
CXL技术:历史、技术与展望
- High Performance Computing
- 2025-05-14
- 1380 Views
- 0 Comments
- 2552 Words
Research on the CXL Memory
CXL (Compute Express Link) 技术是一种基于PCIe IO的缓存一致性互联标准, 其旨在提供主机处理器与加速器、内存缓冲器和智能 I/O 设备之间的高带宽、低延迟连接。
CXL在延迟和带宽方面比传统的远程直接内存访问(RDMA)技术有所改进,基于 CXL 内存的存算分离架构的趋势会继续,更多标准化和生态开发会出来。但在处理高并发和高吞吐量任务时,与本地内存相比仍有很大差距。随着技术的不断发展和市场的不断成熟,创新的内存管理和调度策略将使 CXL 内存成为云计算领域的关键角色,大幅提高性能和效率。
Motivation & 现有内存的挑战
在数据中心内,我们面临三个主要内存挑战:
- 内存层级中的延迟差距:直接附加的 DRAM 和固态硬盘(SSD)存储之间存在三个数量级的延迟差距。当处理器耗尽直接附加内存的容量时,必须依赖 SSD,导致处理器等待时间(延迟)增加,显著影响计算性能。
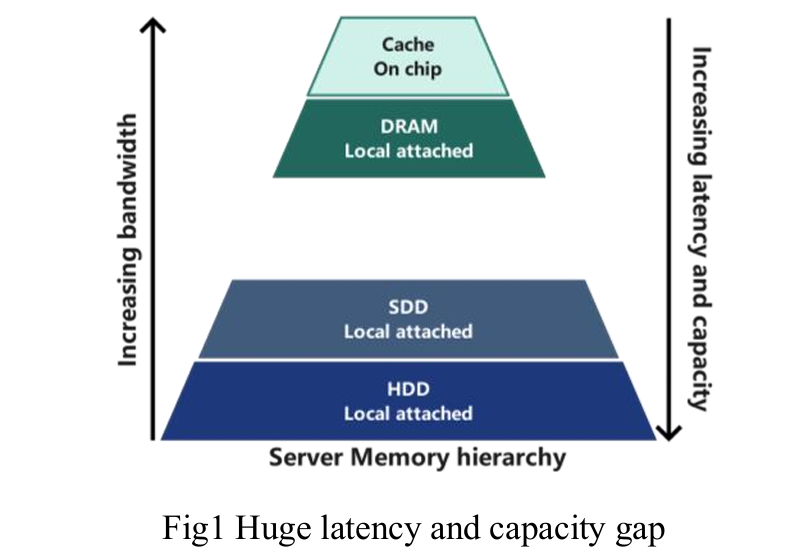
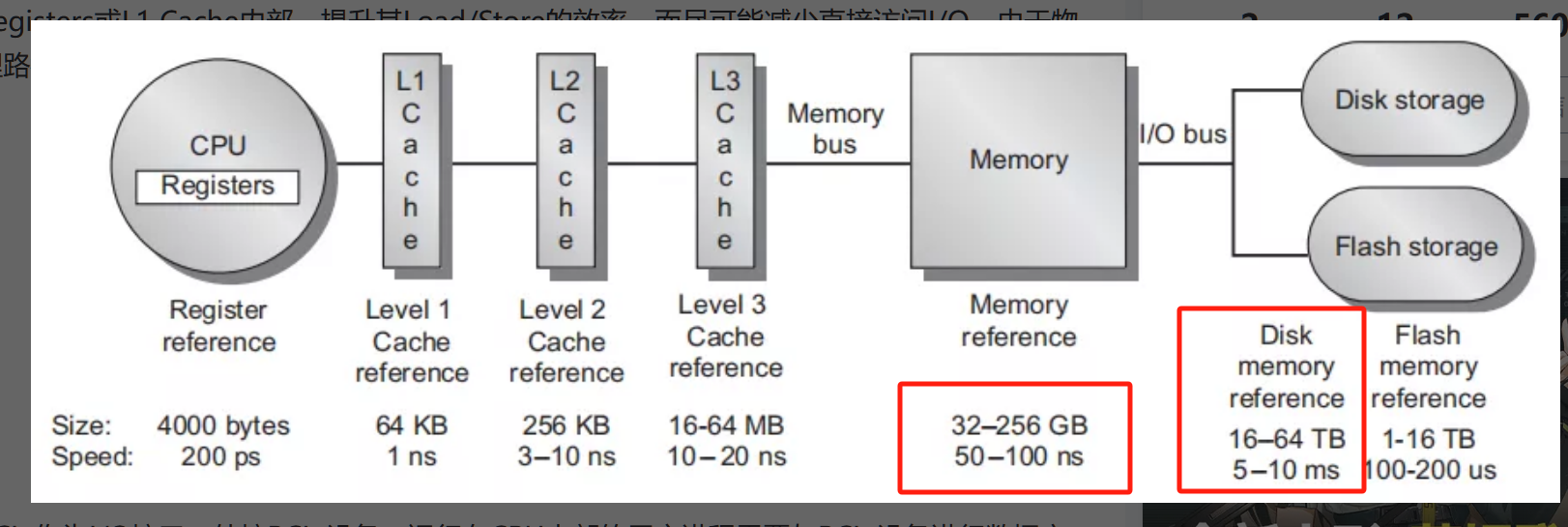
-
多核处理器核心数增长与内存带宽不匹配:多核处理器的核心数增长速度远超主内存通道的扩展速度。超过一定数量的核心会因内存带宽不足而无法充分利用,导致添加更多核心的收益递减。
