
OSDI 23 BWoS 更好的多线程work-stealing技术——分块
- Paper Reading
- 2025-07-30
- 570 Views
- 0 Comments
- 1105 Words
一篇有趣的文章,做的是新的多生产者多消费者的队列。
我猜这篇是他们做量化的同学搞的哈哈哈哈哈。
PowerPoint Presentation
OSDI 2023 论文评述 Day3-Session11: Verify Your Bits - 知乎
stdexec/include/exec/detail/bwos_lifo_queue.hpp at main · NVIDIA/stdexec
BWoS Work-Stealing Queue简介 · icysky's blog
摘要
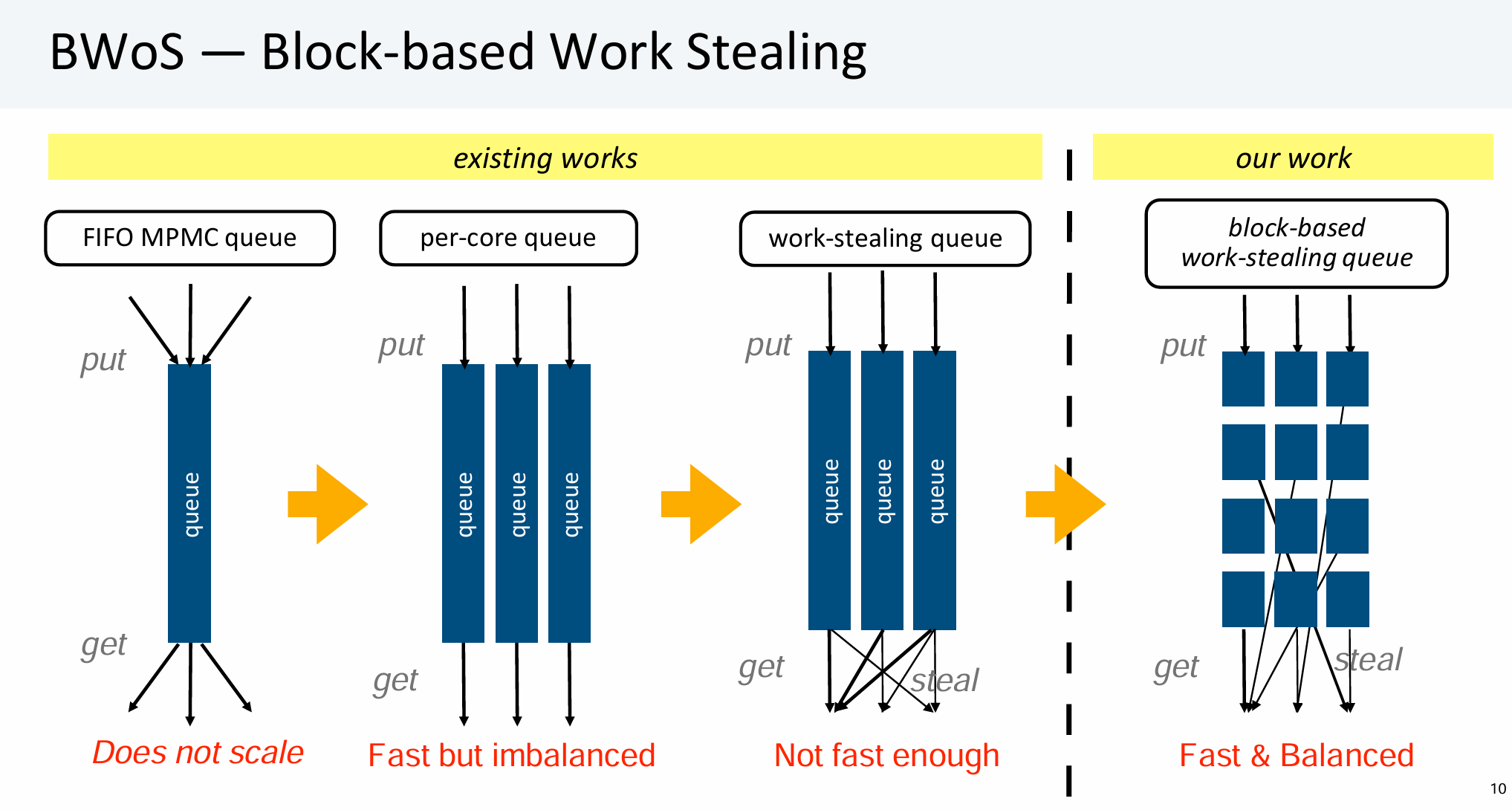
工作窃取是一种常见的调度技术,当每个核心都拥有一个调度队列时,可能出现某些核心已经空闲但其他某些核心却堆积了大量任务的情况,此时就需要利用工作窃取技术。先前的工作大多着眼于平衡各个核心的负载,但是却忽视了工作窃取这一过程本身会给任务的原所有者带来的性能影响。
