
计算机体系结构未来发展预测
- Computer Science
- 2025-05-09
- 1372 Views
- 1 Comments
- 4553 Words
tldr:
- 专用的硬件将成为计算主流
- 多节点情况下,CPU的核数将稳定保持在16-48核内。多节点的目标不再是更多CPU,而是能控制更多GPU等特殊硬件
- 特殊内存、特殊网络通信等组件将更加主流
- 云服务主导,个人与仓储计算差异化
- 软件-硬件协同设计
- 可持续计算,能耗成为一个关键因素
计算机CPU性能增长缓慢
下文来自David Pattersen的《计算机体系结构:量化研究方法》:
提高能效-性能-成本的唯一途径是专业化。

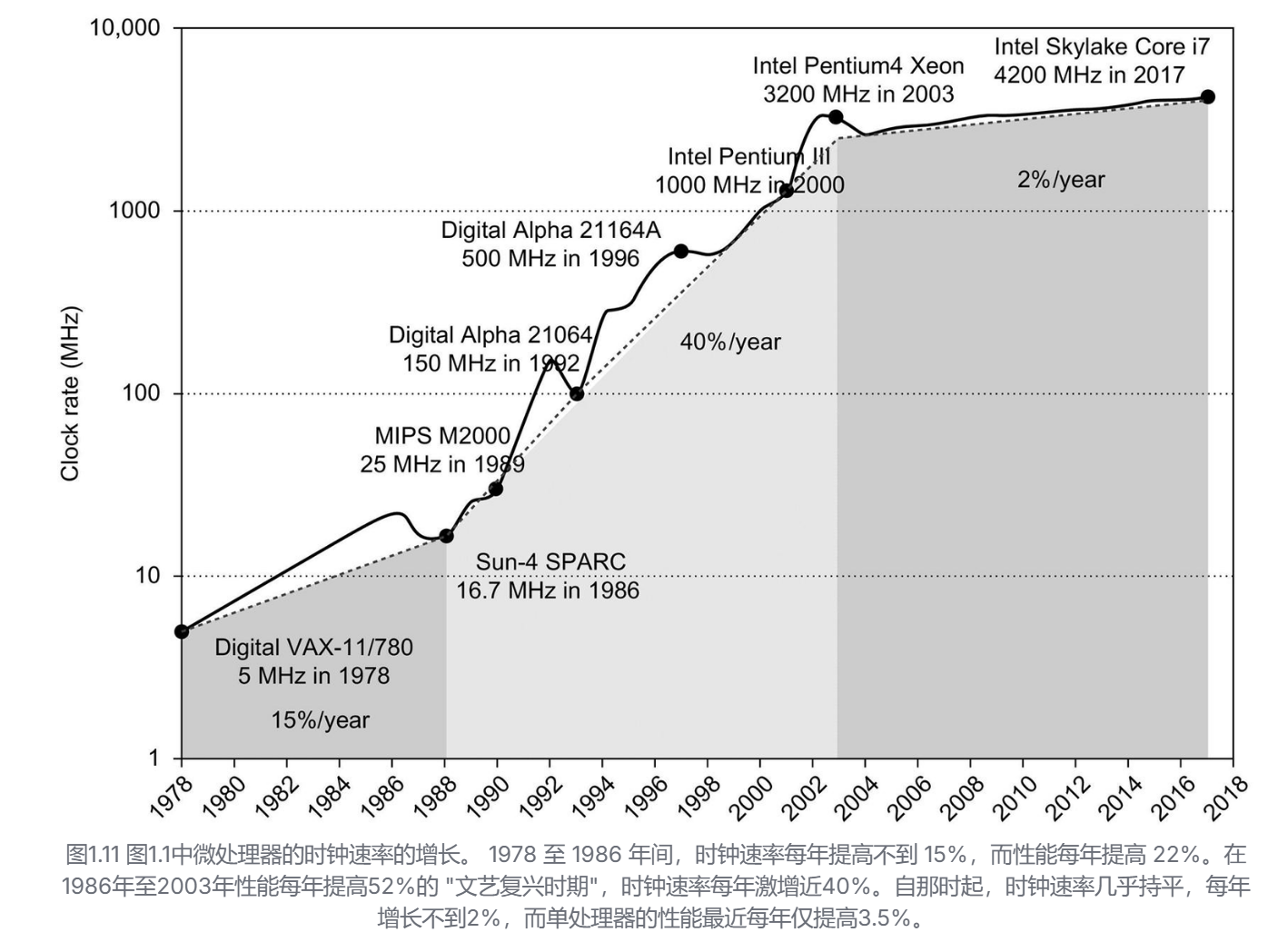
时钟增长缓慢
性能趋势:带宽的提升大于延迟
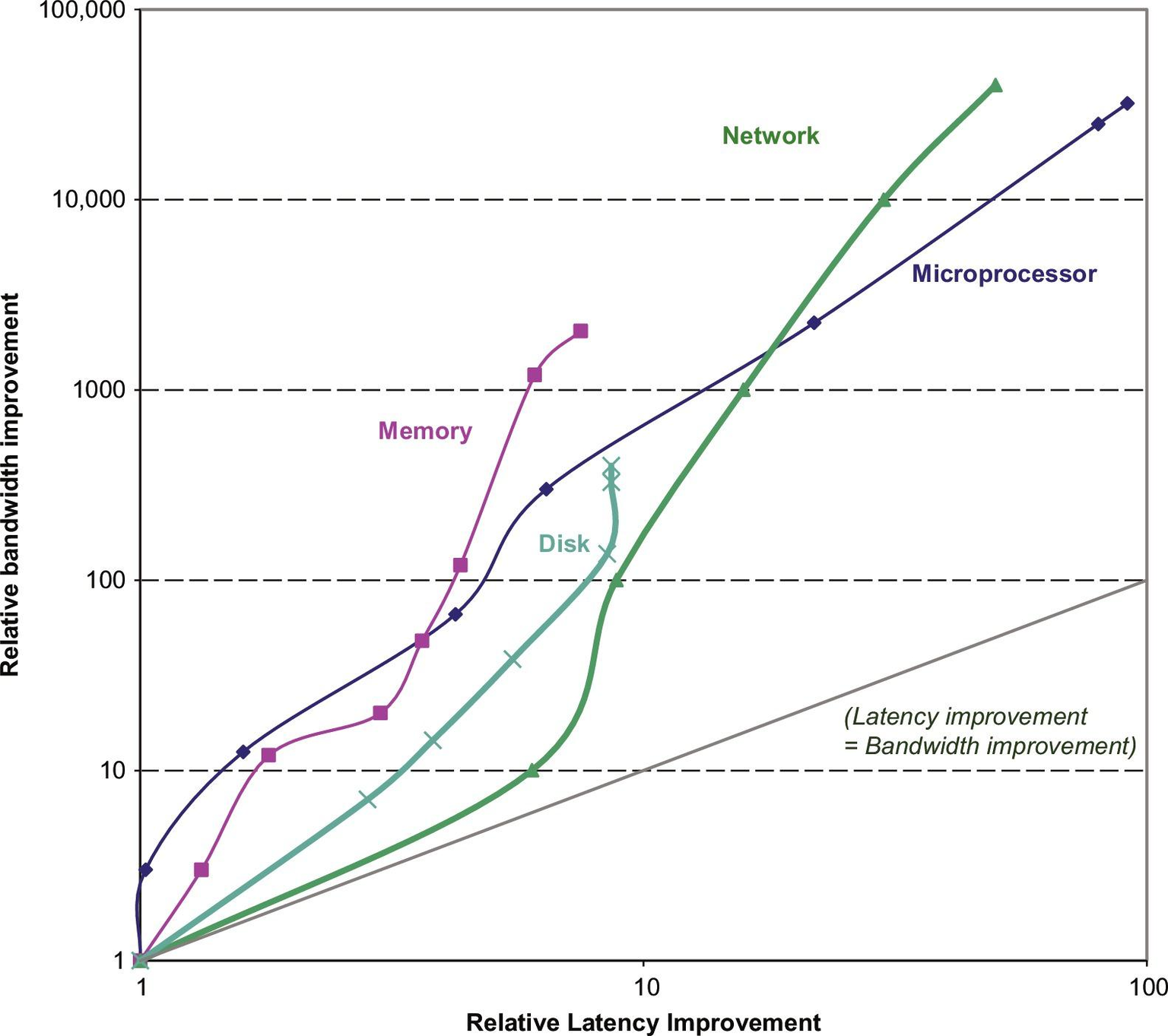
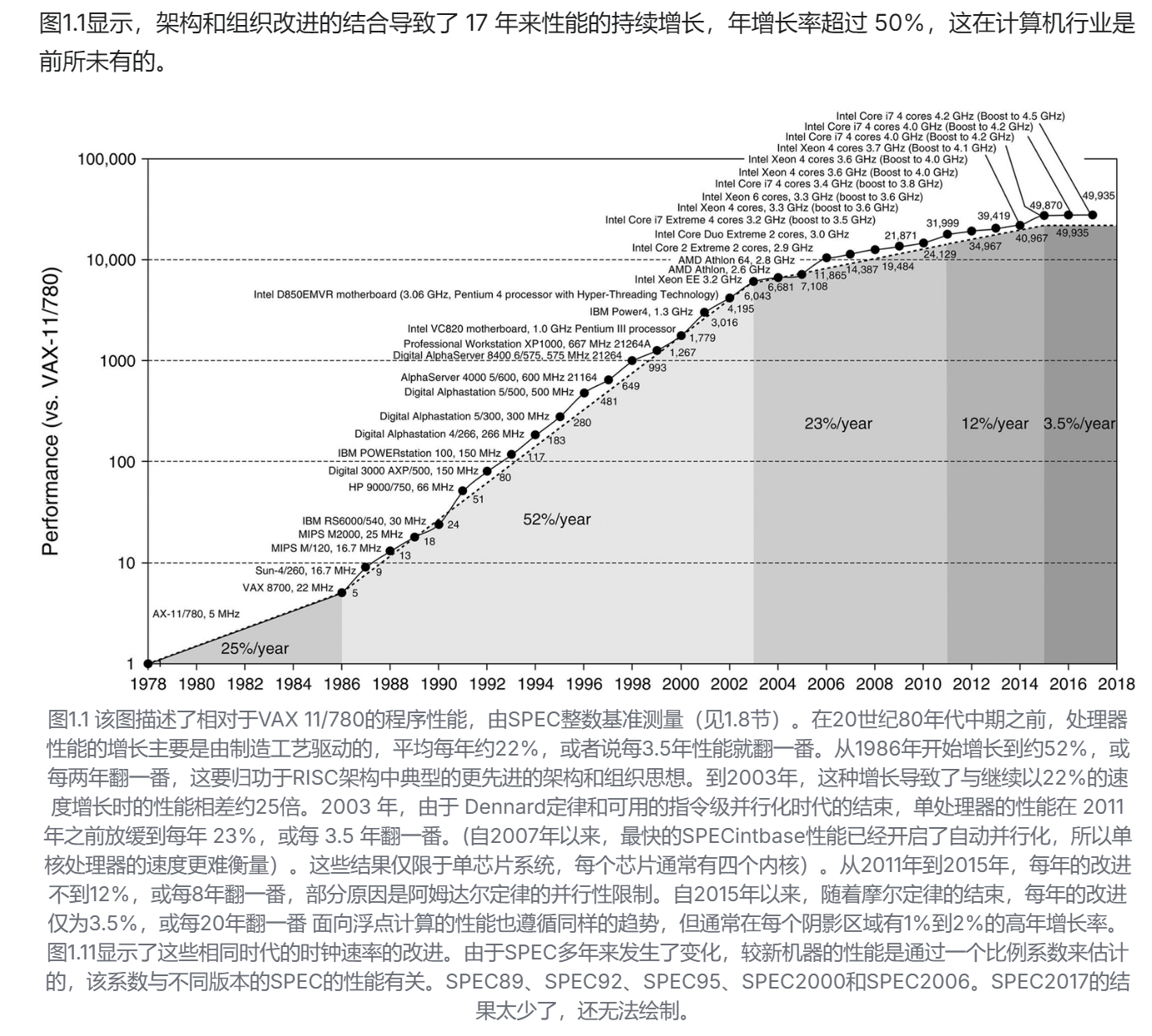
微处理器、内存、网络和磁盘在25-40年内的性能里程碑。 微处理器的里程碑是几代IA-32处理器,从16位总线、微编码80286到64位总线、多核、乱序执行、超流水线(superpipelined)的Core i7。内存模块的里程碑,从16位宽的普通DRAM到64位宽的双数据率第三版同步DRAM。