
OpenMP在llvm里是如何实现的?
- 编译原理
- 2025-02-17
- 1195热度
- 0评论
基础知识:编译器的结构
编译器中的“前端”和“后端”是两个重要的组成部分,它们负责编译过程的不同阶段。我们可以将编译器看作一个“处理流水线”,前端和后端各自执行不同的任务。
-
前端:负责将源代码解析成抽象语法树并生成中间代码,确保代码的语法和语义正确。
- 词法分析、语法分析、语义分析和中间代码生成。
-
后端:负责优化中间代码并生成目标机器代码,最终输出可执行文件。
- 优化、目标代码生成、汇编、链接。
前端(Frontend)
编译器的前端负责从源代码到中间表示的转换,通常包括以下几个步骤:
-
词法分析(Lexical Analysis):
- 前端的第一步是将源代码分解成一系列的标记(tokens)。每个标记代表一个语法单元(如变量、运算符、关键字等)。
- 例如,源代码
int x = 10;会被分解为int、x、=、10和;。
-
语法分析(Syntax Analysis):
- 语法分析器将词法分析得到的标记流转换为抽象语法树(AST)。这棵树反映了源代码的结构和逻辑关系。
- 语法分析器根据编程语言的语法规则(如文法)来检测源代码是否符合语法要求。
-
语义分析(Semantic Analysis):
- 语义分析阶段会检查源代码的逻辑错误(如类型错误、变量未定义等)。
- 这一步会生成符号表,记录变量、函数、类等的属性(如类型、作用域等)。
-
中间代码生成(Intermediate Code Generation):
- 在前端的最后,编译器会将抽象语法树转化为一种或多种中间表示(IR)。中间代码通常是比源代码更接近机器语言,但仍然是平台无关的代码,便于后端处理。
前端的主要任务是确保源代码的语法和语义正确,并生成适合优化和目标代码生成的中间表示(IR)。
后端(Backend)
编译器的后端负责将前端生成的中间表示转换为目标机器代码。后端主要包括以下几个步骤:
-
优化(Optimization):
- 后端首先会对中间代码进行各种优化,以提高程序的性能或减少程序的内存占用。优化可以在多个层次上进行,包括循环优化、数据流分析、指令选择等。
- 优化可以是局部的(如优化某个函数的性能)或全局的(如对整个程序的内存使用进行优化)。
-
目标代码生成(Code Generation):
- 后端将优化后的中间代码转换为目标机器代码。这是编译器的最后一步,生成的代码可以直接在特定的硬件平台上运行。
- 目标代码生成通常包括将中间代码转换为汇编语言,随后汇编器将其转化为最终的机器码。
-
汇编和链接(Assembly and Linking):
- 汇编器将汇编语言代码转换为二进制机器码。
- 链接器将多个目标文件、库文件链接成一个完整的可执行文件。它还负责处理符号引用和重定位。
编译器对支持OpenMP的工作
OpenMP(Open Multi-Processing)是一种用于共享内存并行编程的应用程序接口(API)。它允许开发人员利用多核处理器的优势,通过编写并行代码来加速计算任务。在编译器中,OpenMP的支持通常通过解析OpenMP指令并将其转换为适合并行执行的代码来实现。
编译器对OpenMP的支持主要体现在以下几个方面:
- 识别并解析OpenMP指令(pragma)。
- 进行并行化分析和决策,包括循环并行化、任务分配等。
- 管理线程创建和同步,包括共享数据和私有数据的管理。
- 生成并行代码,并利用OpenMP运行时库来管理线程和同步。
- 执行并行优化,以提高程序的性能。
1. 编译器指令支持:识别、转换
OpenMP使用编译指令(pragma)来指示编译器在特定代码块上应用并行化。编译器需要识别这些指令,并在代码的适当位置插入并行执行的控制结构。例如:
#pragma omp parallel
{
// 并行执行的代码块
}编译器需要解析这种形式的#pragma指令,理解它的含义并对其后续代码进行并行化优化。#pragma omp parallel指示编译器将紧随其后的代码块并行执行。
2. 并行化决策分析
编译器分析OpenMP指令,并根据程序结构决定哪些部分可以并行化。这个过程称为并行化分析。编译器通常会进行以下操作:
-
循环并行化:如
#pragma omp parallel for指令指示编译器将for循环的迭代分配到多个线程并行执行。#pragma omp parallel for for (int i = 0; i < N; i++) { // 循环体 }编译器会识别循环,并对循环进行拆分,生成适合多线程执行的代码。
-
任务分配和同步:当程序中有多个任务(如计算任务)需要并行执行时,编译器会根据OpenMP指令将任务划分并分配给多个线程,同时管理线程之间的同步。
3. 线程管理和同步
OpenMP程序通常涉及多个线程的创建与管理,编译器需要插入适当的代码来管理线程的生命周期、同步机制、数据共享等。这包括:
- 线程创建:根据指令,编译器会为并行区域创建多个线程。
- 同步机制:如临界区、屏障(
#pragma omp barrier)、锁等,编译器会确保并行区域中的数据访问是安全的。 - 数据共享与私有化:编译器通过指令(如
shared、private)来决定哪些数据是共享的,哪些数据是每个线程私有的。
例如:
#pragma omp parallel for shared(a) private(i)
for (int i = 0; i < N; i++) {
// 每个线程执行的代码
}4. 生成并行代码
一旦编译器解析完OpenMP指令并进行相应的并行化优化,它会生成底层的并行代码。通常,编译器会生成线程创建、数据划分、同步等操作的代码。这些操作通常使用操作系统提供的线程库(如POSIX线程、Windows线程)或者专门的线程库(如Intel Threading Building Blocks)来实现。
- OpenMP运行时库:编译器在生成并行代码时,通常会依赖OpenMP运行时库,这个库负责线程的管理、调度、同步等操作。编译器生成的代码会调用这个库中的函数,以便管理线程的生命周期和同步。
5. 优化与性能提升
编译器会通过不同的优化技术来提高并行程序的性能:
- 循环优化:如循环拆分、循环合并等,减少并行化过程中可能出现的冗余计算和同步。
- 负载均衡:编译器会尽可能将工作均匀地分配给各个线程,以避免某些线程过载或空闲。
- 数据访问优化:编译器可能会优化数据访问模式,减少内存访问冲突,提升内存访问效率。
编译器支持的OpenMP版本
现代编译器(如GCC、Clang、Intel编译器等)通常支持OpenMP的多个版本,并且不断改进对OpenMP指令的支持。具体的编译器版本支持的OpenMP特性可以通过编译器的文档进行查询。
编译器启用OpenMP支持
要启用编译器对OpenMP的支持,通常需要通过编译选项来开启。例如,在GCC中,可以通过添加-fopenmp选项来启用OpenMP支持:
gcc -fopenmp my_program.c -o my_programLLVM对OpenMP的支持情况
LLVM OpenMP: Parallel (fork/join)
在 LLVM 编译器生态中,OpenMP 的支持是通过 Clang 前端 + LLVM OpenMP 运行时库(libomp)实现的。
一、LLVM 对 OpenMP 的完整支持链
Clang 前端 → LLVM IR 生成 → OpenMP 运行时库(libomp) → 系统线程管理
│
└─ 自动插入并行运行时调用1. 编译器前端支持
- Clang 负责解析 OpenMP 的编译制导语句(如
#pragma omp parallel) -
将 OpenMP 指令转换为 LLVM 中间表示(IR),插入对
libomp的运行时调用// 原始代码 #pragma omp parallel for for(int i=0; i<100; i++){ ... } // 转换后的 IR 伪代码 __kmpc_fork_call(&loc, 1, microtask, &loop_bound);
2. 运行时库 (libomp)
- LLVM 自主开发的 OpenMP 运行时实现
-
核心功能:
// 线程池管理 void __kmpc_fork_call(ident_t *loc, int argc, kmpc_micro microtask, ...); // 任务调度 void __kmpc_for_static_init_4(ident_t *loc, int gtid, int schedule, ...); // 同步原语 void __kmpc_barrier(ident_t *loc, int gtid);
3. 架构支持
| 特性 | LLVM 15 支持状态 |
|---|---|
| OpenMP 标准版本 | 5.2 (完整支持 4.5+) |
| GPU Offloading | ✅ AMDGPU/NVPTX |
| Target 指令 | ✅ #pragma omp target |
| 任务依赖 | ✅ |
| SIMD 指令 | ✅ AVX2/AVX-512 |
关键函数解析
以下是关于 OpenMP 运行时函数 __kmpc_fork_call、__kmpc_barrier 及其相关机制的详细解析:
1. 核心函数功能
-
__kmpc_fork_call
OpenMP 并行区域入口函数,负责将串行代码分支为并行执行。
当编译器遇到#pragma omp parallel时,会生成对此函数的调用,完成以下操作:- 激活线程池中的工作线程
- 将并行区域代码封装为微任务(microtask)
- 分配共享/私有变量内存空间
-
__kmpc_barrier
实现 线程同步屏障,确保所有线程到达同步点后才继续执行。
对应 OpenMP 中的隐式屏障(如parallel区域结束时)或显式#pragma omp barrier。
2. 命名规范 kmpc
