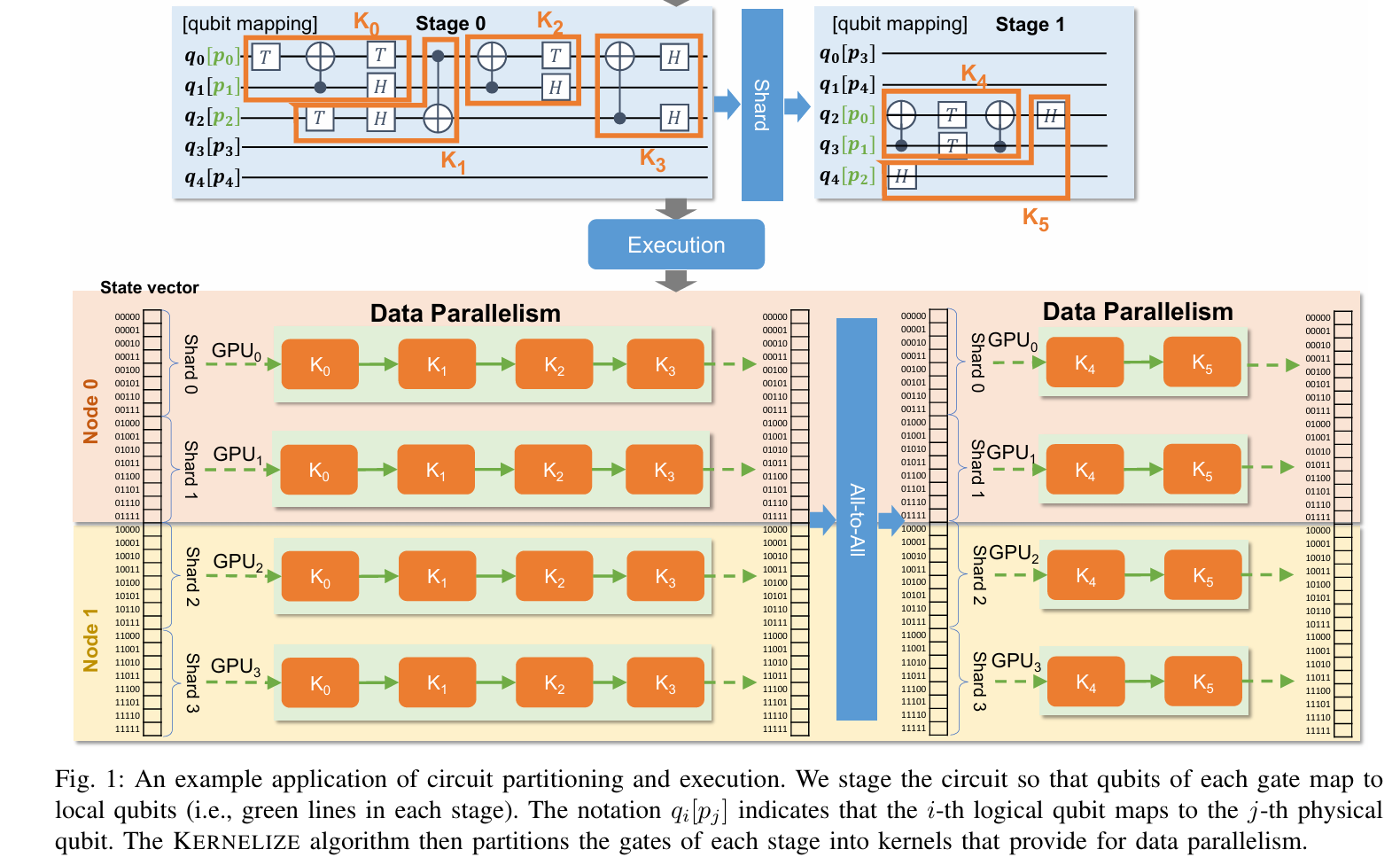
Resource Utilization and Package Management
George Michelogiannakis B309
AcceleratorsArtificial Intelligence/Machine LearningCodesignState of the PracticeSystem Administration
TP
Session ChairGeorge Michelogiannakis
Presentations
10:30am - 11am EST
Unlocking High-Performance with Low-Bit NPUs and CPUs for Highly Optimized HPL-MxP on Cloud Brain II
在low bit NPU上更好的实现HPL-MXP

AuthorsWeicheng XueKai YangYongxiang LiuDengdong FanPengxiang XuYonghong Tian
11am - 11:30am EST
田永鸿,北京大学博雅特聘教授,博士生导师,IEEE Fellow,北京大学深圳研究生院信息工程学院院长,鹏城实验室网络智能部副主任兼云脑研究所所长,鹏城云脑技术总师,香港中文大学(深圳)和华中科技大学兼职教授,2018年国家杰出青年基金获得者。
摘要—混合精度计算对于人工智能和科学计算应用至关重要。然而,随着新型具有创新架构的芯片的出现,如何充分利用其计算能力成为了一个巨大的挑战。尽管现有的HPL-MxP LU分解算法在同质系统上表现优秀,但在专业的异构架构上经常遇到困难。这一不足源于计算、内存访问和通信优化不足,限制了混合精度加速的有效性。本文提出了一种LU分解算法-硬件协同优化方法,适用于专业的NPU和CPU,充分利用它们的独特架构。我们提出了一种新的多迭代融合方法,针对一般矩阵乘法进行优化,旨在最大化L1缓存的利用率,有效克服著名的“内存墙”问题。此外,本文还提出了一种多阶段、多层次的异构管道,用于在加速器-CPU云环境中进行LU分解,其中计算密集型的矩阵乘法任务被卸载到NPU,而CPU则处理剩余的任务。该协同优化方法促进了CPU与加速器之间的深度协作,从而释放了更高的性能潜力。
• We propose a novel multi-iteration fusion method for gen eral matrix multiplication (GEMM) to efficiently address the ”memory wall” challenge. This approach effectively reduces data transfer from global memory and maximizes the utilization of the low-latency and high-bandwidth on chip L1 buffer on the NPU.
• Wepropose a co-acceleration method for triangular solve with matrix (TRSM) using both the CPU and NPU to effectively tackle the ”mixed-precision optimization”challenge. This involves offloading low-cost small matrix inversion calculations in TRSM to the CPU using FP32, while assigning matrix multiplication in TRSM to the NPU using FP16.
• We propose a novel multi-stage, multi-level heteroge neous pipeline for LU factorization on the CPU and NPU, addressing the ”heterogeneous pipeline optimiza tion” challenge. By performing only GEMM on the NPU and the rest on the CPU, this optimization significantly enhances the performance. Overall, this method integrates the multi-iteration fusion method and the co-acceleration method for TRSM.
鹏城云脑:
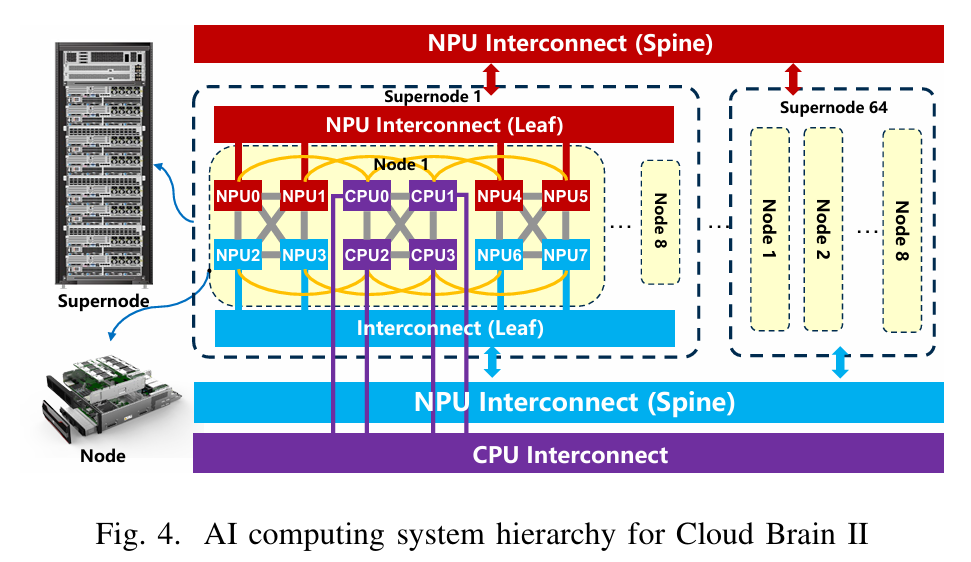
Pipeline
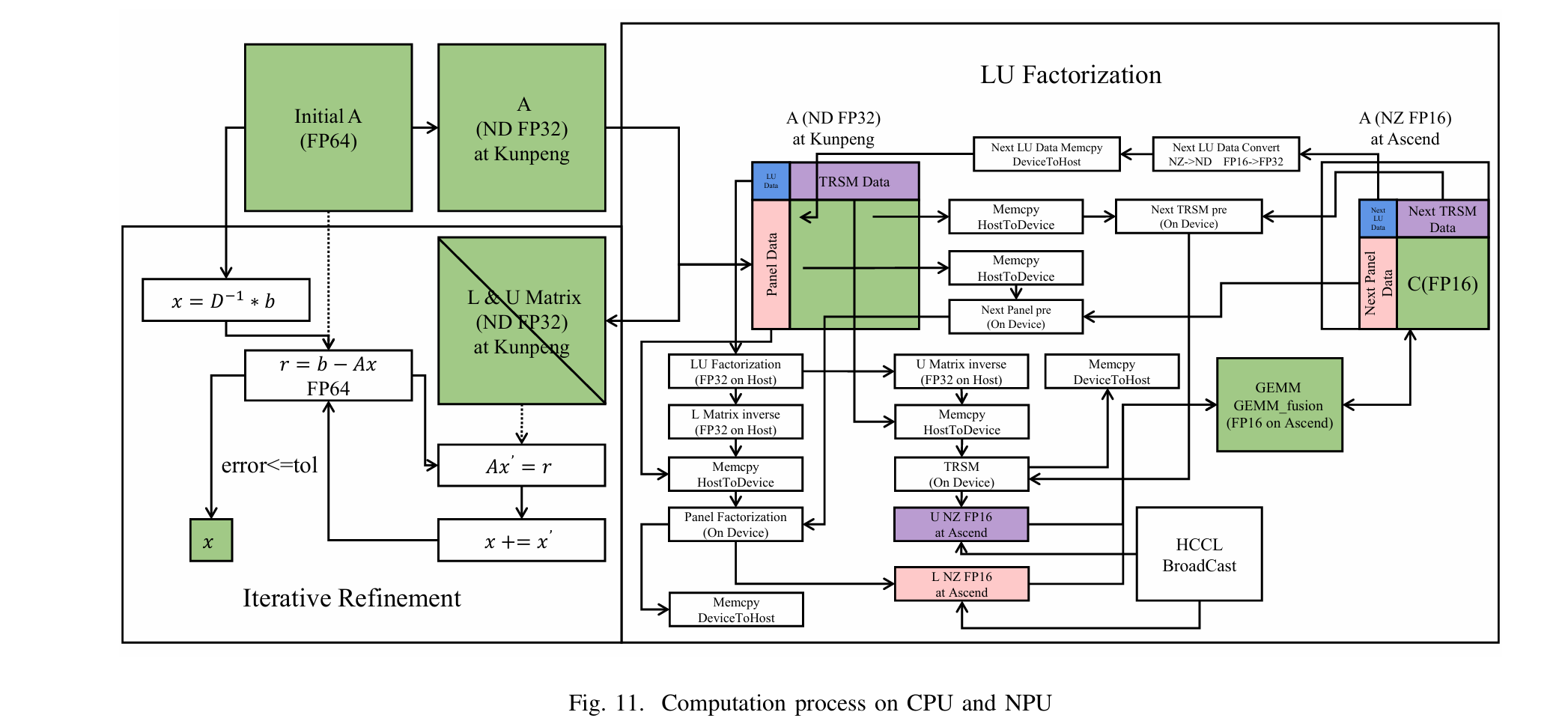
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
原来这就是幻方!!!