以太网从10 Mbits/s推进到400 Gbits/s。磁盘的里程碑是基于旋转速度,从3600转/分提高到15000转/分。每种情况都是最佳的带宽,而延迟是假设没有竞争的简单操作的时间。更新自Patterson, D., 2004. 延迟落后于带宽。
性能是微处理器和网络的主要区别因素,因此它们的收益最大。带宽提高了32,000-40,000倍,延迟提高了50-90倍。对于内存和磁盘来说,容量通常比性能更重要,所以容量的提高更多,但400-2400倍的带宽进步仍然比8-9倍的延迟进步大得多。
显然,在这些技术中,带宽已经超过了延迟,而且可能会继续这样做。一个简单的经验法则是,带宽的增长至少是延时改进的平方。计算机设计者应该据此制定计划。
第一个被淘汰的是Dennard定律。Dennard在1974年的观察是,随着晶体管变小,功率密度是不变的。如果一个晶体管的线性区域缩小了2倍,那么电流和电压也减少了2倍,因此它使用的功率下降了4倍。Dennard定律在被观察到30年后结束了,不是因为晶体管没有继续变小,而是因为集成电路的可靠性限制了电流和电压可以下降的程度。阈值电压被驱动得如此之低,以至于静态功率成为总功率的一个重要部分。
下一个例子是硬盘驱动器。虽然磁盘没有规律可循,但在过去30年中,硬盘的最大面积密度--它决定了磁盘容量--每年提高30%-100%。在最近几年里,每年的增长率低于5%。每块硬盘密度的提高主要来自于在硬盘上增加更多的盘片。
