SC Paper Reading 3
- Paper Reading
- 2025-03-12
- 936 Views
- 0 Comments
- 14676 Words

总链接:
https://www.haibinlaiblog.top/index.php/sc-2024-passage/
Paper
Computational Efficiency and Learning Techniques
Murali Emani B311
AcceleratorsApplications and Application FrameworksArtificial Intelligence/Machine LearningModeling and SimulationNumerical Methods
TP
Session ChairMurali Emani
Presentations
1:30pm - 2pm EST
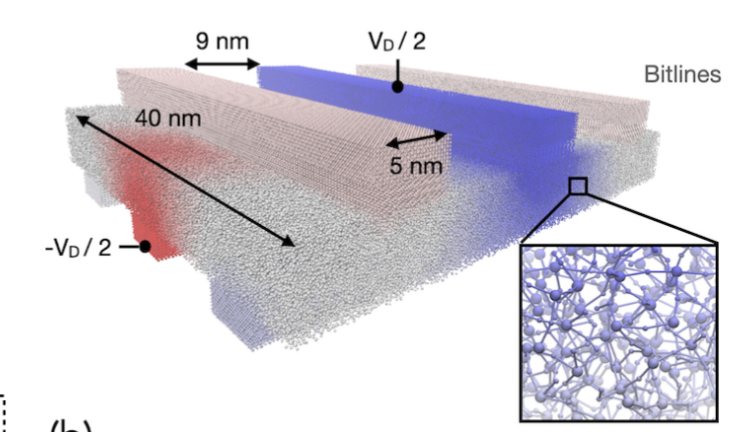
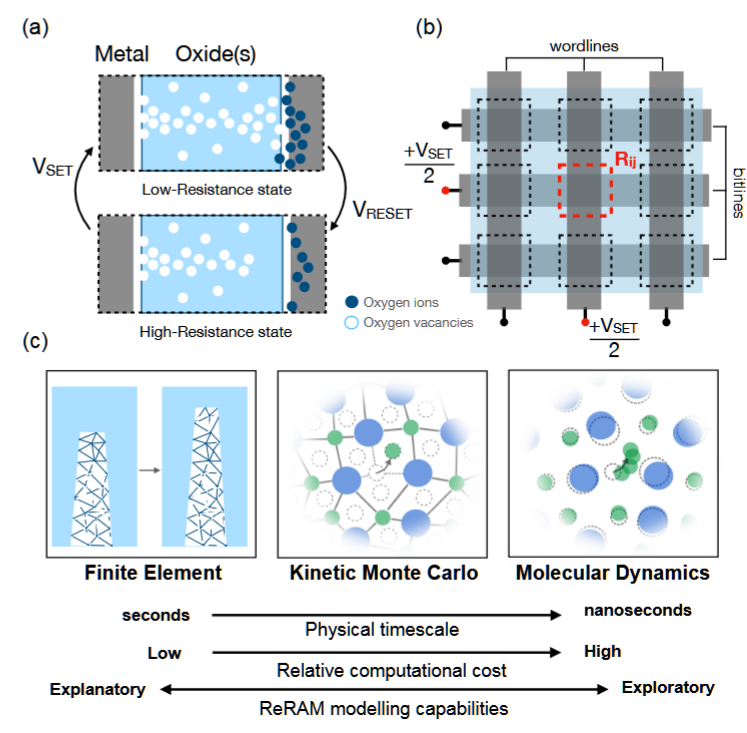
Accelerated Kinetic Monte Carlo Simulations of Atomistically-Resolved Resistive Memory Arrays
AuthorsManasa KaniselvanAlexander MaederMarko MladenovicMathieu LuisierAlexandros Ziogas
2pm - 2:30pm EST
用应用模拟忆阻器存储阵列
摘要——模拟新兴的电阻开关存储器件,如忆阻器,需要能够处理点缺陷在纳米尺度领域内运动的建模框架。场驱动的动力学蒙特卡罗(d-KMC)方法可以用来模拟在外部电势和热场的作用下,原子坐标的离散结构演化。虽然在物理上与传统的KMC方法类似,场驱动的方法呈现出不同的计算模式,并引入了全局通信。在此,我们开发了首个可扩展的d-KMC代码,用于原子尺度分辨率下的电阻存储器阵列。我们在LUMI超级计算机的GPU分区上加速了这一延迟敏感的模拟,利用同一节点上GPU之间的高速互连。该代码应用于具有技术相关性的HfOx材料堆栈,实现了首个3×3阵列电阻开关存储单元的原子尺度模拟,包含超过100万个原子,尺寸与制造的结构相匹配。
关键词——KMC,共轭梯度,多GPU,无网格,新兴非易失性存储
Large Language Models for Anomaly Detection in Computational Workflows: from Supervised Fine-Tuning to In-Context Learning
AuthorsHongwei JinGeorge PapadimitriouKrishnan RaghavanPawel ZukPrasanna BalaprakashCong WangAnirban MandalEwa Deelman
2:30pm - 3pm EST
计算工作流中的异常检测对于确保系统的可靠性和安全性至关重要。然而,传统的基于规则的方法在检测新型异常时表现不佳。本文利用大语言模型(LLMs)进行工作流异常检测,利用其学习复杂数据模式的能力。研究了两种方法:1)监督微调(SFT),即对预训练的LLMs进行微调,以便在标注数据上进行句子分类以识别异常;2)上下文学习(ICL),即通过包含任务描述和示例的提示,引导LLMs在无需微调的情况下进行少样本异常检测。本文评估了SFT模型的性能、效率和泛化能力,并探索了零样本和少样本ICL提示,以及通过链式推理提示增强可解释性。通过多个工作流数据集的实验,证明了LLMs在复杂执行中的异常检测方面具有良好的潜力。
主要做的实验:对话得到。。。?

