
MIT6.824 存档:学习笔记
- Books Reading
- 2025-08-01
- 460 Views
- 0 Comments
- 7676 Words
分布式系统组成要素
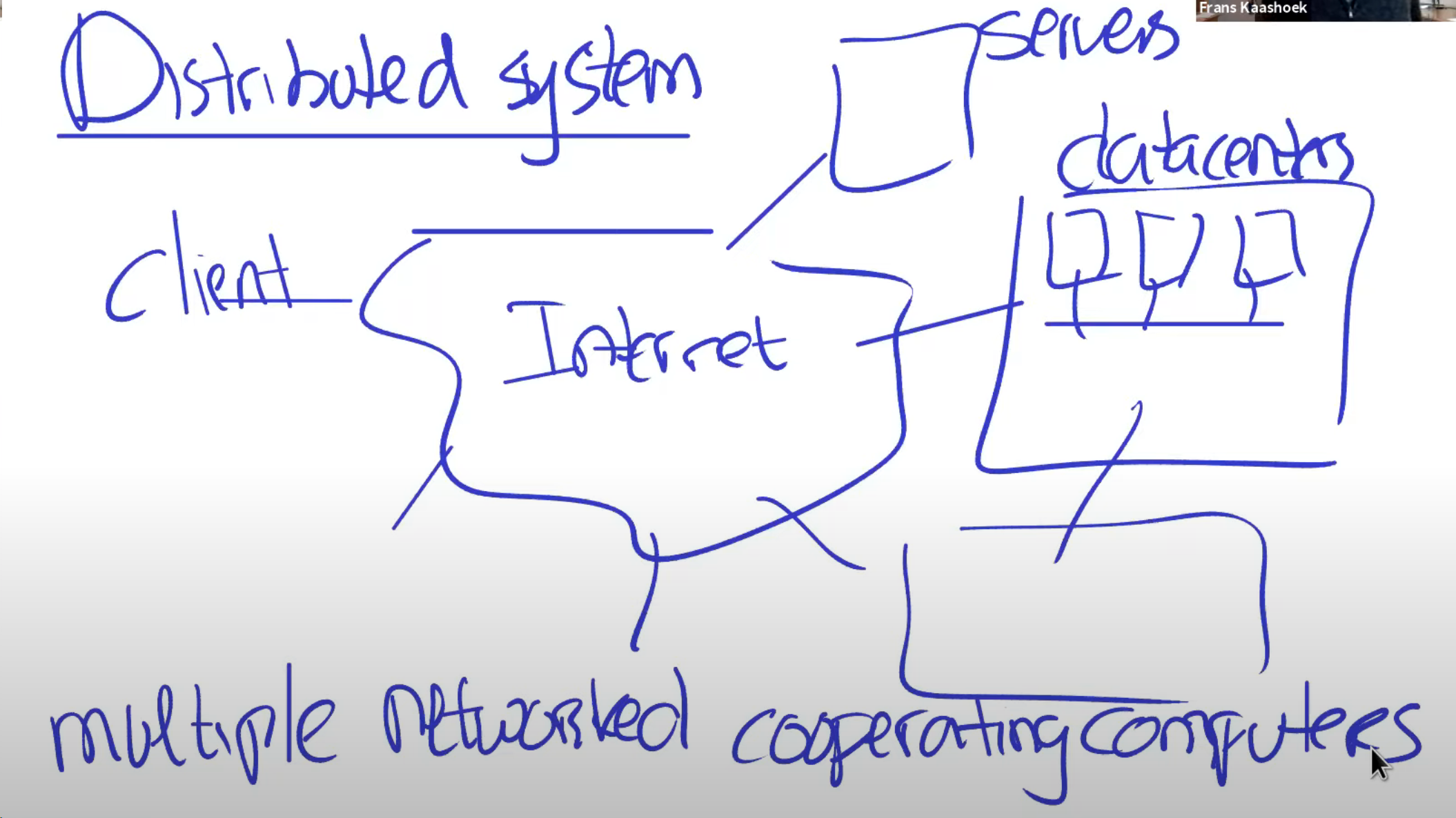
目标:security
fault tolerance
parallel computing
人们使用大量的相互协作的计算机驱动力是:
- 人们需要获得更高的计算性能。可以这么理解这一点,(大量的计算机意味着)大量的并行运算,大量CPU、大量内存、以及大量磁盘在并行的运行。
- 另一个人们构建分布式系统的原因是,它可以提供容错(tolerate faults)。比如两台计算机运行完全相同的任务,其中一台发生故障,可以切换到另一台。
- 第三个原因是,一些问题天然在空间上是分布的。例如银行转账,我们假设银行A在纽约有一台服务器,银行B在伦敦有一台服务器,这就需要一种两者之间协调的方法。所以,有一些天然的原因导致系统是物理分布的。
- 最后一个原因是,人们构建分布式系统来达成一些安全的目标。比如有一些代码并不被信任,但是你又需要和它进行交互,这些代码不会立即表现的恶意或者出现bug。你不会想要信任这些代码,所以你或许想要将代码分散在多处运行,这样你的代码在另一台计算机运行,我的代码在我的计算机上运行,我们通过一些特定的网络协议通信。所以,我们可能会担心安全问题,我们把系统分成多个的计算机,这样可以限制出错域。
所有的这些分布式系统的问题(挑战)在于:
- 因为系统中存在很多部分,这些部分又在并发执行,你会遇到并发编程和各种复杂交互所带来的问题,以及时间依赖的问题(比如同步,异步)。这让分布式系统变得很难。
- 另一个导致分布式系统很难的原因是,分布式系统有多个组成部分,再加上计算机网络,你会会遇到一些意想不到的故障。如果你只有一台计算机,那么它通常要么是工作,要么是故障或者没电,总的来说,要么是在工作,要么是没有工作。而由多台计算机组成的分布式系统,可能会有一部分组件在工作,而另一部分组件停止运行,或者这些计算机都在正常运行,但是网络中断了或者不稳定。所以,局部错误也是分布式系统很难的原因。
- 最后一个导致分布式系统很难的原因是,人们设计分布式系统的根本原因通常是为了获得更高的性能,比如说一千台计算机或者一千个磁盘臂达到的性能。但是实际上一千台机器到底有多少性能是一个棘手的问题,这里有很多难点。所以通常需要倍加小心地设计才能让系统实际达到你期望的性能。
历史
1980 单人的邮件服务器
datacenter
AFS AFS 指的是 Andrew File System,一种分布式文件系统,由卡内基梅隆大学开发,用于在多个客户端和工作站之间提供透明的文件访问
DNS
1990
big website开始出现
shopping, web search
2000s
Map Reduce
cloud computing
current: still develop
当你只有1-2个用户时,一台计算机就可以运行web服务器和数据,或者一台计算机运行web服务器,一台计算机运行数据库。但是有可能你的网站一夜之间就火了起来,你发现可能有一亿人要登录你的网站。你该怎么修改你的网站,使它能够在一台计算机上支持一亿个用户?你可以花费大量时间极致优化你的网站,但是很显然你没有那个时间。所以,为了提升性能,你要做的第一件事情就是购买更多的web服务器,然后把不同用户分到不同服务器上。这样,一部分用户可以去访问第一台web服务器,另一部分去访问第二台web服务器。因为你正在构建的是类似于Reddit的网站,所有的用户最终都需要看到相同的数据。所以,所有的web服务器都与后端数据库通信。这样,很长一段时间你都可以通过添加web服务器来并行的提高web服务器的代码效率。
Challenge
- many concurrent part
