
CPP Project5: The beginning of Accelerated Computing
- CPP
- 2024-09-09
- 2558 Views
- 1 Comments
- 19608 Words
CS205·C/C++ Programming
Project5 Report: The beginning of Accelerated Computing
PDF 版本:Project 5
Github: https://github.com/HaibinLai/CS205-CPP-Programing-Project
摘要
“这是一个令人惊叹的时代,因为我们正处于一场新的工业革命的开始,过去蒸汽机、电力、PC和互联网带来了信息革命,现在是人工智能。前所未有的是,我们正在同时经历两种转变:通用计算的结束和加速计算的开始。”
—— Jensen Huang
nvcc会不会对GPUKernel做优化?NCCL是如何让GPU互相通信的?复杂的递归DFS算法能不能用到并行的GPU程序中?怎么样对单个线程进行编程?GPU如何处理if分支语句?谁可能是下一代BLAS?在本次Project中,上面的问题都会得到探讨。
关键词:CUDA;GPU;HPC;AI;
Part 1: 为什么需要加速计算
在本次Project中我们将探讨NVIDIA GPU在SGEMM中的运行情况与CUDA优化策略,同时查看在不同应用场景与价位下GPU的架构设计、技术细节与性能表现情况,通过这些学习,对加速计算给一个简单的概览。
Part 2: B=aA+b实现
本次实现建立在Project4的实现的矩阵类上,增添了这么几个函数:
a * A函数
GPU Kernel:

CPU host:

-
A’ + b
GPU:

CPU hosts:

测试:
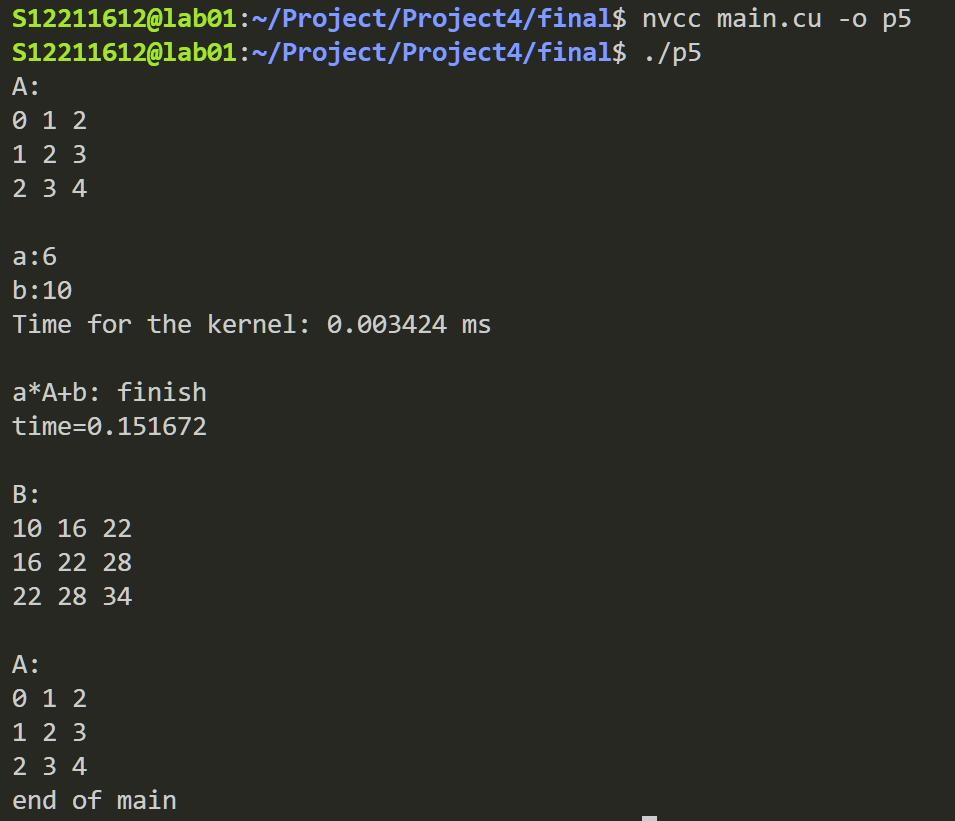
Part 3: cuBLAS速度对比
- 时间测量:
CUDA专门提供了测量时间的API函数: cudaEvent_t, cudaEventRecord(), cudaEventElapsedTime() 等函数,具体操作如下:
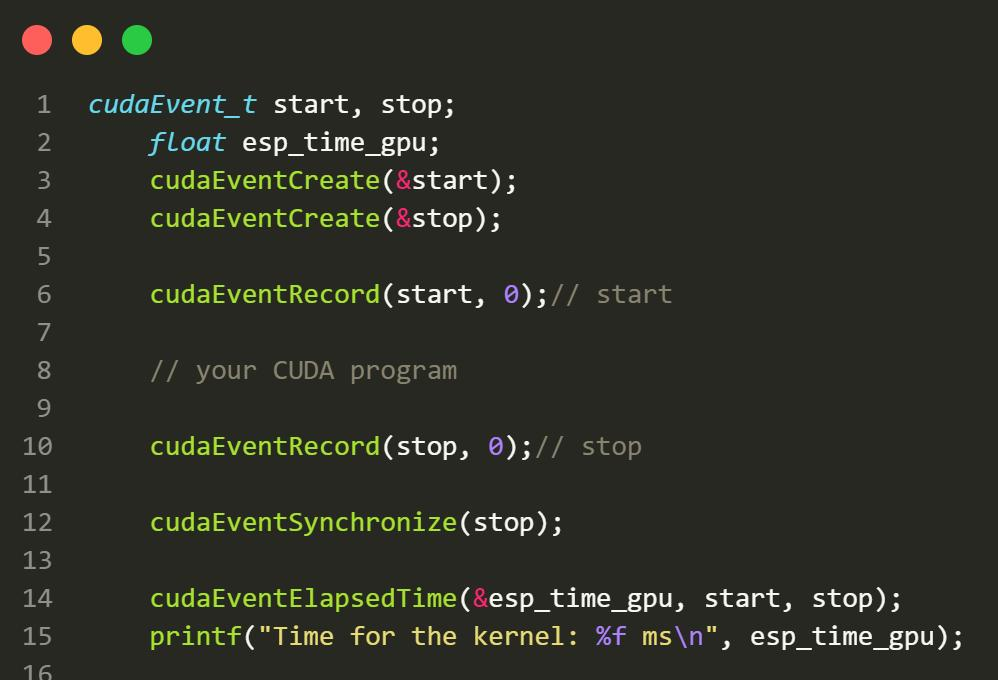
在CPU情况下,我们依旧使用project3中HPL的测量方法进行时间测量。
我们首先得出CPU BLAS SGEMM的计算时间:
| CPU | N |
|---|---|
| Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz | 4096 |
| MKL 单次 | MKL 1000次循环平均值 | OpenBLAS |
|---|---|---|
| 0.118 | 0.5962 | 0.114 |
单位:秒
具体的测试分析我们已经在Project3中提到。我们这里是第一次对MKL的JIT进行测试,看来它还是取得了不错的效果。
我们接下来实现cuBLAS:
我们在RTX2080Ti上进行多次测试,求得4096*4096下的CUDA SGEMM时间约为78.06 ms,比CPU的BLAS有一定的提升。
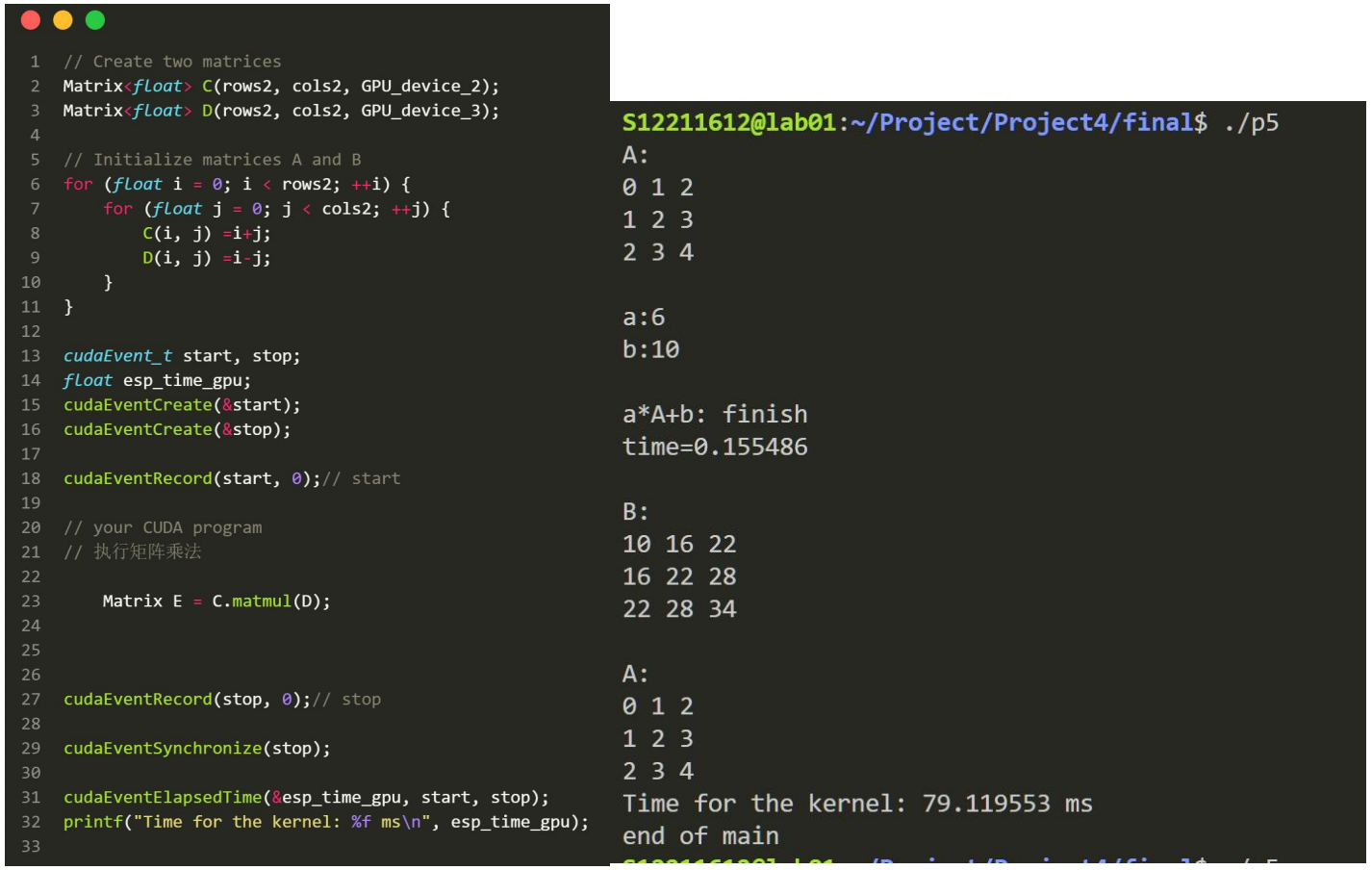
有趣的是,如果我们这里改进一下,把Matrix E这里加一个for循环:

按照道理它会耗时 78*100 毫秒,但是实验的结果是,它仅耗时约1600ms。我认为造成这样的主要原因是缓存仍停留在SM中,这使得CUDA可以重复利用数据。
诶,那用我们原始的plain方法,大概能多少呢?
151ms。虽然比CPU还好,但是跟cuBLAS还是差了一倍。

去掉if,减少Thread divergence。

然后我们更换一下我们的blockDim。查看他们所需要的毫秒数。
| 16*16 | 32*32 | 48*48 | 64*64 |
|---|---|---|---|
| 137 | 133 | 114 | 144 |
这些是由于GPU的结构引起的。我们接下来由于有一个不错的范本,我们就可以跟着这个范本来研究如何加速cuBLAS。
Part 4: 矩阵乘法加速分析
Github上有个人的GEMM算法写的挺好的,我对此进行分析和借鉴:
cuda_sgemm/gemm.cu at master · njuhope/cuda_sgemm (github.com)
- grid 数和block数。

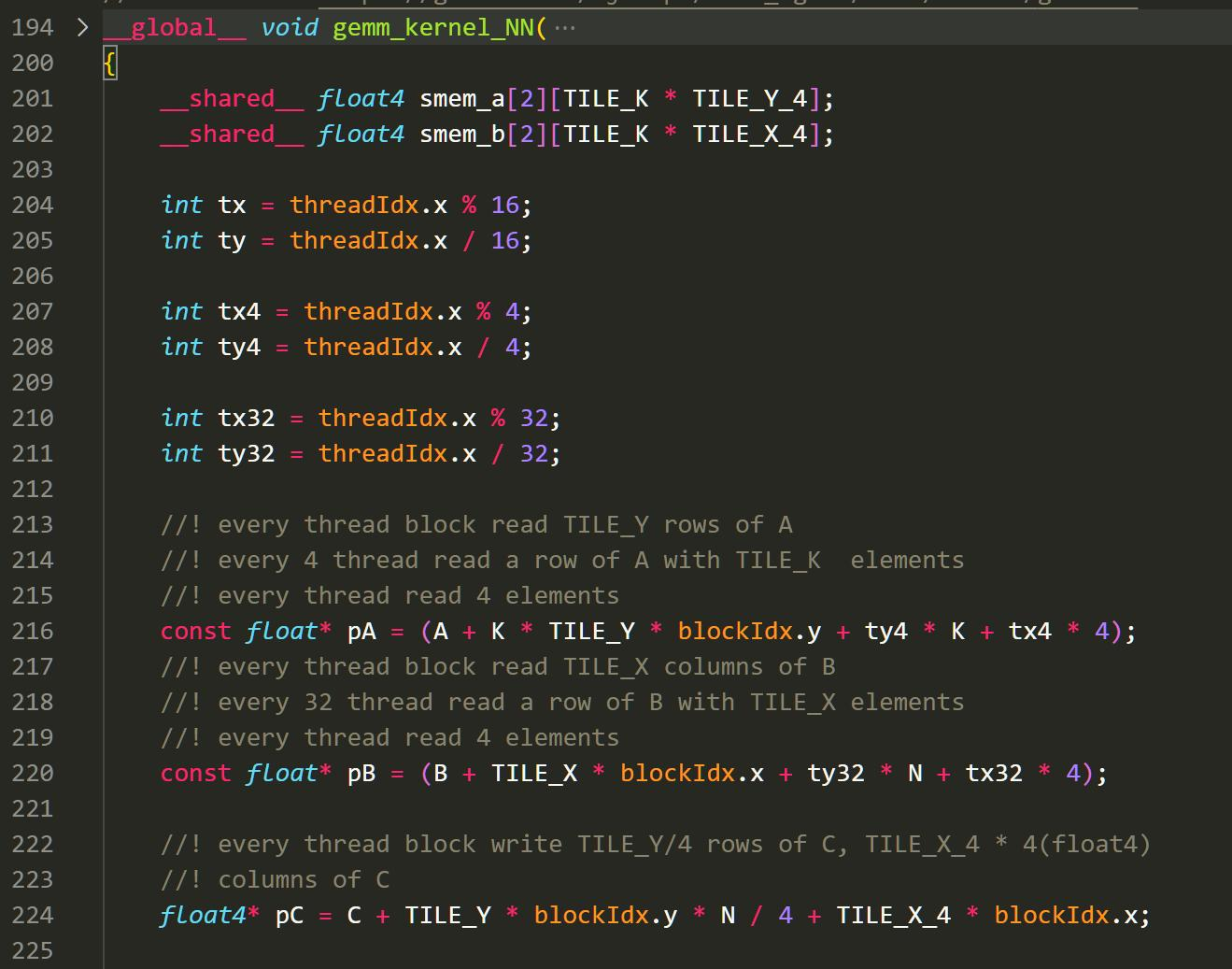
我们将GEMM进行分块,每一个grid分到128*128的小块,每一个Block分到256的块。然后,我们在核函数中对这256*256小块进行细分地操作。
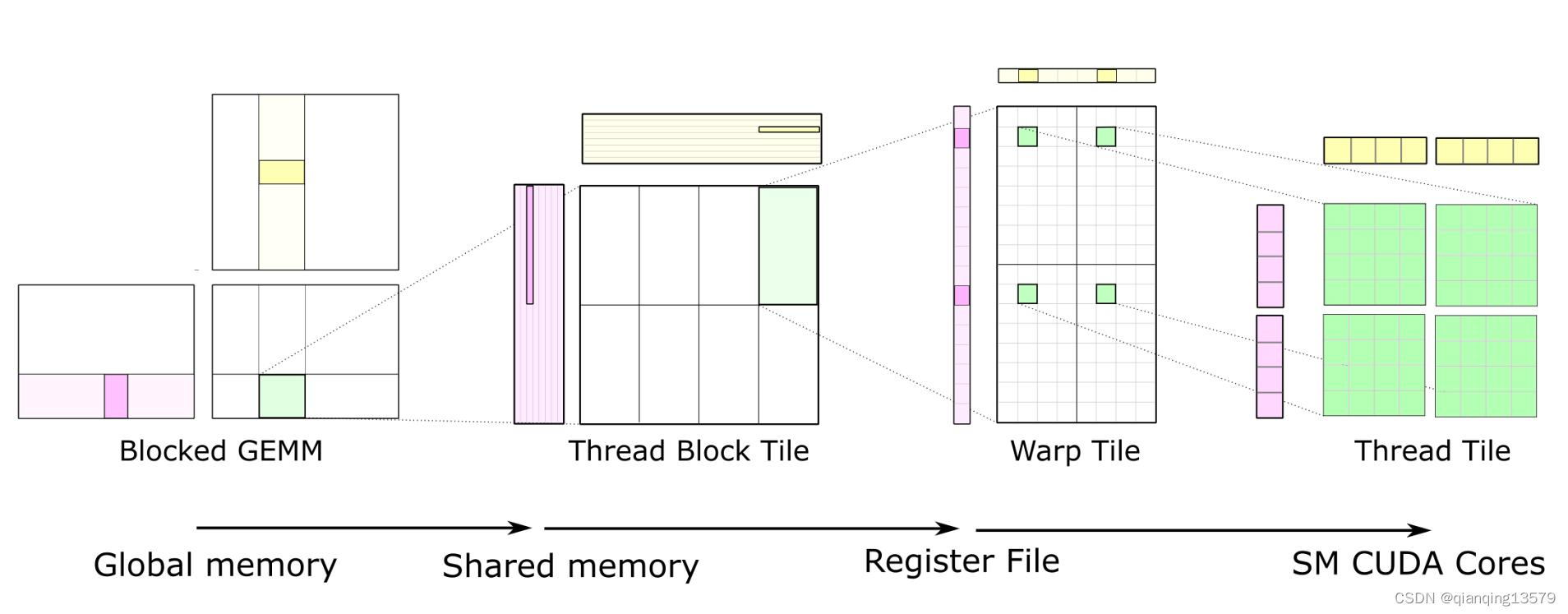
核函数:
- 循环展开
跟在CPU一样,给每一个线程分配多个任务,可以让线程更加地连续,同时线程访问存储的速度也会因为连续而更快。
Reg的使用是PTX CUDA汇编的操作,通过使用寄存器,我们相当于是人肉NVCC的O3优化,将数据拉到SIMD更近的地方进行操作。
#pragma unroll是NVCC编译器独特的辅助编译方式,它可以帮助我们进一步将循环展开分配。

- share共享内存
在同一个warp内使用共享内存,这样的话计算的时候就可以分配任务,各个线程执行各个矩阵小块的工作。注意到GPU内的共享内存其实是非常的宝贵的,我们这里是smem并不能设置的太大。
- 连续数据
我们将共享内存中的数据导入到各自的reg中,这样可以提升我们的乘法计算速度。
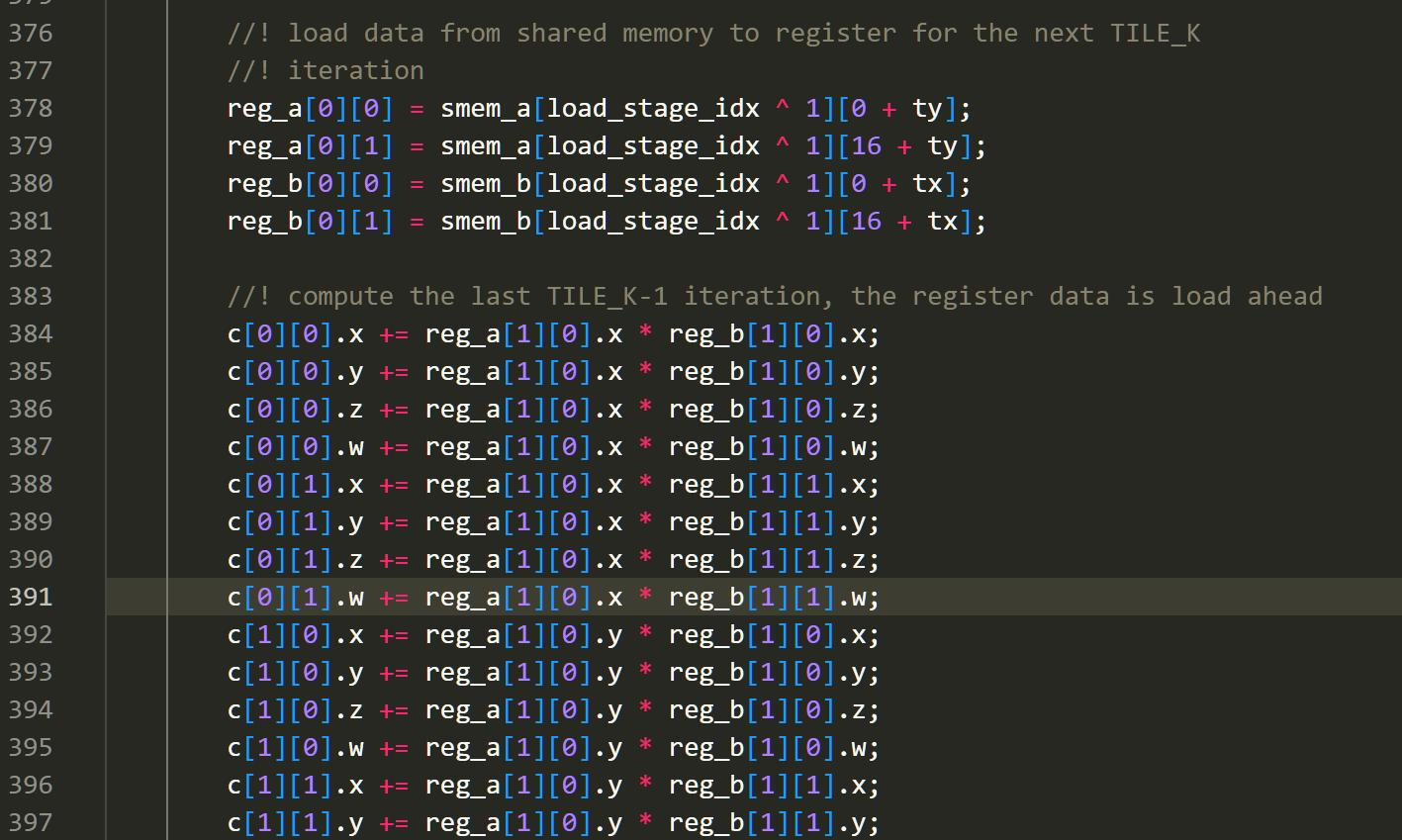
在这样之后,我们的gemm在访存上就被很大地优化了。同时,我们的线程分配也让我们的计算效率基本上最大化。
我这里统计了一下身边可以计算的卡。然后对他们进行一一的测试。但是由于时间限制,我没有测算我们的自己的cuBLAS时间。
| 名称 | 类型 | 架构 | 发布日期 | CUDA 支持版本 | 功耗 | 价格 |
|---|---|---|---|---|---|---|
| A100 80G | AI、HPC数据中心 | Ampere | June 26th, 2021 | 12.4 | 300W | 170000RMB |
| A100 40G | AI、HPC数据中心 | Ampere | May 15th, 2020 | 12.4 | 300W | 84000RMB |
| V100 | AI、HPC数据中心 | Volta | May 11th, 2017 | 12.1 | 43000RMB | |
| TITAN RTX | 图形学、深度学习 | Turing | Dec 3rd, 2018 | 12.3 | 6000RMB | |
| RTX 2080Ti | 游戏 | Turing | Oct 8th, 2018 | 12.4 | 250W | 2600RMB |
| RTX 3060 Laptop | 游戏 | Ampere | Feb 2nd, 2021 | 12.4 | <100W | 2200RMB |
| GT 1030 | 游戏 | Pascal | May 17th, 2017 | 9.1 | 100W | 248RMB |
| Quadro P2000 | 图形学 | Fermi | Dec 24th, 2010 | 2.1 | 80W | 93RMB |
| GPU | cuBLAS花费时间 |
|---|---|
| RTX 3060 Laptop | 150.32 |
| A100 80G | 18.09 |
| A100 40G | 46.15 |
| V100 | 41.44 |
| RTX 2080Ti | 79.80 |
| Quadro P2000 | 3603.50 |
| GT 1030 | 2353.65 |

Quadro 2000,淘宝87块钱的高级货,搭配E5-2666 v3神教
GT1030,入门级显卡
本次的Project,我想把时间更投入到对GPU的研究进展当中,所以我就没有再进行GEMM的具体计算和探究。
论文1: MBE on GPU
没活了,给大伙表演一个论文解读吧。通过几篇论文,我们就能对GPU研究领域中的一个方向有所了解。接下来这篇会议论文是:GPU上MBE算法的加速。我们将看到GPU研究中的一个方向:复杂算法加速。(Accelerating Maximal Biclique Enumeration on GPUs https://arxiv.org/pdf/2401.05039)

摘要介绍:

MBE是当今很重要的算法,但是基本都是在CPU上实现。这篇文章里,我们将MBE算法引入到GPU。但是这里边我们遇到了3个主要问题:
- 内存不足。MBE图规模大,对内存需求高,GPU内存不够;
2. 线程分歧多。MBE中有很多if分支,GPU在分支上会遇到Thread divergence,GPU的运算效率会下降;
- 负载不均衡。MBE中不同的搜索由于图形状不同,运算所需时间也不一样,导致有的线程跑的时间长,有的短。

针对这三个问题,本文提出了对应的3个方法:
-
设计 node reuse approach降低内存用量。
-
使用pro-active method剪枝,利用节点邻居数,减少线程分歧。
-
设计load-aware 任务调度框架实现GPU warps内部线程负载均衡。
我们的效果:在A100 上运行速度比96核服务器快70.6倍。
什么是MBE算法?