In-context learning(上下文学习)是一种利用预训练语言模型进行任务处理的技术,在这种方法中,模型通过提示(prompt)提供任务的描述和示例,来引导其理解任务并执行相应的操作,而无需进行额外的微调或训练。
具体来说,上下文学习通过以下几个步骤工作:
- 提示设计:给模型提供一个包含任务描述和相关示例的“提示”,这些提示能够帮助模型理解任务的目标和要求。
- 少样本学习:模型基于提示中的示例,能够在没有大量训练数据的情况下进行推理和预测,这通常被称为“少样本学习”(few-shot learning)。
- 灵活性:上下文学习利用预训练语言模型的强大能力,通过对话或指令的上下文来进行推理,从而完成多种不同类型的任务,而无需重新训练模型。
这种方法的优势在于它利用了预训练模型的知识,而不需要针对特定任务进行昂贵的再训练或微调。
Chain-of-Thought (CoT) 是一种增强大语言模型推理能力的技术,通过在模型生成答案时引导其进行逐步推理,模拟人类思考过程,从而提高模型在复杂任务中的表现。
具体来说,Chain-of-Thought 方法要求语言模型在做出最终结论之前,先生成一系列的中间推理步骤或“思路链”(chain of thought)。这种做法帮助模型更清晰地展示其思考过程,并逐步推理出正确的答案,而不是直接给出最终的答案。
关键特点:
- 逐步推理:CoT通过让模型将推理过程分解为多个小步骤,帮助模型在复杂任务中进行更清晰、系统的推理。
- 增强可解释性:由于模型展示了推理的中间步骤,它的决策过程更加透明,增加了可解释性,用户可以更容易理解模型的思维逻辑。
- 提高准确性:在许多任务中,逐步推理能够帮助模型更准确地解决问题,尤其是涉及数学推理、逻辑推理、复杂问题解答等任务时。
应用:
- 推理任务:例如数学问题求解、逻辑推理等,模型可以通过展示推理过程来得出正确答案。
- 复杂问答系统:帮助模型理清思路,从而更有效地回答多步骤的问题。
总体而言,Chain-of-Thought 通过引导模型进行有序的推理,增强了其在面对复杂任务时的能力和表现。
Designing a GPU-Accelerated Communication Layer for Efficient Fluid-Structure Interaction Computations on Heterogenous Systems
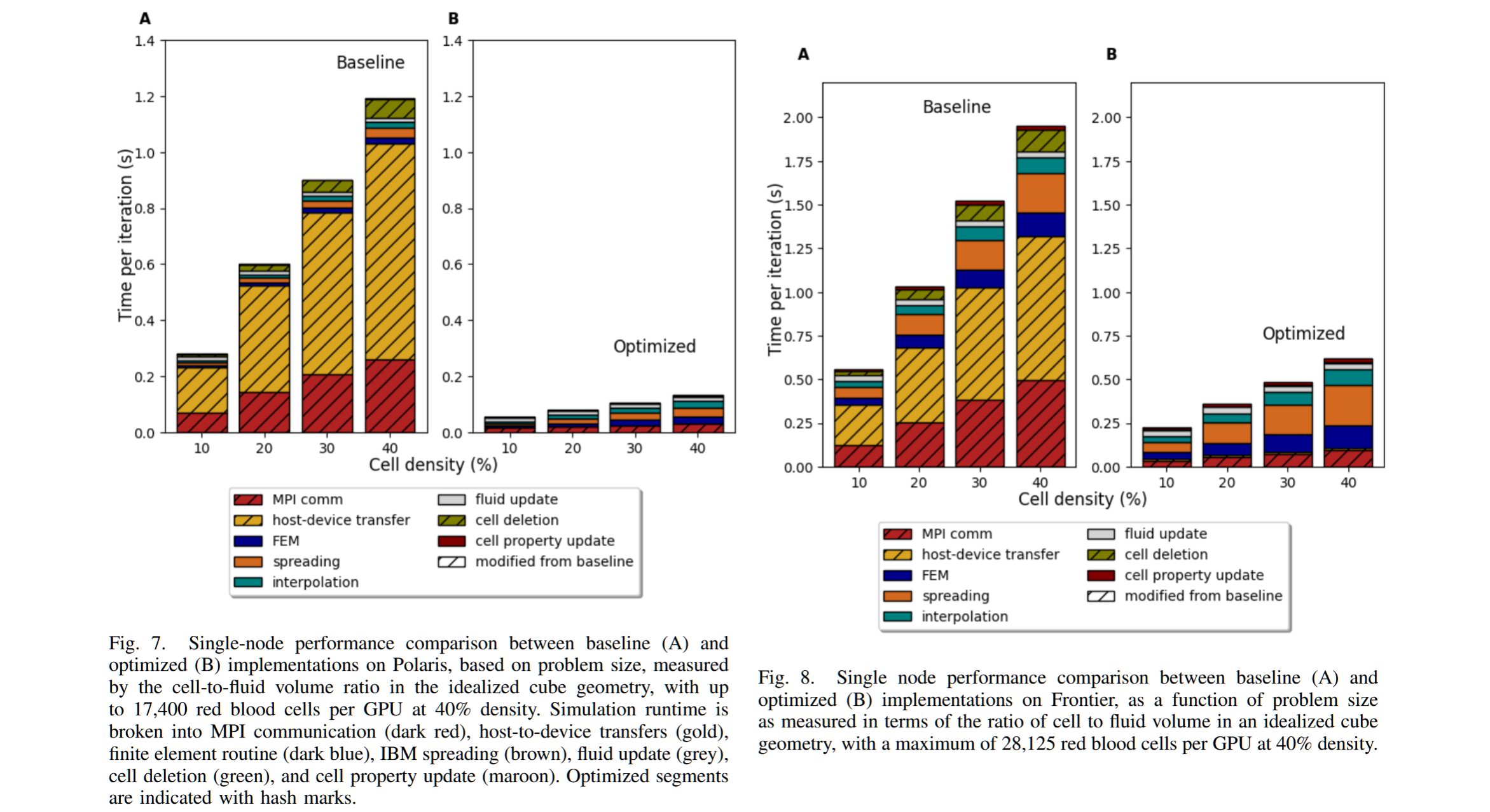
随着生物学研究对越来越大规模的细胞数进行模拟的需求,优化这些模型以便在异构超级计算资源上大规模部署变得至关重要。这要求重新设计围绕分布式数据结构编写的流体-结构相互作用任务,这些数据结构是为基于CPU的系统构建的,其中设计灵活性和整体内存占用是关键考虑因素,而这些任务必须在CPU-GPU机器上具有良好的性能。
本文描述了将通信任务卸载到GPU的权衡,并讨论了所需的底层数据结构的相应变化,以及显著减少解决时间的新算法。我们在Polaris和Frontier领导系统上评估了GPU实现的规模化性能。涉及数百万可变形细胞的现实工作负载进行了评估。我们分析了在设计流体-结构相互作用代码的通信层时需要考虑的相互制约因素,包括代码效率、复杂性和GPU内存需求,并为其他面临类似决策的高性能计算应用提供了建议。
关键词 — 计算流体力学,流体-结构相互作用,GPU计算,高性能计算
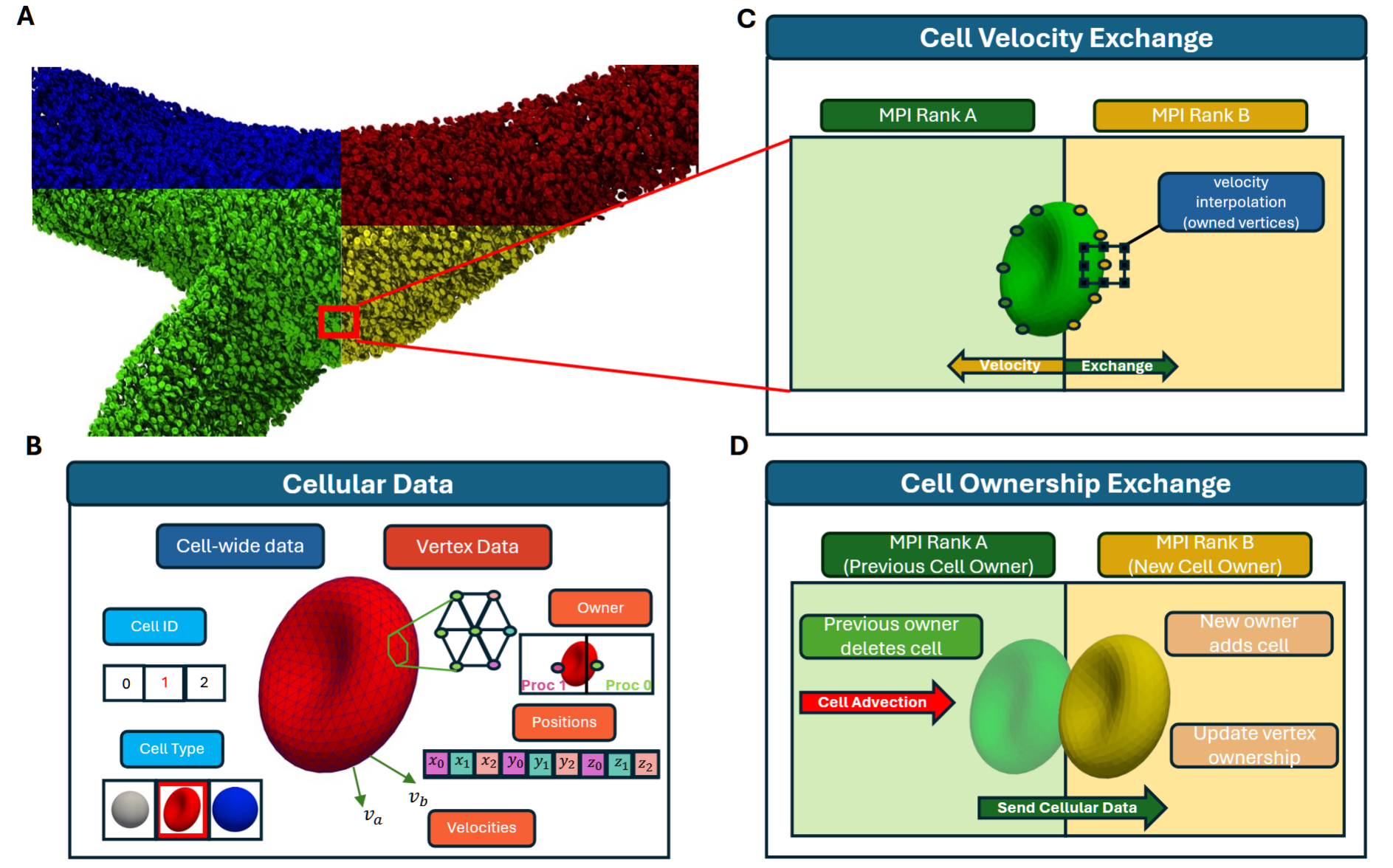
图1. 分布式流体-结构相互作用计算中涉及的通信任务概述。
A)模拟空间被细胞填充,并在MPI进程中划分。
B)每个浸没边界细胞由一个包含10,242个顶点和20,480个元素的网格描述,封装了诸如细胞类型和ID等元数据,以及每个元素和顶点的数据,如坐标、速度和所有权,后者由顶点所在的MPI进程域决定。
C)这些细胞的顶点速度通过从周围流体网格插值更新,这一过程仅限于由进程拥有的顶点,以涵盖所有相关的本地流体点。这要求MPI进程交换共享但未被拥有的顶点的速度数据。
D)当一个细胞过渡到另一个进程的域时,触发数据传输。涉及从原始所有者到接收方传输细胞数据的MPI通信(如B所示)是必需的,以便接收方能够在本地重建接收到的细胞。C)和D)中概述的通信例程是分布式浸没边界细胞代码的关键部分。
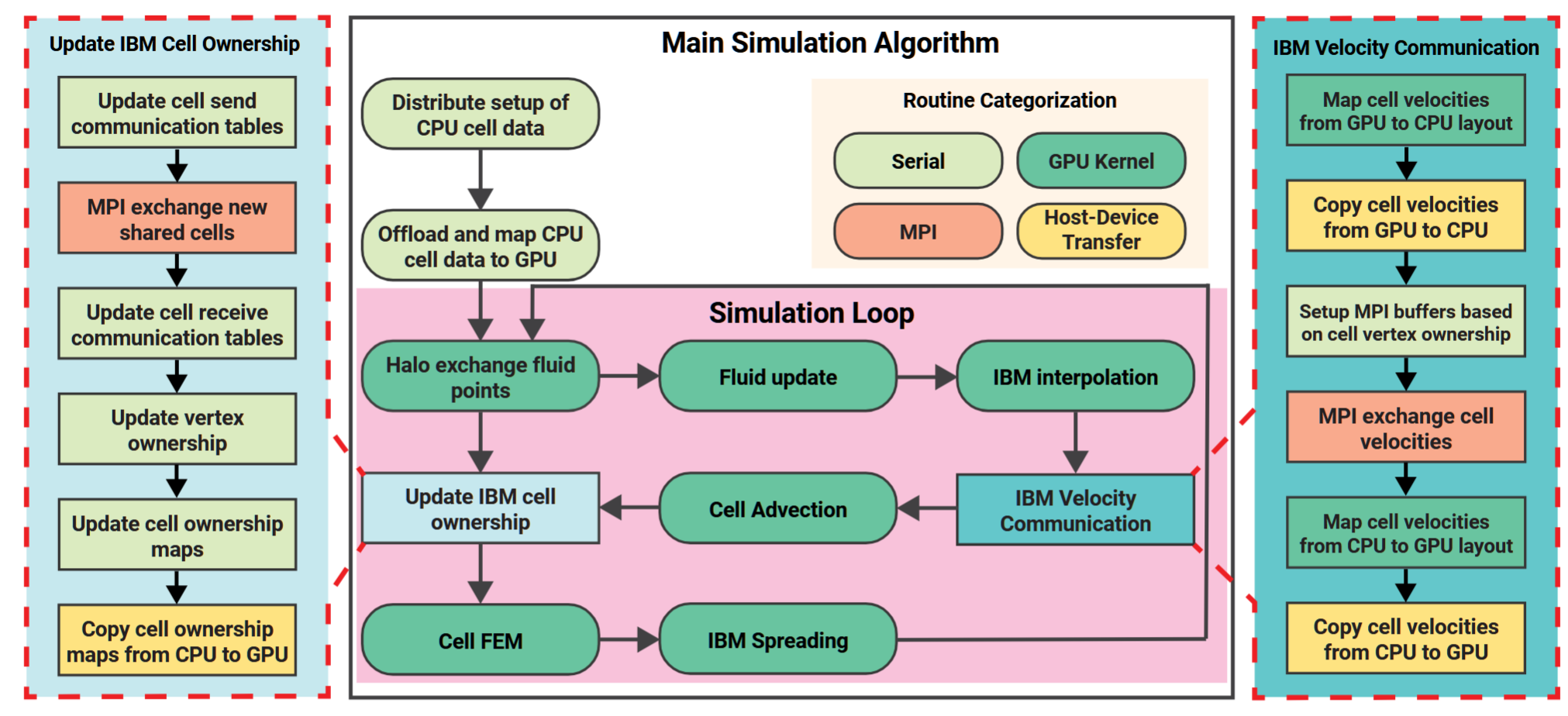
图3. 我们的分布式流体-结构相互作用算法的基线实现概述。主要的模拟算法位于中央,首先是MPI交换流体halo点,然后是一个单一的内核,用于更新模拟中的流体部分。浸没边界组件将流体速度插值到细胞顶点上,随后进行MPI通信和主机到设备的传输,以进行速度交换和位置更新。主机端处理根据新位置更新细胞和顶点的所有权,涉及额外的数据传输。尽管大多数计算发生在GPU上,但由主机驱动的任务(在左右两侧展开)主导了运行时间。
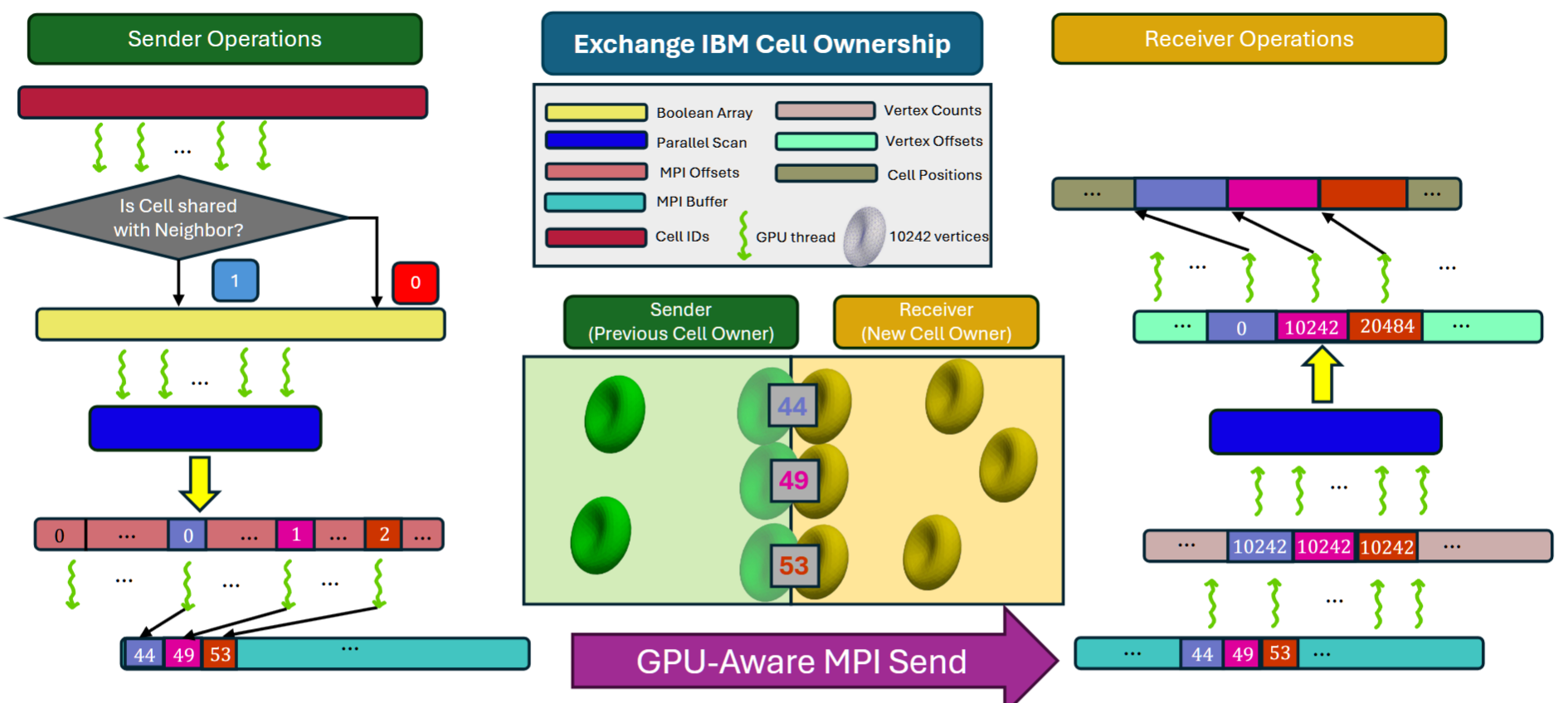
增强的GPU并行方法用于IBM细胞所有权交换,分为两个主要内核阶段:发送方操作(左侧)和接收方操作(右侧)。在发送方,线程评估细胞邻居组合之间的细胞共享状态,生成一个布尔数组。该数组被扫描以创建偏移量,从而允许线程将发送项写入连续的MPI发送缓冲区。然后,GPU感知MPI将数据传输到接收方。在接收方,GPU任务扫描传入的顶点计数以确定内存偏移量,使线程能够插入新接收到的细胞数据。在这个例子中,细胞44、49和53的数据被传输到接收方。
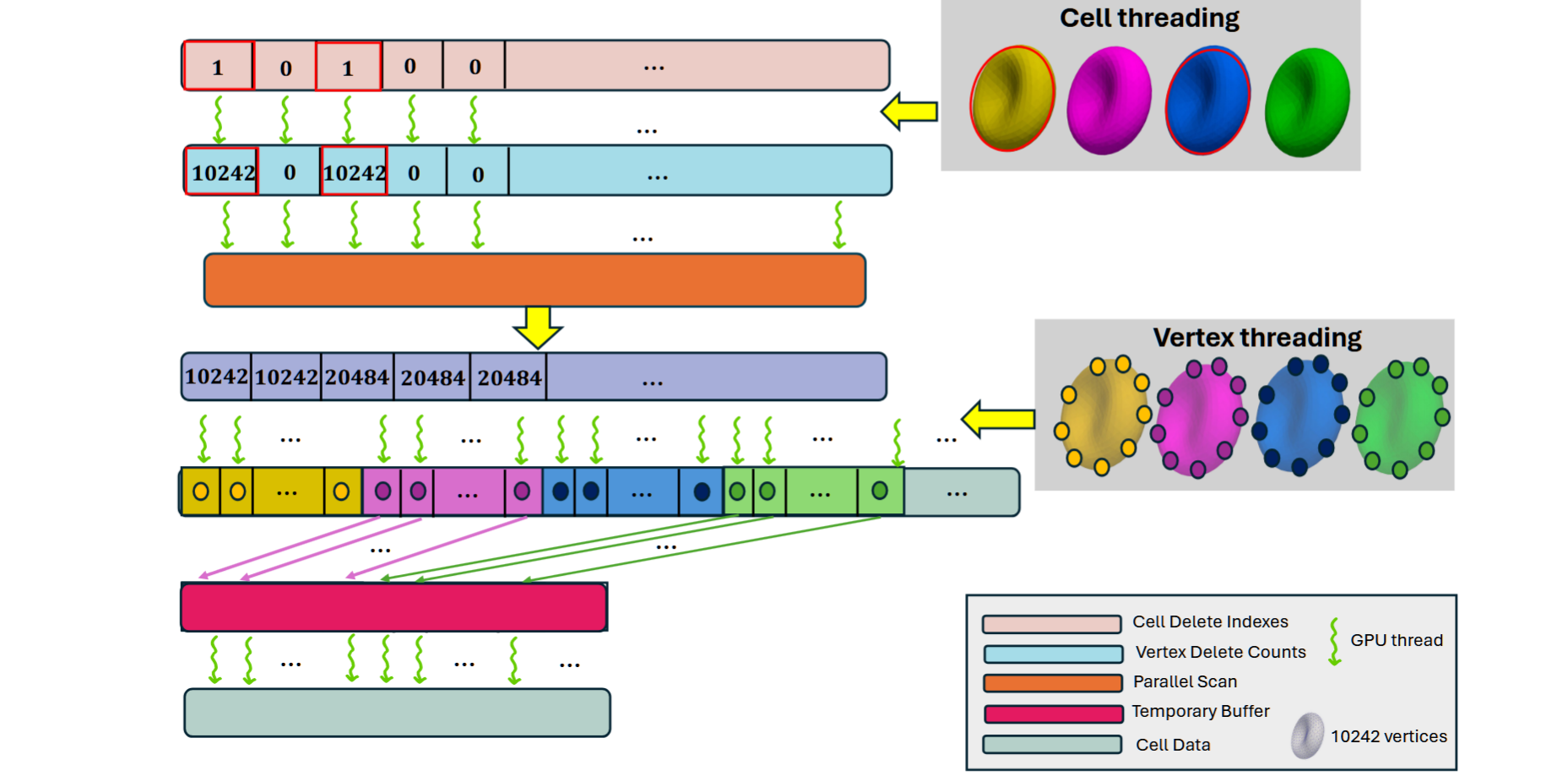
GPU内核实现用于细胞删除。这个过程包括标记一部分细胞以进行删除,标记的细胞通过删除数组(顶部)指示,并且通过红色圆圈突出显示。删除数组是计算前缀和的初步步骤,例如用于顶点移除的并行扫描。每个标记为删除的细胞的数据,包括其10,242个顶点,将通过随后的数据在压缩过程中被覆盖。在这个例子中,标记为删除的细胞顶点级数据通过被下游数据覆盖来有效地删除。线程将左移的细胞数据数组写入一个临时缓冲区,写入偏移量由相关的前缀和提供信息。最后,线程交换临时数组的条目与正在修改的细胞缓冲区,这一过程发生在一个额外的复制内核中。
Scale–Up Interconnects
Sergio Iserte B312-B313A
AcceleratorsData Movement and MemoryEmerging TechnologiesHardware TechnologiesHeterogeneous ComputingLinear AlgebraNetwork
TP
Session ChairSergio Iserte
Presentations
1:30pm - 2pm EST
Efficient Tensor Offloading for Large Deep-Learning Model Training based on Compute Express
AuthorsDong XuYuan FengKwangsik ShinDaewoo KimHyeran JeonDong Li
2pm - 2:30pm EST
SK hynix做的硬件体验
https://dl.acm.org/doi/10.1109/SC41406.2024.00100
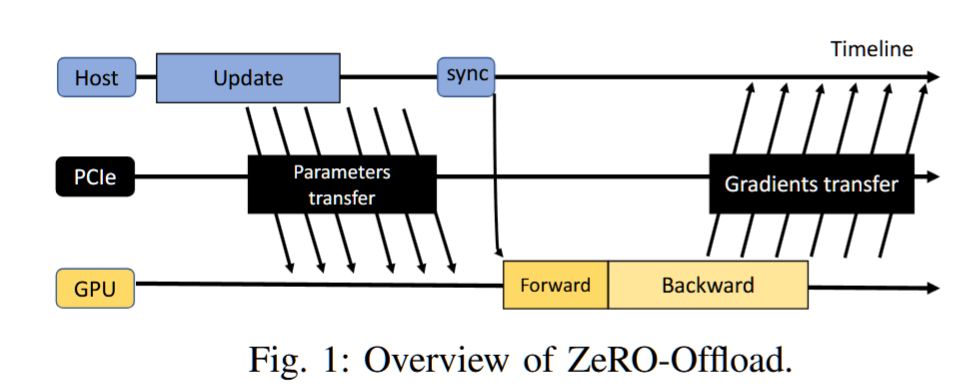
摘要——深度学习模型(DL)正在变得越来越大,往往超出了单一加速器的内存容量。最近在大规模深度学习训练中的进展利用了CPU内存作为加速器内存的扩展,并将张量卸载到CPU内存以节省加速器内存。
该解决方案在两种内存之间传输张量,从而造成了一个主要的性能瓶颈。我们在张量传输过程中识别出两个问题:
(1)粗粒度的张量传输使得隐藏传输开销变得困难,和(2)冗余的传输不必要地将未改变值的字节从CPU迁移到加速器。
我们提出了一种基于计算扩展链接(CXL)的缓存一致性互连,在CPU内存和加速器内存之间建立缓存一致性域。通过略微扩展CXL以支持更新的缓存一致性协议,并避免不必要的数据传输,我们在不改变模型收敛性和准确性的前提下,将训练时间减少了33.7%(最多可达55.4%),与DeepSpeed [62]中的最先进方法相比。
文章
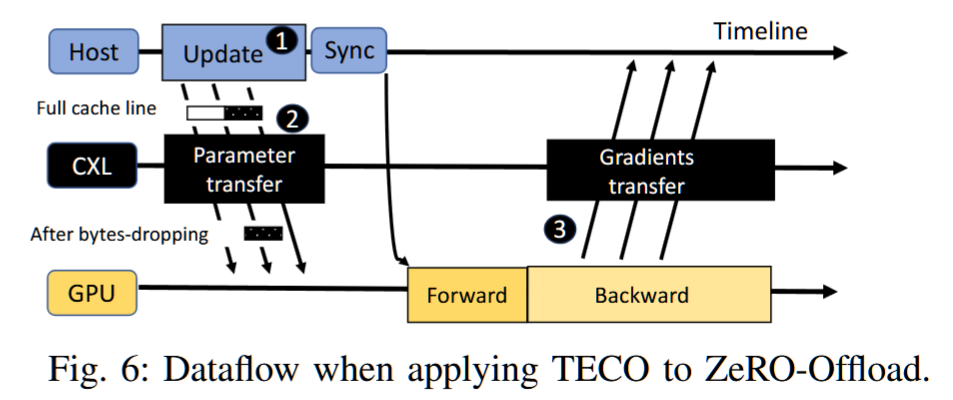
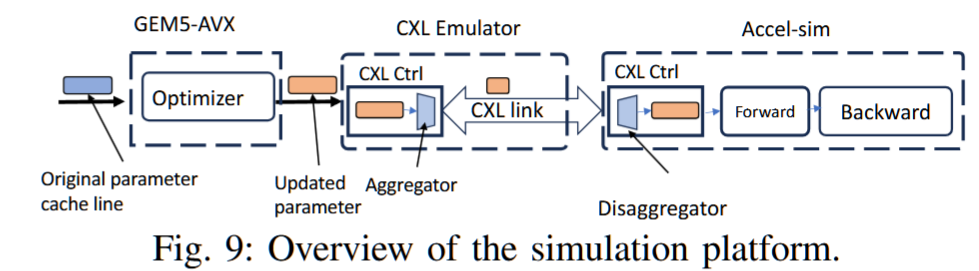
CXL介绍
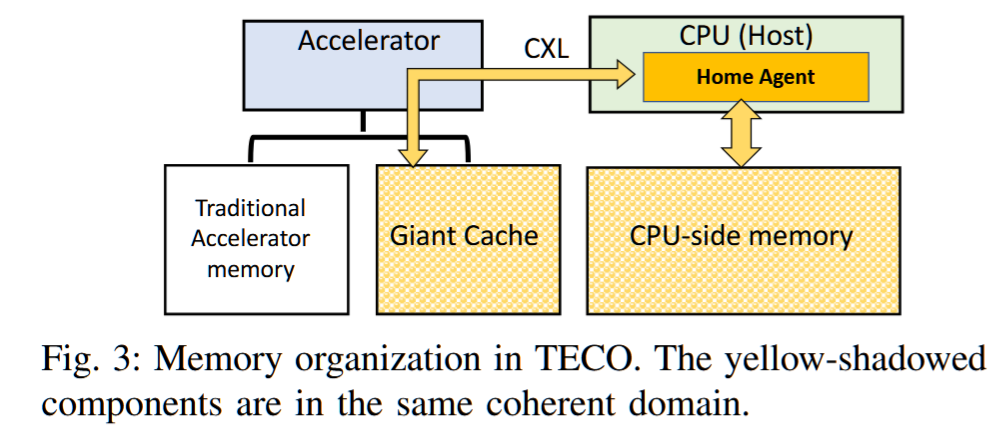
Compute Express Link(CXL)作为一种先进的互连技术,在当今高性能计算领域引起了广泛关注,其高带宽、低延迟的特性使其成为连接处理器、加速器、存储等关键组件的理想选择。本文将深入探讨CXL技术,从其起源、特点,到应用领域和与其他技术的比较,全面了解CXL对现代数据中心生态系统的重要性。
CXL (Compute Express Link) 技术是一种新型的高速互联技术,旨在提供更高的数据吞吐量和更低的延迟,以满足现代计算和存储系统的需求。它最初由英特尔、AMD和其他公司联合推出,并得到了包括谷歌、微软等公司在内的大量支持。
CXL的目标:解决CPU和设备、设备和设备之间的内存鸿沟。服务器有巨大的内存池和数量庞大的基于PCIe运算加速器,每个上面都有很大的内存。内存的分割已经造成巨大的浪费、不便和性能下降。CXL就是为解决这个问题而诞生。
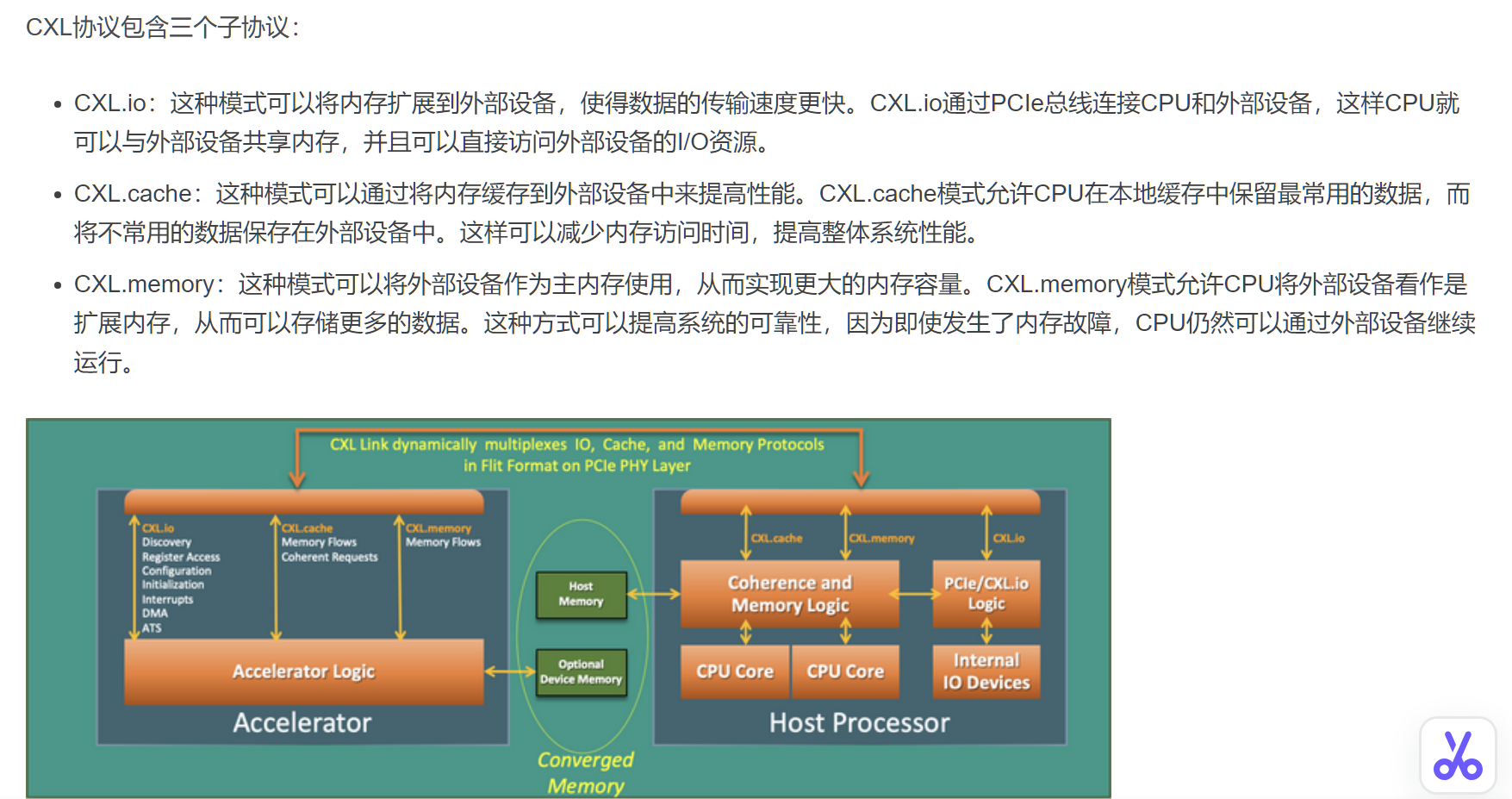
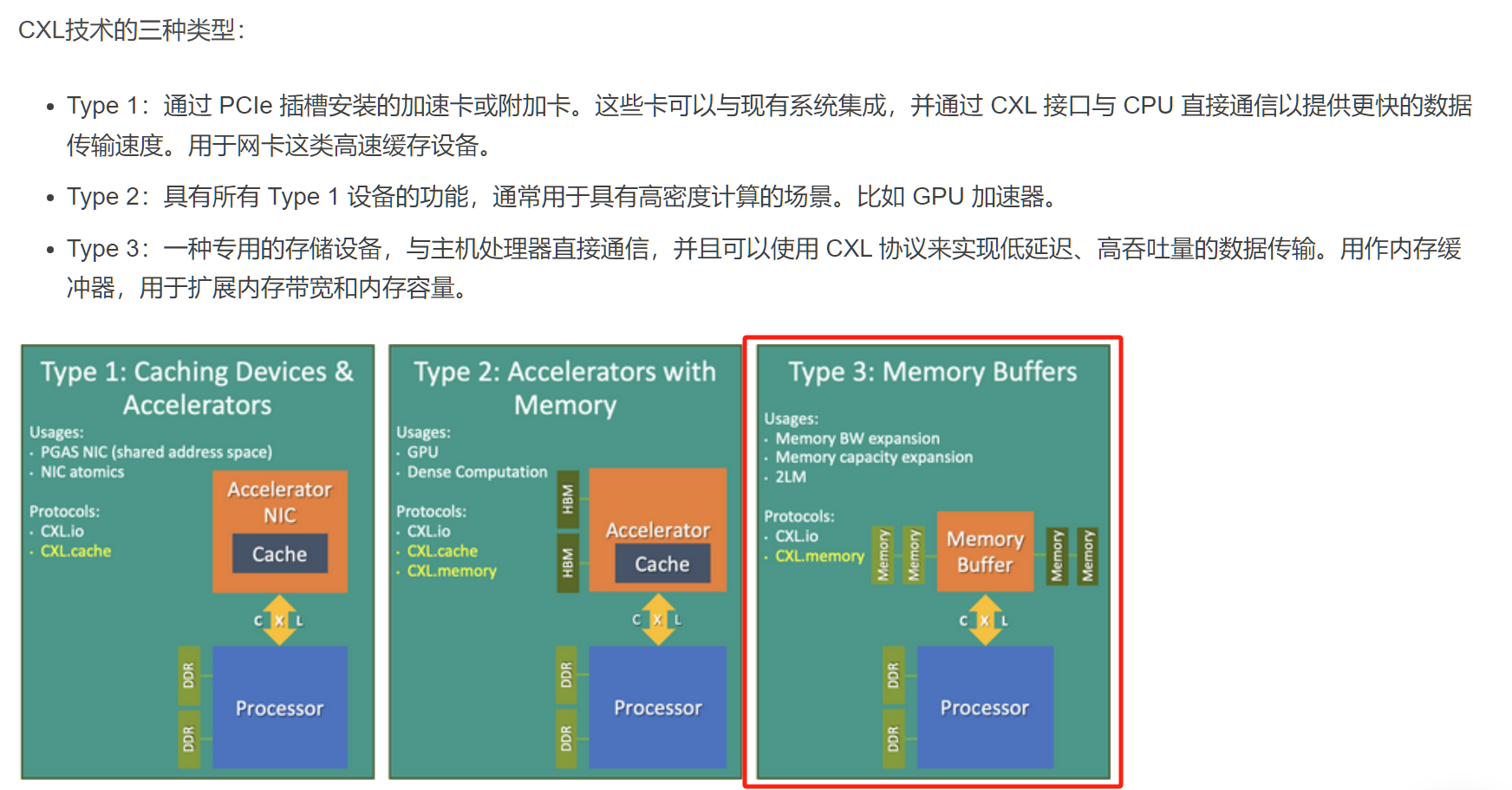
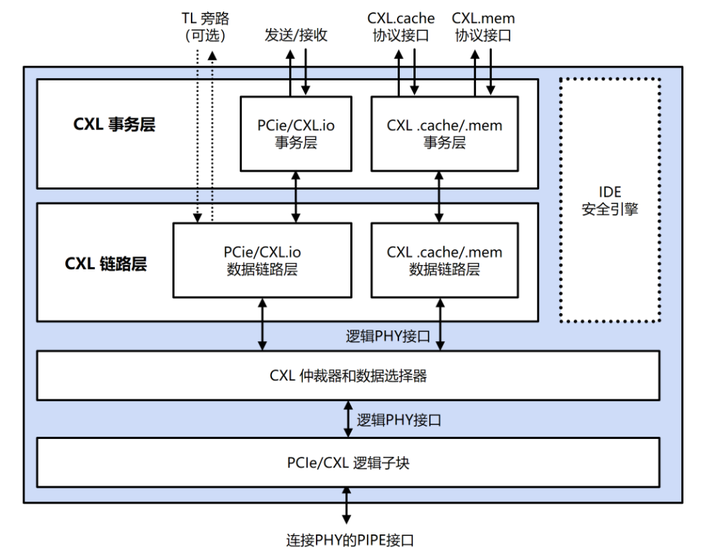
CXL的出现很好地解决了这个问题,通过将设备挂载到PCIe总线上,CXL实现了设备到CPU之间的互联,实现了存储计算分离。CXL 还允许 CPU 以低延迟和高带宽访问连接设备上更大的内存池,从而扩展内存。这可以增加 AI/ML 应用程序的内存容量和性能。CXL利用灵活的处理器端口,可以在 PCIe 或 CXL 模式下运行。这两种设备类别均可在 PCIe5.0 中实现 32 GT/s 的数据速率,在 PCIe6.0 中实现高达 64 GT/s 的数据速率,为 AI/ML 应用提供了额外的功能和优势。
其创新的另一个关键是CXL®支持内存分离架构,允许多个主机使用同一个内存池,从而推动更具可扩展性且资源优化的数据中心基础设施。
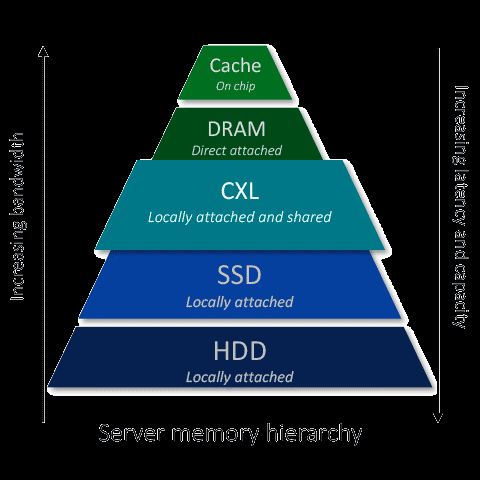
CXL®内存非常适合内存密集型工作负载,例如AI/ML、高性能计算(HPC)和内存数据库(IMDB),其中大内存容量和大带宽对于高效处理至关重要。 对于数据中心和云基础设施,CXL®通过支持多个主机的内存池和共享,从而优化资源利用率并显著降低总体拥有成本(TCO)。
COAXIAL: A CXL-Centric Memory System for Scalable Servers
AuthorsAlbert ChoAnish SaxenaMoinuddin QureshiAlexandros Daglis
2:30pm - 3pm EST
Albert Cho† Anish Saxena† Moinuddin Qureshi Alexandros Daglis
Georgia Institute of Technology
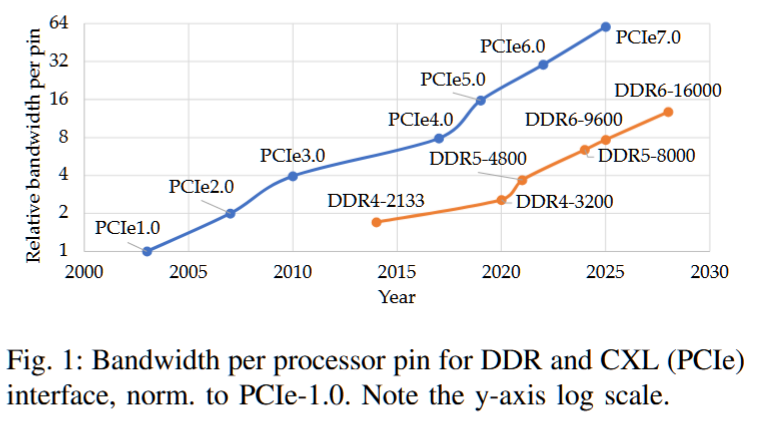
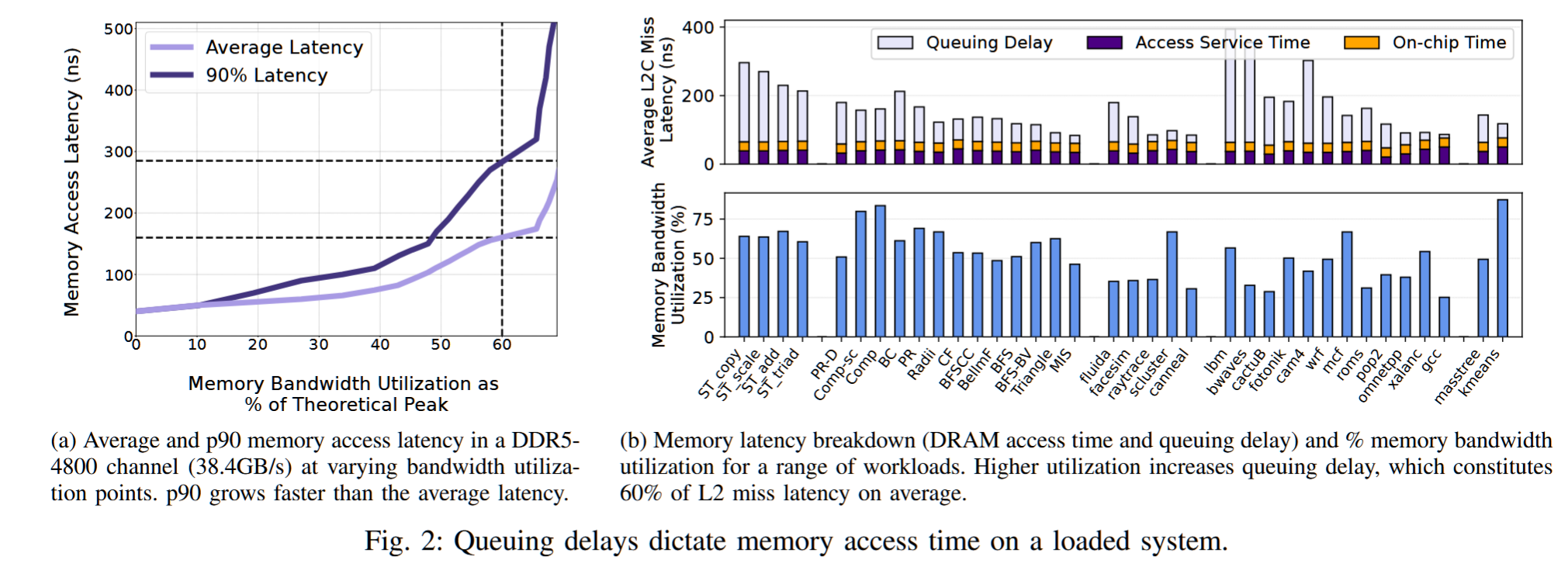
摘要——内存系统是服务器处理器性能的主要决定因素。不断增长的核心数量和数据集需求要求更高的内存带宽和容量。DDR——处理器与内存之间的主流接口——需要大量的片上引脚,而这些引脚是有限资源,从而限制了处理器的内存带宽。在带宽有限的情况下,多个并发内存请求会经历显著的排队延迟,这些延迟通常会掩盖DRAM的服务时间并降低性能。
我们提出了COAXIAL,一种面向吞吐量的多核服务器内存系统设计,它用引脚高效的CXL接口替代了处理器的所有DDR接口,CXL每个引脚提供的带宽是DDR的4倍。虽然这种替代会带来相当大的延迟开销,但我们证明,对于许多工作负载,并且经过精心集成,CXL更高的带宽足以弥补其延迟的额外成本。我们的评估显示,COAXIAL在多核吞吐量导向的服务器上平均提高了1.39倍,最高可达3倍。
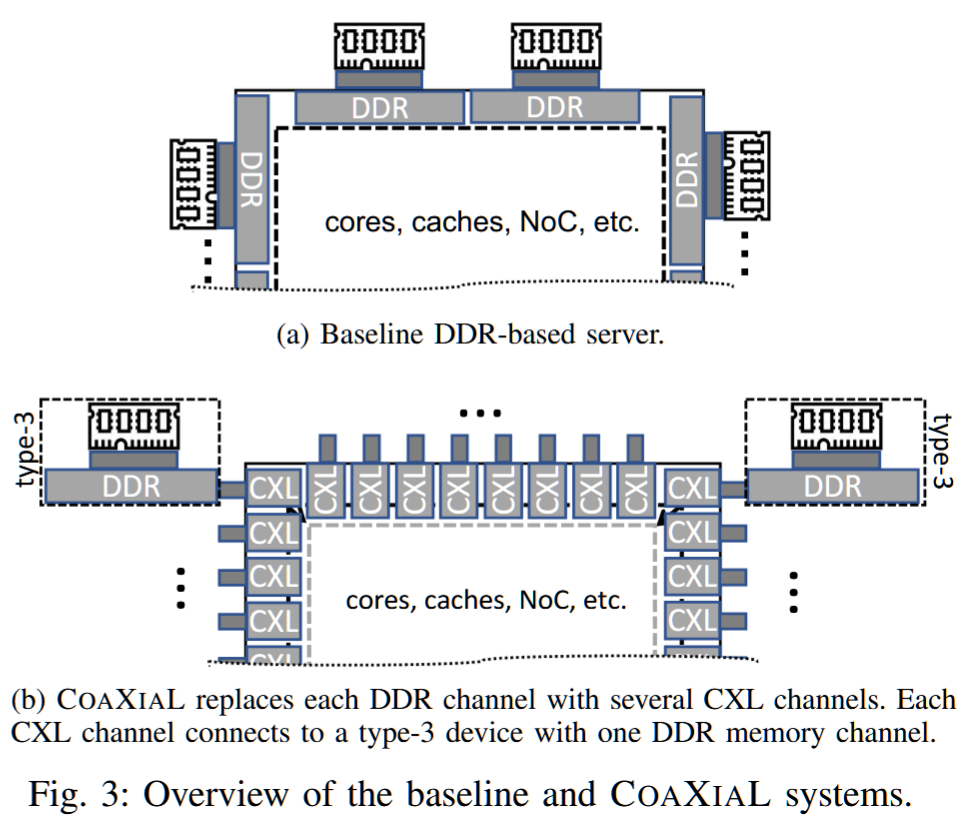
CXL performance modeling. For COAXIAL, we model CXL controllers and PCIe bus on both the processor and the Type-3 device. A CXL port incurs an unloaded uni-directional delay of 12.5ns accounting for flit-packing, encoding/decoding, packet processing, etc., as reported by PLDA and Intel’s IP [47],[51].
Switch-Less Dragonfly on Wafers: A Scalable Interconnection Architecture based on Wafer-Scale Integration
Institute for Interdisciplinary Information Sciences (IIIS)
Tsinghua University, Beijing, China
硬件
摘要——现有的高性能计算(HPC)互连架构基于高基数交换机,这限制了注入/局部性能,并引入了延迟/能量/成本开销。新的晶圆级封装和高速电缆技术提供了高密度、低延迟和高带宽的连接,因此有望支持直接连接的高基数互连架构。本文提出了一种基于晶圆的互连架构,称为“无交换机龙形拓扑晶圆”。通过利用分布式高带宽的芯片上网络(network-on-chip-on-wafer),消除了龙形拓扑中昂贵的高基数交换机,同时提高了注入/局部吞吐量,并保持了全局吞吐量。在所提出的架构基础上,我们还引入了基线和改进的死锁-free 最小/非最小路由算法,仅需要一个额外的虚拟通道。广泛的评估表明,Switch-Less-Dragonfly-on-Wafers在成本和性能上均优于传统的基于交换机的龙形拓扑。类似的方法可以应用于其他基于交换机的直接拓扑,从而有望为未来的大规模超级计算机提供动力。
关键词——晶圆级集成,高性能计算互连网络,龙形拓扑,芯片上网络,路由算法。
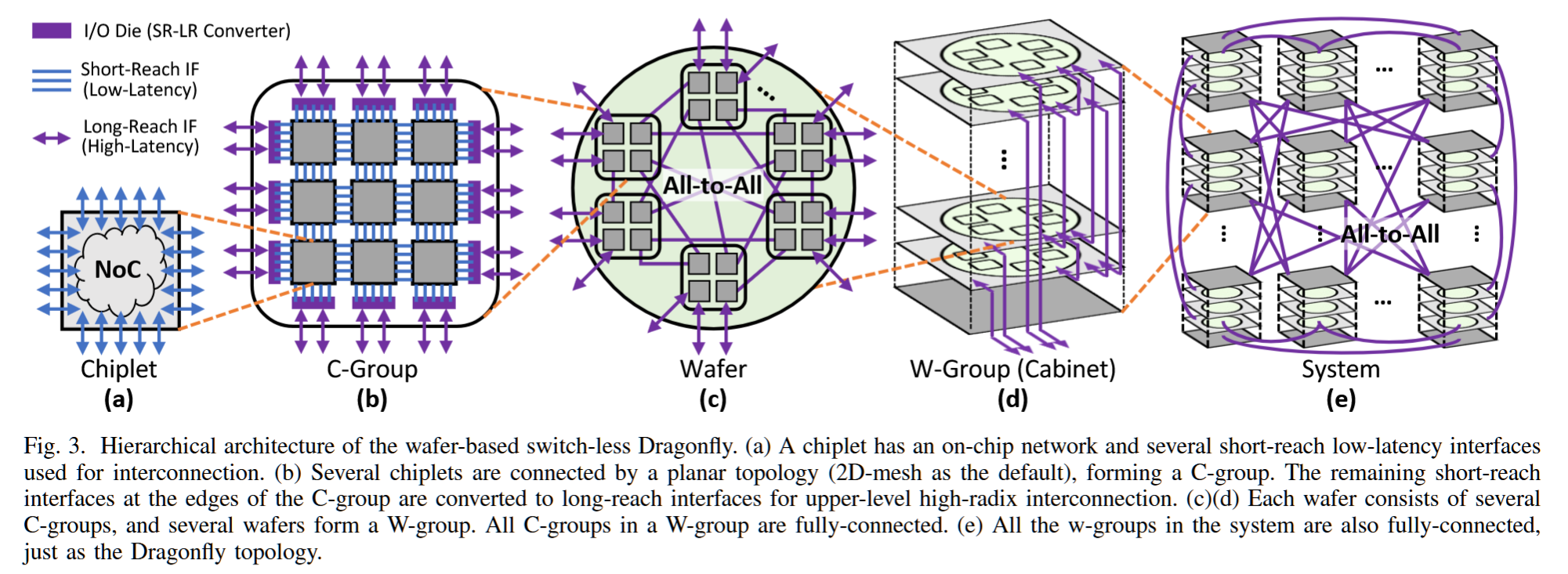
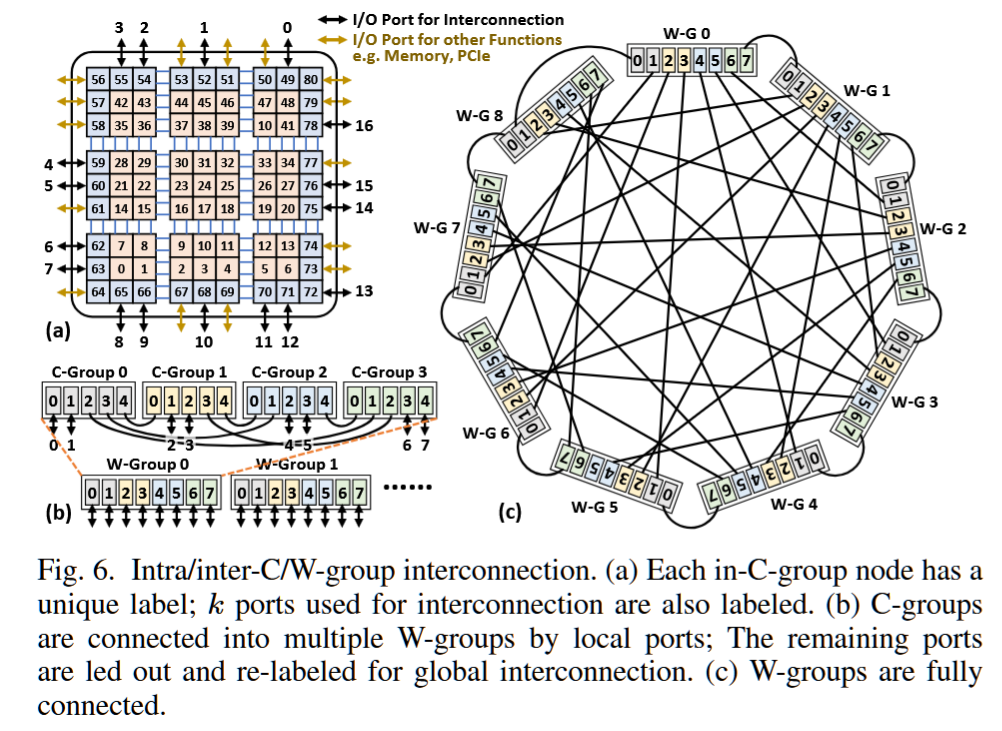
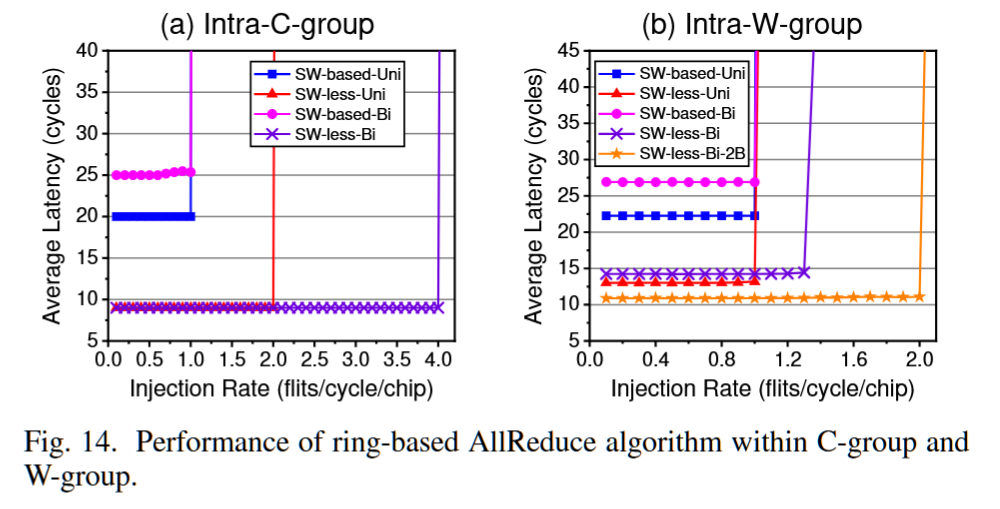
Scaling and Checkpointing
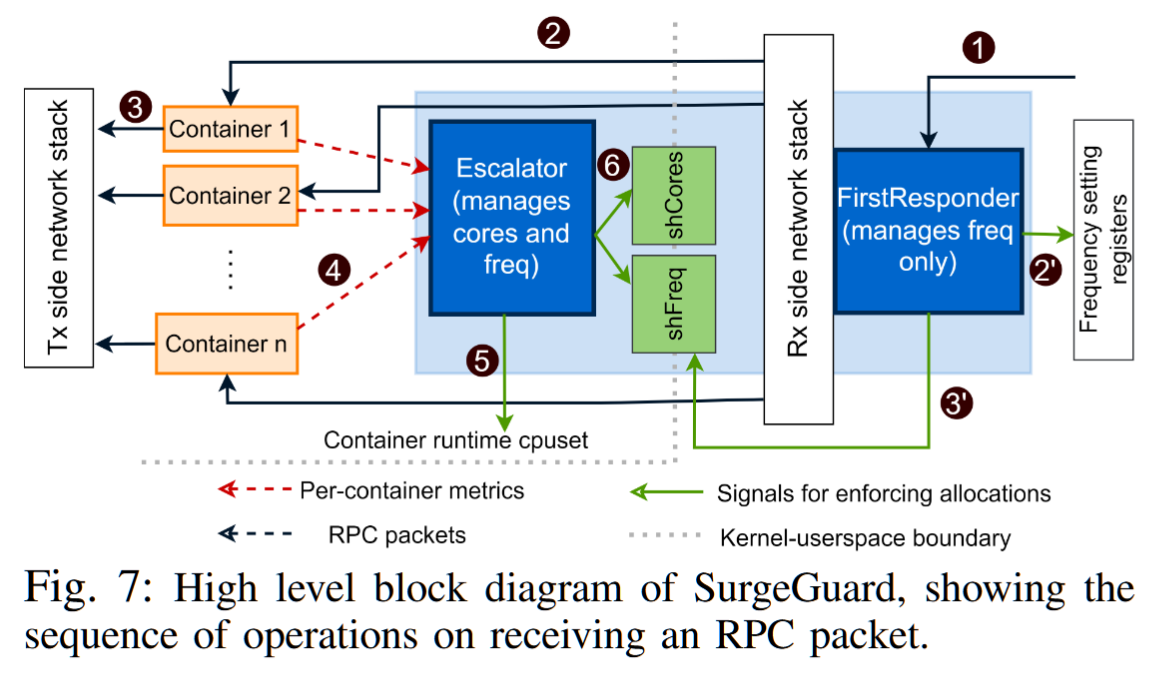
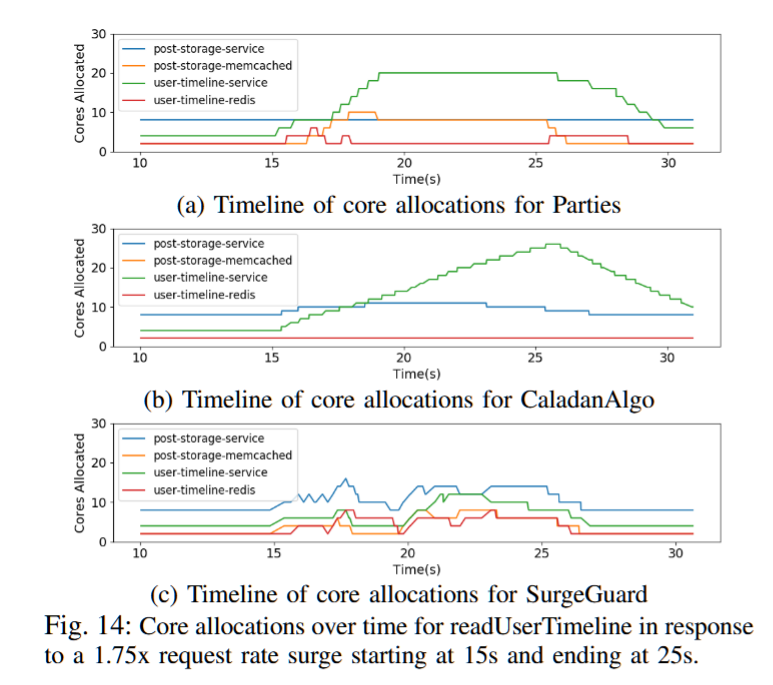
Fast and Efficient Scaling For Microservices with SurgeGuard
AuthorsAnyesha GhoshNeeraja YadwadkarMattan Erez
Cloud ComputingResource Management
The University of Texas at Austin
2pm - 2:30pm EST
摘要——微服务架构因其灵活性和适应大规模在线应用的能力而日益流行。然而,现有的资源管理机制在检测服务质量(QoS)违规时会导致高延迟,因此在常见的负载波动条件下,无法有效分配资源。这导致了过度分配,并伴随着延迟响应,从而增加了总拥有成本和每次QoS违规事件的严重性。我们提出了SurgeGuard,一个专为在负载和网络延迟激增时保护应用QoS而设计的分散式资源控制器。SurgeGuard的核心理念是:为了快速检测和有效管理QoS违规,控制器必须了解任务图中微服务之间的延迟和通信模式中的可用空闲时间。我们的实验表明,在DeathStarBench的工作负载下,SurgeGuard与著名的Parties和Caladan算法相比,平均分别减少了61.1%和93.7%的违规严重性和持续时间,并且比Parties算法需要少8%的资源。
关键词——云计算,微服务,无服务器,服务质量,资源管理,数据中心
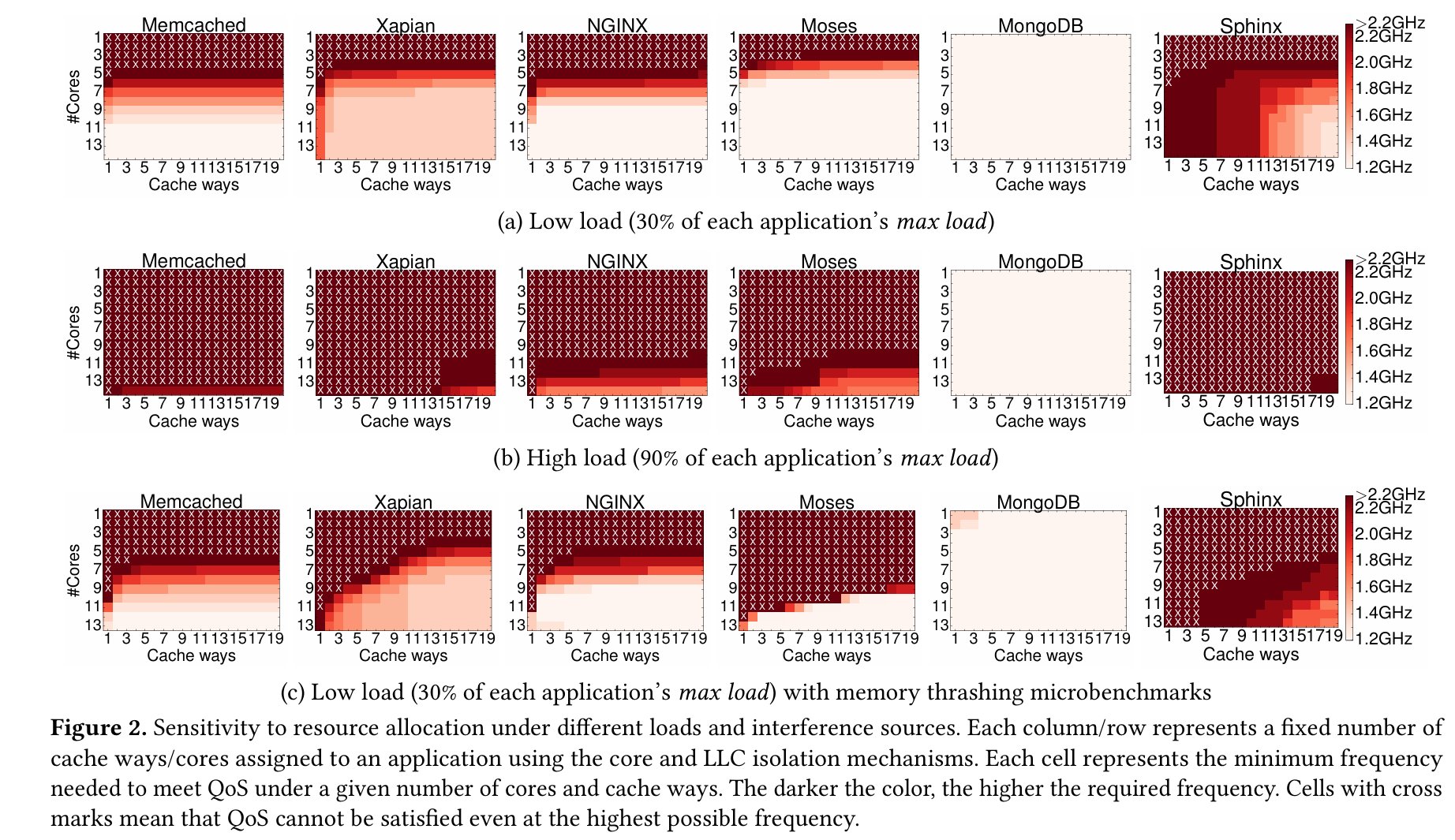
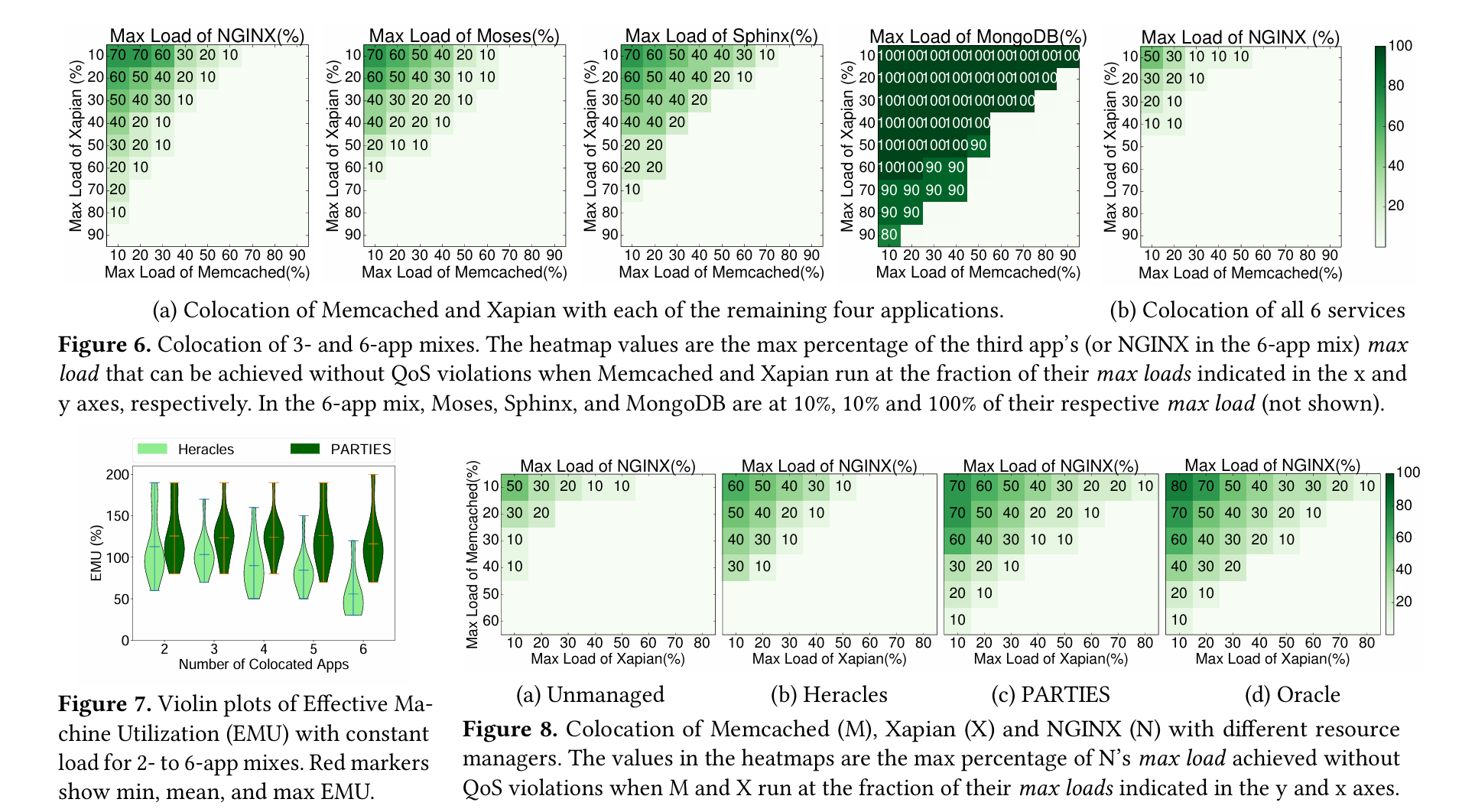
PARTIES
PARTIES: QoS-Aware Resource Partitioning for Multiple Interactive Services
PARTIES: QoS-Aware Resource Partitioning for Multiple Interactive Services | Welcome to Shuang Chen's Homepage
动机
1. 云应用逐渐从批处理转变成低延迟的服务。比如传统的以吞吐率为主的图像处理和大数据的应用在采用Spark和X-Stream框架后进入内存计算的阶段,这让任务执行延迟变为几毫秒或秒。
2. 云应用正在经历重大的重新设计——从单体式服务Monolith(它封装了完整的功能到单个二进制中)转变为成百上千个松耦合的微服务。仅管一个大规模的端到端的服务的延迟依旧保持在几毫秒或秒的粒度,每个微服务也必须满足更加严格的延迟约束,通常是几百微秒的级别。
3. 每个微服务处于一个小的且基本是无状态的容器中,这意味着许多容器需要被调度到一台物理机上以最大化利用率。当前的技术(每台物理机上只允许有一个高优先级的延迟敏感(LC)的服务与几个低优先级的批处理任务)无法满足新的场景
创新点
1. 验证“资源置换性(fungibility)”这个概念
2. 提出PARTIES(对多个交互式服务的划分),它是第一个针对多个延迟敏感(LC)应用的QoS有感资源管理器,它不需要应用的先验知识,通过动态监测,利用系统/硬件层面可划分9个共享资源。此外,PARTIES适用于动态变化的负载,并利用用资源替换性来快速实现收敛