接下来是古老的摩尔定律。自从每块芯片的晶体管数量每隔一到两年就翻一番以来,已经有一段时间了。例如,2014年推出的DRAM芯片包含80亿个晶体管,直到2019年我们才会有160亿个晶体管的DRAM芯片投入量产。但如果按照摩尔定律的预测,那将会有640亿个晶体管的DRAM芯片。
此外,平面逻辑晶体管数目的实际扩张的结束甚至被预测为到2021年。图1.22显示了两版《国际半导体技术路线图》(ITRS)对逻辑晶体管门长度的预测。与2013年报告预测到2028年栅极长度将达到5纳米不同,2015年报告预测到2021年长度停止在10纳米。此后的密度改进将不得不来自缩小晶体管尺寸以外的其他方式。这并不像ITRS建议的那样可怕,因为像英特尔和台积电这样的公司已经计划将逻辑门长度缩小到3纳米,但是变化的速度正在下降。
多核处理器、分布式集群将不再承担主要计算业务
分布式存储是非常成功的,但是分布式计算是失败的。
谬论 多核处理器是银弹。
2005年左右转向每片多处理器并不是因为有什么突破,大大简化了并行编程或使建立多核计算机变得容易。发生这种变化是因为由于ILP墙和功率墙的存在,没有其他选择。每个芯片上的多个处理器并不能保证更低的功率;设计一个使用更高功率的多核芯片当然是可行的。潜力只是有可能通过用几个较低时钟频率的高效内核取代一个高时钟频率的低效内核来继续提高性能。