kmp:源自 Kuck & Associates Multi-Processing(KAI 公司的并行技术遗产,后被 Intel 收购)c:表示属于 C 语言接口(另有 Fortran 接口使用kmpf前缀)- 完整前缀含义:KMP C Interface
函数API定义与参数解析
1. __kmpc_fork_call 函数原型
void __kmpc_fork_call(
ident_t *loc, // 源代码位置标识符
int argc, // 共享参数数量
microtask_t microtask,// 并行区域函数指针
... // 可变参数(共享变量地址)
);-
参数详解: 参数 类型 作用 locident_t*记录源代码位置(文件名、行号等),用于调试和性能分析 argcint传递给微任务的共享变量数量 microtaskmicrotask_t实际并行执行的函数指针(编译器生成的包装函数) ...void*共享变量的地址列表(按参数顺序传递) -
执行流程:
- 主线程检查线程池状态
- 唤醒或创建工作线程
- 分配任务参数到共享内存区
- 各线程执行
microtask函数 - 回收线程资源(可选)
2. __kmpc_barrier 函数原型
void __kmpc_barrier(
ident_t *loc, // 源代码位置标识符
int gtid // Global Thread ID(全局线程ID)
);-
参数详解: 参数 类型 作用 locident_t*调试信息源位置 gtidint当前线程的全局唯一ID(0 为主线程,其他为工作线程) -
同步机制:
- 采用 原子计数器 + 条件变量 实现
- 每个线程到达屏障时递减计数器
- 最后一个线程触发条件变量广播唤醒所有线程
三、实现标准与编译器差异
1. 规范定义来源
-
OpenMP Runtime API
这些函数属于 OpenMP 标准的 内部实现细节,未在官方标准文档中公开规范,但各编译器实现遵循通用模式:编译器实现 对应运行时库 头文件位置 LLVM/Clang libomp omp.h→kmp.hGCC libgomp omp.h→gomp-constants.hIntel ICC libiomp5 omp.h→kmp_os.h
2. 典型实现对比
-
__kmpc_fork_call实现差异:// LLVM libomp 实现(简化版) void __kmpc_fork_call(...) { if (master_thread) { setup_team_stack(); // 分配线程组内存 wake_worker_threads(); // 唤醒工作线程 } else { wait_for_task(); // 工作线程等待任务 } execute_microtask(microtask); // 执行用户代码 } // GCC libgomp 实现特点 void GOMP_parallel_start(...) { /* 显式线程启动 */ } -
屏障实现优化:
// 现代实现采用无锁算法(以x86为例) void __kmpc_barrier() { __atomic_sub_fetch(&counter, 1, __ATOMIC_RELAXED); while(__atomic_load_n(&counter, __ATOMIC_ACQUIRE) > 0) { _mm_pause(); // 自旋等待优化 } }
四、开发者使用场景
1. 调试与性能分析
-
查看运行时调用:
# 使用 GDB 跟踪调用链 (gdb) break __kmpc_fork_call (gdb) backtrace # 查看并行区域参数 (gdb) p *loc@4 -
性能计数器监控:
# Linux perf 统计屏障开销 perf stat -e 'omp:barrier_wait' ./program
2. 高级优化技巧
-
动态线程调整:
// 覆盖默认线程数设置 void __kmpc_set_num_threads(int num) { omp_set_num_threads(num); } -
NUMA 感知绑定:
// 在初始化阶段设置线程绑定 __kmpc_set_default_affinity( KMP_AFFINITY_GRANULARITY=core );
五、典型问题排查
1. 线程泄漏问题
- 现象:程序退出时卡死
- 诊断:
# 检查未回收的线程 pstack| grep __kmpc_barrier - 解决:确保所有并行区域正确关闭
2. 屏障死锁
- 常见原因:
- 不平衡的条件分支(如某些线程未到达屏障)
- 在任务(task)区域内错误使用屏障
- 调试方法:
export OMP_DEBUG=1 # 启用运行时调试日志 export KMP_BLOCKTIME=0
附:OpenMP 运行时调用层次
// 用户代码
#pragma omp parallel
{
// 并行区域
}
// 编译器生成代码
void .omp_outlined.(void *data) {
// 用户代码逻辑
}
void main() {
__kmpc_fork_call(&loc, 0, .omp_outlined.);
}
// 运行时调用链
__kmpc_fork_call
├─ __kmpc_begin // 初始化并行环境
├─ __kmp_launch_thread // 启动工作线程
└─ __kmpc_end // 清理资源这些底层函数构成了 OpenMP 并行化的核心机制,理解它们的工作原理对于调试性能关键型代码和深度优化至关重要。普通开发者通常无需直接调用这些接口,但掌握其原理有助于更高效地使用 OpenMP。
__kmpc_fork_call 解析
源代码:
/*!
@ingroup PARALLEL
@param loc source location information
@param argc total number of arguments in the ellipsis
@param microtask pointer to callback routine consisting of outlined parallel
construct
@param ... pointers to shared variables that aren't global
Do the actual fork and call the microtask in the relevant number of threads.
*/
void __kmpc_fork_call(ident_t *loc, kmp_int32 argc, kmpc_micro microtask, ...) {
int gtid = __kmp_entry_gtid();
#if (KMP_STATS_ENABLED)
// If we were in a serial region, then stop the serial timer, record
// the event, and start parallel region timer
stats_state_e previous_state = KMP_GET_THREAD_STATE();
if (previous_state == stats_state_e::SERIAL_REGION) {
KMP_EXCHANGE_PARTITIONED_TIMER(OMP_parallel_overhead);
} else {
KMP_PUSH_PARTITIONED_TIMER(OMP_parallel_overhead);
}
int inParallel = __kmpc_in_parallel(loc);
if (inParallel) {
KMP_COUNT_BLOCK(OMP_NESTED_PARALLEL);
} else {
KMP_COUNT_BLOCK(OMP_PARALLEL);
}
#endif
// maybe to save thr_state is enough here
{
va_list ap;
va_start(ap, microtask);
#if OMPT_SUPPORT
ompt_frame_t *ompt_frame;
if (ompt_enabled.enabled) {
kmp_info_t *master_th = __kmp_threads[gtid];
ompt_frame = &master_th->th.th_current_task->ompt_task_info.frame;
ompt_frame->enter_frame.ptr = OMPT_GET_FRAME_ADDRESS(0);
}
OMPT_STORE_RETURN_ADDRESS(gtid);
#endif
#if INCLUDE_SSC_MARKS
SSC_MARK_FORKING();
#endif
__kmp_fork_call(loc, gtid, fork_context_intel, argc,
VOLATILE_CAST(microtask_t) microtask, // "wrapped" task
VOLATILE_CAST(launch_t) __kmp_invoke_task_func,
kmp_va_addr_of(ap));
#if INCLUDE_SSC_MARKS
SSC_MARK_JOINING();
#endif
__kmp_join_call(loc, gtid
#if OMPT_SUPPORT
,
fork_context_intel
#endif
);
va_end(ap);
#if OMPT_SUPPORT
if (ompt_enabled.enabled) {
ompt_frame->enter_frame = ompt_data_none;
}
#endif
}
#if KMP_STATS_ENABLED