【论文解读】DeepSeek「多快好省」的 AI 训练集群—— Fire-Flyer AI-HPC - 知乎
这篇论文里提出了一个「省钱」的 AI 训练集群方案:用 1 万张 「平民级」PCIe 接口的 A100 显卡,构建出成本仅为行业标杆(NVIDIA DGX-A100)一半、能耗降低 40% 的高性能 AI 训练集群,却能实现 80% 的等效算力。
AuthorsWei AnXiao BiGuanting ChenShanhuang ChenChengqi DengHonghui DingKai DongQiushi DuWenjun GaoKang GuanJianzhong GuoYongqiang GuoZhe FuYing HePanpan HuangJiashi LiWenfeng LiangXiaodong LiuXin LiuYiyuan LiuYuxuan LiuShanghao LuXuan LuXiaotao NieTian PeiJunjie QiuHui QuZehui RenZhangli ShaXuecheng SuXiaowen SunYixuan TanMinghui TangShiyu WangYaohui WangYongji WangZiwei XieYiliang XiongYanhong XuShengfeng YeShuiping YuYukun ZhaLiyue ZhangHaowei ZhangMingchuan ZhangWentao ZhangYichao ZhangChenggang ZhaoYao ZhaoShangyan ZhouShunfeng ZhouYuheng Zou
11:30am - 12pm EST
文章回顾了 HPC 和 AI 集群的发展历程,并分析了现有方案的优缺点:
-
传统超算(如 TianHe-2A、Stampede 2、Sunway TaihuLight):主要关注双精度计算,不支持 FP16 精度,不适合 DL 训练。
-
GPU-based HPC(如 Frontier、Aurora、Summit、Perlmutter):利用高性能 GPU 进行大规模计算,但成本较高。
-
大型公司 GPU 集群(如 Meta、ByteDance、Alibaba、NVIDIA):
-
Meta:采用软硬件协同设计,使用 IB(InfiniBand,一种高速网络技术)或 RoCE(RDMA over Converged Ethernet,一种基于以太网的 RDMA 技术)。
-
ByteDance:早期采用 CPU+PCIe GPU 方案,后期转向类似 DGX 的架构。
-
Alibaba:使用 NVIDIA H800 GPU,并开发了自己的 HPN 网络。
-
NVIDIA:构建了 Eos AI-HPC,但 DGX 系统的成本较高。
-
AI DSA 集群(如 Google TPU、Intel Habana Gaudi、Tesla Dojo、Huawei Ascend):定制的 AI 加速器,在特定任务上性能优异,但软件生态不如 NVIDIA。
-
云服务提供商(如 Azure):提供灵活的资源,但长期使用成本较高。
Fire-Flyer AI-HPC 的核心思路是软硬件协同设计,通过优化软件和硬件架构,以更低的成本获得接近 DGX-A100 的性能。具体来说,包括:
- 采用 PCIe A100 GPU:相比 SXM 接口的 A100,PCIe 版本的成本更低。
- 定制化的网络拓扑:采用 Two-Layer Fat-Tree 结构,并集成了存储和计算网络,降低了网络成本。
- HFReduce 通信库:通过 CPU 异步 allreduce,优化 PCIe 架构下的通信性能。
- HaiScale 框架:针对 PCIe 架构优化了数据并行、流水线并行、张量并行等策略。
- 3FS 分布式文件系统:解决 I/O 瓶颈,优化存储和计算集成网络。
- HAI 平台:提供任务调度、故障处理和灾难恢复功能,提高资源利用率。
1。 A100 网络拓扑
-
Fire-Flyer 2 硬件架构
-
计算节点:
-
2*AMD 32 Cores EPYC Rome/Milan CPU
-
512GB 16-Channels DDR4-3200Mhz 内存
-
8*PCIe-A100-40GB GPU
-
1*Mellanox InfiniBand cx6 200Gbps NIC
-
网络拓扑:Two-Layer Fat-Tree 结构,分为两个 Zone,每个 Zone 连接约 600 个 GPU 计算节点。
-
存储节点:每个节点配备 1615.36TB PCIe 4.0x4 NVMe SSD 和 2Mellanox CX6 200Gbps NIC。
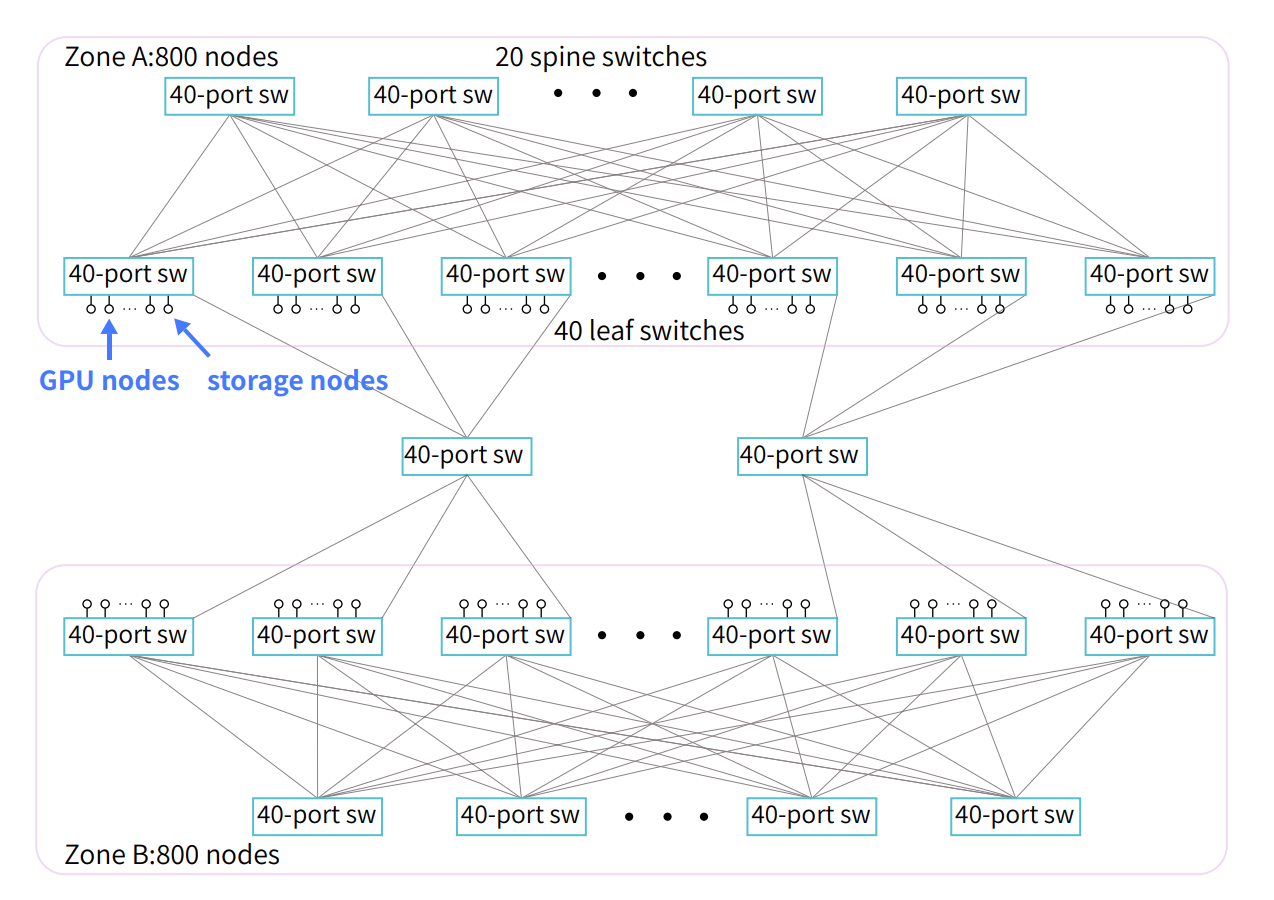
Fat-Tree 是一种树状网络拓扑,具有高带宽和可扩展性。它由多层交换机组成,越靠近根部的交换机带宽越高,类似于树干越来越粗。
选择 Two-Layer Fat-Tree 的原因仍然是成本。Three-Layer Fat-Tree 的扩展性更好,但需要更多的交换机和更复杂的配置。Two-Layer Fat-Tree 在满足 DeepSeek-AI 需求的前提下,可以降低网络成本。
HFReduce
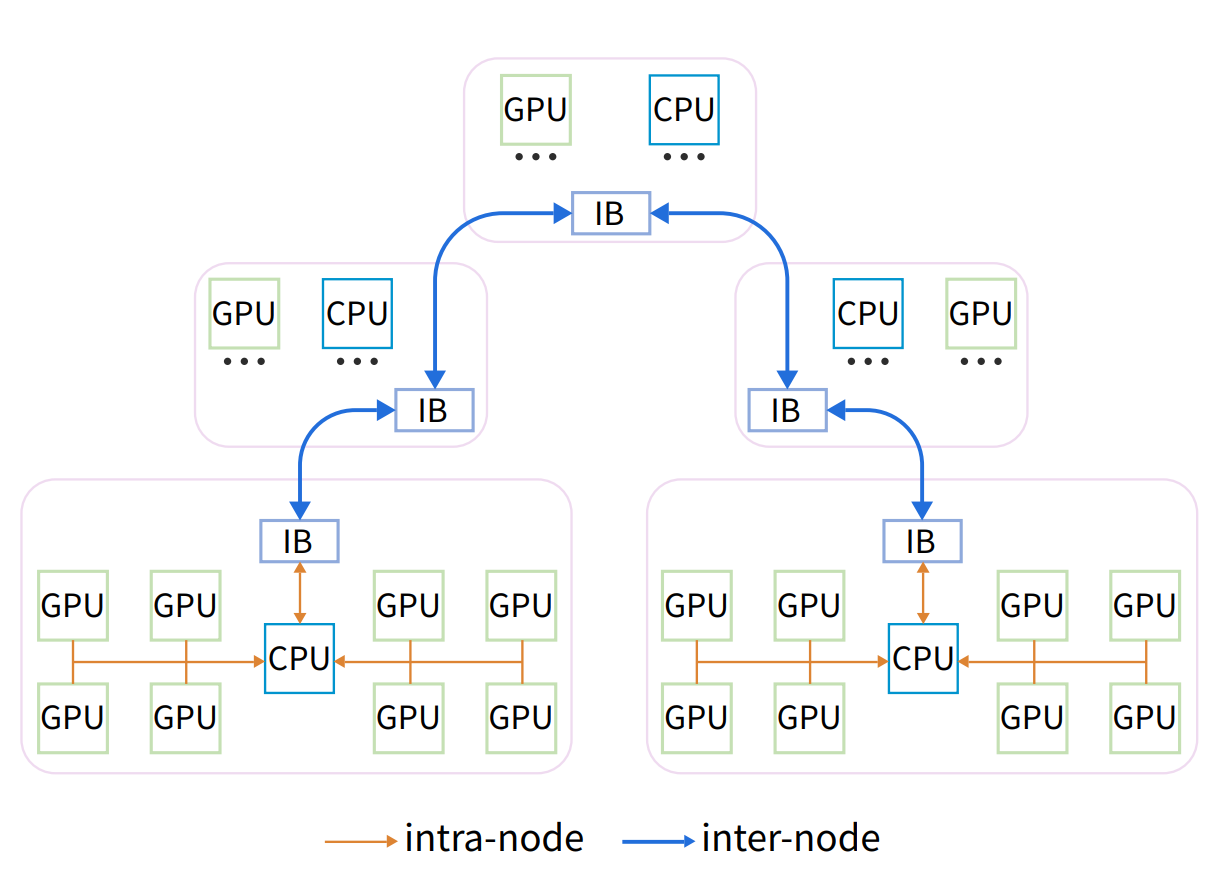
HFReduce 的核心思想是利用 CPU 进行辅助计算,减少 GPU 之间的直接通信。
-
原理:先在节点内进行 reduce,然后通过 CPU 进行节点间 allreduce。
-
步骤:
-
GPU 上的梯度数据异步传输到 CPU 内存。
-
CPU 使用向量指令进行 reduction add 操作。
-
使用 Double Binary Tree 算法进行节点间 allreduce。
-
CPU 将 reduce 后的梯度数据返回给 GPU。
-
优势:降低 PCIe 带宽消耗,没有 GPU Kernel 开销。
HaiScale
HaiScale 框架主要针对 LLM 训练进行了优化,关键策略包括:
-
DDP Overlap AllReduce:在反向传播阶段,异步 allreduce 计算出的梯度,使通信与计算重叠。
-
LLM 训练优化:
-
NVLink Bridge 实现 PCIe GPU 间的 Tensor Parallel。
-
Pipeline Parallel 优化,配置 Data Parallel rank,使同一节点上的 GPU 属于不同的 DP rank,错开 PP 的时序。
-
Fully Sharded Data Parallel (FSDP),优化内存管理,重叠 allgather 和 reduce-scatter 通信与正向和反向计算。
3FS 分布式文件系统
3FS 文件系统的设计目标是充分利用 NVMe SSD 的高 IOPS 和吞吐量,以及 RDMA 网络。它通过以下方式解决 I/O 瓶颈:
-
架构:包括 cluster manager、meta service、storage service 和 client 四个角色。
-
关键技术:
-
使用分布式 key-value 存储系统存储文件元数据。
-
采用 Chain Replication with Apportioned Queries (CRAQ) 实现强一致性。
-
在存储服务和客户端实现 request-to-send 控制机制,缓解拥塞。

HAI 平台的作用是什么?它如何提高集群的利用率?
HAI 平台是一个任务调度和资源管理平台,旨在提高集群的利用率和稳定性。它通过以下方式实现:
-
时间分片调度:将 GPU 资源按照时间片分配给不同的任务,实现 GPU 资源的复用。
-
任务中断和恢复:支持任务的中断和恢复,可以灵活地调整任务的优先级和资源分配。
-
故障处理和灾难恢复:提供故障检测和自动恢复功能,保证集群的稳定运行。
-
鼓励并行训练:鼓励用户充分利用多个 GPU 进行并行训练,提高 GPU 的利用率。
不足
-
PCIe 架构的局限性:虽然通过软件优化弥补了一些性能差距,但 PCIe 接口的带宽限制仍然存在。
-
NVLink Bridge 的问题:NVLink Bridge 的故障率较高,可能影响集群的稳定性。
-
Congestion Control 的 trade-off:在 computation-storage integrated network 中,为了避免 HFReduce traffic 和 3FS storage traffic 的相互影响,选择关闭了 DCQCN,这实际上是一种 trade-off,可能会对某些特定 workload 下的性能产生影响。
-
通用性:该方案是针对 DeepSeek-AI 的特定需求和环境设计的,可能不适用于所有场景。
GPU相关的PCIe、SXM、NvLink、OAM你都清楚吗?
GPU相关的PCIe、SXM、NvLink、OAM你都清楚吗?-百合树AI写作-专业学术论文写作助手 -
SXM A100:采用 SXM(Socketed eXtended Module)接口,通过 NVLink 高速互联,GPU 之间可以直接通信,带宽更高。
-
PCIe A100:采用 PCIe 接口,GPU 之间的通信需要经过 CPU,带宽较低。

论文中提到未来会采用 Multi-Plane 网络,这是什么意思?有什么优势?
