
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
- Paper Reading
- 2025-06-22
- 480 Views
- 0 Comments
- 1207 Words
推理引擎会成为新时代的操作系统吗?
RG-1210
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
2406.06282
【【RG 24 Fall】PowerInfer: Fast Large Language Model Serving with a Consumer-grad..】 https://www.bilibili.com/video/BV1A2qbYREnT/?share_source=copy_web&vd_source=72eac555730ba7e7a64f9fa1d7f2b2d4
【RG Q&A Summary】 [SOSP'24] PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU - 知乎
他们这篇的idea有点像2-8定律。推理时少数神经元会频繁激活,大部分神经元很少激活。于是他们把热神经元放GPU,冷神经元放CPU推理,做CPU-GPU协同.
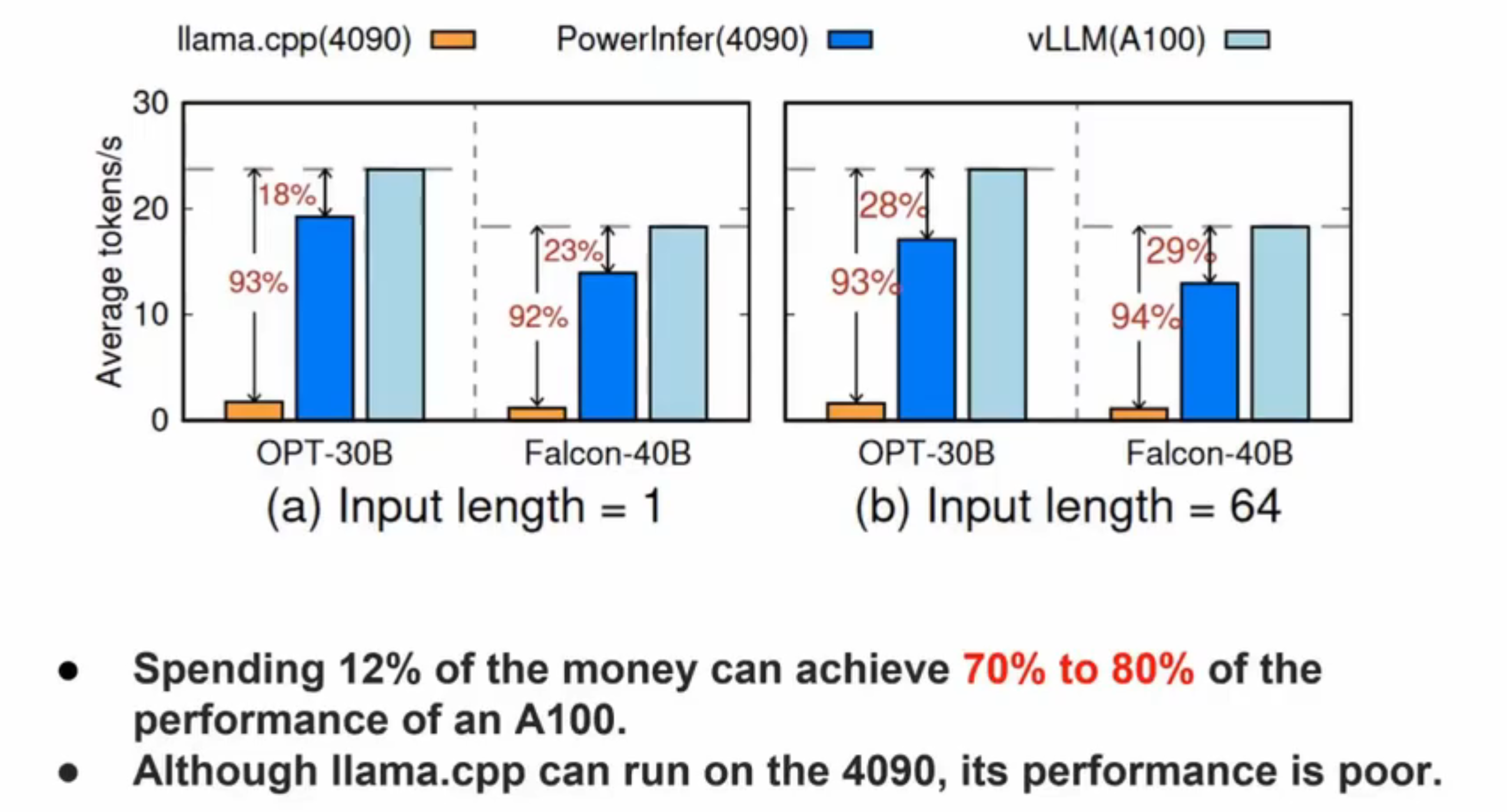
hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons are computed on the CPU, thus significantly reducing GPU memory demands and CPU-GPU data transfers.