论文:
Realizing Joint Extreme-Scale Simulations on Multiple Supercomputers - Two Superfacility Case Studies
AuthorsTheresa PollingerAlexander Van CraenPhilipp OffenhäuserDirk Pflüger
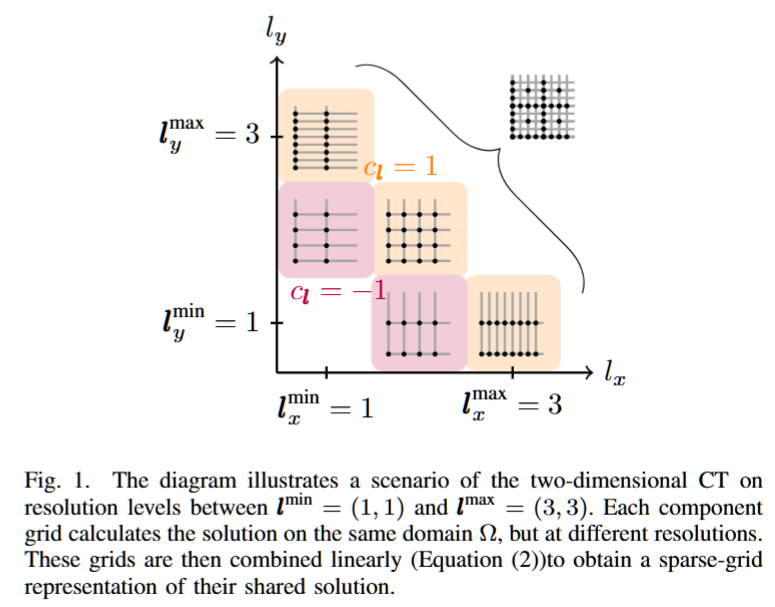
摘要——高维网格基础的仿真既是多领域研究的工具,也是面临的挑战。这些方法的主要挑战是众所周知的维度灾难,特别是在高保真应用中需要细致分辨率的情况下,这一问题更加严重。组合技术(CT) 提供了一种直接的方式来执行此类仿真,同时缓解了维度灾难。最近的研究展示了CT将多个系统同时联合起来执行单一高维仿真的潜力。本文展示了如何将这一技术扩展到三个或更多系统,并解决了一些剩余的挑战:异构硬件上的负载平衡;利用压缩技术最大化通信带宽;通过硬件映射进行高效的I/O管理;以及通过算法优化提高内存利用率。结合这些贡献,我们展示了CT在极大规模超级设施场景下的可行性,其中包括在两个系统上进行46万亿自由度(DOF)和在三个系统上进行35万亿自由度的仿真。在这些分辨率下,使用全网格求解器(每个求解器>1,000非亿自由度)将无法解决此类问题。
关键词——耦合HPC系统、大规模、组合技术、多级方法、高维仿真、等离子体湍流、文件传输
高维时变偏微分方程(PDEs)在金融[1]、等离子体物理[2]、天体物理[3]、量子化学[4]以及许多其他科学领域中都有应用。尽管在物理信息神经网络方面取得了近期进展,但学习方法仍然远未解决高空间维度中的时变PDEs:当前方法通常会受到饱和误差的影响(没有已发布的数值收敛性)[5]–[10]。这一点也反映在学习领域中,“高维度”有时被定义为未知函数的二维或三维领域[7],[9],而在数值计算文献中,“高维”指的是四个或更多的空间维度。暂时而言,解决高维物理问题仍然需要“经典”的仿真科学。基于网格的仿真在这个过程中既是不可或缺的工具,也是一个重大挑战。


