huawei 384 节点推理系统赏析
- Paper Reading
- 2025-06-22
- 107热度
- 0评论
我最好奇的是,这种extreme parallelism是怎么做的。
技术报告
*Serving Large Language Models on Huawei CloudMatrix384
用1机384节点来执行Deepseek R1 671B的推理,采用了3个优化
- 优化1 一个p2p的架构,将LLM推理拆解为prefill, decode, caching
- 优化2 large-scale expert parallelism for MoE
- 优化3 晟腾高性能算子,pipeline,int8 量化

笔记
当前 LLM 的趋势
Ever-Larger Parameter Counts.
Llama 4 Maverick, comprises 400 billion parameters
DeepSeek-AI, contains 671 billion parameters
PaLM model 540B
Grok-1 features 314 billion parameters
Sparsity through MoE.
Notable implementations include Mixtral 8×7B, which comprises 46.7 billion total parameters but activates only 12.9 billion per token by routing each token to 2 of 8 experts per layer, achieving performance comparable to GPT-3.5 while maintaining computational efficiency
Llama 4 Maverick utilizing 128 experts and Llama 4 Scout employing 16 experts, both maintaining 17 billion active parameters per token
Alibaba’s Qwen3-235B model incorporates 128 experts, activating 22 billion parameters per token, balancing large-scale capacity with computational efficiency
Extension of Context Windows.
OpenAI’s GPT-4.5 supports a context window of 128,000 tokens
Google’s Gemini 2.5 Pro offers a context window of up to 1 million tokens
Challenge
-
scaling Communication-intensive parallelism
we need to deploy Tensor parallelism + expert parallelism on multi compute GPU -
Maintaining High Utilization under Heterogeneous AI Workloads
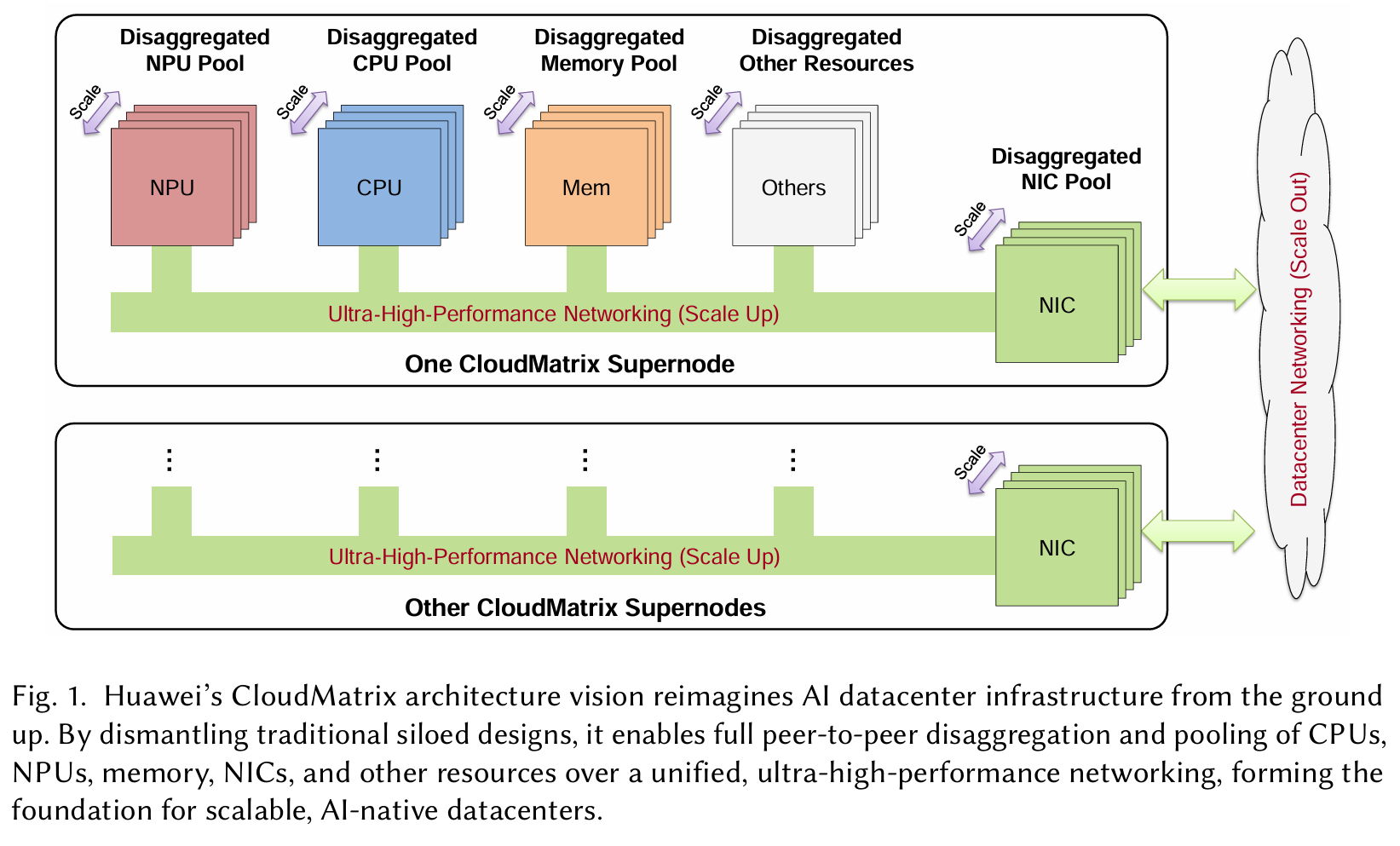
Mem, GPU, CPU are very complex. To maximize efficiency and adaptability, modern AI infrastructure must enable dynamic, fine-grained composition of heterogeneous resources -
Enabling Converged Execution of AI and Data-Intensive Workloads.
These converged execution patterns demand high-throughput, low-latency communication and flexible resource orchestration. -
Delivering Memory-class Storage Performance.
Modern AI pipelines operate at unprecedented data scales that far exceed the capabilities of traditional storage systems.
CloudMatrix 硬件架构
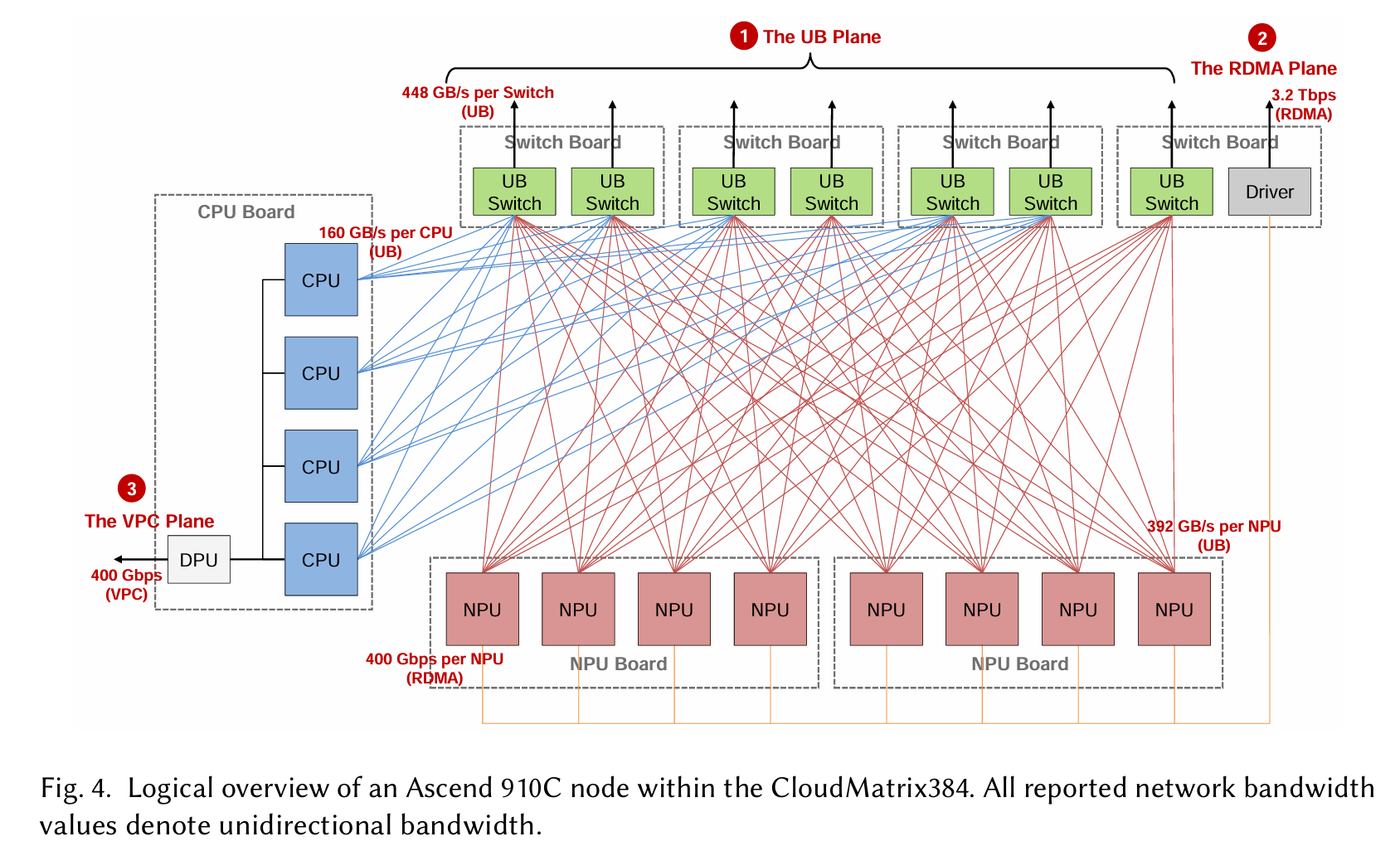
CloudMatrix384 is engineered as an AI supernode that integrates 384 Ascend 910C neural-network processing units (NPUs) and 192 Kunpeng central processing units (CPUs), as illustrated in Figure 2.