随着缩小晶体管的技术改进,它可以将电容和电源电压都缩小一些,这样我们就可以在每一代的内核数量上得到适度的增加。例如,在过去的几年里,英特尔在他们的高端芯片中每一代都会增加两个内核。 正如我们将在第4章和第5章中看到的,性能提升现在是程序员的工作。程序员依靠硬件设计者来使他们的程序更快,而不用动一根手指的La-Z-Boy时代已经正式结束了。如果程序员希望他们的程序每一代都能更快,他们必须使他们的程序更加并行。 摩尔定律的流行版本--随着每一代技术的发展而提高性能--现在由程序员决定了。
陷阱 沦为阿姆达尔“心碎”定律的牺牲品。
几乎每个从业的计算机架构设计者都知道阿姆达尔定律。尽管如此,我们几乎都会在测量其使用情况之前,偶尔花费巨大的精力来优化某些功能。只有当整体的速度提升令人失望时,我们才会想起,在我们花了这么多精力来提升它之前,我们应该先测量一下它!
陷阱 单点故障。
1.7节使用阿姆达尔定律进行的可靠性改进的计算表明,可靠性不会比链条中最弱的一环更强。无论我们如何提高电源的可靠性,正如我们在例子中所做的那样,单个风扇将限制磁盘子系统的可靠性。这个阿姆达尔定律的观察导致了一个容错系统的经验法则,即确保每一个组件都是冗余的,这样就没有一个组件的故障会使整个系统崩溃。第六章展示了软件层如何避免WSCs内部的单点故障。
谬论 改进硬件的性能也会提高能效,或者在最坏的情况下是能耗不增加也不减少。
