
SC Paper Summary 5
- Paper Reading
- 2025-03-23
- 1336 Views
- 0 Comments
- 11194 Words

总链接:
https://www.haibinlaiblog.top/index.php/sc-2024-passage/
Matrix Computations on Tensor Cores
AmgT: Algebraic Multigrid Solver on Tensor Cores
(Best Paper Finalist)
Super Scientific Software Laboratory, Dept. of CST, China University of Petroleum-Beijing, China
摘要--代数多网格(AMG)方法因其良好的灵活性和适应性,在求解各种稀疏线性系统时尤为高效。尽管 GPU 等现代并行设备为 AMG 带来了大规模并行性,但最新的主要硬件特性,即张量核心单元及其低精度计算能力,尚未被用于加速 AMG。
本文提出了一种新的 AMG 求解器 AmgT,它能在 AMG 算法的多个阶段利用最新 GPU 的张量核和混合精度能力。考虑到稀疏通用矩阵-矩阵乘法(SpGEMM)和稀疏矩阵-矢量乘法(SpMV)分别在设置和求解阶段被广泛使用,我们提出了一种基于新的统一稀疏存储格式的新方法,充分利用了张量核及其可变精度。 我们的方法既提高了 GPU 内核的性能,也降低了 AMG 整个数据流中格式转换的成本。 为了更好地利用现有库中的算法组件,AmgT求解器的数据格式和计算内核被纳入了HYPRE库。在 NVIDIA A100、H100 和 AMD MI210 GPU 上的实验结果表明,AmgT 的性能比原始 GPU 版本的 HYPRE 分别高出 1.46 倍、1.32 倍和 2.24 倍(最高可达 2.10 倍、2.06 倍和 3.67 倍)。
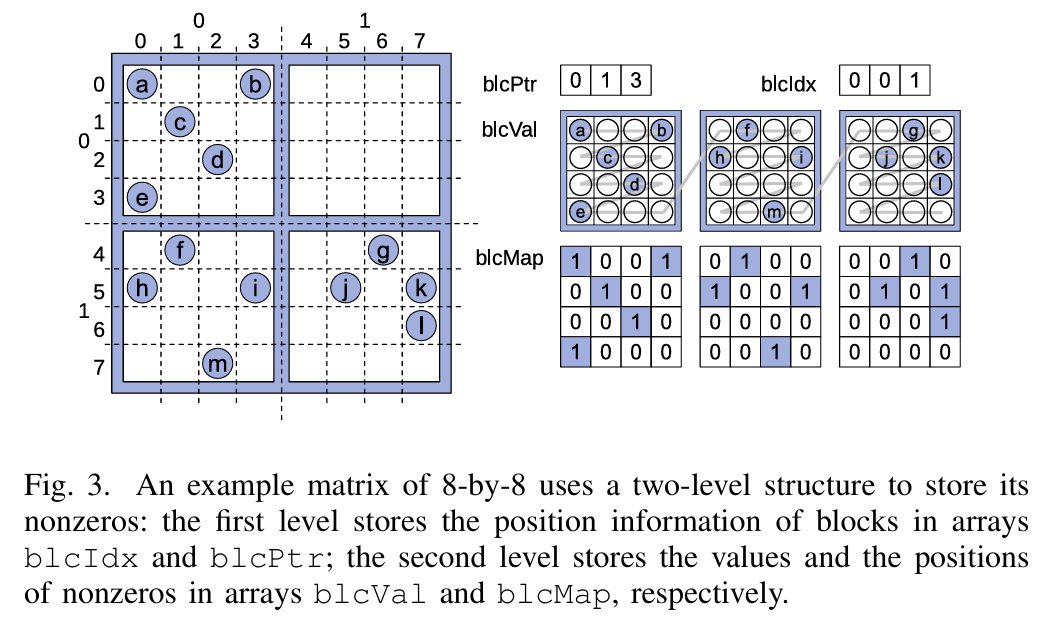
AmgT(Algebraic Multigrid Solver on Tensor Cores) 的代数多重网格(AMG)求解器旨在利用现代 GPU 的张量核心(Tensor Cores)和混合精度计算能力来加速稀疏线性系统的求解。以下是工作的简单概述:
核心创新:
- 提出了一个统一的稀疏矩阵格式(mBSR),支持张量核心优化的 SpGEMM(稀疏矩阵-矩阵乘法) 和 SpMV(稀疏矩阵-向量乘法) 操作。
- 设计了适用于张量核心和混合精度的 SpGEMM 和 SpMV 内核,通过结合高精度(如双精度)和低精度(如单精度和半精度)计算,提升性能。
-
将这些优化内核集成到 HYPRE 库中,开发了 AmgT 求解器。
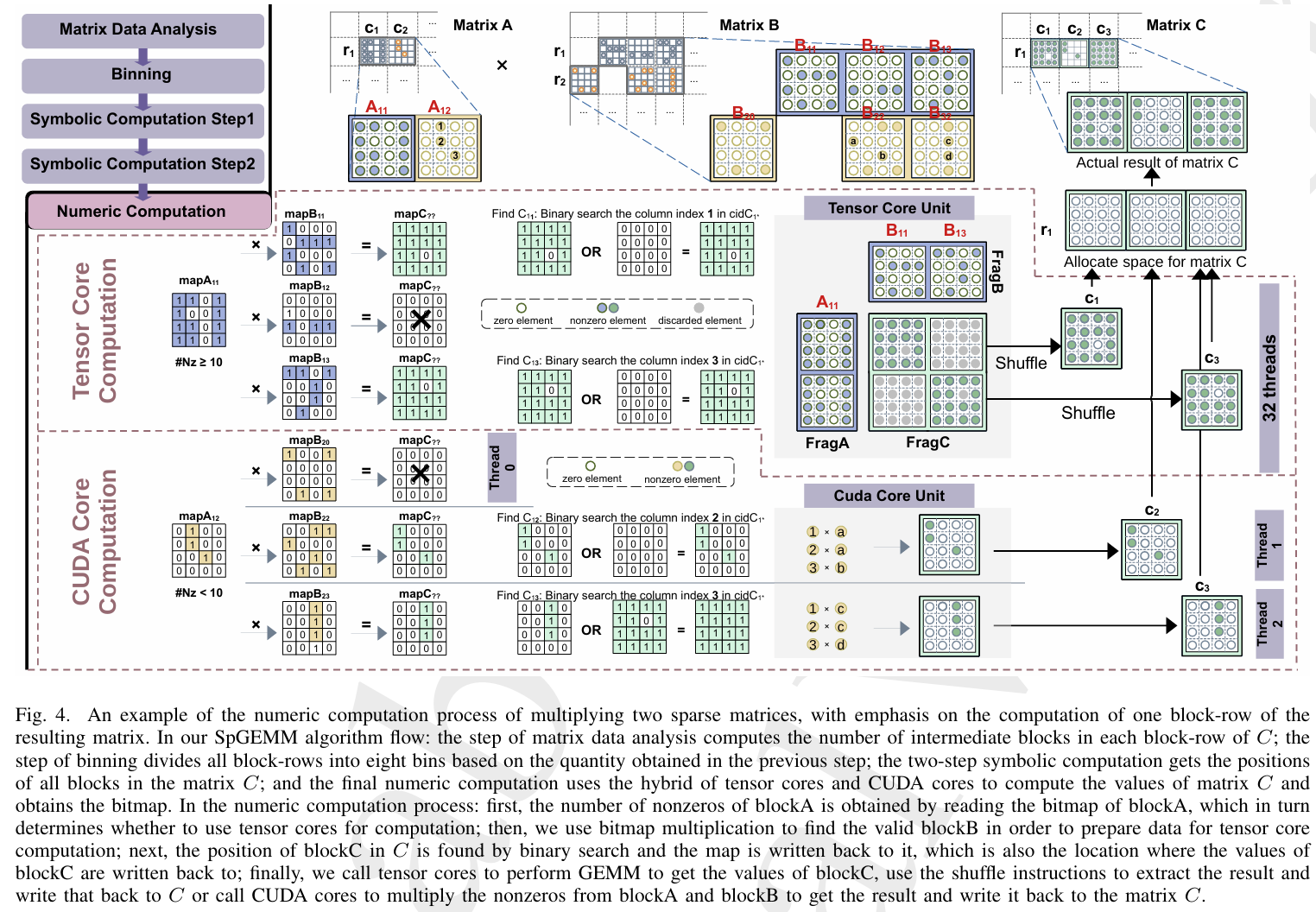
实现与测试:
- 在 NVIDIA A100、H100 和 AMD MI210 GPU 上实现并测试了 AmgT,使用 SuiteSparse Matrix Collection 中的 16 个代表性稀疏矩阵进行评估。
- 支持单 GPU 和多 GPU(8 个 A100)环境,展示了其分布式计算能力。


性能成果:
- 双精度 AmgT 相比 HYPRE v2.31.0 的 GPU 版本,在 A100、H100 和 MI210 上分别实现了平均 1.46×、1.32× 和 2.24× 的加速(最高可达 2.10×、2.06× 和 3.67×)。
- 混合精度 AmgT 在 A100 和 H100 上进一步提升了性能,平均加速比双精度 AmgT 高 1.03× 和 1.04×。
- 在多 GPU 环境下(8 个 A100),双精度 AmgT 平均加速 1.35×,混合精度 AmgT 再提升 1.06×。
- 独立内核测试显示,AmgT 的 SpGEMM 和 SpMV 分别比 cuSPARSE 和 rocSPARSE 有显著性能优势。
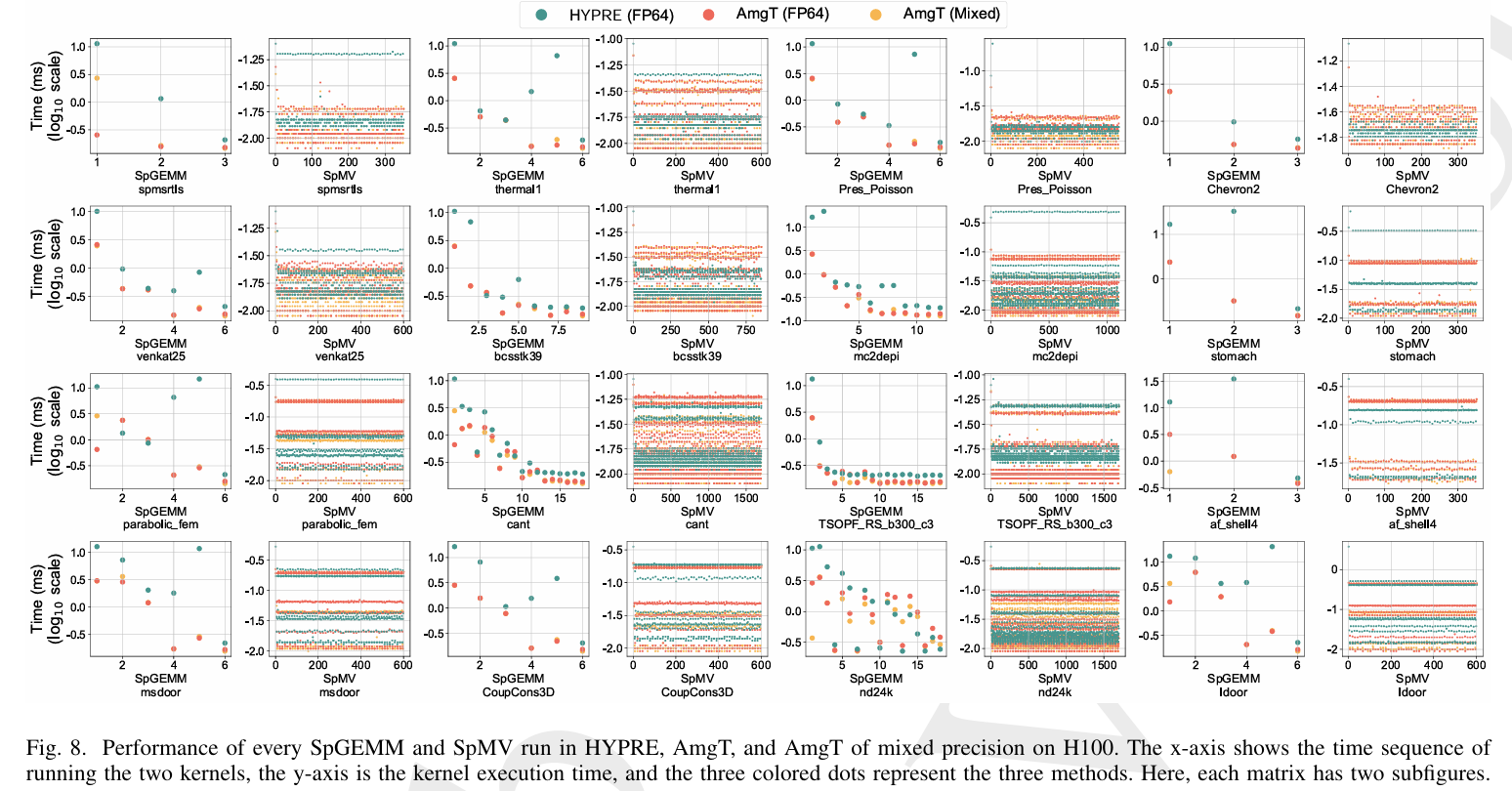
主要贡献:
- 统一的稀疏矩阵格式设计。
- 张量核心和混合精度优化的 SpGEMM 和 SpMV 内核。
- AmgT 求解器的开发及其与 HYPRE 的集成。
- 在最新 GPU 上验证了显著的性能提升。
总之,AmgT 通过充分利用张量核心的计算能力和混合精度技术,为 AMG 方法提供了高效的 GPU 加速方案,适用于单节点和分布式计算环境,展示了其在科学计算领域的潜力。
LoRAStencil: Low-Rank Adaptation of Stencil Computation on Tensor Cores
天才想法!用Tensor Core加速 模版计算!!