- some part may go failure
hard problem, but powerful solution
gets hand on experience! and do it in real world
只要单台web服务器没有给数据库带来太多的压力,你可以在出现问题前添加很多web服务器,但是这种可扩展性并不是无限的。很可能在某个时间点你有了10台,20台,甚至100台web服务器,它们都在和同一个数据库通信。现在,数据库突然成为了瓶颈,并且增加更多的web服务器都无济于事了。所以很少有可以通过无限增加计算机来获取完整的可扩展性的场景。因为在某个临界点,你在系统中添加计算机的位置将不再是瓶颈了。在我们的例子中,如果你有了很多的web服务器,那么瓶颈就会转移到了别的地方,这里是从web服务器移到了数据库。
这时,你几乎是必然要做一些重构工作。但是只有一个数据库时,很难重构它。而虽然可以将一个数据库拆分成多个数据库(进而提升性能),但是这需要大量的工作。
我们在本课程中,会看到很多有关分布式存储系统的例子,因为相关论文或者系统的作者都在运行大型网站,而单个数据库或者存储服务器不能支撑这样规模的网站(所以才需要分布式存储)。
所以,有关扩展性是这样:我们希望可以通过增加机器的方式来实现扩展,但是现实中这很难实现,需要一些架构设计来将这个可扩展性无限推进下去。
某些系统通过这种方式提供可用性。比如,你构建了一个有两个拷贝的多副本系统,其中一个故障了,另一个还能运行。当然如果两个副本都故障了,你的系统就不再有可用性。所以,可用系统通常是指,在特定的故障范围内,系统仍然能够提供服务,系统仍然是可用的。如果出现了更多的故障,系统将不再可用。
除了可用性之外,另一种容错特性是自我可恢复性(recoverability)。这里的意思是,如果出现了问题,服务会停止工作,不再响应请求,之后有人来修复,并且在修复之后系统仍然可以正常运行,就像没有出现过问题一样。这是一个比可用性更弱的需求,因为在出现故障到故障组件被修复期间,系统将会完全停止工作。但是修复之后,系统又可以完全正确的重新运行,所以可恢复性是一个重要的需求。
对于一个可恢复的系统,通常需要做一些操作,例如将最新的数据存放在磁盘中,这样在供电恢复之后(假设故障就是断电),才能将这些数据取回来。甚至说对于一个具备可用性的系统,为了让系统在实际中具备应用意义,也需要具备可恢复性。因为可用的系统仅仅是在一定的故障范围内才可用,如果故障太多,可用系统也会停止工作,停止一切响应。但是当足够的故障被修复之后,系统还是需要能继续工作。所以,一个好的可用的系统,某种程度上应该也是可恢复的。当出现太多故障时,系统会停止响应,但是修复之后依然能正确运行。这是我们期望看到的。
为了实现这些特性,有很多工具。其中最重要的有两个:
-
一个是非易失存储(non-volatile storage,类似于硬盘)。这样当出现类似电源故障,甚至整个机房的电源都故障时,我们可以使用非易失存储,比如硬盘,闪存,SSD之类的。我们可以存放一些checkpoint或者系统状态的log在这些存储中,这样当备用电源恢复或者某人修好了电力供给,我们还是可以从硬盘中读出系统最新的状态,并从那个状态继续运行。所以,这里的一个工具是非易失存储。因为更新非易失存储是代价很高的操作,所以相应的出现了很多非易失存储的管理工具。同时构建一个高性能,容错的系统,聪明的做法是避免频繁的写入非易失存储。在过去,甚至对于今天的一个3GHZ的处理器,写入一个非易失存储意味着移动磁盘臂并等待磁碟旋转,这两个过程都非常缓慢。有了闪存会好很多,但是为了获取好的性能,仍然需要许多思考。
-
对于容错的另一个重要工具是复制(replication),不过,管理复制的多副本系统会有些棘手。任何一个多副本系统中,都会有一个关键的问题,比如说,我们有两台服务器,它们本来应该是有着相同的系统状态,现在的关键问题在于,这两个副本总是会意外的偏离同步的状态,而不再互为副本。对于任何一种使用复制实现容错的系统,我们都面临这个问题。lab2和lab3都是通过管理多副本来实现容错的系统,你将会看到这里究竟有多复杂。
