
LLM Pytorch Profiling on CPU
- High Performance Computing
- 2025-04-05
- 1018 Views
- 0 Comments
- 1021 Words
This passage is for my own profile for LLM meta-llama/Llama-3.2-1B
We do an indepth analysis for LLM using pytorch profiler and Intel Vtune
life is short, but it’s long enough to be foolish
import torch
from transformers import pipeline
from torch.profiler import profile, record_function, ProfilerActivity
from torch.utils.tensorboard import SummaryWriter # 用于 TensorBoard 日志
# 设置随机种子以确保结果可重复
torch.manual_seed(123)
# 模型 ID
model_id = "meta-llama/Llama-3.2-1B"
# 创建文本生成 pipeline
print("Device set to use cpu")
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device="cpu",
max_new_tokens=256,
)
# 输入提示
prompt = "The key to life is"
# 使用 PyTorch Profiler 分析
with profile(
activities=[ProfilerActivity.CPU],
record_shapes=True,
profile_memory=True,
with_stack=True,
on_trace_ready=torch.profiler.tensorboard_trace_handler("log_dir") # 直接写入 TensorBoard 日志
) as prof:
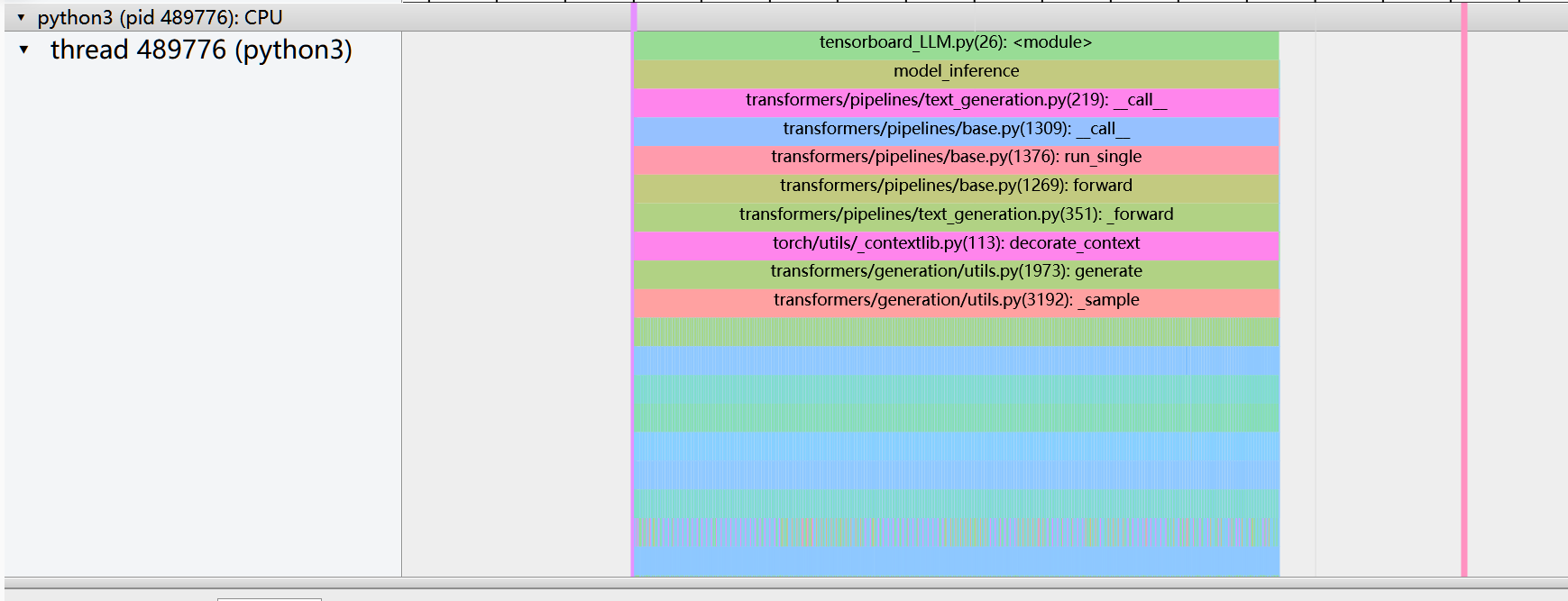
with record_function("model_inference"):
res = pipe(prompt)
# 输出生成结果
print("Generated text:", res[0]["generated_text"])
# 打印表格(可选)
print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=10))
Result analysis
----------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg CPU Mem Self CPU Mem # of Calls
----------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
model_inference 16.49% 3.372s 100.00% 20.442s 20.442s 0 b -7.37 Gb 1
aten::linear 0.51% 105.276ms 55.05% 11.253s 389.015us 250.22 Mb 0 b 28928
aten::matmul 1.13% 230.398ms 53.50% 10.936s 374.714us 250.25 Mb 0 b 29184
aten::mm 51.54% 10.535s 51.58% 10.545s 364.509us 250.22 Mb 250.22 Mb 28928
aten::sort 4.73% 967.869ms 4.90% 1.003s 3.916ms 375.75 Mb 125.25 Mb 256
aten::scaled_dot_product_attention 0.18% 35.865ms 3.51% 717.321ms 175.127us 16.31 Mb -520.00 Kb 4096
aten::_scaled_dot_product_flash_attention_for_cpu 2.84% 580.198ms 3.33% 681.456ms 166.371us 16.82 Mb -100.39 Mb 4096
aten::reshape 0.55% 111.473ms 2.83% 577.555ms 13.673us 4.17 Gb 0 b 42240
aten::cat 1.83% 373.101ms 2.67% 546.518ms 31.923us 1.06 Gb 1.06 Gb 17120
aten::to 0.34% 69.092ms 2.23% 455.568ms 9.413us 226.32 Mb 0 b 48399
----------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 20.442s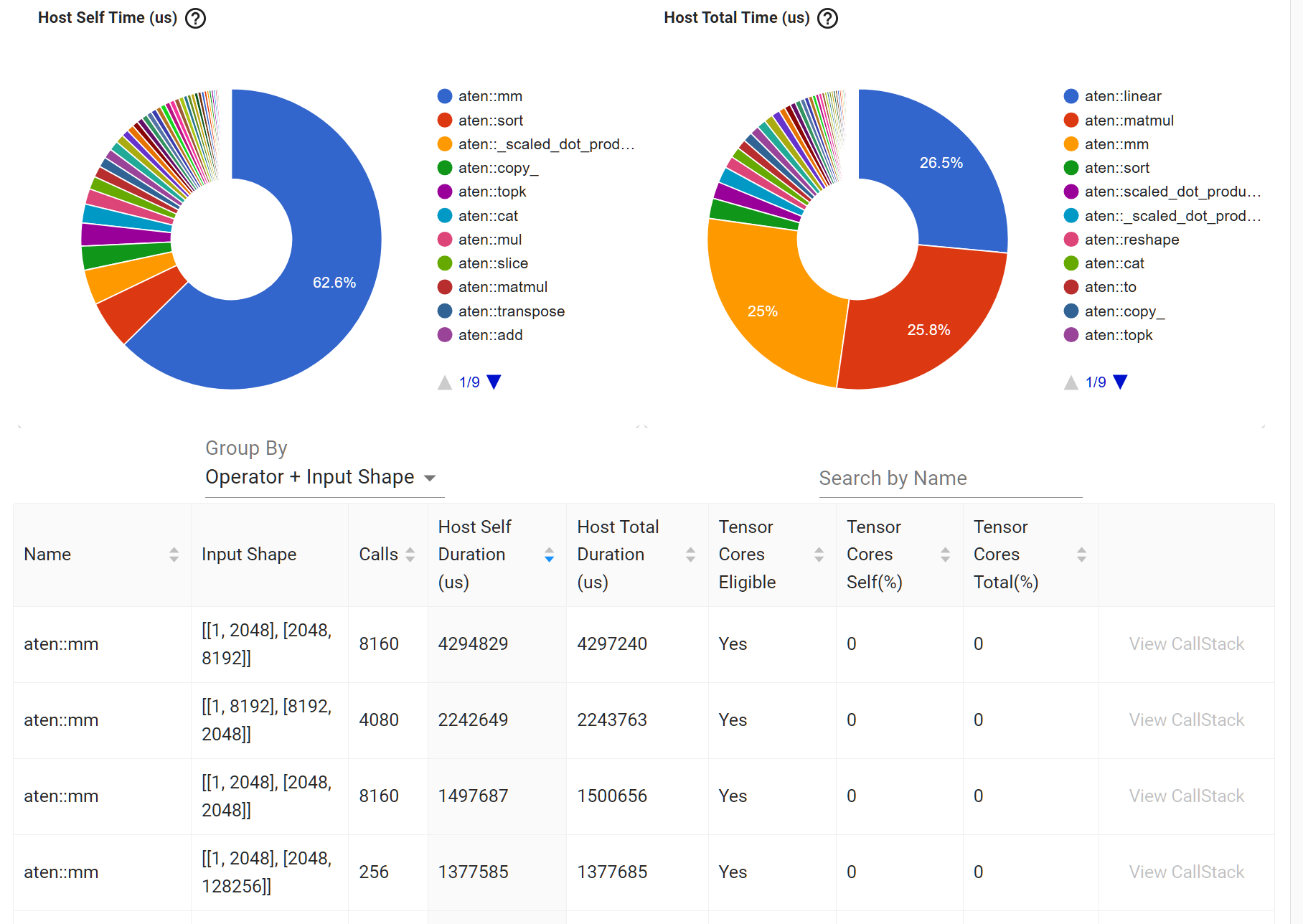
pytorch/aten/src/ATen/native/Linear.cpp at main · pytorch/pytorch
Tensor linear(const Tensor& input, const Tensor& weight, const std::optional<Tensor>& bias_opt) {
// _matmul_impl checks this again later, but _flatten_nd_linear does not work on scalars inputs,
// so let's try to catch this here already
const auto input_dim = input.dim();
const auto weight_dim = weight.dim();
TORCH_CHECK(input_dim != 0 && weight_dim != 0,
"both arguments to linear need to be at least 1D, but they are ",
input_dim, "D and ", weight_dim, "D");
// See [Note: hacky wrapper removal for optional tensor]
auto bias = bias_opt.has_value()
? c10::MaybeOwned<Tensor>::borrowed(*bias_opt)
: c10::MaybeOwned<Tensor>::owned(std::in_place);
if (input.is_mkldnn()) {
return at::mkldnn_linear(input, weight, *bias);
}
#if defined(C10_MOBILE)
if (xnnpack::use_linear(input, weight, *bias)) {
return xnnpack::linear(input, weight, *bias);
}
#endif
if (input_dim == 2 && bias->defined()) {
// Fused op is marginally faster.
