
MINEDRAFT: A Framework for Batch Parallel Speculative Decoding
- Paper Reading
- 9小时前
- 10 Views
- 0 Comments
- 437 Words
MINEDRAFT: A Framework for Batch Parallel Speculative Decoding
把推测解码打成mini batch,随后在drafter和verifier上分批处理。
在vllm上修改,工程量可观。不错的尝试和idea。
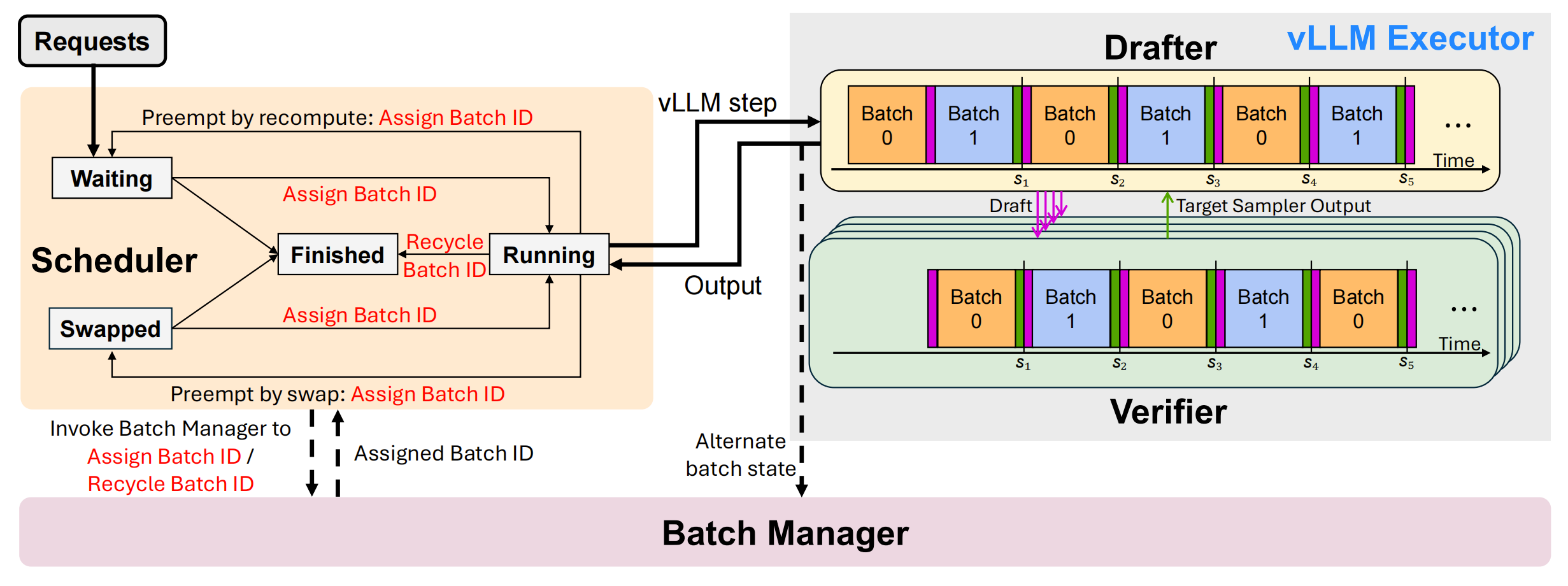
Architecture overview of MINEDRAFT. (Left) The Scheduler manages request life-cycles and batch IDs by coordinating with the Batch Manager, which maintains two batches to enable parallelism in MINEDRAFT. (Right) Parallel execution timeline of the Drafter and Verifier across speculative decoding (SD) steps. Magenta blocks/arrows denote broadcast of drafts from the Drafter to the Verifier, while dark green blocks/arrows denote point-to-point dispatch of target sampler outputs from the Verifier to the Drafter. Ticks indicate