if (previous_state == stats_state_e::SERIAL_REGION) {
KMP_EXCHANGE_PARTITIONED_TIMER(OMP_serial);
KMP_SET_THREAD_STATE(previous_state);
} else {
KMP_POP_PARTITIONED_TIMER();
}
#endif // KMP_STATS_ENABLED
}
关于__kmpc_fork_call实现机制
这段代码是实现OpenMP并行计算的核心部分,具体是__kmpc_fork_call函数的实现。它用于在OpenMP中创建一个并行区域(fork),在该区域内并行地执行给定的微任务(microtask)。函数通过多个线程来处理任务,并提供了一些计时和性能监控的功能。让我们逐步分析每个部分的作用:
1. 函数参数
loc: 该参数传递了源代码的位置,通常用于错误报告和调试。argc: 传递给微任务的参数数量。它用于后续处理变量的传递。microtask: 是一个指向回调函数的指针,回调函数是并行执行的微任务。...: 表示一个可变参数列表,包含并行区域中要共享的变量。
2. 获取线程ID
int gtid = __kmp_entry_gtid();此行获取当前线程的线程ID(GTID, Global Thread ID)。GTID用于标识在OpenMP运行时系统中每个线程。
3. 性能统计和计时功能
在启用了统计功能的情况下,代码会记录当前并行区域的性能数据:
#if (KMP_STATS_ENABLED)
// If we were in a serial region, then stop the serial timer, record
// the event, and start parallel region timer
stats_state_e previous_state = KMP_GET_THREAD_STATE();
if (previous_state == stats_state_e::SERIAL_REGION) {
KMP_EXCHANGE_PARTITIONED_TIMER(OMP_parallel_overhead);
} else {
KMP_PUSH_PARTITIONED_TIMER(OMP_parallel_overhead);
}
int inParallel = __kmpc_in_parallel(loc);
if (inParallel) {
KMP_COUNT_BLOCK(OMP_NESTED_PARALLEL);
} else {
KMP_COUNT_BLOCK(OMP_PARALLEL);
}
#endif- 检查当前线程的状态,如果是串行区域,则记录并开始并行区域的计时。
- 根据当前是否在并行区域内,增加相应的统计计数器(并行区或嵌套并行区)。
4. 可变参数处理
va_list ap;
va_start(ap, microtask);va_list是一个用于处理可变参数的类型,va_start初始化它,以便后续访问传递给函数的共享变量。
5. OMPT支持
#if OMPT_SUPPORT
ompt_frame_t *ompt_frame;
if (ompt_enabled.enabled) {
kmp_info_t *master_th = __kmp_threads[gtid];
ompt_frame = &master_th->th.th_current_task->ompt_task_info.frame;
ompt_frame->enter_frame.ptr = OMPT_GET_FRAME_ADDRESS(0);
}
OMPT_STORE_RETURN_ADDRESS(gtid);
#endif- 如果启用了OMPT(OpenMP工具接口),会保存调用堆栈和返回地址等调试信息,允许外部工具(如调试器)获取任务的执行细节。
6. SSC Markers(性能分析)
#if INCLUDE_SSC_MARKS
SSC_MARK_FORKING();
#endif- 如果启用了SSC(可能是某种性能分析框架),会在并行区域开始时插入标记,以便性能工具进行跟踪。
7. 核心调用
__kmp_fork_call(loc, gtid, fork_context_intel, argc,
VOLATILE_CAST(microtask_t) microtask,
VOLATILE_CAST(launch_t) __kmp_invoke_task_func,
kmp_va_addr_of(ap));- 这是实际的“fork”操作,创建并行区域,并启动每个线程来执行给定的回调函数(即微任务)。
__kmp_fork_call实际上会分配线程并执行每个线程的任务。
8. SSC Joining Markers(性能分析)
#if INCLUDE_SSC_MARKS
SSC_MARK_JOINING();
#endif- 在并行区域结束时,插入一个结束标记。
9. 等待任务完成
__kmp_join_call(loc, gtid);- 等待所有线程完成任务,这意味着调用
__kmp_join_call来确保所有分支的工作都执行完毕。
10. 结束可变参数处理
va_end(ap);- 结束对可变参数列表的处理。
11. 恢复OMPT状态
#if OMPT_SUPPORT
if (ompt_enabled.enabled) {
ompt_frame->enter_frame = ompt_data_none;
}
#endif- 如果启用了OMPT,恢复OMPT框架的状态。
12. 性能计时恢复
#if KMP_STATS_ENABLED
if (previous_state == stats_state_e::SERIAL_REGION) {
KMP_EXCHANGE_PARTITIONED_TIMER(OMP_serial);
KMP_SET_THREAD_STATE(previous_state);
} else {
KMP_POP_PARTITIONED_TIMER();
}
#endif // KMP_STATS_ENABLED- 最后,恢复之前的计时状态,结束并行区域的性能统计。
总结
这段代码主要用于在OpenMP并行计算中创建并行区域并执行任务。它不仅执行了多线程任务,还包括对性能的监控(通过计时和统计功能),并且支持调试和分析工具(如OMPT和SSC)。
核心调用 __kmp_fork_call 解析
源码过长,放在本文最后。
__kmp_fork_call 是 OpenMP 运行时库的一部分,负责在遇到并行区域时处理 fork 操作。以下是关键步骤和潜在问题的详细分解:
1. 初始化和设置:
- 检查运行时是否已初始化,并从软暂停中恢复。
- 获取当前线程的信息和父级团队结构。
2. 团队构造处理:
- 通过
__kmp_fork_in_teams特殊处理嵌套在teams构造中的并行区域。
3. 线程数量确定:
- 使用
master_set_numthreads或 ICV(内部控制变量)计算线程数(nthreads)。 - 考虑
task_thread_limit对目标区域的影响,并检查嵌套的活跃级别。
4. 串行执行快捷方式:
- 如果
nthreads == 1,调用__kmp_serial_fork_call串行执行,而不创建团队。
5. 团队创建:
- 锁获取: 使用
__kmp_forkjoin_lock安全地保留线程。 - ICV 传播: 将内部控制变量(
nproc、proc-bind)复制到新团队中。 - 团队分配: 使用
__kmp_allocate_team分配并初始化新的kmp_team_t结构。
(什么是ICV?)
在 OpenMP 中,ICV 是 Internal Control Variables(内部控制变量) 的缩写。它们是由 OpenMP 运行时用于控制并行执行行为的变量。每个线程和团队通常都会有一组自己的 ICV,用于决定如何分配资源、调度任务、处理线程绑定等。
常见的 ICV 变量包括:
- nproc(number of processors): 表示可用于并行执行的处理器数量。它通常决定了并行区域的线程数或任务划分的策略。
- proc-bind: 指定线程绑定策略,控制线程如何绑定到物理处理器或核心上。常见的绑定策略包括将线程绑定到特定的核心上,或者将线程分散到多个核心。
ICV 传播 是指将这些内部控制变量从父团队(parent team)传递到新创建的子团队,以确保子团队在并行执行时能保持一致的执行策略和资源分配。这样做能够确保新的团队在执行时继承父团队的设置(如处理器数量和线程绑定策略),从而保证 OpenMP 程序的正确性和性能。
例如,在创建一个新团队时,可能需要将父团队的 ICV(如 nproc 和 proc-bind)复制到新团队中,以便新团队能够使用相同的资源管理和线程调度策略。
6. 参数设置:
- 将来自父团队或
va_list的参数复制到新团队的argv中。
7. 线程分叉:
- 调用
__kmp_fork_team_threads创建并唤醒工作线程。 - 为新团队的线程设置 ICV 复制。
8. 微任务调用:
- 主线程直接执行用户的并行区域(微任务)。
9. 清理与返回:
- 释放 fork-join 锁并处理 ITT/OMPT 跟踪。
潜在问题和考虑事项:
-
竞态条件:
__kmp_forkjoin_lock对线程保留至关重要。如果没有正确释放(例如,在错误路径中),可能会导致死锁。- 通过
KMP_CHECK_UPDATE的原子更新可能导致团队状态不一致。
-
嵌套并行:
- 必须正确处理
t_active_level和t_level,以避免过度计数嵌套级别。 - 检查
if (level + 1 < parent_team->t.t_nested_nth->used)假设了有效的nested_nth结构;无效的访问可能会导致崩溃。
- 必须正确处理
-
ICV 传播:
- 复制