【HPHEX|[SC'24]LoRAStencil: 当大模型中的LoRA技术映射到Tensor Cores上的Stencil科学计算】 https://www.bilibili.com/video/BV1Bv2bYvET1/?share_source=copy_web&vd_source=72eac555730ba7e7a64f9fa1d7f2b2d4
挺像他们组的PPoPP23的best paper:
【HPHEX组会 | [PPOPP'23 Best Paper] ConvStencil:突破HPC与AI的“软硬”边界,开启科学计算新范式】 https://www.bilibili.com/video/BV1BM4m117tM/?share_source=copy_web&vd_source=72eac555730ba7e7a64f9fa1d7f2b2d4
以高性能计算领域的重要算子stencil计算为例,常见的stencil计算采用预定义的计算模式,不断地在时间维度上通过计算其与相邻点的加权和更新每个数据点。这种计算方式使得stencil计算难以直接转化为矩阵乘法,因此无法利用因深度学习而不断涌现的矩阵乘法加速硬件。本文提出了一种新的stencil计算系统ConvStencil,可以高效地将stencil计算转换为在张量核心单元上的矩阵乘法,使得传统高性能计算能够利用深度学习硬件进行加速。

High-Performance Unstructured SpMM Computation Using Tensor Cores
这篇文章介绍了一种名为 SMaT(Sparse Matrix Matrix Tensor Core-accelerated library) 的高性能稀疏矩阵-矩阵乘法(SpMM)库,旨在利用 NVIDIA GPU 的张量核心(Tensor Cores)加速针对无结构稀疏矩阵的计算。以下是工作的简要概述:
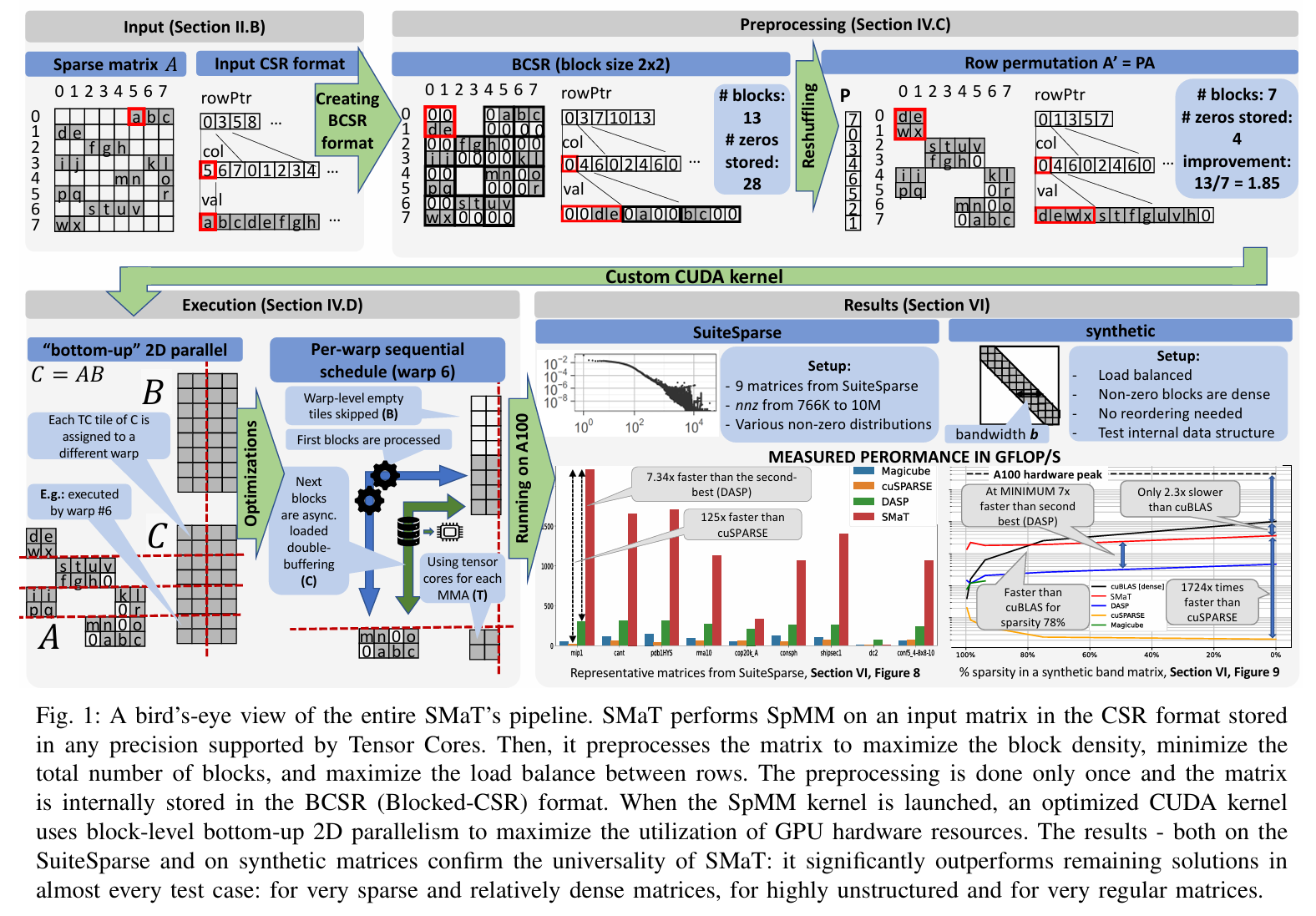
-
核心创新:
- SMaT 支持常见的 CSR(Compressed Sparse Row)格式输入,通过预处理将矩阵转换为 BCSR(Blocked-CSR)格式,以减少稠密块的数量并优化负载均衡。
- 提出了一种基于 Jaccard 相似性度量的行重排序预处理方法,平均减少高达 2.5 倍的块数。
- 设计了高效的 CUDA 内核,利用张量核心的混合精度计算能力和底层 API(如 HMMA16816),结合异步数据加载(cuda::memcpy_async)和 2D 并行调度,最大化硬件资源利用率。
-
实现与测试:
- 在 NVIDIA A100 GPU 上实现并测试,评估对象包括 SuiteSparse 集合中的真实矩阵和合成的带状矩阵,覆盖不同稀疏度和结构。
- 与现有解决方案(cuSPARSE、Magicube、DASP)进行了广泛比较。
-
性能成果:
- 在 SuiteSparse 的 9 个代表性矩阵上,SMaT 平均性能比 cuSPARSE 提升 16.32 倍(最高 125 倍),比次优库(DASP)提升 2.6 倍(最高 7.34 倍)。
- 在合成带状矩阵上,SMaT 比 cuSPARSE 最高加速 2445 倍,且在稀疏度低至 78% 时仍优于 cuBLAS(稠密矩阵库)。
- 对于大尺寸矩阵(如 cop20k_A),SMaT 在扩展稠密矩阵维度时保持优异性能,例如 N=1000 时比 cuSPARSE 快 8.6 倍。
-
主要贡献:
- 提出了通用的 SpMM 解决方案,支持无结构稀疏性和张量核心支持的所有数据类型。
- 开发了减少块数的预处理算法和优化张量核心性能的 BCSR 格式 SpMM 实现。
- 提供了性能模型,量化预处理和内核优化的贡献。
- 通过实验验证了 SMaT 在多种场景下的显著优势。
总之,SMaT 是一个通用的 SpMM 库,通过结合先进的预处理技术和张量核心优化,为科学计算和工业应用中的无结构稀疏矩阵乘法提供了高效的解决方案,显著超越了现有主流库的性能。
Performance Analysis
Versatile Datapath Soft Error Detection on the Cheap for HPC Applications
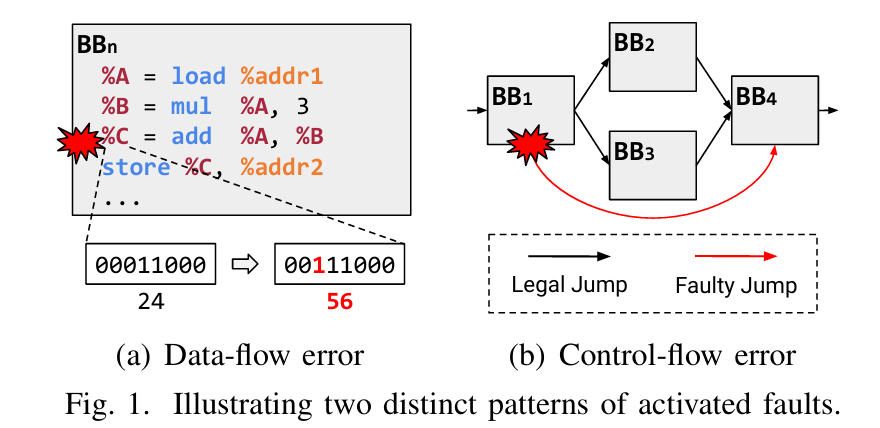
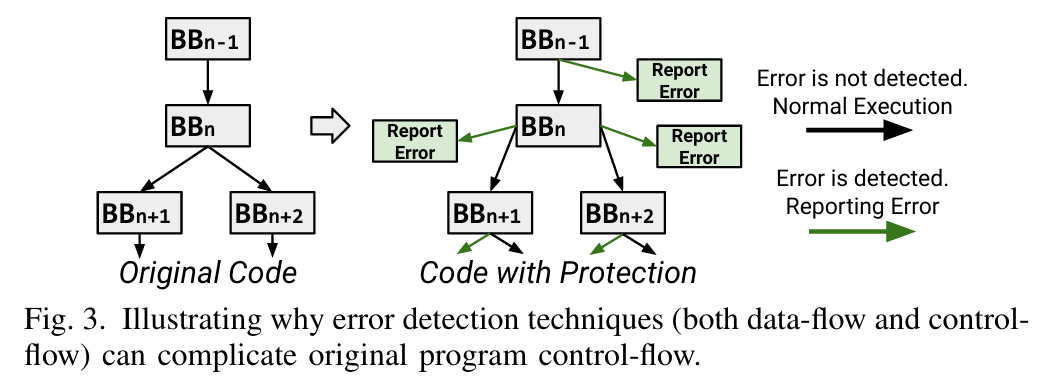
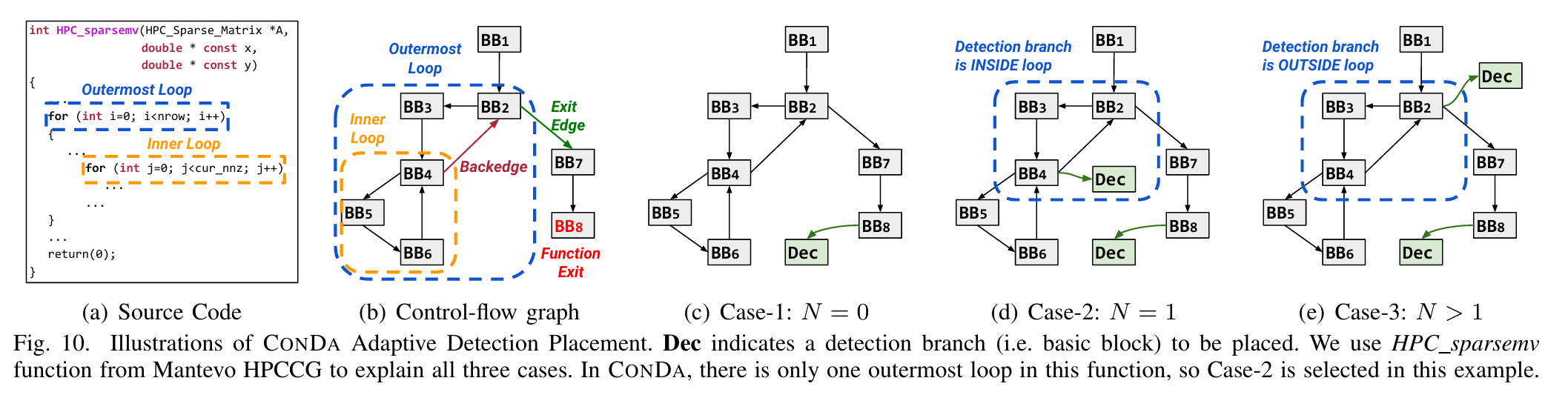
摘要--随着技术尺寸和电压水平的不断降低,现代微处理器越来越容易出现软错误,在程序执行过程中损坏数据通路单元。虽然这些错误类型近来受到了广泛关注,但现有的解决方案要么局限于有限的范围,要么在性能和功耗方面产生巨大的开销,阻碍了实际应用。
在这项工作中,我们提出了基于代码转换和静态程序分析的新型错误检测技术 CONDA,从而以低成本实现了多功能数据通路保护。在编译时,CONDA 会分析程序特性并转换原始程序代码,而不会使其控制流和内存访问模式复杂化。在运行时,CONDA 以较低的开销和延迟检测数据路径错误。 对 38 个基准和并行 HPC 仿真的评估表明,CONDA 只产生 57.79% 的运行时开销,比现有技术快 41.84%,而且错误检测效果和检测延迟都保持在同一水平。
关键词--可靠性、软错误、数据路径保护、代码转换、编译器、高性能计算(HPC)
MCBound: an Online Framework to Characterize and Classify Memory/Compute-bound HPC Jobs
you need data to do this.