course struct
lectures
papers
MapReduce: Scalability, Consistency, Availability
在当时,整个互联网的数据也有数十TB。构建索引基本上等同于对整个数据做排序,而排序比较费时。如果用一台计算机对整个互联网数据进行排序,要花费多长时间呢?可能要几周,几个月,甚至几年。所以,当时Google非常希望能将对大量数据的大量运算并行跑在几千台计算机上,这样才能快速完成计算。对Google来说,购买大量的计算机是没问题的,这样Google的工程师就不用花大量时间来看报纸来等他们的大型计算任务完成。所以,有段时间,Google买了大量的计算机,并让它的聪明的工程师在这些计算机上编写分布式软件,这样工程师们可以将手头的问题分包到大量计算机上去完成,管理这些运算,并将数据取回。
MapReduce的思想是,应用程序设计人员和分布式运算的使用者,只需要写简单的Map函数和Reduce函数,而不需要知道任何有关分布式的事情,MapReduce框架会处理剩下的事情。
抽象来看,MapReduce假设有一些输入,这些输入被分割成大量的不同的文件或者数据块。所以,我们假设现在有输入文件1,输入文件2和输入文件3,这些输入可能是从网上抓取的网页,更可能是包含了大量网页的文件。
MapReduce 论文解读学习
其实我上学期已经解读过了。并且做了一个简单的仓库
https://github.com/HaibinLai/Rust-MapReduce.git
但是这个仓库其实太垃圾了。最简单的,它做不到多节点。而这反而是MapReduce的一个核心:怎么跑到几百个节点。同时MapReduce的容错机制也没有。所以MapReduce看起来很简单,但是内部有很多系统设计被隐藏起来了,在我们看来是Map+Reduce仅仅两个函数,但是背后的设计都没有做。
MapReduce 的核心思想是将复杂的大规模数据处理分解为两个简单阶段:Map(映射)和 Reduce(归约)。这个抽象屏蔽了分布式系统中大量的复杂细节,比如并行化、容错、数据分布、负载均衡等。开发者只需要定义 Map 和 Reduce 函数,就能轻松处理海量数据,而无需关心底层的分布式系统管理。这大大降低了开发门槛,吸引了广泛的关注和应用。在 MapReduce 出现之前,处理大规模数据通常需要手动编写复杂的并行程序,或者依赖昂贵的专用系统。MapReduce 提供了一种通用的、易于理解的编程模型,适合各种数据处理任务(比如日志分析、网页索引、机器学习等)。它的简单性和通用性让它成为大数据处理的基础框架,启发了 Hadoop 等开源实现,推动了整个大数据生态的发展。
MapReduce 的设计天然适合分布式环境。它通过将任务分解为小块(Map 任务)和自动重试机制,很好地解决了节点故障、数据倾斜等问题。这种容错机制在当时是革命性的,特别适合不可靠的廉价硬件集群。
MapReduce 的“简单”是它的表象,背后是深刻的工程洞察。它的简单性是“优雅”的体现:用最少的概念解决最复杂的问题。就像 UNIX 管道的简单思想(组合小工具完成复杂任务),MapReduce 的简单模型隐藏了强大的工程优化和分布式系统设计。这种“大道至简”的哲学让它在学术和工业界都广受推崇。
map reduce键值对
是的,在 MapReduce 模型中,输入数据通常是以键值对(key-value pair)的形式组织的。MapReduce 是一种分布式计算框架,广泛用于处理大规模数据集,其核心思想是将数据处理分为 Map 和 Reduce 两个阶段,而键值对是贯穿整个流程的基本数据结构。
为什么一定是键值对?
