
FALCON: Pinpointing and Mitigating Stragglers for Large-Scale Hybrid-Parallel Training
- Paper Reading
- 2025-09-30
- 677 Views
- 0 Comments
- 1483 Words
FALCON: Pinpointing and Mitigating Stragglers for Large-Scale Hybrid-Parallel Training
Fail-slows, or stragglers, are common but largely unheeded problems in large-scale hybrid-parallel training that spans thousands of GPU servers and runs for weeks to months.
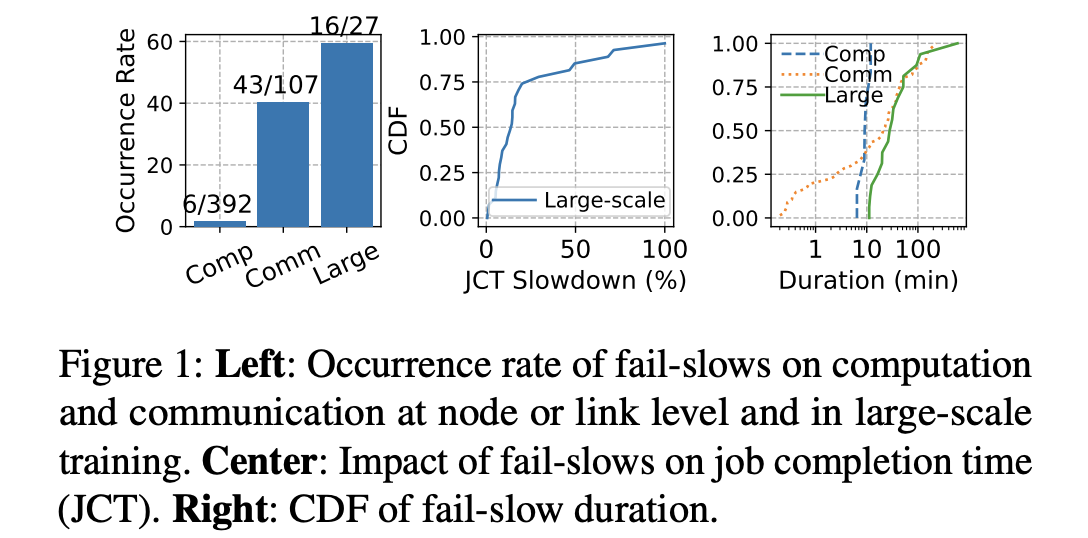
In this paper, we first present a characterization study on a shared production cluster with over 10,000 GPUs1. We find that fail-slows are caused by various CPU/GPU computation and cross-node networking issues, lasting from tens of seconds to nearly ten hours, and collectively delaying the average job completion time by 1.34×.
In this paper, we propose Falcon, a framework that rapidly identifies fail-slowed GPUs and/or communication links, and effectively tackles them with a novel multi-level mitigation mechanism, all without human intervention. We have applied Falcon to detect human-labeled fail-slows in a production cluster with over 99% accuracy. Cluster deployment further demonstrates that Falcon effectively handles manually injected fail-slows, mitigating the training slowdown by 60.1%.
Reviewed by Zhuozhao
The reasons why we have failure, and how the pattern looks like, are the key part of the article!
Main Contribution
In this paper, we propose Falcon, a system that rapidly identifies and reacts to computation and communication fail-slows without human intervention. Falcon achieves this through two subsystems, Falcon-Detect and Falcon-Mitigate.
在本文中,我们提出了 Falcon,这是一个能够快速识别和应对计算和通信缓慢失败而无需人工干预的系统。 Falcon 通过两个子系统实现这一目标:Falcon-Detect 和 Falcon-Mitigate。
Issues in Large Clusters
Reliability Issues. Given the complex nature of distributed training and the sheer scale of resources involved, large model training presents significant reliability challenges, manifested as crash stoppage (fail-stop) and still-functioning but slow stragglers (fail-slow). Both types of failures stem from software or hardware problems, and their impacts are magnified in large-scale setup: a single failure component can crash or slow down the entire training process due to the frequent synchronization required in distributed training.
Fail Stop
1) Fail-stop. Recent studies have focused on addressing fail-stop failures through effective fault tolerance mechanisms to minimize job downtime. These mechanisms either reduce the time spent on dumping and restoring model checkpoints [28, 48, 23] or perform redundant computations to minimize the need for costly checkpointing [45].