Multi-Plane 网络是指将网络划分为多个独立的平面,每个平面负责一部分流量。它的优势在于:
提高带宽:多个平面可以并行传输数据,提高整体的网络带宽。
降低成本:相比于构建一个超大型的单平面网络,Multi-Plane 网络可以使用更小的交换机,降低成本。
提高可靠性:如果一个平面发生故障,其他平面仍然可以正常工作,提高网络的可靠性。
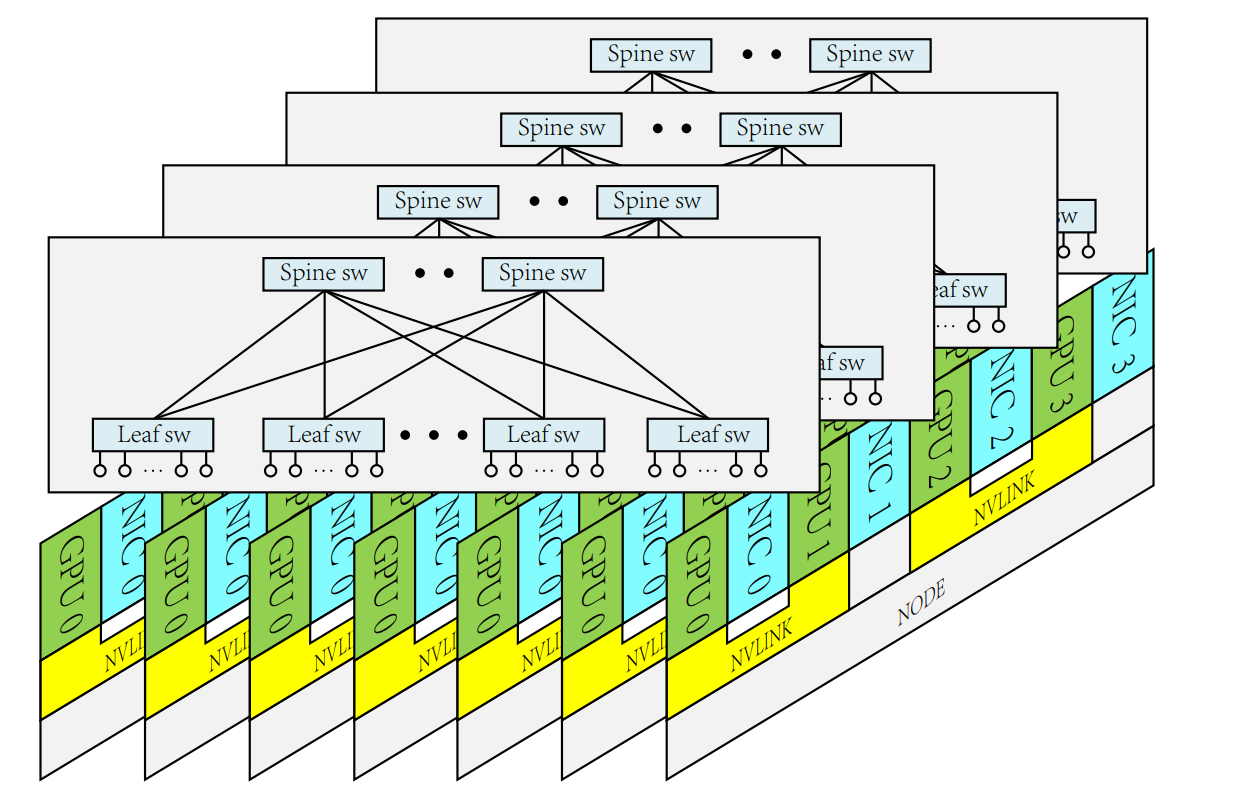
文章提到,在 Computation-storage Integrated Network 中,为了避免 HFReduce Traffic 和 3FS Storage Traffic 的相互影响,选择关闭了 DCQCN,这实际上是一种 trade-off,可能会对某些特定 Workload 下的性能产生影响。那么,有没有更好的 Congestion Control 的策略呢?
文章中提到,他们关闭 DCQCN 的原因是无法找到同时支持 HFReduce 和 3FS 流量的参数。这确实是一种权衡,意味着在某些 workload 下,可能会因为没有有效的拥塞控制而导致性能下降。以下是一些可能的改进策略,可以作为未来研究的方向:
-
更精细化的流量控制:
-
优先级队列:为 HFReduce 和 3FS 流量设置不同的优先级,确保 HFReduce 这种对延迟更敏感的流量优先传输。
-
动态带宽调整:根据 HFReduce 和 3FS 的实际流量需求,动态调整分配给它们的带宽。
-
基于 DPU 的拥塞控制:
-
使用 NVIDIA BF 系列等 DPU,可以自定义拥塞控制算法。
-
可以尝试 HPCC 或 TIMELY 等更高级的拥塞控制算法,这些算法可以更好地适应混合流量的场景。
-
显式拥塞通知(ECN):
-
在 RoCE 网络中,ECN 可以通过在数据包中标记拥塞信息,让发送端感知到网络拥塞,并采取相应的措施。
-
AI 辅助的拥塞控制:
-
使用机器学习算法预测网络拥塞,并提前进行调整。
-
可以根据历史数据和实时流量模式,自动优化拥塞控制参数。
A Probabilistic Approach to Selecting Build Configurations in Package Managers
现代科学软件在高性能计算中的应用通常非常复杂,许多并行应用程序和库依赖于其他多个软件或库。开发者和用户在构建这些复杂软件时,通常使用包管理器。包管理器依赖于人为编码包的约束(用于依赖关系和版本选择),而一个软件包的依赖关系图往往会变得庞大(包含数百个节点)。此外,随着时间的推移,包约束常常变得过时和不一致,因为它们由不同的人为不同的包维护,这是一项繁琐的任务。这可能导致在某些包配置下构建失败。本文提出了一种方法,利用历史构建结果来帮助包管理器选择最佳的包依赖版本,旨在提高构建成功的可能性。我们采用了机器学习(ML)模型,预测Spack包管理器中不同配置的包构建结果的成功概率。在对常见科学软件栈进行评估时,基于机器学习模型的方法比Spack的默认版本选择机制实现了13%的更高构建成功率。
关键词—包管理器,构建配置,版本选择,机器学习

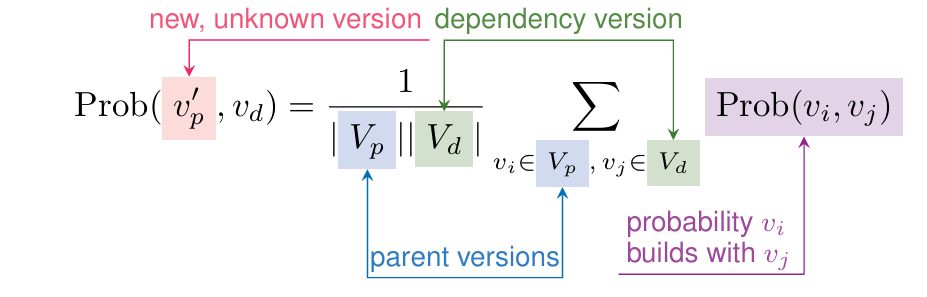
方法概述:将预测的构建概率纳入Spack的版本选择机制。首先,使用图神经网络(Graph Neural Network, GNN)预测所有包对的构建概率。对于新的包版本,我们通过从现有的包对中外推构建概率来估算其构建概率。然后,这些构建概率被编码到Spack的逻辑程序中,与现有的元数据和安装约束一同使用。修改后的逻辑程序随后选择最有可能成功构建的包版本。
Paper
Scientific Data Processing and Visualization
Rosa Filgueira B311
AlgorithmsData Movement and MemoryI/O, Storage, ArchivePerformance OptimizationScientific and Information VisualizationVisualization
TP
Session ChairRosa Filgueira
Presentations
10:30am - 11am EST
A High-Quality Workflow for Multi-Resolution Scientific Data Reduction and Visualization