192核CPU,384NPU
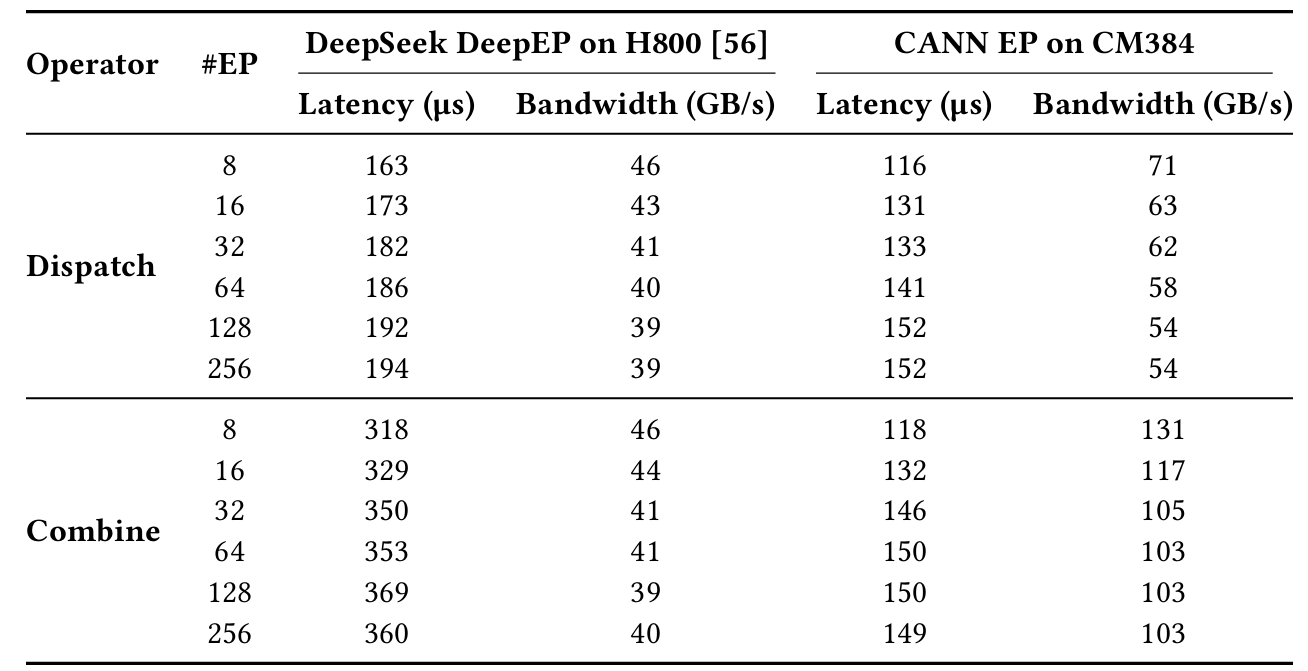
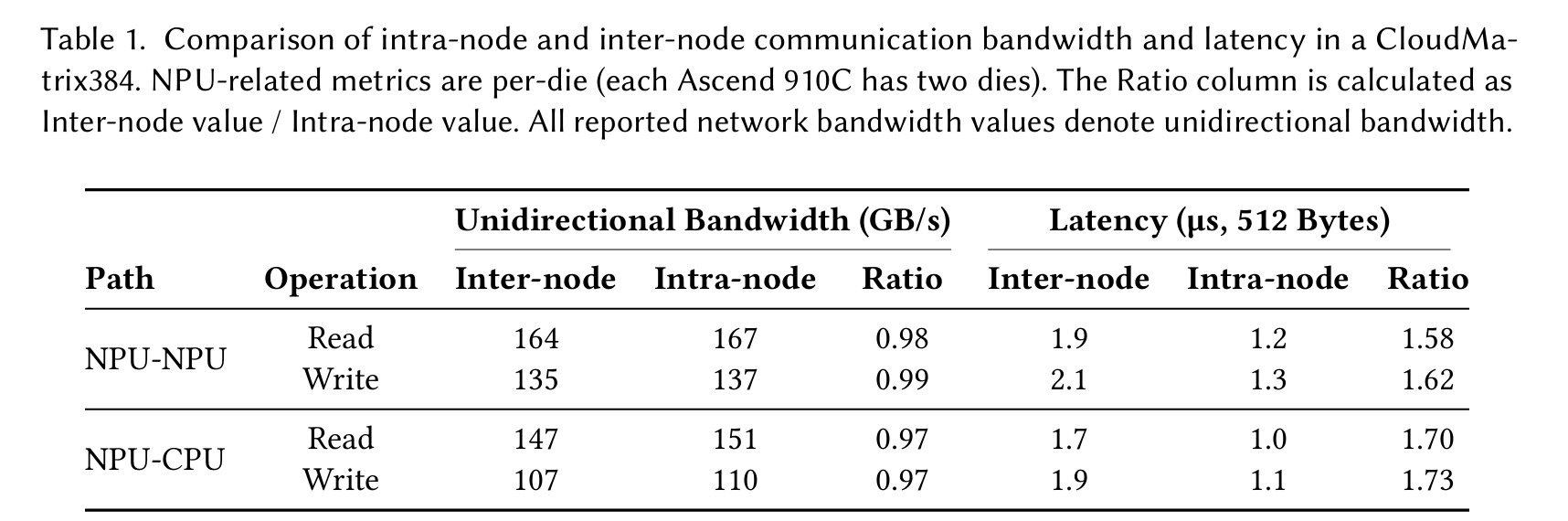
As shown in Table 1, inter-node bandwidth degradation is under 3%, and inter-node latency increase is less than 1 µs.
主要我们需要协同的硬件:
计算:NPU, CPU cores
内存:NPU,CPU Mem
传输:NPU-NPU,CPU-NPU
软件:
模型 参数并行,专家并行
计算NPU,CPU
NPU是晟腾910C
Compute.Eachdiesustainsapproximately 376TFLOPSofdenseBF16/FP16throughput,yielding a total of 752TFLOPS per package. Each die contains 24 AI cube (AIC) cores, optimized for matrix and convolution workloads, and 48 AI vector (AIV) cores for element-wise operations. All compute engines support FP16/BF16 and INT8 data types. The 8-bit quantization can be implemented with INT8 precision, enabling computational efficiency comparable to native FP8 hardware without requiring dedicated FP8 support. The two dies communicate over an on-package interconnect that provides up to 540GB/s of total bandwidth, 270GB/s per direction. Memory. The Ascend 910C package integrates eight memory stacks (16 GB each), providing a total of 128GB of on-package memory (64GB per die). The package delivers up to 3.2TB/s of aggregate memory bandwidth, with 1.6TB/s available per die. Network Interfaces.
CPU节点情况
Each compute node in CloudMatrix384 integrates 8 Ascend 910C NPUs, 4 Kunpeng CPUs, and 7 UB switch chips onboard, as illustrated in Figure 4. The 12 processors (8 NPUs and 4 CPUs) connect to these on-board switches via UB links, creating a single-tier UB plane within the node. Each NPU is provisioned with up to 392GB/s of unidirectional UB bandwidth, while each Kunpeng CPU socket receives approximately 160GB/s of unidirectional UB bandwidth. An individual UB switch chip onboard offers 448GB/s of uplink capacity to the next switching tier in the supernode fabric. Only NPUs participate in the secondary RDMA plane. Each NPU device contributes an additional 400Gbps unidirectional link for scale-out RDMA traffic, yielding an aggregate of 3.2Tbps of RDMA bandwidth per node. Within the CPU complex, the four Kunpeng CPU sockets are interconnected via a full-mesh NUMAtopology,enablinguniformmemoryaccessacrossallCPU-attachedDRAM.OneoftheCPUs hosts the node’s Qingtian card, a dedicated data processing unit (DPU) that not only integrates high speed network interfaces but also performs essential node-level resource management functions. This Qingtian card serves as the primary north–south egress point from the node, interfacing with the third distinct network plane: the datacenter’s VPC plane.