Heterogeneous ComputingPerformance OptimizationState of the Practice
2:30pm - 3pm EST
hair for Scientific Computing, Universit¨at Stuttgart, Germany
§Hewlett Packard Enterprise (HPE), Herrenberger Straße 140, 71034 B¨oblingen, Germany
AutoCheck: Automatically Identifying Variables for Checkpointing by Data Dependency Analysis
摘要——Checkpoint/Restart(C/R)已广泛应用于众多高性能计算(HPC)系统、云计算平台和工业数据中心,这些系统通常由系统工程师管理。然而,目前并没有现有的方法可以帮助没有领域专长的系统工程师,以及没有系统容错知识的领域科学家,识别在C/R故障恢复中保证应用程序正确执行恢复的关键变量。为了解决这个问题,我们提出了一种分析模型和一个工具(AutoCheck),该工具能够自动识别用于C/R的关键变量进行检查点保存。AutoCheck首先通过分析追踪和优化变量与其他应用执行状态之间的数据依赖关系,其次,利用一组启发式算法从优化后的数据依赖图(DDG)中识别出关键变量进行检查点保存。AutoCheck使得程序员能够在几分钟内迅速确定需要保存的关键变量。我们在14个代表性的HPC基准测试上评估了AutoCheck,结果表明,AutoCheck能够高效地识别出正确的关键变量进行检查点保存。
关键词——Checkpoint/Restart、容错、数据依赖分析、LLVM-Trace
检查点/重启模型(Checkpoint/Restart Model)
C/R方法使得长时间运行的高性能计算(HPC)应用能够在故障停机后成功重启。这些长时间运行的HPC应用通常包括三个部分:预处理(或初始化)接口、主计算循环和后处理(或验证)接口。
主计算循环指的是程序中负责执行主要计算任务的部分。这个循环通常是程序的核心,重复执行一系列计算步骤,直到满足特定的终止条件。
为了从故障发生前的迭代开始重启主计算循环,而不是从头开始,我们必须识别出哪些应用程序状态(或变量)对于在故障发生时正确重启应用程序是必要的。
过去的C/R方法是手动识别这些用于检查点保存的关键变量;而我们提供了一种分析模型和工具(AutoCheck),可以自动完成这一任务。一旦识别出这些关键变量,C/R方法会定期将这些变量保存到持久存储中,并在主计算循环的各个迭代之间以一定间隔进行保存。
变量被定义为与符号名称相关联的内存位置,在执行过程中被调用。发生进程或节点故障时,崩溃的执行可以从最新保存的检查点重新启动,并从故障发生前的主计算循环的最后一次迭代继续。
C/R插入:一旦识别出需要保存的变量,插入C/R代码时有两个关键点:
- 读取检查点,插入在主计算循环之前,确保所有关键变量在主循环开始之前被正确恢复。
- 写入检查点,添加到主循环中的每个单独的检查点变量,通常在主循环的最后,确保数据的一致性。
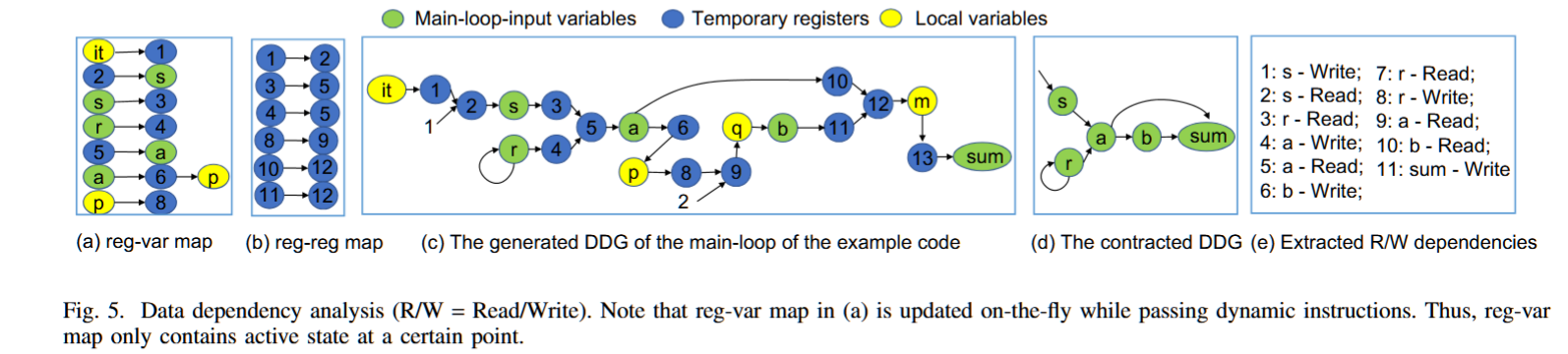
AutoCheck使用LLVM-Tracer生成动态指令执行跟踪。然而,对于计算密集型的HPC应用程序,生成的跟踪文件可能非常庞大。为了提高跟踪处理的效率,我们通过使用OpenMP启用对输入跟踪文件的并行处理。具体来说,我们首先使用主线程将输入文件流划分为子文件流,同时确保不会将单个指令块分割成两个子文件流(见图1)。然后,我们使用工作线程并行处理和读取多个子文件流(在我们的评估中使用了48个OpenMP线程,平均加速比为16倍)。我们允许用户选择是否启用加速功能。
https://github.com/harvard-acc/LLVM-Tracer
https://blog.csdn.net/gitblog_00073/article/details/139762612
Graph Algorithms and Computation on Graphs
SC23 MBE on GPU 原班人马,带着CPU我杀我自己
Zhe Pan, Shuibing He,
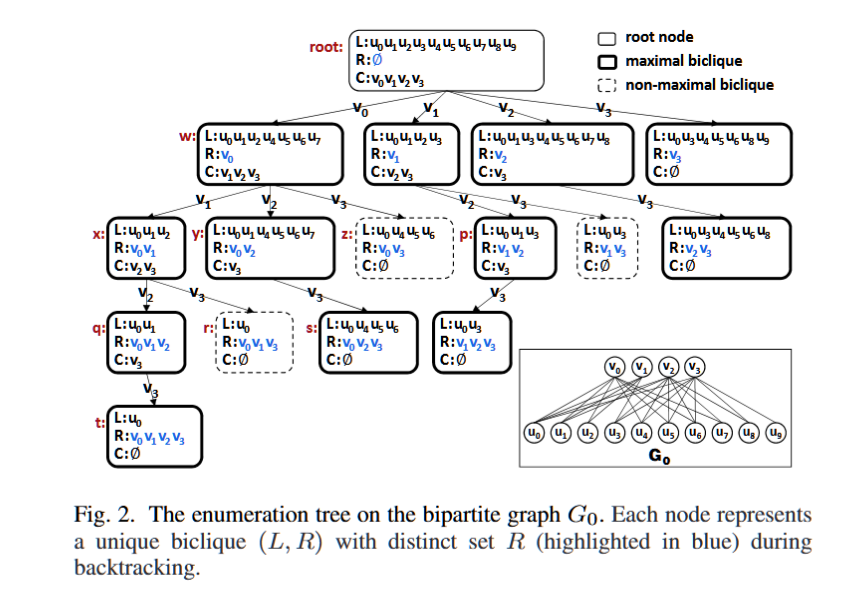
Enumeration of Billions of Maximal Bicliques in Bipartite Graphs without Using GPUs
AuthorsZhe PanShuibing HeXu LiXuechen ZhangYanlong YinRui WangLidan ShouMingli SongXian-He SunGang Chen
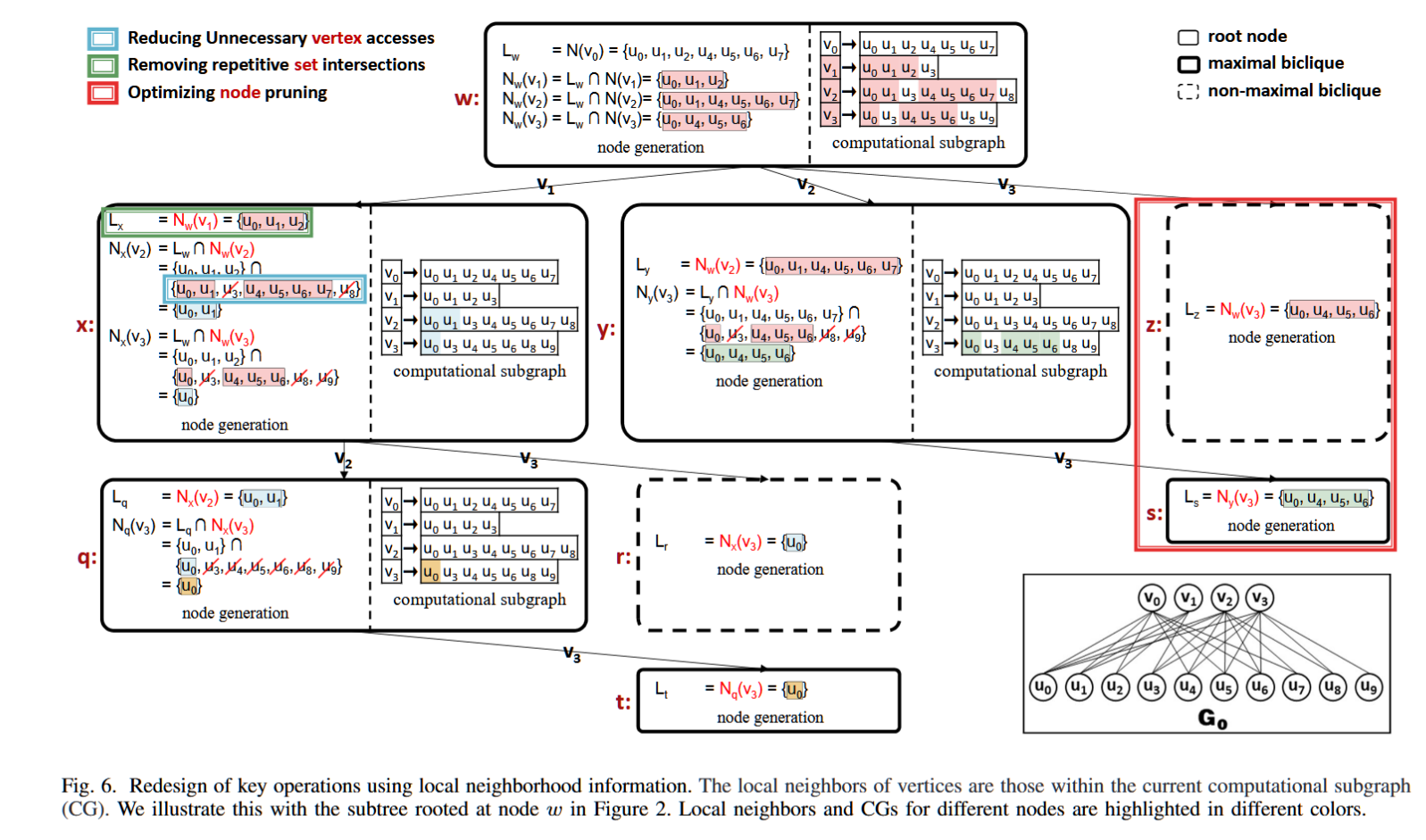
最大双团枚举(MBE)在二部图分析中至关重要。最近的研究依靠静态二分图上的广泛集合交来解决 MBE 问题。然而,计算子图在枚举过程中动态变化,导致冗余内存访问和集合交集性能下降。为了克服这个限制,我们提出了 AdaMBE 算法。首先,我们使用从计算子图导出的局部邻域信息重新设计其核心操作,以最大限度地减少冗余内存访问。其次,我们使用位图动态创建计算子图,利用其快速按位运算来加速集合交集。最后,我们将它们集成到 AdaMBE 中。我们的实验结果表明,AdaMBE 比最接近的基于 CPU 的竞争对手快 1.6×−49.7×,并成功枚举 TVTropes 数据集上的所有 190 亿个最大 bicliques,这是一项超出现有算法能力的大型任务。值得注意的是,在某些数据集上,我们在 CPU 上的并行版本 ParAdaMBE 甚至比 GPU 上的 GMBE 性能高出 5.07 倍。