PowerIn fer further integrates adaptive predictors and neuron-aware sparse operators, optimizing the efficiency of neuron acti vation and computational sparsity.
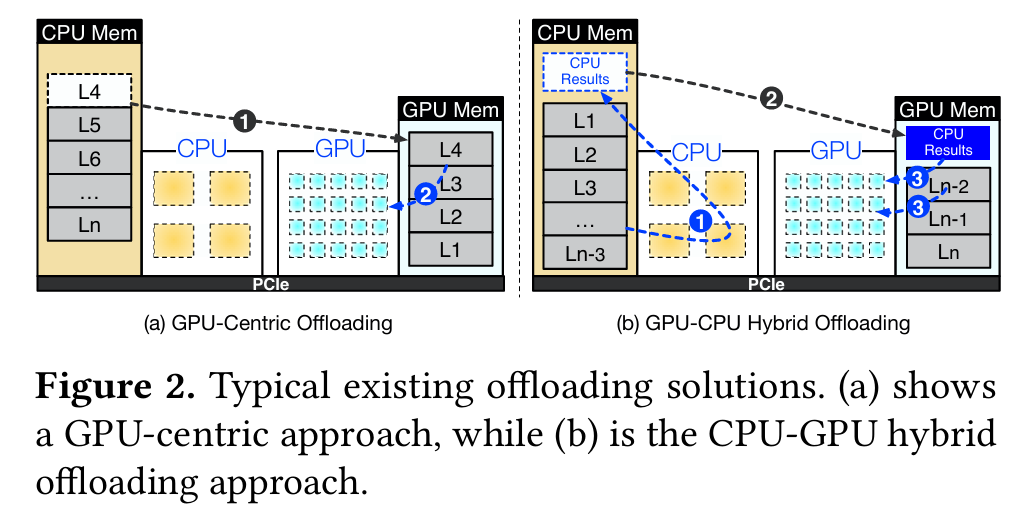
Model offloading is another approach that partitions the model between GPU and CPU at the Transformer layer level [4, 17, 43]. State-of-the-art systems like llama.cpp [17] distribute layers between CPU and GPU memories, lever aging both for inference, thus reducing the GPU resources required. However, this method is hindered by the slow PCIe interconnect and the CPUs’ limited computational capabili ties, resulting in high inference latency.
In this paper, we argue that the key reason for memory issues in LLM inference is the locality mismatch between hardware architecture and the characteristics of LLM in ference. Current hardware architectures are designed with a memory hierarchy optimized for data locality. Ideally, a small, frequently accessed working set should be stored in the GPU,whichoffershigher memorybandwidthbutlimited capacity. better suited for CPUs, which provide more extensive mem ory capacity but lower bandwidth.
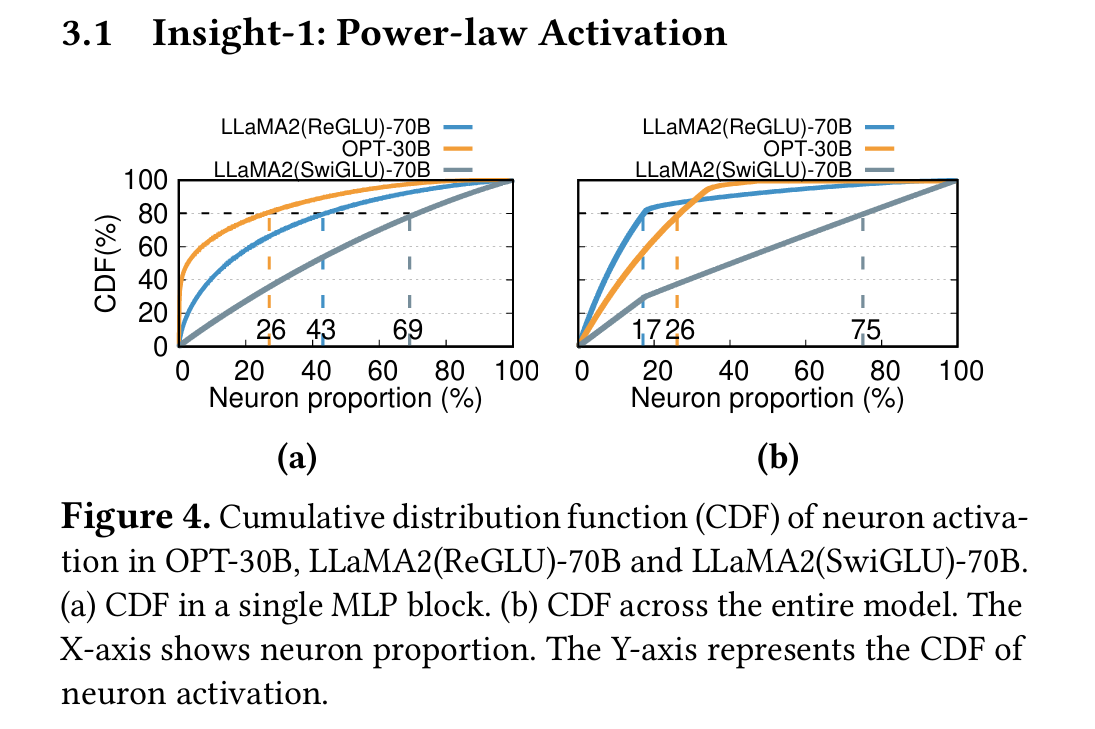
Fortunately, we have observed that neuron activation in an LLM follows a skewed power-law distribution across numerous inference processes: a small subset of neurons consistently contribute to the majority of activations (over 80%) across various inputs (hot-activated), while