MBE算法用于在给定的图G(V,E) 中找到所有的最大完全二部子图maximal bicliques。在离散数学我们学到,二分图就是把一个图的顶点划分为两个不相交子集 ,使得每一条边都分别连接两个集合中的顶点,且集合内顶点不临接。
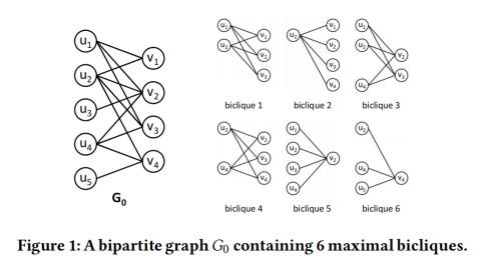
在一个图中寻找最大(点/边最多)完全二部子图是在生物信息学、数据挖掘等应用中的重要算法。

为什么用GPU?
CPU方面我们已经有很好的MBE算法了,但是随着这几年在深度学习、数据挖掘等在GPU上的应用的更多,大家开始希望有GPU上的MBE算法。同时,MBE在社交媒体推荐、基因表达、GNN信息聚合中应用的更多了,但是这些应用的数据量比以前更大,占用内存更多,CPU的计算速度开始逐渐跟不上了。
以往有人研究过这个方面吗?有什么缺点?

有的,最早期的MBE设计出来后,人们就发现计算开销非常高。于是有人从算法设计上开始用剪枝等操作降低开销,但是他们都是在单核上跑的。后来有人设计了多核的,但是还是在CPU上。所以我们需要一个在GPU上的。(另外是,也有人设计了GPU上MBE算法,比如这篇文章,但是他们加速比最高只有38,那他们为什么没有我们快呢?原因就在下面)
我们的三个困难具体是怎么样的?我们如何解决?
首先是内存问题。直接从CPU搬运到GPU的算法需要大内存空间,同时它需要经常分配内存,这种动态内存分配对GPU运算来说也是一种性能损耗。
第二是现有MBE算法存在 irregular computation问题。我们知道假如GPU同时执行1000条加法指令,它会干的很好。但是MBE问题会要求GPU在同一个Warp内的不同线程都执行不一样的路径。而这会导致动态分支。

thread divergence
这里我简单介绍一下thread divergence。我们的CPU是零售的话,我们GPU就是批发。而批发导致我们无法对个别线程很好地处理。比如我们在一个warp中有
if(sum[x] <= 100){
...
}
如果我们是CPU,在计组上我们学过,我们会根据结果flush掉后面刚刚fetch的指令,或者运用分支预测技术选好可能会走下去的分支。
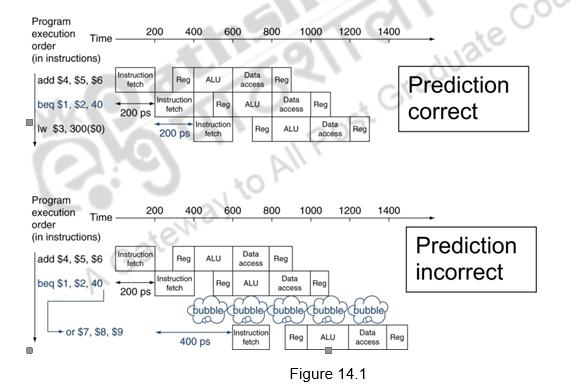
但是我们GPU如果在warp当中,某些数据选择肯定条件,某些选择否定条件,因为我们使用的是SIMD模块进行操作,做法跟CPU完全不同。

在编程层面上,我们常常在核函数中写下这么一句话:
int tid = blockIdx.x* blockDim.x + threadIdx.x;但是,我们的tid其实是一种逻辑化的东西,我们认为线程都是独立连续的。但是在物理实现上,GPU内的线程是以32个线程为一组,编成一个线程束 warp。而GPU正是由这些线程束统一构成,每一个束基本上是执行命令的一个小单元。
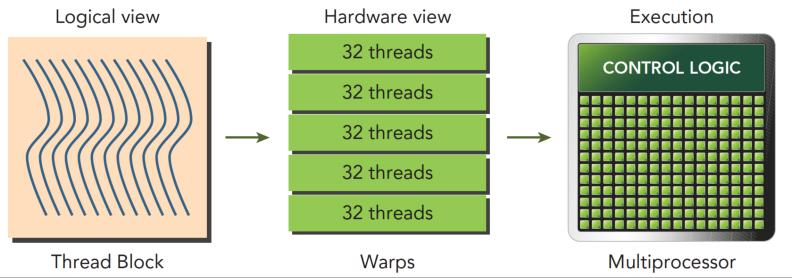
在早期Pascal架构中,面对if分支指令,一个warp会先跑一遍A,B,随后再跑另一边else的X,Y,所用时间是他们的总和,效果非常的铸币。为什么呢?因为一个warp只有一个PC,这个PC只会一次fetch一条指令,才导致了这个后果。
在Volta架构开始,线程开始变得精细化,每个线程都有一个自己的PC,这代表着每个线程可以执行自己想执行的指令了。
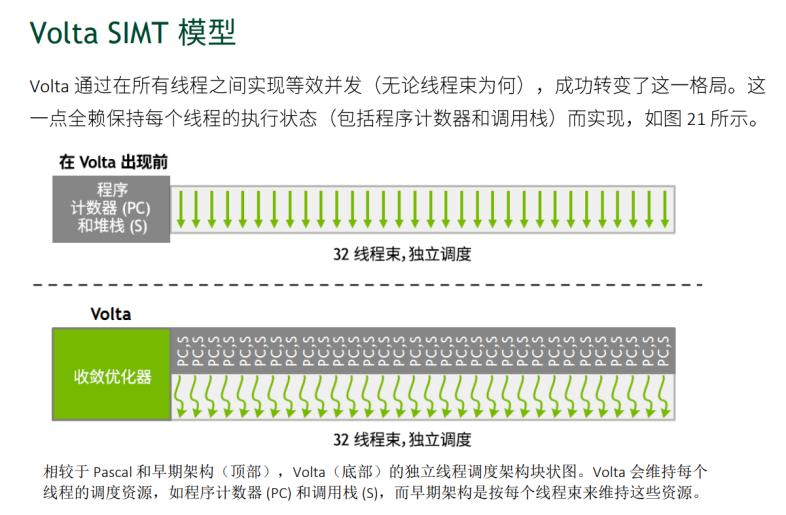
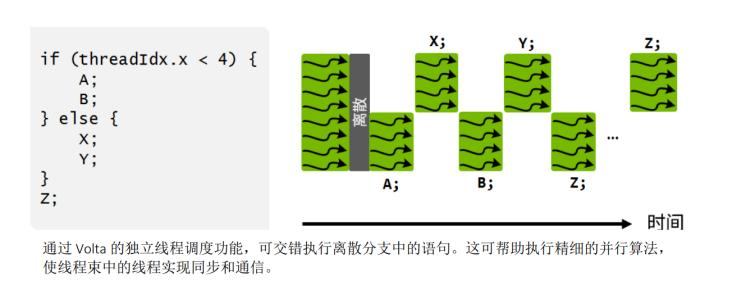
虽然这听起来就像南科大任选课程任选专业一样非常的自由,但是在实际执行中我们仍然不能有部分线程执行A,同时有的线程执行X。主要原因是害怕A和X会互相影响。它这么做的目的是可以精细化管理线程。它的力量我们会在后面发现。
不过你这时可能要问了:诶,那这样我们好像执行的时间还比之前早期的用时还长啊!原本时间是A+B+X+Y+Z,现在变成A+X+B+Y+Z+Z了。这里要注意的是,GPU在执行时有访存时间约束。
这就提到GPU的另一个技术:throughput。
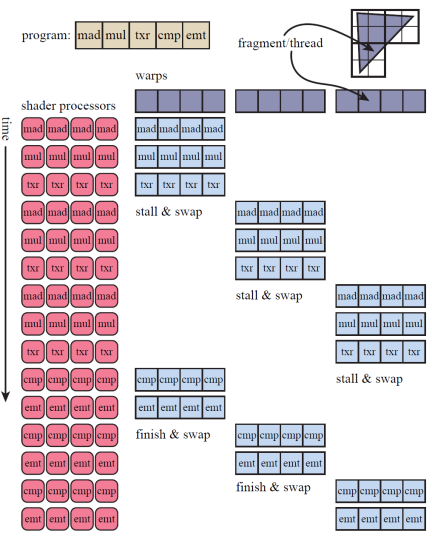
假设我们现在的任务是光栅渲染。现在,我们使用GPU中的warp来渲染。我们将取出数据,EX,然后MEM,这里边,我们会花很多时间进行访存,然后再存储。此时GPU的ALU不就没事干了,但是闲着也是闲着,GPU就会像上下文切换一样,换一批程序进行处理。这样,当比如说我们的着色器程序遇到内存读取操作时,如访问纹理,因为32个threads执行的是相同的程序,所以它们会同时遇到该操作,内存读取意味着该线程组将会阻塞(stall),全部等待内存读取的结果。为了降低延迟,GPU的warp调度器会将当前阻塞的warp换出,用另一组包含32个线程的warp来代替执行。换出操作跟单核的任务调度一样的快,因为在换入换出时,每个线程的数据都没有被触碰,每个线程都有它自己的寄存器,每个warp都负责记录它执行到了哪条指令。换入一个新的warp,不过是将GPU 的shader cores切换到另一组线程上继续执行,除此之外没有其他额外的开销。通过这样精细化线程,我们发现我们可以更好地利用好访存的时间进行别的运算,降低运算总体时间。但是,在这种技术下的运行时间仍然是大于直接运算的时间的。
因此,分支是并行计算里一个比较可怕的事情。因为分支,本来可以一起add的指令,现在只能你add我sub,这样的性能下降是我们在把一般的算法用到CUDA中必须要考虑的问题。
第三个问题是负载均衡问题。可能有的子图非常大,给一个线程算就太慢了。而GPU每次就必须等最慢的那个子图算完才能输出,此时其他线程都在围观,这是非常难受的。
以往的GPU在图论方面的算法有maximal clique enumeration, graph pattern mining,优化方法有data graph partitioning, two-level parallelism, adaptive buffering, hybird order。但是他们都只适用于小点数的图,面对大点数的MBE无能为力。
但是我们就比较牛。第一,面对内存问题,我们将递归变回for+栈(递归本质),同时重复利用root node的Memory而不是自己copy新的一份。第二面对分支问题,我们使用local neighborhood size来减少搜索空间,从而减少if的次数。第三面对负载问题,我们会根据subtree的具体大小来动态分配线程任务。
我们用的操作是使用 fast CUDA primitives 线程束级原语来实现我们的GPU上MBE(后称GMBE)算法。"线程束级原语" 指的是 CUDA 中针对线程束(thread warp)级别的操作或功能。线程束是 CUDA 中最小的并行执行单元,通常包含 32 个线程。线程束级原语允许开发者直接操作线程束,以实现更细粒度的控制和优化。
我们拿下面这个例子进行介绍,在一个带选择分支的语句中,我们先算出这个线程的tid(thread id),然后根据线程id进行判断。但是正如我们刚才所说,这会导致一个warp内32个线程,有16个走左边,16个走右边的情况发生。而我们希望的是,一个warp 32线程走左边,另一个warp 32线程走右边。
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if (tid % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}那么我们就可以这样写我们的代码:在判断时加上warpSize,第一个线程束内的线程编号tid从0到31,tid/warpSize都等于0,那么就都执行if语句。第二个线程束内的线程编号tid从32到63,tid/warpSize都等于1,执行else语句。
这样,我们的线程束内就没有了分支,提高了我们的效率。 线程束级原语的设计是目前学界感兴趣的一项研究项目。文章[7]探讨了不同的线程束级原语的设计及对效率的影响。文章[8]使用了原语来实施最小生成树算法(如右图)。文章[9]利用了原语中的Scan(类似于MPI Scan,将各个线程的结果发至一个线程),实现了GPU上的高效快速排序和稀疏矩阵乘法,并将其应用到图形浅水流体模拟上。文章[16]则是一篇古老的文章,它是最早将渲染算法用更精细的原语实现的文章。
原语中有很多精细的操作。比如当warp中的线程需要执行比数据交换原语所提供的更复杂的通信或选择操作时,可以使用该syncwarp()原语来同步warp中的线程。它类似于syncthreads()原语(同步线程块中的所有线程),但粒度更细。
void __syncwarp(unsigned mask=FULL_MASK);
__syncwarp() 原语使正在执行的线程等待,直到指定的所有线程mask都已执行了__syncwarp()(具有相同的mask),然后才恢复执行。它还提供了一个 内存屏障, 以允许线程在调用原语之前和之后通过内存进行通信。
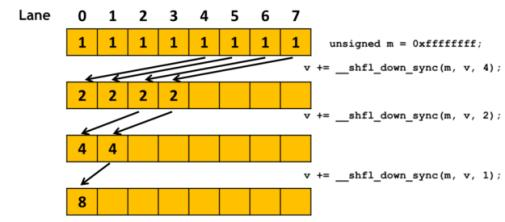
每个“同步数据交换”原语在线程束中的一组线程之间执行集合操作。例如,表2显示了其中的三个。每个线程在同一warp中从一个线程调用__shfl_sync()或 __shfl_down_sync()接收数据,并且每个调用的线程都__ballot_sync()接收一个位掩码,该掩码表示warp中所有传递谓词参数真值的线程。
int __shfl_sync(unsigned mask, int val, int src_line, int width=warpSize);
int __shfl_down_sync(unsigned mask, int var, unsigned detla,
int width=warpSize);
int __ballot_sync(unsigned mask, int predicate);参与调用每个原语的线程集使用32位掩码指定,这是这些原语的第一个参数。必须使所有参与线程同步,以使选择操作正常工作。因此,如果这些原语尚未同步,则它们首先将同步线程。
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize) % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}另外,我也看到可以使用下面的命令查看CUDA运行时的branch efficiency:
nvprof _--metrics branch_efficiency ./divergence_
这个branch efficiency是由下面这个计算公式得来的:

有趣的是,文章中还提到,这种分支效率有时候会被nvcc编译器优化改进。也就是说,我们的nvcc还是会做一些优化的,只不过不是CPU上的优化,而是在GPU上的。
接下来就是论文里的具体操作了。原始的方法是使用递归进行操作,然后每一个线程负责不同的节点底下不同的分支,在DFS下找到新的节点,判断构建的二部图是否可以继续扩大。
那么我们首先进行一下内存的分析。首先按照这样的算法的操作,我们根据测试案例,给到每一个SM的子图大概需要3.67GB。而如果想利用上A100内的108个SM,我们需要397GB。
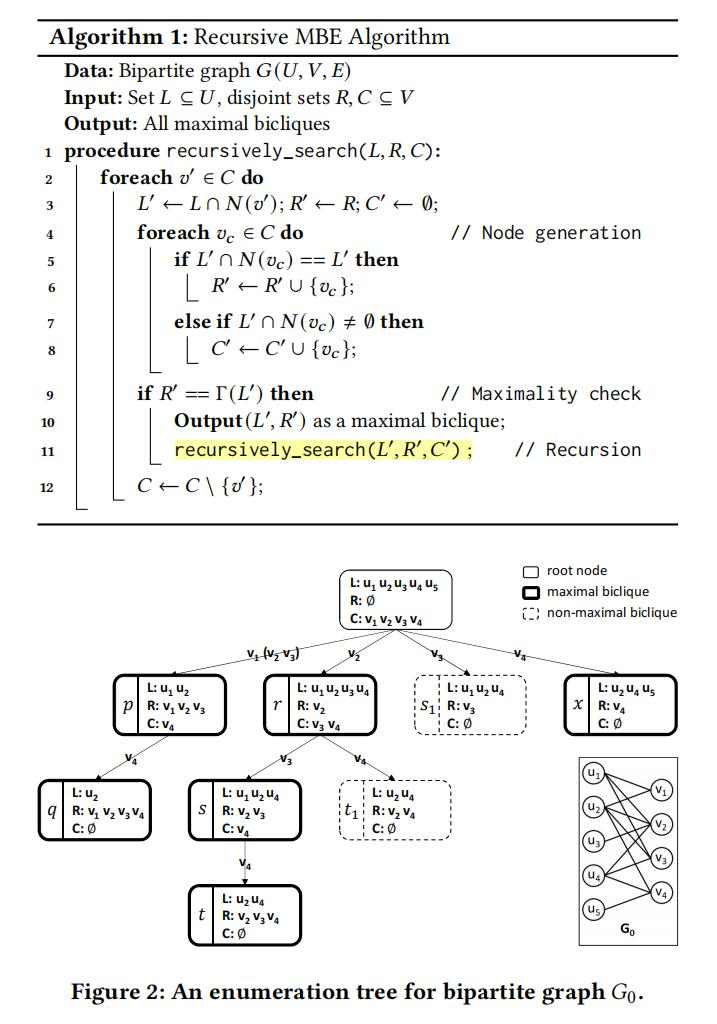
那么我们自然会想到,诶既然你给每一个SM都来一个子图,你为什么不造一个更大的图,然后几个SM一起共用,这样子不就节省了一些内存吗?确实,他们就是这么做的。请看算法。
如图所示,将递归更改成栈之后,我们的node buffer就可以继续利用下去,从而使得GPU内的资源就可以重复利用。虽然这样存储单个子树的大小提高,但是整体的大小变小。在选用的数据集上,因为每个过程只需要(3×13,601 + 2×53,915)×sizeof(int) = 595 KB。与3.1节中讨论的简单实现需要13,601×(13,601+53,915)×sizeof(int)= 3.67 GB相比,这种节点重用方法极大节省了内存空间。

Pruning
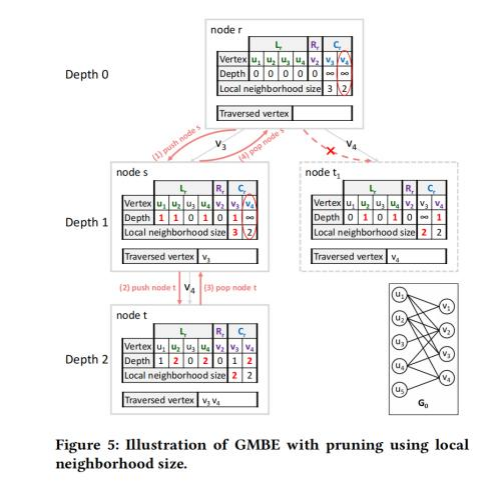
下一个优化是剪枝。由于这里跟文章的算法紧密相关,我就简单介绍一下。我们这个GMBE算法里最大的if分支是右图的第10-13行。而在这之中作者通过证明发现,我们将一个顶点v∈V的local neighbors定义为v连接的其他节点。比如图5中的v4,连着u4,u5两个点,local neighbors数量为2。V3连着u1,u2,u4,数量为3。接着,我们发现如果跳出遍历子节点到别的节点,它们当中的点的local neighbors大小不改变,我们就可以不用去检验大小不改变的节点。这样的剪枝方法具有较低的线程散度,因为不同的线程总是检查同一候选集中的元素。