摘要--现代高性能计算(HPC)系统执行来自不同领域的计算密集型工作,在推动科学研究方面发挥着重要作用。然而,高性能计算作业的特点是计算要求相互冲突,这可能导致资源使用、系统吞吐量和能源消耗效率低下。解决这一问题的方法之一是在作业提交时区分内存约束作业和计算约束作业,以便在执行作业时做出明智决策。
在本文中,我们提出了 MCBound,这是首个在线数据驱动框架,可在作业执行前将高性能计算作业分为内存/计算约束作业,而无需用户干预。 我们提出了一种系统表征技术,可从历史数据中生成参考数据集,用于初始分类模型训练。利用提出的特征描述技术,我们分析了超级计算机 Fugaku1 上 220 万次作业运行的数据,这是安装在日本理化学研究所计算科学中心的一个生产型 HPC 系统。我们为 Fugaku 实施了 MCBound,并对 2024 年 2 月期间执行的作业进行了分类。我们的方法被证明是有效的,因为它获得了至少 0.89 的 F1-macro 平均分作为预测质量,同时对系统操作产生的开销几乎可以忽略不计。我们基于 Python 实现的 MCBound 可以在其他高性能计算系统中无缝配置和部署
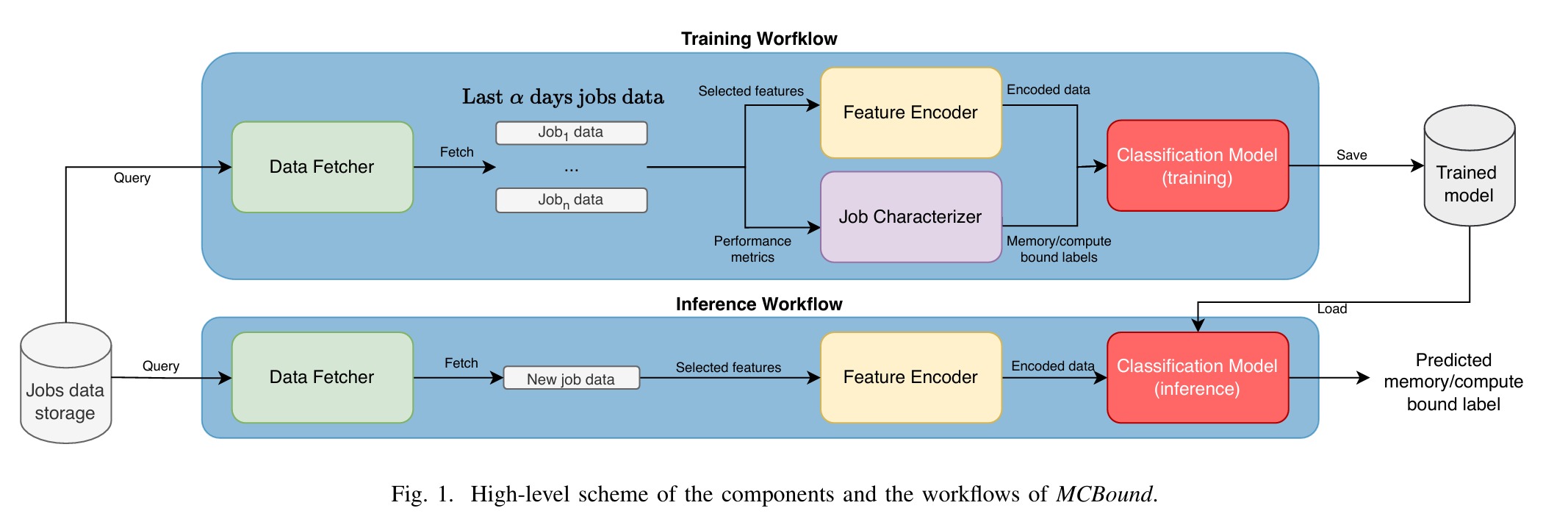
这篇文章介绍了一个名为 MCBound 的在线数据驱动框架,旨在在高性能计算(HPC)作业执行前,将其分类为内存受限(memory-bound)或计算受限(compute-bound)。以下是工作的简要概述:
-
核心目标与创新:
- MCBound 是首个无需用户干预、能在作业提交时实时分类 HPC 作业为内存或计算受限的框架。
- 通过分析历史作业数据,结合 Roofline 模型、机器学习(ML)和自然语言处理(NLP)技术,构建并定期更新分类模型,实现对新提交作业的提前预测。
-
方法与实现:
- 提出了一种系统化的作业特征化方法,利用 Fugaku 超级计算机上 220 万个作业的历史数据生成参考数据集,用于初始模型训练。
- 框架包括数据获取(Data Fetcher)、特征编码(Feature Encoder)、作业特征化(Job Characterizer)和分类模型(Classification Model)等组件,支持实时数据流处理和周期性模型更新。
- 使用两种 ML 模型(KNN 和 Random Forest),结合 Sentence-BERT 编码作业特征,在 Fugaku 上实现了高效部署。
-
实验与成果:
- 在 2024 年 2 月的 70 万个 Fugaku 作业上测试,分类预测的 F1-macro 分数达到至少 0.89,表明高准确性。
- 分析显示 Fugaku 作业中内存受限作业占主导(约 3.5 倍于计算受限作业),且许多作业未充分利用系统资源。
- 运行时开销极低(每日训练和推理总时间远低于作业平均等待时间),适合生产环境部署。
-
应用价值:
- 通过分类结果指导作业调度(如内存与计算受限作业的协同调度)和频率选择(如调整至适合的 2.0GHz 或 2.2GHz 模式),可提升系统吞吐量和能效。
- 估算表明,若优化频率选择,可节省约 14 GJoules 能量和 1700 小时计算时间。
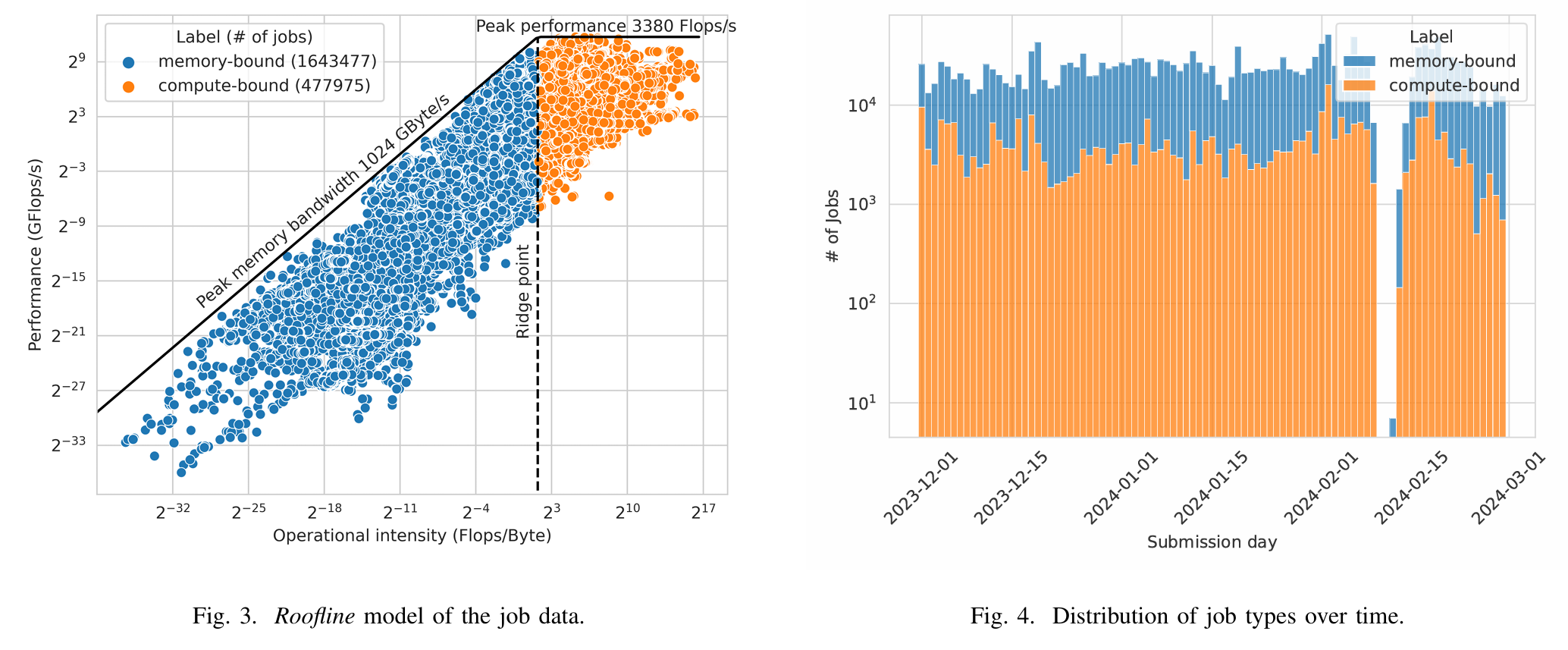
总之,MCBound 提供了一种通用的、实用的解决方案,通过在作业执行前准确分类其内存/计算特性,为 HPC 系统优化资源分配和能效提供了重要支持。未来计划扩展框架以分类更多作业类型(如 interconnect-bound、GPU-bound)并集成到作业管理系统中。
GVARP: Detecting Performance Variance on Large-Scale Heterogeneous System
Hailong Yang - Homepage
I am also the supervisor of Beihang Supercomputing Team, which has won the Silver Prize of ASC’17, Bronze Prize of ISC’17, Highest Linpack Award, Application Innovation Award and First Class Award of ASC competitions.
摘要--性能差异是大规模异构系统的一个令人讨厌的隐患,它可能导致并行程序出现意外和不可预测的性能下降。这种性能问题通常是由各种硬件和软件故障引起的,因此在具体情况下要准确找出性能差异的原因非常困难。
在本文中,我们提出了适用于大规模异构系统的性能差异检测工具 GVARP。 GVARP 采用静态分析来识别内核函数的性能关键参数。此外,GVARP 还通过外部库调用和异步内核操作对程序执行进行分割。然后,GVARP 构建一个状态转移图,并估算每个程序段的工作量,以识别和聚类类似工作量的实例,促进性能差异的检测。我们的评估结果表明,GVARP 能以可接受的开销有效地检测大规模性能差异,并提供直观的洞察力来定位性能差异的来源。 索引词条-大规模异构系统 性能差异 性能分析

这篇文章提出了 GVARP,一个针对大规模异构系统性能差异检测的工具。以下是工作的简要介绍:
研究背景与问题:
- 大规模异构系统(如基于 GPU 的超算和数据中心)在运行并行程序时常面临性能差异问题,即同一程序在相同输入下多次运行时性能差异显著,导致不可预测的性能下降。
-
这些差异通常由硬件(如内存故障、网络拥塞)和软件(如操作系统干扰)的随机故障引起,难以精确定位根本原因。

核心贡献:
- GVARP 通过静态分析识别内核函数的性能关键参数,并结合异步状态转移图(ASTG)追踪程序执行,检测性能差异。
- 它将程序执行分为段,估计每段工作负载,聚类相似负载实例,从而识别性能异常。
-
提供轻量级跟踪和并行分析工具,并在真实应用中验证了其有效性。