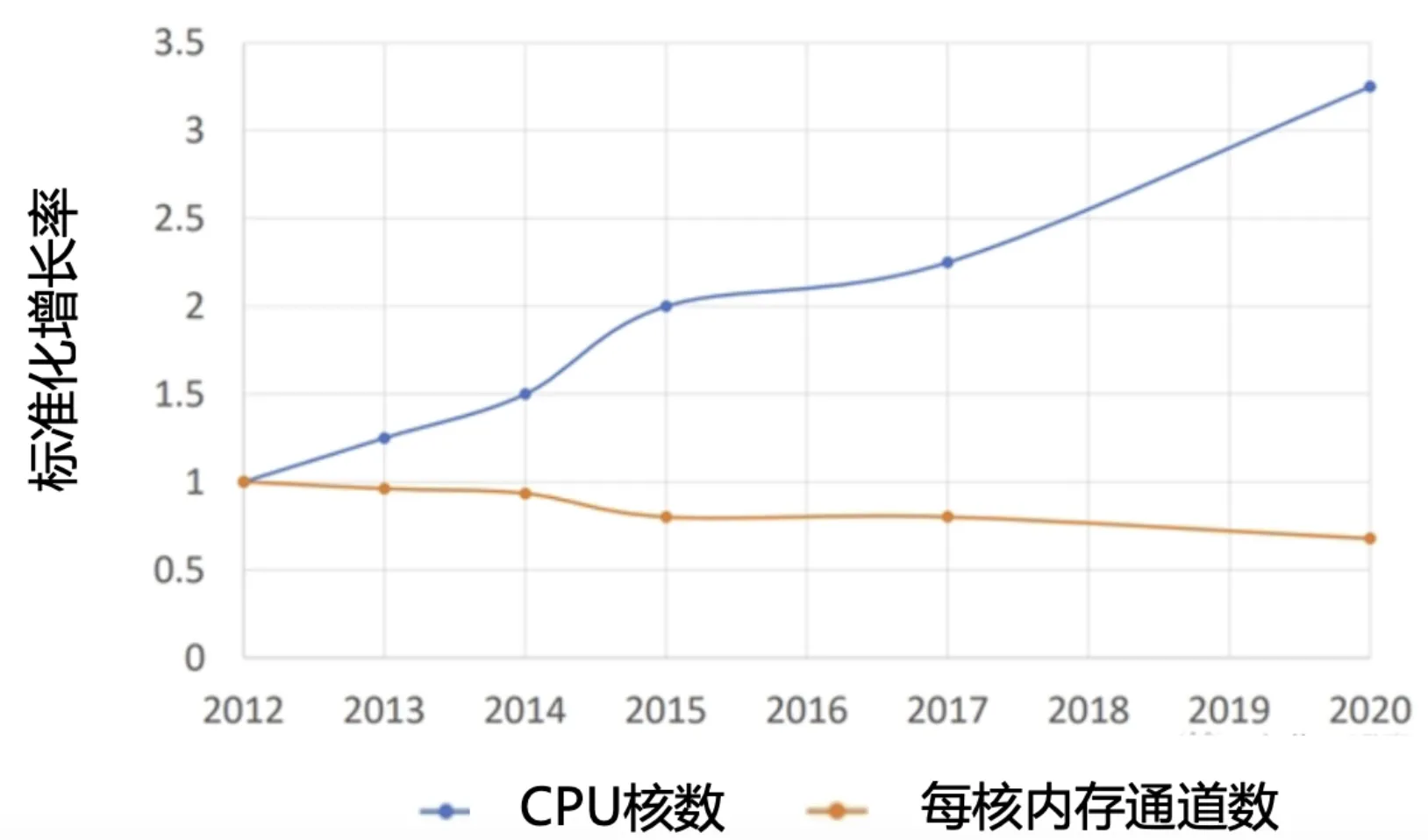
-
加速计算中的内存资源浪费:随着加速计算的普及,加速器(如GPU、FPGA)通常配备自己的直接附加内存,导致内存资源未被充分利用或闲置(孤立内存),造成资源浪费。
所以,我们需要一个协议,把所有的内存统一起来,这样,他们的速度虽然比直接访问DRAM内存慢,但是比传统的固态SDD快。
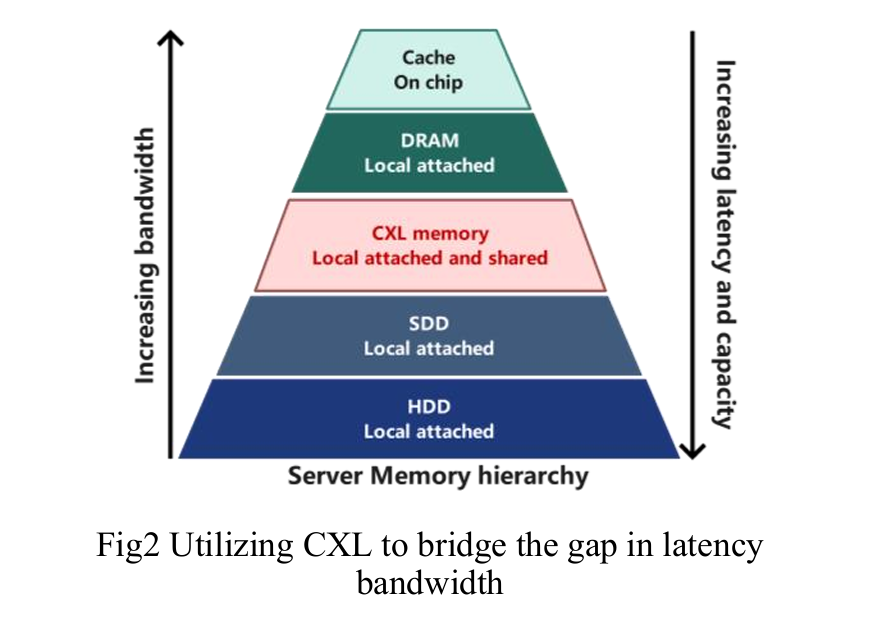
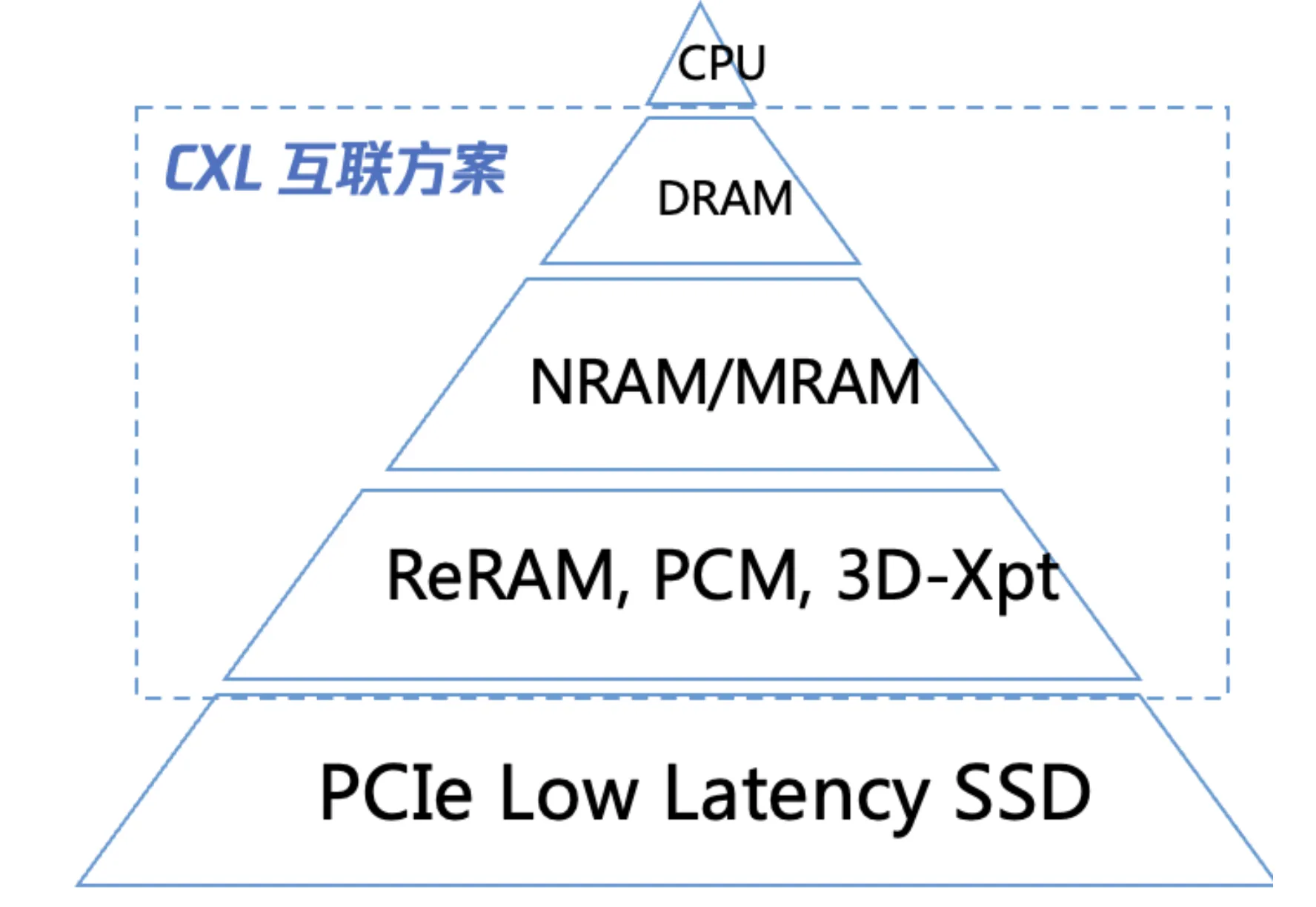
CXL technology offers a novel approach to addressing the memory challenges in data centers. By utilizing CXL memory, a new layer of memory is created between DRAM and SSD, bridging the significant gap in bandwidth and latency. This effectively unleashes the potential of multi core processors by providing them with more efficient access to memory resources.
Compute Express Link (CXL) 就是一种开放行业标准互连技术,旨在提供主机处理器与加速器、内存缓冲器和智能 I/O 设备之间的高带宽、低延迟连接。