return at::addmm(*bias, input, weight.t());
}
if (bias->defined() && !input.is_xla()) {
// Also hit the fused path for contiguous 3D input, if not using xla
// backend. Reshaping/flattening has some performance implications on xla.
if (input.is_contiguous() && input_dim == 3) {
return _flatten_nd_linear(input, weight, *bias);
} else if (input.is_contiguous() && input.layout() == c10::kStrided && weight.layout() == c10::kStrided && bias->dim() == 1) {
return _flatten_nd_linear(input, weight, *bias);
} else if (parseLinearFlatten3d() && input_dim == 3) {
// If user forces flattening via env var
const Tensor input_cont = input.contiguous();
return _flatten_nd_linear(input_cont, weight, *bias);
}
}
// Haibin: matmul!
auto output = at::matmul(input, weight.t());
if (bias->defined()) {
// for composite compliance use out-of-place version of `add`
if (isTensorSubclassLike(*bias) ||
bias->_fw_grad(/*level*/ 0).defined()) {
output = at::add(output, *bias);
} else {
output.add_(*bias);
}
}
return output;
}Mem
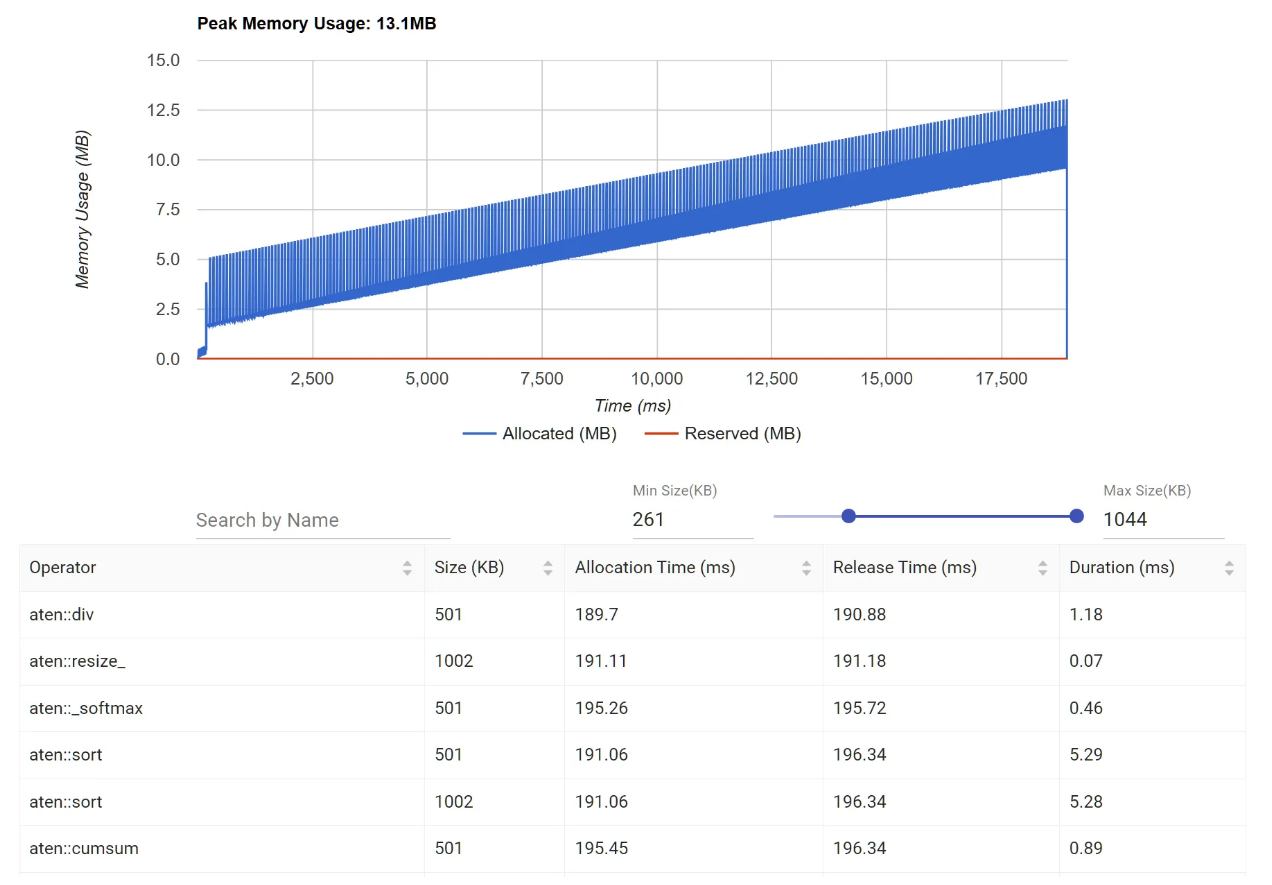
aten::reshape 和 aten::cat 占用大量内存,尝试减少中间张量的创建或复用内存。