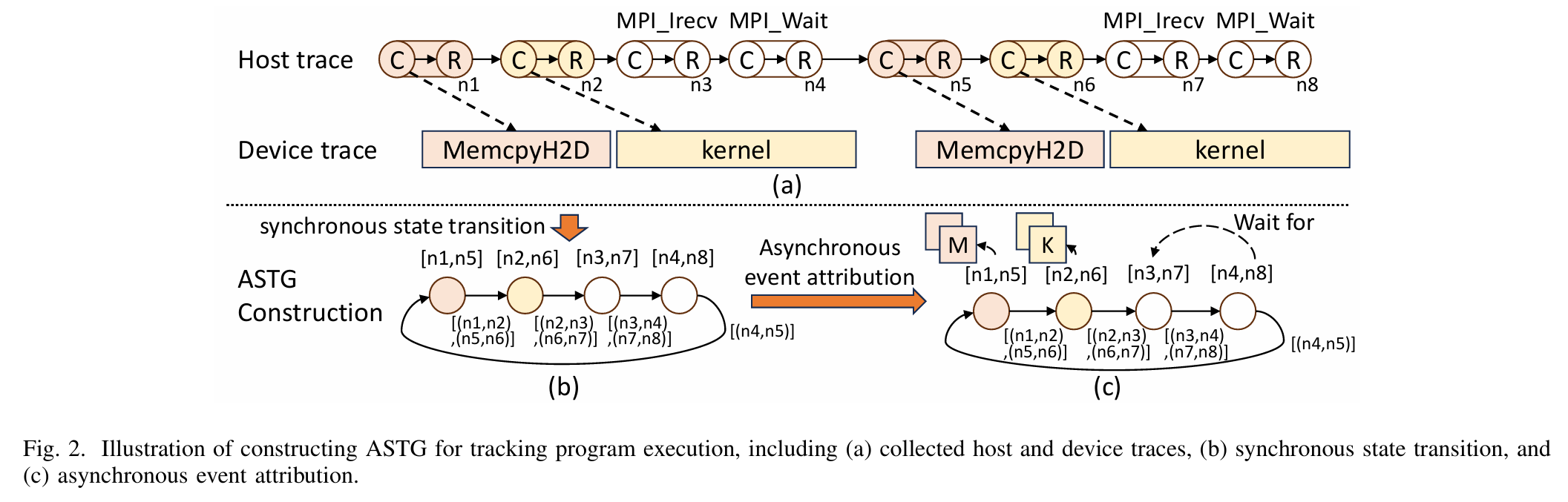
技术方法:
- 静态分析:基于 LLVM 框架分析 GPU 内核函数的关键参数(如线程数、循环迭代次数)。
- 程序分段与 ASTG:通过拦截外部库调用(如 MPI、HIP API)和异步内核操作,构建 ASTG,捕捉异步计算、通信和数据传输。
- 工作负载估计与聚类:基于参数估计设备计算、主机-设备数据传输和通信负载,聚类固定工作负载段。
-
性能差异检测:通过性能归一化和数据平滑,结合可视化热图,直观展示差异来源。
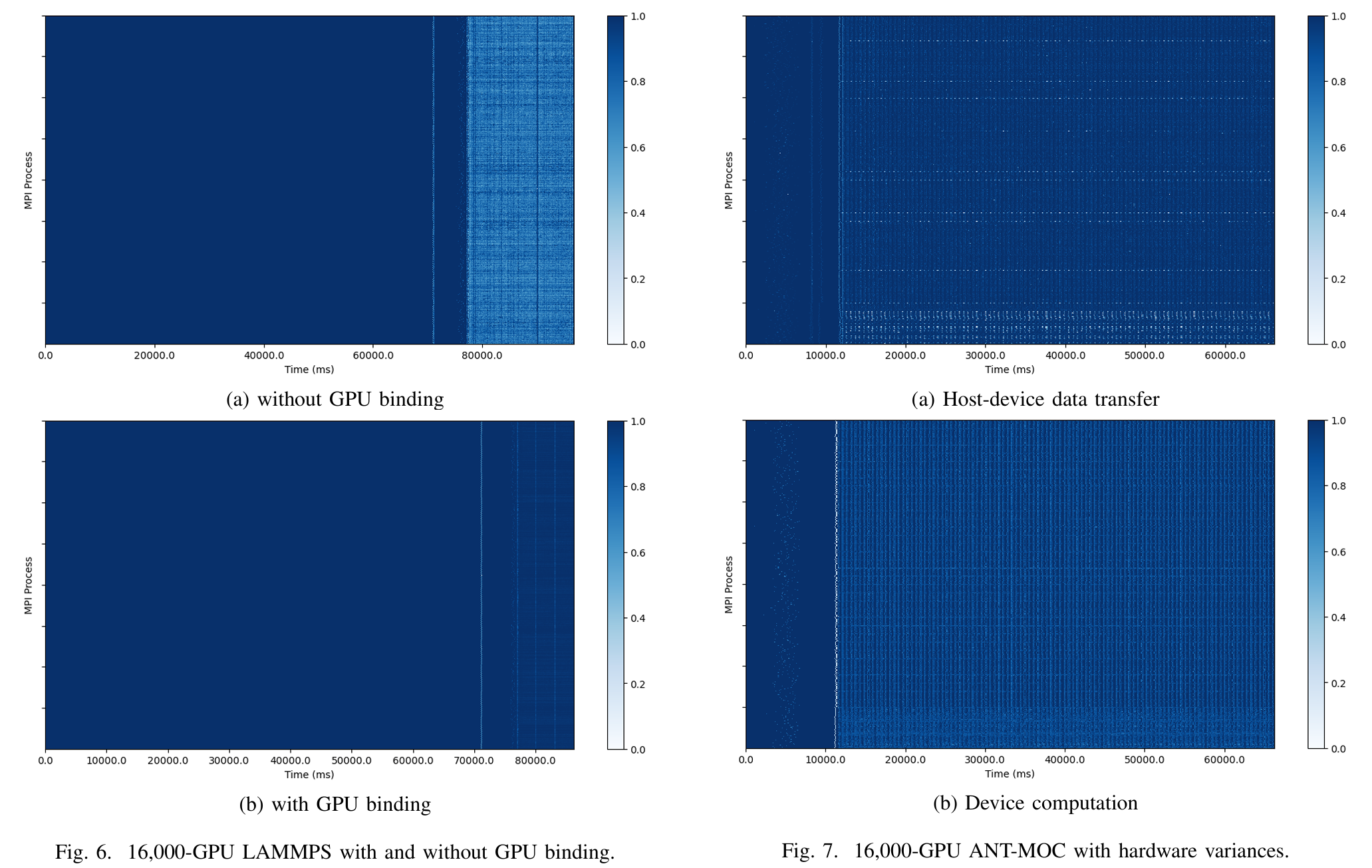
实验结果:
- 在配备高达 16,000 个 GPU 的 AMD 集群上测试,GVARP 有效检测性能差异,跟踪开销低(128 GPU 时 <1%,16,000 GPU 时 <20%)。
-
在 HPCG、ANT-MOC 和 LAMMPS 等应用中,检测覆盖率优于现有工具(如 VAPRO),并通过案例研究识别了网络拥塞、启动问题和硬件差异等问题。
应用价值:
- GVARP 无需重新编译,支持生产环境二进制文件,提供低开销、高覆盖的性能差异检测方案。
- 通过直观的可视化报告,帮助开发者和管理员定位硬件和软件问题,提升大规模异构系统的可靠性。
总之,GVARP 通过创新的异步追踪和负载分析方法,解决了大规模异构系统中性能差异检测的难题,为高性能计算提供了实用工具。
High-Performance Solvers
Mille-feuille: A Tile-Grained Mixed-Precision Single-Kernel Conjugate Gradient Solver on GPUs
Super Scientific Software Laboratory, Dept. of CST, China University of Petroleum-Beijing, China
摘要-共轭梯度(CG)和双共轭梯度稳定(BiCGSTAB)是用于求解稀疏线性系统的有效方法。本文提出了一种新的求解器 Mille-feuille,用于在 GPU 上加速 CG 和 BiCGSTAB。我们首先分析了这两种方法,并列出了与混合精度的使用、内核同步成本的降低和迭代步骤中部分收敛的意识有关的三个发现。然后,
(1) 为了实现瓦片粒度混合精度,我们开发了一种瓦片稀疏格式;
(2) 为了降低同步成本,我们利用原子操作使整个求解过程在单个 GPU 内核内运行;
(3) 为了支持部分收敛感知混合精度策略,我们在运行时在单个内核内实现瓦片片上动态精度转换。
在英伟达™(NVIDIA®)A100 和 AMD MI210 上的实验结果表明,Mille-feuille 求解器的性能优于使用供应商支持的 cuSPARSE/hipSPARSE 以及 PETSc 和 Ginkgo 这两个最先进库的基线实现,平均高出 3.03 倍/2.68 倍、5.37 倍、4.36 倍(最高达 8. 77x/7.14x、16.54x、15.69x),BiCGSTAB 平均为 2.65x/2.32x、3.57x、3.78x(高达 7.51x/6.63x、16.64x、11.73x),PETSc 平均为 3.82x/3.47x(高达 40.38x)。 47倍(最高为40.38倍/47.75倍),预处理CG(PCG)平均为1.79倍/1.63倍(最高为45.63倍/44.34倍),预处理BiCGSTAB(PBiCGSTAB)平均为1.79倍/1.63倍(最高为45.63倍/44.34倍)。
索引词条-CG, BiCGSTAB, mixed precision, GPU

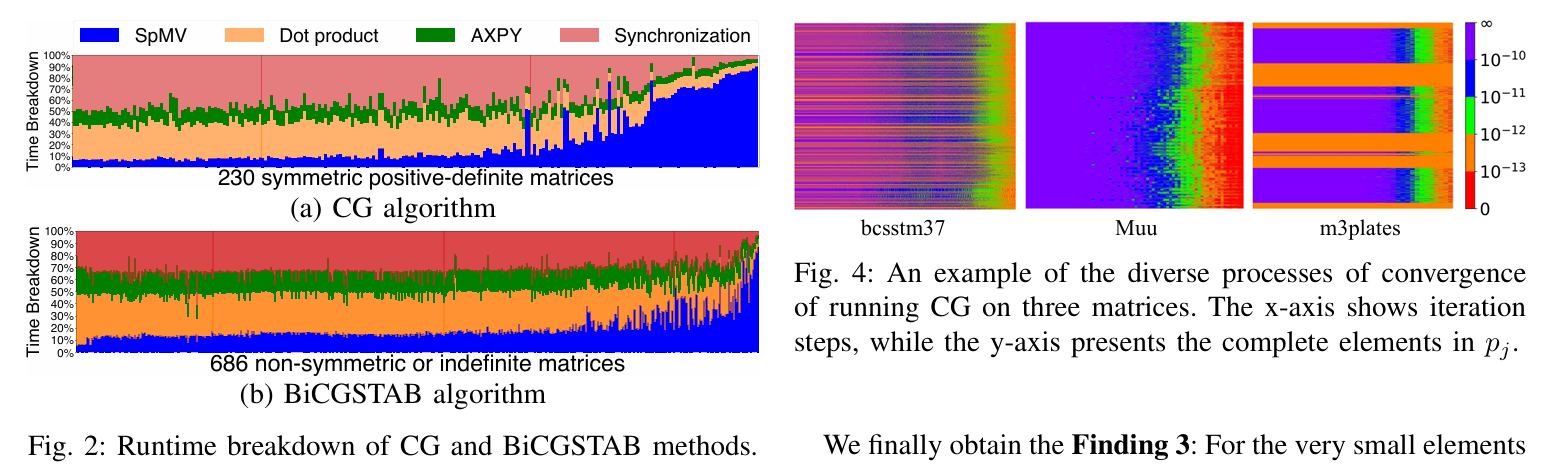
这篇文章题为《Mille-feuille: 基于GPU的瓦片粒度混合精度单核共轭梯度求解器》,由中国石油大学(北京)和中国科学院计算技术研究所等机构的研究团队合作完成。文章提出了一种名为“Mille-feuille”的新型求解器,旨在加速GPU上共轭梯度法(CG)和双共轭梯度稳定法(BiCGSTAB)求解稀疏线性系统的问题。以下是工作的简要介绍:
-
研究背景:
- CG和BiCGSTAB是求解稀疏线性系统的有效迭代方法,但传统实现面临同步开销大和精度选择效率低的问题,尤其在现代GPU架构上。
-
核心贡献:
- 提出了瓦片粒度的混合精度存储格式,根据矩阵非零元的数值特性选择合适的精度(FP64、FP32、FP16、FP8),减少存储和计算开销。
- 设计了单核实现方案,将多个计算操作(如SpMV、点积和AXPY)融合到一个GPU核中,消除核间同步成本并优化片上内存使用。
- 实现了运行时动态精度调整,利用部分收敛特性,在迭代过程中根据解向量元素的收敛情况降低对应矩阵列的计算精度甚至跳过计算。
- 新求解器“Mille-feuille”在NVIDIA和AMD GPU上显著优于现有方法(如cuSPARSE、PETSc和Ginkgo)。
-
技术亮点:
- 瓦片存储:将矩阵划分为统一大小的瓦片(16×16),采用两级稀疏格式存储,兼顾瓦片间和瓦片内信息。
- 单核优化:通过原子操作和片上内存重用,最小化全局内存访问和同步开销。
- 动态精度:根据迭代中解向量的部分收敛特性,实时调整瓦片的计算精度。
-
实验结果:
- 在NVIDIA A100 GPU上,Mille-feuille在CG中比cuSPARSE快3.03倍,比PETSc快5.37倍,比Ginkgo快4.36倍;在BiCGSTAB中也有类似提升。
- 尽管混合精度可能增加少量迭代次数(平均1.06倍),但整体求解时间大幅缩短。
-
应用意义:
- 该求解器通过混合精度和单核优化提升了稀疏线性系统求解的性能,为科学计算和高性能计算领域提供了高效工具,特别适用于大规模矩阵运算。