CXL technology offers a novel approach to addressing the memory challenges in data centers. By utilizing CXL memory, a new layer of memory is created between DRAM and SSD, bridging the significant gap in bandwidth and latency. This effectively unleashes the potential of multi core processors by providing them with more efficient access to memory resources.
CXL技术发展历史
- 发展历程:CXL 自 2019 年推出以来,经历了 1.0、2.0 和 3.0 三个主要版本迭代。2022 年,英特尔发布支持 CXL 的第四代 Xeon CPU,三星和 SK 海力士推出 CXL 内存原型产品,推动了其应用发展。
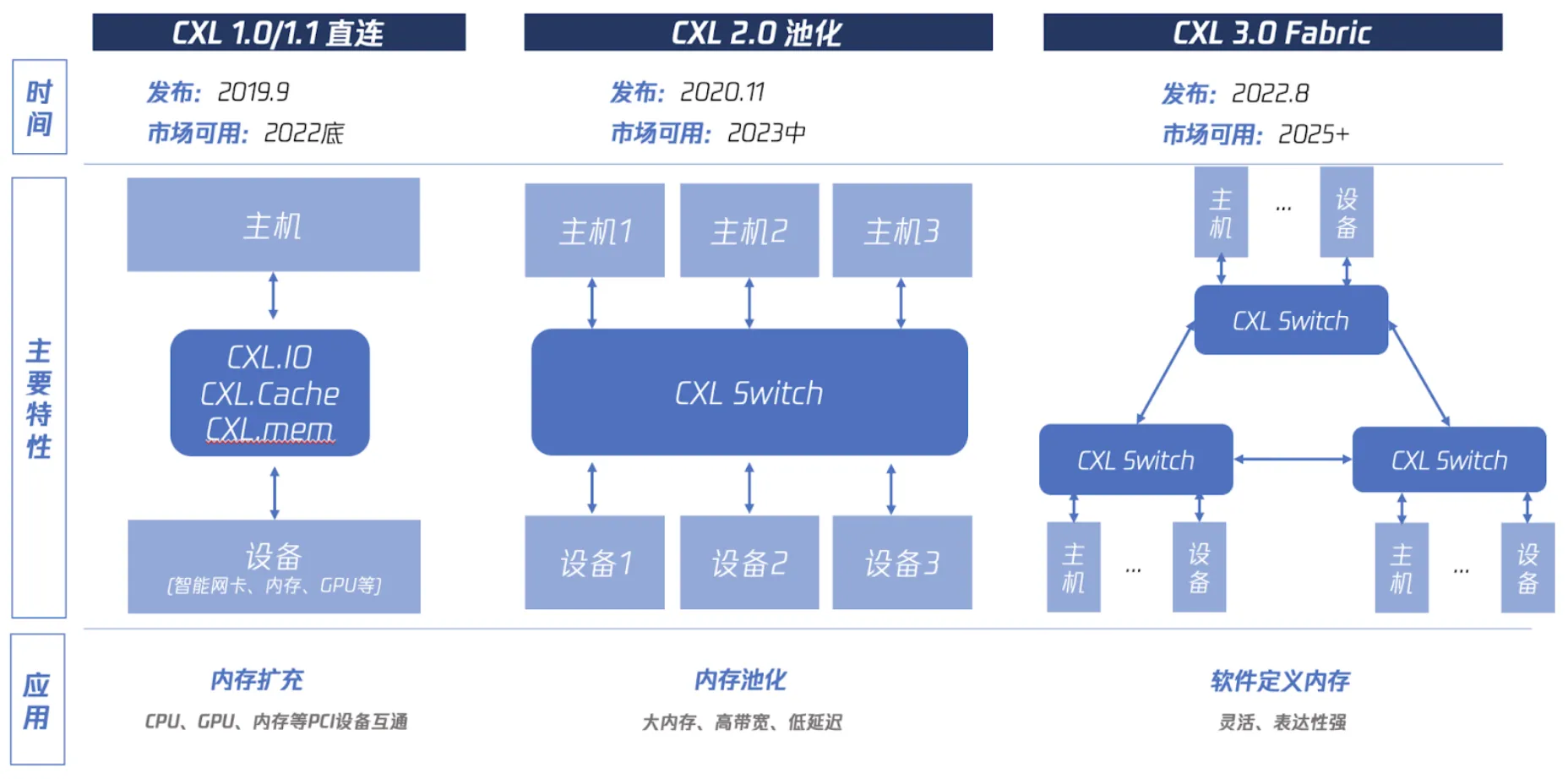
CXL1.0/1.1 可归纳为“直连”,也就是让主机CPU可以直接访问PCIe设备的内存,具体分为三个子协议:CXL.io用于设备注册发现、CXL.cache用于设备访问CPU内存、CXL.mem 用于CPU访问设备内存。这可达到主机内存扩充的目的。
CXL2.0 可归纳为“池化”,就是让多个主机CPU和多个设备可通过一个CXL Switch硬件连接在一起,可以相互访问,在较小延迟影响的前提下提供高容量大带宽。这可达到内存池化的目的。