通信速度

通信拓扑
Adefining feature of CloudMatrix384 is its peer-to-peer, fully interconnected, ultra-high-bandwidth network that links all NPUs and CPUs via the UB protocol.
The CloudMatrix384 supernode spans 16 racks: 12 compute racks, which collectively host the 48 Ascend 910C nodes (384 NPUs in total), and 4 communication racks. These communication racks house the second-tier (L2) UB switches that interconnect all the nodes within the supernode.
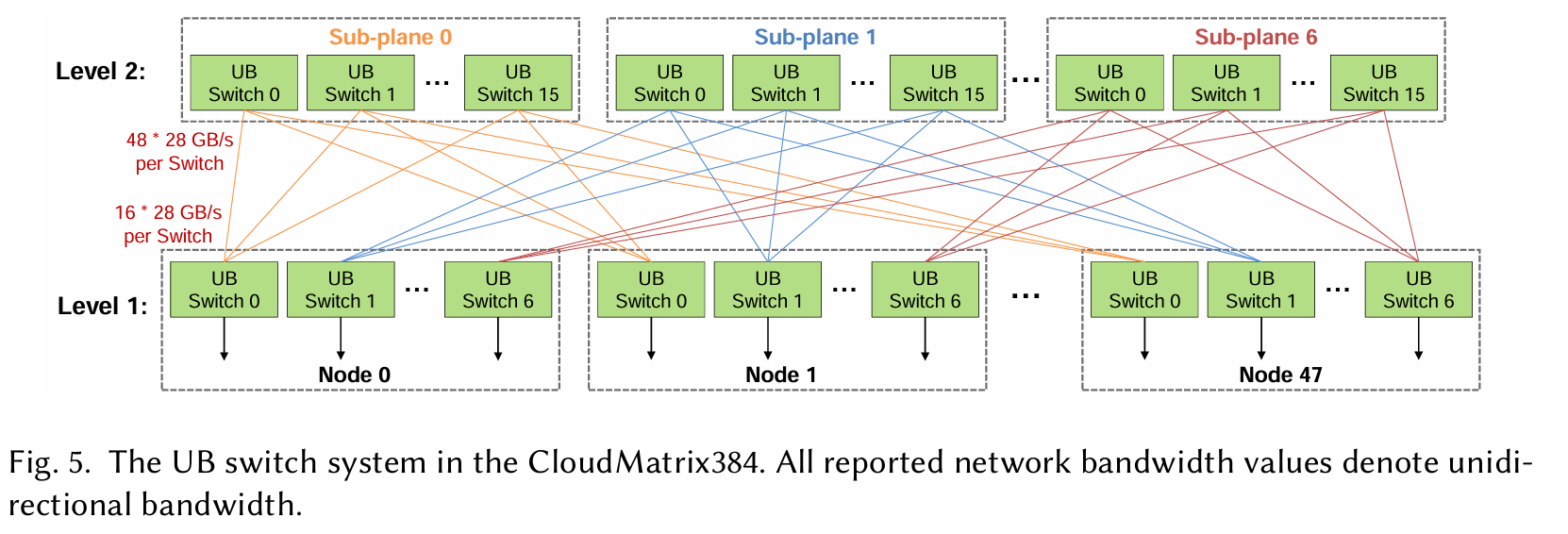
看来哪怕是单机,其实内部还是靠网线通信的。。
软件栈

In summary, CANN delivers a vertically-integrated software stack including driver, runtime, and libraries comparable to NVIDIA’s CUDA while being tailored to Ascend NPUs. Its GE compiles whole-graph representations into highly-optimized execution plans, and rich framework adapters make porting existing workloads almost friction-free. Together, these components enable devel opers to harness Ascend hardware with minimal code changes while achieving near-peak device performance across a broad spectrum of AI applications.
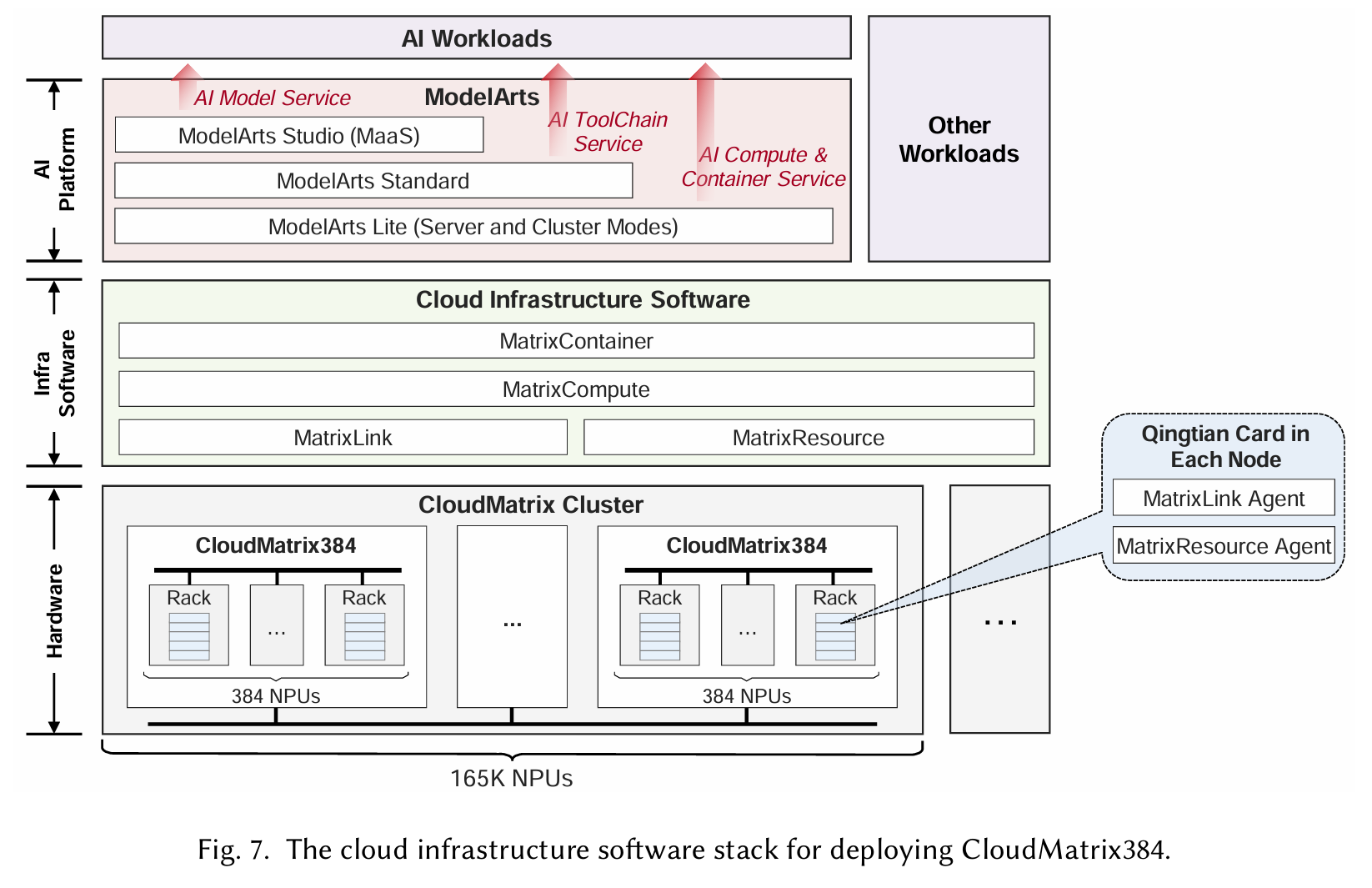
云基础设施分为4层:
MatrixResource manages physical resource provisioning within a supernode, including com pute instance allocation based on topology-aware scheduling. The instance provisioning tasks are executed by a MatrixResource agent that runs on the Qingtian card in each compute node of the CloudMatrix384.
MatrixLink delivers service-oriented networking for the UB and RDMA networks, supporting QoS guarantees and dynamic routing. It manages link-level configurations and enables network aware workload placement for optimal communication efficiency. These tasks are also executed by a MatrixLink agent on the Qingtian card in each compute node.
MatrixCompute coordinates the lifecycle of CloudMatrix instances, from bare-metal provi sioning to auto-scaling and fault recovery. It orchestrates resource composition across multiple physical nodes to create tightly-coupled logical supernode instances.
MatrixContainer provides container services based on Kubernetes, enhanced with topology aware scheduling to exploit CloudMatrix’s high-performance interconnect. It enables users to deploy distributed AI workloads using familiar containerized workflows.

Overview: A Peer-to-Peer Serving Architecture with PDC Disaggregation
PDC架构
Our peer-to-peer serving architecture in CloudMatrix-Infer takes full advantage of the Cloud Matrix384’s ultra-high-bandwidth UB interconnect. This enables uniform access to a distributed caching cluster (Section 4.4) built on a disaggregated memory pool.