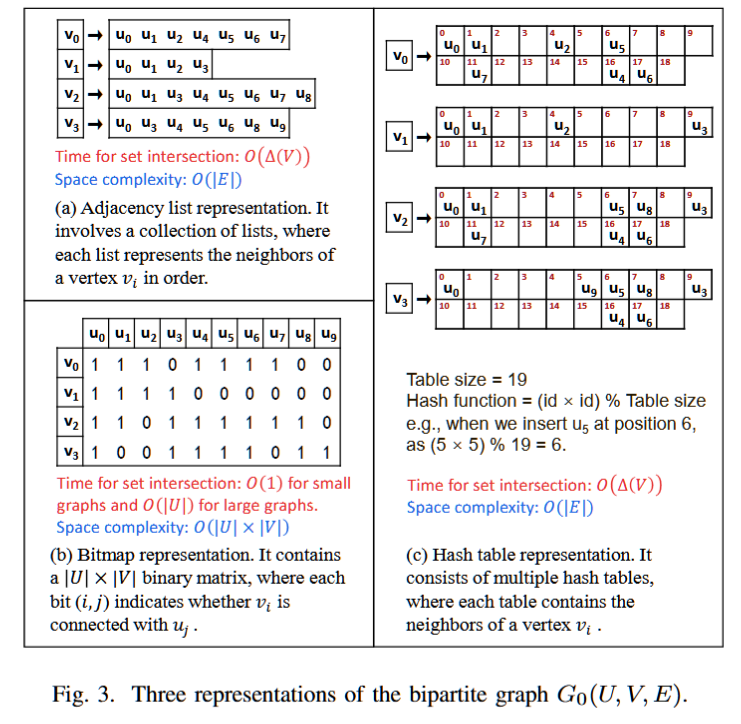

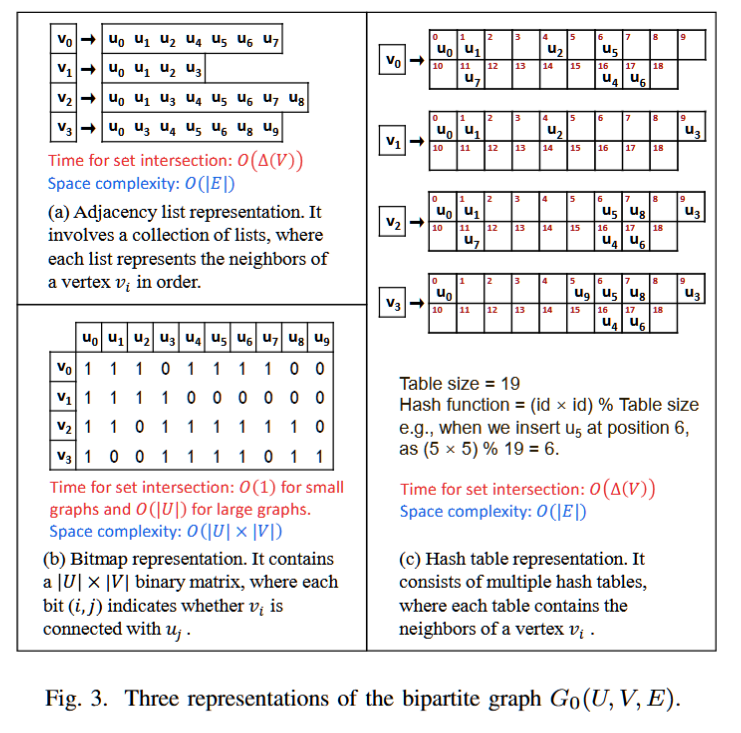
Bitmap
https://blog.csdn.net/qq_18108083/article/details/85063072
https://zhuanlan.zhihu.com/p/67920410
从第一个0开始数数,把对应数字的位置置为1,比如说第一个1那就是第2个位置置为1,第二个3就是把第4个位置置为1,依此论推...
1 => 0 1 0 0 0 0 0 0
3 => 0 0 0 1 0 0 0 0
7 => 0 0 0 0 0 0 0 1
2 => 0 0 1 0 0 0 0 0
5 => 0 0 0 0 0 1 0 0叠加起来最终的串就是:
0 1 1 1 0 1 0 1其实最终的数字和二进制没有什么关系,纯粹是数数,这个串就可以代表最大到7的数字,然后我们就开始数数,从0开始:
比如第1个位置是1,那就记个1
比如第2个位置是1,那就记个2
比如第3个位置是1,那就记个3
比如第5个位置是1,那就记个5
比如第7个位置是1,那就记个7结果就是 1 2 3 5 7,不仅仅排序了,而且还去重了!如果按照这种转换机制,1个int类型,32位的话,可以表示0-31之间的数字!
https://www.cnblogs.com/dragonsuc/p/10993938.html
Doubling Graph Traversal Efficiency to 198 TeraTEPS on the Supercomputer Fugaku
摘要——广度优先搜索(BFS)是许多高性能计算应用程序的基本构建模块,除了图分析之外,还被称为Graph500榜单中的基准问题。随着全球数据量的增加,要求高效的分布式BFS,但这一需求却受到计算节点之间交换顶点数据的高通信成本的制约。为了解决这个挑战,本文提出了四种技术:(i)森林修剪,通过消除那些对搜索不必要的顶点来减少顶点数量;
(ii)分组重排序;
(iii)多级位图压缩,减少图数据的内存占用,从而使得更少的节点能够管理更大的图;
(iv)自适应参数调优,快速优化BFS算法的超参数。
在使用超级计算机Fugaku的152,064个节点进行的评估中,我们的实现达到了198太遍历边每秒,是Fugaku上最新Graph500相关研究报告的两倍性能。
关键词——广度优先搜索,图,算法, 并行计算,Fugaku,Graph500
混合BFS在处理较大、较密集的图时提供了更高的效率,并且通过优化超参数进一步提升性能。为了实现这一目标,我们提出了四种技术:(i)森林修剪,通过减少顶点数量,使输入图变得更加密集,从而在计算和空间上更加高效;(ii)分组重排序;(iii)多级位图压缩,这两者都旨在减少图数据的内存占用;(iv)自适应参数调优,快速优化混合BFS在运行时的超参数。以下小节将详细描述每种技术,并展示我们的实现概述。
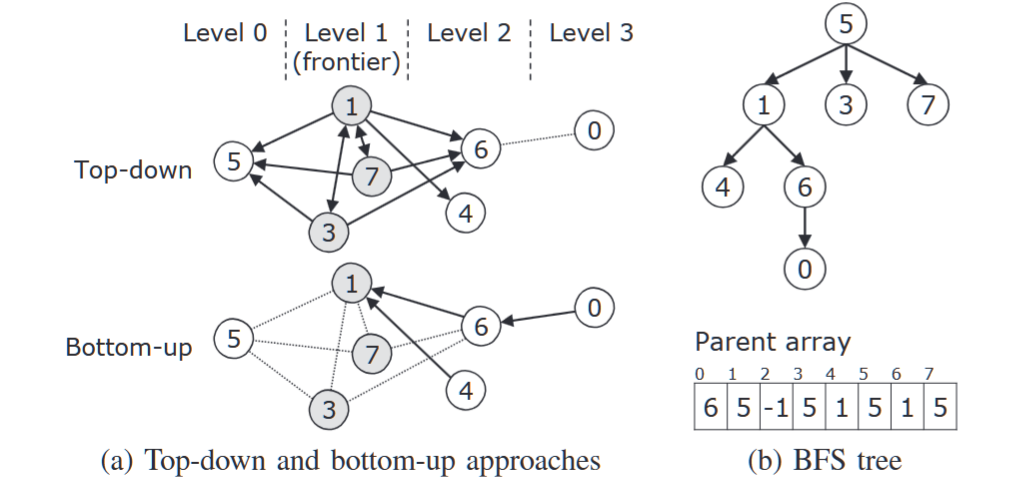

每个节点使用稀疏矩阵的数据结构(如压缩稀疏行(CSR)格式)存储2D划分图。CSR通过使用一个dst数组来有效表示图,该数组是所有顶点邻居的连接,另一个是row-starts数组,表示每个顶点邻居在dst中的起始索引。然而,使用2D划分会使row-starts的长度增加C倍,因为同一行中的每个节点都维护着相同顶点集合的row-starts。
为了解决这个问题,Ueno等人[5]提出了基于位图的CSR(bitmap CSR)格式。它通过引入一个位图数组和一个偏移数组,消除了row-starts中对应于未连接顶点的元素。位图的第v位表示顶点v是否有边。因此,在位图中,第v位之前的设定位数作为v元素在row-starts中的索引。设定位数通过使用偏移数组高效计算,其中偏移数组的第j个值是位图中第j个字之前所有设定位的累积计数。图4a和4b分别展示了CSR和bitmap CSR的示例。Bitmap CSR是有效的,因为在2D划分图中的顶点比在整个图中的顶点邻居少。例如,如图3b所示,顶点4在节点0中有一个邻居,但在节点1中没有邻居。
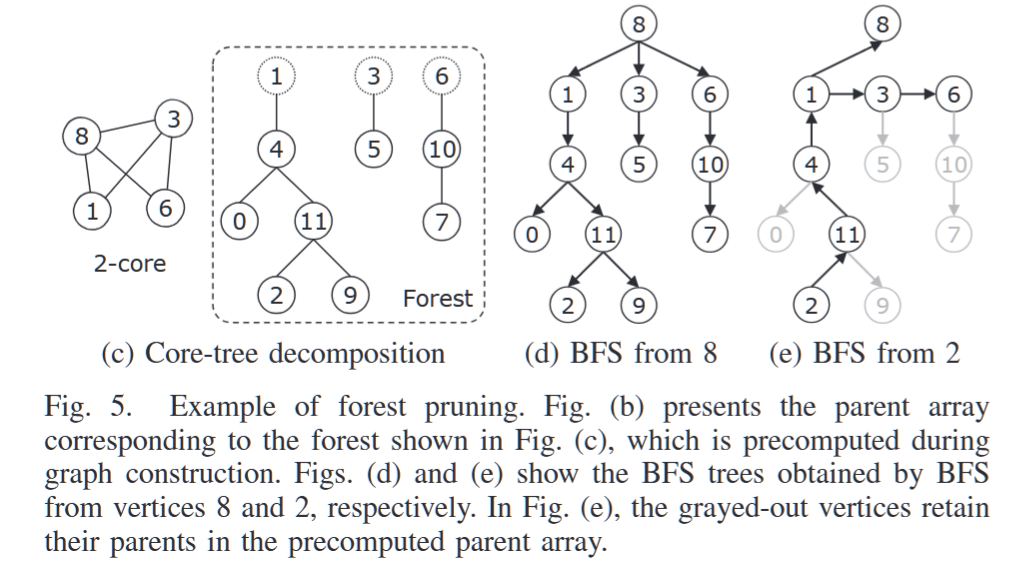
森林修剪的主要思想是在可以在给定搜索键之前确定顶点父节点的子图中修剪搜索。这允许在不需要搜索整个图的情况下为给定的搜索键构建父节点数组。我们的算法专注于树状子图的修剪,因为在大多数情况下,它们在不做任何修改的情况下成为BFS树的一部分。一组树被称为森林。例如,考虑图5a所示的图。它包含一个根节点分别为顶点1、3和6的树的森林,如图5c所示。考虑从顶点8进行BFS,这些树在BFS树中出现时保持原样,如图5d所示。森林修剪在图构建过程中预先计算出与森林对应的父节点数组(图5b),并在给定搜索键时将其复制到父节点数组构建中。此外,我们可以从图中移除森林,因为它们在BFS算法中不再需要。这通过减少图中的顶点数量,从而减少了计算成本和内存消耗。后续部分将详细介绍森林修剪的预计算和父节点数组构建过程。
Group Reordering

Bitmap Compressing
Multilevel Bitmap Compression

自动调整:什么时候top down ,什么时候 bottom up
Hybrid BFS starts the top-down approach, goes the bottom-up approach in the middle,
and ends the top-down approach

Asynchronous Distributed-Memory Parallel Algorithms for Influence Maximization
摘要——影响力最大化(Influence maximization)(IM)是寻找图中k个最具影响力节点的问题。我们提出了分布式内存并行算法,用于一种最先进的IM算法实现的两个主要内核,即通过鞅进行影响力最大化(IMM)。
基线方法依赖于批同步并行方法,并使用复制来减少通信并实现近似负载平衡,但代价是同步和高内存需求。相比之下,我们的方法完全分布数据,从而提高了内存可扩展性,并使用精细粒度的异步并行性来提高网络利用率和降低更多通信的成本。我们展示了我们的设计和实现能够在合成和真实世界的网络图上,相比基于MPI的最先进方法实现高达29.6倍的加速。此外,我们的实现是首个可以在200秒内使用NERSC Perlmutter超级计算机的8K CPU核心运行IMM,找出‘twitter’图(41M节点和14亿边)中的影响者。
关键词——影响力最大化,FA-BSP,PGAS,IMM
cs224w 图神经网络 学习笔记(十四)Influence Maximization in Networks_影响力传播模型和图神经网络-CSDN博客
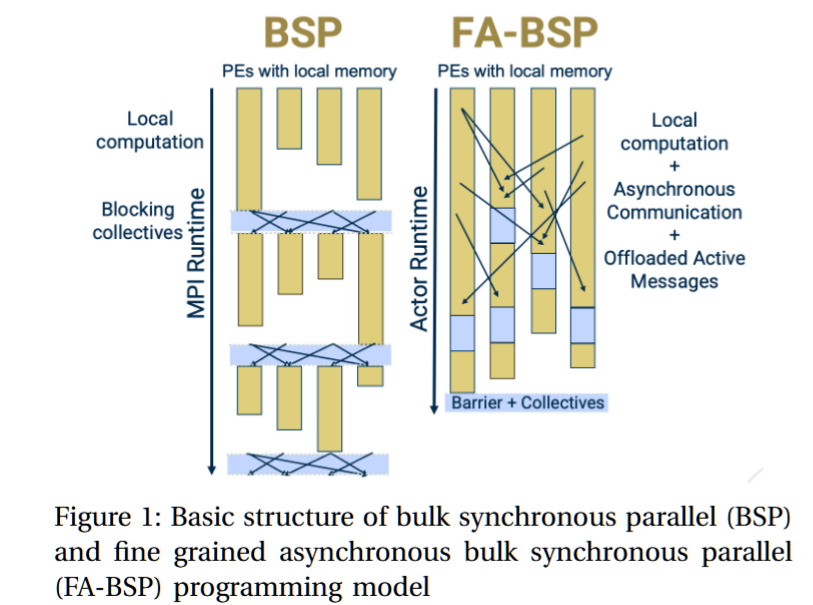
我们的主要贡献是通过两种算法提出了一种新的分布式内存并行方法来实现IMM。这两种算法源自两个创新。首先,我们完全分布输入图,而不是对其进行复制。这减轻了内存压力,但也带来了一个新问题:由于不规则并行性,导致更多的通信和负载不平衡。为了缓解这些问题,我们的第二个创新是将算法设计为BSP风格的变种,称为精细粒度异步批同步并行(FA-BSP)[12]。FA-BSP通过支持细粒度的点对点通信,扩展了BSP的功能。
“经典”BSP阶段或超步的净效应在图1中作了示意说明。
我们的第二个贡献是实现本身,我们在一个公开可用的运行时系统HClib [13]的基础上构建了这些实现。HClib通过一种演员模型编程抽象(接口)支持FA-BSP风格的计算,并通过消息聚合实现通信效率。我们将把这款软件作为开源发布。
尽管需要进行更多的通信,我们的整体方法可以更快且具有更好的时间和内存可扩展性,因为它利用了网络并行性并且能够更好地实现计算-通信重叠。我们的基本算法专注于内存可扩展性和FA-BSP,相较于Ripples,它实现了10倍的端到端加速。它也是第一个解决迄今为止最大的IM实例——‘twitter-2010’图的算法。
We then improve this basic algorithm by proposing a new method for one of the IMM substeps。利用FA-BSP风格和HClib运行时,使得该步骤加速了25-50倍,从而在真实世界的图上实现了比Ripples基线快29.6倍的整体端到端加速。
总的来说,这些技术的结合为IM问题设定了新的标杆。其算法策略可能会扩展到网络或图分析中的其他问题,并展示了如何使用FA-BSP策略以及其在HClib中的实现。