CXL3.0 可归纳为Fabric,可以让多个Switch形成级联结构,支持更复杂的结构。这可以达到“软件定义内存”的目的,此处借用了“软件定义网络”的概念
- 主要特点:
- 高带宽、低延迟:CXL 提供比传统 RDMA(远程直接内存访问)更高的带宽和更低的延迟,适用于大数据和 AI 模型等高内存需求场景。
- 内存扩展与池化:支持内存容量扩展和内存池化架构,提升数据中心资源利用率。
- 缓存一致性:CXL 3.0/3.1 支持内存共享,硬件自动管理多节点间的缓存一致性,简化分布式共享内存(DSM)架构。
CXL 内存的应用形式
文中介绍了 CXL 内存的两种主要产品形式:
-
内存扩展(Memory Expansion):
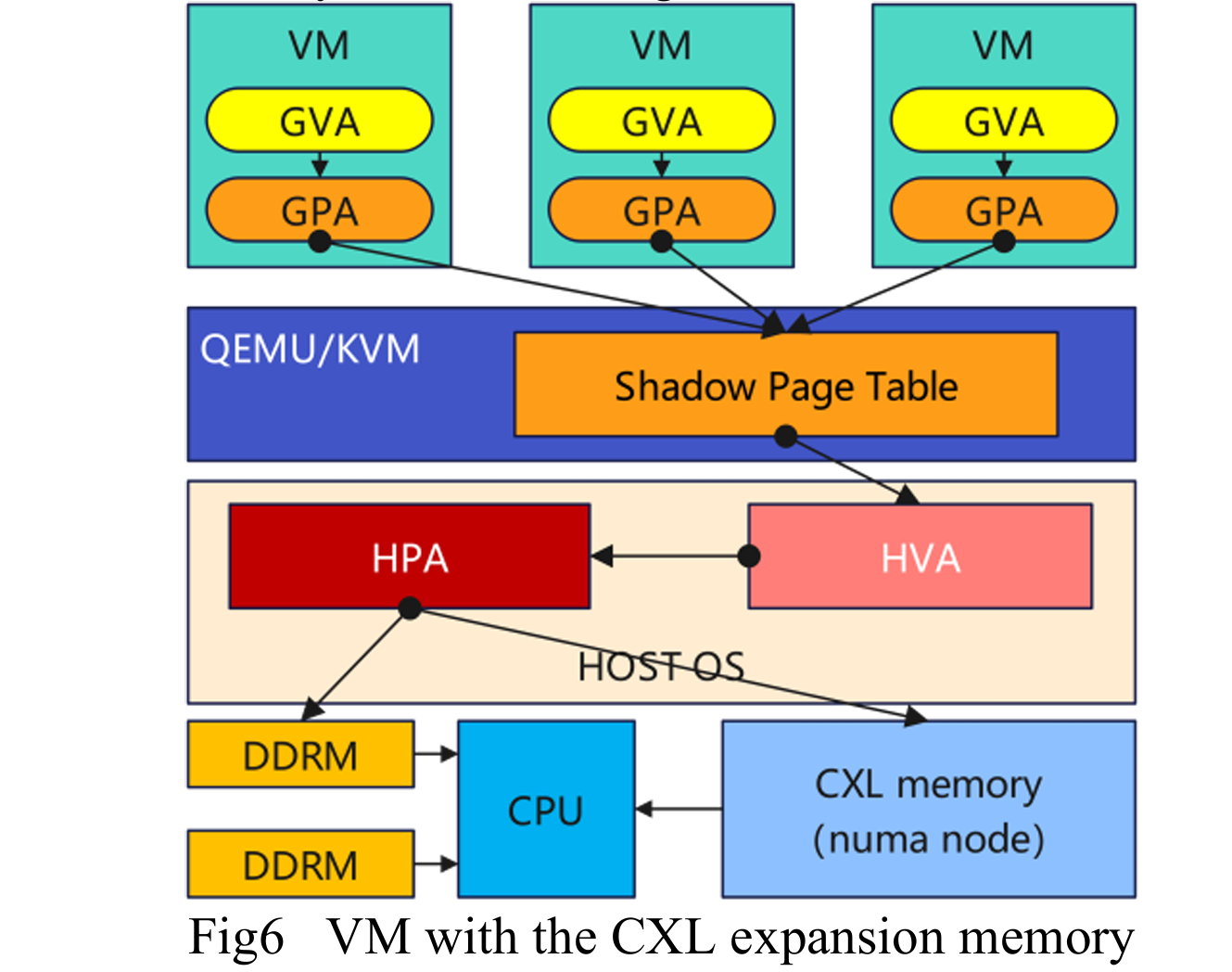
- 架构:通过 CXL.io 协议进行设备发现和初始化,通过 CXL.mem 协议处理内存读写请求。支持 E3.S 和 EDSFF 规范的内存扩展模块。
- 应用:在单一计算节点内扩展内存容量,满足大规模数据处理和复杂计算任务需求(如大型 AI 模型和高性能计算)。
- 虚拟化支持:QEMU/KVM 支持将 CXL 内存分配给虚拟机,作为独立 NUMA 节点,与本地内存统一寻址,但需智能调度热/冷数据以优化性能。
-
内存池化(Memory Pooling):
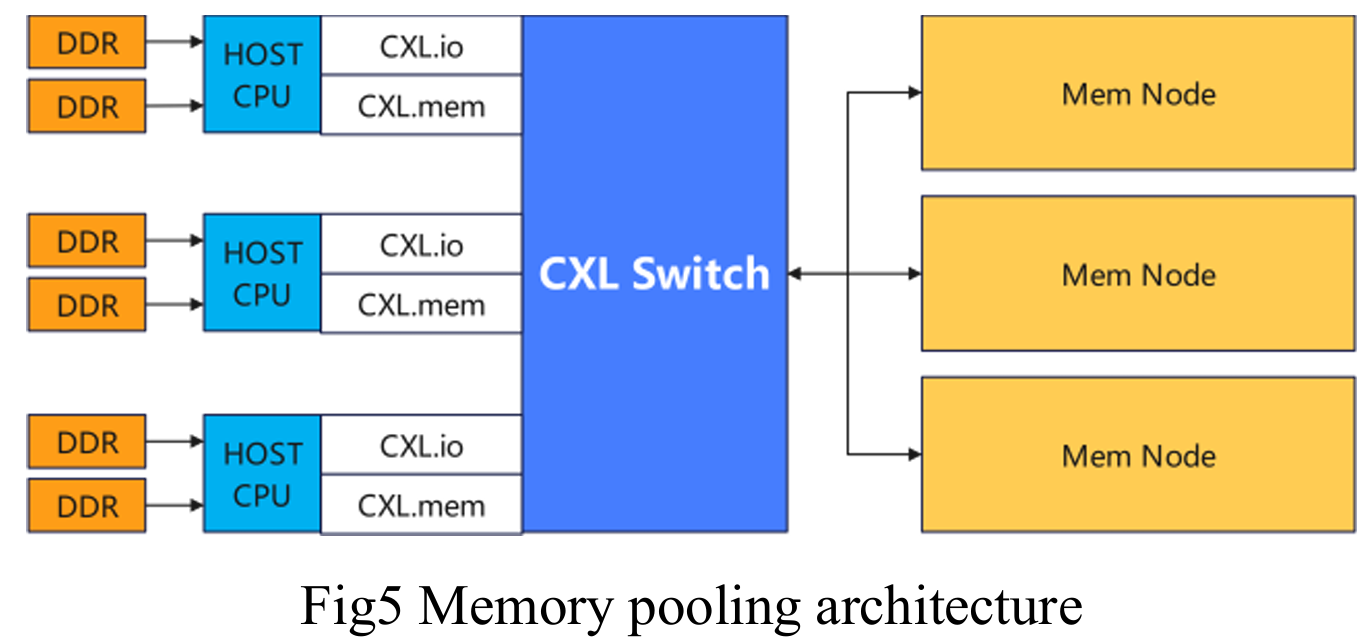
- 架构:通过 CXL 交换机连接多个主机(Root Ports),支持多逻辑设备(MLD)或单逻辑设备的内存池化。