总之,“Mille-feuille”结合瓦片粒度混合精度和单核设计,充分利用GPU硬件特性,显著提高了CG和BiCGSTAB方法的效率,为现代计算架构下的数值线性代数问题提供了创新解决方案。
DBSR: An Efficient Storage Format for Vectorizing Sparse Triangular Solvers on Structured Grids
https://github.com/YXJ-123/DBSR.git
摘要
稀疏三角求解器(SPTRSV)在解决结构网格问题中起着至关重要的作用。然而,结构网格方法常用的稀疏矩阵存储格式无法有效支持 SPTRSV 利用现代多核 CPU 提供的指令并行性。我们引入了新的稀疏存储格式 DBSR,使 SPTRSV 能够利用 SIMD 指令的优势。 DBSR 促进了连续内存访问和矢量化计算,同时还优化了内存使用。 我们将 DBSR 应用于多网格算法和零填充不完整 LU 预处理,对其进行了评估。我们在四种架构(三种 ARMv8 系统和一种 x86 系统)上进行的评估表明,DBSR 在各种评估工作负载和平台上的表现始终优于主流存储格式。
Dezun Dong
关键词-结构化网格 稀疏三角求解器 Vec torization
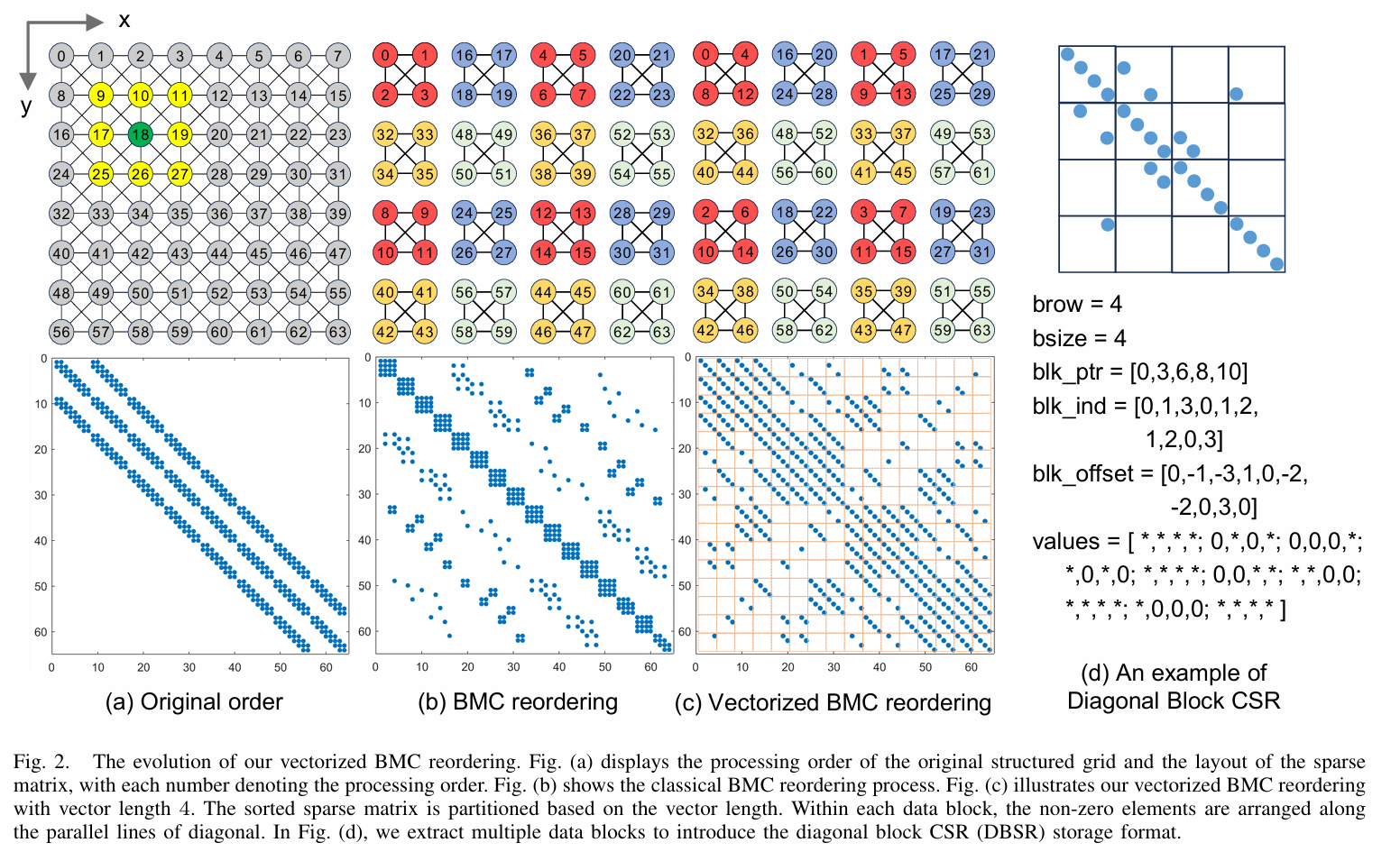
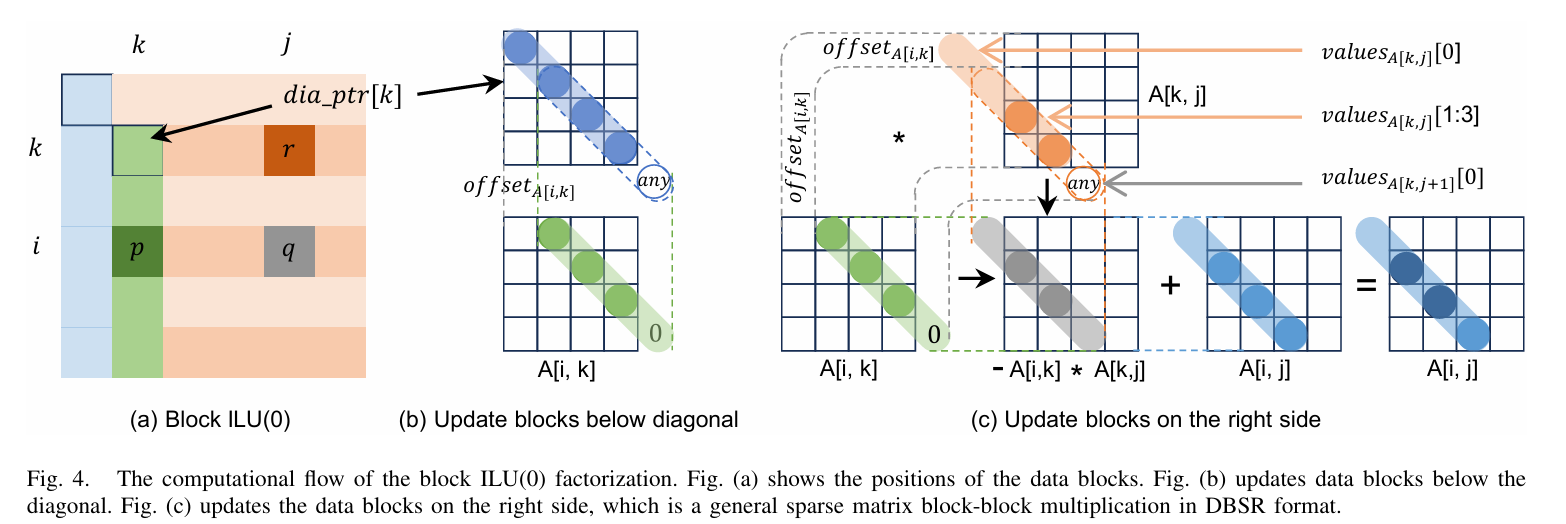
这篇文章题为《DBSR: 一种用于在结构化网格上矢量化稀疏三角求解器的高效存储格式》,由国防科技大学和湘潭大学的研究团队合作完成。文章提出了一种名为“DBSR”(Diagonal Block Compressed Sparse Row)的新型稀疏矩阵存储格式,旨在优化结构化网格问题中稀疏三角求解器(SPTRSV)的性能,尤其是在多核CPU上利用SIMD指令并行性。以下是工作的简要介绍:
-
研究背景:
- 稀疏三角求解器(SPTRSV)在结构化网格问题的求解中至关重要,但传统稀疏矩阵存储格式(如CSR)难以有效支持现代多核CPU的指令并行性,导致计算效率低下。
-
核心贡献:
- 提出了DBSR存储格式,通过基于矢量化的块多色排序(Vectorized BMC),将矩阵划分为数据块,仅存储每个块内的单条对角线元素,从而减少存储开销并支持连续内存访问。
- 展示了DBSR在多种预处理器和平滑器(如SYMGS和ILU(0))中的适用性,并将其集成到HPCG基准测试中,提升了结构化网格问题的求解性能。
- 通过避免gather指令并结合SIMD技术(如AVX512和NEON),显著提高了矢量化计算效率。
-
技术亮点:
- DBSR格式:基于块划分和对角线存储,减少了行和列索引的存储需求(相比CSR分别减少至1/bsize和2/bsize),并优化了数据局部性。
- 矢量化优化:利用BMC方法对网格点重排序,使同一颜色的块内操作可并行执行,支持无gather的矢量加载。
- 多平台支持:在x86(Intel Xeon)和ARMv8(KunPeng 920、Thunder X2、Phytium 2000+)架构上验证了性能提升。
-
实验结果:
- 在HPCG基准测试中,DBSR结合现有优化技术后,比最优方法提升18.8%至23.9%,比厂商优化版本(如MKL和ARM)加速1.47倍至3.40倍。
- 在ILU(0)预处理器中,DBSR在双精度下比最佳并行策略提升17%至26%,单精度下提升22%至46%,同时展现良好的弱扩展性。
-
应用意义:
- DBSR通过减少存储开销、优化内存访问和提升并行性,为结构化网格上的稀疏线性系统求解提供了高效解决方案,适用于科学计算和高性能计算领域。
总之,DBSR结合矢量化BMC重排序和对角线块存储,充分利用多核CPU的SIMD能力,显著提升了SPTRSV及相关算法的性能,为结构化网格问题的数值计算提供了创新工具。未来工作计划将其扩展至非结构化网格和异构架构(如GPU)。
Many-Body Electronic Correlation Energy using Krylov Subspace Linear Solvers
本文介绍了通过密度泛函理论中的随机相近似计算多体电子相关能的高性能算法的制定与实现。我们的方法规避了直接方法固有的计算效率低下问题,因为直接方法的计算效率与系统规模呈四分缩放关系。我们的方法需要求解系数矩阵为复对称的块线性系统;这些系统的数值难度差异很大。
我们为这些系统开发了一种短期递归块克雷洛夫子空间求解器,并利用动态块大小选择来缓解负载不平衡问题。这种选择平衡了线性求解器每次迭代所增加的成本,减少了缓慢收敛系统的迭代次数。数值实验表明,我们的实现具有良好的并行可扩展性,即使在所测试的最小化学系统上,也能实现比直接方法更快的求解时间,而且由于其立方扩展性和更高的计算局部性,还能扩展到更大的系统和处理器数量。
Krylov算法入门 - 知乎
[1811.09025] An Introduction to Krylov Subspace Methods



HPC for Physics and Material Science
Enabling 13K-Atom Excited-State GW Calculations via Low-Rank Approximations and HPC on the New Sunway Supercomputer
摘要--GW 近似是精确描述半导体激发态的一种强大方法。然而,GW 的计算成本高达 O(N4),内存使用量也高达 O(N3),即使在领先的超级计算机上也只能应用于成千上万(2,742)个原子。
