Eurosys24 Orion – GPU Kernel Scheduling for ML Inference
- Paper Reading
- 2025-10-10
- 874 Views
- 0 Comments
- 2489 Words
Paper
Orion: Interference-aware, Fine-grained GPU Sharing for ML Applications
Github
eth-easl/orion: An interference-aware scheduler for fine-grained GPU sharing
Abstract
GPUs are critical for maximizing the throughput-per-Watt of deep neural network (DNN) applications. However, DNN applications often underutilize GPUs, even when using large batch sizes and eliminating input data processing or commu nication stalls. DNN workloads consist of data-dependent operators, with different compute and memoryrequirements. While an operator may saturate GPU compute units or mem, it often leaves other GPU resources idle. Despite the prevalence of GPU sharing techniques, current approaches are not sufficiently fine-grained or interference aware to maximize GPU utilization while minimizing inter ference at the granularity of 10s of 𝜇s.
We propose Orion, a system that transparently intercepts GPU kernel launches from multiple clients sharing a GPU. Orion schedules work on the GPU at the granularity of individual operators and minimizes interference by taking into account each operator’s compute and memory requirements. We integrate Orion in PyTorch and demonstrate its benefits in various DNN workload collocation use cases. Orion significantly improves tail latency compared to state-of-the-art baselines for a high priority inference job while collocating best-effort inference jobs to increase per-GPU request throughput by up to 7.3×, or while collocating DNN training, saving up to 1.49× in training costs compared to dedicated GPU allocation.
GPU 对于最大化深度神经网络(DNN)应用的 吞吐量每瓦(throughput-per-Watt) 至关重要。
然而,即使采用了大批量(large batch size)并消除了输入数据处理或通信的瓶颈,DNN 应用仍然常常没有充分利用 GPU。DNN 工作负载由数据依赖的算子(operators) 构成,这些算子对计算和内存的需求各不相同。某个算子可能会使 GPU 的计算单元或内存带宽饱和,但往往会让其他 GPU 资源闲置。
虽然已有很多 GPU 共享技术,但当前的方法还不够细粒度,也没有足够关注干扰问题,无法在 几十微秒(10s of μs)级别上最大化 GPU 利用率并最小化干扰。
我们提出了 Orion 系统,它能够透明地截获多个客户端共享 GPU 时的 kernel 启动请求。Orion 在 算子级别(operator-level) 调度 GPU 工作,并根据每个算子的计算和内存需求来最小化干扰。我们将 Orion 集成到 PyTorch 中,并在各种 DNN 工作负载共置(collocation)场景中验证了它的优势。
实验表明,Orion 相比现有最先进的基线方法:在有高优先级推理任务的情况下,显著改善了 尾延迟(tail latency);在同时运行低优先级推理任务时,使得单 GPU 的请求吞吐量提升高达 7.3 倍;在共置 DNN 训练任务时,相比独占 GPU,训练成本节省最多 1.49 倍。
So:
数量级 order of magnitude: 10us
- 算子级别调度:把 GPU 调度粒度细化到 operator 级,而不是整条任务。
- 干扰感知:在调度时考虑算子的 compute/memory profile,避免两个同样吃带宽的算子同时跑导致互相拖慢。
- 透明拦截:不需要用户改代码,直接拦截 PyTorch 的 kernel launch。
那么这里就有一个问题了,你的微秒级别的调度,调度的时间可能会占很大,你怎么调度?算子级别的调度很可能会出问题?
如果我们关注推理,推理的调度就是很快很快的,比训练快很多!