本工作提出了BWoS,通过对任务队列分块以优化工作窃取。窃取方以块的粒度与任务所有者进行同步,避免与其在同一个块内进行操作,减少了窃取方与被窃取方间的性能影响,从而实现了整体性能的提高。同时BWoS实现了一种基于随机采样的victim选择算法,以减少此过程的开销。在Java G1GC中使用本优化可以在macrobenchmark中实现1.25倍性能提升,在Go语言的JSON处理程序中实现1.26倍性能提升。此外本工作利用模型检查器对BWoS进行了形式化验证,以确保其在弱内存模型中的正确性。
Cache Miss
Stealing会更新队列的Metadata,而队列的Metadata由Owner和Thief共享,这会导致Owner接下来访问队列发生Cache Miss。对于任务分配尤其不均衡的情况,这种Cache Miss发生得尤其频繁。Batching(批量处理)能够一定程度上减轻这种问题,但会导致偷取过多的任务,从而导致额外性能开销。
弱内存模型
弱内存模型(简称WMO,Weak Memory Ordering),是把是否要求强制顺序这个要求直接交 给程序员的方法。换句话说,CPU不去保证这个顺序模型(除非他们在一个CPU上就有依赖 ),程序员要主动插入内存屏障指令来强化这个“可见性”。也没有一个全局的对所有CPU都 是一样的Total Order。允许多线程/多核对内存的读写可以乱序执行,只在同步点保证一致性。
好处是更高性能,缺点是需要程序员用 fence / atomic 明确指定关键位置的顺序。
