
Risgraph
- Paper Reading
- 2025-01-12
- 535 Views
- 0 Comments
- 3006 Words
RisGraph: A Real-Time Streaming System for Evolving Graphs to Support Sub-millisecond Per-update Analysis at Millions Ops/s
low latency and high though put
Batch 能解决 high thoughput , 但是很多信息消失,同时实时性不够
stream 能解决 low latency
每个更新更新一次
per-update analysis does not ingest multiple updates as a whole or analyzes them together. T herefore,per-updatesystemscannotreuseexistingtechniquesde signed for batching or benefit from batched updates, such as amor tizing overheads across multiple updates.
我们的motivation
Guiding Ideas. We propose two guiding ideas to address the challenge, localized data access and inter-update parallelism.
we can avoid these scans by only accessing the necessary vertices affected by updates, we will gain much better performance, thus we propose to use data structures called Indexed Adjacency Lists and sparse arrays to enable localized accesses.
We further improve throughput by processing updates in par allel (inter-update parallelism) while maintaining the per-update semantics to applications. We propose an algorithm to identify up dates that can be safely executed in parallel and execute the rest of updates one by one to keep low latency, as well as atomicity, isolation, and correctness of per-update analysis

RisGraph ensures that more than 99.9% updates can be processed within 20 milliseconds without breaking per-update analysis semantics.
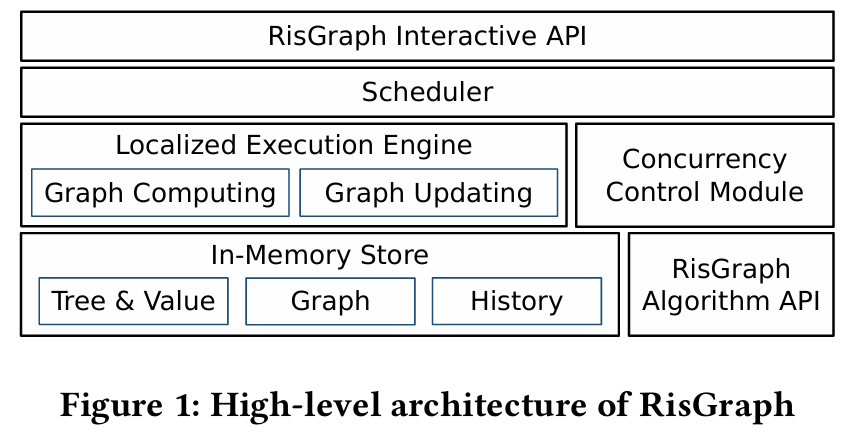
本地化
与批量更新系统不同,每次更新分析系统需要对每个更新进行分析,因此无法在多个更新之间分摊批处理的开销。为了解决这一挑战,我们设计了具有本地化数据访问的 RisGraph,这意味着在计算新结果时仅访问必要的顶点,包括要更新结果的顶点以及更新顶点的邻居。本地化数据访问背后的基本原理是增量计算只需要访问部分顶点,但不正确的数据结构需要部分计算才能访问整个图。系统应使用适当的数据结构以避免不必要的操作。 RisGraph 通过利用图形感知和本地化数据访问,将我们的评估提高了 2-4 个数量级。我们对图存储和图计算引擎进行了全新设计,消除冗余扫描。
图存储
对于每次更新分析,图存储需要处理每个单独的更新,并提供更新后的图,以便在短时间内进行高效分析。现有文献[43, 87]已经表明,使用数组的数组来存储邻接表可以支持更新并提供与压缩稀疏行(CSR)相当的计算性能。 GraphOne [43]、GraphBolt [54] 和 KickStarter 等图流系统也采用数组数组作为图存储。然而,它们的数据结构无法满足本地化数据访问,因为它们在应用更新时扫描所有顶点,即使处理单个更新也是如此。使用布隆过滤器,LiveGraph [87] 很好地支持细粒度的边缘插入,但在删除边缘时会受到扫描集线器上的边缘(高度顶点)的影响。