PT
面对下一个负载均衡的问题,研究人员使用了一个叫 persistent thread 持久线程的东西。什么是持久性线程?
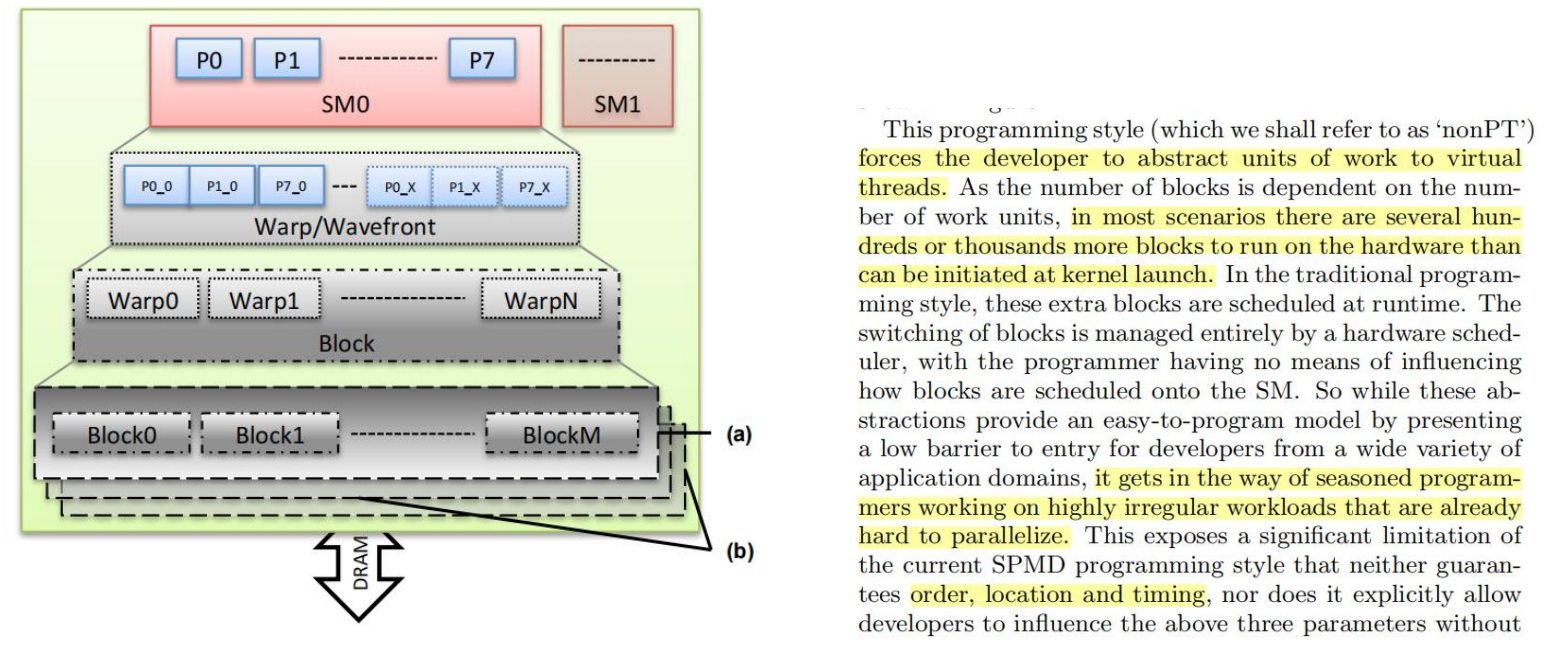
这是一个更加底层并且提升效率的线程设计。文章[5]重点分析了这个设计。GPU的硬件和编程风格的设计使得它们严重依赖于单指令多线程(SIMT)和单程序多数据(SPMD)编程范例。这两种范式都虚拟化了多层次的底层硬件,从实际的硬件操作中抽象出软件程序员的视图。物理SIMD流多处理器(SM)的每个通道都被虚拟化成更大批量的线程,这些线程是SIMD通道宽度的倍数,称为扭曲或波前(SIMT处理)。就像在SIMD处理中一样,每个warp都以锁步的方式操作,并执行相同的指令,在硬件处理器上进行时间多路复用。多个线程被组合在一起,形成一个更高的抽象,称为线程块blocks,每个块内的线程允许在运行时通过L1缓存/共享内存或寄存器进行通信和共享数据。该过程被进一步虚拟化,多个线程块被同时调度到每个SM上,每个块在不同数据上的不同程序实例上独立运行(SPMD处理)。
这种编程风格(我们将称之为“non-PT”)迫使开发人员将工作单元抽象到虚拟线程中。由于块的数量取决于工作单元的数量,在大多数情况下,在硬件上运行比内核启动时启动的块多几百或数千个块。在传统的编程风格中,这些额外的块在运行时被调度。块的切换完全由一个硬件调度器来管理,而程序员则没有办法影响如何将块调度到SM上。因此,虽然这些抽象通过为来自各种应用程序领域的开发人员提供了一个低的程序进入模型,但它阻碍了经验丰富的程序员工作已经难以并行化的高度不规则的工作负载。这暴露了当前SPMD编程风格的一个重大限制,它既不保证顺序、位置和时间,也不明确允许开发人员不影响上述三个参数。
另外一些可怕的性质,比如,1.主从设备导致GPU只能听从CPU发送具体代码,2.运行时决策使得我们不能保证将在何时何地调度块。3.块状态设计让GPU 的一个新的块被映射到一个特定的SM时,该SM上的旧状态(寄存器和共享内存)会被认为是过时的,不允许块之间的任何通信,即使在同一SM上运行时也是如此。4.块间通信的唯一机制是全局内存,块作为独立内容,这样的通信可能性能不足。5.生产消费结构,内核只能在运行到完成时生成数据。在这个内核产生的GPU上的数据需要另一个内核。6.内核独立单一,即内核不能调用自身的另一个副本(递归),不能生成其他内核,或者动态添加更多块。在调用之间存在数据重用的情况下,这种成本尤其昂贵。
为了规避这些限制,PT诞生了,它可以涉及较低层次的抽象化,通过直接控制调度来提升性能。全文中最直白地解释持久化线程的便是下面这幅图:
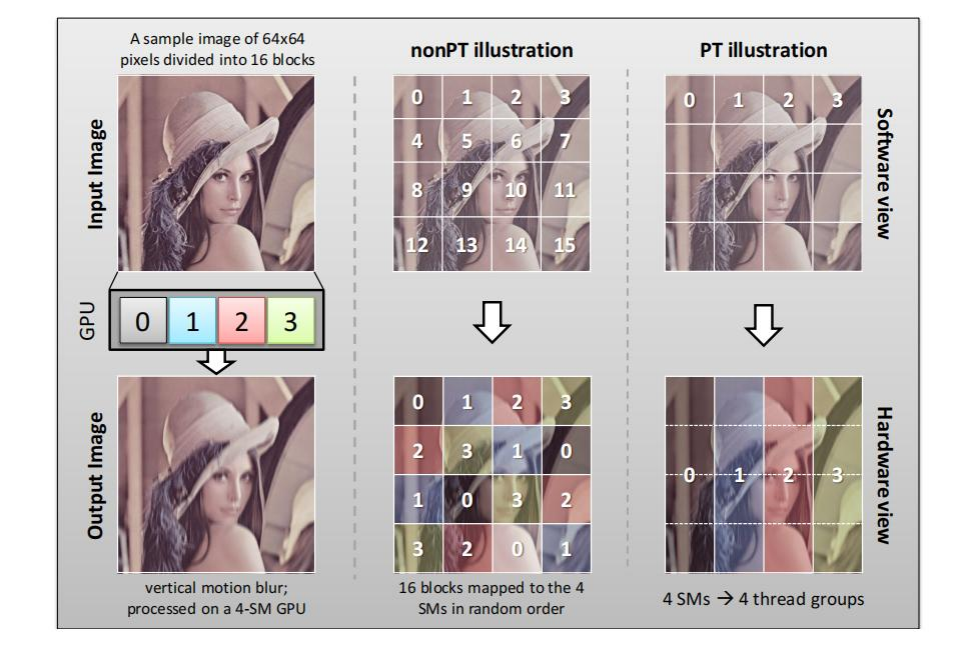
在这幅图片里,假设我们的GPU一共有4个SM来执行对Lenna图像的处理。如果是nonPT的普通线程,GPU内的硬件调度器就会启动16个block来执行处理操作,而这些block会在物理层面上对应到相应的SM上(SM0,SM1,SM2,SM3),但是,我们可以看到这样的操作就有点不是很好,1.调度器要重新分配线程和数据;2.如果是对图像变暗变亮,那还好,但是如果是卷积或者跟相邻块要共用的操作,那我们要花一部分时间重新搬运回数据。
但是我们看右边的PT线程,他们从始至终只有4个,对应4个SM。首先从内存访问上来说,我们可以更好地安排存储,Cache在导入n-way数据后,我们的SM访问时的Cache Hit Rate就可以更高(又是你,计组)。同时,数据在像素跨垂直块边界共享时进行重用,这对卷积什么的操作也挺不错的。
因此,编程的持久线程风格改变了虚拟软件线程的生命周期的概念,使它们更接近物理硬件线程的执行寿命,也就是说,让程序员能够控制线程在内核的持续时间。
那么,PT线程有什么样的功用呢?文章[5]给了4个例子:
- CPU-GPU同步
- 负载均衡(也是我们的前面文章用到的)
- 本地化生产者-消费者
- 全局同步

CPU-GPU同步
对于第一个功用,由于CPU(主机)和GPU(设备)作为主设备和从设备耦合在一起,因此设备缺乏向自己提交工作的能力。除了内核中内置的功能之外,GPU还依赖于主机来发出所有的数据移动、执行和同步命令。如果生产者内核为消费者内核在运行时处理生成可变数量的项目,主机必须发出回读消息,确定消耗中间数据所需的块数,然后启动新内核。读取备份有显著的开销,特别是在主机和设备不共享同一内存空间或不在同一芯片上的系统中。

但是,在有持久性线程后,数据一旦从CPU来到GPU-kP(生产者),之后就能一直计算到GPU-kC,数据不会因为线程结束而自动消失,GPU会保持运算一直到需要再次访问数据的时刻。这样,我们就节省了重新向CPU申请大量数据的时间。
这里涉及到一个生产者消费者模型的概念。我推测它跟OS的生成者消费者模型是差不多的。在我们的CPU多线程中,我们将程序分成生产者和消费者。生产者生产数据,消费者使用数据。
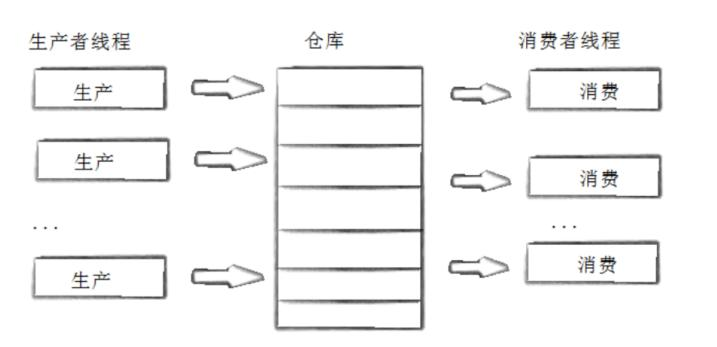
如果生产者生产数据的速度很快,而消费者消费数据的速度很慢,那么生产者就必须等待消费者消费完了数据才能够继续生产数据,同理如果消费者的速度大于生产者那么消费者就会经常处理等待状态,所以为了达到生产者和消费者生产数据和消费数据之间的平衡,那么就需要一个缓冲区buffer用来存储生产者生产的数据。
生产者消费者模式就是通过一个仓库buffer来解决生产者和消费者的速度不匹配问题。生产者和消费者彼此之间不直接通讯,他们通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
这样,我们就可以增加生产者线程或者消费者线程,而不会对整个程序的正确性产生影响,同时我们也可以根据不同硬件访问速度的不同动态地控制两者的比例。
在GPU上,我们通过将生产者和消费者PT化,让他们持久地运输数据或计算数据,就可以避免开启线程以及重新搬运数据的时间。
负载均衡
文章[12]针对光线射线追踪,使用了PT进行加速。
在文章中,PT的主要作用是通过保持一些长时间运行的射线线程,避免了频繁创建和销毁线程的开销,从而提高了SIMD的效率和利用率。通过让每条射线处理时所有的遍历都保持在一个块中,绕过硬件调度器,从而可以提高线程对数据的重复利用。而在短时间内完成渲染的PT,可以接着拿到下一个分配任务。如果我们不使用PT,我们就会重开一个线程,刷新掉缓存里的数据,开销就更大了。
因此,PT对于不规则的数据处理,比如树、图,是比较有效的。
本地化生产者-消费者
在我们了解了CPU内的生产者消费者模型后,这个标题我们自然也很好理解了。
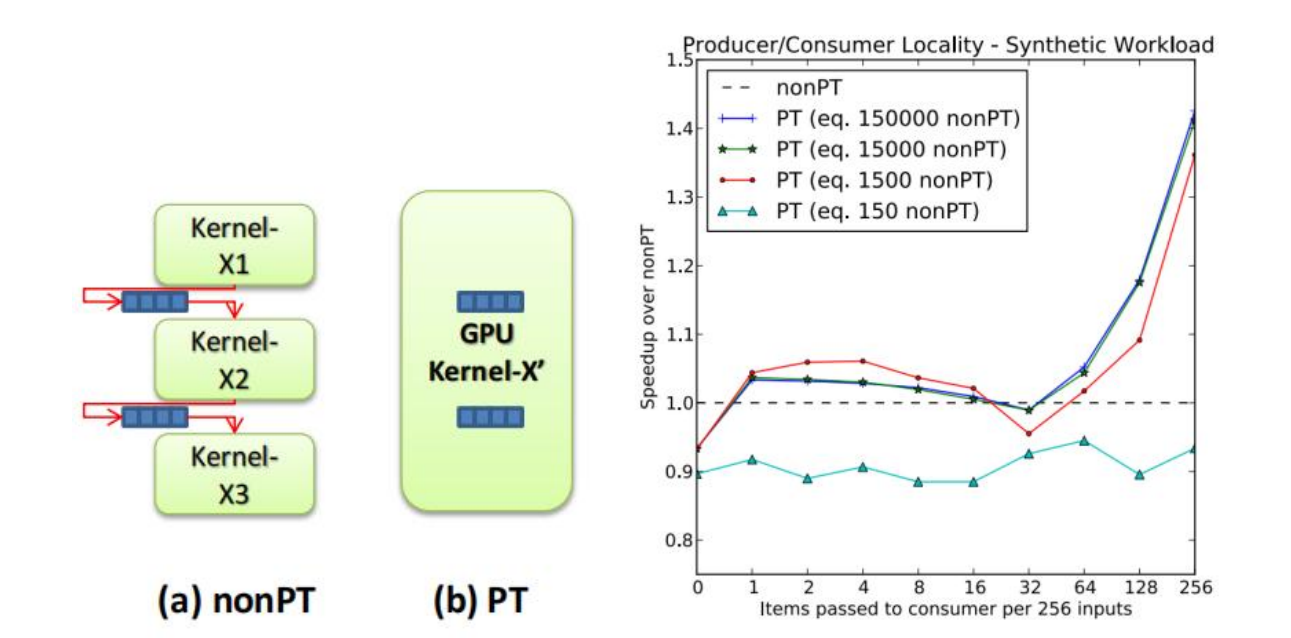
对于一个生产者消费者,如果我们不使用PT,我们的Kernel之间想实现这个模型,就只能是一个生产者模型,一个消费者模型。他们通过GPU L2 Cache或者DRAM通信。这样的成本就非常大了。但是,如果我们现在只使用一个Kernel,它经历两个阶段:阶段A是生产者,将数据拉到GPU并尝试填满内存;如果内存满了,Kernel进入阶段B:消费者,Kernel开始搬运数据试图清空内存。此时Kernel由于是在PT情况下执行,这些内存始终是在离Kernel物理执行的SM处最近的地方,因此此时访存的成本就可以大大降低了。
全局同步
GPU为在同一个块中的线程同步提供了硬件支持,但GPU对在同一个SM中的不同block乃至整个GPU中,没有提供同步。那么我们同样是可以使用一个大PT来解决问题的。我们将不同的Kernel合并成一个Kernel-X’,当每个blocks完成一个计算时,它就开始处理下一个阶段的blocks。这个阶段就是对块进行全局同步的阶段。


所以我们可以看到,PT作为一个持久化的线程,让我们更好地操作我们的GPU。它的语法格式也还比较简单,具体类似如下:
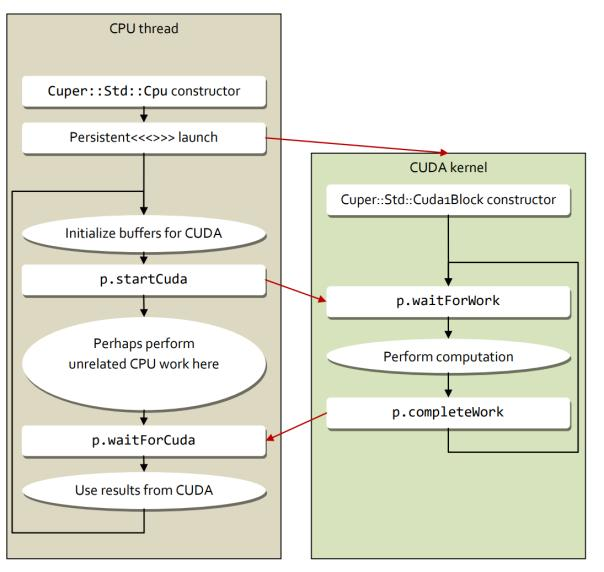
CPU在lunch线程后,CUDA会接收说哪个线程现在处于启动状态(有点像CPU的线程启动模式),然后CPU说线程启动,CUDA就开始计算,CPU会在waitforCUDA那边等待GPU线程完成的信号。
现在我们回到论文,通过在PT上进行改进,我们就可以对特定的搜索给定特定的线程,从而加速搜索的速度。
随后文章就到了实施细节和测试环节。实施环节提到了写算法时要特地注意的部分,测试则针对不同的数据集,不同的GPU,多GPU进行了测试,并比较了三个优化产生的效果。这里我们就不再详细查看。但是总结一下的话,这篇文章里我们学到了下面3个技术以及研究方向:
-
线程束级原语——更精细化的核函数设计
-
PT持久线程——核函数间更负载均衡
-
内存复用——更好的内存设计

从这篇文章中我们可以看到,1.内存是我们开始加速计算的一个起点,解决不了内存问题,加速计算就无从谈起。2.线程计算的精细化与复杂化是目前加速计算研究的一个方向,如何让线程计算更复杂的算法,让原本单核运行的算法多核化,才能让加速计算的应用方向更加广泛。
在GPU上复杂算法的实现是目前GPU研究中的一个重要方向。在矩阵计算之外,我们还有很多算法支撑着我们的生活,而要想更快,我们的移植是无法阻挡的。在这之中,想实现一个好的移植算法,我们就要操控好线程,进行精细化的设计。
“
有个周末我带女儿 Madison 去书店,然后就看到了这本书 OpenGL手册,定义了硅谷图形的计算机图形处理方式。一本 68 美元,我带了几百块钱,买了三本。
我把书带回办公室,对大家说:「我找到了咱们的未来。」我把三本书分发下去传阅,中间有大幅的折叠插页,这个插页就是OpenGL流水线计算机图形处理流水线。我把它交给了与我共同创办公司的那些天才手中。
我们以前所未有的方式实现了OpenGL流水线,构建出了世界从未见过的东西。其中有很多经验教训。对我们公司来说,那一刻给了我们极大的信心:即使对所做的事情一无所知,也能成功创造出未来。
现在这就是我对任何事情的态度。当有人跟我说我没听过的事情,或者听说过但不懂原理,我的想法总是:能有多难呢?可能看本书就搞定了,可能找一篇论文就能搞清楚原理。
我确实花了很多时间阅读论文,这是真的。当然,你不能照搬别人的做法,指望会有不同的结果。但你可以了解某件事情的实现原理,然后回归问题的本质,扪心自问:基于现有的条件、动机、手段和工具,以及一切如今的变革,我会怎么去重做这件事?我会如何重新发明它?我会如何设计它?
如果今天造一辆车,我会沿用过去的方式吗?如果今天让我创造一台计算机,我会采用怎样的方式?如果今天让我来编写软件呢?
这么想有道理吗?即使是今天的公司,我也经常回归本质,从头思考。这是因为世界已经变了。过去编写软件的方式是单一的,是为超级计算机设计的,但现在软件架构已经解耦等等。我们今天思考软件、计算机的方式一直在改变。经常促使公司和自己回归问题本质,会创造出大量的机会。
”
论文2: GPU通信
看完这个方向后,我们再往一个系统一点的方向看看:GPU通信。虽然我们在Project4有所了解,但是我们可以再深入了解一下。

我们从这篇2020年的综述性的文章开始,它评估了现代GPU通信方法:PCIe,NVLink,NV-SLI,NVSwithc, GPUDirect。
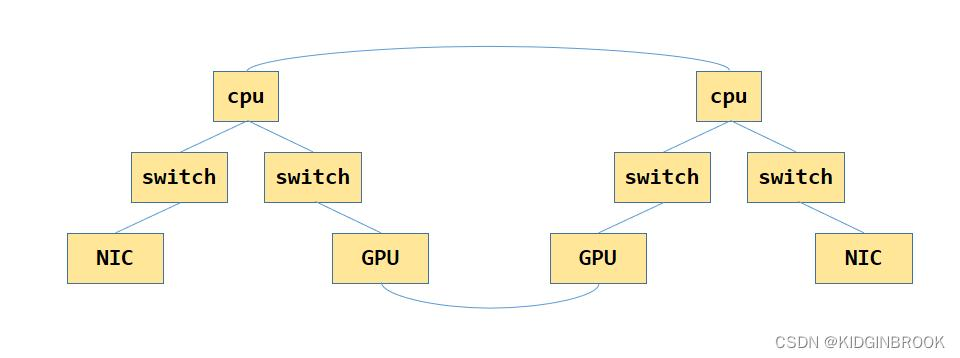
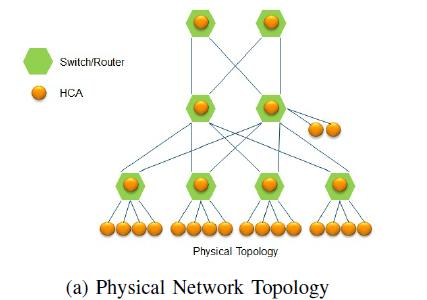
PCIe(Peripheral-Component-Interconnect-Express-Bus)是高速串行计算机扩展总线的标准,我们在Project4里详细介绍了PCIe与GPUDirect技术的点滴。然而,这对于需要大量数据的GPU来说,还是太慢了。传统的基于PCIe的CPU-GPU节点连接是一个树结构,CPU与GPU之间使用PCIe交换机连接,CPU内部使用QPI总线连接。但是,这意味着当GPU想跨树进行通信时,就得经过CPU。
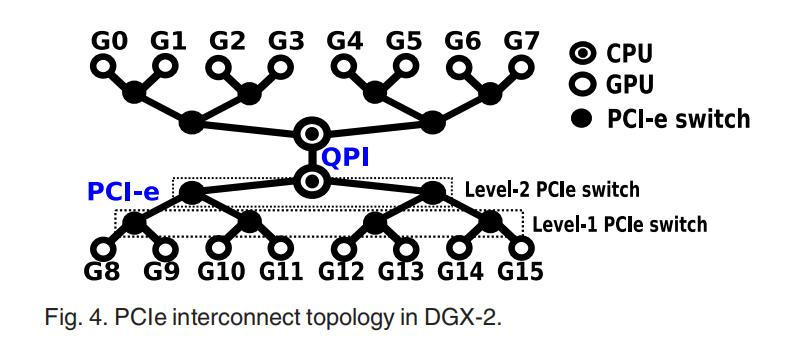
于是,英伟达提出了NVLink技术。对于一机8卡,除了传统的PCIe连接CPU与GPU以外,GPU-GPU通信使用NVLink技术,即图中的立方体的黑线。
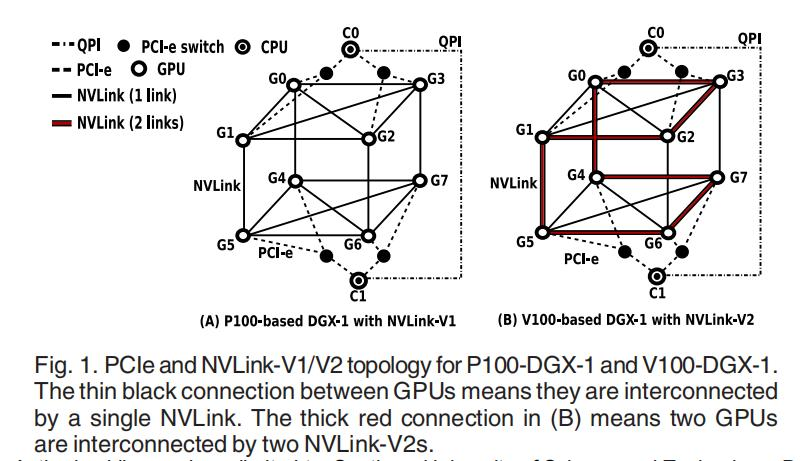
这种设计结构的特点在于,对于上平面和下平面,对角线也是连接的,形成两个完全连通的子集。这种拓扑设计是平衡的,在平面内具有更强的连通性。换句话说,在一个平面内访问是UMA,而跨平面访问节点会导致NUMA(当它们没有直接连接时,例如,从GPU-0到GPU-7)或者跨节点。我们平常说的NUMA性,意思拓展为节点内通信时长与成本并不相同。
NVLink2技术并没有选择进一步加强平面内的连通性,而是在超立方体-网格网络内形成了一个快速的骨干环。与其他链路相比,这个环中的每个连接都支持2倍的带宽,速度提升了两倍。NVLink2技术的目的不是消除NUMA性,而是提高集体沟通的效率。
Scalable Link Interface (SLI)可伸缩的链接接口将两个GPU配对,这样它们就可以相互通信和代码游戏,共同运行GPGPU任务,或共同共享GPU内存空间。这是给游戏玩家想用两张卡搭建的便携方案,让玩家低成本地玩到NVLink。