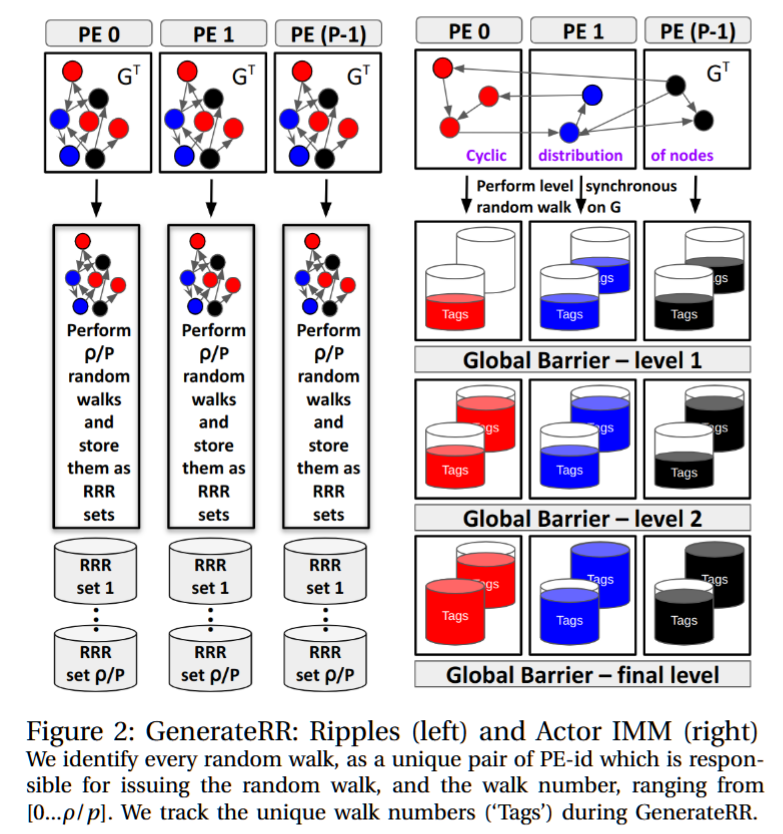
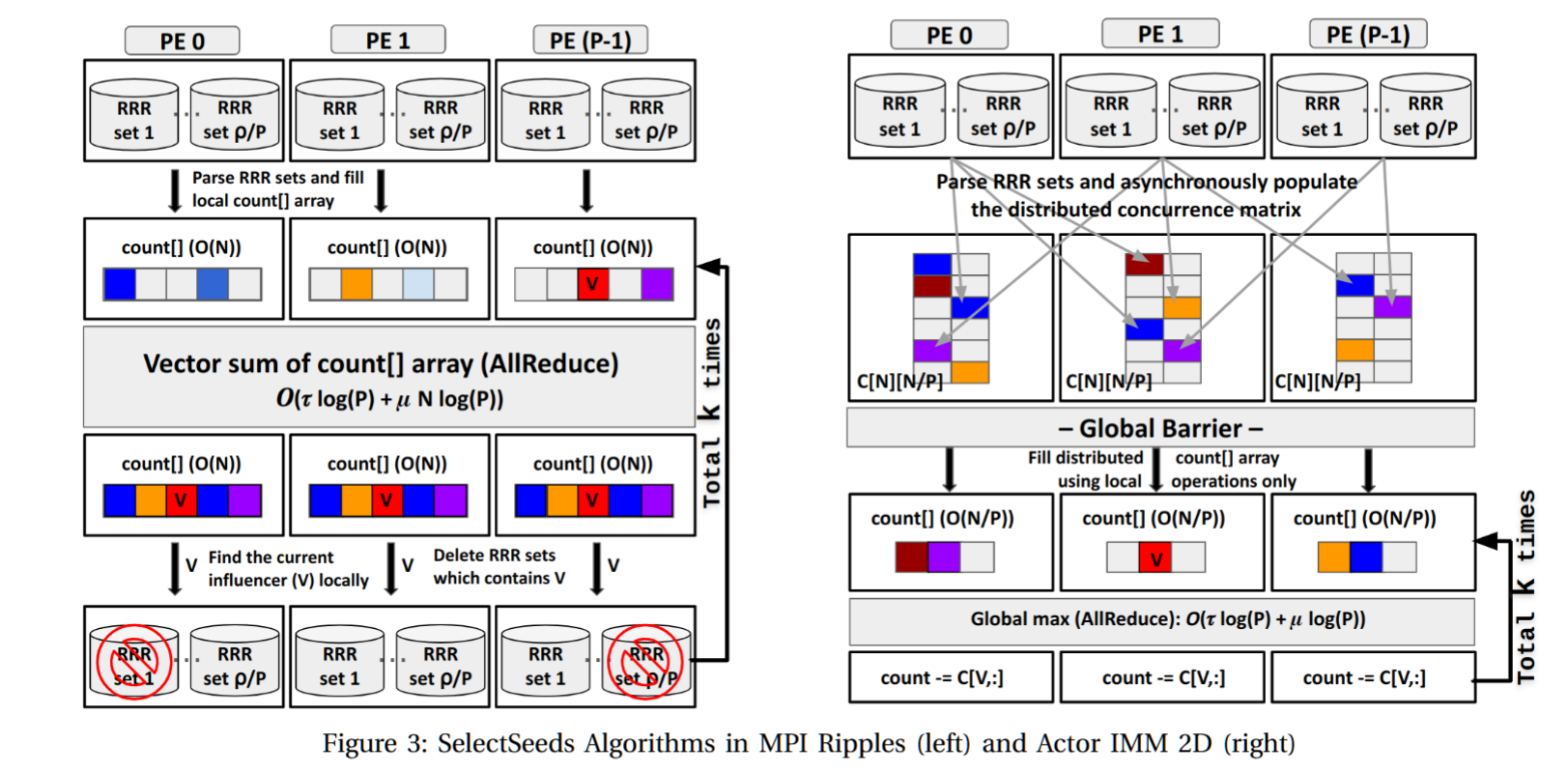
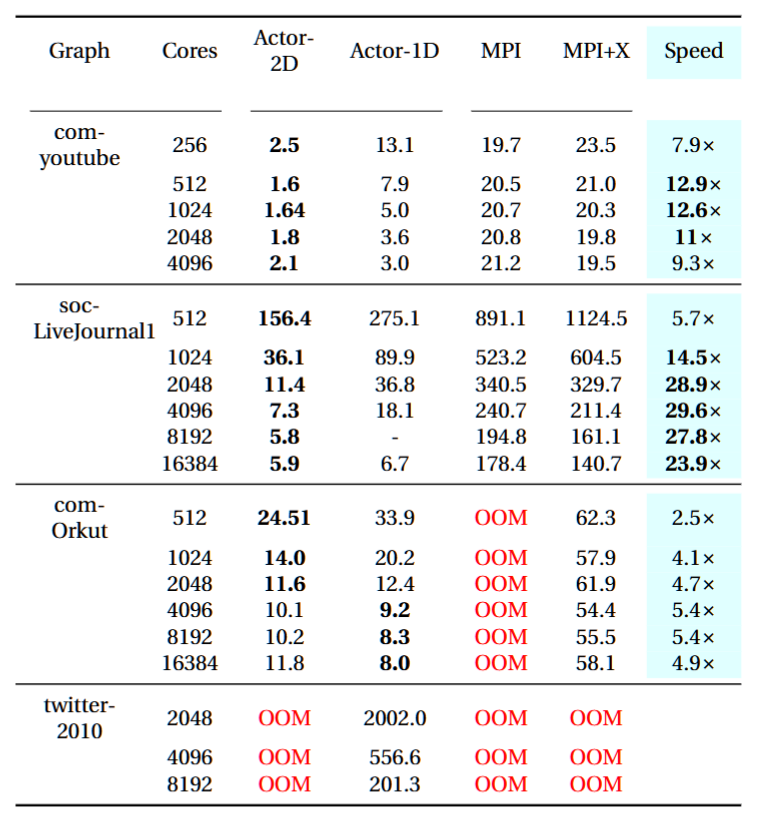
TABLE IV: Strong scaling of IMM Workload on Perlmutter OOM refers to Out Of Memory and T is the number of OpenMP threads. We report the best performance for OpenMP+MPI Ripples amongst all possible configurations for a particular number of cores. Actor-2D refers to Actor IMM 2D, Actor-1D refers to Actor IMM, MPI refers to single-threaded ripples and MPI+X refers to MPI+OpenMP ripples.
Scale–Out Interconnects
Network-Offloaded Bandwidth-Optimal Broadcast and Allgather for Distributed AI
Authors Mikhail Khalilov Salvatore Di GirolamoMarcin ChrapekRami NudelmanGil BlochTorsten Hoefler
4pm - 4:30pm EST
ETH Zurich | NVIDIA Corporation
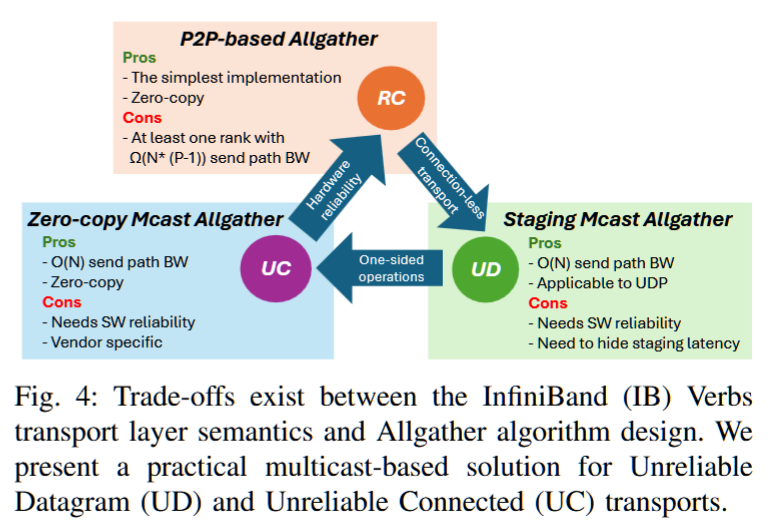
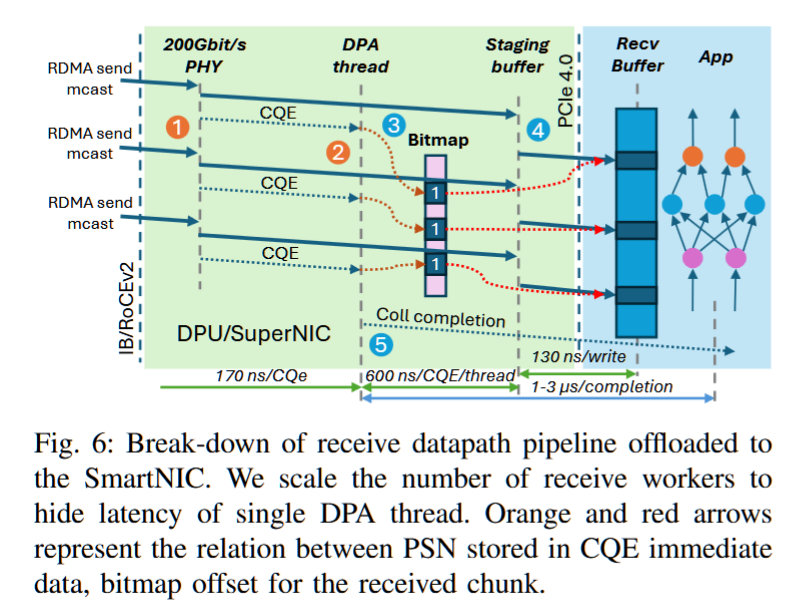
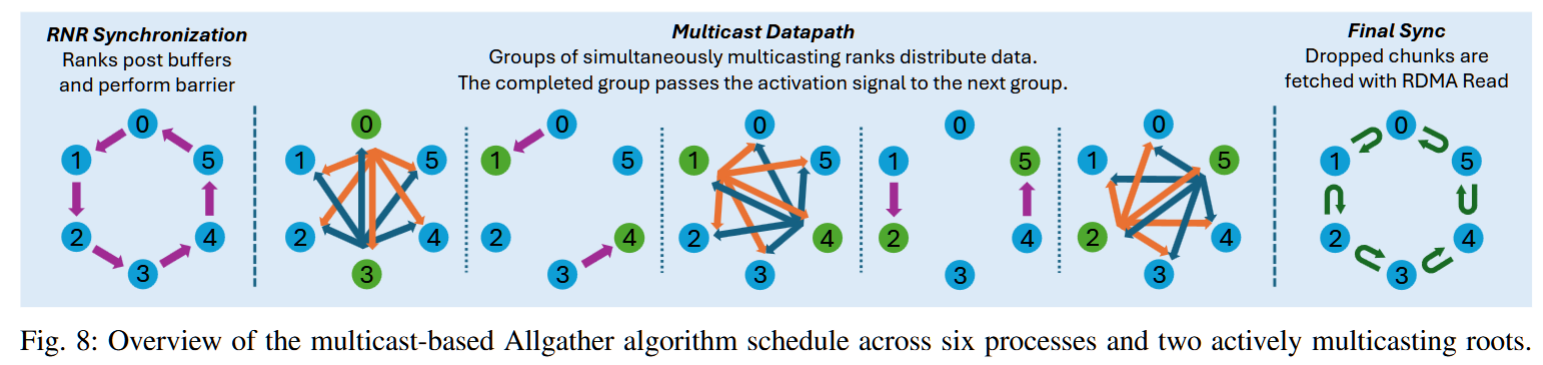
摘要——在完全分片数据并行(FSDP)训练管道中,可以交错进行集体操作,以最大化通信/计算的重叠。在这种情况下,像Allgather和Reduce-Scatter这样的重要操作可能会争夺注入带宽,从而产生管道气泡。为了解决这个问题,我们提出了一种新颖的带宽最优Allgather集体算法,利用硬件多播。我们使用多播构建了一种常数时间可靠的广播协议,这是构建最优Allgather调度的构建块。我们的Allgather算法在188节点的测试平台上实现了2倍的流量减少。为了让主机端不再运行该协议,我们采用了SmartNIC卸载技术。我们提取了Allgather算法中的并行性,并将其映射到专门用于隐藏数据移动成本的SmartNIC上。我们展示了我们的SmartNIC卸载集体进度引擎能够扩展到下一代1.6 Tbit/s链路。
关键词——网络,AI加速器,集群
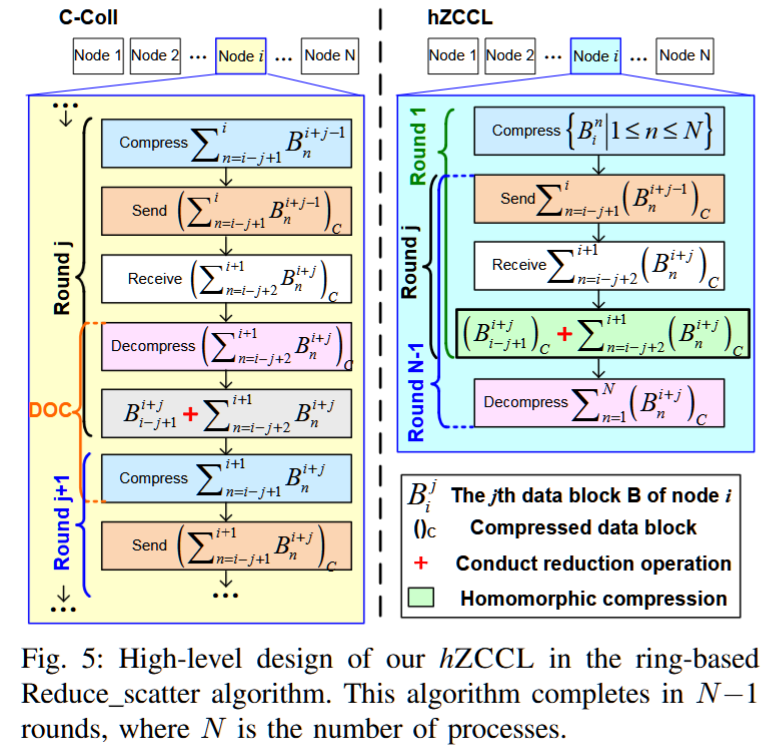
hZCCL: Accelerating Collective Communication with Co-Designed Homomorphic Compression
AuthorsJiajun HuangSheng DiXiaodong YuYujia ZhaiJinyang LiuZizhe JianXin LiangKai ZhaoXiaoyi LuZizhong ChenFranck CappelloYanfei GuoRajeev Thakur
4:30pm - 5pm EST
摘要——随着网络带宽难以跟上快速增长的计算能力,集体通信的效率已成为超大规模分布式和并行应用中的一个关键挑战。传统方法直接利用带有误差边界的有损压缩来加速集体计算操作,但由于昂贵的解压操作-压缩(DOC)工作流,导致性能不尽如人意。为了解决这个问题,我们提出了一种首创的同态压缩-通信协同设计,hZCCL,它使得操作可以直接在压缩数据上执行,从而节省了耗时的解压和重新压缩的成本。除了协同设计框架外,我们还构建了一种轻量级的压缩器,专门针对多核CPU平台进行了优化。我们还提出了一种带有运行时启发式算法的同态压缩器,用于动态选择高效的压缩管道,从而减少DOC处理的成本。我们在最多512个节点和五个应用数据集上评估了hZCCL。实验结果表明,我们的同态压缩器实现了高达379.08 GB/s的CPU吞吐量,比传统的DOC工作流提高了最多36.53倍。此外,我们的hZCCL加速的集体通信在单线程和多线程模式下,分别与原始MPI集体通信相比,分别提供了最高2.12倍和6.77倍的加速,同时保持了数据的准确性。
关键词——集体通信,同态压缩,分布式计算,并行算法
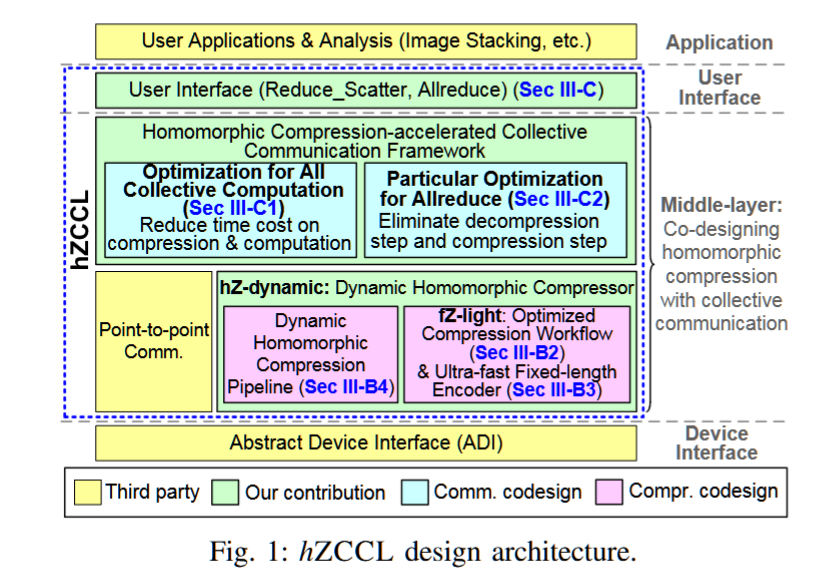
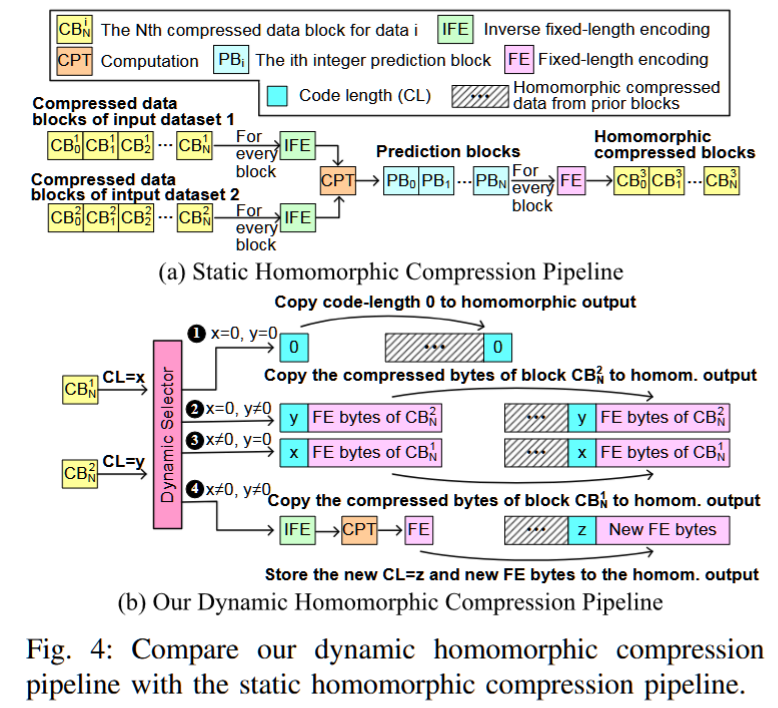
同态压缩
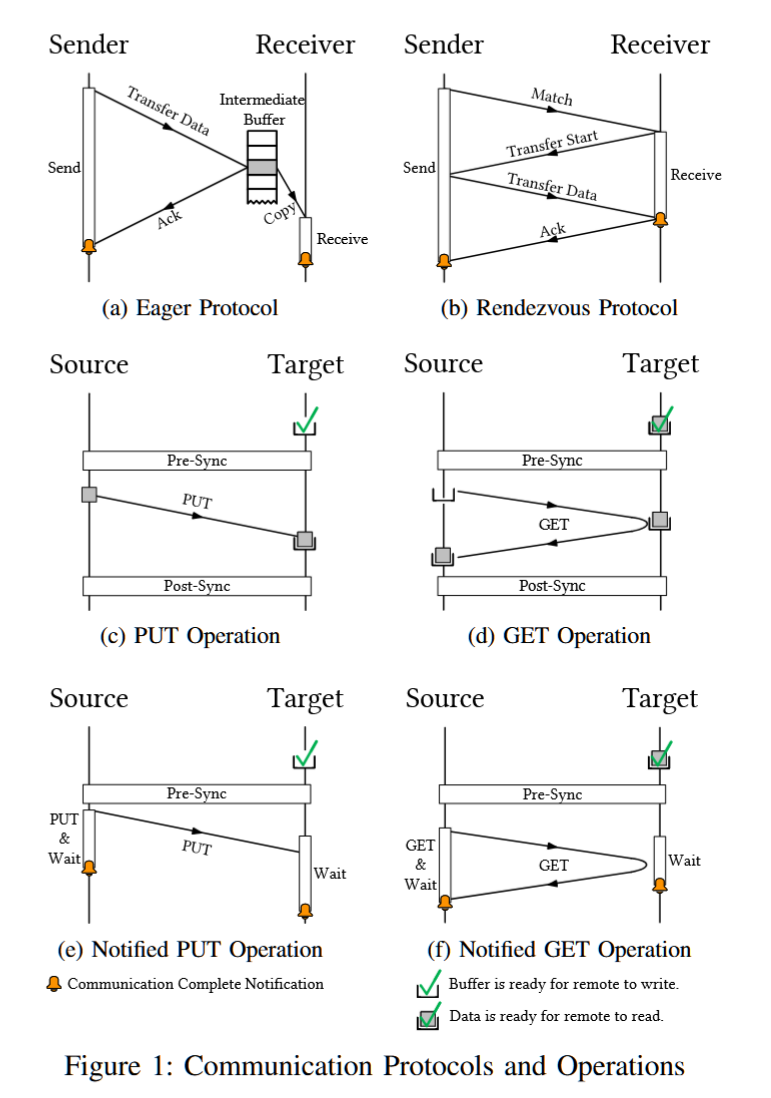
UNR: Unified Notifiable RMA Library for HPC
AuthorsGuangnan FengJiabin XieDezun DongYutong Lu
摘要——远程内存访问(RMA)使得可以直接访问远程内存,从而为高性能计算(HPC)应用提供高效的性能。然而,大多数现代并行编程模型缺乏用于远程进程检测RMA操作完成的方案。许多先前的研究提出了用于通知通信对等体的编程模型和扩展,但它们未能解决多网卡聚合、可移植性、硬件-软件协同设计和可用性等问题。在本研究中,我们提出了一种统一可通知RMA(UNR)库,用于解决这些挑战。此外,我们还展示了如何在一个现实世界的科学应用PowerLLEL中使用UNR的最佳实践。我们在四个不同互联的HPC系统上部署了UNR。结果表明,UNR驱动的PowerLLEL在天河-星忆超级计算系统的1728个节点上实现了最高36%的加速。
关键词——远程内存访问,通信优化,同步,并行编程模型,MPI
我的一位同事有一个很好的类比。MPI_Send和MPI_Recv就像邮件递送一样,收件人必须为包裹签名。他们可以在门口无限期地等待(MPI_Send)或留下便条让你回电(MPI_ISend)。
MPI_Put就像亚马逊的送货员走进你的房子,把杂货放好。MPI_Get就像你走进一家关门的杂货店,然后抓起你需要的东西。
与本例类似,MPI_Put和MPI_Get依赖于信任和良好的设计。只有当共享内存和单向数据移动有效时,才应该使用它们。
一些应用程序使用RMA更容易或更自然地编写。例如,考虑一个2D模拟应用程序,其中每个进程都拥有网格的某些部分,但需要来自其他进程的数据才能计算其迭代。使用消息传递原语需要每个进程匹配send/recv对,每个接收者都要理解每条消息的含义(请在此处写入此数据)。程序员必须小心地使用协调的发送和接收,或者通常所说的“异步”I中间操作来避免死锁。使用RMA原语不需要目标消息理解请求,因为它的含义是隐含的(请给我或写下这个数据)。
Paper
Storage Management
Bogdan Nicolae B309
I/O, Storage, Archive
TP
Session ChairBogdan Nicolae
Presentations
3:30pm - 4pm EST
EXO: Accelerating Storage Paravirtualization with eBPF
牛!
Dr. Yiming Zhang is a full professor at School of Informatics, Xiamen University, China. His research is focused on operating/networking/storage/AI systems and services computing. As the first/corresponding author, he has published many highly-influential papers in top conferences like NSDI, FAST, EuroSys, ATC, and famous Journals like TOCS, TOS. He is an associate editor of IEEE Transactions on Computers and IEEE Transactions on Services Computing, and a member of 2022 EuroSys Roger Needham Award Committee. He has received the National Science and Technology Award (2nd prize), the Natural Science Award of Hunan province (1st prize), and the (top 10) Outstanding Dissertation Award. His research (TianheGraph) is ranked No. 1 in the latest Graph500 on Tianhe supercomputer. As the Project Leader, he won the CCF Award of Science and Technology (1st prize) in 2021.
摘要——KVM是Linux上主流的虚拟机管理程序,并依赖QEMU实现virtio设备族的后端,如virtio-blk。然而,基于KVM/QEMU的半虚拟化由于多个上下文切换,延长了客户机I/O路径。随着快速的NVMe存储设备被广泛使用,软件开销变得不可忽视。本文提出了EXO,这是一个用于高效KVM/QEMU存储半虚拟化的virtio-blk扩展。其核心思想是,无论QEMU后端的处理多么复杂,主机存储栈只需要知道请求的客户机到主机的地址映射,就可以处理客户机I/O请求。因此,我们保留了virtio-blk原有的慢I/O路径作为后备方案,并利用eBPF引入一个内核内快速路径,该路径可以直接查询地址映射,而无需切换到用户空间后端处理。大量评估表明,与现有的存储半虚拟化解决方案相比,EXO实现了类似甚至更高的性能。
关键词——eBPF,存储虚拟化,Linux内核
code: https://github.com/system-xmu/EXO.git
评价:exo! eBPF! 这很难不让人想到95年的exoKernel和22年的XRP。
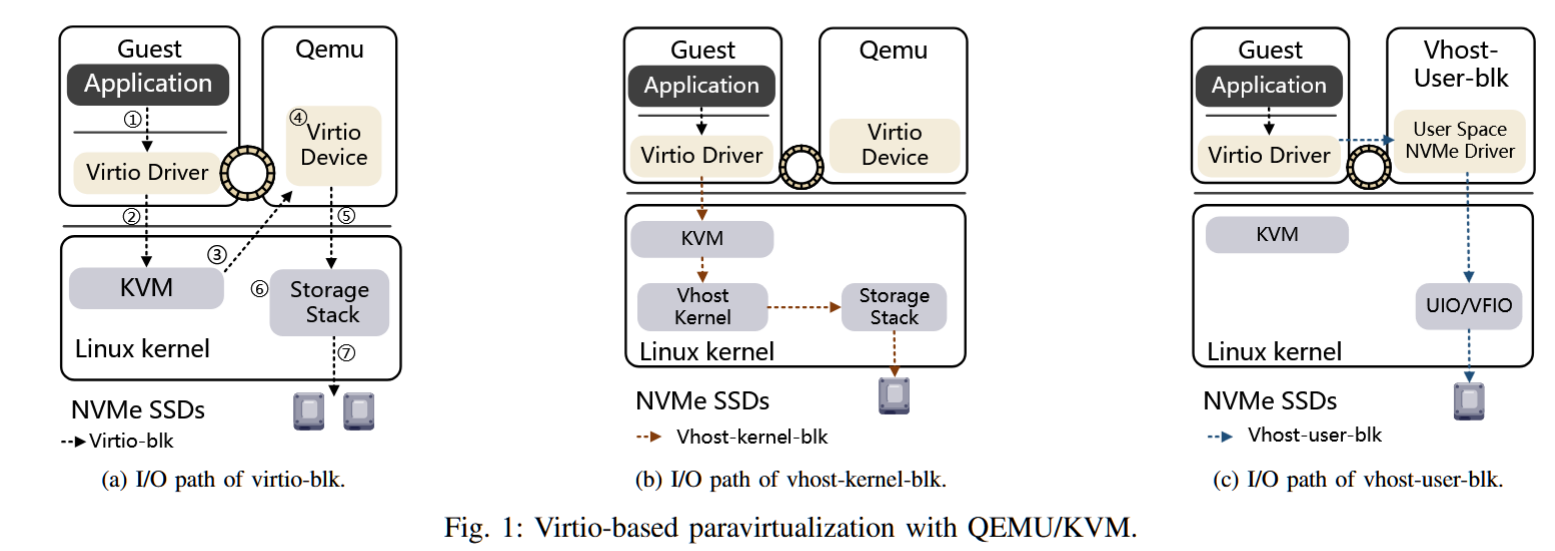
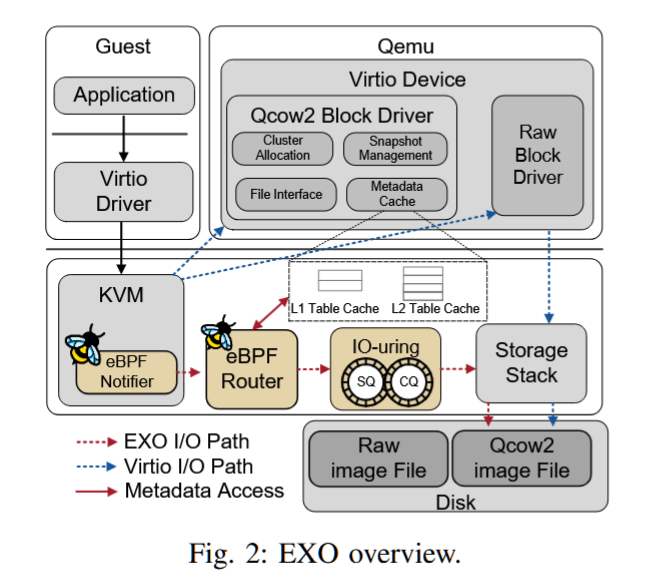
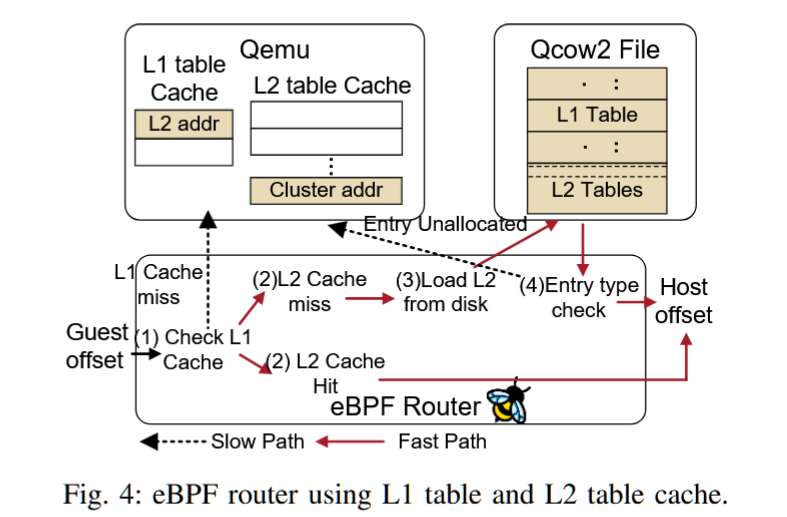
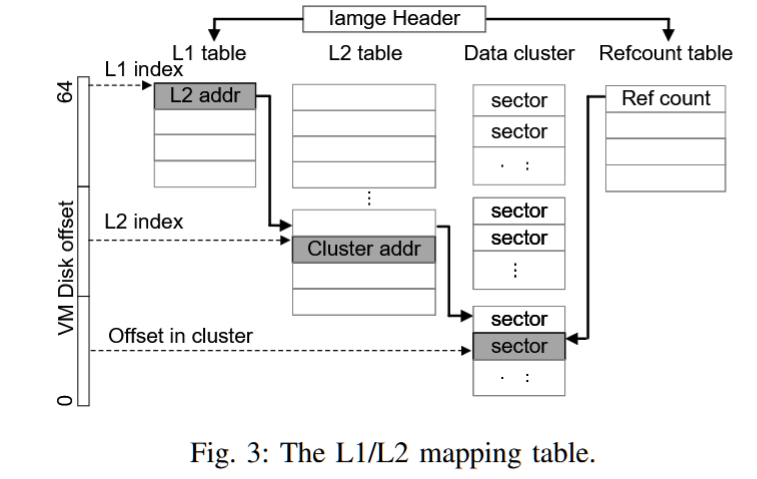
AuthorsShi QiuLi WangYiming Zhang
I/O, Storage, Archive
4pm - 4:30pm EST
CoRD: Combining Raid and Delta for Fast Partial Updates in Erasure-Coded Storage Clusters
AuthorsHai ZhouDan FengYuchong HuWei WangHuadong Huang
I/O, Storage, Archive
4:30pm - 5pm EST
HIKVISION
Yuchong Hu
Huazhong University of Science and Technology
摘要——擦除编码的一个显著缺点是遭遇昂贵的更新流量。对实际生产跟踪数据的分析显示,部分更新(包括部分块更新和部分条带更新)是常见的。现有的方案无法有效处理部分更新。基于RAID的方案协调多个更新的整个块来更新校验码,但对于部分块更新,它会产生显著的网络流量。基于Delta的方案传输更新部分并独立更新校验码,但无法共享计算出的Delta部分来处理部分条带更新。我们提出了CoRD,它通过优化地结合基于RAID和基于Delta的方案,以最小化更新流量。它利用多个更新块之间的偏移地址交集,仅传输更新部分来协调校验码更新。CoRD还通过翻转一些专用块来解决跨块更新场景,从而提高性能。 综合评估验证了CoRD在最新跟踪数据中的有效性,相比于最先进的方案,更新流量减少了37.02%-87.19%,性能提升了36.54%-231.92%。
关键词——擦除编码,存储集群,部分更新,更新流量
纠删码(erasure coding,EC)
https://zhuanlan.zhihu.com/p/554262696
https://cloud.tencent.com/developer/article/1829995
纠删码(erasure coding,EC)是一种数据保护方法,它将数据分割成片段,把冗余数据块扩展、编码,并将其存储在不同的位置,比如磁盘、存储节点或者其它地理位置。
总数据块 = 原始数据块 + 校验块, 常见表示为,n = k + m
当冗余级别为n时,将这些数据块分别存放在n个硬盘上,这样就能容忍m个(假设初始数据有k个)硬盘发生故障。当不超过m个硬盘发生故障时,只需任意选取k个正常的数据块就能计算得到所有的原始数据。纠删码以更低的存储成本备受青睐,目前Microsoft、Google、Facebook、Amazon、淘宝(TFS)都已经在自己的产品中采用了Erasure Code.
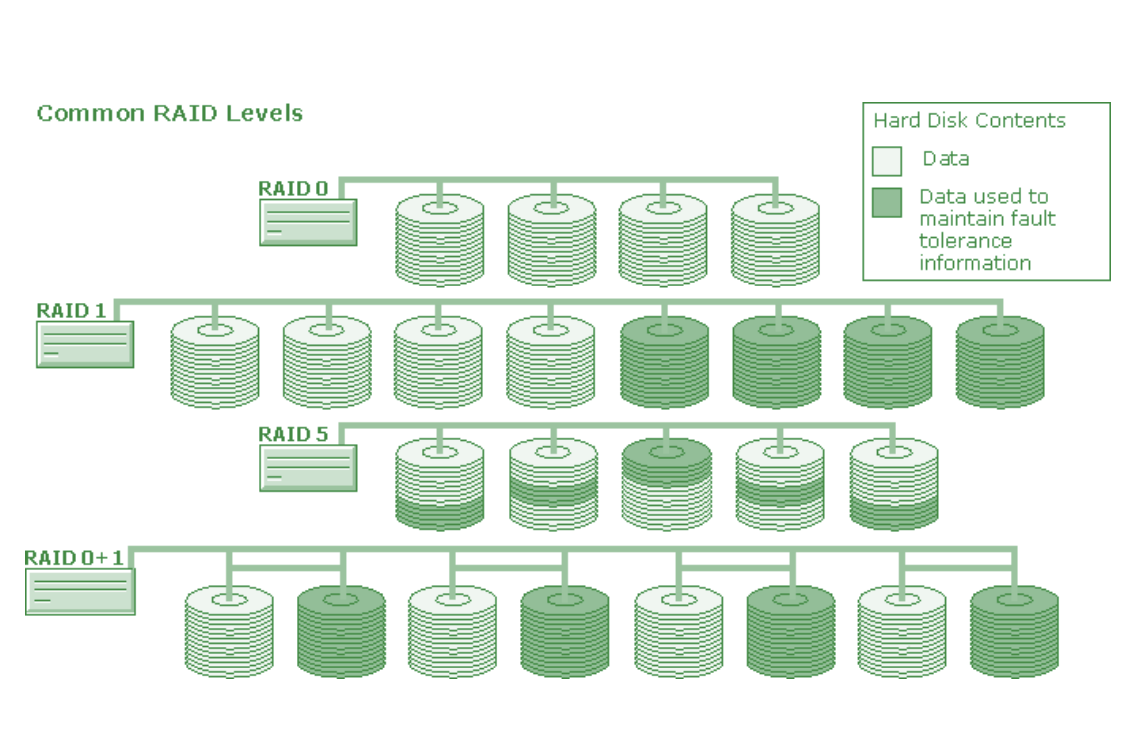
起源: RAID
RAID 是 "Redundant Array of Independent Disk" 的缩写,中文意思是独立冗余磁盘阵列 是一种古老的磁盘冗余备份技术,也许你从未了解其中的原理,但肯定也听说过它的大名。简单地解释,就是将N台硬盘通过RAID Controller(分Hardware,Software)结合成虚拟单台大容量的硬盘使用,其特色是N台硬盘同时读取速度加快及提供容错性.
RAID 根据实现技术的不同有 RAID0~9, RAID10 等等。目前用得比较多的是 RAID 0, RAID 1, RAID 5, RAID 10.
ErasureCode(纠删码)以更低成本的方式提供近似三副本的可靠性,吸引众多分布式存储/云存储的厂商和用户。可以说纠删码是云存储,尤其是现在广泛使用的对象存储的核心。纠删码(Erasure Coding,EC)是一种编码容错技术,最早是在通信行业解决部分数据在传输中的损耗问题。其基本原理就是把传输的信号分段,加入一定的校验再让各段间发生相互关联,即使在传输过程中丢失部分信号,接收端仍然能通过算法将完整的信息计算出来。在数据存储中,纠删码将数据分割成片段,把冗余数据块扩展和编码,并将其存储在不同的位置,例如磁盘、存储节点或者其他地理位置。
现在思考一个问题:现在有 2 份数据(有可能其实是一份数据被分割成了两部分),允许你做 2 的冗余(就是实际存储的使用是要存储数据的 (2+2)/2 = 2 倍),要求达到这样的效果:任意两份数据丢失,数据都能恢复。
如何来解决这个问题呢。一个简单的想法是,给两个数据都做一下备份。
将数据存储为 X1, X2, X3, X4 分别等于 A1, A2, A1, A2;这样假设数据 X1 X2 丢失了,数据就可以从 X3,X4 中恢复出来。但是这样存储存在问题:如果丢失的数据刚好是 X1, X3 呢,那么原先的数据 A1 就彻底丢失找不回来了。但是你可以使用下面的一种存储方式 X1, X2 还是不变,X3=A1+A2, X4=A1+2*A2 这样任意两份数据丢失,都可以恢复出 A1 和 A2 了。
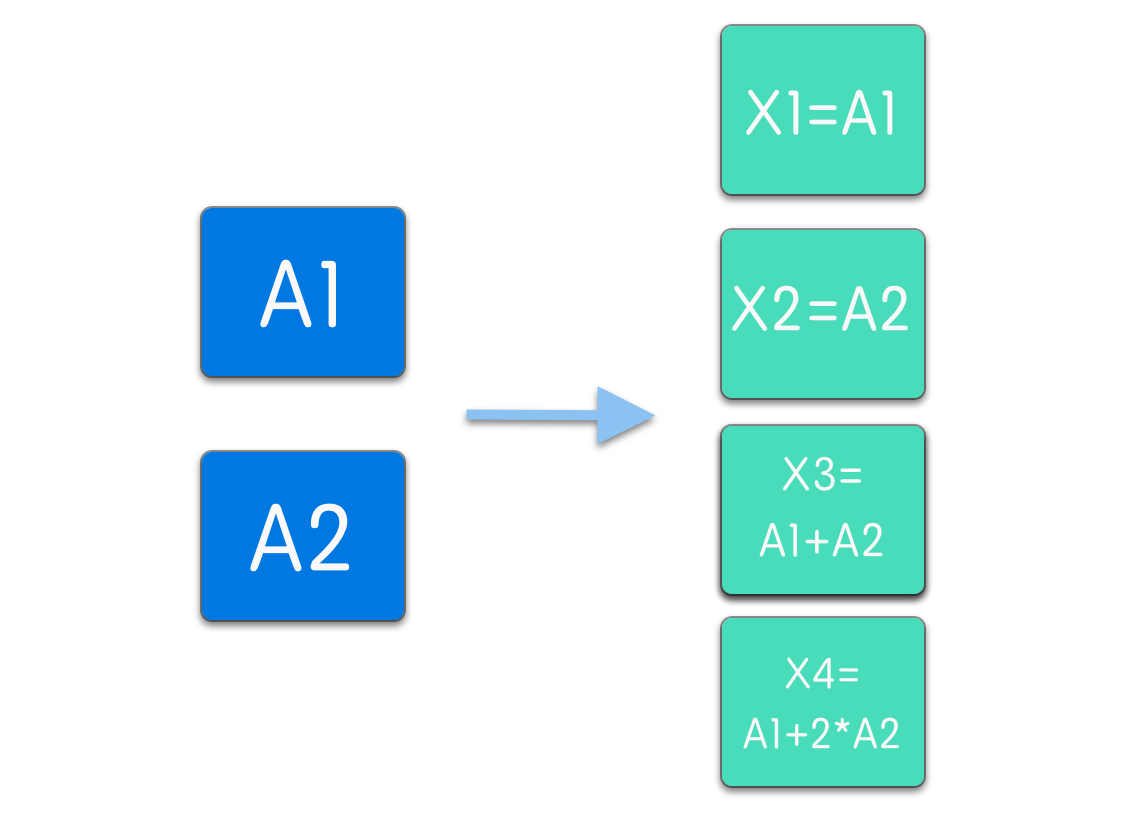
本质是解方程,下面4个式子中,随意损失两个都没有问题:
A1
A2
A1+A2
A1*A2
纠删码的核心原理就是这样了,当然实际上并不会这么简单,这种算法只是一种简化。实际在计算的时候常用一种叫做 RS 码的方法,根据设置好的 m, n 值,生成一个 RS 矩阵,存储时通过 RS 矩阵计算出校验块,单任意 m 块数据损坏时,通过还存在的数据块,和 RS 的矩阵的部分的逆矩阵做运算,既可以恢复出所有的数据。具体的计算原理请参考这篇文章
Mathematical Analysis