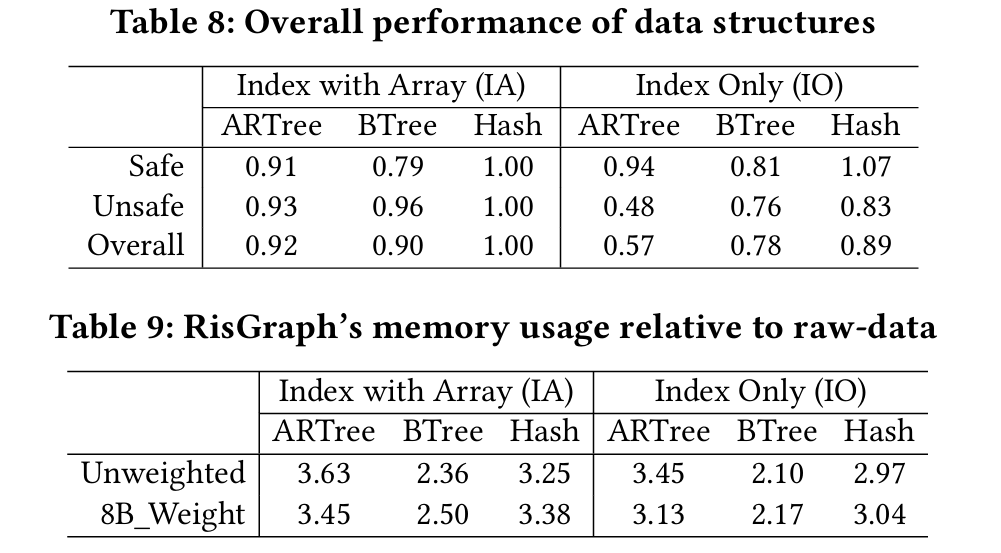
索引邻接表 RisGraph 提出了一种名为索引邻接表(Indexed Adjacency Lists)的数据结构(如图 3 所示),它使用数组阵列来存储边以进行高效分析,同时还维护边的索引,以解决前述方法的不足。在 RisGraph 中,每个顶点都有一个动态数组(容量满时加倍),用于存储出站边,包括目的顶点 ID 和数据。数组确保了所有出站边的连续存储,这对高效分析至关重要[87]。然而,数组在边缘查找时会受到细粒度更新扫描的影响。为了加快查找速度,Ris Graph 维护了边的⟨DstVid→Offset⟩的键值对,以指示数组中的边位置。索引只针对度数大于阈值的顶点创建,通过过滤掉幂律图中的低度顶点,在内存消耗和查找性能之间进行了权衡(见第 5 节)。
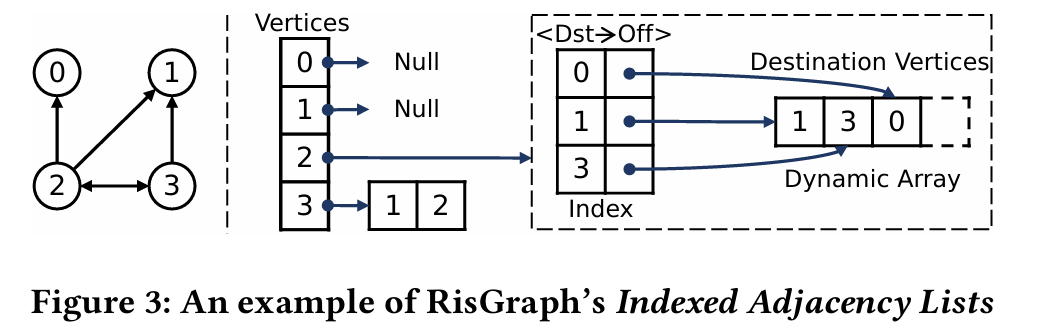
RisGraph 使用哈希表作为默认索引,因为我们的哈希表数据结构为每次更新提供平均 O(1) 时间复杂度。此外,索引不会损害RisGraph的分析性能,因为图计算引擎可以直接访问邻接表而不涉及索引。
计算
最近的图处理系统 [84, 86] 和图存储 [43, 87] 更喜欢密集数组或位图来存储活动顶点,因为密集表示在图计算中比稀疏数组表现更好。图 5 显示了密集数组和稀疏数组的示例。 KickStarter 也使用位图,但是,检查整个顶点集并清除位图对于增量计算来说代价高昂。例如,在 Twitter-2010 上,清除和检查位图占用了 Kick Starter 90.3% 的 BFS 计算时间。
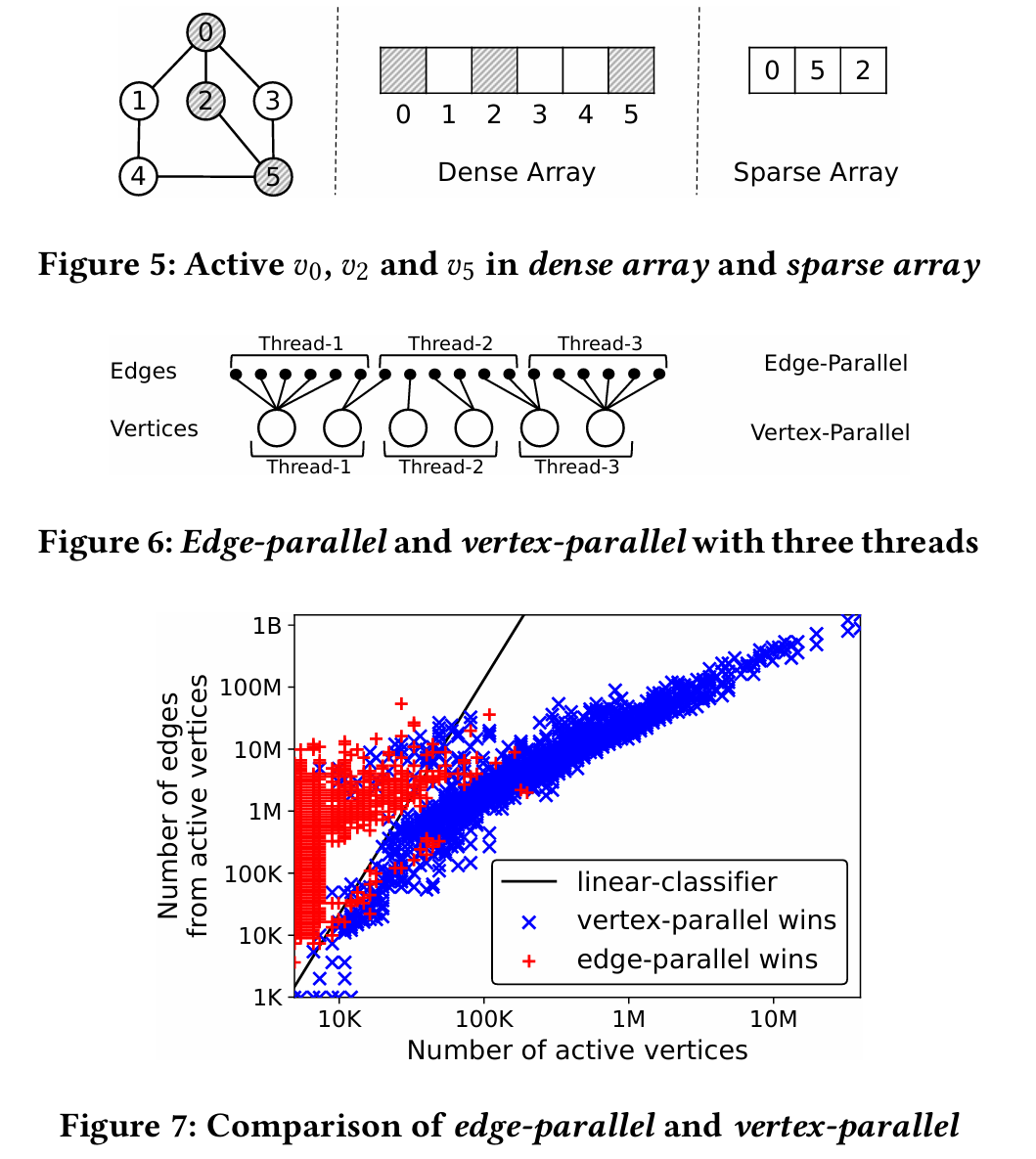
对于每次更新分析和增量计算,稀疏射线可以避免访问不必要的顶点,并将平均计算时间从 50 多毫秒缩短到几微秒。在其他情况下,当 Twitter-2010 上的批处理量小于 200K 时,稀疏阵列仍能提高计算性能。原因是稀疏阵列不是最优的,但对于许多活动顶点甚至整个顶点集来说仍是可以接受的[72]。例如,在 Twitter-2010 上直接计算 BFS 而不是增量计算,Ris Graph 需要 2.21 秒,而使用密集阵列计算 GraphOne 需要 0.76 秒。 