Esmaeilzadeh等人(2011年)使用Turbo模式(第1.5节)在2.67GHz英特尔酷睿i7的一个核心上测量了SPEC2006。当时钟频率提高到2.94GHz时,性能提高了1.07倍(或1.10倍),但i7增加了1.37倍功耗和1.47倍的能耗!。
硬件的发展解决了数据量的问题,而数据库软件的发展(PostgreSQL,ParadeDB,DuckDB)解决了查询模式的问题,而这导致分析领域 —— 所谓的“大数据” 行业基本工作假设面临挑战。
正如 DuckDB 发表的宣言《大数据已死》所主张的:大数据时代已经结束了 —— 大多数人并没有那么多的数据,大多数数据也很少被查询。大数据的前沿随着软硬件发展不断后退,99% 的场景已经不再需要所谓“大数据”了。
如果 99% 的场景甚至都可以放在一台计算机上用单机/主从的 DuckDB 或 PostgreSQL 搞定,那么使用专用的分析组件还有多少意义?如果每台手机都可以自由自主收发短信,那么 BP 机还有什么存在价值?(北美医院还在用BP机,正好比也还有 1% 不到的场景也许真的需要“大数据”)
基本工作假设的变化,将重新推动数据库世界从百花齐放的“合久必分”阶段,走向“分久必合”的阶段,从大爆发到大灭绝,大浪淘沙中,新的大一统超融合数据库将会出现,重新统一 OLTP 与 OLAP。而承担重新整合数据库领域这一使命的会是谁?