MegaMmap: Blurring the Boundary Between Memory and Storage for Data-Intensive Workloads
AuthorsLuke LoganAnthony KougkasXian-He Sun
Illinois Institute of Technology
摘要——在高性能计算(HPC)中,大规模数据分析、科学仿真和深度学习代码执行的计算量远超主内存的容量。这些超出核心内存的算法面临着严重的数据传输惩罚、编程复杂性和有限的代码复用性。为了解决这个问题,HPC站点不断增加DRAM容量。然而,由于财务和环境成本的限制,这种做法不可持续。一个更加优雅、低成本且可移植的解决方案是将内存扩展到分布式多层存储中。在本研究中,我们提出了MegaMmap:一种软件分布式共享内存(DSM),通过智能的分层DRAM和存储管理扩展有效内存容量。MegaMmap提供了工作负载感知的数据组织、驱逐和预取策略,以减少DRAM的消耗,同时确保对关键数据的快速访问。通过直观的提示系统,提供了多种内存一致性优化。评估结果表明,各种工作负载可以在仅使用部分DRAM的情况下执行,同时提供具有竞争力的性能。
关键词——高性能计算,系统软件,内存分层,存储分层
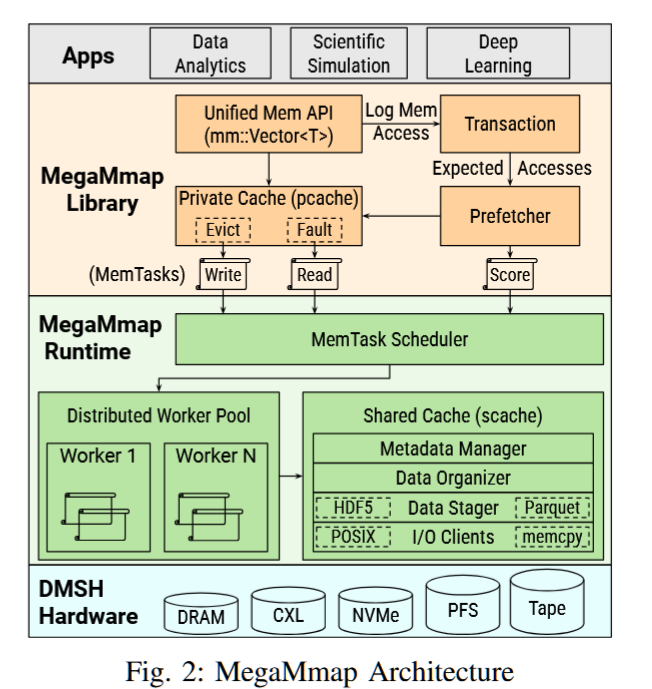
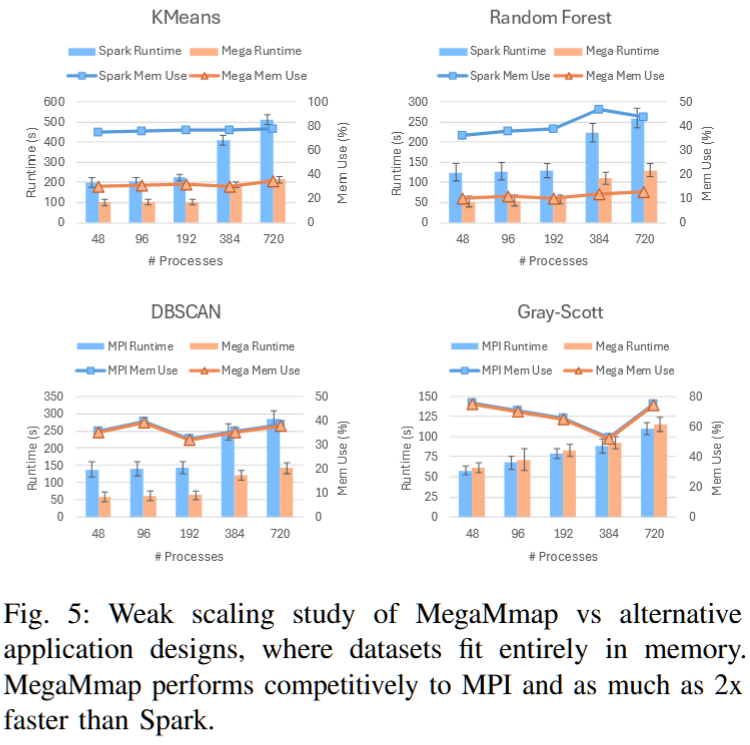
Leadership-class Supercomputers
An Evaluation of the Effect of Network Cost Optimization for Leadership Class Supercomputers
(Best Paper Finalist)
Oak Ridge National Laboratory, TN, USA, 2University of Pittsburgh, PA, USA
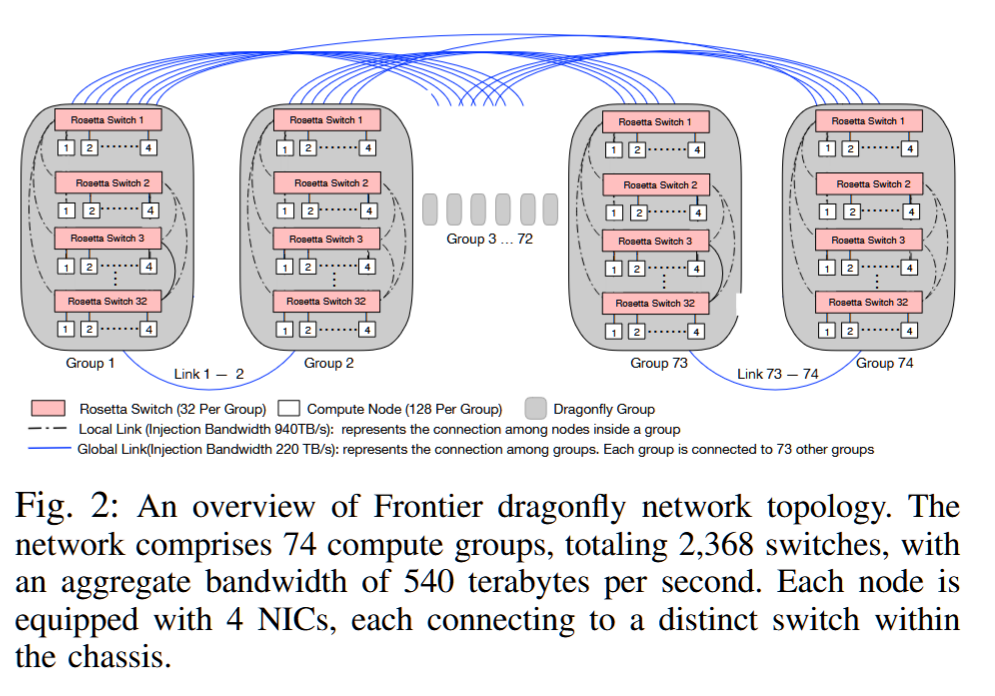
摘要——龙蝇Dragonfly 网络是一种广泛应用于大规模高性能计算的网络拓扑,因其成本效益和高效性而被广泛采用。美国将在不久后部署三台用于领导级工作负载的Exascale超级计算机,这些计算机将采用龙蝇网络。与类似规模的间接网络相比,龙蝇网络显著减少了电缆长度、电缆数量和交换机数量,从而为给定的系统规模带来了显著的网络成本节省。然而,这些成本的降低也导致了全局最小路径的减少和更具挑战性的路由问题。此外,大规模的龙蝇网络通常需要在全局链路级别进行收敛,从而导致比其他传统的非阻塞拓扑更低的分割带宽。尽管龙蝇网络已被广泛研究,但它们在面向能力工作负载的极限规模(即Exascale)系统中的表现尚未得到充分评估。本文展示了对Exascale系统(Frontier)中龙蝇网络的首次大规模评估结果,并将其行为与上一代TOP500系统(Summit)中类似规模的fat-tree网络进行了比较。该评估旨在通过衡量收敛拓扑对能力工作负载的影响,确定网络成本优化的效果。我们的评估基于一组合成的微基准、迷你应用和全规模应用程序。它比较了龙蝇网络(Frontier)与fat-tree网络(Summit)系统在每个基准测试中的扩展效率。结果表明,龙蝇网络比fat-tree拓扑更具成本效益,约提高30%,这一节省摊销到Exascale系统成本的约3%。此外,尽管收敛的龙蝇网络带来了显著的权衡,但其影响并不像最初想象的那样广泛,主要体现在具有全局通信模式的应用中,尤其是全到全的通信(例如基于FFT的算法),但也出现在对网络性能波动敏感的局部通信模式(例如最近邻算法)中。
关键词——高性能计算系统,龙蝇与fat-tree网络拓扑,网络成本优化
http://blog.sysu.tech/%E7%BD%91%E7%BB%9C/Dragonfly%E6%8B%93%E6%89%91%E7%AE%80%E4%BB%8B/
http://blog.sysu.tech/about/
UNR的作者,真是了不起的phd
Dragonfly是一种现在比较时髦的拓扑结构,它由John Kim等人在2008年的论文Technology-Driven, Highly-Scalable Dragonfly Topology中提出,它的特点是网络直径小、成本较低,对于高性能计算有着非常大的优势。现在已经被运用在使用Cray XC系列网络的各种超算中[1],如2017年11月排名第3的超算PIZ DAINT、2018年11月排名第6的超算TRINITY、2016年11月排名第5的超算CORI。未来也将要被应用在使用Slingshot网络的许多超算中,如:最新一期2021年6月排名第5的Perlmutter超算。