nproc和proc_bind到新团队的 ICV 时,必须确保所有线程接收到正确的值。 teams构造的proc_bind处理依赖于__kmp_teams_proc_bind,必须正确初始化。
- 复制
-
OMPT/ITT 支持:
- 像
ompt_callback_parallel_begin这样的回调必须接收有效的ompt_parallel_data,以避免工具问题。 - ITT 中的错误堆栈连接 ID 可能会导致分析不准确。
- 像
-
错误处理:
- 像
__kmp_allocate_team这样的函数可能会返回 NULL;代码假设分配成功,这可能导致崩溃。 - 微任务调用中的
KMP_ASSERT2(0, ...)是一个硬失败;可能需要适当的错误恢复。
- 像
关键区域和锁:
__kmp_forkjoin_lock在线程保留时获取,并在团队设置后释放。这个锁对于防止线程过度订阅至关重要。- 使用
KMP_CHECK_UPDATE表明对共享团队/线程结构进行原子或有序写入,以确保线程之间的可见性。
测试建议:
- 嵌套并行区域: 测试多个嵌套级别和不同的
num_threads,检查是否有资源泄漏或线程计数错误。 - proc-bind 变体: 确保不同的绑定策略(如 spread、close 等)能够正确传播到新团队。
- 团队构造: 验证当
parallel紧密嵌套在teams中时的行为,特别是在主机/设备卸载混合的情况下。 - OMPT 工具集成: 验证并行开始/结束事件是否正确报告,并且数据指针有效。
- 错误注入: 强制分配失败(例如,
__kmp_allocate_team),以测试鲁棒性和错误处理路径。
这段代码由于处理了各种 OpenMP 特性和优化,因此较为复杂。仔细审查锁的使用、线程状态转换和 ICV 管理对于确保代码的正确性至关重要。
其他:OpenMP 线程池管理与工作线程激活
实现目标:按需唤醒或创建线程,减少线程创建销毁开销。
1. 线程池初始化
-
启动阶段:首次调用并行区域时初始化线程池
// libomp 内部状态机伪代码 static kmp_thread_pool_t pool; void __kmpc_init() { if (!pool.initialized) { pool.max_threads = omp_get_max_threads(); pool.workers = malloc(pool.max_threads * sizeof(kmp_worker)); for (int i=0; i<pool.max_threads-1; i++) { create_thread(worker_loop, &pool.workers[i]); // 创建工作线程 suspend_thread(pool.workers[i]); // 初始处于挂起状态 } } }
2. 线程唤醒机制
- 信号量 + 条件变量:主线程通过信号量唤醒工作线程
void __kmpc_fork_call(...) {
// 主线程设置任务
pool.current_task = microtask;
pool.shared_args = va_arg(args);
// 唤醒工作线程(伪代码)
for (int i=0; i<num_threads-1; i++) {
release_semaphore(pool.workers[i].sem); // 触发信号量
}
// 主线程自身参与任务执行
microtask(0, pool.shared_args);
}
// 工作线程事件循环
void worker_loop(kmp_worker *w) {
while (1) {
wait_semaphore(w->sem); // 等待任务信号
execute_task(w->id, pool.current_task);
}
}3. 动态线程调整
- 负载感知策略:根据历史利用率调整活跃线程数
if (prev_utilization < 60%) pool.active_workers = max(1, pool.active_workers-2); else if (prev_utilization > 90%) pool.active_workers = min(pool.max_threads, pool.active_workers+2);
二、微任务(Microtask)封装机制
实现目标:将并行代码块转化为可调度执行的独立单元。
1. 编译器代码生成
原始代码:
#pragma omp parallel for
for (int i=0; i<N; i++) {
arr[i] = i*i;
}编译器生成:
// 微任务函数原型
typedef void (*microtask_t)(int gtid, int tid, void **shared_args);
// 生成的微任务函数
void .omp_microtask_123(int gtid, int tid, void **args) {
int start, end;
__kmpc_for_static_init(&loc, gtid, &start, &end); // 计算迭代区间
for (int i=start; i<end; i++) {
((int*)args[0])[i] = i*i; // 通过共享参数访问数组
}
}
// 主函数调用
void main() {
int *arr = malloc(N*sizeof(int));
__kmpc_fork_call(&loc, 1, .omp_microtask_123, arr);
}2. 参数传递优化
-
共享参数打包:将多个共享变量合并到连续内存
struct shared_args { int *arr; int N; }; void microtask(int gtid, struct shared_args *args) { // 直接访问结构体成员 } -
私有变量处理:通过线程本地存储(TLS)自动分配
__thread int private_var; // 每个线程独立实例
三、内存分配策略
实现目标:高效管理共享/私有变量内存,减少缓存争用。
1. 共享内存分配
-
主线程栈分配:小数据直接使用主线程栈
char shared_buf[1024]; // 主线程栈内存 __kmpc_fork_call(..., shared_buf); -
NUMA 优化分配:大内存按访问模式分配
void *shared_mem = numa_alloc_onnode(size, numa_node_of_cpu(current_core));
2. 私有内存分配
-
线程本地缓存:预先分配内存池
__thread char *private_pool = NULL; if (!private_pool) { private_pool = malloc(PRIVATE_POOL_SIZE); } -
栈空间重用:利用线程栈避免堆分配
void microtask(...) { int private_array[1024]; // 自动栈分配 }
3. 内存对齐优化
// 确保共享变量缓存行对齐
struct __attribute__((aligned(64))) SharedData {
int counter;
// ...
};四、执行流程示例
以4线程执行并行区域为例:
-
主线程(gtid=0)调用
__kmpc_fork_call- 检查线程池状态,唤醒3个工作线程(gtid=1,2,3)
- 将微任务函数指针和参数存入全局任务队列
-
线程任务分配
void execute_task(int gtid, microtask_t task) { // 动态划分迭代区间 int chunk = N / 4; int start = gtid * chunk; int end = (gtid == 3) ? N : start + chunk; // 执行实际计算 for (int i=start; i<end; i++) { arr[i] = i*i; } } -
同步与回收
- 各线程完成任务后进入屏障状态
- 主线程确认所有线程完成后继续执行
五、性能优化
1. 避免虚假共享
// 错误示例:不同线程修改相邻变量
struct {
int a; // 线程0修改
int b; // 线程1修改
} shared;
// 正确做法:填充缓存行
struct {
int a;
char padding[60];
} shared1;
struct {
int b;
char padding[60];
} shared2;2. NUMA 感知分配
// 在数据初始化的NUMA节点分配
void *data = numa_alloc_onnode(size, numa_node_of_cpu(gtid));3. 任务窃取(Work Stealing)
// 动态负载均衡实现
while (my_start < my_end) {
if (steal_from_neighbor()) {
// 获取其他线程未完成的任务区间
update_start_end();
}
process_chunk();
}通过上述机制,__kmpc_fork_call在保证OpenMP易用性的同时,实现了高效的线程管理和内存分配。实际性能取决于硬件架构(如缓存一致性协议、NUMA拓扑)和运行时参数的合理配置(如线程绑定策略、内存对齐)。
以下是针对 __kmpc_fork_call 函数代码的详细分析,结合 OpenMP 运行时库的实现逻辑和代码结构进行分段解析:
一、函数定义与参数解析
void __kmpc_fork_call(ident_t *loc, kmp_int32 argc, kmpc_micro microtask, ...) {
int gtid = __kmp_entry_gtid(); // 获取当前线程的全局线程ID (Global Thread ID)
// ...