链接:https://zhuanlan.zhihu.com/p/685247647
许多 Benchmark 正在失效,业务在改变,硬件在变强
谬误 基准永远有效。
有几个因素影响了基准作为实际性能预测的有用性,而且有些因素会随着时间的推移而改变。一个重要的事实是,基准有用性本身与 "基准标准化 "或 "基准流行化 "的趋势相抵触。一旦一个基准变得标准和流行,就会有巨大的压力,使得设计者通过有针对性的优化或对运行基准的规则进行大量分析来提高性能。当设计小kernel或程序将时间花在一小段代码上时,这将对基准的有用性产生消极影响。 例如,尽管有最好的意图,最初的SPEC89基准套件包括一个小kernel,称为matrix300,它由8个不同的300×300矩阵乘法组成。在这个kernel,99%的执行时间都在一行中(见SPEC,1989)。当IBM的一个编译器对这个内循环进行优化时(使用一个叫做blocking的好策略,将在第二章和第四章中讨论),性能比之前版本的编译器提高了9倍!这个基准测试的这个编译器优化,当然不是整体性能的良好表征,也不是这个特定优化的价值所在。
图1.19表明,如果我们忽视历史,我们可能会被迫重复它。SPEC Cint2006已经有十年没有更新了,这给了编译器编写者大量的时间来磨练他们的优化器以适应这个套件。请注意,除了libquantum之外,所有基准的SPECRate都在AMD计算机的16-52范围内,而英特尔则在22-78之间。Libquantum在AMD上的运行速度约为250倍,在英特尔上为7300倍! 这个 "奇迹 "是英特尔编译器优化的结果,该编译器自动将代码在22个核心上并行化,并通过使用比特打包(bit packing)优化内存,将多个短整型(narrow-range integers)打包在一起,以节省内存空间,从而节省内存带宽。如果我们放弃这个基准并重新计算几何平均值,AMD SPEC Cint2006从31.9下降到26.5,英特尔从63.7下降到41.4。现在英特尔计算机的速度大约是AMD计算机的1.5倍,而不是2.0倍,如果我们包括libquantum,这肯定更接近他们的真实相对性能。SPECCPU2017放弃了libquantum。
为了说明基准的短命,图1.17列出了各个SPEC版本中所有82个基准的状态;gcc是SPEC89中唯一的幸存者。令人惊讶的是,SPEC2000或更早的所有程序中,约有70%从下一个版本中被放弃。
谬误 磁盘的额定平均故障时间为120万小时,即近140年,所以磁盘实际上从未发生故障。
