
Distributed System 3: Vector Clock
- Distributed Systems
- 2025-10-11
- 316 Views
- 0 Comments
- 1636 Words
Review:
Time is important in Distributed, for determine sequence.
But we can't find a sync time for everyone.
Vector Clock
Lamport didn't solve:

Solution:
use a vector clock

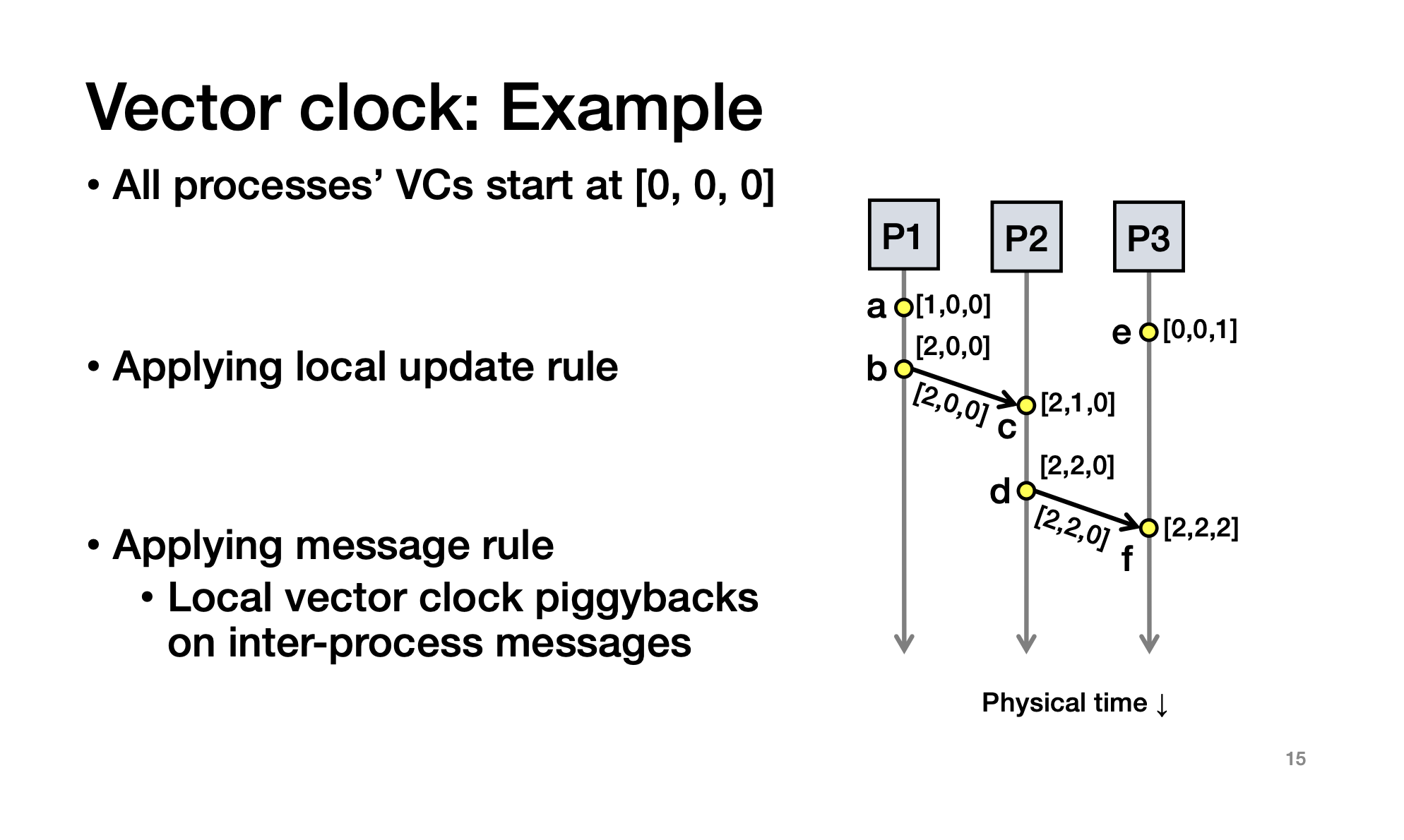
两个向量一样:同一个事件
一个向量小于另一个向量:所有元素都小于等于,但是不能全部等于
并发事件:中间有的元素小,有的元素大,如a和e