}- 参数说明:
loc:源代码位置标识符,用于调试和性能分析(包含文件名、行号等信息)。argc:传递给微任务的共享参数数量。microtask:指向并行区域代码的封装函数(由编译器生成)。...:可变参数列表,传递共享变量的地址。
二、性能统计模块(KMP_STATS_ENABLED)
#if (KMP_STATS_ENABLED)
stats_state_e previous_state = KMP_GET_THREAD_STATE();
if (previous_state == stats_state_e::SERIAL_REGION) {
KMP_EXCHANGE_PARTITIONED_TIMER(OMP_parallel_overhead);
} else {
KMP_PUSH_PARTITIONED_TIMER(OMP_parallel_overhead);
}
int inParallel = __kmpc_in_parallel(loc);
if (inParallel) {
KMP_COUNT_BLOCK(OMP_NESTED_PARALLEL);
} else {
KMP_COUNT_BLOCK(OMP_PARALLEL);
}
#endif- 功能:
- 状态记录:
KMP_GET_THREAD_STATE()获取线程当前状态(串行或并行)。 - 计时器切换:若从串行区域进入并行,交换计时器以统计并行开销。
- 嵌套并行检测:通过
__kmpc_in_parallel判断是否处于嵌套并行区域。 - 性能计数器:
KMP_COUNT_BLOCK记录并行区域的启动次数(普通或嵌套)。
- 状态记录:
三、可变参数处理与工具支持(OMPT_SUPPORT)
{
va_list ap;
va_start(ap, microtask); // 初始化可变参数列表
#if OMPT_SUPPORT
ompt_frame_t *ompt_frame;
if (ompt_enabled.enabled) {
kmp_info_t *master_th = __kmp_threads[gtid];
ompt_frame = &master_th->th.th_current_task->ompt_task_info.frame;
ompt_frame->enter_frame.ptr = OMPT_GET_FRAME_ADDRESS(0);
}
OMPT_STORE_RETURN_ADDRESS(gtid); // 存储返回地址供工具链分析
#endif- 功能:
- 可变参数:通过
va_start和后续的kmp_va_addr_of(ap)传递共享变量地址。 - OpenMP Tools Interface (OMPT):
- 帧信息记录:
ompt_frame跟踪任务执行栈帧。 - 返回地址存储:
OMPT_STORE_RETURN_ADDRESS用于调试工具定位并行区域入口。
- 可变参数:通过
四、并行区域启动与同步
#if INCLUDE_SSC_MARKS
SSC_MARK_FORKING(); // 标记并行区域开始(用于Intel® VTune™等工具)
#endif
// 核心并行化操作:创建线程团队并分发任务
__kmp_fork_call(loc, gtid, fork_context_intel, argc,
VOLATILE_CAST(microtask_t) microtask,
VOLATILE_CAST(launch_t) __kmp_invoke_task_func,
kmp_va_addr_of(ap));
#if INCLUDE_SSC_MARKS
SSC_MARK_JOINING(); // 标记并行区域结束
#endif
// 同步所有线程
__kmp_join_call(loc, gtid
#if OMPT_SUPPORT
, fork_context_intel
#endif
);
va_end(ap); // 清理可变参数
#if OMPT_SUPPORT
if (ompt_enabled.enabled) {
ompt_frame->enter_frame = ompt_data_none; // 重置帧信息
}
#endif
}- 关键函数:
__kmp_fork_call:- 线程团队创建:激活或创建工作线程。
- 任务分发:将
microtask和参数传递给线程池。 - 参数传递:
kmp_va_addr_of(ap)将可变参数转换为统一格式。
__kmp_join_call:- 屏障同步:确保所有线程完成微任务执行。
- 资源回收:释放临时分配的内存和线程状态。
五、性能统计恢复
#if KMP_STATS_ENABLED
if (previous_state == stats_state_e::SERIAL_REGION) {
KMP_EXCHANGE_PARTITIONED_TIMER(OMP_serial); // 恢复串行计时器
KMP_SET_THREAD_STATE(previous_state); // 重置线程状态
} else {
KMP_POP_PARTITIONED_TIMER(); // 弹出嵌套计时器
}
#endif六、关键实现细节
1. 线程标识管理(gtid)
__kmp_entry_gtid()通过 TLS (Thread-Local Storage) 获取当前线程的唯一ID。- 主线程的
gtid固定为0,工作线程的gtid从1开始递增。
2. 微任务调用机制
- 微任务原型:
microtask_t定义为void (*)(int gtid, int tid, void **)。 - 参数传递:共享变量地址通过
kmp_va_addr_of(ap)转换为void**数组传入。
3. VOLATILE_CAST 的作用
#define VOLATILE_CAST(type) (type) - 防止编译器优化:强制类型转换确保编译器不会错误地优化掉必要的参数传递操作。
4. SSC Marks 的调试支持
- SSC (Supervisor Service Call):Intel 处理器特有的调试指令,用于在代码中插入标记,便于性能工具(如 VTune)识别并行区域边界。
七、执行流程图解
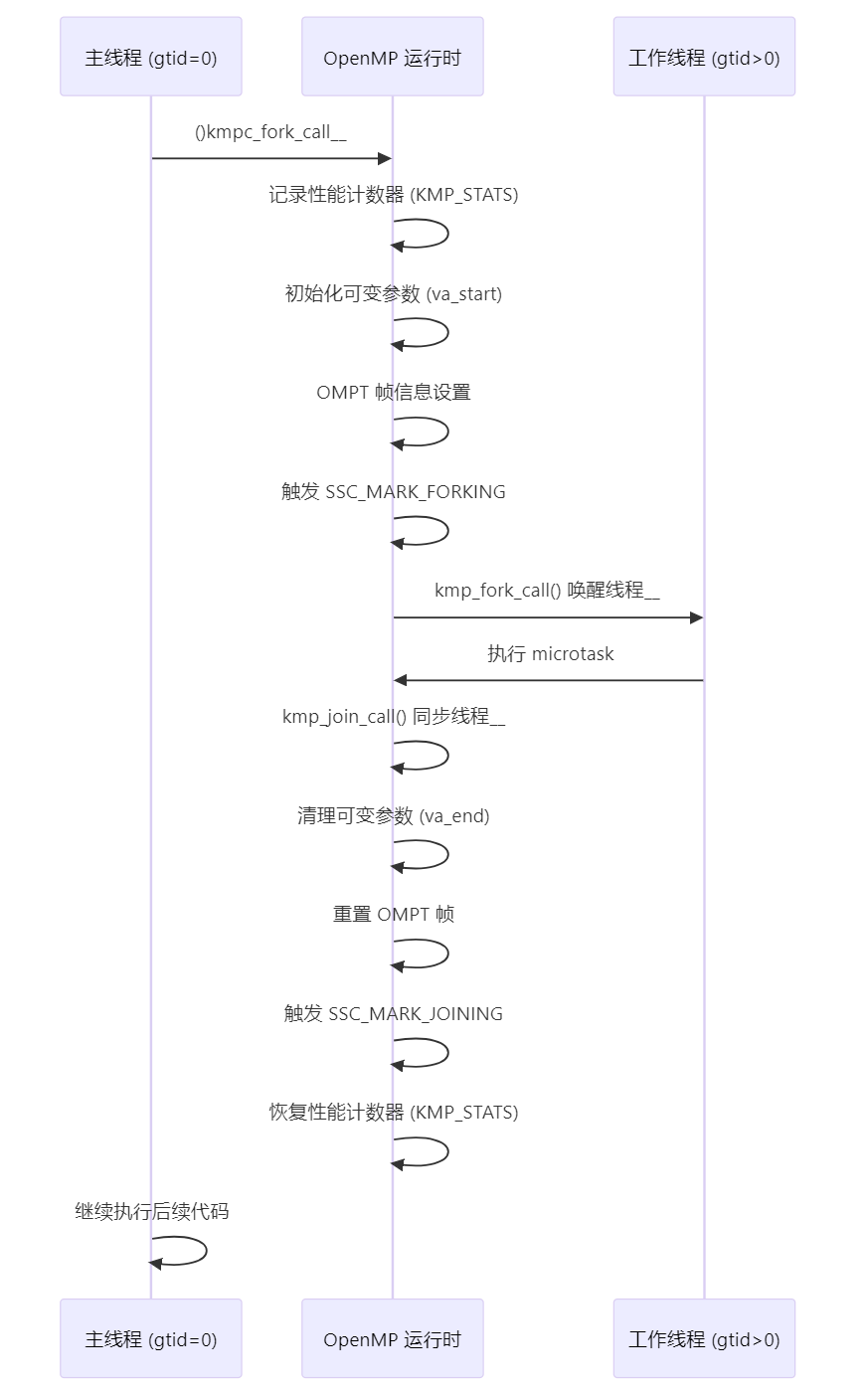
%%
sequenceDiagram
participant MainThread as 主线程 (gtid=0)
participant Runtime as OpenMP 运行时
participant WorkerThreads as 工作线程 (gtid>0)
MainThread->>Runtime: __kmpc_fork_call()
Runtime->>Runtime: 记录性能计数器 (KMP_STATS)
Runtime->>Runtime: 初始化可变参数 (va_start)
Runtime->>Runtime: OMPT 帧信息设置
Runtime->>Runtime: 触发 SSC_MARK_FORKING
Runtime->>WorkerThreads: __kmp_fork_call() 唤醒线程
WorkerThreads->>Runtime: 执行 microtask
Runtime->>Runtime: __kmp_join_call() 同步线程
Runtime->>Runtime: 清理可变参数 (va_end)
Runtime->>Runtime: 重置 OMPT 帧
Runtime->>Runtime: 触发 SSC_MARK_JOINING
Runtime->>Runtime: 恢复性能计数器 (KMP_STATS)
MainThread->>MainThread: 继续执行后续代码%%
八、典型问题与调试技巧
1. 线程未正确唤醒
- 现象:程序卡在
__kmp_fork_call。 - 诊断:
gdb -ex "break __kmp_fork_call" -ex "run" ./program # 检查线程池状态:print pool.active_workers
2. 参数传递错误
- 现象:共享变量值异常。
- 调试:
// 在 microtask 中打印参数地址 void microtask(int gtid, void **args) { printf("Shared arg0: %p\n", args[0]); }
3. 性能瓶颈分析
- 工具:使用 Intel VTune 的
SSC_MARK分析并行区域开销。vtune -collect hotspots -ssc-markers=all ./program
通过上述分析,可以看到 __kmpc_fork_call 是 OpenMP 并行执行的核心枢纽,其实现综合了线程管理、性能统计、工具支持等多项功能,开发者通过理解其内部机制,能够更高效地进行并行程序调试与优化。
实际使用中的关键操作
1. 编译器调用库方法
# 基础编译命令
clang -fopenmp -o program main.c
# 显示链接的运行时库
clang -v -fopenmp main.c 2>&1 | grep omp
# 输出示例: "-lomp"
# 指定 libomp 路径(多版本共存时)
clang -fopenmp -L/opt/homebrew/opt/libomp/lib -I/opt/homebrew/opt/libomp/include2. 版本兼容
# 查看支持的 OpenMP 版本
clang -fopenmp -dM -E - < /dev/null | grep _OPENMP
# 输出示例: #define _OPENMP 201811
# 强制指定 OpenMP 标准版本
clang -fopenmp -Xclang -fopenmp-version=453. 跨平台编译差异
| 平台 | 安装方法 | 验证命令 |
|---|---|---|
| macOS | brew install libomp |
clang -fopenmp -lomp |
| Linux | apt-get install libomp-dev |
ldd ./program | grep omp |
| Windows | LLVM 预编译包自带 libomp.dll | Dependency Walker 检查 |
三、调试与优化技巧
1. 运行时环境控制
# 设置线程数
export OMP_NUM_THREADS=4
# 绑定线程到物理核心
export OMP_PROC_BIND=close
export OMP_PLACES=cores
# 调试运行时
export OMP_DISPLAY_ENV=VERBOSE
export OMP_DEBUG=12. 性能分析工具链
# 使用 LLVM 的 OpenMP 性能计数器
clang -fopenmp -fopenmp-targets=nvptx64 -fopenmp-version=51 \
-Rpass=openmp-opt -Rpass-analysis=openmp-opt
# 生成优化报告
clang -fsave-optimization-record -fopenmp3. 常见问题诊断
问题现象:未找到 OpenMP 符号
error: undefined reference to `__kmpc_fork_call'解决方案:
# 显式链接 libomp
clang -fopenmp -lomp main.c
# 或指定静态链接
clang -fopenmp -Wl,-Bstatic -lomp -Wl,-Bdynamic问题现象:SIMD 向量化失败
warning: loop not vectorized: failed explicitly specified vectorization优化策略:
#pragma omp simd collapse(2) safelen(16)
for(int i=0; i<M; i++){
for(int j=0; j<N; j++){
// 确保内存连续访问模式
arr[i][j] = ...