目前磁盘制造商的市场营销会误导用户。MTTF是如何计算的呢?首先,制造商会把成千上万的磁盘放在一个房间里,运行几个月,然后统计故障磁盘的数量。MTTF由磁盘累计工作的总时长除以故障的数量得出。
一个问题是,这个数字远远超过了磁盘的使用寿命,通常假设为五年或43800小时。为了使这个大MTTF有一定的意义,磁盘制造商争辩说,这个统计模型可以这样解释:对应于一个购买磁盘的用户,然后按照计划寿命,每5年更换一次磁盘。他们声称,如果许多客户(以及他们的曾孙)在下个世纪都这样做的话,按照平均统计,他们会在发生故障前更换27次磁盘,或者大约140年。
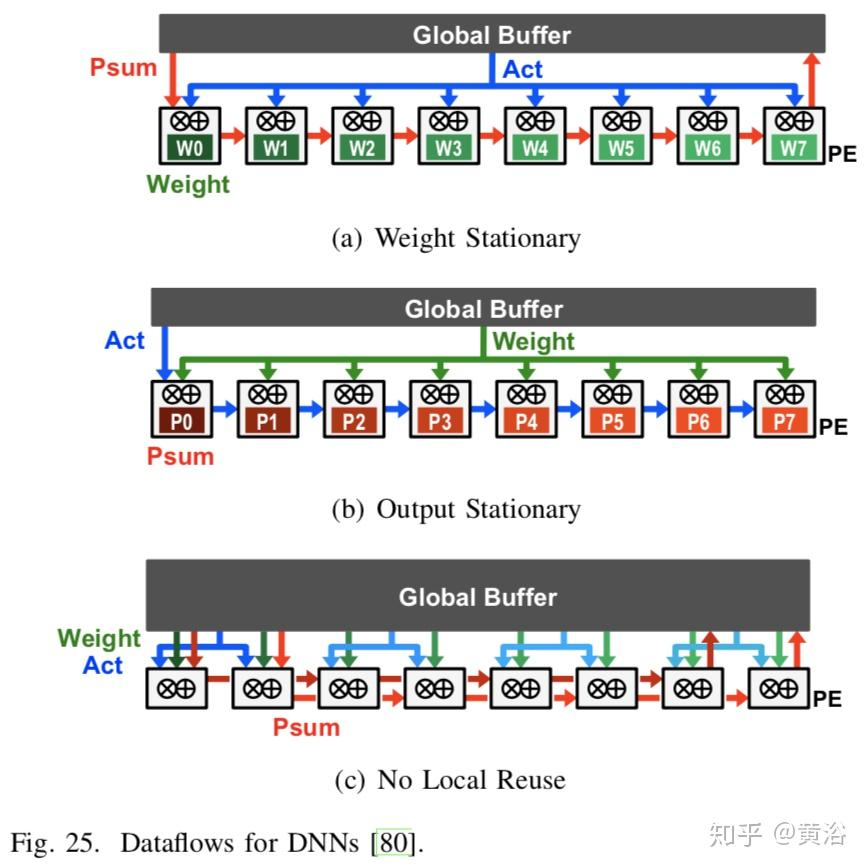
更多的专用处理器、更多的算子
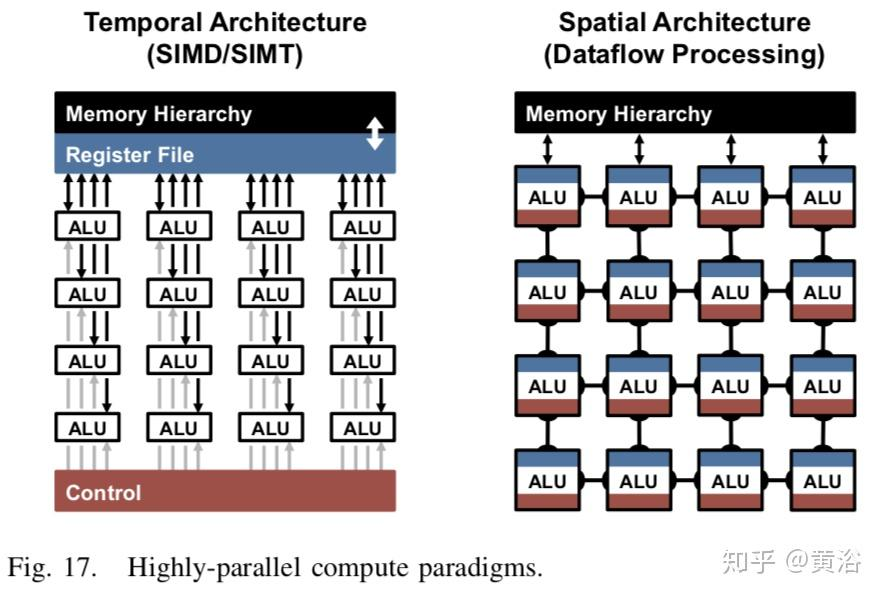
时域架构(temporal architecture)主要出现在CPU或GPU中,可以采用各种技术来改善其并行性,比如向量(SIMD)或并行线程(SIMT)。这种时域架构对大量算术逻辑单元(arithmetic logic unit,ALU)进行集中控制。这些ALU只从分层内存结构中获取数据,并且相互之间不直接通信。
相反,空域架构(spatial architecture)使用数据流处理,意思是,ALU形成直接将数据从一个传递到另一个的处理链。有时每个ALU都有自己的控制逻辑和本地内存,称为暂存器(scratchpad)或寄存器文件,而具有本地内存的ALU称为处理引擎(processing element,PE)。空域架构通常用于基于ASIC和FPGA设计的神经网络。
存算分离,OLAP与OLTP计算分离
分布式存储”、“共享存储集群”、 “计算下推”同时具备这三个要素的架构,是理想的数据库架构。
分布式(集群)数据库有两种架构模式:1、每个数据库节点各自管理自己的持久化存储, 节点之间不共享数据,如TiDB、OceanBase、ClickHouse等,就是这一类;2、数据库节点 与底层存储设备是分离的,底层存储在所有数据库节点之间共享,例如Oracle RAC、 PolarDB等,都是这一类数据库。第1类是存算一体的Share nothing架构,第2类是存算 分离的架构。第1类的优点是,不需要专门的存储系统,数据库自己管理存储系统,数据 库自己负责把数据复制为几份,自己管理冗余数据副本。
存算分离的主要意义在于,可以独立对存储和计算进行扩容和缩容。其次,存算分离架 构可以充分利用专业存储系统的能力,提升系统整体的可靠性、可用性和易用性。