synchronization points between SD steps. During the initial SD step (before s1), the Drafter sequentially drafts Batch 0, broadcasts drafts to the Verifier, then drafts Batch 1, while the Verifier immediately processes Batch 0 upon receipt and returns outputs to the Drafter. In subsequent SD steps, the two batches alternate roles between drafting and verification, enabling overlapped execution. Batch alternation is triggered when the Drafter returns outputs to the Scheduler at the end of each SD step
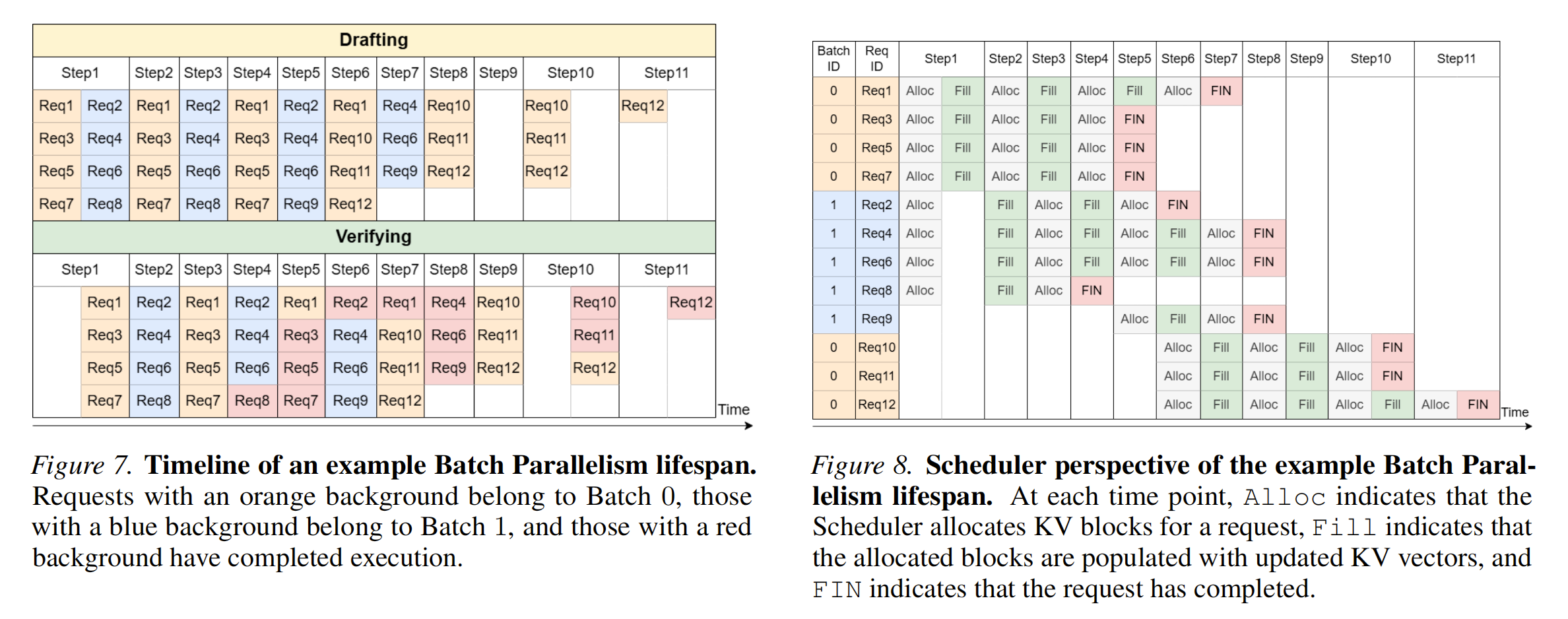
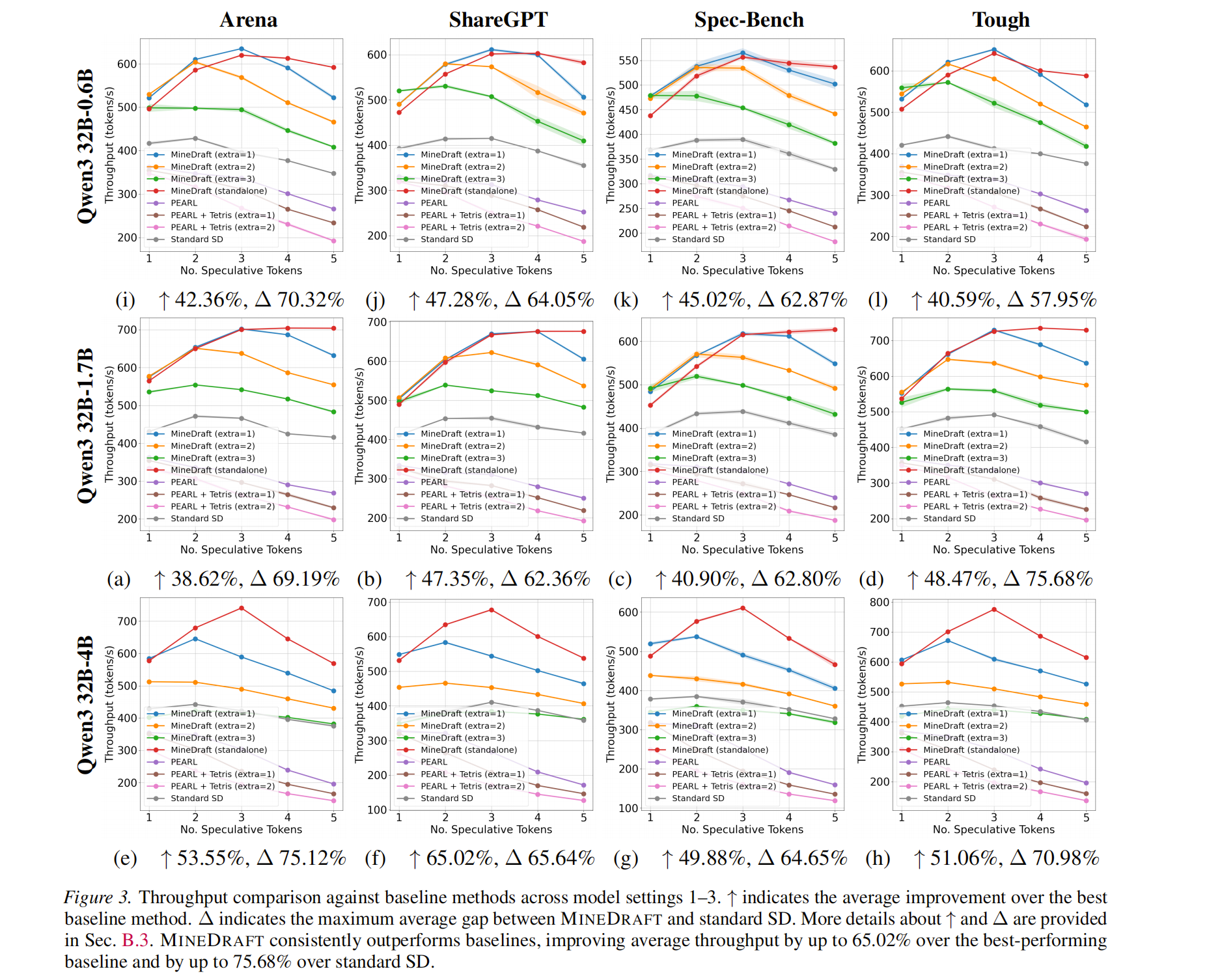
吞吐量跟多个因素有关:
- 模型正确率。小模型速度能更快,但是token变多正确率可能有问题
- 小模型size。小模型越大,模型越准,但是时间也越长。
- 推测token。如果一次性推测的token太多,大模型就要等小模型。反之小模型就要等大模型。
精彩QA
Question 2. Why does MINEDRAFT maintain two batches instead of more? Why is the “Batch Parallelism size” fixed to 2?
Answer. The design of MINEDRAFT is intrinsically tied to the two-stage structure of speculative decoding (SD): drafting and verification. Compared to autoregressive decoding, the additional drafting stage introduces extra latency, which can become prohibitive when either the number of draft tokens per step is large or the draft model is computationally expensive.
MINEDRAFT mitigates this overhead by overlapping the drafting of one set of requests with the verification of another. This design naturally requires exactly two batches: one for drafting and one for verification. Introducing additional batches would not produce further parallelism benefits, as there are no additional stages to overlap, and would instead incur unnecessary scheduling and management overhead.
用nsight能看到两个cuda kernel可以被overlap