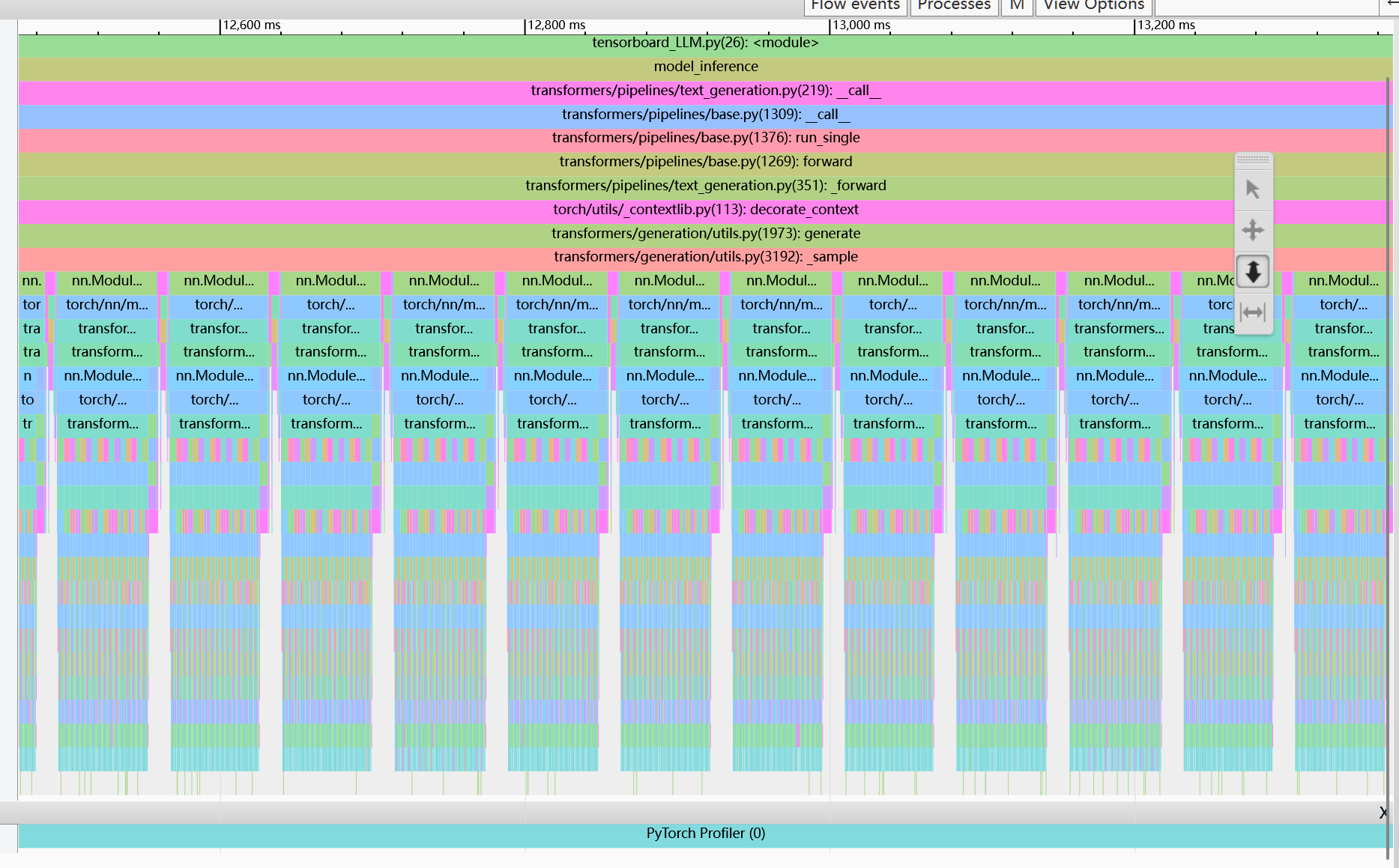
Module
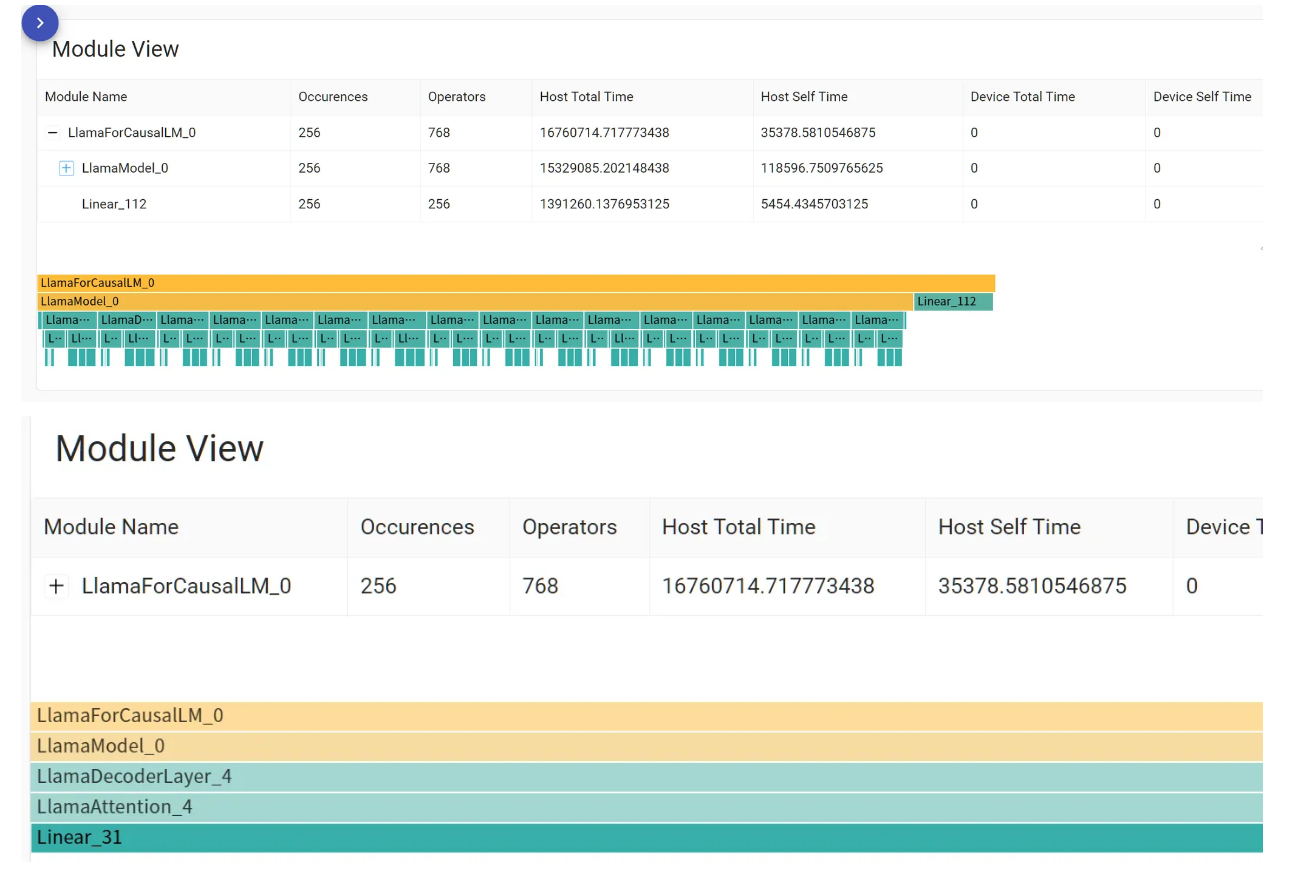

https://pytorch.ac.cn/tutorials/intermediate/torchserve_with_ipex.html
https://pytorch.org/tutorials/intermediate/torchserve_with_ipex.html
ATen
#pragma once
#include algorithm
#include atomic
#include cstddef
#include exception
#ifdef _OPENMP
#define INTRA_OP_PARALLEL
#include omp.h
#endif
#ifdef _OPENMP
namespace at::internal {
template typename F
inline void invoke_parallel(
int64_t begin,
int64_t end,
int64_t grain_size,
const F& f) {
std::atomic_flag err_flag = ATOMIC_FLAG_INIT;