AuthorsDaoce WangPascal GrossetJesus PulidoTushar AthawaleJiannan TianKai ZhaoZarija LurićAxel HueblZhe WangJames AhrensDingwen Tao
11am - 11:30am EST
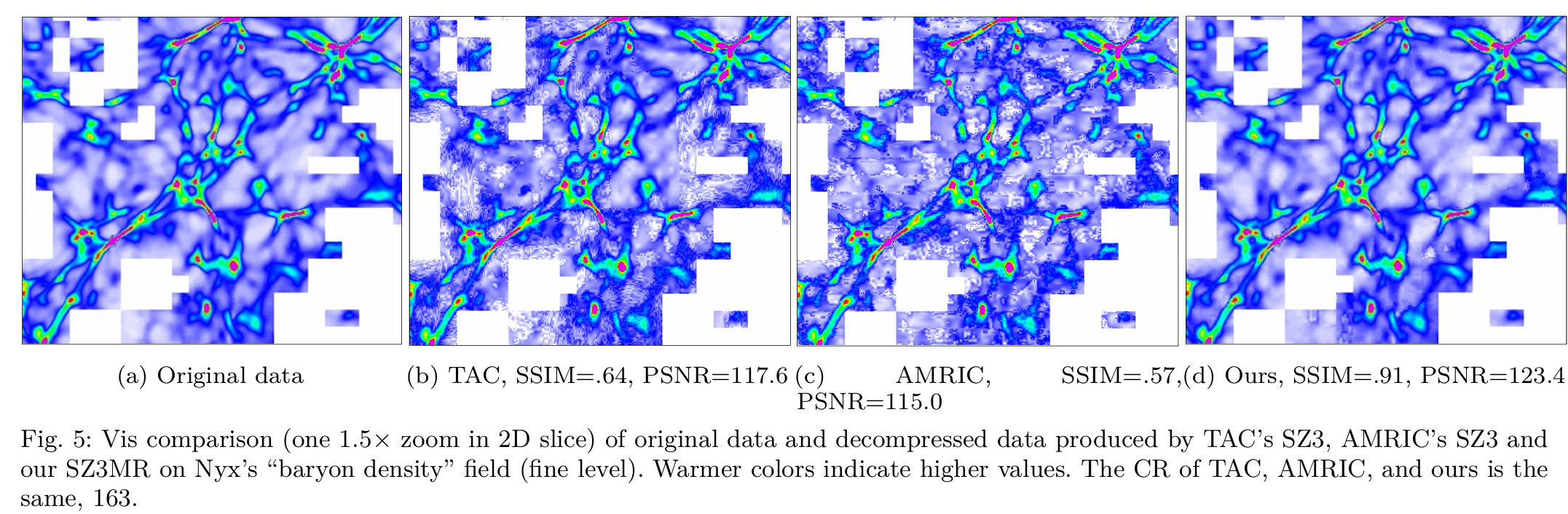
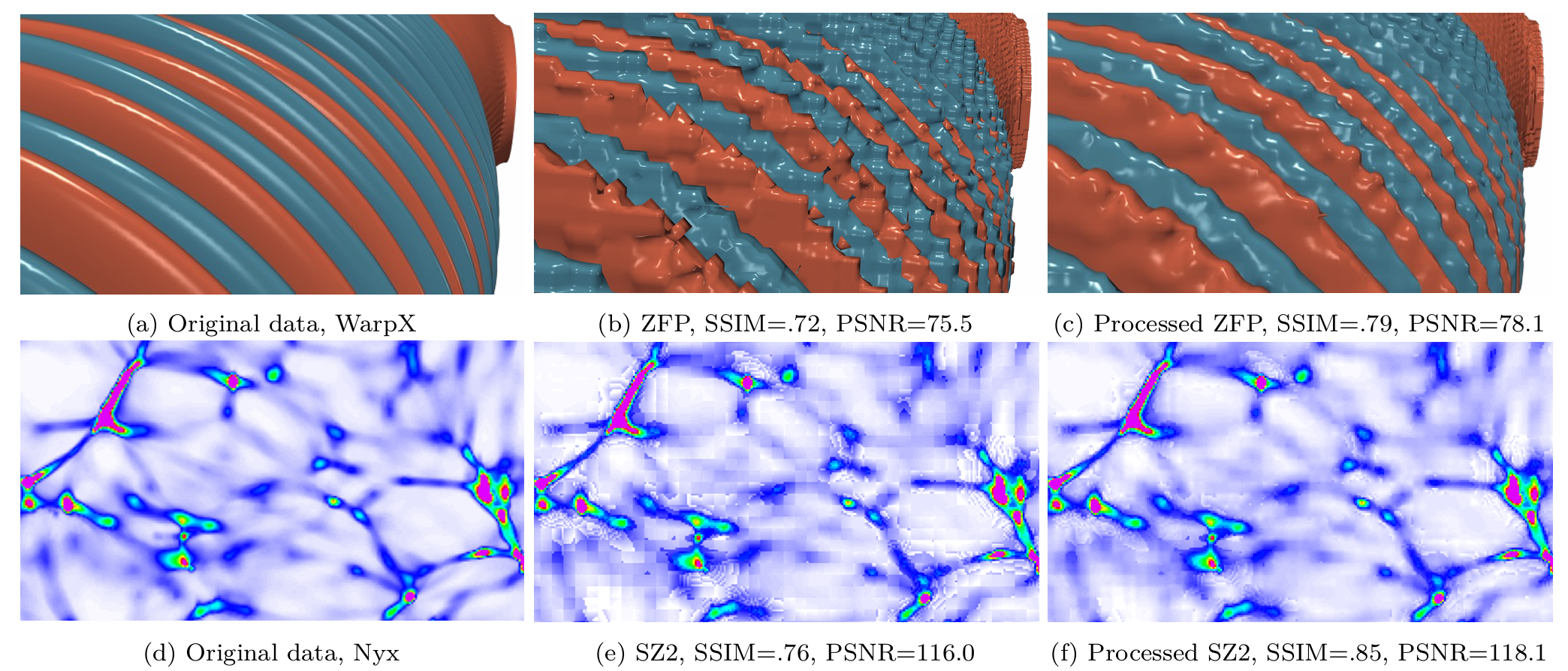
摘要—多分辨率方法,如自适应网格细化 Adaptive Mesh Refinement(AMR),可以提升高性能计算(HPC)应用在生成大量数据时的存储效率。然而,这些方法的适用性有限,不能普遍应用于所有应用程序。此外,将有损压缩与多分辨率技术结合以进一步提高存储效率面临重大障碍。为此,本文提出了一种创新的工作流程,旨在促进统一和AMR模拟的高质量多分辨率数据压缩。 首先,为了扩展多分辨率技术的可用性,我们的工作流程采用了一个面向压缩的兴趣区域(ROI)提取方法,将统一数据转换为多分辨率格式。随后,为了弥合多分辨率技术与有损压缩之间的差距,我们优化了三种不同的压缩算法,确保它们在多分辨率数据上的最佳性能。 这些优化可以在相同数据质量损失的情况下,提升当前最先进方法的压缩比高达3.3倍。最后,我们将一种先进的不确定性可视化方法融入到工作流程中,以了解有损压缩的潜在影响。实验评估表明,我们的工作流程显著提高了压缩质量。
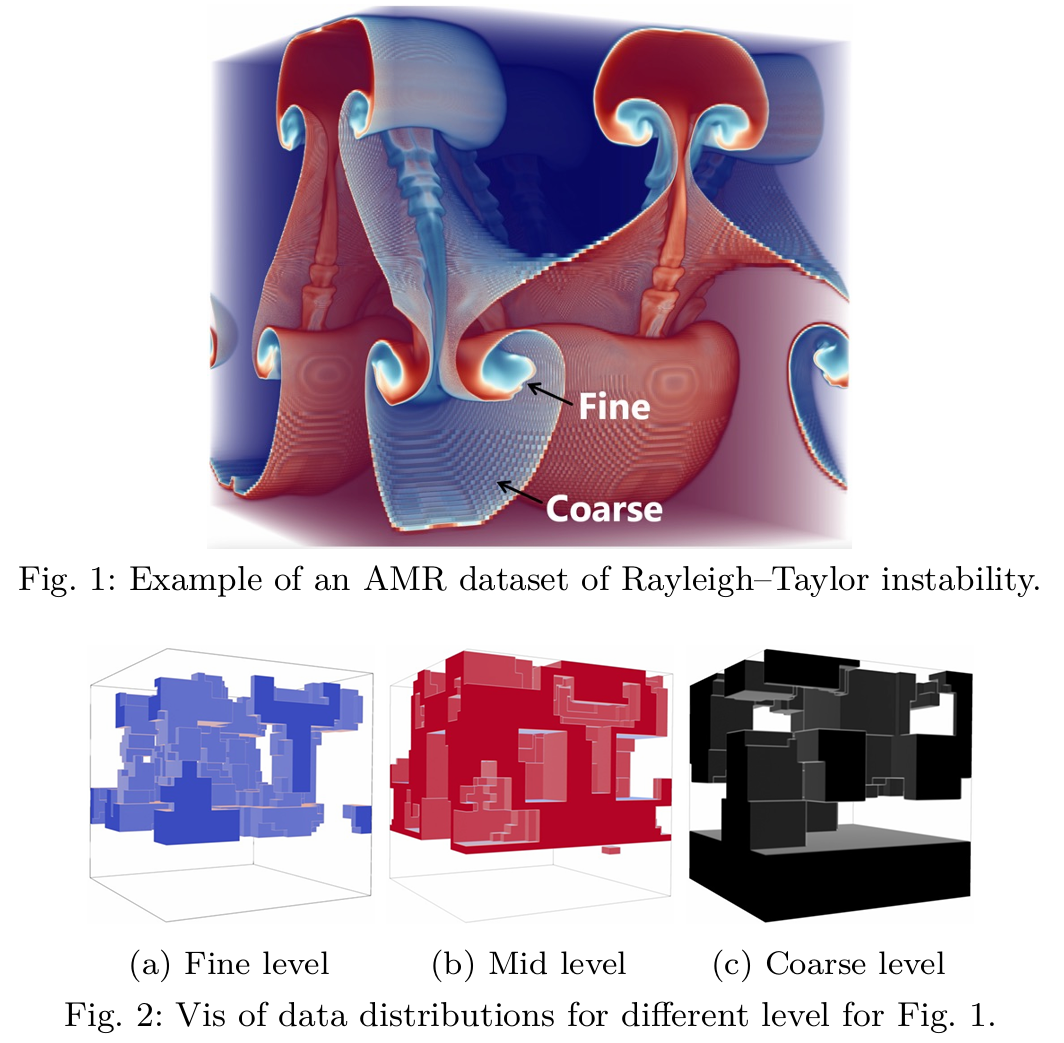
自适应网格细化(Adaptive Mesh Refinement,AMR)是一种在计算流体动力学、气象模拟、天体物理等领域中常用的数值方法。它通过动态地调整网格的分辨率来提高计算效率和精度。具体来说,AMR方法会根据模拟过程中不同区域的需求,在重要的区域使用更细的网格,而在其他区域则使用较粗的网格,从而优化计算资源的使用。
AMR的主要优点包括:
- 高效性:通过仅在需要高分辨率的区域细化网格,AMR减少了不必要的计算,从而节省了存储和计算资源。
- 灵活性:它能够根据问题的需求动态调整网格精度,在细节要求较高的地方自动增加网格密度。
- 提高精度:在复杂问题中(如流体动力学中的激波、湍流等),AMR能够在关键区域提供更高的精度。
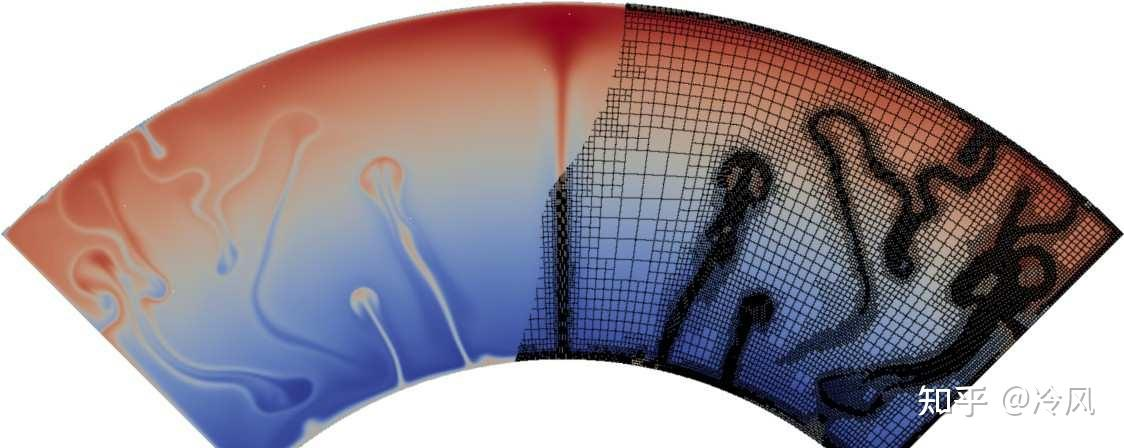
这是一个热对流的例子,你可以把这个当成地球的一部分,里面是地核,外面则是地壳。由于地核比地壳热得多,所以有热的材料会往上升(就像一个沸腾的锅,会有水蒸气往上升一样);同样的,地壳的温度比较低,会有一些材料从表面落下,然后中间有一些介质。
当我们需要画网格时,我们只需要针对图上有材料上升或者下降附近的区域进行细化即可(因为在这些区域中,解的二阶导数很大)。图片的右侧就是画好的网格的示意图,
只在"有事情发生"的地方(即在局部,解的二阶导数很大)进行细化。


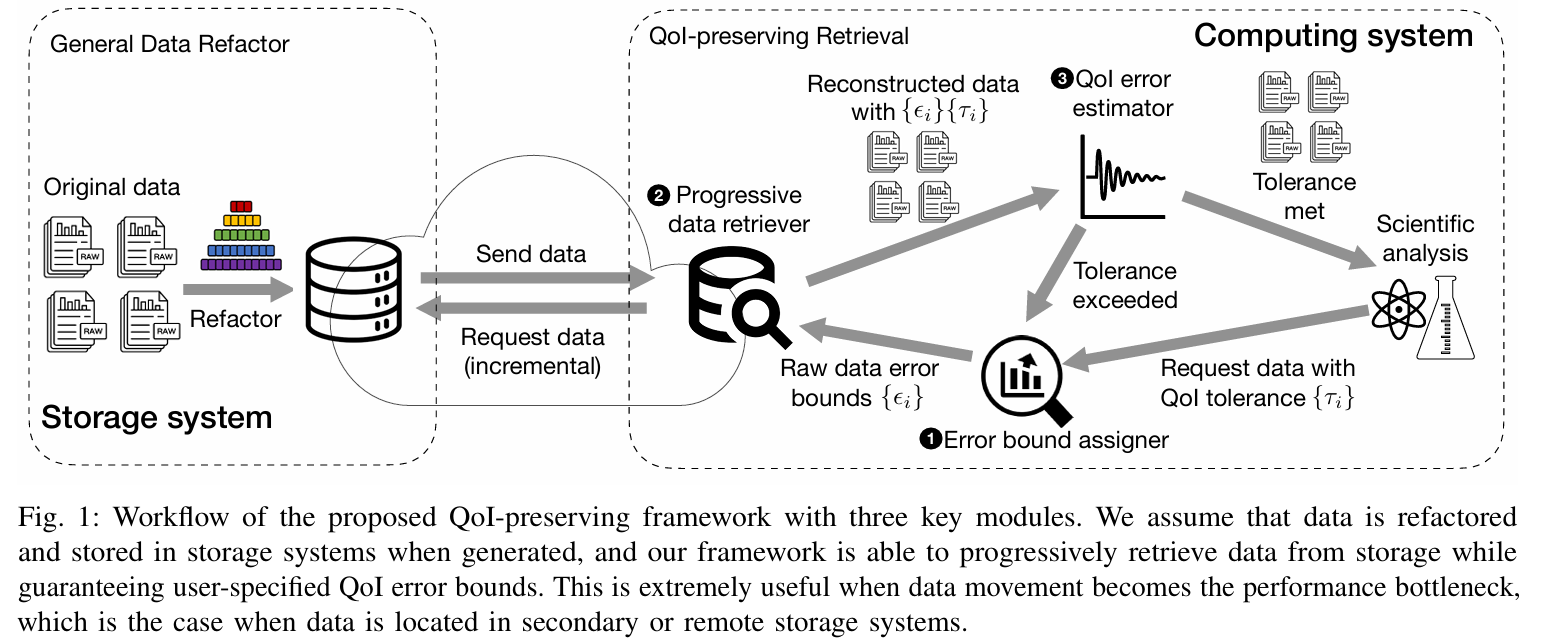
Error-controlled Progressive Retrieval of Scientific Data under Derivable Quantities of Interest
AuthorsXuan WuQian GongJieyang ChenQing LiuNorbert PodhorszkiXin LiangScott Klasky
New Jersey Institute of Technology
11:30am - 12pm EST
摘要——前所未有的科学数据量对当前的数据存储和传输系统带来了巨大的压力,特别是需要从中央存储库中检索数据并通过广域网传输时,必须考虑传输成本。为缓解这一问题,提出了渐进式压缩方法,它提供了按需精度的数据访问 。然而,现有方法仅考虑了对原始数据的精度控制 ,而忽略了从原始数据派生的兴趣量(QoIs) 的不确定性。本文提出了一种渐进式数据检索框架,能够在推导的兴趣量(QoIs)上提供保证的误差控制。我们的贡献有三方面:(1) 我们严格推导了在渐进式检索过程中控制QoI误差的理论。我们的理论是通用的,可以应用于任何可以通过本文证明的可推导QoI基础进行组合的QoI。(2) 我们设计并开发了一个基于所提出理论的通用渐进式检索框架,并通过探索可行的渐进式表示进行优化。(3) 我们使用五个真实世界数据集进行评估,涵盖了多种QoI。实验结果表明,我们的框架能够在评估的应用中忠实地遵循任何用户指定的QoI误差界限。这导致了在数据传输任务中比传输原始数据提高了超过2.02倍的性能,同时保证了QoI误差小于1E-5。
