
NSDI26: Can we use MLFQ in LLM Serving?
- Paper Reading
- 2025-10-21
- 932 Views
- 0 Comments
- 835 Words
This paper is in arxiv for 2 years. Then it goes into NSDI26. Maybe we can see the difference between versions of 2023 and 2026.
Paper link:
https://arxiv.org/pdf/2305.05920
Main idea: Can we use MLFQ, a scheduling algorithm in Linux BSD, for LLM Inference Scheduling?
没想到在OS课上学习的MLFQ,也有人用到文章里。
To learn MLFQ
From "OSTEP":
https://pages.cs.wisc.edu/~remzi/OSTEP/cpu-sched-mlfq.pdf
A good Chinese Videos for introduction
【冠以图灵奖之名的调度算法:MLFQ 多级反馈队列!】 https://www.bilibili.com/video/BV18T1FYMEiJ/?share_source=copy_web&vd_source=72eac555730ba7e7a64f9fa1d7f2b2d4
Implementation:
https://github.com/ananthamapod/Multi-Level-Feedback-Queue-Scheduling-Algorithm.git
Some experiments in Linux 2.6
https://pages.cs.wisc.edu/~ltorrey/papers/torrey_spe06.pdf
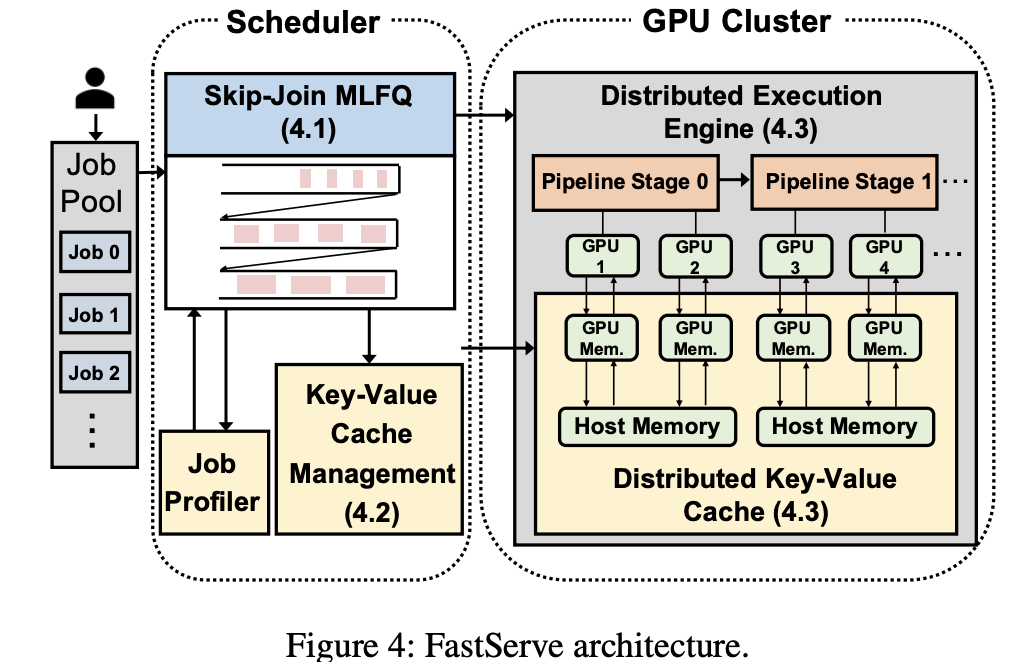
The article titled "Fast Distributed Inference Serving for Large Language Models" proposes and implements FastServe, a distributed inference serving system specifically designed for large-scale language models. It aims to address the issues of high latency and head-of-line blocking in existing LLM serving systems.