Fail Slow
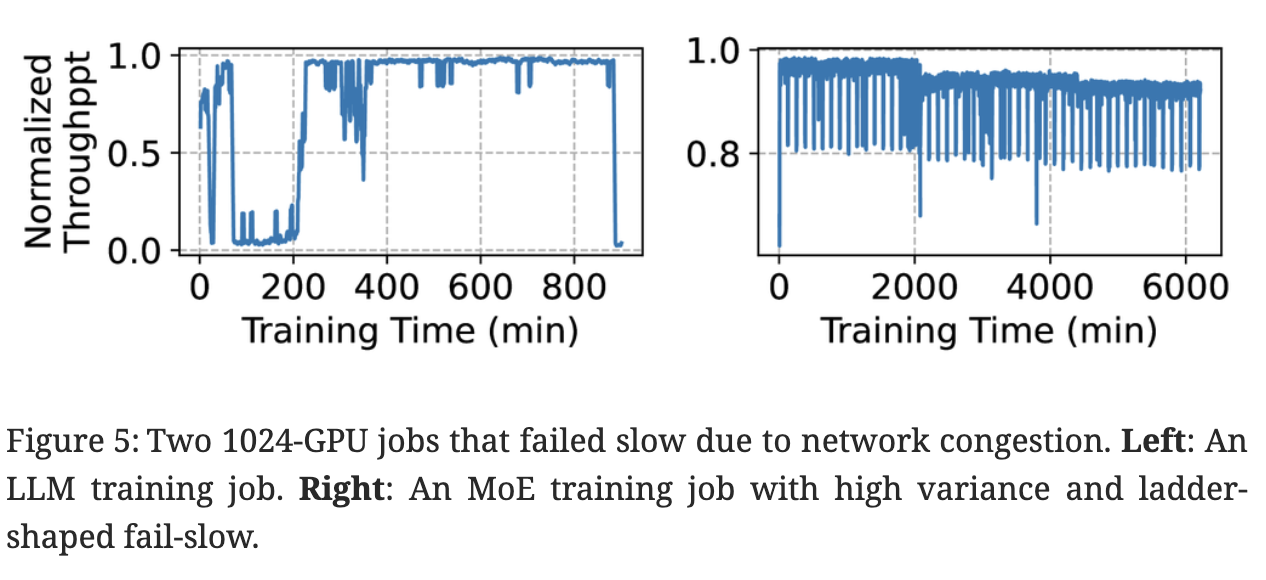
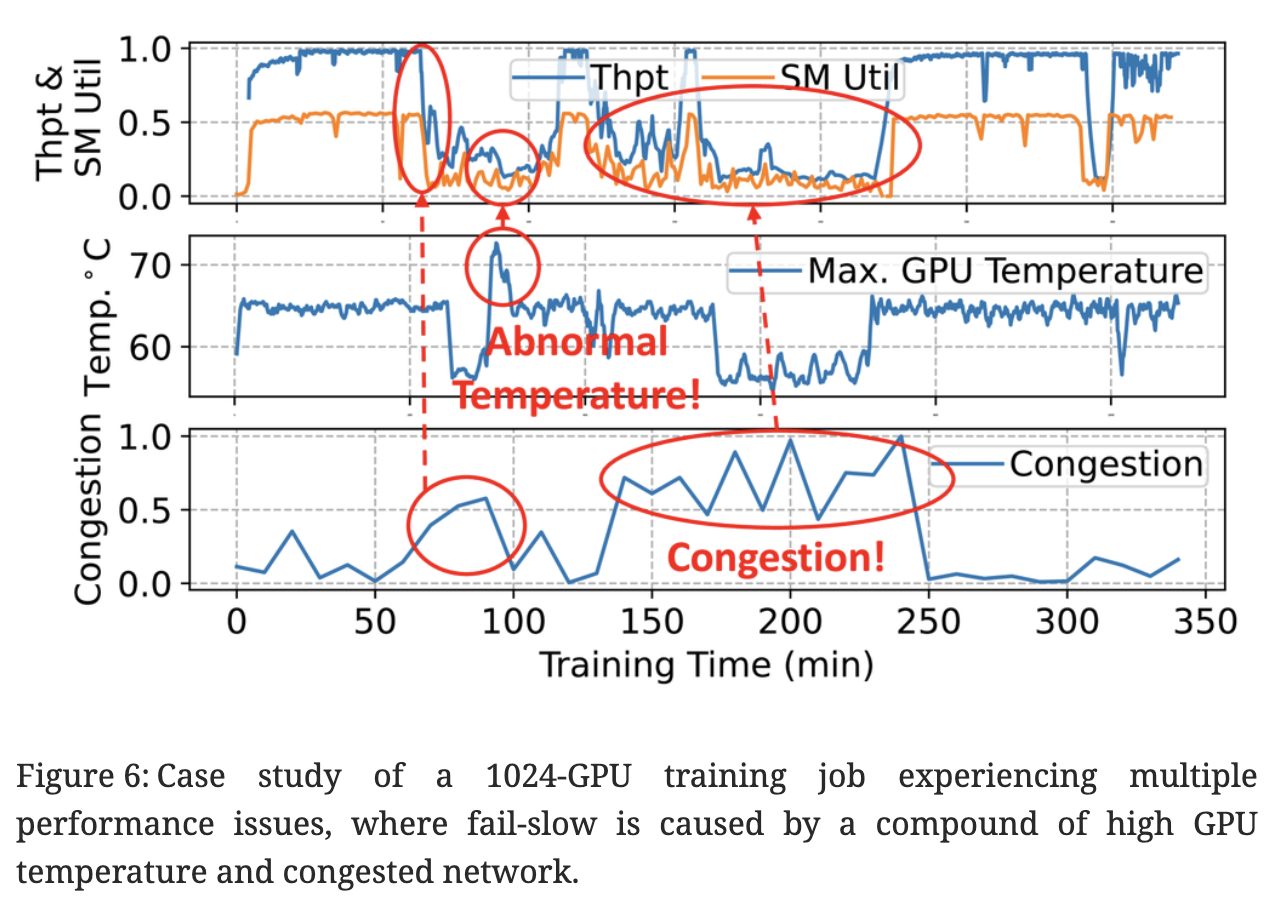
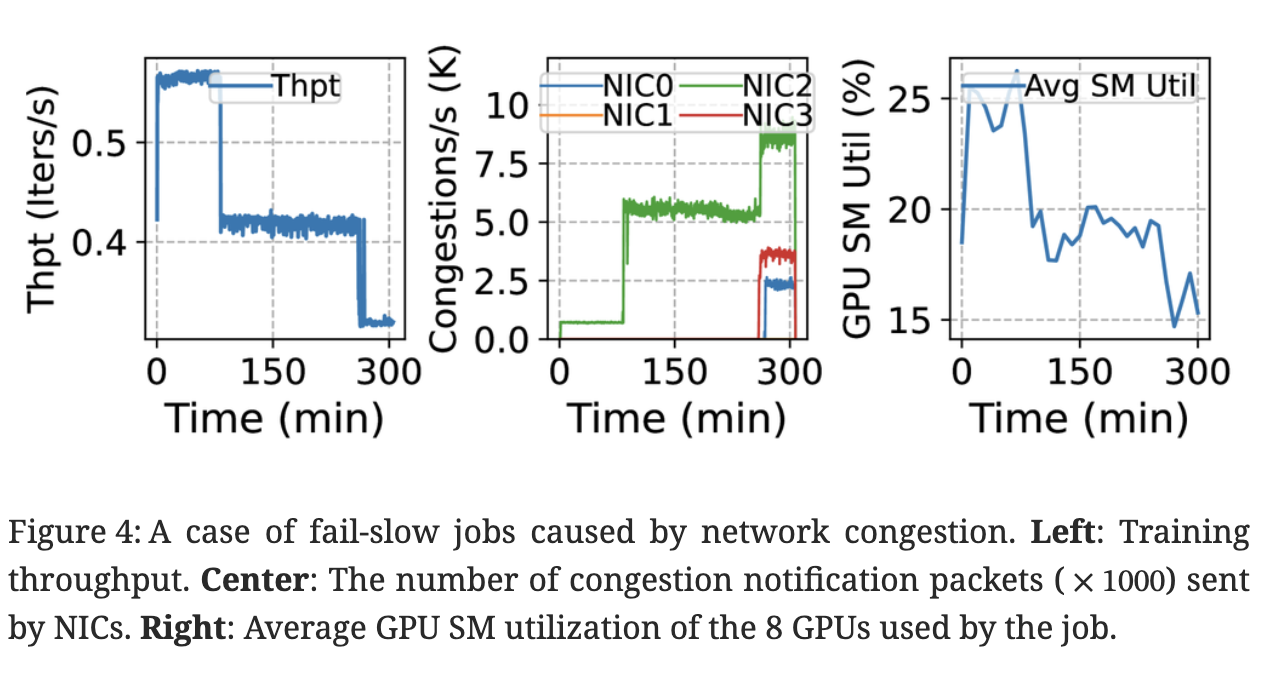
2) Fail-slow. Fail-slow, or straggler, is another a common problem in large-scale training. It can be caused by degraded hardware (such as network links or GPUs), buggy software, or contention from colocated jobs in a shared cluster. Compared to fail-stop issues, fail-slow problems are hard to detect [8], necessitating sophisticated performance analysis tools [18, 49]. Despite brief reports from recent studies [49, 8, 18], the overall characteristics of fail-slows remains largely unknown, which motivates our characterization study.