关键词——高性能计算,数据压缩,渐进式检索,科学数据,误差控制
'quantity of interest'一般可以简写为QoI,翻译为“感兴趣的量”、“感兴趣的参量”。在科技论文中,人们对某个问题感兴趣,而这个问题题中某个参数、或者函数等对问题的求解至关重要,那么就可以用'QoI'来表示。举个例子,' u(x) is the solution of the PDEs and is determined by the parameter γ(x), which is our quantity of interest (QoI) for the inverse design problem. '
https://www.zhihu.com/question/547730365/answer/2950431590

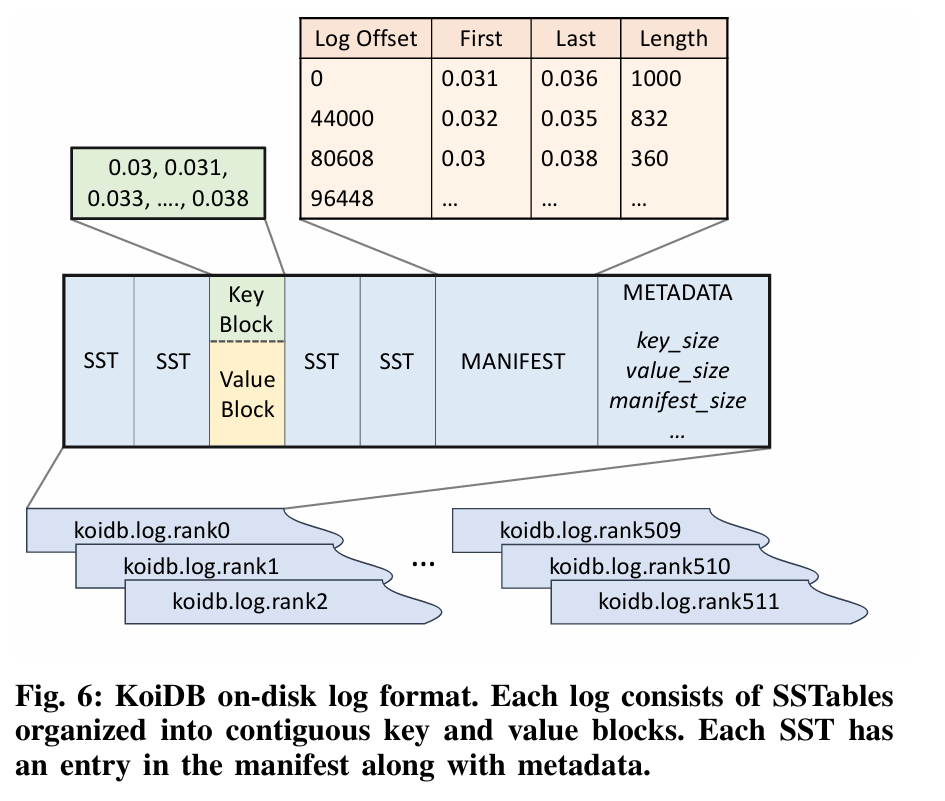
CARP: Range Query-Optimized Indexing for Streaming Data
摘要——高性能科学应用生成的数据的摄取继续给现有的存储资源带来压力 。通过对感兴趣的属性重新排序,可以启用对这些数据的高效基于范围的分析,但需要进行昂贵的后处理排序才能实现重新排序的查询效益。尽管就写入效率而言,原位索引技术具有优势,但其在范围查询中的性能比排序索引慢几个数量级。范围查询对于分析连续的物理属性和跟踪现象(如能带和波前)是必需的。
我们提出了CARP,一种用于范围查询的可扩展数据分区器,它在数据流式存储时根据应用I/O将数据原位重新排序 。基于我们的发现,实际应用的分布往往高度偏斜且动态变化,CARP能够动态发现并适应这些数据分区的变化。因此,CARP能够在没有摄取开销的情况下近似排序的查询性能,使其比之前的工作快5倍。
关键词——数据分析,排序,叠加网络,原位索引
Intro background Challenge Design IMPLEMENTATION EVALUATION DISCUSSION CONCLUSION
Paper
Communication Optimization for ML
Nikoli Dryden B308
Artificial Intelligence/Machine LearningDistributed ComputingHeterogeneous ComputingPerformance Optimization
TP
Session ChairNikoli Dryden
Presentations
1:30pm - 2pm EST
Optimizing Distributed ML Communication with Fused Computation-Collective Operations
AMD 算子融合
AuthorsKishore PunniyamurthyKhaled HamidoucheBradford Beckmann
Artificial Intelligence/Machine LearningDistributed ComputingHeterogeneous ComputingPerformance Optimization
2pm - 2:30pm EST
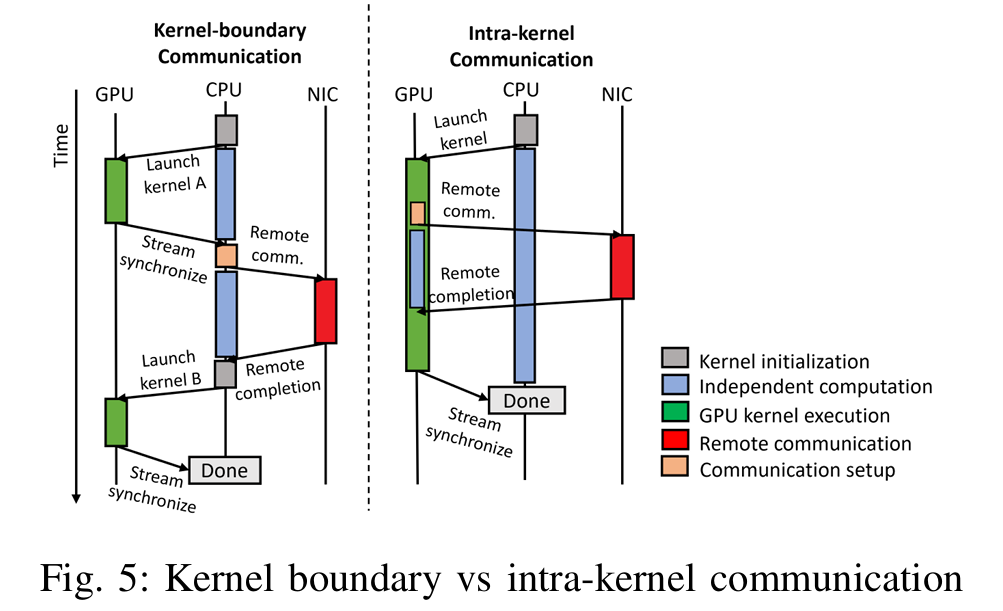
摘要——为了满足不断增长的计算能力和计算需求,机器学习模型通常使用多种并行策略分布到多个节点上。因此,集体通信经常成为关键路径,且由于缺乏独立计算,难以通过重叠内核级别的通信与计算来隐藏通信延迟。
本文提出了一种通过利用GPU的巨大并行性和GPU启动的通信,将计算与依赖的集体通信融合的方法。我们开发了自包含的GPU内核,其中线程块/工作组(WGs)在完成计算后立即将结果与远程GPU进行通信。同时,同一内核中的其他WGs执行重叠计算,保持高ALU利用率。这样精细粒度的重叠提供了额外的好处:减少了网络带宽的峰值需求,并且通信贯穿应用的整个生命周期,而不仅限于内核边界。此外,我们提出了零拷贝优化,用于规模化通信,其中一个GPU计算的数据直接传送给同行GPU,消除了中间存储和缓冲。