Dragonfly的拓扑结构分为三层:Switch层,Group层,System层也叫路由器(Router)、组(Group)、系统(system)层。
-
Switch层:包括一个交换机,及其相连的 p 个计算节点
-
Group层:包含 a 个Switch层,这 a 个Switch层的 a 个交换机是全连接(All-to-all)的,换言之,每个交换机都有 a-1 条链路连接分别连接到其他的 a-1 台交换机
-
System层:包含 g 个Group层,这 g 个Group层也是全连接的
对于单个switch交换机,它有p 个端口连接到了计算节点,a-1 个端口连接到Group内其他交换机,h 个端口连接到其他Group的交换机
因此,我们可以计算得到网络中的如下属性:
-
每个交换机的端口数为 k=p+(a-1)+h
-
Group的数量为 g=ah+1
-
网络中一共有 N=ap(ah+1) 个计算节点
-
如果我们把一个Group内的交换机都合成一个,将它们视为一个交换机,那么这个交换机的端口数为 k‘=a(p+h)
在一个较小规模的网络中, g=ah+1 个group可能会较多,可以将任意两个Group之间的连接数由一条增加为多条,这样任意两个Group之间就有 floor((ah+1)/g) 条链路连接。
不难发现,在确定了 p,a,h,g 四个参数之后我们就可以确定一个dragonfly的拓扑,因此一个Dragonfly的拓扑可以用 dfly(p,a,h,g) 来表示
一种推荐的较为平衡的配置是方法是:a=2p=2h
Dragonfly+
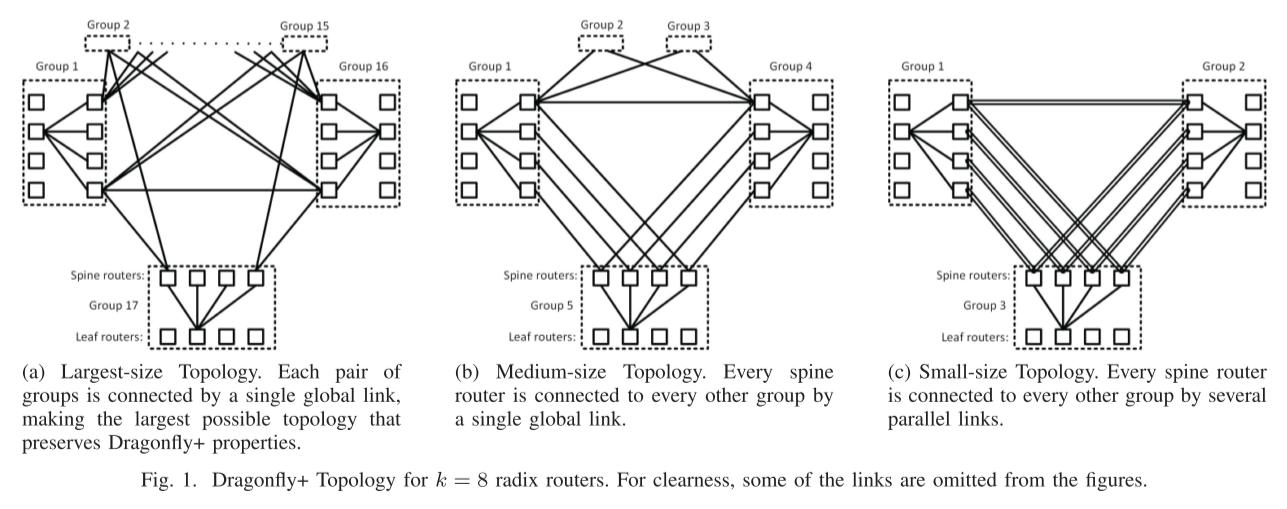
Dragonfly+: Low Cost Topology for Scaling Datacenters

Application-Driven Exascale: The JUPITER Benchmark Suite
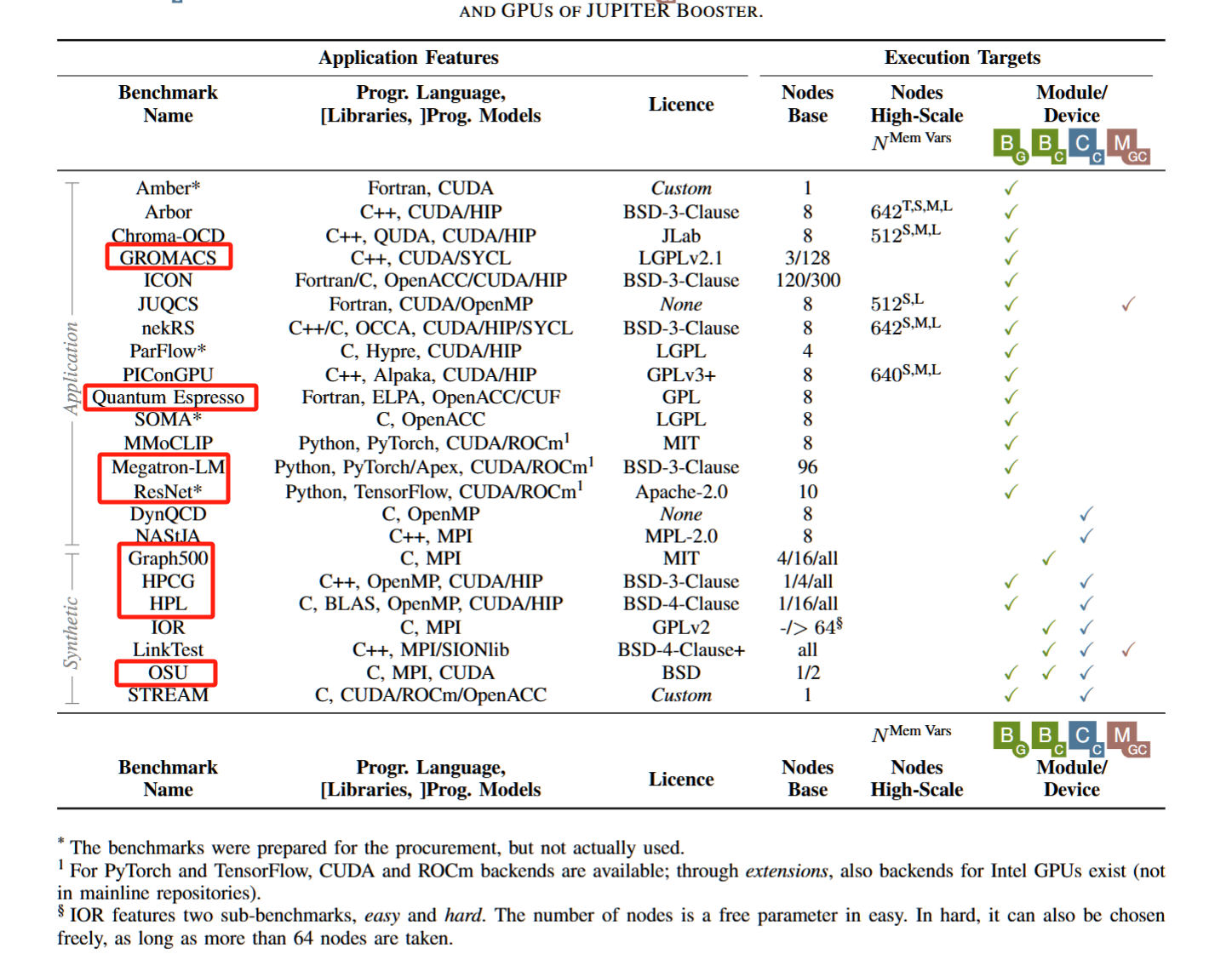
摘要——基准测试在现代高性能计算(HPC)系统的设计中至关重要,因为它们定义了系统组件的关键方面。除了合成工作负载外,纳入代表用户需求的实际应用程序到基准测试套件中同样重要,这有助于确保新系统的高可用性和广泛采用。考虑到在Exascale时代对领导级超级计算机的重大投资,这一点尤为重要,并且需要与开放科学和可重复性愿景相一致。在本研究中,我们介绍了JUPITER基准测试套件,该套件包含来自不同领域的16个应用程序。该套件专为欧洲首台Exascale超级计算机JUPITER的采购设计并使用。我们识别了需求和挑战,并概述了项目和软件基础设施的设置。我们提供了选定应用程序的描述和可扩展性研究,并总结了一些关键要点。JUPITER基准测试套件作为开源软件与本文一起发布,托管在github.com/FZJ-JSC/jubench上。
关键词——基准测试,采购,Exascale,系统设计,系统架构,GPU,加速器
Jülich, Germany
我的目标是全跑一遍!!!!

Exploring GPU-to-GPU Communication: Insights into Supercomputer Interconnects
Sapienza University of Rome
NVIDIA
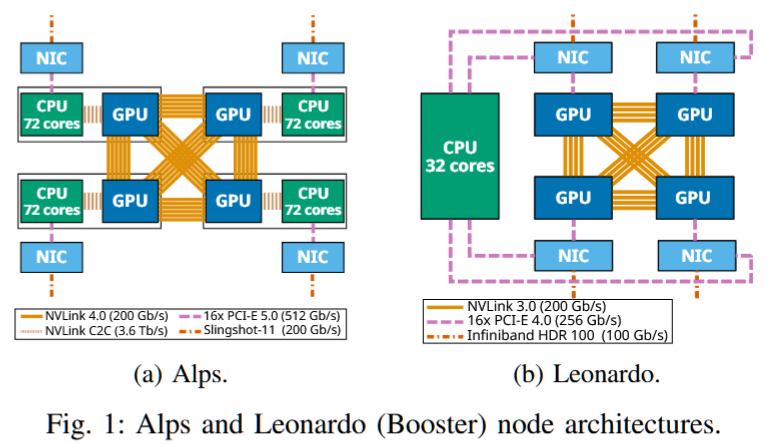
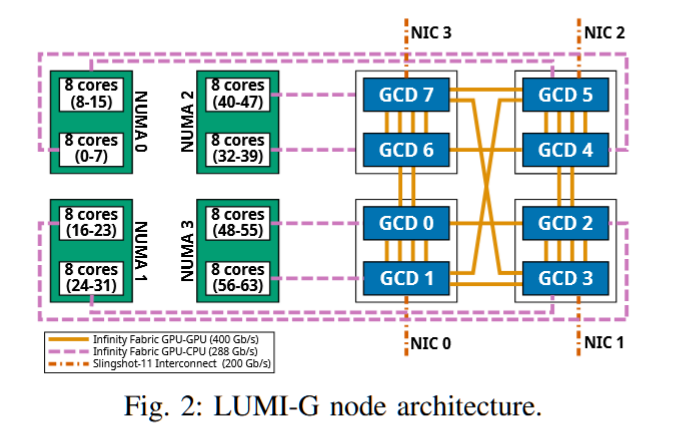
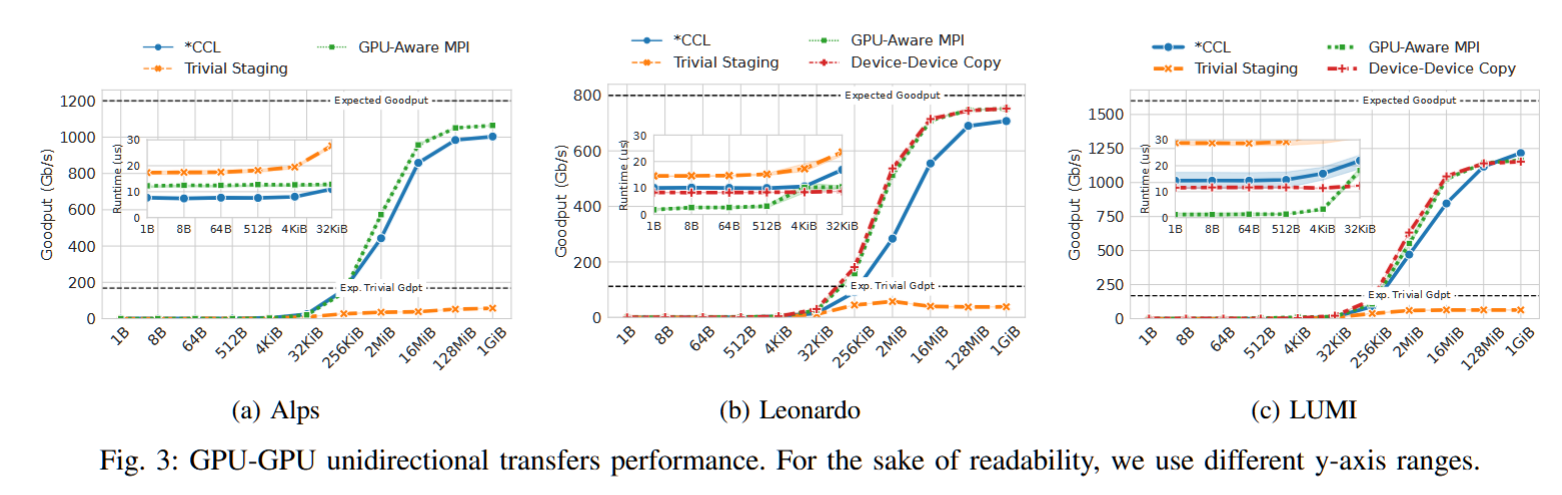
摘要——在快速发展的Exascale超级计算机领域,多GPU节点变得越来越普遍。在这些系统中,同一节点上的GPU通过专用网络连接,带宽可达几太比特每秒。然而,由于不同的技术、设计选项和软件层次,评估性能预期并最大化系统效率具有挑战性。本文全面描述了三台超级计算机——Alps、Leonardo和LUMI——它们各自具有独特的架构和设计。我们重点评估了最多4,096个GPU的节点内和节点间互连的性能,使用了混合的节点内和节点间基准测试。通过分析其局限性和机遇,我们旨在为从事多GPU超级计算的研究人员、系统架构师和软件开发人员提供实际指导。我们的结果表明,仍有未开发的带宽,且在网络到软件优化的各个方面仍有许多优化机会。
超算广告:快来用我们的超算,不然我们就没钱住大酒店开会了!!!!