在本文中,我们介绍了在领先超级计算机上利用低秩近似和高性能计算对精确高效的立方尺度平面波 GW 计算进行大规模并行实施的方法。通过使用一系列低秩近似,我们可以将昂贵的 GW 计算降低到立方缩放计算成本 O(N3)和二次内存使用量 O(N2)。 在并行和通信优化的帮助下,平面波 GW 计算的整体速度提高了 70 倍以上,并在几分钟内利用新的 Sunway 超级计算机上的 449 280 个内核有效地扩展到 13 824 个原子。 这一成果为介观尺度(10,000 个原子)的激发态量子力学材料模拟和下一代半导体器件的设计铺平了道路。
索引词条-第一性原理计算、ab initio 电子结构、激发态 GW 计算、低秩近似、高性能计算、新Sunway超级计算机、复杂系统材料模拟、下一代半导体器件
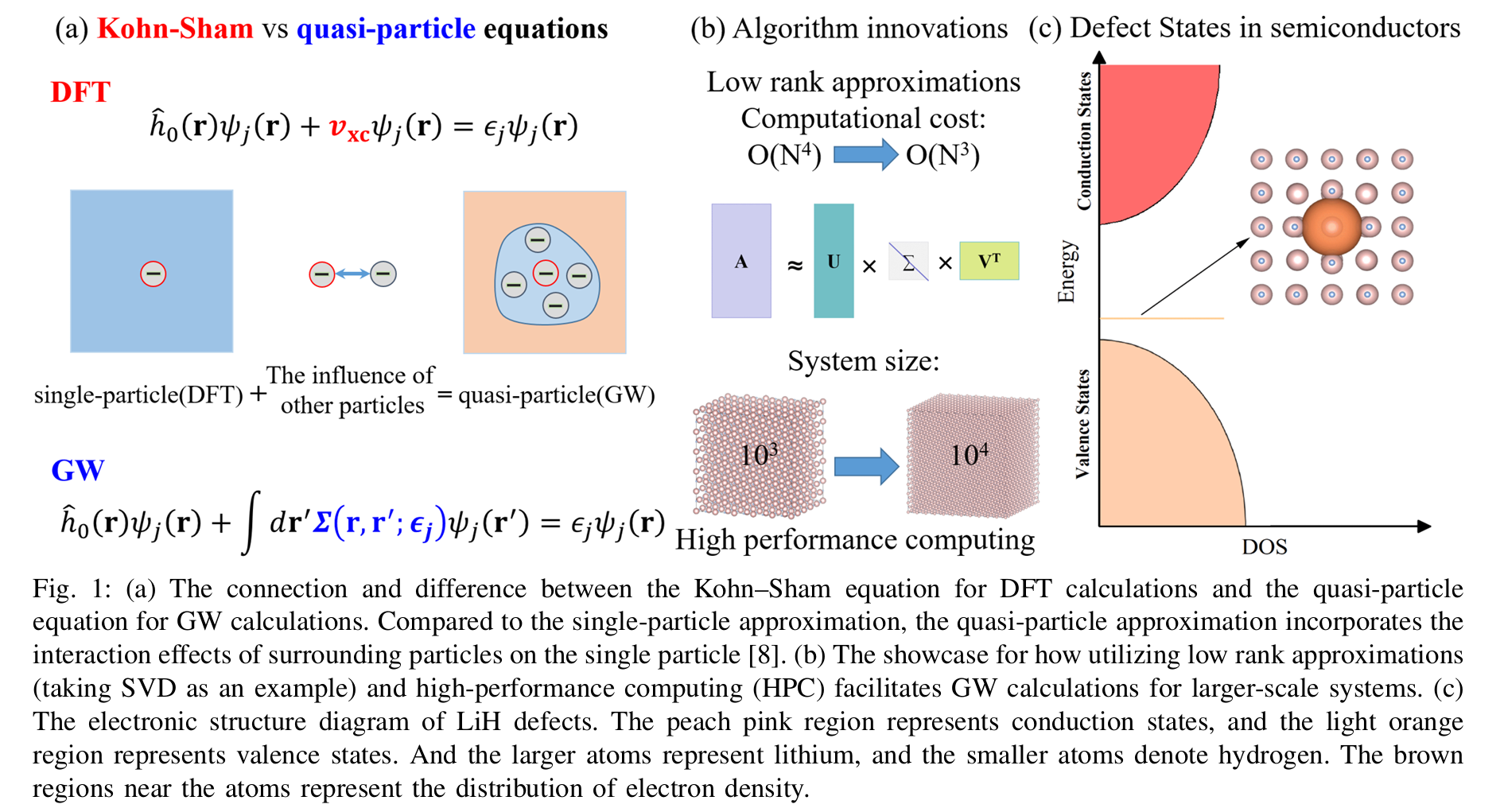
这篇文章题为《通过低秩近似和高性能计算在新神威超级计算机上实现13K原子激发态GW计算》,介绍了在新型神威超级计算机上利用低秩近似和高性能计算(HPC)技术,实现对大规模半导体系统(高达13,824原子)进行高效GW激发态计算的工作。以下是主要内容的简要概述:
-
研究背景与挑战:
- GW近似是一种精确描述半导体激发态的理论方法,但其计算复杂度高(标准G₀W₀为O(N⁴)至O(N⁵))且内存需求大(O(N³)),限制了其在大规模系统上的应用,通常仅限于数百原子规模。
-
核心贡献:
- 提出了一种优化的GW计算方法(ISDF-SMW),通过低秩近似(如插值可分离密度拟合ISDF、Sherman-Morrison-Woodbury公式等)将计算复杂度降低至O(N³),内存需求降至O(N²)。
- 在神威超级计算机上实现了高效并行优化,包括数据分布、通信优化和计算-通信重叠,显著提升计算效率。
- 成功模拟了包含13,824原子的LiH系统,远超传统GW计算的规模(此前最佳记录约2,742原子)。
-
技术方法:
- 使用平面波基组在PWDFT框架内实现GW计算,结合低秩算法减少冗余计算。
- 优化并行方案,如行/列/二维数据分区、MPI通信优化和异步广播矩阵乘法,隐藏通信延迟。
- 对硅(Si)和氢化锂(LiH)系统进行测试,验证算法的准确性和可扩展性。
-
实验结果:
- 在神威超算(107,520节点,1.5 EFLOPS峰值性能)上,实现了从4,096到13,824原子的弱扩展测试,计算时间从29.8秒增至284.8秒,表现出接近O(N²)的理想弱扩展性。
- 强扩展测试显示,使用260,000核心时并行效率仍达43.9%。
- 与BerkeleyGW相比,PWDFT-GW在相同规模下快约10⁴倍,且精度高(LiH带隙误差<0.1 eV)。
-
应用意义:
- 展示了GW计算在预测LiH缺陷电子结构中的应用,准确描述带隙和缺陷能级,支持下一代半导体器件设计。
- 为量子材料激发态研究奠定了基础,推动了高性能计算在物理和化学领域的应用。
这项工作通过算法创新和超算优化,突破了GW计算的规模限制,为大规模激发态电子结构研究提供了高效工具。
Reshaping High-Energy Physics Applications for Near-Interactive Execution Using TaskVine
Supercomputing Paper Accepted | Barry Sly-Delgado
摘要--高能物理实验每年产生数 PB 的数据,必须对这些数据进行缩减,才能深入了解自然规律。早期阶段的还原需要在跨越多个设施的数千个节点上执行长期运行的高吞吐量工作流,以生成共享数据集。后期阶段通常由个人或小组编写,必须经过多次改进和重新运行以确保正确性。缩短后期阶段的迭代时间是加速发现的关键。
我们展示了在数千个节点上重塑后期分析应用程序的经验。仅仅扩大规模是不够的:有必要在整个堆栈中做出改变,包括存储系统、数据管理、任务调度和应用设计。 我们在开源数据分析框架(Coffea、Dask 和 TaskVine)上构建的两个分析应用程序中演示了这些变化。我们评估了这些应用在opportunistic campus cluster上的性能,结果表明它们可以有效扩展到 7200 个内核,从而显著提高了速度
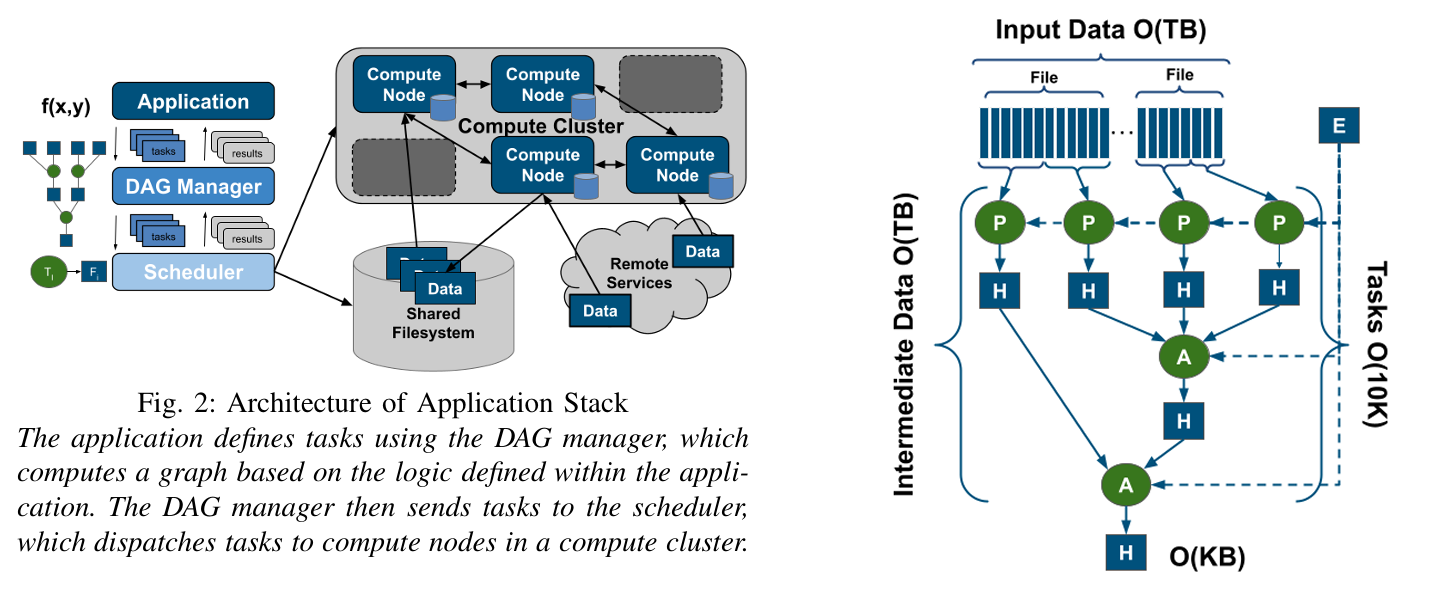
这篇文章题为《通过TaskVine重塑高能物理应用以实现近交互式执行》,由圣母大学的研究团队撰写,介绍了如何通过优化计算框架和硬件堆栈,将高能物理(HEP)后期数据分析应用从长时间运行转变为近交互式执行,从而加速科学发现。以下是工作的简要概述:
-
研究背景:
- 高能物理实验(如CERN的CMS实验)每年产生PB级数据,早期处理依赖大规模分布式高吞吐量计算,而后期分析通常由个人或小组进行,需要多次迭代优化代码,缩短迭代时间对加快研究进程至关重要。
-
核心贡献:
- 通过调整存储系统、数据管理、任务调度和应用设计,利用TaskVine框架优化了两款基于开源框架(Coffea、Dask)的分析应用(DV3和RS-TriPhoton)。
- 实现了从数百核到7200核的有效扩展,将执行时间从数小时缩短至数分钟,显著提升了分析效率。
-
技术方法:
- 数据访问与移动:通过专用数据存储和节点间对等传输,减少对共享文件系统的依赖,提升数据访问速度。
- 任务执行:引入无服务器执行模式,减少任务启动开销(如Python解释器调用和库加载),并通过“导入提升”优化库加载。
- DAG优化:调整任务图结构(如从单节点归约改为树形归约),降低存储需求并提高并行效率。
-
实验结果:
- 在校园HTCondor集群上测试,DV3应用(1.2TB数据,17,000任务)从3545秒缩短至272秒, speedup达13倍。
- 最大规模测试(DV3-Huge,185,000任务)在7200核上运行,完成时间不到1小时,展现了优异的扩展性。
-
应用意义:
- 通过TaskVine优化,显著降低了后期分析的迭代时间,支持高能物理研究的高效进行,并将改进融入Coffea、Dask和TaskVine开源框架,惠及更广泛的科学界。