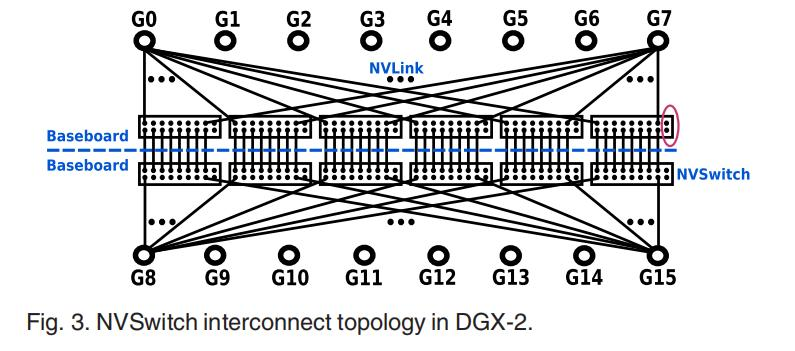
随着深度学习对GPU的需求大幅提高,NVSwitch终于到来。NVSwitch是一种基于NVLinkV2的交换机节点内通信芯片,每个交换机有18个NVLink端口。如下图所示,我们的单个节点内有两个基板,每个基板包含6个NVSwitchs,节点内共有8个GPU。一个V100 GPU包含6个NVLink插槽,8个GPU一共48个口,正好对应6个交换机的8个口。每个NVSwitch的带宽在50 GB/s,并且还是双工通信(天啊,这比UART高到不知道哪里去了)。
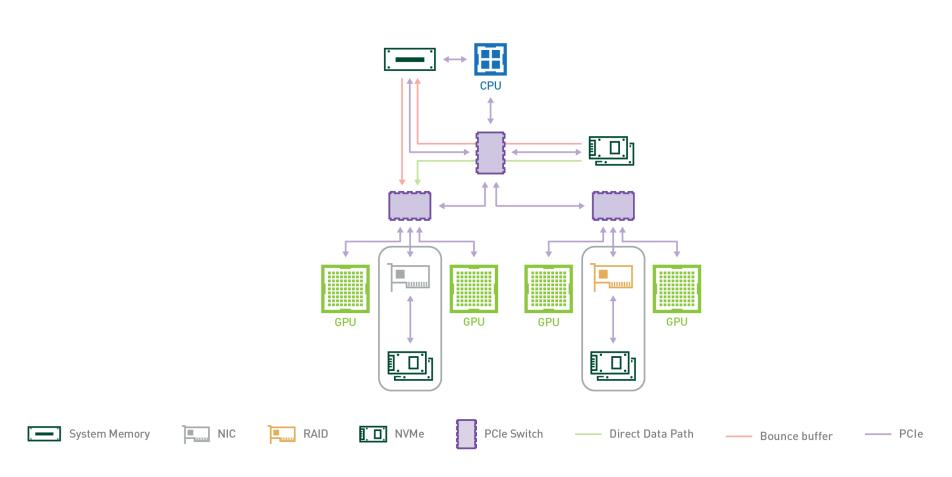
自Kepler架构以来,NVIDIA GPU引入了GPUDirect-RDMA(AMD其实也提出了ROCn-RDMA )。它使第三方PCIe设备,特别是IB主机通道适配器(即HCA)可以通过PCIe直接访问GPU设备内存,无需CPU或主存分段,显著提高了节点间GPU通信的效率。为了实现IB RDMA,GPU供应商提供了一个OS内核扩展,以返回一个针对GPU设备内存的DMA总线映射。当用户创建一个IB区域时,它用GPU设备内存的目标地址向IB驱动器发出信号。IB驱动程序然后调用一个例程来获取DMA映射。最后,一个正常的IB虚拟内存结构被返回给用户程序,就像它针对正常的CPU内存一样。
上面我们介绍了这么多的通信方法,这些方法可以让我们的GPU访问存储、互相通信地更快。但是,如果没有一个好模型,写多机多卡的CUDA程序员是会骂娘的。正如文章所说:有效地实现CL通信是具有挑战性的,因为:
(a)需要理解底层硬件网络拓扑,以实现协调映射;
(b)需要处理同步、重叠和死锁的问题;
(c)性能指标可能因应用程序特性而不同(例如,小传输面向延迟,但大传输面向带宽)。
为了减轻用户的这些负担,NVIDIA提供了集体通信库(NCCL),使用与MPI集体类似的原语,(AMD提供了RCCL)。NCCL目前支持五种CL模式:broadcast, all-gather, reduce, all-reduce, and reduce-scatter。
为了提供最大的带宽,NCCL在通信的GPU,CPU之间构造环状网络,通过将数据分割成小块,并以管道的方式沿着环状数据进行传输,可以有效地实现广播和减少。NVIDIA声称,该环算法可以为大多数标准的NCCL库内的操作提供接近最优的带宽,并且可以很容易地应用于各种网络拓扑。
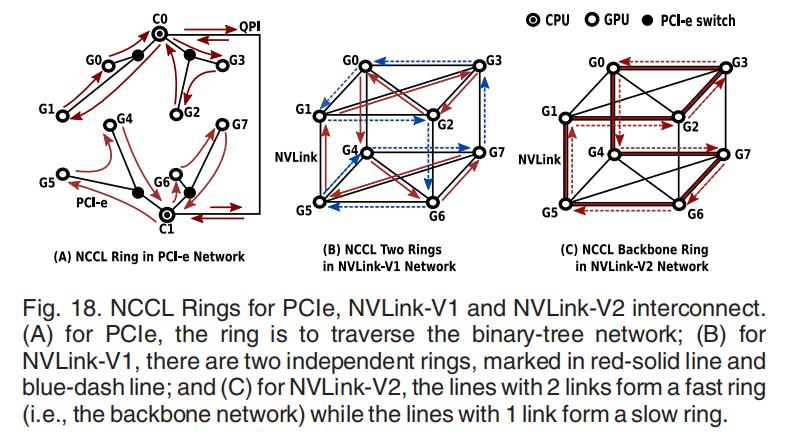
NCCL做了什么?
比较可惜的是,NCCL库只开源了旧版本。我们可以从博客[7]中简单看看NCCL会做什么。这里一共有14篇文章,把他们总结下来就是:
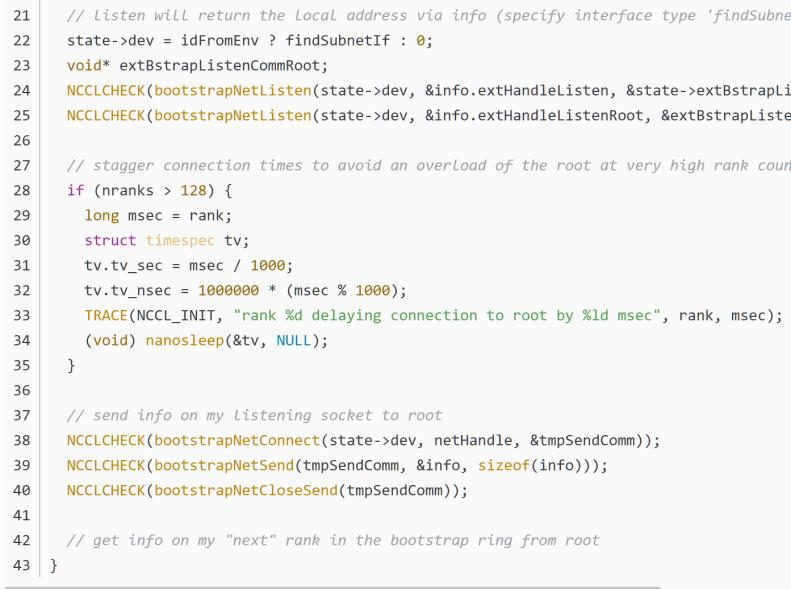
初始化
在初始化的过程,NCCL获取了当前机器上所有可用的GPU、对应的IB网卡和普通以太网卡的信息(如ip,连接方法),并保存下来,给每一个机器和端口生成ncclUniqueId。
建立网络
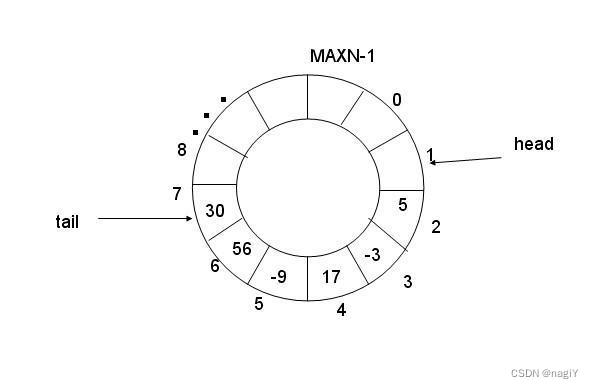
- 在每一个GPU都有自己的编号后,我们就能做到上图18所想要的环形算法了。NCCL会创建bootstrap环形网络连接,并保存到ncclComm里。而这里边的连接还是使用MPI,MPI给每一个GPU发送信号,给到他们的rank数。接着rank n的GPU会给rank n+1的GPU信号,构建环网。
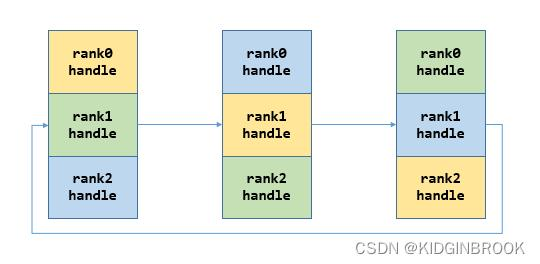
建立拓扑树
然而,这里NCCL还不知道我们集群的拓扑结构是怎么样的,它只是找到了所有人然后给他们轮成一圈。这里边每个人牵着谁的线还不知道呢。不过找结构的方法也没有想象的那么难,NCCL会根据每个rank GPU的hosthash进行判断,如果相等的话说明在同一个机器。接着,它会建一个树结构:
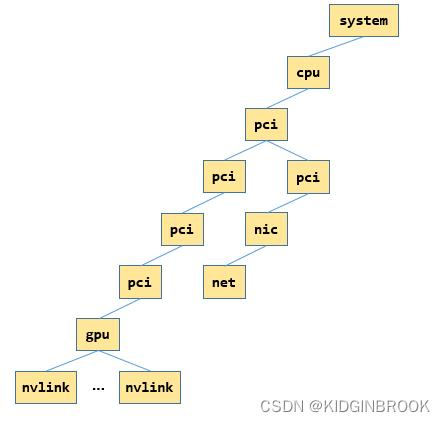
建立集群拓扑
在拿到节点树后,NCCL会把它变成UML格式。接着就可以建成我们之前看到的三维图了。具体其实跟DFS差不多,先从根节点递归遍历下去,直到遇到nvlink xml节点,然后拿到nvlink的父节点,即gpu节点,然后通过tclass获取对端PCI设备类型,如果是gpu或者cpu,直接返回对端node,如果是nvswitch,那就先创建nvswitch节点,然后创建当前gpu节点和对端的双向边。然后通过ncclTopoConnectCpus将cpu两两连接。建好的图就像下面这样:
求解最优带宽下的路径
接下来NCCL会先计算GPU和NIC节点到其他任意节点之间的最优路径,以及对应的带宽,即最优路径上所有边的带宽的最小值。算法设计一下,相当于给定一个无向图,每条边有一个权值,给定查询(u, v),求节点u到节点v的路径,使得路径上的权值最小的边的权值尽可能大。这其实就是个网络流问题,对应到ADAH就是Lab10。我们看洛谷P1396,用二分+SPFA可以通过,或者使用有的人说的MST+LCA。(哦,算法!)

不过博客介绍说,NCCL用的是并查集,在最后生成的图中,将不需要的网卡路径剪枝删除。嘛反正能达到目的就行。
利用SM建立 NCCL Channels
虽然建立了最小路径,但是,我们接下来要做的是建立NCCL Channels。这是什么呢?一个github issue是这么回答的:“Channels map to GPU SMs, so using more channels means using more GPU compute resources. NCCL tries to minimize the number of SMs it uses, while delivering the best performance. For TCP/IP sockets, the speed we're trying to achieve is usually less than 10GB/s, which we should be able to achieve with the minimal number of channels (2 currently, to ensure proper overlap and no bubbles).”
也就是说,我们可以把Channel理解为NCCL动态调配的一个通信网络口。它可以让GPU与别的GPU在SM中通信。如果Channel或者通信SM过少,我们的不能及时完成任务,如果Channel过多,对SM的资源占用也就过多。NCCL的目标是利用必要的最小SM数量以实现最佳性能。
这里有几个有用的名词:
NCCL_NSOCKS_PERTHREAD:此参数允许将单个通道的传输分散到多个套接字上。通过在多个套接字上分配工作量,它有助于减轻创建额外通道(从而利用更多GPU资源)的需要。
NCCL_SOCKET_NTHREADS:此参数用于将网络TCP/IP封装工作分配到多个CPU核心上,使用多线程。它解决了单CPU核心可能无法实现最大网络带宽的情况,特别是在像100GbE卡这样的高速网络适配器的情况下。
NCCL_MIN_NCHANNELS:此参数指定NCCL使用的最小通道数。增加此参数可以帮助克服网络限制、解决CPU瓶颈或增加GPU并行性。NCCL会根据系统的需求动态调整通道数量。
那么怎么去具体实现说想要几个Channel呢?我们仔细想想,一个人收数据,一个人发数据,其实跟我们之前学习的生产者消费者很像。我们能不能用生产者消费者确定要几个生产者消费者的算法,来确定NCCL Channel呢?
博客提到,NCCL内的channel数据结果collectives,就是一个类似于生产者消费者模型里的环形队列。这个环形队列就是我们之前buffer的具体实现。当环形队列为空或为满时,生产者和消费者才会相遇。消费者不能超过生产者,生产者不能超过消费者一个圈。生产者关心的是还剩多少剩余空间,消费者关心的是现有多少数据。生产者和消费者访问下标的行为互斥的,我们需要用一个char,把它称为锁,来解决判定互斥问题。
static ncclResult_t setupChannel(struct ncclComm* comm, int channelId, int rank, int nranks, int* ringRanks) {
TRACE(NCCL_INIT, "rank %d nranks %d", rank, nranks);
NCCLCHECK(initChannel(comm, channelId));
struct ncclRing* ring = &comm->channels[channelId].ring;
_// Reorganize ranks to start with rank._
int shift;
for (shift = 0; shift<nranks; shift++) {
if (ringRanks[shift] == rank) {
break;
}
}
for (int i=0; i<nranks; i++) {
ring->userRanks[i] = ringRanks[(i+shift)%nranks];
}那么在这里,生产者就是发送方SM,消费者就是接收方SM。在多GPU同时计算且它们需要数据交换和同步时,这样的NCCL通道提供了一种有效的机制来管理数据传输。面对不同的Channel,有多个不一样的生产者消费者,NCCL就会基于之前找到的机器结构,搜索出多组channel用于之后的数据通信。这些Channel会被记录到ncclTopoGraph中。
建立通讯链路
接下来是建立通讯链路的过程。博客写的很抽象,我也没学过计网,所以基于他给的总结尽量画图解释。
7.1 接收端执行recv setup,创建buffer,它将作为我们数据的临时集散地(因此这个buffer也自然是一个FIFO数据结构)。将相关信息记录到connectIndo,启动一个监听socket,ip port同样记录到connectInfo,通过bootstrap发送connectInfo到发送端。
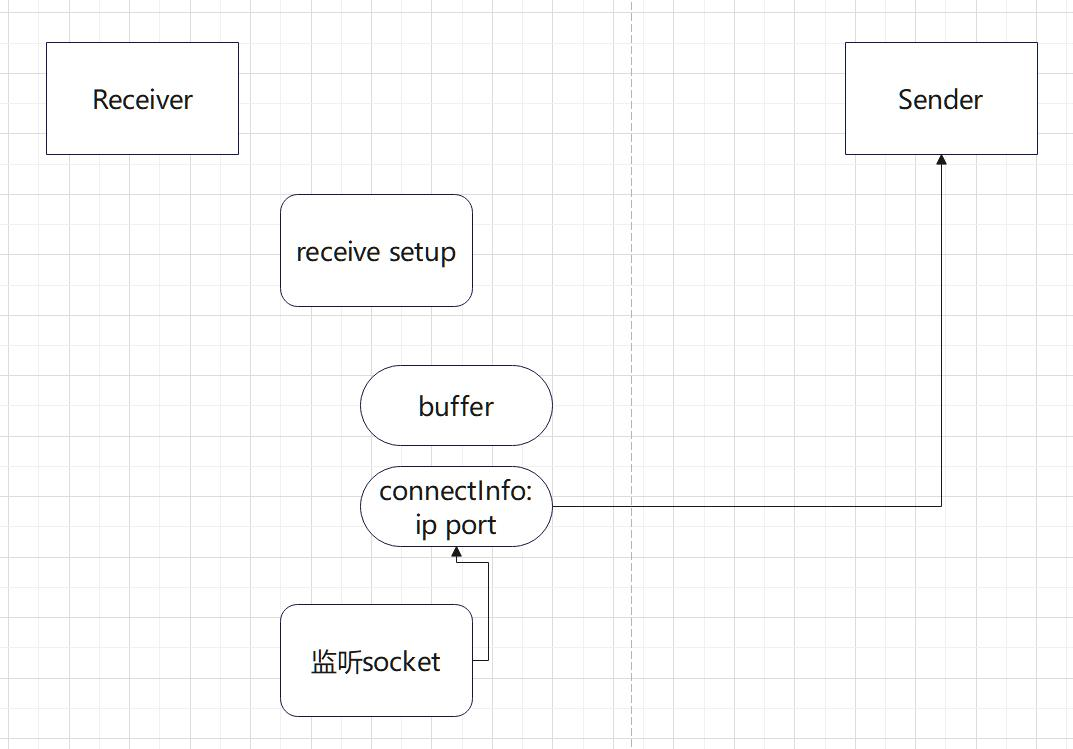
简单记录一下Socket是什么。Socket是一种在计算机网络通信中使用的编程接口,用于在不同主机之间进行通信。它提供了一种抽象层,使得应用程序能够通过网络发送和接收数据。Socket通常用于实现客户端-服务器模型,其中一个程序充当服务器,等待来自客户端的连接请求,而另一个程序充当客户端,向服务器发送请求并接收响应。
7.2 发送端执行send setup,创建buffer等,将相关信息记录到connectInfo,然后发送给接收端。这一步如果是RDMA场景,我们就不用connectInfo(Project4探索了部分RDMA的连接操作,RDMA的通信记录会跟OS内的RDMA驱动程序和相关库深度绑定,我们NCCL就不用再来管理这方面的记录)。
7.3 发送端接受到步骤1中接收端的信息,然后建立发送端到接收端的链接,p2p场景的话只是简单记录对端buffer,RDMA场景的话需要初始化QP到INIT状态。RDMA中的QP(Queue Pair,队列对)是RDMA通信中的一个重要概念,用于定义通信的端点和消息队列。每个QP都与一个本地端点和一个远程端点相关联,其中本地端点表示QP所在主机的地址和端口信息,远程端点表示与之通信的远程主机的地址和端口信息。
一个QP包含两个消息队列:发送队列(Send Queue)和接收队列(Receive Queue)。发送队列用于存储待发送的数据和RDMA操作请求,接收队列用于存储接收到的数据和RDMA操作完成事件。RDMA适配器在进行RDMA操作时会自动处理这些队列,从而实现数据传输和通信的目的。因此,这里QP其实就充当Buffer的作用,NCCL会根据系统状态自动判定是否需要再启用buffer。
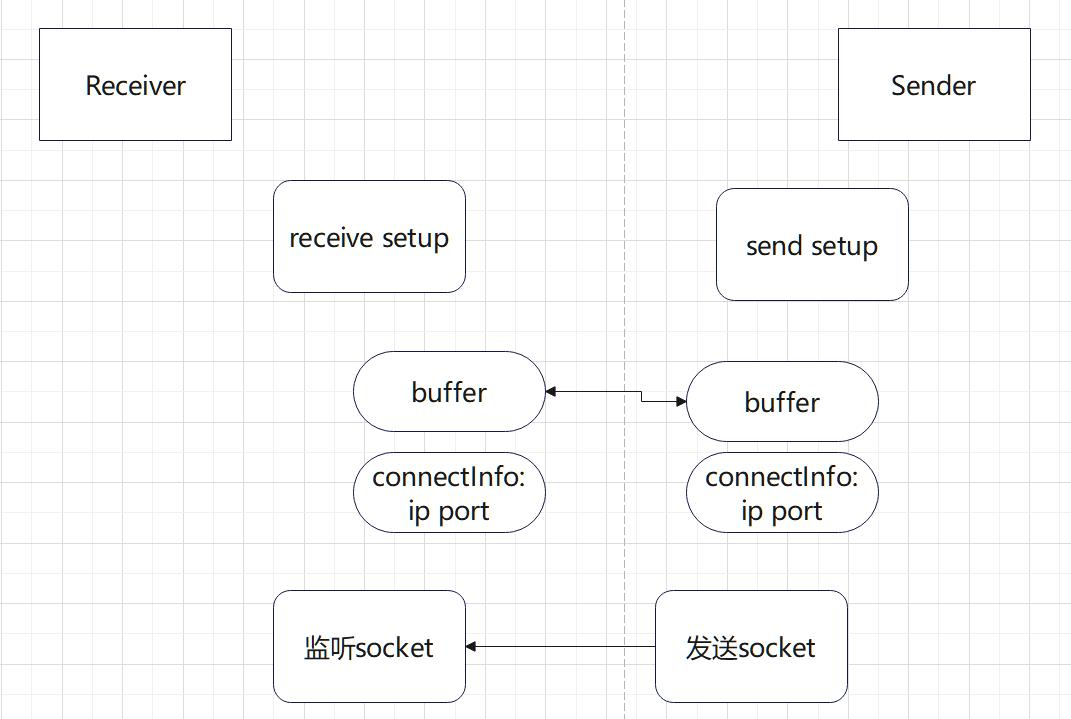
7.4 接收端 接受到步骤2中send发送的信息,然后建立接收端到发送端的链接,p2p场景还是记录对端buffer,RDMA场景需要初始化QP到RTS状态,将本端的QP信息发送回对端。(RTS状态表示发送端已经准备好发送数据,请求发送数据帧)
7.5 如果RDMA场景的话,发送端还需接收对端的QP状态初始化本端的QP到RTS状态。这是RDMA的QP是一个双向队列所需的额外确认。
在这之后,不同的接收端发送端就可以进行通信了。
NCCL中单节点2GPU通信
单节点两个GPU P2P通信的情况。
这里ncclSend/ncclRecv的过程,主要就是两步,先通过peerlist将用户的操作记录下来,根据记录生成kernel所需要的参数,然后启动kernel执行拷贝即可。
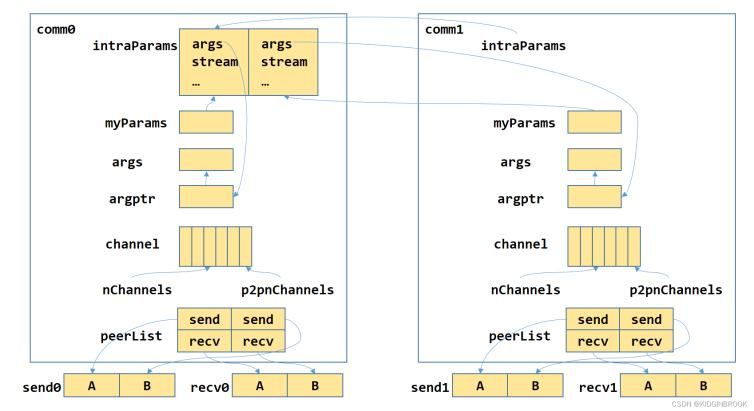
放到文中的图来讲,应该就是我们的数据 args stream被打包好后,由一个ptr带队(跟Project4 里的data*挺像的),然后选择我们GPU内的一个Channel,填写好发送方,随后发送。发送和接收的过程会根据我们之前确定的Channel,启动对应的CUDA核函数,在对应的SM上执行通信。每个ncclColl会执行ncclSendRecvKernel<4, FuncSum<int8_t>, int8_t>,有的线程负责发送,有的负责接收,还有一部分负责同步。在接收到数据后,还有一个核函数ReduceOrCopyMulti,它执行从buffer或者QP里数据的拷贝,每次拷贝长度为blockSize。
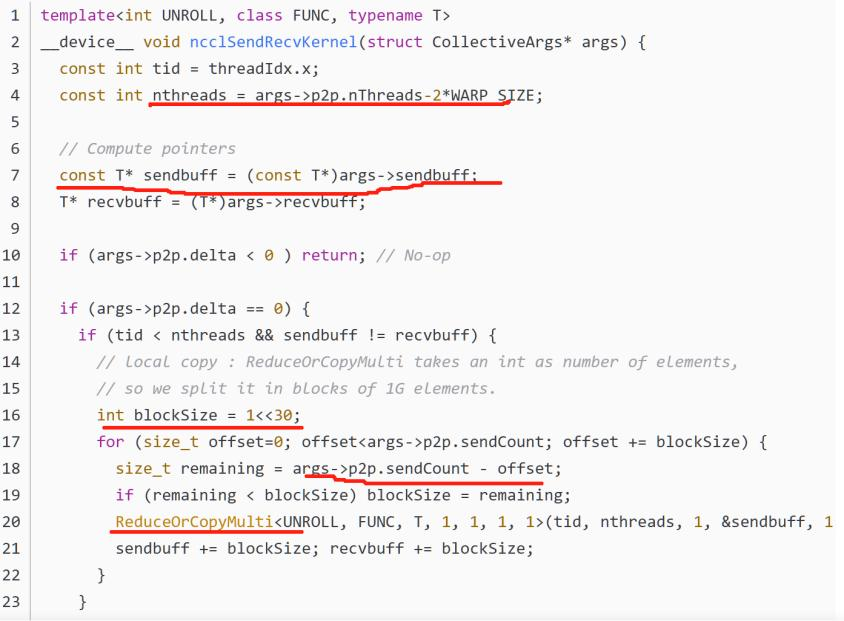
对于不同卡的情况,send将数据从用户指定的sendbuff拷贝到NCCL P2P transport的buff,recv将数据从buff拷贝到用户指定的recvbuff,NCCL通过head,tail指针来完成对发送和接收过程的协调;对于同卡的情况直接通过kernel将数据从sendbuff拷贝到recvbuff即可。
那么这里边buffer有一个重要的事情就是,记录数据传输到哪里了。这里是我看代码的理解,如果错了还请指出:就是我们建立连接的两端buffer是同步的,但是我们需要两个ptr,对准我们发送的数据。第一个ptr是tailptr,它是负责记录我们接收方接收数据到哪里了。第二个是send ptr,它是负责记录发送方发到哪里了。每次这些ptr都会前进block个数据(因为发送和接收就是这个速度),这样两边的连接就可以根据发送与接收的速度动态调整自己的线程接收情况,他们还要判断buffer是否是满的,这样才能保证数据被完整发送接收。
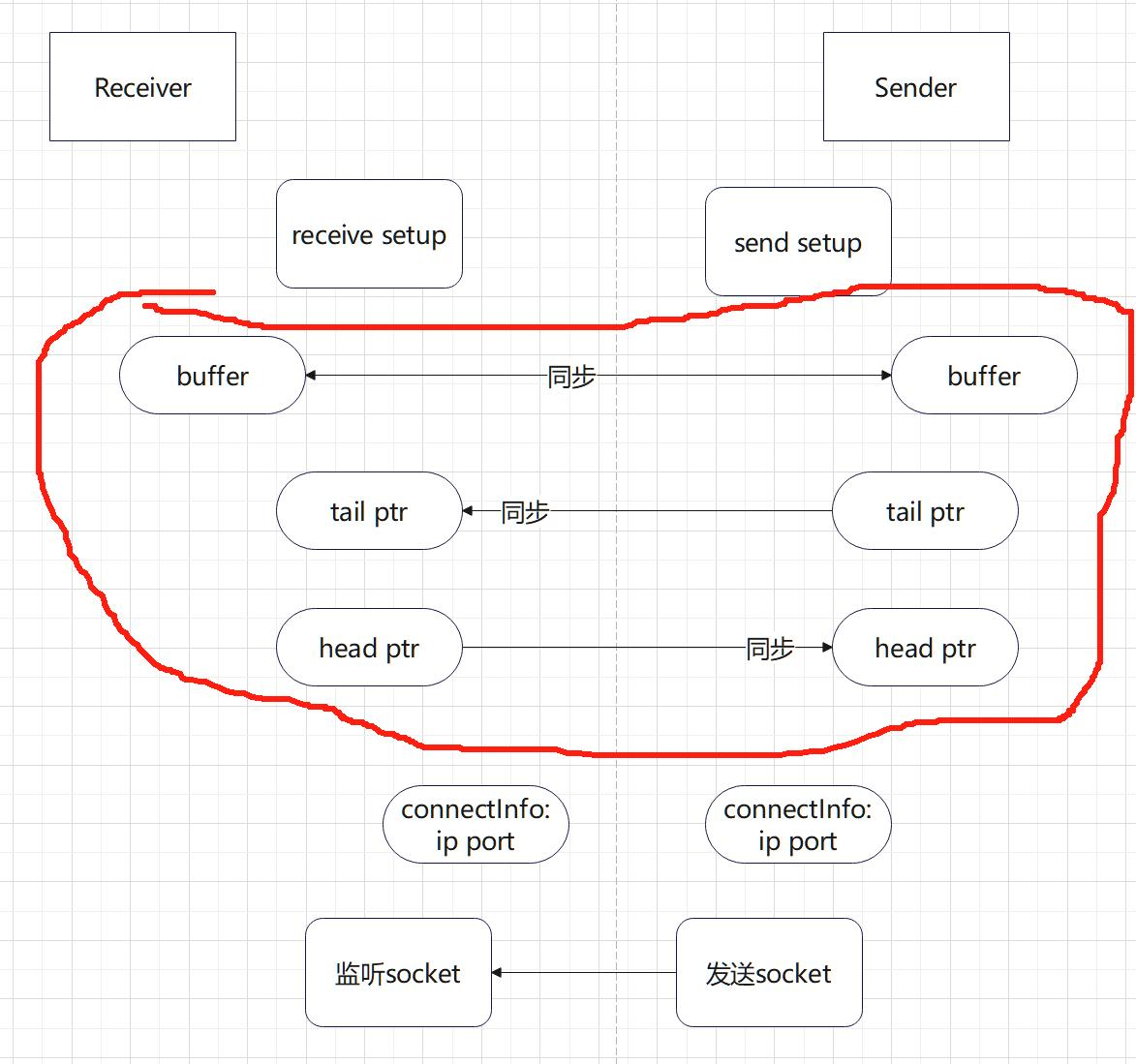
诶,这不就是我们的OS 生产者消费者模型吗?
多机多卡通信
刚刚我们看完了P2P通信,那么,怎么样PnP呢?我们开启n个Kernel,n个buffer,然后再在Kernel中每个都来一次上面的setup。但是,这样的话,好像一个Kernel管理的事情有点多,能不能Kernel就负责发数据,然后另一个人送数据呢?所以,我们采用了一个经典的proxy的思路。Proxy就像一个代理,它负责专门将一个GPU内不同的SenderKernel的buffer的数据送给不同的机器,GPU kernel负责计算所需传输的数据的地址以及数据量大小,而Proxy线程负责完成实际的数据传输。
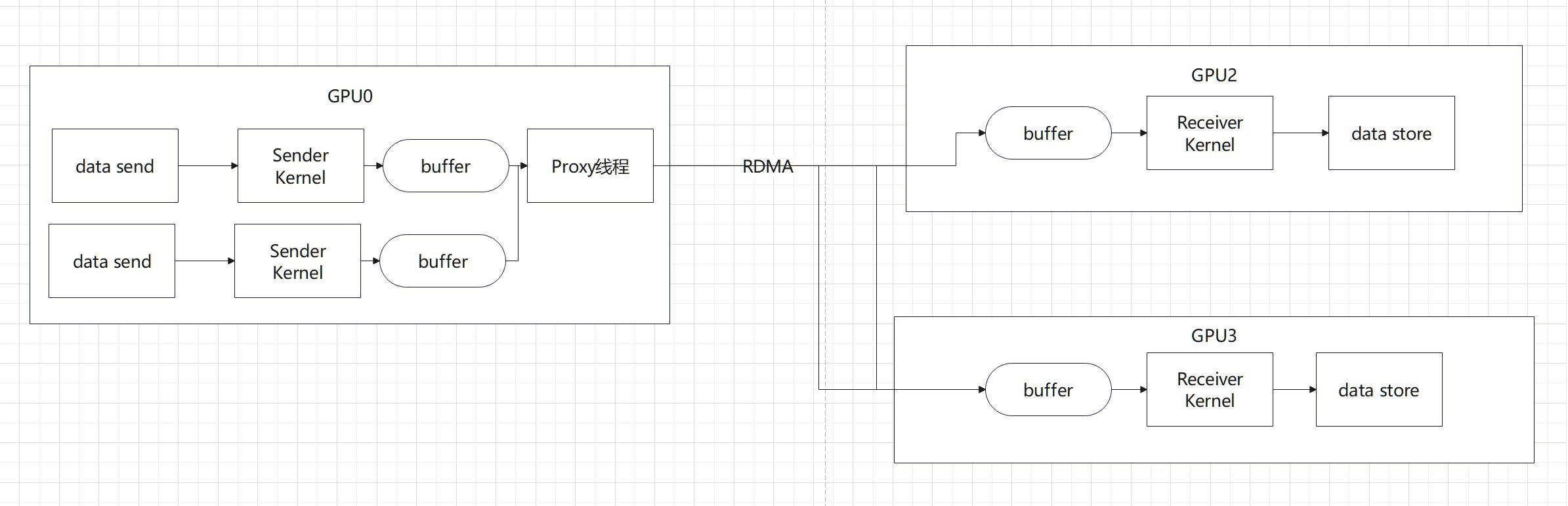
通信由kernel和proxy线程协调完成,send端kernel负责将数据从input搬运到buf,proxy线程负责将buf中数据通过网络发送给recv端。kernel和proxy间通过队列实现生产者消费者模式。
send端通过rdma send发送数据,和recv端通过队列实现生产者消费者模式,队列位于send端,recv端每次下发一个wr到rq之后会执行rdma write通知send端。
实现了多机多卡以后,后面的事情就好说了。比如文章10提到的ring allreduce环通信,文章11的double binary tree树通信,还有PS通信(父亲节点发信号给子节点,上传下达),我们只要管理proxy里下一个数据发给谁就好了,自从把proxy独立出来后,后面的协议都能比较简洁地实现。
这也包括后面交换机的引入。通过相关的树算法,我们就能建立GPU与Switch的网络拓扑树,实现在IB下的IB SHARP和NVLink下的NVLink SHARP。SHARP技术是IB交换机的计算卸载(Compute Offload)技术。它的核心思想是将计算任务的一部分从CPU卸载到网络交换机中进行处理,以减轻CPU的负担,并提高网络通信的效率和性能。同样的,这个技术也减轻了GPU通信负担,并在NVLink SHARP中得到了专门针对GPU的优化操作。
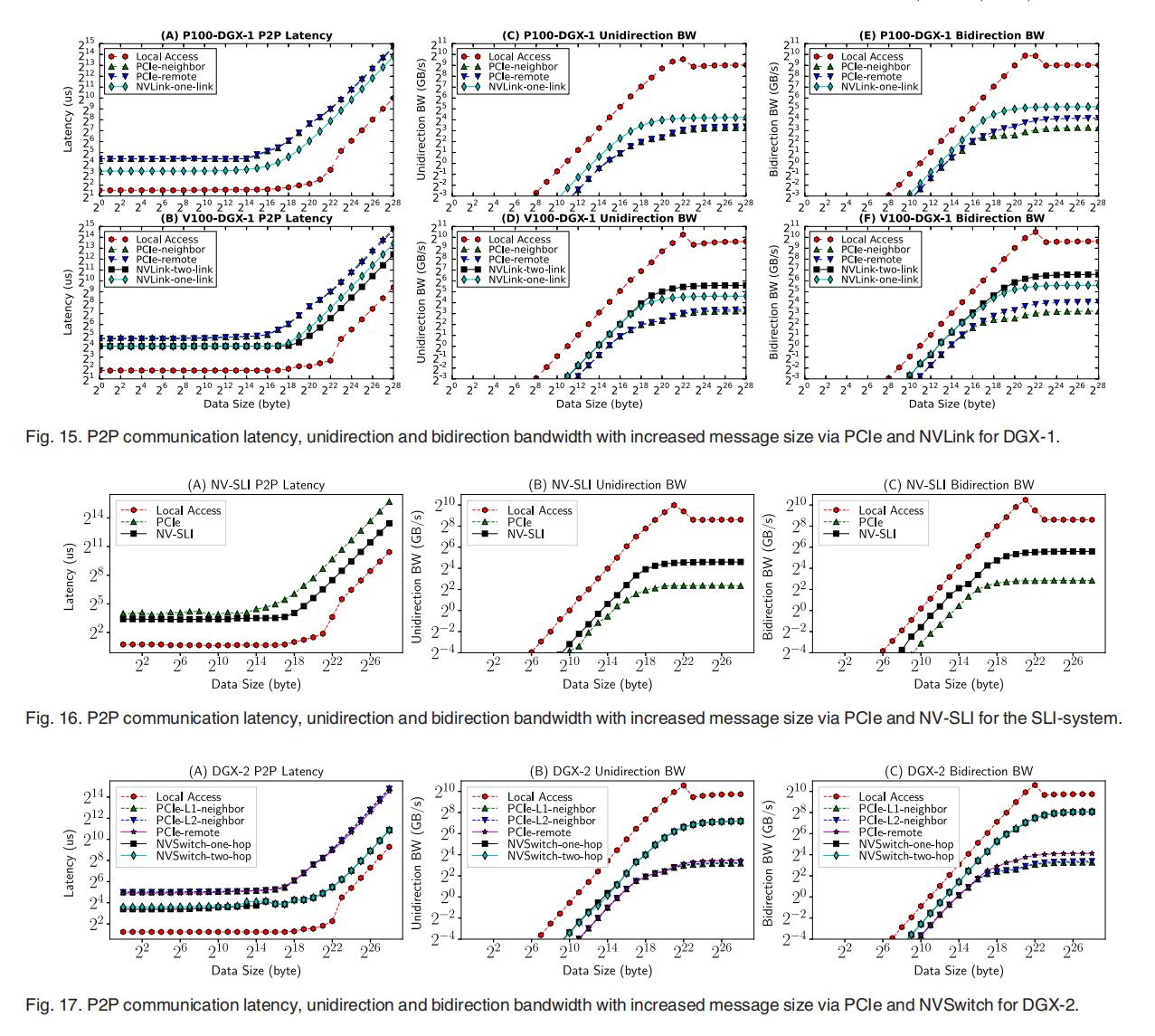
在上完这节计网课后,再回过头看看文章中的测试结果,是不是觉得很多都可以进行解释了?比如说,我们的数据latency,它有一个拐点,过了一定的数据规模后,latency就会突然疯狂上涨。我们就有理由怀疑,是不是我们的生产者消费者模型中的buffer填满了,导致接收端接收数据的速度慢下来了?
我们可以看到,latency的拐点出现处其实跟我们的通信BW(GB/s)其实不是完全对齐的,比如在Fig16里的A图,PCIe拐点在14次方,但是B图PCIe带宽拐点在18次方。NV-SLI的latency拐点在18次方,而B图里大概是18多一点,相比PCIe还是有显著的改进。Local address似乎在18次方-22次方里就有所涨幅,但是它的带宽一直到20次方才满。不过为什么local address会有一个山峰的趋势呢?我猜可能是Kernel的数量导致的,从而引起了SM的竞争。不过这只是推测。
More on Algorithm
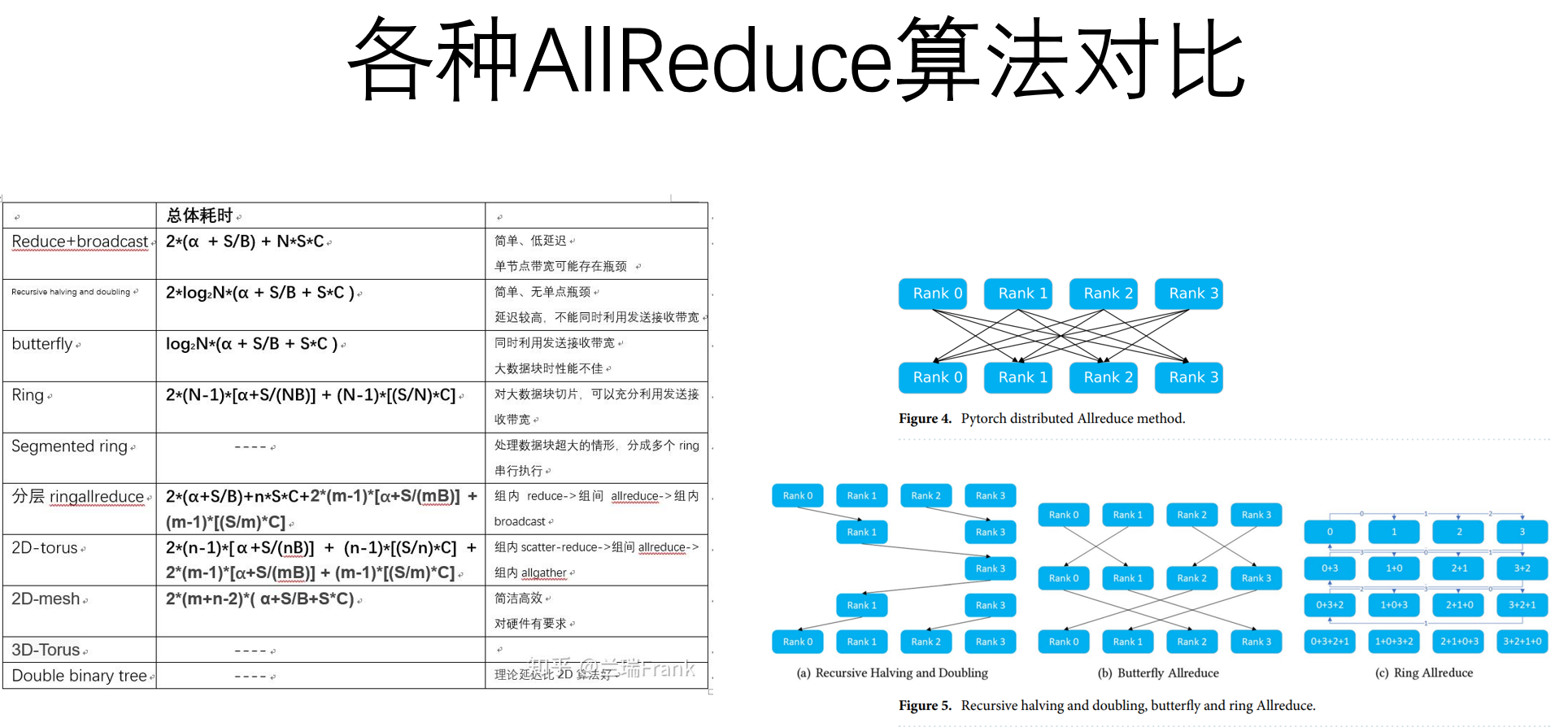
虽然我们在刚刚的NCCL中已经完成了通信树的建立,进而在这一拓扑上实现了P2P,PnP通信。但是,这样的通信一定是最佳的通信方式吗?这就像在一群快递站内,路径已经找到了最短,但是,快递站之间会互相发消息,他们按照怎么样的方式通信,可以达到最少的通信次数、以最快的时间完成一个大型的分布式算法呢?
这个问题在近年来比较火,人们围绕如何用GPU算大模型算的更快的问题,一直在讨论。
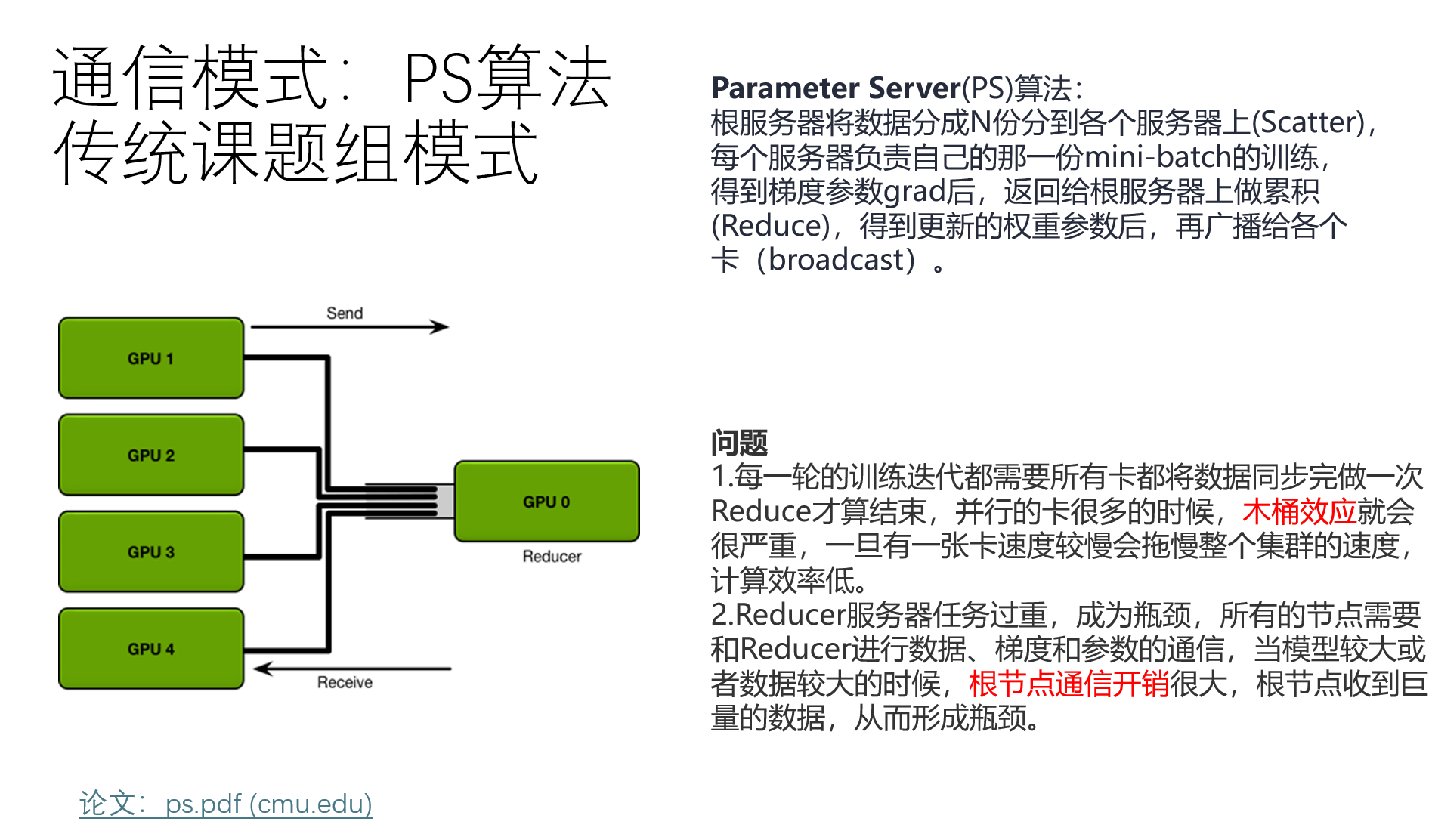
一种方法是,一台GPU当根服务器,然后互相训练与广播。
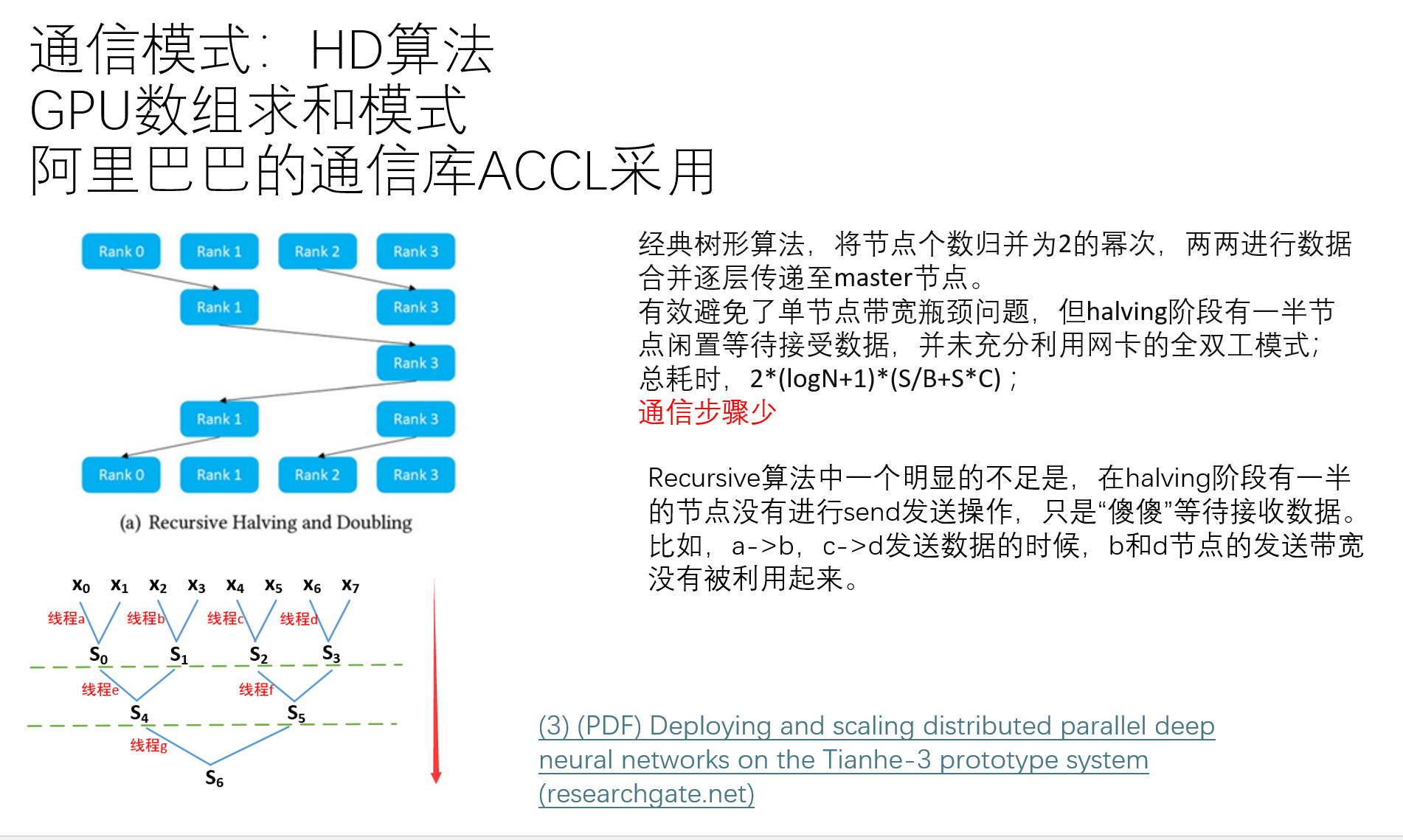
另一种方法是HD通信模式:
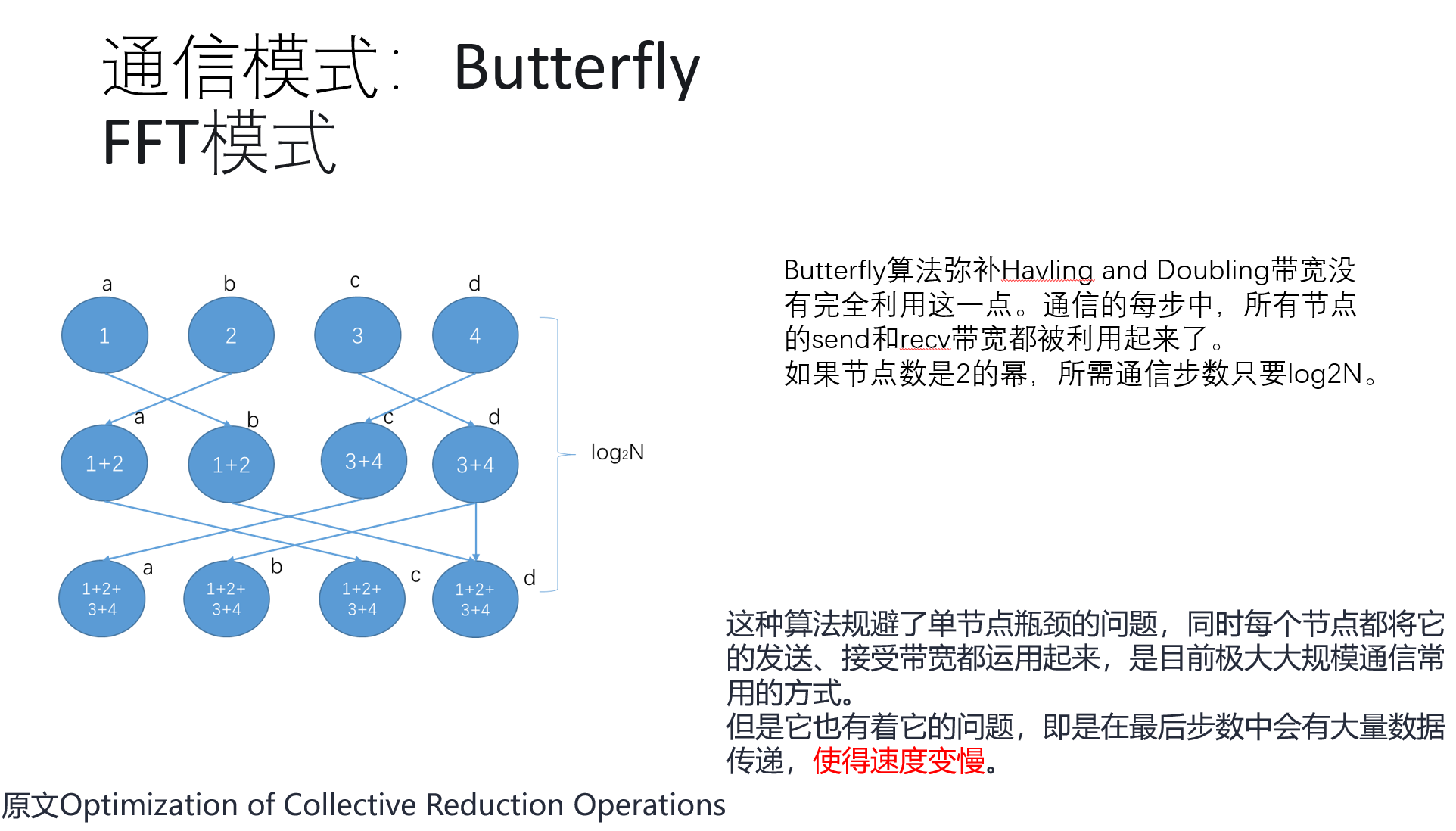
以及:
在NVIDIA中,使用的是Ring通信
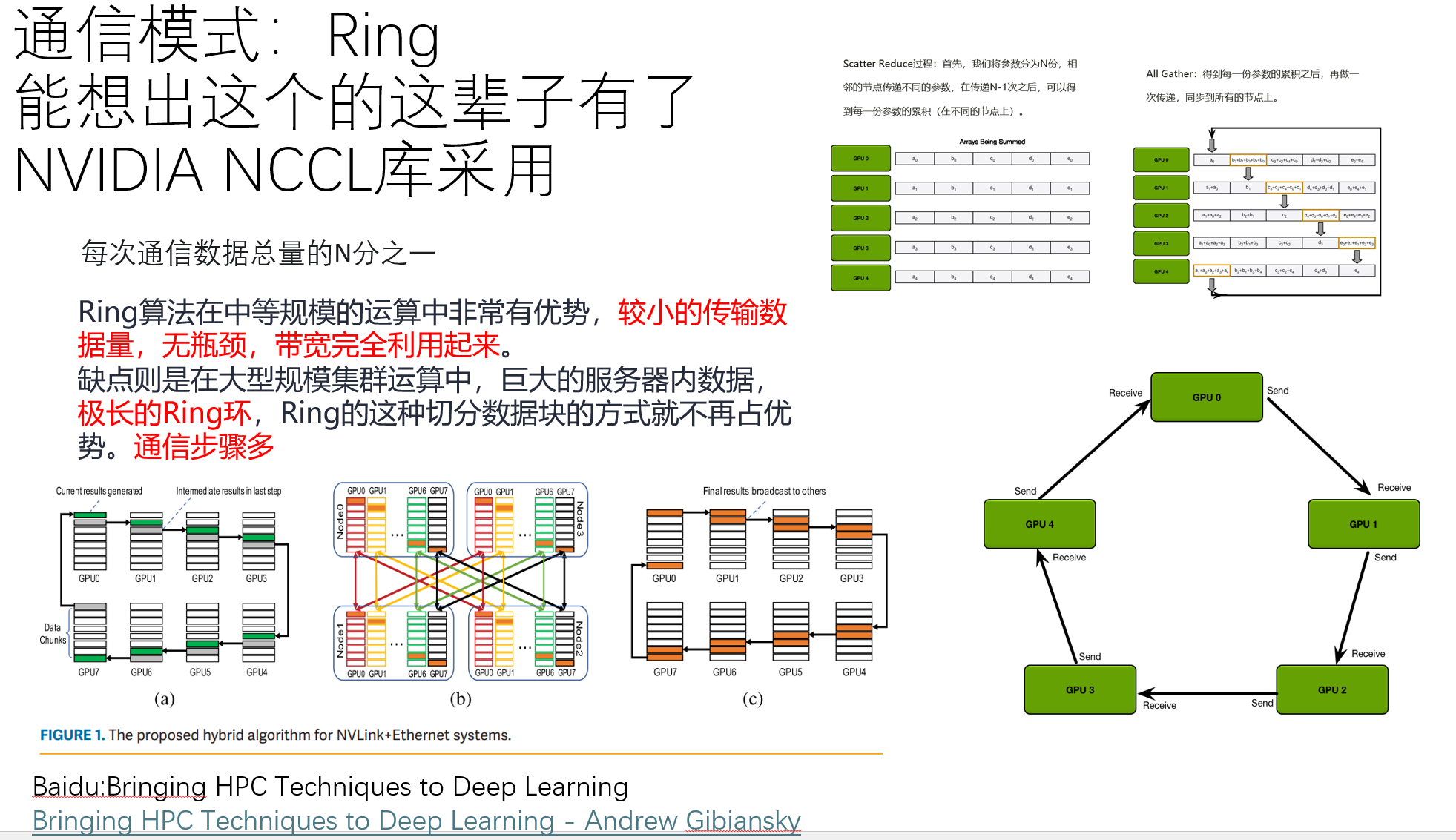
这些算法各有好坏,并且,与集群的拓扑结构非常有关系。他们最早在MPI中就有所实现与思考。