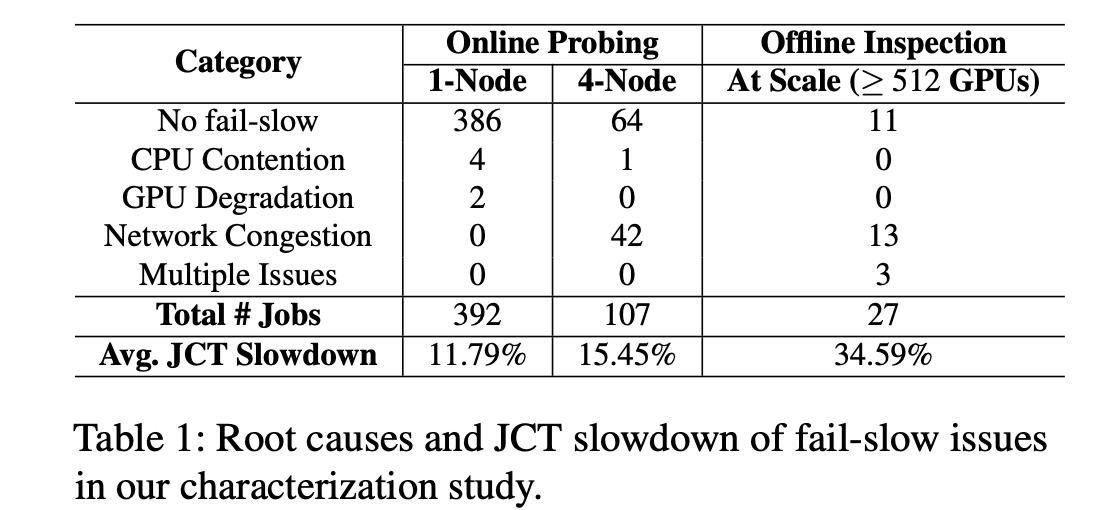
Specific Reason 具体原因
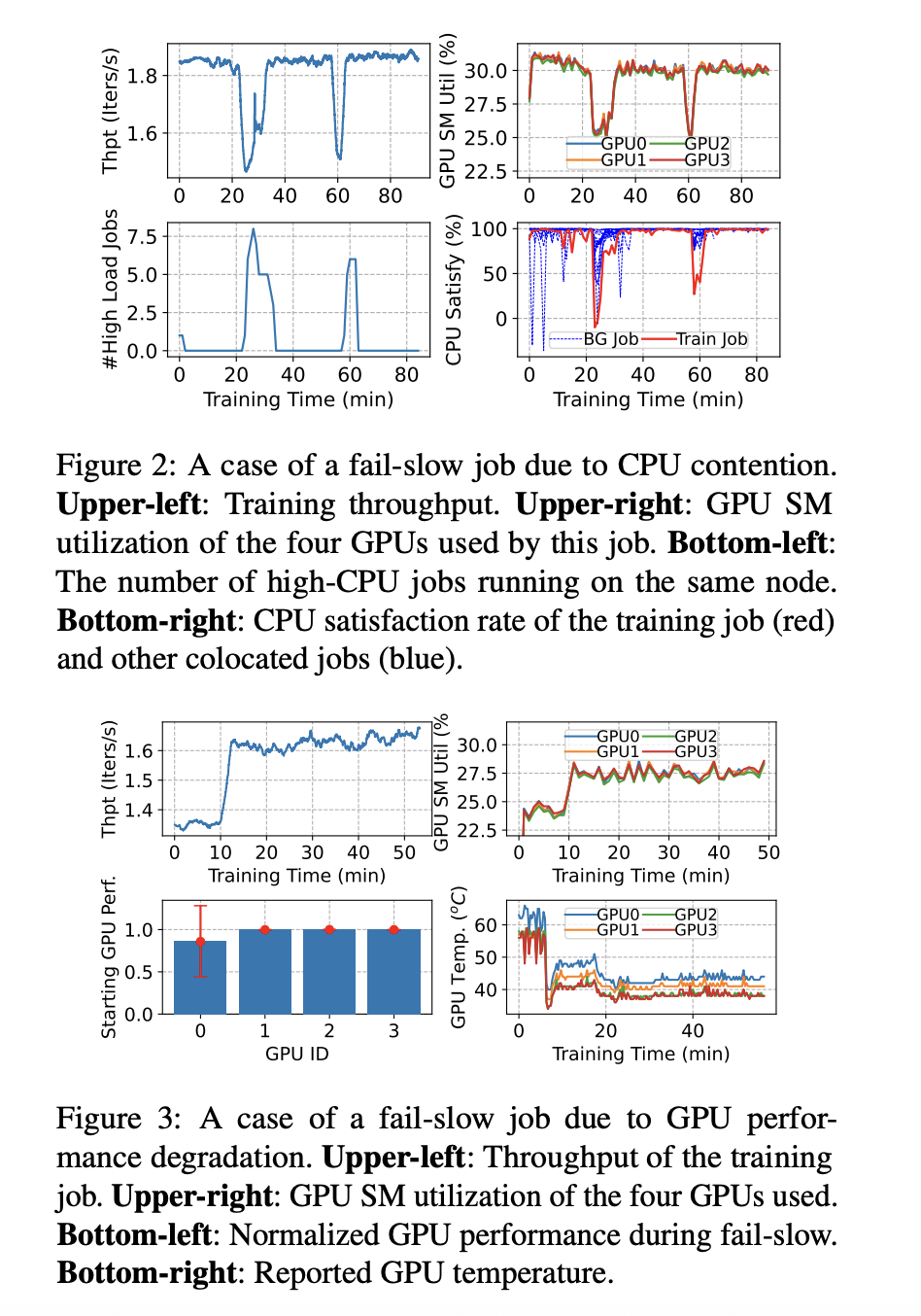
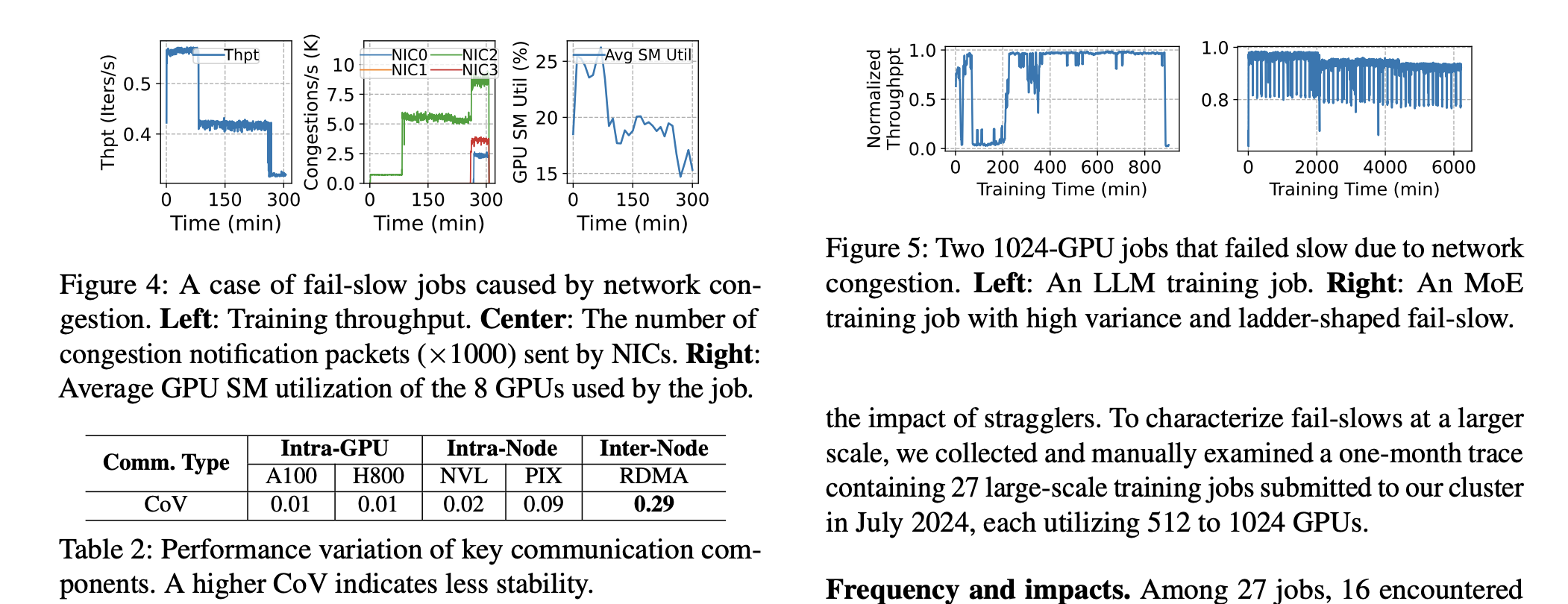
Design
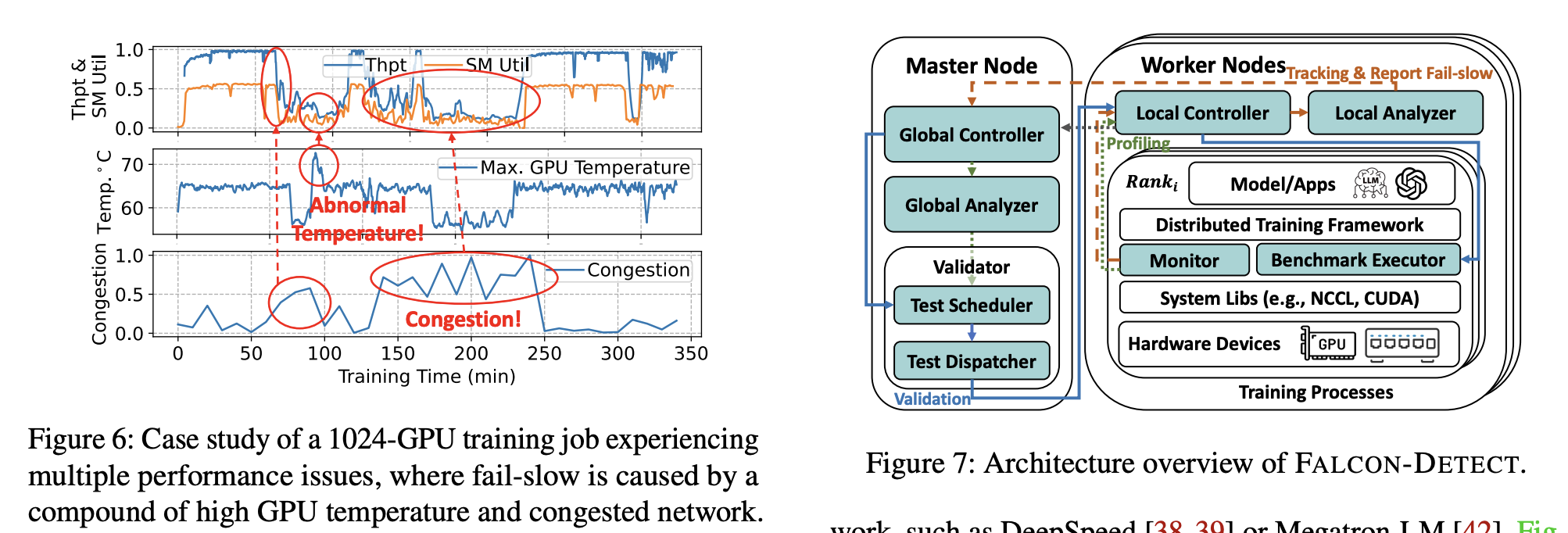
Detect
Falcon-Detect employs a non-intrusive, framework-agnostic mechanism for fail-slow detection. It keeps track of the training iteration time on each worker and identifies prolonged iterations using the Bayesian Online Change-point Detection (BOCD) algorithm [2]. It then initiates lightweight profiling on each worker to obtain a fine-grained execution profile for each parallelization group, without interrupting the ongoing training job. By analyzing these execution profiles, it narrows the search space to a few suspicious worker groups where fail-slows may reside. To pinpoint their exact locations within these groups, Falcon-Detect briefly pauses the training job and runs benchmarking tests to validate the GPU computation and link communication performance on each worker. Slow GPUs and links are then flagged as computation and communication fail-slows. Compared to full-job validation that involves benchmarking all GPUs and communication links, this design offers a lightweight solution.