这项工作通过多层次优化,成功重塑了高能物理应用的执行模式,为处理大规模HEP数据提供了高效、灵活的解决方案。
Towards Exascale Simulations of Nanoelectronic Devices in the GW Approximation
ETH Zurich
摘要--栅极周围硅纳米线场效应晶体管(NWFET)是鳍式场效应晶体管的可行替代品,其实验开发可通过技术计算机辅助设计加以补充。这就需要有先进的器件模拟器,依靠量子传输(QT)方法,不使用任何经验参数作为输入。具体来说,所有材料特性都应从第一原理出发进行描述,并对整个物理过程进行精确建模,尤其是在 NWFET 等高约束结构中发生的强烈电子-电子相互作用。
为了揭示这些多体效应,我们在自洽 GW 近似中将其应用到名为 QuaTrEx 的原子序数 QT 求解器中,该求解器基于密度泛函理论和非平衡格林函数形式主义。然后,我们在LUMI超级计算机的GPU分区上模拟了由多达10560个原子组成的晶体管,弱(强)扩展的并行效率达到74%(60%),在1800个节点上的双精度总体计算性能达到69.3 Pflop/s。
索引词条-量子输运、器件模拟、硅纳米线、GW近似、超大规模计算
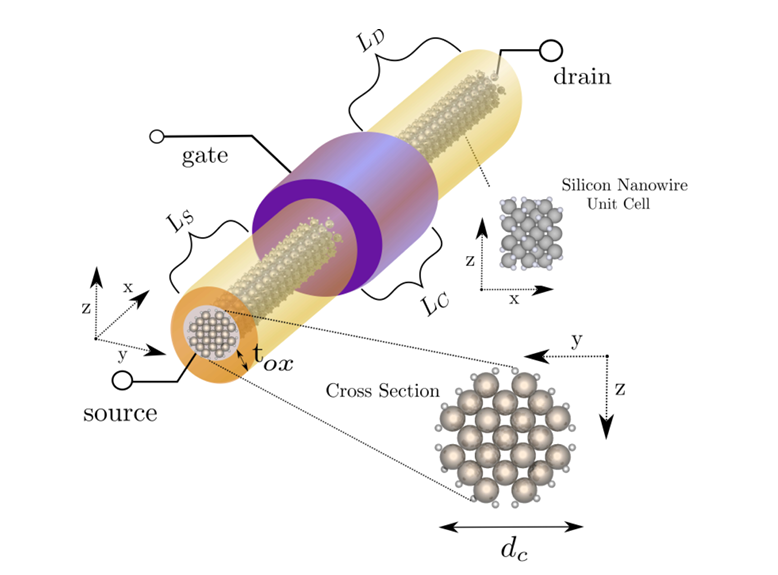
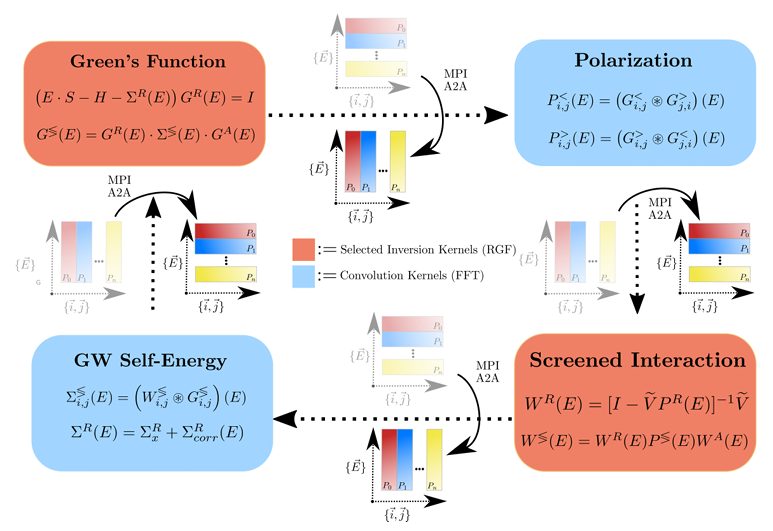
这篇文章题为《迈向GW近似下纳米电子器件的百亿亿次模拟》,由苏黎世联邦理工学院集成系统实验室的研究团队撰写,介绍了一种基于非平衡格林函数(NEGF)和自洽GW近似的高精度量子输运(QT)求解器,用于模拟超大规模纳米电子器件的行为。以下是工作的简要概述:
-
研究背景:
- 随着半导体器件尺寸缩小到纳米级,传统的NEGF方法因计算复杂度和对电子-电子(e-e)相互作用的忽略,难以准确模拟现代晶体管(如FinFET及其后继者)的性能。GW近似作为一种多体方法,能有效捕获e-e相互作用,提升模拟精度。
-
核心贡献:
- 开发了名为QuaTrEx的QT求解器,将密度泛函理论(DFT)与NEGF和自洽GW近似结合,模拟了超大规模的全栅硅纳米线场效应晶体管(GAA NWFETs),原子数最高达10,560个。
- 在LUMI超级计算机的GPU分区上,每迭代计算时间缩短至约30秒,实现了高效的“电流-电压”特性分析。
-
技术方法:
- 算法优化:通过非线性特征值求解、块三对角线性求解和快速傅里叶变换(FFT),降低了计算复杂度,并利用GPU加速矩阵运算。
- 并行策略:采用能量并行和原子索引并行,结合递归格林函数(RGF)算法,优化了计算和通信效率。
- 物理建模:引入e-e相互作用,精确描述了带隙、电流分布等关键特性。
-
实验结果:
- 在1,800个LUMI GPU节点上,实现了69.3 Pflop/s的计算性能(双精度),并行效率在弱扩展中达74%,强扩展中达60%。
- 科学结果显示,e-e相互作用显著影响器件性能,如带隙增宽1.1 eV,并揭示了能量转移和电流反射现象。
-
应用意义:
- 该工作突破了传统方法的限制,使超大规模纳米器件的精确模拟成为可能,为下一代半导体设计(如单光子雪崩光电二极管)提供了强大工具。
总之,这项研究通过算法创新和超级计算资源的高效利用,推动了纳米电子器件模拟向百亿亿次(Exascale)计算迈进,为器件设计和物理研究开辟了新路径。
Performance Modeling
LLAMP: Assessing Network Latency Tolerance of HPC Applications with Linear Programming
Best Paper Finalist
这篇文章提出了 LLAMP(LogGPS and Linear Programming based Analyzer for MPI Programs),一个用于评估高性能计算(HPC)应用程序网络延迟容忍度的创新工具链。以下是其工作的简要介绍:
背景与动机
随着AI工作负载推动数据中心和HPC集群向高带宽网络发展,网络延迟问题日益凸显,对通信密集型HPC应用的性能产生了负面影响。不同MPI(消息传递接口)应用的网络延迟容忍度差异显著,传统评估方法依赖专用硬件或复杂模拟,效率低下且难以扩展。LLAMP旨在通过分析方法快速量化应用的延迟敏感性和容忍度。
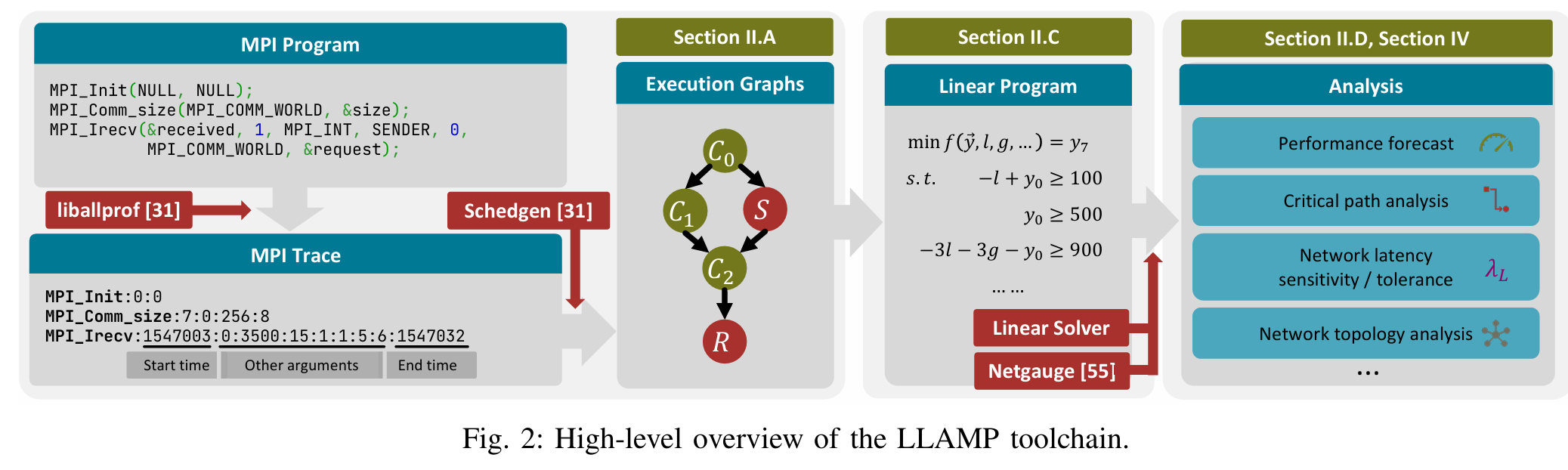
核心贡献
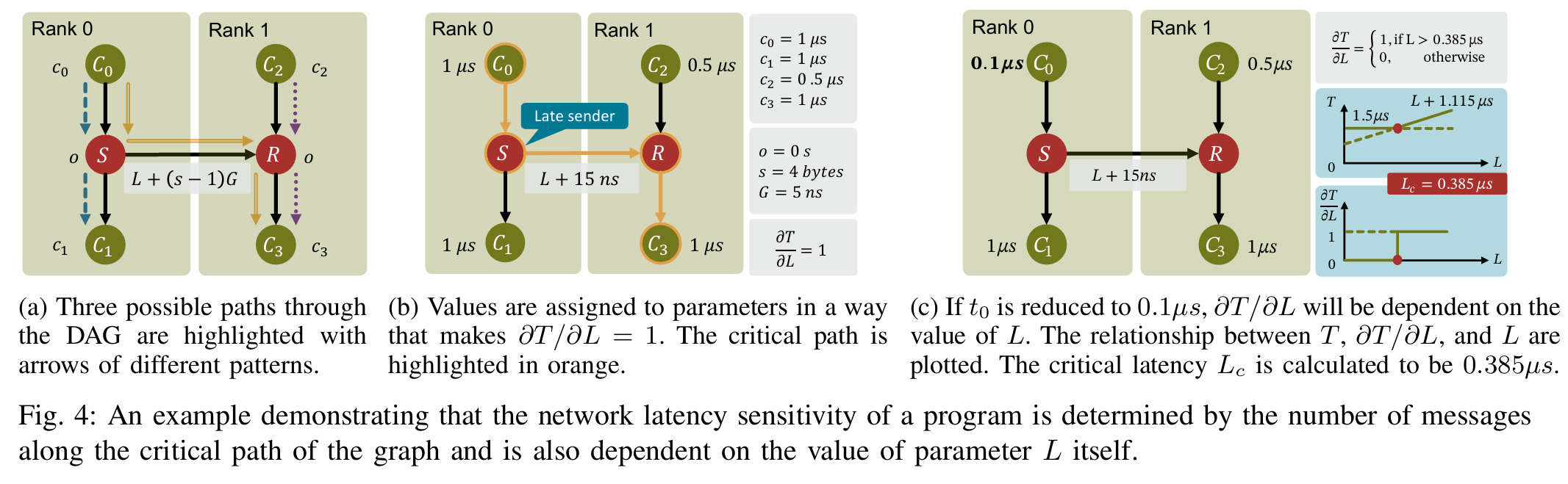
- 分析模型:基于LogGPS通信模型和线性规划(LP),LLAMP将MPI应用的执行图转化为线性程序,数学化定义并计算网络延迟敏感性((\lambda_L))和容忍度(最大可承受延迟)。
- 工具链实现:开发了开源工具链LLAMP,利用执行图和LP快速预测运行时间、关键路径等性能指标,支持开发者和架构师优化应用部署和网络设计。
- 延迟注入与验证:设计了便携式软件延迟注入器,无需专用硬件即可模拟流级网络延迟,在MILC、LULESH、ICON等应用上验证了LLAMP预测精度,误差通常低于2%。
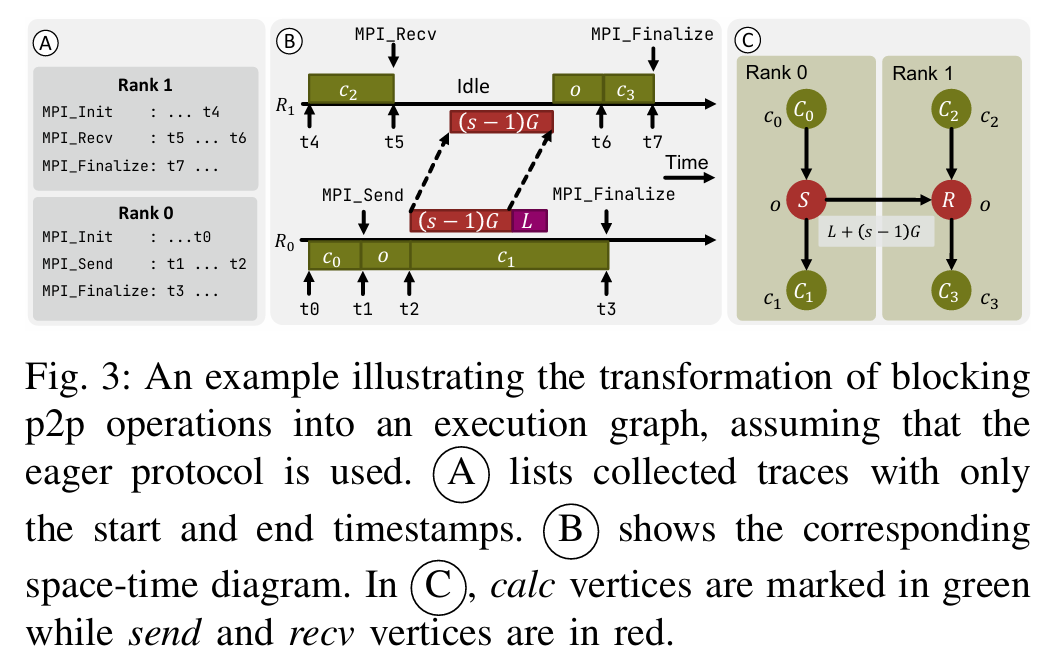
实现与评估
-
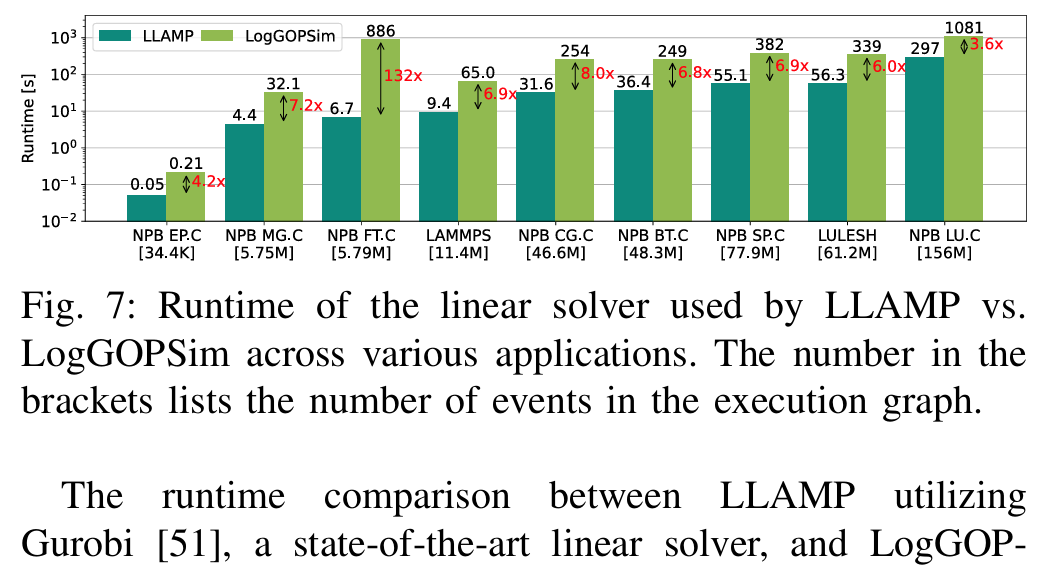
方法:LLAMP通过LogGOPSim记录MPI跟踪,生成执行图,再用LP求解器(如Gurobi)分析,比传统模拟器(如LogGOPSim)快6倍以上。
-
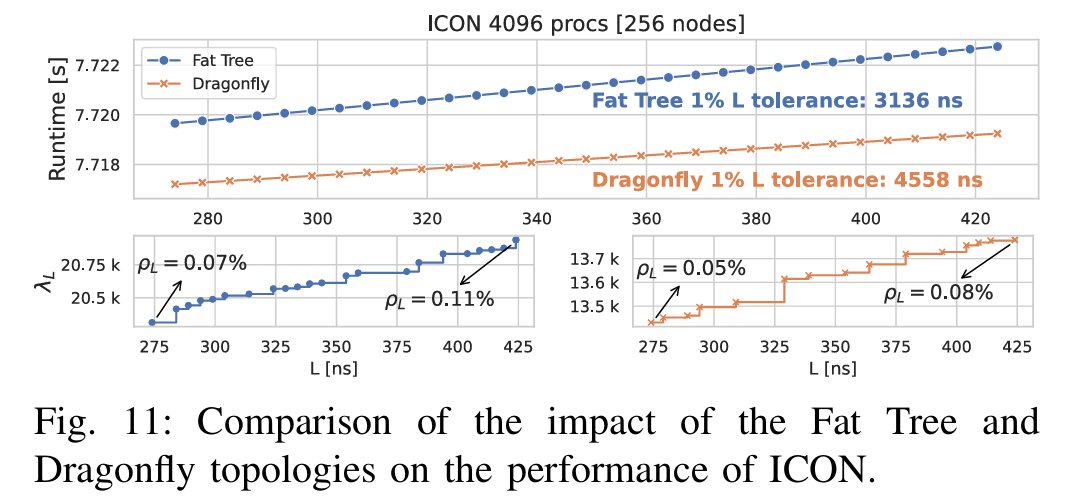
案例研究:以ICON气候模型为例,展示了LLAMP在评估集体算法(如MPI_Allreduce)和网络拓扑(如Fat Tree和Dragonfly)影响方面的广泛适用性。