我们通过创建三个原型融合操作符(嵌入 + All-to-All、GEMV + AllReduce 和 GEMM + All-to-All)来解决在深度学习推荐模型(DLRM)、Transformer 和专家混合(MoE)模型架构中观察到的广泛通信开销。为了展示我们的方法能够集成到机器学习框架中,并在生产环境中广泛应用,我们将我们的融合操作符作为新的PyTorch操作符进行公开,并扩展Triton框架以支持这些操作符。
我们的评估表明,我们的方法能够有效地将通信与计算重叠,从而比现有的基于集体库的方法减少执行时间。我们的GEMV + AllReduce和GEMM + All-to-All规模化实现分别将执行时间降低了13%(最高22%)和12%(最高20%),而融合的嵌入 + All-to-All则在节点内和节点间配置下分别减少了20%和31%的执行时间。大规模扩展的仿真表明,我们的方法可以在128节点系统上将DLRM的执行时间减少21%。
关键词——GPU,分布式机器学习,集体通信,DLRM,Transformer,MoE
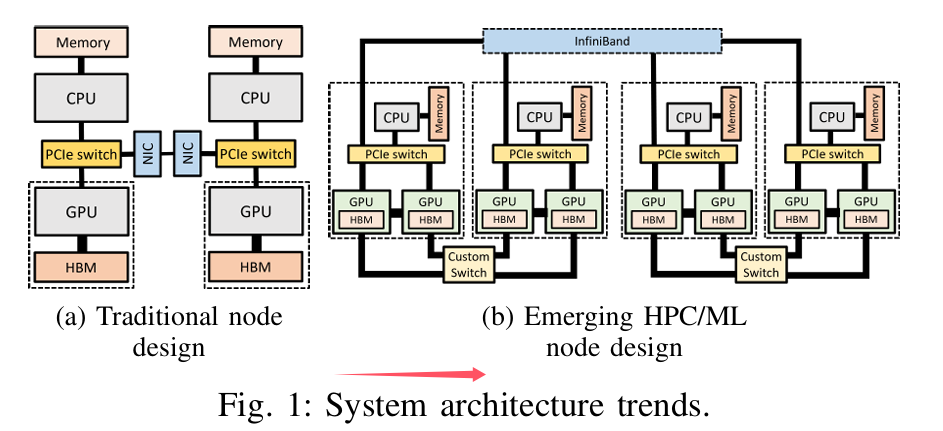
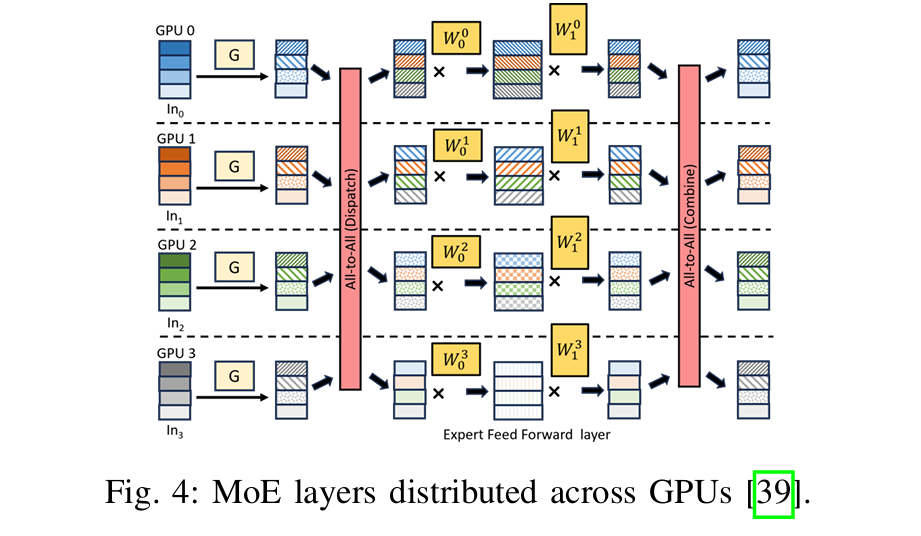
Fused Embedding + All-to-All Operator
gpt翻译:
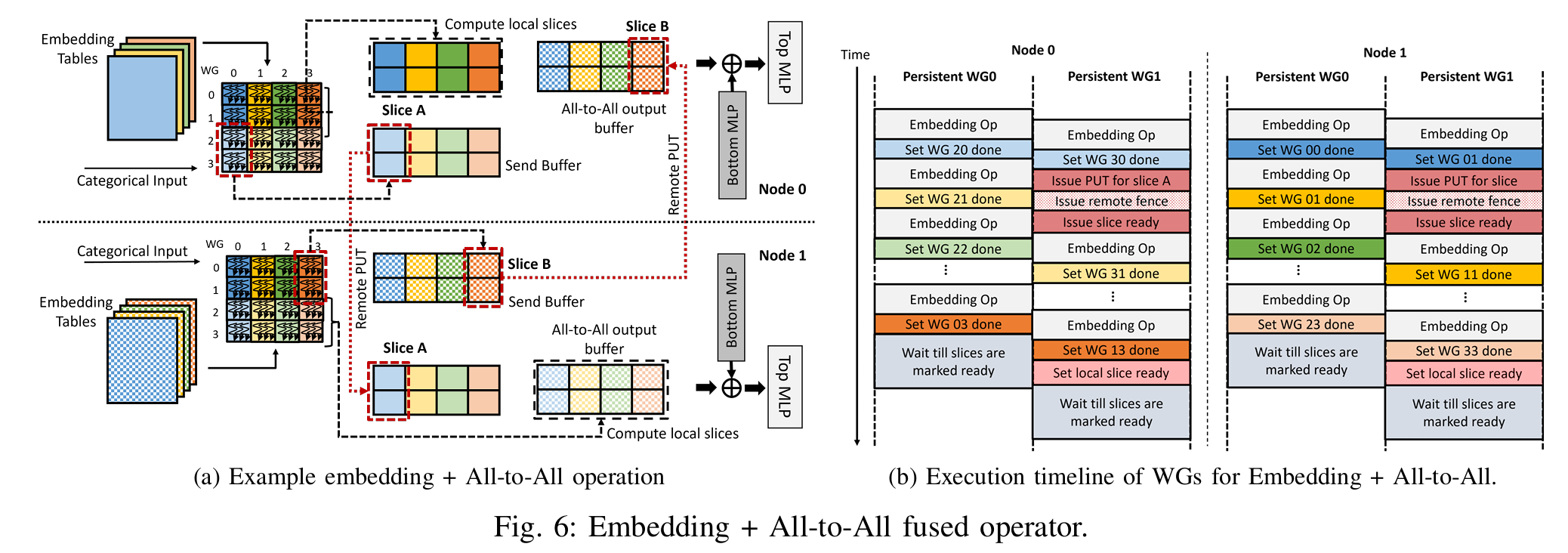
我们开发了融合的嵌入 + All-to-All 操作符,并将其实现为一个持久化的GPU HIP [10]内核,该内核同时执行嵌入池化(类似归约的)计算和All-to-All通信。我们使用了ROC SHMEM [25]库来执行内核内的通信,图6展示了其执行过程。该图展示了一个两节点系统,其中嵌入表以模型并行的方式分布,每个节点有四个表。All-to-All的输出和发送缓冲区都分配在每个GPU的对称堆(使用roc shmem malloc() API)中。分配在对称堆中的内存会注册到网络接口卡(NIC),因此允许NIC直接在这些GPU缓冲区之间移动数据。
我们将融合的嵌入 + All-to-All操作符实现为一个持久化线程内核[35][45],该内核将多个逻辑嵌入池化操作复用到GPU中执行的长期工作组(WG)中。这样,我们可以将计算相同切片(输出片段)的逻辑WG一起调度(类似于[45]中使用的方法),进一步减少内核调用的次数。内核以固定的、与输入无关的网格大小启动(小于或等于根据HIP占用API [20]确定的最大占用率)。每个长期运行(即持久化)工作组执行一个任务循环,其中每次迭代对应原始嵌入内核的一个逻辑工作组的计算(EmbeddingBag updateOutputKernel sum mean)。
图6a显示了逻辑工作组,并通过颜色编码指示每个工作组处理的表。我们的融合内核将分类输入和嵌入表作为内核参数。所示的示例假设全局批处理大小为4,切片大小为两个嵌入输出向量,并且每个输出嵌入向量由一个工作组计算。来自每个表的池化输出嵌入向量在两个节点之间均匀地进行洗牌,全球批次的前一半存储在节点0中,后一半存储在节点1中。根据它们的嵌入切片,工作组可能需要将结果存储在本地或将其传输到远程节点。工作组计算的切片的索引可以通过输出嵌入条目和切片的大小来确定。然后,可以使用切片索引、全局批次大小和节点数来确定是否需要将切片远程通信。逻辑工作组WG 00-WG 13计算与全局批次前半部分对应的输出,而WG 20-WG 33计算后半部分的输出。对于节点0,WG 00-WG 13计算输出条目。
GEMV + AllReduce
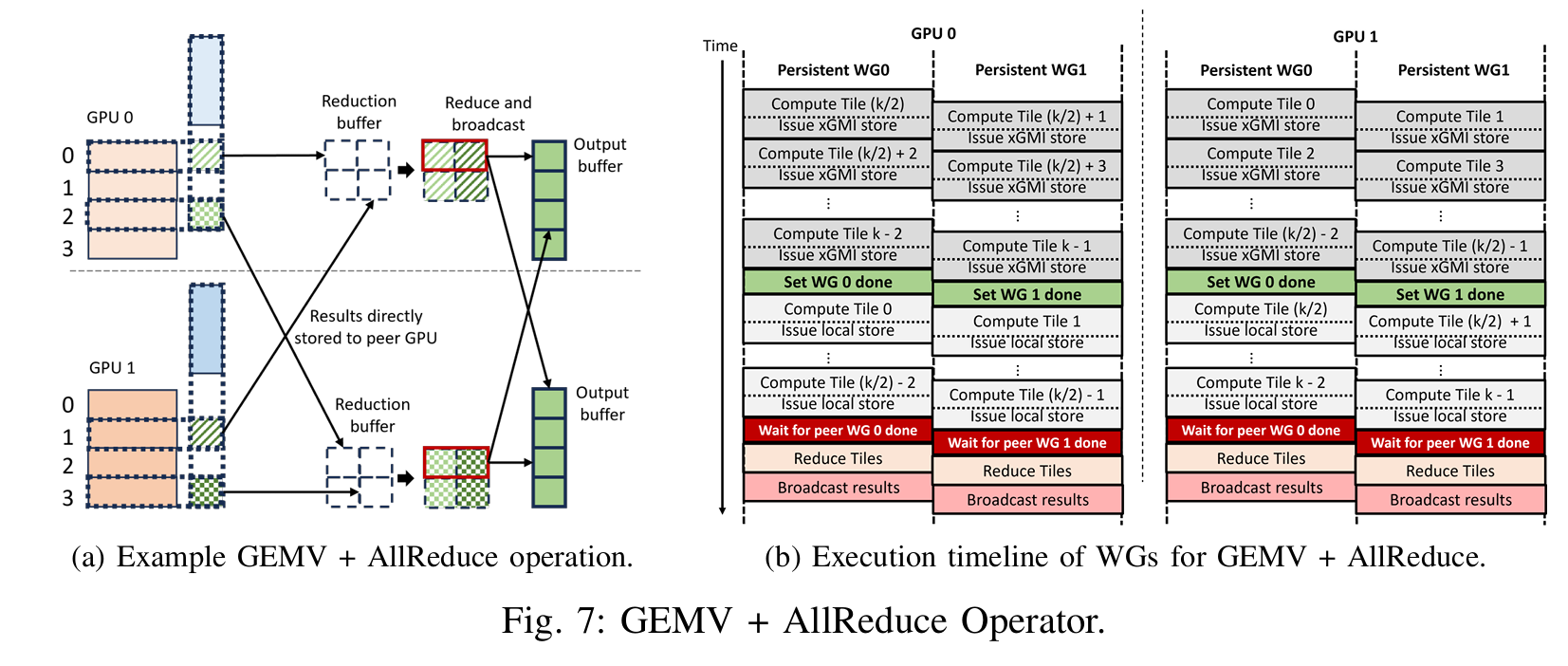
图7展示了我们提出的融合GEMV + AllReduce操作符。该操作符假设两个GPU通过Infinity Fabric™连接在同一个节点中,并且每个GPU使用临时缓冲区进行归约操作。我们将融合操作符实现为一个持久化内核,其中每个物理工作组(WG)迭代执行多个逻辑工作组(WG),负责计算各自的输出块。每个物理WG负责跨GPU计算相同的输出块,从而简化归约过程中的依赖关系。在我们的方法中,我们使用了一种两阶段直接算法来实现AllReduce,因为它具有最少的步骤,并且在完全连接的GPU上能够实现较低的延迟。每个GPU负责归约1/#GPU数量的输出块(归约分散阶段),并将结果广播给其他GPU(全收集阶段),如图7a所示。在这个例子中,每个GPU将计算整个GEMV输出向量,但一半的输出块会在本地进行归约,而另一半则会被传输到对等GPU进行归约。例如,GPU 0将归约前两个输出块,而GPU 1将归约最后两个输出块。