MPI本身也有很多原语,人们在这些原语的基础上搭建了这些算法逻辑

既然和集群拓扑有关,那能不能根据特定拓扑,写出特定的算法呢?当然可以:
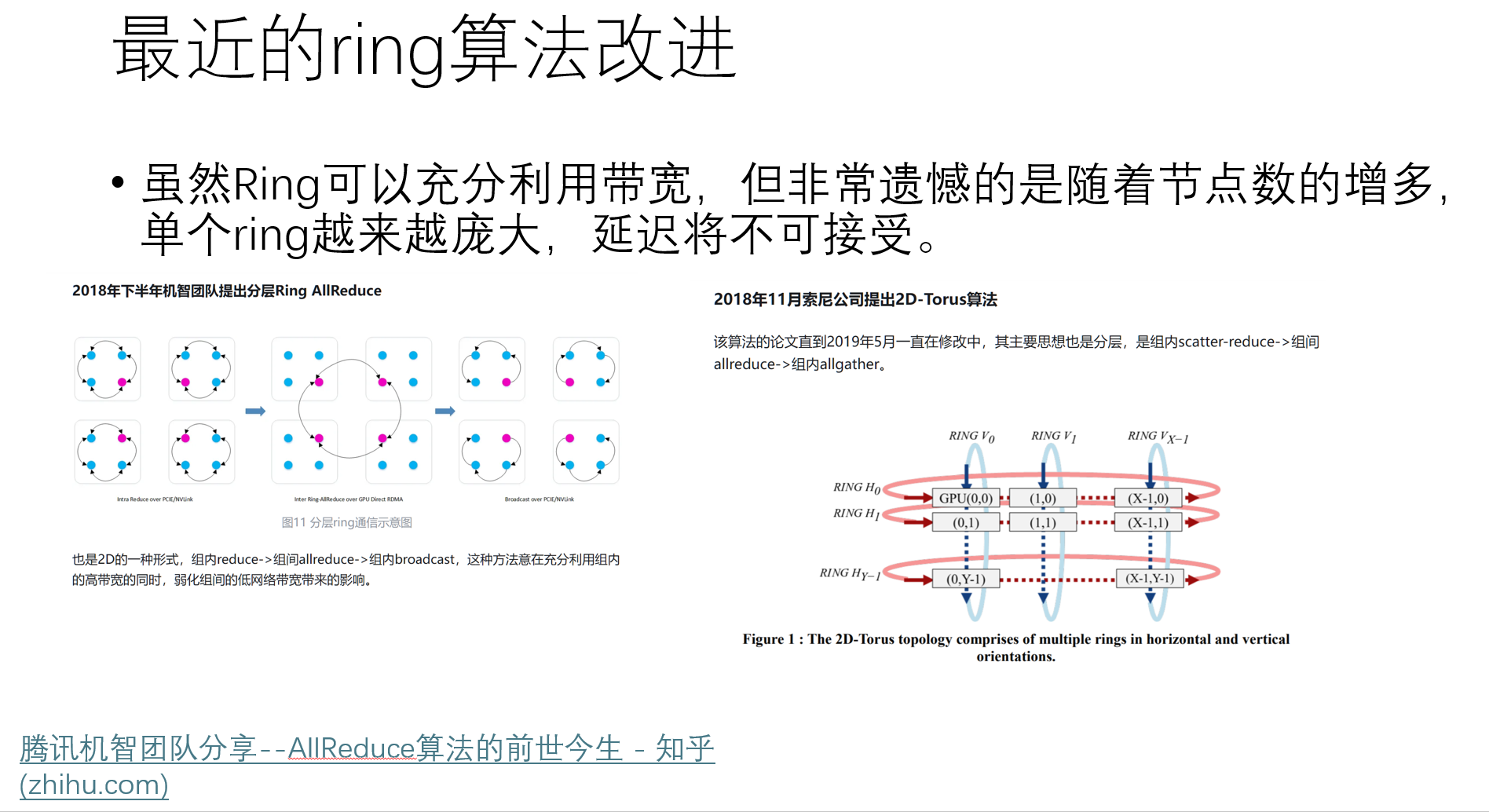
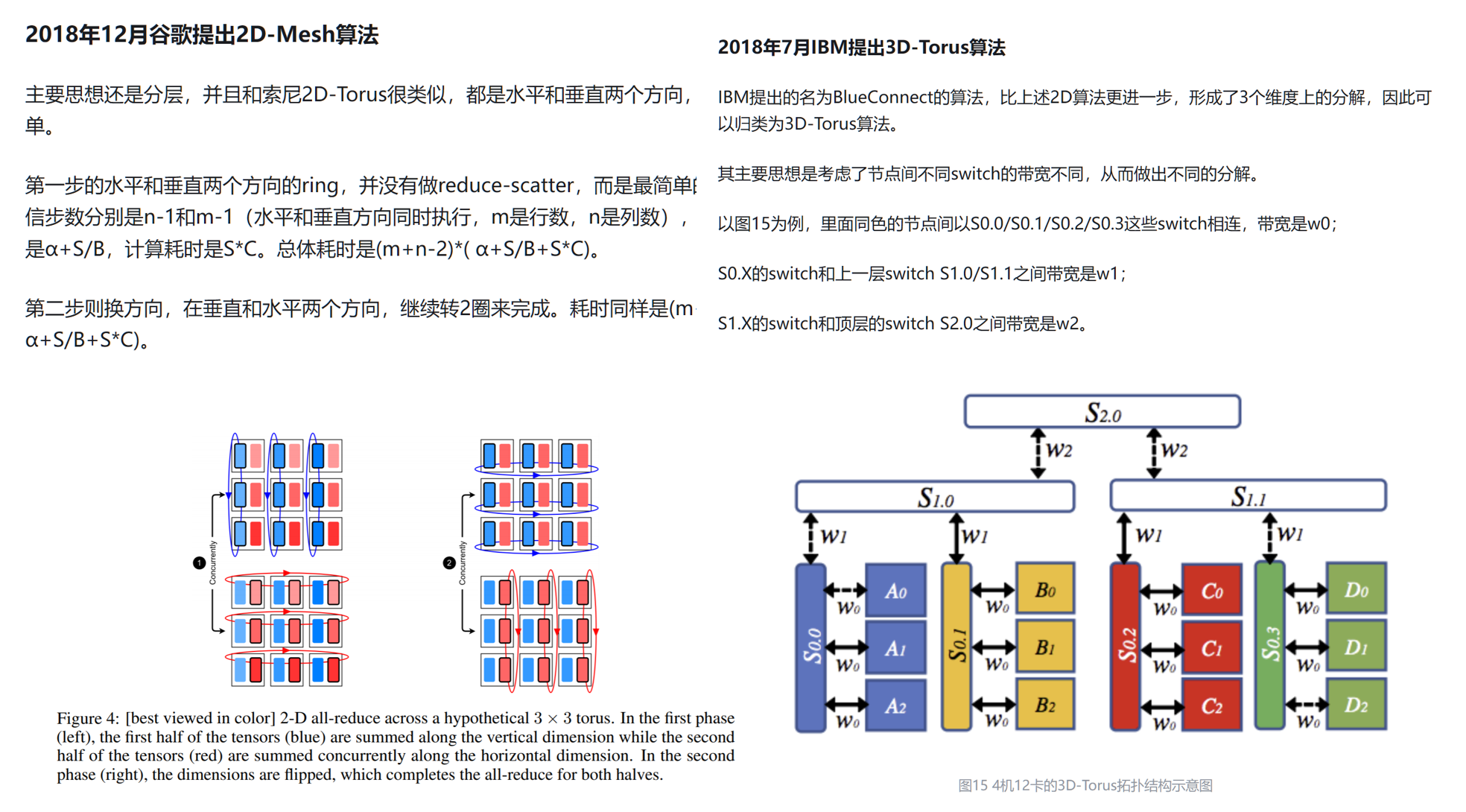
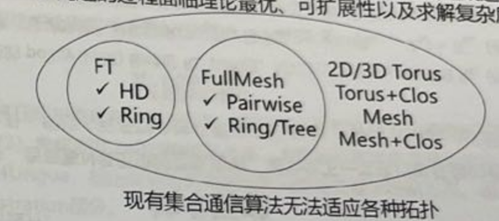
这些算法各有千秋,目前仍在做具体的研究。
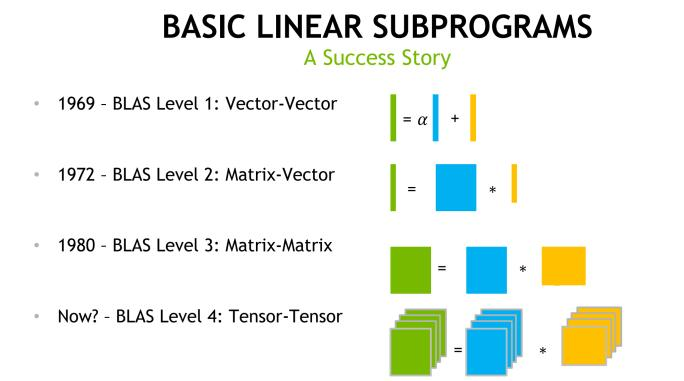
下一代BLAS:Tensor-Tensor
在科学计算的历史上,BLAS的成功是毋庸置疑的,它让无数计算得到了更快更好的匹配和优化。不过,“随着生成式人工智能时代的到来”,英伟达说,下一代BLAS应该是高维矩阵的乘加指令,也就是Tensor的运算,对此,他们也提供了新的API。