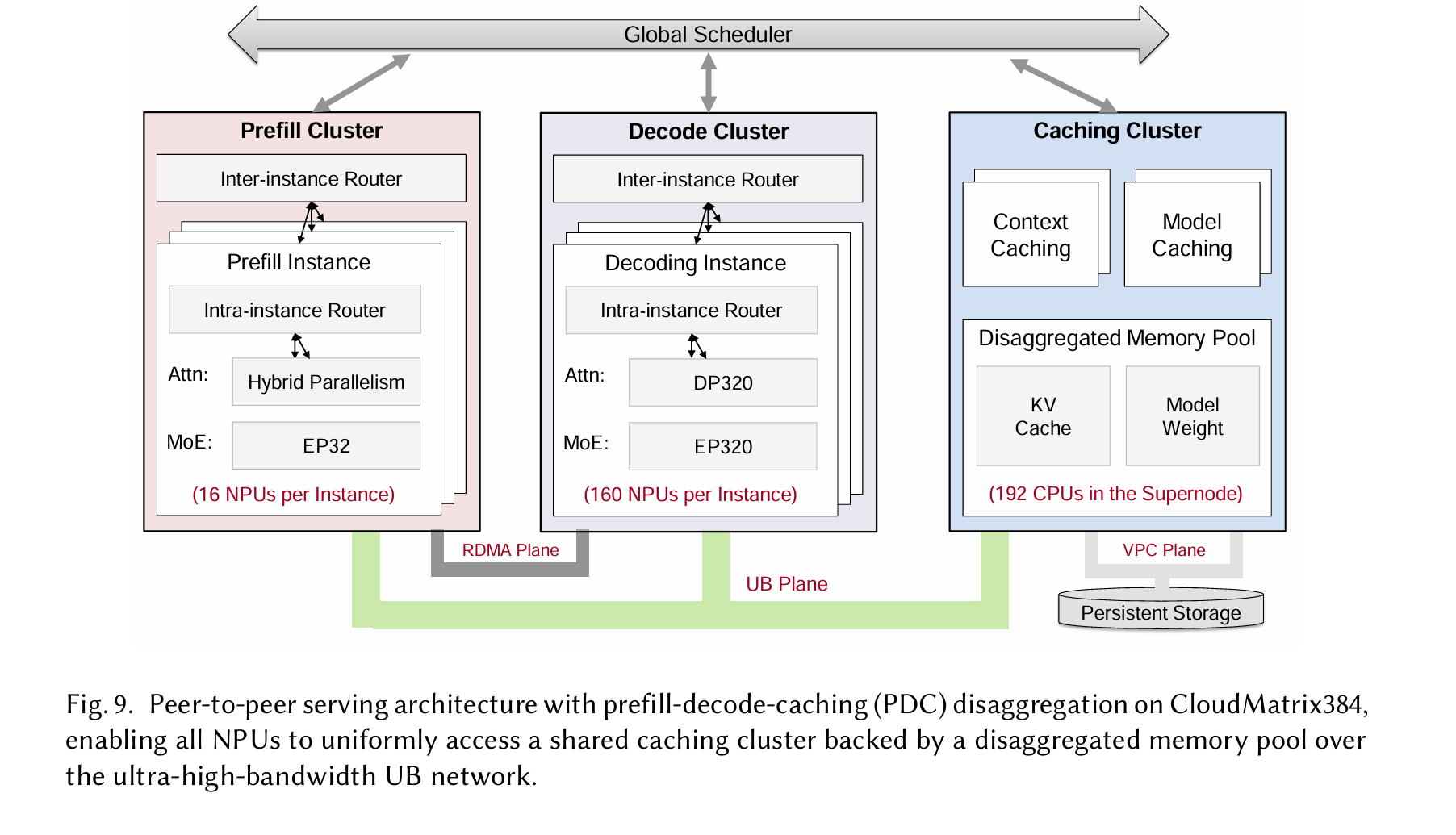
In real-world online serving scenarios, the disaggregated PDC serving architecture enables dynamic, fine-grained ad justment of the numbers of prefill, decode, and caching nodes based on the statistical characteristics of incoming workloads. For example, requests with longer input prompts increase the relative demand for prefill nodes, while workloads generating longer outputs require more decode capacity.
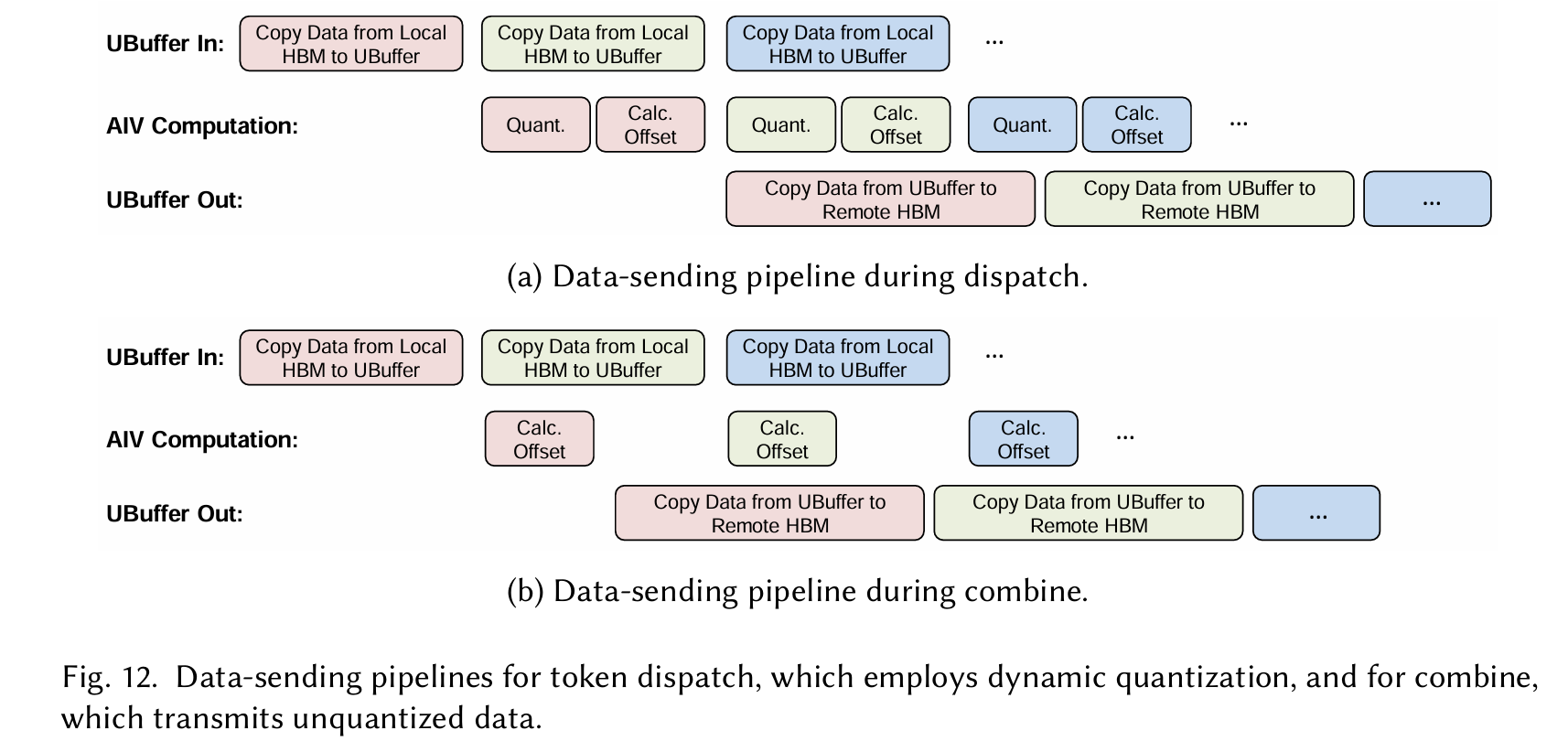
To address these inefficiencies, we developed FusedDispatch and FusedCombine, two fused operators that integrate communication and computation, specifically designed to achieve optimal decode performance on CloudMatrix384.
