OSDI25 PipeThreader
- Paper Reading
- 2025-08-21
- 470 Views
- 0 Comments
- 403 Words
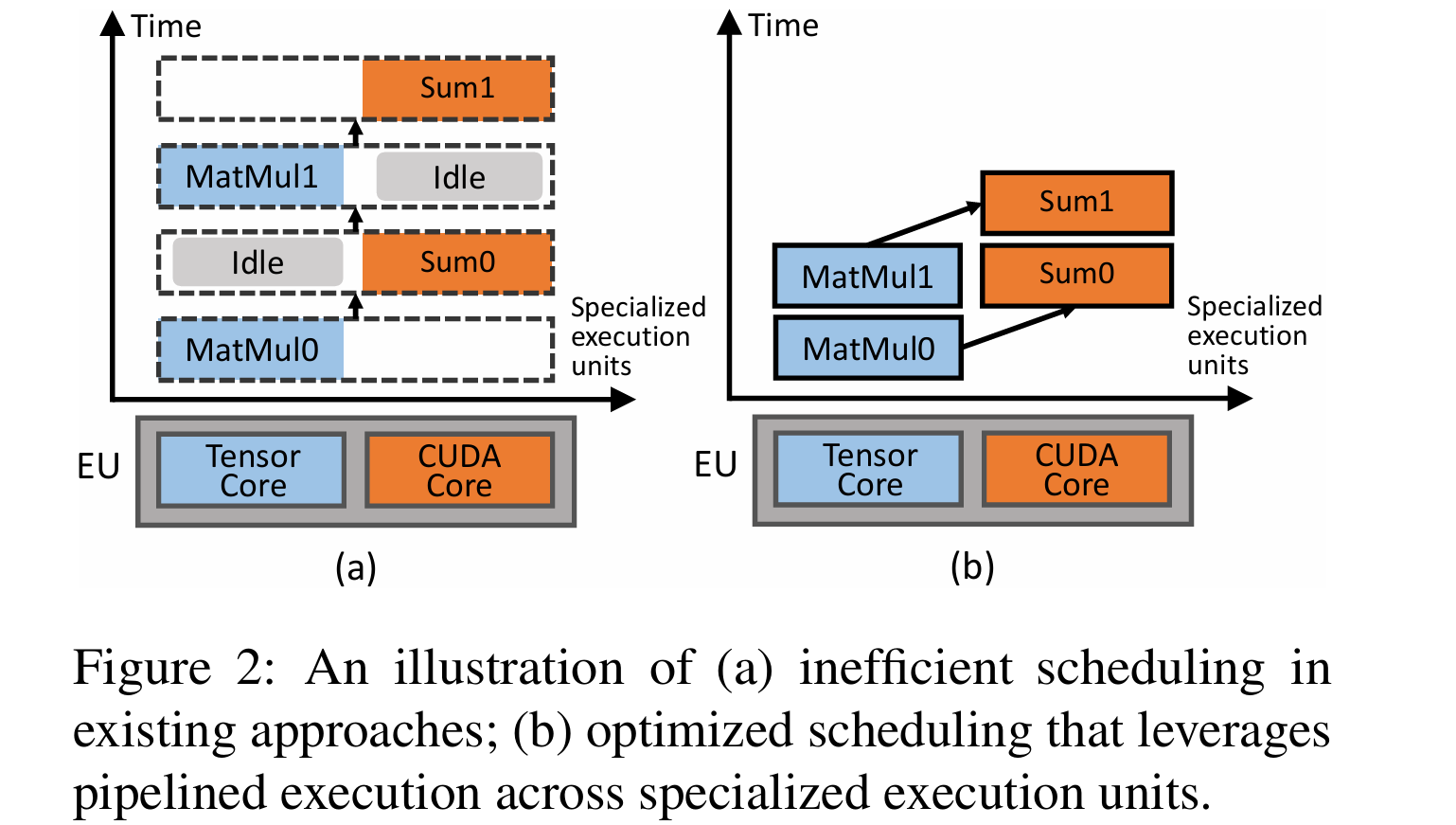
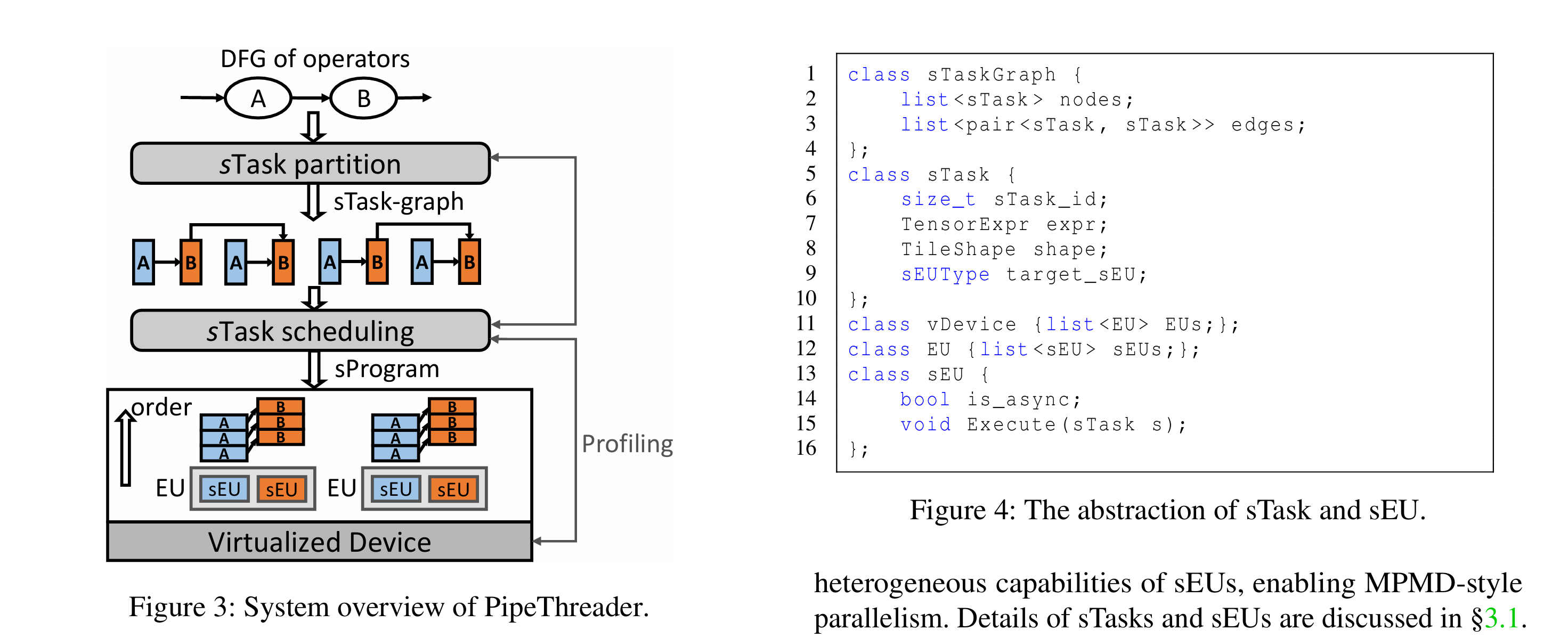
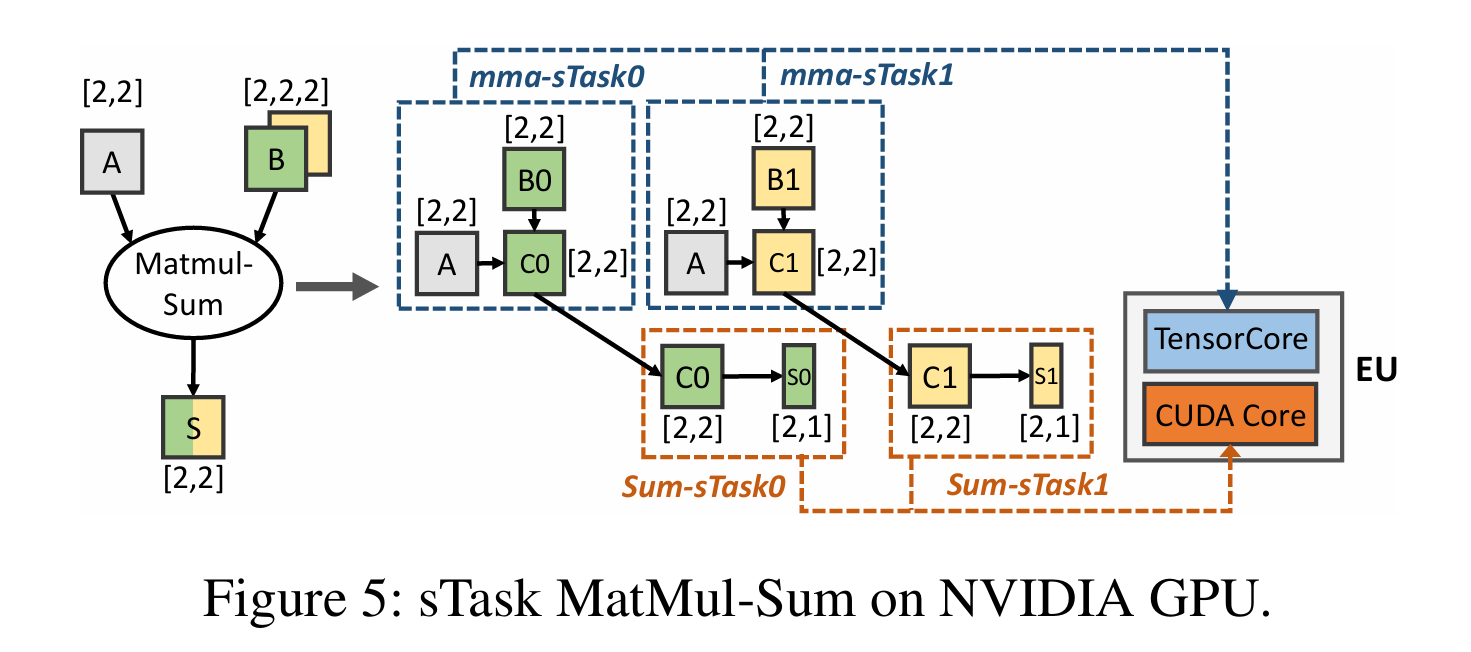
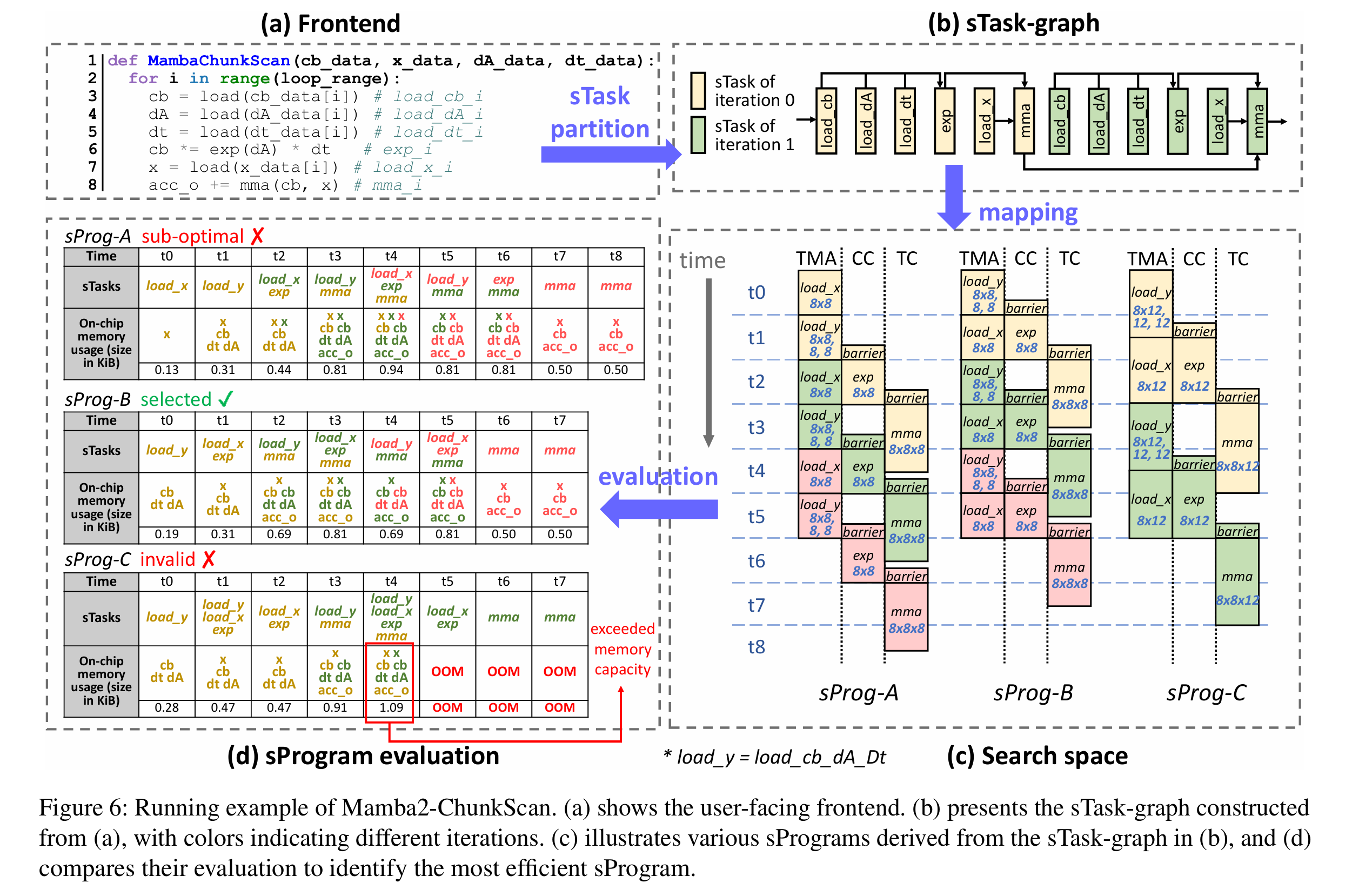