the majority are involved in the remaining activations, which are deter mined based on the inputs at runtime (cold-activated). This observation suggests an inherent locality in LLMs with high activation sparsity, which could be leveraged to address the aforementioned locality mismatch.
PowerInfer exploits the locality in LLMinference through a two-step process: (1) PowerInfer preselects hot and cold neurons based on their statistical activation frequency, preloading them onto the GPU and CPU, respectively, during an offline phase. (2) At runtime, it employs online predictors to identify which neurons (both hot and cold) are likely to be activated for each specific input. This approach allows the GPU and CPU to independently process their respective sets of activated neurons, thereby minimizing the need for costly PCIe data transfers.
The online inference engine of PowerInfer was imple mented by extending llama.cpp with an additional 4,200 lines of C++ and CUDA code.
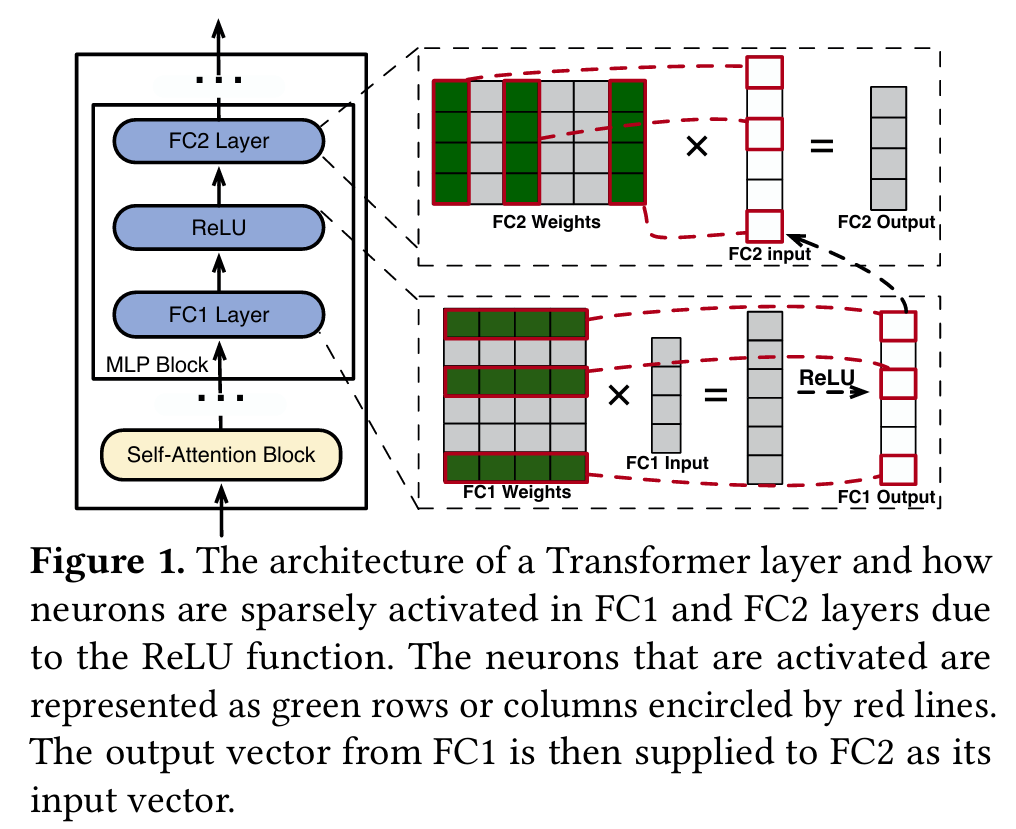
在图1(右)中,MLP块的层FC1和FC2通过矩阵乘法生成向量。每个输出元件都来自输入向量的点产物和神经元(权重矩阵中的行/列)。激活功能(例如Relu [2]和Silu [40])充当选择性保留或丢弃值的门,从而影响FC1和FC2中的神经元激活。例如,此图中的relu过滤了负值,仅允许FC1中的正值估值神经元影响输出。这些神经元在本文中被视为激活。 同样,这些值也会影响FC2中哪些神经元被激活并参与其输出的计算。

稀疏神经元的比例
$$
\text{SwiGLU}(x, W, V, b, c) = \text{SiLU}(Wx + b) \otimes (Vx + c)
$$
这里的用时是600ms(b方案,还是太慢)