GEMM + All-to-All
Our fused GEMM + All-to-All operator also has a similar implementation as explained above except it is implemented in Triton with communication extensions. GPUs perform GEMM operations and the output tiles are communicated to peer GPUs. In this case, no reduction is performed as GEMM operation is fused with All-to-All collective
Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
SKLP, Institute of Computing Technology, Chinese Academy of Sciences, China;
Meta
Summer Deng†, Yuchen Hao
AuthorsHao FengBoyuan ZhangFanjiang YeMin SiChing-Hsiang ChuJiannan TianChunxing YinZhaoxia (Summer) DengYuchen HaoPavan BalajiTong GengDingwen Tao
Artificial Intelligence/Machine LearningDistributed ComputingHeterogeneous ComputingPerformance Optimization
2:30pm - 3pm EST
摘要——DLRM 是一种先进的推荐系统模型,已经在多个行业应用中得到广泛采用。然而,DLRM 模型的庞大规模要求使用多个设备/GPU 来进行高效训练。在这一过程中,一个显著的瓶颈是需要耗时的 All-to-All 通信来从所有设备收集嵌入数据。
为了缓解这一问题,我们提出了一种方法,采用误差有界的有损压缩来减少通信数据的大小并加速 DLRM 的训练 。我们开发了一种新型的误差有界有损压缩算法,基于对嵌入数据特征的深入分析,以实现高压缩比。此外,我们引入了一种双层自适应策略来调整误差边界,涵盖了表级和迭代级的调整,以平衡压缩带来的好处与对准确性的潜在影响。我们进一步优化了针对 GPU 上 PyTorch 张量的压缩器,最小化了压缩开销。评估结果显示,我们的方法实现了 1.38 倍的训练加速,同时对准确性的影响最小。

APTMoE: Affinity-aware Pipeline Tuning for MoE Models on Bandwidth-constrained GPU Nodes
AuthorsYuanxin WeiJiangsu DuJiazhi JiangXiao ShiXianwei ZhangDan HuangNong XiaoYutong Lu
Artificial Intelligence/Machine Learning
Distributed Computing Heterogeneous Computing Performance Optimization
摘要——近年来,sparsely-gated 混合专家(MoE)架构引起了广泛关注。为了让更多人受益,将 MoE 模型在更具成本效益的集群上进行微调,通常这些集群由有限数量的带宽受限的 GPU 节点组成,这一方法具有较大潜力。然而,由于数据与计算之间的比例增大,将现有的成本效益微调方法应用于 MoE 模型并非易事。本文提出了一种名为 APTMoE 的方法,它采用了感知亲和性的流水线并行技术,在带宽受限的 GPU 节点上微调 MoE 模型。我们提出了一种感知亲和性的卸载技术,通过增强流水线并行性来提高计算效率和模型大小,并且从分层加载策略和需求优先调度策略中受益。为了提高计算效率并减少数据移动量,分层加载策略设计了三个加载阶段,并在这些阶段中高效地将计算分配到 GPU 和 CPU,利用不同级别的专家流行度和计算亲和性。为了缓解三个加载阶段之间的相互干扰并最大化带宽利用率,需求优先调度策略主动并动态地协调加载执行顺序。实验表明,APTMoE 在大多数情况下优于现有方法。特别地,APTMoE 成功地在 4 台 Nvidia A800 GPU(40GB)上微调了一个 61.2B 的 MoE 模型,相较于现有最先进方法(SOTA)提高了最多 33%的吞吐量。