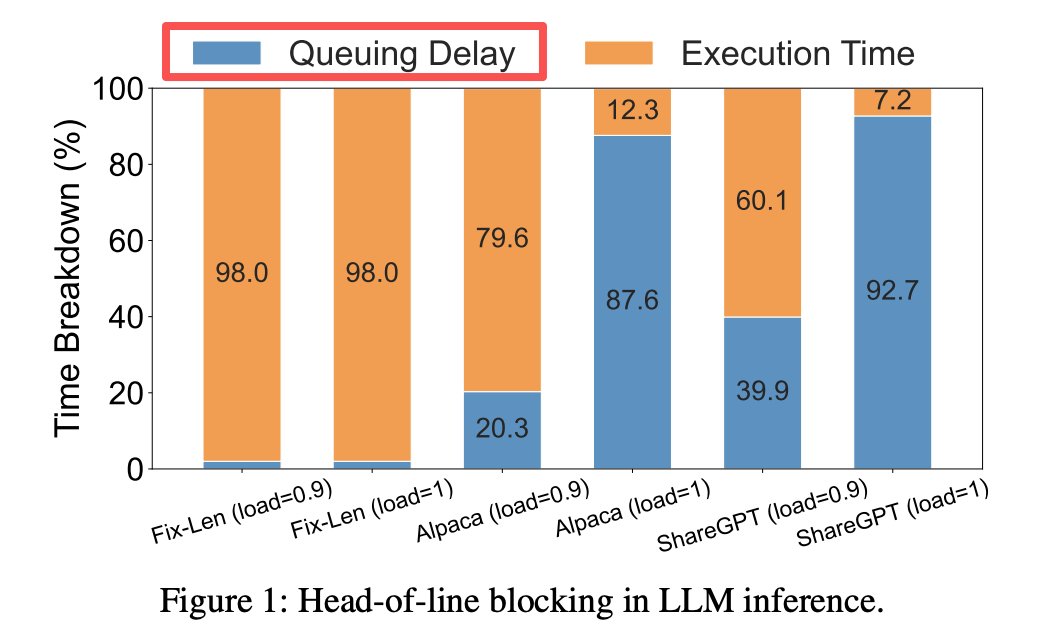
Motivation
- LLM inference has an autoregressive nature, generating one token at a time with an uncertain output length.
- Existing systems (such as vLLM and Orca) use First-Come-First-Served (FCFS) and run-to-completion scheduling strategies, leading to:
- Head-of-line blocking: Long tasks block short tasks, causing queuing delays to account for over 90% of the total latency.
Core Contributions
Try to use Multi-Level Feedback Queue (MLFQ)
Each job in Scheduling is a inference request.
We can't use MLFQ simply. Since LLM has Decode and Prefill. So they design Skip-join mechanism for scheduling Prefilling (They will upload the priority for MLFQ)
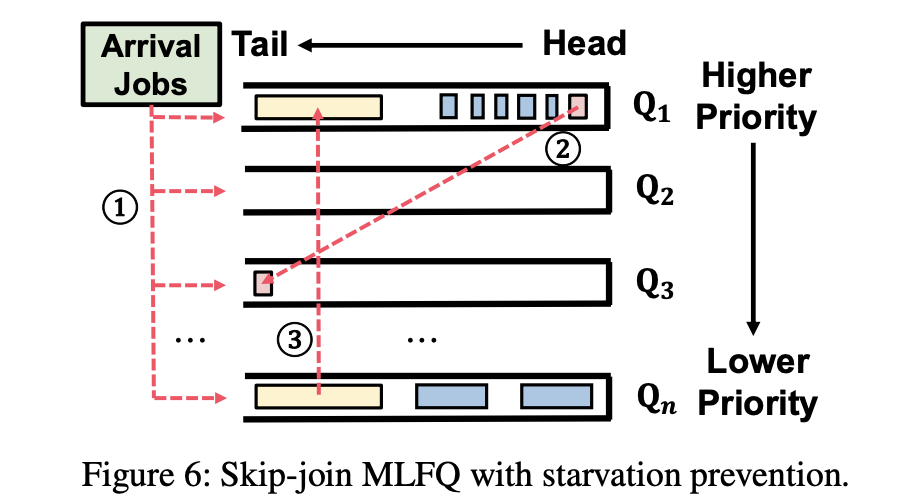
- Leverages the semi-known information characteristic of LLM inference:
- Input length is known, allowing prediction of the first token's generation time;
- Output length is unknown.
补丁/solved bugs: Skip-Join
- New tasks do not always enter the highest-priority queue but "skip" certain queues based on their initial phase execution time, directly joining a suitable priority queue.
- Avoids frequent preemption due to long initial phases, reducing ineffective scheduling.
- Introduces a starvation prevention mechanism to periodically elevate the priority of tasks that have been waiting for an extended period.

2. Proactive Key-Value Cache Management Mechanism
This is caused by using MLFQ. We have to stored KVCache.
就是如果你用MLFQ,就会导致KVCache经常堆积(因为很多请求来不及处理,KVCache也必须先记录着,所以才有这个设计)
This time GPU mem is not enough. So we have to store them in CPU.
One optimization is to overlap the time for transferring J2 data and compute J1.