总之,稀疏阵列为每次更新分析提供了数量级的改进,并能很好地处理大多数批量大小。 同时,稀疏阵列也适用于角落情况甚至整个图的分析。以 Twitter-2010 上的 BFS 为例,批量为 2 亿条边时,RisGraph 的性能只下降了 26.6%,而重新计算 BFS 时则下降了 65.6%。因此,我们选择稀疏阵列来存储活动顶点。
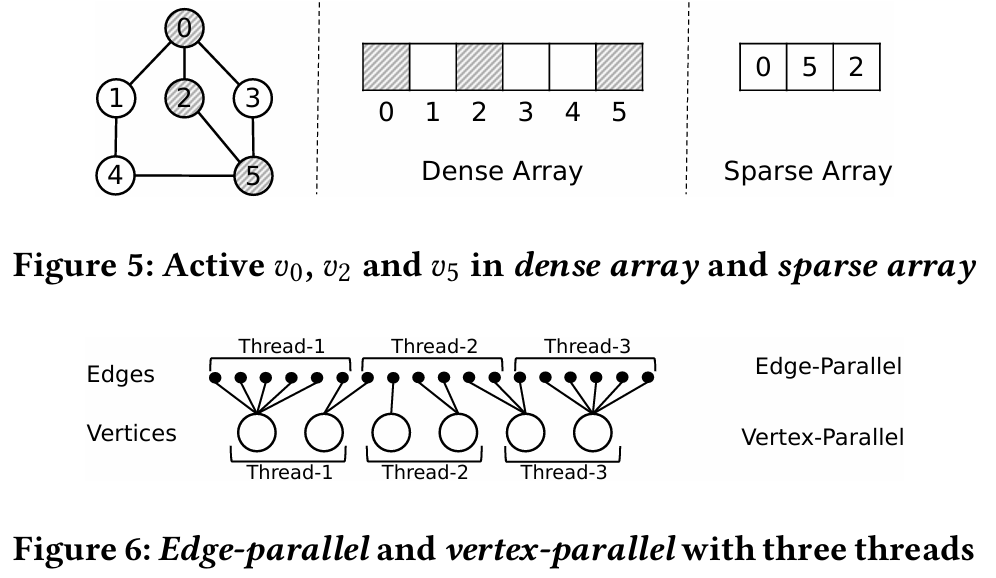
混合并行模式。对于稀疏阵列,推送操作有两种并行模式:顶点并行和边缘并行。 如图 6 所示,顶点并行将活动顶点作为并行单元,而边缘并行则是细粒度的,在所有边缘上并行,而不仅仅是顶点。图计算中的一个常见结论是顶点并行总是优于边缘并行 [84]。但是,在增量计算中,边并行有时会优于顶点并行,特别是考虑到倾斜的顶点和边并行。
图 7 显示了在 UK-2007 [16, 17] 数据集上运行四种不同算法(BFS、SSSP、SSWP 和 WCC)时,边并行和顶点并行的比较结果。
红点表示边缘并行的结果优于顶点并行的结果,蓝叉表示顶点并行的结果优于边缘并行的结果。当活动顶点较少而活动边较多(图的左上角)时,边缘并行比顶点并行更好。 我们通过线性回归训练的线性分类器(图 7 中的黑色直线)将边缘并行和顶点并行进行整合。在我们的评估中,混合模式比常用的仅顶点平行模式优胜 24.2%。
使用ML来决定系统参数??!!ML4Sys
并行、观察
观察。根据增量计算模型,所有顶点的结果仅依赖于依赖树上的边。由于依赖树中每个顶点最多有一个父顶点,因此最多有 |𝑉 | (顶点数)树上的边,而不是|𝐸| (图中的总边)。其他边与结果无关,因此,修改这些边不会改变任何结果。 这一事实给了我们启发,并引出了一个自然的问题:更新会对结果产生多大的改变。我们在表 3 中列出的 10 个图上分析了四种算法(BFS、SSSP、SSWP 和 WCC)。我们还改变了初始加载边的数量 (|𝐸|),包括 10%、50% 和 90% 的边,以显示平均度数的影响 (|𝐸| / |𝑉 |)。生成更新和不同程度的方法与第 6 节中的评估相同。表 3 还列举了 BFS、SSSP 和 SSWP 的根选择以及从根到访问顶点的百分比(边数为 90%)。
我们发现,大多数情况下,只有一小部分更新改变了结果,如表4所示。在115个算法和数据集的组合(总共120个实验)中,修改结果的更新比例不到20%。在100/120的实验中,该比例小于10%。77/120的实验表明,不到5%的更新修改了结果。 观察指南提出了一种单调算法的特定于域的并发控制机制,以避免跟踪内存访问。我们将不改变任何结果的更新命名为安全更新。 相应地,不安全更新修改结果或依赖关系树。如果我们识别安全更新并仅并行处理它们,我们不仅可以保持每次更新分析的正确性,还可以提高吞吐量。

然后,我们设计了一个并行的循环模式,利用分类所带来的等距线性来提高吞吐量并确保正确性。 图 9 显示了 RisGraph 在处理来自多个会话的更新日期时的单循环模式。 RisGraph 将更新分为安全(S)、不安全(U)和下一时序(N)。在不安全的更新日期之后,同一会话中的所有更新都是下一时序更新,这意味着这些更新应被归入下一时序,因为任何不安全的操作都可能会修改结果并改变后面更新的分类。相比之下,RisGraph 逐个处理不安全更新,并对每个更新进行并行增量计算(数据内部并行)。
为了提高用户友好性,RisGraph 保证来自会话的更新将在更新顺序相同的情况下执行,并提供顺序一致性。RisGraph 的调度程序会控制每个进程的大小,并尽可能满足用户所需的尾部延迟(处理时间延迟[39]),这将在第 5 节中讨论。 在我们的实验中(第 6.2 节),RisGraph 的吞吐量比没有数据间并行的吞吐量高出 14.1 倍,而 99.9 百分位数(P999)的延迟低于 20 毫秒。
与只写事务类似,在同时维护多个算法时,只有当更新对每个算法都安全时,更新才是安全的。安全更新的比例会随着事务规模增大或算法增多而降低,从而减少更新间并行性带来的吞吐量。与未打包到事务中的更新相比,当每个事务的大小为 16 时,RisGraph 的吞吐量平均降低了 51.1%。无论如何,即使所有事务或更新都不安全,本地化数据访问仍能提供数千倍于现有系统的吞吐量。
on ten graph datasets in Table 3. LinkBench (128M vertices) and LDBC SNB (SF1000) are interactive datasets from graph database benchmarks [12, 27], con sisting of a pre-populated graph and incoming updates.
We load 90% edges first, select 10% edges as the deletion updates from loaded edges, and treat the re maining (10%) edges as the insertion updates. If datasets are times tamped, wechoosethelatest10%astheinsertionsetandtheoldest 10% as the deletion set; otherwise, we randomly select edges as up dates. The ratio of insertions to deletions is 50% by default, and we alternately request insertions and deletions of each edge.
Weset upexperiments on two dual-socket servers, running Ris Graph and clients respectively. Each server has two Intel Xeon Gold 6126 CPU (12 physical cores per CPU), 576GB main memory, an Intel Optane P4800X 750GB SSD, an 100Gb/s Infiniband NIC, and runs Ubuntu 18.04 with Linux 4.15 kernel
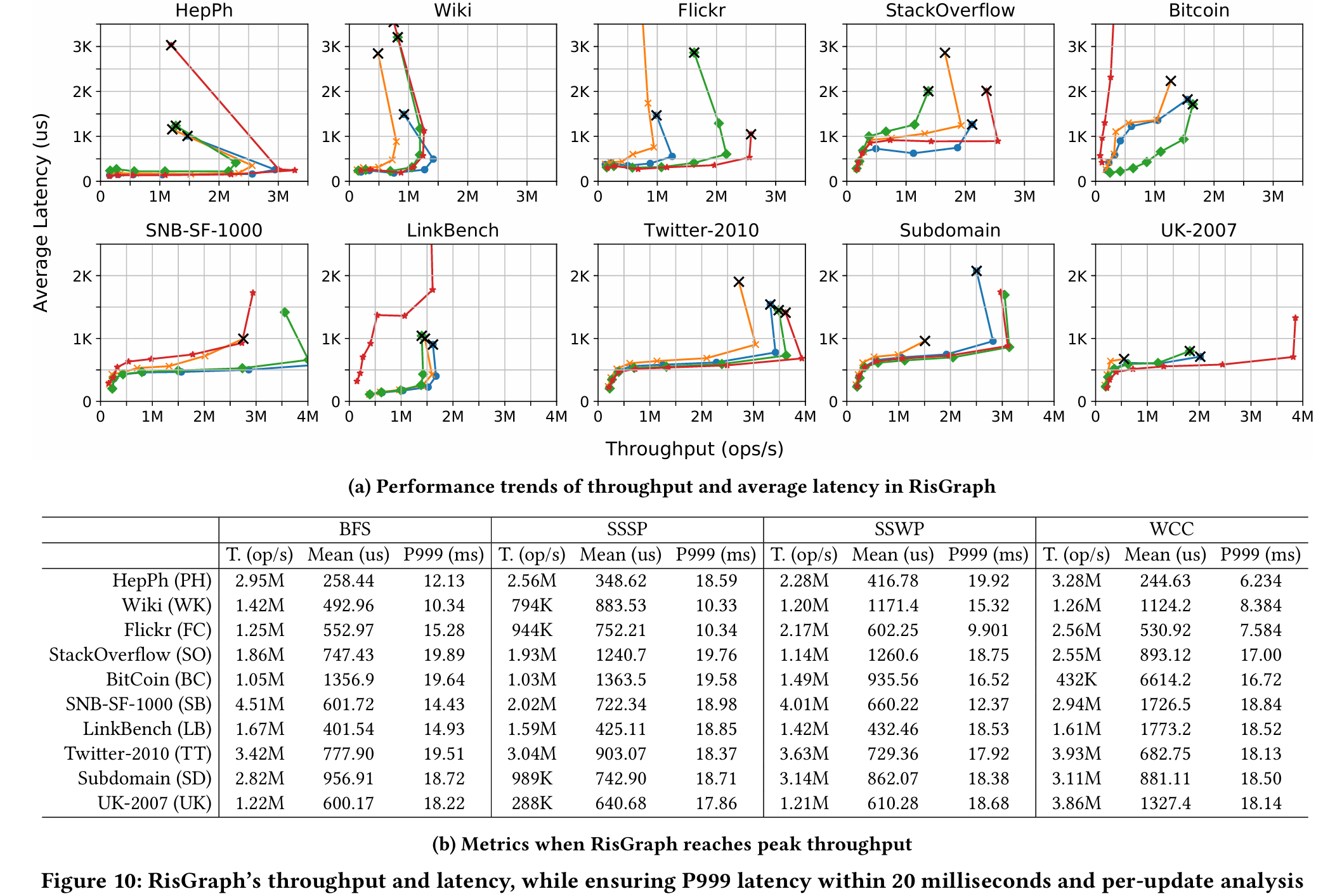
All modules in RisGraph are enabled, including the write-ahead log, the scheduler andthehistorystore.Onthenextpage,Figure10
Figure 10b lists detailed metrics when throughput reaches the peak. In Figure 10b, T. represents throughput, while Mean and P999 are average latency and tail latency, respectively. RisGraph’s throughput reaches hundreds of thousands or millions of updates per second, meanwhile, the P999 latency is under 20 milliseconds. T hese results indicate that the designs of RisGraph can provide high throughput under per-update analysis.
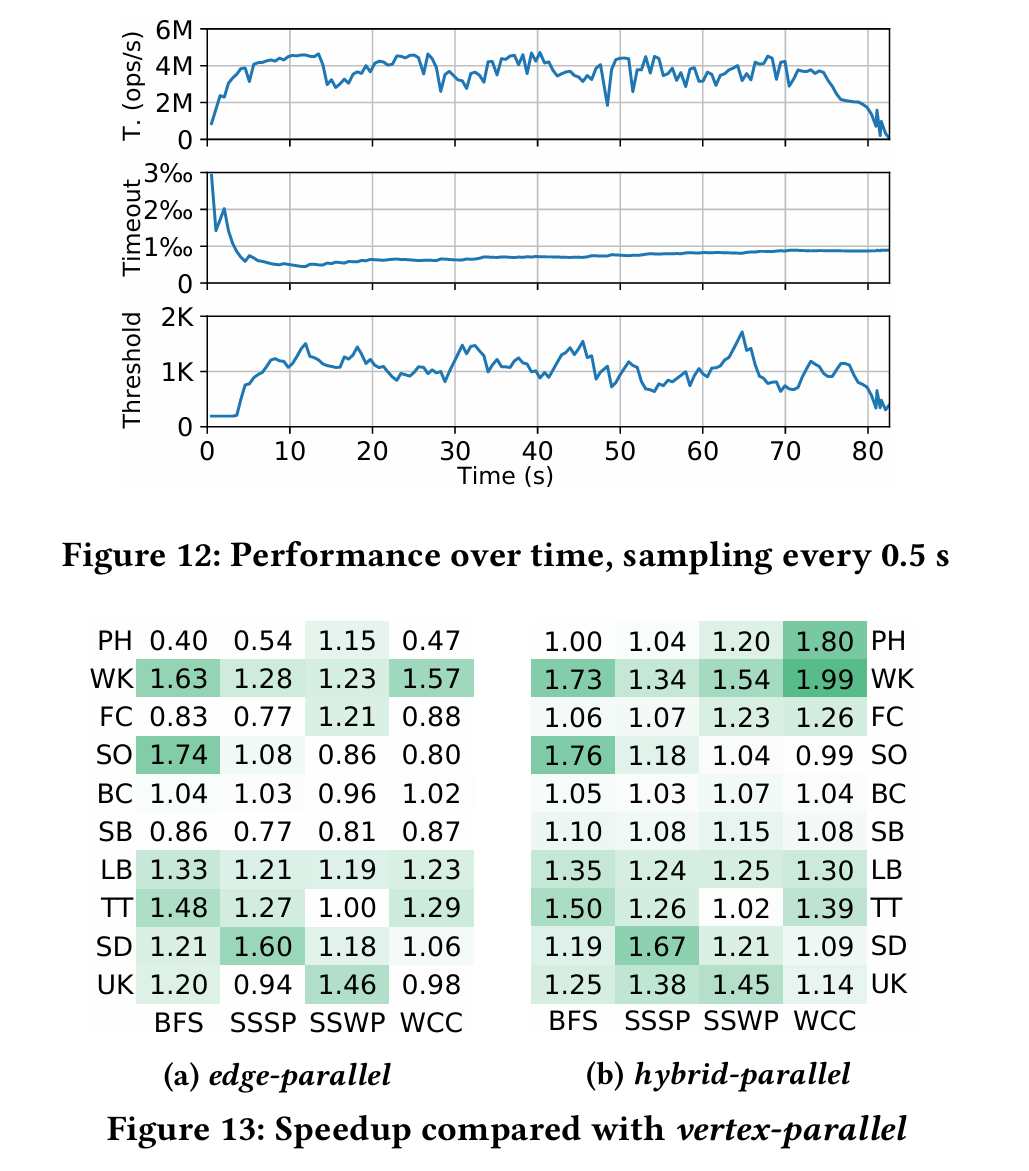
图 11 显示了 RisGraph 在不同算法下的性能分解情况。按我们算法的平均值计算,作为 RisGraph 核心的图形更新引擎(UpdengEng)和计算引擎(CmpengEng)分别耗费了 36.4% 和 29.2% 的时间。为了追踪结果,历史存储(HisStore)耗时 5.7%。并发控制模块(CC)和调度程序(Sched)非常轻量级,总共只占用了 3.6% 的时间。WAL 提供持久性,网络与客户端交互,分别占用 14.0% 和 11.1% 的时间。
DataStruct

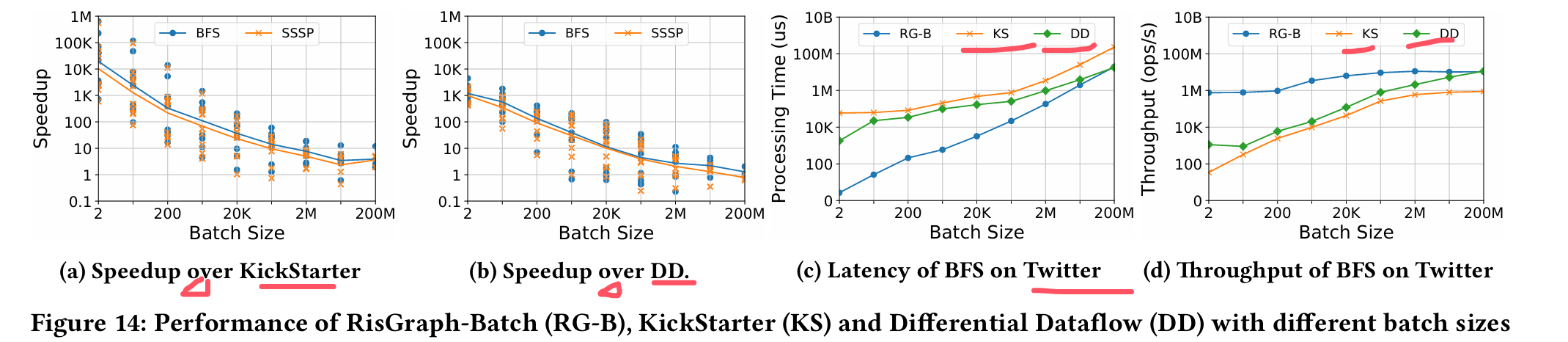
*KickStarter
数据集