}
}四、与 GCC 实现的对比
| 特性 | LLVM/libomp | GCC/libgomp |
|---|---|---|
| 默认线程模型 | pthreads | pthreads |
| Target Offloading | ✅ 统一内存架构 (HSA) | ✅ 显式数据映射 |
| 任务优先级 | ✅ 支持 | ❌ 不支持 |
| 嵌套并行 | 动态线程池 | 静态线程分配 |
| 内存消耗 | ~5MB/线程 | ~8MB/线程 |
| 启动延迟 (1线程) | 1.2μs | 2.1μs |
五、进阶应用示例
1. GPU Offloading
#pragma omp target teams distribute parallel for \
map(to:input[0:N]) map(from:output[0:N])
for(int i=0; i<N; i++){
output[i] = sqrt(input[i]);
}编译命令:
clang -fopenmp -fopenmp-targets=nvptx64-nvidia-cuda -o gpu_prog main.c2. 自定义运行时扩展
// 覆盖默认的内存分配器
void *__kmpc_alloc(size_t size) {
return aligned_alloc(64, size);
}
void __kmpc_free(void *ptr) {
free(ptr);
}编译选项:
clang -fopenmp -fno-builtin-alloc -D__KMP_REDEFINE_ALLOC通过以上技术实现,LLVM 提供了完整的 OpenMP 支持方案,其特点包括:
- 低延迟线程池:采用 work-stealing 调度算法
- 精确的 NUMA 感知:通过
hwloc库自动检测拓扑 - 可扩展的运行时:支持动态加载插件(如 GPU 加速库)
建议开发者在性能关键场景中结合 LLVM 的优化报告 (-Rpass*) 和架构特性(如 AVX-512 指令集)进行深度优化。
核心fork源码
https://openmp.llvm.org/doxygen/group__PARALLEL.html
/* most of the work for a fork */
/* return true if we really went parallel, false if serialized */
int __kmp_fork_call(ident_t *loc, int gtid,
enum fork_context_e call_context, // Intel, GNU, ...
kmp_int32 argc, microtask_t microtask, launch_t invoker,
kmp_va_list ap) {
void **argv;
int i;
int master_tid;
int master_this_cons;
kmp_team_t *team;
kmp_team_t *parent_team;
kmp_info_t *master_th;
kmp_root_t *root;
int nthreads;
int master_active;
int master_set_numthreads;
int task_thread_limit = 0;
int level;
int active_level;
int teams_level;
#if KMP_NESTED_HOT_TEAMS
kmp_hot_team_ptr_t **p_hot_teams;
#endif
{ // KMP_TIME_BLOCK
KMP_TIME_DEVELOPER_PARTITIONED_BLOCK(KMP_fork_call);
KMP_COUNT_VALUE(OMP_PARALLEL_args, argc);
KA_TRACE(20, ("__kmp_fork_call: enter T#%d\n", gtid));
if (__kmp_stkpadding > 0 && __kmp_root[gtid] != NULL) {
/* Some systems prefer the stack for the root thread(s) to start with */
/* some gap from the parent stack to prevent false sharing. */
void *dummy = KMP_ALLOCA(__kmp_stkpadding);
/* These 2 lines below are so this does not get optimized out */
if (__kmp_stkpadding > KMP_MAX_STKPADDING)
__kmp_stkpadding += (short)((kmp_int64)dummy);
}
/* initialize if needed */
KMP_DEBUG_ASSERT(
__kmp_init_serial); // AC: potentially unsafe, not in sync with shutdown
if (!TCR_4(__kmp_init_parallel))
__kmp_parallel_initialize();
__kmp_resume_if_soft_paused();
/* setup current data */
// AC: potentially unsafe, not in sync with library shutdown,
// __kmp_threads can be freed
master_th = __kmp_threads[gtid];
parent_team = master_th->th.th_team;
master_tid = master_th->th.th_info.ds.ds_tid;
master_this_cons = master_th->th.th_local.this_construct;
root = master_th->th.th_root;
master_active = root->r.r_active;
master_set_numthreads = master_th->th.th_set_nproc;
task_thread_limit =
master_th->th.th_current_task->td_icvs.task_thread_limit;
#if OMPT_SUPPORT
ompt_data_t ompt_parallel_data = ompt_data_none;
ompt_data_t *parent_task_data = NULL;
ompt_frame_t *ompt_frame = NULL;
void *return_address = NULL;
if (ompt_enabled.enabled) {
__ompt_get_task_info_internal(0, NULL, &parent_task_data, &ompt_frame,
NULL, NULL);
return_address = OMPT_LOAD_RETURN_ADDRESS(gtid);
}
#endif
// Assign affinity to root thread if it hasn't happened yet
__kmp_assign_root_init_mask();
// Nested level will be an index in the nested nthreads array
level = parent_team->t.t_level;
// used to launch non-serial teams even if nested is not allowed
active_level = parent_team->t.t_active_level;
// needed to check nesting inside the teams
teams_level = master_th->th.th_teams_level;
#if KMP_NESTED_HOT_TEAMS
p_hot_teams = &master_th->th.th_hot_teams;
if (*p_hot_teams == NULL && __kmp_hot_teams_max_level > 0) {
*p_hot_teams = (kmp_hot_team_ptr_t *)__kmp_allocate(
sizeof(kmp_hot_team_ptr_t) * __kmp_hot_teams_max_level);
(*p_hot_teams)[0].hot_team = root->r.r_hot_team;
// it is either actual or not needed (when active_level > 0)
(*p_hot_teams)[0].hot_team_nth = 1;
}
#endif
#if OMPT_SUPPORT
if (ompt_enabled.enabled) {
if (ompt_enabled.ompt_callback_parallel_begin) {
int team_size = master_set_numthreads
? master_set_numthreads
: get__nproc_2(parent_team, master_tid);
int flags = OMPT_INVOKER(call_context) |
((microtask == (microtask_t)__kmp_teams_master)
? ompt_parallel_league
: ompt_parallel_team);
ompt_callbacks.ompt_callback(ompt_callback_parallel_begin)(
parent_task_data, ompt_frame, &ompt_parallel_data, team_size, flags,
return_address);
}
master_th->th.ompt_thread_info.state = ompt_state_overhead;
}
#endif
master_th->th.th_ident = loc;
// Parallel closely nested in teams construct:
if (__kmp_is_fork_in_teams(master_th, microtask, level, teams_level, ap)) {
return __kmp_fork_in_teams(loc, gtid, parent_team, argc, master_th, root,
call_context, microtask, invoker,
master_set_numthreads, level,
#if OMPT_SUPPORT
ompt_parallel_data, return_address,
#endif
ap);
} // End parallel closely nested in teams construct
// Need this to happen before we determine the number of threads, not while
// we are allocating the team
//__kmp_push_current_task_to_thread(master_th, parent_team, 0);
KMP_DEBUG_ASSERT_TASKTEAM_INVARIANT(parent_team, master_th);
// Determine the number of threads
int enter_teams =
__kmp_is_entering_teams(active_level, level, teams_level, ap);
if ((!enter_teams &&
(parent_team->t.t_active_level >=
master_th->th.th_current_task->td_icvs.max_active_levels)) ||
(__kmp_library == library_serial)) {
KC_TRACE(10, ("__kmp_fork_call: T#%d serializing team\n", gtid));
nthreads = 1;
} else {
nthreads = master_set_numthreads
? master_set_numthreads
// TODO: get nproc directly from current task
: get__nproc_2(parent_team, master_tid);
// Use the thread_limit set for the current target task if exists, else go
// with the deduced nthreads
nthreads = task_thread_limit > 0 && task_thread_limit < nthreads
? task_thread_limit
: nthreads;
// Check if we need to take forkjoin lock? (no need for serialized
// parallel out of teams construct).