Falcon-Detect 采用一种非侵入性的、与框架无关的缓慢失败检测机制。 它跟踪每个工作器上的训练迭代时间,并使用贝叶斯在线变点检测 (BOCD) 算法 [2] 识别持续时间过长的迭代。 然后,它在每个工作节点上启动轻量级分析,以获取每个并行组的细粒度执行配置文件,而不会中断正在进行的训练作业。 通过分析这些执行配置文件,它将搜索空间缩小到几个可疑的工作节点组,其中可能存在慢速失败。 为了精确确定这些组内的确切位置,Falcon-Detect 会短暂暂停训练作业,并运行基准测试以验证每个工作节点的 GPU 计算和链路通信性能。 速度慢的 GPU 和链路随后会被标记为计算和通信慢速失败。 与涉及对所有 GPU 和通信链路进行基准测试的完整作业验证相比,这种设计提供了一种轻量级的解决方案。
Mitigate
Once fail-slows are detected, Falcon reacts with Falcon-Mitigate, using an efficient mitigation mechanism. As fail-slows are usually transient (e.g., due to network congestion or CPU contention), simply handling them as fail-stops using checkpoint-and-restart is an overkill. In general, fail-slows can be tackled using four strategies: (S1) doing nothing, (S2) redistributing micro-batches across data parallel groups to alleviate the load on slow GPUs, (S3) adjusting the parallelization topology to move congested links to light-traffic groups, and (S4) treating fail-slows as fail-stops using checkpoint-and-restart. As we move from S1 to S4, the mitigation effectiveness improves, but the cost also increases. Therefore, the choice of optimal strategy depends on the duration (and severity) of the ongoing fail-slows, which cannot be known a priori. This problem resembles the classical ski-rental problem [19]. Drawing inspirations from its solution, we propose an effective ski-rental-like heuristic that starts with a low-cost strategy (S1) and progressively switches to a more effective, yet costly one if fail-slow persists and the current strategy proves ineffective. The mechanism falls back to checkpoint-and-restart as a last resort.
一旦检测到慢速失败,Falcon 就会使用Falcon-Mitigate 响应,使用一种有效的缓解机制。 由于慢速失败通常是瞬时的(例如,由于网络拥塞或 CPU 争用),简单地将它们作为失败停止处理(使用检查点和重启)是一种过度杀伤。 通常,可以使用四种策略来解决慢速失败:(S1) 不做任何事,(S2) 在数据并行组之间重新分配微批次以减轻慢速 GPU 的负载,(S3) 调整并行化拓扑以将拥塞的链路移至低流量组,以及 (S4) 使用检查点和重启将慢速失败视为失败停止。 当我们从 S1 移至 S4 时,缓解效果会提高,但成本也会增加。 因此,最佳策略的选择取决于正在进行的慢速失败的持续时间(和严重程度),而这些持续时间无法_事先_知道。 这个问题类似于经典的滑雪租赁问题 [19]。 从其解决方案中汲取灵感,我们提出了一种有效的类似滑雪租赁的启发式方法,该方法从低成本策略 (S1) 开始,如果慢速失败持续存在并且当前策略被证明无效,则逐渐切换到更有效但成本更高的策略。 该机制退回到检查点和重启作为最后的手段。
S1-S4 to solve network problems