Lamport 和 vector 区别:有多个数可以处理因果关系
The reading paper is Lamport's paper about Lamport time. He introduced the main idea in last class and gave a formal mathematical proof on the theorem.
https://lamport.azurewebsites.net/pubs/pubs.html#time-clocks
现实设计隐藏了这些idea
用 Kafka 做“全序多播(Totally-Ordered Multicast)”时,核心认知是:
-
Kafka 只保证“分区内(partition-local)顺序”,不保证跨分区的全局顺序。
-
想要“所有副本都按同一顺序交付”,最简单且工程可行的是:用单分区主题,并让每个副本用不同的 consumer group 订阅同一主题(这样每个副本都会收到全部消息且顺序一致)。
下面给你一套可直接跑的 Java 示例(纯 Kafka 客户端,不用 Streams),演示如何实现一个小规模可用的“全序多播”:
方案 A(简单可靠,适合中小规模)
单分区主题 = 全局全序
-
创建主题时
--partitions 1,Kafka 天然保证该分区内的严格顺序。 -
为了“多播”(每个副本都收到消息),每个副本使用不同 group.id(或直接
assign)订阅同一个主题。 -
为了可靠性与幂等:生产端开 幂等 + 事务;消费端用
isolation.level=read_committed。
1) 创建主题(命令行)
kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--topic totord-demo \
--partitions 1 \
--replication-factor 32) 生产者(全序广播)
// File: ToProducer.java
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.Scanner;
public class ToProducer {
public static void main(String[] args) {
Properties p = new Properties();
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 全序 & 可靠性关键参数
p.put(ProducerConfig.ACKS_CONFIG, "all");
p.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
p.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1); // 保序
p.put(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE));
// 事务:保证“只读到已提交的消息”
p.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "totord-producer-1");
try (KafkaProducer<String,String> producer = new KafkaProducer<>(p);
Scanner scanner = new Scanner(System.in)) {
producer.initTransactions();
System.out.println("Type lines to multicast (Ctrl-D/Ctrl-Z to end)…");
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
producer.beginTransaction();
// 单分区主题:不需要 key 也全序;若要做“每发送方可追踪”,可用 key=senderId
ProducerRecord<String,String> rec = new ProducerRecord<>("totord-demo", null, line);
producer.send(rec).get(); // 阻塞拿到结果,进一步保证局部程序顺序
producer.commitTransaction();
System.out.println("Sent: " + line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}3) 消费者(每个副本都看到相同顺序)
// File: ToConsumer.java
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class ToConsumer {
public static void main(String[] args) {
// 每个副本用不同 group.id(或传参),以“多播”效果:所有副本都能消费到全部消息
String group = args.length > 0 ? args[0] : "totord-replica-" + UUID.randomUUID();
Properties c = new Properties();
c.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
c.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
c.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
c.put(ConsumerConfig.GROUP_ID_CONFIG, group);
// 只读取已提交的事务消息,避免“脏读”
c.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
// 手动提交,交付后再提交,贴近“交付 = 可见”的模型
c.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 避免重平衡造成并发处理混乱(小样例中也可忽略)
c.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
try (KafkaConsumer<String,String> consumer = new KafkaConsumer<>(c)) {
consumer.subscribe(Collections.singletonList("totord-demo"));
System.out.println("Replica group: " + group + " started.");
while (true) {
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String,String> r : records) {
// Kafka 对“同一分区”的消息天然按 offset 顺序回放
System.out.printf("Delivered (p=%d, off=%d): %s%n", r.partition(), r.offset(), r.value());
// 在这里做你的“应用交付”
}
consumer.commitSync();
}
}
}
}运行:
# 终端1(生产者)
javac ToProducer.java && java ToProducer
# 终端2(副本1)
javac ToConsumer.java && java ToConsumer replica-A
# 终端3(副本2)
java ToConsumer replica-B你会看到 replica-A 和 replica-B 的输出顺序完全一致(因为单分区)。
常见问答
Q1:吞吐会不会受限?
会。单分区是实现“全局全序”的简单方式,但吞吐受限于该分区的单 leader。
- 如果吞吐不够,可增大消息大小/批量(linger.ms、batch.size),或加机器提高 broker I/O。
- 真要更大规模的“全局全序”,请看方案 B。
Q2:崩溃&重启后会乱序吗?
不会。Kafka 用偏移量(offset)严格线性化分区日志。启用 幂等 + acks=all + 事务,消费者 read_committed,即可获得“端到端一次性可见”的效果(Exactly-Once 语义在 Streams 下最完整,这里是最小化示例)。
Q3:多个发送者并发发送,会不会互相打乱?
不会超出“全序日志”的定义——所有消息在该分区内被一个统一的顺序线性化。你不需要 Lamport 时钟;Kafka 的分区日志就是“全局序列”。
方案 B(要更大吞吐又想“全局全序”)
Kafka 没有原生“跨分区全局顺序”。常见工程做法:
-
Sequencer 单分区:
- 多生产者先写到一个高并发输入主题(多分区);
- 一个“排序器(sequencer)服务”从所有分区读取,为每条消息分配全局序号,然后写入一个单分区“有序主题”。
- 消费端只读“有序主题”。
- 本质上还是单分区瓶颈,但把入口与排序解耦,利于扩展和管控。
-
业务可分片:
- 如果业务允许“按 key 独立全序”,那就按 key 分区(Kafka 天生保证“同 key 同分区”顺序)。
- 再配合上层聚合逻辑实现“跨 key 的最终一致”。
-
共识/日志复制系统:
- 将“全局全序”交给专门的共识层(如 Raft/Paxos 的日志),Kafka 作为复制与分发层;
- 复杂度提升,但可实现强一致下的大规模全序。
小结
- 要“所有副本看到同一顺序”:单分区主题 + 每个副本不同 group 就能实现,最简单稳定。
- 要“全局全序 + 高吞吐”:需要 Sequencer/共识层 之类的额外架构;Kafka 本身不保跨分区顺序。
- 你不需要显式 Lamport:Kafka 的分区日志天然就是一个“全序日志”。
如果你想继续,我可以把上面的 Sequencer 模式 也配一版最小可运行的 Java 原型(一个消费者融合多分区、写到单分区“ordered”主题),你选择更贴近你场景的那版即可。