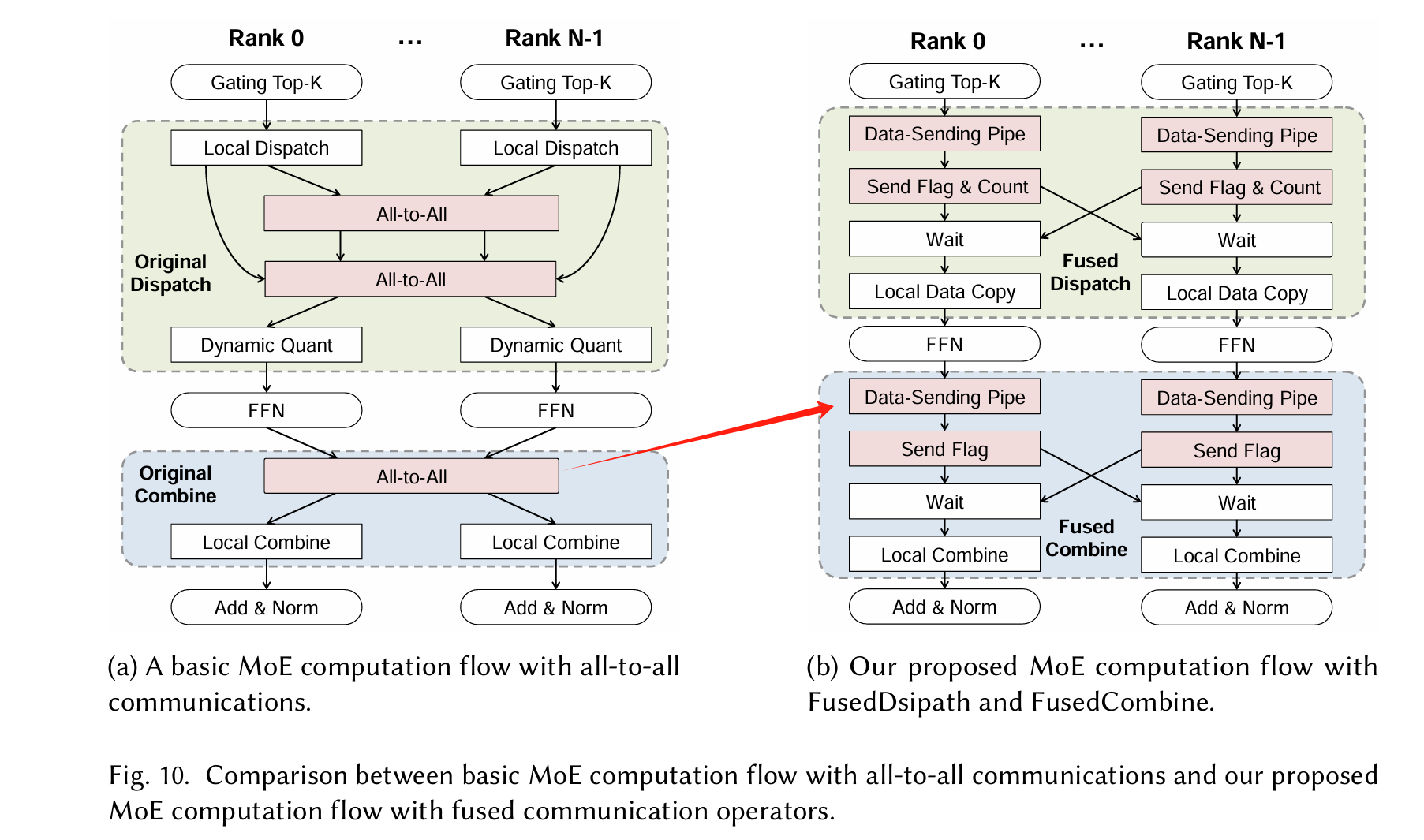
这是把all to all 算子拆了
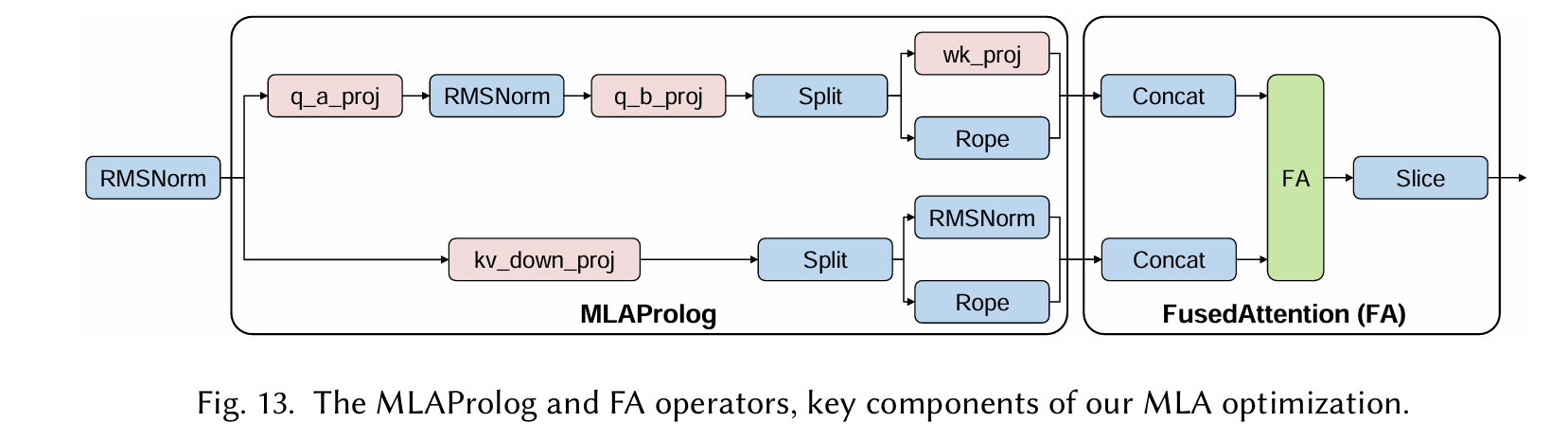
Fused Attention
Fused Operators: MLAProlog and Fused Attention (FA). To drastically reduce the launch overhead from numerous small operators in the MLA computation path, we employ aggressive operator fusion, as illustrated conceptually in Figure 13.
Firstly, multiple pre-attention operations, including RMSNorm, Q/K/V projections, and RoPE, are consolidated into a single composite operator, termed MLAProlog. This fusion reduces the operator startup costs from those of many individual operators to only one. Furthermore, MLAProlog is designed with internal micro-parallelism, dividing its workload into multiple sub-tasks that are executed in a pipelined fashion across the AIC and AIV units. This fine-grained AIC-AIV parallelism allows the computation times of different sub-tasks on these heterogeneous cores to effectively mask each other, further minimizing the fused operator’s execution time.
Secondly, to complement MLAProlog, we develope dafused attention (FA) operator that integrates FlashAttention with adjacent data shaping operations, such as pre-attention Concat (for preparing Q, K, V) and post-attention Slice (for extracting relevant outputs). This further minimizes kernel launches and improves data locality throughout the attention computation path.
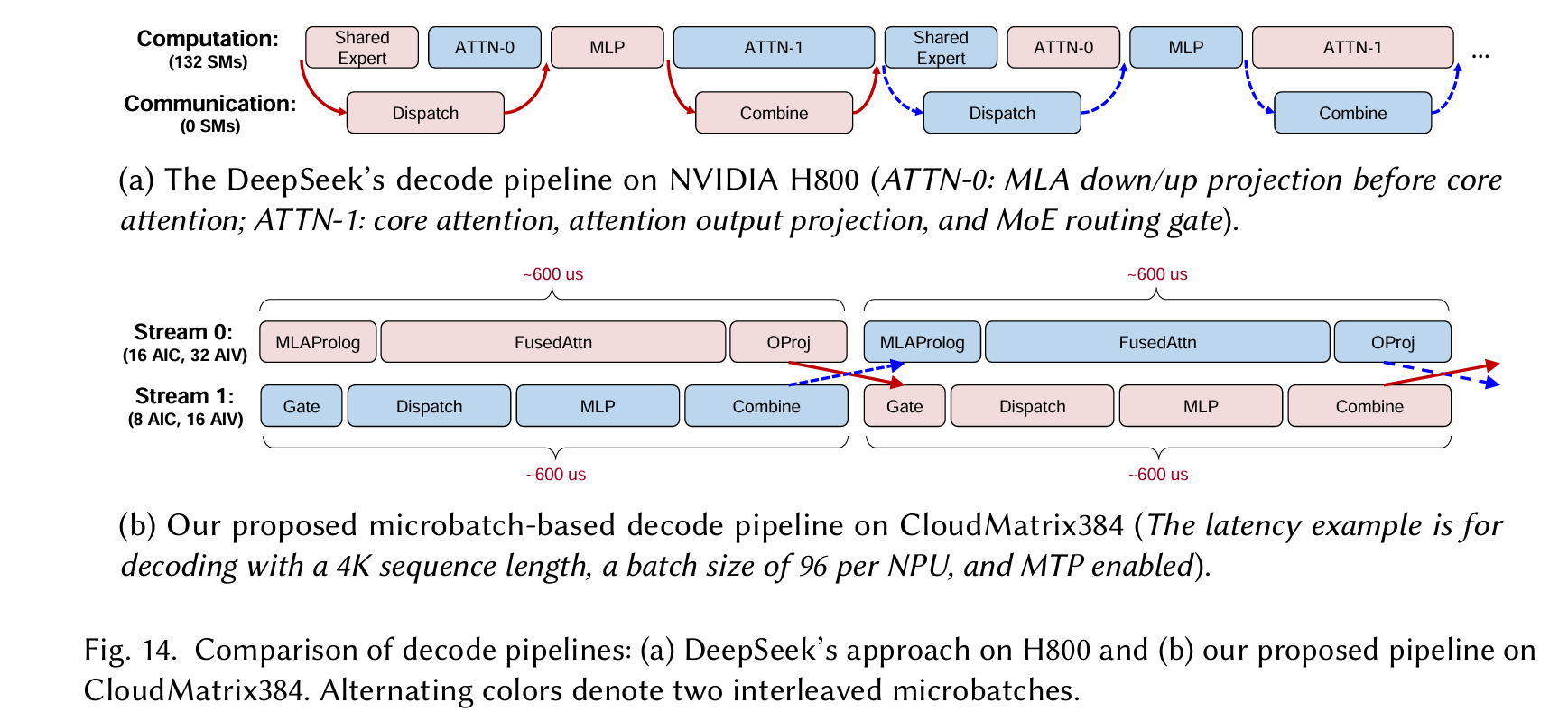
Microbatch
we design a tailored microbatch-based decode pipeline for CloudMatrix384 that maximizes resource utilization and reduces execution latency via fine-grained latency overlap across two streams.