- 优势:集中管理多个节点的内存资源,实现动态分配和优化利用,降低延迟,提升系统可扩展性和灵活性。
- 实例:2023 年 Flash Memory Summit 上,三星、MemVerge 和 H3 展示了 2TB 池化 CXL 内存系统,支持 8 个主机按需使用内存,并配备可视化、分层和动态分配软件。
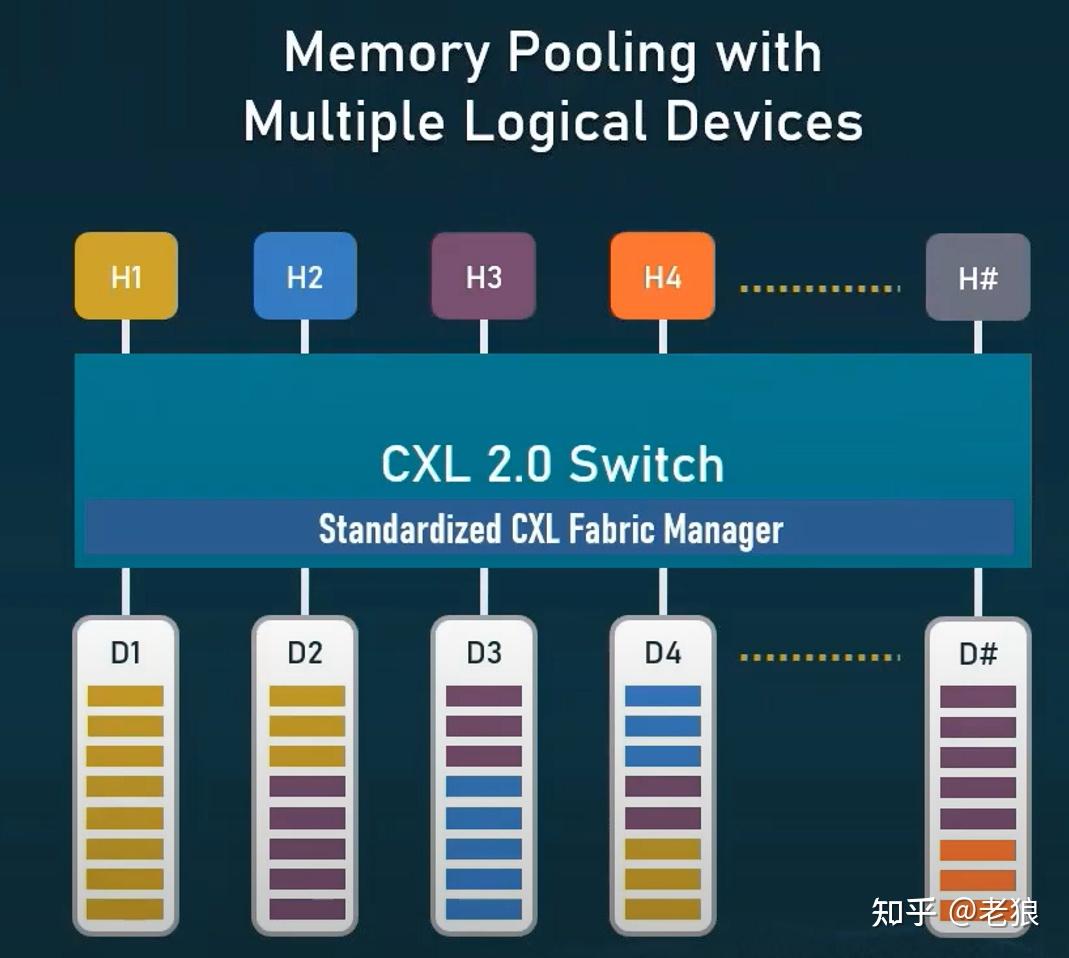
在图示的例子中,D1的所有内存都被分配给了H1;D2一部分内存被分给了H1,一部分给了H3。假设过了一段时间,H3可以通过HOT Remove释放一些内存,释放的内存可以通过HOT Add给到H1。MLD的分配颗粒度更小,更加灵活。需要注意的是,MLD的LD设备2.0定义,最多只能16个。
MLD的精细颗粒度调度给云服务器典型应用提供了极大的灵活性,VMM可以根据调度VM的使用情况,灵活调度资源,达到按需分配的目标。MLD虽好,但并不是所有CXL设备都可以做成MLD。因为显而易见的原因,只有Type 3这种纯内存扩展才能是MLD,而GPGPU和DPU等等加速器只能SLD。
CXL 的应用
目前看来全新的机会包括,1)系统层的内存管理软件,以及2)应用层内存即服务,其余的均为现有系统的优化增强。
系统层的内存管理软件
先从系统软件层面看,由于CXL需要支持这么复杂内存共享结构,必须有一套新软件支撑,包括三个机会:
- 内存调度管理器;
- 内存高级数据特性,包括内存压缩、快照、克隆、备份等;
- 内存安全防护;
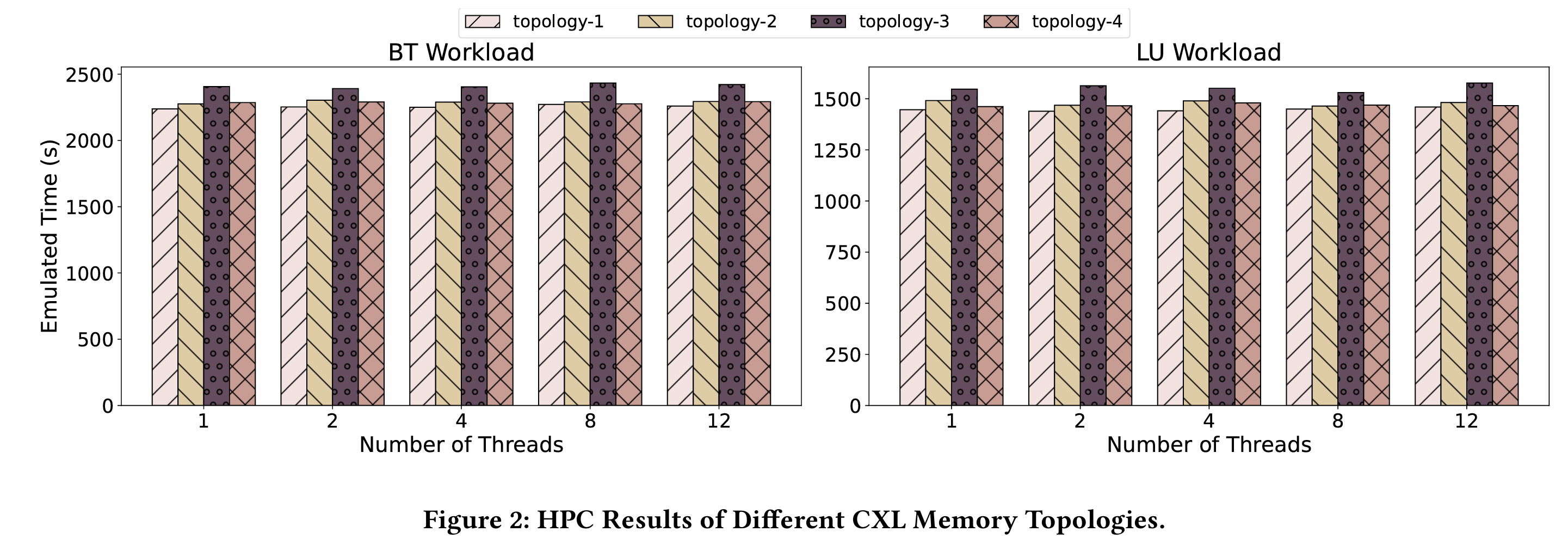