应用对于存储和计算需求,并不总是确定不变的,有时候应用需要更多的计算资源,有 时又需要更多存储资源,如果存储和计算之间的比例不可弹性变化,那么就有很大概率 存在浪费。一般来说,share nothing的存算一体分布式数据库集群更适合OLAP应用。但是Snowflake采用了存算分离架构,并且表现非常出色。
既然分布式数据库自己就能管理硬盘,能做三副本,硬盘故障之后也能做数据重构,为 什么还需要数据专业的数据存储系统?对存储数据来说,专业的数据存储系统,比兼职的数据库做得更好。存储系统一般都支持快照、克隆等特性,并可以可以基于快照实现 块存储层的备份,速度快,数据一致性有保障。专业存储会定期读出数据做校验,如果发现错误,则用冗余副本来恢复。专业存储支持纠删码等冗余方式,每TB存储成本更低。
存算分离架构已经成了比较明显的趋势。甚至连TiDB、ClickHouse等Share Nothing架构 的分布式数据库也准备推出存算分离的版本。
工业软件专业化,开源软件出现巨无霸
这是随着硬件发展,软件也会这样发展
zStorage 是云和恩墨针对数据库应用自主研发的高性能分布式块存储。相比支持多种协议(块/文件/对象协议)的传统架构,zStorage 的架构更精简,数据处理单元由变长改为定长,处理机制更简单,减少了1/3写I/O处理流程,三节点集群可以达到300万以上的IOPS随机读写性能,P99时延小于0.8毫秒。zStorage 兼具分布式存储的高扩展性、软件定义云化能力与集中式存储的低时延,以及丰富的数据保护特性,可以为数据库提供云化的高性能、高可靠、高扩展数据底座。
吞食天地的 PostgreSQL
数据库领域有许多“细分领域”:时序数据库,地理空间数据库,文档数据库,搜索数据库,图数据库,向量数据库,消息队列,对象数据库。而 PostgreSQL 在任何一个领域都不会缺席。
一个 PostGIS 插件,成为了地理空间事实标准;一个 TimescaleDB 扩展,让一堆“通用”时序数据库尴尬的说不出话来;一个向量扩展 PGVector 插件,更是让整个专用向量数据库细分领域 变成笑话。
同样的事情已经发生过很多次,而现在,我们将在拆分最早,地盘最大的一个子领域 OLAP 分析中再次见证这一点。但 PostgreSQL 要替代的可不仅仅是 OLAP 数仓,它的野望是整个数据库世界!
同时,未来的体系结构会更强调软硬件深度集成,比如通过开放标准(如RISC-V)定制化芯片,或通过AI驱动的编译器优化硬件利用率。
算子专业化,硬件模块化
某些计算有高度需求
GPU将成为并行计算的通用处理器
能耗有需求

Good shout.