-
Map 阶段:
- 输入数据被分割成多个小块(splits),每个小块以键值对的形式提供给 Map 函数。
- Map 函数处理输入的键值对,生成一组新的中间键值对。例如,输入可能是
(key1, value1),Map 函数输出(key2, value2)的列表。 - 键值对的设计便于分布式处理,键(key)通常用于分组或索引,而值(value)包含实际的数据。
-
Shuffle 和 Sort 阶段:
- MapReduce 框架会自动对中间键值对进行分区(partitioning)、排序(sorting)和分组(grouping),将相同的键聚合在一起。
- 键值对的结构使得框架能够高效地对数据进行分布式排序和传递。
-
Reduce 阶段:
- Reduce 函数接收到的是一个键以及与该键关联的所有值的列表,例如
(key2, [value2_1, value2_2, ...])。 - Reduce 函数对这些值进行处理,生成最终的输出键值对。
- Reduce 函数接收到的是一个键以及与该键关联的所有值的列表,例如
必须是键值对?
- 严格来说,MapReduce 的设计是基于键值对的,因为它的核心机制(分组、排序、聚合)依赖于键值对的结构。
- 但在实际应用中,输入数据的格式可以是任意的(例如文本、JSON、CSV 等),MapReduce 框架会通过特定的输入格式处理器(InputFormat)将数据解析为键值对。例如:
- 在处理文本文件时,键可能是文件的偏移量(offset),值是每一行的内容。
- 在处理数据库表时,键可能是行 ID,值是行的字段内容。
- 如果输入数据不是键值对,MapReduce 框架需要用户定义如何将其转换为键值对(通过自定义 InputFormat)。
在 MapReduce 模型中,送入的数据需要被解析为键值对,因为整个计算流程(Map、Shuffle、Reduce)都依赖于键值对的结构。如果输入数据本身不是键值对,框架会通过预处理将其转换为键值对。因此,可以说送进 MapReduce 模型的“逻辑上”一定是键值对。
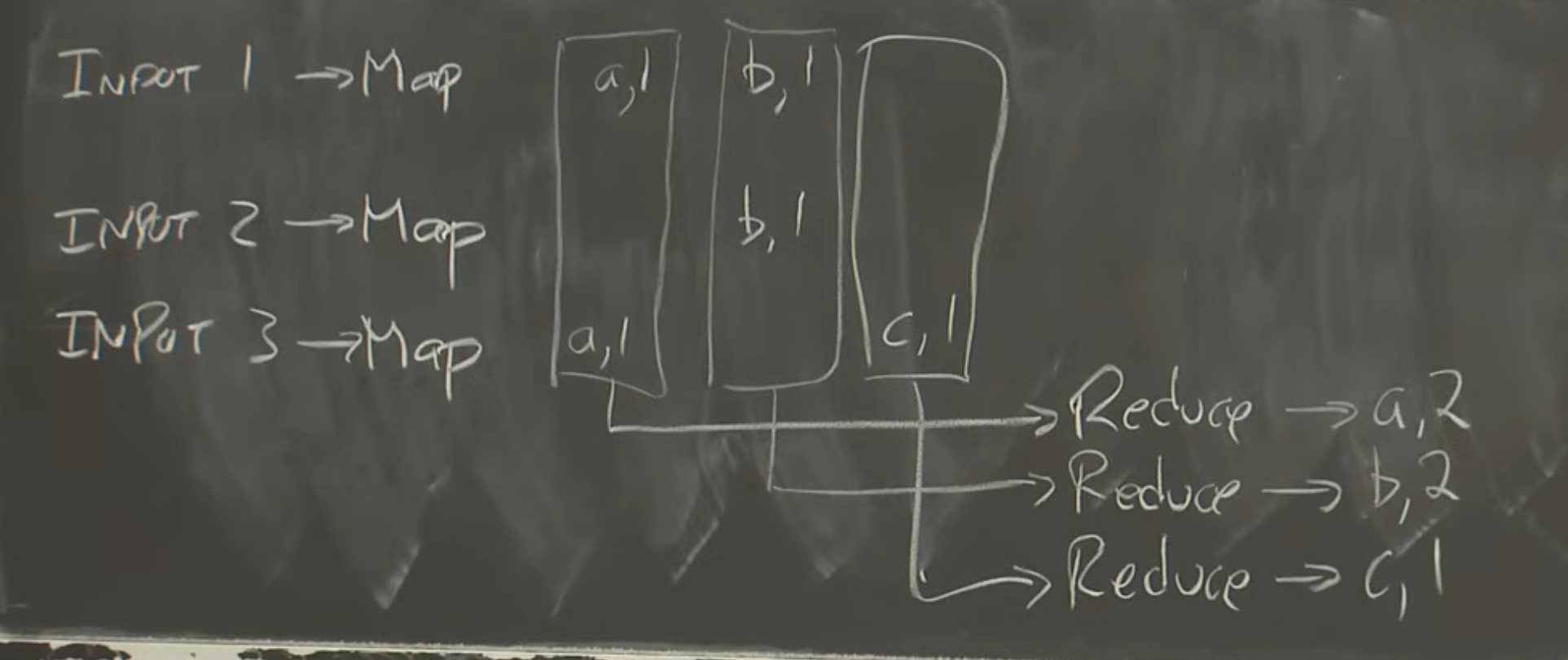
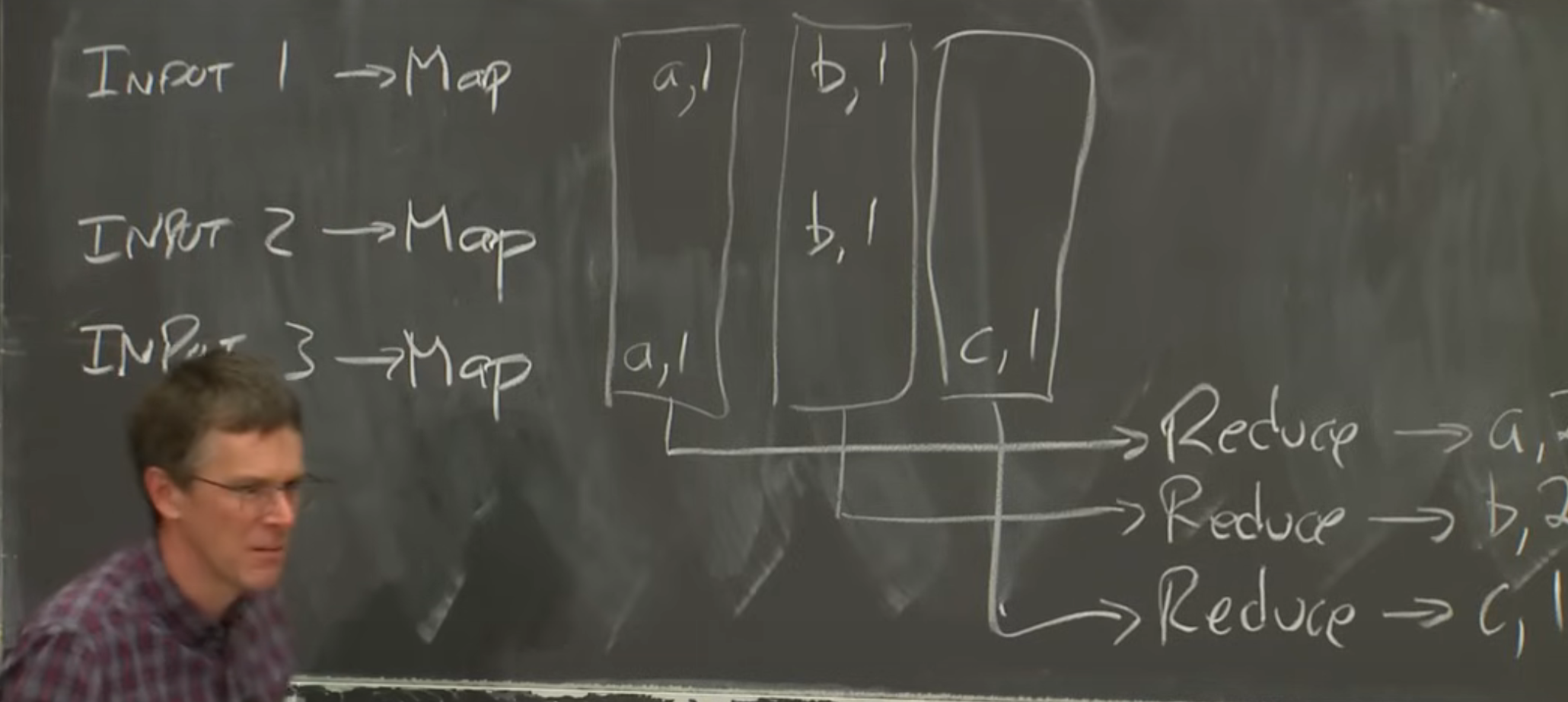
学生提问:可以将Reduce函数的输出再传递给Map函数吗?