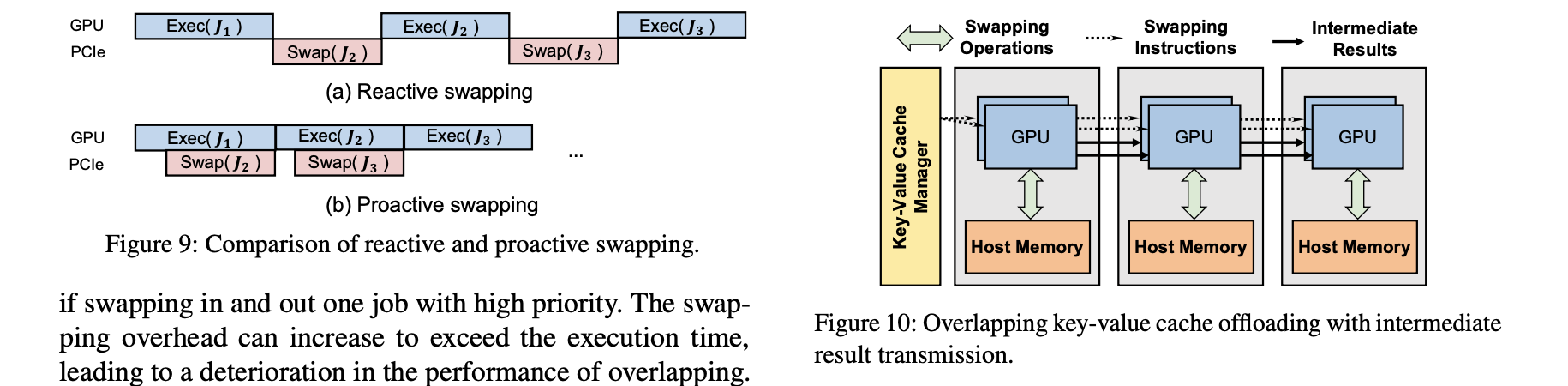
To reach this, the time for this is:

- Preemptive scheduling generates significant intermediate states (KV Cache), occupying GPU memory.
- When GPU memory is insufficient, FastServe:
- Proactively swaps out the KV Cache of low-priority tasks to host memory;
- Swaps it back in just before task execution;
- Uses pipelining and asynchronous operations to overlap swap-in/swap-out overhead with computation, hiding transfer latency.
3. Distributed LLM Serving Support
他们自己做了一个推理引擎,所以工程量挺大的.
The Engine was built with 13000 lines CUDA/C++ and 3000 lines python.
- Supports tensor parallelism and pipeline parallelism, suitable for ultra-large-scale models (e.g., OPT-175B).
- Both the scheduler and KV cache manager support distributed execution, ensuring multi-GPU collaboration.
📊 Experimental Results