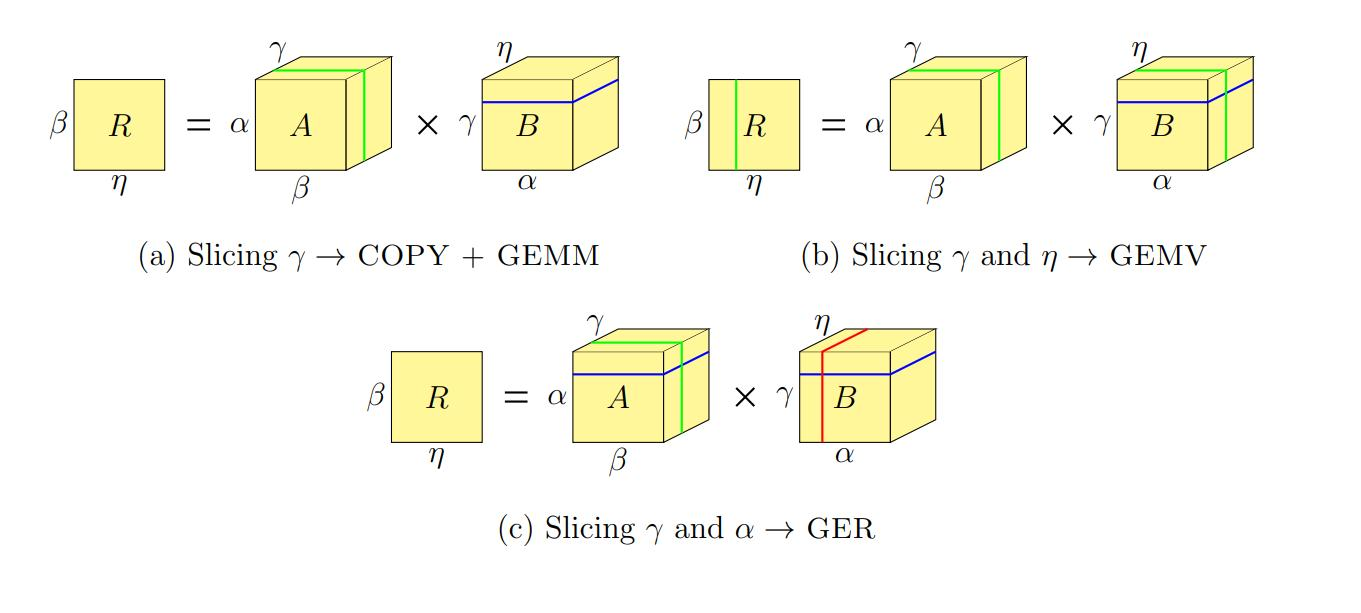
Tensor的乘法跟GEMM相比,又多了许多新的优化方向,比如说,我们之前说的数据重排的操作,这回随着高维矩阵的引入,可能要重新思考了。同时,我们可能要把SM们分层n维,每一个维度的SM做那个维度的乘法。文章[17]试图将这种高维的方法规约回GEMM。不过,新的算法的到来应该会继续加速这个算法。
“
我认为我们正处于生成式人工智能革命的开端。如今,世界上进行的大部分计算仍然基于检索。检索意味着您触摸手机上的某些内容,它会向云端发送信号以检索一条信息。它可能会用一些不同的东西组成一个响应,并使用 Java 将其呈现在您的手机的漂亮屏幕上。未来,计算将更加基于 RAG(Retrieval-augmented generation:检索增强生成,这是一个框架,允许大型语言模型从其通常参数之外提取数据),它的检索部分会更少,而个性化生成部分会高得多。
那一代将由 GPU 完成。所以我认为我们正处于这场检索增强的生成计算革命的开端,生成人工智能将成为几乎所有事物不可或缺的一部分。
”
CUDA汇编:PTX
我们知道对于不同的体系结构的CPU,比如RISC-V,他们都有一套自己的指令集。那么,GPU有没有自己的一套ISA呢?
事实上,GPU的编译很有意思,它很像Java。nvcc首先会将cuda代码转化成PTX代码。这很像Java的字节码,它只是将代码变成一种中间形式。随后,nvcc会根据不同目标的GPU,在编译时使用compute=SM_80等指令,可以讲代码编译为不同架构下的底层代码:SASS。
nvcc是怎么编译我们的CUDA代码的呢?我们看看官方教程[11]是怎么说的。
CUDA 编译工作原理如下:输入程序经过预处理后进行设备编译,并编译成 CUDA 二进制(cubin)和/或 PTX 中间代码,然后将其放入二进制文件(fatbinary)中。输入程序再次进行预处理,以进行主机编译,并进行合成以嵌入二进制文件,并将 CUDA 特定 C++ 扩展转换为标准 C++ 结构。然后,C++ 主机编译器将合成的主机代码与嵌入的二进制文件一起编译成主机对象。实现这一目标的具体步骤如下图所示。
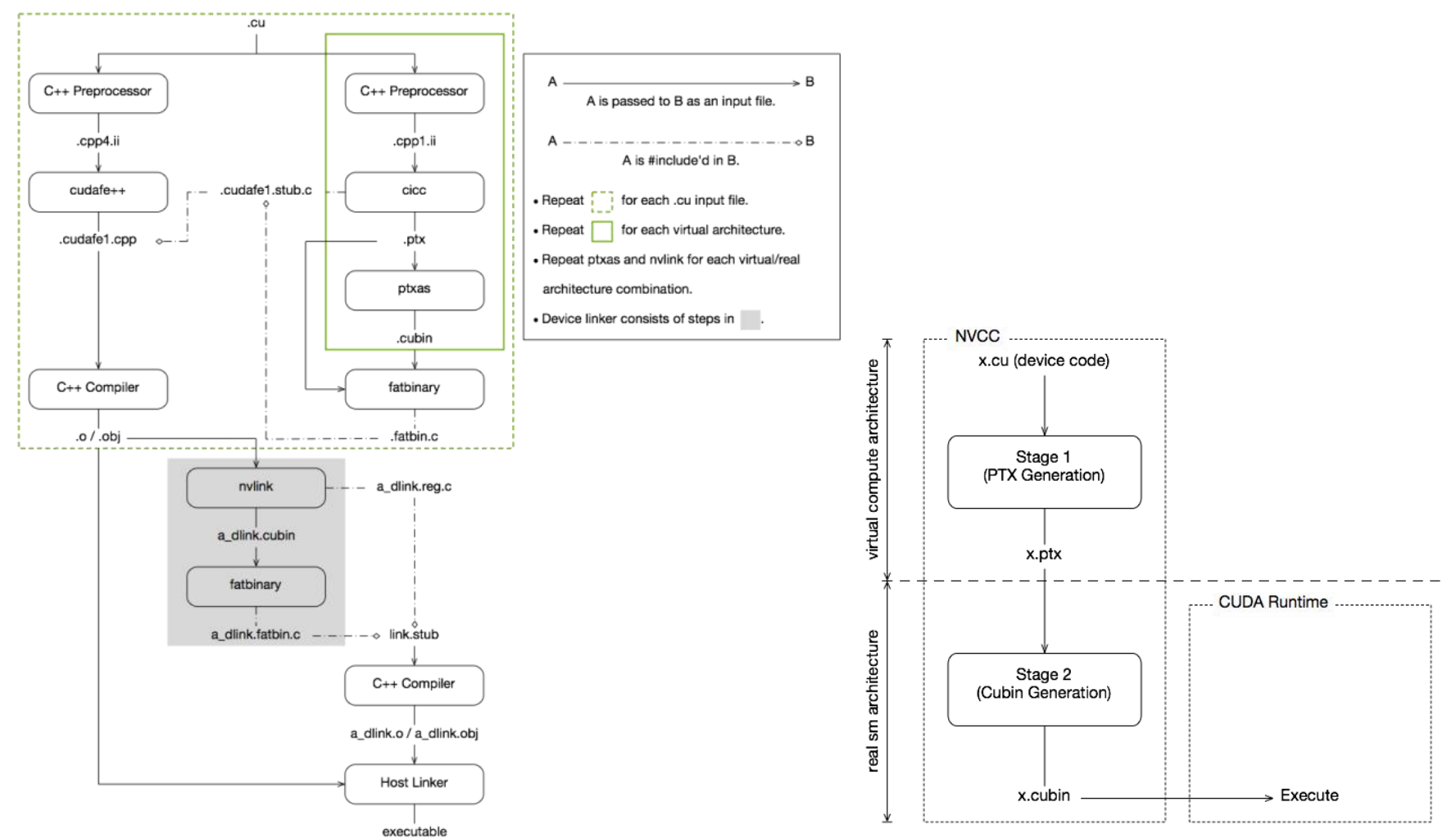
每当宿主程序启动设备代码时,CUDA 运行时系统都会检查嵌入的二进制文件,以便为当前的 GPU 获取合适的二进制文件。
CUDA 程序默认以整个程序编译模式编译,即设备代码不能引用来自单独文件的实体。在整个程序编译模式下,设备链接步骤不起作用。
PTX,并行线程执行(Parallel Thread eXecution,PTX)是一个a low-level parallel thread execution virtual machine and instruction set architecture (ISA),这个指令会被发送到GPU上,由线程调度器来执行具体的SIMT操作。博客[9]探索了在nvcc编译器编译后的cuda中间字节码是什么样的。
可以看到,编译过程其实分两部分,一部分是主机端和普通c++一样的编译,另一部分是针对CUDA中扩展的C++程序的编译,GPU设备端的编译最终的结果文件为fatbinary文件,GPU(的驱动)通过fatbinary文件来执行GPU功能。
那么为什么要有个PTX的中间层?其实和Java的想法是一样的:一次编译,到处运行。GPU到目前迭代了那么多代,如果像gcc一样只出那么几代的话,那么nvcc的底层要疯狂地写,这是非常不现实的。我们能做的就是转换成PTX,它作为一个虚拟GPU的程序集。虚拟GPU提供的这个通用的PTX指令集下,不同的硬件只要实现了,就可以运行,在此二进制指令编码是一个无关紧要的问题。
因此,nvcc编译命令总是使用两种体系结构:虚拟中间体系结构,以及真实的GPU体系结构来指定要执行的目标处理器。要使这样的nvcc命令有效,真正的体系结构必须是虚拟体系结构的实现。这些虚拟框架由compute_开头,比如sm_50。
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50由此可见,如果我们在写程序时始终尽可能小的用虚拟架构中的ISA,我们就能最大限度地提高运行的实际GPU。可是这样就会继续带来问题:我们的新指令假如效果更高,受到通用程序的影响,我们又不敢用新指令了。这可怎么办?
在我们的老朋友即时编译(JIT)的帮助下,GPU设备有能力知道它应该用哪个PTX。
通过指定虚拟代码架构而非真实 GPU,nvcc 可将 PTX 代码的组装推迟到应用程序运行时,因为此时目标 GPU 已完全确定。例如,当应用程序在 sm_50 或更高架构上启动时,下面的命令允许生成完全匹配的 GPU 二进制代码。
即时编译的缺点是会增加应用程序的启动延迟,但这可以通过让 CUDA 驱动程序使用编译缓存来缓解(请参阅 "第 3.1.1.2 节:即时编译",《CUDA C++ 编程指南》),该缓存可在应用程序的多次运行中持续存在。
当然,一个更普适性的想法是,既然我们的LLVM下的JIT还要制定代码来执行,那我为什么不在编译时就把compute_50,compute_40等等等等全部编译出来,到时候执行的时候哪个中我就用哪个呢?
这就是刚刚那副图中fatbinary的来历。它存储了多个计算框架,这些代码能够保存相同GPU源代码的多个翻译。 在运行时,CUDA驱动程序将在设备功能启动时选择最合适的翻译。

按照博客[12]里的总结如下:
-
CUDA程序的编译必须经历两个过程,即虚拟框架和真实框架,虚拟框架决定了程序最小的可运行GPU框架,而真实框架决定了程序可运行的最小的实际GPU。例如-arch=compute_30;-code=sm_30表示计算能力3.0及以上的GPU都可以运行编译的程序。但计算能力2.0的GPU就不能运行了。
-
即时编译(Just-In-Time)机制让程序可以在大的GPU框架内动态选择与电脑GPU最合适的小代。
-
–generate-code保证用户GPU可以动态选择最适合的GPU框架(最适合GPU的大代和小代)。
所以,我们之前用的O3优化,在CUDA这里可能起的作用就不是非常的大。博客[13]对此做出了一些解释。我们的O3是在CPU端的优化,而想优化GPU上的,我们就得加上-Xptxas,这个东西会选择最好的PTX指令。但是,更好的优化地区还是在我们自己程序员上。
当然,我们可以用nvcc-gdb或者Nsight来看看具体执行的情况。Nsight就像我们之前看的VTune一样。
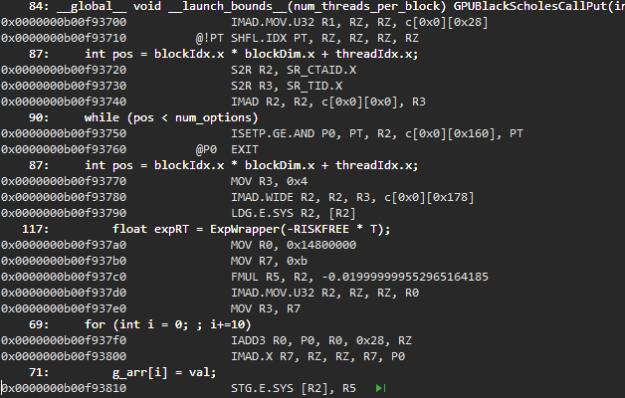
下面是CUDA官方教程的一个例子。程序的前两行跟我们的asm文件中.text差不多,就是定义变量r1 r2 (32bit,可以是int),array[N](32位float)。然后就是.main,将我们的thread id赋值给r1,然后将r1向左移动2位;接着将全局的array[idx/4]赋值给r2,然后r2+=0.5;看起来在全局Kernel里这可能是给数组内的一部分施行加法操作。

GPU的ISA有Vector形式。翻翻RISC-V的V拓展指令集,它里边就实现了32位的寄存器集体SIMD操作,里边也有Vector的操作。Vector的操作基本和数组差不多。
很快教程又介绍了高维矩阵Tensor的方法。教程这样说道“PTX Tensor instructions treat the tensor data in the global memory as a multi-dimensional structure and treat the data in the shared memory as a linear data.”对于高维矩阵的操作,底层的PTX最高只支持到5维数据,这里边怎么对数据降维是一个有趣的研究方向。另外,教程额外花了很多篇幅描述数组越界OOB的处理情况。
在CUDA内就像CPU的状态寄存器PSW一样,在块中(在指令集里,CUDA称他们为CTA),有%tid寄存器,记录当前是哪个线程,有%ntid,多少个线程;%warpid,warp的id;%ctaid,我们的块CTA的id;%smid,SM的id;%clusterid,grid中存储的集群的id等等。
当然,GPU内也有特殊指令。比如NVIDIA发家的视频图像处理:

另外一个有趣的指令叫DPX,这是Hopper架构里的指令。我们看文章使用 NVIDIA Hopper GPU DPX 指令提高动态编程性能 - NVIDIA 技术博客。这个指令专门用来加速DP动态规划算法。
在DP里边,最重要的事情是状态转移方程。写出这个方程,DP基本上就完成80%了。而这个状态转移方程也是TPX想加速的地方。比如这个指令 viaddmin_s16x2_relu,这样的指令就可以很好地实现我们的DP转移方程。TPX加速了Smith-Waterman、Needleman-Wunsch 等DP算法。这感觉真不戳,以后算法课再也不怕卡常了。
看懂GPU的ISA,可以帮我们在日后更好地调程序。
虚拟化与安全技术
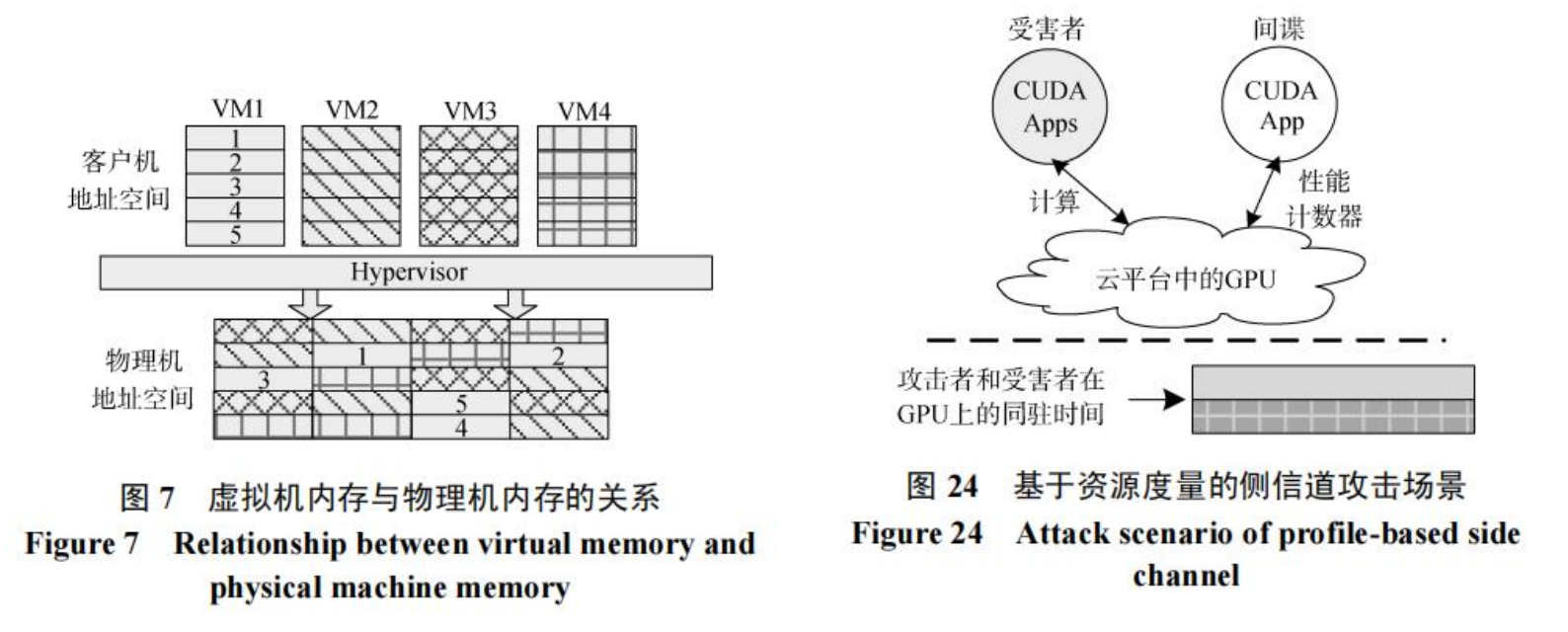
训练AI的数据是用户的隐私。但是人们发现,我们可以从GPU上进行攻击,绕过CPU与OS搭建的安全防御系统。比如我们想象一下之前的持久化线程,假如用户A先在SM1训练了一堆数据,接下来用户B的任务要在这个SM上执行任务。如果是为了效率,我们可以不刷新数据,让B的任务直接跑起来。但是这就意味着B可能可以拿到A的计算结果。这可能是SHA256或者什么密码,造成攻击。
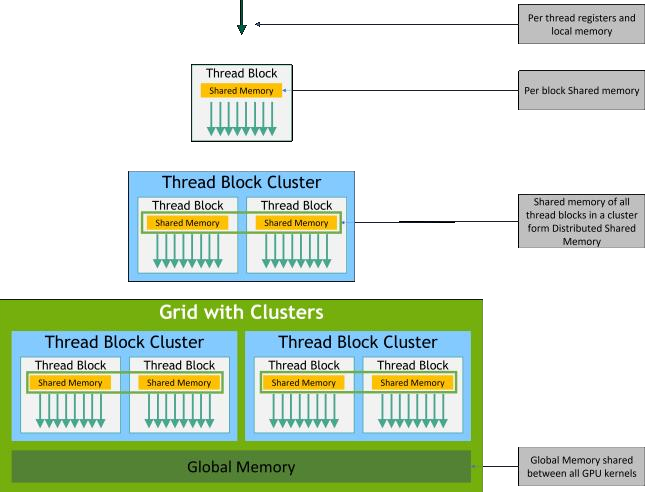
同时,多个用户使用的多个程序部署到GPU上也是一个问题。GPU就像以前的大型机一样,要有一个时分复用以及调度系统。怎么样调配不同的SM给到不同的用户,让GPU也可以多路复用,这是GPU要考虑的一个重要问题。
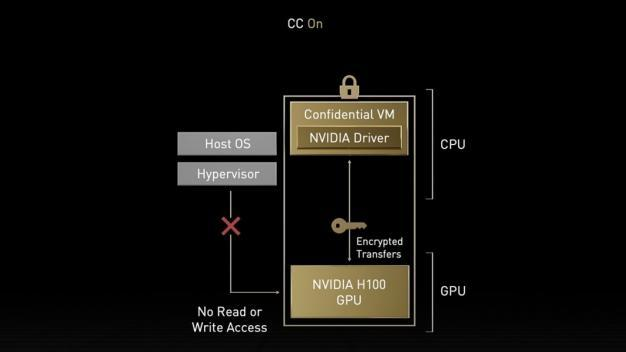
在H100中,工程师设计了一个Confidential VM,它将CPU内的驱动锁住。新的机密计算支持保护用户数据,抵御硬件和软件攻击,并在虚拟化和 MIG环境中更好地隔离和保护虚拟机(VM)。 H100 实现了世界上第一个本机机密计算GPU,并以全PCIe 线速率使用 CPU 扩展了可信执行环境( TEE )。
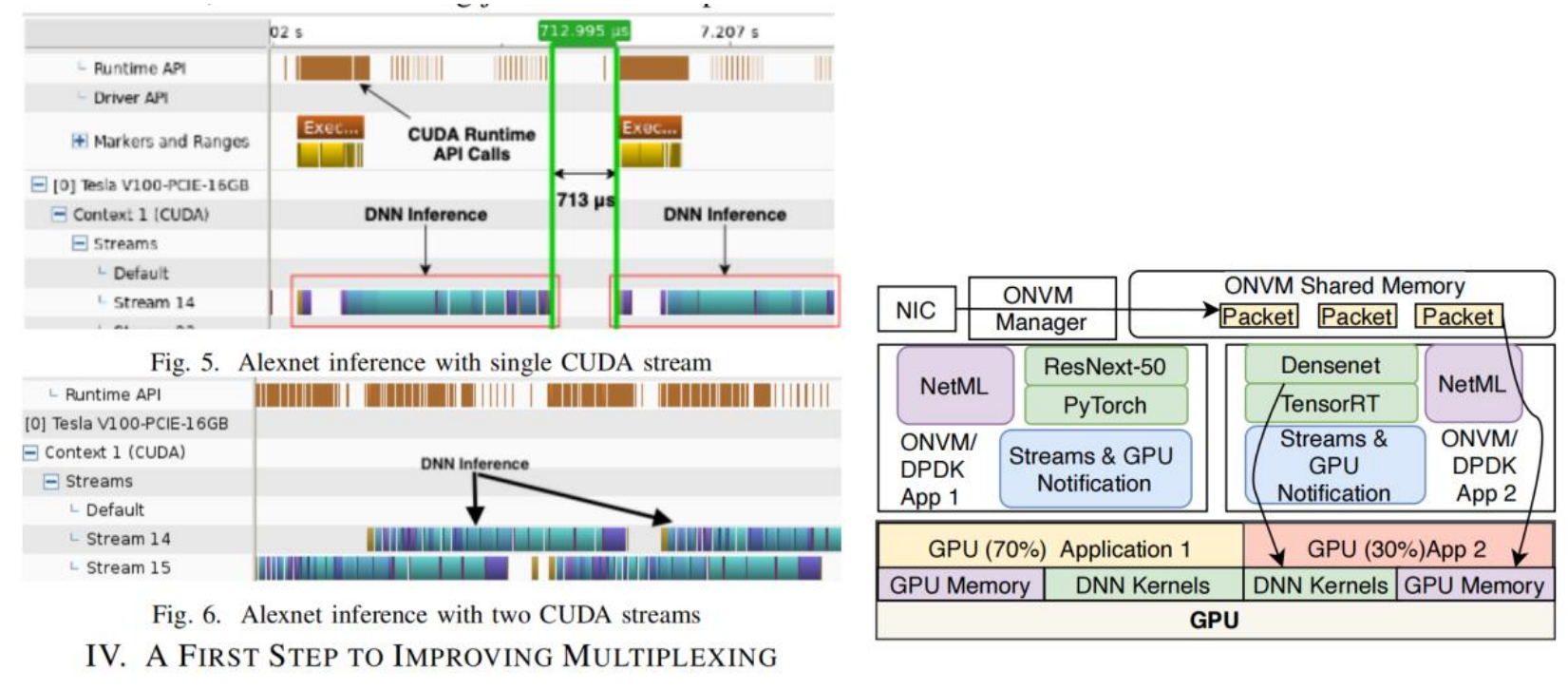
另外,在多路复用中,GPU也开始注意性能的。如何更好地切换以及多路复用[27]。
vLLM:降低GPU训练LLM的内存需求
随着LLM训练数据的增加,KV缓存的大小也在迅速扩大,这在处理大规模数据时尤为明显。
KV缓存是指关键-值缓存,它是在大型语言模型中用于存储上下文信息的一种数据结构。在语言模型中,关键-值缓存用于存储先前生成的令牌的上下文信息,以便在生成下一个令牌时使用。关键-值缓存中的关键是输入的令牌,而值是与该令牌相关的上下文信息。通过使用KV缓存,语言模型可以利用先前生成的令牌的上下文信息来生成更准确的下一个令牌,从而加速LLM的训练速度。
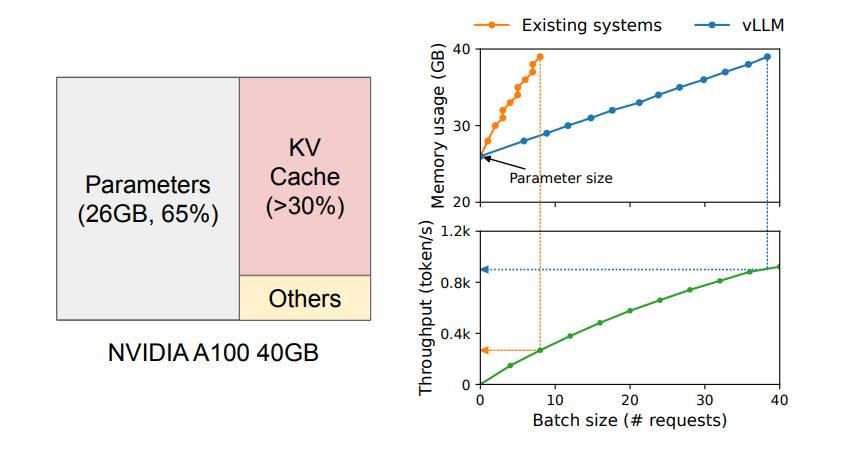
以一个含有13B参数的OPT模型为例,每一个token的KV缓存就需要占用800 KB的空间。而OPT模型能生成的token序列最多可达2048个,因此在处理一个请求时,KV缓存所需的内存空间可能高达1.6 GB。这种情况在当前GPU的资源稀缺环境下尤为突出,因为即便是主流GPU的内存容量也只有几十个GB,如果将所有可用内存都分配给KV缓存,那么也仅能处理几十个请求。而且,如果内存管理不够高效,还会进一步降低批处理的大小,导致资源利用率进一步降低。与此同时,GPU的计算速度的增长速度是超过内存容量的,这让我们相信,随着时间的推进,内存的瓶颈问题将变得越来越明显,可能会严重影响数据处理和模型训练的效率。
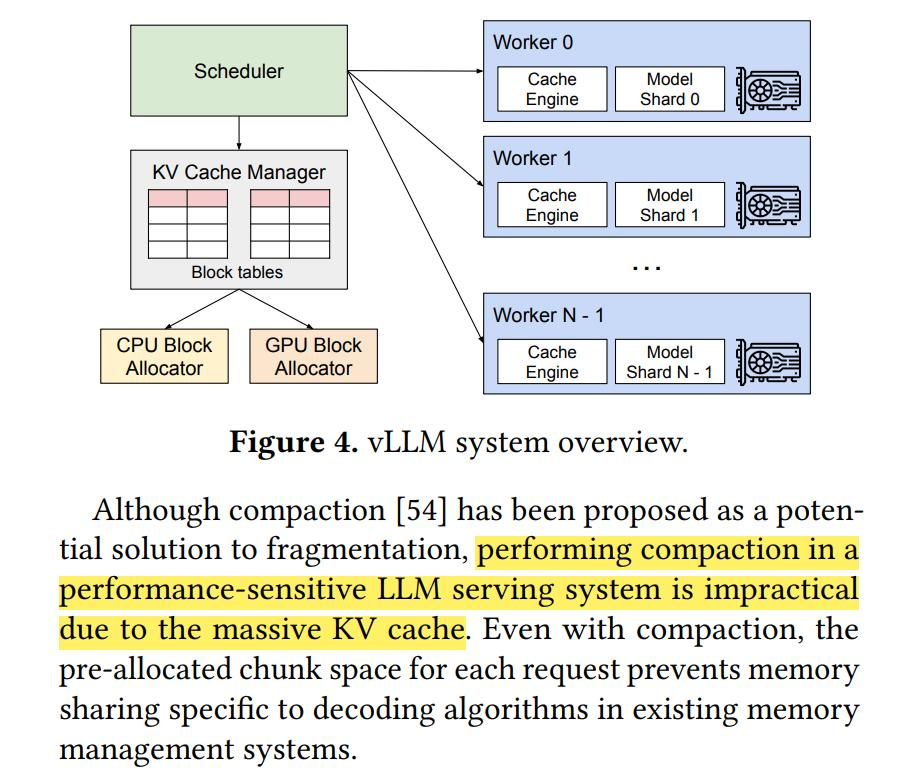
vLLM这个系统采用一个集中式的调度器来协调分布式的GPU工作节点。其中的KV缓存管理器能够以“分页”的方式有效地管理KV缓存,这正是得益于PagedAttention算法。具体来说,KV缓存管理器通过中央调度器发送的指令来管理GPU工作节点上的物理KV缓存内存。
传统的注意力算法往往要求在连续的内存空间中存储键和值,但PagedAttention允许在非连续的内存空间中存储连续的键和值。
- PagedAttention将每个序列的KV缓存分割成多个KV块。
- 每个块包含固定数量tokens的键和值向量,这个固定的数量被称为KV块大小。3. 公式部分给出了如何将传统的注意力计算转换为基于块的计算[16]。
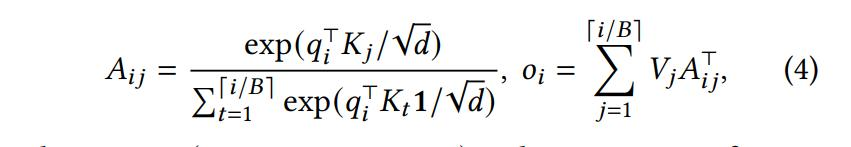
在这种页注意力机制下,不同的page被分配到不同的内存空间中。vLLM通过动态地为逻辑块分配新的物理块,随着更多tokens及其KV缓存的生成,优化了内存的利用。在这种机制下,所有的块都是从左到右填充的,仅当所有之前的块都已满时,才会分配一个新的物理块。这种设计帮助将一个请求的所有内存浪费限制在一个块内,从而可以更有效地利用所有的内存。
这种内存管理策略不仅有助于减少内存浪费,还通过允许更多的请求适应于内存中的批处理,提高了系统的吞吐量。每个请求的处理变得更为高效,因为现有的内存资源得到了更好的利用。当一个请求完成其生成过程后,其占用的KV块可以被释放,从而为其他请求的KV缓存提供存储空间。
这种动态分配和释放物理块的机制,为LLM服务中的内存管理提供了一种解决方案。
流水线
我们在Project4里分析了一部分关于GPU内存中统一内存的发展。但是,我们还没有仔细思考过如何使用内存。比如说,模型是one-hot编码进去,还是用什么编码方式进入GPU。
我们接下来以Megatron-LM这一经典的流水线训练模型为例子(文章[29])。通过pipeline并行, 一个模型可以被拆解为多份放到不同节点上, 以transformer为例,在transformer中block多次重复,所以每个device会分别处理相同个数的layer,对于非对称结构不好切分,这里不做考虑。如下图,不同TransformerLayer做为不同的pipeline的stage,也称为partition。
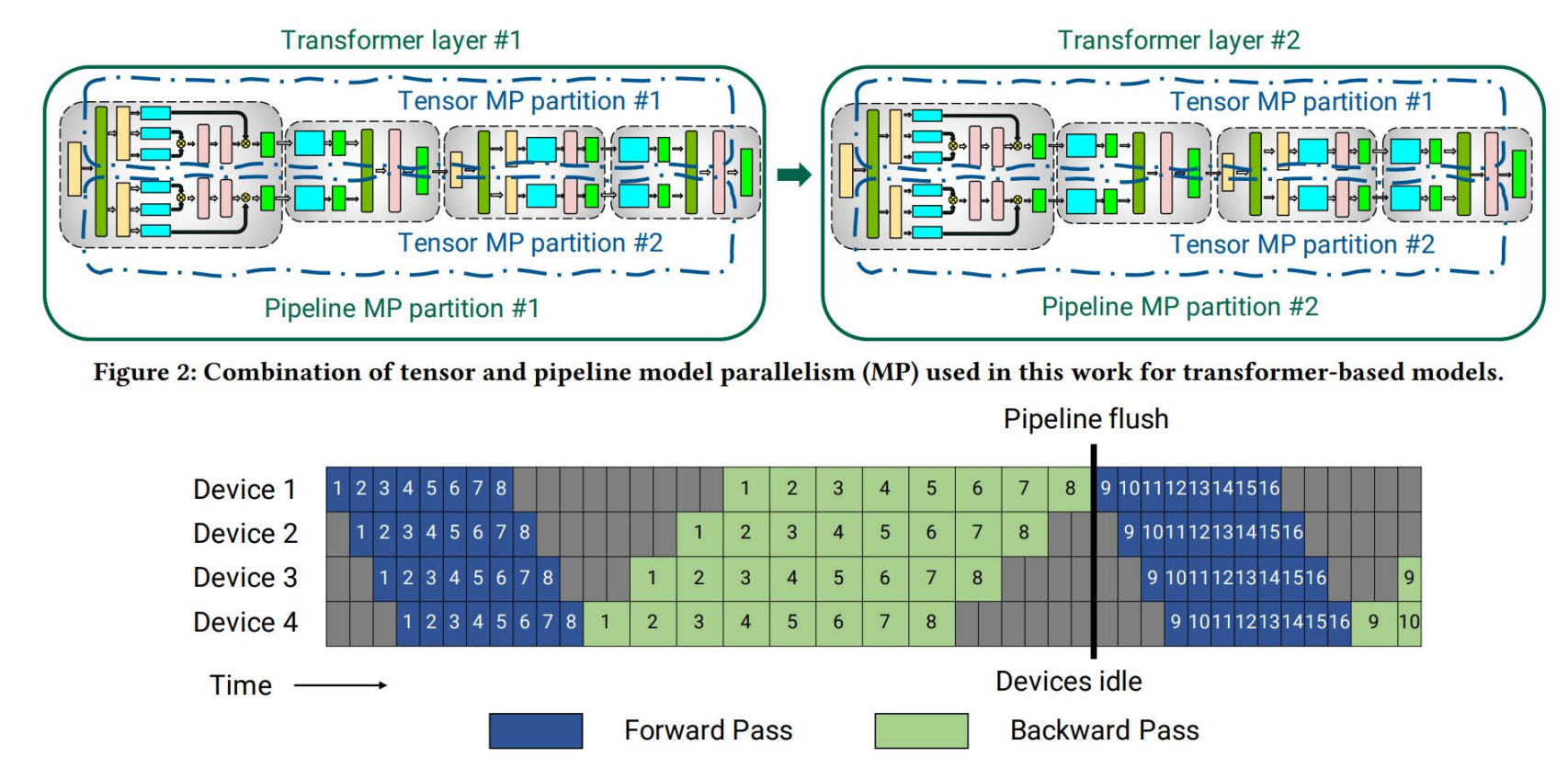
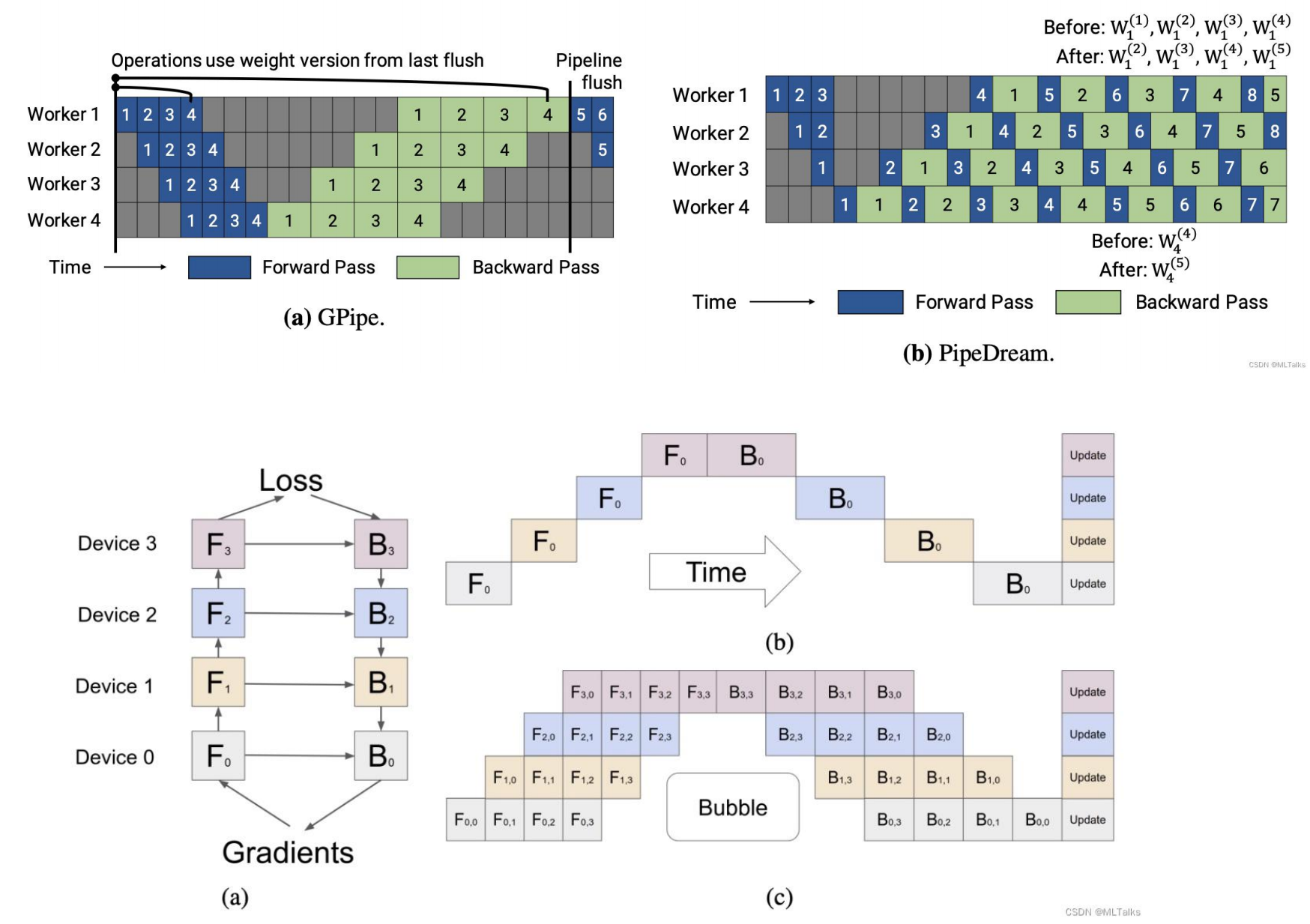
这就像CPU里的流水线,我们的模型训练也可以使用pipeline进行操作。当然,还有很多的操作和优化的地方,博客[15]进行了更宽泛的综述。
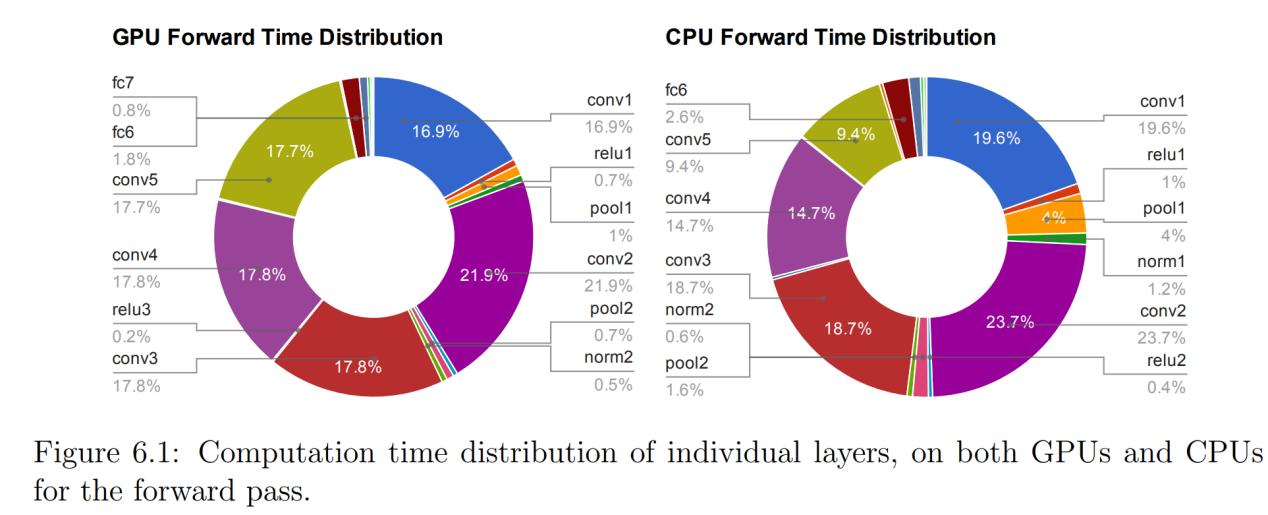
下面这个图,是一项针对GPU中训练AI的时间分配的研究结果。
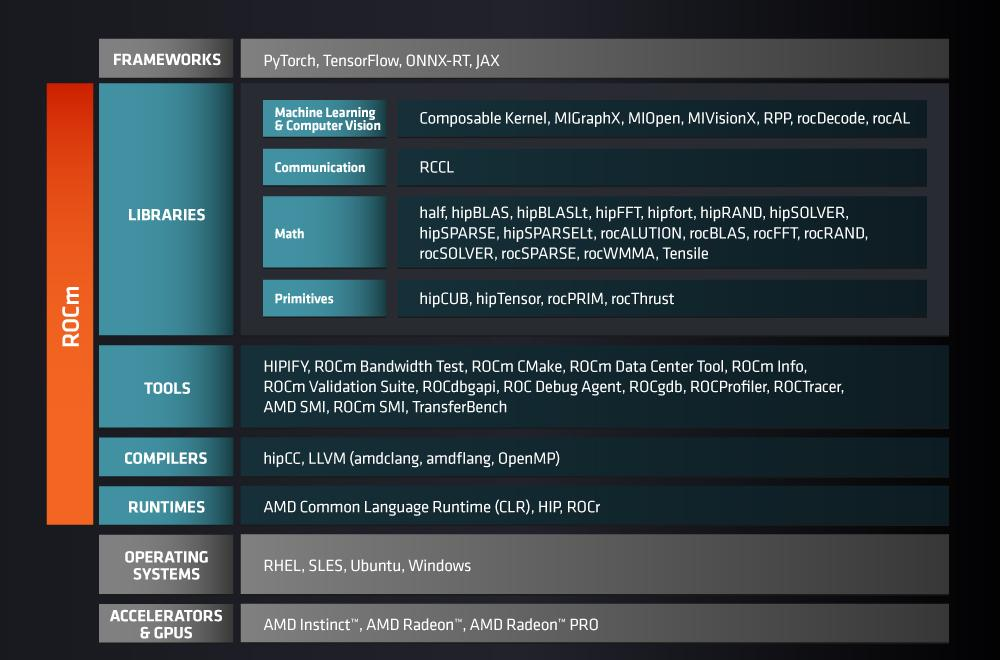
AMD:你好,我也要恰饭的
看了这么多CUDA,AMD有没有任何动作呢?其实也有的,那就是他们的ROCm。但是我不喜欢AMD,他们的软件栈文档又得重新学习,遇到的问题社区里很少有回答,并且很多旧A卡是使用不了ROCm的。但是我们也可以看一眼他们的架构,跟CUDA生态还是比较类似的。
总结
本次Project我们简单学习了一下CUDA编程,比较了几个计算参数。同时我们读了几篇文章,深入了解了几个GPU的技术,了解了GPU目前的一些研究方向。虽然时间不足,但是毋庸置疑地是将来我还会跟它打交道。这次的Project学习的东西无疑是一个好基础。
主持人:对于计算机或者工程学专业的学生,你会给他们什么建议,来提高成功的机会?
黄仁勋:
我认为我的一大优势是,我期望值很低。我认为大多数斯坦福毕业生期望值很高。
期望值很高的人通常韧性很低。不幸的是,韧性在成功中很重要。我不知道如何教你们,除了我希望痛苦发生在你们身上。
我很幸运,我成长的环境中,我的父母为我们提供了成功的条件,但同时,也有足够的挫折和痛苦的机会。
直到今天,我在我们公司里常常使用“痛苦和折磨”这个词。
伟大不是智力,伟大来自于性格。聪明人需要经历痛苦才能打造出这样的性格。
主持人:如果您能分享一条简短的建议给斯坦福,会是什么呢?
黄仁勋:拥有一个核心信念。每天都发自内心地检视目标竭尽全力追求、持之以恒地追求。
和您爱的人一起,携手踏上正途。这就是 NVIDIA 的故事。Is it over?
No, it is just beginning.

Reference
引用博客/文章
[1] CUDA 基础】3.2 理解线程束执行的本质(Part I) | 谭升的博客 (face2ai.com)
[2] CUDA Warp-Level级原语 - 吴建明wujianming - 博客园 (cnblogs.com)
[3] Improving-Real-Time-Performance-With-CUDA-Persistent-Threads.pdf (concurrent-rt.com)
[4] 【Linux】深入理解生产者消费者模型-阿里云开发者社区 (aliyun.com)
[5] Improving-Real-Time-Performance-With-CUDA-Persistent-Threads.pdf (concurrent-rt.com)
[6] Overview of NCCL — NCCL 2.21.5 documentation (nvidia.com)
[7] NVIDIA NCCL 源码学习(一)- 初始化及ncclUniqueId的产生-CSDN博客
[8] Using CUDA Warp-Level Primitives | NVIDIA Technical Blog
[9] CUDA进阶第二篇:巧用PTX_cuda ptx-CSDN博客
[10] 用 NVIDIA CUDA 11 . 2 C ++编译器提高生产率和性能 - NVIDIA 技术博客
[11] NVIDIA CUDA Compiler Driver
[12] CUDA:NVCC编译过程和兼容性详解_nvcc把cuda代码转换成什么-CSDN博客
[13] cuda - 如何让 nvcc CUDA 编译器进行更多优化? - IT工具网 (coder.work)
[14] What is ROCm? — ROCm Documentation (amd.com)
[15] 详解MegatronLM流水线模型并行训练(Pipeline Parallel)_efficient large-scale language model training on g-CSDN博客
[16] 解锁 vLLM:大语言模型推理的速度与效率双提升-腾讯云开发者社区-腾讯云 (tencent.com)
[17] njuhope/cuda_sgemm (github.com)
引用学术文章
[18] K. Gupta, J. A. Stuart and J. D. Owens, "A study of Persistent Threads style GPU programming for GPGPU workloads," 2012 Innovative Parallel Computing (InPar), San Jose, CA, USA, 2012, pp. 1-14, doi: 10.1109/InPar.2012.6339596.
[19] Stuart, J.A., & Owens, J.D. (2011). Efficient Synchronization Primitives for GPUs. ArXiv, abs/1110.4623.
[20] W. Wang, S. Guo, F. Yang and J. Chen, "GPU-Based Fast Minimum Spanning Tree Using Data Parallel Primitives," 2010 2nd International Conference on Information Engineering and Computer Science, Wuhan, China, 2010, pp. 1-4, doi: 10.1109/ICIECS.2010.5678261.
[21] Shubhabrata Sengupta, Mark Harris, Yao Zhang, and John D. Owens. 2007. Scan primitives for GPU computing. In Proceedings of the 22nd ACM SIGGRAPH/EUROGRAPHICS symposium on Graphics hardware (GH '07). Eurographics Association, Goslar, DEU, 97–106.
[22] Ang Li, Shuaiwen Leon Song, Jieyang Chen, Jiajia Li, Xu Liu, Nathan R. Tallent, and Kevin J. Barker. 2020. Evaluating Modern GPU Interconnect: PCIe, NVLink, NV-SLI, NVSwitch and GPUDirect. IEEE Trans. Parallel Distrib. Syst. 31, 1 (Jan. 2020), 94–110. https://doi.org/10.1109/TPDS.2019.2928289
[23] He, J., & Zhai, J. (2024). FastDecode: High-Throughput GPU-Efficient LLM Serving using Heterogeneous Pipelines. [Preprint]. arXiv. Retrieved from https://arxiv.org/abs/2403.11421
[24] Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron. Accelerating leukocyte tracking using CUDA: A case study in leveraging manycore coprocessors. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, May 2009.
[25] Timo Aila and Samuli Laine. Understanding the efficiency of ray traversal on GPUs. In Proceedings of High Performance Graphics 2009, pages 145–149, August 2009.
[26] Toledo, R.D., & Lévy, B. (2005). Extending the graphic pipeline with new GPU-accelerated primitives.
[27] Di Napoli, E., Fabregat-Traver, D., Quintana-Ortí, G., & Bientinesi, P. (2013, July 22). Towards an Efficient Use of the BLAS Library for Multilinear Tensor Contractions.
[28] Shi, Y., Niranjan, U. N., Anandkumar, A., & Cecka, C. (2016, December). Tensor Contractions with Extended BLAS Kernels on CPU and GPU. In 2016 IEEE 23rd International Conference on High Performance Computing (HiPC) (pp. 1-10). IEEE. doi:10.1109/hipc.2016.031
[29] 吴再龙,王利明,徐震,等.GPU虚拟化技术及其安全问题综述[J].信息安全学报,2022,7(02):30-58.DOI:10.19363/J.cnki.cn10-1380/tn.2022.03.03.
[30] A. Dhakal, S. G. Kulkarni and K. K. Ramakrishnan, "Machine Learning at the Edge: Efficient Utilization of Limited CPU/GPU Resources by Multiplexing," 2020 IEEE 28th International Conference on Network Protocols (ICNP), Madrid, Spain, 2020, pp. 1-6, doi: 10.1109/ICNP49622.2020.9259361.
[31] Saumya, C., Sundararajah, K., & Kulkarni, M. (2021). CFM: SIMT Thread Divergence Reduction by Melding Similar Control-Flow Regions in GPGPU Programs. CoRR, abs/2107.05681. https://arxiv.org/abs/2107.05681
[32] Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., & Catanzaro, B. (2020). Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv preprint arXiv:1909.08053.
[33] Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., & Stoica, I. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv preprint arXiv:2309.06180.