Moreover, it is possible to predict neuron activations a few layers in advance within the ongoing model iteration. Based on this observation, DejaVu [28] employs MLP-based online predictors during inference and only processes the activated neurons, achieving over a 6x speedup while maintaining an impressive accuracy rate of at least 93% in predicting neuron activation. However, the activation sparsity is input-specific for each inference iteration, meaning that the activation of specific neurons is directly influenced by the current input and cannot be predetermined before the model’s inference iteration begins.
Main Design
我用一个predictor,先把热神经元放GPU,冷神经元放CPU,随后再开始计算。
那通信怎么办?,第4步后难道没有通信吗。仔细想想,因为CPU-GPU都是一起算同一个算子,那确实是没有通信的。
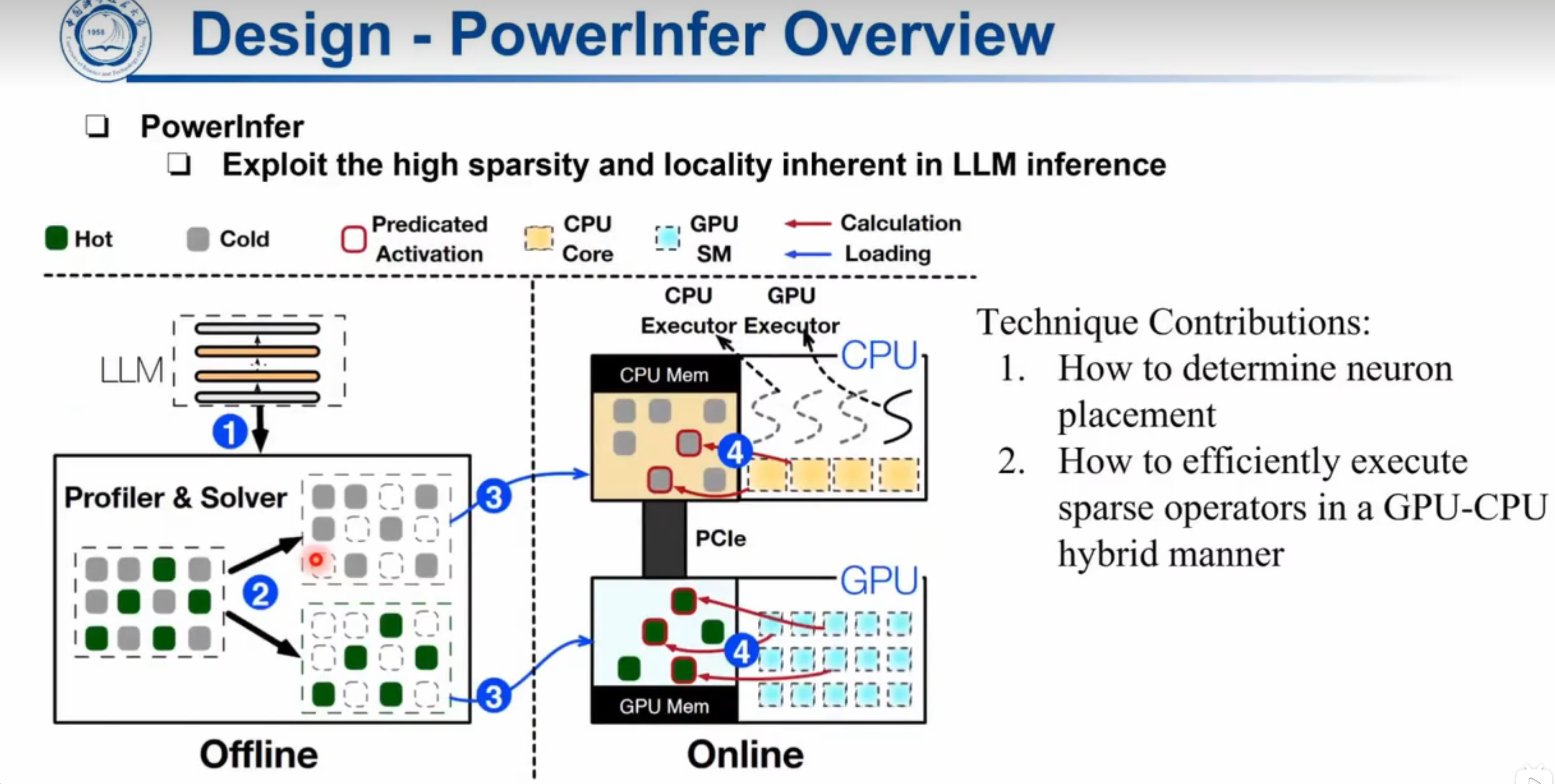
Neuron-awareLLMInferenceEngine(Online):Before processing user requests, the online engine assigns the two types of neurons to their respective processing units (Step ③), as per the offline solver’s output. During runtime, the engine creates GPU and CPU executors, which are threads running on the CPU side, to manage concurrent CPU-GPU computations (Step ④). The engine also predicts neuron activation and skips non-activated ones. Activated neurons preloaded in GPU memory are processed there, while the CPU calculates and transfers results for its neurons to the GPUfor integration. The engine uses sparse-neuron-aware operators on both CPU and GPU, focusing on individual neuron rows/columns within matrices.
Exp
GPU-centric offloading utilizes CPU memory to store portions of the model parameters that exceed the GPU’s capacity.
下面这个图就显示他们的速度,可以看到大部分时间都是在PCIe上了
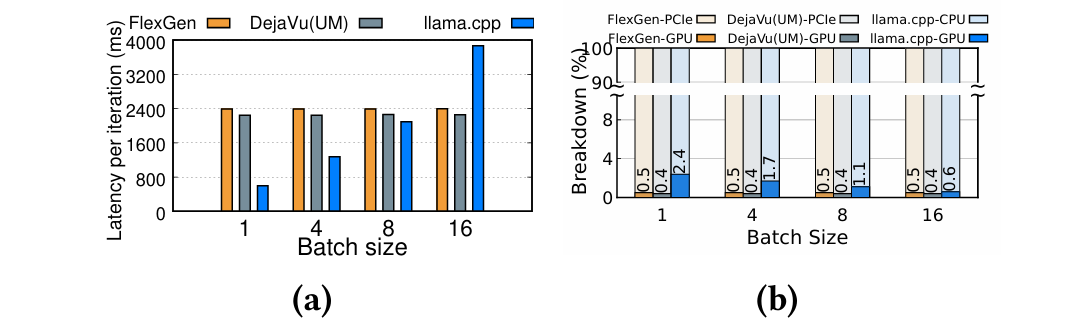
Performance comparison and analysis for serving OPT 30B on NVIDIA RTX 4090 GPU.The yellow blocks refer to FlexGen, the gray blocks refer to DejaVu(UM) and the blue blocks refer to llama.cpp.(a) The Y-axis indicates execution time for one iteration and the X-axis represents batch sizes for input. (b) The Y-axis indicates the proportion of execution time, and the X-axis indicates batch sizes for input.
the CPU handles initial layer processing and then offloads intermediate results to the GPU for token generation. This method reduces inference latency to approximately 600ms, as shown in Figure 3a, by minimizing data transfer and addressing PCIe bandwidth limitations. However, this latency is still significantly higher than the 45ms achieved by a 30B model on an A100 GPU, indicating that the speed is considered too slow in comparison.
Hybrid offloading struggles with a locality mismatch, causing suboptimal latency. Each inference iteration accesses the entire model, leading to poor locality in hierarchical GPU-CPU memory structures. Despite GPUs' computational power, their memory capacity is limited. For example, a 30B-parameter model on a 24GB NVIDIA RTX 4090 GPU can only store 37% of the model, offloading most tasks to the CPU. The CPU, with greater memory but less computational power, handles 98% of the total computational time, as shown in Figure 3b.