
Fail at Scale: Reliability in the face of rapid change
- Paper Reading
- 2025-06-11
- 625 Views
- 1 Comments
- 1071 Words
本keynote来自 Fail at Scale: Reliability in the face of rapid change
Fail at Scale: Reliability in the face of rapid change: Queue: Vol 13, No 8
One of Facebook's cultural values is embracing failure. This can be seen in the posters hung around the walls of our Menlo Park headquarters: "What Would You Do If You Weren't Afraid?" and "Fortune Favors the Bold."
- 大部分故障都来自 Human error, 包括手工误操作,频繁上线,需要做好 canary 灰度发布,通知相关上下游密切关注 metrics
- 微服务增加了故障排查的难度,尤其是云上环境,需要构建可观测 Observability, 方便 debug, 这是一个系统工程
- DERP 方法论:Detection 如何检测故障, Escalation 故障如何上报,是否找到了正确的人, Remediation 修复故障的步骤能否自动化, Prevention 如何避免此类故障
Why Do Failures Happen?
Individual machine failures
Legitimate workload changes
When Barack Obama won the 2008 U.S. Presidential election, his Facebook page experienced record levels of activity.
Human error
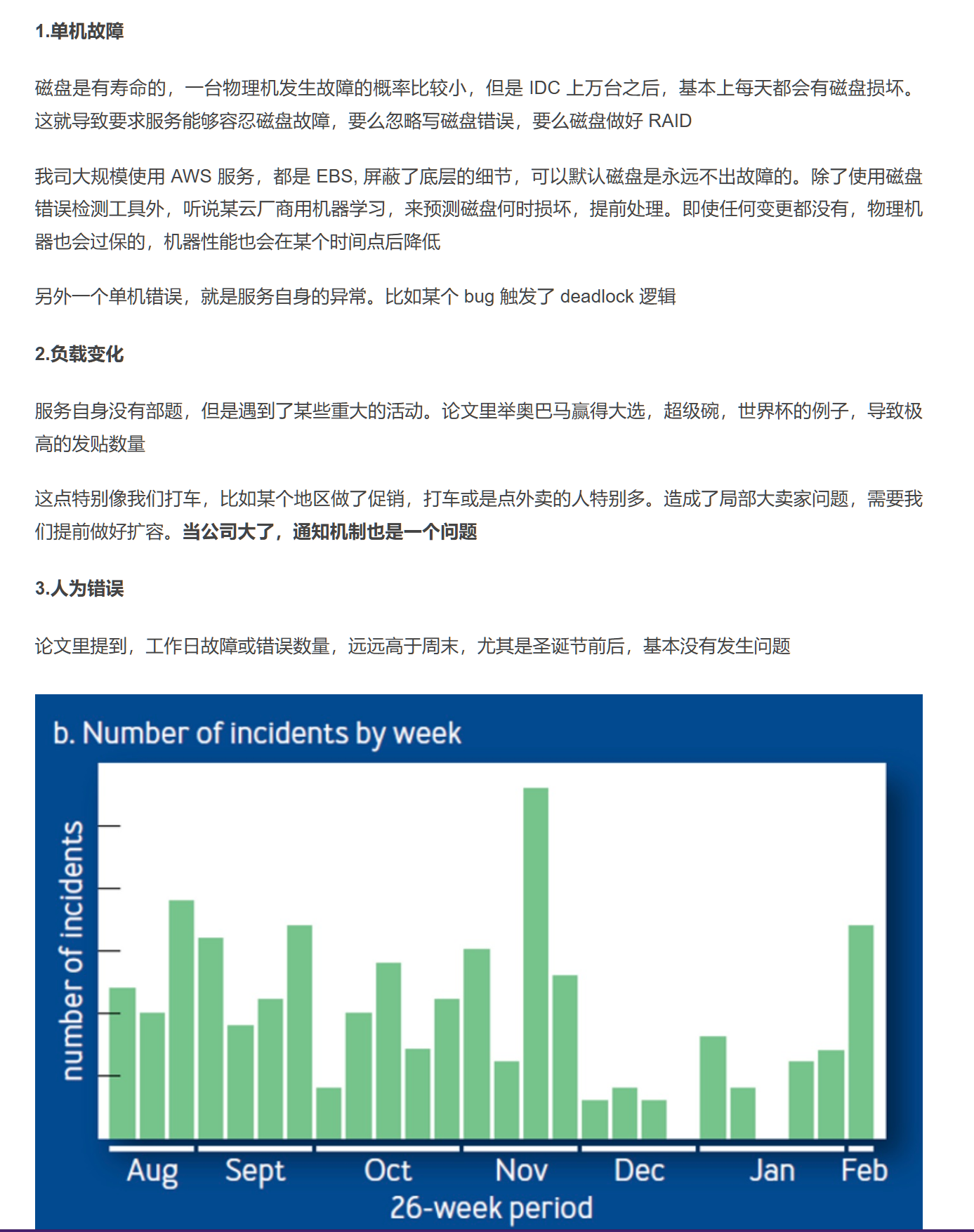
虽然故障原因千奇变怪,但是本质分为三大类,或多或少都是因为这些放大了失败,引起级联故障
1.配置变更
2.对核心服务的强依赖
3.延迟增加资源耗尽
让每个人都使用通用的配置系统。
使用通用配置系统可确保过程和工具适用于所有类型的配置。在 Facebook,我们发现团队有时会倾向于以一次性的方式处理配置。
静态验证配置更改。 许多配置系统允许松散类型的配置,例如 JSON 结构。这些类型的配置使工程师很容易键入字段名称错误、在需要整数的地方使用字符串或犯其他简单错误。最好使用静态验证来捕获这些类型的简单错误。
运行 Canary。 首先,将配置部署到服务的较小范围可以防止更改成为灾难性的。金丝雀可以采用多种形式。最明显的是 A/B 测试,例如仅向 1% 的用户启动新配置。可以同时运行多个 A/B 测试,并且您可以使用一段时间内的数据来跟踪量度。
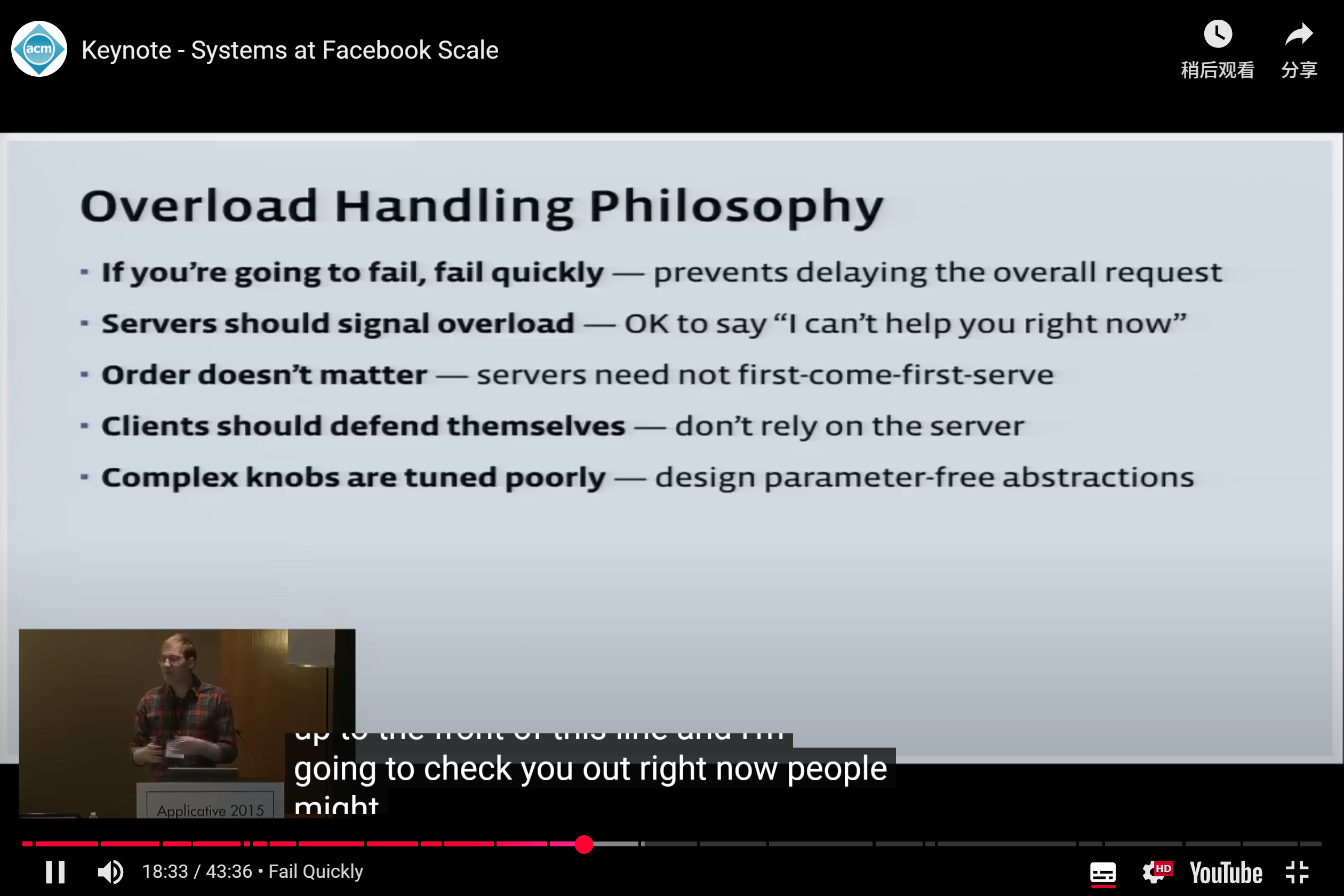
For Request
And, LIFO may be better for cache (? Really?)
大多数服务以 FIFO 的顺序处理队列。然而,在大量排队期间,先入的请求往往已经等了很久,用户可能已经放弃了请求相关的行为。这时候处理先入队的请求,会将资源耗费在一个不太可能使用户受益的请求上。
FB 的服务使用自适应后进先出的算法来处理请求。在正常的操作条件下,请求是 FIFO 处理模式,但是当队列开始任务堆积时,则切换至 LIFO 模式。如图 2 所示,自适应 LIFO 和 CoDel 可以很好地配合。CoDel 设置了较短的超时时间,防止了形成长队列,而自适应 LIFO 模式将新的请求放在队列的前面,最大限度地提高了它们满足 CoDel 设置的最后期限的机会。HHVM 实现了这个后进先出算法。
当业务请理慢,请求堆积时,超时的请求,用户可能己经重试了,还不如处理后入队的请求

Queuing


Methods
Facebook has developed a methodology called DERP (for detection, escalation, remediation, and prevention) to aid in productive incident reviews.
• Detection. How was the issue detected—alarms, dashboards, user reports?
• Escalation. Did the right people get involved quickly? Could these people have been brought in via alarms rather than manually
• Remediation. What steps were taken to fix the issue? Can these steps be automated?
• Prevention. What improvements could remove the risk of this type of failure happening again? How could you have failed gracefully, or failed faster to reduce the impact of this failure?
DERP helps analyze every step of the incident at hand. With the aid of this analysis, even if you cannot prevent this type of incident from happening again, you will at least be able to recover faster the next time.

A "move-fast" mentality does not have to be at odds with reliability. To make these philosophies compatible,
Facebook's infrastructure provides safety valves: our configuration system protects against rapid deployment of bad configurations; our core services provide clients with hardened APIs to protect against failure; and our core libraries prevent resource exhaustion in the face of latency.
所有的研究要复盘。并且要总结错误。其实就跟第一次配博客一样,每一次的工程失败其实都是经验。他们并非代表说我们是笨蛋,而是会让我们更加成熟。
这篇文章还是太有含金量了,重读一遍有了新收获