MySummary/软件构架设计/理解弱内存顺序模型.rst at master · Kenneth-Lee/MySummary
深入探索并发编程系列(九)-弱/强内存模型 | High Performance
| 分类 | 特点 | 示例 |
|---|---|---|
| 强内存模型(strong / sequential consistency) | 所有线程观察到的所有操作按一个全局顺序执行,和程序顺序一致 | 理论上的 Sequential Consistency (SC) |
| 弱内存模型(weak / relaxed) | 允许更多指令乱序或延迟,只对特定同步点(比如 lock、barrier、fence)保证顺序 | x86, ARM, POWER, RISC-V 默认 |
| 架构 | 特点 |
|---|---|
| x86 TSO(Total Store Order) | 默认对 store → load 有顺序,但允许 store buffer |
| ARM, POWER | 更弱,需要显式 barrier 才能保证顺序 |
| C++11 memory model | 提供 memory_order_relaxed, acquire, release, seq_cst 等原子顺序 |
| GPU (CUDA) | block 内强一致;block 间要用 __threadfence 等保证可见性 |
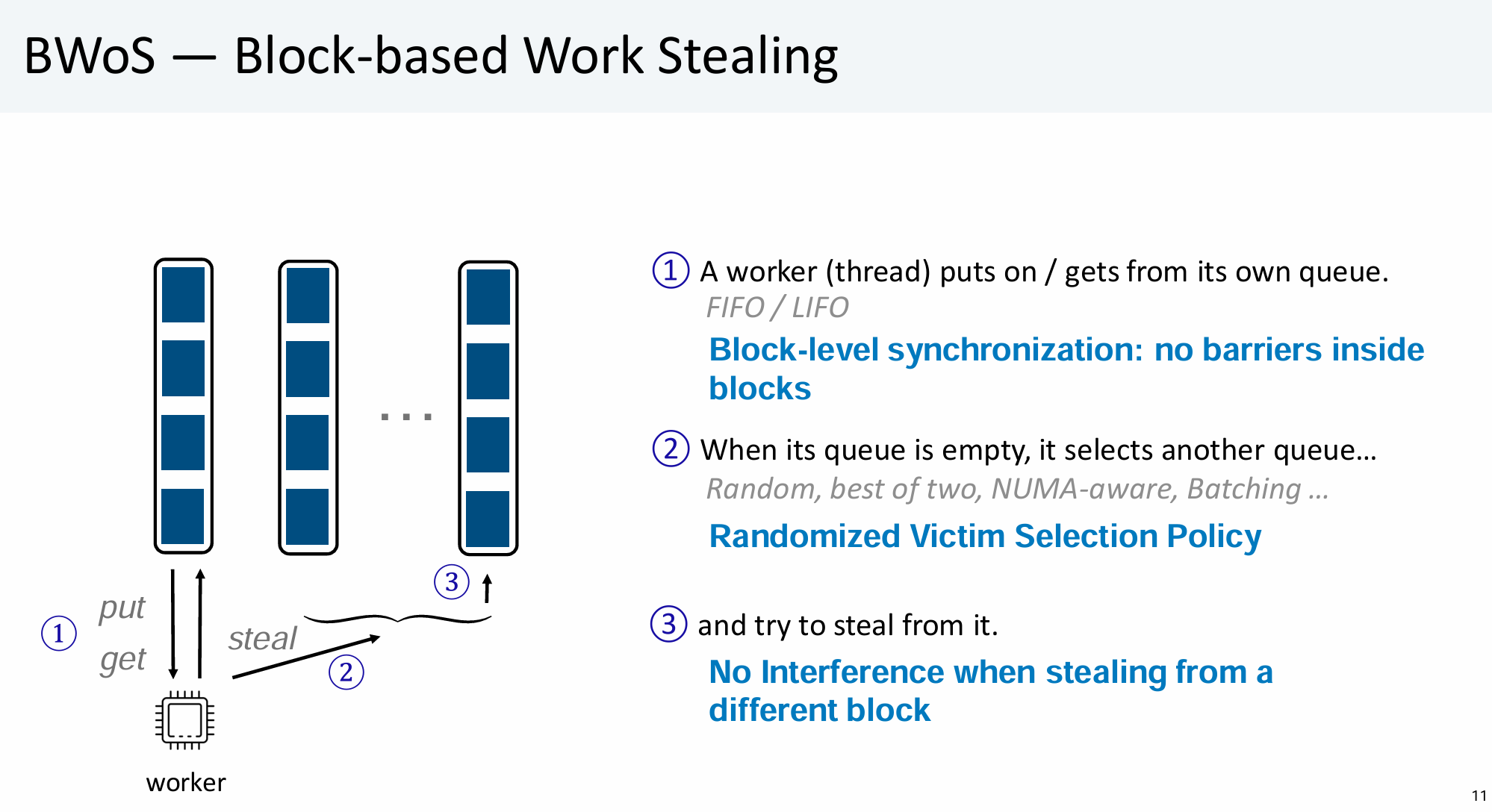
Main Design
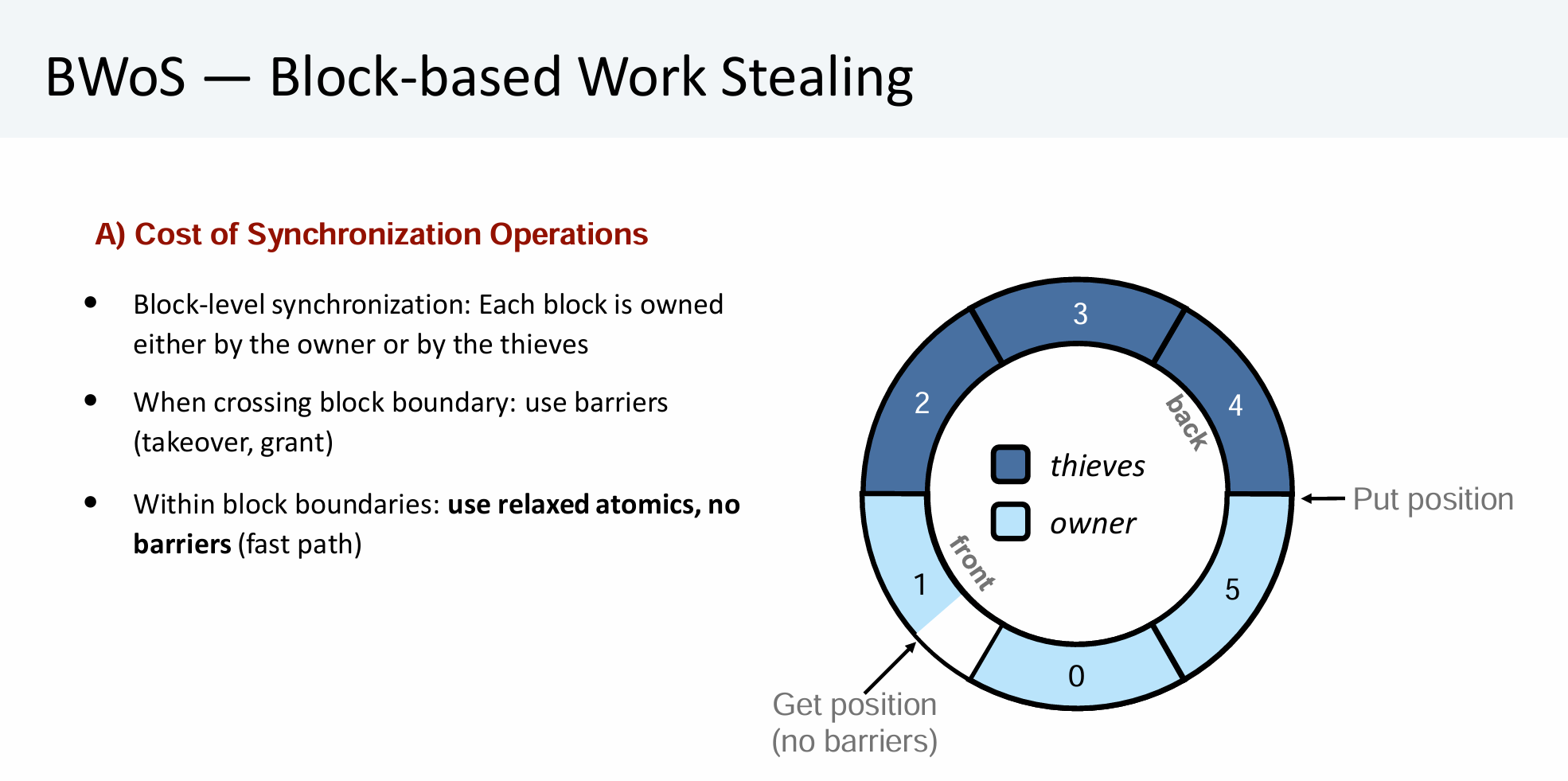
Block-level同步保证了Thief永远不会从Owner正在执行get的Block上Steal。每个Block要么由Owner占用,要么被Thief占用。Owner可以将一个Block 赋予(grant) Thief(允许该Block上的Stealing操作),也可以从Thief处 收回(take over) 一个Block(在advanceGetBlock里)。
每个Block均要记录最后一次访问的轮数(Round Numbers),当执行advanceBlock方法时,当前Block的轮数会被带到下一个Block。如果循环完了一轮,此时所有Block的轮数均相等,则给轮数加一(借助atomic_compare_exchange实现)。在更新轮数时,可能当前Block上一轮的数据还没有被读取完(不论是get还是steal),此时必须等待当前Block上一轮的数据全部读取完才能更新轮数。这保证了数据既不会被覆盖,也不会被重复读取。
底层技术其实一直都有人在打磨优化。尤其是音视频,底层传输,在这些方面很多人做了很多的工作。
这些老工作其实性能非常强大。我在想他们能不能继续用在不规则方面的计算,但是我想做这些程序的人会能做的非常好。