
HPDC19: Parsl: Pervasive Parallel Programming in Python
- Paper Reading
- 2025-06-12
- 337 Views
- 0 Comments
- 931 Words
《Parsl: Pervasive Parallel Programming in Python》,发表在HPDC '19会议上,作者来自芝加哥大学、阿贡国家实验室等机构。以下是对文章内容的简要介绍:
核心内容
文章介绍了一个名为 Parsl 的Python并行脚本库,旨在通过简单、可扩展和灵活的方式增强Python的并行编程能力。Parsl通过在Python中引入特定的构造(constructs),允许开发者轻松表达程序中的并行性,构建动态依赖图(dependency graph),并在单处理器或多处理器上高效执行。它特别适用于需要并行计算的场景,例如大数据处理和科学计算,尤其是在摩尔定律逐渐失效的背景下。
主要特点
-
并行表达:
- Parsl通过装饰器(如
@python_app和@bash_app)将Python函数标记为可并行执行的“Apps”,并利用futures机制实现异步调用。 - 开发者只需定义函数的输入输出,Parsl会自动追踪数据依赖并构建任务图,从而实现并行执行。
- Parsl通过装饰器(如
-
可扩展的执行模型:
- Parsl设计了多种执行器(executors),包括:
- 低延迟执行器(LLEX):适用于需要快速响应的任务,延迟低至5毫秒。
- 高吞吐量执行器(HTEX):支持超过65000个并发工作者,吞吐量超1000任务/秒。
- 极大规模执行器(EXEX):可在8000多个节点上扩展至250000个工作者。
- 这些执行器适应不同的计算需求,从笔记本电脑到超级计算机。
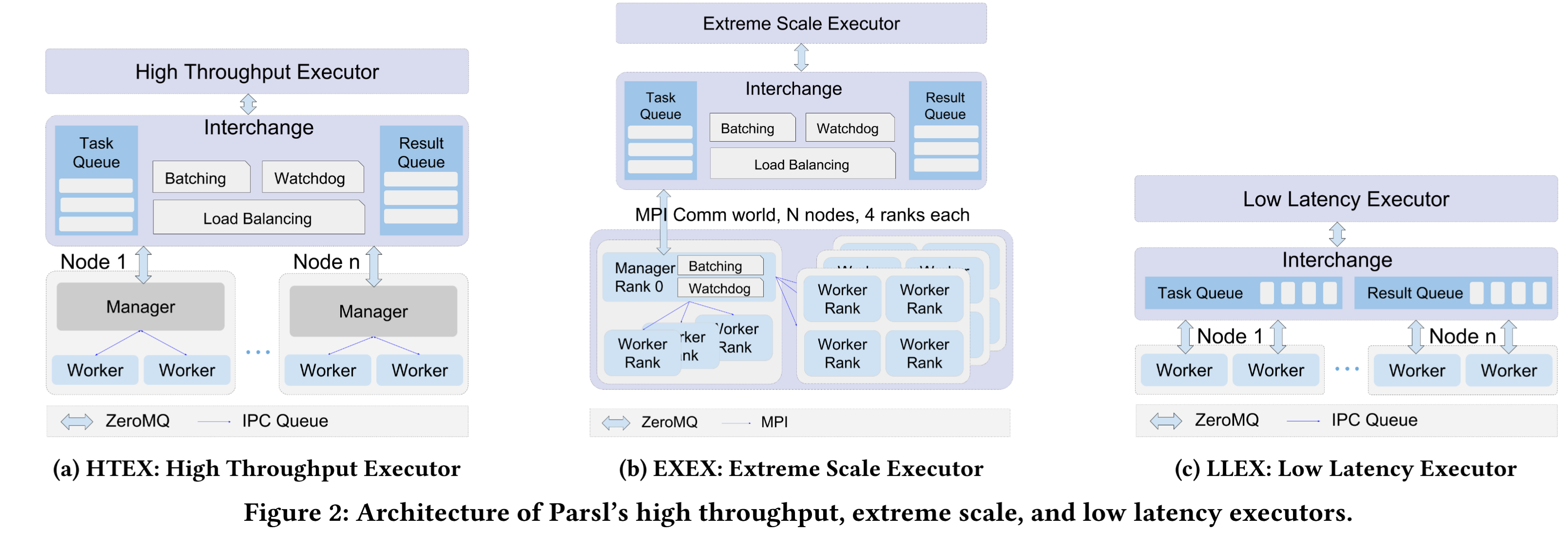
- Parsl设计了多种执行器(executors),包括:
-
灵活性和容错性:
- 支持弹性资源分配,根据任务需求动态调整计算资源。
- 提供故障容错机制,确保大规模任务执行的可靠性。
- 集成了广域数据管理,支持跨地域的数据传输。
-
Python生态整合:
- Parsl充分利用Python的生态系统(如Pandas、Scikit-learn、Jupyter等),开发者无需学习新语言即可实现并行功能。
应用场景
文章通过五个科学用例(DNA序列分析、机器学习推理、材料科学、神经科学、宇宙学)展示了Parsl的适用性。这些用例涵盖了多种计算模式(如多任务计算、交互式计算、在线计算),验证了Parsl在生物学、宇宙学和材料科学等领域的实用性。
实验验证
作者在Blue Waters超级计算机上进行了性能测试,结果表明:
- Parsl的执行开销低至5毫秒。
- 可扩展至250000个工作者,覆盖8000多个节点。
- 任务吞吐量高达1200任务/秒。
与IPyParallel、FireWorks和Dask等工具相比,Parsl在延迟、扩展性和吞吐量上表现出色,尤其适合大规模并行任务。
创新点
- 动态任务图:不同于静态DAG(有向无环图)模型,Parsl支持动态生成任务依赖,提升灵活性。
- 模块化设计:将程序逻辑与执行配置分离,便于在不同资源上移植。
- 广泛适用性:支持从短时任务到长时间任务、从少量到数百万任务的执行。
结论
Parsl填补了Python并行计算生态中的空白,提供了从小型集群到超大规模系统的解决方案。它不仅易于学习和使用,还能满足科学计算中多样化的并行需求。未来计划包括增强数据管理功能和支持更多并行构造。
这篇文章适合对并行编程、高性能计算或Python科学计算感兴趣的读者,尤其是希望在现有Python代码中引入并行能力的开发者。