- Stream 0 (Attention Path): Executes MLAProlog, FusedAttention, and O_PROJ. These are compute-heavy or memory-intensive operators and thus assigned more NPU resources—16 AICs and 32 AIVs. Under typical decode conditions (4K sequence, batch size 96, MTP enabled), this stream has a per-microbatch latency of 600 𝜇s.
- Stream 1 (MoE Path): Handles the MoE sequence: Gate, Dispatch, MLP, and Combine. Due to the inclusion of both compute and communication phases, this stream is given 8 AICs and 16 AIVs, half the resources of Stream 0, yet achieves a comparable latency ( 600 𝜇s) owing to lower computational load but higher communication latency
Load Imbalance with Multi-Token Prediction (MTP): When MTP is enabled, the decode phase must validate multiple tokens predicted in the previous step. This results in varying effective sequence lengths for different queries within the same batch (as detailed in §4.2.4) 一次预测+生成多token 在Transformer的解码器中,添加额外的层或机制(如多标记预测头)来并行预测多个标记
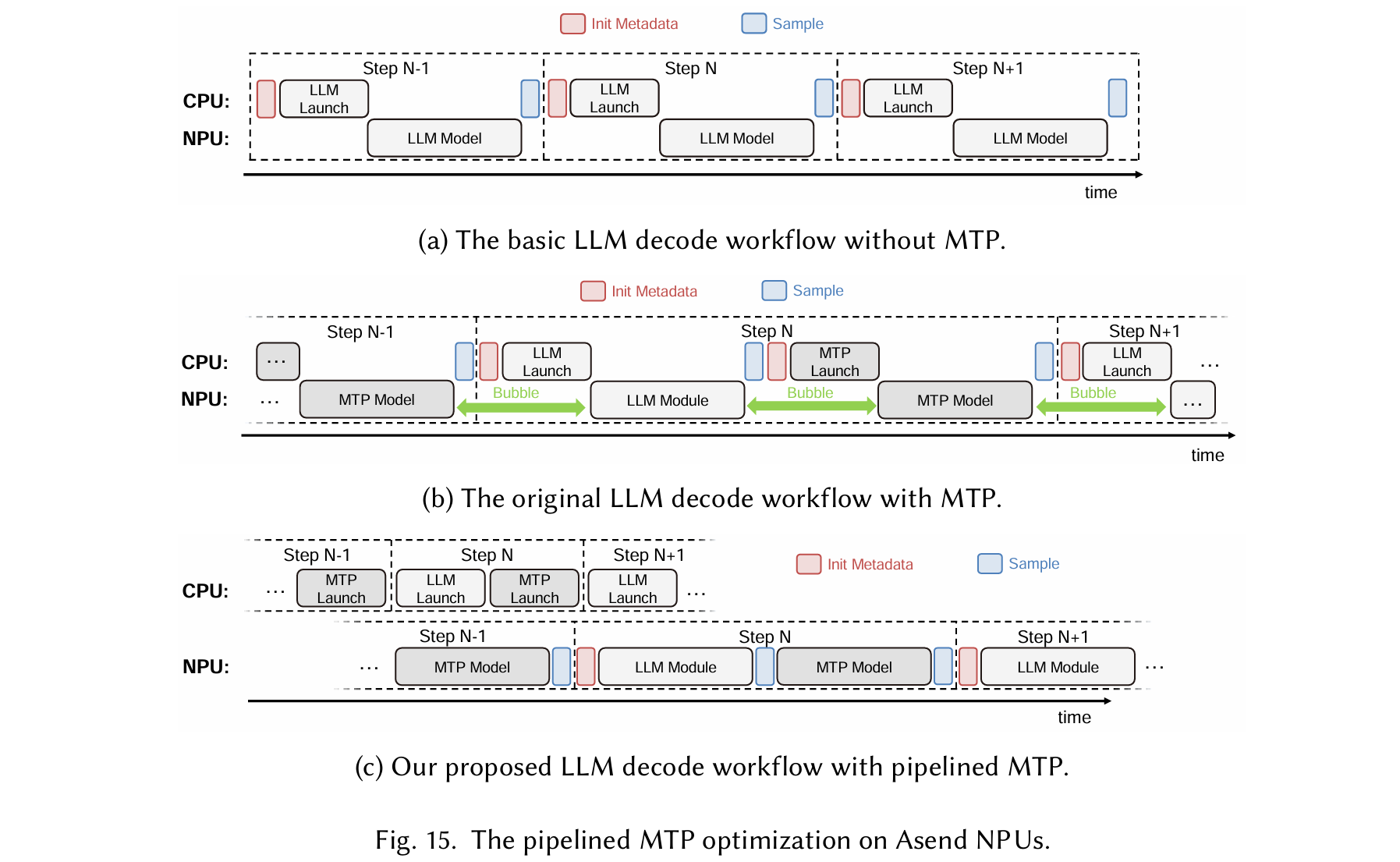
- Stream 0 (Attention Path): Executes MLAProlog, FusedAttention, and O_PROJ. These are compute-heavy or memory-intensive operators and thus assigned more NPU resources—16 AICs and 32 AIVs. Under typical decode conditions (4K sequence, batch size 96, MTP enabled), this stream has a per-microbatch latency of 600 𝜇s. •
- Stream 1 (MoE Path): Handles the MoE sequence: Gate, Dispatch, MLP, and Combine. Due to the inclusion of both compute and communication phases, this stream is given 8 AICs and 16 AIVs, half the resources of Stream 0, yet achieves a comparable latency ( 600 𝜇s) owing to lower computational load but higher communication latency
混合并行
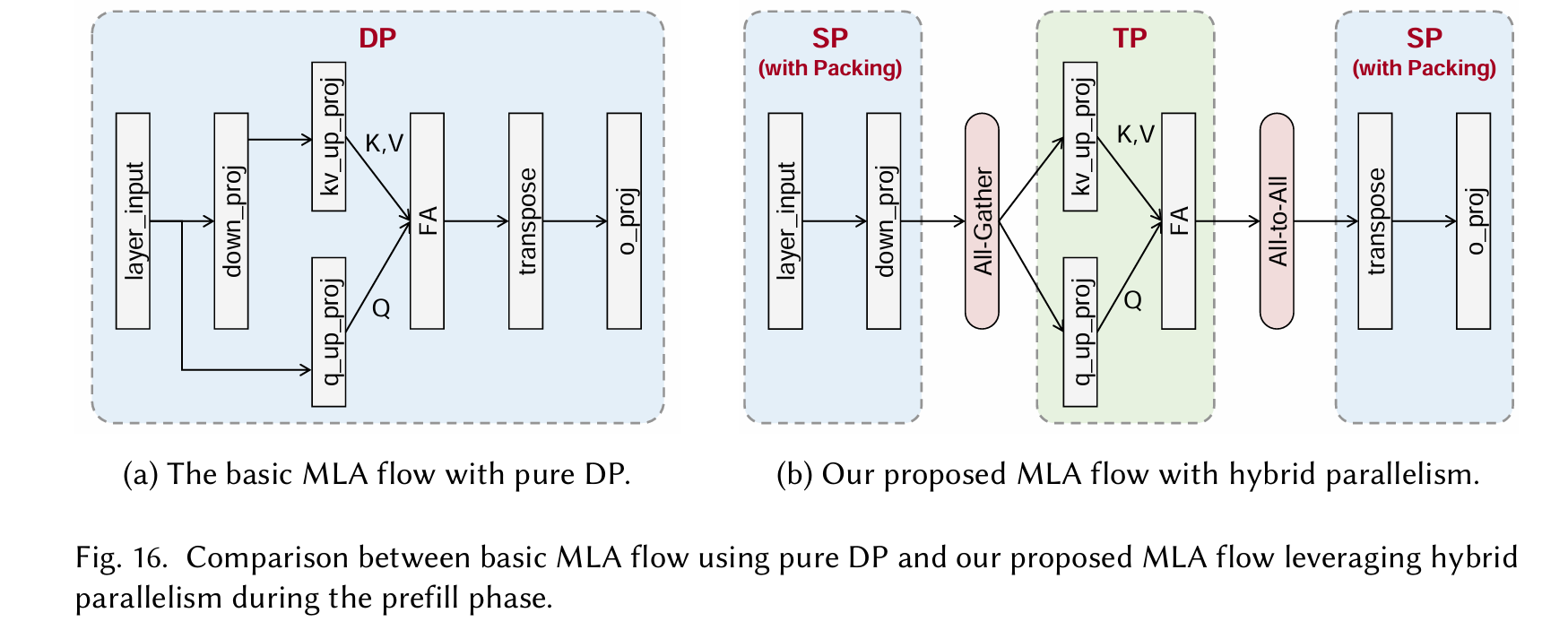
we leverage Sequence Parallelism (SP) combined with sequence packing, replacing pure DP 通过将输入序列分割并分配到多个计算设备(如GPU或TPU)上并行处理,从而减少内存需求并加速训练或推理。