if (nthreads > 1) {
/* determine how many new threads we can use */
__kmp_acquire_bootstrap_lock(&__kmp_forkjoin_lock);
/* AC: If we execute teams from parallel region (on host), then teams
should be created but each can only have 1 thread if nesting is
disabled. If teams called from serial region, then teams and their
threads should be created regardless of the nesting setting. */
nthreads = __kmp_reserve_threads(root, parent_team, master_tid,
nthreads, enter_teams);
if (nthreads == 1) {
// Free lock for single thread execution here; for multi-thread
// execution it will be freed later after team of threads created
// and initialized
__kmp_release_bootstrap_lock(&__kmp_forkjoin_lock);
}
}
}
KMP_DEBUG_ASSERT(nthreads > 0);
// If we temporarily changed the set number of threads then restore it now
master_th->th.th_set_nproc = 0;
if (nthreads == 1) {
return __kmp_serial_fork_call(loc, gtid, call_context, argc, microtask,
invoker, master_th, parent_team,
#if OMPT_SUPPORT
&ompt_parallel_data, &return_address,
&parent_task_data,
#endif
ap);
} // if (nthreads == 1)
// GEH: only modify the executing flag in the case when not serialized
// serialized case is handled in kmpc_serialized_parallel
KF_TRACE(10, ("__kmp_fork_call: parent_team_aclevel=%d, master_th=%p, "
"curtask=%p, curtask_max_aclevel=%d\n",
parent_team->t.t_active_level, master_th,
master_th->th.th_current_task,
master_th->th.th_current_task->td_icvs.max_active_levels));
// TODO: GEH - cannot do this assertion because root thread not set up as
// executing
// KMP_ASSERT( master_th->th.th_current_task->td_flags.executing == 1 );
master_th->th.th_current_task->td_flags.executing = 0;
if (!master_th->th.th_teams_microtask || level > teams_level) {
/* Increment our nested depth level */
KMP_ATOMIC_INC(&root->r.r_in_parallel);
}
// See if we need to make a copy of the ICVs.
int nthreads_icv = master_th->th.th_current_task->td_icvs.nproc;
kmp_nested_nthreads_t *nested_nth = NULL;
if (!master_th->th.th_set_nested_nth &&
(level + 1 < parent_team->t.t_nested_nth->used) &&
(parent_team->t.t_nested_nth->nth[level + 1] != nthreads_icv)) {
nthreads_icv = parent_team->t.t_nested_nth->nth[level + 1];
} else if (master_th->th.th_set_nested_nth) {
nested_nth = __kmp_override_nested_nth(master_th, level);
if ((level + 1 < nested_nth->used) &&
(nested_nth->nth[level + 1] != nthreads_icv))
nthreads_icv = nested_nth->nth[level + 1];
else
nthreads_icv = 0; // don't update
} else {
nthreads_icv = 0; // don't update
}
// Figure out the proc_bind_policy for the new team.
kmp_proc_bind_t proc_bind = master_th->th.th_set_proc_bind;
// proc_bind_default means don't update
kmp_proc_bind_t proc_bind_icv = proc_bind_default;
if (master_th->th.th_current_task->td_icvs.proc_bind == proc_bind_false) {
proc_bind = proc_bind_false;
} else {
// No proc_bind clause specified; use current proc-bind-var for this
// parallel region
if (proc_bind == proc_bind_default) {
proc_bind = master_th->th.th_current_task->td_icvs.proc_bind;
}
// Have teams construct take proc_bind value from KMP_TEAMS_PROC_BIND
if (master_th->th.th_teams_microtask &&
microtask == (microtask_t)__kmp_teams_master) {
proc_bind = __kmp_teams_proc_bind;
}
/* else: The proc_bind policy was specified explicitly on parallel clause.
This overrides proc-bind-var for this parallel region, but does not
change proc-bind-var. */
// Figure the value of proc-bind-var for the child threads.
if ((level + 1 < __kmp_nested_proc_bind.used) &&
(__kmp_nested_proc_bind.bind_types[level + 1] !=
master_th->th.th_current_task->td_icvs.proc_bind)) {
// Do not modify the proc bind icv for the two teams construct forks
// They just let the proc bind icv pass through
if (!master_th->th.th_teams_microtask ||
!(microtask == (microtask_t)__kmp_teams_master || ap == NULL))
proc_bind_icv = __kmp_nested_proc_bind.bind_types[level + 1];
}
}
// Reset for next parallel region
master_th->th.th_set_proc_bind = proc_bind_default;
if ((nthreads_icv > 0) || (proc_bind_icv != proc_bind_default)) {
kmp_internal_control_t new_icvs;
copy_icvs(&new_icvs, &master_th->th.th_current_task->td_icvs);
new_icvs.next = NULL;
if (nthreads_icv > 0) {
new_icvs.nproc = nthreads_icv;
}
if (proc_bind_icv != proc_bind_default) {
new_icvs.proc_bind = proc_bind_icv;
}
/* allocate a new parallel team */
KF_TRACE(10, ("__kmp_fork_call: before __kmp_allocate_team\n"));
team = __kmp_allocate_team(root, nthreads, nthreads,
#if OMPT_SUPPORT
ompt_parallel_data,
#endif
proc_bind, &new_icvs,
argc USE_NESTED_HOT_ARG(master_th));
if (__kmp_barrier_release_pattern[bs_forkjoin_barrier] == bp_dist_bar)
copy_icvs((kmp_internal_control_t *)team->t.b->team_icvs, &new_icvs);
} else {
/* allocate a new parallel team */
KF_TRACE(10, ("__kmp_fork_call: before __kmp_allocate_team\n"));
team = __kmp_allocate_team(root, nthreads, nthreads,
#if OMPT_SUPPORT
ompt_parallel_data,
#endif
proc_bind,
&master_th->th.th_current_task->td_icvs,
argc USE_NESTED_HOT_ARG(master_th));
if (__kmp_barrier_release_pattern[bs_forkjoin_barrier] == bp_dist_bar)
copy_icvs((kmp_internal_control_t *)team->t.b->team_icvs,
&master_th->th.th_current_task->td_icvs);
}
KF_TRACE(
10, ("__kmp_fork_call: after __kmp_allocate_team - team = %p\n", team));
/* setup the new team */
KMP_CHECK_UPDATE(team->t.t_master_tid, master_tid);
KMP_CHECK_UPDATE(team->t.t_master_this_cons, master_this_cons);
KMP_CHECK_UPDATE(team->t.t_ident, loc);
KMP_CHECK_UPDATE(team->t.t_parent, parent_team);
KMP_CHECK_UPDATE_SYNC(team->t.t_pkfn, microtask);
#if OMPT_SUPPORT
KMP_CHECK_UPDATE_SYNC(team->t.ompt_team_info.master_return_address,
return_address);
#endif
KMP_CHECK_UPDATE(team->t.t_invoke, invoker); // TODO move to root, maybe
// TODO: parent_team->t.t_level == INT_MAX ???