- Evaluated on OPT-13B/66B/175B models using real-world datasets (ShareGPT, Alpaca).
- Compared to vLLM:
- Up to 31.4× throughput improvement under average latency
- Up to 17.9× throughput improvement under tail latency
- Compared to FasterTransformer: Achieved even more significant improvements (up to 74.9×).
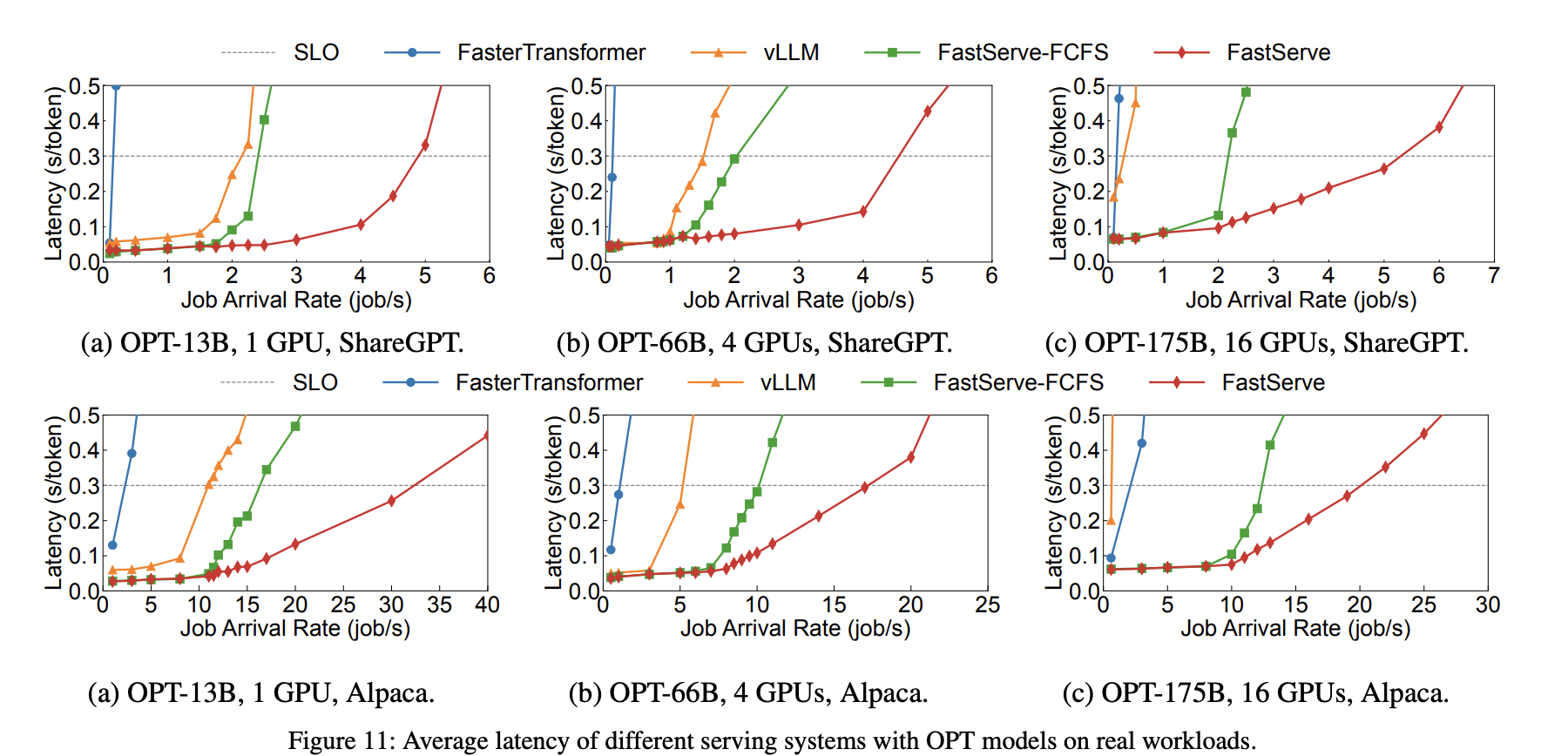
请求的数量其实挺少的
Summary
FastServe delivers optimized performance through:
- Iteration-level preemptive scheduling
- Intelligent queue-skipping mechanism
- Proactive KV cache management
- Distributed execution optimization
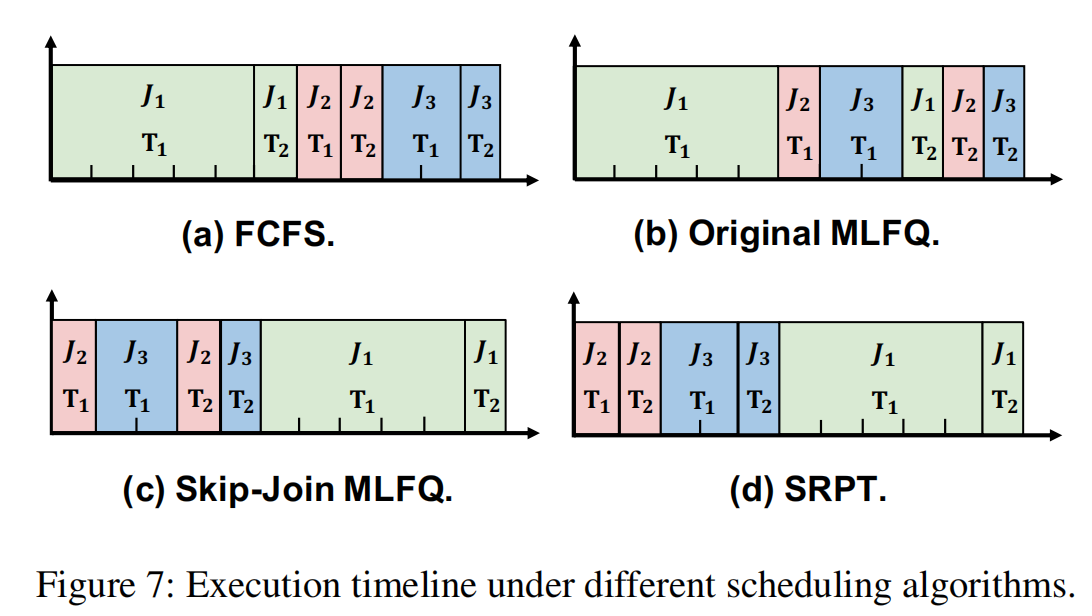
文章的核心点还是在MLFQ上面,什么skip-join跟KVCache overlap,其实都是因为MLFQ导致的。这其实很糟糕,因为是你为了用MLFQ而用MLFQ,而不是说我专门解决LLM调度而去解决问题。凭什么一定要用MLFQ?不知道。所以有点像拿锤子找钉子。
在实验上,MLFQ其实有很多超参,然后MLFQ的overhead,这两个都没怎么测。文章的实验只测了调度的效果。所以其实实验部分做的不是很好。
一篇文章为什么没有中,这方面的经验一定要多学。我很认可作者的实力,我相信NSDI26的camera ready一定比23年的这个版本好很多。