LLAMP提供了一种高效、可扩展的分析方法,帮助理解HPC应用的延迟容忍度,支持在高延迟网络环境中优化系统设计和应用性能。未来可通过集成更复杂的模型(如LogGOPSC)或支持动态调度框架(如charm++)进一步增强其功能。
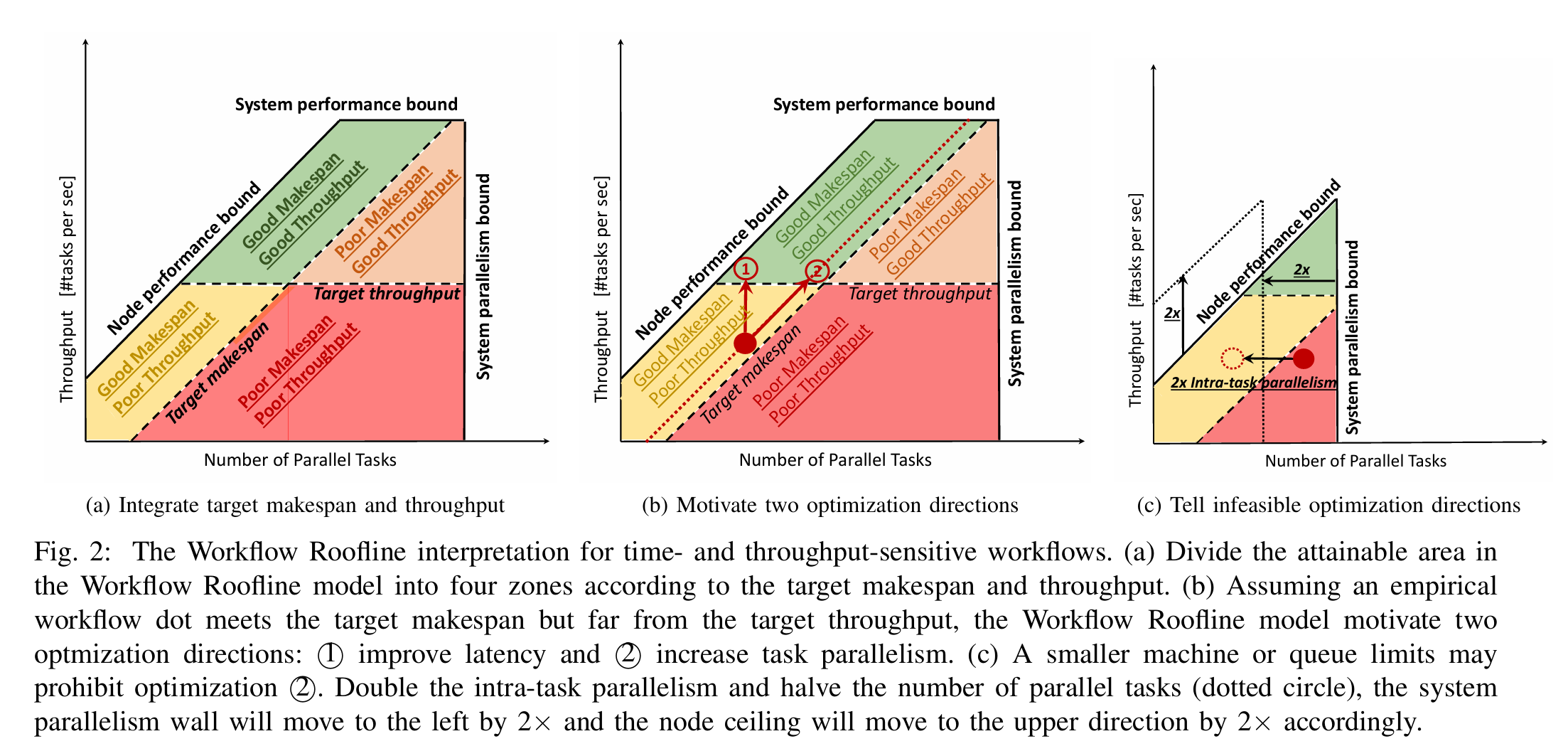
Workflow Roofline Model for End-to-end Workflow Performance Analysis
屋顶线性能模型(Roofline Performance Model) 简称 屋顶线模型(Roofline Model),用于分析模型在特定计算平台上所能达到的理论计算性能上限(由于环境等因素的影响,实际性能测试结果一般差于Roofline模型给出的结果)。
Roofline模型的构建与应用 - 知乎

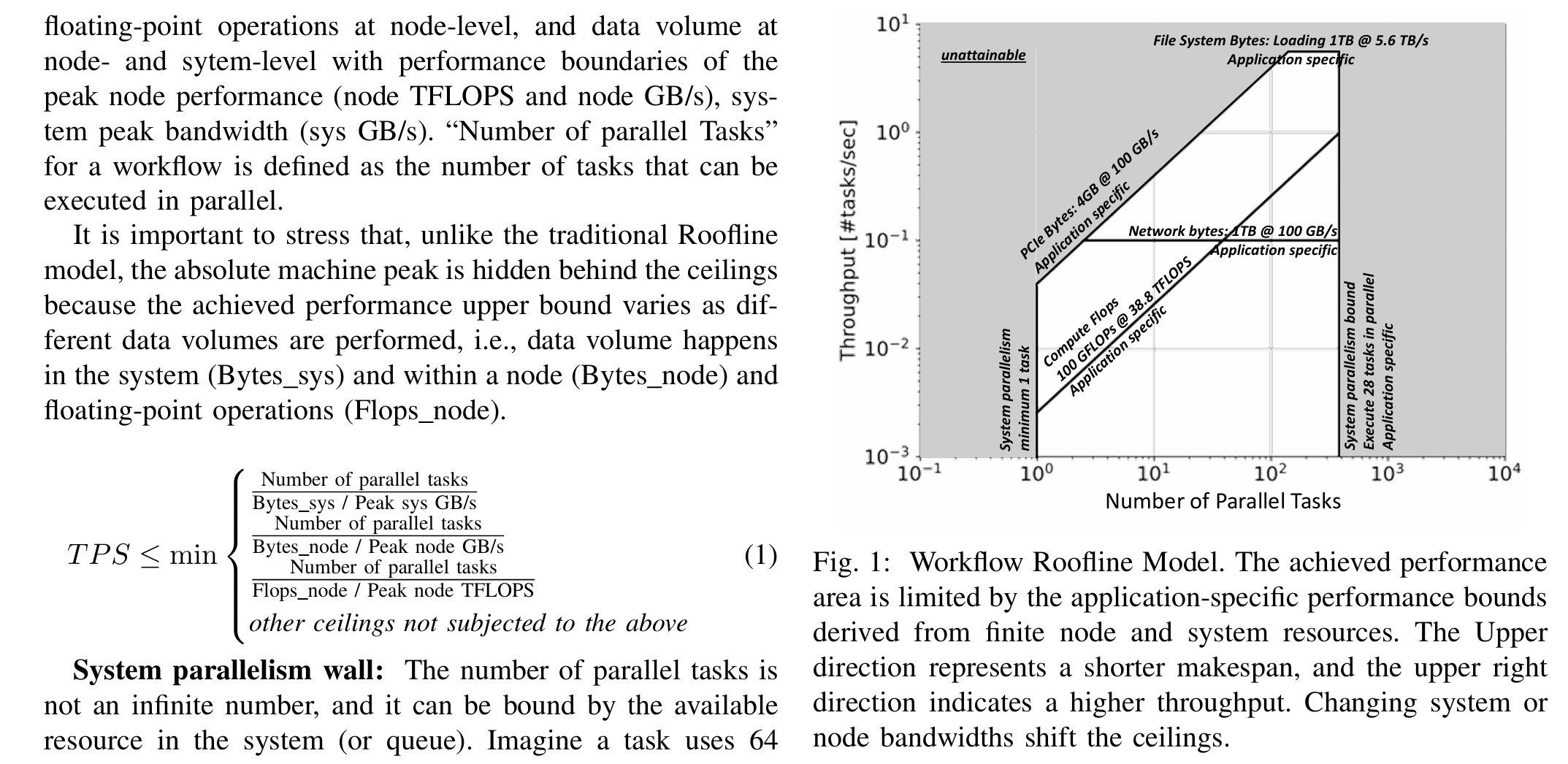
这篇文章提出了工作流Roofline模型(Workflow Roofline Model),用于端到端分析高性能计算(HPC)工作流的性能。以下是其工作的简要介绍:
背景与动机
随着新一代科学仪器(如实验和观测设备)分辨率提升和数据采集速度加快,HPC工作流需要更高的可移植性和性能以满足高效产出的需求。传统Roofline模型适用于单内核性能分析,但无法有效处理由多个任务和数据处理步骤组成的工作流。作者提出了一种新的方法,旨在识别工作流的性能瓶颈并指导优化。

核心贡献
- 工作流Roofline模型:扩展了传统Roofline模型,从关注单节点计算和内存带宽,转向分析工作流的吞吐量(每秒任务数,TPS)和延迟(makespan)。模型结合节点级(浮点运算、数据移动)和系统级(文件系统、网络带宽)性能指标,定义了性能上限(ceilings)。
- 性能瓶颈识别:通过可视化方式(如图表),将工作流性能划分为不同区域(如计算受限或系统带宽受限),直观展示潜在瓶颈,并指导优化方向(如增加并行任务或提升节点效率)。
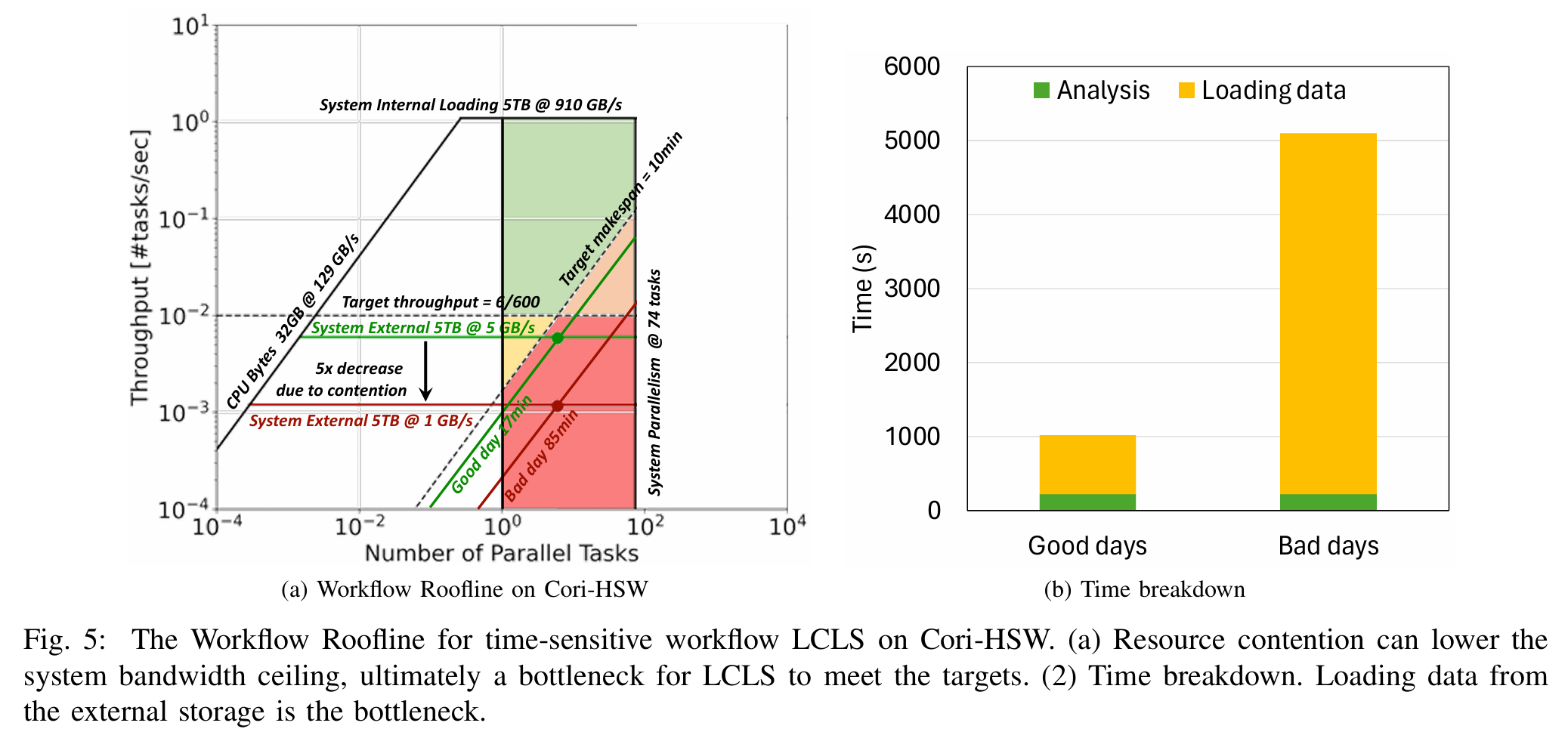
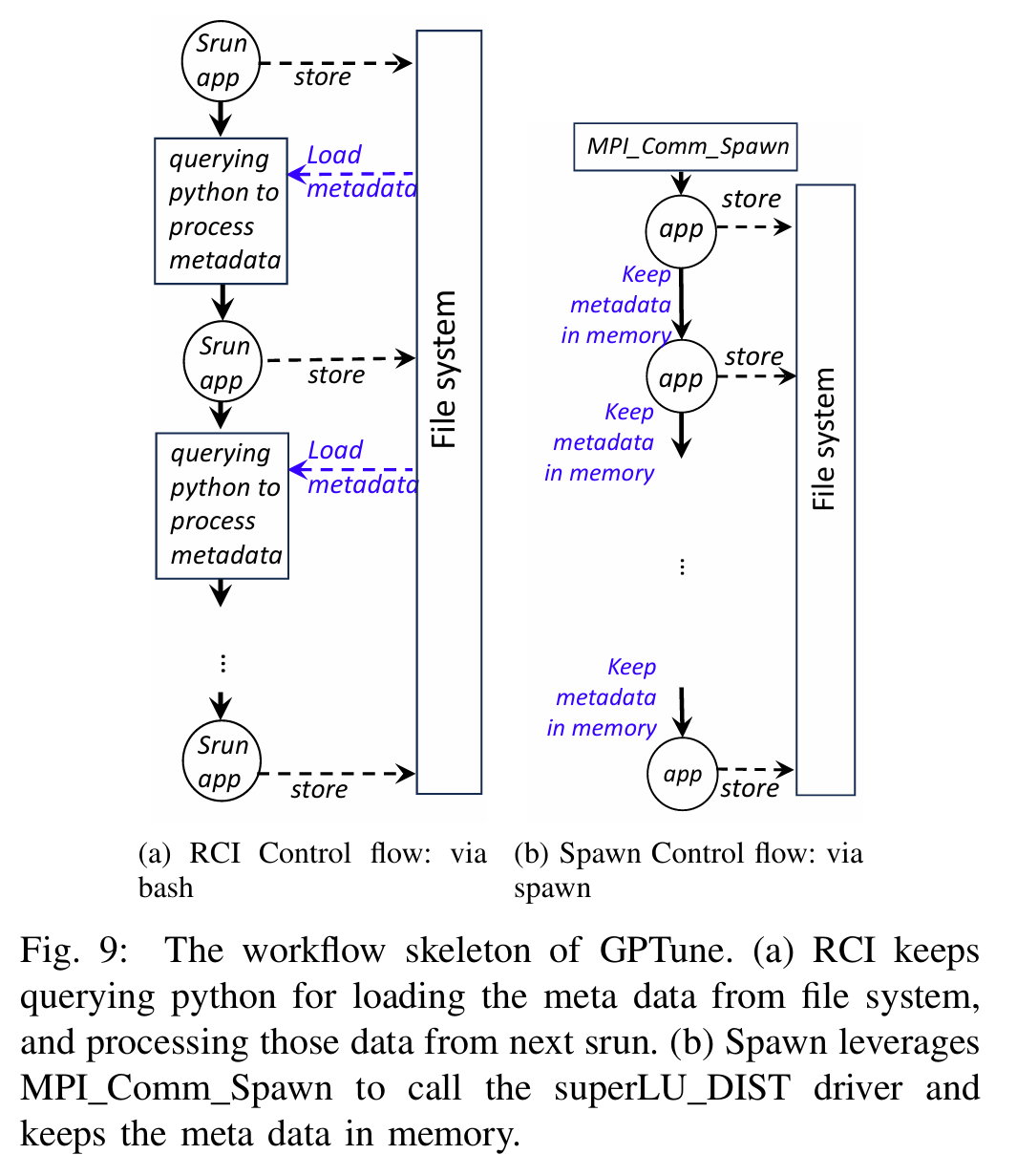
- 案例研究:在Perlmutter超级计算机上验证了模型,分析了BGW、Cosmoflow、GPTune等实际工作流,展示了其在传统HPC和AI驱动任务中的适用性。例如,GPTune的分析表明Spawn模式通过减少I/O和bash开销显著提升性能。
方法与实现
- 指标定义:使用并行任务数、节点浮点运算、系统和节点数据量等轻量级指标,结合硬件峰值性能(如Perlmutter的5.6 TB/s文件系统带宽)构建模型。
- 应用场景:针对时间敏感型(如LCLS)和吞吐敏感型工作流,提出优化建议,如调整任务并行性或改进系统带宽。
意义与局限
该模型提供了一个统一的分析框架,帮助系统架构师、工作流开发者和用户优化HPC工作流性能。未来需解决的局限包括:关键路径长度未显式体现,以及节点级性能分析的开销较大。
总之,工作流Roofline模型通过结合节点和系统视角,为复杂工作流的性能优化提供了实用工具和洞察。
Learning Generalizable Program and Architecture Representations for Performance Modeling
PerfVec/PerfVec: A generalizable machine learning-based performance modeling framework.
这篇文章提出了 PerfVec,一个用于性能建模的新颖框架,旨在通过深度学习实现程序和微架构性能影响的分离,从而提升模型的通用性和预测效率。以下是其工作的简要介绍:
背景与动机
性能建模在性能优化、设计空间探索和资源分配等领域至关重要。然而,传统方法如模拟器计算成本高、分析模型精度低,而基于机器学习(ML)的模型虽然较快且精度较高,但缺乏通用性,难以适应新的程序或微架构。PerfVec 旨在解决这一问题,构建一个可跨程序和微架构通用的性能预测模型。
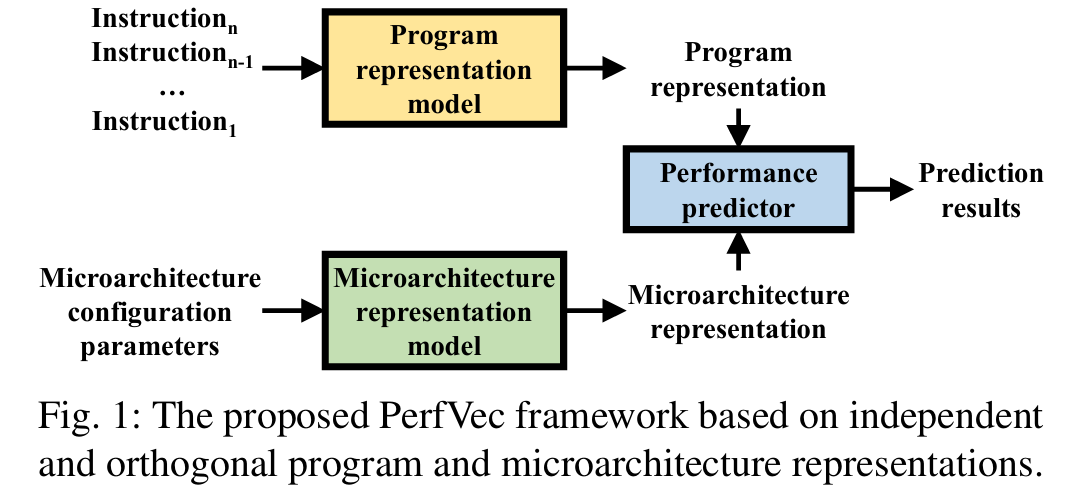
核心贡献
- 框架设计:PerfVec 将程序和微架构的性能影响分离,通过三个机器学习模型实现:程序表示模型(基于指令执行轨迹生成微架构无关的表示)、微架构表示模型(生成程序无关的表示)和性能预测器(结合两者预测性能)。
- 指令表示基础模型:提出了一种“基础模型”,通过分析指令及其邻近指令的执行特性,学习指令的性能表示。程序表示由所有执行指令的表示累加组成,具有可组合性,确保对任意程序的通用性。
- 高效训练:引入微架构采样(无需完整微架构模型)和指令表示重用,大幅降低训练开销。例如,在 NVIDIA A100 GPU 上,训练时间从 26 天减少到 8 小时。
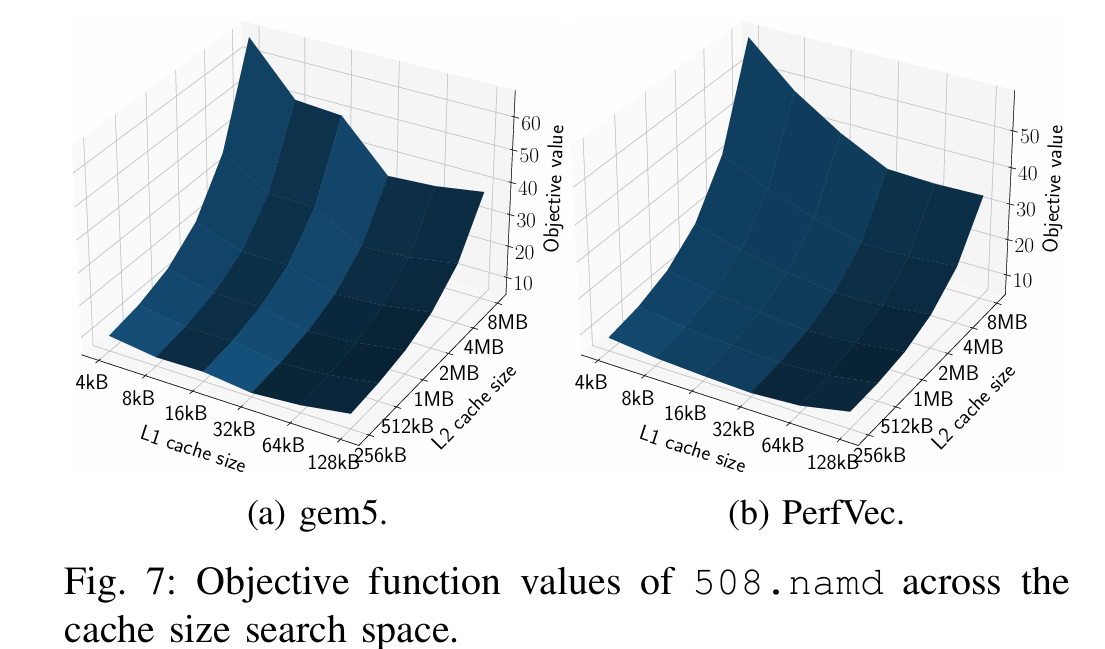
- 验证与应用:在 SPEC CPU2017 基准测试和 gem5 模拟器上验证,PerfVec 对已见和未见程序/微架构的预测误差分别低于 8% 和 10%。展示了设计空间探索(DSE)和程序分析(如循环平铺优化)的应用,相比传统模拟快 15-50 倍。
方法与实现
- 输入特征:使用 51 个微架构无关的指令特征(如栈距离和分支熵)捕捉性能特性。
- 模型架构:采用 2 层 256 维 LSTM 作为基础模型,预测指令增量延迟。
- 数据集:基于 gem5 模拟 77 个微架构和 SPEC CPU2017 的 17 个程序,生成 2TB 数据。
意义与局限
PerfVec 提供了一个快速、通用且准确的性能建模工具,支持硬件设计和程序优化。当前局限在于仅针对顺序程序,未来计划扩展到并行程序建模。
总之,PerfVec 通过创新的表示分离和高效训练方法,为性能建模领域带来了新的可能性。代码已开源于 GitHub。