PipeThreader: Software-Defined Pipelining for Efficient DNN Execution
AlpaServe 简单总结
- 背景问题
- 现在的深度学习模型越来越大,单块 GPU 内存不够用。
- 多模型在线服务要保证低延迟、高吞吐量,但请求量有时会突然激增,传统方法效率低。
- 核心想法
- 模型并行:把一个模型拆成几部分放到多块 GPU 上。
- 统计多路复用:当一个模型暂时不用 GPU,其他模型可以使用空闲 GPU,提高资源利用率,减少等待时间。
- 权衡:模型并行能提高吞吐量和突发处理能力,但会增加通信开销,可能单个请求慢一点。
- AlpaServe 系统
- 自动帮你决定模型怎么拆分、放在哪块 GPU、用哪种并行策略。
-
有两种核心算法:
- 贪婪模拟器算法:试不同组合,选出最能满足延迟要求的放置。
- 枚举算法:全面搜索更优解。
- 运行时调度:把请求分配给最空的 GPU 组,预测超时的请求可以拒绝。
- 效果
- 在 64 GPU 集群上,处理速度最高提升 10 倍。
- 延迟目标可严格 2.5 倍。
- 能应对更突发的请求,SLO 达成率高达 99%。
- 主要贡献
- 系统分析模型并行在多模型服务中的利弊。
- 提出新算法优化多模型放置。
- 提供完整的 AlpaServe 系统,实现自动化、多模型推理优化。
总结:
AlpaServe 让多模型推理更快、更稳定,特别适合内存有限、请求突发和要求低延迟的场景。
OSDI 2025 论文评述 Day 3 Session 9: AI + Systems III - 知乎
PipeThreader: Software-Defined Pipelining for Efficient DNN Execution - About