Intro
DNN workload still underutilized GPU
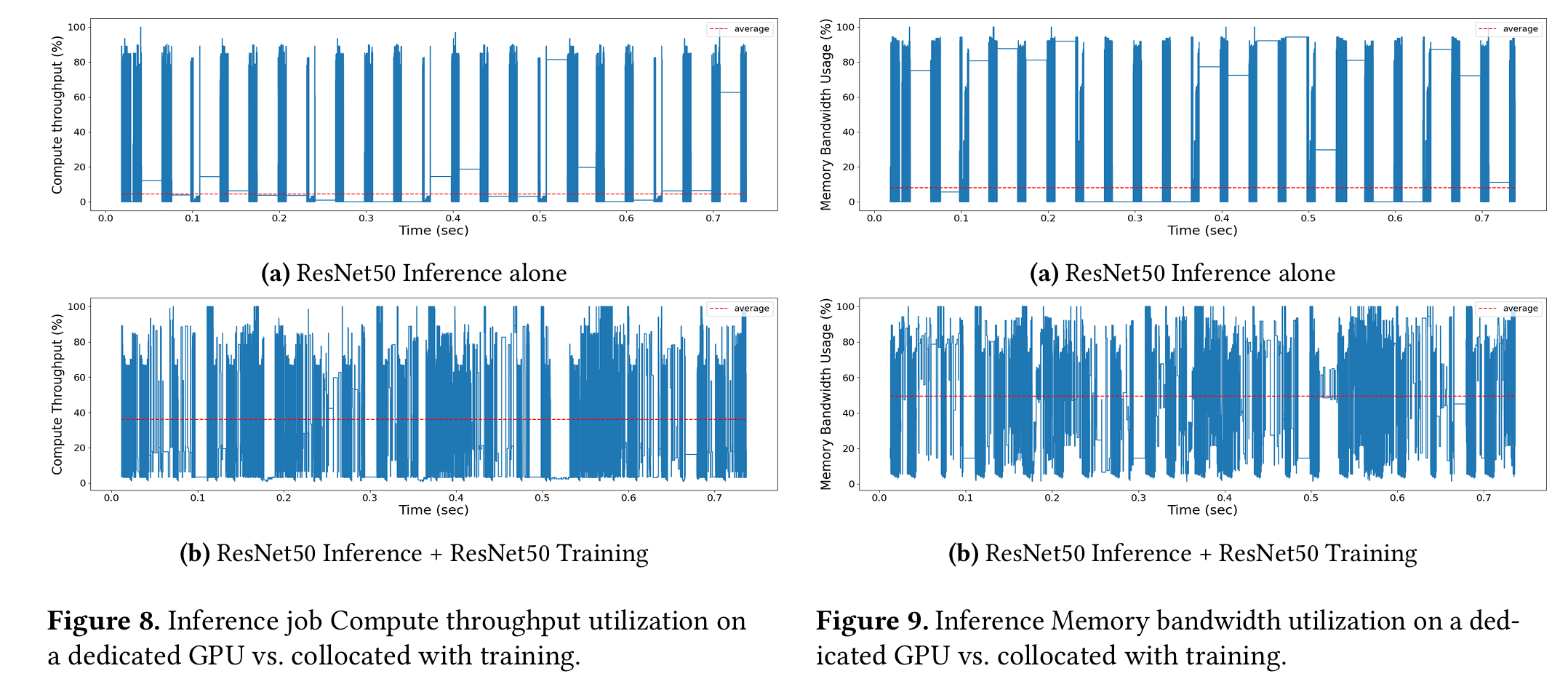
DNN workload consists of many data dependent operators that run for short periods of time (10s 1000s of 𝜇s), each with different compute and memory re quirements. Utilization is bursty and low on average (see red dotted lines) as individual operators saturate compute units or memory bandwidth, but often leave a resource type idle.
Here the figure shows the training process of MobileNet.
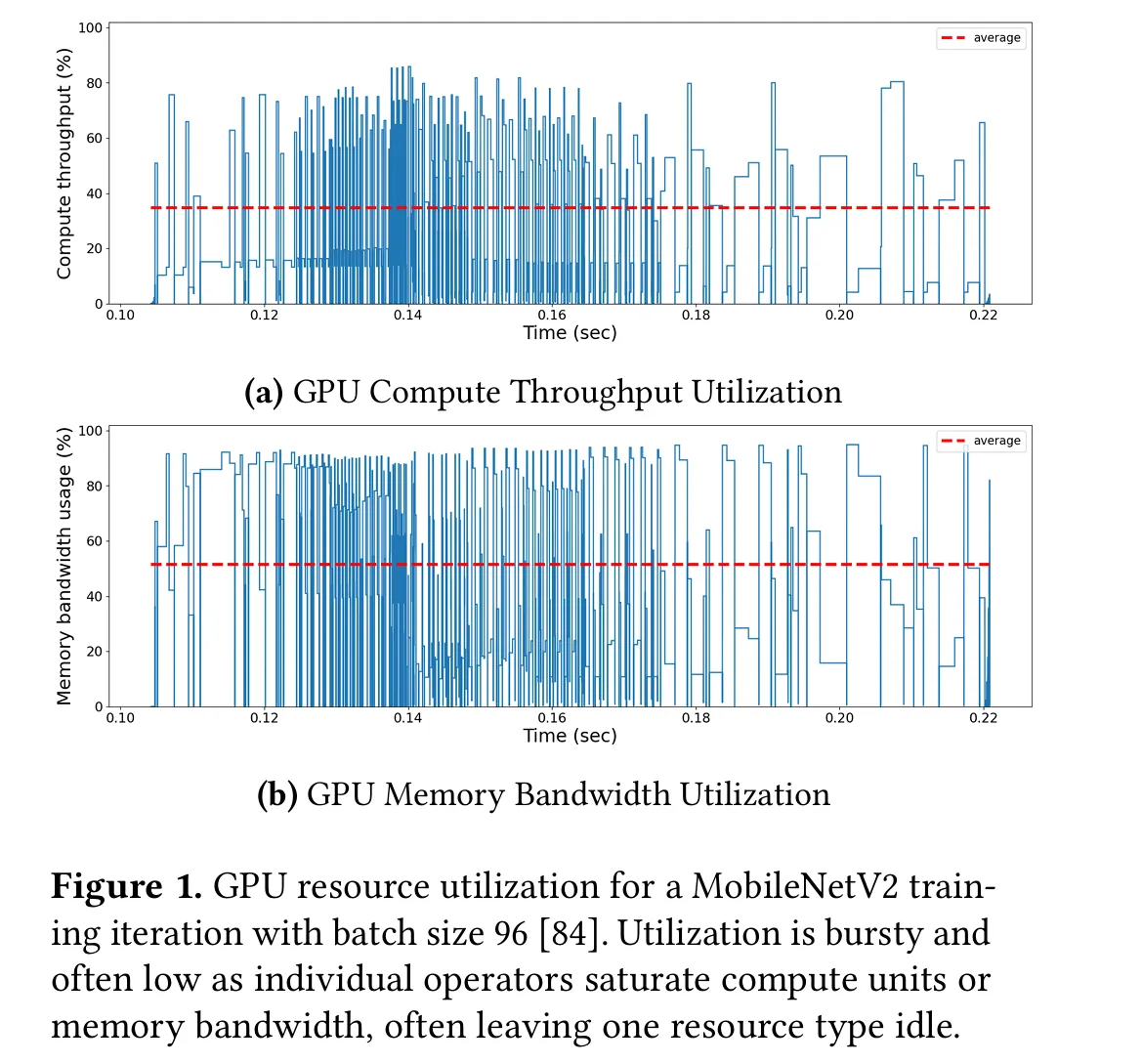
The problem of GPU underutilization is only getting worse as hardware vendors continue to scale GPU memory and compute capacity.
however, current techniques are either too coarse-grained (e.g., Multi-Instance GPUs [12], Zico [67], Tick-Tock [94]) or are not sufficiently interference-aware (e.g., Multi-Process Service (MPS) [25], GPU Streams [15], REEF [50], Paella [75]).
For MPS and MIG difference:
ICPP25 Conference story: Day 1-学术活动-Haibin's blog
Nowadays advanced techniques on sharing:
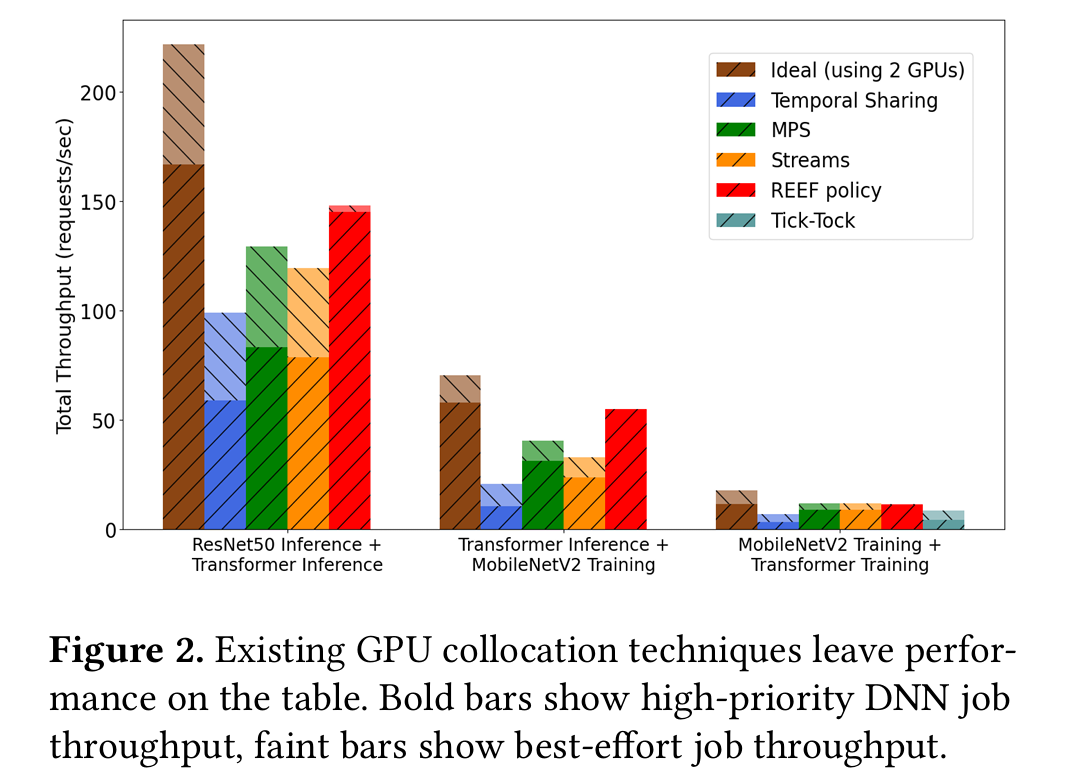
To help close this gap, we propose Orion1, a fine-grained, interference-aware GPU scheduler. Orion maintains perfor mance for a high-priority workload while collocating best effort jobs to maximize GPU utilization and save costs.
To understand why low performance
We need to know GPU Arch
GPU hardware scheduling. As shown in Figure 3, the GPU buffers each CUDA stream’s kernels in a separate work queue onthedevice. Most GPUs,inparticular NVIDIA GPUs, do not allow users to preempt kernels after submission [50]. The GPU hardware scheduler dispatches thread blocks from kernels in each work queue based on stream priority. The scheduler assigns a thread block to an SM when the thread block’s data dependencies are met and an SM with sufficient resources is available. Users cannot control which SM will execute a particular thread block, though researchers have reverse-engineered hardware scheduling policies for popular GPU architectures [30, 45, 46].
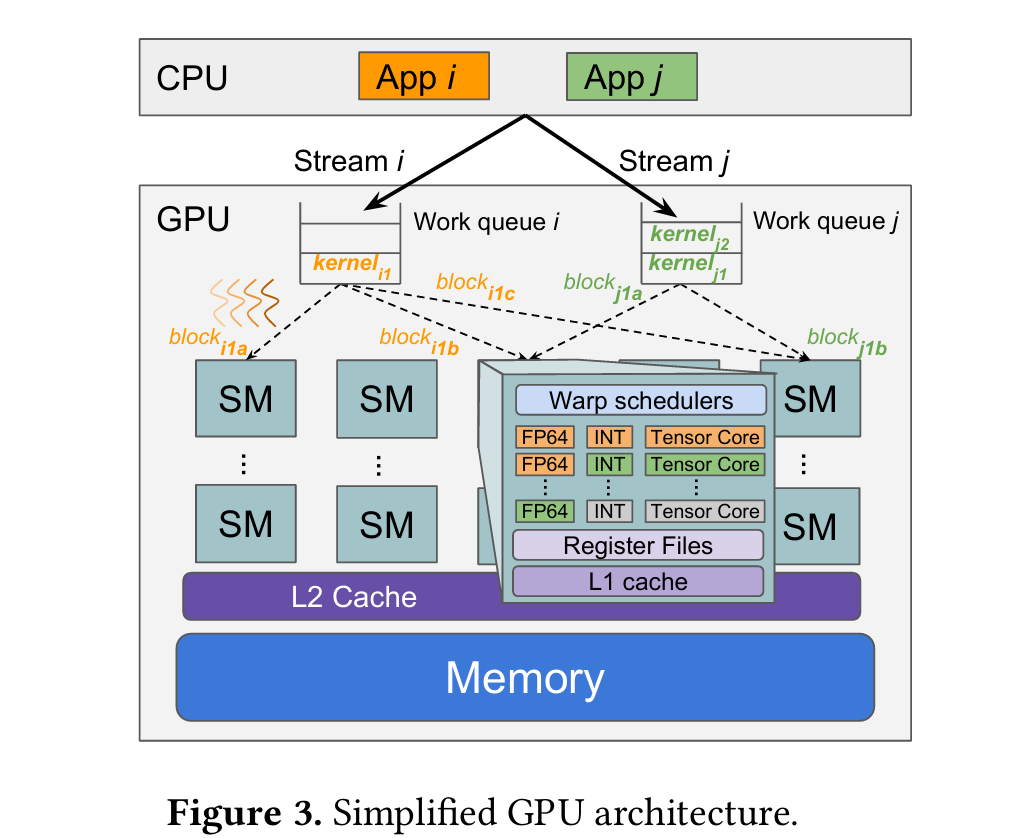
GPU utilization metrics. The most common GPU uti lization metric is SM utilization, which is the percentage of SMs that are busy (i.e., executing at least one warp). SM utilization does not fully capture GPU utilization as an SM is considered busy even if only a small part of its resources are in use. Using the NVIDIA Nsight Compute tool
DNN workload
However, even after eliminating input data, communication, and gang-scheduling bottlenecks, DNN jobs still struggle to keep GPUs fully utilized, especially when modest batch sizes are used. Real-time inference jobs, such as computer vision tasks in self-driving cars [42, 77], speech recognition services [42] and online recommendation systems [16] usually employ small batch sizes, in order to avoid SLO viola tions [41, 49, 50, 75].
真实的LLM服务哪里有这么小的???
Throughput-oriented training jobs use large batch sizes, but maximizing batch sizes to reach GPU memory limits is not always beneficial [71, 78, 95]. Increasing the batch size beyond a certain point can degrade the statistical efficiency of training [56, 57, 61, 70, 82, 88], and have diminishing re turns in the training procedure, increasing the time needed to reach a target accuracy [78], and decreasing the model’s validation performance [82]. Shallue et al. [88] studied the effects of increasing the batch size in a variety of models and tasks. They observed that, beyond a certain point, fur ther increase in the batch size does not lead to reductions in training time. Researchers have proposed adapting the learn ing rate as the batch sizes increase [47].
DeepPool [78] demonstrates convergence issues in distributed setups with large global batch sizes, when per-GPUbatchsizeremainsconstantwhile increasing the number of GPUs. Hence, they recommend strong scaling: when scaling out training to more GPUs for large models, the optimal per-GPU batch size decreases. Sim ilarly, Crossbow [57] exhibits the best time-to-accuracy with smaller batch sizes. These trends leave memory capacity and GPUresources underutilized.
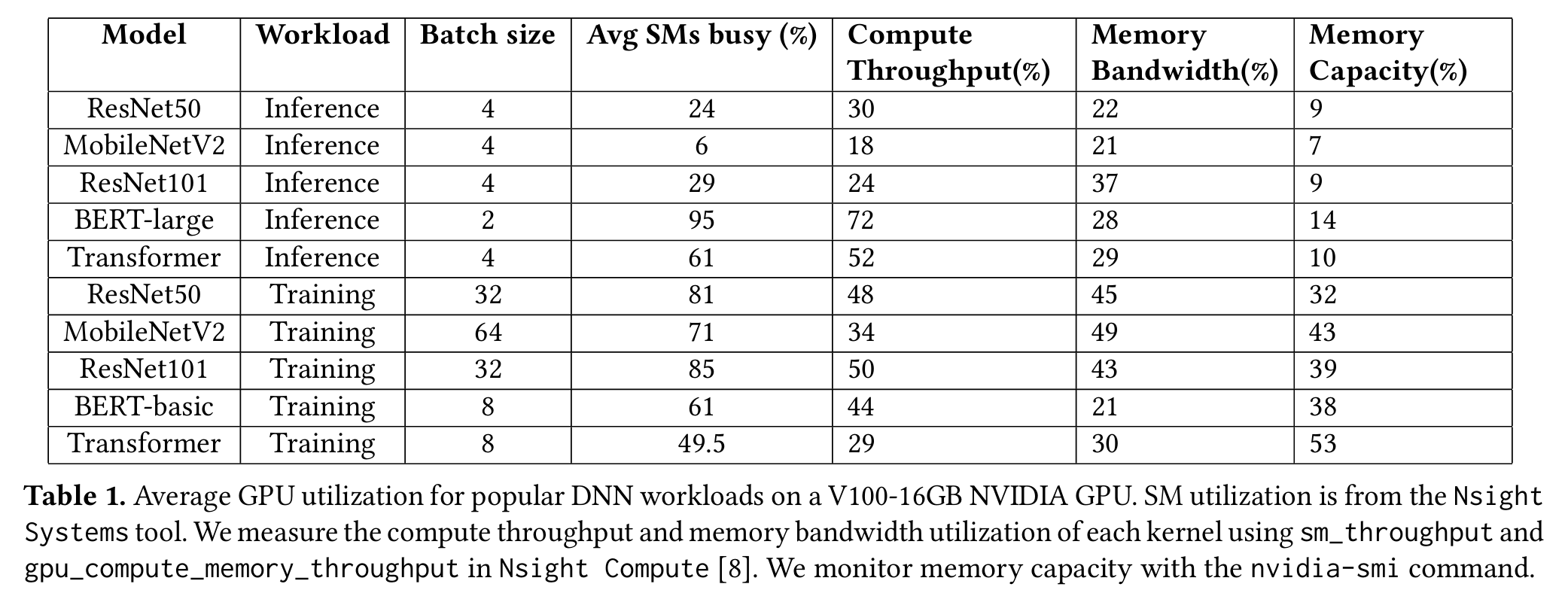
We profile a variety of popular DNN workloads execut ing on an NVIDIA V100-16GB GPU without stalls.
Figure 4 classifies each workload’s kernels as compute-intensive (performance is bounded by GPU compute throughput) or memory-intensive (performance is bounded by GPUmemory bandwidth).4 Kernels typically execute for 10s to 100s of 𝜇s (for inference) or 100s to 1000s of 𝜇s (for training). As kernels from an individual DNN job execute sequentially due to data dependencies, when a kernel satu rates GPU compute or memory bandwidth, it often leaves other GPU resources idle for short periods of time.
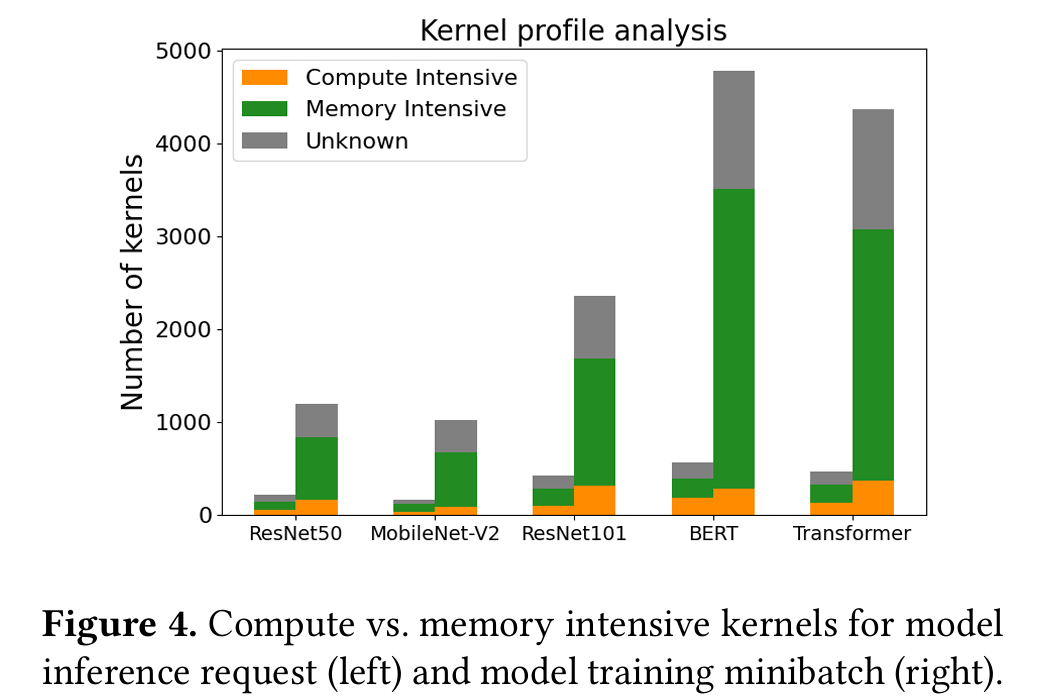
Idea: merge multiple jobs into a big job
A promising way to improve GPU utilization is to collocate kernels with opposite resource intensity. While overlapping kernel execution within a DNN job is limited due to data dependencies, we can collocate kernels from different jobs.
Takeaway: Individual DNN jobs consist of kernels with various compute and memory requirements, as shown in Figure 4. Since kernels need to execute sequentially, due to data dependencies, they often underutilize GPU’s compute and memory bandwidth. Sharing GPUs between DNN jobs is necessary to maximize utilization. Our toy experiment, described in Table 2, has shown that spatial collocation is most effective for kernels with opposite compute vs. mem ory intensity. Since DNN jobs consist of both compute- and memory-intensive kernels (Figure 4), colocating opposite profile kernels from different DNN jobs would help increase utilization, while minimizing interference.
Design
Orion intercepts GPU operations submitted by each client and buffers the operations in per-client software queues. Operations include GPU kernels (e.g., convolution, batch normalization) and memory management operations (e.g., memory allocations, memory copies). Orion submits operations from per-client software queues to the GPU hardware using the scheduling policy described in §5.1, leveraging kernel characteristics collected during an offline workload profiling phase, described in §5.2. Orion operates on the level of a single GPU device. In distributed DNN job deployments, a separate instance of Orion runs per GPU device.
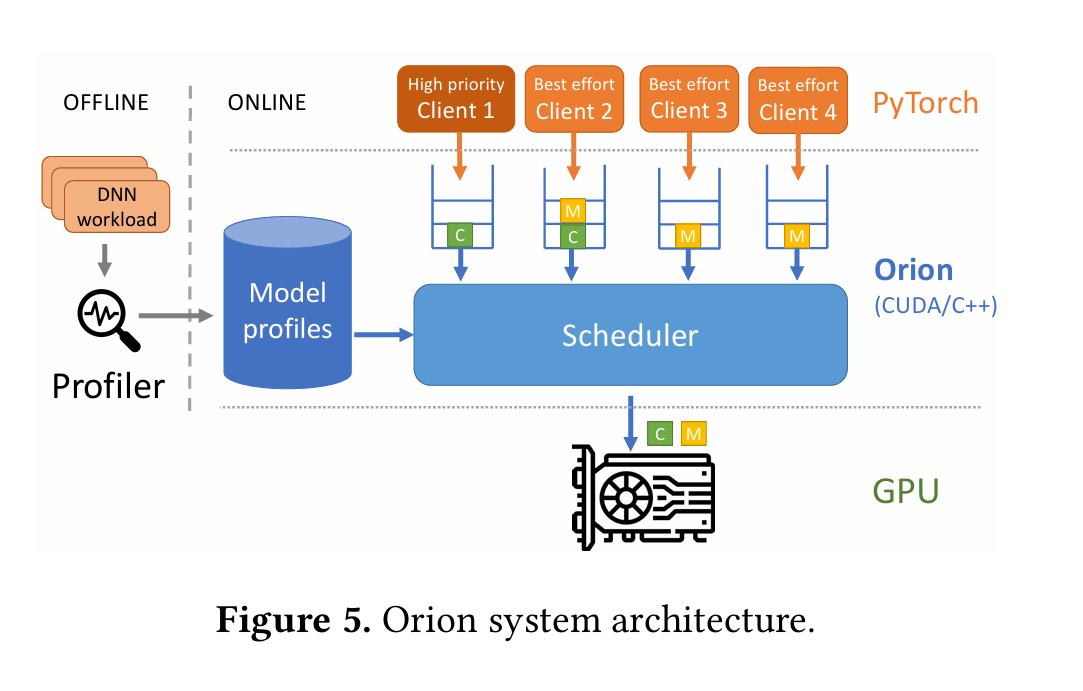
Scheduler
- 场景:GPU 上同时跑 高优先级任务 (client_hp) 和 低优先级 / 尽力而为任务 (client_be)。
- 目标:保证高优先级任务的延迟(比如推理的 tail latency 或训练的迭代时间),同时尽可能让低优先级任务利用 GPU 闲置资源,提高整体利用率。
- 难点:GPU 没有用户可见的 kernel 级抢占机制,一旦 kernel 启动就不能中断 → 所以必须在 提交前做出明智的选择。
-
调度循环 (run_scheduler)
- 不断轮询各个客户端的软件队列:
- 如果有高优先级任务 → 直接提交到 专用 stream(保证顺序执行,保持数据依赖)。
- 如果有低优先级任务 → 调用
schedule_be()判断是否合适提交。
-
高优先级任务处理
- 高优先级 client (比如推理请求) 的 kernel 直接提交。
- 因为它使用独立的 stream,保证串行顺序,不会被其他任务干扰。
- 低优先级任务处理 (schedule_be)
Orion 需要判断:现在能不能在不干扰高优先级任务的情况下提交这个 kernel?
判断条件主要有三个:
-
是否有高优先级任务在执行
- 如果有 → 默认不要提交大 kernel。
-
资源需求匹配 (Compute vs. Memory)
- 如果 best-effort kernel 很小(占用 SM 少),可以和高优先级 kernel 共存。
- 如果 best-effort kernel 的 profile 与高优先级 kernel 互补(比如一个算力密集,一个带宽密集),也允许共置,降低干扰。
- 引入
SM_THRESHOLD:- 避免低优先级 kernel 占用所有 SM → 否则高优先级 kernel 会被饿死。
- 默认设为 GPU 上 SM 总数,但可以动态调节(比如如果高优先级任务是训练,可以调高容忍度)。
-
持续时间限制 (DUR_THRESHOLD)
- Orion 维护一个 outstanding kernel 列表,跟踪正在运行的低优先级 kernel 的预计持续时间(来自 profiling)。
- 如果 outstanding kernel 的总持续时间快接近高优先级任务的延迟预算(推理:请求延迟,训练:迭代时长),则暂停提交新的低优先级 kernel。
- 默认
DUR_THRESHOLD = 2.5%的高优先级延迟预算。
-
多客户端支持
- 如果有多个 best-effort client,Orion 采用 Round-robin 轮转调度。
-
每个 client 使用独立的 GPU stream 来避免相互依赖。
⚙️ Orion 调度的关键思想
- 高优先级任务 → 始终优先执行,绝不排队。
- 低优先级任务 → 只在“合适的条件”下插入,条件包括:
- 空闲 / 互补资源;
- 占用 SM 不超过阈值;
- 总持续时间不突破 QoS 限制。
- 没有 kernel 级 preemption → 只能依赖“提交前的判断” + “profiling 信息”。
Exp: V100 x1
Experiment testbed. We evaluate Orion on an NVIDIA V100-16GB GPU using a Google Cloud n1-standard-8 VM, which has 8 vCPU cores and 30 GB of DRAM. We use Py Torch 1.12 with Python 3.9 and CUDA 10.2. We also show that Orion generalizes to other GPU architectures by evaluat ing Orion on an A100-40GB GPU using an a2-highgpu-1g VM, with CUDA 11.3. For all experiments, we ensure jobs execute with no data preprocessing or communication bot tlenecks. Hence, we evaluate Orion’s ability to improve GPU utilization while minimizing interference in the most chal lenging setting, where each individual job maximizes its own GPUutilization. We repeat each experiment three times.
Merge Streams into Batches