关键词——大规模语言模型,硬件加速,高性能计算
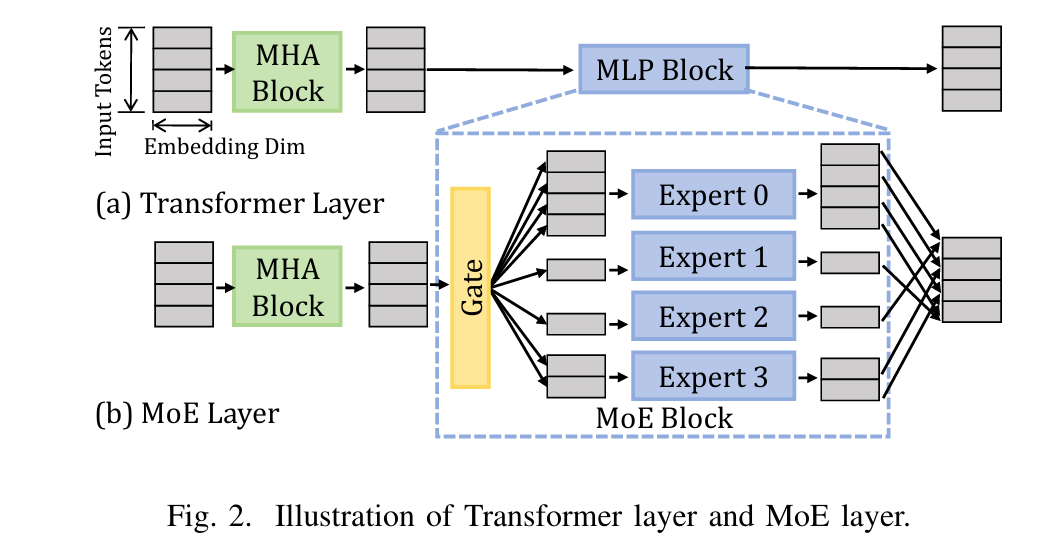
MoE介绍:
Mixture-of-Experts (MoE) 经典论文一览 - 知乎
一个系统中包含多个分开的网络,每个网络去处理全部训练样本的一个子集。这种方式可以看做是把多层网络进行了模块化的转换。让不同的 expert 单独计算 loss,然后在加权求和得到总体的 loss。这样的话,每个专家,都有独立判断的能力,而不用依靠其他的 expert 来一起得到预测结果。下面是一个示意图:
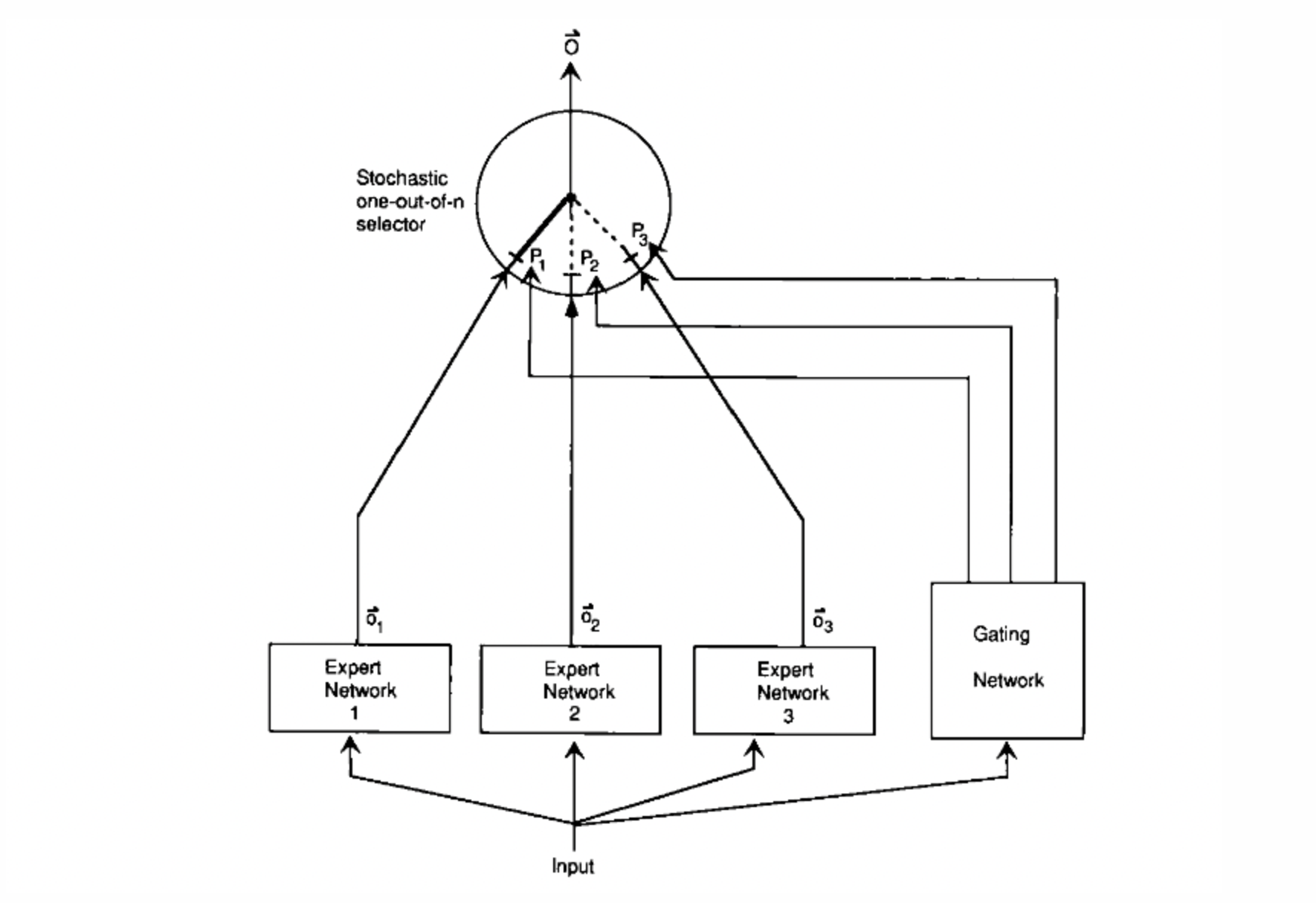
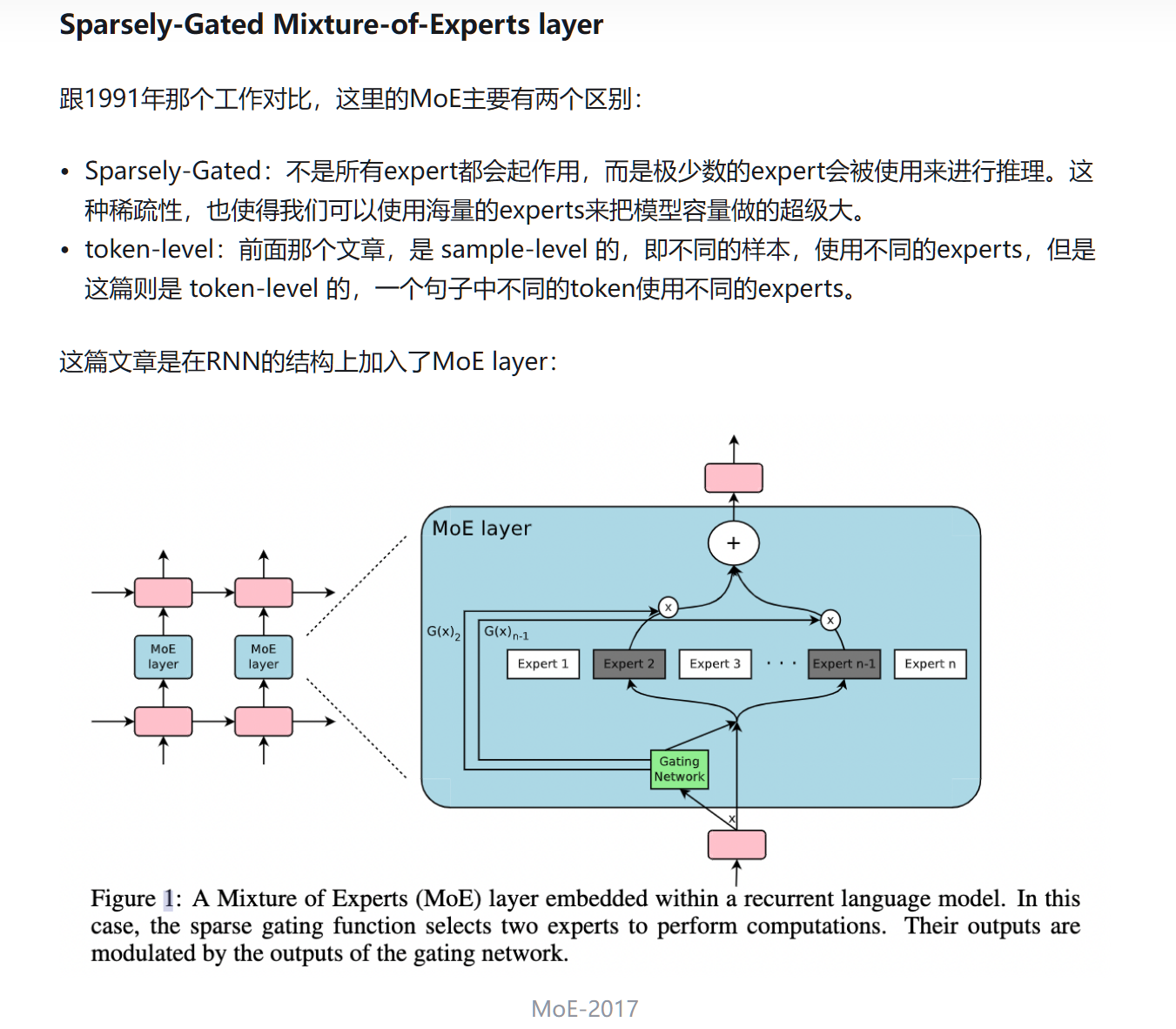
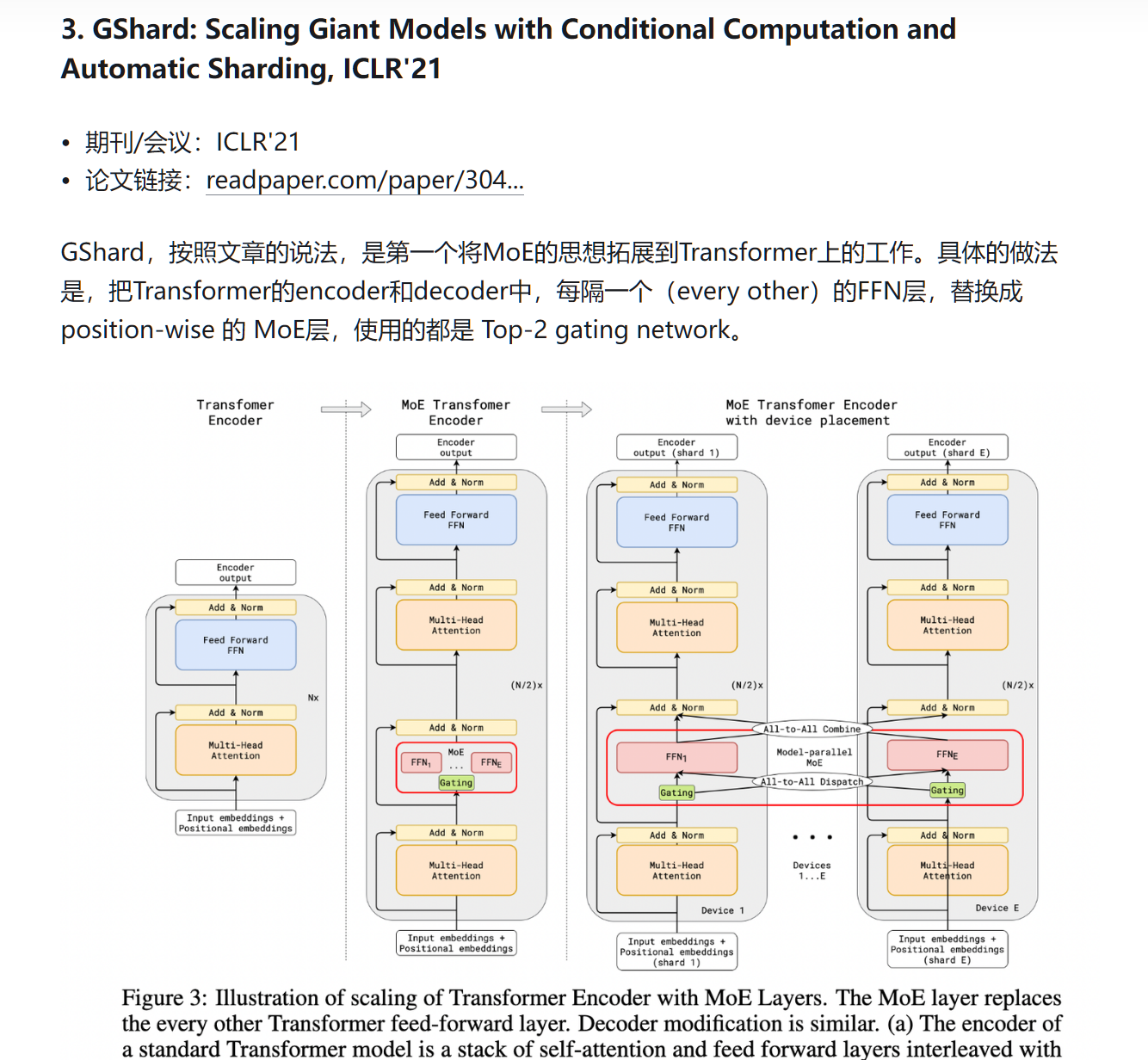
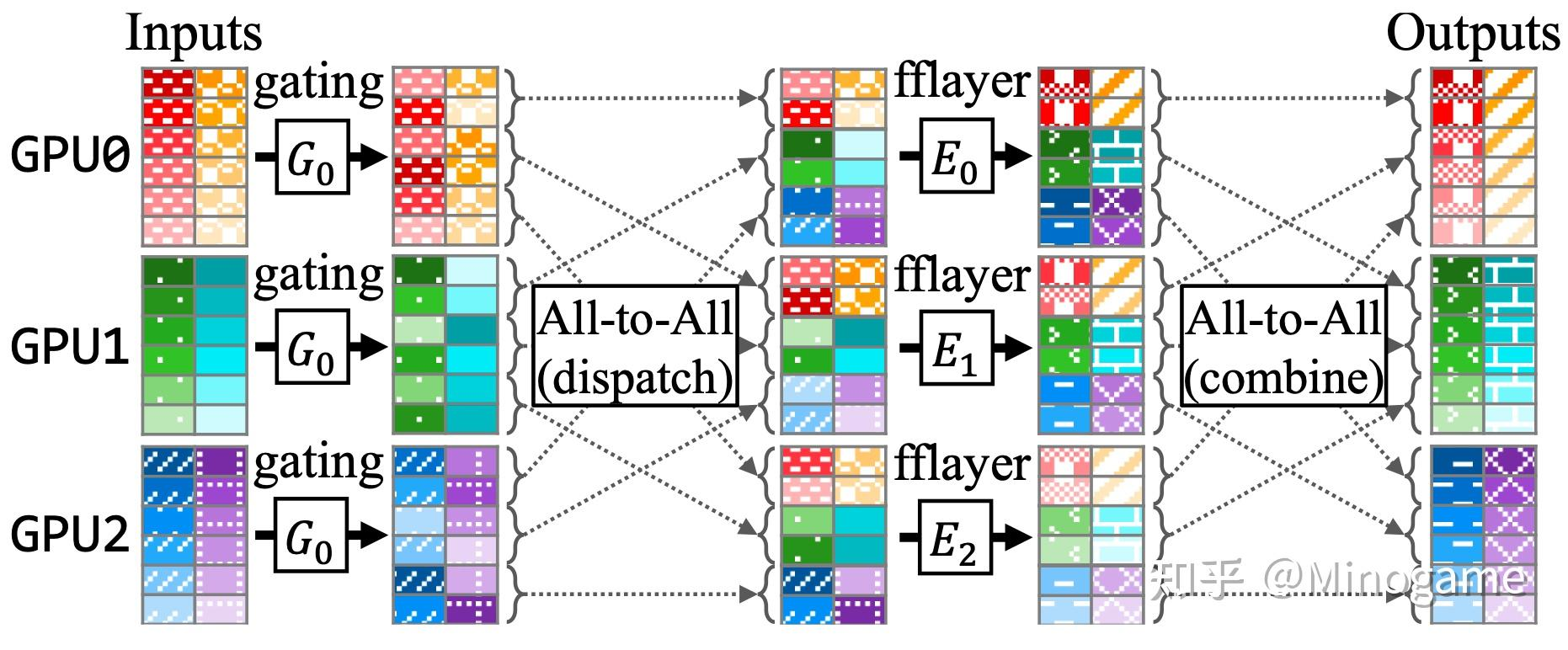
概括地讲,当下Sparsely-Gated Mixture of Experts的运行模式大致可以做如下解释:
形而上地看Sparsely-Gated Mixture of Experts - 知乎
- 将一个Transformer的部份FFN层(也可以是全部的),复制N份,用以代表N个不同的Experts,每个GPU上对应储存其中的一部份Experts;
- 在所有的Experts-FFN层之前,有一个Gating函数,用来负责每一个token往后的计算路径;
- Gating函数中首先有一个projection-softmax结构,用以计算每一个token对于每一个expert的倾向分数[11],比较类似于一个classifier去区分某个token要对应哪个expert;
- 随后,Gating函数通过一系列吊诡的采样机制,确定每一个token最终所选择的TopK专家路径;
- 在以上采样机制中,存在诸如Capacity/Random Token Selection等机制,保证token的对专家的分配均衡;
- 将每一个token,dispatch到对应的专家的存贮GPU上运算,注意这里的token是temporal-independent的(类似于对于某一段输入所以提取的特征向量,后述),随后再度combine成原始的sequence;
- 其他一切照旧,该norm的norm,该attention的attention,该residual的residual,该假装看论文摸鱼的假装看论文摸鱼。
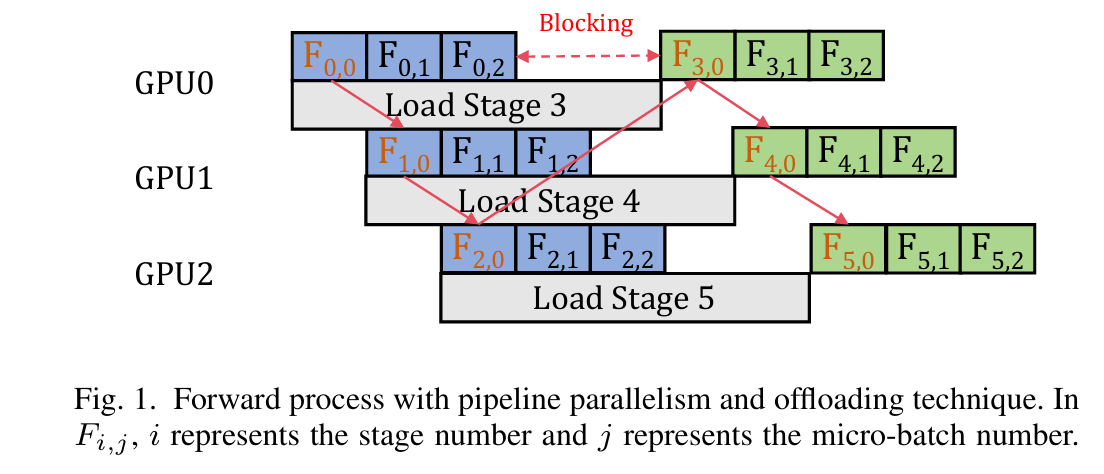
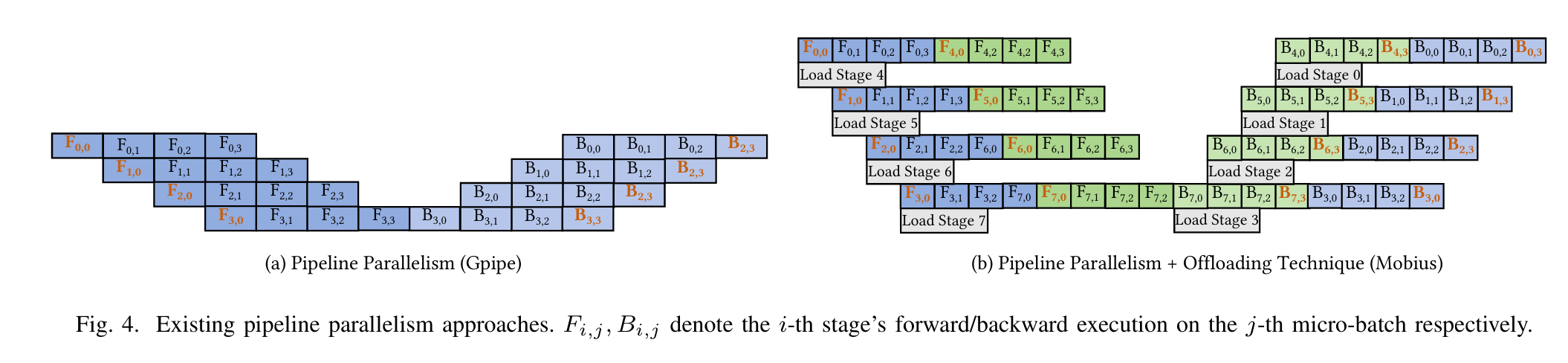
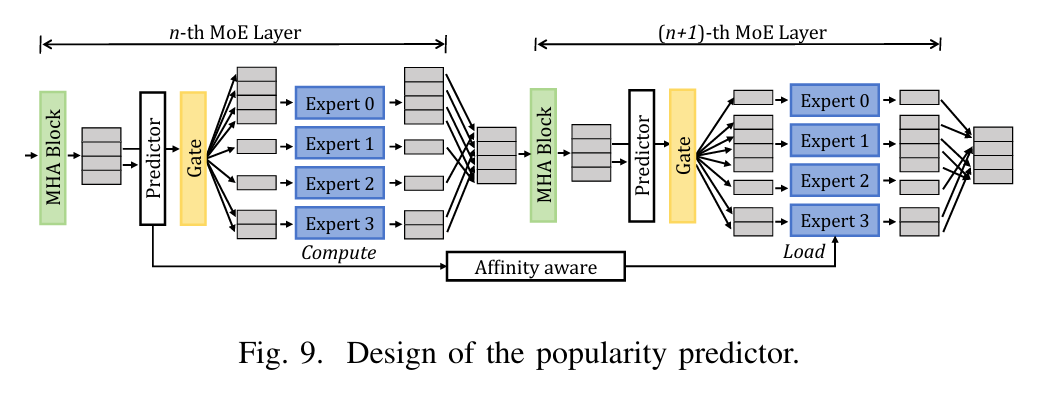
APTMoE是一种针对带宽受限GPU节点的MoE模型的亲和性感知管道调优系统。该系统旨在提高在带宽受限的GPU节点上微调MoE模型的计算效率和模型规模。APTMoE通过亲和性感知卸载技术来增强管道并行性,其核心思想是将部分亲和性计算卸载到CPU,以便更好地管理异构内存中的数据1。
主要贡献
APTMoE的主要贡献包括:
-
分层加载策略:利用专家受欢迎度和计算亲和性的先验知识,采用三个加载阶段来贪婪地分配具有最高亲和性的计算,并最小化数据移动量。
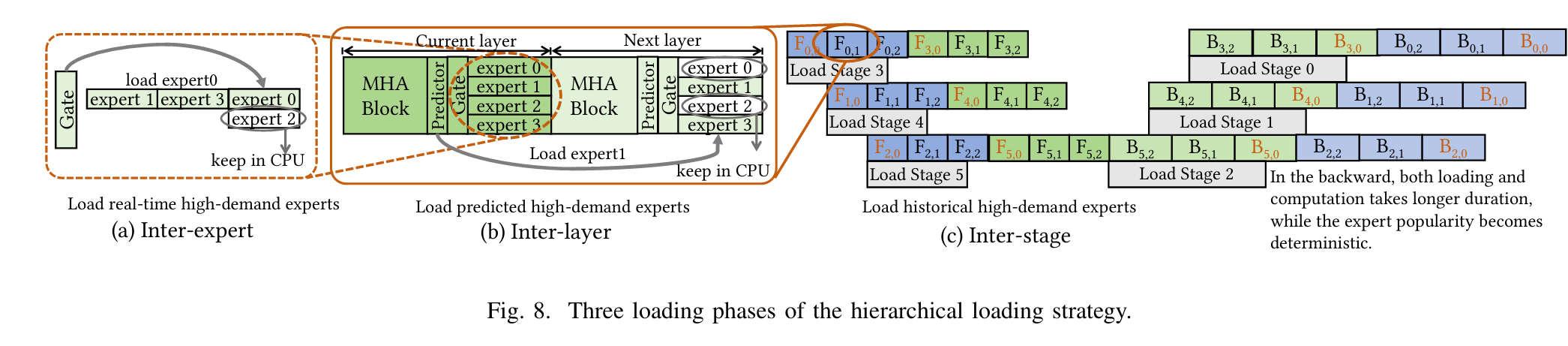
-
需求优先调度策略:用于缓解加载阶段之间的相互干扰,并通过动态协调加载顺序来最大化带宽利用率。
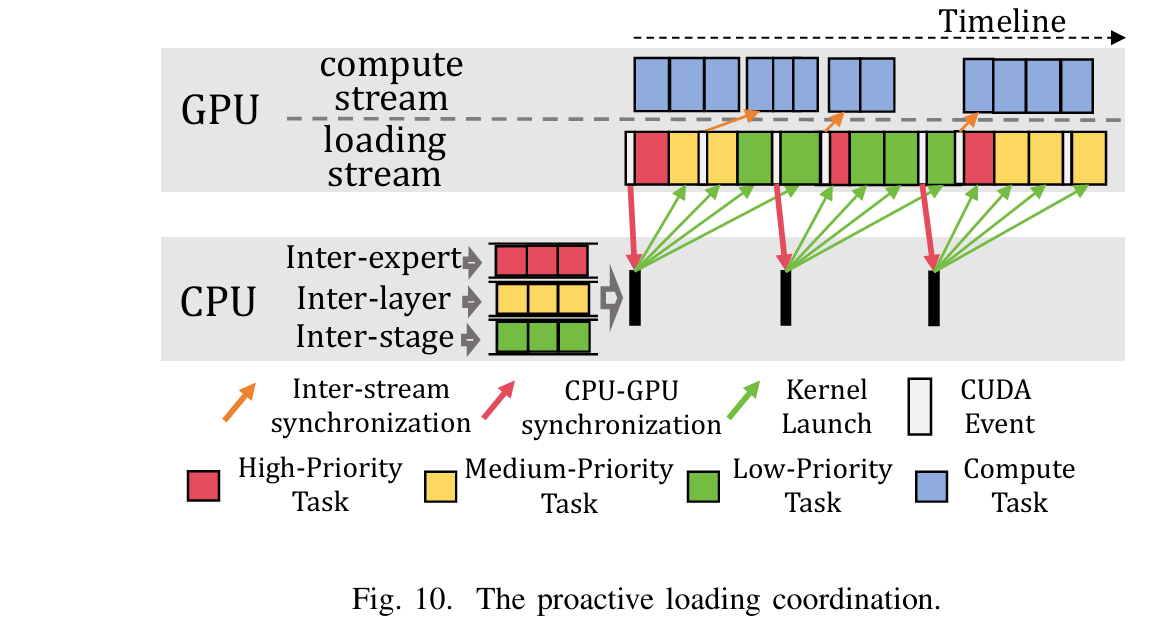
-
专家受欢迎度模拟器:用于评估APTMoE在微调MoE模型时的表现1。
系统概述
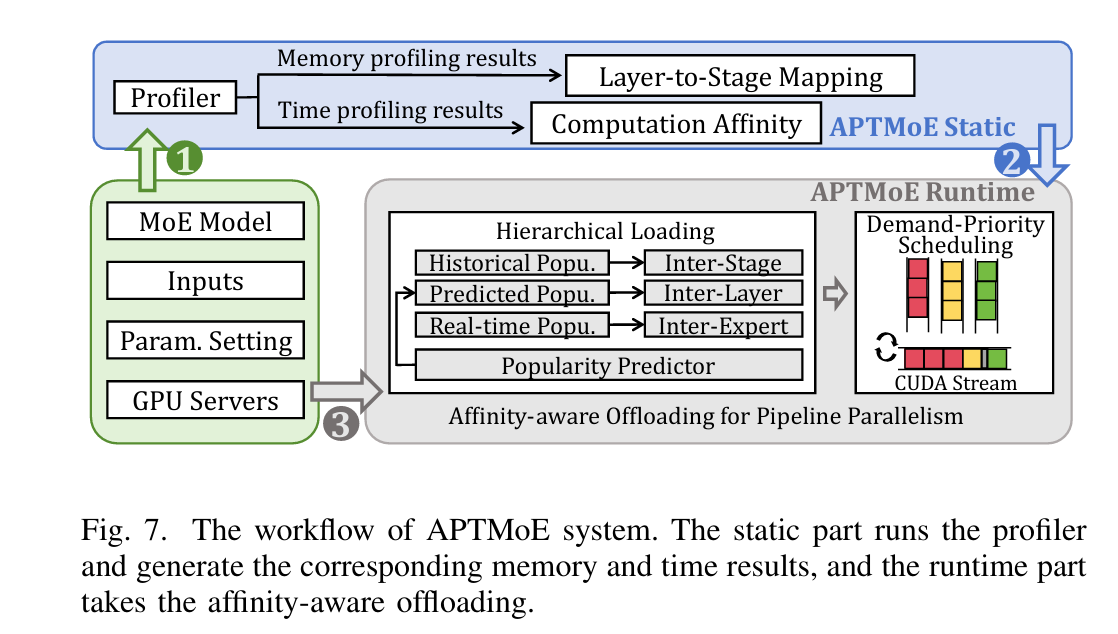
APTMoE系统分为静态部分和运行时部分。其工作流程如下:
-
静态部分:分析内存使用情况和执行时间,生成层到阶段的映射和执行时间查找表。
-
运行时部分:采用亲和性感知卸载技术,包括分层加载策略和需求优先调度策略,以增强带宽受限GPU节点上的管道并行性1。
本期到此结束,下次继续!