Robert教授:在现实中,这是很常见的。MapReduce用户定义了一个MapReduce Job,接收一些输入,生成一些输出。之后可能会有第二个MapReduce Job来消费前一个Job的输出。对于一些非常复杂的多阶段分析或者迭代算法,比如说Google用来评价网页的重要性和影响力的PageRank算法,这些算法是逐渐向答案收敛的。我认为Google最初就是这么使用MapReduce的,他们运行MapReduce Job多次,每一次的输出都是一个网页的列表,其中包含了网页的价值,权重或者重要性。所以将MapReduce的输出作为另一个MapReduce Job的输入这很正常。
学生提问:如果可以将Reduce的输出作为Map的输入,在生成Reduce函数的输出时需要有什么注意吗?
Robert教授:是的,你需要设置一些内容。比如你需要这么写Reduce函数,使其在某种程度上知道应该按照下一个MapReduce Job需要的格式生成数据。这里实际上带出了一些MapReduce框架的缺点。如果你的算法可以很简单的由Map函数、Map函数的中间输出以及Reduce函数来表达,那是极好的。MapReduce对于能够套用这种形式的算法是极好的。并且,Map函数必须是完全独立的,它们是一些只关心入参的函数。这里就有一些限制了。事实上,很多人想要的更长的运算流程,这涉及到不同的处理。使用MapReduce的话,你不得不将多个MapReduce Job拼装在一起。而在本课程后面会介绍的一些更高级的系统中,会让你指定完整的计算流程,然后这些系统会做优化。这些系统会发现所有你想完成的工作,然后有效的组织更复杂的计算。
学生提问:MapReduce框架更重要还是Map/Reduce函数更重要?
Robert教授:从程序员的角度来看,只需要关心Map函数和Reduce函数。从我们的角度来看,我们需要关心的是worker进程和worker服务器。这些是MapReduce框架的一部分,它们与其它很多组件一起调用了Map函数和Reduce函数。所以是的,从我们的角度来看,我们更关心框架是如何组成的。从程序员的角度来看,所有的分布式的内容都被剥离了。
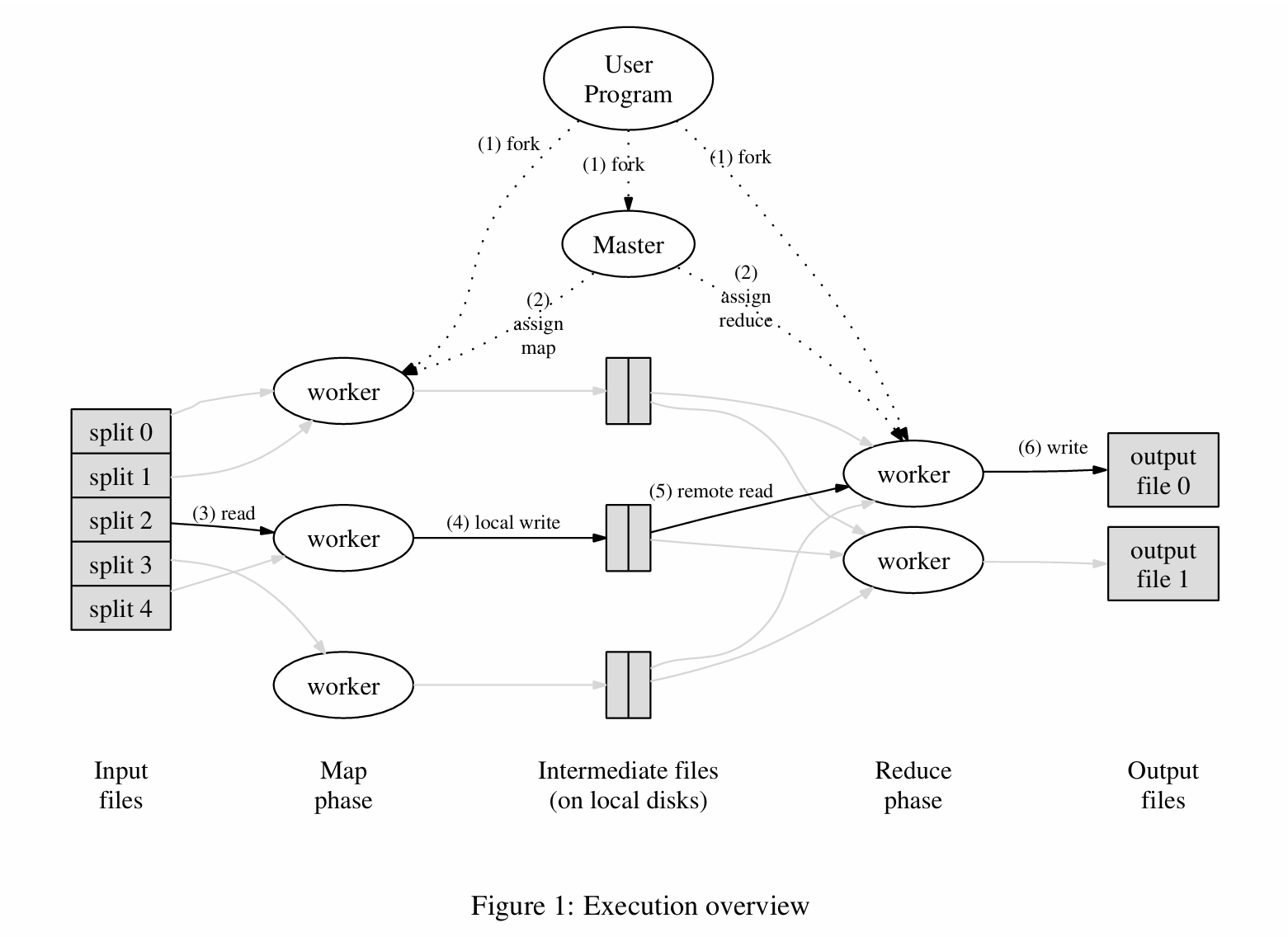
学生提问:当你调用emit时,数据会发生什么变化?emit函数在哪运行?
Robert教授:首先看,这些函数在哪运行。这里可以看MapReduce论文的图1。现实中,MapReduce运行在大量的服务器之上,我们称之为worker服务器或者worker。同时,也会有一个Master节点来组织整个计算过程。这里实际发生的是,Master服务器知道有多少输入文件,例如5000个输入文件,之后它将Map函数分发到不同的worker。所以,它会向worker服务器发送一条消息说,请对这个输入文件执行Map函数吧。之后,MapReduce框架中的worker进程会读取文件的内容,调用Map函数并将文件名和文件内容作为参数传给Map函数。 worker进程还需要实现emit,这样,每次Map函数调用emit,worker进程就会将数据写入到本地磁盘的文件中。所以,Map函数中调用emit的效果是在worker的本地磁盘上创建文件,这些文件包含了当前worker的Map函数生成的所有的key和value。
所以,Map阶段结束时,我们看到的就是Map函数在worker上生成的一些文件。之后,MapReduce的worker会将这些数据移动到Reduce所需要的位置。对于一个典型的大型运算,Reduce的入参包含了所有Map函数对于特定key的输出。通常来说,每个Map函数都可能生成大量key。所以通常来说,在运行Reduce函数之前。运行在MapReduce的worker服务器上的进程需要与集群中每一个其他服务器交互来询问说,看,我需要对key=a运行Reduce,请看一下你本地磁盘中存储的Map函数的中间输出,找出所有key=a,并通过网络将它们发给我。 所以,Reduce worker需要从每一个worker获取特定key的实例。这是通过由Master通知到Reduce worker的一条指令来触发。一旦worker收集完所有的数据,它会调用Reduce函数,Reduce函数运算完了会调用自己的emit,这个emit与Map函数中的emit不一样,它会将输出写入到一个Google使用的共享文件服务中。
Network bandwidth is a relatively scarce resource in our computing environment. We conserve network band width by taking advantage of the fact that the input data (managed by GFS [8]) is stored on the local disks of the machines that make up our cluster. GFS divides each f ile into 64 MB blocks, and stores several copies of each block (typically 3 copies) on different machines. The MapReduce master takes the location information of the input files into account and attempts to schedule a map task on a machine that contains a replica of the corre sponding input data. Failing that, it attempts to schedule a maptask neara replica of that task’s input data (e.g., on a worker machine that is on the same network switch as the machine containing the data). When running large MapReduce operations on a significant fraction of the workers in a cluster, most input data is read locally and consumes no network bandwidth
有关输入和输出文件的存放位置,这是我之前没有提到的,它们都存放在文件中,但是因为我们想要灵活的在任意的worker上读取任意的数据,这意味着我们需要某种网络文件系统(network file system)来存放输入数据。所以实际上,MapReduce论文谈到了GFS(Google File System)。GFS是一个共享文件服务,并且它也运行在MapReduce的worker集群的物理服务器上。GFS会自动拆分你存储的任何大文件,并且以64MB的块存储在多个服务器之上。所以,如果你有了10TB的网页数据,你只需要将它们写入到GFS,甚至你写入的时候是作为一个大文件写入的,GFS会自动将这个大文件拆分成64MB的块,并将这些块平均的分布在所有的GFS服务器之上,而这是极好的,这正是我们所需要的。如果我们接下来想要对刚刚那10TB的网页数据运行MapReduce Job,数据已经均匀的分割存储在所有的服务器上了。如果我们有1000台服务器,我们会启动1000个Map worker,每个Map worker会读取1/1000输入数据。这些Map worker可以并行的从1000个GFS文件服务器读取数据,并获取巨大的读取吞吐量,也就是1000台服务器能提供的吞吐量。
