
OSDI23 Johnny Cache: the End of DRAM Cache Conflicts (in Tiered Main Memory Systems)
- Paper Reading
- 2025-07-23
- 303 Views
- 0 Comments
- 1374 Words
本文解决的是这样的一种情况:
在计算机有CXL、SSD等比DRAM 的存储level更低的存储(文中一般称PMEM)下,现有的“把DRAM当PMEM的Cache”的操作易导致生日冲突,引起Rewrite性能下降。Johnny Cache用了新策略(线性的写)避免了该冲突。
In par ticular, we demonstrate that the poor performance observed in earlier hardware-based systems is due to cache conflicts resulting from Linux’s page allocation policy, and that simple improvements to the page allocation policy can reduce cache conflicts with little or no overhead.
全文最核心的一句话在这里:
Linux’s page allocation does not take into consideration the location of pages in hardware caches. As a consequence, Linux suffers from the birthday paradox: the DRAM cache is large, but many pages tend to map to a subset of the available cache locations.
(Linux 页分配没有考虑硬件 cache 中页的位置,因此出现了生日悖论:虽然 DRAM cache 很大,但很多页倾向于映射到少量的 cache slot 上。)
当 Linux 分配内存页时(比如 4KB 页),它只考虑:
- 页是否空闲;
- 是否在指定的 zone / node(如 DMA zone, normal zone, highmem zone, 或者 NUMA 节点)。
它不关心这些页会被映射到 DRAM 的哪个 bank / row / rank,更不会去优化行缓存的命中率。DRAM 会将物理地址按某种方式映射到不同的 bank/row/buffer。
计组Recall: Cache
计组里有3种Cache。对应了一个大DRAM但是小Cache的系统下把数据放到哪里:
| 类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 直接映射(Direct-mapped) | 每个内存块只能映射到 cache 中唯一的一个位置 | 硬件简单,访问快 | 冲突严重 |
| 全相联(Fully associative) | 内存块可以放到 cache 任何位置 | 冲突最少 | 硬件复杂,访问慢 |
| N 路组相联(N-way set associative) | 折中:cache 分成若干个 set,每个 set 有 N 个槽位(way) | 较低冲突率+较低复杂度 | 硬件适中 |
所以这就是我们的目标:尽可能的把最近使用的数据放进Cache里,并且访存快。
在这种情况下:
- Cache 被分成
S个 set。 - 每个 set 里有
N个槽位(叫 way) - 地址映射到 set:
- 根据地址的 index 位找到哪个 set。
- 在该 set 内,数据可以放到任意一个 way(由替换策略决定,如逼近的 LRU)。
举个例子:
假设:
- Cache 总大小:32KB
- cache line 大小:64 bytes
- N=4(4 路组相联)(意味着数据可以放到4个中的一个)
计算:
- 总行数 = 32KB / 64B = 512 行
- 分成多少个 set:
- set 数 = 总行数 / 相联度 = 512 / 4 = 128 个 set
- 每个 set 有 4 个槽位(way)