CXL 内存在带宽和延迟上优于 RDMA,但与本地内存仍有差距,需通过智能调度和优化弥补。不同比例的DDR+CXL效果不一样:
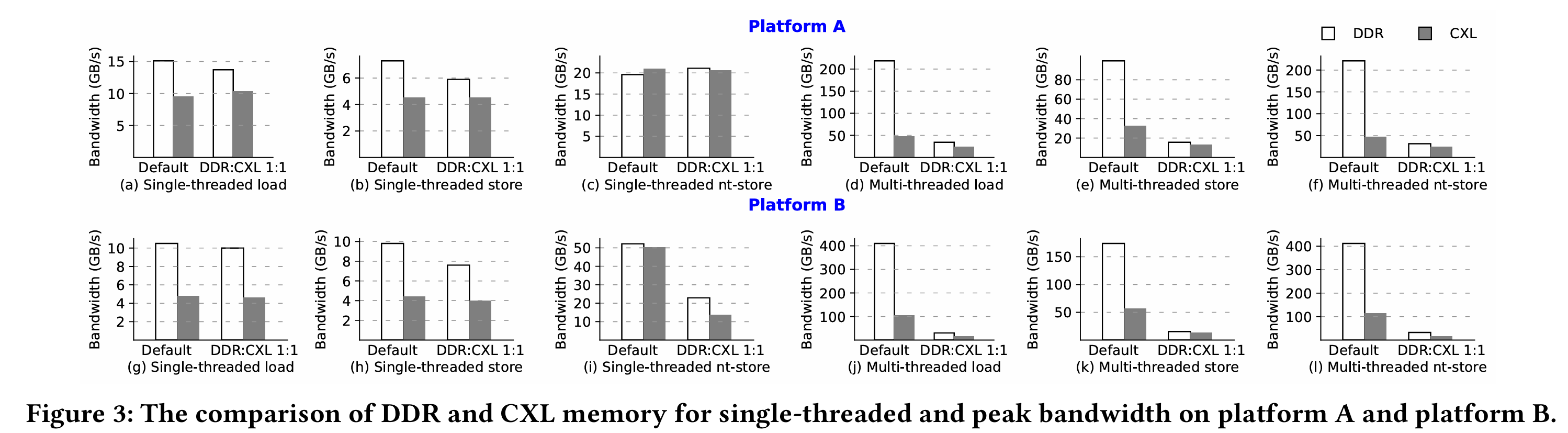
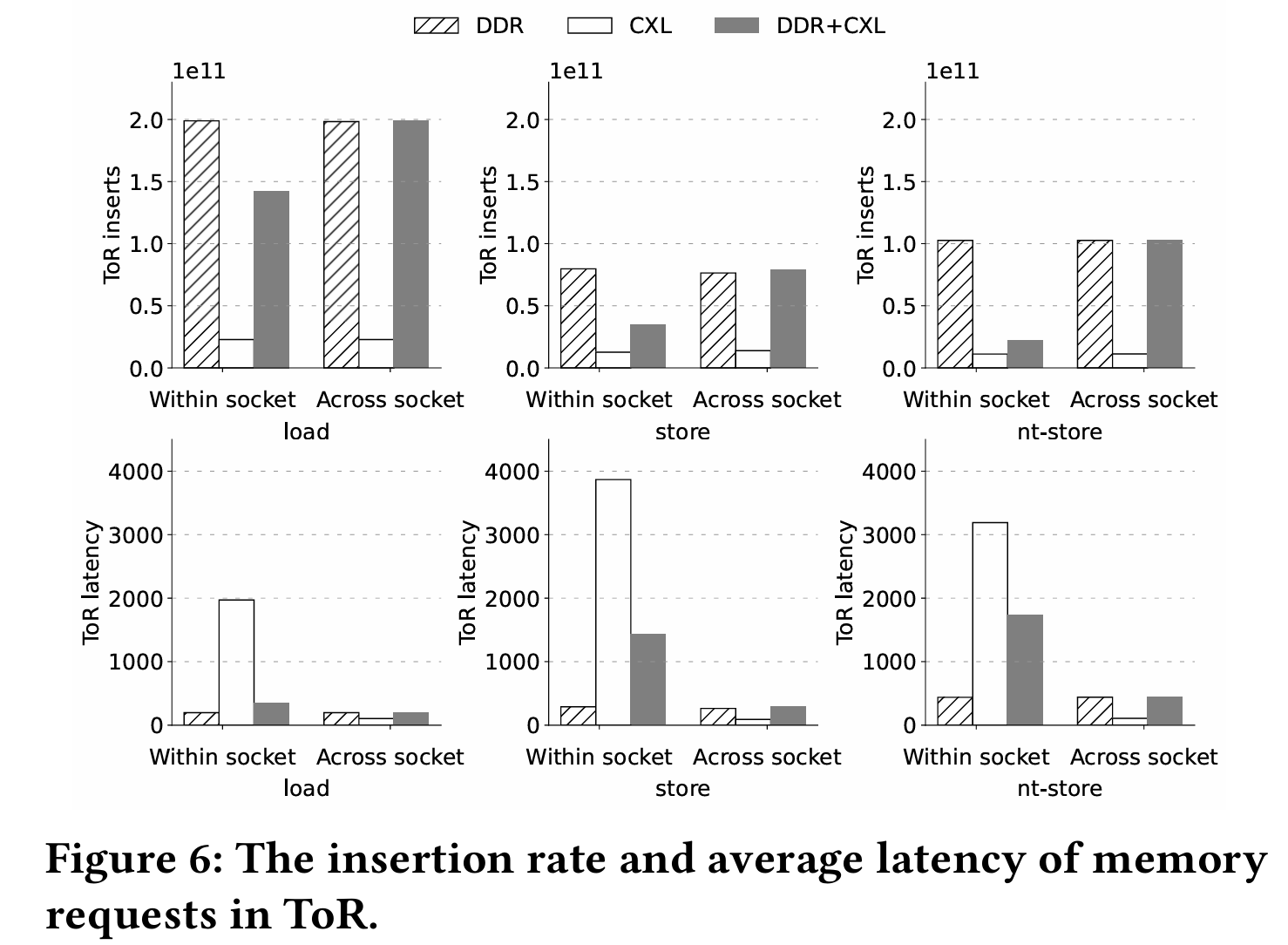
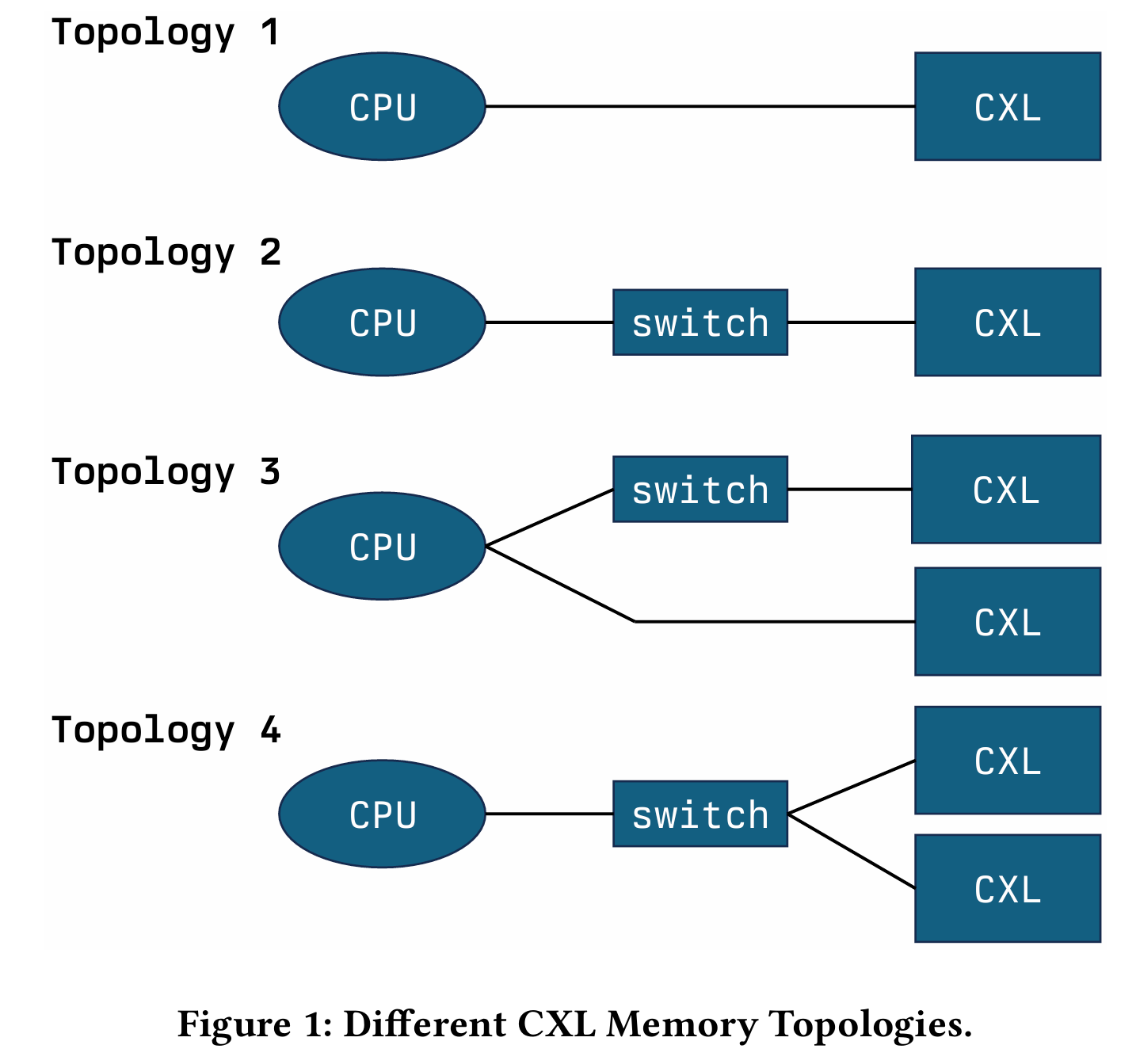
不同的拓扑也有调度的优化空间.
应用层内存即服务
池化内存容量大、粒度细、分配灵活,直接衍生出“内存即服务”模式,这个是利好云厂商的。
云厂商卖内存通常有以下痛点:
- 内存必须绑定计算实例售卖
- 内存售卖粒度较粗
- 内存无法超卖
- 售卖的内存大部分闲置,内存利用率低
在内存池化场景下,云厂商可以提供内存PaaS API服务,只卖内存给应用;也可以细粒度按需分配,收费更灵活,同时可以超卖内存,并将平常闲置的内存进行更高效的利用。
也可以用来加速LLM

调查发现,在微软Azure,有高达25%的内存都是闲置的,有50%的虚拟机使用的内存占比仅为50%。谷歌也类似,谷歌服务器集群中DRAM内存平均利用率约为40%,这将是巨大的机会
- 实例:阿里巴巴云于 2023 年推出 10TB CXL 内存池化产品,Pond 计划在 Microsoft Azure 上部署 CXL 内存池。
挑战与发展趋势
- 挑战:
- 生态兼容性:需与现有硬件(处理器、操作系统)和软件(虚拟化、API)无缝集成。
- 资源管理:高并发场景下,需智能调度热/冷数据以缩小与本地内存的性能差距。