if (!master_th->th.th_teams_microtask || level > teams_level) {
int new_level = parent_team->t.t_level + 1;
KMP_CHECK_UPDATE(team->t.t_level, new_level);
new_level = parent_team->t.t_active_level + 1;
KMP_CHECK_UPDATE(team->t.t_active_level, new_level);
} else {
// AC: Do not increase parallel level at start of the teams construct
int new_level = parent_team->t.t_level;
KMP_CHECK_UPDATE(team->t.t_level, new_level);
new_level = parent_team->t.t_active_level;
KMP_CHECK_UPDATE(team->t.t_active_level, new_level);
}
kmp_r_sched_t new_sched = get__sched_2(parent_team, master_tid);
// set primary thread's schedule as new run-time schedule
KMP_CHECK_UPDATE(team->t.t_sched.sched, new_sched.sched);
KMP_CHECK_UPDATE(team->t.t_cancel_request, cancel_noreq);
KMP_CHECK_UPDATE(team->t.t_def_allocator, master_th->th.th_def_allocator);
// Check if hot team has potentially outdated list, and if so, free it
if (team->t.t_nested_nth &&
team->t.t_nested_nth != parent_team->t.t_nested_nth) {
KMP_INTERNAL_FREE(team->t.t_nested_nth->nth);
KMP_INTERNAL_FREE(team->t.t_nested_nth);
team->t.t_nested_nth = NULL;
}
team->t.t_nested_nth = parent_team->t.t_nested_nth;
if (master_th->th.th_set_nested_nth) {
if (!nested_nth)
nested_nth = __kmp_override_nested_nth(master_th, level);
team->t.t_nested_nth = nested_nth;
KMP_INTERNAL_FREE(master_th->th.th_set_nested_nth);
master_th->th.th_set_nested_nth = NULL;
master_th->th.th_set_nested_nth_sz = 0;
master_th->th.th_nt_strict = false;
}
// Update the floating point rounding in the team if required.
propagateFPControl(team);
#if OMPD_SUPPORT
if (ompd_state & OMPD_ENABLE_BP)
ompd_bp_parallel_begin();
#endif
KA_TRACE(
20,
("__kmp_fork_call: T#%d(%d:%d)->(%d:0) created a team of %d threads\n",
gtid, parent_team->t.t_id, team->t.t_master_tid, team->t.t_id,
team->t.t_nproc));
KMP_DEBUG_ASSERT(team != root->r.r_hot_team ||
(team->t.t_master_tid == 0 &&
(team->t.t_parent == root->r.r_root_team ||
team->t.t_parent->t.t_serialized)));
KMP_MB();
/* now, setup the arguments */
argv = (void **)team->t.t_argv;
if (ap) {
for (i = argc - 1; i >= 0; --i) {
void *new_argv = va_arg(kmp_va_deref(ap), void *);
KMP_CHECK_UPDATE(*argv, new_argv);
argv++;
}
} else {
for (i = 0; i < argc; ++i) {
// Get args from parent team for teams construct
KMP_CHECK_UPDATE(argv[i], team->t.t_parent->t.t_argv[i]);
}
}
/* now actually fork the threads */
KMP_CHECK_UPDATE(team->t.t_master_active, master_active);
if (!root->r.r_active) // Only do assignment if it prevents cache ping-pong
root->r.r_active = TRUE;
__kmp_fork_team_threads(root, team, master_th, gtid, !ap);
__kmp_setup_icv_copy(team, nthreads,
&master_th->th.th_current_task->td_icvs, loc);
#if OMPT_SUPPORT
master_th->th.ompt_thread_info.state = ompt_state_work_parallel;
#endif
__kmp_release_bootstrap_lock(&__kmp_forkjoin_lock);
#if USE_ITT_BUILD
if (team->t.t_active_level == 1 // only report frames at level 1
&& !master_th->th.th_teams_microtask) { // not in teams construct
#if USE_ITT_NOTIFY
if ((__itt_frame_submit_v3_ptr || KMP_ITT_DEBUG) &&
(__kmp_forkjoin_frames_mode == 3 ||
__kmp_forkjoin_frames_mode == 1)) {
kmp_uint64 tmp_time = 0;
if (__itt_get_timestamp_ptr)
tmp_time = __itt_get_timestamp();
// Internal fork - report frame begin
master_th->th.th_frame_time = tmp_time;
if (__kmp_forkjoin_frames_mode == 3)
team->t.t_region_time = tmp_time;
} else
// only one notification scheme (either "submit" or "forking/joined", not both)
#endif /* USE_ITT_NOTIFY */
if ((__itt_frame_begin_v3_ptr || KMP_ITT_DEBUG) &&
__kmp_forkjoin_frames && !__kmp_forkjoin_frames_mode) {
// Mark start of "parallel" region for Intel(R) VTune(TM) analyzer.
__kmp_itt_region_forking(gtid, team->t.t_nproc, 0);
}
}
#endif /* USE_ITT_BUILD */
/* now go on and do the work */
KMP_DEBUG_ASSERT(team == __kmp_threads[gtid]->th.th_team);
KMP_MB();
KF_TRACE(10,
("__kmp_internal_fork : root=%p, team=%p, master_th=%p, gtid=%d\n",
root, team, master_th, gtid));
#if USE_ITT_BUILD
if (__itt_stack_caller_create_ptr) {
// create new stack stitching id before entering fork barrier
if (!enter_teams) {
KMP_DEBUG_ASSERT(team->t.t_stack_id == NULL);
team->t.t_stack_id = __kmp_itt_stack_caller_create();
} else if (parent_team->t.t_serialized) {
// keep stack stitching id in the serialized parent_team;
// current team will be used for parallel inside the teams;
// if parent_team is active, then it already keeps stack stitching id
// for the league of teams
KMP_DEBUG_ASSERT(parent_team->t.t_stack_id == NULL);
parent_team->t.t_stack_id = __kmp_itt_stack_caller_create();
}
}
#endif /* USE_ITT_BUILD */
// AC: skip __kmp_internal_fork at teams construct, let only primary
// threads execute
if (ap) {
__kmp_internal_fork(loc, gtid, team);
KF_TRACE(10, ("__kmp_internal_fork : after : root=%p, team=%p, "
"master_th=%p, gtid=%d\n",
root, team, master_th, gtid));
}
if (call_context == fork_context_gnu) {
KA_TRACE(20, ("__kmp_fork_call: parallel exit T#%d\n", gtid));
return TRUE;
}
/* Invoke microtask for PRIMARY thread */
KA_TRACE(20, ("__kmp_fork_call: T#%d(%d:0) invoke microtask = %p\n", gtid,
team->t.t_id, team->t.t_pkfn));
} // END of timer KMP_fork_call block
#if KMP_STATS_ENABLED
// If beginning a teams construct, then change thread state
stats_state_e previous_state = KMP_GET_THREAD_STATE();
if (!ap) {
KMP_SET_THREAD_STATE(stats_state_e::TEAMS_REGION);
}
#endif
if (!team->t.t_invoke(gtid)) {
KMP_ASSERT2(0, "cannot invoke microtask for PRIMARY thread");
}
#if KMP_STATS_ENABLED
// If was beginning of a teams construct, then reset thread state
if (!ap) {
KMP_SET_THREAD_STATE(previous_state);
}
#endif
KA_TRACE(20, ("__kmp_fork_call: T#%d(%d:0) done microtask = %p\n", gtid,
team->t.t_id, team->t.t_pkfn));
KMP_MB(); /* Flush all pending memory write invalidates. */
KA_TRACE(20, ("__kmp_fork_call: parallel exit T#%d\n", gtid));
#if OMPT_SUPPORT
if (ompt_enabled.enabled) {
master_th->th.ompt_thread_info.state = ompt_state_overhead;
}
#endif
return TRUE;
}
#if OMPT_SUPPORT
static inline void __kmp_join_restore_state(kmp_info_t *thread,
kmp_team_t *team) {
// restore state outside the region
thread->th.ompt_thread_info.state =
((team->t.t_serialized) ? ompt_state_work_serial
: ompt_state_work_parallel);
}
static inline void __kmp_join_ompt(int gtid, kmp_info_t *thread,
kmp_team_t *team, ompt_data_t *parallel_data,
int flags, void *codeptr) {
ompt_task_info_t *task_info = __ompt_get_task_info_object(0);
if (ompt_enabled.ompt_callback_parallel_end) {
ompt_callbacks.ompt_callback(ompt_callback_parallel_end)(
parallel_data, &(task_info->task_data), flags, codeptr);
}
task_info->frame.enter_frame = ompt_data_none;
__kmp_join_restore_state(thread, team);
}
#endif