当访问一个地址:
- 根据地址 index 部分选中某个 set(128 个 set 中的一个)。
- 在该 set 的 4 个 way 里比较 tag,看是否命中。
假设 32 位地址、4 路组相联、64B 行大小、128 个 Set:
- 块内偏移(Offset):低 6 位(2⁶ = 64B)。用来在 64B cache line 内找到具体字节。
- Set 索引(Index):中间 7 位(2^7 = 128 Set)。用来定位地址属于哪一个 set。
- 标签(Tag):剩余高位(32 - 6 - 7 = 19 位)。区分不同内存块 (链接DRAM和Cache)
访问地址时:
- 根据 Set 索引 定位到某个 Set。
- 在该 Set 的所有 Way 中比较 Tag。
- 若匹配则命中;否则触发替换。
为什么有生日攻击
复习完计组,看这个就看懂了:
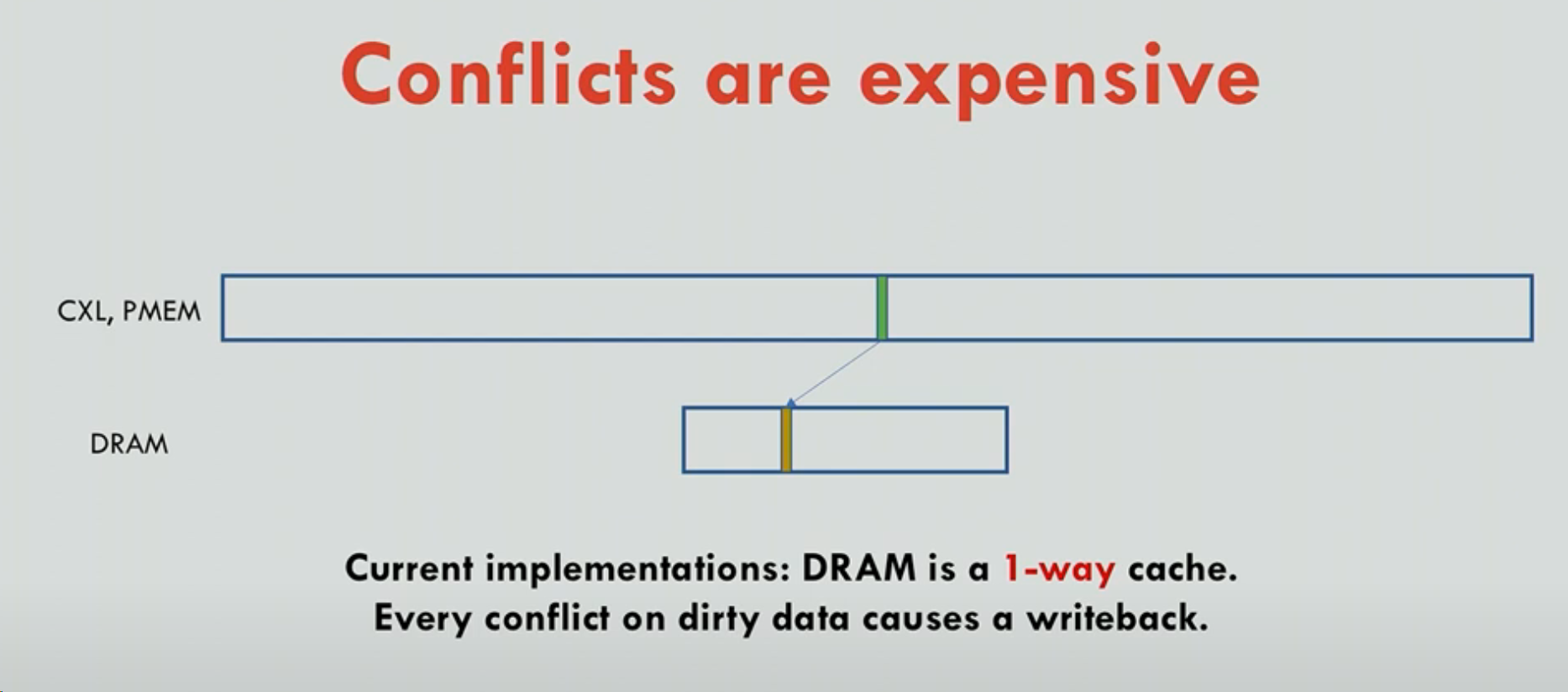
计算机程序在使用CXL、SSD、PMEM时,虽然虚拟地址是连续的,但是物理上其实是使用的Random access。但是如果把DRAM当Cache,此时OS Page的设计是直接copy Page到上面,而硬件的设计直接映射/1路组相联。因此如果随机访问,这里就很容易造成在 Tag mod CacheSize行数一样的情况时,会发生冲突,而这就是生日悖论。
当你分配很多页时,每个页的物理地址通过:PFN mod slots 映射到一个 slot。虽然 DRAM cache 很大(有很多 slot),但一旦有很多页要分配,就很容易让多个页落在同一个 slot(产生 cache conflict)。比如cache 有 2M 个 slot,看似很多,但一旦有几百万个页,就会出现冲突。
设计
Design其实就比较简单了。具体可以去看原文。
We propose the following simple static page allocation policy to reduce conflicts: we allocate a new page such that its physical address maps to a cache slot with the fewest pages currently mapped to it. For example, if we have a cache with 2 million slots and 4 million pages to be allocated, we allocate 2 pages to each slot. The static policy has no noticeable overhead, but it vastly reduces conflicts.
静态策略:分配页时统计哪个 slot(bin)当前冲突少,就往那分。
这里还是会可能有冲突,但是线性的冲突在这个2百万/4百万,能够把随机的冲突(可能非常高)给压下来。

We also investigate a dynamic policy that takes into ac count the access frequency of pages, distinguishing between hot and cold pages. The dynamic policy allocates a new page to the cache slot with the lowest access frequency and reacts to workload changes by dynamically remapping pages when it detects conflicts.
动态策略:监控热点页,发现冲突就迁移。
另一个是冷热page的想法。
假设
- DRAM cache 有 2M 个 slot。
- 程序需要频繁访问 200MB 热数据(≈ 50,000 页)。
这些页随机分配后:
- 50,000 页对 2M slot,看似比例才 2.5%;
- 但根据生日悖论,冲突概率远高于 2.5%,会有不少页落到相同 slot;
- cache miss 增加,性能下降。如果多个热页映射到同一 slot,它们会互相踢出 → ping-pong。