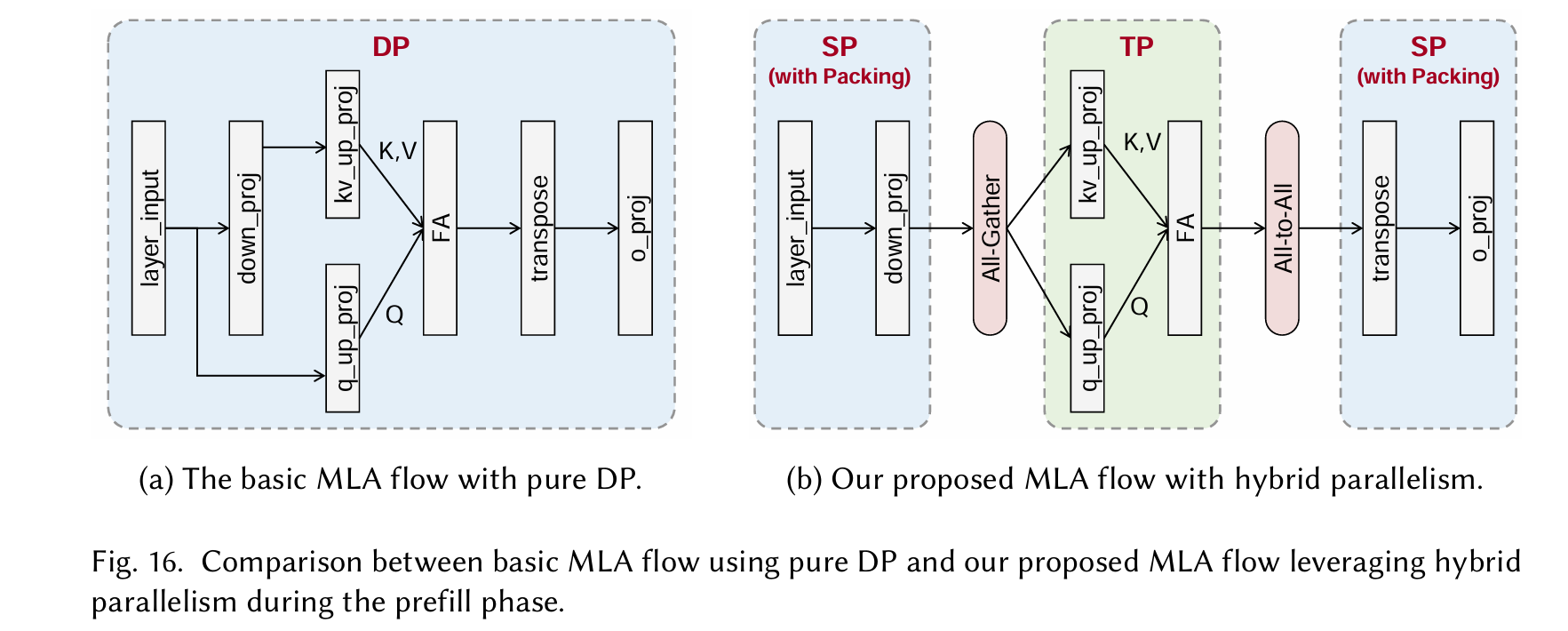
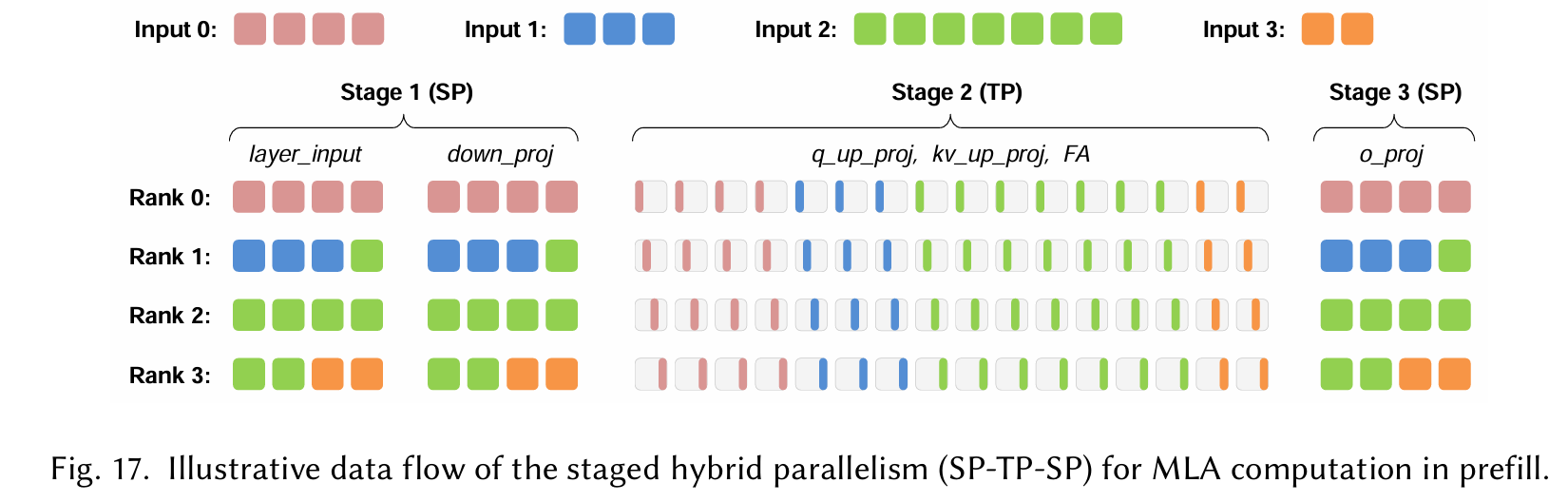
Dispatch 指的是将数据、计算任务或模型参数从一个设备(或主节点)分发到多个计算设备的过程,以实现并行计算。 Combine 指的是将多个设备上的计算结果(如梯度、中间输出或预测)合并或聚合,以生成最终结果或更新模型状态。
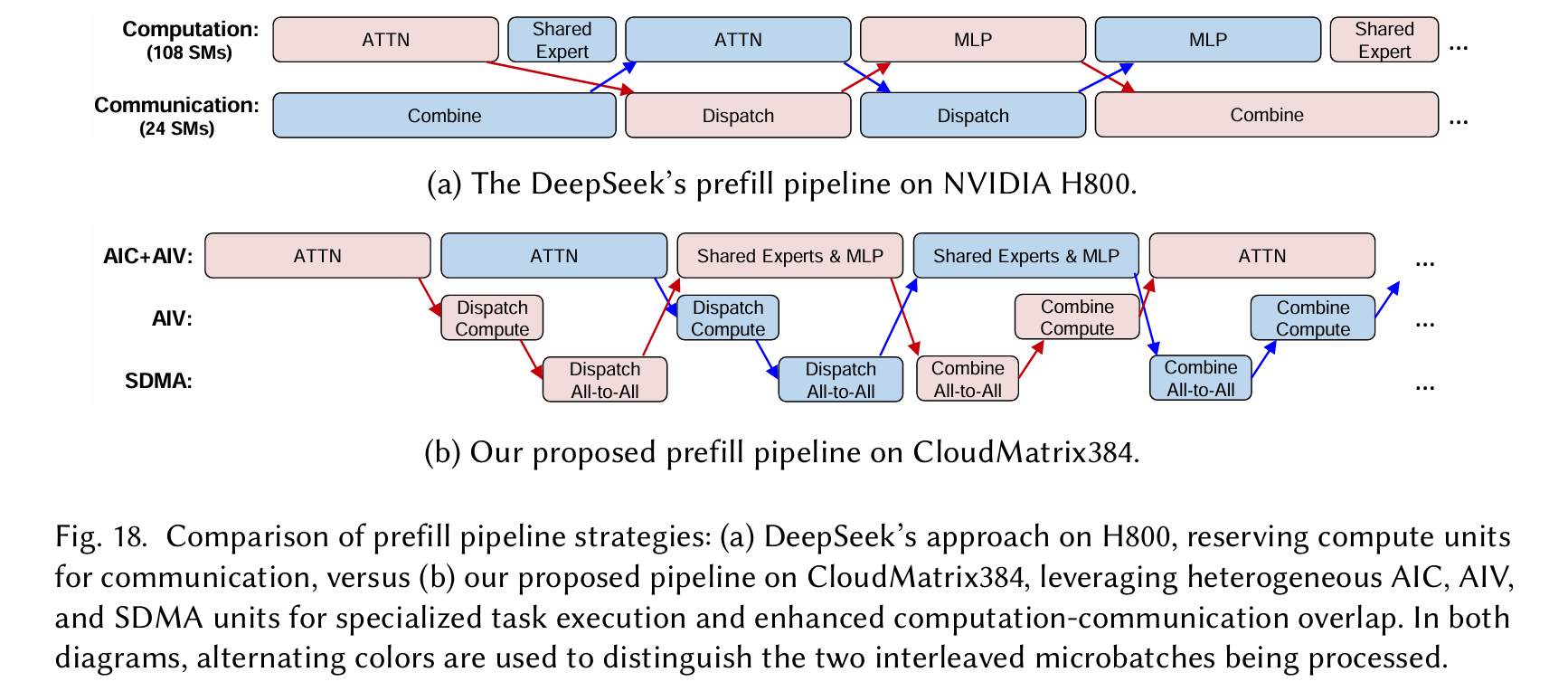
microbatch-based prefill pipeline forCloudMatrix384, illustrated in Figure18b.Ourdesignorchestratesworkloaddistributionacross theAIC,AIV,andSDMAsubsystemsasfollows
UB-Driven Distributed Caching with Unified Memory Access
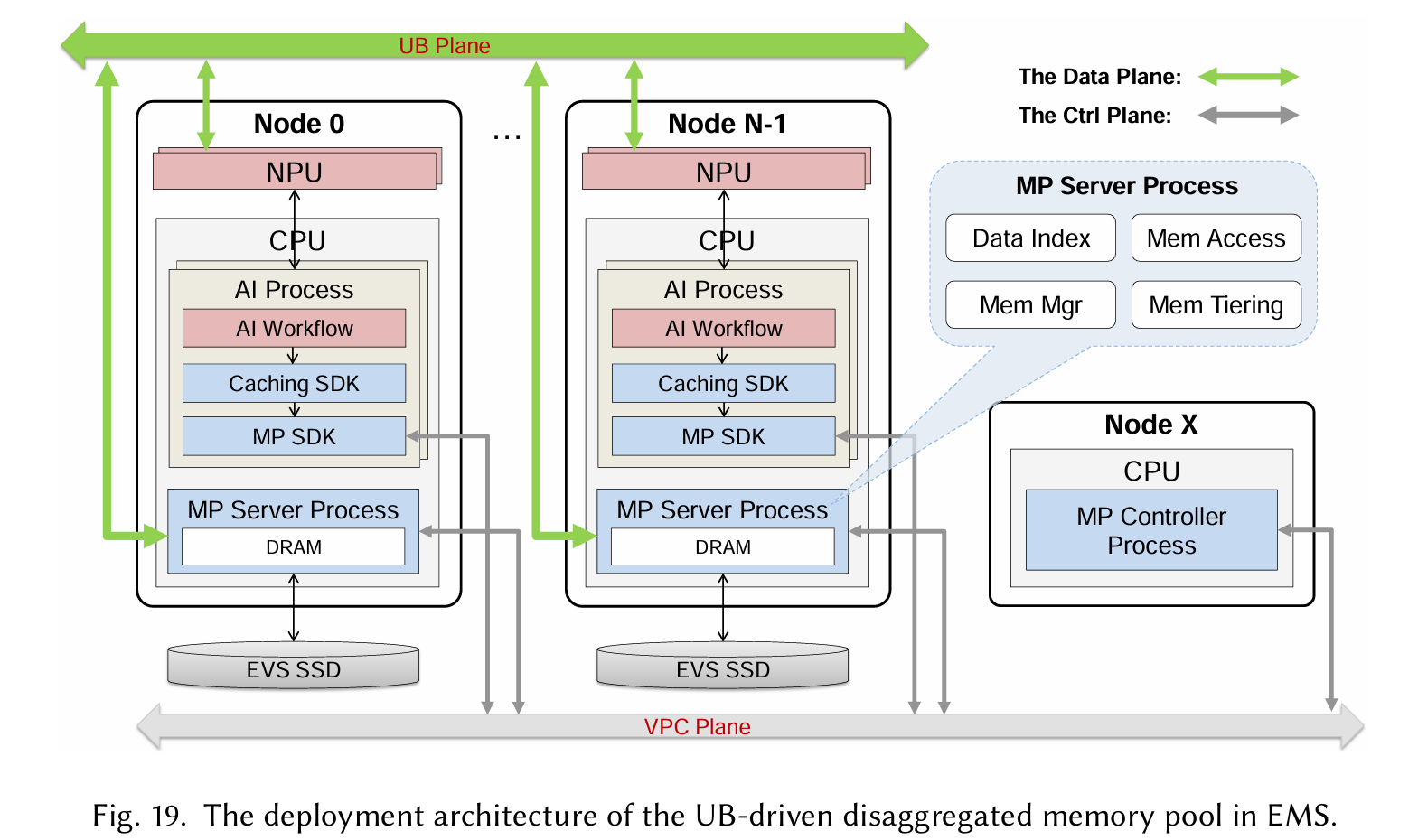
- Disaggregated Memory Pooling
- Context Caching
- Model Caching

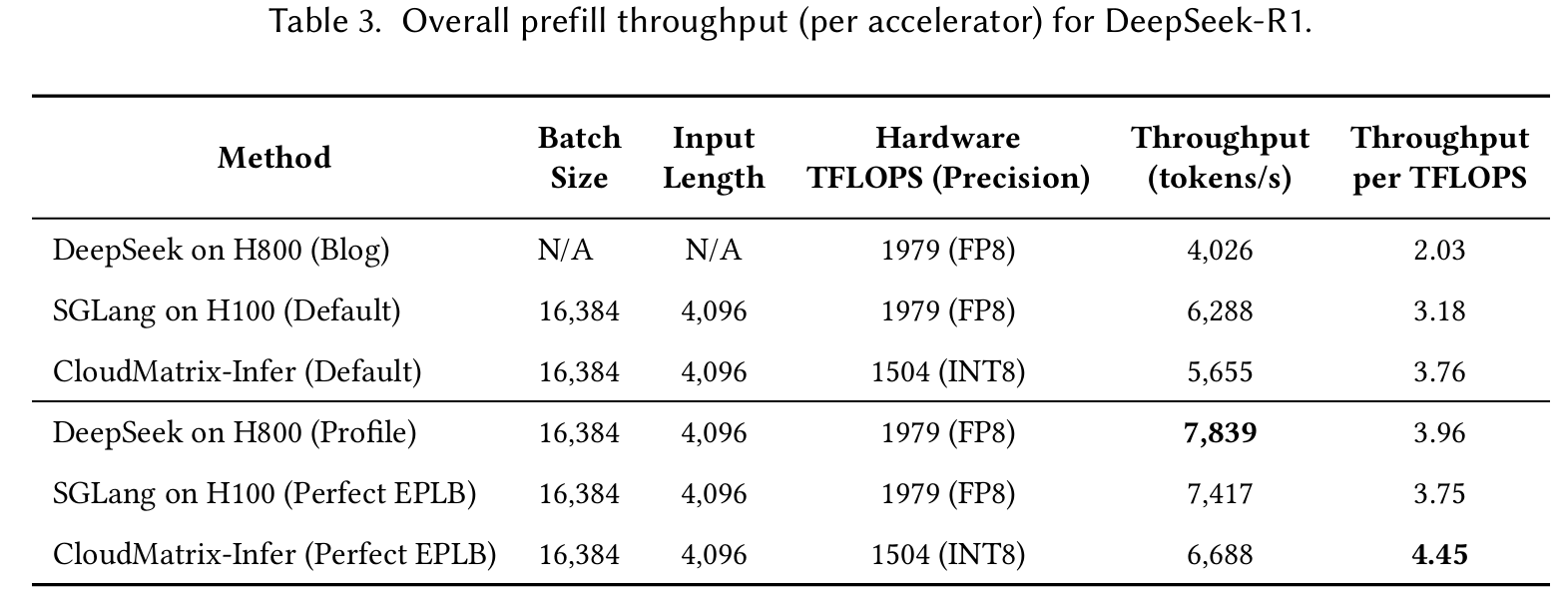
Our extensive evaluations with the DeepSeek-R1 model demonstrate that CloudMatrix-Infer achieves remarkable throughput, delivering 6,688 tokens/s per NPU in the prefill stage and 1,943 tokens/s per NPU during decoding
实验
最经济