- 数据一致性:多节点共享环境中,需新协议和算法确保数据一致性和高效同步。
-
发展趋势:
- 标准化与优化:随着云计算需求增长,CXL 硬件和软件将向标准化和性能优化方向发展。
- 计算-存储分离架构:基于 CXL 的解耦架构逐渐被行业认可,市场成熟度提升。
- 广泛采用:通过技术创新和生态发展,CXL 内存有望成为云计算和数据中心的关键技术,提升性能和效率。
总结
CXL 技术通过高带宽、低延迟的互连,解决了数据中心内存容量和访问效率的瓶颈,支持内存扩展和池化,适用于大数据、AI 模型和高性能计算场景。尽管性能仍需优化,但其在分布式共享内存和计算-存储分离架构中的潜力使其成为未来云计算的重要技术方向。
参考
CXL 2.0会极大地改变服务器业态 https://zhuanlan.zhihu.com/p/526411925
CXL是什么,有什么新的机会 https://developer.aliyun.com/article/1117134
CXL的实际应用的想法 https://zhuanlan.zhihu.com/p/553321200
CXL协议记录 https://zhuanlan.zhihu.com/p/426525531
X. Lin, J. Peng, R. Liu and X. Gao, "Research on the CXL Memory," 2024 IEEE 6th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 2024, pp. 1428-1432, doi: 10.1109/IMCEC59810.2024.10575852.
Jianbo Wu, Jie Liu, Gokcen Kestor, Roberto Gioiosa, Dong Li, and Andres Marquez. 2024. Performance Study of CXL Memory Topology. In Proceedings of the International Symposium on Memory Systems (MEMSYS '24). Association for Computing Machinery, New York, NY, USA, 172–177. https://doi.org/10.1145/3695794.3695809
Architectural and System Implications of CXL-enabled Tiered Memory [2503.17864] Architectural and System Implications of CXL-enabled Tiered Memory
Efficient Tensor Offloading for Large Deep-Learning Model Training based on Compute Express
Efficient Tensor Offloading for Large Deep-Learning Model Training based on Compute Express Link | Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis