
Eurosys 25 Skyserve
- Paper Reading
- 2025-07-30
- 295 Views
- 0 Comments
- 365 Words
来自大名鼎鼎的UCB Sky Computing Lab
他们尝试在云里运行LLM Serve
然后他们考虑的场景是 Spot inference。这个场景类似于云的instance很吃紧,然后会经常的扩增和缩小。在这种动态场景下做一个能fault tolerance, load balance的一个推理引擎调度系统。
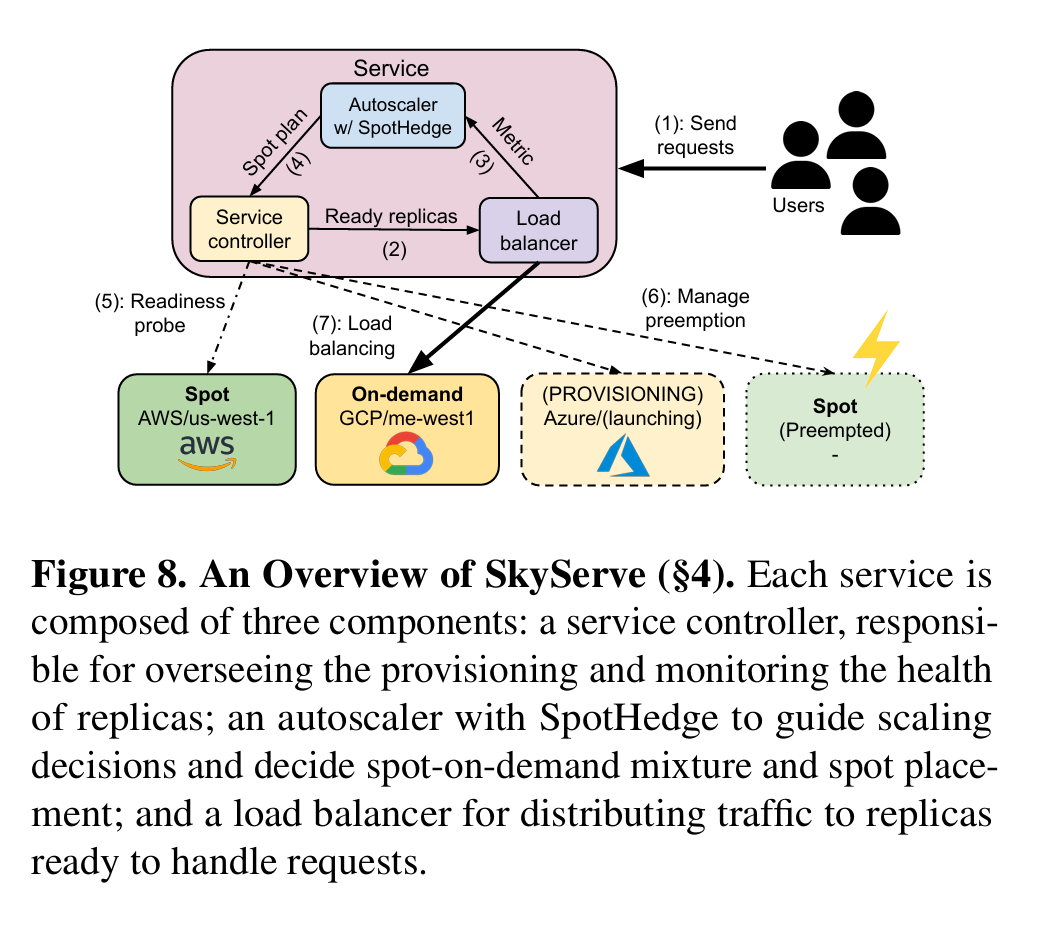
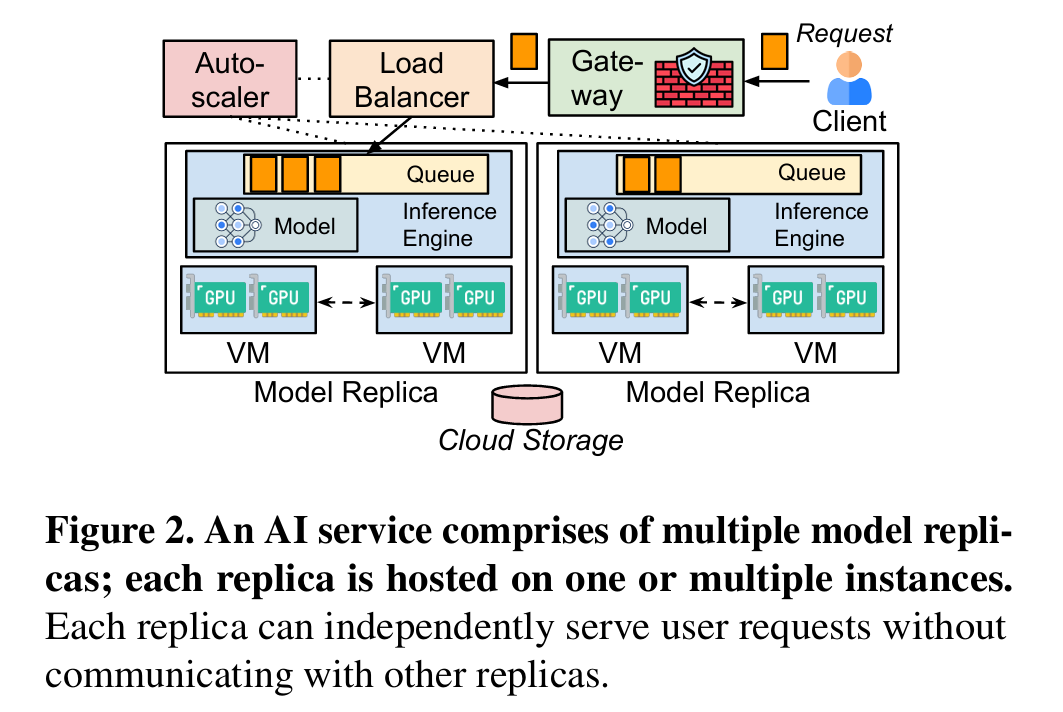
AI也是微服务
Sky serve 首先把LLM服务当成微服务看待。在这种情况下
In summary, this paper makes four main contributions:
• The design of SpotHedge, a simple yet effective policy that manages a mixture of spot and on-demand replicas across regions and clouds. SpotHedge achieves high availability while improving both cost and service quality.
• The implementation of SkyServe as a distributed, multi cloud serving system with mechanisms to scale across spot and on-demand replicas to efficiently serve AI models.
• Anextensive evaluation of SpotHedge, comparing it to both research and production systems as well as state-of-the-art policies on spot GPU instances.
• An open-source serving system SkyServe1 to facilitate further research and policy design for serving on spot in stances
Existing Systems. Existing systems [4, 26, 44, 53, 77] made promising progress toward reducing cost with spot instances. First, SpotServe [53] is a system that adjusts (data, tensor, pipeline) parallelism upon preemption within a replica. However, SpotServe does not consider or implement instance provisioning, placement, or scheduling [28]. Second, prior work has investigated training on spot instances [36, 45, 63, 67, 69, 74]. However, training aims to finish jobs within dead lines and can be paused and resumed from checkpoints upon spot instance preemption. Hence, training presents signifi cantly different goals from serving. Third, while serverless systems share a similar goal of reducing cost, serverless sys tems typically execute short-lived tasks and are not suited for long-running model serving; AWS Lambda does not yet support GPUs. Next, we show why these systems are still limited in serving AI models on spot instances
所以,这是一个新场景文章