Robert教授:随着Google这些年对MapReduce系统的改进,答案也略有不同。通常情况下,如果我们在一个例如GFS的文件系统中存储大的文件,你的数据分散在大量服务器之上,你需要通过网络与这些服务器通信以获取你的数据。在这种情况下,这个箭头表示MapReduce的worker需要通过网络与存储了输入文件的GFS服务器通信,并通过网络将数据读取到MapReduce的worker节点,进而将数据传递给Map函数。这是最常见的情况。并且这是MapReduce论文中介绍的工作方式。但是如果你这么做了,这里就有很多网络通信。 如果数据总共是10TB,那么相应的就需要在数据中心网络上移动10TB的数据。而数据中心网络通常是GB级别的带宽,所以移动10TB的数据需要大量的时间。在论文发表的2004年,MapReduce系统最大的限制瓶颈是网络吞吐。如果你读到了论文的评估部分,你会发现,当时运行在一个有数千台机器的网络上,每台计算机都接入到一个机架,机架上有以太网交换机,机架之间通过root交换机连接(最上面那个交换机)。
如果随机的选择MapReduce的worker服务器和GFS服务器,那么至少有一半的机会,它们之间的通信需要经过root交换机,而这个root交换机的吞吐量总是固定的。如果做一个除法,root交换机的总吞吐除以2000,那么每台机器只能分到50Mb/S的网络容量。这个网络容量相比磁盘或者CPU的速度来说,要小得多。所以,50Mb/S是一个巨大的限制。
在MapReduce论文中,讨论了大量的避免使用网络的技巧。其中一个是将GFS和MapReduce混合运行在一组服务器上。所以如果有1000台服务器,那么GFS和MapReduce都运行在那1000台服务器之上。当MapReduce的Master节点拆分Map任务并分包到不同的worker服务器上时,Master节点会找出输入文件具体存在哪台GFS服务器上,并把对应于那个输入文件的Map Task调度到同一台服务器上。所以,默认情况下,这里的箭头是指读取本地文件,而不会涉及网络。虽然由于故障,负载或者其他原因,不能总是让Map函数都读取本地文件,但是几乎所有的Map函数都会运行在存储了数据的相同机器上,并因此节省了大量的时间,否则通过网络来读取输入数据将会耗费大量的时间。
我之前提过,Map函数会将输出存储到机器的本地磁盘,所以存储Map函数的输出不需要网络通信,至少不需要实时的网络通信。但是,我们可以确定的是,为了收集所有特定key的输出,并将它们传递给某个机器的Reduce函数,还是需要网络通信。假设现在我们想要读取所有的相关数据,并通过网络将这些数据传递给单台机器,数据最开始在运行Map Task的机器上按照行存储(例如第一行代表第一个Map函数输出a=1,b=1),
论文里称这种数据转换之为洗牌(shuffle)。所以,这里确实需要将每一份数据都通过网络从创建它的Map节点传输到需要它的Reduce节点。所以,这也是MapReduce中代价较大的一部分。
学生提问:是否可以通过Streaming的方式加速Reduce的读取?
Robert教授:你是对的。你可以设想一个不同的定义,其中Reduce通过streaming方式读取数据。我没有仔细想过这个方法,我也不知道这是否可行。作为一个程序接口,MapReduce的第一目标就是让人们能够简单的编程,人们不需要知道MapReduce里面发生了什么。对于一个streaming方式的Reduce函数,或许就没有之前的定义那么简单了。
不过或许可以这么做。实际上,很多现代的系统中,会按照streaming的方式处理数据,而不是像MapReduce那样通过批量的方式处理Reduce函数。在MapReduce中,需要一直要等到所有的数据都获取到了才会进行Reduce处理,所以这是一种批量处理。现代系统通常会使用streaming并且效率会高一些。
之前有人提过,想将Reduce的输出传给另一个MapReduce job,而这也是人们常做的事情。在一些场景中,Reduce的输出可能会非常巨大,比如排序,比如网页索引器。10TB的输入对应的是10TB的输出。所以,Reduce的输出也会存储在GFS上。但是Reduce只会生成key-value对,MapReduce框架会收集这些数据,并将它们写入到GFS的大文件中。所以,这里有需要一大轮的网络通信,将每个Reduce的输出传输到相应的GFS服务器上。你或许会认为,这里会使用相同的技巧,就将Reduce的输出存储在运行了Reduce Task的同一个GFS服务器上(因为是混部的)。或许Google这么做了,但是因为GFS会将数据做拆分,并且为了提高性能并保留容错性,数据会有2-3份副本。这意味着,不论你写什么,你总是需要通过网络将一份数据拷贝写到2-3台服务器上。所以,这里会有大量的网络通信。这里的网络通信,是2004年限制MapReduce的瓶颈。在2020年,因为之前的网络架构成为了人们想在数据中心中做的很多事情的限制因素,现代数据中心中,root交换机比过去快了很多。并且,你或许已经见过,一个典型的现代数据中心网络,会有很多的root交换机而不是一个交换机(spine-leaf架构)。每个机架交换机都与每个root交换机相连,网络流量在多个root交换机之间做负载分担。所以,现代数据中心网络的吞吐大多了。