
RAG、GraphRAG介绍
- Machine Learning
- 2025-02-22
- 1530 Views
- 1 Comments
- 3274 Words
本文是对这两个概念的转载与学习
部署效果:
RAG介绍
检索增强生成(RAG) 是一种结合信息检索和生成模型的技术,用于提高大语言模型(LLM)的回答准确性和深度12。
检索增强生成(Retrieval Augmented Generation,RAG)整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,显著提升了回答的准确性与深度。
LLM 擅长语言理解、推理和生成等任务,但也存在一些问题:
- 信息滞后:LLM 的知识是静态的,来源于当时训练时的数据,也就是 LLM 无法直接提供最新的信息。
- 模型幻觉:实践表明,当前的生成式 AI 技术存在一定的幻觉,而在一些常见的业务应用中,我们是希望保证事实性的。
- 私有数据匮乏:LLM 的训练数据主要来源于互联网公开的数据,而垂类领域、企业内部等有很多专属知识,这部分是 LLM 无法直接提供的。
- 内容不可追溯: LLM 生成的内容往往缺乏明确的信息来源,影响内容的可信度。RAG 将生成内容与检索到的原始资料建立链接,增强了内容的可追溯性,从而提升了用户对生成内容的信任度。
- 长文本处理能力较弱: LLM 在理解和生成长篇内容时受限于有限的上下文窗口,且必须按顺序处理内容,输入越长,速度越慢。
2020 年,Meta AI 研究人员提出了RAG的方法,用于提高 LLM 在特定任务上的性能。RAG 通过检索和整合长文本信息,强化了模型对长上下文的理解和生成,有效突破了输入长度的限制,同时降低了调用成本,并提升了整体的处理效率。
RAG 通过将检索到的相关信息提供给 LLM,让 LLM 进行参考生成,可以较好地缓解上述问题。因此,合理使用 RAG 可以拓展 LLM 的知识边界,使其不仅能够访问专属知识库,还能动态地引入最新的数据,从而在生成响应时提供更准确、更新的信息。
RAG组成部分
- 自定义知识库,用于RAG检索的知识来源:
- 结构化的数据库形态:比如MySQL
- 非结构化的文档体系:比如文件、图片、音频、视频
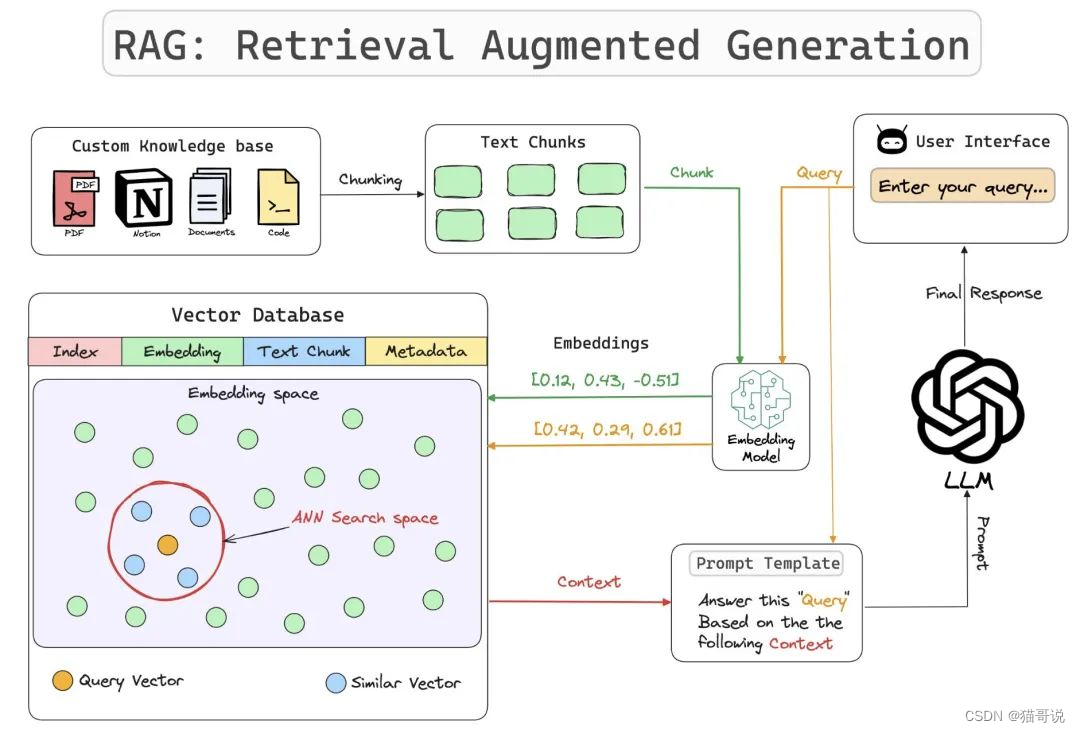
RAG 是一个完整的系统,其工作流程可以简单地分为数据处理、检索、增强和生成四个阶段:
数据处理阶段
对原始数据进行清洗和处理。将处理后的数据转化为检索模型可以使用的格式。将处理后的数据存储在对应的数据库中。
检索阶段
将用户的问题输入到检索系统中,从数据库中检索相关信息。
增强阶段
对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用。
生成阶段
将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。
原文链接:https://blog.csdn.net/baidu_33256174/article/details/139574571
相应简易API代码
数据处理
首先,对原始数据进行清洗和处理,然后将其转化为检索模型可以使用的格式,并存储在数据库中。
import os
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader, UnstructuredFileLoader
from langchain.text_splitters import RecursiveCharacterTextSplitter
def load_document(file):
name, extension = os.path.splitext(file)
if extension == '.pdf':
loader = PyPDFLoader(file)
elif extension == '.docx':
loader = Docx2txtLoader(file)
elif extension == '.txt':
loader = UnstructuredFileLoader(file)
else:
return None
return loader.load()
def chunk_data(data, chunk_size=256, chunk_overlap=150):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
return text_splitter.split_documents(data)向量化存储
将分块后的文本使用embedding模型持久化存储,以便后续检索。
from langchain_community.embeddings import HuggingFaceBgeEmbeddings, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma, FAISS
def get_embedding(embedding_name):
if embedding_name == "bge":
embedding_path = os.environ[embedding_name]
model_kwargs = {'device': 'cpu'}
return HuggingFaceBgeEmbeddings(model_name=embedding_path, model_kwargs=model_kwargs)
def create_embeddings_faiss(vector_db_path, embedding_name, chunks):
embeddings = get_embedding(embedding_name)
db = FAISS.from_documents(chunks, embeddings)
if not os.path.isdir(vector_db_path):
os.mkdir(vector_db_path)
db.save_local(folder_path=vector_db_path)
return db构建生成模型
定义生成模型,加载并使用它生成答案。
from llama_cpp import Llama
from langchain.llms.base import LLM
class QwenLLM(LLM):
model_name: str = "Qwen_q2"
temperature: float = 0.1
n_ctx: int = 2048
max_tokens: int = 1024
def _call(self, prompt: str):
qwen_path = os.environ[self.model_name]
llm = Llama(model_path=qwen_path, n_ctx=self.n_ctx)
response = llm.create_chat_completion(
messages=[{"role": "system", "content": "你是一个智能超级助手,请用专业的词语回答问题。"},{"role": "user", "content": prompt}],
temperature=self.temperature,
max_tokens=self.max_tokens)
return response['choices'][0]['message']['content']构建应用
使用Streamlit构建一个简单的RAG应用。
import streamlit as st
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
def ask_and_get_answer(vector_store, q, k=3):
llm = ChatOpenAI(model='gpt-3.5-turbo', temperature=1)
retriever = vector_store.as_retriever(search_type='similarity', search_kwargs={'k': k})
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
return chain.run(q)
if __name__ == "__main__":
st.subheader('LLM Question-Answering Application 🤖')
api_key = st.text_input('OpenAI API Key:', type='password')
if api_key:
os.environ['OPENAI_API_KEY'] = api_key
uploaded_file = st.file_uploader('上传文件:', type=['pdf', 'docx', 'txt'])
if uploaded_file:
bytes_data = uploaded_file.read()
file_name = os.path.join('./', uploaded_file.name)
with open(file_name, 'wb') as f:
f.write(bytes_data)
data = load_document(file_name)
chunks = chunk_data(data)
vector_store = create_embeddings_faiss(vector_db_path="./vector_db", embedding_name="bge", chunks=chunks)
prompt = st.text_input("Say something")
if prompt:
response = ask_and_get_answer(vector_store, prompt)
st.markdown(response)GraphRAG
手把手教你构建基于知识图谱的GraphRAG之结构化数据篇【LangChain+Neo4j】 - 文章 - 开发者社区 - 火山引擎
知识图谱是一种基于图结构的语义网络,用于表示现实世界中的知识。知识图谱不仅包含实体和关系,还包含它们的语义信息。它通常使用图数据库来存储和管理数据,但增加了语义层次,以提供更高级的知识表示和推理能力。
GraphRAG就是一种对存储在图数据库中的知识图谱(而非存储在向量数据库中的知识向量)进行检索,获得关联知识并实现增强生成的LLM应用。 这种方法可以更好的表示人类复杂的知识及其关系,并提供高效的检索能力,产生更加相关与丰富的上下文,让LLM生成最佳答案。
- 知识图谱更适合于需要精确表示实体间关系和进行复杂推理的场景。
- 向量化方案则更适合于基于相似性匹配和快速检索自然语言知识的应用。
GraphRAG在整体架构与传统RAG并无更大区别,区别在于检索的知识采用图结构的方式进行构建、存储并检索:
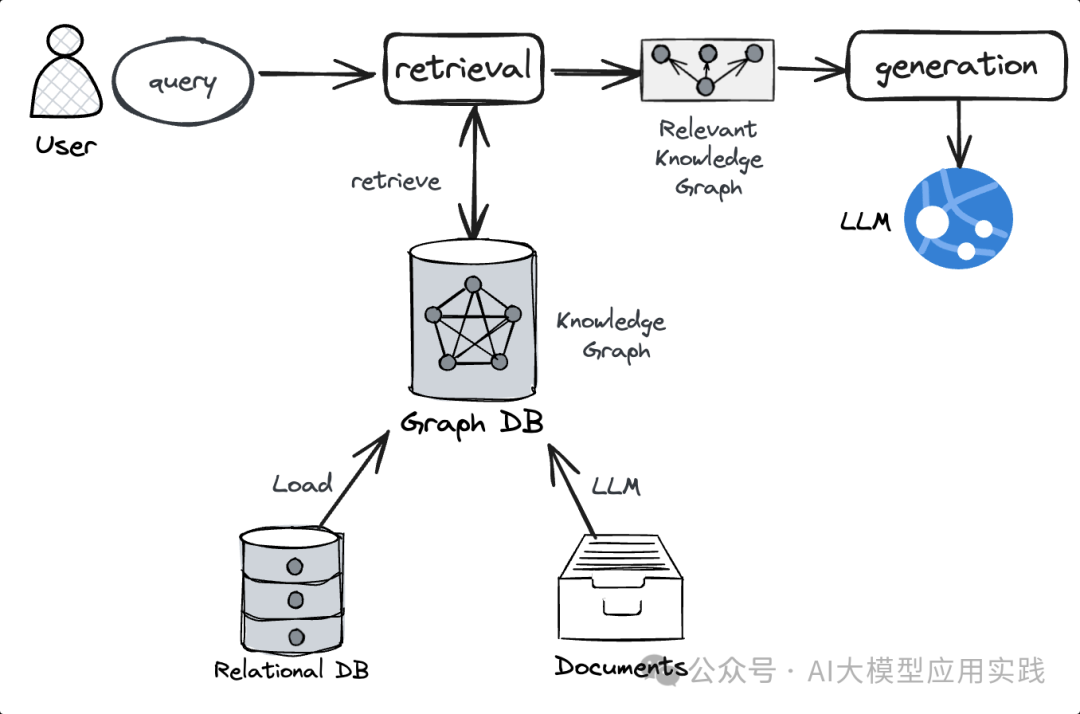
图基础:数学概念、图数据库
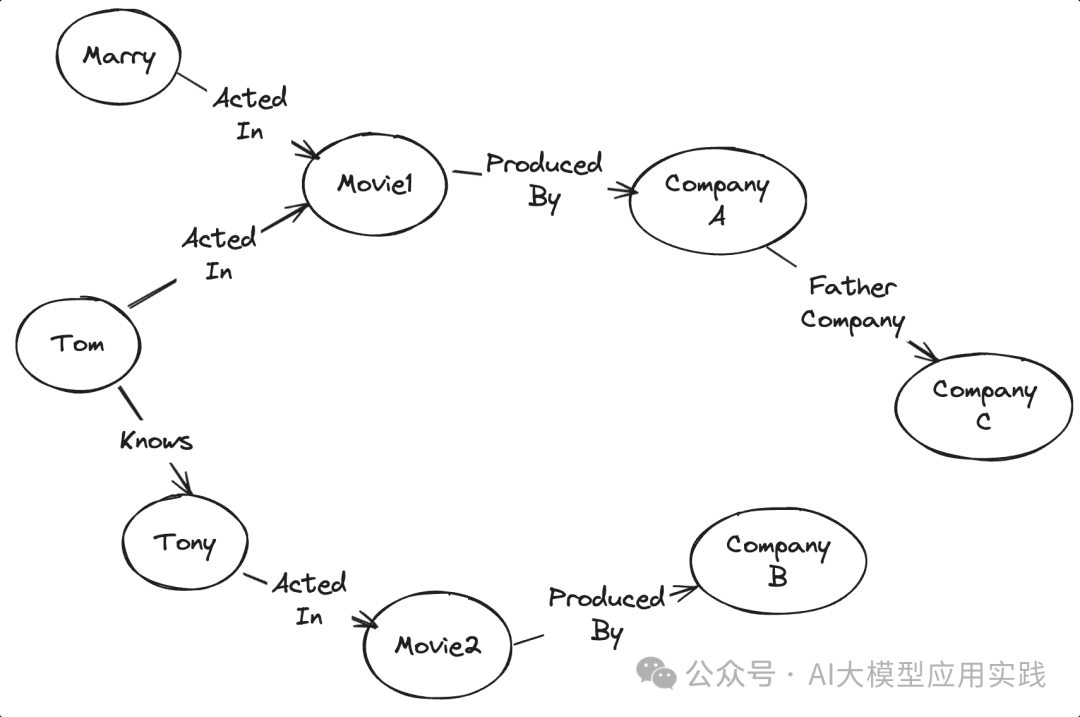
图(Graph)是一种用来表示对象以及它们之间关系的数学结构。 任何两个对象之间都可以直接发生联系,所以适合表达更复杂的关系信息。一个图结构的主要的组成是节点和边。
- 节点 :用来表示一个对象。比如社交网络的一个用户。
- 边 :用来表示对象之间的关系。比如用户之间的关系,如相互关注。
下面是一个关于明星、电影、公司这几种实体的一个Graph例子:
图数据库(GraphDB)
图数据库是一种专门用于存储和操作图结构数据的数据库管理系统。与关系型数据库不同,图数据库使用节点、边和属性来表示和存储数据。这使得 它们非常适合处理高度连接的数据,提供高性能的复杂查询能力,用来遍历与发现有洞察力的数据关系 。其最大特点是:
- 灵活的模型 :可以方便地表示复杂的关系。
- 高效的查询 :特别是多跳关系的查询,比关系数据库更高效。
- 可扩展性 :能够处理大量节点和边。
图数据库通常具备强大的知识图谱的多跳检索能力:通过多次的关系跳跃来发现相关的信息,这在处理复杂查询与发现关系时特别有用。比如对上面的图提问:
“查找Tom的朋友主演的电影的制作公司的母公司”
这样的查询借助于图数据库的效率要远远高于传统的关系数据库的表连接。
最 常见的图数据库管理系统有 Neo4j 、 Amazon Neptune、OrientDB、TigerGraph等,被广泛应用于社交网络分析、推荐系统、金融欺诈检测等。
GraphRAG图检索
基于图数据库进行知识图谱检索的时候,又可以有两种常见方式(取决于图数据库的支持能力):
借助Text-to-GraphQL :把自然语言的输入借助LLM与Text-to-GraphQL技术转换为图数据库的查询语言(比如Neo4j的 Cypher 语言),再使用图数据库的查询语言从知识图谱中检索出需要的知识。
借助Vector索引 :在构建的Graph基础上进一步对其中的节点与关系创建向量索引,并通过向量相似性来检索出相关的节点和关系信息;还可以结合传统的关键词做混合检索(注意区分直接对原始知识做向量检索)。
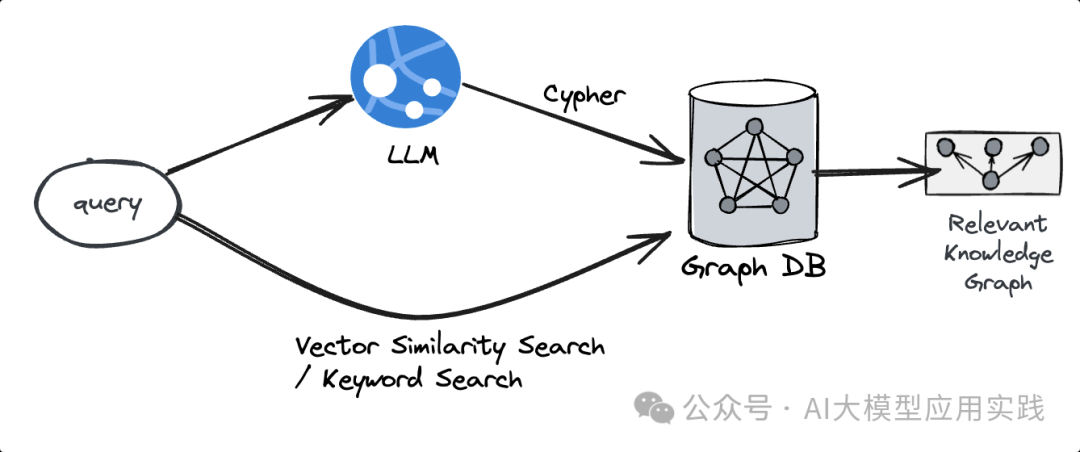
图数据库的强大之处在于你可以同时把结构化与非结构化的数据通过转化映射,以知识图谱的方式存储到单一的库中。通常来说,Text-to-GraphQL更适合对结构化数据生成的Graph进行查询,而Vector索引更适合对非结构化数据生成的Graph进行查询。
构建方法
GraphRAG通过以下4步实现。
图索引构建
GraphRAG首先使用大型语言模型(LLM)从源文档中提取实体、关系和属性,构建一个丰富的知识图谱。这个过程包括:
- 文本分块和实体识别
- 关系提取
-
属性和声明的识别
社区检测
利用Leiden算法等社区检测方法,GraphRAG将图索引划分为多个层次的社区。这种层次结构允许系统在不同粒度上组织和访问信息。
社区摘要生成
对每个检测到的社区,使用LLM生成描述性摘要。这些摘要提供了社区内容的高级概述,为后续的查询处理奠定基础。
查询处理
当收到查询时,GraphRAG采用以下步骤:
- 将查询映射到相关的社区
- 并行生成每个相关社区的部分回答
- 综合所有部分回答,生成最终的全局回答
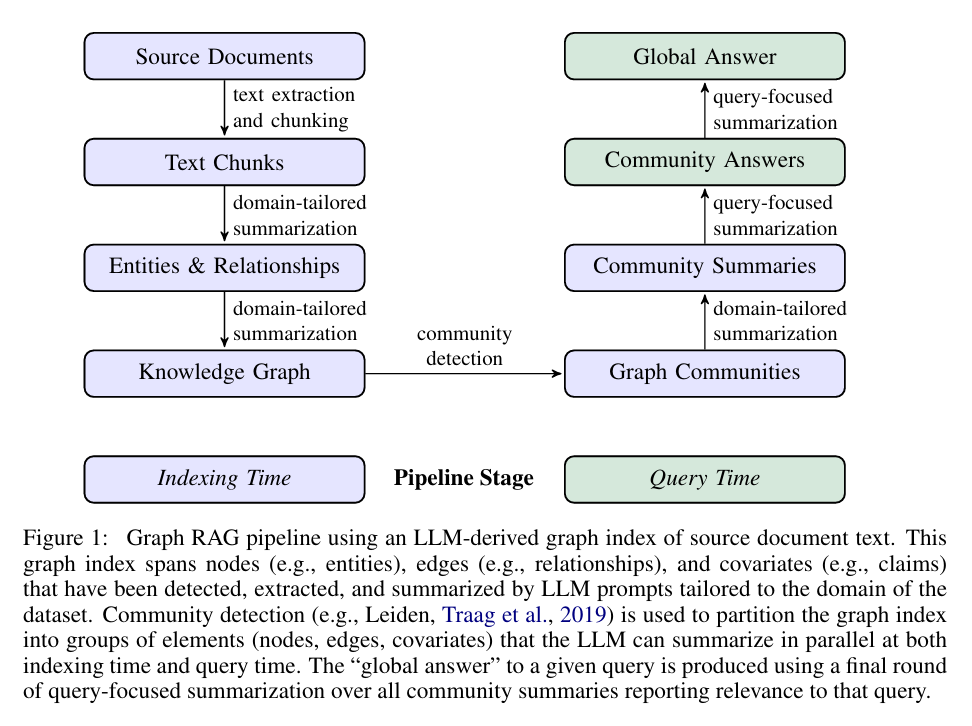
https://blog.csdn.net/m0_59163425/article/details/141143564
简易代码
数据准备
为了构建一个知识图谱驱动的应用,我们需要准备两个主要部分的数据:文本数据和知识图谱数据。文本数据可以从公开的数据集中获取,例如Wikipedia、CommonCrawl等。知识图谱数据可以选择现有的知识图谱数据集,如DBpedia、Wikidata等。也可以自己构建一个小型的知识图谱。
假设我们选择使用DBpedia作为知识图谱数据源,可以使用Neo4j数据库来存储和管理这些数据:
from py2neo import Graph, Node, Relationship
# 连接到Neo4j数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 创建节点和关系
alice = Node("Person", name="Alice")
bob = Node("Person", name="Bob")
knows = Relationship(alice, "KNOWS", bob)
# 将节点和关系保存到图数据库
graph.create(alice)
graph.create(bob)
graph.create(knows)模型训练
接下来,我们需要训练一个GraphRAG模型。我们将使用Hugging Face的Transformers库来实现这一点。
pip install transformers训练模型:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
# 初始化Tokenizer、Retriever和模型
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
# 准备训练数据
train_data = [
{"context": "Alice is a software engineer.", "question": "What does Alice do?", "answer": "Alice is a software engineer."},
{"context": "Bob is a data scientist.", "question": "What does Bob do?", "answer": "Bob is a data scientist."}
]
# 将数据转换为模型输入格式
train_encodings = tokenizer([d["context"] for d in train_data], [d["question"] for d in train_data], truncation=True, padding=True)
train_labels = tokenizer([d["answer"] for d in train_data], truncation=True, padding=True).input_ids
# 训练模型
model.train()
for epoch in range(5):
outputs = model(input_ids=train_encodings.input_ids, attention_mask=train_encodings.attention_mask, labels=train_labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")应用部署
训练完成后,我们可以将模型部署到一个简单的Web应用中,以便用户进行交互。
创建Flask应用:
from flask import Flask, request, jsonify
from transformers import RagTokenizer, RagSequenceForGeneration
app = Flask(__name__)
# 加载预训练模型
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
@app.route('/generate', methods=['POST'])
def generate():
data = request.json
context = data['context']
question = data['question']
# 编码输入
inputs = tokenizer(context, question, return_tensors='pt')
# 生成答案
generated_ids = model.generate(inputs['input_ids'], num_beams=5, max_length=50)
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return jsonify({'answer': generated_text})
if __name__ == '__main__':
app.run(debug=True)运行Flask应用:
flask run通过本文的介绍,相信你已经对GraphRAG有了初步的了解,并能够动手构建一个简单的知识图谱驱动应用。GraphRAG结合了知识图谱的结构化信息和自然语言处理的强大能力,为生成高质量的文本提供了有力的支持。
这样,你可以更好地理解如何通过结合知识图谱和自然语言处理来创建一个智能的应用程序。
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.