std::exception_ptr eptr;
#pragma omp parallel
{
// choose number of tasks based on grain size and number of threads
// can't use num_threads clause due to bugs in GOMP's thread pool (See
// #32008)
int64_t num_threads = omp_get_num_threads();
if (grain_size > 0) {
num_threads = std::min(num_threads, divup((end - begin), grain_size));
}
int64_t tid = omp_get_thread_num();
int64_t chunk_size = divup((end - begin), num_threads);
int64_t begin_tid = begin + tid * chunk_size;
if (begin_tid < end) {
try {
internal::ThreadIdGuard tid_guard(tid);
f(begin_tid, std::min(end, chunk_size + begin_tid));
} catch (...) {
if (!err_flag.test_and_set()) {
eptr = std::current_exception();
}
}
}
}
if (eptr) {
std::rethrow_exception(eptr);
}
}
} // namespace at::internal
#endif // _OPENMPVTune Profiler
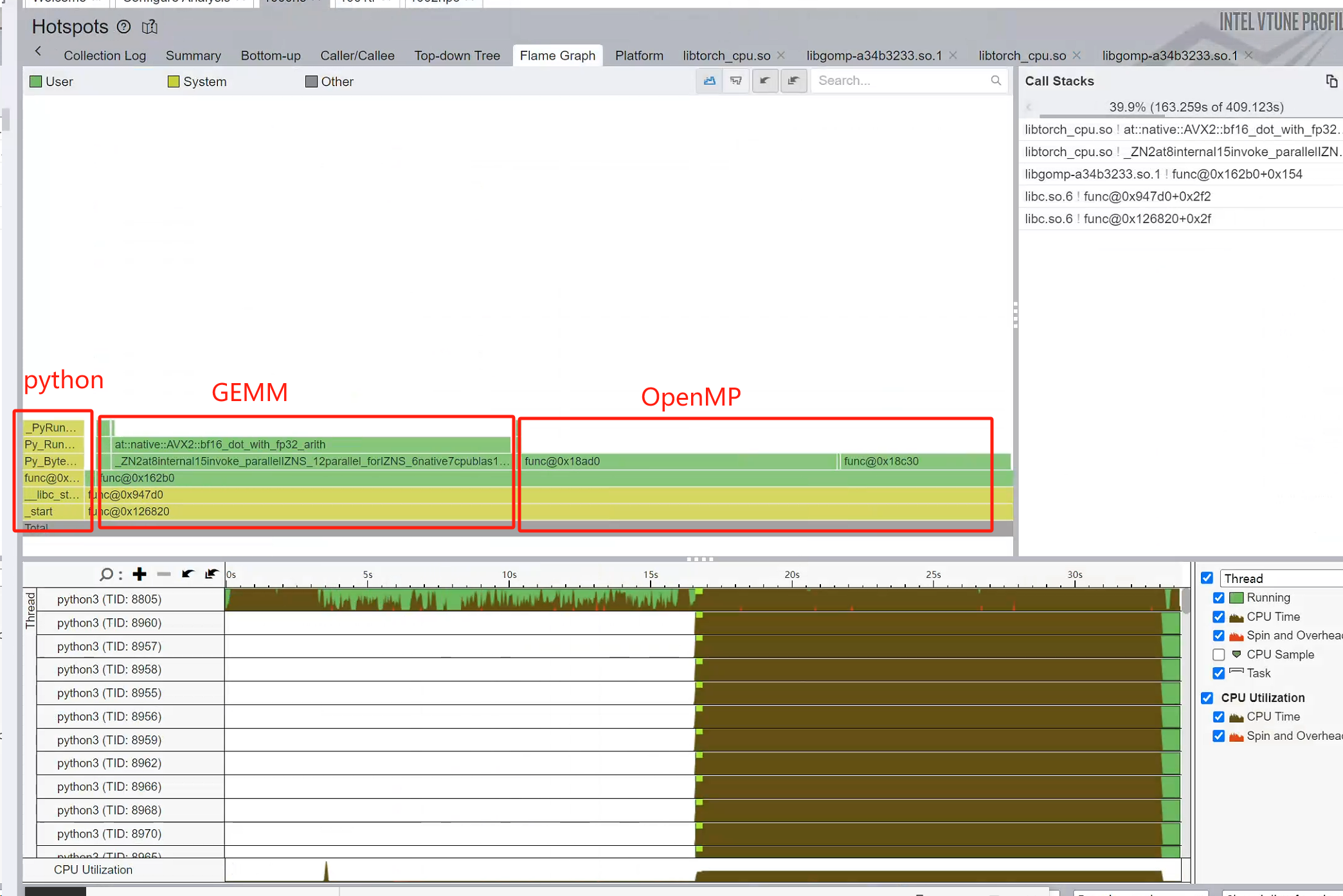
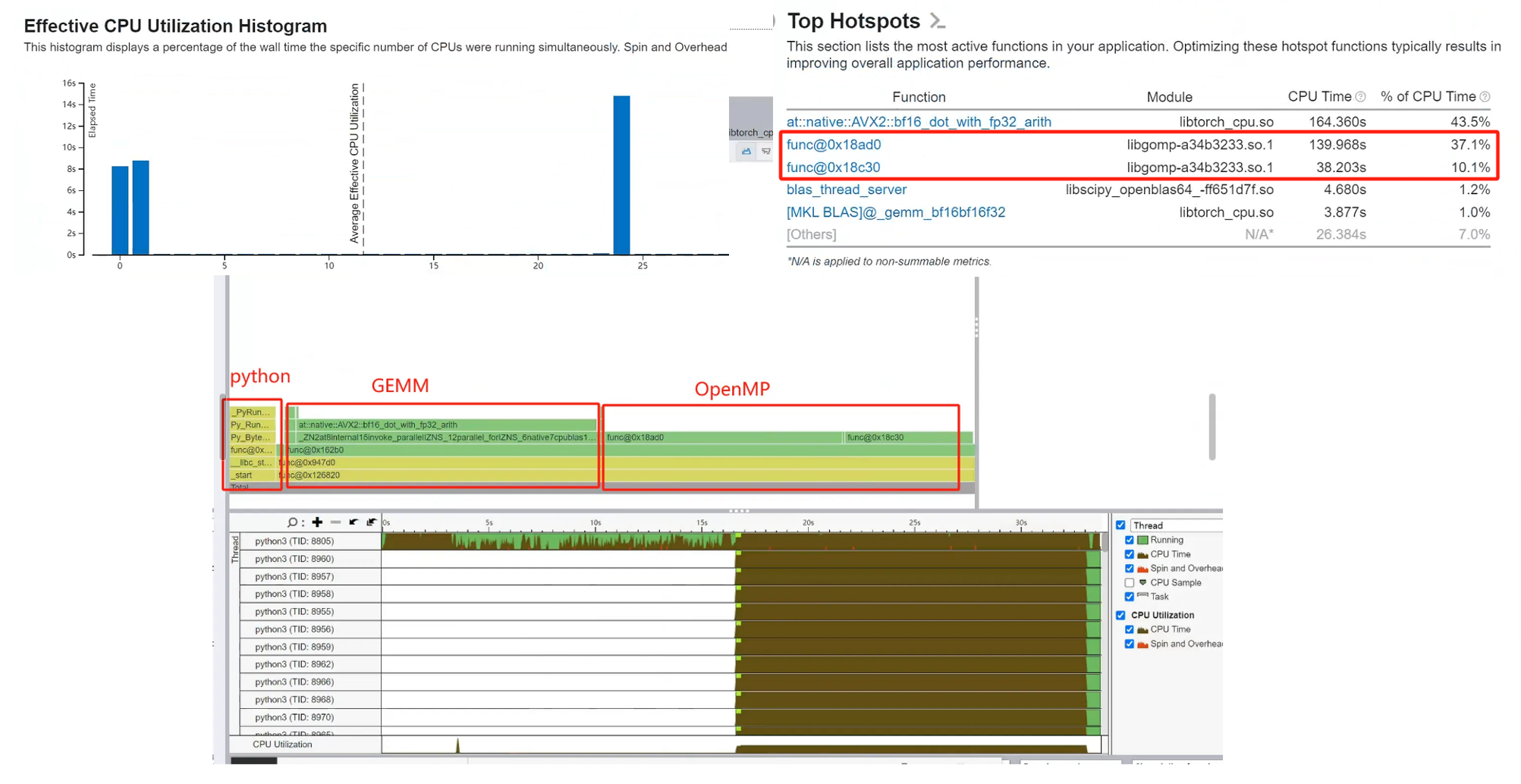
Lock
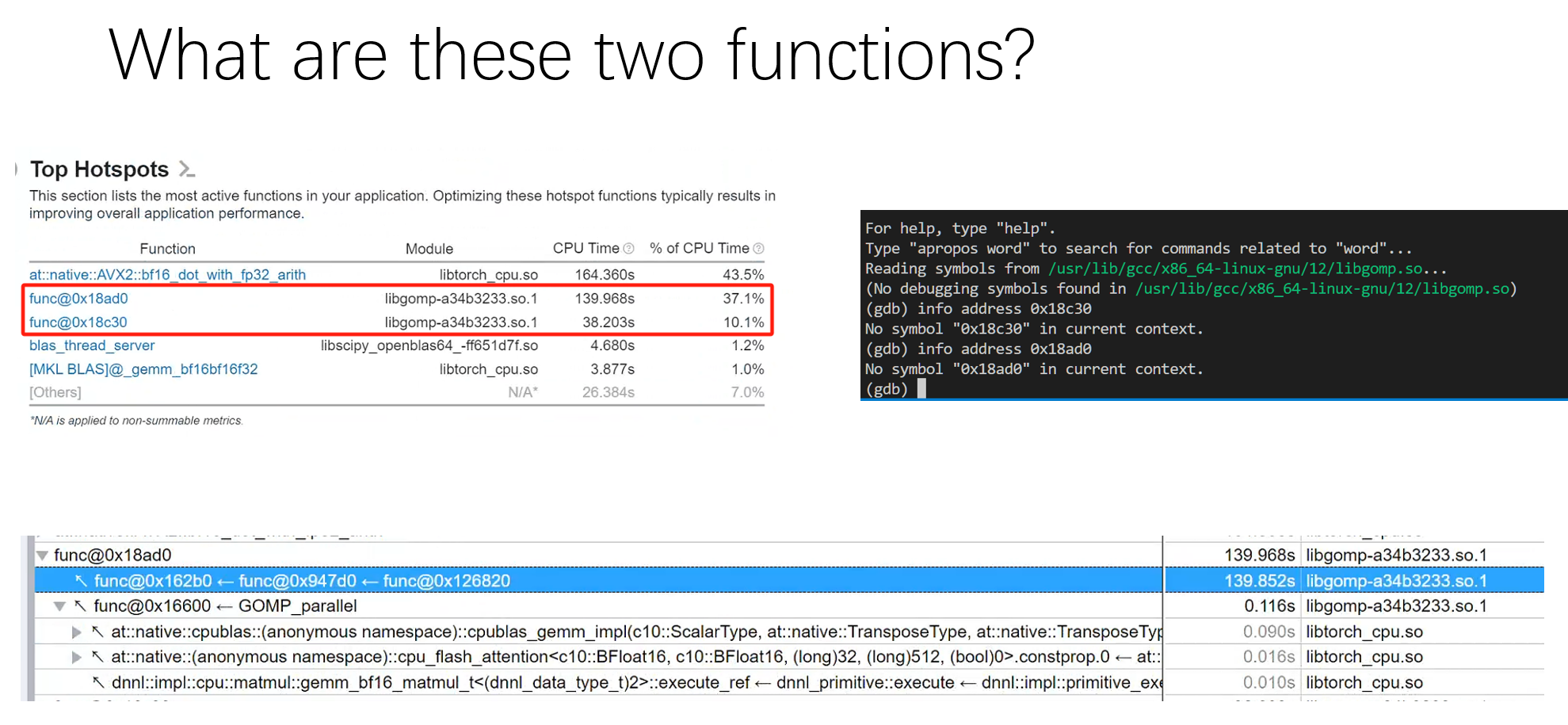
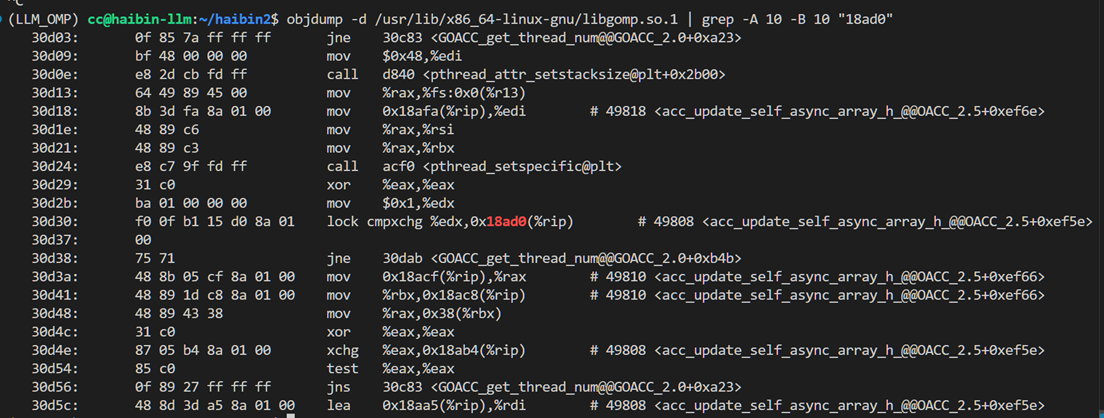
This is the most imp function:

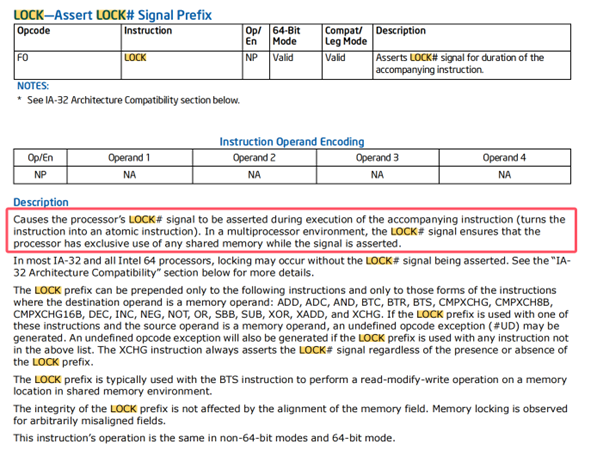
From intel x86-64 instruction book:
Instruction Content:
f0: This is the machine code for thelockprefix, indicating that the instruction is an atomic operation. It locks the bus or cache to ensure thread safety in a multi-core environment.0f b1: This is the opcode forcmpxchg(Compare and Exchange), used to compare and swap values.15 d0 8a 01: This is a 32-bit relative address offset, indicating that the target memory address of the operation is located at the current instruction pointer (RIP) plus0x18ad0.%edx: The target register, indicating that the value to be compared with the memory value and potentially swapped is stored in theedxregister.
Token Generation
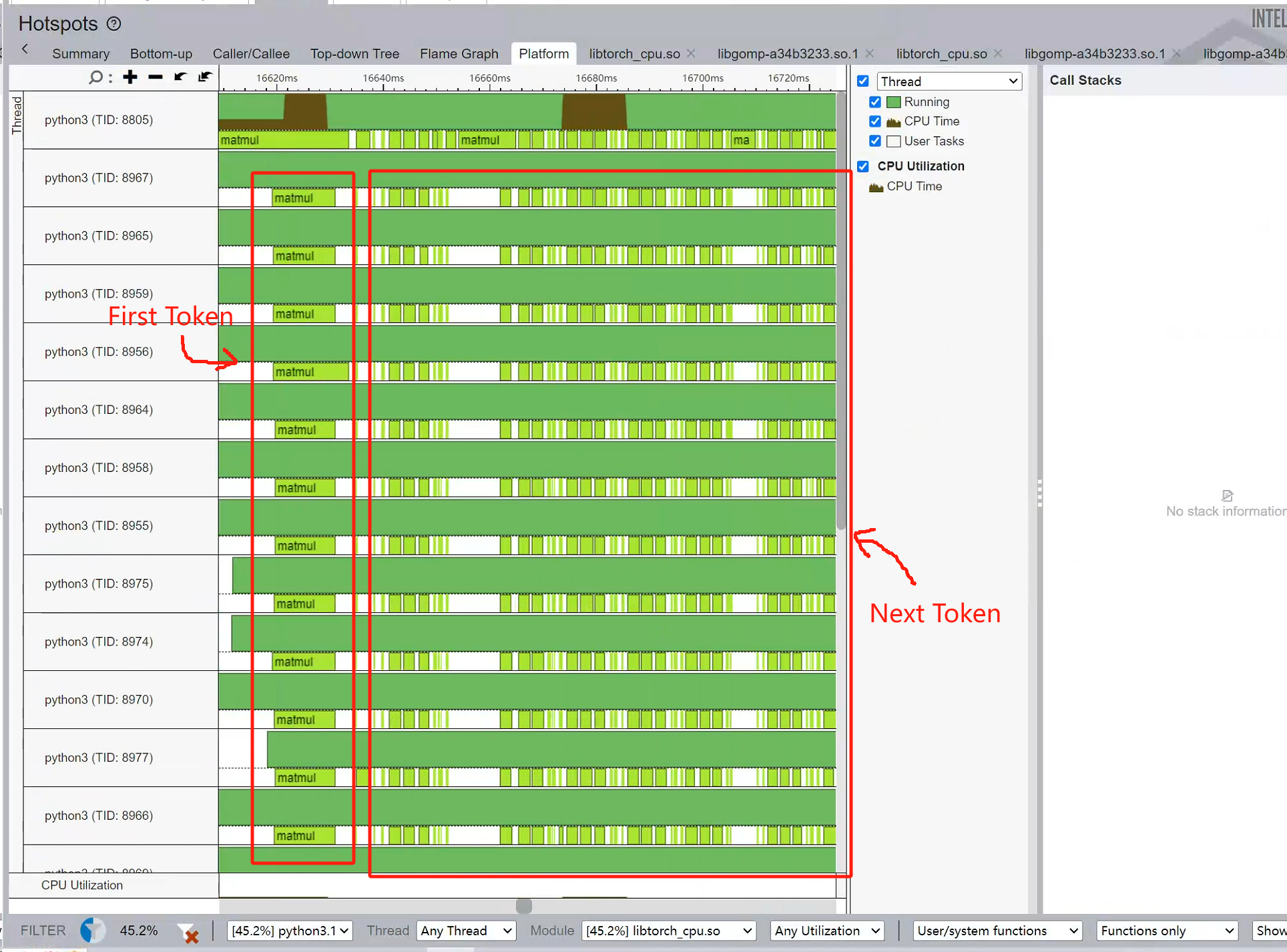
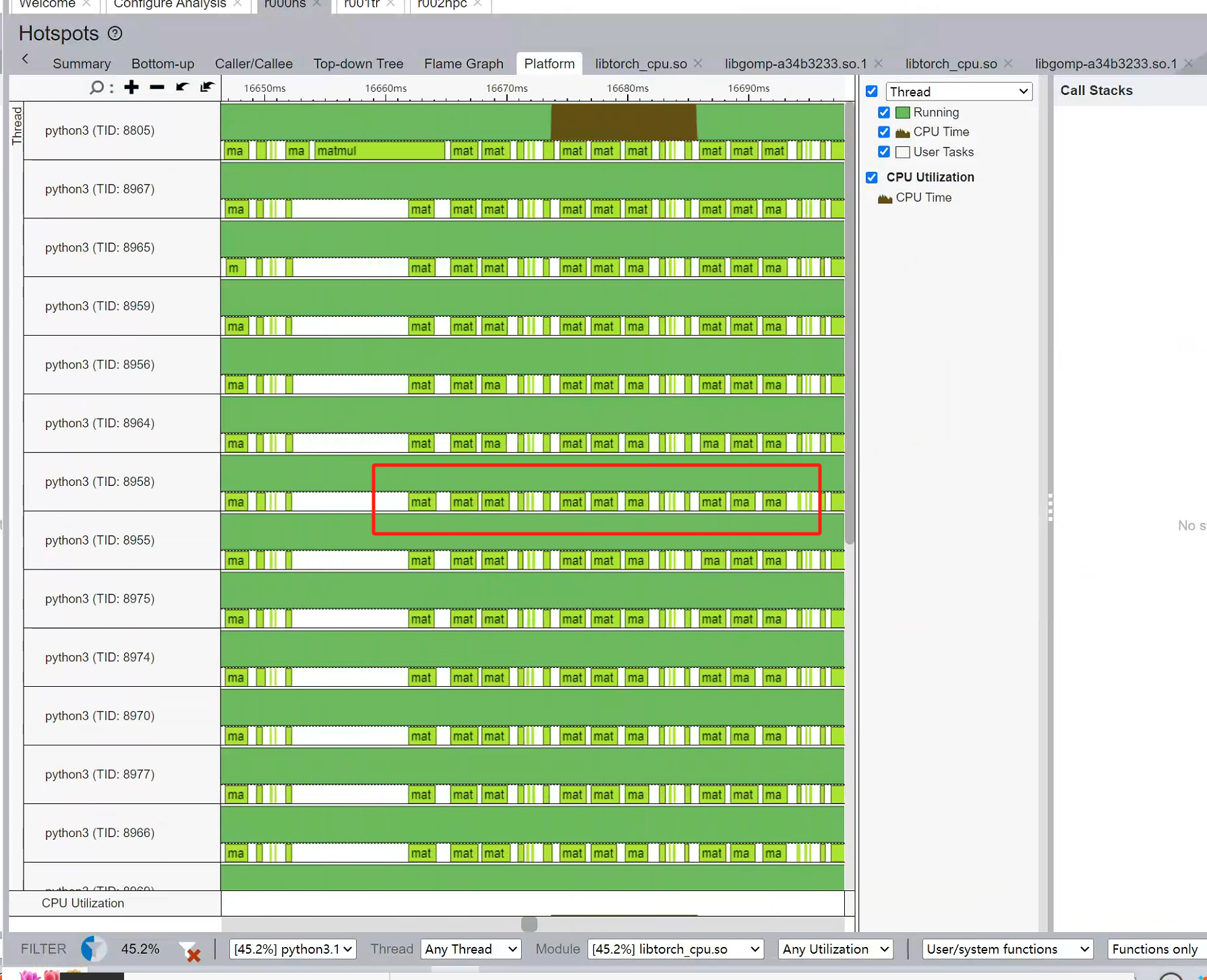

NUMA

Good for 2 core
BLAS
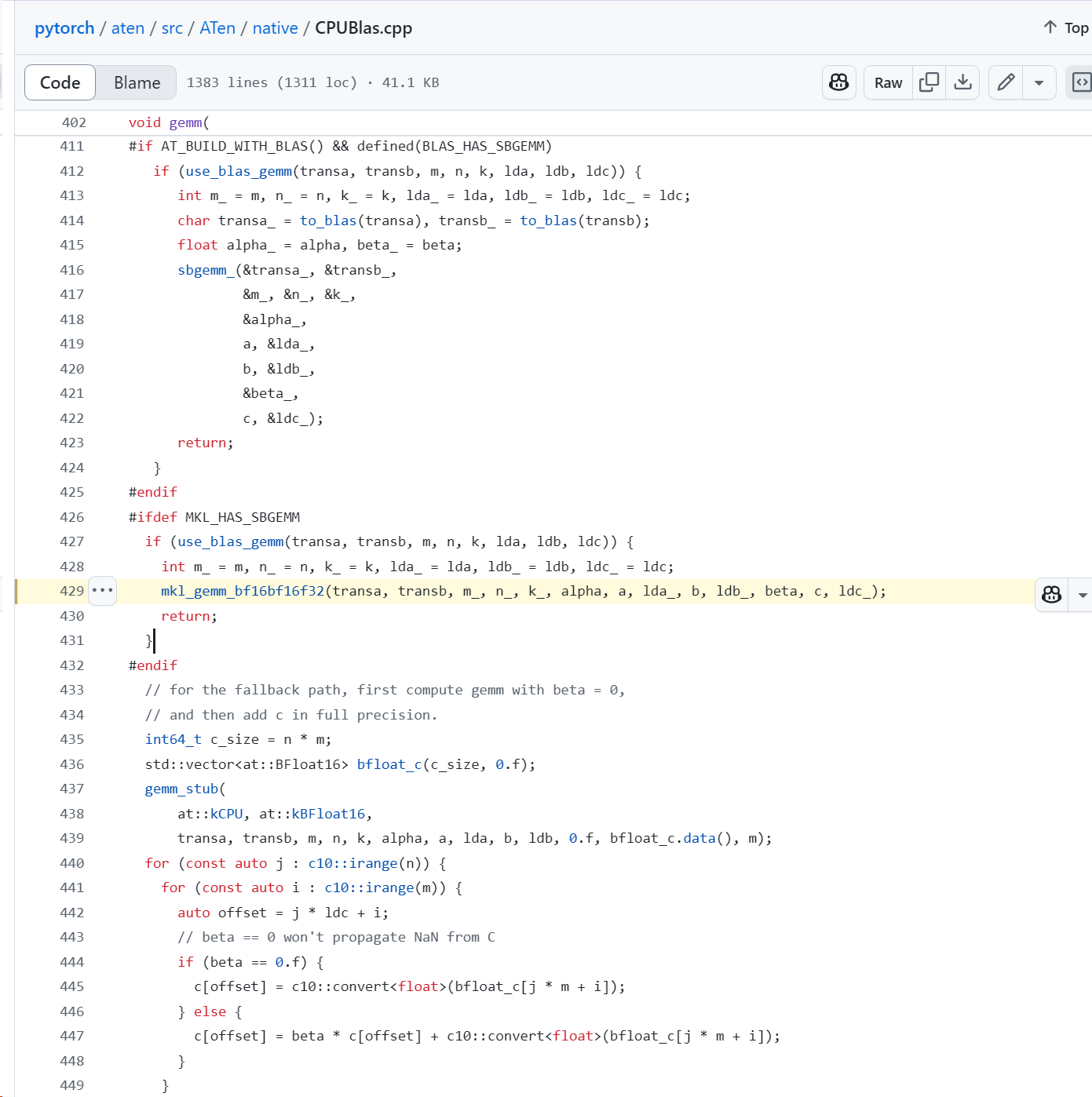
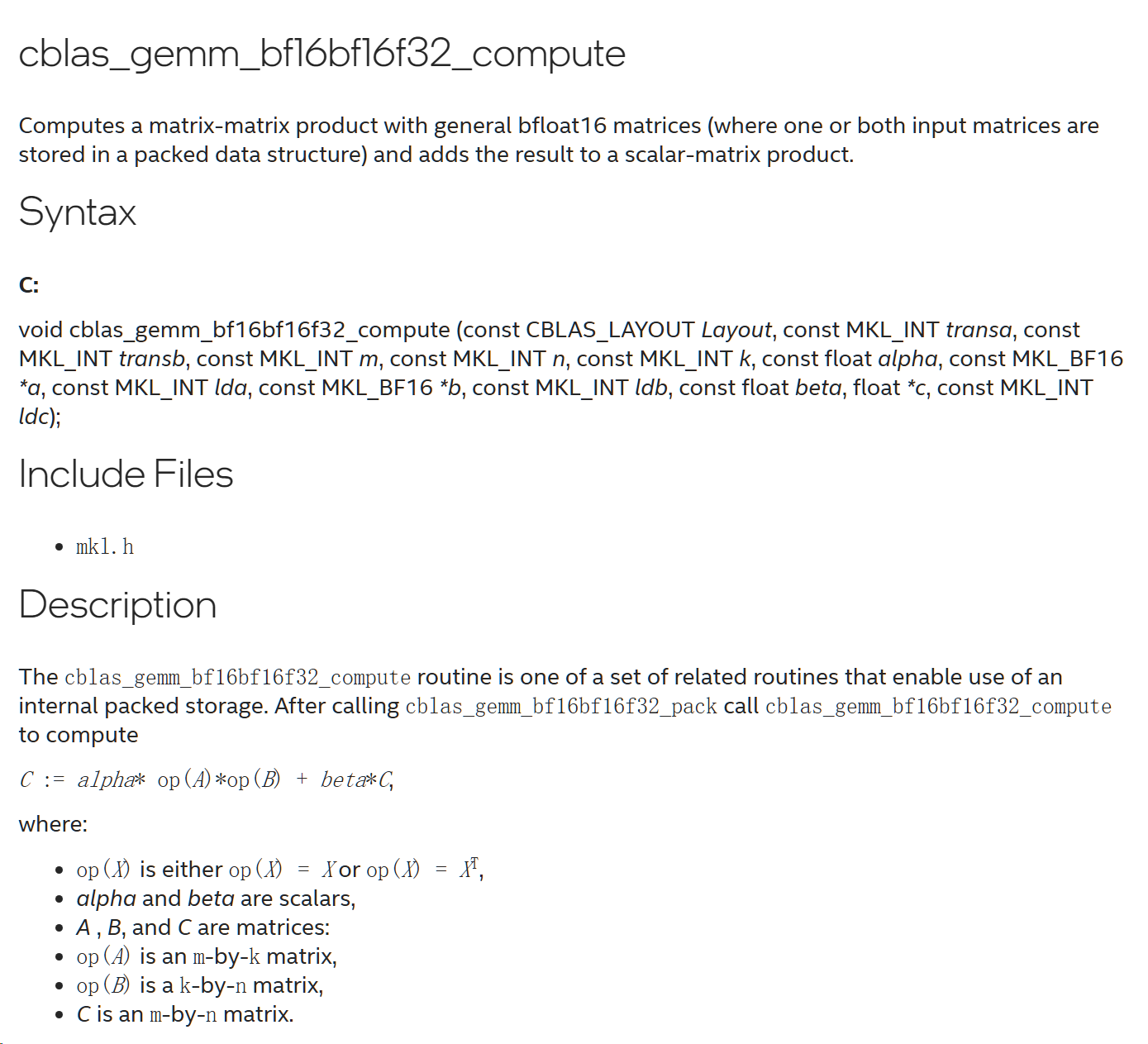
bound: for loading data from mem to CPU reg
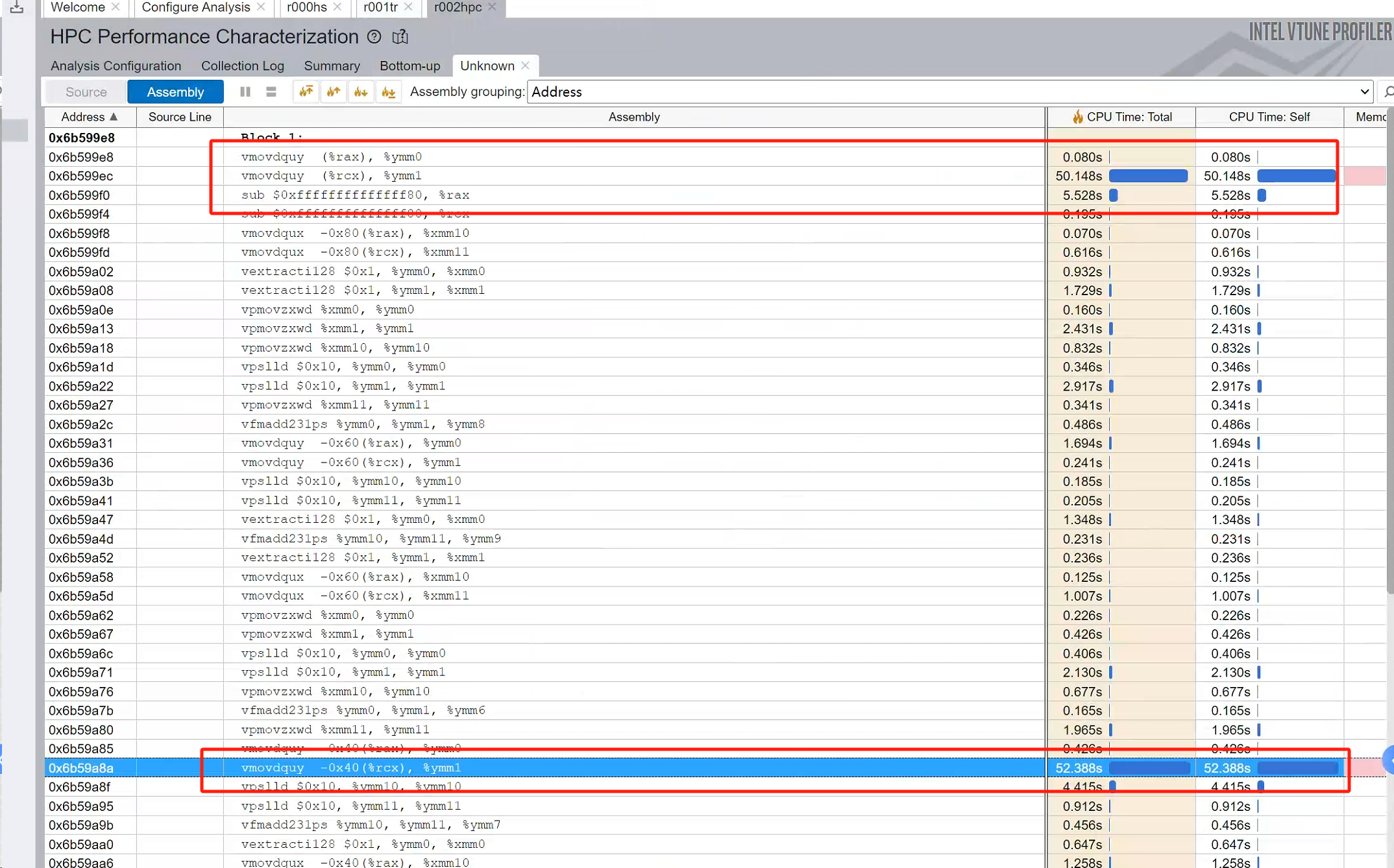
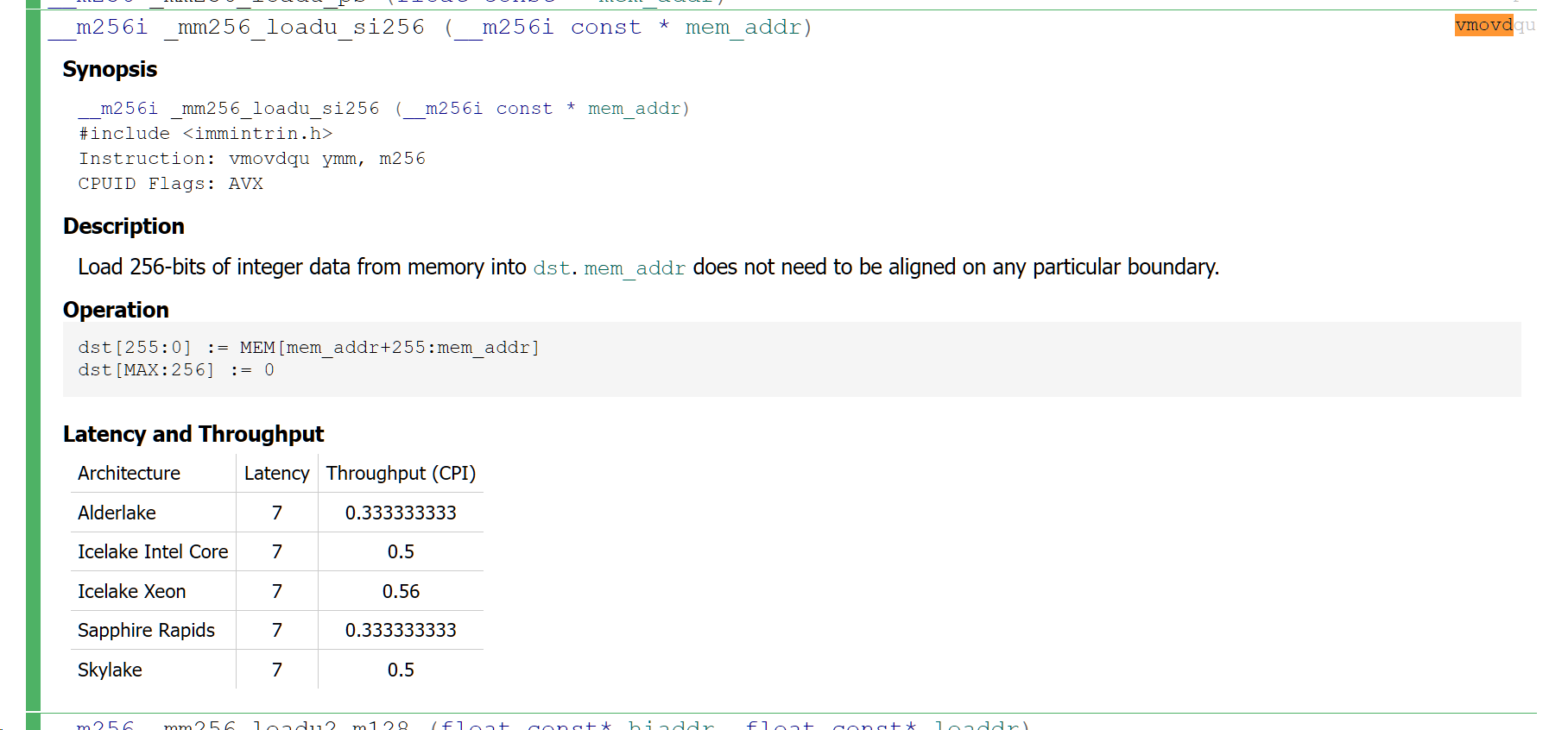
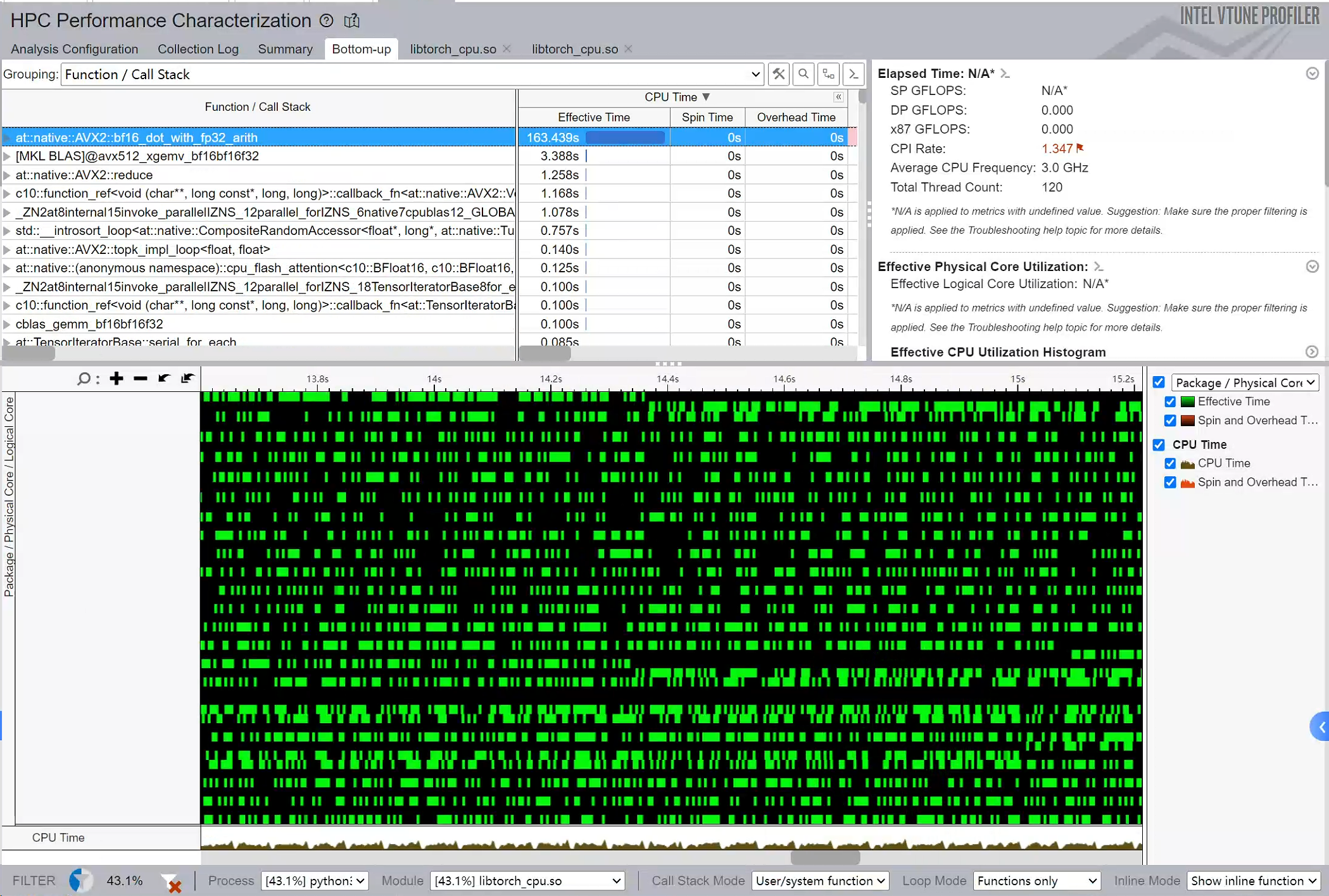
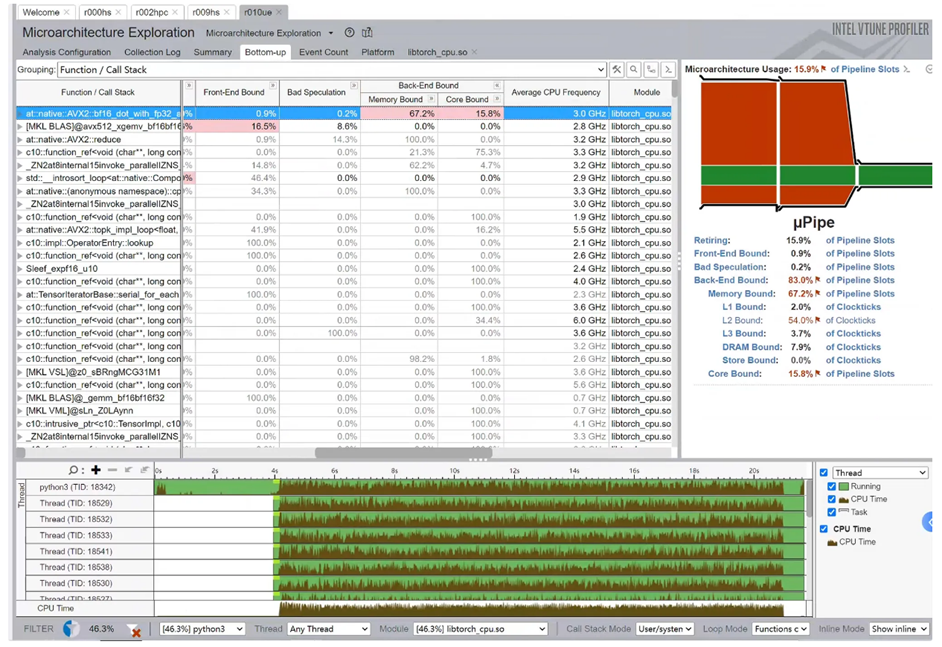
Intel
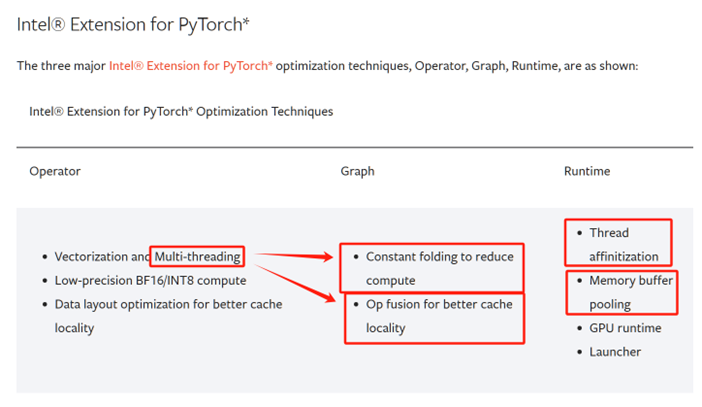
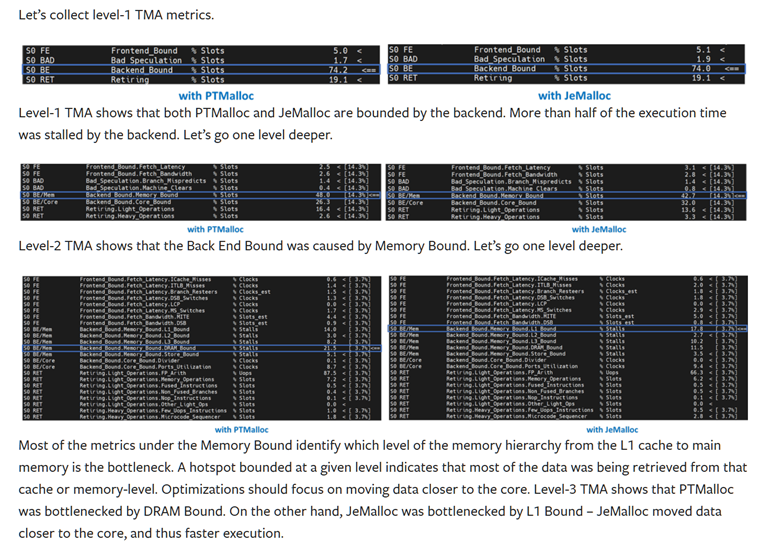
Intel Use DNN as an Example. But what about LLM? Don’t know yet
